1. Introduction
In China, the breeding of sika deer has developed into a characteristic industry with significant economic value, the core of which lies in the continuously growing market demand for products such as deer antler in traditional medicine and health care products [
1]. This economic orientation not only puts forward higher requirements for improving the efficiency of breeding and product quality, but also brings new challenges to ensuring animal welfare and achieving sustainable production in an intensive or semi-intensive breeding environment. The traditional management methods of sika deer, such as relying on manual observation for health assessment, determination of the maturity of deer antler, or when precise operations are required (such as the preparatory work before collecting deer antler), mainly depend on manual fixation or chemical fixation (using sedatives or anesthetics) [
2]. These two methods not only generally have problems such as high labor intensity, need for professional skills, and high operational risks, but more importantly, such invasive or compulsory close-range contact operations are very likely to trigger a strong stress response in sika deer. This kind of stress not only seriously damages animal welfare, but also may affect the quality of deer products (such as deer antler). Therefore, the development of non-contact, automated, and precise monitoring and management technologies has become an urgent need to promote the transformation and upgrading of the sika deer breeding industry towards modernization, humanization, and sustainability [
3].
In recent years, computer vision technology centered on deep learning has made breakthrough progress [
4,
5], providing strong technical support for addressing the above-mentioned challenges. The object detection algorithm based on deep learning, as one of the core technologies in this field, has been widely applied in ecology and precision animal husbandry [
6]. In ecology, the automatic identification of wild animals has been successfully achieved. For instance, Sibusi Oreu Benbakana and others proposed a lightweight and efficient wild animal identification model based on YOLOv5s [
7]. Through StemBlock optimization, MobileBottleneckBlock replacement, and BiFPN feature fusion, the parameters are reduced by 28.5%, the FLOPs are decreased by 50.9%, the loading speed is faster, and it is suitable for real-time monitoring in resource-constrained fields, providing efficient technical support for ecological protection. Lingli Chen et al. [
8] proposed the YOLO-SAG model to balance accuracy and speed. Softplus enhances stability, AIFI module strengthens the interaction of features at the same scale, GSConv and VoV-GSCSP lightweight neck. On the self-built wildlife dataset, mAP50 reached 96.8%, which is 3.2% higher than the original model, 25% faster than inference, and only requires 7.2 GFLOPs of computing power. The model performs well in complex backgrounds and small target detection, and is suitable for long-term real-time monitoring scenarios in the field. Langkun Jiang et al. [
9] proposed an improved YOLOv8n model that integrates extended Kalman filtering, integrating DCNv3 and EMGA attention mechanisms to optimize multi-object tracking. Enhanced by StableDiffusion data, the detected mAP50 reached 88.5%, and the tracked MOTA increased by 3.9%. It effectively dealt with occlusion and small targets, providing a reliable technical solution for ecological monitoring and endangered species protection.
In precision livestock farming, target detection technology enables the individual identification and behavior analysis of livestock. For instance, Junpeng Zhang et al. [
10] proposed a behavior detection method for dairy goats based on YOLO11 and ElSlow fast-LSTM. The target is located through YOLO11, and spatio-temporal feature modeling is carried out by combining the improved SlowFast network and LSTM to achieve the recognition of five behaviors such as standing and walking. A mAP of 78.70% was achieved on the self-built DairyGoat dataset, with lower parameters and higher computational efficiency than the traditional model. Xiwen Zhang et al. [
11] proposed the lightweight sheep facial recognition model LSR-YOLO. It adopted ShuffleNetv2 and the Ghost module to reduce the number of parameters and introduced the CA attention mechanism to enhance feature extraction. The model size was only 9.5 MB, and the mAP50 reached 97.8%. Verified on the self-built dataset, the number of parameters decreased by 33.4%, FLOPs decreased by 25.5%, and the mobile terminal was successfully deployed to achieve real-time detection. Ye Mu et al. [
12] proposed an improved CBR-YOLO model of YOLOv8 for the behavior recognition of beef cattle under multiple weather conditions. Combining the Inner-MPDIoU loss function, the MCFP multi-scale feature pyramid and the lightweight LMFD detection head, the mAP reached 90.2% in the complex weather dataset and the FLOPs was reduced by 3.9 G. Experiments show that the model is superior to 12 SOTA models in terms of the number of parameters and computational efficiency, and is suitable for the real-time monitoring system of pastures. Based on the improvement of YOLOv8, He Gong et al. [
3] enhanced feature fusion by introducing the C2f_iAFF module, replaced SPPF with the AIFI module to process high-level semantics, designed the CSA module to optimize feature extraction, and combined it with the SPFPN detection head to improve multi-scale feature fusion. Experiments show that the model achieves an average accuracy of 91.6% on the self-built dataset, with a 4.6% increase in mAP50, which outperforms other models in the YOLO series. This model can effectively achieve non-contact real-time monitoring of sika deer postures in complex breeding environments, providing technical support for health assessment.
However, the existing research mainly focuses on the detection of individual animals themselves [
13]. For more refined management requirements, such as accurately identifying and locating specific parts of an animal’s body, the research is relatively insufficient, especially in the breeding or management scenarios of large mammals. More importantly, to achieve stable and reliable part detection in a real and dynamically changing breeding environment, the algorithm must be able to cope with many practical challenges such as light changes, background interference, diverse and unpredictable animal postures, and the target parts being often occlusions. This greatly increases the difficulty of algorithm design and optimization. Precise positioning of key body parts is precisely the fundamental prerequisite and core link for achieving downstream automated operations (such as robot guidance [
14]), health monitoring [
15] (such as non-contact body scale measurement, automated gait analysis), and complex behavior recognition [
16] (such as distinguishing between feeding and alert postures).
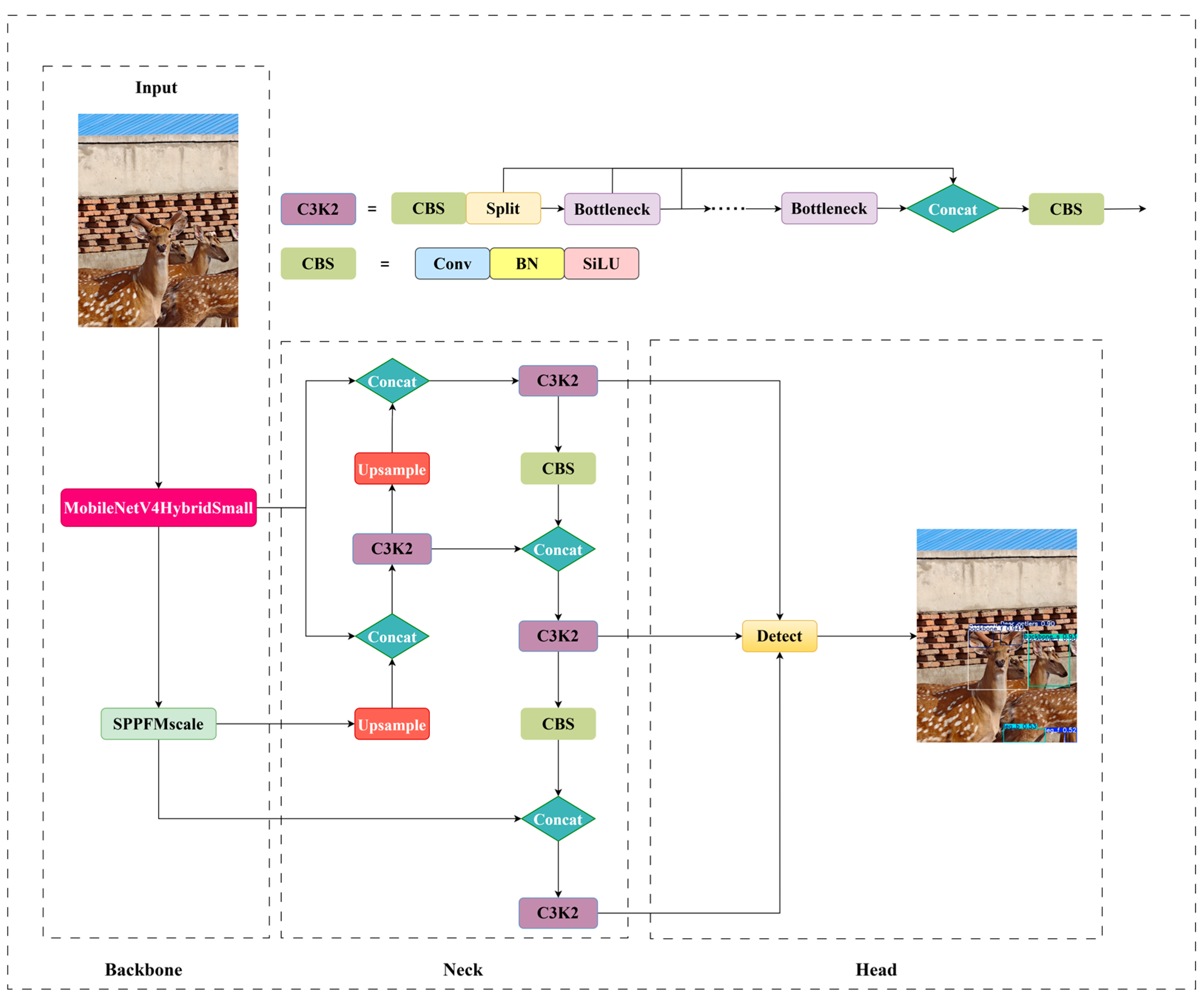
In response to the actual demands in the management of sika deer breeding, the gaps in existing technologies, and the challenges brought by the real environment, this study aims to develop a deep learning model based on YOLO11 to achieve automatic, rapid, and accurate detection of multiple key body parts of sika deer. The parts we focus on include deer antlers, the front of the head, the sides of the head, the front legs, and the hind legs. The selection of these specific body parts is based on their value as key information in the interpretation of the biological characteristics of sika deer, the assessment of their health status, and modern breeding management practices. Precise deer antler detection is the basis for assessing economic value (such as maturity to determine the harvest timing) and provides visual evidence for related automated processes. Accurate identification of the head (side and front) is crucial for interpreting behavioral patterns such as feeding and alertness. Precise leg detection makes automated gait analysis possible, which is conducive to the early diagnosis of health problems such as lameness. This is far superior to traditional observation in ensuring animal welfare and production performance. Therefore, reliable detection of these specific parts is a technical prerequisite for achieving refined, intelligent, and humanized management of sika deer.
4. Discussion
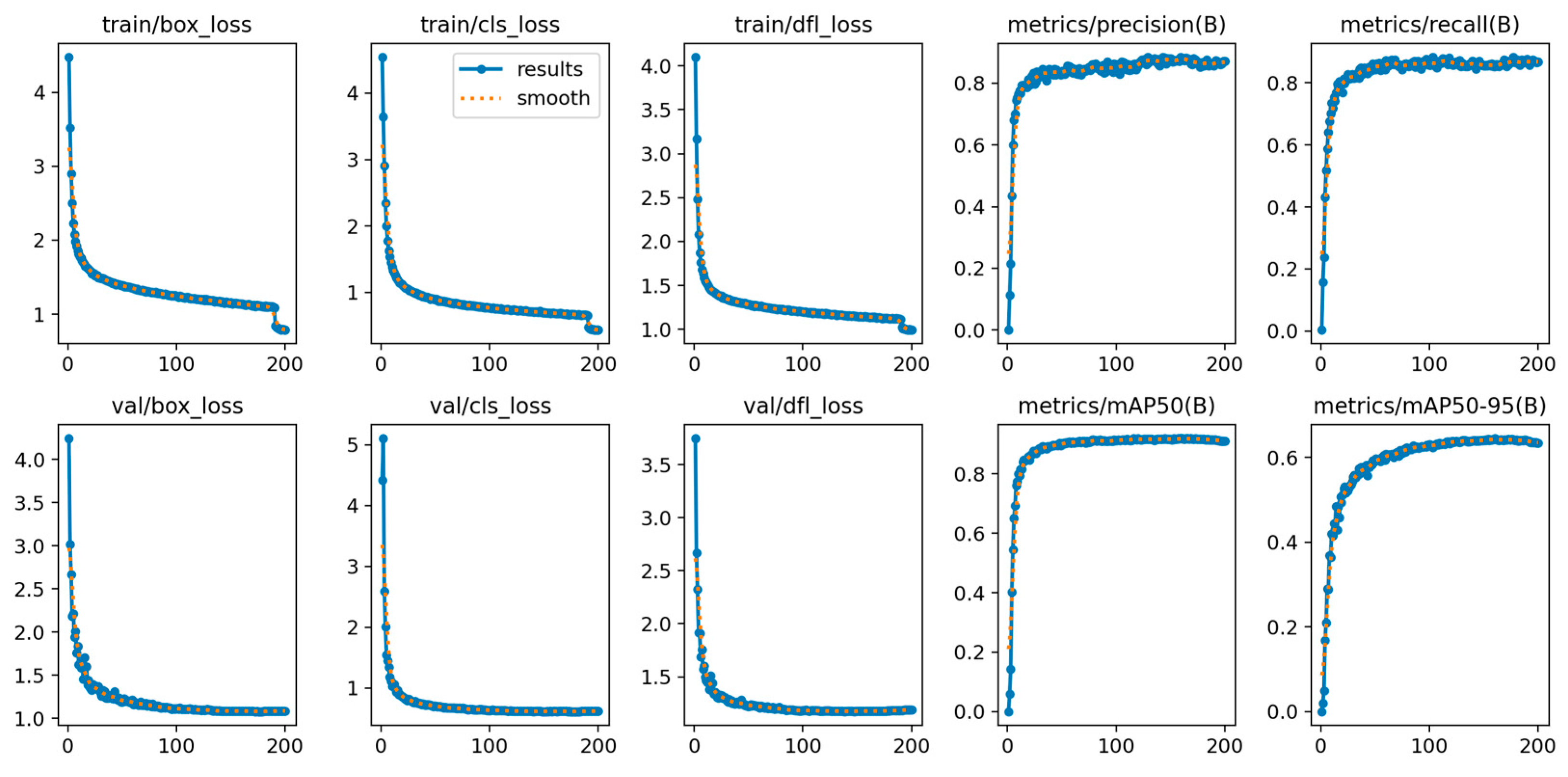
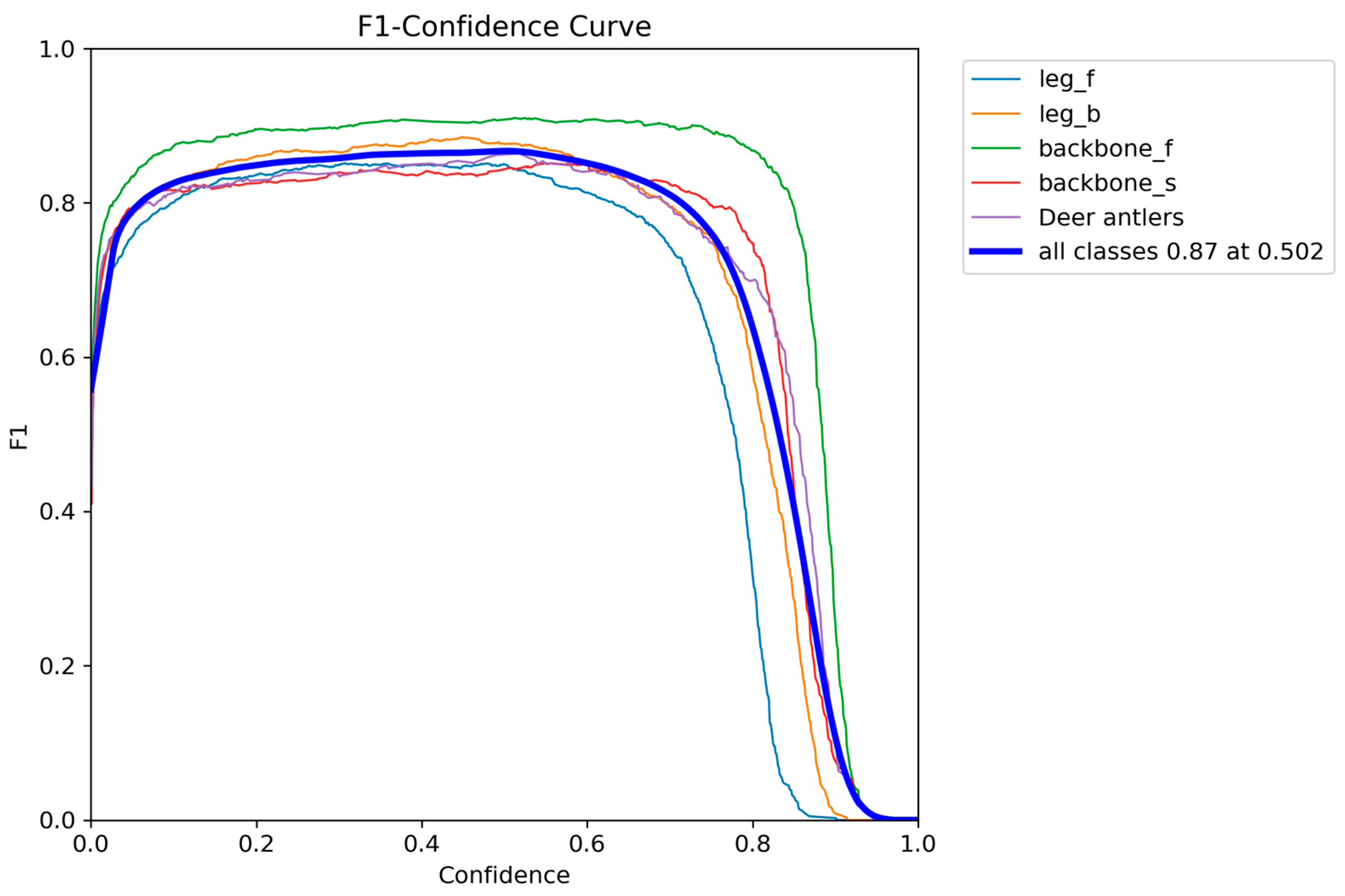
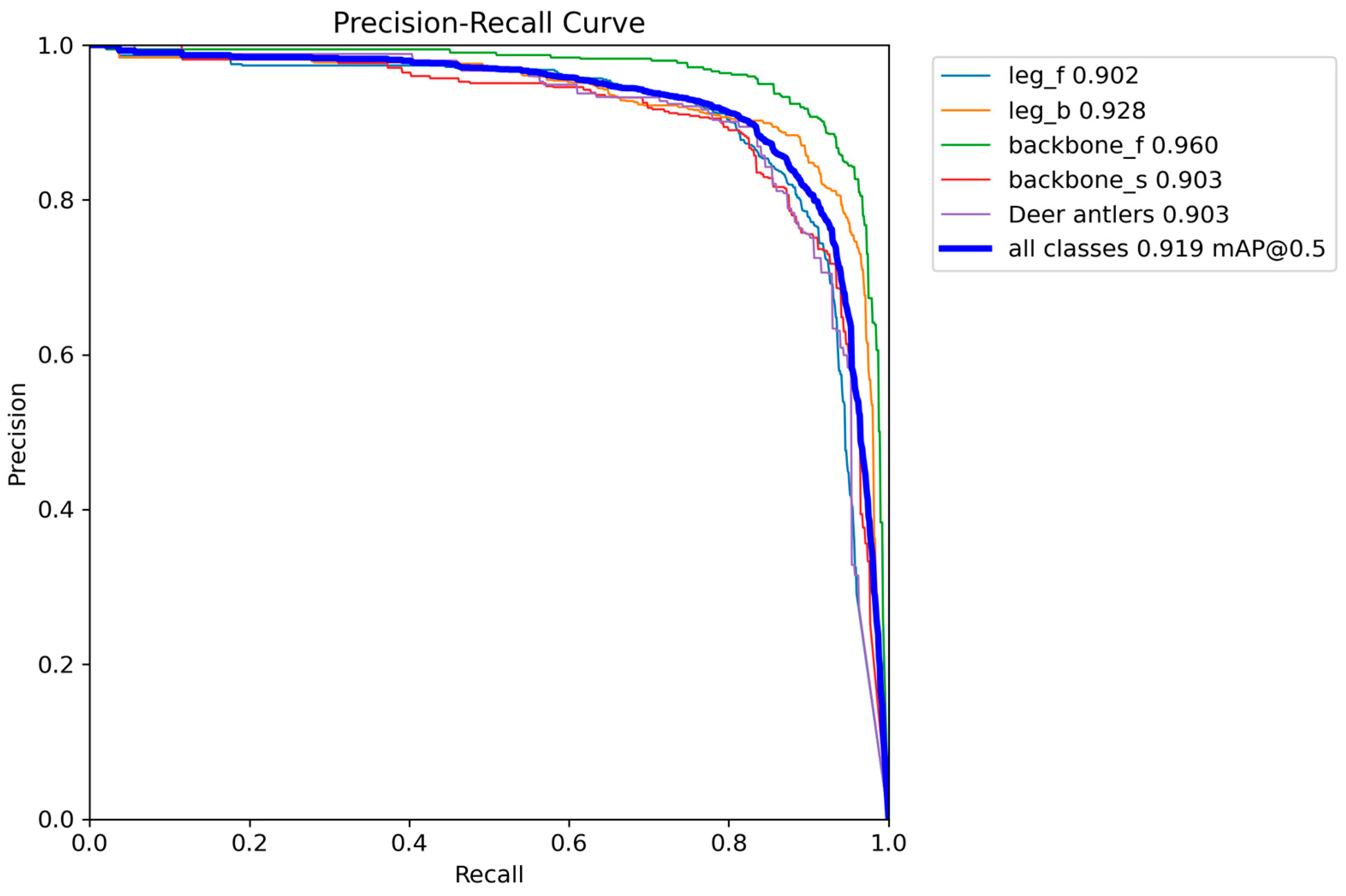
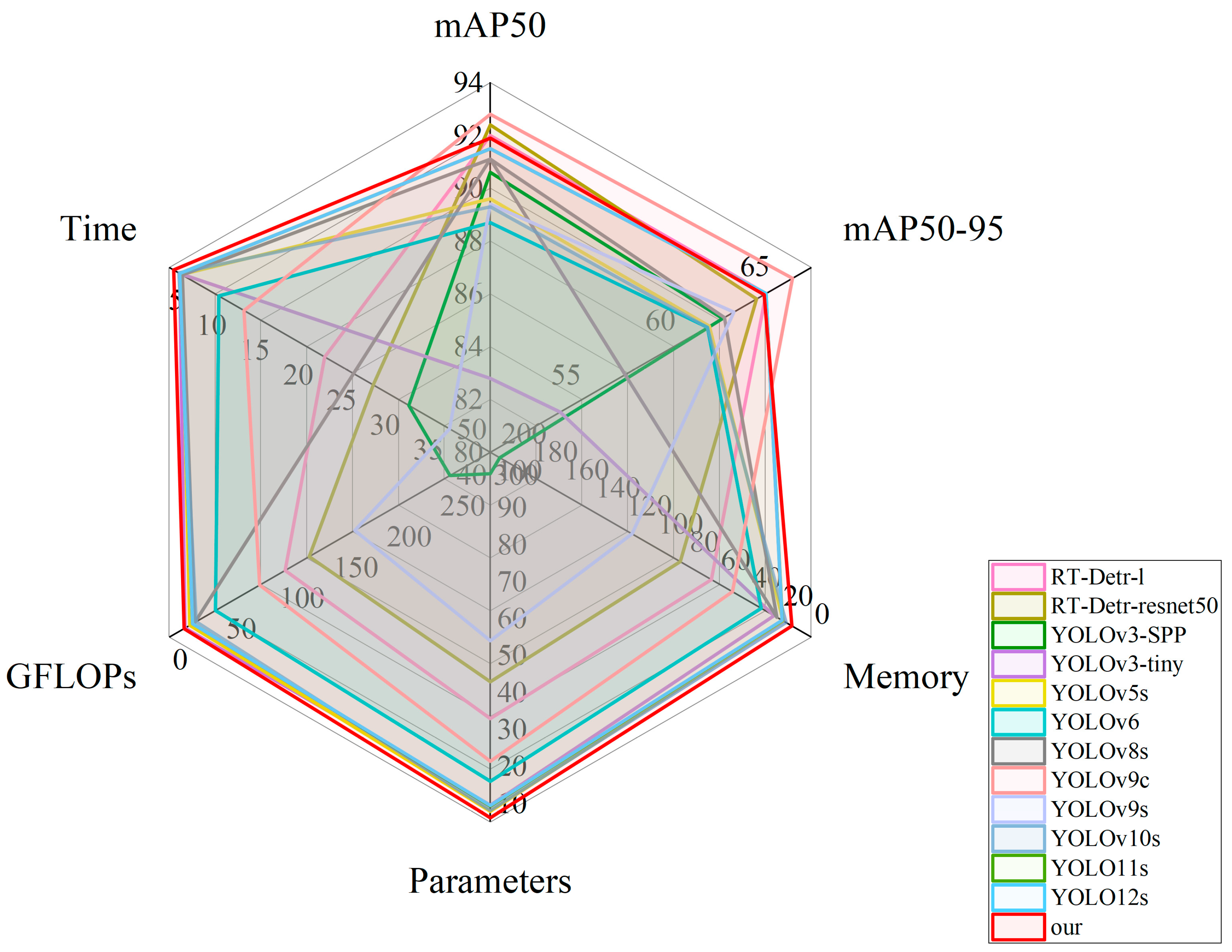
This study successfully developed a deep learning model based on YOLO11. This algorithm can achieve automated, rapid and accurate detection of key body parts such as deer antlers, heads (distinguishing between front and side), and front and hind legs in a real sika deer breeding environment. The research results show that the mAP50 and MAP50-95 of MFFW-YOLO reach 91.9% and 64.5%, respectively. Meanwhile, it outperformed in terms of model efficiency, with only 5.9 million parameters, a computational cost of 12.8 GFLOPs, and an inference speed of 3.8 ms.
The most core contribution of this study lies in its great potential to promote the realization of a non-contact management model, which is expected to significantly enhance the animal welfare level of sika deer. The significant stress response caused by traditional physical and chemical fixation methods to sika deer is a key issue that urgently needs to be addressed in modern humanized breeding. Our algorithm provides a key technical basis for replacing or assisting these invasive operations by offering long-distance and automated precise location positioning capabilities. For instance, in the future, when combined with automated equipment (such as mechanical arms used for deer antler collection and preparation), the visual perception information provided by this algorithm is the core prerequisite for achieving safe and low-stress operations. This shift from “forced contact” to “intelligent perception” aligns with the ethical requirements and development trends of enhancing farm animal welfare standards and achieving sustainable production on a global scale. From a methodological perspective, this study verified the effectiveness of MFW-YOLO in dealing with the complex task of refined detection of specific parts of large mammals, especially in challenging real breeding environments (such as light variations, background disturbances, diverse postures, and occlusion, etc.). This provides valuable references for computer vision applications in similar scenarios. Of course, the research also has limitations. For instance, the current model training mainly relies on the dataset obtained from the intelligent sika deer breeding base of Jilin Agricultural University. Although this dataset covers various scenarios of this specific site, data from a single source may not fully represent the diversity of the sika deer breeding environment. Therefore, the generalization ability of this model in a broader environment or different deer populations needs to be further verified. Furthermore, to stably deploy the algorithm in actual production, further research on model compression techniques (such as pruning) is still needed to significantly reduce computing resource consumption and memory usage while maintaining acceptable detection accuracy, in order to adapt to challenges such as edge computing devices [
32,
33].
Based on the foundation and limitations of the current research, future studies will focus on the following aspects: Firstly, continuously optimize the algorithm performance by using generative adversarial networks to synthesize challenging samples (such as rare poses, extreme lighting, or partial occlusion) to further enhance detection accuracy, speed, and robustness [
34]. Secondly, explore multimodal information fusion and combine data sources such as infrared and depth to obtain more comprehensive animal status information [
35]. Furthermore, conduct system integration and empirical research, embed the algorithm into the actual monitoring or management system, and carry out long-term verification in the real production environment. Finally, evaluate the feasibility of migrating and applying this method to other species (such as domestic animals like pigs, cattle and sheep). To sum up, this study proposes the MFW-YOLO detection algorithm for specific parts of sika deer. Not only has significant progress been made at the technical level, but more importantly, it has opened up a new way for the intelligent, non-contact, and humanized management of sika deer and similar large animals. This algorithm is expected to promote the innovation of traditional animal management models and play a key role in improving animal welfare, optimizing production management, and deepening health monitoring capabilities, fully demonstrating the significant value and broad potential of deep learning in addressing the challenges of modern agricultural management.
5. Conclusions
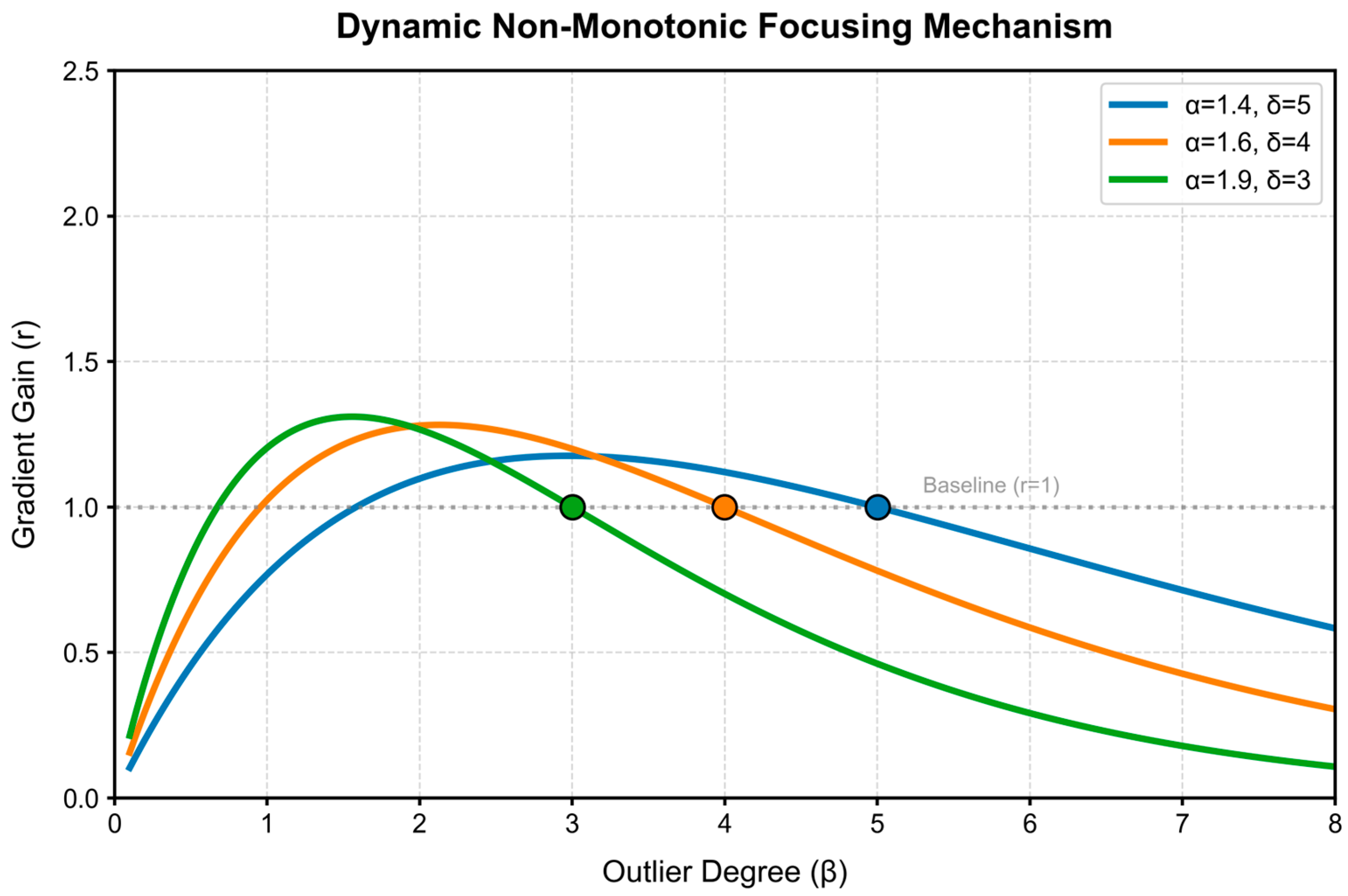
In this study, aiming at the problems such as low efficiency of management methods (physical fixation and chemical fixation), strong stress, and damage to animal welfare existing in the sika deer breeding industry, a target detection algorithm based on the YOLO11 framework has been successfully developed. MFFW-YOLO achieves precise detection of key body parts of sika deer (antlers, head, and front and hind legs) in a real breeding environment through non-contact visual technology. Experimental evaluations conducted on the sika deer dataset indicate that MFW-YOLO has excellent performance: Its mAP50 and MAP50-95 reached 91.9% and 64.5%, respectively. Meanwhile, it performed outstandingly in terms of model efficiency, with only 5.9 million parameters, a computational load of 12.8 GFLOPs, and an inference speed of 3.8 ms, achieving an excellent balance between accuracy and efficiency. This performance improvement is attributed to three key targeted enhancements: First, the design of the lightweight backbone network MobileNetV4HybridSmall effectively integrates convolution and self-attention mechanisms. Second, a multi-scale fast pyramid pooling module SPPFMscale was designed, which enhanced the ability of multi-scale feature aggregation. Thirdly, the advanced WIoU v3 loss function was adopted to optimize the robustness of bounding box regression. These innovations work together to significantly enhance the model’s detection ability in complex scenarios.
The core value of this research lies in providing strong technical support for the intelligent, non-contact and humanized management of sika deer. The success of this algorithm not only promotes the improvement of animal welfare, but also lays the foundation for downstream applications such as automated health monitoring (for example, analysis based on deer antler morphology, head behavior, or leg gait) and data-driven refined management decisions. This is of great significance for improving production efficiency, reducing risks and promoting the sustainable development of the industry. Despite the significant progress made, this study still has limitations. Mainly, the model validation is based on a single data source, and its generalization ability in a broader environment needs to be further confirmed. The future research directions will include: expanding the diversity of the dataset to enhance the generalization ability of the model; continuously optimizing the algorithm architecture and training strategy; exploring multimodal information fusion to obtain more comprehensive animal states; conducting system integration and large-scale field verification; and assessing the possibility of expansion into other species domains.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}