1. Introduction
China is the global leader in vegetable production and consumption. In 2022, global vegetable production totaled 1.173 billion tons, with China accounting for 618 million tons, representing 52.69% of the total output [
1]. The annual demand for vegetable seedlings in China reaches 680 billion plants, including 50 billion grafted seedlings [
2]. Grafting is a technique that involves attaching a branch or bud from one plant to the stem or root of another so that the two parts grow into a complete plant. Widely adopted in modern vegetable production, grafting effectively mitigates issues such as continuous cropping obstacles, pests, and diseases [
3,
4,
5,
6] while enhancing crop resistance and yield [
7,
8,
9]. Common vegetable-grafting methods include splice, side, approach, and cleft grafting.
Manual grafting is inefficient, labor-intensive, and suffers from a shortage of skilled grafters, creating an urgent demand for automation in grafting in the vegetable industry. Grafting robots can precisely execute tasks such as seedling clamping, cutting, alignment, and clipping, significantly improving automation levels and production efficiency. However, morphological variations among vegetable seedlings often necessitate manual assistance during seedling feeding, resulting in reduced grafting machine efficiency. Consequently, automated seedling-feeding has emerged as a critical technical bottleneck in grafting technology. In recent years, deep learning has found extensive applications in agricultural domains, including crop growth monitoring, fruit harvesting, and pest and disease early warning systems [
10,
11]. Nevertheless, complex background interference during detection often reduces recognition accuracy and segmentation precision. Leveraging advanced machine learning and deep learning algorithms for melon seedling feature detection and segmentation can provide crucial information guidance for fully automated grafting machines, particularly in automated seedling-feeding.
In the field of seedling feature segmentation, researchers have developed various innovative methods tailored to diverse application scenarios. Lai et al. [
12] addressed the need for automatic scion detection in vegetable-grafting machines by proposing a lightweight segmentation network based on an improved UNet. They employed MobileNetV2 as the backbone network and incorporated the Ghost module. The refined Mobile-UNet model demonstrated improvements of 5.69%, 1.32%, 4.73%, and 3.12% in mIoU, precision, recall, and Dice coefficient, respectively, achieving precise segmentation of the scion cotyledons in the clamping mechanism. Deng et al. [
13] proposed a CPHNet-based stem segmentation algorithm for seedlings, which demonstrated enhanced precision and stability in stem segmentation compared to alternative models. On a self-constructed dataset, the model achieved an mIoU of 90.4%, mAP of 93.0%, mR of 95.9%, and an F1 score of 94.4%. Zi et al. [
14] proposed a semantic segmentation network model based on an optimized ResNet to accurately segment corn seedlings and weeds in complex field environments. By adjusting the backbone network and integrating an atrous spatial pyramid pooling module and a strip pooling module, the model showed enhanced capability to capture multi-scale contextual information and global semantic features. The experimental results revealed that the model achieved an mIoU of 85.3% on a self-built dataset, showcasing robust segmentation performance and generalization ability, thereby offering valuable insights for developing intelligent weeding devices.
In segmentation and localization research, investigators are committed to achieving enhanced precision while maintaining low complexity and computational demands. Jiang et al. [
15] proposed an improved YOLOv5-seg instance segmentation algorithm for bitter gourd-harvesting robots, integrating a CA mechanism and a refinement algorithm. The model achieved mean precision values of 98.15% and 99.29% for recognition and segmentation, respectively, representing improvements of 1.39% and 5.12% over the original model. The localization errors for the three-dimensional coordinates (X, Y, Z) were 7.025 mm, 5.6135 mm, and 11.535 mm, respectively. This method offers valuable insights for accurately recognizing and localizing bitter gourd harvesting points. Zhang et al. [
16] proposed a lightweight weed localization algorithm based on YOLOv8n-seg, incorporating FasterNet and CDA. The model reduced computational costs by 26.7%, model size by 38.2%, and floating-point operations to 8.9 GFLOPs while achieving a weed segmentation accuracy of 97.2%. Fan et al. [
17] proposed an improved weed recognition and localization method based on an optimized Faster R-CNN framework with data augmentation techniques. The enhanced model achieved an average inference time of 0.261 s per image with an mAP of 94.21%. Paul et al. [
18] compared the performance of YOLO algorithms for pepper detection and peduncle segmentation. In the pepper detection task, the YOLOv8s model achieved an mAP of 0.967 at an IoU threshold of 0.5. For peduncle detection, the YOLOv8s-seg model achieved mAP values of 0.790 and 0.771 for Box and Mask detection, respectively. Using a RealSense D455 RGB-D camera, the laboratory tests achieved target point localization with maximum errors of 8 mm, 9 mm, and 12 mm in the longitudinal, vertical, and lateral directions, respectively.
Researchers have proposed various innovative solutions in the field of detection and segmentation algorithms for complex problems. Wu et al. [
19] addressed the challenge of apple detection and segmentation in occluded scenarios by proposing the SCW-YOLOv8n model. By integrating the SPD-Conv module, GAM, and Wise-IoU loss function, the model significantly improved apple detection and segmentation accuracy. The detection mAP and segmentation mAP of the original YOLOv8n model were increased to 75.9% and 75.7%, respectively, while maintaining a real-time processing speed of 44.37 FPS. Zuo et al. [
20] tackled the challenges of varying scales and irregular edges in the branches and leaves of fruits and vegetables by proposing a segmentation network model that integrates target region semantics and edge information. They combined the UNET backbone network with an edge-aware module and added an ASPP module between the encoder and decoder to extract feature maps with different receptive fields. The results show that the average pixel accuracy of the test set reached 90.54%.
In summary, there has been limited research on feature detection and segmentation of melon-grafting seedlings, and while existing studies exhibit certain limitations, they provide valuable references for this work. To address the need for the rapid and high-precision detection and segmentation of seedling features in automated melon-grafting machines, this study employs an improved YOLOv8-SDC model to process individual seedlings’ dual-view (top and side) image data. The proposed approach enhances the speed and accuracy of seedling detection and segmentation. Extracting stem–cotyledon separation points and cotyledon deflection angles establishes the necessary prerequisites for precisely adjusting cotyledon direction and seedling height.
The main contributions of this study are as follows: (1) In the Backbone layer, SAConv is introduced to replace Conv, dynamically adjusting the receptive field of convolutional kernels, thereby enhancing the model’s ability to extract multi-scale features, particularly suitable for target detection tasks in complex scenarios. This improvement enhances the model’s detection accuracy and robustness without significantly increasing computational costs. (2) In the Neck layer, the c2f_DWRSeg module replaces the c2f module, enabling the network to flexibly adapt to segmentation tasks involving targets of varying shapes. This enhances the model’s precision in perceiving edges and contours and improves its ability to capture irregular shapes and detailed features. (3) Introducing the CA mechanism enhances the model’s ability to focus on key features by capturing spatial and inter-channel relationships. This reduces the influence of irrelevant regions, such as the background, effectively improving the model’s target recognition and localization accuracy in complex backgrounds.
3. Methods
3.1. Improved YOLOv8-SDC Network Model
The YOLOv8 model retains the same fundamental principles as its predecessors, with the Ultralytics team introducing new improvement modules based on YOLOv5 to further enhance the model’s detection performance. Compared to two-stage detection algorithms such as Faster R-CNN and Mask R-CNN [
22,
23], YOLOv8 offers faster inference speed and end-to-end training capabilities, particularly excelling in real-time detection scenarios [
24,
25,
26,
27,
28]. The YOLOv8 network model primarily consists of four parts: Input, Backbone, Neck, and Head. YOLOv8n-Seg is a fast and high-precision instance segmentation algorithm that has shown significant effectiveness in plant segmentation tasks [
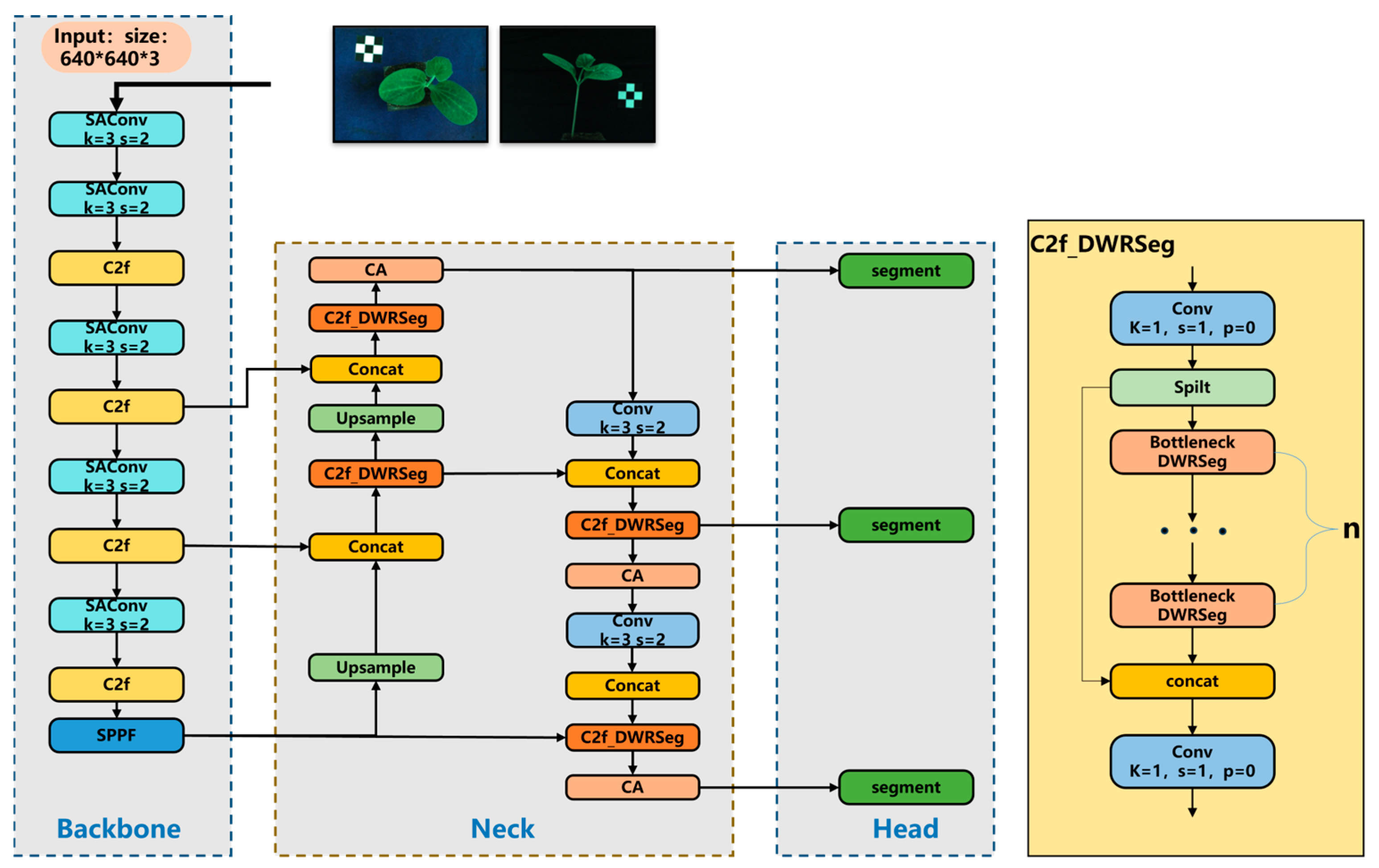
29]. The base model used in this study is YOLOv8n-seg, and the improved model is named YOLOv8-SDC. Its network structure is illustrated in
Figure 4.
This paper proposes three critical improvements to the base YOLOv8n-seg model: (1) replacement of standard convolutional layers with SAConv modules in the backbone network to enhance receptive field adaptation, (2) substitution of the original c2f modules with c2f_DWRSeg blocks in the neck network for improved feature fusion, and (3) integration of CA mechanisms prior to each segmentation module output for optimized feature representation. The processing pipeline begins by resizing input seedling images (640 × 480 pixels) to a standardized 640 × 640 resolution through LetterBox transformation while preserving the original aspect ratio via gray padding. The enhanced architecture subsequently performs multi-scale feature extraction through the modified backbone network to capture hierarchical features, while the neck layer enhances target discriminability. The detection heads’ output predicted bounding boxes and class information, while the segmentation heads generated prototype masks and coefficient matrices. This integrated system ultimately produces detection boxes, class labels, and corresponding binarized masks, achieving real-time, end-to-end instance segmentation while maintaining high precision.
3.2. SAConv Module and Its Components
3.2.1. Introduction to the SAConv Module
Wang et al. [
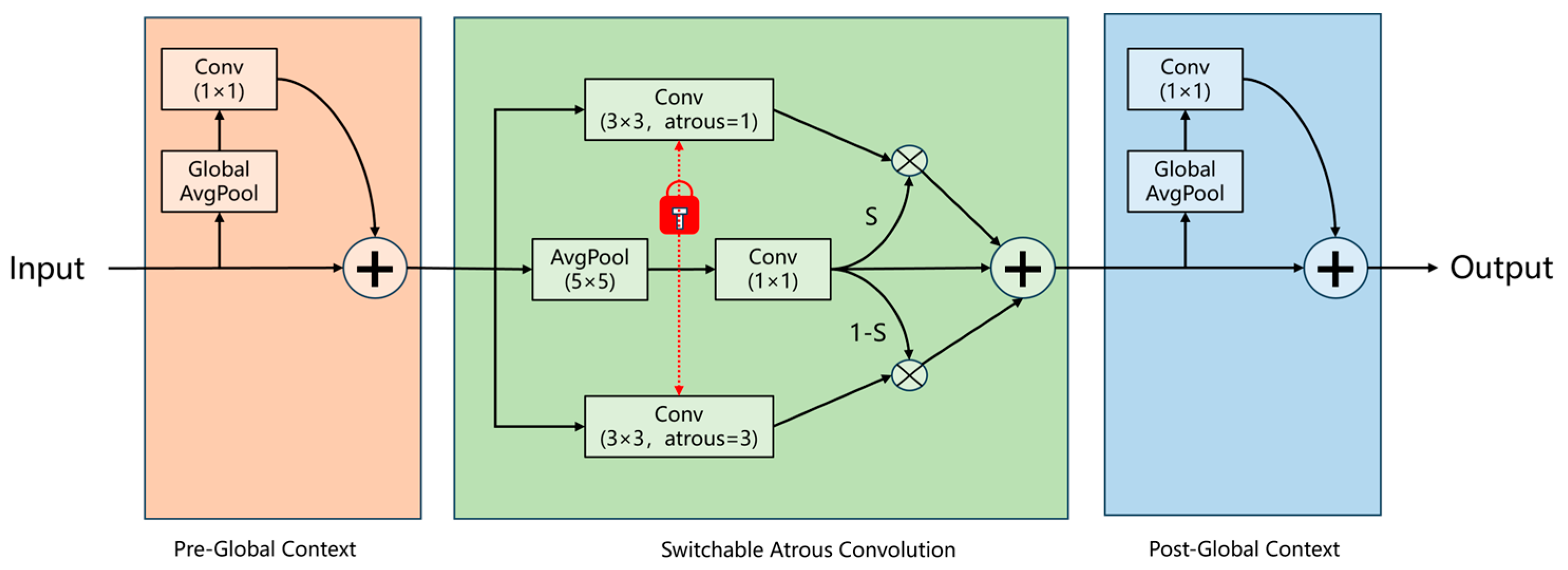
30] proposed a novel convolutional module, SAConv, for semantic segmentation tasks. This module replaces the conventional Conv2d layers and consists of three key components: two global modules positioned before and after the SAConv component, as illustrated in
Figure 5. During the feature extraction phase, the network progressively downsamples the input through multiple stages, each containing several SAConv modules. The core innovation lies in its switchable atrous rate mechanism, which dynamically adjusts the convolutional receptive field. This mechanism learns path weights to automatically select optimal feature extraction patterns. Each SAConv module is followed by BatchNorm normalization and SiLU activation functions, effectively preserving local detailed features while enhancing multi-scale contextual awareness. The feature maps undergo systematic downsampling from an initial resolution of 320 × 320 (stride = 2) to 20 × 20 (stride = 32), ultimately generating a three-level feature pyramid at resolutions of 80 × 80, 40 × 40, and 20 × 20.
The global context module processes the input feature map. First, the feature map undergoes global average pooling, followed by a 1 × 1 convolution. The input feature map and the output of the 1 × 1 convolution are then fused through addition to integrating features from different layers. After this processing, the fused features enter the SAC stage. One branch applies two 3 × 3 convolutional kernels with dilation rates of 1 and 3, enabling switching between different dilation rates to expand the receptive field of the convolutional kernels and capture larger regional information. The other branch performs 5 × 5 average pooling on the fused feature map to further extract the average features of local regions, followed by a convolution operation. The switch (S) in the figure determines the contribution ratio of features from each dilation rate through weights, and these features are then weighted and fused. These operations share the same weights to reduce the number of parameters and dynamically adjust the receptive field. The addition operation combines the convolution results from different dilation rates and the convolution results after average pooling. Finally, the features enter the global context module, where the context module processes them similarly to produce the final output.
3.2.2. Principles and Mechanisms of SAC Convolution
SAC is an advanced convolution mechanism primarily designed to enhance feature extraction capabilities in object detection and segmentation tasks. The core idea of SAC is to apply convolutions with different “dilation rates” to the same feature map, as shown in
Figure 6. Dilated convolution expands the receptive field by inserting “holes” into the convolutional kernel without increasing the number of parameters or computational cost, allowing SAC to capture features at different scales. SAC also incorporates a unique design: a “switch function” determines how to combine the results of convolutions with different dilation rates. This switch is “spatially dependent”, as each position in the feature map can have its switch to determine the appropriate dilation rate. This enhances the network’s flexibility in handling objects of varying sizes and scales.
3.3. Introduction to the c2f_DWRSeg Module
The C2f_DWRSeg module is designed to extract multi-scale features more efficiently. It first adjusts the number of input channels using a 1 × 1 convolution and then processes the feature map through multiple Bottleneck_DWRSeg modules. Finally, the output feature maps from the main and residual branches are concatenated and passed through a convolution operation to produce the final feature map. This design improves the model’s performance in visual tasks by combining local and global information, especially in scenarios that demand efficient computation and fine-grained feature extraction.
3.3.1. Introduction to the Bottleneck_DWRseg Module
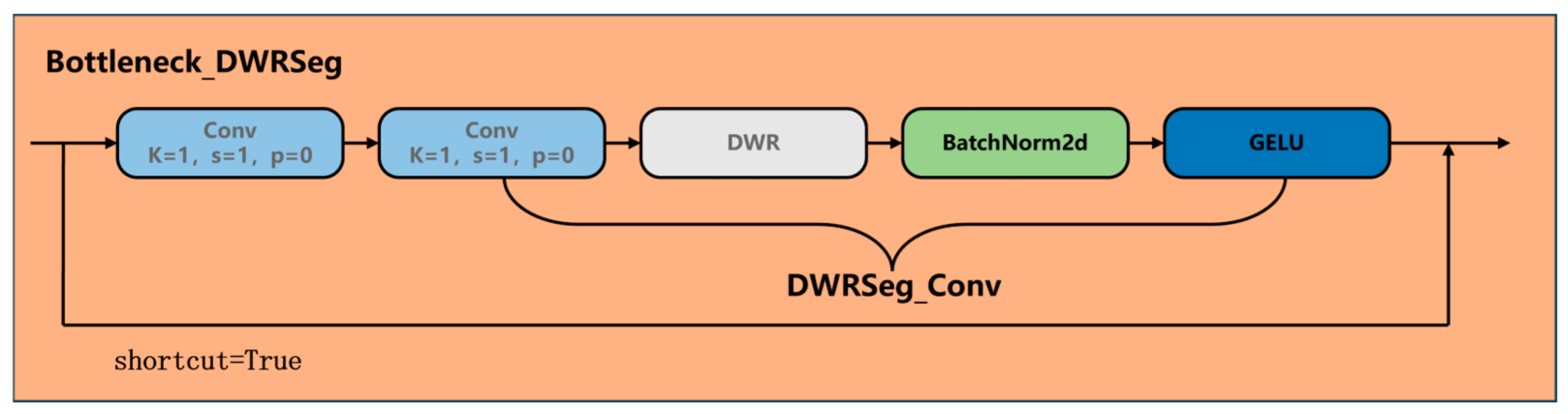
The Bottleneck_DWRseg module architecture is illustrated in
Figure 7. Its core design combines depthwise separable convolution with residual connections. The module initially employs a 1 × 1 convolution for channel dimension reduction, followed by a 3 × 3 depthwise separable convolution for spatial feature extraction, which significantly reduces computational complexity. Finally, a 1 × 1 convolution restores the channel dimension while incorporating residual connections.
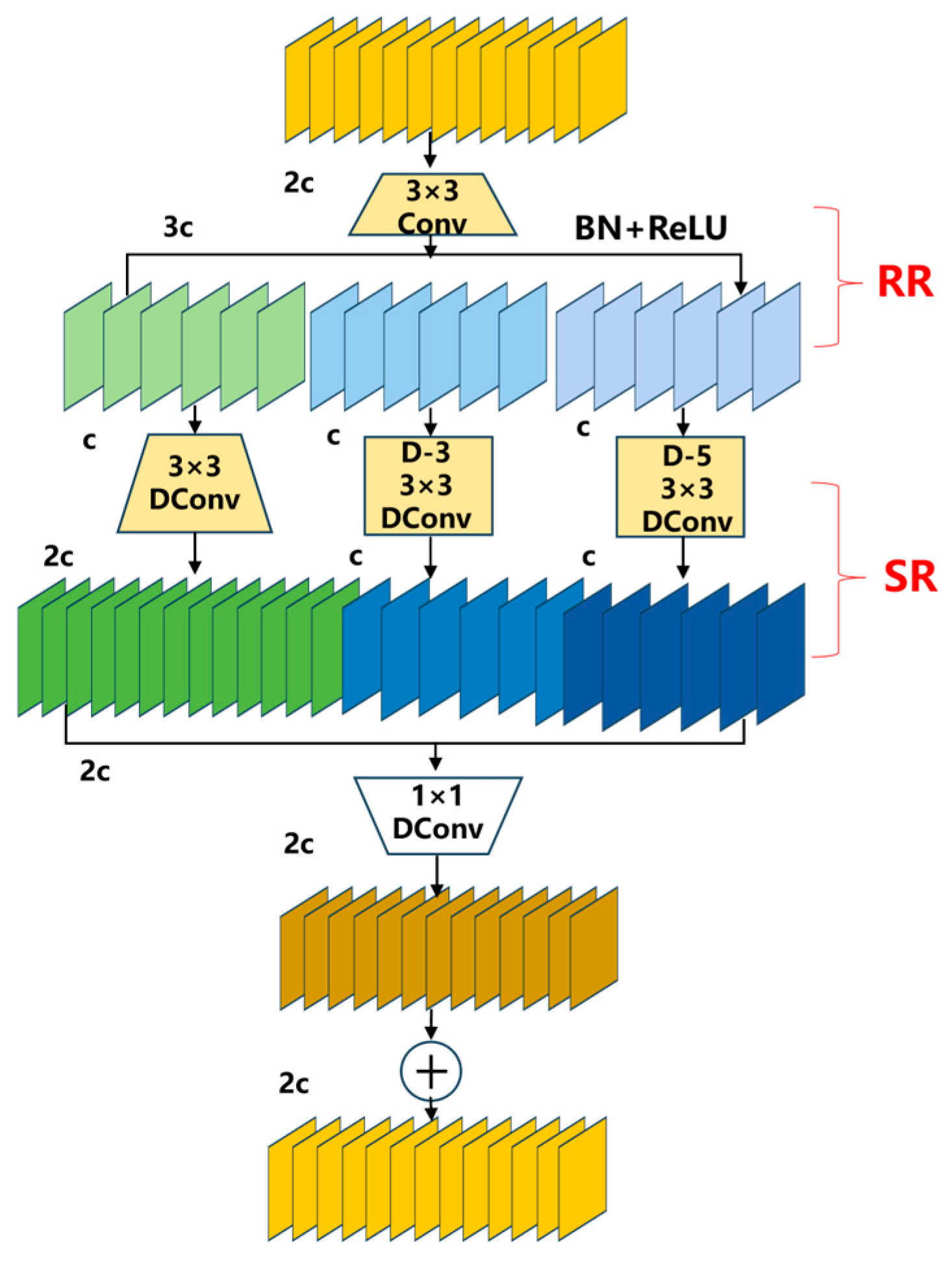
3.3.2. Introduction to the DWR Module
The innovative DWR module [
31] is shown in
Figure 8. It is an efficient convolutional module that combines Depthwise separable convolution and residual connections. First, the DWR module processes the input feature map using a standard 3 × 3 convolution. After the convolution operation, the feature map undergoes batch normalization and ReLU activation to further adjust its distribution and introduce nonlinear transformations. The convolution results are then split into multiple branches, each applying a different dilation rate (e.g., d = 1, d = 3, d = 5) for dilated convolution. Next, the concatenated feature map is processed by a 1 × 1 convolution and further normalized using BN. Finally, through residual connections, the addition operation enables information sharing between the input and output feature maps, which helps mitigate the vanishing gradient problem and facilitates network training.
The DWR module proposes a two-step residual feature extraction method to enhance multi-scale information capture efficiency for real-time segmentation tasks. This approach consists of two distinct phases: Regional Residualization and Semantic Residualization. During the Regional Residualization phase, the input feature maps are first divided into groups, with each group processed by depthwise separable dilated convolutions employing different dilation rates. This architecture enables an adaptive perception of various seedling morphologies, ensuring accurate identification regardless of leaf shapes (including elliptical forms and other configurations). The Semantic Residualization phase subsequently generates concise representations of the regionally residualized features, precisely extracting seedling edges and contour information. This processing maintains clear segmentation boundaries even when confronted with irregular leaf margins. The phase employs depthwise separable dilated convolution with a single dilation rate for semantic filtering, effectively eliminating redundant information while preserving critical features. The final output is produced through feature concatenation.
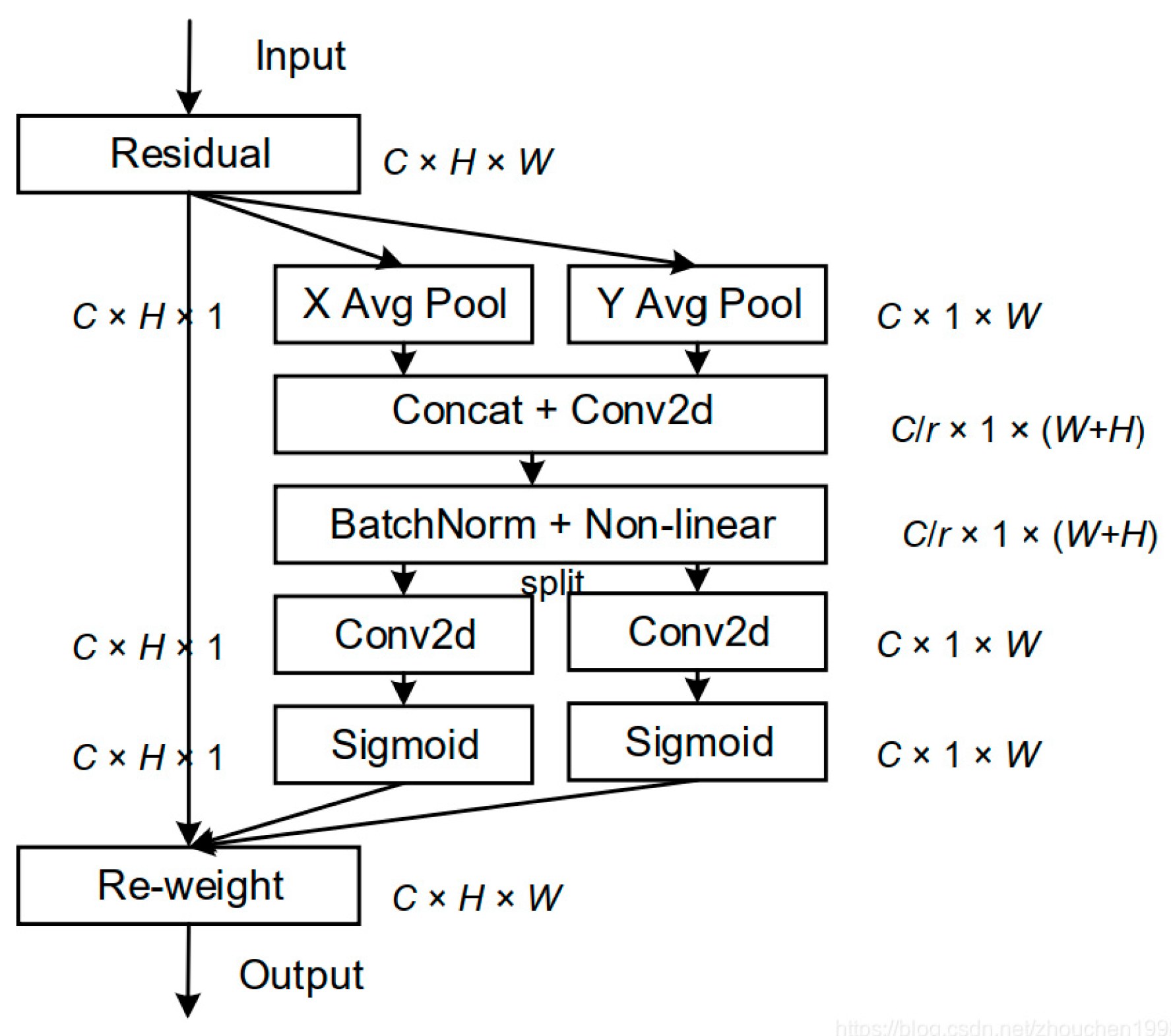
3.4. Introduction to the CA Mechanism Module
The CA mechanism is a feature enhancement mechanism that dynamically adjusts channel weights to improve feature representation [
32]. The module initially performs coordinate-wise dimension reduction on the input features, conducting global pooling operations separately along the horizontal and vertical axes to generate orientation-aware feature descriptors. Subsequently, these descriptors undergo convolutional transformation followed by Sigmoid activation to produce attention weight maps. Ultimately, these weight maps are multiplied with the original features to achieve spatial-channel collaborative optimization.
The CA module encodes precise positional information through two key steps, coordinate information embedding and coordinate attention generation, as illustrated in
Figure 9.
First, regarding coordinate information embedding, traditional global pooling operations lose positional information. The CA module addresses this issue by decomposing global pooling into two one-dimensional feature encoding operations. Specifically, for the input feature map X, pooling kernels of size (H, 1) and (1, W) are applied to encode each channel along the horizontal and vertical directions, respectively. The output of the c-th channel at height h is expressed by the following Formula (1).
The output of the c-th channel at width w is expressed by the following Formula (2).
This operation generates a pair of direction-aware attention maps, which capture spatial long-range dependencies while preserving precise positional information, thereby helping the network locate targets more accurately.
In the coordinate information embedding stage, a pair of direction-aware attention maps is generated by performing one-dimensional pooling operations along the horizontal and vertical directions. At the same time, precise positional information along the other spatial direction is retained, helping the network locate targets more accurately. This process corresponds to the figure’s X Avg Pool and Y Avg Pool sections. Next, a coordinate attention generation operation is designed to better utilize the generated feature maps. Specifically, the two generated feature maps are concatenated and then transformed via a shared 1 × 1 convolution to generate an intermediate feature map f, as shown in Formula (3).
Here, F
1 represents the 1 × 1 convolution, and δ is the activation function. Next, f is split along the spatial dimension into f
h and f
w, which are then transformed into feature maps with the same number of channels as the input X through two separate 1 × 1 convolutions, F
h and F
w, as shown in Formulas (4) and (5).
Here, σ is the activation function. Finally, g
h and g
w are expanded into attention weights, and the final output of the CA module is expressed as shown in Formula (6).
Through the above design, the CA module simultaneously implements attention mechanisms in both horizontal and vertical directions while retaining channel attention characteristics. This structure captures long-range dependencies and precise positional information and effectively enhances the model’s ability to locate and recognize targets. Moreover, its lightweight design ensures minimal computational overhead, making it highly suitable for integration into existing networks.
In seedling segmentation tasks, the CA mechanism enhances the model’s ability to extract seedling features by adaptively adjusting channel weights, enabling better differentiation of seedling targets from complex backgrounds. At the same time, the CA module utilizes precise positional information encoding to significantly enhance the localization accuracy of seedlings, particularly when seedling edges are blurry, or shapes are irregular, enabling the more accurate capture of their contours and spatial positions. This combination of background suppression and precise localization makes the CA mechanism excel in seedling segmentation tasks.
3.5. Model Testing
To verify the difference between the improved model and other models, YOLOV8-SDC, YOLOv5, YOLACT, Mask R-CNN, and YOLOv11 were compared, and the optimal model weight file was selected for testing. During the test, the image was automatically divided into two categories: side view and top view. The first category is that the top view has a growth point area. If it is the first category, the two cotyledons are identified as leaf1 and leaf2. By comparing the pixel areas of leaf1 and leaf2, the cotyledon with a larger area is defined as the reference cotyledon. The geometric center points of the growth point and the reference cotyledon are automatically found, and the angle between the line connecting the two points and the vertical direction is the cotyledon deflection angle. The second category is that the side view has a seedling stem area. If it is the second category, the two cotyledons are identified as leaves, and the overlap point between the seedling stem area and the two cotyledon areas is automatically found as the stem–cotyledon separation point. In order to further verify the recognition accuracy of the model, manual testing was used to find the growth point center and stem–cotyledon separation point of the grafting feature in the original top view and the test image; finally, the model was verified by model testing and manual testing.
5. Discussion
The dual perspectives segment the various parts of the seedlings. This paper proposes three key improvements to the base YOLOv8n-seg model. First, in the Backbone layer, the original convolution is replaced with SAConv as the basic module. By applying convolutions with different dilation rates on the same input features and combining them using a switch function, the model can adaptively capture multi-scale feature information, significantly enhancing the recognition accuracy and segmentation precision for targets in images. Second, in the Neck network, c2f_DWRSeg replaces c2f, utilizing Depthwise separable dilated convolutions for multi-scale feature extraction. Through an efficient two-step residual approach, the network can more flexibly adapt to segmentation tasks involving targets of varying shapes, improving the model’s precision in perceiving edges and contours. Finally, a CA mechanism module is added before the output of each segmentation module. The model can more accurately locate and identify target regions by integrating channel attention and spatial positional information. Due to its lightweight design, it introduces almost no additional computational burden, making it highly suitable for integration into existing lightweight network architectures.
The improved model will be deployed on the vegetable-grafting robot in the future, and the performance requirements of the model are very high. First of all, the accuracy of the external feature recognition of the rootstock is the most important, which is the guarantee of successful grafting. Secondly, the mechanical grafting process is required to be completed quickly in about 3 s, so the speed of detection is also particularly important. Finally, the problem of model deployment on the edge computing platform needs to be considered. For the previous comprehensive considerations, the improved YOLOv8-SDC network model was finally selected by comparing different network models. It is the best regarding the detection speed and average detection accuracy and can be deployed on the edge computing platform. The parameters of the cotyledon deflection angle and the stem–cotyledon separation point obtained by post-processing are compared with the manual measurement values to verify the feasibility of the proposed method. However, in future studies, the obtained feature parameters will be further processed, and the actual coordinates will be found in combination with the depth information to obtain the true parameter values. In addition, we plan to test the improved model in the environment of automatic seedling removal in the plug tray so that it can work in the seedling growth environment. The proposed improved network model provides a valuable reference for studying seedlings with irregular morphology in complex environments and promotes the development and application of fully automatic grafting machines.
6. Conclusions
This paper proposes an improved YOLOv8n-SDC model for feature detection and the segmentation of melon rootstock seedlings to obtain the cotyledon deflection angle and the coordinates of the stem–cotyledon separation point. The following conclusions can be drawn based on the experiment:
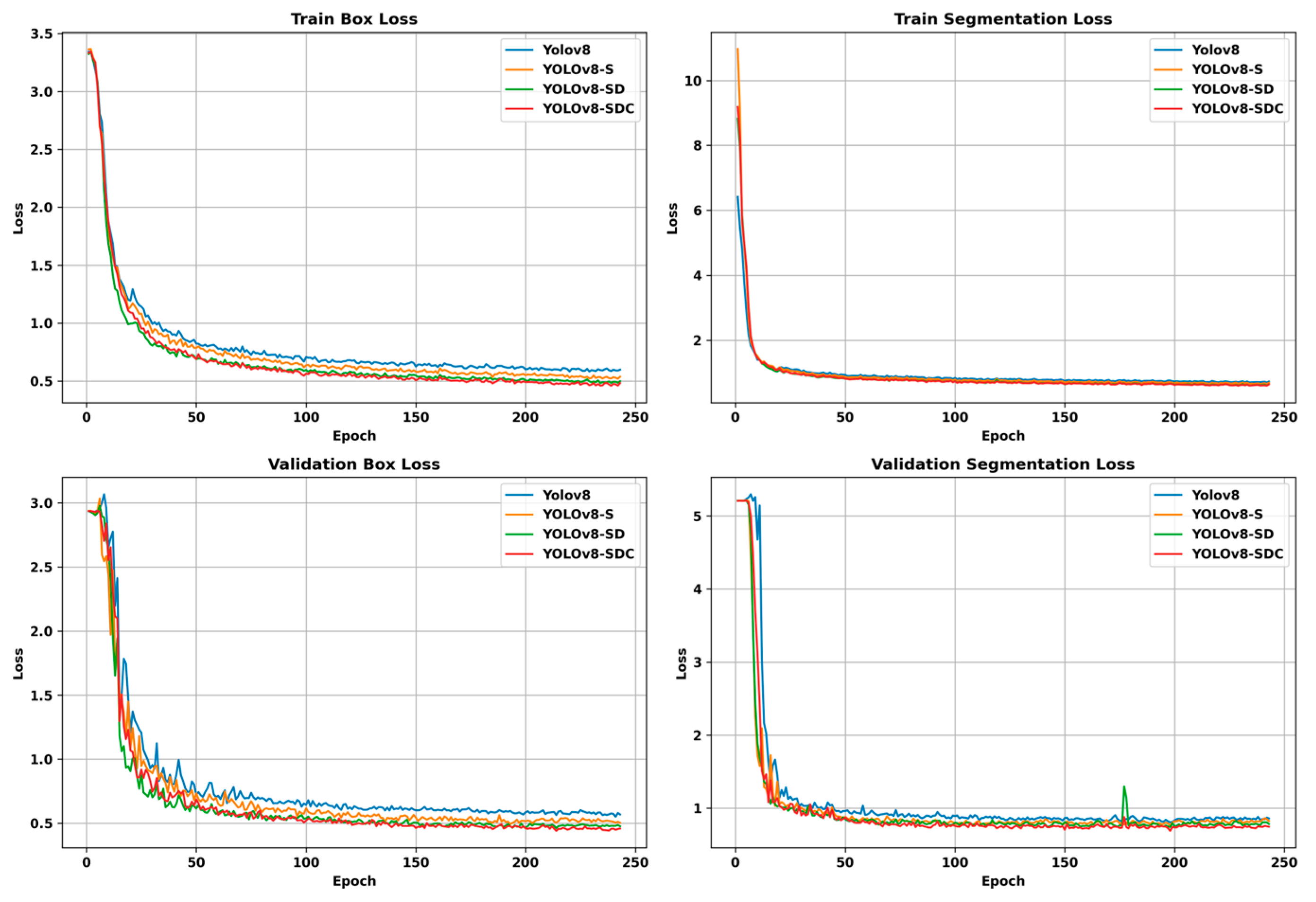
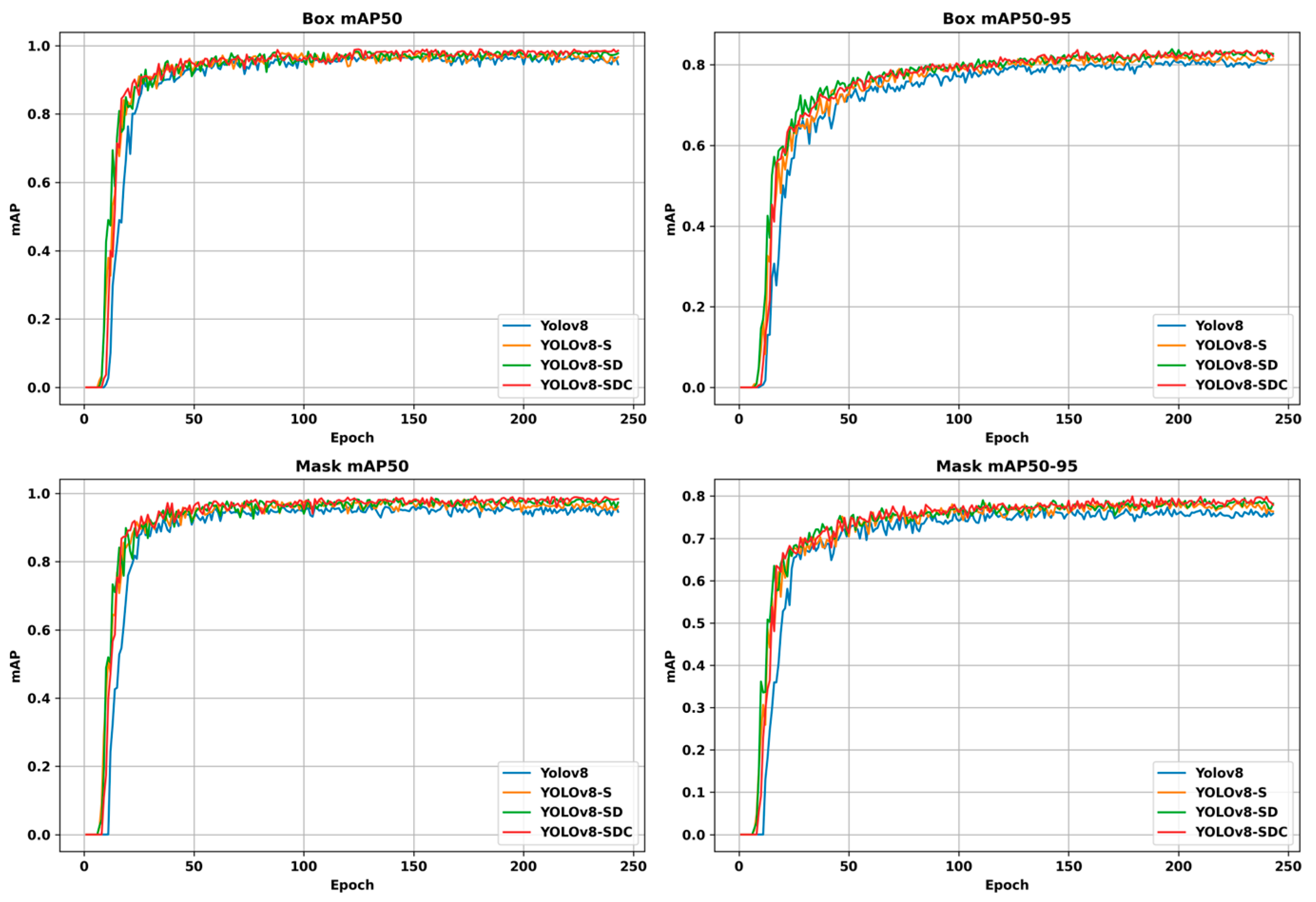
(1) Compared with the YOLOv5, YOLACT, Mask R-CNN, and YOLOv11 models, the improved YOLOv8n-SDC model performs best, with a segmentation speed far higher than other models, and an increase of about 18.34% over the original model. Most importantly, the improved model has the highest average Box and Mask accuracies, which were 98.6% and 99.1%, respectively. The weight file size of the improved model is 8.3 MB, which meets the requirements of edge computing platform deployment.
(2) Through the verification test of the cotyledon deflection angle and the stem–cotyledon separation point, it is found that the error is within the allowable range of grafting, which fully meets the accuracy requirements of the cotyledon deflection angle and the stem–cotyledon separation point during the automatic seedling raising process, and also provides the prerequisite for the precise adjustment of the cotyledon direction and the seedling raising height during the automatic seedling raising process of the grafting robot.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}