1. Introduction
Tomatoes are a globally significant crop, consistently ranking among the top vegetables in terms of production and consumption [
1]. Variations in growth stages during cultivation often necessitate that farmers rely on manual observations to grade maturity, estimate yields, and determine harvesting schedules to meet market demands [
2]. However, manual methods are labor-intensive, time-consuming, and prone to human error, particularly during large-scale operations. Research shows that inaccuracies in classifying tomato maturity during harvesting and handling can result in substantial post-harvest losses, reducing profitability and impacting food supply chains [
3]. These challenges have driven the adoption of automation and robotics in agriculture, offering innovative solutions to improve efficiency and precision in maturity detection, harvesting, and post-harvest handling.
In recent years, extensive studies have been conducted on crop ripeness detection and recognition, particularly for tomatoes, yielding significant results [
4,
5,
6,
7]. Traditional methods primarily focus on analyzing visual features such as color, texture, and shape, from which features are extracted and classified using algorithms. For instance, significant region detection with an improved Hough transform method identified unripe tomatoes with 77.6% accuracy under uniform backgrounds but struggled in complex environments [
8]. Convexity analysis for locating ripe fruits achieved an accuracy of 85–90% but was less effective with occlusions or irregular shapes [
9]. Machine vision-based sorting of cherry tomatoes combined color and shape features but lacked validation in dynamic environments [
10].
Beyond color-based detection methods, classification algorithms like support vector machines (SVMs) have also been used for ripeness identification. For example, SVMs have been applied to classify tomato color features, achieving a classification accuracy of 90.8% [
11]. A three-stage SVM-based system was also proposed for tomato classification, achieving high accuracy, though the algorithm is computationally complex [
12]. Another approach combined the HSV color space with the watershed algorithm for red tomato detection, demonstrating high efficiency under natural light conditions [
13]. In addition to traditional image processing, spectral analysis techniques have been applied to tomato ripening detection. A method combining visible/near-infrared spectroscopy with machine vision achieved a classification accuracy of 90.67% using a partial least squares (PLS) model [
14]. Another study classified tomatoes into four maturity stages based on hyperspectral imaging and sparse representation models, achieving a high classification accuracy of 98.3% [
6]. However, these traditional methods are often insufficient for practical applications, as they lack robustness in complex, dynamic environments, require extensive hyperparameter tuning, and fail to provide the real-time performance required for modern agricultural automation.
With the rapid development of artificial intelligence, deep learning models have become a cornerstone for solving complex agricultural problems, particularly in fruit maturity detection [
15]. Object detection methods play a crucial role in agricultural applications, including fruit maturity classification, crop monitoring, and automated harvesting. These methods serve two primary functions: detection and classification, where they not only locate the object within an image but also determine its category [
16]. Object detection models are generally divided into two types: one-stage and two-stage models. One-stage models, such as the YOLO [
17] series and SSD [
18], directly predict both the position and category of the object in a single step. This makes them faster and more suitable for real-time applications. In contrast, two-stage models, such as faster R-CNN [
19], generate region proposals first and then classify them, offering higher accuracy but at the cost of slower processing speeds.
Faster R-CNN has been effectively applied to tomato maturity detection, particularly in dense agricultural environments. For example, enhancements integrating feature pyramid networks (FPN) achieved an accuracy of 92.1% and an IoU of 0.85 in detecting tomato maturity [
7]. The main advantage of faster R-CNN is its high precision, which makes it particularly suitable for detecting small or occluded objects. However, its computational intensity and slower processing speed limit its use in real-time, large-scale applications, making it less ideal for automated systems that require fast processing.
In recent years, vision transformer (ViT)-based models such as the Swin transformer [
20] have achieved impressive accuracy in object detection tasks, particularly excelling in scenarios that require global context understanding, such as detecting fruits in cluttered or occluded environments. However, their reliance on transformer architectures leads to slower inference speeds, higher computational complexity, and greater memory consumption compared to traditional CNN-based models, which significantly limits their deployment on resource-constrained devices commonly used in agricultural automation. Therefore, despite their strong performance in controlled settings, ViT-based models are currently less suitable for real-time, efficient operation in practical agricultural applications.
In response to the challenges of tomato maturity detection, YOLO (you only look once) models have gained prominence due to their speed and efficiency. These models enable real-time processing by predicting both object position and category in a single pass.
An enhanced YOLOv7-based model has demonstrated high accuracy in detecting ripe tomatoes in complex environments, achieving 96.5% accuracy and an mAP@0.5 of 97.3% [
21]. While YOLO models offer fast and accurate detection, their performance may be affected by occlusion and small, distant objects, whereas two-stage models like faster R-CNN can perform better.
To address these limitations, an improved YOLOv8 model integrates multi-head self-attention (MHSA) mechanisms, enhancing accuracy while reducing computational costs. This version achieved an accuracy of 91.2% and an mAP@0.5 of 90.4%, making it suitable for resource-constrained deployment [
4].
Further improvements include RDE-YOLOv7, a lightweight version optimized for detecting dragon fruits, achieving an mAP@0.5 of 96.9%, significantly reducing computational demands [
22]. However, its efficiency comes at the cost of slight accuracy reduction compared to larger models. Similarly, MobileNetV3 has been integrated into YOLOv5, achieving an mAP of 96.9% with improved real-time performance on low-power devices [
23], though it may struggle in cluttered environments.
A recent advancement, YOLO-deepSort, integrates target tracking with multi-object detection, enabling continuous monitoring of tomato growth stages. This model achieves 93.1% accuracy for flowers, 96.4% for green tomatoes, and 97.9% for red tomatoes [
15]. While providing valuable insights for large-scale agricultural monitoring, its increased computational complexity may limit real-time applications in resource-constrained environments.
Building on this, a recent study introduced the YOLOv8-EA model [
24], proposed in 2024, which optimizes multi-stage feature fusion mechanisms to maintain tracking accuracy while significantly reducing computational complexity. By employing a dynamic attention reallocation technique, the model reduced inter-frame feature similarity computation by 42.3% and achieved a real-time processing speed of 128 FPS for tomato growth monitoring. Experimental results showed that the improved system decreased inference time on the NVIDIA Jetson Nano embedded platform from 3.2 s to 1.8 s compared to the original model, with a 37.5% reduction in memory usage, providing a viable solution for resource-constrained environments. However, its processing speed remains insufficient for practical deployment.
Overall, YOLO models, particularly the enhanced versions like YOLOv7 [
25], YOLOv8 [
26], and YOLOv5 [
27], have proven to be effective in tomato maturity detection due to their high accuracy and real-time processing capabilities. Despite some challenges, such as reduced accuracy in cluttered scenes or occlusions, YOLO-based models are increasingly being optimized for practical agricultural applications, offering the potential for scalable solutions in automated harvesting and precision farming.
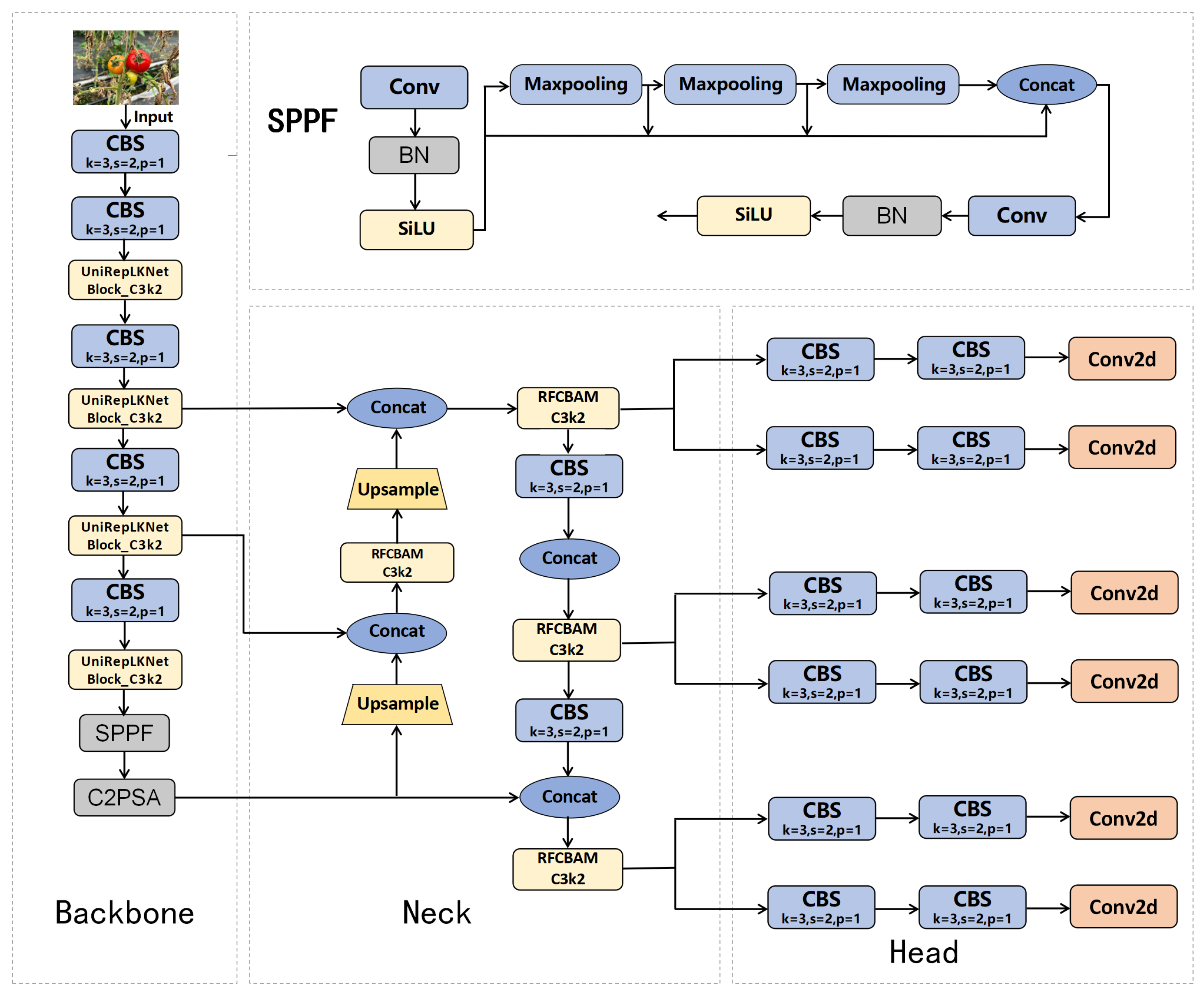
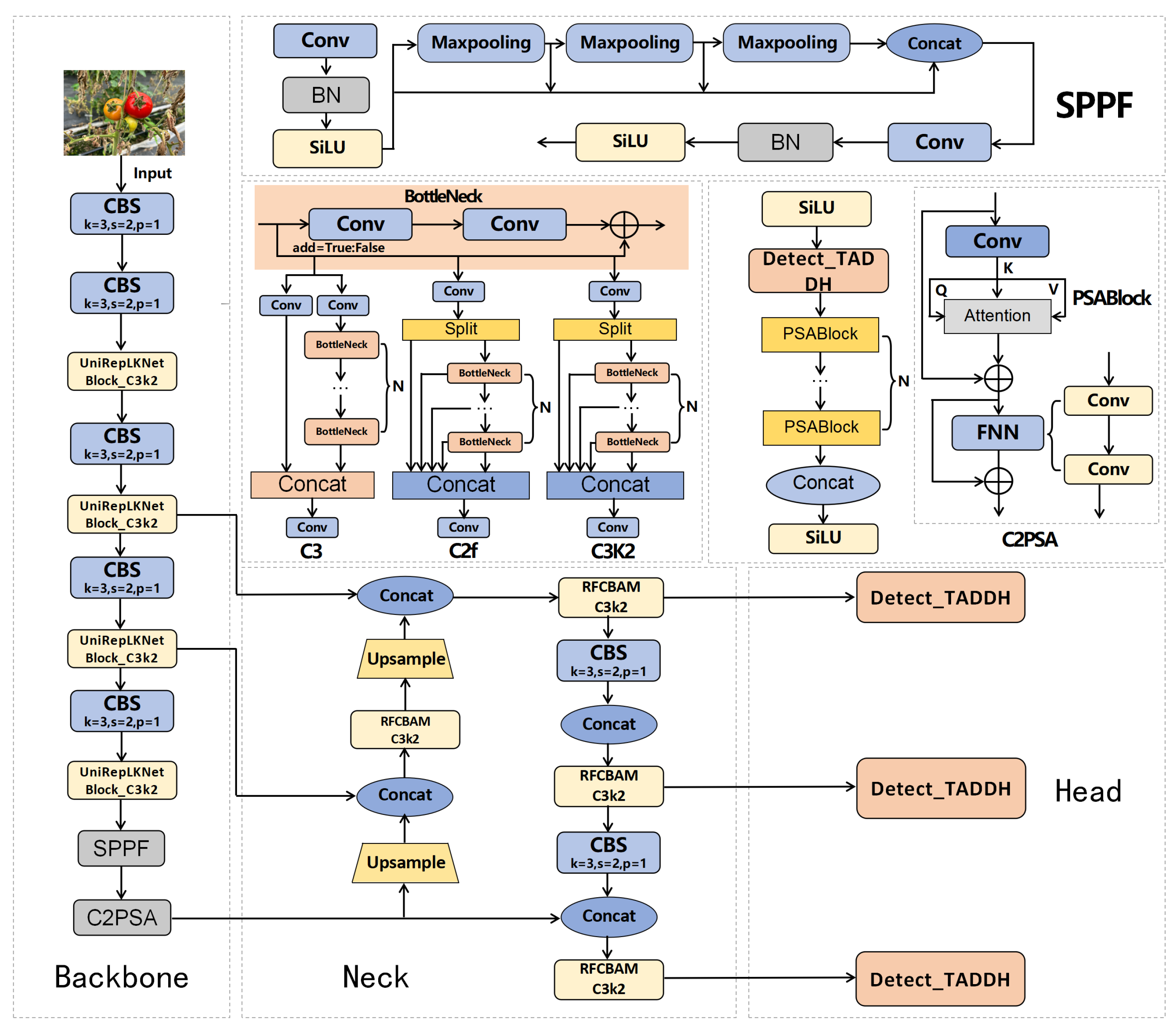
The YOLO series has now been updated to YOLOv11. Building upon its predecessors, YOLOv11 introduces several new features and improvements, including the C3k2 module, the C2PSA module, and a more lightweight classification detection head. These enhancements have significantly boosted both detection accuracy and speed through iterative advancements. With these updates, YOLOv11 is able to maintain a high detection rate across a wider range of targets at various scales while maintaining its processing speed. As a result, YOLOv11 surpasses previous models in terms of both performance and efficiency, making it a more powerful solution for real-time applications.
On this basis, the proposed method further optimizes the accuracy and real-time processing ability of the YOLO model. By specifically improving the structure and algorithm of the model, this study improves the accuracy of object occlusion, illumination changes, and other complex scenes and overcomes the limitations of the YOLO model in special environments. In addition, this method maintains effective computing speed in different environments and ensures real-time performance and efficiency, thus providing a more practical solution for agricultural automation in harvesting and precision agriculture. These improvements make the model more suitable for practical application in agricultural production and provide higher scalability and adaptability. Our specific contributions are as follows:
- (1)
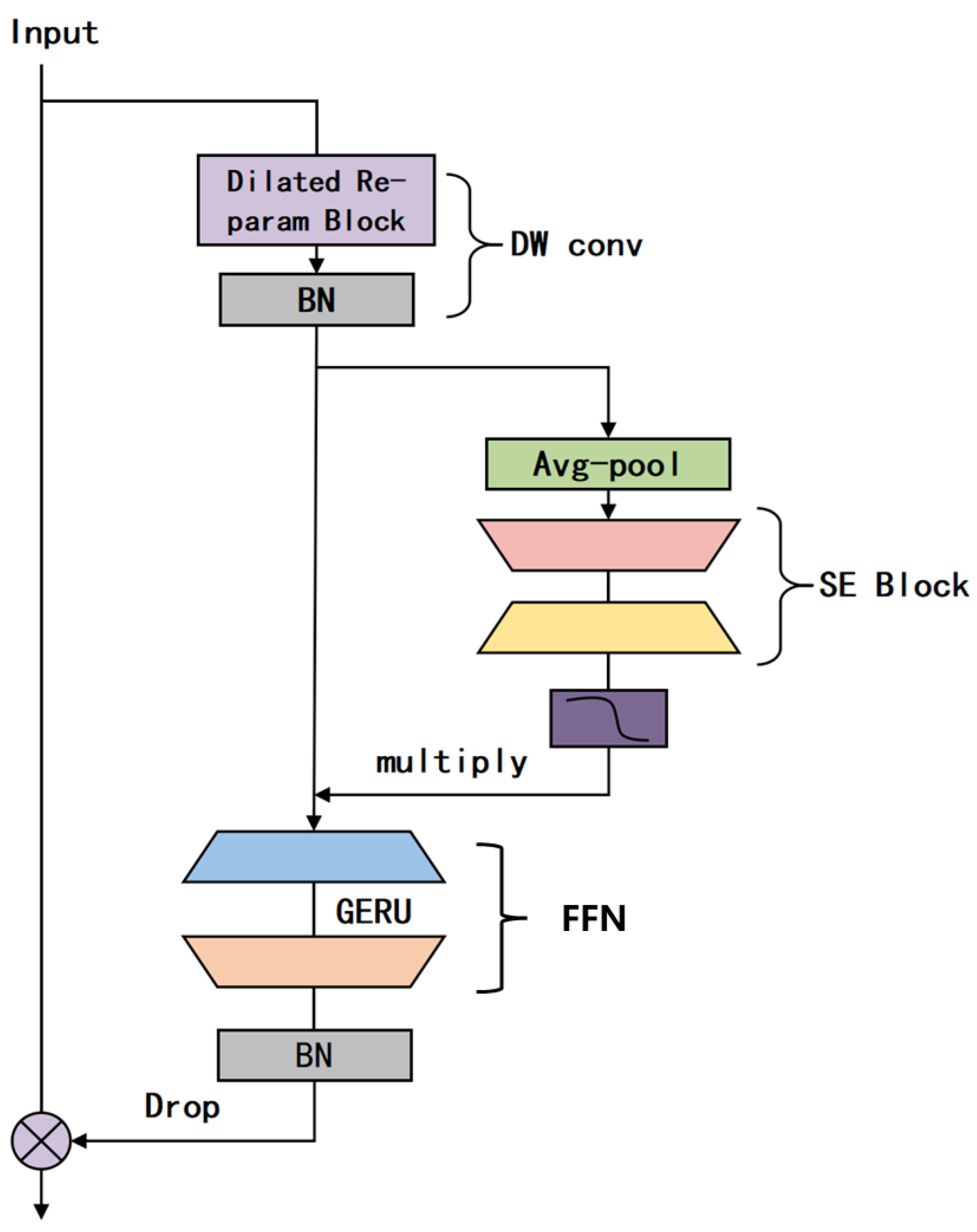
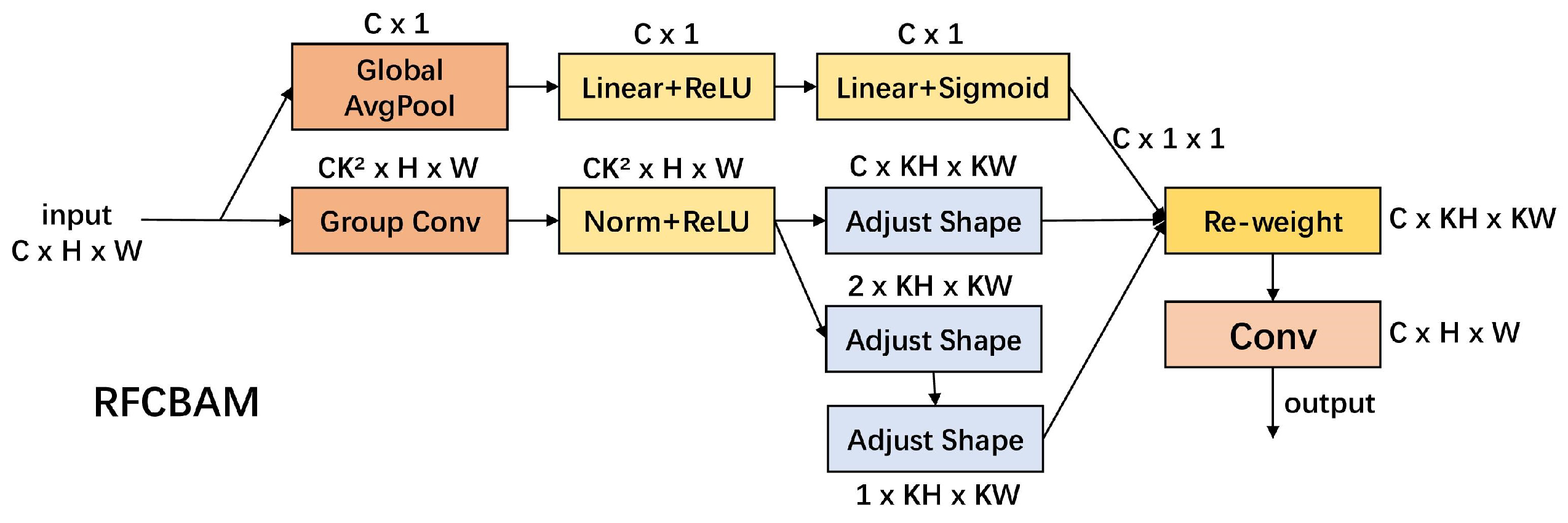
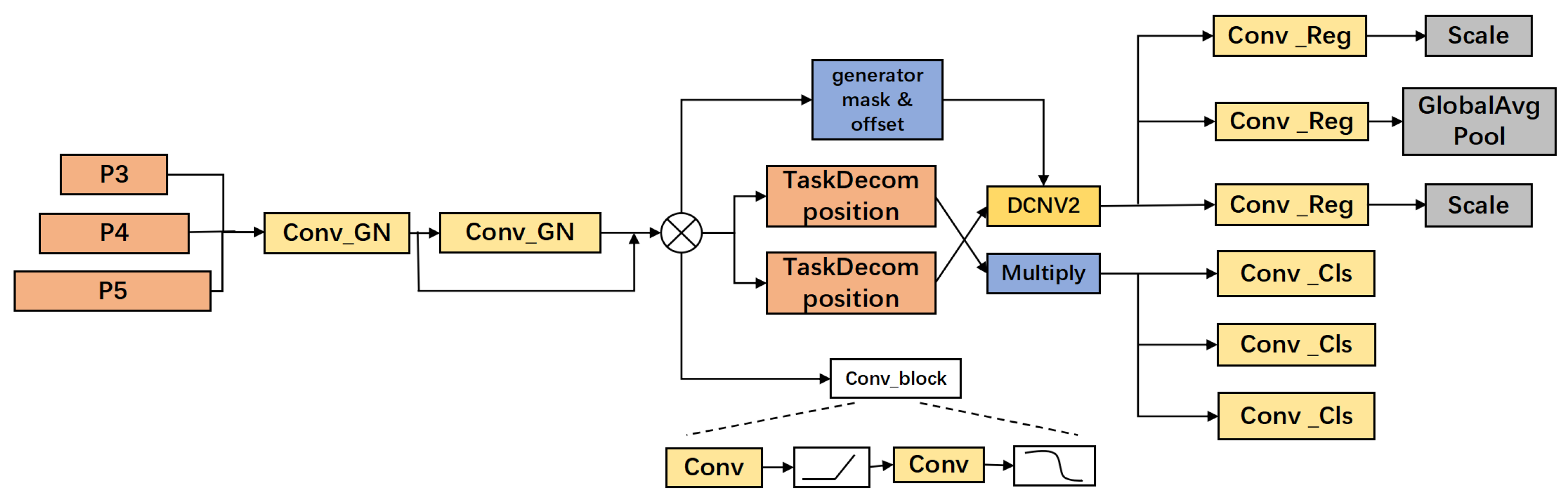
This study proposes an improved YOLOv11 model, URT-YOLOv11, to address the limitations of traditional tomato recognition algorithms in complex agricultural environments. By optimizing its architecture, the model enhances detection performance and computational efficiency. The UniRepLKNet block replaces the original C3K2 module in the backbone, expanding the receptive field and improving recognition across different scales. In the neck, the RFCBAMConv attention module replaces the standard Conv module, integrating channel and spatial attention to enhance small object detection and robustness under varying lighting conditions. The TADDH module optimizes the detection head, balancing classification and regression tasks for greater accuracy and stability. These improvements significantly boost computational efficiency, enhance the model’s ability to recognize tomatoes of different sizes, and increase overall detection accuracy.
- (2)
The improved YOLOv11 model demonstrates enhanced performance in complex agricultural environments, especially when dealing with issues such as lighting changes, object occlusion, scale variations, and complex backgrounds. The model shows significant stability and advantages in both accuracy and computational efficiency.
- (3)
This study provides a tomato dataset designed for specific agricultural environments, containing six categories and 5474 images. The dataset focuses on addressing issues such as lighting changes, object occlusion, scale variations, and complex backgrounds. It includes tomato images under various environmental conditions, offering high diversity and challenge, making it ideal for training and evaluating tomato object detection models. The dataset enhances the robustness and accuracy of models in real-world applications. It provides a challenging benchmark for research in the field of tomato object detection and contributes to advancing crop monitoring technologies in smart agriculture.
3. Results
3.1. Training Results of the Proposed Model
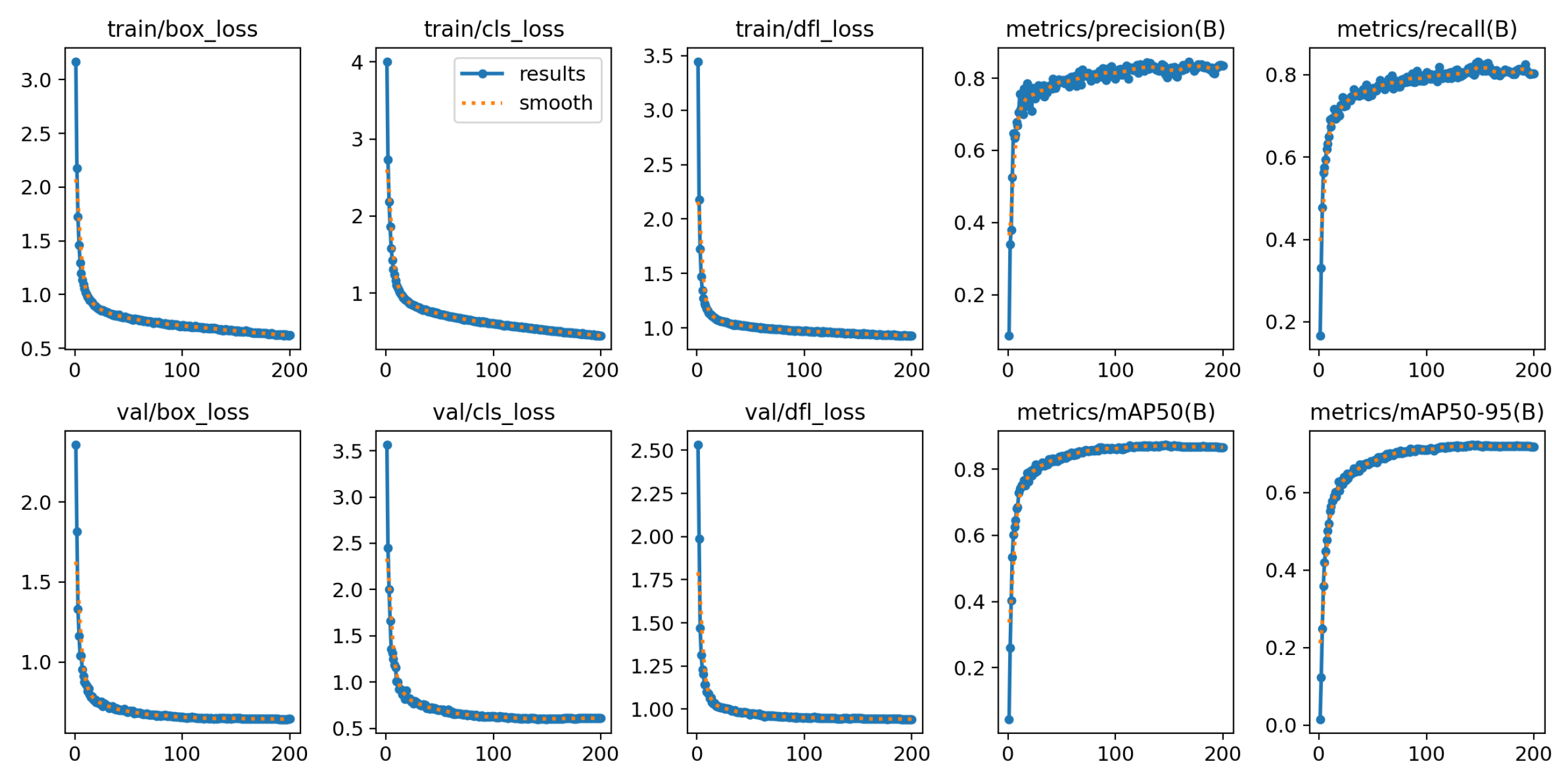
The loss and accuracy curves shown in
Figure 8 reveal essential details about the training process of the proposed model. In the initial stages of training (early epochs), the loss curve declines rapidly, suggesting that the model is quickly learning from the training data and improving its fit. As the training proceeds, both the training and validation losses gradually plateau, indicating that the model has achieved a better fit to the data. Similarly, the curves for precision, recall, and mAP show a parallel upward trend, eventually stabilizing at a higher level, further confirming the model’s effectiveness. This sequence of results demonstrates that the tomato ripeness detection model has not overfitted during training, with stable index values and excellent convergence. The smoothness of the loss curve shows that the model has successfully fitted the data, and the continued improvement of the validation metrics suggests significant progress on the validation set as well. Thus, the model exhibits strong generalization ability and stability in both the training and validation phases.
3.2. Model Evaluation Metrics
To comprehensively evaluate the performance of the proposed URT-YOLOv11 model, we consider several key evaluation metrics commonly used in object detection tasks. These include precision, recall, F1-score, mAP50, parameters, FPS, GFLOPs, and VRAM (GB). Each metric provides insights into different aspects of the model’s accuracy, efficiency, and computational complexity.
Precision measures the proportion of correctly detected tomatoes among all detected objects. It is calculated as follows:
where
(true positives) are correctly detected tomatoes, and
(false positives) are incorrect detections (e.g., background misclassified as a tomato). A higher precision indicates that the model produces fewer false positives, which is crucial in applications where misclassification could lead to incorrect assessments of tomato ripeness.
Recall quantifies the model’s ability to detect all actual tomatoes in an image. It is provided by the following:
where
(false negatives) are missed detections (e.g., tomatoes not detected at all). A higher recall indicates that the model successfully detects most tomatoes in the dataset, reducing the likelihood of missing important objects.
The F1-score provides a balanced measure of precision and recall and is computed as follows:
The F1-score is especially useful when balancing precision and recall is necessary, such as when detecting tomatoes at different ripening stages in complex backgrounds.
Mean average precision (mAP) is a key metric in object detection.
mAP50 measures the accuracy of predictions where the
intersection over union (IoU) threshold is set to 0.5, meaning a prediction is considered correct if at least 50% of the detected bounding box overlaps with the ground truth.
The total number of learnable parameters in a model impacts its computational complexity and memory footprint. A lower parameter count generally results in a more efficient model suitable for real-time applications.
FPS measures the model’s inference speed by evaluating how many images can be processed per second. A higher FPS is desirable for real-time applications in smart agriculture where timely decisions (e.g., automated tomato harvesting) are necessary.
GFLOPs indicate the number of floating-point calculations the model performs per second. It is an important metric for evaluating computational efficiency, especially for edge devices.
VRAM consumption is a critical factor when deploying models on embedded or GPU-constrained devices. Efficient memory usage ensures the model can run smoothly on real-time agricultural systems.
3.3. Cross-Validation for Stability and Generalization
To further validate the stability and generalization ability of the model, k-fold cross-validation was employed in addition to the standard validation set. This approach divides the dataset into k subsets (folds), where each fold is used as a validation set while the remaining folds are used for training. This process was repeated k = 5 times, each time with a different fold serving as the validation set.
We chose k = 5 to balance computational cost and ensure reliable model performance evaluation across different data splits. This method allowed us to assess the model’s performance on different subsets of the data, minimizing the risk of overfitting to any particular split and providing more robust estimates of its generalization ability.
The results of the cross-validation were consistent, with the model showing stable performance across different folds. The performance metrics for each fold are summarized in
Table 4, which includes mAP, precision, recall, mAP50, and the percentage fluctuation for each metric. These results reinforce the model’s robustness and reliability in real-world applications.
The results from the five-fold cross-validation demonstrate that the model performs consistently across different folds. The average mAP was 0.869, with precision of 0.840, recall of 0.794, and mAP50-95 of 0.723. These values reflect the model’s balanced performance across all metrics. The fluctuation percentages for each metric were minimal, highlighting the model’s stability across data splits. mAP showed a small fluctuation at 0.7%, indicating high consistency in the model’s overall accuracy. The recall metric exhibited a slightly higher fluctuation of 1.5%, which may suggest some variability in the detection of true positives across different subsets of the dataset. Overall, these results confirm that the model’s performance is robust, making it suitable for real-world applications where consistency is crucial.
3.4. Failure Analysis
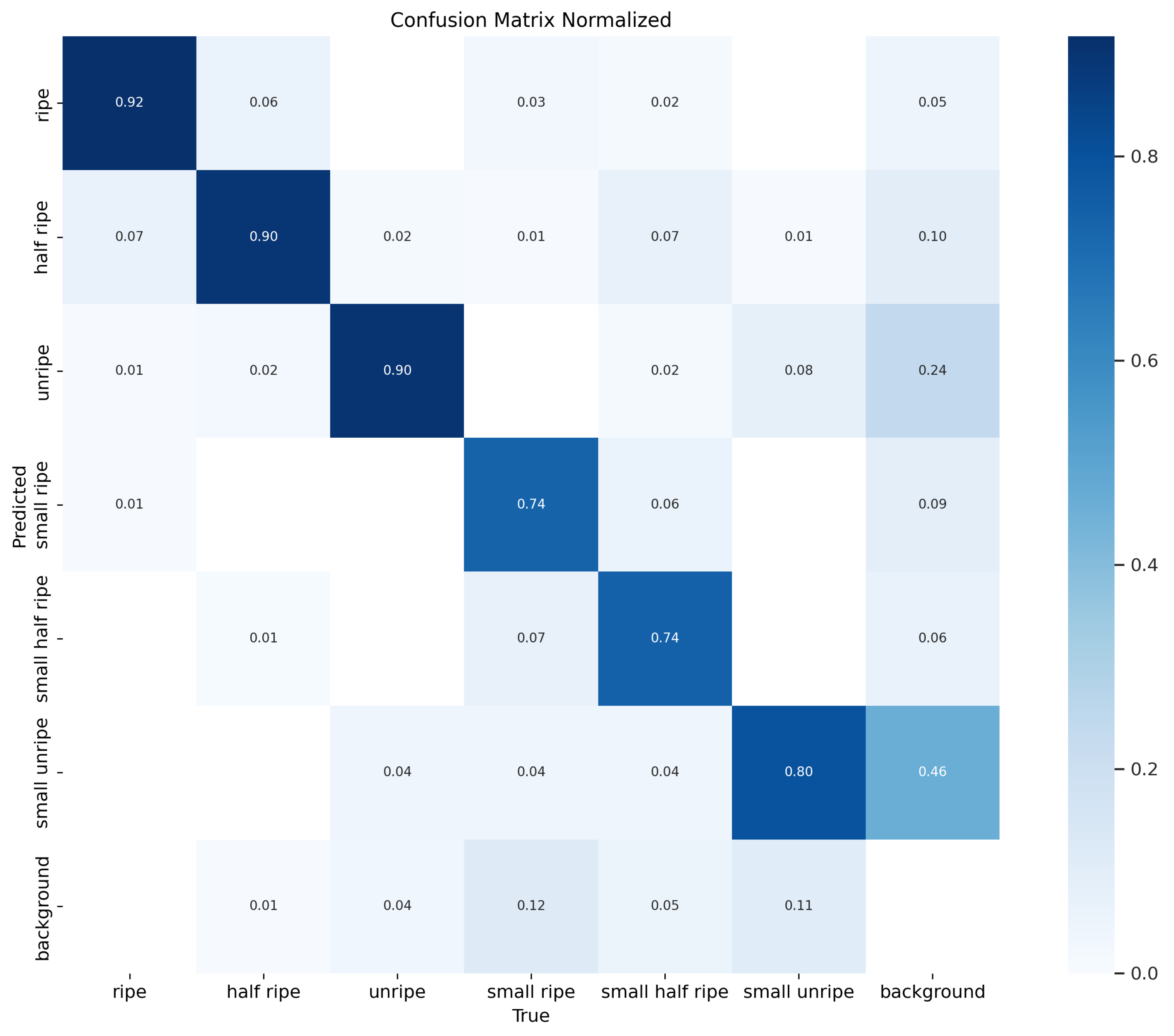
A confusion matrix is a tool used to evaluate classification models by comparing the true and predicted labels. It helps identify misclassifications and provides insight into where the model makes errors. Since our dataset contains imbalanced categories, we normalized the confusion matrix to ensure fair visualization of performance across all classes.
The confusion matrix in
Figure 9 shows that the model performs well in the ripe and half-ripe categories, with correct classifications of 92% and 90%, respectively. For small ripe, small half-ripe, and small unripe tomatoes, the model’s accuracy is 74%, 74%, and 80%, respectively. However, misclassifications occur, with 12%, 5%, and 11% of these tomatoes being identified as background. Due to their smaller size, these categories are more difficult to detect and are more easily misclassified as background compared to larger categories. While the model shows strong performance for larger categories, it still provides reliable results for smaller objects. Improving small object detection and background separation will further enhance its accuracy.
3.5. Ablation Experiment
In this study, the original YOLOv11 model is used as a benchmark for ablation experiments to evaluate the contribution of different modules. We use mAP@0.5:0.95, mAP@0.5, precision, and recall as performance metrics to evaluate the effectiveness of the model on the customized tomato dataset. The results of the ablation experiments are shown in
Table 5. As shown in the table, the addition of the UniRepLKNetBlock module improves recall by
1.1%. After integrating the RFCBAM module, mAP@0.5 increases by
1%. With the addition of the TAADH module, mAP@0.5:0.95 further increases by
0.8%, and parameters decrease by
0.38 M. In addition, when the UniRepLKNetBlock module is used in conjunction with the RFCBAM module, the model performance is significantly improved, with precision increasing by
4.7% and mAP@0.5:0.95 improving by
1.9%. When all three modules (UniRepLKNetBlock, RFCBAM, and TAADH) are used in combination, the performance is significantly improved, with mAP@0.5 and mAP@0.5:0.95 increasing by
1.9% and
1.6%, respectively. Precision and recall are also improved by
5.7% and
1.1%, respectively. Compared to the non-use of the TAADH module, parameters are reduced by
0.25 M, and precision and recall are also improved by
5.7% and
1.1%, respectively. These results indicate that combining the various modules together can significantly improve the overall performance of the model, thus further validating the effectiveness of each module.
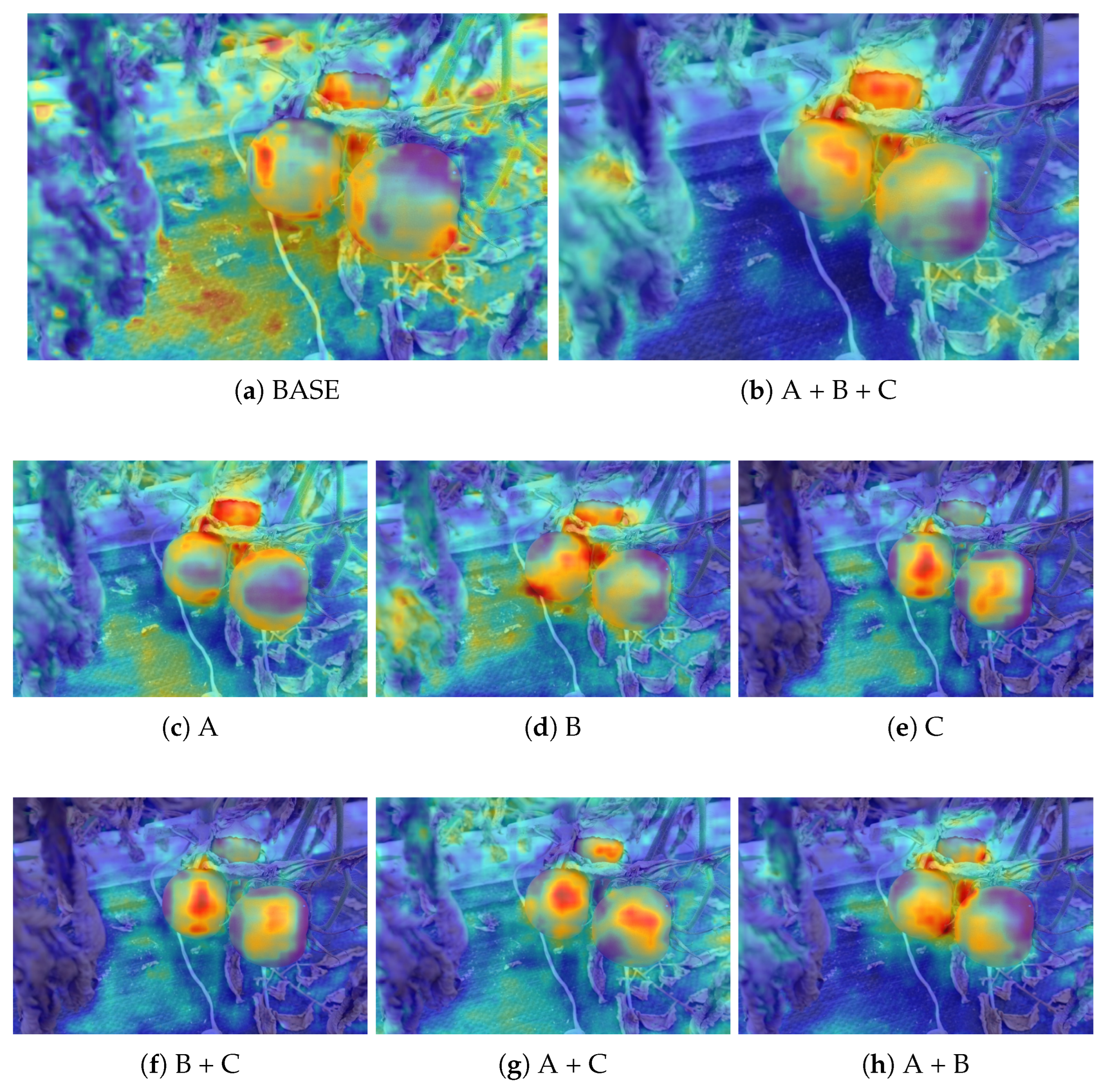
To further validate the impact of each module, Grad-CAM visualizations are used to analyze the model’s attention distribution before and after module integration, as shown in
Figure 10. The baseline YOLOv11 model exhibits dispersed attention, highlighting not only the target fruits but also irrelevant regions like branches and the background, leading to potential false detections.
With the addition of UniRepLKNetBlock, the model’s recall improves as it captures more contextual information, though some background noise remains. The RFCBAM module enhances object–background differentiation, reducing distractions and increasing mAP@0.5. Incorporating TAADH further sharpens attention on the fruits while reducing parameters, leading to better efficiency. When all three modules are combined, the model achieves the most precise attention, with significant improvements in mAP, precision, and recall, confirming the effectiveness of each module in refining detection performance.
3.6. Comparison Between Different Target Detection Networks
To evaluate the actual detection performance of the improved algorithm, a comparison is made between the proposed algorithm and several classical object detection methods. The object detection algorithms included in this comparison are SSD, faster R-CNN, YOLOv5, YOLOv8, YOLOv9, YOLOv10, and DETR. The SSD model uses MobileNetv2 as its backbone network, while faster R-CNN employs ResNet101 as the backbone. The other models are based on their default architectures. The experimental results are presented in
Table 6.
Table 6 demonstrates that our improved YOLO model achieves superior performance, attaining a
2.2% higher mAP@0.5 compared to the state-of-the-art YOLOv11 benchmark. Specifically, URT-YOLOv11 achieves an accuracy of
84.0%, a recall of
80.3%, an mAP of
87.3%, and an
F1-score of 82.2%, highlighting a substantial enhancement in detection accuracy and robustness under complex agricultural conditions.
In addition to improved accuracy, URT-YOLOv11 demonstrates significant computational efficiency. The model reduces the parameter count by approximately 16.4% (from 2.58 M to 2.16 M), leading to a decrease in memory usage (from 4.2 GB to 3.9 GB) and a notable increase in processing speed (576 FPS vs. 479 FPS). GFLOPs are also reduced from 6.3 to 5.8, reinforcing the model’s suitability for real-time applications on resource-constrained platforms.
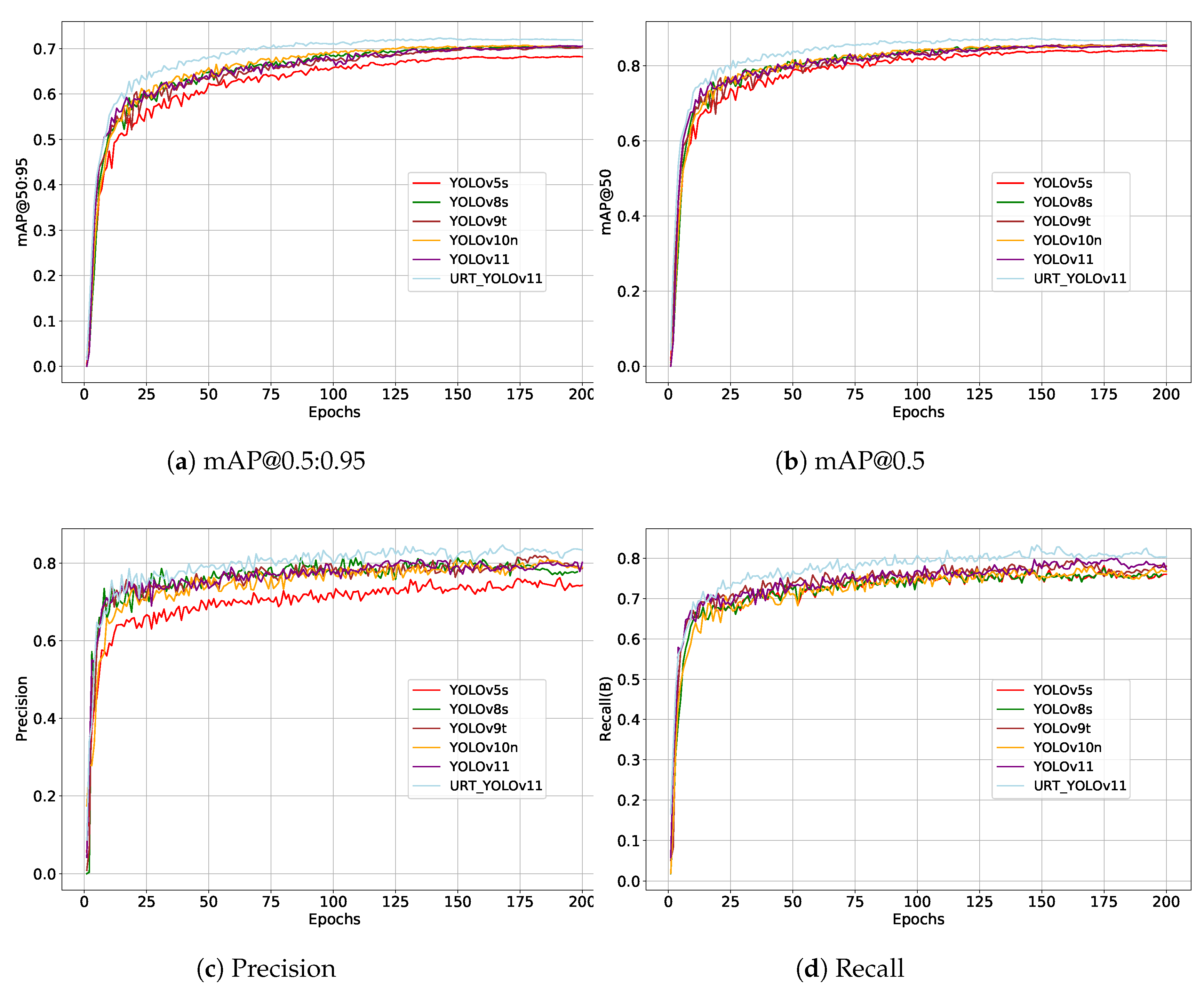
Additionally, this study presents the trends of the
mAP@0.5 and
mAP@0.5:0.95 metrics on the test set throughout the training process, as illustrated in
Figure 11a and
Figure 11b, respectively, providing further insights into their comparative performance. As shown specifically in
Figure 11, these trends offer a detailed analysis of the model’s performance during training.
Table 7 presents a comparative analysis of performance metrics between the proposed model (“ours”) and the baseline
YOLOv11 model across various object classes. The evaluation metrics include
precision,
recall,
F1-score,
mAP50, and
model size.
For the overall performance across all categories, our model achieves a precision of 84.0% and a recall of 81.0%, resulting in an F1-score of 82.6% and an mAP50 of 85.0%. In comparison, the YOLOv11 model achieves 81.5% precision, 81.2% recall, and an F1-score of 82.0%, with a higher mAP50 of 88.0%.
Analyzing individual object classes, our model exhibits notable improvements in specific cases. For the large half-ripe class, our model outperforms YOLOv11, achieving higher precision (89.4% vs. 84.6%) although the base model retains a slight recall advantage. Similarly, for the small unripe class, our model surpasses YOLOv11 in both precision (82.8% vs. 82.2%) and F1-score (82.2% vs. 80.4%), demonstrating its robustness in detecting smaller objects.
In terms of model efficiency, our approach maintains a competitive balance between accuracy and computational complexity. Notably, our model achieves a model size of 2.16 M parameters, compared to the 2.58 M parameters required by YOLOv11. This reduction in complexity highlights that our model is more efficient while still achieving high detection accuracy.
These results collectively indicate that the proposed model achieves comparable or superior detection performance across various object classes while maintaining a more optimized model size, making it an attractive candidate for real-time applications and deployment in resource-constrained environments.
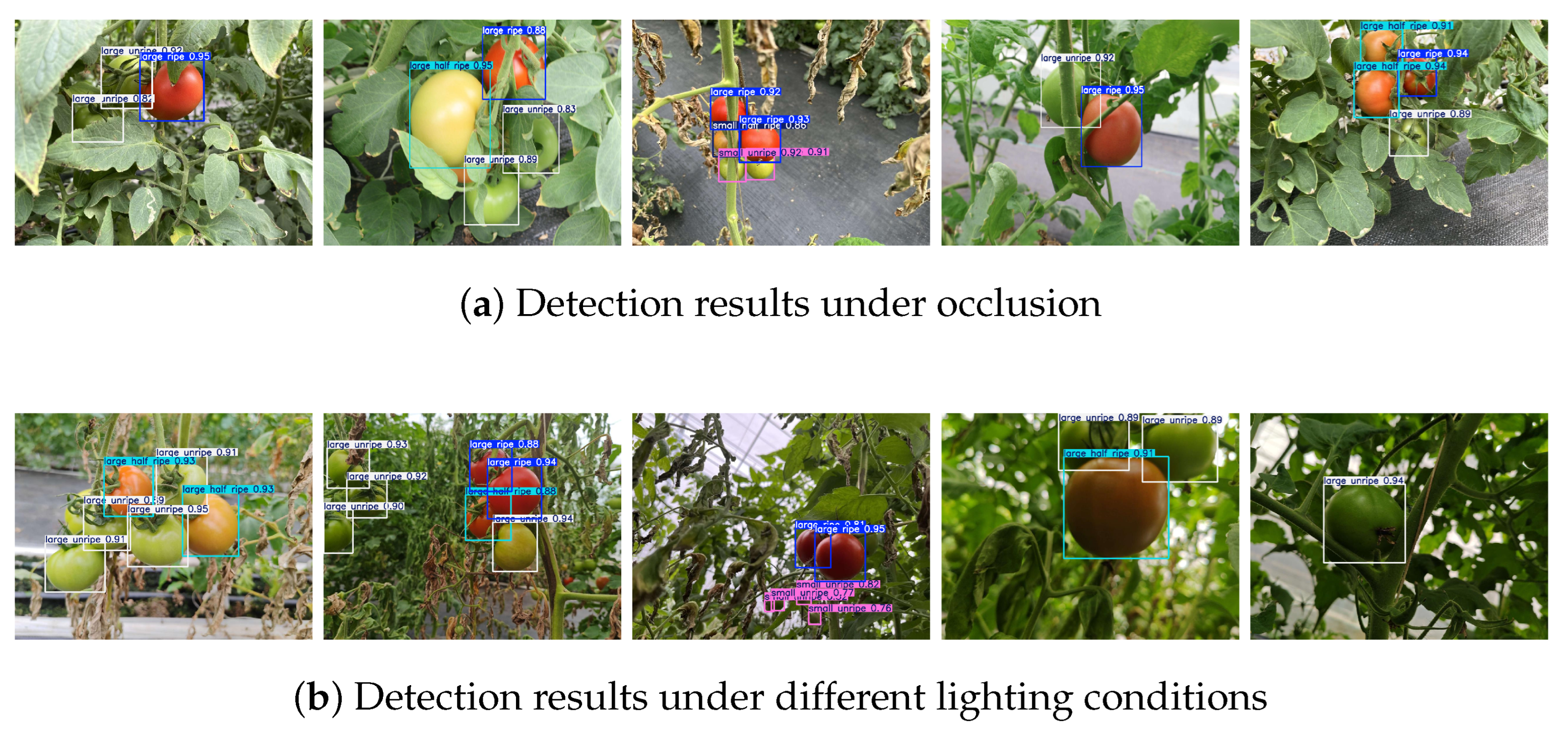
3.7. Testing in Occluded Conditions
In practical tomato cultivation environments, occlusions frequently arise from branches, leaves, and overlapping fruits, which complicate the accurate detection and classification of tomatoes. To systematically assess the robustness of our model in the presence of such occlusions, we artificially introduce occlusions into the test dataset by modifying the original images.
Figure 12 presents examples of artificially created occlusions, demonstrating different occlusion conditions designed to simulate real-world challenges encountered in paddy fields.
Table 8 summarizes the performance of our model when tested under occlusion conditions. The results demonstrate that the proposed approach maintains strong detection capabilities despite occlusions. The overall mean average precision (mAP) for all tomato species reaches 83.5%, with each individual species achieving an mAP above 70%. These findings highlight the generalization ability of our model in challenging field conditions.
3.8. Testing Under Different Lighting Conditions
In real-world applications, variations in lighting conditions can significantly impact image-based models. Factors such as weather changes, time of day, or artificial lighting can lead to differences in brightness levels. For instance, overcast conditions or night-time settings may cause reduced illumination, while strong sunlight can result in excessive brightness. To analyze the robustness of our proposed model, we simulate various lighting conditions by adjusting the illumination factor
and evaluate the model’s performance accordingly. The brightness adjustment follows the equation below:
where
represents the original pixel intensity at position
, and
denotes the adjusted pixel value after brightness modification. The illumination factor
is used to control brightness, where
increases brightness,
decreases brightness, and
preserves the original lighting conditions. The images under different brightness levels are shown in
Figure 13.
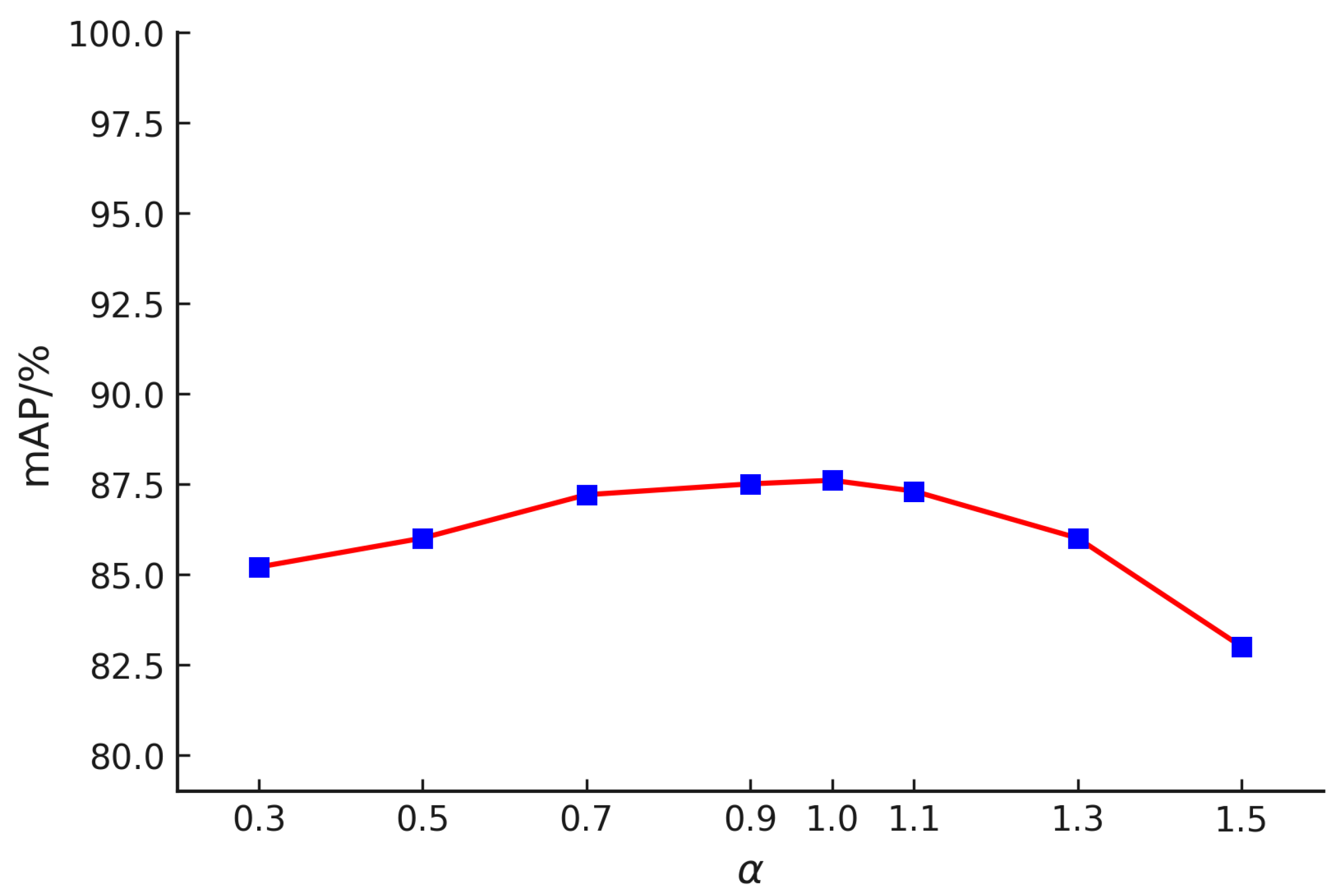
To further assess model stability, we test different values of
and summarize the results in
Figure 14. Our observations indicate that when
is within the range of 0.3 to 1.1, the model maintains stable performance, with mAP values consistently above 85%. However, as
further increases, a gradual decline in mAP is observed, though it remains above 82%. This suggests that the model effectively adapts to both low-light and moderately bright conditions, demonstrating strong generalization capabilities across varying illumination settings.
3.9. Edge Deployment on Raspberry Pi
To verify the practical applicability of the proposed method in real-world agricultural environments, the URT-YOLOv11n model is deployed on Raspberry Pi 5, an edge AI computing platform. The deployment system consists of Raspberry Pi 5 (8 GB RAM) and a Hailo-8 accelerator (26 TOPS INT8), integrated with a 12-megapixel IMX477R camera (CSI interface). Field experiments conducted in a commercial tomato orchard demonstrate that the system achieves stable real-time inference at 30 FPS, with a total power consumption of approximately 15 W.
These results confirm that the proposed model delivers high precision and real-time detection performance on a low-power embedded device, validating its potential for integration into agricultural robots and other field-deployable platforms.
5. Discussion
This study introduces an advanced deep learning approach tailored for tomato ripeness detection, significantly enhancing both accuracy and processing efficiency. Conventional image processing techniques, such as those used in previous studies [
45], often encounter challenges related to computational complexity and prolonged processing times. To overcome these obstacles, our model leverages deep learning to address the intricate problem of tomato ripeness detection within diverse and complex environments. A major limitation of the baseline model is its difficulty in differentiating tomatoes of varying sizes. To mitigate this issue, we incorporate several novel modules that expand multi-scale receptive fields and enhance object detection capabilities. As a result, the model effectively identifies both tomato ripeness and size with high precision.
5.1. Comparison with Traditional Methods
In contrast to conventional machine learning approaches such as SVM, which relies on handcrafted color and texture features and lacks robustness in complex agricultural environments, URT-YOLOv11 autonomously learns high-dimensional feature representations, significantly improving its adaptability to variations in lighting and occlusion. Traditional SVM-based methods require extensive manual feature engineering and perform poorly when background complexity increases. While these models may achieve high accuracy in controlled settings, they struggle with real-world agricultural conditions where factors such as occlusion, non-uniform lighting, and variable fruit sizes significantly impact detection performance.
Another key feature of our model is its real-time performance optimization, striking a balance between detection accuracy and computational efficiency. While faster R-CNN achieves high accuracy in structured environments, its inference speed (26 FPS) and computational cost (180 GFLOPs) limit its feasibility for real-time applications. URT-YOLOv11 addresses this by reducing computational complexity to 5.8 GFLOPs while maintaining high detection performance at 576 FPS, making it ideal for edge computing in agricultural automation. This ensures practical applicability in time-sensitive agricultural applications where rapid decision-making is crucial.
Compared to existing models, which often focus solely on detecting larger tomatoes or are constrained to controlled environments such as greenhouses [
46], our approach significantly bridges a gap in the current literature. By training on a diverse dataset that includes tomatoes of multiple sizes and varying growth conditions, URT-YOLOv11 enhances robustness and scalability, ensuring superior detection performance across different field conditions.
5.2. Method Limitations
Despite the significant improvements of URT-YOLOv11 over conventional methods, several challenges remain in real-world agricultural applications. These limitations primarily include lighting variations, object occlusion, small object detection, and computational constraints.
5.2.1. Lighting Variations
While the proposed RFCBAMConv module enhances feature extraction under varying lighting conditions, extreme cases such as harsh sunlight and deep shadows still present challenges. In particular, unripe tomatoes often exhibit colors similar to the background in strong light conditions, leading to misclassification. Future research could explore advanced data augmentation techniques or adaptive exposure control mechanisms to further mitigate these effects.
5.2.2. Object Occlusion
The model’s performance is affected by object occlusion, especially in dense foliage environments where tomatoes are partially obscured by leaves or other fruits. Although the integration of attention mechanisms has improved feature extraction, occluded tomatoes still present a challenge for accurate detection. As shown in
Table 7, while the model demonstrates notable enhancement in detecting small targets, particularly with the precision for the “small ripe” class reaching a level comparable to that of the large classes, there remains a noticeable gap in precision for the “small half-ripe” and “small unripe” classes relative to the large classes. This discrepancy may be attributed to the fact that unripe tomatoes tend to grow closely together, as illustrated in
Figure 1, leading to frequent occlusions and increased detection difficulty. In contrast, mature tomatoes are typically more spaced out, which reduces occlusion and facilitates more accurate detection. Potential solutions include the incorporation of depth information from RGB-D sensors or multi-view detection strategies.
5.2.3. Small Object Detection
URT-YOLOv11 has demonstrated significant improvements in detecting tomatoes of different ripeness levels, but its recall on small tomatoes, particularly distant unripe ones, remains a limitation. The model’s receptive field has been expanded through UniRepLKNetBlock, yet small object detection is still constrained by the resolution of input images and feature extraction capabilities. Further enhancements, such as the use of super-resolution techniques or feature fusion networks, may improve performance.
5.2.4. Computational Constraints
Although URT-YOLOv11 is designed as a lightweight model with only 2.16 M parameters and 5.8 GFLOPs, its deployment on ultra-low-power agricultural devices remains a challenge. While the model is optimized for real-time performance (576 FPS on an NVIDIA RTX 4090D GPU), agricultural robotics and UAVs with limited computational resources may still struggle to run the model efficiently. Future efforts could focus on model quantization, pruning, or developing a mobile-friendly variant to ensure broader applicability.
5.3. Future Research Directions
Several key areas remain for future exploration to further enhance the model’s robustness, scalability, and efficiency. One critical direction is domain adaptation, ensuring that models trained on one dataset can generalize better to unseen agricultural environments with varying weather conditions, soil types, and growth stages. Additionally, multi-modal learning, integrating RGB images with thermal or hyperspectral data, could improve the detection of subtle ripeness variations that are not easily captured through standard RGB-based methods.
Another key challenge is scalability and real-world deployment. While URT-YOLOv11 has demonstrated high accuracy in controlled conditions, further research is needed to adapt the model for other crops, such as strawberries, apples, or peppers, using transfer learning techniques. This would enhance the model’s versatility and broaden its impact in precision agriculture. Moreover, continuous learning frameworks could be explored, allowing the model to be updated incrementally with new data over multiple growing seasons, improving long-term adaptability and preventing performance degradation.
To facilitate large-scale adoption, hardware optimization is crucial. Future research should focus on model quantization and edge AI implementations, enabling URT-YOLOv11 to run efficiently on low-power IoT sensors, embedded systems, and agricultural drones. The integration of hardware-efficient AI accelerators, such as TPUs and FPGAs, could further enhance inference speed while reducing power consumption, making real-time ripeness detection more accessible to smallholder farmers and scalable for large-scale precision agriculture systems.
Furthermore, future research should explore the ethical implications of AI-driven agricultural automation. While such systems offer enhanced efficiency and reduced resource waste, they may also impact employment in traditional farming by reducing the demand for manual labor in fruit sorting and quality assessment. Developing human–AI collaborative models that assist rather than replace farm workers could help mitigate these concerns. Additionally, as AI systems collect vast amounts of agricultural data, ensuring secure data management and privacy protection will be essential to prevent misuse or unauthorized access. Research into privacy-preserving machine learning and blockchain-based agricultural data security could address these challenges and ensure responsible AI deployment in precision agriculture.
By addressing these challenges, URT-YOLOv11 can evolve into a versatile, lightweight, and adaptive tool for smart farming applications, driving improvements in food production efficiency and sustainability. Furthermore, refining the model’s effectiveness and expanding its potential applications in agricultural automation, intelligent fruit quality assessment, and broader smart farming technologies will enhance its impact. The findings of this study not only contribute to precision agriculture but also lay the groundwork for optimizing real-time fruit monitoring systems, ultimately leading to more sustainable and efficient agricultural practices.
6. Conclusions
This research delves into the challenges of traditional fruit recognition algorithms and critically examines the shortcomings of current methods in complex agricultural settings. To overcome these issues, we introduce an enhanced YOLOv11 model that integrates multiple architectural improvements. Notably, the UniRepLKNetBlock substitutes the C3k2 block in the backbone, improving computational efficiency, expanding the receptive field for multi-scale feature extraction, and significantly reducing overall computational demands. In the neck structure, we implement the RFCBAMConv module, which replaces the C3k2 block, combining residual feature extraction with a channel-spatial attention mechanism (RFCBAM). This modification boosts the model’s ability to detect smaller objects and improves its robustness under varying lighting conditions. Additionally, the detection head is optimized with the task-adaptive detection decoding head (TADDH), which applies a task-adaptive optimization strategy, effectively balancing classification and regression, thus enhancing detection performance across different object scales.
Experimental evaluations show that the proposed enhancements result in substantial gains in both accuracy and computational efficiency. The model achieves an mAP@50 of 87.3% and a recall of 80.3%, demonstrating a 2.2% improvement in mAP@50 and a 5% increase in precision compared to the original YOLOv11 model. Furthermore, the model complexity is reduced to 2.14 million parameters, which results in significant computational savings without sacrificing detection accuracy. This lightweight architecture makes the model more suitable for deployment on embedded systems and mobile devices, allowing for real-time detection in environments with limited resources. The efficacy of each modification was confirmed through ablation studies, which highlighted the positive contributions of UniRepLKNetBlock, RFCBAMConv, and TADDH in optimizing model performance.
In conclusion, the improved YOLOv11 algorithm demonstrates exceptional performance in detecting tomato ripeness, especially in challenging environments characterized by occlusions and fluctuating lighting conditions. By refining the model architecture and enhancing detection precision, this study presents a robust solution for smart agriculture, advancing the capabilities of real-time tomato ripeness detection. These outcomes not only contribute to more precise crop management but also offer a promising approach to boosting the efficiency and quality of agricultural production, highlighting the practical potential of this technology in real-world applications.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}