
YOLO-SegNet: A Method for Individual Street Tree Segmentation Based on the Improved YOLOv8 and the SegFormer Network


Abstract
1. Introduction
- (1)
- Street tree datasets were reconstructed. The original images [13] were re-annotated and re-transformed according to the YOLO dataset format to produce a new street tree dataset for object detection. Our method was applied to this public street tree segmentation dataset.
- (2)
- The BiFormer module was introduced into YOLOv8 to reduce the background interference in street tree segmentation tasks, enabling the backbone network to capture long-distance dependencies effectively. The experimental results also show that the street tree object detection results markedly affect the image segmentation task.
- (3)
- This new YOLO-SegNet model, combined with the improved YOLO + BiFormer and SegFormer models, was used to accurately segment individual street trees of different species.
2. Materials and Methods
2.1. Street Tree Dataset
2.1.1. Image Acquisition
2.1.2. Image Annotation
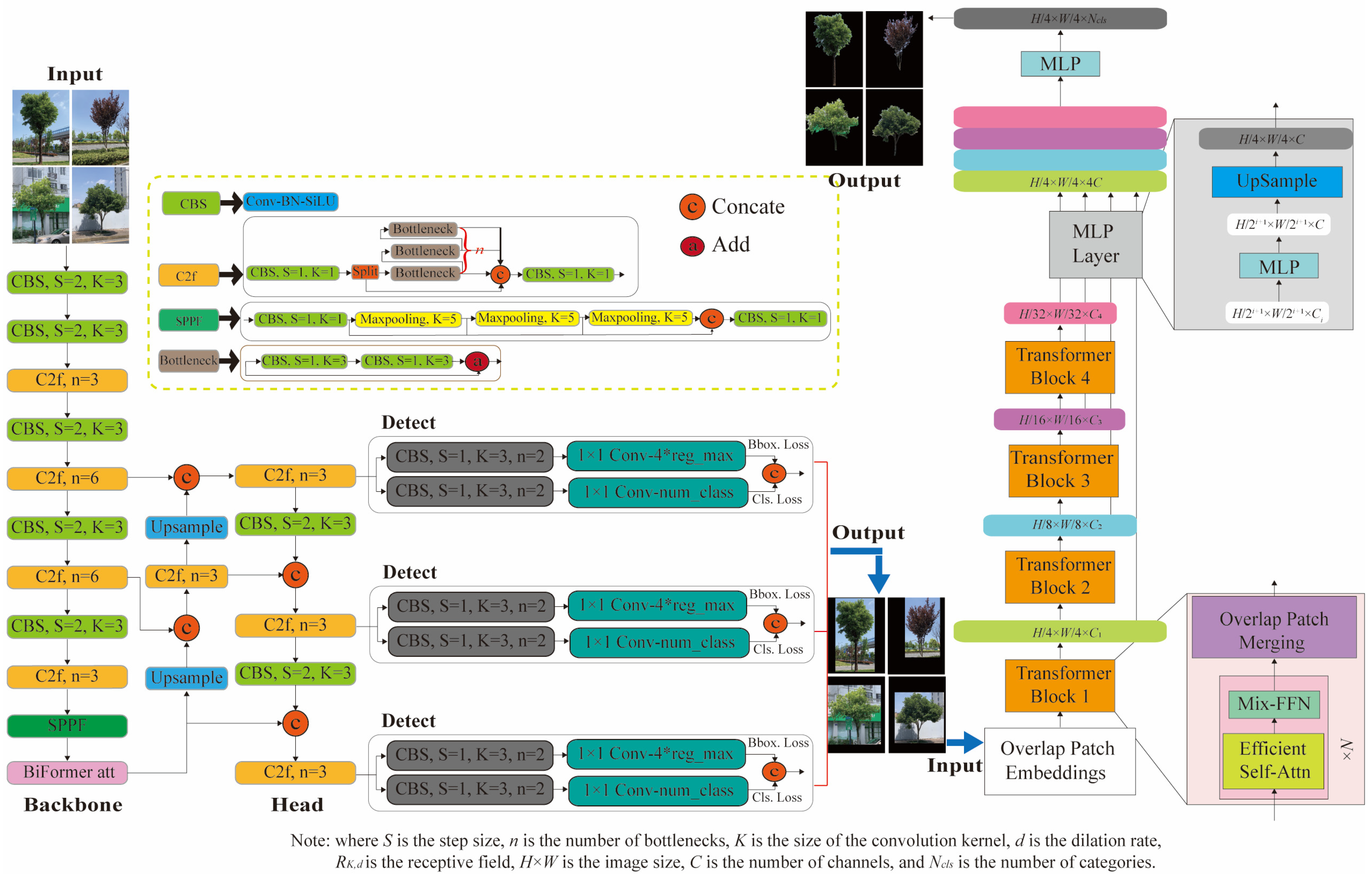
2.2. YOLO-SegNet Model
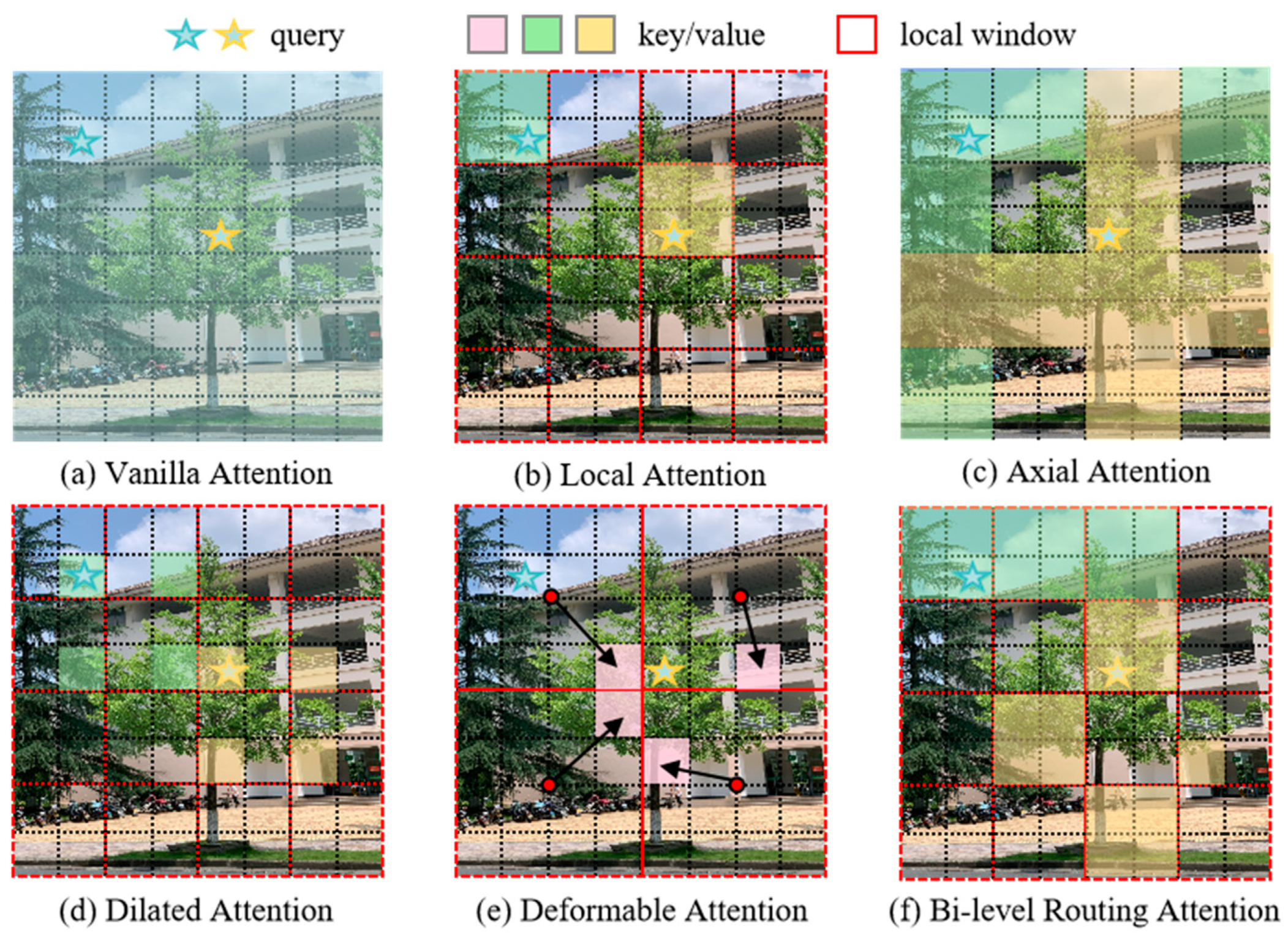
2.2.1. YOLOv8 with the BiFormer Attention Mechanism
2.2.2. SegFormer Network
3. Results and Analysis
3.1. Experimental Environment and Evaluation Indicators
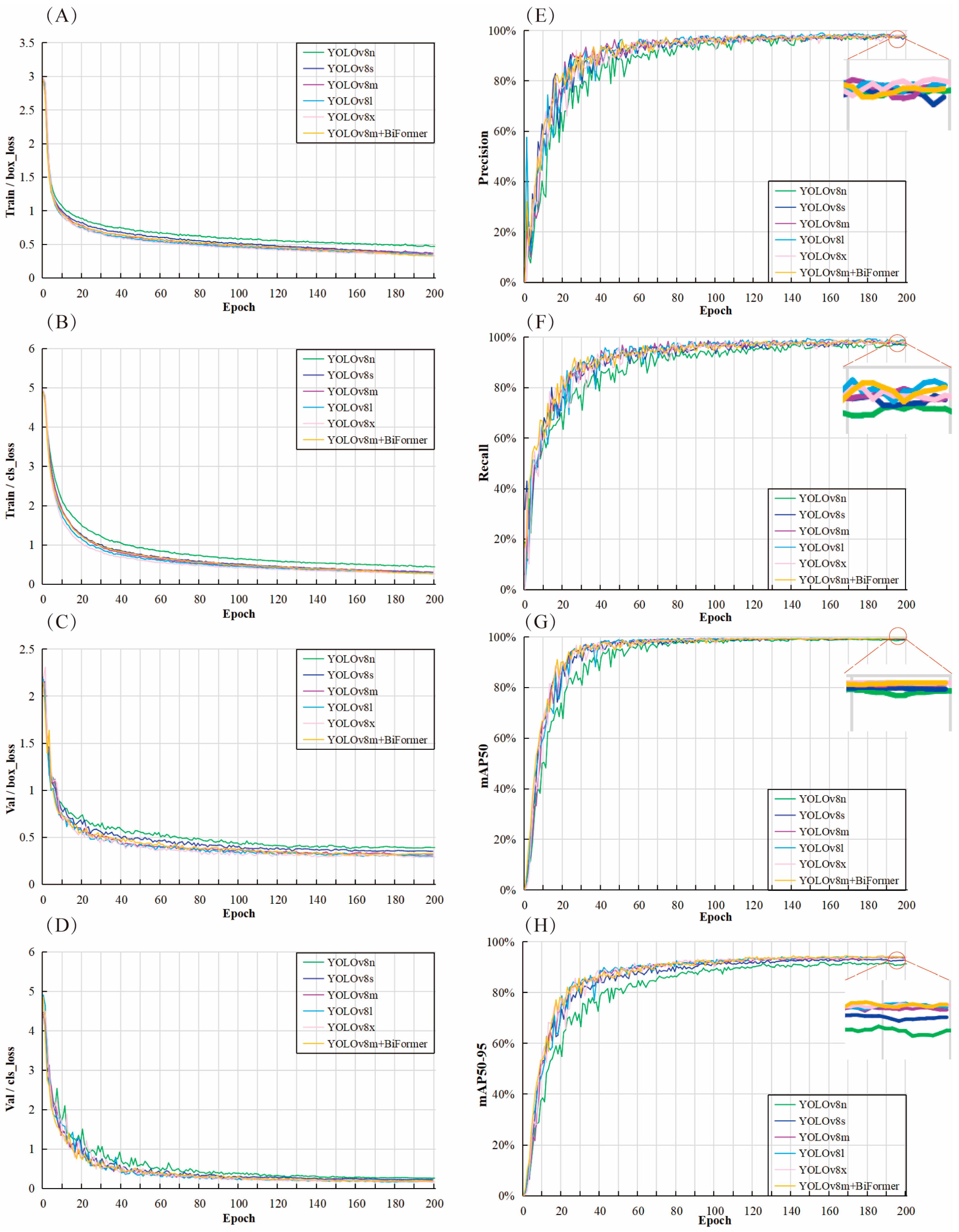
3.2. YOLOv8m+BiFormer Model Results and Analysis
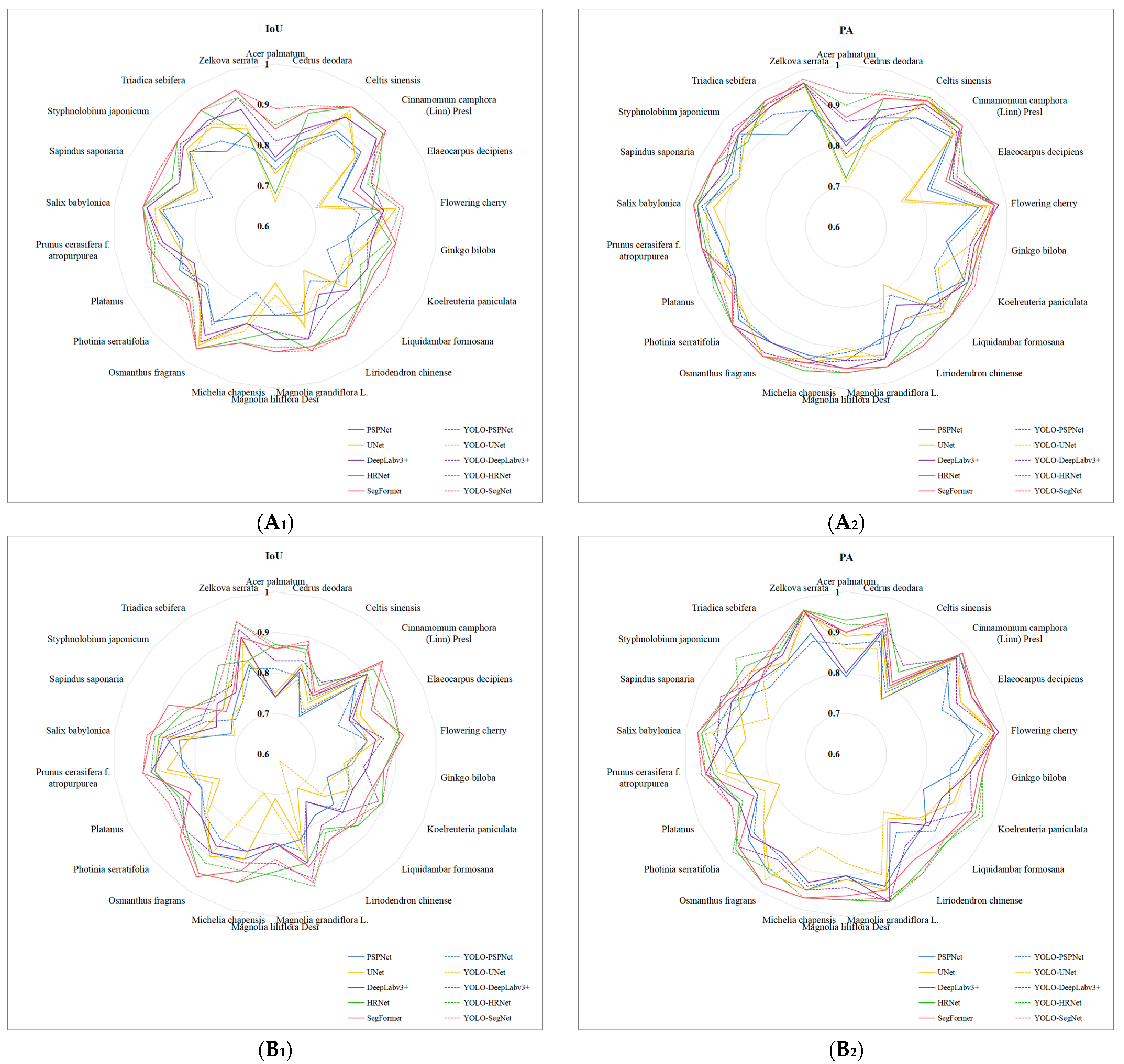
3.3. Results and Analysis of the Different Segmentation Models
4. Discussion
4.1. YOLOv8m+BiFormer Module
4.2. YOLO-SegNet Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Miao, C.; Li, P.; Huang, Y.; Sun, Y.; Chen, W.; Yu, S. Coupling outdoor air quality with thermal comfort in the presence of street trees: A pilot investigation in Shenyang, Northeast China. J. For. Res. 2022, 34, 831–839. [Google Scholar] [CrossRef]
- Jareemit, D.; Srivanit, M. A comparative study of cooling performance and thermal comfort under street market shades and tree canopies in tropical savanna climate. Sustainability 2022, 14, 4653. [Google Scholar] [CrossRef]
- Havu, M.; Kulmala, L.; Kolari, P.; Vesala, T.; Riikonen, A.; Jarvi, L. Carbon sequestration potential of street tree plantings in Helsinki. Biogeosciences 2022, 19, 2121–2143. [Google Scholar] [CrossRef]
- Kim, J.Y.; Jo, H.K. Estimating carbon budget from growth and management of urban street trees in South Korea. Sustainability 2022, 14, 4439. [Google Scholar] [CrossRef]
- Ma, B.; Hauer, R.J.; Ostberg, J.; Koeser, A.K.; Wei, H.; Xu, C. A global basis of urban tree inventories: What comes first the inventory or the program. Urban For. Urban Green. 2021, 60, 127087. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, D.; Fan, J.; Zhang, H.; Eichhorn, M.P.; Wang, X.; Yun, T. A reinterpretation of the gap fraction of tree crowns from the perspectives of computer graphics and porous media theory. Front. Plant Sci. 2023, 14, 1109443. [Google Scholar] [CrossRef]
- Galle, N.J.; Halpern, D.; Nitoslawski, S.; Duarte, F.; Ratti, C.; Pilla, F. Mapping the diversity of street tree inventories across eight cities internationally using open data. Urban For. Urban Green. 2021, 61, 127009. [Google Scholar] [CrossRef]
- Wu, X.M.; Xu, A.J.; Yang, T.T. Passive Measurement Method of Tree Height and Crown Diameter Using a Smartphone. IEEE Access 2020, 8, 11669–11678. [Google Scholar] [CrossRef]
- Yang, T.T.; Zhou, S.Y.; Xu, A.J.; Yin, J.X. A Method for Tree Image Segmentation Combined Adaptive Mean Shifting with Image Abstraction. J. Inf. Process Syst. 2020, 16, 1424–1436. [Google Scholar] [CrossRef]
- Li, Q.J.; Yan, Y.; Li, W.Z. Coarse-to-fine segmentation of individual street trees from side-view point clouds. Urban For. Urban Green. 2023, 89, 128097. [Google Scholar] [CrossRef]
- Hakula, A.; Ruoppa, L.; Lehtomaki, M.; Yu, X.; Kukko, A.; Kaartinen, H.; Hyyppä, J. Individual tree segmentation and species classification using high-density close-range multispectral laser scanning data. ISPRS Open J. Photogramm. Remote Sens. 2023, 9, 100039. [Google Scholar] [CrossRef]
- Xu, X.; Iuricich, F.; Calders, K.; Armston, J.; Florian, L.D. 2023.Topology-based individual tree segmentation for automated processing of terrestrial laser scanning point clouds. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103145. [Google Scholar] [CrossRef]
- Yang, T.T.; Zhou, S.Y.; Huang, Z.J.; Xu, A.J.; Ye, J.H.; Yin, J.X. Urban Street Tree Dataset for Image Classification and Instance Segmentation. Comput. Electron. Agric. 2023, 209, 107852. [Google Scholar] [CrossRef]
- Borrenpohl, D.; Karkee, M. Automated pruning decisions in dormant sweet cherry canopies using instance segmentation. Comput. Electron. Agric. 2023, 207, 107716. [Google Scholar] [CrossRef]
- Sun, X.; Xu, S.; Hua, W.; Tian, J.; Xu, Y. Feasibility study on the estimation of the living vegetation volume of individual street trees using terrestrial laser scanning. Urban For. Urban Green. 2022, 71, 127553. [Google Scholar] [CrossRef]
- Jiang, K.; Chen, L.; Wang, X.; An, F.; Zhang, H.; Yun, T. Simulation on different patterns of mobile laser scanning with extended application on solar beam illumination for forest plot. Forests 2022, 13, 2139. [Google Scholar] [CrossRef]
- Wang, Y.J.; Chen, Q.; Zhu, Q.; Liu, L.; Li, C.; Zheng, D. A survey of mobile laser scanning applications and key techniques over urban areas. Remote Sens. 2019, 11, 1540. [Google Scholar] [CrossRef]
- Wu, B.; Yu, B.; Yue, W.; Shu, S.; Tan, W.; Hu, C.; Huang, Y.; Wu, J.; Liu, H. A voxelbased method for automated identification and morphological parameters estimation of individual street trees from mobile laser scanning data. Remote Sens. 2013, 5, 584–611. [Google Scholar] [CrossRef]
- Majeed, Y.; Zhang, J.; Zhang, X.; Fu, L.; Karkee, M.; Zhang, Q.; Whiting, M.D. Deep learning based segmentation for automated training of apple trees on trellis wires. Comput. Electron. Agric. 2020, 170, 105277. [Google Scholar] [CrossRef]
- Wan, H.; Zeng, X.; Fan, Z.; Zhang, S.; Kang, M. U2ESPNet-A lightweight and high-accuracy convolutional neural network for real-time semantic segmentation of visible branches. Comput. Electron. Agric. 2023, 204, 107542. [Google Scholar] [CrossRef]
- Zhang, J.; He, L.; Karkee, M.; Zhang, Q.; Zhang, X.; Gao, Z. Branch Detection with Apple Trees Trained in Fruiting Wall Architecture using Stereo Vision and Regions-Convolutional Neural Network (R-CNN). In Proceedings of the 2017 ASABE Annual International Meeting, Spokane, WA, USA, 16–19 July 2017; American Society of Agricultural and Biological Engineers: Saint Joseph, MI, USA, 2017; p. 1. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Kok, E.; Wang, X.; Chen, C. Obscured tree branches segmentation and 3D reconstruction using deep learning and geometrical constraints. Comput. Electron. Agric. 2023, 210, 107884. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNnet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.J.; Ke, Z.H.; Zhang, W.; Lau1y, R. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 24 June 2023. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO (Version 8.0.0) [Computer Software]. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 May 2023).
- Xie, E.; Wang, W.H.; Yu, Z.D.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar] [CrossRef]
- Everingham, M.; Ali Eslami, S.M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Feng, X.; Ren, A.; Qi, H. Improved Highway Vehicle Detection Algorithm for YOLOv8n. In Proceedings of the 2023 9th International Conference on Mechanical and Electronics Engineering (ICMEE), Xi’an, China, 17–19 November 2023. [Google Scholar] [CrossRef]
- Yang, F.; Wang, T.; Wang, X. Student Classroom Behavior Detection based on YOLOv7-BRA and Multi-Model Fusion. ArXiv 2023, arXiv:2305.07825. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–5 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. NAACL (North American Chapter of the Association for Computational Linguistics). 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 10 May 2023).
- Reddy, D.M.; Basha, S.M.; Hari, M.C.; Penchalaiah, N. Dall-e: Creating images from text. UGC Care Group I J. 2021, 8, 71–75. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar]
- Dong, X.Y.; Bao, J.M.; Chen, D.D.; Zhang, W.M.; Yu, N.H.; Yuan, L.; Chen, D.; Guo, B.N. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Liu, Z.; Lin, Y.T.; Cao, Y.; Hu, H.; Wei, Y.X.; Zhang, Z.; Lin, S.; Guo, B.N. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tu, Z.Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y.X. Maxvit: Multi-axis vision transformer. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Wang, W.X.; Yao, L.; Chen, L.; Lin, B.B.; Cai, D.; He, X.F.; Liu, W. Crossformer: A versatile vision transformer hinging on cross-scale attention. In Proceedings of the International Conference on Learning Representations (ICLR), online, 25–29 April 2022. [Google Scholar]
- Xia, Z.F.; Pan, X.R.; Song, S.J.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Laurens, V.D.M.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar] [CrossRef]
- Rizvi, S.M.H.; Naseer, A.; Rehman, S.U.; Akram, S.; Gruhn, V. Revolutionizing Agriculture: Machine and Deep Learning Solutions for Enhanced Crop Quality and Weed Control. IEEE Access 2024, 12, 11865–11878. [Google Scholar] [CrossRef]
- Bonfanti-Gris, M.; Herrera, A.; Paraíso-Medina, S.; Alonso-Calvo, R.; Martínez-Rus, F.; Pradíes, G. Performance evaluation of three versions of a convolutional neural network for object detection and segmentation using a multiclass and reduced panoramic radiograph dataset. J. Dent. 2024, 144, 104891. [Google Scholar] [CrossRef]
- Sun, S.; Mo, B.; Xu, J.; Li, D.; Zhao, J.; Han, S. Multi-YOLOv8: An infrared moving small object detection model based on YOLOv8 for air vehicle. Neurocomputing 2024, 588, 127685. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Street Tree Dataset | Ratio | Number | Dataset Format (Object Detection) | Dataset Format (Segmentation) |
|---|---|---|---|---|
| Train set | 8 | 3168 | YOLO [27] | VOC2012 [29] |
| Validation set | 1 | 395 | ||
| Test set | 1 | 386 |
| Model | Size (Pixels) | Params (M) | FLOPs (B) | Layers | Preprocess (ms) | Inference (ms) | Postprocess (ms) |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 3.0 | 8.2 | 225 | 1.6 | 0.6 | 1.6 |
| YOLOv8s | 640 | 11.1 | 28.7 | 225 | 0.5 | 1.0 | 0.8 |
| YOLOv8m | 640 | 25.8 | 79.1 | 295 | 1.3 | 2.1 | 1.1 |
| YOLOv8l | 640 | 43.6 | 165.5 | 365 | 0.5 | 3.7 | 1.3 |
| YOLOv8x | 640 | 68.2 | 257.5 | 365 | 0.6 | 5.5 | 0.3 |
| YOLOv8m+BiFormer | 640 | 36.3 | 178.5 | 306 | 0.2 | 2.3 | 0.5 |
| Model | Recall | Precision | mAPval50 | mAPval50-95 |
|---|---|---|---|---|
| YOLOv8n | 96.9 | 97.1 | 99.1 | 91.8 |
| YOLOv8s | 97.1 | 98.1 | 99.3 | 93.2 |
| YOLOv8m | 98.2 | 97.6 | 99.4 | 93.9 |
| YOLOv8l | 99.4 | 97.5 | 99.5 | 94.3 |
| YOLOv8x | 97.5 | 98.4 | 99.5 | 94.1 |
| YOLOv8m+BiFormer | 98.9 | 97.5 | 99.4 | 94.6 |
| Model | mIoU | mPA | f_Score | |
|---|---|---|---|---|
| Not based on YOLOv8m+BiFormer module | FCN [44] | 81.5 | - | - |
| LR-ASPP [45] | 82.3 | - | - | |
| PSPNet [46] | 87.0 | 92.7 | 95.8 | |
| UNet [25] | 85.2 | 91.7 | 85.3 | |
| DeepLabv3+ [47] | 87.5 | 92.5 | 97.0 | |
| HRNet [48] | 89.3 | 94.7 | 97.0 | |
| SegFormer [28] | 91.0 | 95.4 | 97.8 | |
| Based on YOLOv8m+BiFormer module | YOLO-FCN | 82.8 | - | - |
| YOLO-LR-ASPP | 84.8 | - | - | |
| YOLO-PSPNet | 87.9 | 93.3 | 97.0 | |
| YOLO-UNet | 84.7 | 91.4 | 88.6 | |
| YOLO-DeepLabv3+ | 88.3 | 93.4 | 97.6 | |
| YOLO-HRNet | 90.5 | 95.3 | 97.4 | |
| Ours: YOLO-SegNet | 92.0 | 95.9 | 98.0 |
| Model | mIoU | mPA | |
|---|---|---|---|
| Not based on YOLOv8m+BiFormer module | FCN | 71.3 | - |
| LR-ASPP | 76.6 | - | |
| PSPNet | 80.6 | 88.6 | |
| UNet | 81.2 | 89.6 | |
| DeepLabv3+ | 83.2 | 90.7 | |
| HRNet | 88.1 | 93.5 | |
| SegFormer | 87.3 | 93.1 | |
| Based on YOLOv8m+BiFormer module | YOLO-FCN | 79.3 | - |
| YOLO-LR-ASPP | 83.4 | - | |
| YOLO-PSPNet | 81.1 | 88.9 | |
| YOLO-UNet | 79.7 | 88.5 | |
| YOLO-DeepLabv3+ | 86.0 | 92.6 | |
| YOLO-HRNet | 87.7 | 94.0 | |
| Ours: YOLO-SegNet | 88.4 | 93.7 |
| Model | Size (Pixels) | Params (M) | FLOPs (B) | Layers | Preprocess (ms) | Inference (ms) | Postprocess (ms) |
|---|---|---|---|---|---|---|---|
| YOLOv8m [27] | 640 | 25.8 | 79.1 | 295 | 0.1 | 1.6 | 0.9 |
| YOLOv8n+BiFormer | 640 | 3.3 | 18.6 | 236 | 1.8 | 1.2 | 2.3 |
| YOLOv8s+BiFormer | 640 | 12.2 | 70.0 | 236 | 0.6 | 1.2 | 0.7 |
| YOLOv8l+BiFormer | 640 | 80.9 | 357.4 | 376 | 0.4 | 4.5 | 1.1 |
| YOLOv8x+BiFormer | 640 | 126.4 | 557.9 | 376 | 0.2 | 6.3 | 0.7 |
| Ours: YOLOv8m+BiFormer | 640 | 36.3 | 178.5 | 306 | 0.2 | 2.4 | 0.5 |
| Model | Recall | Precision | mAPval50 | mAPval50-95 |
|---|---|---|---|---|
| YOLOv8m [27] | 98.2 | 97.6 | 99.4 | 93.9 |
| YOLOv8n+BiFormer | 98.1 | 97.1 | 99.4 | 92.5 |
| YOLOv8s+BiFormer | 97.9 | 96.9 | 99.3 | 93.4 |
| YOLOv8l+BiFormer | 98.6 | 98.9 | 99.5 | 94.9 |
| YOLOv8x+BiFormer | 98.4 | 98.9 | 99.5 | 94.9 |
| Ours: YOLOv8m+BiFormer | 98.9 | 97.5 | 99.4 | 94.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, T.; Zhou, S.; Xu, A.; Ye, J.; Yin, J. YOLO-SegNet: A Method for Individual Street Tree Segmentation Based on the Improved YOLOv8 and the SegFormer Network. Agriculture 2024, 14, 1620. https://doi.org/10.3390/agriculture14091620
Yang T, Zhou S, Xu A, Ye J, Yin J. YOLO-SegNet: A Method for Individual Street Tree Segmentation Based on the Improved YOLOv8 and the SegFormer Network. Agriculture. 2024; 14(9):1620. https://doi.org/10.3390/agriculture14091620
Chicago/Turabian StyleYang, Tingting, Suyin Zhou, Aijun Xu, Junhua Ye, and Jianxin Yin. 2024. "YOLO-SegNet: A Method for Individual Street Tree Segmentation Based on the Improved YOLOv8 and the SegFormer Network" Agriculture 14, no. 9: 1620. https://doi.org/10.3390/agriculture14091620
APA StyleYang, T., Zhou, S., Xu, A., Ye, J., & Yin, J. (2024). YOLO-SegNet: A Method for Individual Street Tree Segmentation Based on the Improved YOLOv8 and the SegFormer Network. Agriculture, 14(9), 1620. https://doi.org/10.3390/agriculture14091620