
Deep Learning for Multi-Source Data-Driven Crop Yield Prediction in Northeast China

 ,
,
Abstract
1. Introduction
2. Materials and Methods
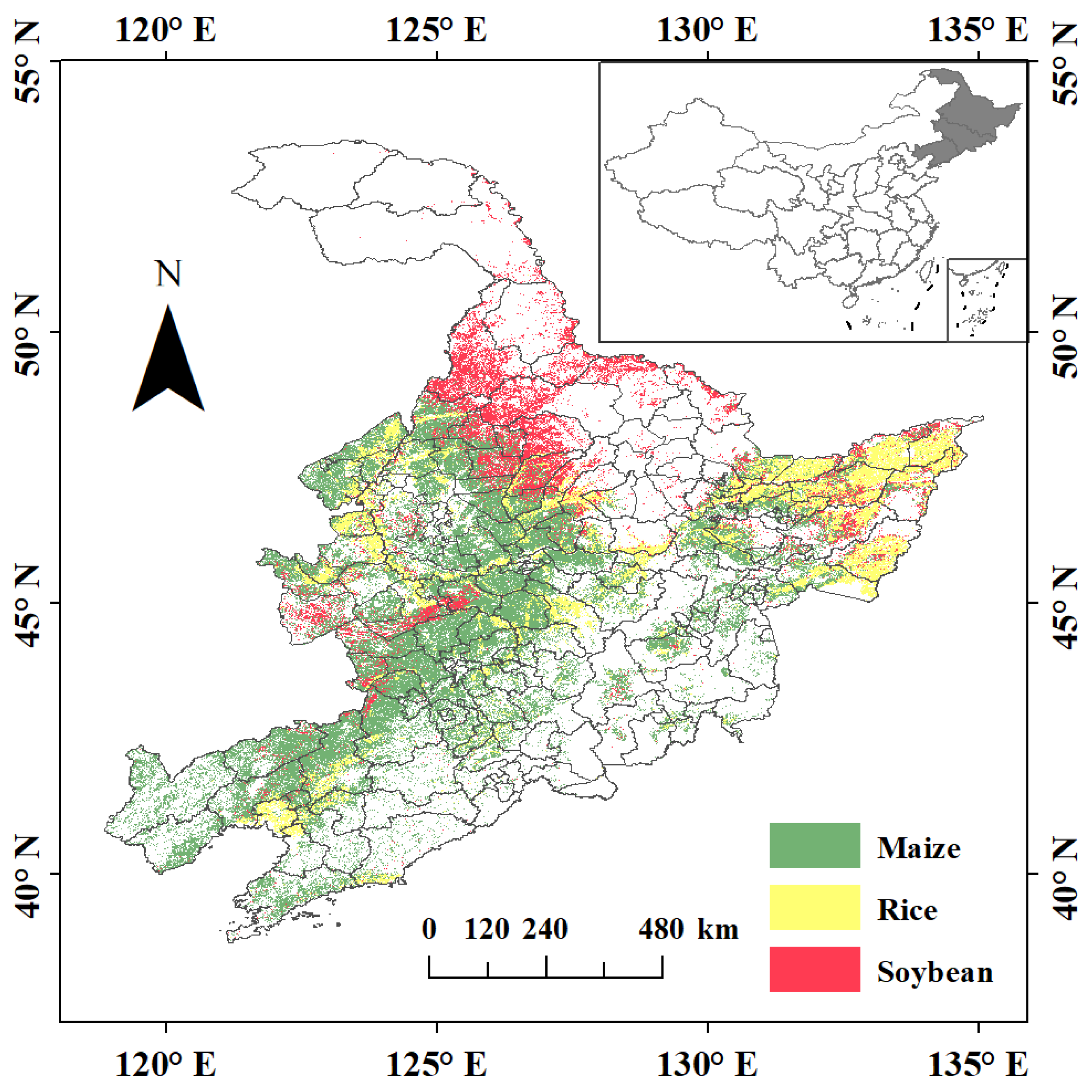
2.1. Study Area
2.2. Data
2.2.1. Crop Yield and Planting Area
2.2.2. Vegetation Indices
2.2.3. Environmental Variables
2.2.4. Photosynthetically Active Variables
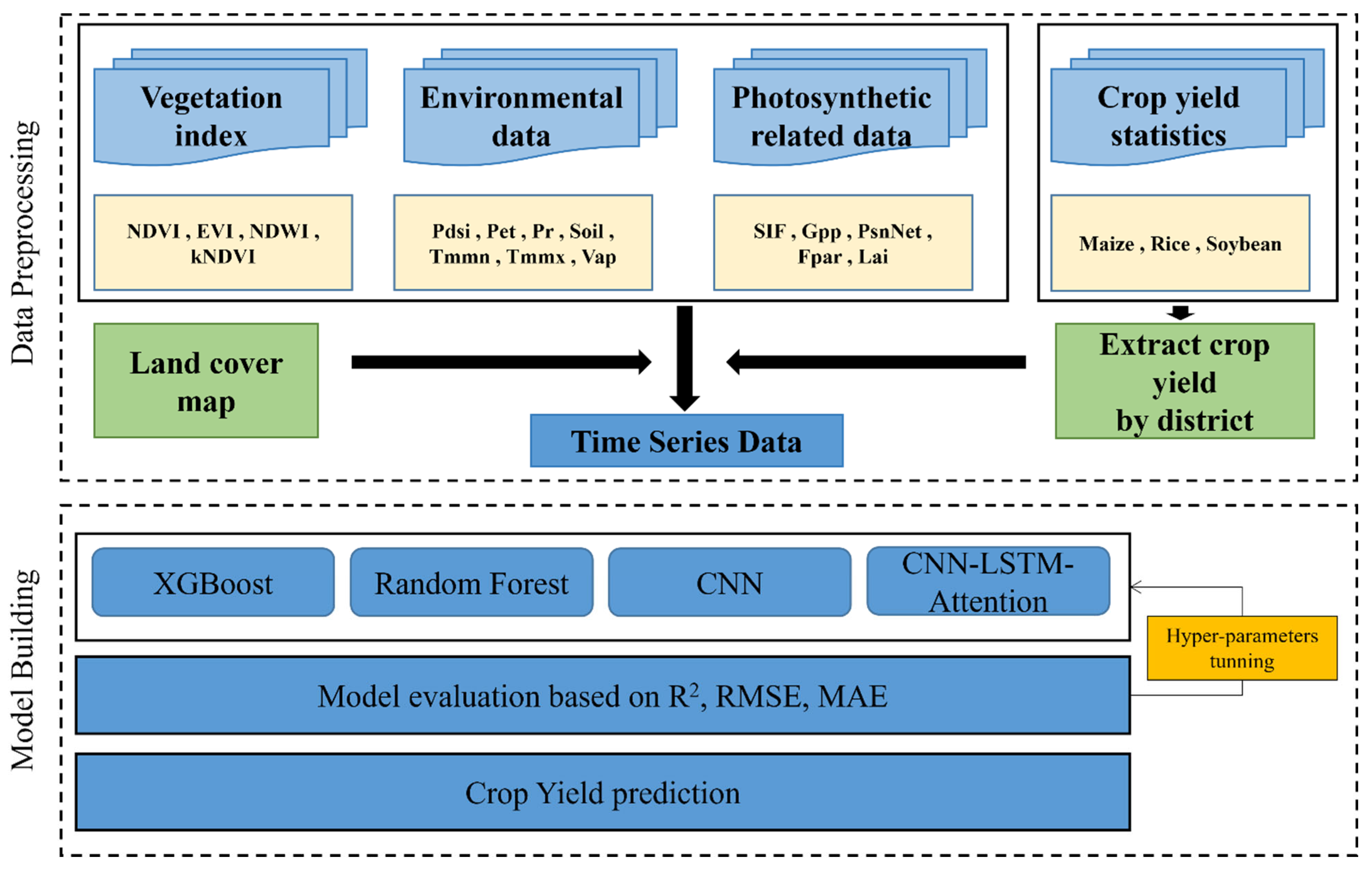
2.3. Methodology
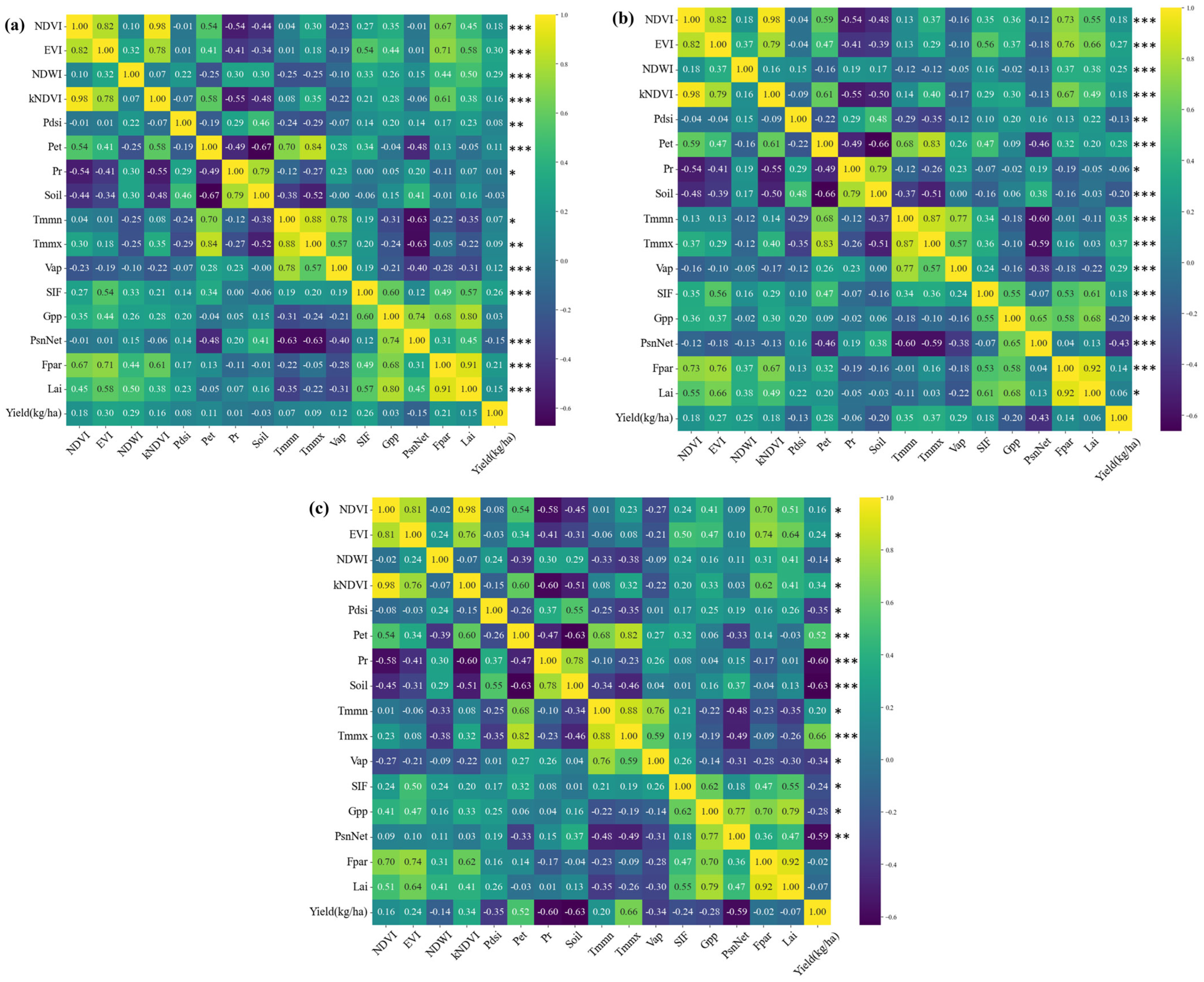
2.3.1. Exploratory Data Analysis
2.3.2. Random Forest
2.3.3. XGBoost
2.3.4. CNN
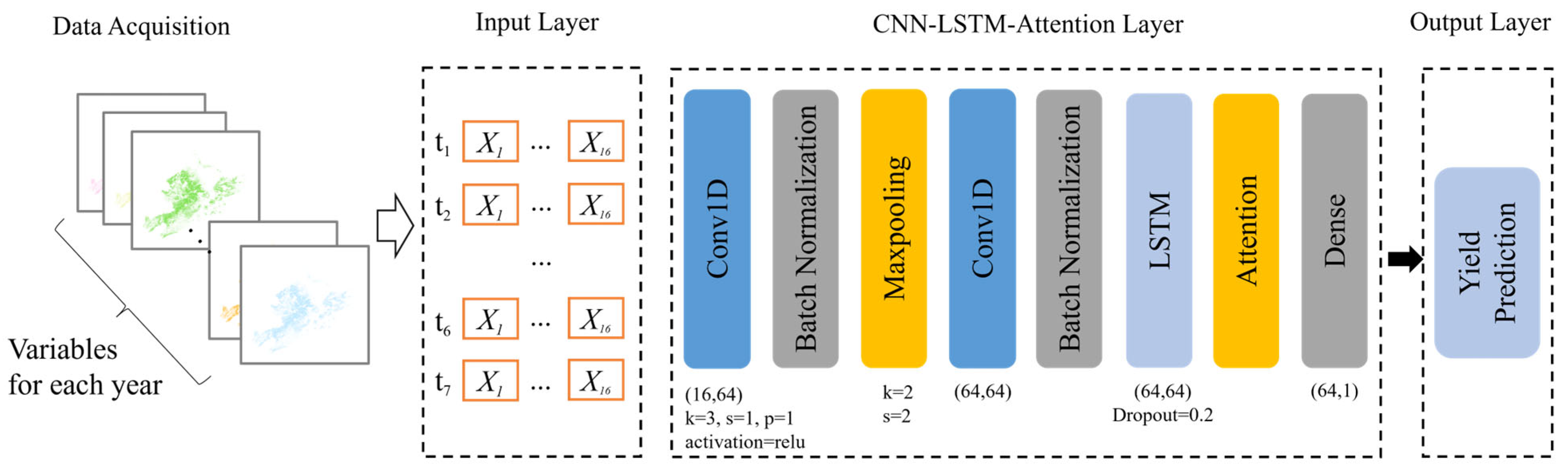
2.3.5. CNN-LSTM-Attention
2.3.6. Performance Evaluation
3. Results
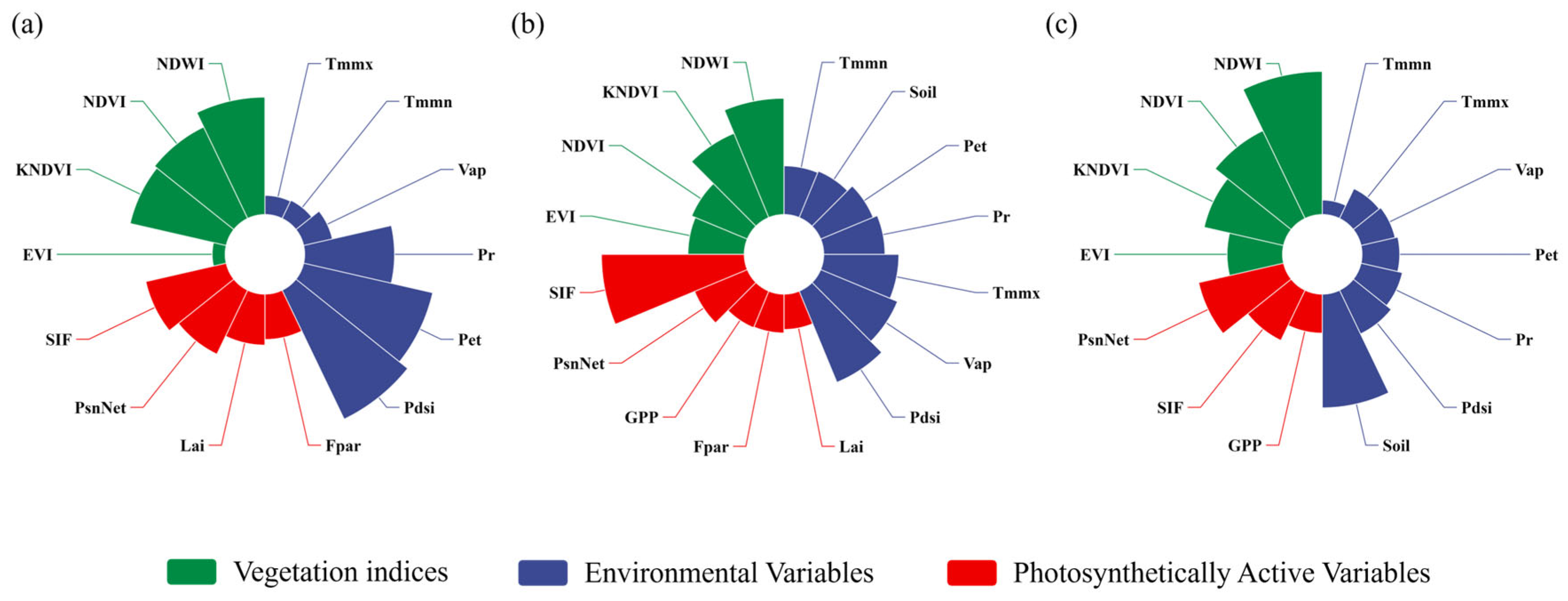
3.1. Input Variable Selection for Different Crops
3.2. Multi-Model Yield Prediction for Diverse Crops
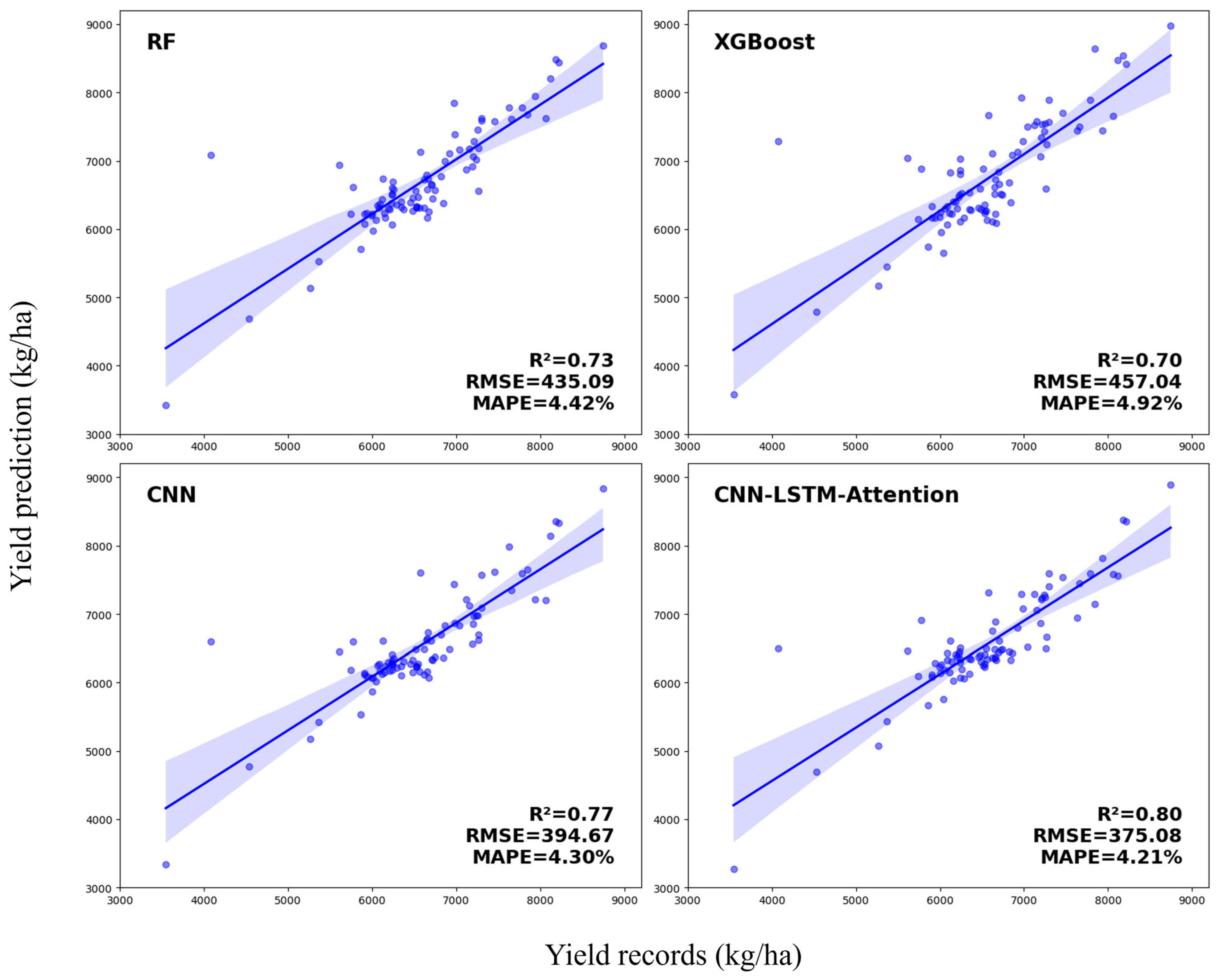
3.2.1. Comparative Yield Prediction Models for Maize
3.2.2. Comparative Yield Prediction Models for Rice
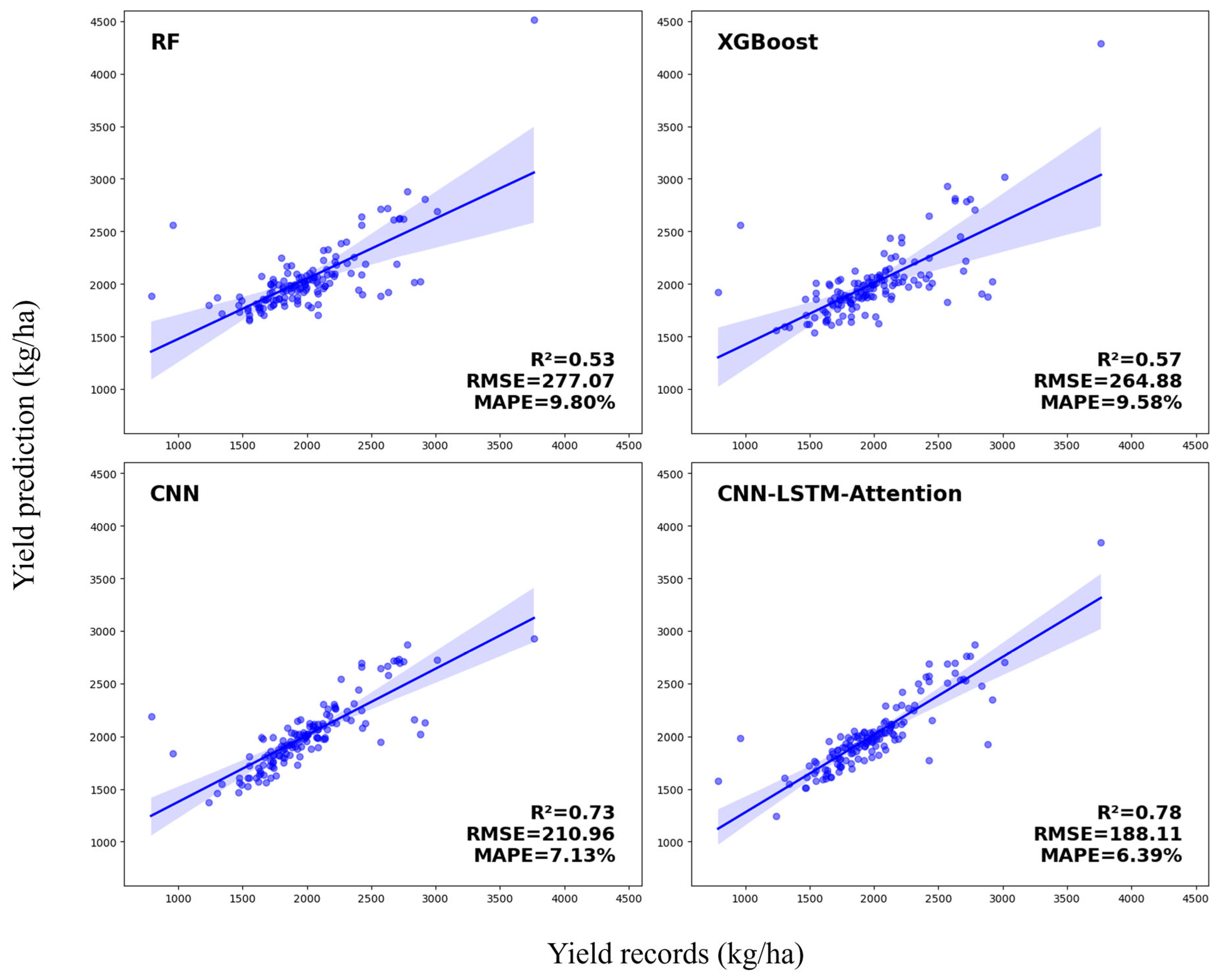
3.2.3. Comparative Yield Prediction Models for Soybean
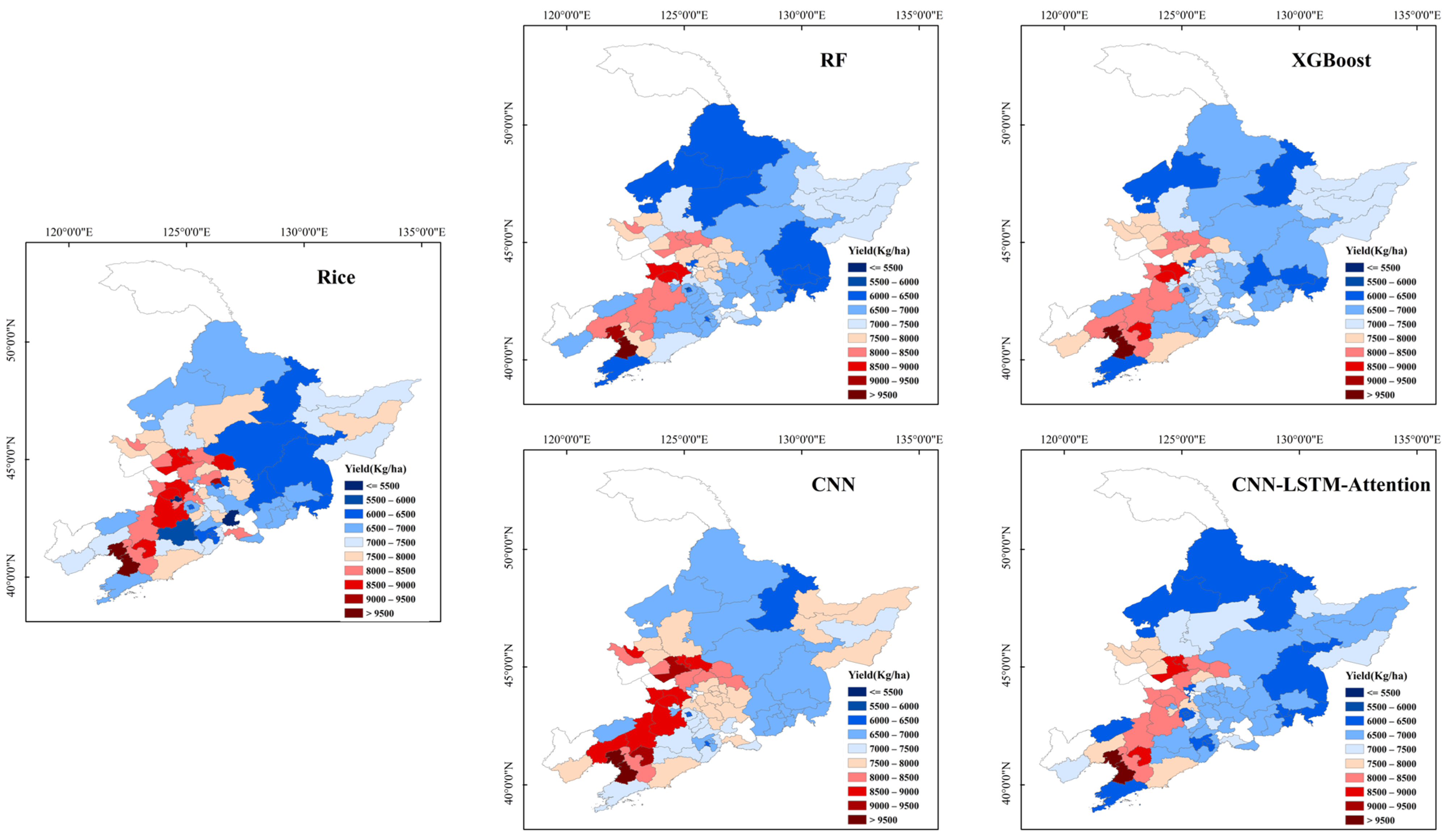
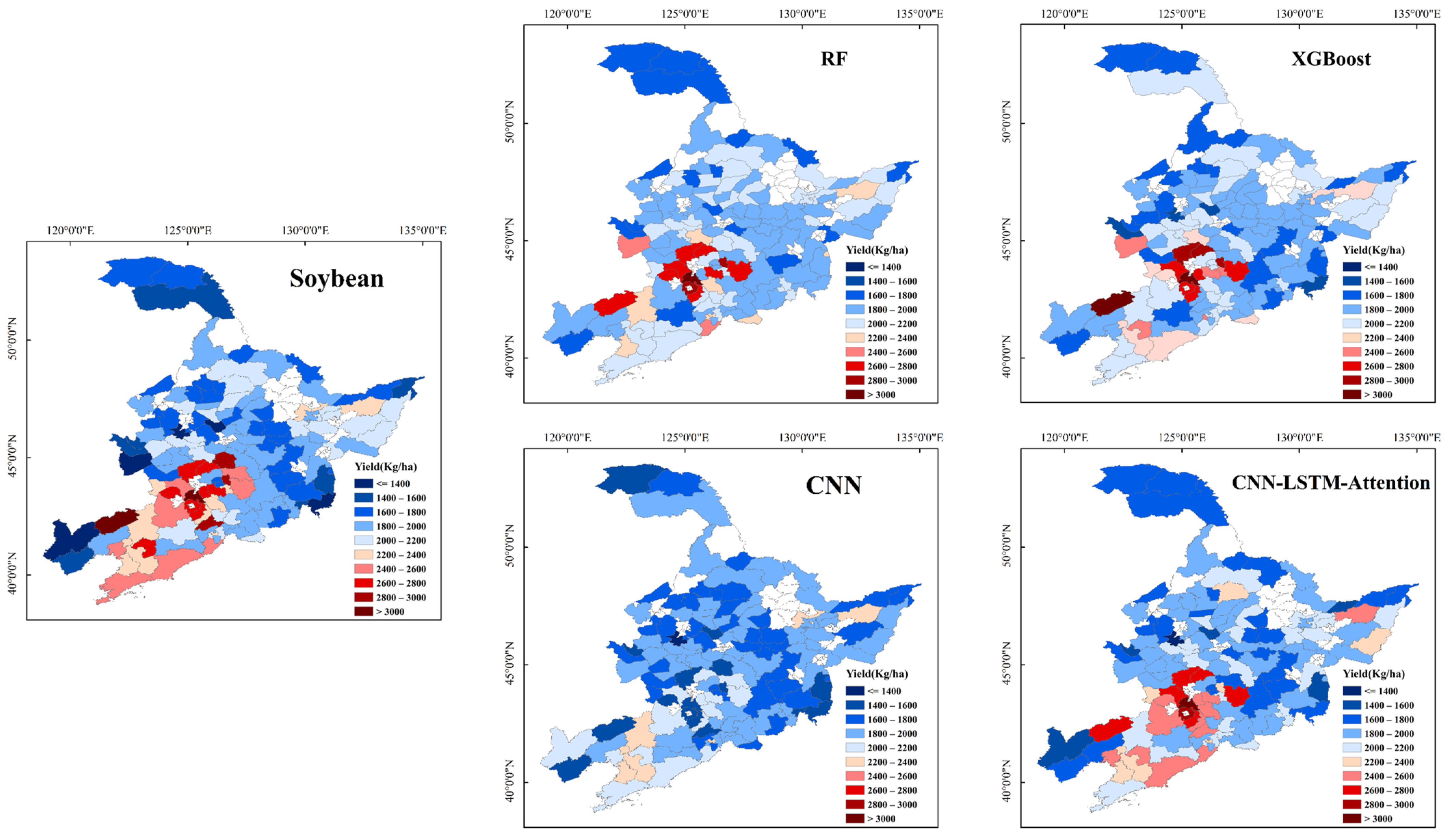
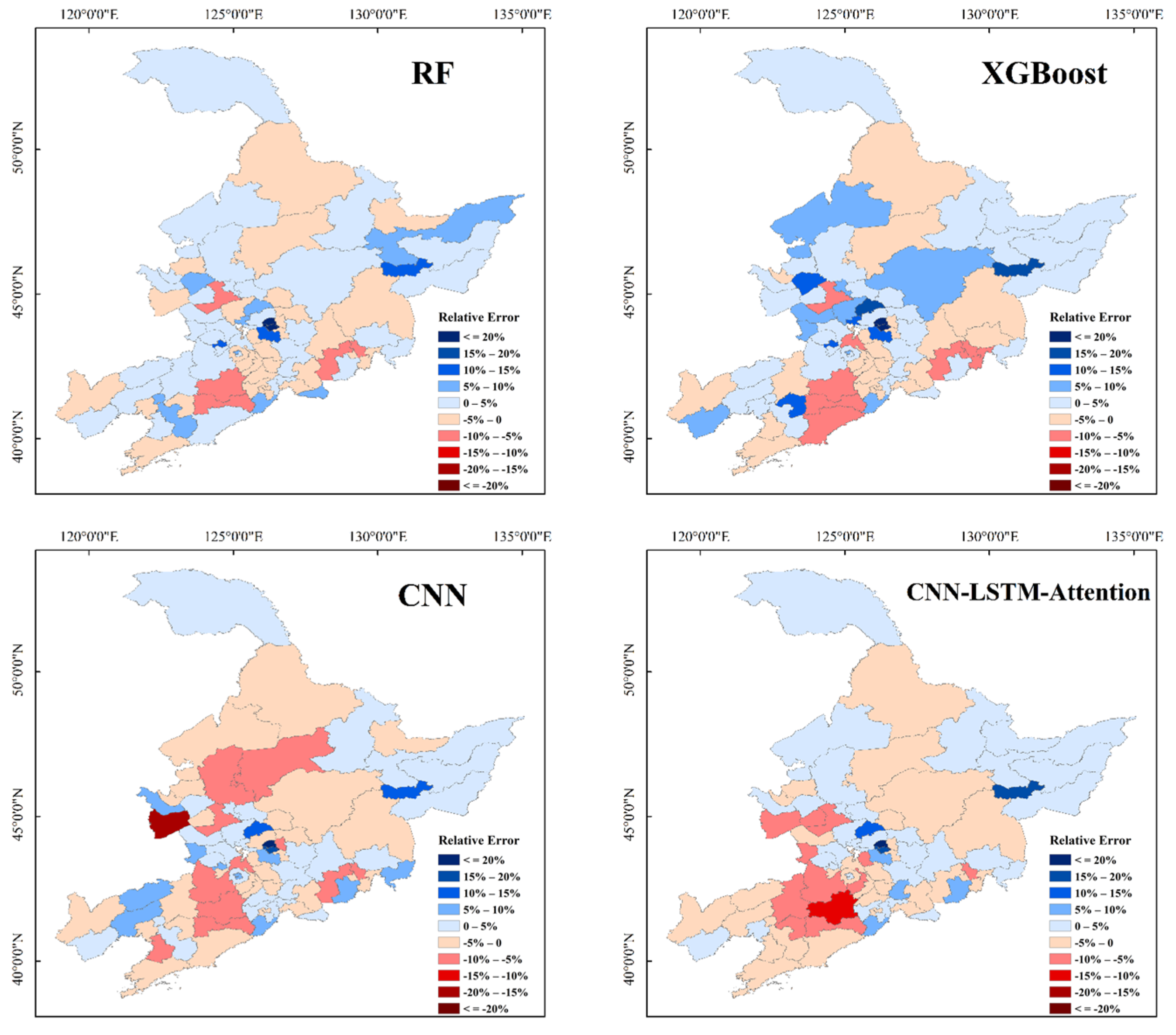
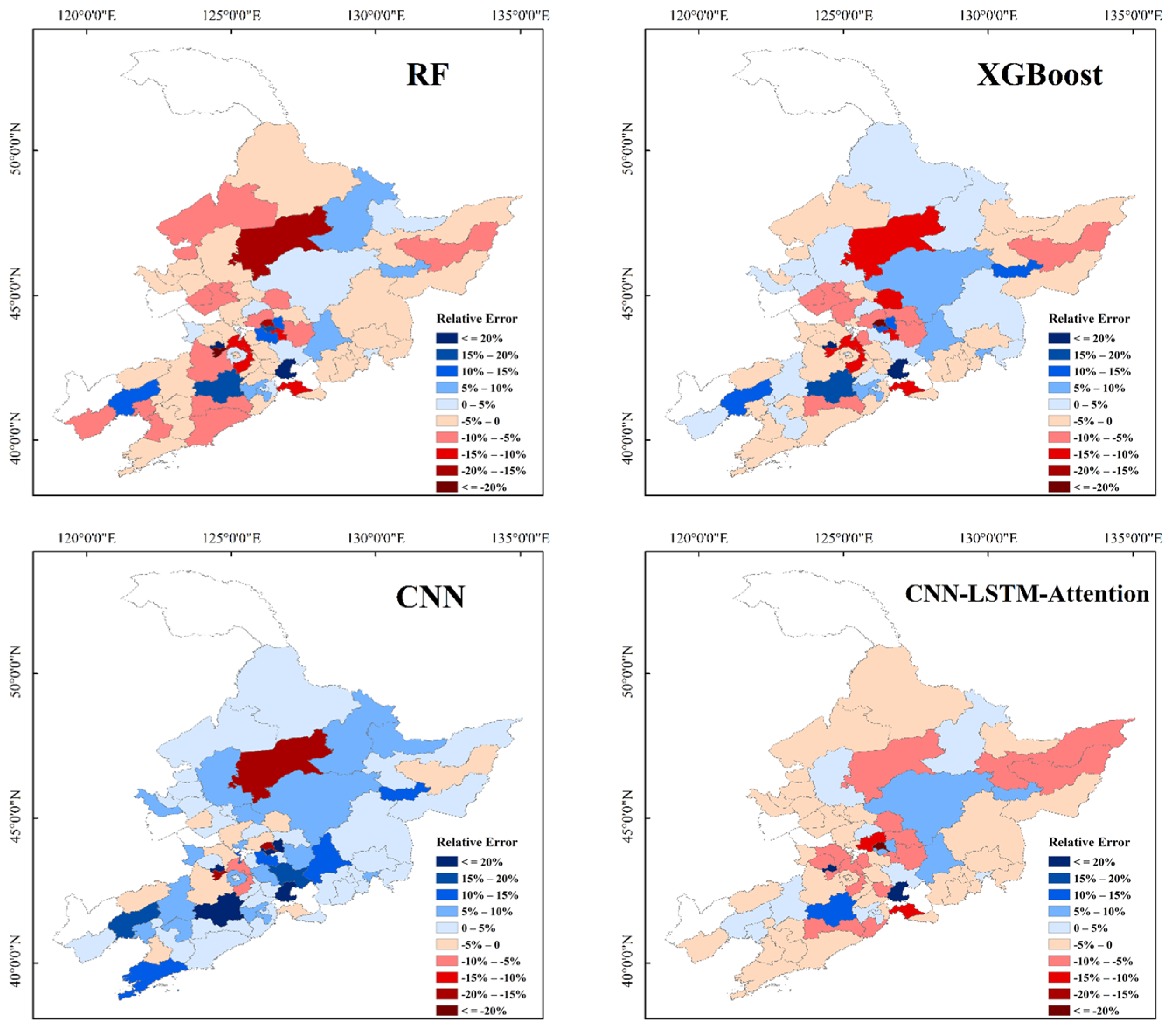
3.3. Spatial Patterns in Yield Prediction for the Three Crop Types
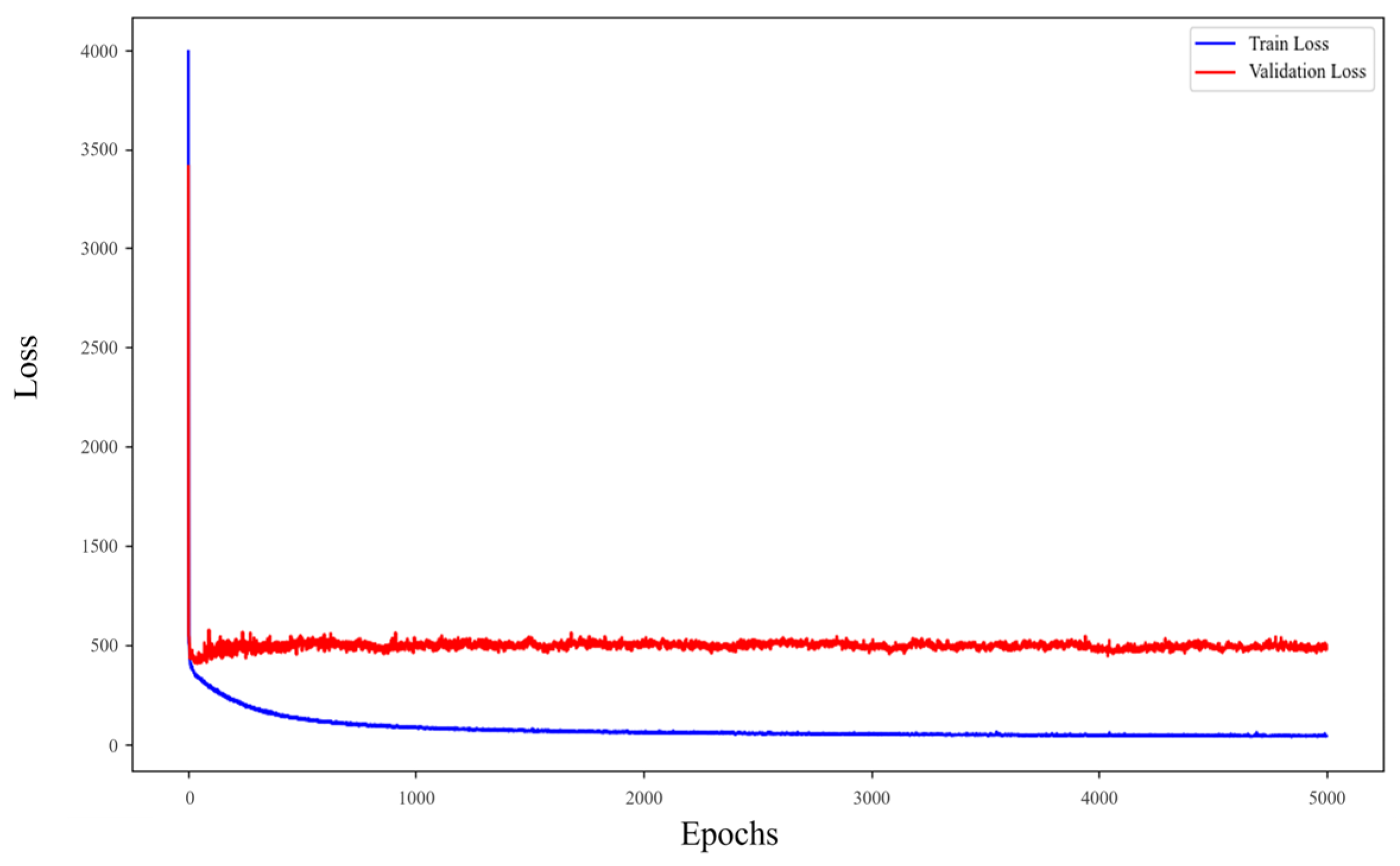
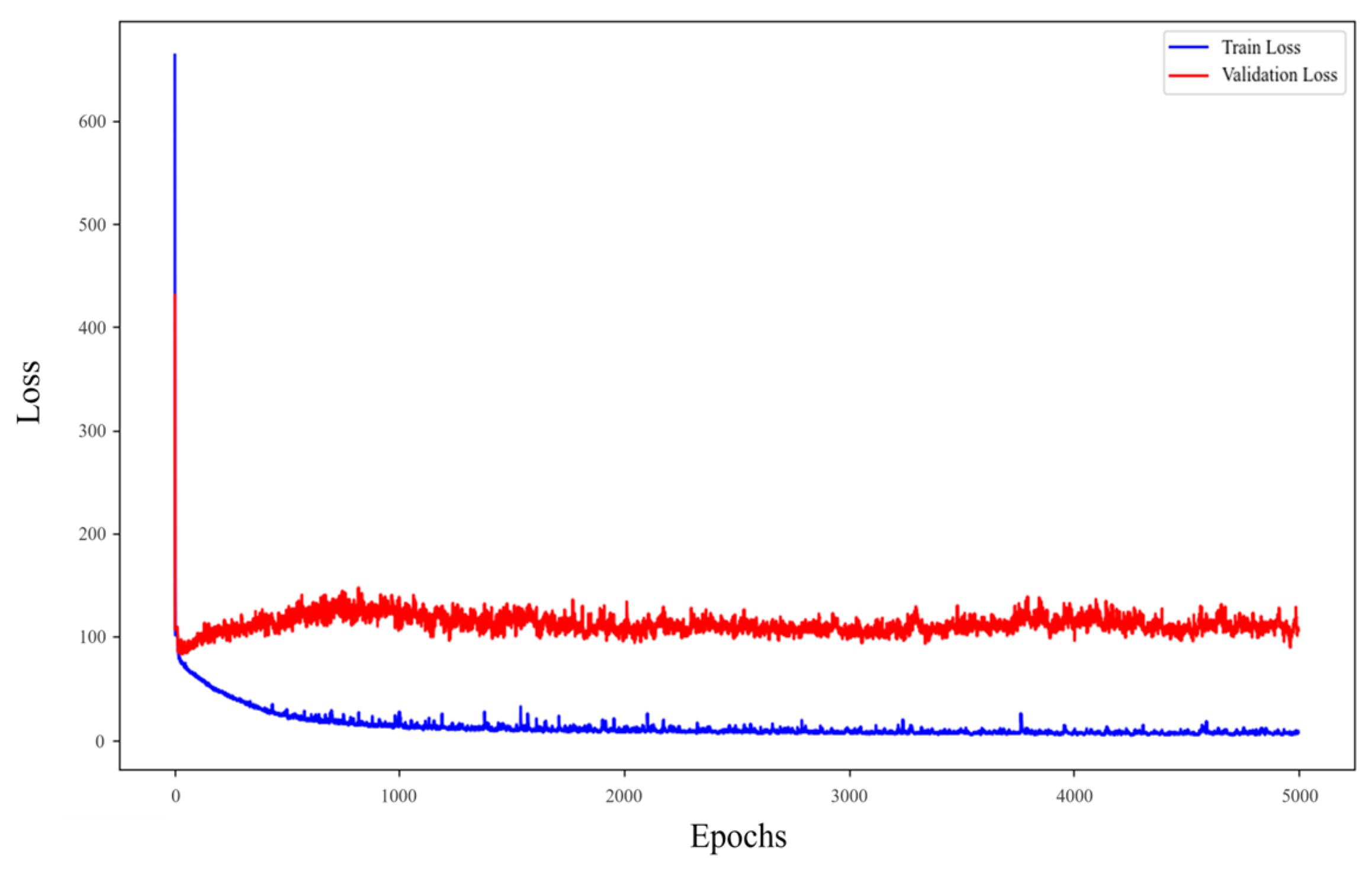
3.4. Training and Validation Loss Analysis for CNN-LSTM-Attention Model
3.5. Importance of Predictor Variables in Yield Prediction
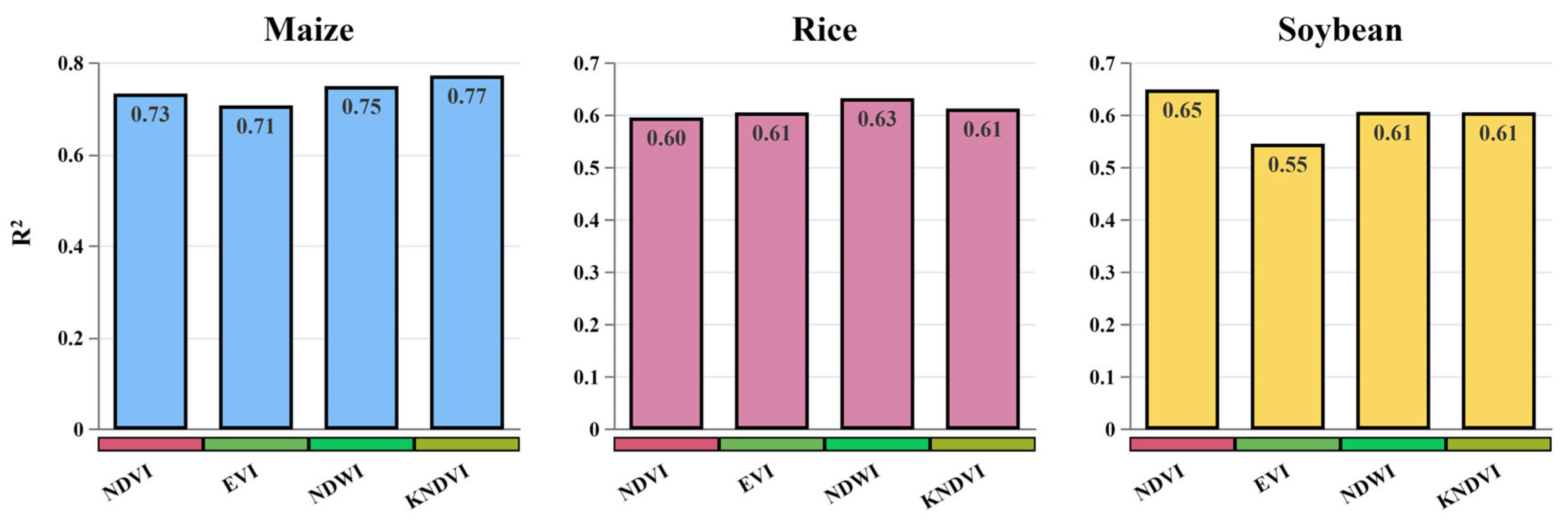
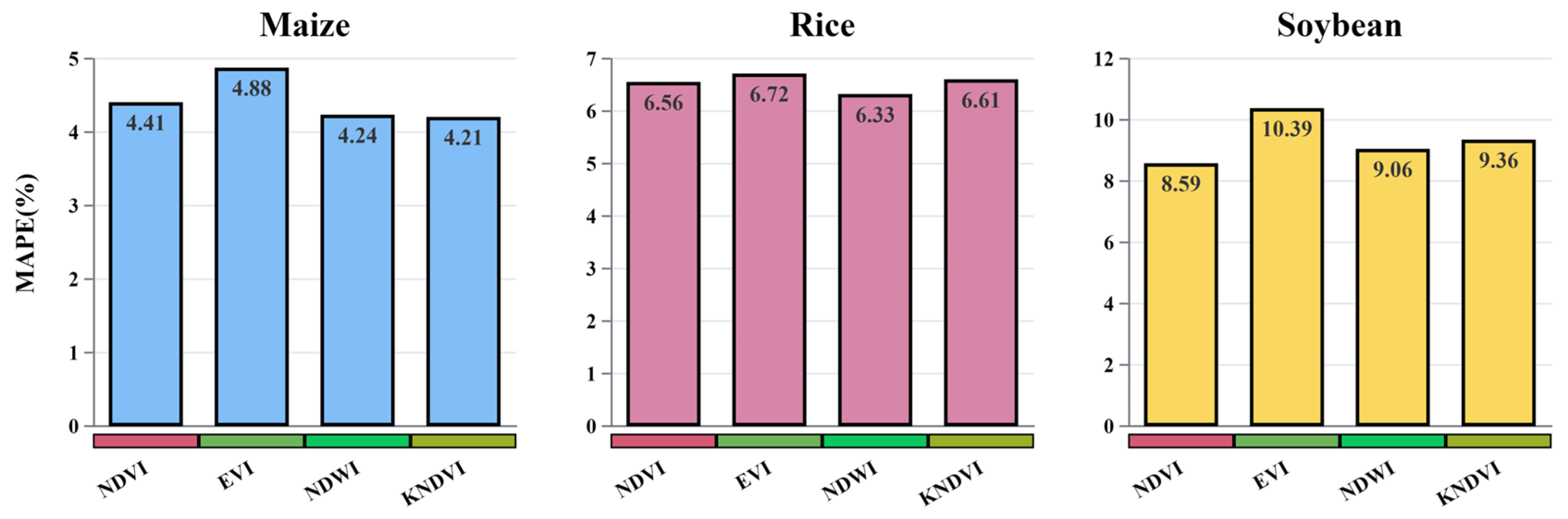
3.6. Analysis of Vegetation Indices in Crop Yield Prediction
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Barakat, S.; Cochrane, L.; Vasekha, I. The humanitarian-development-peace nexus for global food security: Responding to the climate crisis, conflict, and supply chain disruptions. Int. J. Disaster Risk Reduct. 2023, 98, 104106. [Google Scholar] [CrossRef]
- Loizou, E.; Karelakis, C.; Galanopoulos, K.; Mattas, K. The role of agriculture as a development tool for a regional economy. Agric. Syst. 2019, 173, 482–490. [Google Scholar] [CrossRef]
- Luo, J.; Hu, M.; Huang, M.; Bai, Y. How does innovation consortium promote low-carbon agricultural technology innovation: An evolutionary game analysis. J. Clean. Prod. 2023, 384, 135564. [Google Scholar] [CrossRef]
- Li, M.; Jia, N.; Lenzen, M.; Malik, A.; Wei, L.; Jin, Y.; Raubenheimer, D. Global food-miles account for nearly 20% of total food-systems emissions. Nat. Food 2022, 3, 445–453. [Google Scholar] [CrossRef]
- Xin, F.; Xiao, X.; Dong, J.; Zhang, G.; Zhang, Y.; Wu, X.; Li, X.; Zou, Z.; Ma, J.; Du, G.; et al. Large increases of paddy rice area, gross primary production, and grain production in Northeast China during 2000–2017. Sci. Total Environ. 2020, 711, 135183. [Google Scholar] [CrossRef]
- Niu, Y.; Xie, G.; Xiao, Y.; Liu, J.; Wang, Y.; Luo, Q.; Zou, H.; Gan, S.; Qin, K.; Huang, M. Spatiotemporal Patterns and Determinants of Grain Self-Sufficiency in China. Foods 2021, 10, 747. [Google Scholar] [CrossRef]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef]
- Anderson, K.; Strutt, A. Food security policy options for China: Lessons from other countries. Food Policy 2014, 49, 50–58. [Google Scholar] [CrossRef]
- Muruganantham, P.; Wibowo, S.; Grandhi, S.; Samrat, N.H.; Islam, N. A Systematic Literature Review on Crop Yield Prediction with Deep Learning and Remote Sensing. Remote Sens. 2022, 14, 1990. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Lv, Z.; Huang, H.; Li, X.; Zhao, M.; Benediktsson, J.A.; Sun, W.; Falco, N. Land Cover Change Detection with Heterogeneous Remote Sensing Images: Review, Progress, and Perspective. Proc. IEEE 2022, 110, 1976–1991. [Google Scholar] [CrossRef]
- Zhuo, W.; Fang, S.; Gao, X.; Wang, L.; Wu, D.; Fu, S.; Wu, Q.; Huang, J. Crop yield prediction using MODIS LAI, TIGGE weather forecasts and WOFOST model: A case study for winter wheat in Hebei, China during 2009–2013. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102668. [Google Scholar] [CrossRef]
- Leolini, L.; Bregaglio, S.; Ginaldi, F.; Costafreda-Aumedes, S.; Di Gennaro, S.F.; Matese, A.; Maselli, F.; Caruso, G.; Palai, G.; Bajocco, S.; et al. Use of remote sensing-derived fPAR data in a grapevine simulation model for estimating vine biomass accumulation and yield variability at sub-field level. Precis. Agric. 2023, 24, 705–726. [Google Scholar] [CrossRef]
- Zhai, W.; Li, C.; Cheng, Q.; Ding, F.; Chen, Z. Exploring Multisource Feature Fusion and Stacking Ensemble Learning for Accurate Estimation of Maize Chlorophyll Content Using Unmanned Aerial Vehicle Remote Sensing. Remote Sens. 2023, 15, 3454. [Google Scholar] [CrossRef]
- Naghdyzadegan Jahromi, M.; Zand-Parsa, S.; Razzaghi, F.; Jamshidi, S.; Didari, S.; Doosthosseini, A.; Pourghasemi, H.R. Developing machine learning models for wheat yield prediction using ground-based data, satellite-based actual evapotranspiration and vegetation indices. Eur. J. Agron. 2023, 146, 126820. [Google Scholar] [CrossRef]
- Wang, J.; Wang, P.; Tian, H.; Tansey, K.; Liu, J.; Quan, W. A deep learning framework combining CNN and GRU for improving wheat yield estimates using time series remotely sensed multi-variables. Comput. Electron. Agric. 2023, 206, 107705. [Google Scholar] [CrossRef]
- Amin, E.; Pipia, L.; Belda, S.; Perich, G.; Graf, L.V.; Aasen, H.; Van Wittenberghe, S.; Moreno, J.; Verrelst, J. In-season forecasting of within-field grain yield from Sentinel-2 time series data. Int. J. Appl. Earth Obs. Geoinf. 2024, 126, 103636. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Campos-Taberner, M.; Moreno-Martínez, Á.; Walther, S.; Duveiller, G.; Cescatti, A.; Mahecha, M.D.; Muñoz-Marí, J.; García-Haro, F.J.; Guanter, L.; et al. A unified vegetation index for quantifying the terrestrial biosphere. Sci. Adv. 2021, 7, eabc7447. [Google Scholar] [CrossRef]
- Zheng, Z.; Schmid, B.; Zeng, Y.; Schuman, M.C.; Zhao, D.; Schaepman, M.E.; Morsdorf, F. Remotely sensed functional diversity and its association with productivity in a subtropical forest. Remote Sens. Environ. 2023, 290, 113530. [Google Scholar] [CrossRef]
- Wang, Q.; Moreno-Martínez, Á.; Muñoz-Marí, J.; Campos-Taberner, M.; Camps-Valls, G. Estimation of vegetation traits with kernel NDVI. ISPRS J. Photogramm. Remote Sens. 2023, 195, 408–417. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, X.; Jiao, Y.; Cheng, Y.; Zhu, Z.; Wang, S.; Zhang, H. Investigating the spatio-temporal pattern evolution characteristics of vegetation change in Shendong coal mining area based on kNDVI and intensity analysis. Front. Ecol. Evol. 2023, 11, 1344664. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, S.; Tao, F.; Aboelenein, R.; Amer, A. Improving Winter Wheat Yield Forecasting Based on Multi-Source Data and Machine Learning. Agriculture 2022, 12, 571. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, Q.; Li, T.; Zhang, K. Dynamic Vegetation Responses to Climate and Land Use Changes over the Inner Mongolia Reach of the Yellow River Basin, China. Remote Sens. 2023, 15, 3531. [Google Scholar] [CrossRef]
- Feng, X.; Tian, J.; Wang, Y.; Wu, J.; Liu, J.; Ya, Q.; Li, Z. Spatio-Temporal Variation and Climatic Driving Factors of Vegetation Coverage in the Yellow River Basin from 2001 to 2020 Based on kNDVI. Forests 2023, 14, 620. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Luo, Y.; Zhang, L.; Zhang, J.; Li, Z.; Tao, F. Wheat yield predictions at a county and field scale with deep learning, machine learning, and google earth engine. Eur. J. Agron. 2021, 123, 126204. [Google Scholar] [CrossRef]
- Joshi, A.; Pradhan, B.; Chakraborty, S.; Behera, M.D. Winter wheat yield prediction in the conterminous United States using solar-induced chlorophyll fluorescence data and XGBoost and random forest algorithm. Ecol. Inform. 2023, 77, 102194. [Google Scholar] [CrossRef]
- Li, L.; Wang, B.; Feng, P.; Li Liu, D.; He, Q.; Zhang, Y.; Wang, Y.; Li, S.; Lu, X.; Yue, C.; et al. Developing machine learning models with multi-source environmental data to predict wheat yield in China. Comput. Electron. Agric. 2022, 194, 106790. [Google Scholar] [CrossRef]
- Chen, X.; Feng, L.; Yao, R.; Wu, X.; Sun, J.; Gong, W. Prediction of Maize Yield at the City Level in China Using Multi-Source Data. Remote Sens. 2021, 13, 146. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, S.; Wang, X.; Chen, B.; Chen, J.; Wang, J.; Huang, M.; Wang, Z.; Ma, L.; Wang, P.; et al. Exploring the superiority of solar-induced chlorophyll fluorescence data in predicting wheat yield using machine learning and deep learning methods. Comput. Electron. Agric. 2022, 192, 106612. [Google Scholar] [CrossRef]
- Cheng, E.; Zhang, B.; Peng, D.; Zhong, L.; Yu, L.; Liu, Y.; Xiao, C.; Li, C.; Li, X.; Chen, Y.; et al. Wheat yield estimation using remote sensing data based on machine learning approaches. Front. Plant Sci. 2022, 13, 1090970. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, D.; Li, S.; Tang, K.; Yu, H.; Yan, R.; Li, Z.; Wang, X.; Xin, X. Comparative Analysis of Feature Importance Algorithms for Grassland Aboveground Biomass and Nutrient Prediction Using Hyperspectral Data. Agriculture 2024, 14, 389. [Google Scholar] [CrossRef]
- Fei, S.; Hassan, M.A.; Xiao, Y.; Su, X.; Chen, Z.; Cheng, Q.; Duan, F.; Chen, R.; Ma, Y. UAV-based multi-sensor data fusion and machine learning algorithm for yield prediction in wheat. Precis. Agric. 2023, 24, 187–212. [Google Scholar] [CrossRef]
- Kang, Y.; Ozdogan, M.; Zhu, X.; Ye, Z.; Hain, C.; Anderson, M. Comparative assessment of environmental variables and machine learning algorithms for maize yield prediction in the US Midwest. Environ. Res. Lett. 2020, 15, 064005. [Google Scholar] [CrossRef]
- Tian, H.; Wang, P.; Tansey, K.; Zhang, J.; Zhang, S.; Li, H. An LSTM neural network for improving wheat yield estimates by integrating remote sensing data and meteorological data in the Guanzhong Plain, PR China. Agric. For. Meteorol. 2021, 310, 108629. [Google Scholar] [CrossRef]
- Garibaldi-Márquez, F.; Flores, G.; Mercado-Ravell, D.A.; Ramírez-Pedraza, A.; Valentín-Coronado, L.M. Weed Classification from Natural Corn Field-Multi-Plant Images Based on Shallow and Deep Learning. Sensors 2022, 22, 3021. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Paudel, D.; de Wit, A.; Boogaard, H.; Marcos, D.; Osinga, S.; Athanasiadis, I.N. Interpretability of deep learning models for crop yield forecasting. Comput. Electron. Agric. 2023, 206, 107663. [Google Scholar] [CrossRef]
- Zhou, S.; Xu, L.; Chen, N. Rice Yield Prediction in Hubei Province Based on Deep Learning and the Effect of Spatial Heterogeneity. Remote Sens. 2023, 15, 1361. [Google Scholar] [CrossRef]
- Zhu, Y.; Wu, S.; Qin, M.; Fu, Z.; Gao, Y.; Wang, Y.; Du, Z. A deep learning crop model for adaptive yield estimation in large areas. Int. J. Appl. Earth Obs. Geoinf. 2022, 110, 102828. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Z.; Feng, L.; Ma, Y.; Du, Q. A new attention-based CNN approach for crop mapping using time series Sentinel-2 images. Comput. Electron. Agric. 2021, 184, 106090. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Zhang, J.; Han, J.; Xie, J. Integrating Multi-Source Data for Rice Yield Prediction across China using Machine Learning and Deep Learning Approaches. Agric. For. Meteorol. 2021, 297, 108275. [Google Scholar] [CrossRef]
- Lu, J.; Fu, H.; Tang, X.; Liu, Z.; Huang, J.; Zou, W.; Chen, H.; Sun, Y.; Ning, X.; Li, J. GOA-optimized deep learning for soybean yield estimation using multi-source remote sensing data. Sci. Rep. 2024, 14, 7097. [Google Scholar] [CrossRef] [PubMed]
- Xuan, F.; Dong, Y.; Li, J.; Li, X.; Su, W.; Huang, X.; Huang, J.; Xie, Z.; Li, Z.; Liu, H.; et al. Mapping crop type in Northeast China during 2013–2021 using automatic sampling and tile-based image classification. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103178. [Google Scholar] [CrossRef]
- Modica, G.; Messina, G.; De Luca, G.; Fiozzo, V.; Praticò, S. Monitoring the vegetation vigor in heterogeneous citrus and olive orchards. A multiscale object-based approach to extract trees’ crowns from UAV multispectral imagery. Comput. Electron. Agric. 2020, 175, 105500. [Google Scholar] [CrossRef]
- Stamatiadis, S.; Taskos, D.; Tsadila, E.; Christofides, C.; Tsadilas, C.; Schepers, J.S. Comparison of passive and active canopy sensors for the estimation of vine biomass production. Precis. Agric. 2010, 11, 306–315. [Google Scholar] [CrossRef]
- Gao, Y.; Mas, J.F.; Navarrete, A. The improvement of an object-oriented classification using multi-temporal MODIS EVI satellite data. Int. J. Digit. Earth 2009, 2, 219–236. [Google Scholar] [CrossRef]
- Moreno, A.; Maselli, F.; Chiesi, M.; Genesio, L.; Vaccari, F.; Seufert, G.; Gilabert, M.A. Monitoring water stress in Mediterranean semi-natural vegetation with satellite and meteorological data. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 246–255. [Google Scholar] [CrossRef]
- Gu, Z.; Chen, X.; Ruan, W.; Zheng, M.; Gen, K.; Li, X.; Deng, H.; Chen, Y.; Liu, M. Quantifying the direct and indirect effects of terrain, climate and human activity on the spatial pattern of kNDVI-based vegetation growth: A case study from the Minjiang River Basin, Southeast China. Ecol. Inform. 2024, 80, 102493. [Google Scholar] [CrossRef]
- Smith, T.; Boers, N. Author Correction: Reliability of vegetation resilience estimates depends on biomass density. Nat. Ecol. Evol. 2024. [Google Scholar] [CrossRef]
- Wang, X.; Biederman, J.A.; Knowles, J.F.; Scott, R.L.; Turner, A.J.; Dannenberg, M.P.; Köhler, P.; Frankenberg, C.; Litvak, M.E.; Flerchinger, G.N.; et al. Satellite solar-induced chlorophyll fluorescence and near-infrared reflectance capture complementary aspects of dryland vegetation productivity dynamics. Remote Sens. Environ. 2022, 270, 112858. [Google Scholar] [CrossRef]
- Mahaut, L.; Choler, P.; Denelle, P.; Garnier, E.; Thuiller, W.; Kattge, J.; Lemauviel-Lavenant, S.; Lavorel, S.; Munoz, F.; Renard, D.; et al. Trade-offs and synergies between ecosystem productivity and stability in temperate grasslands. Glob. Ecol. Biogeogr. 2023, 32, 561–572. [Google Scholar] [CrossRef]
- Dai, A.; Zhao, T.; Chen, J. Climate Change and Drought: A Precipitation and Evaporation Perspective. Curr. Clim. Chang. Rep. 2018, 4, 301–312. [Google Scholar] [CrossRef]
- Cheng, M.; Jiao, X.; Jin, X.; Li, B.; Liu, K.; Shi, L. Satellite time series data reveal interannual and seasonal spatiotemporal evapotranspiration patterns in China in response to effect factors. Agric. Water Manag. 2021, 255, 107046. [Google Scholar] [CrossRef]
- Li, L.; Zeng, Z.; Zhang, G.; Duan, K.; Liu, B.; Cai, X. Exploring the Individualized Effect of Climatic Drivers on MODIS Net Primary Productivity through an Explainable Machine Learning Framework. Remote Sens. 2022, 14, 4401. [Google Scholar] [CrossRef]
- Chen, X.; Huang, Y.; Nie, C.; Zhang, S.; Wang, G.; Chen, S.; Chen, Z. A long-term reconstructed TROPOMI solar-induced fluorescence dataset using machine learning algorithms. Sci. Data 2022, 9, 427. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Jia, J.; Lu, Y.; Yang, T.; Lyu, S.; Shi, K.; Zhou, F.; Yu, G. Determining dominating control mechanisms of inland water carbon cycling processes and associated gross primary productivity on regional and global scales. Earth-Sci. Rev. 2021, 213, 103497. [Google Scholar] [CrossRef]
- Tan, K.P.; Kanniah, K.D.; Cracknell, A.P. On the upstream inputs into the MODIS primary productivity products using biometric data from oil palm plantations. Int. J. Remote Sens. 2014, 35, 2215–2246. [Google Scholar] [CrossRef]
- Tan, C.; Wang, D.; Zhou, J.; Du, Y.; Luo, M.; Zhang, Y.; Guo, W. Remotely Assessing Fraction of Photosynthetically Active Radiation (FPAR) for Wheat Canopies Based on Hyperspectral Vegetation Indexes. Front. Plant Sci. 2018, 9, 776. [Google Scholar] [CrossRef] [PubMed]
- Vaesen, K.; Gilliams, S.; Nackaerts, K.; Coppin, P. Ground-measured spectral signatures as indicators of ground cover and leaf area index: The case of paddy rice. Field Crops Res. 2001, 69, 13–25. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, J.; Mu, J. Exploring the relationships between climatic variables and climate-induced yield of spring maize in Northeast China. Agric. Ecosyst. Environ. 2015, 207, 79–90. [Google Scholar] [CrossRef]
- Chen, X.; Chen, J.; Jia, X.; Somers, B.; Wu, J.; Coppin, P. A Quantitative Analysis of Virtual Endmembers’ Increased Impact on the Collinearity Effect in Spectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2945–2956. [Google Scholar] [CrossRef]
- Parmezan, A.R.S.; Souza, V.M.A.; Batista, G.E.A.P.A. Evaluation of statistical and machine learning models for time series prediction: Identifying the state-of-the-art and the best conditions for the use of each model. Inf. Sci. 2019, 484, 302–337. [Google Scholar] [CrossRef]
- Thirumal, S.; Latha, R. Automated Rice Crop Yield Prediction using Sine Cosine Algorithm with Weighted Regularized Extreme Learning Machine. In Proceedings of the 2023 7th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 17–19 May 2023; pp. 35–40. [Google Scholar]
- Canizo, M.; Triguero, I.; Conde, A.; Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 2019, 363, 246–260. [Google Scholar] [CrossRef]
- Liu, P.; Liu, J.; Wu, K. CNN-FCM: System modeling promotes stability of deep learning in time series prediction. Knowl.-Based Syst. 2020, 203, 106081. [Google Scholar] [CrossRef]
- Zhou, W.; Song, C.; Liu, C.; Fu, Q.; An, T.; Wang, Y.; Sun, X.; Wen, N.; Tang, H.; Wang, Q. A Prediction Model of Maize Field Yield Based on the Fusion of Multitemporal and Multimodal UAV Data: A Case Study in Northeast China. Remote Sens. 2023, 15, 3483. [Google Scholar] [CrossRef]
- Sun, Z.; Li, Q.; Jin, S.; Song, Y.; Xu, S.; Wang, X.; Cai, J.; Zhou, Q.; Ge, Y.; Zhang, R.; et al. Simultaneous Prediction of Wheat Yield and Grain Protein Content Using Multitask Deep Learning from Time-Series Proximal Sensing. Plant Phenomics 2022, 2022, 9757948. [Google Scholar] [CrossRef]
- Qiao, M.; He, X.; Cheng, X.; Li, P.; Zhao, Q.; Zhao, C.; Tian, Z. KSTAGE: A knowledge-guided spatial-temporal attention graph learning network for crop yield prediction. Inf. Sci. 2023, 619, 19–37. [Google Scholar] [CrossRef]
- Tian, H.; Wang, P.; Tansey, K.; Han, D.; Zhang, J.; Zhang, S.; Li, H. A deep learning framework under attention mechanism for wheat yield estimation using remotely sensed indices in the Guanzhong Plain, PR China. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102375. [Google Scholar] [CrossRef]
- Zhao, Y.; He, J.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.; Tian, Y. Wheat Yield Robust Prediction in the Huang-Huai-Hai Plain by Coupling Multi-Source Data with Ensemble Model under Different Irrigation and Extreme Weather Events. Remote Sens. 2024, 16, 1259. [Google Scholar] [CrossRef]
- Soriano-González, J.; Angelats, E.; Martínez-Eixarch, M.; Alcaraz, C. Monitoring rice crop and yield estimation with Sentinel-2 data. Field Crops Res. 2022, 281, 108507. [Google Scholar] [CrossRef]
- Wijewardana, C.; Reddy, K.R.; Bellaloui, N. Soybean seed physiology, quality, and chemical composition under soil moisture stress. Food Chem. 2019, 278, 92–100. [Google Scholar] [CrossRef] [PubMed]
- de Borja Reis, A.F.; Moro Rosso, L.; Purcell, L.C.; Naeve, S.; Casteel, S.N.; Kovács, P.; Archontoulis, S.; Davidson, D.; Ciampitti, I.A. Environmental Factors Associated With Nitrogen Fixation Prediction in Soybean. Front. Plant Sci. 2021, 12, 675410. [Google Scholar] [CrossRef] [PubMed]
- Di Mauro, G.; Cipriotti, P.A.; Gallo, S.; Rotundo, J.L. Environmental and management variables explain soybean yield gap variability in Central Argentina. Eur. J. Agron. 2018, 99, 186–194. [Google Scholar] [CrossRef]
- Kira, O.; Wen, J.; Han, J.; McDonald, A.J.; Barrett, C.B.; Ortiz-Bobea, A.; Liu, Y.; You, L.; Mueller, N.D.; Sun, Y. A scalable crop yield estimation framework based on remote sensing of solar-induced chlorophyll fluorescence (SIF). Environ. Res. Lett. 2024, 19, 044071. [Google Scholar] [CrossRef]
- Wang, C.; Liu, L.; Zhou, Y.; Liu, X.; Wu, J.; Tan, W.; Xu, C.; Xiong, X. Comparison between Satellite Derived Solar-Induced Chlorophyll Fluorescence, NDVI and kNDVI in Detecting Water Stress for Dense Vegetation across Southern China. Remote Sens. 2024, 16, 1735. [Google Scholar] [CrossRef]
- Xu, M.; Guo, B.; Zhang, R. A Novel Approach to Detecting the Salinization of the Yellow River Delta Using a Kernel Normalized Difference Vegetation Index and a Feature Space Model. Sustainability 2024, 16, 2560. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, B.; Chen, J.; Zhou, J.; He, Q.-Q.; Yu, H. Response of Vegetation Productivity to Greening and Drought in the Loess Plateau Based on VIs and SIF. Forests 2024, 15, 339. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Variables | Time Coverage | Spatial Resolution | Data Source |
|---|---|---|---|---|
| Crop statistics | Yield data for maize, rice, and soybeans (kg/ha) | 2014–2020 | County/City Level | Provincial Statistics Bureaus |
| Planting area | Crop type maps | 2014–2021 | 30 m | https://doi.org/10.6084/m9.figshare.20411424.v1 (accessed on 15 June 2023). |
| Vegetation indices | NDVI, EVI, NDWI, kNDVI | 2014–2020 | 500 m | MODIS |
| Environmental variables | Pdsi, Pet, Pr, Soil, Tmmn, Tmmx, Vap | 2014–2021 | 4 km | TerraClimate |
| Photosynthetically active indices | SIF | 2014–2022 | 0.05° | https://data.tpdc.ac.cn/ (accessed on 23 June 2023). |
| GPP, PsnNet, Fpar, LAI | 2014–2023 | 500 m | MODIS |
| Model | Hyperparameter | Range/Values Tested | Selected Value |
|---|---|---|---|
| Random Forest | n_estimators | 100, 200, 300 | 200 |
| min_samples_leaf | 1, 2, 4 | 4 | |
| random_state | Fixed value | 2 | |
| XGBoost | n_estimators | 100, 200, 300 | 200 |
| max_depth | 3, 6, 9 | 6 | |
| subsample | 0.6, 0.8, 1 | 0.8 | |
| colsample_bytree | 0.6, 0.8, 1 | 0.8 | |
| min_child_weight | 1, 3, 5 | 1 | |
| random_state | Fixed value | 2 | |
| CNN | filters | 32, 64, 128 | 64, 128 |
| kernel_size | 3, 5, 7 | 3 | |
| pool_size | 2, 3 | 2 | |
| dense_layers | 1, 2 | 2 | |
| dense_neurons | 64, 128 | 128, 64 | |
| learning_rate | 0.0001, 0.0006, 0.001 | 0.0006 | |
| loss_function | MSE, MAE, Huberloss | Huberloss | |
| batch_size | 16, 32, 64 | 32 | |
| epochs | 1000, 3000, 5000 | 5000 | |
| CNN-LSTM-Attention | filters | 32, 64, 128 | 64, 128 |
| lstm_units | 50, 100, 150 | 100 | |
| attention_size | 10, 50, 100 | 50 | |
| learning_rate | 0.0001, 0.0006, 0.001 | 0.0006 | |
| loss_function | MSE, MAE, Huberloss | Huberloss | |
| batch_size | 16, 32, 64 | 32 | |
| epochs | 1000, 3000, 5000 | 5000 |
| Experiment Type | Description | Results |
|---|---|---|
| Preliminary Experiments | Initial tests to determine the effectiveness of different model architectures (RF, XGBoost, CNN, and CNN-LSTM-Attention) | CNN-LSTM-Attention showed the best performance with the highest R2 score. |
| Hyperparameter Tuning | Grid search and random search methods applied to identify the best hyperparameters for each model | Optimal hyperparameters were identified and listed in Table 2. |
| Cross-validation | Five-fold cross-validation to evaluate the model performance and prevent overfitting | Stable and high R2 scores were achieved across all folds, indicating good generalization. |
| Crop Type | Model | Training Dataset | Testing Dataset | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE (kg/ha) | MAPE (%) | R2 | RMSE (kg/ha) | MAPE (%) | ||
| Maize | RF | 0.75 | 392.25 | 4.20% | 0.73 | 435.09 | 4.42% |
| XGBoost | 0.74 | 400.18 | 4.30% | 0.70 | 457.04 | 4.92% | |
| CNN | 0.80 | 350.12 | 3.90% | 0.77 | 394.67 | 4.30% | |
| CNN-LSTM-Attentiom | 0.85 | 320.45 | 3.70% | 0.80 | 375.08 | 4.21% | |
| Rice | RF | 0.70 | 610.30 | 6.00% | 0.62 | 658.52 | 6.38% |
| XGBoost | 0.72 | 580.24 | 5.80% | 0.67 | 612.10 | 6.12% | |
| CNN | 0.75 | 550.12 | 5.40% | 0.70 | 585.40 | 5.59% | |
| CNN-LSTM-Attentiom | 0.80 | 510.05 | 5.00% | 0.76 | 519.07 | 4.67% | |
| Soybean | RF | 0.60 | 250.20 | 9.00% | 0.53 | 277.07 | 9.80% |
| XGBoost | 0.62 | 240.10 | 8.80% | 0.57 | 264.88 | 9.58% | |
| CNN | 0.75 | 200.15 | 7.00% | 0.73 | 210.96 | 7.13% | |
| CNN-LSTM-Attentiom | 0.80 | 180.10 | 6.50% | 0.78 | 188.11 | 6.39% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Li, J.; Fu, H.; Tang, X.; Liu, Z.; Chen, H.; Sun, Y.; Ning, X. Deep Learning for Multi-Source Data-Driven Crop Yield Prediction in Northeast China. Agriculture 2024, 14, 794. https://doi.org/10.3390/agriculture14060794
Lu J, Li J, Fu H, Tang X, Liu Z, Chen H, Sun Y, Ning X. Deep Learning for Multi-Source Data-Driven Crop Yield Prediction in Northeast China. Agriculture. 2024; 14(6):794. https://doi.org/10.3390/agriculture14060794
Chicago/Turabian StyleLu, Jian, Jian Li, Hongkun Fu, Xuhui Tang, Zhao Liu, Hui Chen, Yue Sun, and Xiangyu Ning. 2024. "Deep Learning for Multi-Source Data-Driven Crop Yield Prediction in Northeast China" Agriculture 14, no. 6: 794. https://doi.org/10.3390/agriculture14060794
APA StyleLu, J., Li, J., Fu, H., Tang, X., Liu, Z., Chen, H., Sun, Y., & Ning, X. (2024). Deep Learning for Multi-Source Data-Driven Crop Yield Prediction in Northeast China. Agriculture, 14(6), 794. https://doi.org/10.3390/agriculture14060794