
Object Detection Algorithm for Lingwu Long Jujubes Based on the Improved SSD


Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Collection of Lingwu Long Jujubes
2.2. Lingwu Long Jujubes Sample DataSets
2.3. Experimental Setup
2.4. Evaluation Indicators
2.5. Structure of the Peleenet Module
- In contrast to the primal network construction, the modified model uses only the first two dense block modules [35]. The numbers of convolutional groups in the dense connection mechanism are 6 and 8, respectively, instead of 3 and 4 in the original network in order to deepen the network and improve the feature extraction capability of the Lingwu long jujubes images;
- The attention modules are added at the end of each convolutional group in the dense block module in order to suppress the unimportant network features while focusing the network more on the region of interest with the addition of an attention mechanism;
- The final pooling layer 2 × 2 convolution of this module is replaced to 3 × 3, its step size is altered to 1, and the obtained feature map is modified from 19 × 19 pixels to 38 × 38 pixels to satisfy the demand of the input feature map for the object detection network.
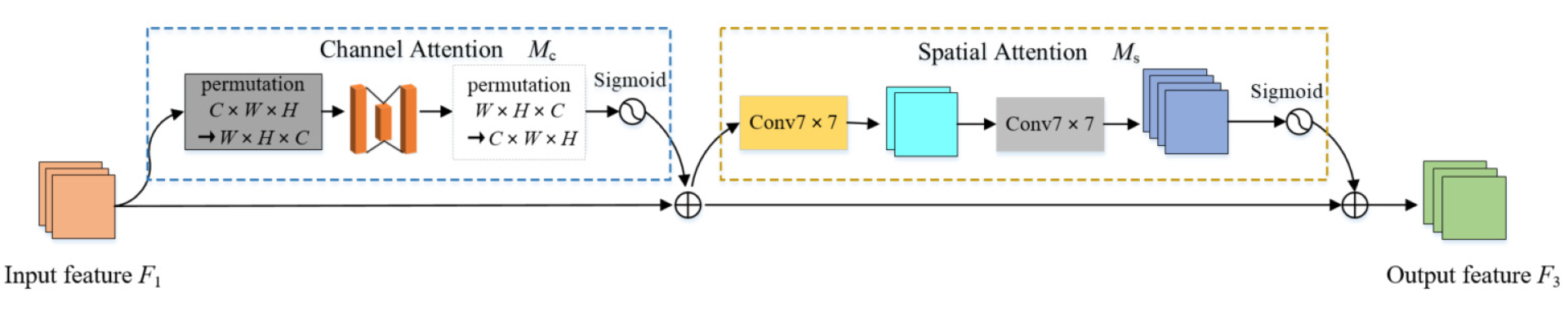
2.6. CA Module and the GAM Module
2.7. Inceptionv2 Module
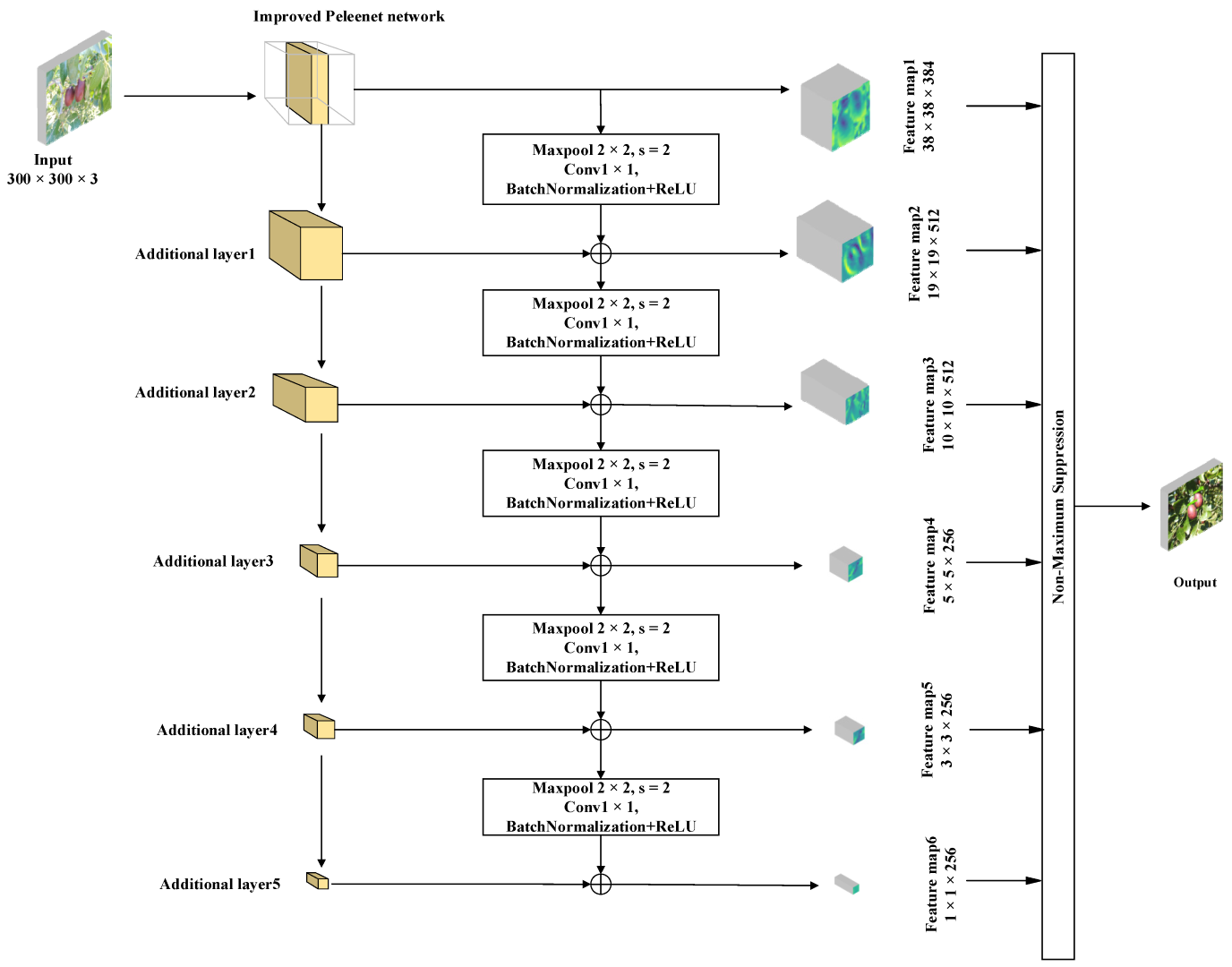
2.8. Modified SSD Object Detection Structure
- The VGG16 network in the original network is switched to the modified Peleenet module as the trunk network;
- The convolution module in the first three additional layers of the original network is exchanged by the Inceptionv2 module. The multi-scale network structure of the module is utilized to enhance the network depth and further strengthen the capacity of the object detection network to retrieve the multi-scale messages from the jujubes;
- The output of each additional level is appended to the export of the sub-level through the convolution and pooling operations to realize the integration of image feature messages between the various levels.
3. Results
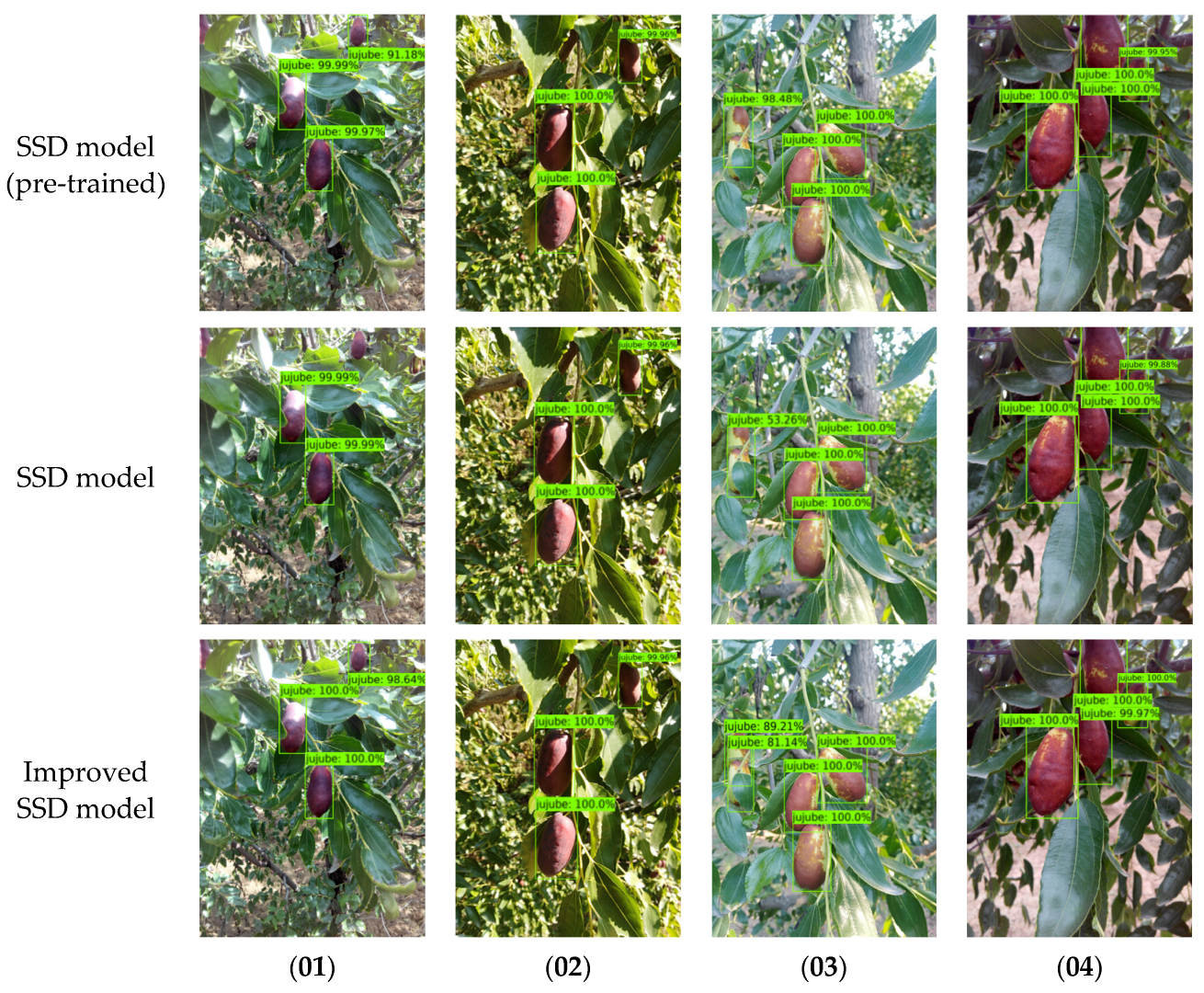
3.1. Comparison of the Improved Model and the Original Model
3.2. Improved Peleenet Network Structures
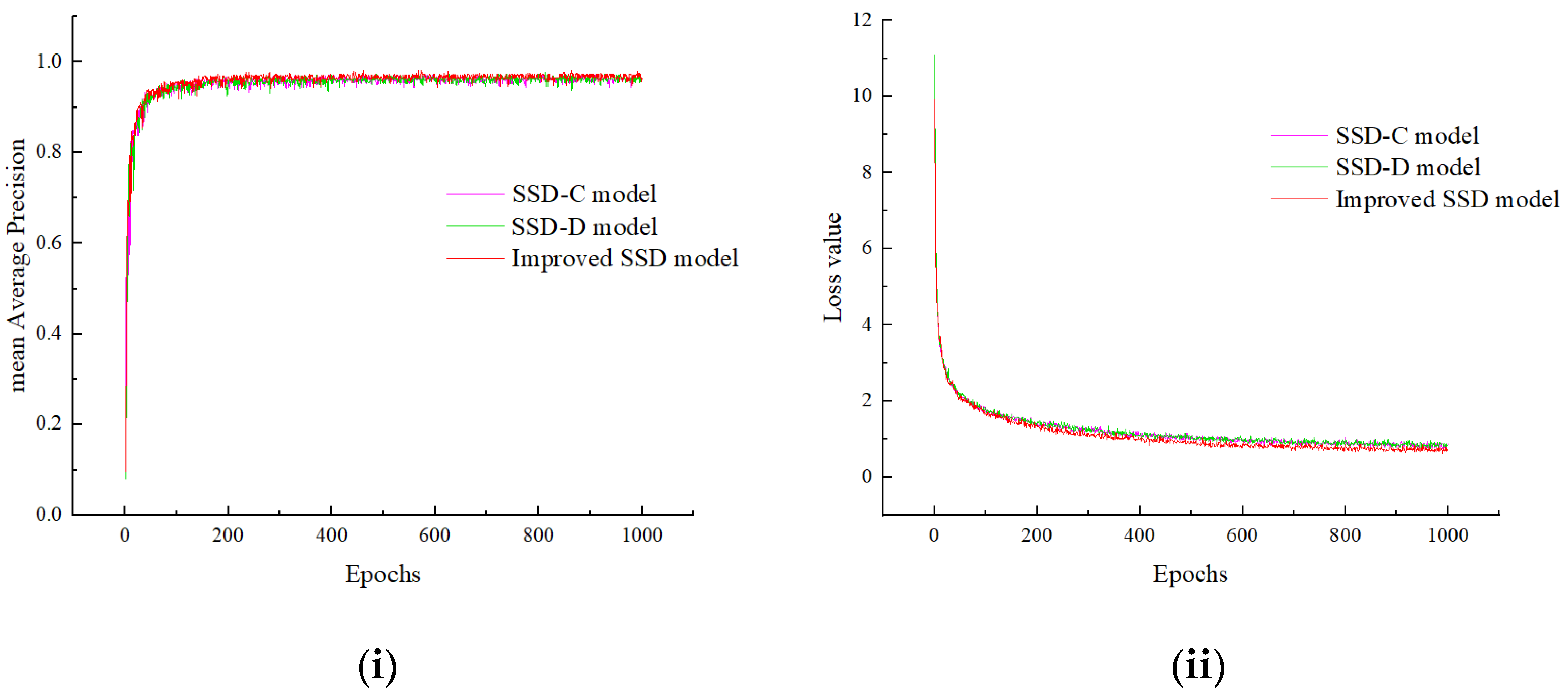
3.3. Effectiveness of the Additional Layer Structure
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, L.H.; Cao, B. Effect of cover-cultivation on soil temperature and growth of Ziziphus jujuba Mill. ‘Lingwu Changzao’. In Proceedings of the 29th International Horticultural Congress on Horticulture—Sustaining Lives, Livelihoods and Landscapes (IHC): 3rd International Jujube Symposium, Brisbane, Australia, 17–22 August 2014; pp. 89–92. [Google Scholar]
- Yu, K.Q.; Zhao, Y.R.; Li, X.L.; Shao, Y.N.; Zhu, F.L.; He, Y. Identification of crack features in fresh jujube using Vis/NIR hyperspectral imaging combined with image processing. Comput. Electron. Agric. 2014, 103, 1–10. [Google Scholar] [CrossRef]
- Chen, J.P.; Liu, X.Y.; Li, Z.G.; Qi, A.R.; Yao, P.; Zhou, Z.Y.; Dong, T.; Tsim, K.W.K. A Review of Dietary Ziziphus jujuba Fruit (Jujube): Developing Health Food Supplements for Brain Protection. Evid. Based Complement. Altern. Med. 2017, 2017, 3019568. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.G.; He, J.G.; Liu, G.S.; Wang, S.L.; He, X.G. Detection of common defects on jujube using Vis-NIR and NIR hyperspectral imaging. Postharvest Biol. Technol. 2016, 112, 134–142. [Google Scholar] [CrossRef]
- Aquino, A.; Ponce, J.M.; Andujar, J.M. Identification of olive fruit, in intensive olive orchards, by means of its morphological structure using convolutional neural networks. Comput. Electron. Agric. 2020, 176, 105616. [Google Scholar] [CrossRef]
- Wang, C.L.; Liu, S.C.; Wang, Y.W.; Xiong, J.T.; Zhang, Z.G.; Zhao, B.; Luo, L.F.; Lin, G.C.; He, P. Application of Convolutional Neural Network-Based Detection Methods in Fresh Fruit Production: A Comprehensive Review. Front. Plant Sci. 2022, 13, 868745. [Google Scholar] [CrossRef] [PubMed]
- Gene-Mola, J.; Sanz-Cortiella, R.; Rosell-Polo, J.R.; Morros, J.R.; Ruiz-Hidalgo, J.; Vilaplana, V.; Gregorio, E. Fruit detection and 3D location using instance segmentation neural networks and structure-from-motion photogrammetry. Comput. Electron. Agric. 2020, 169, 105165. [Google Scholar] [CrossRef]
- Mai, X.C.; Zhang, H.; Jia, X.; Meng, M.Q.H. Faster R-CNN With Classifier Fusion for Automatic Detection of Small Fruits. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1555–1569. [Google Scholar] [CrossRef]
- Paturkar, A.; Sen Gupta, G.; Bailey, D. Apple Detection for Harvesting Robot Using Computer Vision. Helix 2018, 8, 4370–4374. [Google Scholar] [CrossRef]
- Silwal, A.; Karkee, M.; Zhang, Q. A hierarchical approach to apple identification for robotic harvesting. Trans. ASABE 2016, 59, 1079–1086. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Yu, J.Y.; Chen, Y.; Yang, W.; Zhang, W.B.; He, Y. Real-time strawberry detection using deep neural networks on embedded system (rtsd-net): An edge AI application. Comput. Electron. Agric. 2022, 192, 106586. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.L.; Liu, H.; Yang, L.; Zhang, D.X. Real-Time Visual Localization of the Picking Points for a Ridge-Planting Strawberry Harvesting Robot. IEEE Access 2020, 8, 116556–116568. [Google Scholar] [CrossRef]
- Rodriguez, J.P.; Corrales, D.C.; Aubertot, J.N.; Corrales, J.C. A computer vision system for automatic cherry beans detection on coffee trees. Pattern Recognit. Lett. 2020, 136, 142–153. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Gao, F.F.; Fu, L.S.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Lin, P.; Lee, W.S.; Chen, Y.M.; Peres, N.; Fraisse, C. A deep-level region-based visual representation architecture for detecting strawberry flowers in an outdoor field. Precis. Agric. 2020, 21, 387–402. [Google Scholar] [CrossRef]
- Fu, L.S.; Feng, Y.L.; Majeed, Y.; Zhang, X.; Zhang, J.; Karkee, M.; Zhang, Q. Kiwifruit detection in field images using Faster R-CNN with ZFNet. In Proceedings of the 6th International-Federation-of-Automatic-Control (IFAC) Conference on Bio-Robotics (BIOROBOTICS), Beijing, China, 13–15 July 2018; pp. 45–50. [Google Scholar]
- Wang, Y.T.; Dai, Y.P.; Xue, J.R.; Liu, B.H.; Ma, C.H.; Gao, Y.Y. Research of segmentation method on color image of Lingwu long jujubes based on the maximum entropy. EURASIP J. Image Video Process. 2017, 2017, 34. [Google Scholar] [CrossRef]
- Yuan, R.R.; Liu, G.S.; He, J.G.; Wan, G.L.; Fan, N.Y.; Li, Y.; Sun, Y.R. Classification of Lingwu long jujube internal bruise over time based on visible near-infrared hyperspectral imaging combined with partial least squares-discriminant analysis. Comput. Electron. Agric. 2021, 182, 106043. [Google Scholar] [CrossRef]
- Geng, L.; Xu, W.L.; Zhang, F.; Xiao, Z.T.; Liu, Y.B. Dried Jujube Classification Based on a Double Branch Deep Fusion Convolution Neural Network. Food Sci. Technol. Res. 2018, 24, 1007–1015. [Google Scholar] [CrossRef]
- Al-Saif, A.M.; Abdel-Sattar, M.; Aboukarima, A.M.; Eshra, D.H. Identification of Indian jujube varieties cultivated in Saudi Arabia using an artificial neural network. Saudi J. Biol. Sci. 2021, 28, 5765–5772. [Google Scholar] [CrossRef]
- Feng, L.; Zhu, S.S.; Zhou, L.; Zhao, Y.Y.; Bao, Y.D.; Zhang, C.; He, Y. Detection of Subtle Bruises on Winter Jujube Using Hyperspectral Imaging With Pixel-Wise Deep Learning Method. IEEE Access 2019, 7, 64494–64505. [Google Scholar] [CrossRef]
- Luo, X.Z.; Ma, B.X.; Wang, W.X.; Lei, S.Y.; Hu, Y.Y.; Yu, G.W.; Li, X.Z. Evaluation of surface texture of dried Hami Jujube using optimized support vector machine based on visual features fusion. Food Sci. Biotechnol. 2020, 29, 493–502. [Google Scholar] [CrossRef]
- Qi, X.X.; Ma, B.X.; Xiao, W.D. On-Line Detection of Hami Big Jujubes’ Size and Shape Based on Machine Vision. In Proceedings of the 2011 International Conference on Computer Distributed Control and Intelligent Environmental Monitoring, Changsha, China, 19–20 February 2011. [Google Scholar]
- Ma, B.; Qi, X.; Wang, L.; Zhu, R.; Chen, Q.; Li, F.; Wang, W. Size and defect detection of Hami Big Jujubes based on computer vision. Adv. Mate. Res. 2012, 562–564, 750–754. [Google Scholar] [CrossRef]
- Li, S.L.; Zhang, S.J.; Xue, J.X.; Sun, H.X.; Ren, R. A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube. Agriculture 2022, 12, 717. [Google Scholar] [CrossRef]
- Lu, Z.; Zhao, M.; Luo, J.; Wang, G.; Wang, D. Design of a winter-jujube grading robot based on machine vision. Comput. Electron. Agric. 2021, 186, 106170. [Google Scholar] [CrossRef]
- Liang, Q.; Zhu, W.; Long, J.; Wang, Y.; Sun, W.; Wu, W. A real-time detection framework for on-tree mango based on SSD network. In Proceedings of the 11th International Conference on Intelligent Robotics and Applications, Newcastle, NSW, Australia, 9–11 August 2018; pp. 423–436. [Google Scholar]
- Xie, X.; Han, X.; Liao, Q.; Shi, G. Visualization and pruning of SSD with the base network VGG16. In Proceedings of the 2017 International Conference on Deep Learning Technologies, Chengdu, China, 2–4 June 2017; pp. 90–94. [Google Scholar]
- Zhao, S.D.; Hao, G.Z.; Zhang, Y.C.; Wang, S.C. A real-time classification and detection method for mutton parts based on single shot multi-box detector. J. Food Process Eng. 2021, 44, e13749. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Yuan, T.; Lv, L.; Zhang, F.; Fu, J.; Gao, J.; Zhang, J.X.; Li, W.; Zhang, C.L.; Zhang, W.Q. Robust Cherry Tomatoes Detection Algorithm in Greenhouse Scene Based on SSD. Agriculture 2020, 10, 160. [Google Scholar] [CrossRef]
- Sunil, G.; Zhang, Y.; Koparan, C.; Ahmed, M.R.; Howatt, K.; Sun, X. Weed and crop species classification using computer vision and deep learning technologies in greenhouse conditions. J. Agric. Food Res. 2022, 9, 100325. [Google Scholar] [CrossRef]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A Real-Time Object Detection System on Mobile Devices. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N.J.A. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Xia, Y.; Chen, B.; Li, Y.H.; Chen, M. Application research based on region of the image threshold segmentation algorithm of RGB Jujube. Mod. Instrum. 2022, 222, 156–176. [Google Scholar]
- Jiang, J.X.; Zhou, J.H. Dried Jujubes Online Detection Based on Machine Vision. Adv. Mater. Res. 2013, 655–657, 673–678. [Google Scholar] [CrossRef]
- Zhang, J.X.; Ma, Q.Q.; Li, W.; Xiao, T.T. Feature extraction of jujube fruit wrinkle based on the watershed segmentation. Int. J. Agric. Biol. Eng. 2017, 10, 165–172. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.J.; Dong, Y.Q. Surface Defect Detection of Chinese Dates Based on Machine Vision. Adv. Mater. Res. 2011, 403–408, 1356–1359. [Google Scholar] [CrossRef]
- Xiao, A.L.; Huang, X.C.; Zhang, J.X.; Li, W. The research of detecting method on crackled Chinese date based on chrominance components. Biotechnol. Indian J. 2014, 10, 4945–4954. [Google Scholar]
- Zhao, J.; Liu, S.; Zou, X.; Shi, J.; Yin, X. Recognition of defect Chinese dates by machine vision and support vector machine. Nongye Jixie Xuebao Trans. Chin. Soc. Agric. Mach. 2008, 39, 113–116. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Pre-Trained Weights | CA + GAM | Inceptionv2 | Multilevel Fusion | mAP (%) | AR (%) | Speed (Fps) | Parameters/ (×106) |
|---|---|---|---|---|---|---|---|---|---|
| SSD model | VGG16 | √ | × | × | × | 97.19 | 76.81 | 45.39 | 11.92 |
| SSD model | VGG16 | × | × | × | × | 96.35 | 75.67 | 45.39 | 11.92 |
| Improved SSD model | Improved Peleenet | × | √ | √ | √ | 97.32 | 78.23 | 41.15 | 3.62 |
| Methods | Backbone | Pre-Trained weights | CA + GAM | Inceptionv2 | Multilevel Fusion | mAP (%) | AR(%) | Speed (Fps) | Parameters /(×106) |
|---|---|---|---|---|---|---|---|---|---|
| SSD-A model | Improved Peleenet | × | × | √ | √ | 96.47 | 75.56 | 23.81 | 3.52 |
| SSD-B model | Improved Peleenet (3,4) | × | √ | √ | √ | 95.49 | 75.17 | 23.31 | 3.04 |
| Improved SSD model | Improved Peleenet | × | √ | √ | √ | 97.32 | 78.23 | 41.15 | 3.62 |
| Methods | Backbone | Pre-Trained Weights | CA + GAM | Inceptionv2 | Multilevel Fusion | mAP(%) | AR(%) | Speed(Fps) | Parameters /(×106) |
|---|---|---|---|---|---|---|---|---|---|
| SSD-C model | Improved Peleenet | × | √ | × | √ | 96.37 | 75.69 | 28.65 | 5.46 |
| SSD-D model | Improved Peleenet | × | √ | √ | × | 96.11 | 75.43 | 25.89 | 2.89 |
| Improved SSD model | Improved Peleenet | × | √ | √ | √ | 97.32 | 78.23 | 41.15 | 3.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Xing, Z.; Ma, L.; Qu, A.; Xue, J. Object Detection Algorithm for Lingwu Long Jujubes Based on the Improved SSD. Agriculture 2022, 12, 1456. https://doi.org/10.3390/agriculture12091456
Wang Y, Xing Z, Ma L, Qu A, Xue J. Object Detection Algorithm for Lingwu Long Jujubes Based on the Improved SSD. Agriculture. 2022; 12(9):1456. https://doi.org/10.3390/agriculture12091456
Chicago/Turabian StyleWang, Yutan, Zhenwei Xing, Liefei Ma, Aili Qu, and Junrui Xue. 2022. "Object Detection Algorithm for Lingwu Long Jujubes Based on the Improved SSD" Agriculture 12, no. 9: 1456. https://doi.org/10.3390/agriculture12091456
APA StyleWang, Y., Xing, Z., Ma, L., Qu, A., & Xue, J. (2022). Object Detection Algorithm for Lingwu Long Jujubes Based on the Improved SSD. Agriculture, 12(9), 1456. https://doi.org/10.3390/agriculture12091456