




Machine Learning for Detection and Prediction of Crop Diseases and Pests: A Comprehensive Survey




Abstract
:1. Introduction
2. Literature Review
2.1. Data Acquisition
2.1.1. Variables Influencing Crop Diseases and Pests
Temperature
Humidity
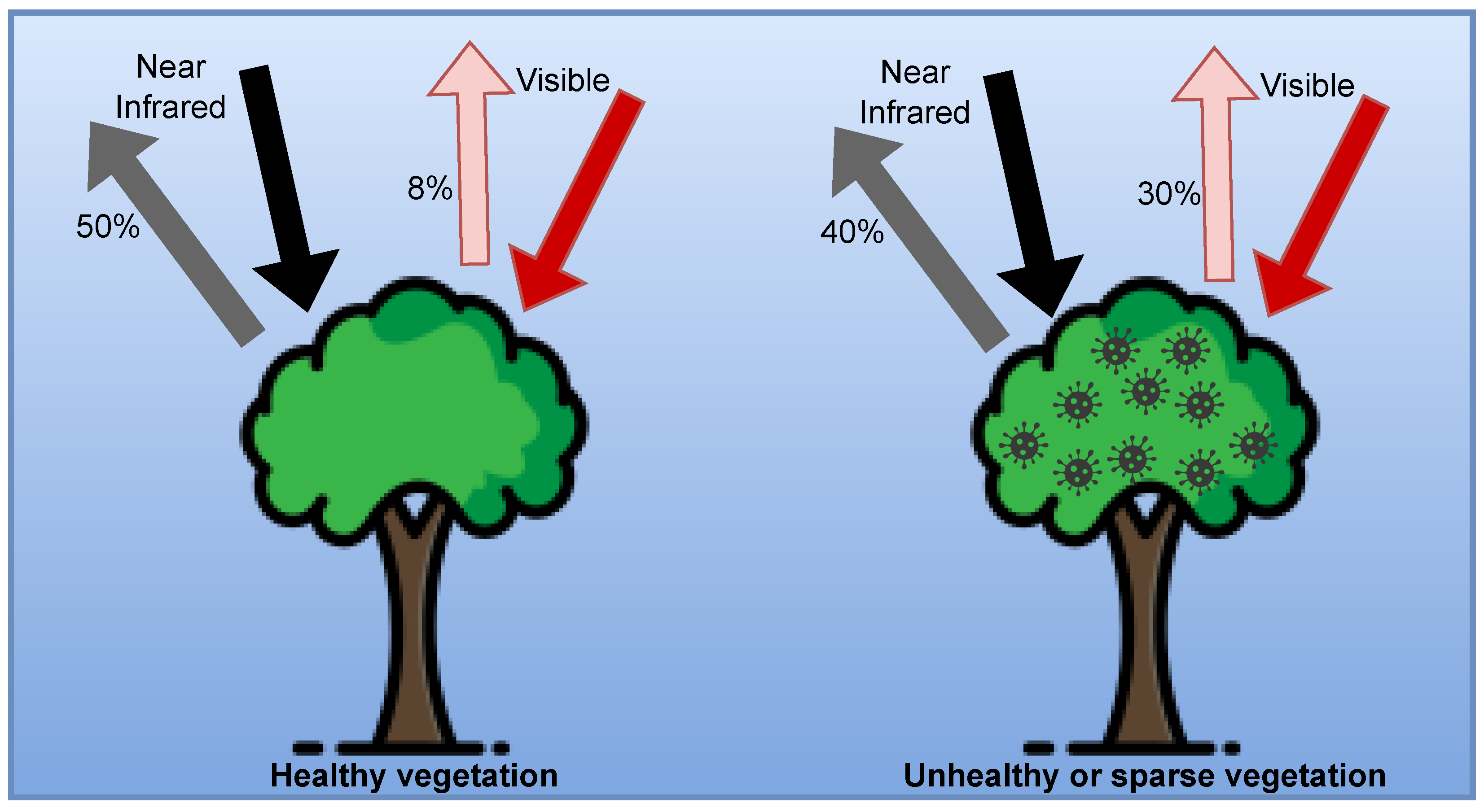
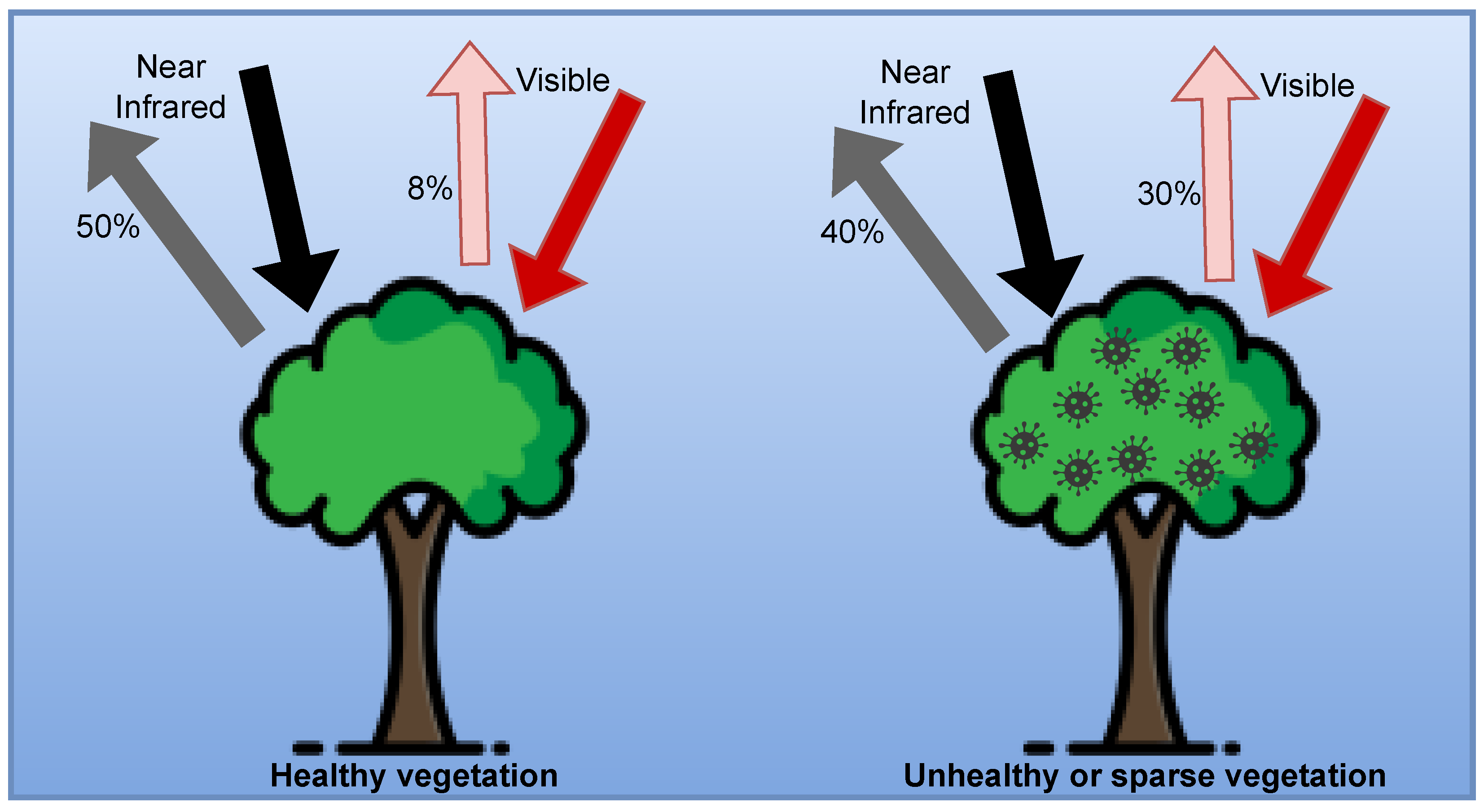
Leaf Reflectance
2.1.2. Agriculture Data-Sets
- PlantVillage [61]: popular data-set used for plant disease classification. Specifically for tomato, it contains 18,160 images representing leaves affected by bacterial spot, early blight, late blight, leaf mold, septoria leaf spot, spider mites, two-spotted spider mite, target spot and tomato yellow leaf curl virus. It also includes images of healthy leaves. Figure 3 depicts two sample images taken from this data-set.
- IP102 [62]: data-set for pest classification with more than 75,000 images belonging to 102 categories. Part of the image set (19,000 images) also includes bounding box annotations. This is a very difficult data-set because of the variety of insects, their corresponding development stages (egg, larva, pupa, and adult) and image backgrounds. The data-set is also very imbalanced. Figure 4 presents two examples of images from this data-set.
- PlantDoc [63]: contains pictures representing tomato diseases which were acquired in the fields. Among the considered diseases are: tomato bacterial spot, tomato early blight, tomato late blight, tomato mold, tomato mosaic virus, tomato septoria leaf spot, tomato yellow virus and healthy tomatoes.
- Flavia [64]: contains photos of isolated plant leaves over a white background and in the absence of stems. This data-set covers 33 plant species.
- MalayaKew Leaf [65]: was gathered in England’s Royal Botanic Gardens at Kew. It contains images of leaves from 44 different species. There are situations where leaves from different species are very similar, presenting a greater challenge for the development of plant identification models.
2.1.3. Field-Collected vs. Laboratory-Collected Data
2.2. Data Pre-Processing
2.2.1. Noise Reduction
2.2.2. Image Segmentation
2.2.3. Feature Extraction
2.2.4. Cropping and Resizing Images
2.2.5. Pre-Processing in Tabular Data
2.2.6. Pre-Processing in Deep Learning
2.3. Machine Learning Models
2.3.1. Support Vector Machine
2.3.2. Random Forest
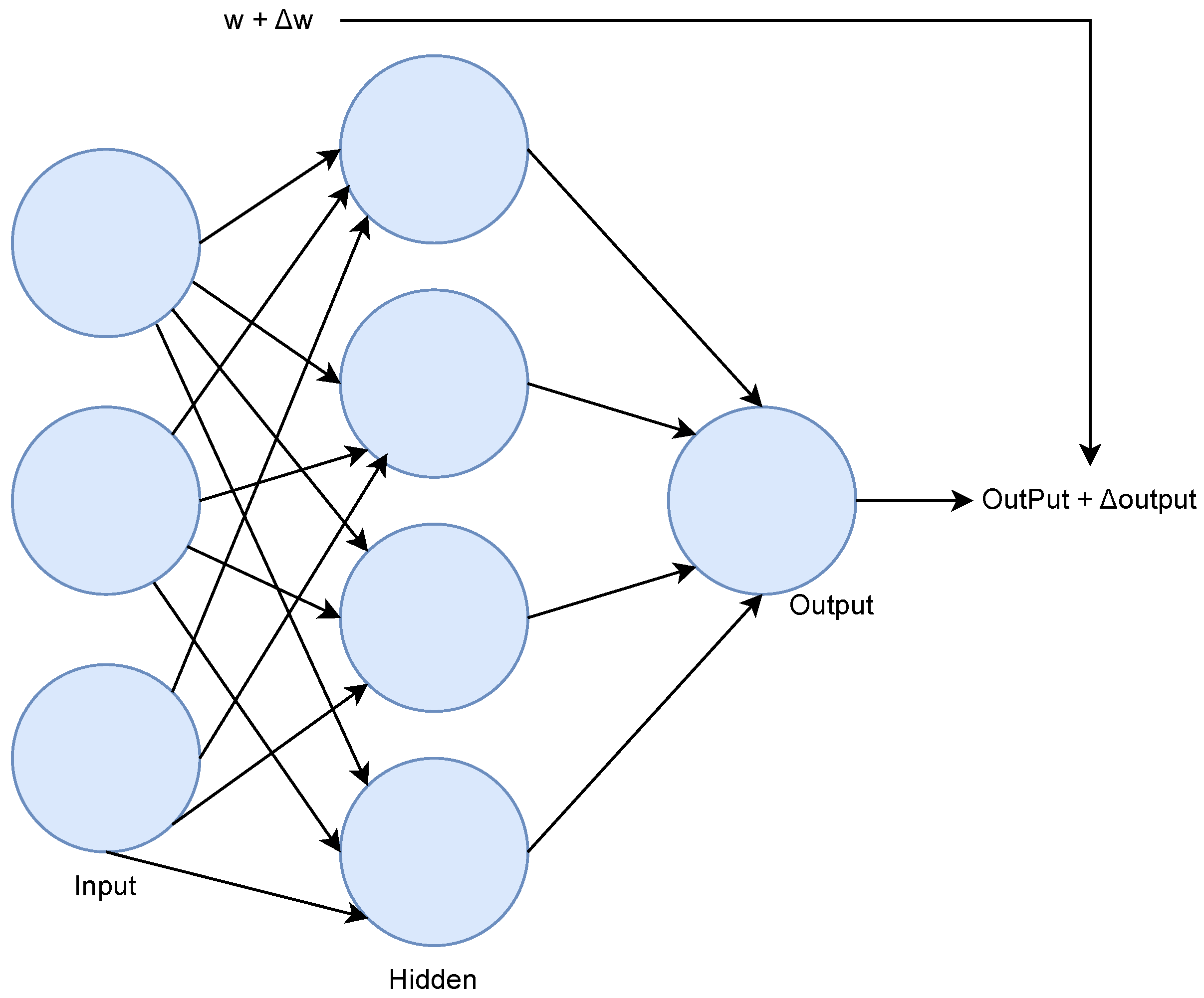
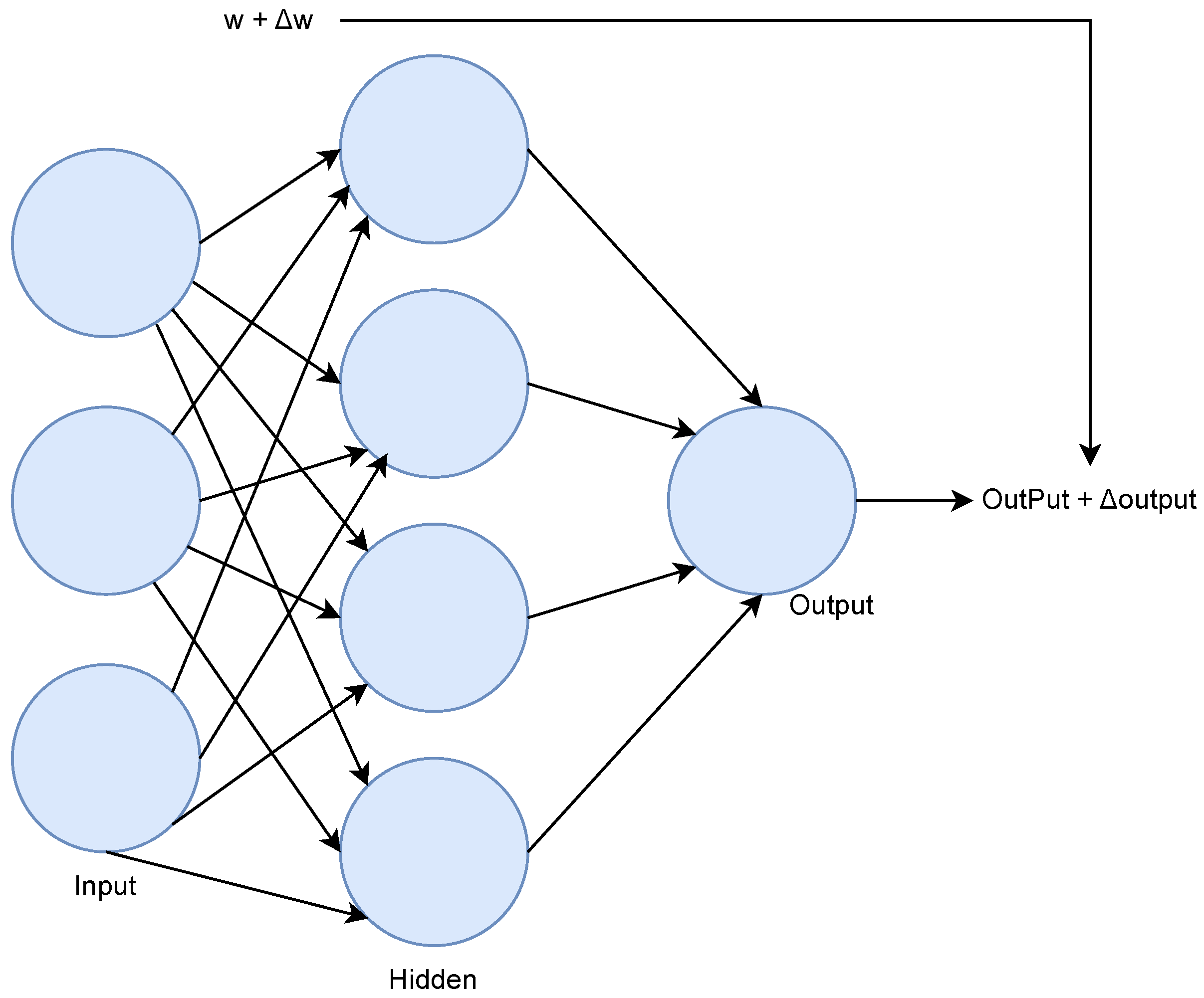
2.3.3. Artificial Neural Networks
User-Defined Network Architectures
Convolutional Neural Network Architectures
2.3.4. Transfer Learning
3. Discussion
3.1. Data Acquisition
3.2. Data Pre-Processing
3.3. Machine Learning Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| GLCM | Grey Level Co-occurrence Matrix |
| HoG | Histogram of oriented Gradient |
| ILSVRC | Large Scale Visual Recognition Challenge |
| JU | ECSEL Joint Undertaking |
| KNN | K-Nearest Neighbor |
| LPB | Local Binary Pattern |
| LSTM | Long Short Term Memory |
| ML | Machine Learning |
| MLP | Multi-Layer Perceptron |
| NDVI | Normalized Difference Vegetation Index |
| NIR | Near Infra-Red |
| PETA | Progressive Environmental and Agricultural Technologies |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| SGD | Stochastic Gradient Descent |
| SIFT | Scale Invariant Feature Transform |
| SURF | Speeded Up Robust Features |
| SVM | Support Vector Machine |
| TF | Transfer Learning |
| TPMD | Tomato Powdery Mildew Disease |
References
- Roser, M. Future population growth. In Our World in Data; University of Oxford: Oxford, UK, 2013. [Google Scholar]
- Fróna, D.; Szenderák, J.; Harangi-Rákos, M. The challenge of feeding the world. Sustainability 2019, 11, 5816. [Google Scholar] [CrossRef]
- Ray, D.K.; Mueller, N.D.; West, P.C.; Foley, J.A. Yield trends are insufficient to double global crop production by 2050. PLoS ONE 2013, 8, e66428. [Google Scholar] [CrossRef]
- FAO. The Future of Food and Agriculture: Trends and Challenges; FAO: Rome, Italy, 2017. [Google Scholar]
- Deutsch, C.A.; Tewksbury, J.J.; Tigchelaar, M.; Battisti, D.S.; Merrill, S.C.; Huey, R.B.; Naylor, R.L. Increase in crop losses to insect pests in a warming climate. Science 2018, 361, 916–919. [Google Scholar] [CrossRef] [PubMed]
- Food and Agriculture Organization of the United Nations FAOSTAT Pesticides Use. Available online: https://www.fao.org/faostat/en/#data/RP/visualize (accessed on 10 January 2022).
- Kartikeyan, P.; Shrivastava, G. Review on emerging trends in detection of plant diseases using image processing with machine learning. Int. J. Comput. Appl. 2021, 975, 8887. [Google Scholar] [CrossRef]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldú, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest X-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Wang, L.; Lee, C.Y.; Tu, Z.; Lazebnik, S. Training deeper convolutional networks with deep supervision. arXiv 2015, arXiv:1505.02496. [Google Scholar]
- Soni, A.; Dharmacharya, D.; Pal, A.; Srivastava, V.K.; Shaw, R.N.; Ghosh, A. Design of a machine learning-based self-driving car. In Machine Learning for Robotics Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 139–151. [Google Scholar]
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine learning and the physical sciences. Rev. Mod. Phys. 2019, 91, 045002. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Xiao, Q.; Li, W.; Kai, Y.; Chen, P.; Zhang, J.; Wang, B. Occurrence prediction of pests and diseases in cotton on the basis of weather factors by long short term memory network. BMC Bioinform. 2019, 20, 688. [Google Scholar] [CrossRef]
- Gutierrez, A.; Ansuategi, A.; Susperregi, L.; Tubío, C.; Rankić, I.; Lenža, L. A benchmarking of learning strategies for pest detection and identification on tomato plants for autonomous scouting robots using internal databases. J. Sens. 2019, 2019, 5219471. [Google Scholar] [CrossRef]
- Plantix App. Available online: https://plantix.net/en/ (accessed on 11 January 2022).
- Saillog. Available online: https://www.saillog.co/ (accessed on 11 January 2022).
- CropDiagnosis. Available online: https://www.cropdiagnosis.com/portal/crops/en/home (accessed on 11 January 2022).
- Gamaya. Available online: https://www.gamaya.com/ (accessed on 11 January 2022).
- iFarmer. Available online: https://ifarmer.asia/ (accessed on 11 January 2022).
- Chostner, B. See & Spray: The next generation of weed control. Resour. Mag. 2017, 24, 4–5. [Google Scholar]
- Savla, A.; Israni, N.; Dhawan, P.; Mandholia, A.; Bhadada, H.; Bhardwaj, S. Survey of classification algorithms for formulating yield prediction accuracy in precision agriculture. In Proceedings of the 2015 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 19–20 March 2015; pp. 1–7. [Google Scholar]
- Fenu, G.; Malloci, F.M. Forecasting plant and crop disease: An explorative study on current algorithms. Big Data Cogn. Comput. 2021, 5, 2. [Google Scholar] [CrossRef]
- Vikas, L.; Dhaka, V. Wheat yield prediction using artificial neural network and crop prediction techniques (a survey). Int. J. Res. Appl. Sci. Eng. Technol. 2014, 2, 330–341. [Google Scholar]
- Moysiadis, V.; Sarigiannidis, P.; Vitsas, V.; Khelifi, A. Smart farming in Europe. Comput. Sci. Rev. 2021, 39, 100345. [Google Scholar] [CrossRef]
- Choudhuri, K.B.R.; Mangrulkar, R.S. Data Acquisition and Preparation for Artificial Intelligence and Machine Learning Applications. In Design of Intelligent Applications Using Machine Learning and Deep Learning Techniques; Chapman and Hall/CRC: Boca Raton, FL, USA, 2021; pp. 1–11. [Google Scholar]
- Raza, S.E.A.; Prince, G.; Clarkson, J.P.; Rajpoot, N.M. Automatic detection of diseased tomato plants using thermal and stereo visible light images. PLoS ONE 2015, 10, e0123262. [Google Scholar] [CrossRef]
- Rustia, D.J.A.; Lin, T.T. An IoT-based wireless imaging and sensor node system for remote greenhouse pest monitoring. Chem. Eng. Trans. 2017, 58, 601–606. [Google Scholar]
- Kaundal, R.; Kapoor, A.S.; Raghava, G.P. Machine learning techniques in disease forecasting: A case study on rice blast prediction. BMC Bioinform. 2006, 7, 485. [Google Scholar] [CrossRef]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep neural networks based recognition of plant diseases by leaf image classification. Comput. Intell. Neurosci. 2016, 2016, 3289801. [Google Scholar] [CrossRef]
- Mokhtar, U.; Ali, M.A.; Hassanien, A.E.; Hefny, H. Identifying two of tomatoes leaf viruses using support vector machine. In Information Systems Design and Intelligent Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 771–782. [Google Scholar]
- Skawsang, S.; Nagai, M.; K. Tripathi, N.; Soni, P. Predicting rice pest population occurrence with satellite-derived crop phenology, ground meteorological observation, and machine learning: A case study for the Central Plain of Thailand. Appl. Sci. 2019, 9, 4846. [Google Scholar] [CrossRef]
- Significant Remote Sensing Vegetation Indices a Review of Developments and Applications. Available online: https://www.hindawi.com/journals/JS/2017/1353691/ (accessed on 11 January 2022).
- Abdulridha, J.; Ampatzidis, Y.; Kakarla, S.C.; Roberts, P. Detection of target spot and bacterial spot diseases in tomato using UAV-based and benchtop-based hyperspectral imaging techniques. Precis. Agric. 2020, 21, 955–978. [Google Scholar] [CrossRef]
- Earth Observing System Vegetation Indices to Drive Digital Agri Solutions. Available online: https://eos.com/blog/vegetation-indices/ (accessed on 11 January 2022).
- Evangelides, C.; Nobajas, A. Red-Edge Normalised Difference Vegetation Index (NDVI705) from Sentinel-2 imagery to assess post-fire regeneration. Remote Sens. Appl. Soc. Environ. 2020, 17, 100283. [Google Scholar] [CrossRef]
- Albetis, J.; Duthoit, S.; Guttler, F.; Jacquin, A.; Goulard, M.; Poilvé, H.; Féret, J.B.; Dedieu, G. Detection of Flavescence dorée grapevine disease using unmanned aerial vehicle (UAV) multispectral imagery. Remote Sens. 2017, 9, 308. [Google Scholar] [CrossRef]
- Chandel, A.K.; Khot, L.R.; Sallato, B. Apple powdery mildew infestation detection and mapping using high-resolution visible and multispectral aerial imaging technique. Sci. Hortic. 2021, 287, 110228. [Google Scholar] [CrossRef]
- Wang, F.M.; Huang, J.F.; Tang, Y.L.; Wang, X.Z. New vegetation index and its application in estimating leaf area index of rice. Rice Sci. 2007, 14, 195–203. [Google Scholar] [CrossRef]
- Duarte-Carvajalino, J.M.; Alzate, D.F.; Ramirez, A.A.; Santa-Sepulveda, J.D.; Fajardo-Rojas, A.E.; Soto-Suárez, M. Evaluating late blight severity in potato crops using unmanned aerial vehicles and machine learning algorithms. Remote Sens. 2018, 10, 1513. [Google Scholar] [CrossRef]
- Kim, S.; Lee, M.; Shin, C. IoT-based strawberry disease prediction system for smart farming. Sensors 2018, 18, 4051. [Google Scholar] [CrossRef]
- Yin, X.; Kropff, M.J.; McLaren, G.; Visperas, R.M. A nonlinear model for crop development as a function of temperature. Agric. For. Meteorol. 1995, 77, 1–16. [Google Scholar] [CrossRef]
- Henderson, D.; Williams, C.J.; Miller, J.S. Forecasting late blight in potato crops of southern Idaho using logistic regression analysis. Plant Dis. 2007, 91, 951–956. [Google Scholar] [CrossRef]
- Lasso, E.; Corrales, D.C.; Avelino, J.; de Melo Virginio Filho, E.; Corrales, J.C. Discovering weather periods and crop properties favorable for coffee rust incidence from feature selection approaches. Comput. Electron. Agric. 2020, 176, 105640. [Google Scholar] [CrossRef]
- Small, I.M.; Joseph, L.; Fry, W.E. Development and implementation of the BlightPro decision support system for potato and tomato late blight management. Comput. Electron. Agric. 2015, 115, 57–65. [Google Scholar] [CrossRef]
- Ghaffari, R.; Zhang, F.; Iliescu, D.; Hines, E.; Leeson, M.; Napier, R.; Clarkson, J. Early detection of diseases in tomato crops: An electronic nose and intelligent systems approach. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–6. [Google Scholar]
- Holopainen, J.K. Multiple functions of inducible plant volatiles. Trends Plant Sci. 2004, 9, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Diepeveen, D.; Armstrong, L.; Vagh, Y. Identifying key crop performance traits using data mining. In Proceedings of the IAALD-AFITA-WCCA Congress 2008 (World Conference on Agricultural Information and IT), Tokyo, Japan, 25–27 August 2008. [Google Scholar]
- Patil, N.N.; Saiyyad, M.A.M. Machine learning technique for crop recommendation in agriculture sector. Int. J. Eng. Adv. Technol. 2019, 9, 1359–1363. [Google Scholar] [CrossRef]
- Rosenzweig, C.; Iglesius, A.; Yang, X.B.; Epstein, P.R.; Chivian, E. Climate Change and Extreme Weather Events-Implications for Food Production, Plant Diseases, and Pests; NASA Publications: Nebraska, NU, USA, 2001.
- PlantVillage Tomato | Diseases and Pests, Description, Uses, Propagation. Available online: https://plantvillage.psu.edu/topics/tomato/infos (accessed on 11 January 2022).
- Dake, W.; Chengwei, M. The support vector machine (SVM) based near-infrared spectrum recognition of leaves infected by the leafminers. In Proceedings of the First International Conference on Innovative Computing, Information and Control-Volume I (ICICIC’06), Beijing, China, 30 August–1 September 2006; Volume 3, pp. 448–451. [Google Scholar]
- Measuring Vegetation NDVI and EVI. Available online: https://earthobservatory.nasa.gov/features/MeasuringVegetation/measuring_vegetation_2.php (accessed on 11 January 2022).
- Herbert, D.A.; Mack, T.; Reed, R.B.; Getz, R. Degree-Day Maps for Management of Soybean Insect Pests in Alabama; Auburn University: Auburn, AL, USA, 1988. [Google Scholar]
- Research Models: Insects, Mites, Diseases, Plants, and Beneficials-from UC IPM. Available online: http://ipm.ucanr.edu/MODELS/models_scientific.html (accessed on 10 July 2014).
- Entomology, L.O.E. Temperature-Dependent Development of Greenhouse Whitefly and Its Parasite Encarsia formosa. Environ. Entomol. 1982, 11, 483–485. [Google Scholar]
- Miller, P.; Lanier, W.; Brandt, S. Using Growing Degree Days to Predict Plant Stages; Ag/Extension Communications Coordinator, Communications Services, Montana State University-Bozeman: Bozeman, MO, USA, 2001; Volume 59717, pp. 994–2721. [Google Scholar]
- Calculating Degree Days. Available online: https://www.degreedays.net/calculation (accessed on 26 July 2022).
- Tomato Diseases and Disorders|Home and Garden Information Center. Available online: https://hgic.clemson.edu/factsheet/tomato-diseases-disorders/ (accessed on 26 May 2021).
- Seager, S.; Turner, E.L.; Schafer, J.; Ford, E.B. Vegetation’s red edge: A possible spectroscopic biosignature of extraterrestrial plants. Astrobiology 2005, 5, 372–390. [Google Scholar] [CrossRef] [PubMed]
- Hughes, D.; Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar]
- Wu, X.; Zhan, C.; Lai, Y.K.; Cheng, M.M.; Yang, J. Ip102: A large-scale benchmark dataset for insect pest recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8787–8796. [Google Scholar]
- Singh, D.; Jain, N.; Jain, P.; Kayal, P.; Kumawat, S.; Batra, N. PlantDoc: A dataset for visual plant disease detection. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, Hyderabad, India, 5–7 January 2020; pp. 249–253. [Google Scholar]
- Wu, S.G.; Bao, F.S.; Xu, E.Y.; Wang, Y.X.; Chang, Y.F.; Xiang, Q.L. A leaf recognition algorithm for plant classification using probabilistic neural network. In Proceedings of the 2007 IEEE International Symposium on Signal Processing and Information Technology, Giza, Egypt, 15–18 December 2007; pp. 11–16. [Google Scholar]
- Lee, S.H.; Chan, C.S.; Mayo, S.J.; Remagnino, P. How deep learning extracts and learns leaf features for plant classification. Pattern Recognit. 2017, 71, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Bakeer, A.; Abdel-Latef, M.; Afifi, M.; Barakat, M. Validation of tomato powdery mildew forecasting model using meteorological data in Egypt. Int. J. Agric. Sci. 2013, 5, 372. [Google Scholar]
- Brahimi, M.; Boukhalfa, K.; Moussaoui, A. Deep learning for tomato diseases: Classification and symptoms visualization. Appl. Artif. Intell. 2017, 31, 299–315. [Google Scholar] [CrossRef]
- Ferentinos, K.P. Deep learning models for plant disease detection and diagnosis. Comput. Electron. Agric. 2018, 145, 311–318. [Google Scholar] [CrossRef]
- Garcia-Lamont, F.; Cervantes, J.; López, A.; Rodriguez, L. Segmentation of images by color features: A survey. Neurocomputing 2018, 292, 1–27. [Google Scholar] [CrossRef]
- Types of Morphological Operations MATLAB and Simulink. Available online: https://www.mathworks.com/help/images/morphological-dilation-and-erosion.html. (accessed on 11 January 2022).
- Albanese, A.; d’Acunto, D.; Brunelli, D. Pest detection for precision agriculture based on iot machine learning. In International Conference on Applications in Electronics Pervading Industry, Environment and Society; Springer: Berlin/Heidelberg, Germany, 2019; pp. 65–72. [Google Scholar]
- Sannakki, S.S.; Rajpurohit, V.S.; Nargund, V.; Kumar, A.; Yallur, P.S. Leaf disease grading by machine vision and fuzzy logic. Int. J. 2011, 2, 1709–1716. [Google Scholar]
- Sekulska-Nalewajko, J.; Goclawski, J. A semi-automatic method for the discrimination of diseased regions in detached leaf images using fuzzy c-means clustering. In Proceedings of the Perspective Technologies and Methods in MEMS Design, Polyana, Ukraine, 1–14 May 2011; pp. 172–175. [Google Scholar]
- Zhou, Z.; Zang, Y.; Li, Y.; Zhang, Y.; Wang, P.; Luo, X. Rice plant-hopper infestation detection and classification algorithms based on fractal dimension values and fuzzy C-means. Math. Comput. Model. 2013, 58, 701–709. [Google Scholar] [CrossRef]
- Pang, J.; Bai, Z.y.; Lai, J.c.; Li, S.k. Automatic segmentation of crop leaf spot disease images by integrating local threshold and seeded region growing. In Proceedings of the 2011 International Conference on Image Analysis and Signal Processing, Wuhan, China, 21–23 October 2011; pp. 590–594. [Google Scholar]
- Patil, S.B.; Bodhe, S.K. Leaf disease severity measurement using image processing. Int. J. Eng. Technol. 2011, 3, 297–301. [Google Scholar]
- Ramesh, S.; Hebbar, R.; Niveditha, M.; Pooja, R.; Shashank, N.; Vinod, P. Plant disease detection using machine learning. In Proceedings of the 2018 International Conference on Design Innovations for 3Cs Compute Communicate Control (ICDI3C), Bangalore, India, 25–28 April 2018; pp. 41–45. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Heath, M.D.; Sarkar, S.; Sanocki, T.; Bowyer, K.W. A robust visual method for assessing the relative performance of edge-detection algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 1338–1359. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Harwood, D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 582–585. [Google Scholar]
- Tan, L.; Lu, J.; Jiang, H. Tomato Leaf Diseases Classification Based on Leaf Images: A Comparison between Classical Machine Learning and Deep Learning Methods. AgriEngineering 2021, 3, 542–558. [Google Scholar] [CrossRef]
- Amara, J.; Bouaziz, B.; Algergawy, A. A deep learning-based approach for banana leaf diseases classification. In Datenbanksysteme für Business, Technologie und Web (BTW 2017)-Workshopband; Gesellschaft für Informatik e.V.: Bonn, Germany, 2017. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–235. [Google Scholar]
- Gu, Y.; Yoo, S.; Park, C.; Kim, Y.; Park, S.; Kim, J.; Lim, J. BLITE-SVR: New forecasting model for late blight on potato using support-vector regression. Comput. Electron. Agric. 2016, 130, 169–176. [Google Scholar] [CrossRef]
- Bhatia, A.; Chug, A.; Singh, A.P. Hybrid SVM-LR classifier for powdery mildew disease prediction in tomato plant. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020; pp. 218–223. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Guo, X.; Li, Y.; Marinello, F.; Ercisli, S.; Zhang, Z. A survey of few-shot learning in smart agriculture: Developments, applications, and challenges. Plant Methods 2022, 18, 28. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Buscema, M. Back propagation neural networks. Subst. Use Misuse 1998, 33, 233–270. [Google Scholar] [CrossRef]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Patil, R.R.; Kumar, S. Predicting rice diseases across diverse agro-meteorological conditions using an artificial intelligence approach. PeerJ Comput. Sci. 2021, 7, e687. [Google Scholar] [CrossRef]
- Sharma, P.; Singh, B.; Singh, R. Prediction of potato late blight disease based upon weather parameters using artificial neural network approach. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–13. [Google Scholar]
- Dahikar, S.S.; Rode, S.V. Agricultural crop yield prediction using artificial neural network approach. Int. J. Innov. Res. Electr. Electron. Instrum. Control Eng. 2014, 2, 683–686. [Google Scholar]
- Trenz, O.; Št’astnỳ, J.; Konečnỳ, V. Agricultural data prediction by means of neural network. Agric. Econ. 2011, 57, 356–361. [Google Scholar] [CrossRef] [Green Version]
- Ranjeet, T.; Armstrong, L. An Artificial Neural Network for Predicting Crops Yield in Nepal. In Proceedings of the Asian Federation for Information Technology in Agriculture, Perth, Australia, 29 September–2 October 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Pretrained Weights | Training | Testing | Performance |
|---|---|---|---|---|
| [68] | - | L | F | 33.0% acc. |
| F | L | 65.0% acc. | ||
| L + F | L + F | 99.0% acc. | ||
| [63] | ImageNet | L | F | 15.0% acc. |
| ImageNet + PlantVillage | F | F | 30.0% acc. | |
| ImageNet + PlantVillage | F (cropped images) | F (cropped images) | 70.0% acc. | |
| [13] | ImageNet | L | L | 99.0%+ acc. |
| Study | Type | Info |
|---|---|---|
| [13] | Greyscale | - |
| Background Segmentation | Masks | |
| Resize | 256 × 256 | |
| [30] | Data Augmentation | Affine, perspective, rotation |
| Data Cleaning | - | |
| Resize | 256 × 256 | |
| [71] | Resize | 52 × 52, 112 × 112, 224 × 224 |
| [62] | Data Cleaning | - |
| Resize | 224 × 224 | |
| [15] | Data Augmentation | Crop, rotation, Gaussian noise, scale, flip |
| Resize | 600 × 1024, 300 × 300 | |
| [67] | Resize | 256 × 256 |
| [68] | Resize | 256 × 256 |
| [82] | Greyscale | - |
| Resize | 60 × 60 |
| Study | Classification/ Regression | Kernels | |
|---|---|---|---|
| Type | Results | ||
| [52] | Classification | Polynomial | 90.0% acc. |
| Radial Basis Function | 97.4% acc. | ||
| [29] | Regression | Not specified | SVM outperformed |
| [40] | Regression | Linear | = 0.45 |
| [27] | Classification | Linear | 90.0%+ acc. |
| [31] | Classification | Radial Basis Function | 90.5% acc. |
| Quadratic | 92.0% acc. | ||
| Linear | 91.0% acc. | ||
| Multi-Layer Perceptron | |||
| Polynomial | |||
| [67] | Classification | Not specified | 94.6% acc., 93.1% f1 |
| Study | Classification/Regression | Number of Trees | Performance |
|---|---|---|---|
| [40] | Regression | 100 | = 0.75 |
| [32] | Regression | 200 | = 0.75 |
| [77] | Classification | - | 70.0% acc. |
| [67] | Classification | - | 95.5% acc., 94.2% f1 |
| Study | Architecture | Results |
|---|---|---|
| [13] | GoogleNet | 99.3% |
| AlexNet | 99.3% | |
| [30] | CaffeNet | 96.3% |
| [71] | VGG16 | 98.0% validation, 81.0% in new apple orchard |
| [62] | GoogleNet | 43.5% acc., 32.7% f1 |
| FPN | 54.9% mAP 0.5 | |
| ResNet | 49.4% acc., 40.1% f1 | |
| VGGNet | 48.2% acc., 38.7% f1 | |
| AlexNet | 41.8% acc., 34.1% f1 | |
| [67] | GoogleNet | 98.7% acc., 97.1% f1 |
| AlexNet | 99.2% acc., 98.5% f1 | |
| [68] | AlexNet | 99.4% acc. |
| VGG16 | 99.5% acc. | |
| [63] | VGG16 | 60.4% acc., 60.0% f1 |
| InceptionResNet V2 | 70.5% acc., 70.0% f1 | |
| Inception V3 | 62.1% acc., 61.0% f1 | |
| [82] | LeNet | 98.6% acc., 98.6% f1 |
| Study | Model | Dataset for Pretrain | Method | Performance Difference Compared to Training from Scratch |
|---|---|---|---|---|
| [13] | AlexNet, GoogleNet | ImageNet | All layers trainable | ~−2% acc. |
| [30] | CaffeNet | ImageNet | Low learning rate for original layers (0.1), high for top layer (10) | ~−0.50% acc. |
| [62] | AlexNet, GoogleNet, VGGNet, ResNet | ImageNet | Fine tune | ~−14.0% acc. in best model (ResNet) |
| [15] | Faster RCNN (ResNet101, Inception V2, Inception ResNet V2) | COCO | Fine tune | No comparison |
| [67] | AlexNet, GoogleNet | ImageNet | Fine tune | ~−2% |
| [63] | VGG16, Inception V3, Inception ResNet v2 | ImageNet and/or PlantVillage | Fine tune | ~−31.0% using ImageNet and PlantVillage |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Domingues, T.; Brandão, T.; Ferreira, J.C. Machine Learning for Detection and Prediction of Crop Diseases and Pests: A Comprehensive Survey. Agriculture 2022, 12, 1350. https://doi.org/10.3390/agriculture12091350
Domingues T, Brandão T, Ferreira JC. Machine Learning for Detection and Prediction of Crop Diseases and Pests: A Comprehensive Survey. Agriculture. 2022; 12(9):1350. https://doi.org/10.3390/agriculture12091350
Chicago/Turabian StyleDomingues, Tiago, Tomás Brandão, and João C. Ferreira. 2022. "Machine Learning for Detection and Prediction of Crop Diseases and Pests: A Comprehensive Survey" Agriculture 12, no. 9: 1350. https://doi.org/10.3390/agriculture12091350
APA StyleDomingues, T., Brandão, T., & Ferreira, J. C. (2022). Machine Learning for Detection and Prediction of Crop Diseases and Pests: A Comprehensive Survey. Agriculture, 12(9), 1350. https://doi.org/10.3390/agriculture12091350