
A Rice Security Risk Assessment Method Based on the Fusion of Multiple Machine Learning Models



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Cleaning
- (1)
- Noise filtering. Noise in this paper refers to statistical errors caused by errors in the recording of units, as the hazard test results, test units and result are separate from each other, and noise filtering means removing data where the sample test results are determined to be inconsistent with the test results.
- (2)
- Data integration and data normalization. As the different formats of detection results are not conducive to subsequent risk assessment model construction, the detection data format is unified as floating point and the unified hazard detection results are standardized using a trapezoidal membership function, as shown in Equation (1).
2.2. Construction of a Risk Assessment Index System for Rice Hazards
2.2.1. Calculation of Assessment Index Weights Based on AHP Algorithm
2.2.2. Calculation of Assessment Index Weights Based on SC Algorithm
2.2.3. Calculation of Combined Risk Values Based on Indicator Weights
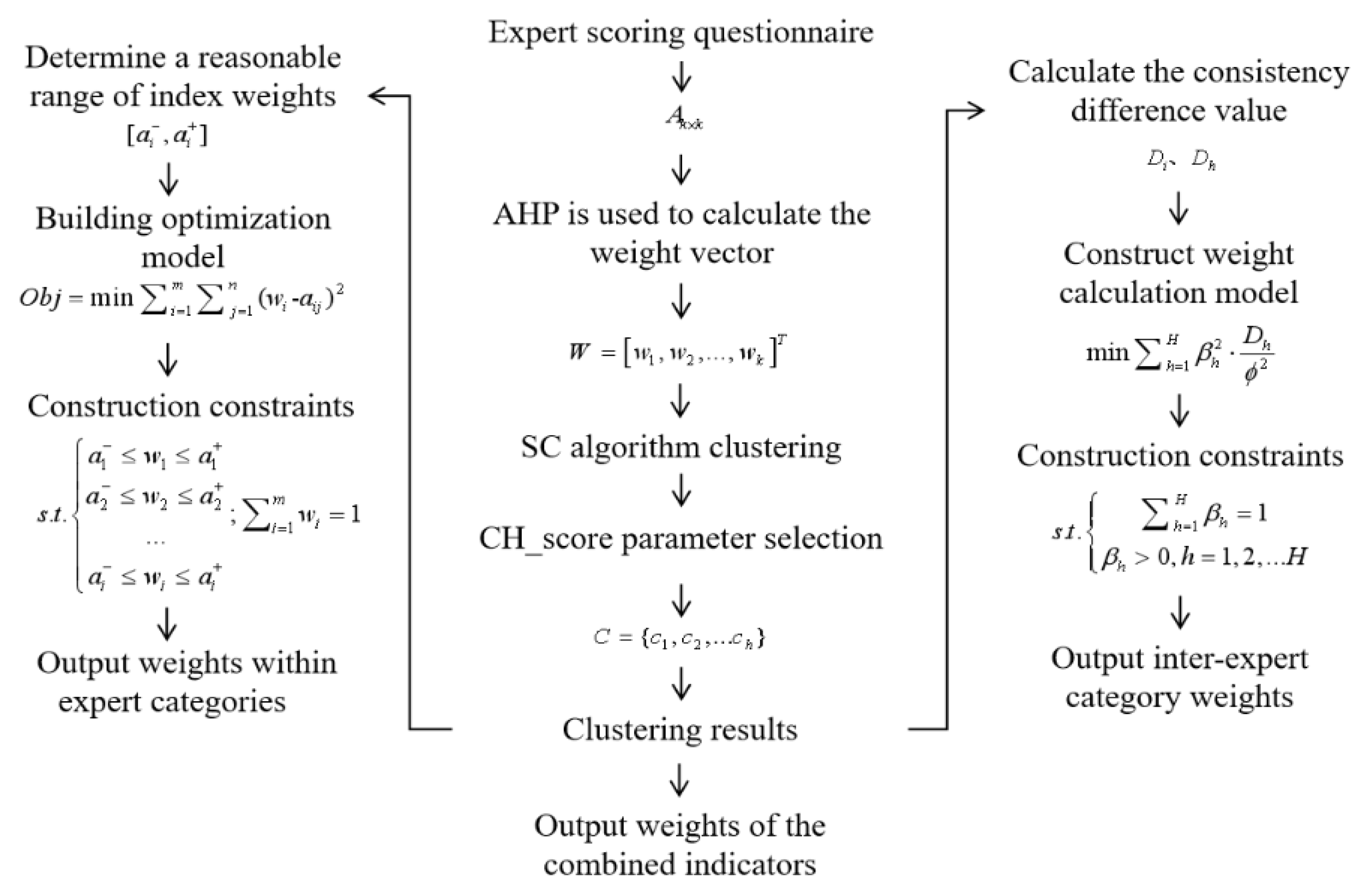
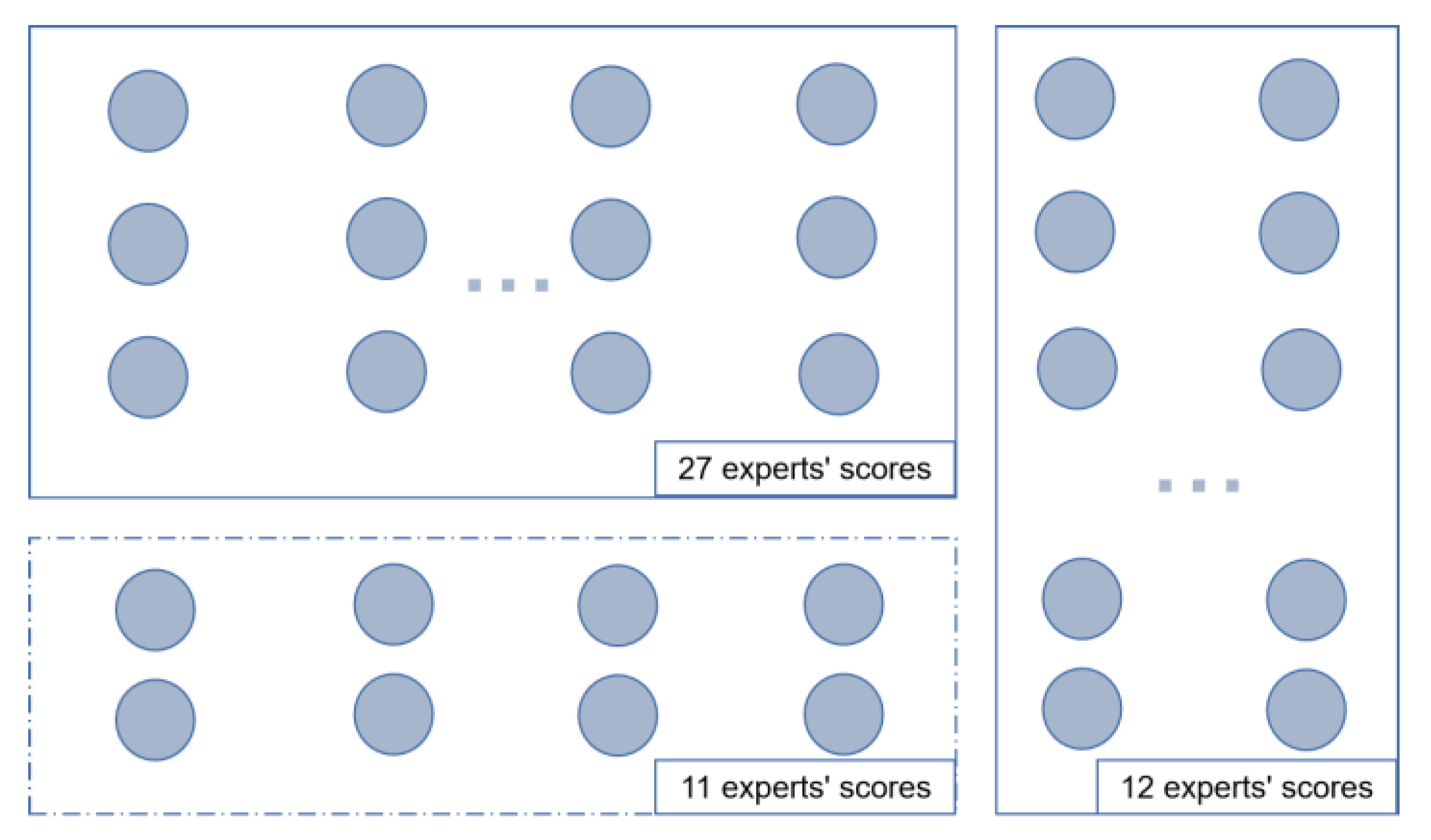
2.2.3.1. Calculation of Weighting between Specialist Categories
2.2.3.2. Calculation of Weights within Expert Categories
- (1)
- Determine the reasonable interval of indicators. Let a cluster contain the weight information given by experts, then each risk indicator has weight values, using the density distribution of weights of the indicators, to determine the reasonable interval of indicators. Where is the -th expert for the -th indicator to give the weight value, for the indicator , all experts can accept the indicator value range is , meet ; indicator value of the interval length is , meet . Let , and is the consistency test criteria. If does not contain other indicator values in field, then is a singularity. By traversing all indicator values and removing all singularities, a reasonable interval for each indicator is determined.
- (2)
- The optimization model of weights within expert categories is constructed. In order to maximize the integration of expert opinions within a reasonable interval, the objective function as shown in Equation (12), in the model satisfies the minimum deviation of the combined weight value within the expert categories and the weight value of each expert indicator ; the constraint in the model is to be within a reasonable interval of indicators and the sum of the weight values of indicators is 1, as shown in Equation (13).
- (3)
- Based on the results of the optimization model for weighting within expert categories, Section 2.2.2. the results of the section clustering and the results of the Section 2.2.3.1. inter-expert category weighting, the weights within expert categories and the weights of the combined elements are obtained as shown in Table 4.
2.3. A Fusion Algorithm-Based Model for Rice Safety Risk Assessment
2.3.1. Learners
XGBoost Algorithm
LightGBM Algorithm
LSTM Algorithm
2.3.2. Optimization Algorithms
BOA Algorithm
GWO Algorithm
Fusion Model Architecture
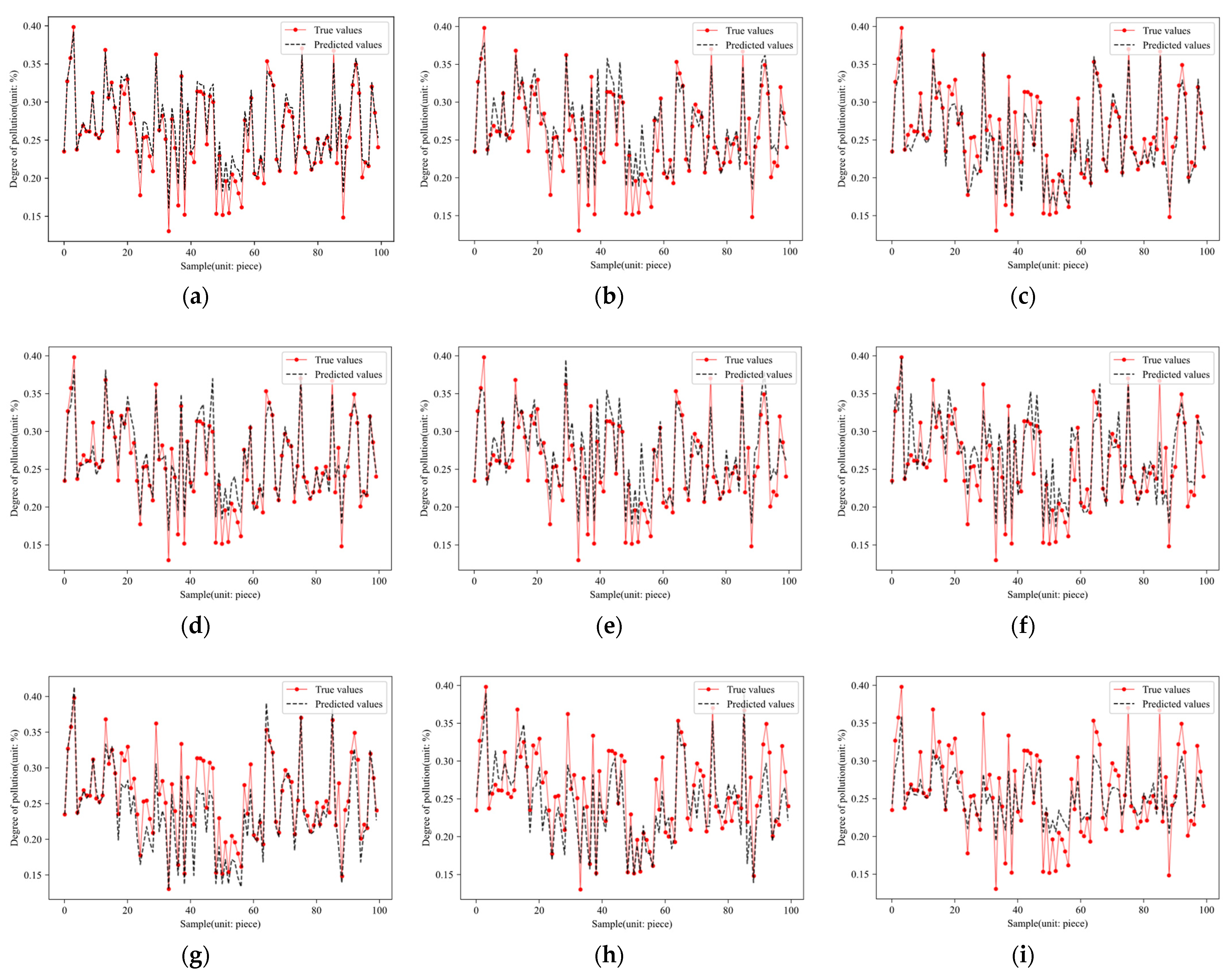
3. Results
4. Discussion
5. Conclusions and Future Prospects
5.1. Conclusions
5.2. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Q.; Zhao, Z.Y.; Wang, X.Y.; Xiong, K.; Shi, C. Microbiological predictive modeling and risk analysis based on the one-step kinetic integrated Wiener process. Innov. Food Sci. Emerg. Technol. 2022, 75, 102912. [Google Scholar] [CrossRef]
- Rosander, A.C. A simple method of scoring and interpreting sequential responses. J. Educ. Res. 2014, 3, 168–177. [Google Scholar] [CrossRef]
- Ma, B.; Han, Y.M.; Cui, S.Y.; Geng, Z.Q.; Li, H.D.; Chu, C. Risk early warning and control of food safety based on an improved analytic hierarchy process integrating quality control analysis method. Food Control 2020, 108, 106824. [Google Scholar] [CrossRef]
- Maduekwe, V.C.; Oke, S.A. Novel Taguchi scheme-based DEMATEL methods and DEMATEL method for the principal performance indicators of maintenance in a food processing industry. Int. J. Intell. Comput. Cybern. 2021, 3, 363–397. [Google Scholar] [CrossRef]
- Rathore, R.; Thakkar, J.J.; Jha, J.K. A quantitative risk assessment methodology and evaluation of food supply chain. Int. J. logist. Manag. 2017, 28, 1272–1293. [Google Scholar] [CrossRef]
- Li, S.L.; Rodríguez, R.M.; Wei, C.P. Two-stage consensus model based on opinion dynamics and evolution of social power in large-scale group decision making. Appl. Soft Comput. 2021, 111, 107615. [Google Scholar] [CrossRef]
- Du, Y.W.; Chen, Q.; Sun, Y.L.; Li, C.H. Knowledge structure-based consensus-reaching method for large-scale multiattribute group decision-making. Knowl.-Based Syst. 2021, 219, 106885–106899. [Google Scholar] [CrossRef]
- Wan, S.P.; Zou, W.C.; Dong, J.Y.; Martínez, L. A probabilistic linguistic dominance score method considering individual semantics and psychological behavior of decision makers. Expert Syst. Appl. 2021, 184, 115372–115386. [Google Scholar] [CrossRef]
- Darko, A.P.; Liang, D.C. Modeling customer satisfaction through online reviews: A flowsort group decision model under probabilistic linguistic settings. Expert Syst. Appl. 2022, 195, 116649–116660. [Google Scholar] [CrossRef]
- Wang, F.; Wan, S.P. Possibility degree and divergence degree based method for interval-valued intuitionistic fuzzy multi-attribute group decision making. Expert Syst. Appl. 2020, 141, 112929. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z.; Herrera, F. Consensus reaching process for large-scale group decision making with double hierarchy hesitant fuzzy linguistic preference relations. Knowl.-Based Syst. 2018, 157, 20–33. [Google Scholar] [CrossRef]
- Morente-Molinera, J.A.; Kou, G.; Samuylov, K.; Cabrerizo, F.J.; Herrera-Viedma, E. Using argumentation in expert’s debate to analyze multi-criteria group decision making method results. Inf. Sci. 2021, 573, 433–452. [Google Scholar] [CrossRef]
- Zhao, Z.Y.; Zhou, Y.Q.; Wang, X.Y.; Wang, Z.Y.; Bai, Y.T. Water quality evolution mechanism modeling and health risk assessment based on stochastic hybrid dynamic systems. Expert Syst. Appl. 2022, 193, 116404. [Google Scholar] [CrossRef]
- You, G.D.; Xu, B.; Su, H.L.; Zhang, S. Evaluation of aquaculture water quality based on improved fuzzy comprehensive evaluation method. Water 2021, 8, 1019. [Google Scholar] [CrossRef]
- Abdollahi, P.; Aslam, M.; Yazdi, A.A. Choosing the best facility layout using the combinatorial method of gray relation analysis and nonlinear programming. JSMS 2019, 6, 1143–1161. [Google Scholar] [CrossRef]
- Zhang, Q.F.; Chen, S.; Fan, Z.P. Bearing fault diagnosis based on improved particle swarm optimized VMD and SVM models. Adv. Mech. Eng. 2021, 6, 1–12. [Google Scholar] [CrossRef]
- Zhou, Y.L.; Li, Y.; Jin, J.L.; Zhou, P.; Zhang, D.; Ning, S.W.; Cui, Y. Stepwise identification of influencing factors and prediction of typhoon precipitation in Anhui province based on the back propagation neural network model. Water 2021, 4, 550. [Google Scholar] [CrossRef]
- Liao, C.W.; Wang, I.C.; Lin, K.P.; Lin, Y.J. A fuzzy seasonal long short-term memory network for wind power forecasting. Mathematics 2021, 11, 1178. [Google Scholar] [CrossRef]
- Qiu, B.; Fan, W. (David) Machine learning based short-term travel time prediction: Numerical results and comparative analyses. Sustainability 2021, 13, 7454. [Google Scholar] [CrossRef]
- Gan, M.; Pan, S.Q.; Chen, Y.P.; Cheng, C.; Pan, H.D.; Zhu, X. Application of the machine learning LightGBM model to the prediction of the water levels of the lower columbia river. J. Mar. Sci. Eng. 2021, 5, 496. [Google Scholar] [CrossRef]
- Fang, S.L.; Guan, Z.H.; Su, C.; Zhang, W.S.; Zhu, J.; Zheng, Y.W.; Li, H.B.; Zhao, P.P.; Liu, X.H. Accurate fish-freshness prediction label based on red cabbage anthocyanins. Food Control 2022, 138, 109018. [Google Scholar] [CrossRef]
- Saeed, R.; Zhang, L.W.; Cai, Z.Z.; Ajmal, M.; Zhang, X.S.; Akhter, M.; Hu, J.Y.; Fu, Z.T. Multisensor monitoring and water quality prediction for live ornamental fish transportation based on artificial neural network. Aquac. Res. 2022, 53, 2833–2850. [Google Scholar] [CrossRef]
- Kudashkina, K.; Corradini, M.G.; Thirunathan, P.; Yada, R.Y.; Fraser, E.D.G. Food structure, function and artificial intelligence. Trends Food Sci. Technol. 2022, 123, 376–381. [Google Scholar] [CrossRef]
- Luo, T.Y.; Wu, C.; Duan, L.X. Fishbone diagram and risk matrix analysis method and its application in safety assessment of natural gas spherical tank. J. Clean. Prod. 2018, 174, 296–304. [Google Scholar] [CrossRef]
- Geng, Z.Q.; Liu, F.F.; Shang, D.R.; Han, Y.M.; Shang, Y.; Chu, C. Early warning and control of food safety risk using an improved AHC-RBF neural network integrating AHP-EW. J. Food Eng. 2021, 292, 110239. [Google Scholar] [CrossRef]
- Lin, X.Y.; Cui, S.Y.; Han, Y.M.; Geng, Z.Q.; Zhong, Y.H. An improved ISM method based on GRA for hierarchical analyzing the influencing factors of food safety. Food Control 2019, 99, 48–56. [Google Scholar] [CrossRef]
- Li, Y.; Liang, G.X.; Zhang, L.; Liu, Z.P.; Yang, D.J.; Li, J.W.; Sun, G.J.; Zhou, P.P. Development and application of a comparative risk assessment method for ranking chemical hazards in food. Food Addit. Contam. A 2022, 38, 1–14. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, L.L.; Zhang, H.; Zhang, Y.Y.; Sun, B.G. Effects of two sterilization methods on the taste compositions of sweet and sour spare ribs flavor. J. Food Compost. Anal. 2021, 104, 104143. [Google Scholar] [CrossRef]
- Sun, Y.; Huang, Y.; Wang, X.Y.; Wu, Z.Y.; Weng, Y.X. Kinetic analysis of PGA/PBAT plastic films for strawberry fruit preservation quality and enzyme activity. J. Food Compost. Anal. 2022, 108, 104439. [Google Scholar] [CrossRef]
- Papapostolou, A.; Karakosta, C.; Apostolidis, G.; Doukas, H. An AHP-SWOT-Fuzzy TOPSIS approach for achieving a cross-border RES cooperation. Sustainability 2020, 7, 2886. [Google Scholar] [CrossRef] [Green Version]
- Qin, H.M.; Pang, Q.Q.; Yu, B.H.; Wang, Z.F. Analysis on cruising process for on-street parking using an spectral clustering method. IET Intell. Transp. Syst. 2020, 14, 2113–2121. [Google Scholar] [CrossRef]
- Wu, L.H.; Liu, P.P.; Lv, Y.X.; Chen, X.J.; Tsai, F.S. Social co-governance for food safety risks. Sustainability 2018, 11, 4246. [Google Scholar] [CrossRef] [Green Version]
- Mao, Z.H.; Xia, M.X.; Jiang, B.; Xu, D.Z.; Shi, P. Incipient fault diagnosis for high-speed train traction systems via stacked generalization. IEEE Trans. Cybern. 2020, 99, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Mahfuzur, R.; Chen, N.S.; Ahmed, E.; Monirul, I.S.; Mehtab, A.; Reza, P.H.; Wang, T.; Jun, Z.; Tian, S.F.; Hamid, F.; et al. Application of stacking hybrid machine learning algorithms in delineating multi-type flooding in Bangladesh. J. Environ. Manag. 2021, 295, 113086. [Google Scholar]
- Hu, L.Y.; Wang, C.; Ye, Z.R.; Wang, S. Estimating gaseous pollutants from bus emissions: A hybrid model based on GRU and XGBoost. Sci. Total Environ. 2021, 783, 146870. [Google Scholar] [CrossRef] [PubMed]
- Zhu, R.; Lv, Y.; Wang, Z.M.; Chen, X. Prediction of the hypertension risk of the elderly in built environments based on the LSTM deep learning and bayesian fitting method. Sustainability 2021, 10, 5724. [Google Scholar] [CrossRef]
- Zhiteneva, V.; Carvajal, G.; Shehata, O.; Hübner, U.; Drewes, J.E. Quantitative microbial risk assessment of a non-membrane based indirect potable water reuse system using Bayesian networks. Sci. Total Environ. 2021, 780, 146462. [Google Scholar] [CrossRef]
- Meng, A.B.; Zeng, C.; Wang, P.; Chen, D.; Zhou, T.M.; Zheng, X.Y.; Yin, H. A high-performance crisscross search based grey wolf optimizer for solving optimal power flow problem. Energy 2021, 225, 120211. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Risk Assessment Methodology | Experts | Examples of Techniques | Advantages | Disadvantages |
|---|---|---|---|---|
| Qualitative assessment methods | Single expert assessments | Index scoring method | Quantitative indicators are clear and easy to follow | Indicator weights are difficult to define reasonably |
| AHP | A clear hierarchy of indicators and a wide range of applications | Reliance on the accuracy of expert assessment results | ||
| DEMATEL | Relatively simplified relationships of system elements | Not conducive to multi-indicator system analysis | ||
| Multiple expert assessments | Subjective weighting methods | The calculation of indicator weights is relatively simple | Indicator weights are heavily influenced by an expert priori information | |
| Objective weighting methods | Indicator weights are less influenced by an expert priori information | The calculation of indicator weights is relatively complex | ||
| Quantitative assessment methods | FCE | Easy to implement, suitable for multiple indicator classification | Indicator weights are difficult to define reasonably | |
| GRA | Simple data calculation | Optimal values for some indicators are difficult to determine | ||
| Machine learning | SVM | High generalization ability | Not suitable for classification of large data samples | |
| BP | High non-linear mapping capability | Prone to local miniaturization problems | ||
| LSTM | Solve the problem of gradient disappearance and gradient explosion during long sequence training | Disadvantages in parallel processing | ||
| XGBoost | Insensitive to missing values, simple and easy to understand | Easy over-fitting | ||
| LightGBM | High operational efficiency and less overfitting | Relatively low model accuracy | ||
| Comprehensive risk assessment methods | Qualitative assessment methods to construct index systems; Quantitative assessment methods to construct risk assessment models | A combination of subjective and objective, comprehensive and accurate analysis | Computationally complex | |
| Provinces Tested | Test Time | Test Element | Content | Unit | Result |
|---|---|---|---|---|---|
| Jiangsu | 2018.06.07 | Chromium | 0.11 | mg/kg | Qualified |
| Henan | 2018.06.27 | Benzo[α]pyrene | 1.00 | μg/kg | Qualified |
| Heilongjiang | 2018.07.01 | Lead | 0.15 | μg/kg | Qualified |
| Anhui | 2018.10.24 | Inorganic arsenic | 0.075 | mg/kg | Qualified |
| Liaoning | 2018.06.07 | Aflatoxin B | <0.01 | μg/kg | Qualified |
| n_clusters | random_state | CH_score | n_clusters | random_state | CH_score |
|---|---|---|---|---|---|
| 2 | 1 | 10.1516 | 10 | 5 | 21.5342 |
| 3 | 1 | 11.1254 | 2 | 6 | 8.2844 |
| … | … | … | … | … | … |
| 6 | 2 | 17.7012 | 10 | 12 | 21.9540 |
| 7 | 2 | 18.0365 | 5 | 13 | 13.4442 |
| Element | Weighting within the First Category of Experts | Weighting within the Second Category of Experts | Weighting within the Third Category of Experts | Combined Element Weights |
|---|---|---|---|---|
| Lead | 0.0960 | 0.1905 | 0.0526 | 0.1027 |
| Cadmium | 0.1323 | 0.1369 | 0.1289 | 0.1324 |
| Chromium | 0.0810 | 0.0809 | 0.0725 | 0.0799 |
| Inorganic arsenic | 0.0920 | 0.0979 | 0.0788 | 0.0910 |
| Total mercury | 0.0810 | 0.0500 | 0.0559 | 0.0738 |
| Aflatoxin B | 0.1839 | 0.1247 | 0.1824 | 0.1760 |
| Ochratoxin A | 0.0647 | 0.0664 | 0.0896 | 0.0681 |
| Deoxynivalenol | 0.0554 | 0.0470 | 0.0803 | 0.0575 |
| Zearalenone | 0.0479 | 0.0622 | 0.0795 | 0.0538 |
| Benzo[α]pyrene | 0.1010 | 0.0876 | 0.1191 | 0.1016 |
| Aluminium phosphide | 0.0649 | 0.0558 | 0.0604 | 0.0632 |
| Models | R2 | MAE | MSE |
|---|---|---|---|
| BXGB-BLGB-GLSTM | 0.9317 | 0.0114 | 0.0002 |
| XGB-LGB | 0.8316 | 0.0188 | 0.0006 |
| XGB-LSTM | 0.8822 | 0.0144 | 0.0004 |
| LGB-LSTM | 0.8986 | 0.0129 | 0.0003 |
| XGBoost | 0.8271 | 0.0194 | 0.0006 |
| LightGBM | 0.7611 | 0.0225 | 0.0008 |
| LSTM | 0.7627 | 0.0213 | 0.0008 |
| BP | 0.7039 | 0.0248 | 0.0010 |
| SVM | 0.7446 | 0.0230 | 0.0008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Wang, Z.; Zhang, X.; Yu, J.; Cui, X.; Zhou, Y.; Zhao, Z. A Rice Security Risk Assessment Method Based on the Fusion of Multiple Machine Learning Models. Agriculture 2022, 12, 815. https://doi.org/10.3390/agriculture12060815
Xu J, Wang Z, Zhang X, Yu J, Cui X, Zhou Y, Zhao Z. A Rice Security Risk Assessment Method Based on the Fusion of Multiple Machine Learning Models. Agriculture. 2022; 12(6):815. https://doi.org/10.3390/agriculture12060815
Chicago/Turabian StyleXu, Jiping, Ziyi Wang, Xin Zhang, Jiabin Yu, Xiaoyu Cui, Yan Zhou, and Zhiyao Zhao. 2022. "A Rice Security Risk Assessment Method Based on the Fusion of Multiple Machine Learning Models" Agriculture 12, no. 6: 815. https://doi.org/10.3390/agriculture12060815
APA StyleXu, J., Wang, Z., Zhang, X., Yu, J., Cui, X., Zhou, Y., & Zhao, Z. (2022). A Rice Security Risk Assessment Method Based on the Fusion of Multiple Machine Learning Models. Agriculture, 12(6), 815. https://doi.org/10.3390/agriculture12060815