A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube



Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Construction
2.1.1. Image Acquisition and the Experimental Environment
2.1.2. The Balance of Data
2.2. The Principle of YOLOv5 Model
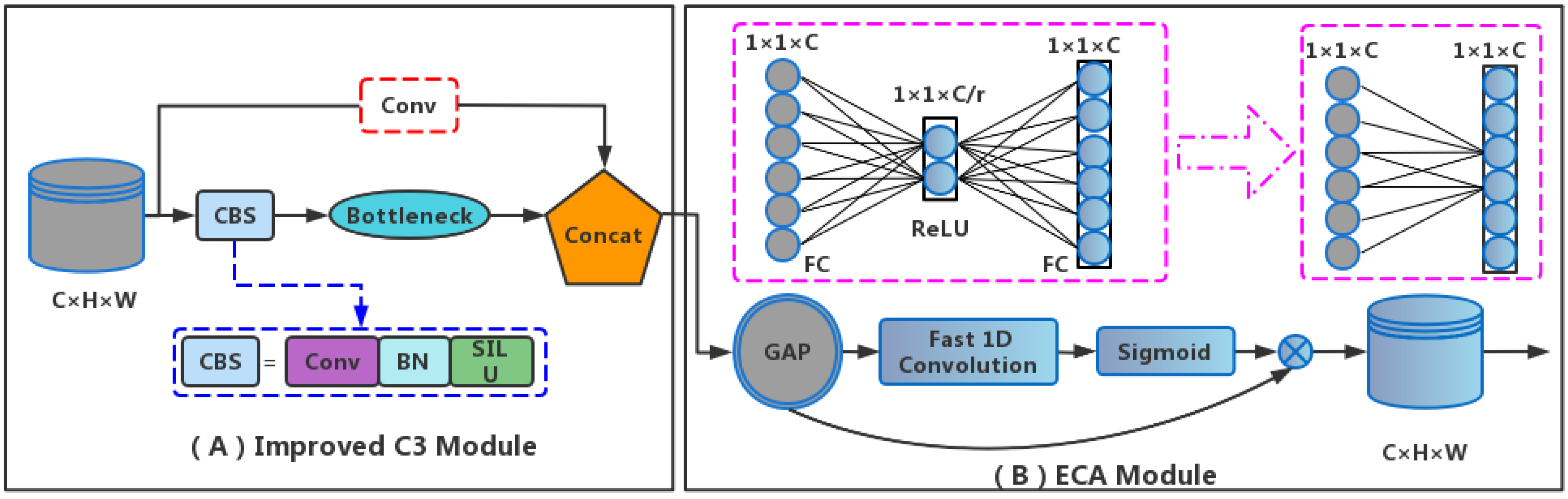
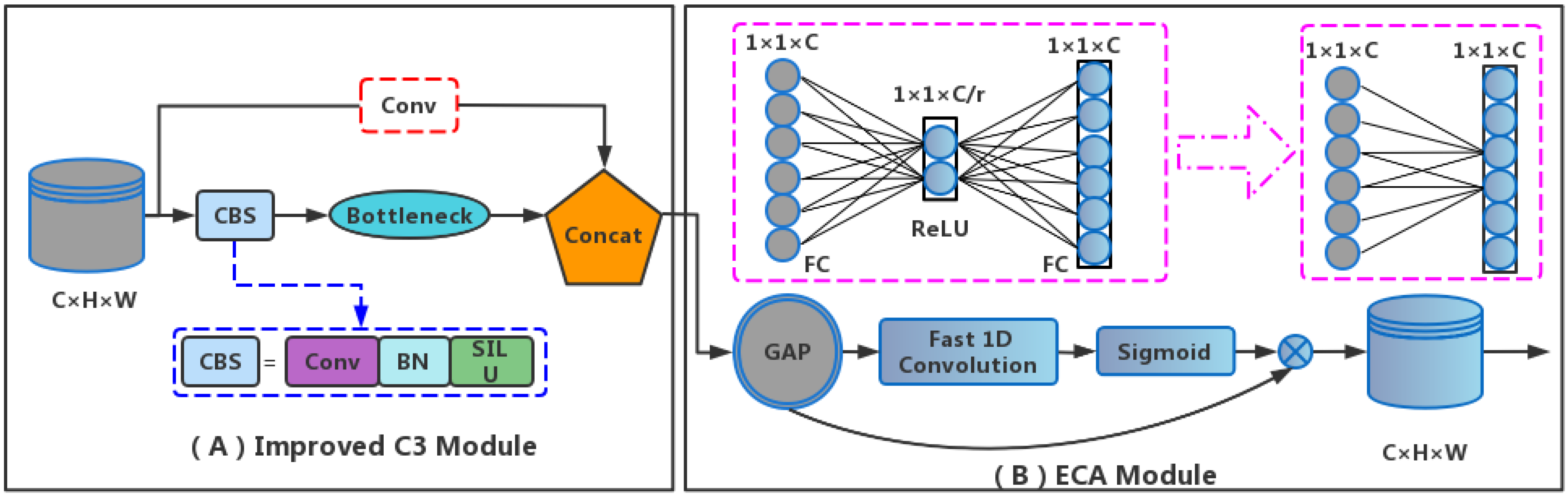
2.3. Improvement of the C3 Module
2.4. The Attention Mechanism
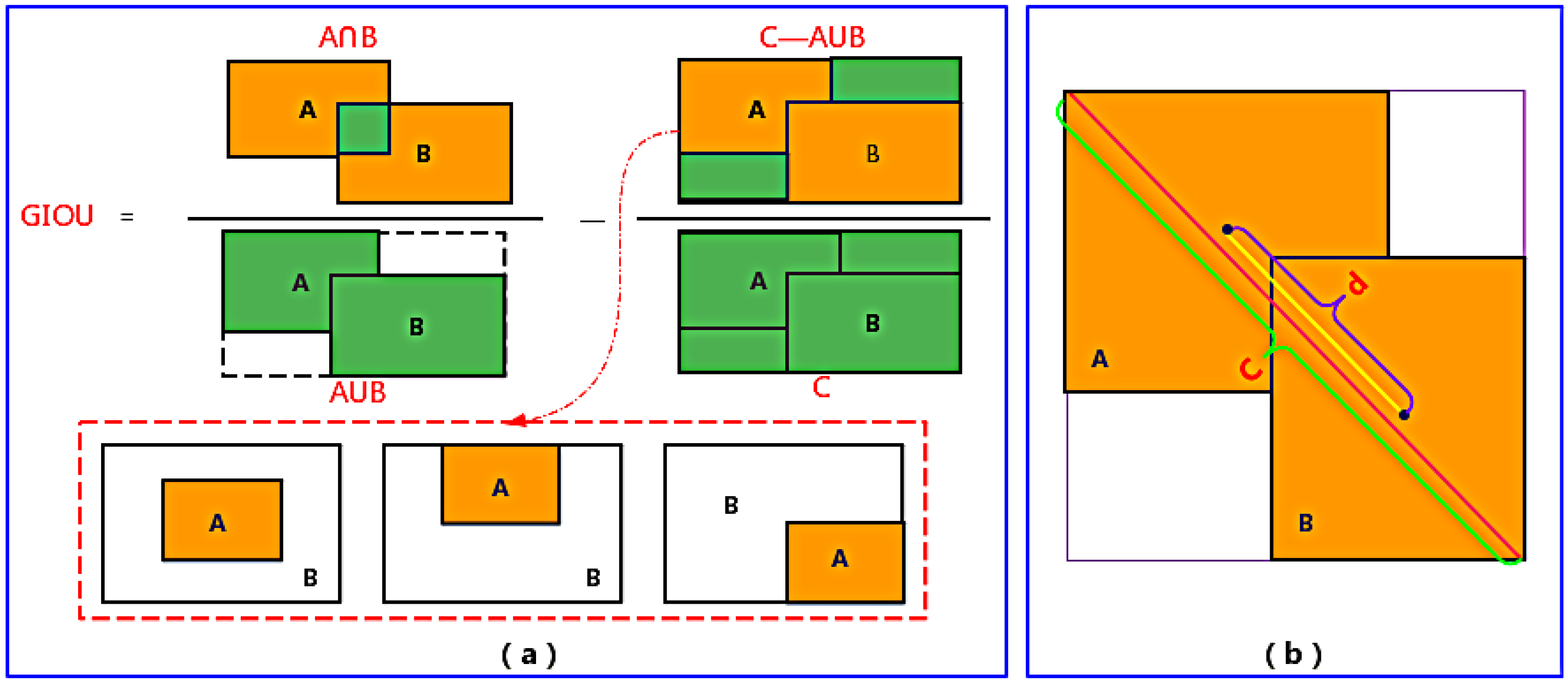
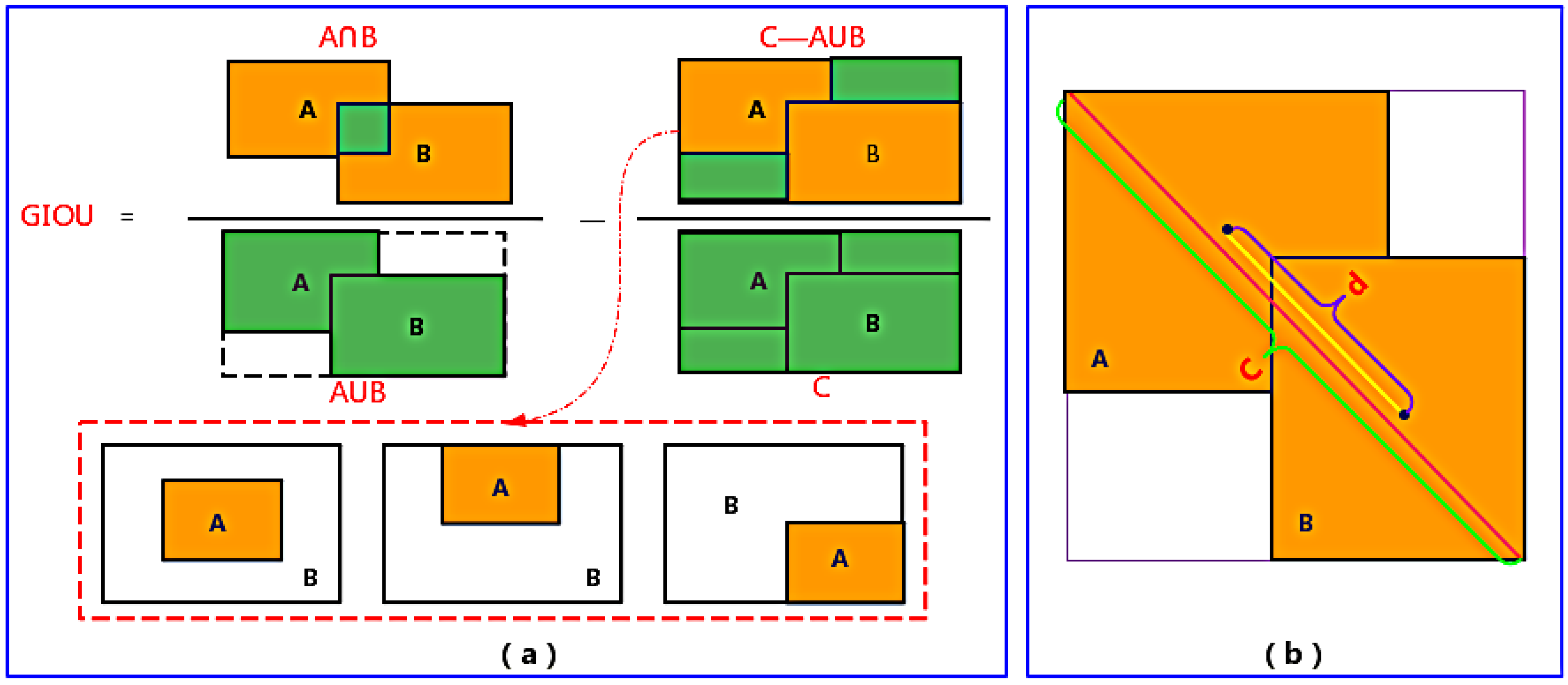
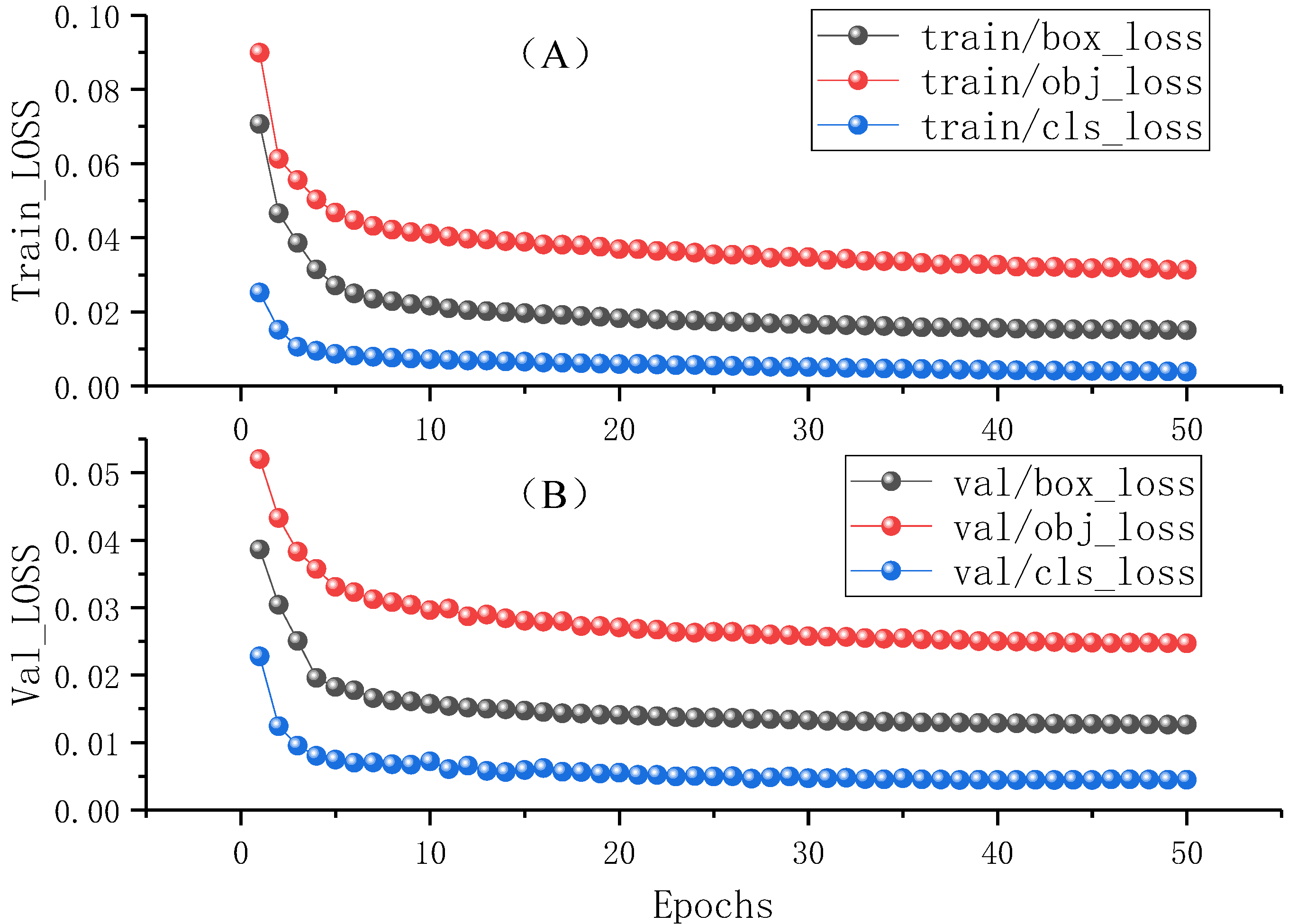
2.5. Optimization of the Loss Function
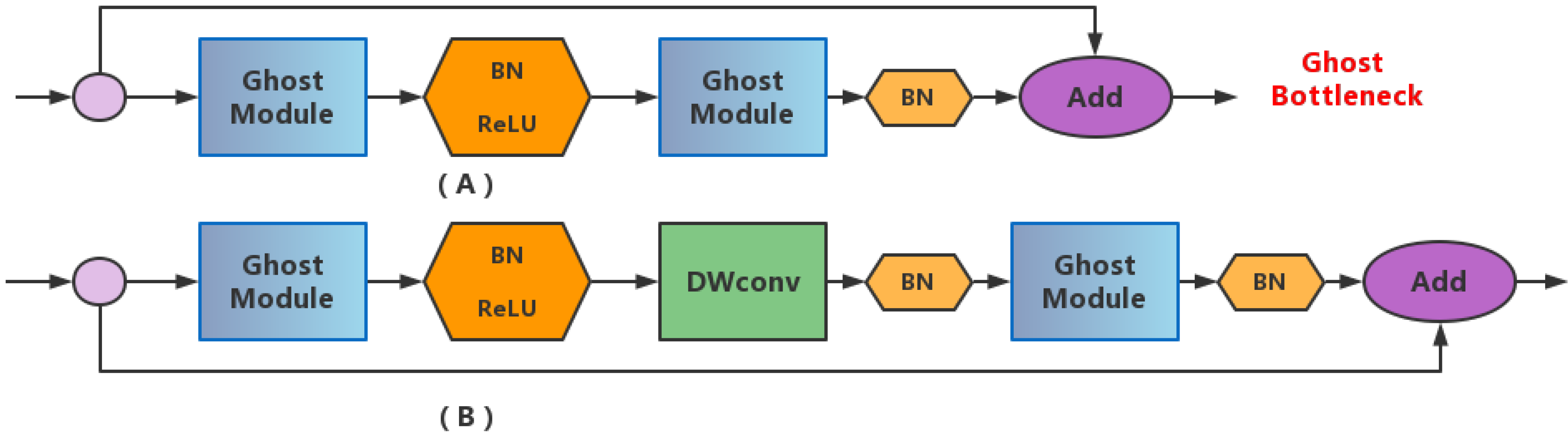
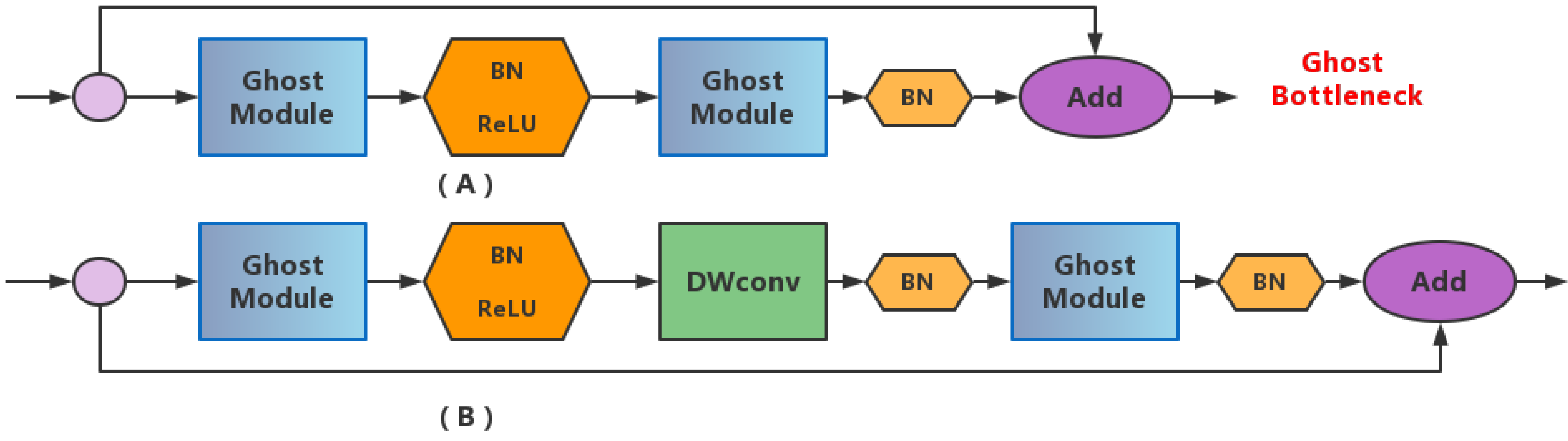
2.6. Lightweight Operation
2.7. Evaluation Metrics
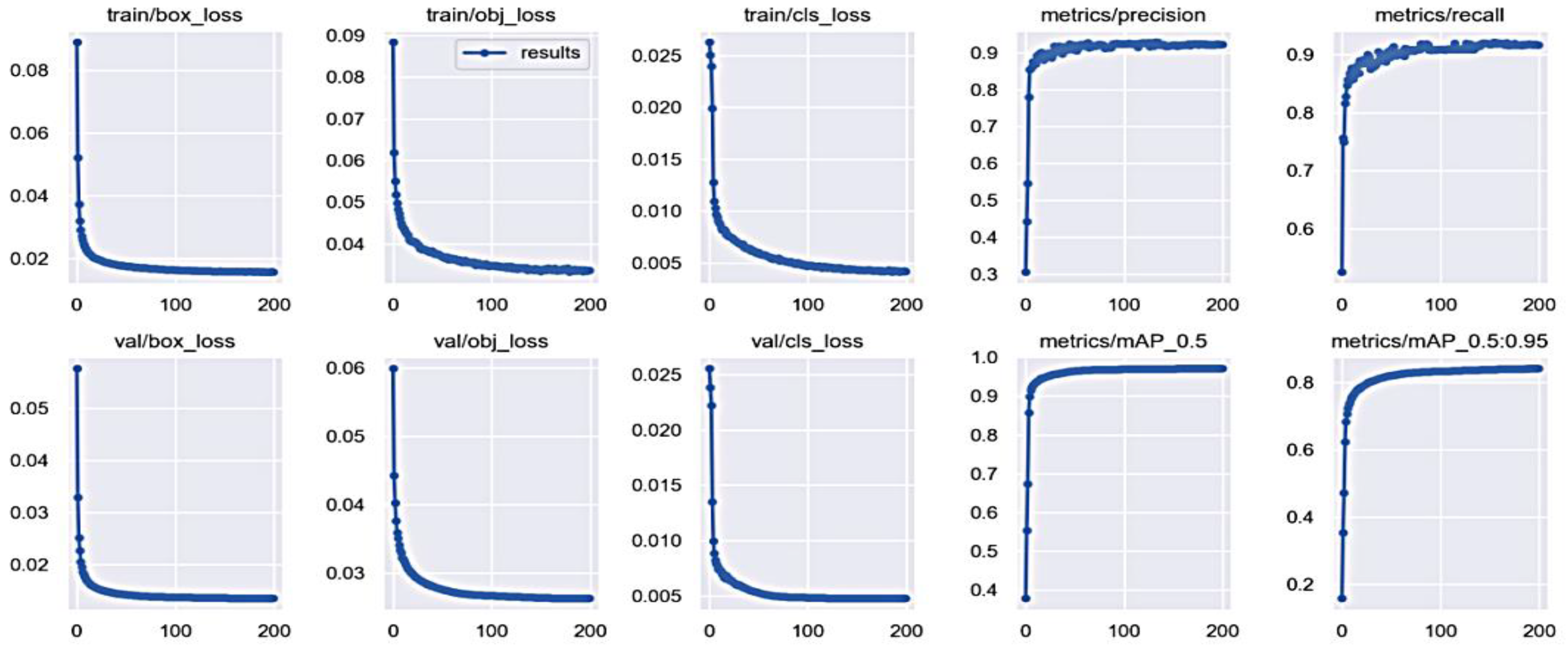
3. Results
3.1. Experiment of Attention Mechanism
3.2. Optimization Experiment of the C3 Module
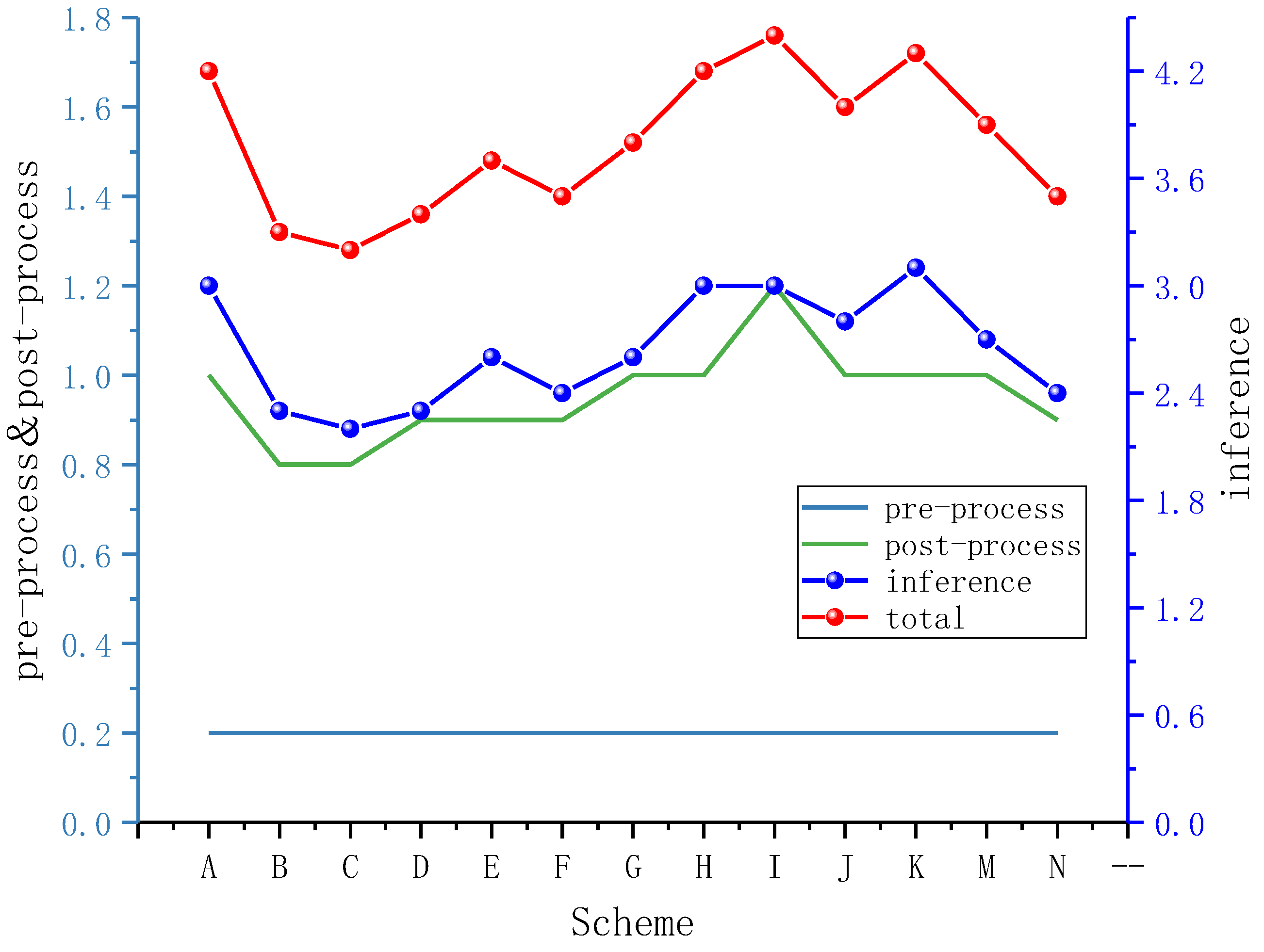
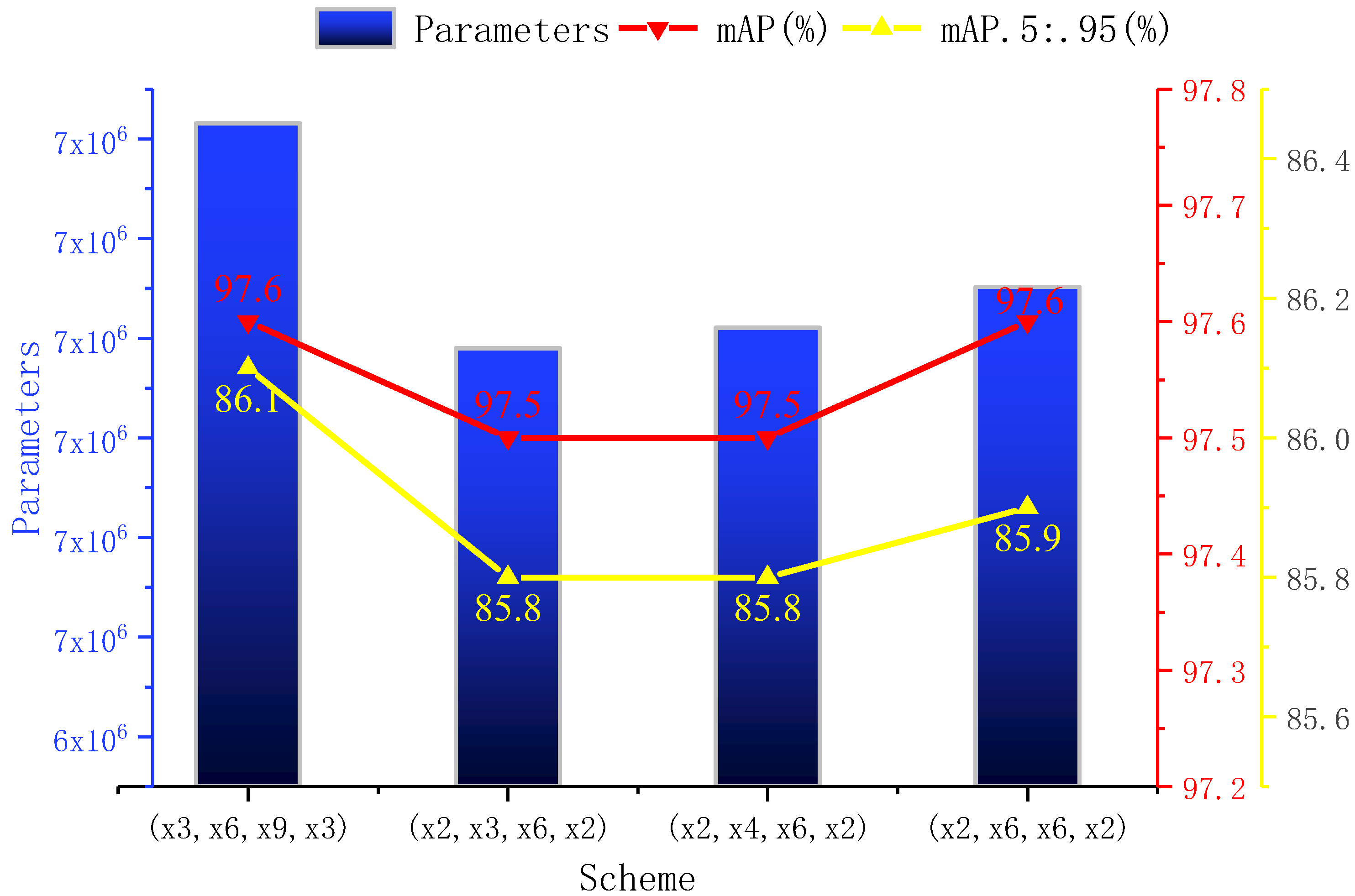
3.3. Performance Analysis of Different Lightweight Schemes
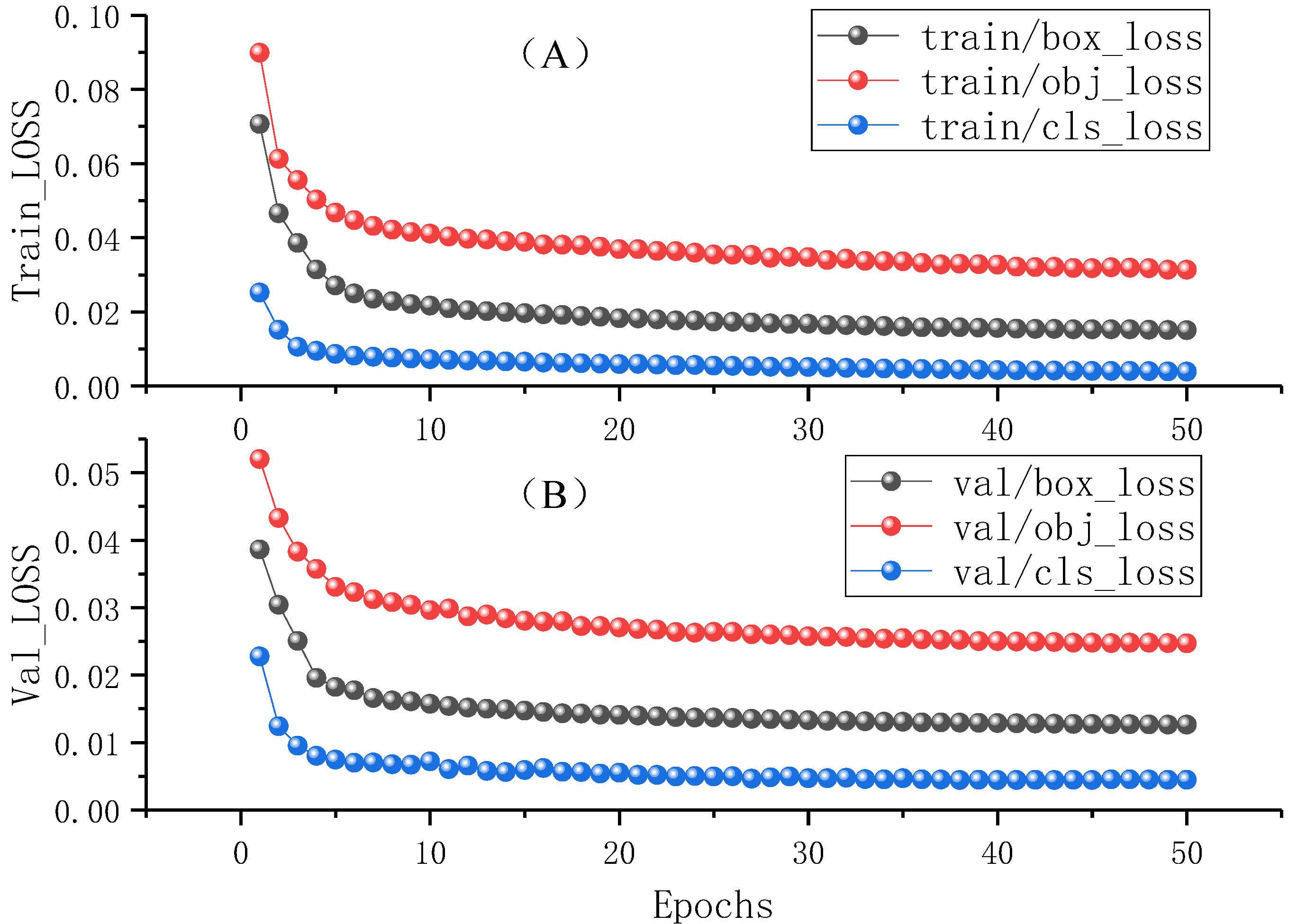
3.4. Ablation Experiment
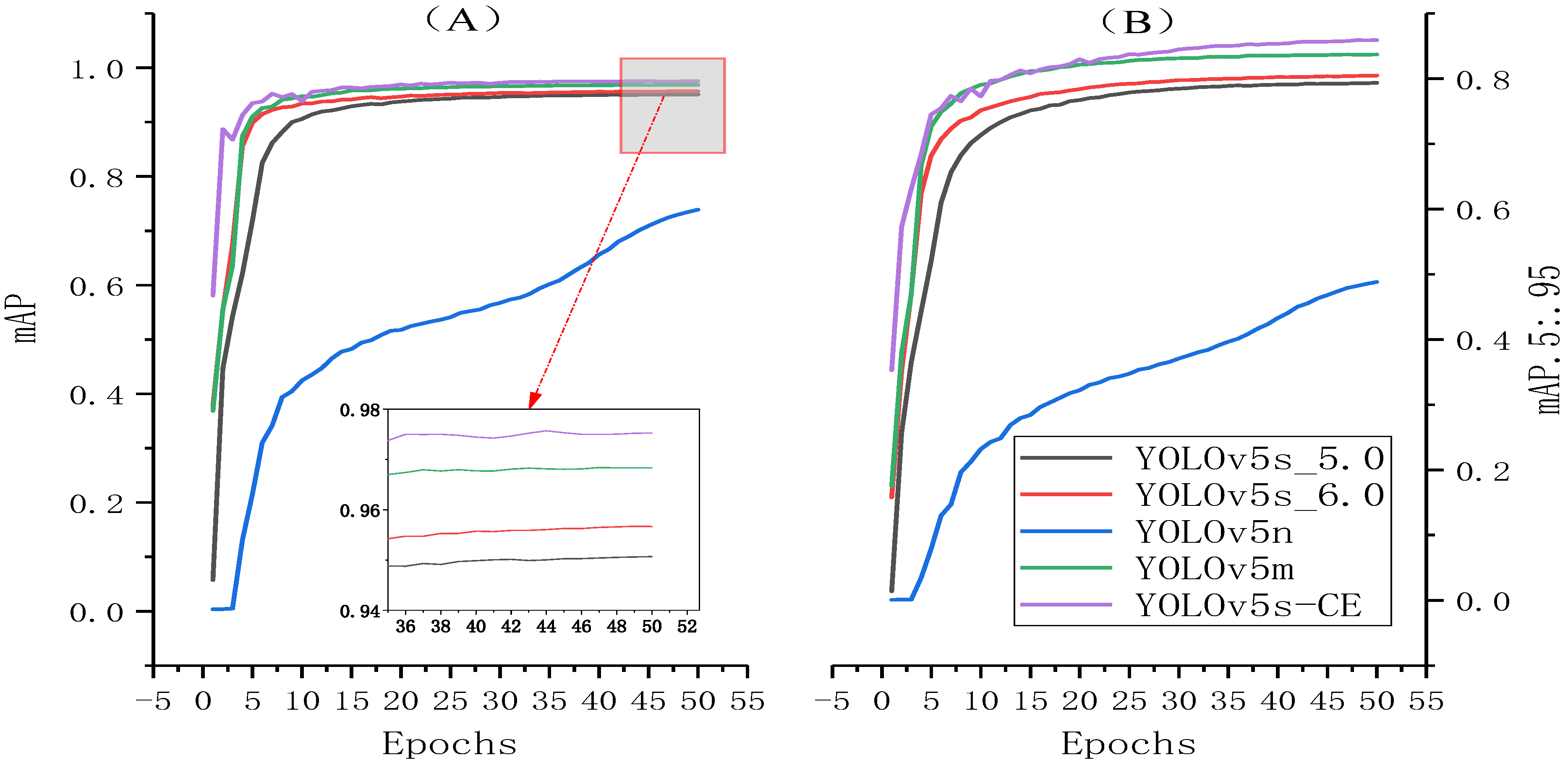
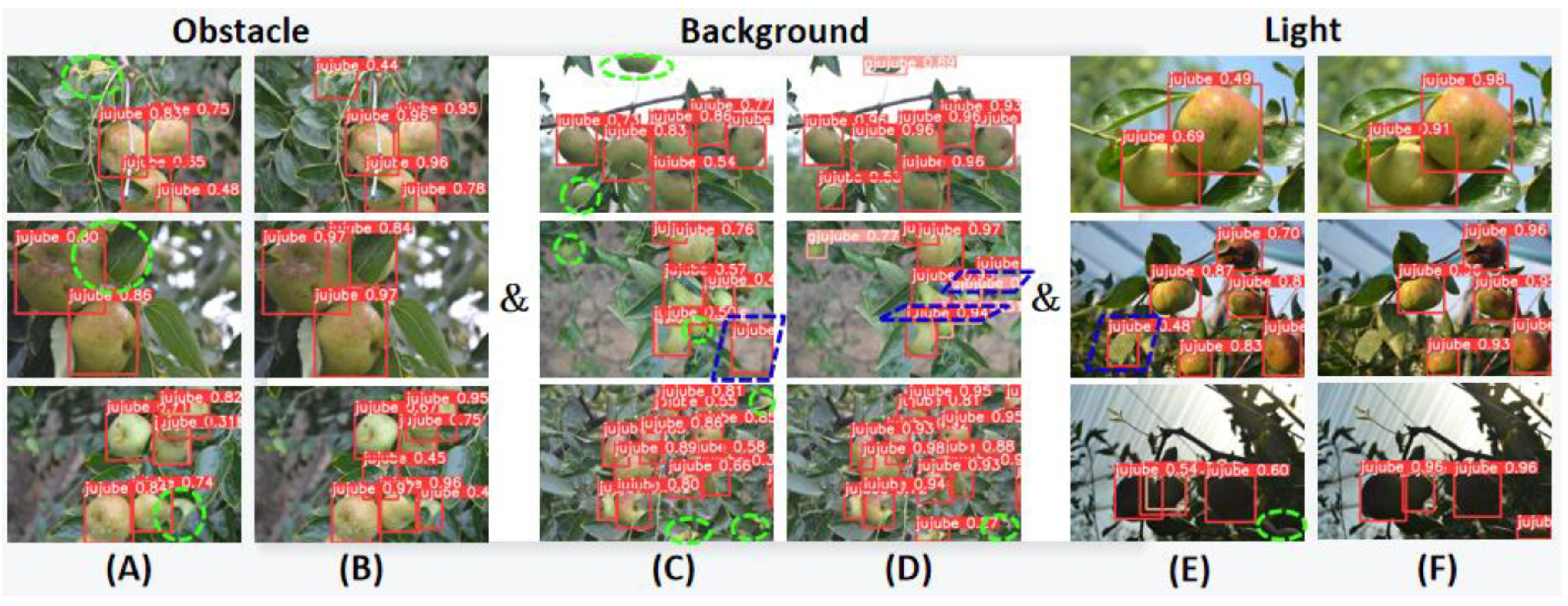
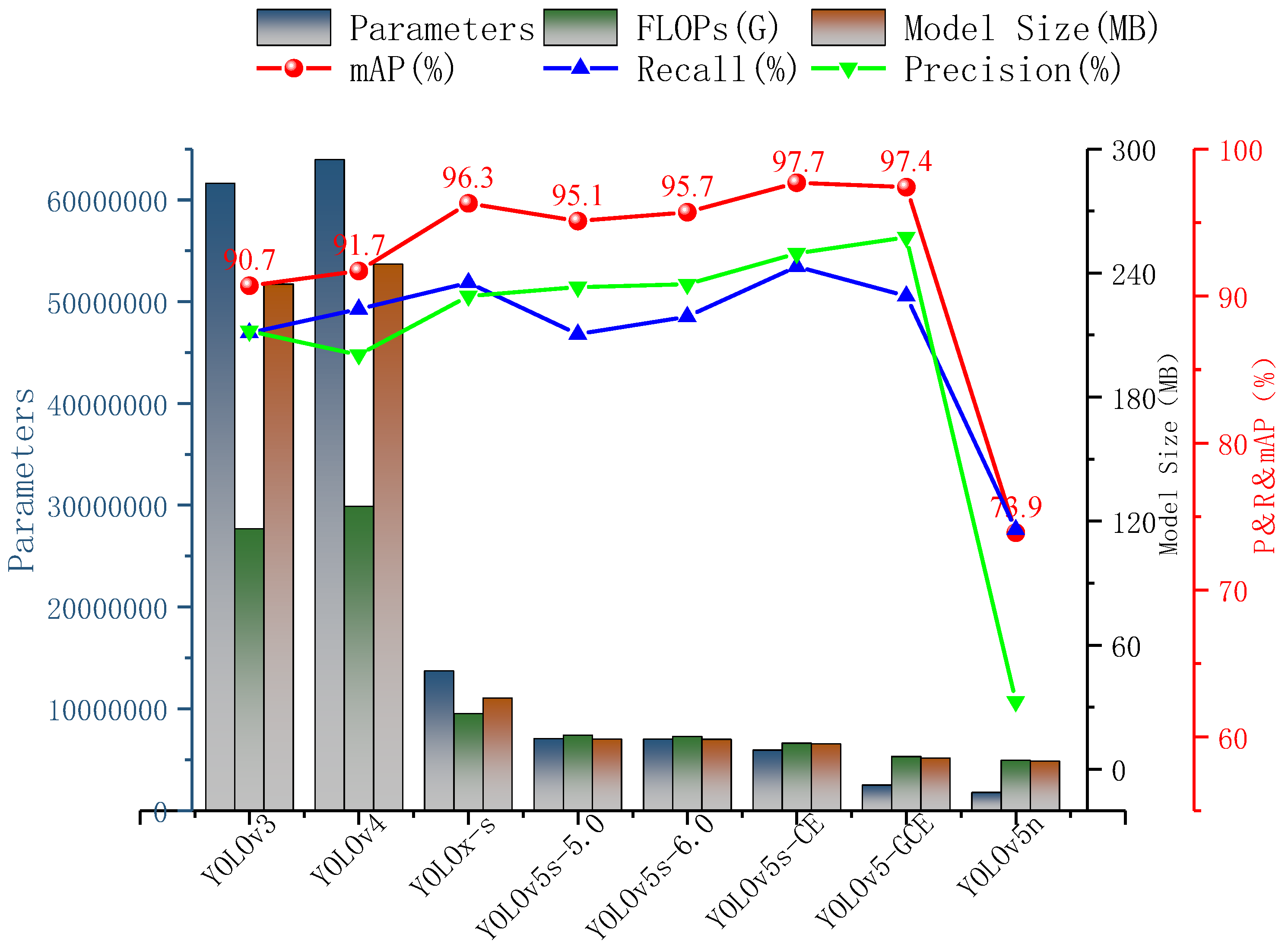
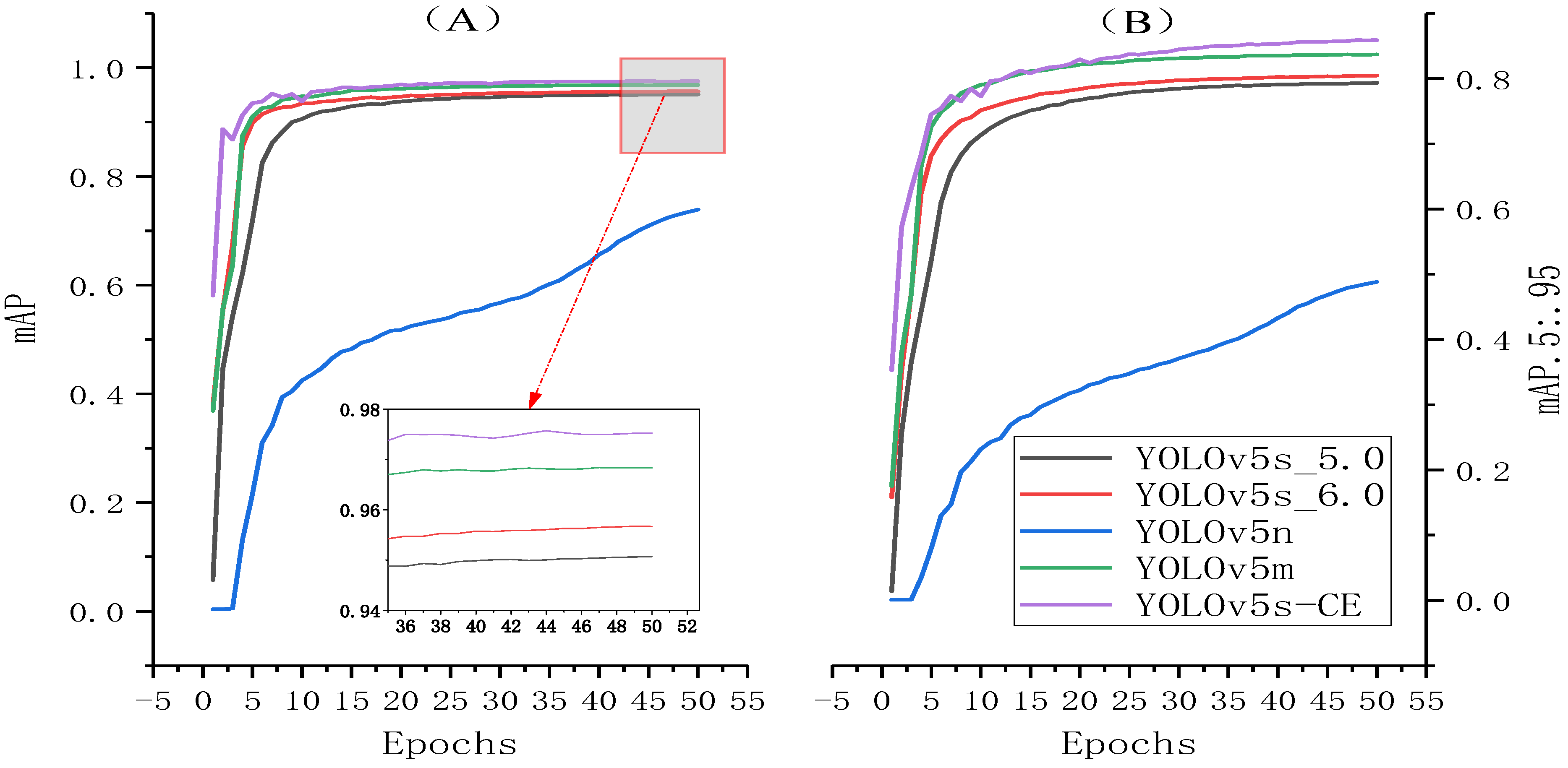
3.5. Comparison Experiments with Different Networks
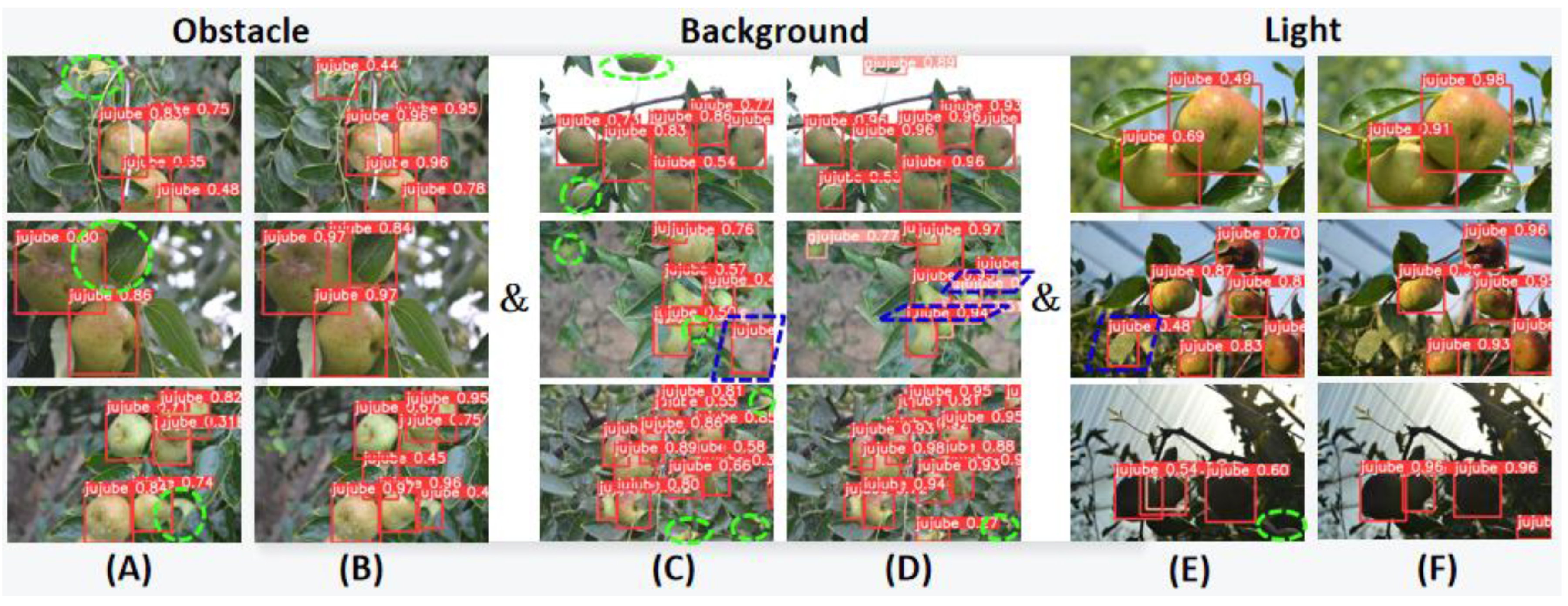
4. Discussion
5. Conclusions
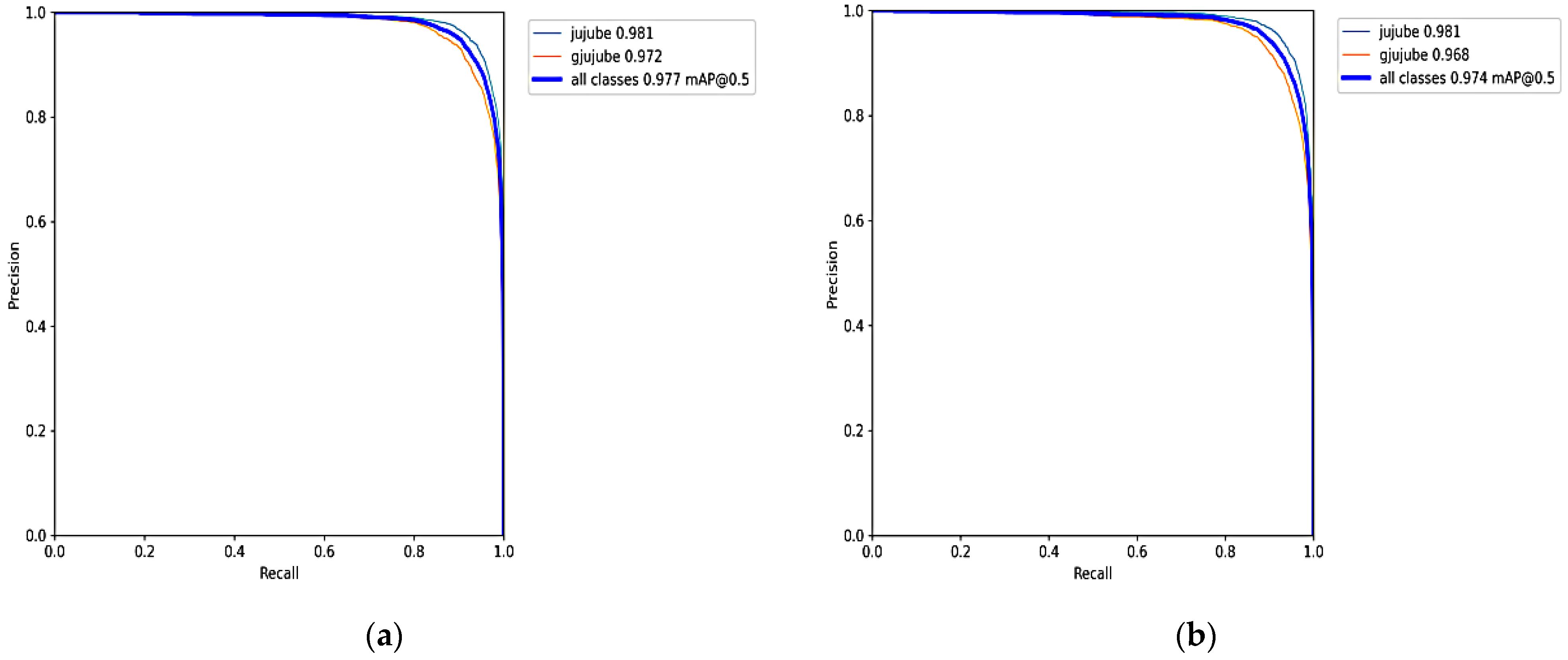
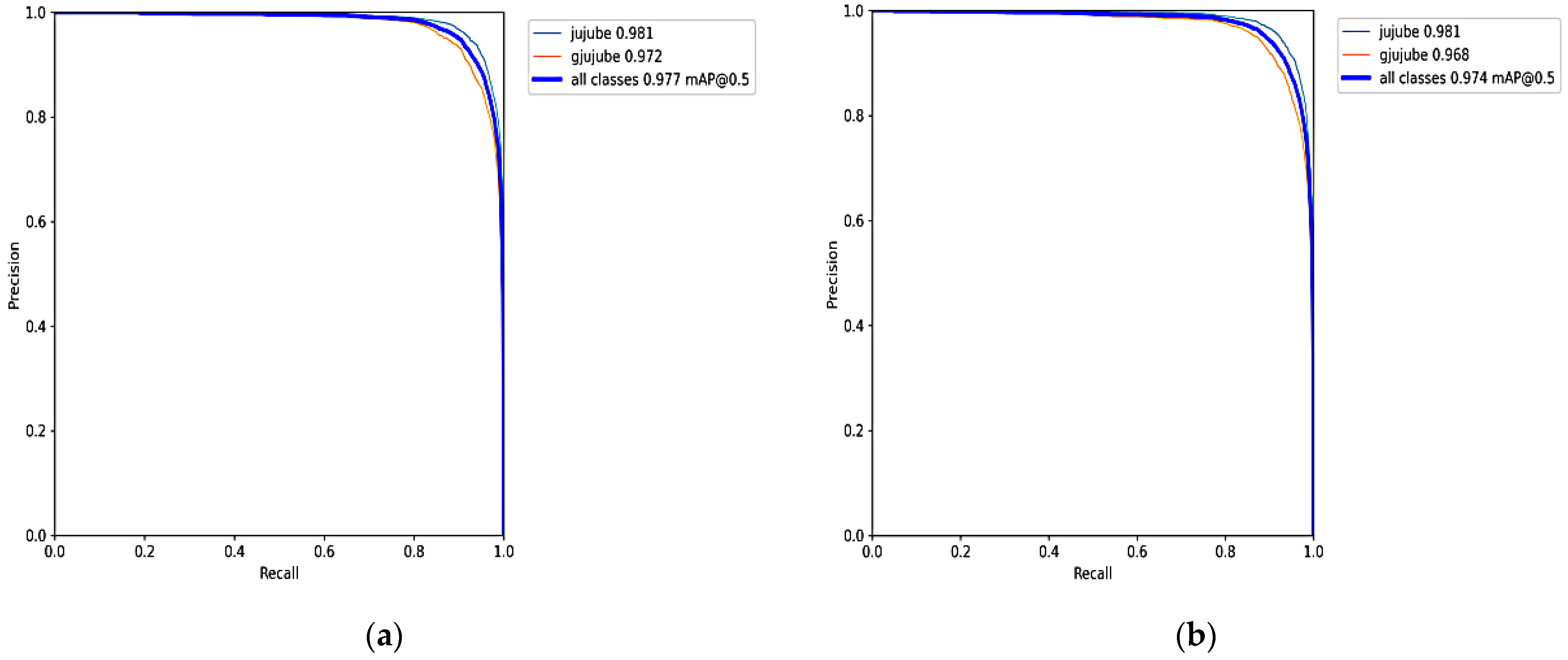
- Through the mixed introduction of multiple attention, the AP of mature and immature jujube reaches 98.1% and 97.2%, respectively. The mAP of the YOLOv5-CE network reaches 97.7%; it increases by 2% compared with the original YOLOv5s network.
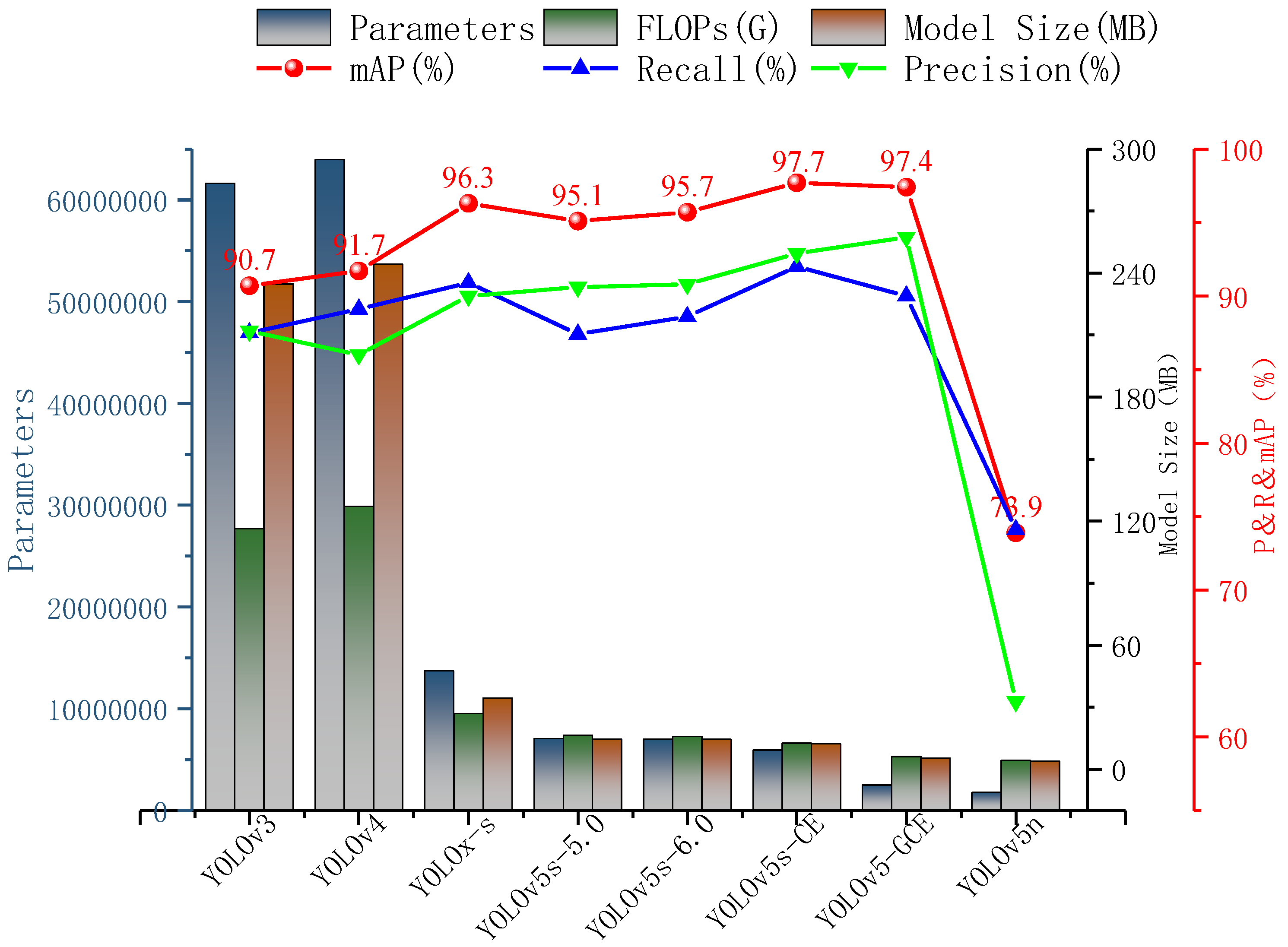
- After the lightweight operation on the improved network, the mAP reaches 97.4%; it increases by 1.7% compared with the original YOLOv5s network. In terms of the complexity of the model, the parameters and the FLOPs decrease by 64.43% and 61.39%, the detection time and the model size are compressed to 3.5 ms and 5.4 MB, respectively.
- Compared with the original YOLOv5s, YOLOv5n, YOLOx-s, YOLOv4, and YOLOv3 model, the mAP of YOLOv5-GCE increases by 1.7%, 23.5%, 9%, 5.7%, and 6.7%, respectively. Additionally, the model size of YOLOv5-GCE reaches 5.4 MB, which is slightly larger than YOLOv5n (3.8 MB), but it is compressed by 62.5%, 84.3%, 97.8%, and 97.7% compared with the rest of the models, respectively.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kateb, F.A.; Monowar, M.M.; Hamid, A.; Ohi, A.Q.; Mridha, M.F. FruitDet: Attentive Feature Aggregation for Real-Time Fruit Detection in Orchards. Agronomy 2021, 11, 2440. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; Liu, Y.; Chen, K.; Li, H.; Duan, Y.; Wu, W.; Shi, Y.; Guo, W. Deep-learning-based in-field citrus fruit detection and tracking. Hortic. Res. 2022, 9, 6526907. [Google Scholar] [CrossRef] [PubMed]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Tassis, L.M.; de Souza, J.E.T.; Krohling, R.A. A deep learning approach combining instance and semantic segmentation to identify diseases and pests of coffee leaves from in-field images. Comput. Electron. Agric. 2021, 186, 106191. [Google Scholar] [CrossRef]
- Math, R.M.; Dharwadkar, N.V. Early detection and identification of grape diseases using convolutional neural networks. J. Plant Dis. Prot. 2022, in press. [Google Scholar] [CrossRef]
- Fan, X.; Xu, Y.; Zhou, J.; Li, Z.; Peng, X.; Wang, X. Detection system for grape leaf diseases based on transfer learning and updated CNN. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 151–159. [Google Scholar] [CrossRef]
- Wang, X.; Tang, J.; Whitty, M. Data-centric analysis of on-tree fruit detection: Experiments with deep learning. Comput. Electron. Agric. 2022, 194, 106748. [Google Scholar] [CrossRef]
- Kimutai, G.; Ngenzi, A.; Said, R.N.; Kiprop, A.; Förster, A. An Optimum Tea Fermentation Detection Model Based on Deep Convolutional Neural Networks. Data 2020, 5, 44. [Google Scholar] [CrossRef]
- Janarthan, S.; Thuseethan, S.; Rajasegarar, S.; Lyu, Q.; Zheng, Y.; Yearwood, J. Deep Metric Learning Based Citrus Disease Classification With Sparse Data. IEEE Access 2020, 8, 162588–162600. [Google Scholar] [CrossRef]
- Luo, Y.; Wei, Y.; Lin, L.; Lin, F.; Su, F.; Sun, W. Origin discrimination of Fujian white tea using gas chromatography-ion mobility spectrometry. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 264–273. [Google Scholar] [CrossRef]
- Caladcad, J.A.; Cabahug, S.; Catamco, M.R.; Villaceran, P.E.; Cosgafa, L.; Cabizares, K.N.; Hermosilla, M.; Piedad, E.J. Determining Philippine coconut maturity level using machine learning algorithms based on acoustic signal. Comput. Electron. Agric. 2020, 172, 105327. [Google Scholar] [CrossRef]
- Turkoglu, M.; Hanbay, D.; Sengur, A. Multi-model LSTM-based convolutional neural networks for detection of apple diseases and pests. J. Ambient Intell. Humaniz. Comput. 2019, 1–11. [Google Scholar] [CrossRef]
- Ren, R.; Zhang, S.; Sun, H.; Gao, T. Research on Pepper External Quality Detection Based on Transfer Learning Integrated with Convolutional Neural Network. Sensors 2021, 21, 5305. [Google Scholar] [CrossRef] [PubMed]
- Hussain, D.; Hussain, I.; Ismail, M.; Alabrah, A.; Ullah, S.S.; Alaghbari, H.M. A Simple and Efficient Deep Learning-Based Framework for Automatic Fruit Recognition. Comput. Intell. Neurosci. 2022, 2022, 6538117. [Google Scholar] [CrossRef]
- Ukwuoma, C.C.; Zhiguang, Q.; Bin Heyat, B.; Ali, L.; Almaspoor, Z.; Monday, H.N. Recent Advancements in Fruit Detection and Classification Using Deep Learning Techniques. Math. Probl. Eng. 2022, 2022, 9210947. [Google Scholar] [CrossRef]
- Shahi, T.B.; Sitaula, C.; Neupane, A.; Guo, W. Fruit classification using attention-based MobileNetV2 for industrial applications. PLoS ONE 2022, 17, e0264586. [Google Scholar] [CrossRef]
- Khudayberdiev, O.; Zhang, J.; Abdullahi, S.M.; Zhang, S. Light-FireNet: An efficient lightweight network for fire detection in diverse environments. Multimedia Tools Appl. 2022, 1–20. [Google Scholar] [CrossRef]
- Park, C.; Lee, S.; Han, H. Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid. Appl. Sci. 2021, 11, 8692. [Google Scholar] [CrossRef]
- Zheng, T.; Jiang, M.; Feng, M. Vision based target recognition and location for picking robot. Instrum. J. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.19650/j.cnki.cjsi.J2107650 (accessed on 13 April 2022). [CrossRef]
- Akshatha, K.R.; Karunakar, A.K.; Shenoy, S.B.; Pai, A.K.; Nagaraj, N.H.; Rohatgi, S.S. Human Detection in Aerial Thermal Images Using Faster R-CNN and SSD Algorithms. Electronics 2022, 11, 1151. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, S.; Yan, Y.; Tang, S.; Zhao, S. Identification and Analysis of Emergency Behavior of Cage-Reared Laying Ducks Based on YoloV5. Agriculture 2022, 12, 485. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, Q.; Pan, D.; Zhang, W. Picking recognition research of pineapple in complex field environment based on improved YOLOv3. J. Chin. Agric. Mech. 2021, 42, 201–206. [Google Scholar] [CrossRef]
- Zhang, H.; Fu, Z.; Han, W.; Yang, G.; Niu, D.; Zhou, X. Detection Method of Maize Seedlings Number Based on Improved YOLO. J. Agric. Mach. 2021, 52, 221–229. [Google Scholar] [CrossRef]
- Hnewa, M.; Hayder, R. Integrated Multiscale Domain Adaptive YOLO. arXiv 2022, arXiv:2202.03527. [Google Scholar]
- Kim, N.; Kim, J.-H.; Won, C.S. FAFD: Fast and Accurate Face Detector. Electronics 2022, 11, 875. [Google Scholar] [CrossRef]
- Gonzales-Martinez, R.; Machacuay, J.; Rotta, P.; Chinguel, C. Hyperparameters Tuning of Faster R-CNN Deep Learning Transfer for Persistent Object Detection in Radar Images. IEEE Lat. Am. Trans. 2022, 20, 677–685. [Google Scholar] [CrossRef]
- Hooda, M.; Rana, C.; Dahiya, O.; Shet, J.P.; Singh, B.K. Integrating LA and EDM for Improving Students Success in Higher Education Using FCN Algorithm. Math. Probl. Eng. 2022, 2022, 7690103. [Google Scholar] [CrossRef]
- Kavitha, T.S.; Prasad, K.S. A novel method of compressive sensing MRI reconstruction based on sandpiper optimization algorithm (SPO) and mask region based convolution neural network (mask RCNN). Multimedia Tools Appl. 2022, 1–24. [Google Scholar] [CrossRef]
- Ortenzi, L.; Figorilli, S.; Costa, C.; Pallottino, F.; Violino, S.; Pagano, M.; Imperi, G.; Manganiello, R.; Lanza, B.; Antonucci, F. A Machine Vision Rapid Method to Determine the Ripeness Degree of Olive Lots. Sensors 2021, 21, 2940. [Google Scholar] [CrossRef]
- Faisal, M.; Albogamy, F.; Elgibreen, H.; Algabri, M.; Alqershi, F.A. Deep Learning and Computer Vision for Estimating Date Fruits Type, Maturity Level, and Weight. IEEE Access 2020, 8, 206770–206782. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; Available online: https://arxiv.org/abs/1506.02640 (accessed on 13 April 2022).
- Zheng, J.; Sun, S.; Zhao, S. Fast ship detection based on lightweight YOLOv5 network. IET Image Process. 2022, 16, 1585–1593. [Google Scholar] [CrossRef]
- Park, S.-S.; Tran, V.-T.; Lee, D.-E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Appl. Sci. 2021, 11, 11229. [Google Scholar] [CrossRef]
- Sharma, T.; Debaque, B.; Duclos, N.; Chehri, A.; Kinder, B.; Fortier, P. Deep Learning-Based Object Detection and Scene Perception under Bad Weather Conditions. Electronics 2022, 11, 563. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, J.; Sun, Z.; Guo, P.; Zhang, L. Improved leukocyte detection algorithm of YOLOV5. Comput. Eng. Appl. 2022, 58, 134–142. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An Attentive Survey of Attention Models. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 International Conferenceon Computer Visionand Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Hsu, W.-Y.; Lin, W.-Y. Adaptive Fusion of Multi-Scale YOLO for Pedestrian Detection. IEEE Access 2021, 9, 110063–110073. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, B.; Peng, J.; Zhang, Z. Research on the use of YOLOv5 object detection algorithm in mask wearing recognition. World Sci. Res. J. 2020, 6, 276–284. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Ibrahim, N.M.; Gabr, D.G.I.; Rahman, A.-U.; Dash, S.; Nayyar, A. A deep learning approach to intelligent fruit identification and family classification. Multimed. Tools Appl. 2022, 1–16. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Algorithm | Models | Backbone | Advantages | Disadvantages | Reference |
|---|---|---|---|---|---|
| One-stage | SSD (Single Shot MultiBox Detector) | VGG-16 (Visual Geometry Group) | Fast detection speed, Strong migration ability, Easy to deploy, Small model size, Low deployment cost. | Not good enough for cluster targets and small targets, Relatively high false and missed detection. | [19,20] |
| YOLO (you only look once) | V1: VGG16 V2: Darknet-19, V3&V4&V5: Darknet-53. | [21,22,23,24,25] | |||
| Two-stage | Faster R-CNN (Region-based Convolutional Neural Networks) | VGG-16 | High accuracy of recognition. | A large amount of computation Slow detection speed. | [26] |
| FCN (Fully Convolutional Networks) | VGG-16 | [27] | |||
| Mask R-CNN | ResNet | [28] |
| Hardware | Configure | Environment | Version |
|---|---|---|---|
| System | Windows10 | Python | 3.9.1 |
| CPU | R7-5800H | PyTorch | 1.9.0 |
| GPU | RTX3070 (8G) | PyCharm | 2019.1.1 |
| RAM | 16G | CUDA | 11.2 |
| Hard-disk | 1.5T | CUDNN | 8.1.1 |
| Datasets | Number | Anchors | Iterations | Precision (%) | Recall (%) | Mean Average Precision (%) | mAP.5:.95 (%) | |
|---|---|---|---|---|---|---|---|---|
| Jujube | G-Jujube | |||||||
| Raw dataset | 9525 | 46,682 | 10,198 | 11,900 | 82.2 | 82.8 | 87.8 | 74.7 |
| Balanced dataset | 12,502 | 51,052 | 34,118 | 156,200 | 90.8 | 88.6 | 95.7 | 80.5 |
| Model | Precision (%) | Recall (%) | mAP (%) | Max Value of mAP (%) | mAP.5:.95 (%) |
|---|---|---|---|---|---|
| YOLOv5s | 90.8 | 88.6 | 95.7 | 95.669 | 80.5 |
| CA | 91.7 | 90.1 | 96.6 | 96.59 | 81.8 |
| ECA | 94.2 | 91 | 97.3 | 97.438 | 87 |
| 4SE | 93.6 | 91.2 | 97.4 | 97.481 | 85.8 |
| 4ECA | 94 | 91.2 | 97.6 | 97.594 | 86.1 |
| 4ECA&CBAM | 93.6 | 91.7 | 97.6 | 97.606 | 86.1 |
| 4ECA&CA(+) | 91.9 | 93.2 | 97.5 | 97.664 | 86 |
| 4ECA&2SE | 93.9 | 90.9 | 97.6 | 97.561 | 85.9 |
| 4ECA&2SE&4CA | 93.3 | 91.8 | 97.6 | 97.644 | 85.9 |
| 4CA&CBAM | 92.6 | 92.4 | 97.6 | 97.573 | 85.9 |
| 8CA&CBAM | 93.9 | 91.1 | 97.6 | 97.601 | 86 |
| 8CA&CBAM(+) | 93.2 | 92.1 | 97.6 | 97.608 | 86.1 |
| 8CA&2SE | 94 | 91.3 | 97.6 | 97.59 | 85.9 |
| 8CA&2SE(+) | 93.8 | 91.2 | 97.6 | 97.561 | 85.9 |
| 7CA&2SE | 92.4 | 92.3 | 97.6 | 97.589 | 86.1 |
| 4CA&2SE | 92.6 | 92.9 | 97.6 | 97.613 | 86 |
| 4CA&2SE&2TR | 94.2 | 90.9 | 97.6 | 97.575 | 85.5 |
| 4CA&CBAM&ECA | 93.3 | 91.9 | 97.6 | 97.559 | 86 |
| 4CA&2ECA | 92.9 | 92 | 97.6 | 97.569 | 86.1 |
| Location | Precision (%) | Recall (%) | mAP (%) | mAP.5:.95 (%) | Parameters | Floating-Point Operations per Second (G) | Inference Time (ms) | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| 4ECA | 94 | 91.2 | 97.6 | 86.1 | 7,015,540 | 15.8 | 3.0 | 14.4 |
| Ghost | 93.4 | 91.2 | 97.4 | 84.5 | 5,853,052 | 12.4 | 3.0 | 12.1 |
| Ghost_neck | 94 | 90.8 | 97.4 | 85.7 | 6,053,252 | 13.9 | 3.1 | 12.5 |
| Ghost_all | 92.8 | 91.5 | 97.3 | 84.2 | 4,899,580 | 10.5 | 2.7 | 10.2 |
| DWconv | 94.3 | 90.5 | 97.4 | 85 | 5,457,460 | 12.1 | 2.5 | 11.2 |
| DWconv_neck | 94.2 | 90.8 | 97.4 | 85.7 | 6,118,644 | 14.7 | 3.0 | 12.5 |
| DWconv_all | 93.4 | 91.3 | 97.4 | 84.7 | 4,560,564 | 11 | 2.3 | 9.5 |
| Ghost&DWconv_all | 91.8 | 91.4 | 97 | 82.9 | 3,398,076 | 7.6 | 2.1 | 7.5 |
| Ghost_neck&DWconv_all | 93.2 | 91.4 | 97.4 | 84.5 | 3,598,276 | 9 | 2.3 | 7.6 |
| Ghost_all&DWconv_all | 92.8 | 90.1 | 97 | 82.1 | 2,435,778 | 5.6 | 2.1 | 5.5 |
| Ghost&DWconv | 93.3 | 90.6 | 97.1 | 82.8 | 4,294,972 | 8.7 | 2.4 | 9.1 |
| (Ghost&DWconv)_neck | 93 | 91.9 | 97.4 | 85.4 | 5,156,356 | 12.7 | 2.9 | 10.7 |
| Ghost_neck&DWconv | 93.6 | 90.6 | 97.3 | 84.7 | 4,495,172 | 10.1 | 2.5 | 9.4 |
| Ghost&DWconv_neck | 92.6 | 91.7 | 97.3 | 84.3 | 4,956,156 | 11.3 | 2.7 | 10.3 |
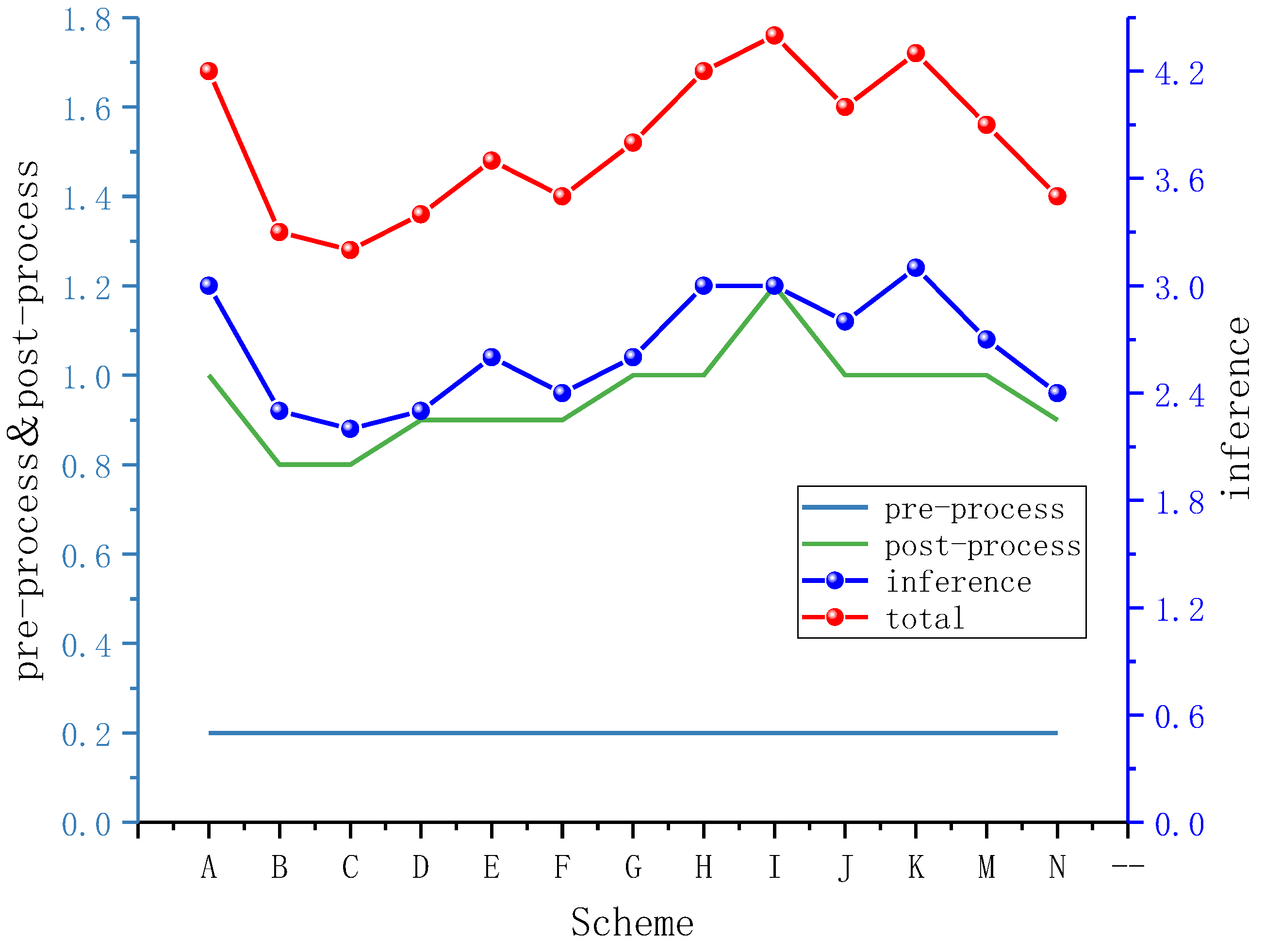
| Lightweight Network | mAP (%) | mAP.5:.95 (%) | Parameters | FLOPs (B) | Detection Time (ms) | Model Size (MB) | |||
|---|---|---|---|---|---|---|---|---|---|
| Pre-Process | Inference | Post-Process | Total | ||||||
| YOLOv5s | 95.7 | 80.5 | 7,015,519 | 15.8 | 0.2 | 3.0 | 1.0 | 4.2 | 14.4 |
| 4ECA | 97.4 | 84.5 | 3,598,276 | 9 | 0.2 | 2.3 | 0.8 | 3.3 | 7.7 |
| ECA & SE | 97.4 | 84.4 | 3,631,044 | 9 | 0.2 | 2.2 | 0.8 | 3.2 | 7.8 |
| 4ECA & SE | 97.3 | 84.1 | 3,466,945 | 8.5 | 0.2 | 2.3 | 0.9 | 3.4 | 7.0 |
| 4ECA & CA | 97.3 | 84.4 | 3,623,924 | 8.6 | 0.2 | 2.6 | 0.9 | 3.7 | 7.8 |
| 4ECA&CBAM | 97.3 | 84.1 | 4,812,326 | 9.1 | 0.2 | 2.4 | 0.9 | 3.5 | 10.1 |
| 4ECA & 2SE & 4CA | 97.2 | 84.1 | 3,706,172 | 8.1 | 0.2 | 2.6 | 1.0 | 3.8 | 8.1 |
| 8CA & CBAM | 97.3 | 84.1 | 3,751,521 | 8.1 | 0.2 | 3.0 | 1.0 | 4.2 | 8.1 |
| 8CA & 2SE(+) | 97.3 | 84.2 | 3,784,191 | 8.2 | 0.2 | 3.0 | 1.2 | 4.4 | 8.1 |
| 4CA&2SE(+) | 97.4 | 84.2 | 3,741,831 | 8.1 | 0.2 | 2.8 | 1.0 | 4.0 | 8.1 |
| 4CA & 2SE & 2TR | 97.3 | 83.9 | 3,333,031 | 7.2 | 0.2 | 3.1 | 1.0 | 4.3 | 7.2 |
| 4CA & CBAM & 3ECA | 97.3 | 84.1 | 3,709,170 | 7.6 | 0.2 | 2.7 | 1.0 | 3.9 | 7.9 |
| 4CA & 2ECA | 97.3 | 84.2 | 2,495,117 | 6.1 | 0.2 | 2.4 | 0.9 | 3.5 | 5.4 |
| Number | Input | Parameters | Module | Tensor Information | Number | Input | Parameters | Module | Tensor Information |
|---|---|---|---|---|---|---|---|---|---|
| 0 | −1 | 3520 | Conv | (3, 32, 6, 2, 2) | 15 | −1 | 1024 | DWconv | (512, 256, 1, 1) |
| 1 | −1 | 704 | DWconv | (32, 64, 3, 2) | 16 | −1 | 0 | Upsample | (None, 2, ’nearest’) |
| 2 | −1 | 18,816 | C3 | (64, 64, 1) | 17 | (−1, 7) | 0 | Concat | (1) |
| 3 | −1 | 1408 | DWconv | (64, 128, 3, 2) | 18 | −1 | 208,608 | Ghost | (512, 256, 1, Fasle) |
| 4 | −1 | 115,712 | C3 | (128, 128, 2) | 19 | −1 | 512 | DWconv | (256, 128, 1, 1) |
| 5 | −1 | 6704 | CA | (128, 128, 32) | 20 | −1 | 0 | Upsample | (None, 2, ’nearest ’) |
| 6 | −1 | 2816 | DWconv | (128, 256, 3, 2) | 21 | (−1, 4) | 0 | Concat | (1) |
| 7 | −1 | 625,152 | C3 | (256, 256, 3) | 22 | −1 | 53,104 | Ghost | (256, 128, 1, Fasle) |
| 8 | −1 | 20,040 | CA | (256, 256, 32) | 23 | −1 | 1408 | DWConv | (128, 128, 3, 2) |
| 9 | −1 | 5632 | DWconv | (256, 512, 3, 2) | 24 | (−1, 19) | 0 | Concat | (1) |
| 10 | −1 | 3 | ECA | (512) | 25 | −1 | 143,072 | Ghost | (256, 256, 1, Fasle) |
| 11 | −1 | 25,648 | CA | (512, 512, 32) | 26 | −1 | 2816 | DWconv | (256, 256, 3, 2) |
| 12 | −1 | 656,896 | SPPF | (512, 512, 5) | 27 | (−1, 15) | 0 | Concat | (1) |
| 13 | −1 | 3 | ECA | (512) | 28 | −1 | 564,672 | Ghost | (512, 512, 1, Fasle) |
| 14 | −1 | 25,648 | CA | (512, 512, 32) | 29 | (22, 25, 28) | 18,879 | Detect | / |
| Model | Data Balance | C3 | Attention | Loss Function | Multi-Scale | Lightweight | mAP (%) | mAP.5:.95 (%) | Parameters | FLOPs (G) | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | × | × | × | × | × | × | 87.8 | 74.7 | 7,015,540 | 15.8 | 14.4 |
| Improvement 1 | √ | × | × | × | × | × | 95.7 | 80.5 | 7,015,519 | 15.8 | 14.4 |
| Improvement 2 | √ | √ | × | × | × | × | 95.7 | 81.9 | 6,851,441 | 15.3 | 13.8 |
| Improvement 3 | √ | √ | √ | × | × | × | 97.6 | 85.9 | 5,942,252 | 12.5 | 12.2 |
| Improvement 4 | √ | √ | √ | √ | × | × | 97.7 | 89.5 | 5,942,252 | 12.5 | 12.2 |
| Multi-scale | √ | √ | √ | √ | √ | × | 97.7 | 89.5 | 5,942,252 | 15.2 | 12.2 |
| Improvement 5 | √ | √ | √ | √ | × | √ | 97.4 | 84.2 | 2,495,117 | 6.1 | 5.4 |
| Model | Precision (%) | Recall (%) | mAP (%) | Parameters | FLOPs (G) | Model Size (MB) |
|---|---|---|---|---|---|---|
| YOLOv3 | 87.6 | 87.5 | 90.7 | 61,631,434 | 116.3 | 234.6 |
| YOLOv4 | 86 | 89.1 | 91.7 | 63,953,841 | 127.2 | 244.3 |
| YOLOx-s | 90 | 90.9 | 96.3 | 13,714,753 | 26.8 | 34.3 |
| YOLOv5s-5.0 | 90.6 | 87.4 | 95.1 | 7,056,607 | 16.3 | 14.5 |
| YOLOv5s-6.0 | 90.8 | 88.6 | 95.7 | 7,015,519 | 15.8 | 14.4 |
| YOLOv5-CE | 92.9 | 92 | 97.7 | 5,942,252 | 12.5 | 12.2 |
| YOLOv5-GCE | 94 | 90 | 97.4 | 2,495,117 | 6.1 | 5.4 |
| YOLOv5n | 62.4 | 74.1 | 73.9 | 1,761,871 | 4.2 | 3.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zhang, S.; Xue, J.; Sun, H.; Ren, R. A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube. Agriculture 2022, 12, 717. https://doi.org/10.3390/agriculture12050717
Li S, Zhang S, Xue J, Sun H, Ren R. A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube. Agriculture. 2022; 12(5):717. https://doi.org/10.3390/agriculture12050717
Chicago/Turabian StyleLi, Shilin, Shujuan Zhang, Jianxin Xue, Haixia Sun, and Rui Ren. 2022. "A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube" Agriculture 12, no. 5: 717. https://doi.org/10.3390/agriculture12050717
APA StyleLi, S., Zhang, S., Xue, J., Sun, H., & Ren, R. (2022). A Fast Neural Network Based on Attention Mechanisms for Detecting Field Flat Jujube. Agriculture, 12(5), 717. https://doi.org/10.3390/agriculture12050717