A Deep Learning-Based Model to Reduce Costs and Increase Productivity in the Case of Small Datasets: A Case Study in Cotton Cultivation



Abstract
:1. Introduction
1.1. Cotton
1.2. Soil Characteristics Effect on Cotton Cultivation
- considering and analyzing 13 essential factors in soil for cotton planting.
- utilizing artificial intelligence methods for reducing costs and increasing productivity and profits in cotton cultivation.
- solving uncertainty for selecting the factors amounts.
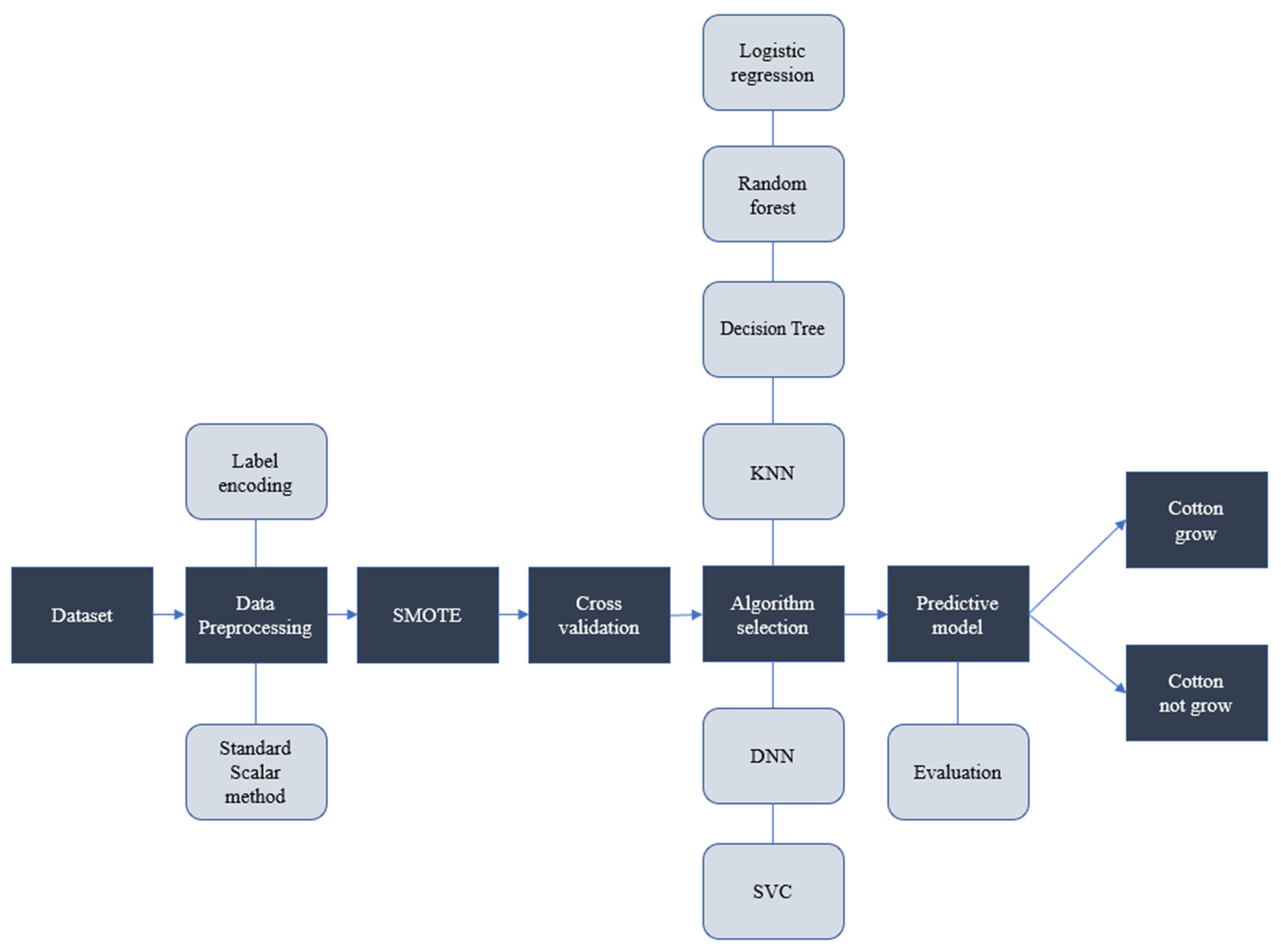
2. Materials and Methods
2.1. Machine Learning
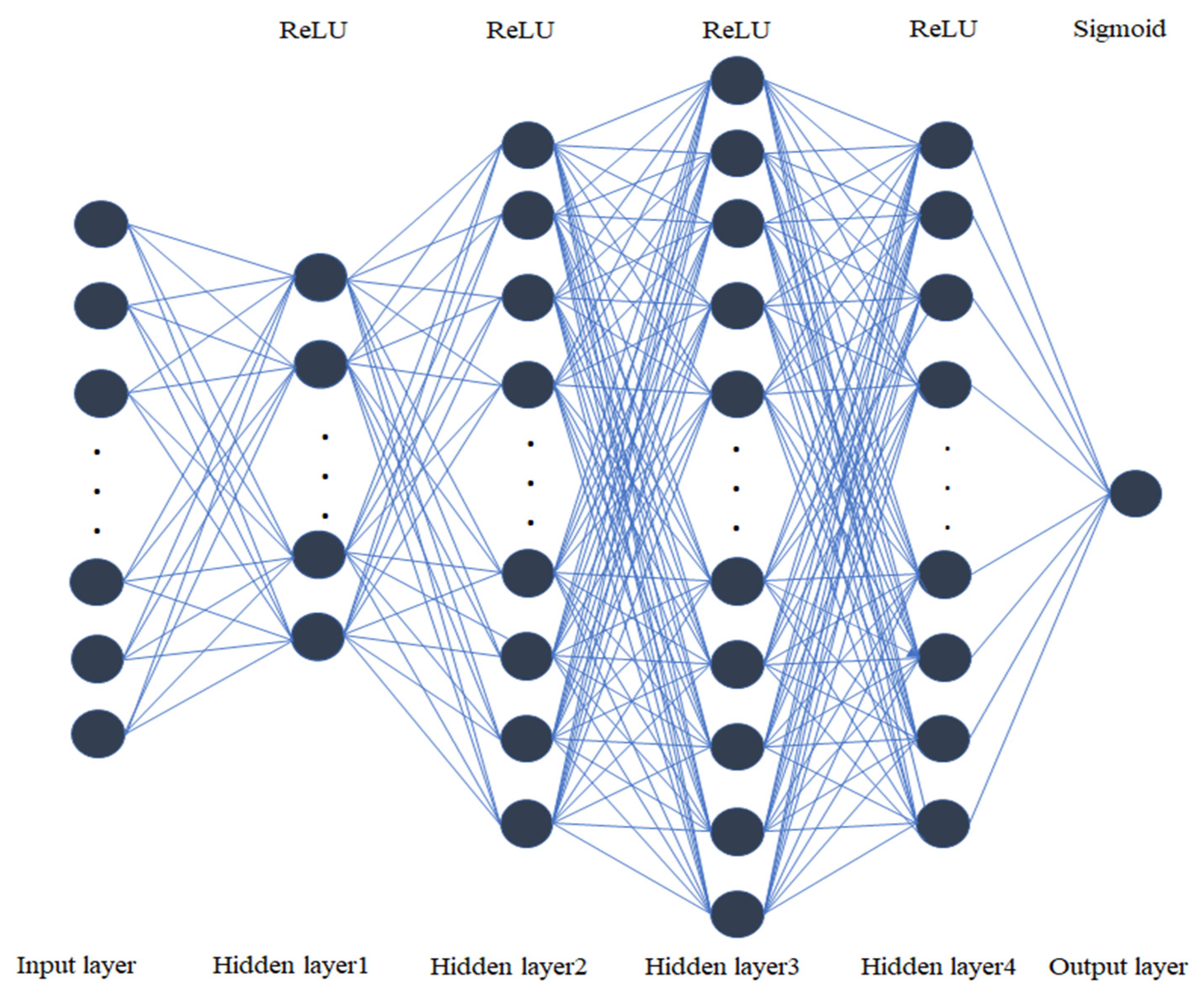
2.2. Deep Learning
- the weights are initialized with small values randomly (i.e., values close to 0);
- each feature is placed in one input node in the input layer;
- Forward-Propagation operation is applied: the neurons from the input layer to the output layer are activated so that the weights limit each neuron’s activation; such operation proceeds until convergence is reached on y prediction.
- the error is calculated by comparing the prediction and actual value;
- in this step, a backpropagation operation is exerted: the weights are updated based on how much they are relevant for the error, while the learning rate value determines the weight update.
- steps 1 to 5 are repeated, but the weights are updated after Batch learning;
- when the process is done, an epoch is completed: more epochs are done to train a better model.
2.3. Data Standardization and Label-Encoding Technique
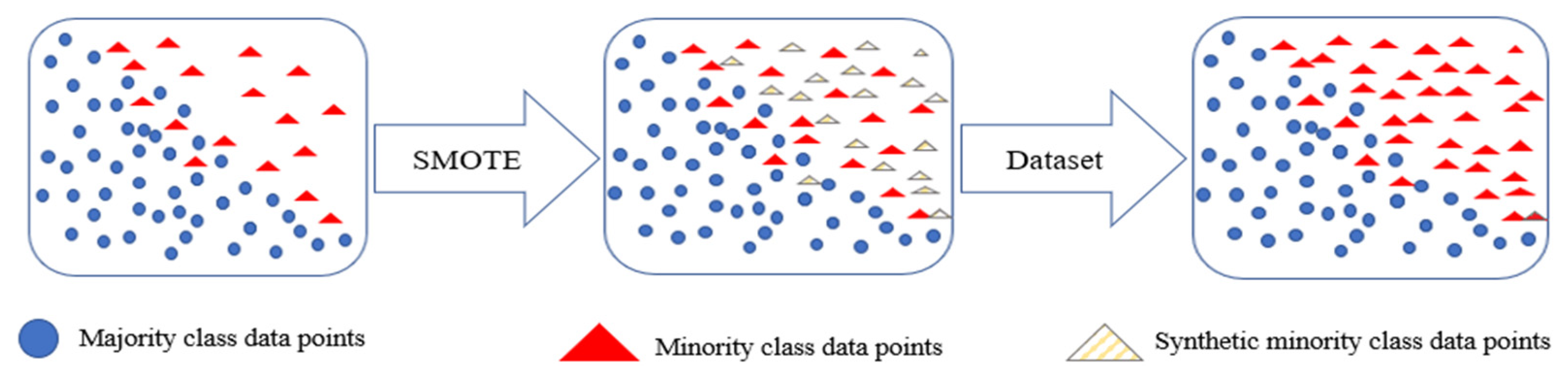
2.4. Synthetic Minority Oversampling Technique
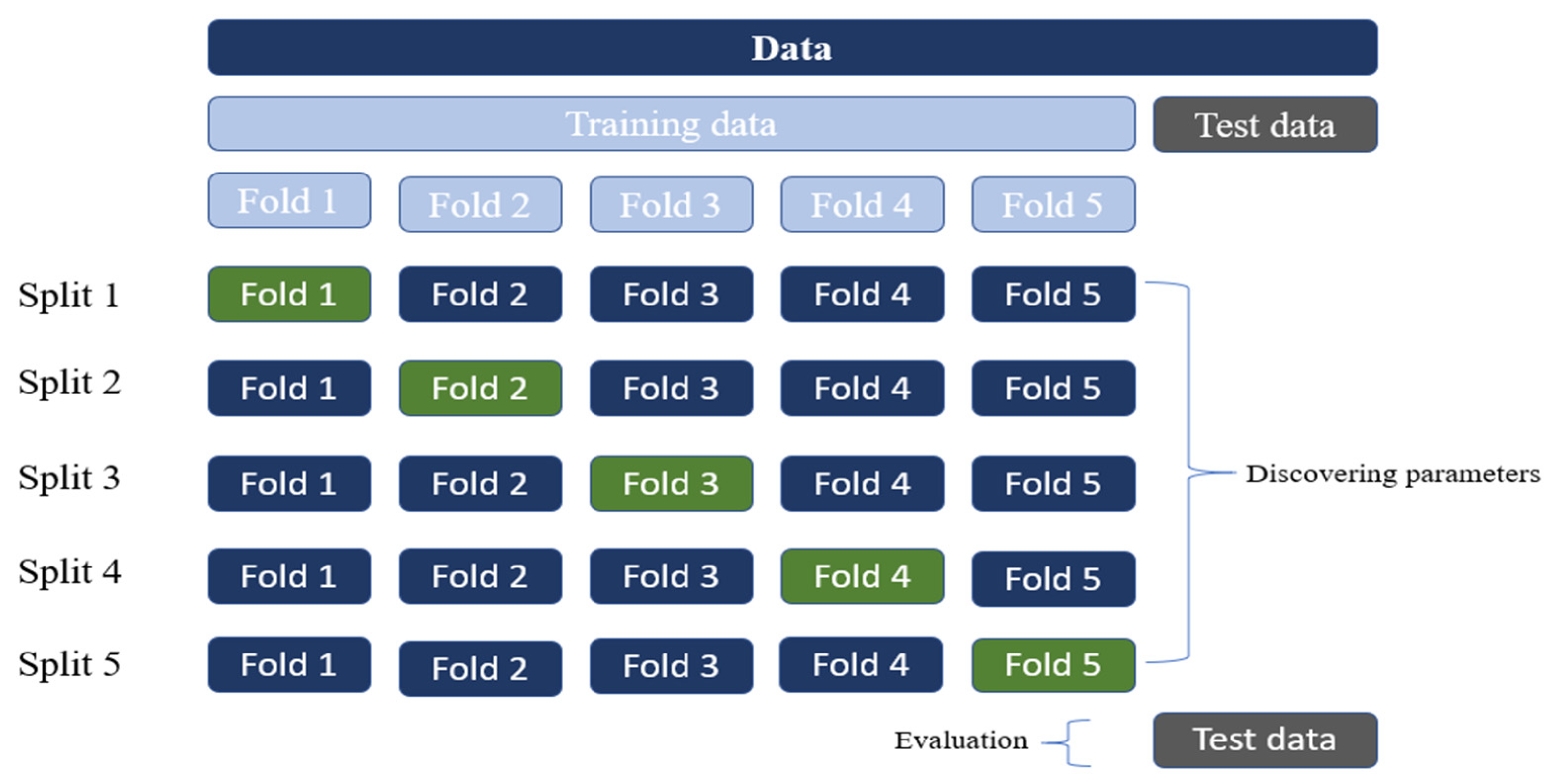
2.5. K-Fold Cross-Validation
2.6. Performance Evaluation Metrics
- −
- True Positive (TP): the predictive model predicted is positive, and the primary value is positive;
- −
- True Negative (TN): the predictive model is predicted negative, and the primary value is negative;
- −
- False Positive (FP): the predictive model is predicted positive, but the primary value is negative (Type 1 error);
- −
- False Negative (FN): the predictive model is predicted negative, but the primary value is positive (Type 2 error).
2.7. Confidence Interval
3. Results and Discussion
3.1. Preprocessing and Hyperparameter Tuning
3.2. Comparison of DNN with Other Machine Learning Algorithms and Model Evaluation
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amani, M.A.; Ebrahimi, F.; Dabbagh, A.; Rastgoo, A. A machine learning-based model for the estimation of the temperature-dependent moduli of graphene oxide reinforced nanocomposites and its application in a thermally affected buckling analysis. Eng. Comput. 2021, 37, 2245–2255. [Google Scholar] [CrossRef]
- Behdinian, A.; Amani, M.A.; Aghsami, A.; Jolai, F. An integrating Machine learning algorithm and simulation method for improving Software Project Management: A real case study. J. Qual. Eng. Prod. Optim. 2022; in press. [Google Scholar] [CrossRef]
- Recchia, L.; Boncinelli, P.; Cini, E.; Vieri, M.; Pegna, F.G.; Sarri, D. Multicriteria Analysis and LCA Techniques: With Applications to Agro-Engineering Problems. Green Energy Technol. 2017, 142, 248–259. [Google Scholar]
- Obalum, S.; Chibuike, G.U.; Peth, S.; Ouyang, Y. Soil organic matter as sole indicator of soil degradation. Environ. Monit. Assess. 2017, 189, 176. [Google Scholar] [CrossRef]
- Yang, M.; Xu, D.; Chen, S.; Li, H.; Shi, Z. Evaluation of machine learning approaches to predict soil organic matter and pH using Vis-NIR spectra. Sensors 2019, 19, 263. [Google Scholar] [CrossRef] [Green Version]
- Ashapure, A.; Jung, J.; Chang, A.; Oh, S.; Yeom, J.; Maeda, M.; Maeda, A.; Dube, N.; Landivar, J.; Hague, S.; et al. Developing a machine learning based cotton yield estimation framework using multi-temporal UAS data. ISPRS J. Photogramm. Remote Sens. 2020, 169, 180–194. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; Furuya, D.E.G.; Santana, D.C.; Teodoro, L.P.R.; Gonçalves, W.N.; Baio, F.H.R.; Pistori, H.; Junior, C.A.S.; et al. Leaf nitrogen concentration and plant height prediction for maize using UAV-based multispectral imagery and machine learning techniques. Remote. Sens. 2020, 12, 3237. [Google Scholar] [CrossRef]
- Parent, L.E.; Natale, W.; Brunetto, G. Machine Learning, Compositional and Fractal Models to Diagnose Soil Quality and Plant Nutrition. In Soil Science—Emerging Technologies, Global Perspectives and Applications; IntechOpen: London, UK, 2021. [Google Scholar]
- Li, Y.; Chao, X. Ann-based continual classification in agriculture. Agriculture 2020, 10, 178. [Google Scholar] [CrossRef]
- Papageorgiou, E.I.; Markinos, A.T.; Gemtos, T.A. Fuzzy cognitive map based approach for predicting yield in cotton crop production as a basis for decision support system in precision agriculture application. Appl. Soft Comput. 2011, 11, 3643–3657. [Google Scholar] [CrossRef]
- Schuster, E.W.; Kumar, S.; Sarma, S.E.; Willers, J.L.; Milliken, G.A. Infrastructure for Data-Driven Agriculture: Identifying Management Zones for Cotton Using Statistical Modeling and Machine Learning Techniques. In Proceedings of the 8th International Conference & Expo on Emerging Technologies for a Smarter World, Hauppauge, NY, USA, 2–3 November 2011; pp. 1–6. [Google Scholar]
- Hong, Y.; Chen, S.; Zhang, Y.; Chen, Y.; Yu, L.; Liu, Y.; Liu, Y.; Cheng, H.; Liu, Y. Rapid identification of soil organic matter level via visible and near-infrared spectroscopy: Effects of two-dimensional correlation coefficient and extreme learning machine. Sci. Total Environ. 2018, 644, 1232–1243. [Google Scholar] [CrossRef]
- Fabric. The Fabric of Our Lives. 2020. Available online: https://thefabricofourlives.com/the-benefits-of-cotton (accessed on 8 December 2021).
- Texprocil Ibtex News Clippings. Ibtex No.26. 2021. Available online: https://texprocil.org/IBTEXNewsClippings.htm (accessed on 8 December 2021).
- Corwin, D.; Lesch, S.; Shouse, P.; Soppe, R.; Ayars, J.E. Identifying soil properties that influence cotton yield using soil sampling directed by apparent soil electrical conductivity. Agron. J. 2003, 95, 352–364. [Google Scholar] [CrossRef] [Green Version]
- Sadras, V.; Bange, M.; Milroy, S. Reproductive allocation of cotton in response to plant and environmental factors. Ann. Bot. 1997, 80, 75–81. [Google Scholar] [CrossRef] [Green Version]
- Bakhsh, K.; Hassan, I.; Maqbool, A. Factors affecting cotton yield: A case study of Sargodha (Pakistan). J. Agric. Soc. Sci. 2005, 1, 332–334. [Google Scholar]
- Braunack, M. Cotton farming systems in Australia: Factors contributing to changed yield and fibre quality. Crop Pasture Sci. 2013, 64, 834–844. [Google Scholar] [CrossRef]
- Paim, E.A.; Dias, A.M.; Showler, A.T.; Campos, K.L.; Castro Grillo, P.P.; Bastos, C.S. Cotton row spacing for boll weevil management in low-input production systems. Crop Prot. 2021, 145, 105614. [Google Scholar] [CrossRef]
- Chen, W.; Jin, M.; Ferré, T.P.; Liu, Y. Soil conditions affect cotton root distribution and cotton yield under mulched drip irrigation. Field Crop. Res. 2020, 249, 107743. [Google Scholar] [CrossRef]
- Hulugalle, N.; Nehl, D.; Weaver, T.B. Soil properties, and cotton growth, yield and fibre quality in three cotton-based cropping systems. Soil Tillage Res. 2004, 75, 131–141. [Google Scholar] [CrossRef]
- Ouattara, K. Improved Soil and Water Conservatory Managements for Cotton-Maize Rotation System in the Western Cotton Area Of Burkina Faso. Ph.D. Thesis, Swedish University of Agricultural Sciences, Uppsala, Sweden, 2007. [Google Scholar]
- Gemtos, T.; Markinos, A.; Nassiou, T. Cotton lint quality spatial variability and correlation with soil properties and yield. Precis. Agric. 2005, 5, 361–368. [Google Scholar]
- Tan, L.; Zhang, Y.; Marek, G.W.; Ale, S.; Brauer, D.K.; Chen, Y. Modeling basin-scale impacts of cultivation practices on cotton yield and water conservation under various hydroclimatic regimes. Agriculture 2022, 12, 17. [Google Scholar] [CrossRef]
- Ali, M.A.; Ilyas, F.; Danish, S.; Mustafa, G.; Ahmed, N.; Hussain, S.; Arshad, M.; Ahmad, S. Soil Management and Tillage Practices for Growing Cotton Crop. In Cotton Production and Uses; Springer: Berlin/Heidelberg, Germany; Singapore, 2020; pp. 9–30. [Google Scholar]
- Kayad, A.; Sozzi, M.; Gatto, S.; Whelan, B.; Sartori, L.; Marinello, F. Ten years of corn yield dynamics at field scale under digital agriculture solutions: A case study from North Italy. Comput. Electron. Agric. 2021, 185, 106126. [Google Scholar] [CrossRef]
- Pluto-Kossakowska, J. Review on multitemporal classification methods of satellite images for crop and arable land recognition. Agriculture 2021, 11, 999. [Google Scholar] [CrossRef]
- Sozzi, M.; Kayad, A.; Gobbo, S.; Cogato, A.; Sartori, L.; Marinello, F. Economic comparison of satellite, plane and uav-acquired NDVI images for site-specific nitrogen application: Observations from Italy. Agronomy 2022, 11, 2098. [Google Scholar] [CrossRef]
- Pezzuolo, A.; Basso, B.; Marinello, F.; Sartori, L. Using SALUS model for medium and long term simulations of energy efficiency in different tillage systems. Appl. Math. Sci. 2014, 8, 6433–6445. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Fitriyani, N.L.; Anshari, M.; Stasa, P.; Svub, J.; Rhee, J. Deep Neural Network for Predicting Diabetic Retinopathy from Risk Factors. Mathematics 2021, 8, 1620. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hale, J. Scale, Standardize, or Normalize with Scikit-Learn. 2019. Available online: https://towardsdatascience.com/scale-standardize-or-normalize-with-scikit-learn-6ccc7d176a02 (accessed on 8 December 2021).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Type | Value | Role |
|---|---|---|---|
| pH | Numerical | Range of numbers | Independent |
| Temperature | Numerical | Range of numbers | Independent |
| Humidity | Numerical | Range of numbers | Independent |
| Density | Numerical | Range of numbers | Independent |
| Electrical conductivity | Numerical | Range of numbers | Independent |
| Grain Surface | Categorical | Smooth, Scaly, Gritty, Fibrous | Independent |
| Nitrogen (N) | Numerical | Range of numbers | Independent |
| Phosphorus (P) | Numerical | Range of numbers | Independent |
| Calcium (Ca) | Numerical | Range of numbers | Independent |
| Particle Spacing | Categorical | Close, Crowded | Independent |
| Potassium (K) | Numerical | Range of numbers | Independent |
| Magnesium (Mg) | Numerical | Range of numbers | Independent |
| Particle Width | Categorical | Narrow, Broad | Independent |
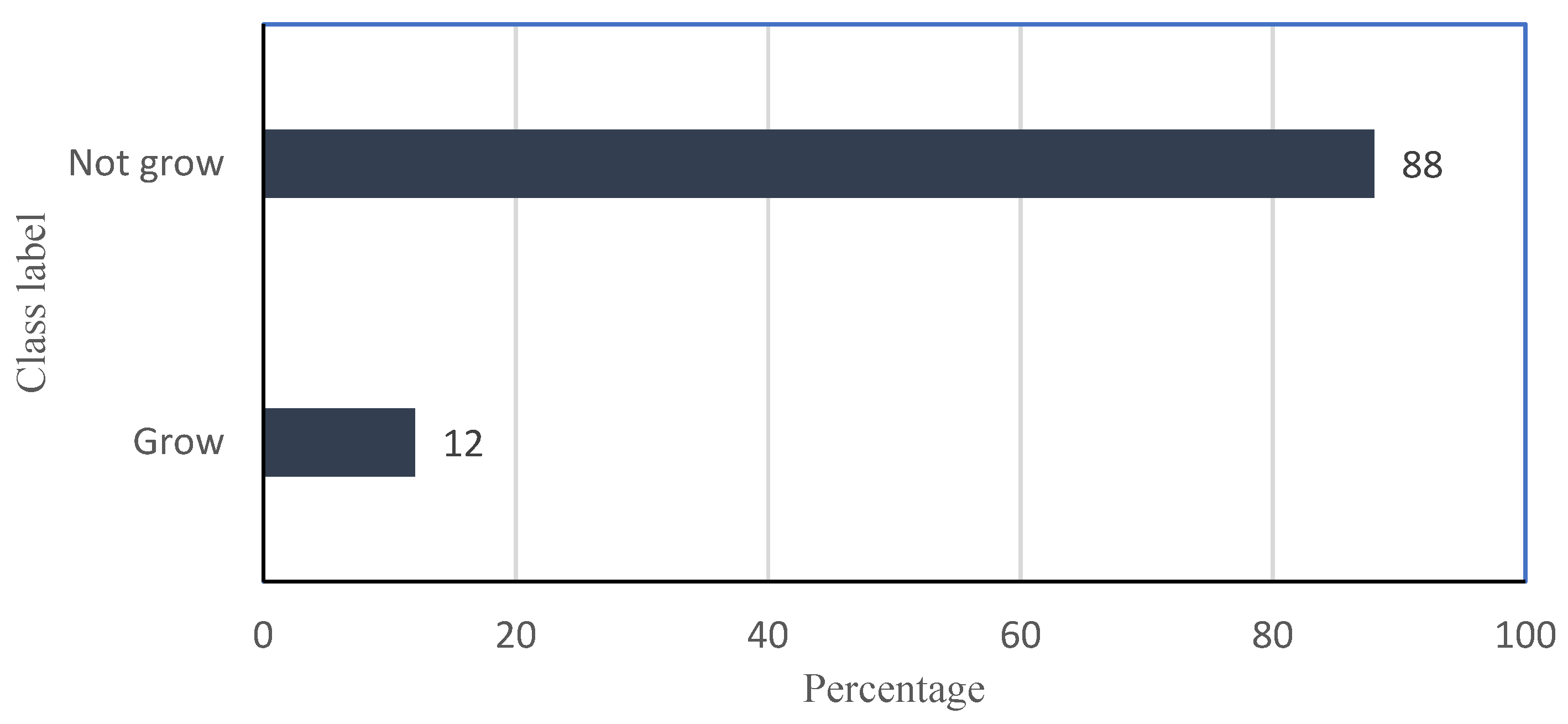
| Cotton grows | Categorical | Yes (1), No (0) | Dependent |
| No | Hyperparameter | Value |
|---|---|---|
| 1 | Layers size | (7, 36, 50, 30, 1) |
| 2 | Optimizer | Adam |
| 3 | Batch size | 10 |
| 4 | Epoche | 100 |
| No | Algorithm | Accuracy (%) |
|---|---|---|
| 1 | Support vector classifier (kernel: RBF, gamma: scale) | 92.1 |
| 2 | Logistic regression (penalty: l2) | 93.2 |
| 3 | Decision tree (criterion: gini, max depth: nodes are expanded until all leaves pure) | 88.5 |
| 4 | KNN (number of neighbors: 5) | 89.3 |
| 5 | Random forest (number of trees: 100) | 92 |
| 6 | DNN | 98.8 |
| Instance | DNN Model | ||
|---|---|---|---|
| Feature (pH, T *, H *, D *, EC *, N *, P *, K *, Ca *, Mg *, GS *, PS *, PW *) | Prediction Class | Actual Class | |
| 1 | (6.5, 20.8, 82, 0.92, 7.4, 100, 50, 43, 30, 19, 3, 0, 1) | 0 | 0 |
| 2 | (7.03, 21.77, 80.31, 1.04, 1.35, 85, 58, 41, 12.25, 5.15, 3, 0, 0) | 0 | 0 |
| 3 | (6.93, 26.1, 71.57, 1.52, 6.16, 129, 44, 27, 18.74, 11.16, 1, 1, 0) | 1 | 1 |
| 4 | (5.97, 18.47, 62.69, 1.54, 6.45, 101, 38, 40, 34.73, 16.91, 1, 1, 0) | 0 | 1 |
| 5 | (6.65, 23.55, 71.59, 1.47, 5.2, 95, 43, 36, 27.49, 19.16, 1, 1, 0) | 1 | 1 |
| 6 | (6.92, 19.02, 17.13, 1.42, 9.21, 23, 72, 84, 6.61, 9.76, 2, 0, 0) | 0 | 0 |
| 7 | (7.23, 24.4, 79.19, 1.4, 6.15, 133, 47, 34, 45.86, 11.14, 1, 1, 0) | 1 | 1 |
| 8 | (6.82, 24.88, 75.62, 1.5, 5.76, 134, 47, 53, 42.9, 23.76, 1, 1, 0) | 1 | 1 |
| 9 | (6.82, 28.17, 81.04, 0.78, 2.2, 10, 56, 16, 11.39, 7.55, 1, 1, 0) | 1 | 1 |
| 10 | (7.03, 28.33, 80.77, 1.51, 11.57, 8, 54, 20, 5.66, 8.84, 3, 1, 1) | 0 | 0 |
| Class | Metrics | ||
|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | |
| 0 | 98 | 99 | 98 |
| 1 | 100 | 98 | 99 |
| Significance Level (%) | Z | Radius (%) | Accuracy Range (%) |
|---|---|---|---|
| 90 | 1.64 | 1.9 | (96.9, 100) |
| 95 | 1.96 | 2.3 | (96.5, 100) |
| 98 | 2.33 | 2.5 | (96.3, 100) |
| 99 | 2.58 | 2.8 | (96, 100) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amani, M.A.; Marinello, F. A Deep Learning-Based Model to Reduce Costs and Increase Productivity in the Case of Small Datasets: A Case Study in Cotton Cultivation. Agriculture 2022, 12, 267. https://doi.org/10.3390/agriculture12020267
Amani MA, Marinello F. A Deep Learning-Based Model to Reduce Costs and Increase Productivity in the Case of Small Datasets: A Case Study in Cotton Cultivation. Agriculture. 2022; 12(2):267. https://doi.org/10.3390/agriculture12020267
Chicago/Turabian StyleAmani, Mohammad Amin, and Francesco Marinello. 2022. "A Deep Learning-Based Model to Reduce Costs and Increase Productivity in the Case of Small Datasets: A Case Study in Cotton Cultivation" Agriculture 12, no. 2: 267. https://doi.org/10.3390/agriculture12020267
APA StyleAmani, M. A., & Marinello, F. (2022). A Deep Learning-Based Model to Reduce Costs and Increase Productivity in the Case of Small Datasets: A Case Study in Cotton Cultivation. Agriculture, 12(2), 267. https://doi.org/10.3390/agriculture12020267