
Tea Sprout Picking Point Identification Based on Improved DeepLabV3+


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Image Annotation
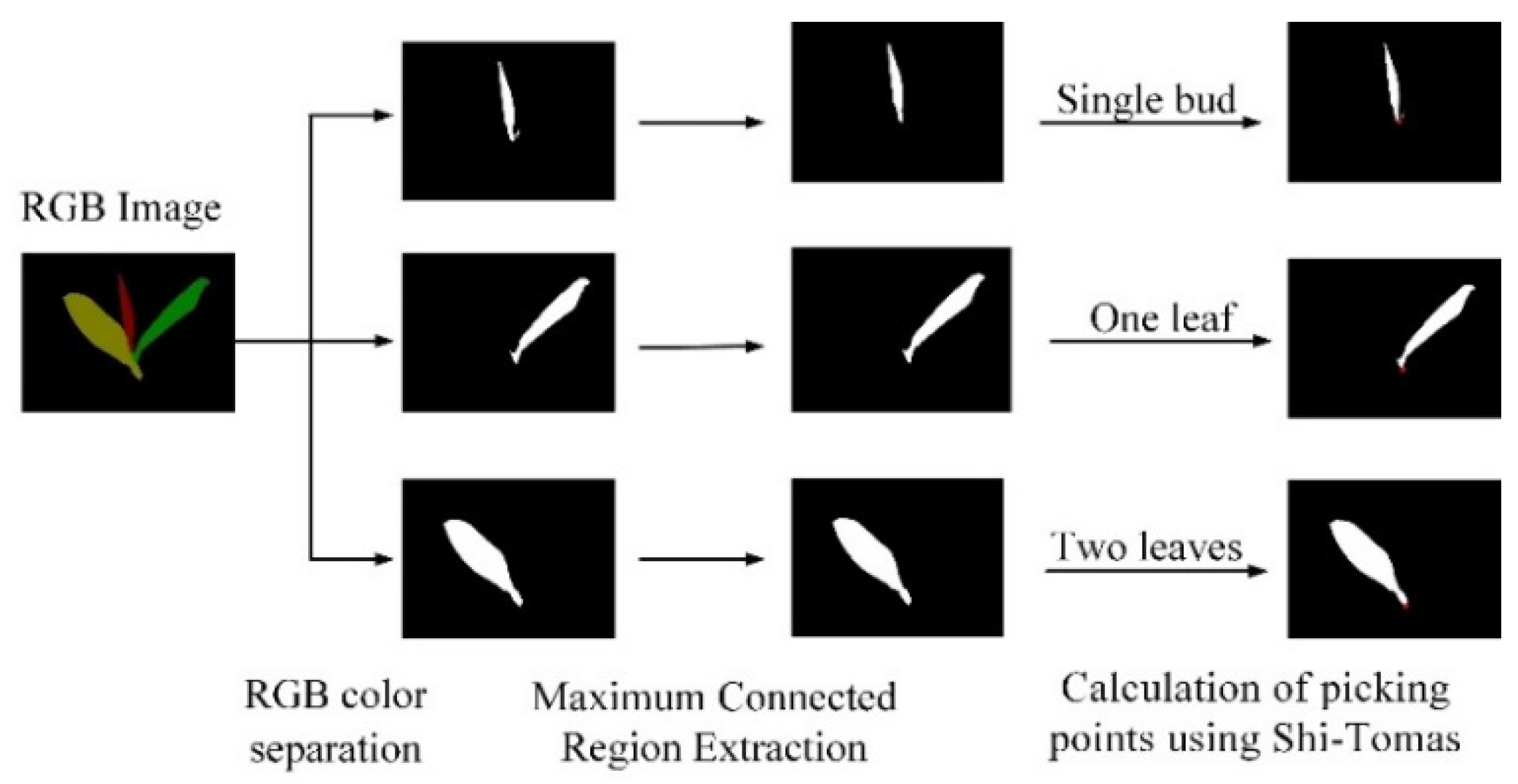
2.3. Description of Tea Sprout Picking Point
2.4. Models
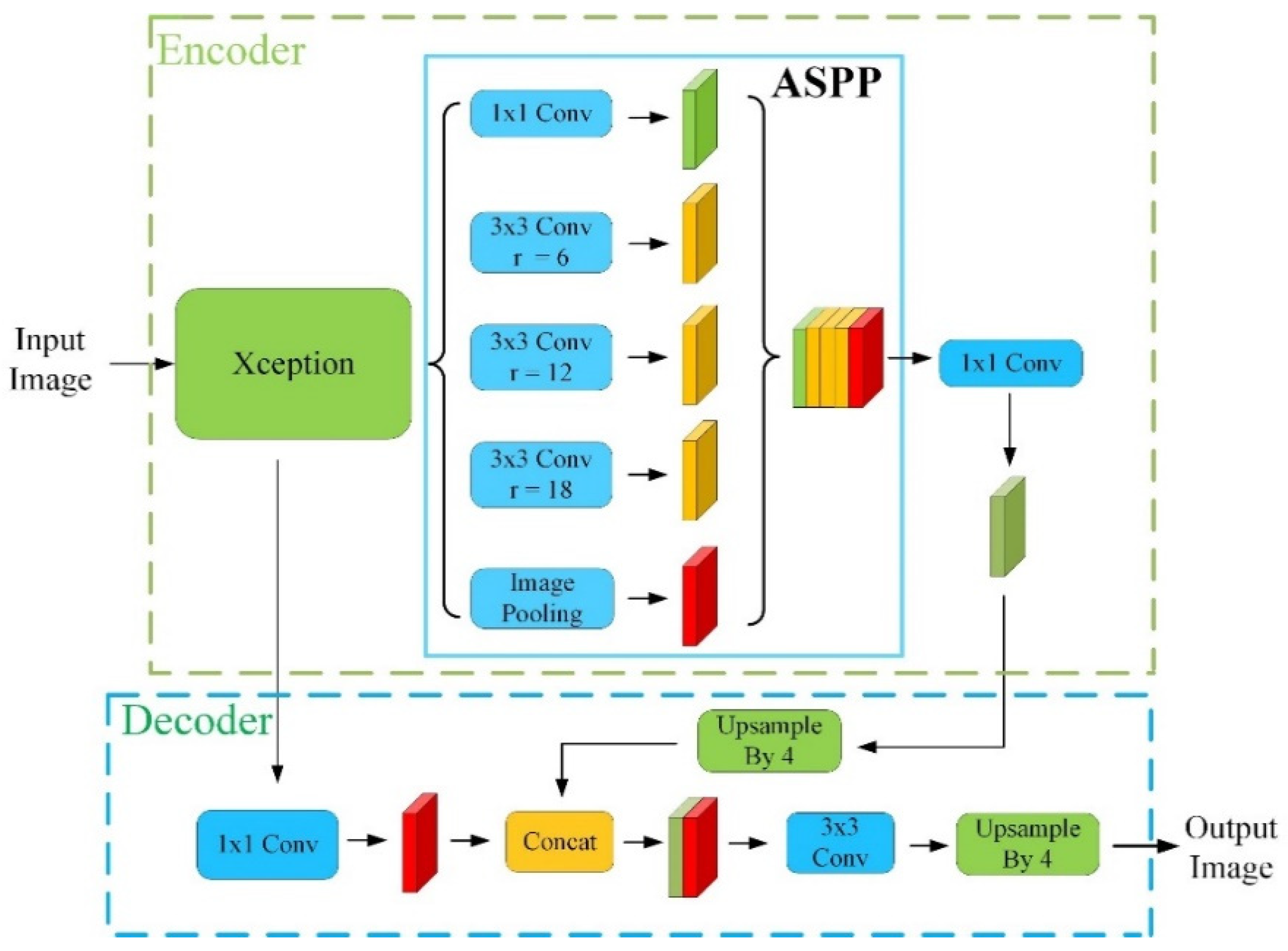
2.4.1. MC-DM Architecture
2.4.2. Lightweight Backbone Network
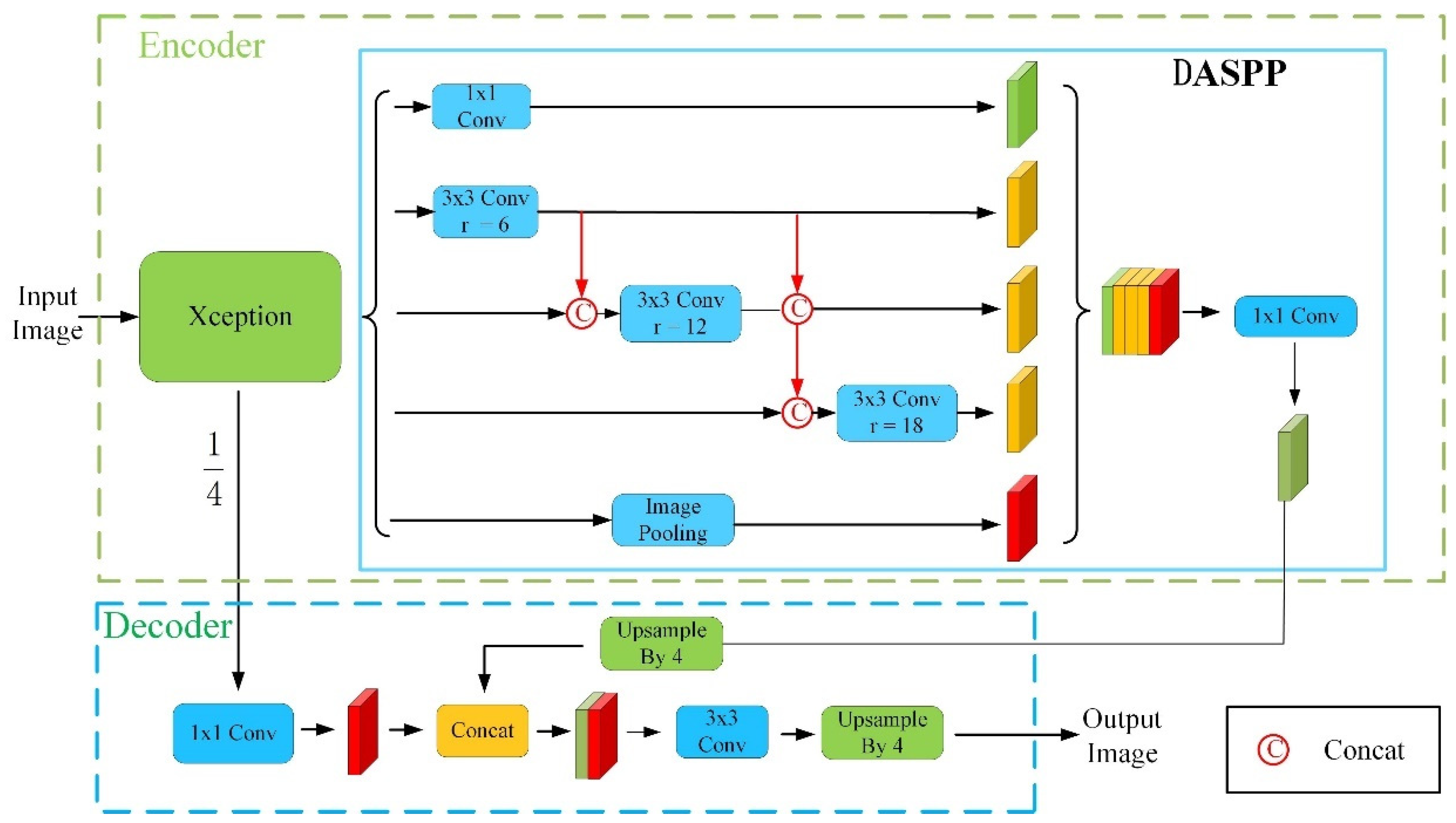
2.4.3. DASPP
2.4.4. Picking Point Positioning Method
2.5. Evaluation Metrics
3. Results and Discussion
3.1. Implementation Details
3.2. Backbone Network Validation
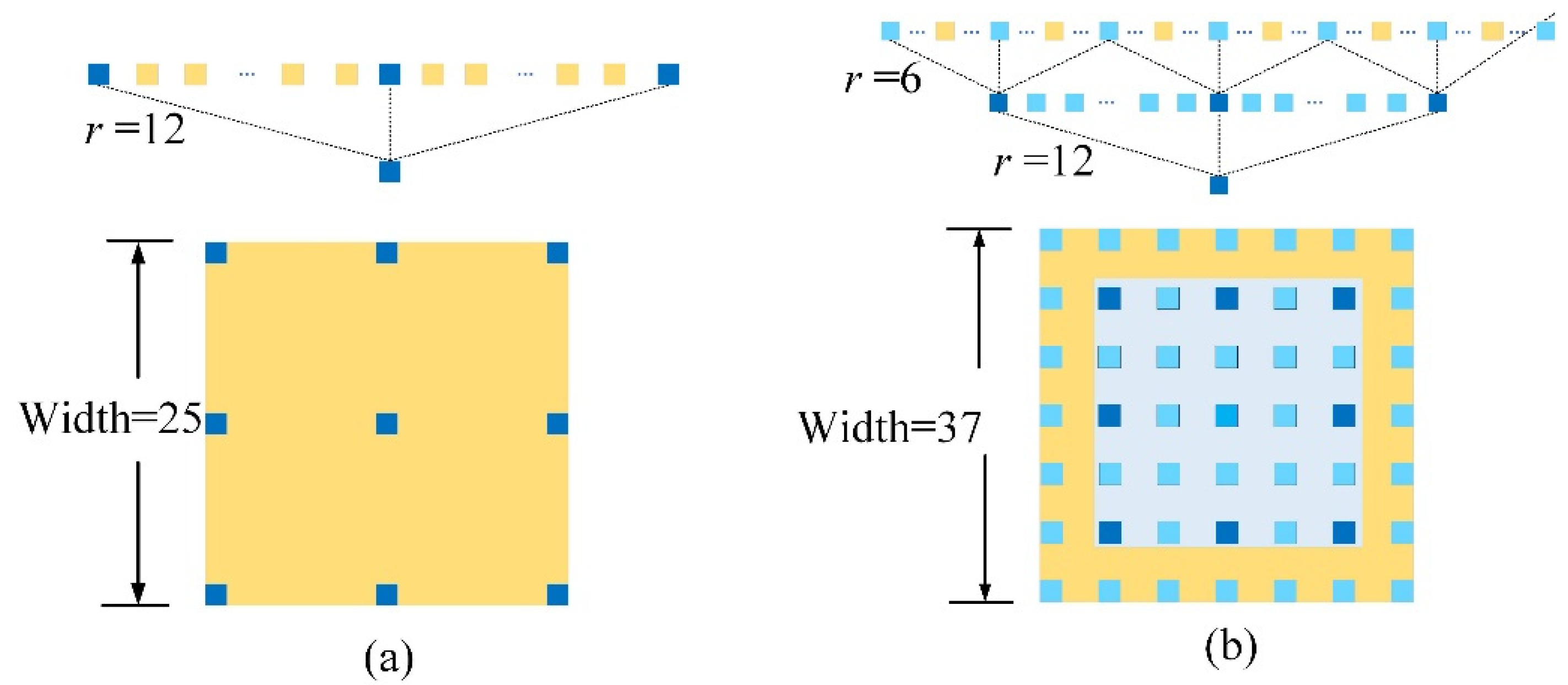
3.3. Analysis of DASPP and Dilation Rate Combinations
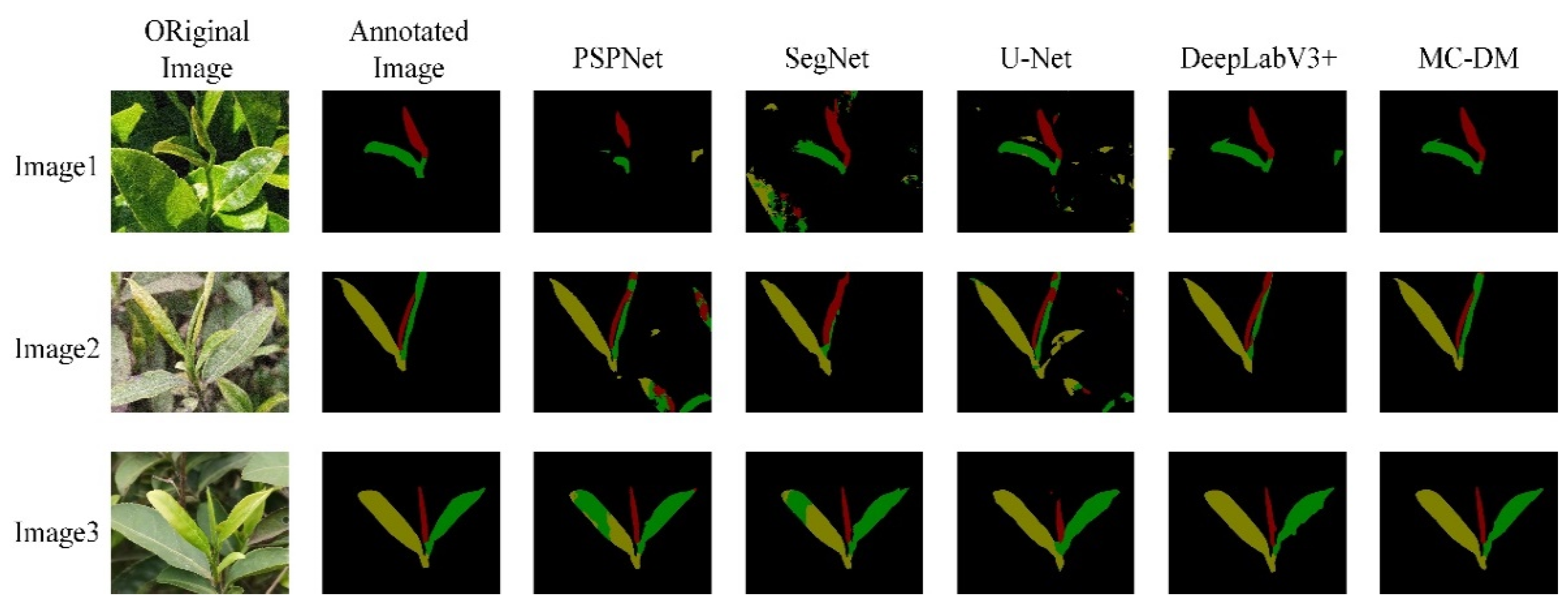
3.4. Comparison with Other Segmentation Models
3.5. Picking Point Marking Validation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Zou, L.; Wu, C.; Chen, J.; Chen, H. Locating Famous Tea’s Picking Point Based on Shi-Tomasi Algorithm. Comput. Mater. Contin. 2021, 69, 1109–1122. [Google Scholar] [CrossRef]
- Zhu, Y.; Wu, C.; Tong, J.; Chen, J.; He, L.; Wang, R.; Jia, J. Deviation Tolerance Performance Evaluation and Experiment of Picking End Effector for Famous Tea. Agriculture 2021, 11, 128. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, S. Localizing plucking points of tea leaves using deep convolutional neural networks. Comput. Electron. Agric. 2020, 171, 105298. [Google Scholar] [CrossRef]
- Zhang, L.; Zou, L.; Wu, C.; Jia, J.; Chen, J. Method of famous tea sprout identification and segmentation based on improved watershed algorithm. Comput. Electron. Agric. 2021, 184, 106108. [Google Scholar] [CrossRef]
- Zhao, B.; Wei, D.; Sun, W.; Liu, Y.; Wei, K. Research on tea bud identification technology based on HSI/HSV color transformation. In Proceedings of the 2019 6th International Conference on Information Science and Control Engineering (ICISCE), Shanghai, China, 20–22 December 2019; pp. 511–515. [Google Scholar] [CrossRef]
- Qian, C.; Li, M.; Ren, Y. Tea sprouts segmentation via improved deep convolutional encoder-decoder network. IEICE Trans. Inf. Syst. 2020, E103-D, 476–479. [Google Scholar] [CrossRef]
- Qi, F.; Xie, Z.; Tang, Z.; Chen, H. Related study based on Otsu Watershed Algorithm and New Squeeze-and-Excitation Networks for Segmentation and Level Classification of Tea Buds. Neural Process. Lett. 2021, 53, 2261–2275. [Google Scholar] [CrossRef]
- Hu, G.; Li, S.; Wan, M.; Bao, W. Semantic segmentation of tea geometrid in natural scene images using discriminative pyramid network. Appl. Soft Comput. 2021, 113, 107984. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Chen, M.; Ma, Z.; Deng, F.; Li, M.; Li, X. Tender Tea Shoots Recognition and Positioning for Picking Robot Using Improved YOLO-V3 Model. IEEE Access 2019, 7, 80998–1810111. [Google Scholar] [CrossRef]
- Peng, H.; Xue, C.; Shao, Y.; Chen, K.; Xiong, J.; Xie, Z.; Zhang, L. Semantic segmentation of litchi branches using DeepLabV3+ model. IEEE Access 2020, 8, 164546–164555. [Google Scholar] [CrossRef]
- Song, Z.; Zhou, Z.; Wang, W.; Gao, F.; Fu, L.; Li, R.; Cui, Y. Canopy segmentation and wire reconstruction for kiwifruit robotic harvesting. Comput. Electron. Agric. 2021, 181, 105933. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, Shrub, and Grass Classification Using Only RGB Images. Remote Sens. 2020, 12, 1333. [Google Scholar] [CrossRef]
- Zhang, X.; Fu, L.; Karkee, M.; Whiting, M.D.; Zhang, Q. Canopy Segmentation Using ResNet for Mechanical Harvesting of Apples. IFAC-PapersOnLine 2019, 52, 300–305. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, C.; Wu, H.; Han, X.; Li, S. ADDLight: An Energy-Saving Adder Neural Network for Cucumber Disease Classification. Agriculture 2022, 12, 452. [Google Scholar] [CrossRef]
- Xiong, J.; Lin, R.; Liu, Z.; He, Z.; Tang, L.; Yang, Z.; Zou, X. The recognition of litchi clusters and the calculation of picking point in a nocturnal natural environment. Biosyst. Eng. 2018, 166, 44–57. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, A.; Liu, J.; Faheem, M. A Comparative Study of Semantic Segmentation Models for Identification of Grape with Different Varieties. Agriculture 2021, 11, 997. [Google Scholar] [CrossRef]
- Ma, D.; Li, P.; Huang, X.; Zhang, Q.; Yang, X. Efficient semantic segmentation based on improved DeepLabV3+. Comput. Eng. Sci. 2022, 44, 737–745. [Google Scholar] [CrossRef]
- Yao, X.; Guo, Q.; Li, A. Light-Weight Cloud Detection Network for Optical Remote Sensing Images with Attention-Based DeeplabV3+ Architecture. Remote Sens. 2021, 13, 3617. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 17–19 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 3, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 234–241. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| 224 × 224 × 3 | Conv2d | - | 32 | 1 | 2 |
| 112 × 112 × 32 | bottleneck | 1 | 16 | 1 | 1 |
| 112 × 112 × 16 | bottleneck | 6 | 24 | 2 | 2 |
| 56 × 56 × 24 | bottleneck | 6 | 32 | 3 | 2 |
| 28 × 28 × 32 | bottleneck | 6 | 64 | 4 | 2 |
| 14 × 14 × 64 | bottleneck | 6 | 96 | 3 | 1 |
| 14 × 14 × 96 | bottleneck | 6 | 160 | 3 | 2 |
| 7 × 7 × 160 | bottleneck | 6 | 320 | 1 | 2 |
| 7 × 7 × 320 | Conv2d 1 × 1 | - | 1280 | 1 | 1 |
| 7 × 7 × 1280 | 7 × 7 Avgpooling | - | 1 | - | |
| 1 × 1 × 1280 | 1 × 1 | - | k | - | - |
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| 640 × 480 × 3 | Conv2d | - | 32 | 1 | 2 |
| 320 × 240 × 32 | bottleneck | 1 | 16 | 1 | 1 |
| 320 × 240 × 16 | bottleneck | 6 | 24 | 2 | 2 |
| 160 × 120 × 24 | bottleneck | 6 | 32 | 3 | 2 |
| 80 × 690 × 32 | bottleneck | 6 | 64 | 4 | 2 |
| 40 × 30 × 64 | bottleneck | 6 | 96 | 3 | 1 |
| 40 × 30 × 96 | bottleneck | 6 | 160 | 3 | 2 |
| 40 × 30 × 160 | bottleneck | 6 | 320 | 1 | 1 |
| ASPP Connection | Dilation | Receptive Field | Effective Elements | β (%) |
|---|---|---|---|---|
| ASPP | 6, 12 | 25 | 9 | 1.44 |
| 6, 12, 18 | 37 | 9 | 0.66 | |
| 6, 12, 18, 24 | 49 | 9 | 0.37 | |
| DASPP | 6, 12 | 37 | 49 | 2.18 |
| 6, 12, 18 | 73 | 255 | 4.79 | |
| 6, 12, 18, 24 | 122 | 961 | 6.46 |
| Bud | One Leaf | Two Leaves | |
|---|---|---|---|
| R | 255 | 0 | 255 |
| G | 0 | 255 | 255 |
| B | 0 | 0 | 0 |
| Method | Backbone | MIoU/% | Parameters/MB | Speed (f/s) |
|---|---|---|---|---|
| Original Deeplabv3+ | Xception | 91.33 | 104.61 | 25.10 |
| Deeplabv3+-Mobilenetv2 | MobilenetV2 | 90.33 | 11.18 | 41.14 |
| ASPP Connection | Dilation Rates | Receptive Field | MIoU | Parameters/MB | Speed (f/s) |
|---|---|---|---|---|---|
| ASPP | 6, 12 | 25 | 85.47 | 6.75 | 45.05 |
| 6, 12, 18 | 37 | 90.33 | 7.56 | 24.77 | |
| 6, 12, 18, 24 | 49 | 90.50 | 8.36 | 37.06 | |
| DASPP | 6, 12 | 37 | 87.60 | 6.76 | 44.78 |
| 6, 12, 18 | 73 | 91.85 | 7.63 | 40.82 | |
| 6, 12, 18, 24 | 122 | 92.02 | 8.56 | 36.89 |
| Model | MIoU/% | Parameters/MB | Speed (f/s) |
|---|---|---|---|
| PSPNet | 83.23 | 29.93 | 40.85 |
| SegNet | 85.79 | 29.45 | 24.77 |
| U-Net | 86.29 | 13.40 | 25.79 |
| DeepLabV3+ | 91.33 | 54.52 | 25.10 |
| MC-DM | 91.85 | 7.63 | 40.82 |
| Sample | 1 | 2 | 3 | 4 | 5 | Total |
|---|---|---|---|---|---|---|
| Number of picking points | 222 | 222 | 222 | 222 | 222 | 1110 |
| Number of successful identifications | 187 | 177 | 182 | 186 | 184 | 916 |
| Number of failed identifications | 35 | 45 | 40 | 36 | 38 | 194 |
| recognition accuracy/% | 84.23 | 79.73 | 81.98 | 83.78 | 82.88 | 82.52 |
| Sample | 1 | 2 | 3 | 4 | 5 | Total |
|---|---|---|---|---|---|---|
| Number of picking points | 221 | 221 | 222 | 222 | 222 | 1108 |
| Number of successful identifications | 201 | 199 | 193 | 201 | 204 | 998 |
| Number of failed identifications | 20 | 22 | 29 | 21 | 18 | 110 |
| recognition accuracy/% | 90.95 | 90.00 | 86.94 | 90.54 | 91.89 | 90.07 |
| Sample | 1 | 2 | 3 | 4 | 5 | Total |
|---|---|---|---|---|---|---|
| Number of picking points | 162 | 167 | 161 | 172 | 166 | 828 |
| Number of successful identifications | 132 | 149 | 136 | 145 | 140 | 702 |
| Number of failed identifications | 30 | 18 | 25 | 27 | 26 | 126 |
| recognition accuracy/% | 81.48 | 89.22 | 84.47 | 84.30 | 84.34 | 84.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, C.; Chen, Z.; Li, Z.; Liu, R.; Li, Y.; Xiao, H.; Lu, P.; Xie, B. Tea Sprout Picking Point Identification Based on Improved DeepLabV3+. Agriculture 2022, 12, 1594. https://doi.org/10.3390/agriculture12101594
Yan C, Chen Z, Li Z, Liu R, Li Y, Xiao H, Lu P, Xie B. Tea Sprout Picking Point Identification Based on Improved DeepLabV3+. Agriculture. 2022; 12(10):1594. https://doi.org/10.3390/agriculture12101594
Chicago/Turabian StyleYan, Chunyu, Zhonghui Chen, Zhilin Li, Ruixin Liu, Yuxin Li, Hui Xiao, Ping Lu, and Benliang Xie. 2022. "Tea Sprout Picking Point Identification Based on Improved DeepLabV3+" Agriculture 12, no. 10: 1594. https://doi.org/10.3390/agriculture12101594
APA StyleYan, C., Chen, Z., Li, Z., Liu, R., Li, Y., Xiao, H., Lu, P., & Xie, B. (2022). Tea Sprout Picking Point Identification Based on Improved DeepLabV3+. Agriculture, 12(10), 1594. https://doi.org/10.3390/agriculture12101594