Driving Type 2 Diabetes Risk Scores into Clinical Practice: Performance Analysis in Hospital Settings

 ,
, 
 and
and
Abstract
1. Introduction
2. Material and Methods
2.1. Study Design
2.1.1. Inclusion and Exclusion Criteria
2.1.2. Sample Size Determination
2.1.3. Retrospective Validation
- Risk score comparison: discrimination and calibration performance of the predictive risk score calculated for every selected case using FINDRISC, ARIC, Framingham, PREDIMED, Cambridge, and San Antonio without calibration.
- Diagnostic power comparison: the proportion of individuals with an HbA1c of 6.0–6.4% or a Fasting Plasma Glucose (FPG) of 110–126 mg/dL thereby being eligible for a preventive intervention, and the proportion of subjects at high risk for the detection model.
- High risk of T2DM cases or T2DM cases.
- A cut-off point for high risk of T2DM cases that would not require blood testing.
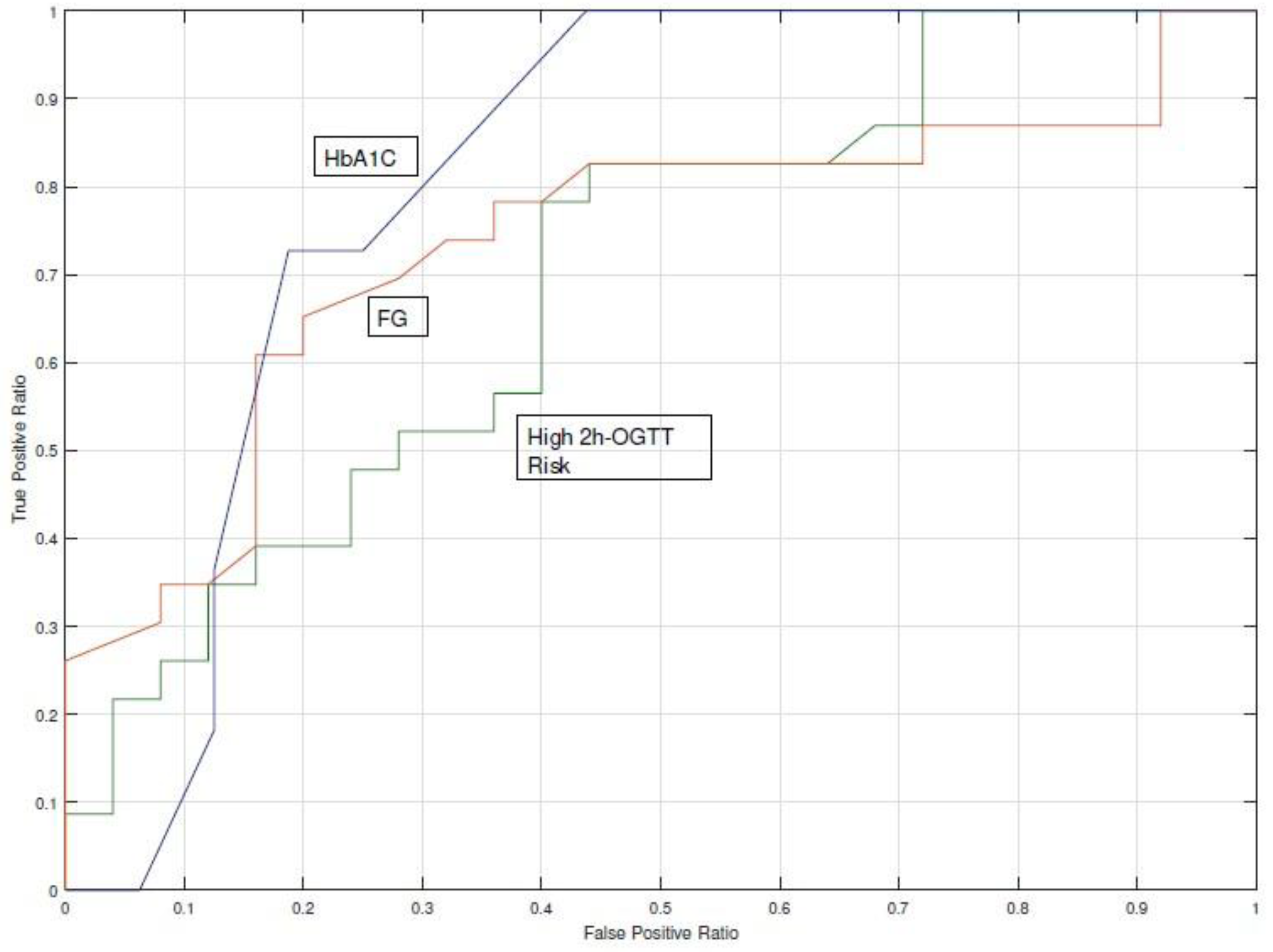
- Area Under the Curve (AUC) of Receiver Operating Characteristics (ROC) of the prediction and detection risk tool on the study dataset (also known as c-statistic).
2.2. Risk Scores for Type 2 Diabetes Mellitus
2.3. Missing Data Imputation
2.4. Assessment of Risk Scores
- Discrimination is the ability of the risk prediction model to differentiate between patients who will be diagnosed with diabetes during the observation period from those who will not. Discrimination is quantified by calculating the area under the receiver operating characteristic curve statistic, the Sensitivity (S), the Specificity (Sp), the Positive Predictive Value (PPV), and the Negative Predictive Value (NPV).
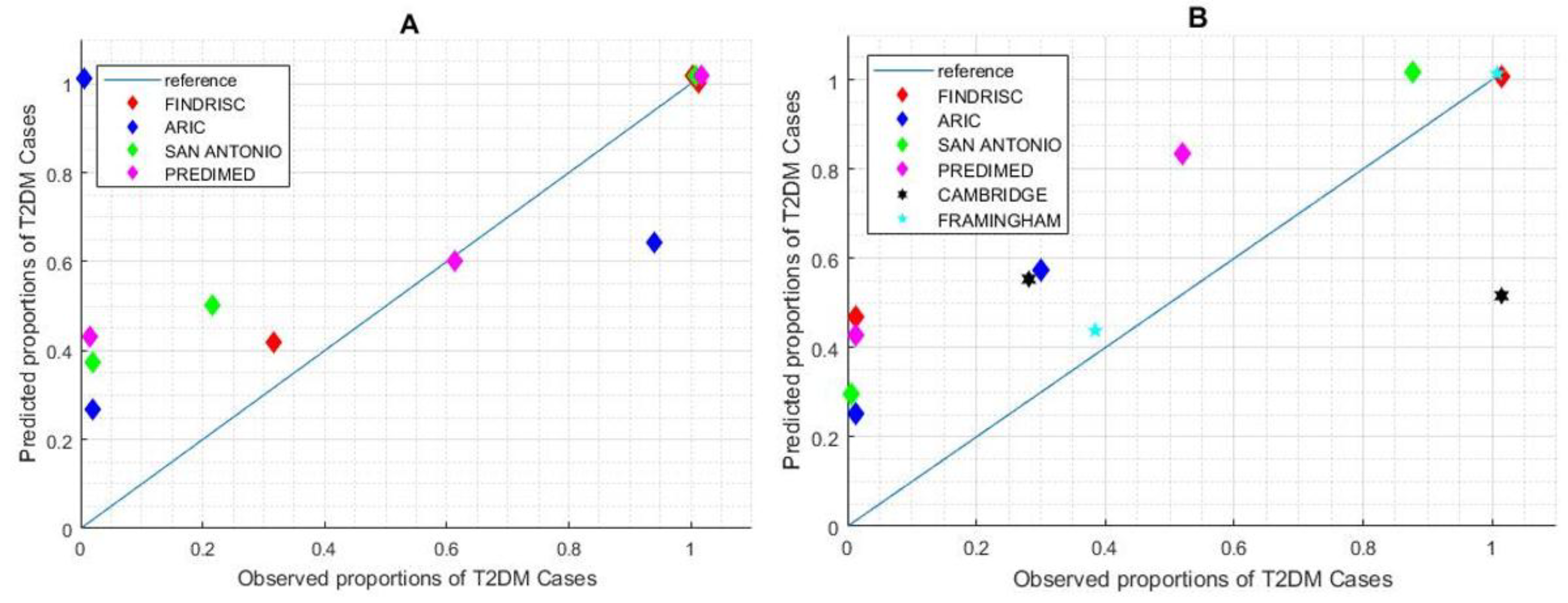
- Calibration refers to how closely the risk score outcome agrees with the observed outcome. Calibration of the risk score can be assessed by plotting observed proportions against predicted probabilities; a 45° line denotes perfect calibration. Calibration is quantified by the Hosmer–Lemershow test for the observed and expected events. The p-value can be calculated as the right-hand tail probability of the corresponding chi2 distribution for the Hosmer–Lemershow statistic. A p-value ≤0.01 indicates poor fitness.
2.5. Clinical Scenarios for Risk Assessment
- Estimate missing variables given available variables measurable with a general practitioner visit and laboratory tests in the EHR and estimate the risk of the subject for developing T2DM.
- Estimate the 2h-OGTT range given all other available variables (helping the doctor to decide whether a test is needed).
Recommendations Based on Expected Risk
- Order a 2h-OGTT for this subject.
- Order an HbA1c test for this subject.
- Refer this subject to an endocrinologist.
- Refer this patient to a general practitioner.
- Start pharmacological treatment.
- Prescribe physical activity habits.
- Prescribe dietary habits.
- Counsel on and promote physical activity habits.
- Counsel on and promote healthy dietary habits.
3. Results
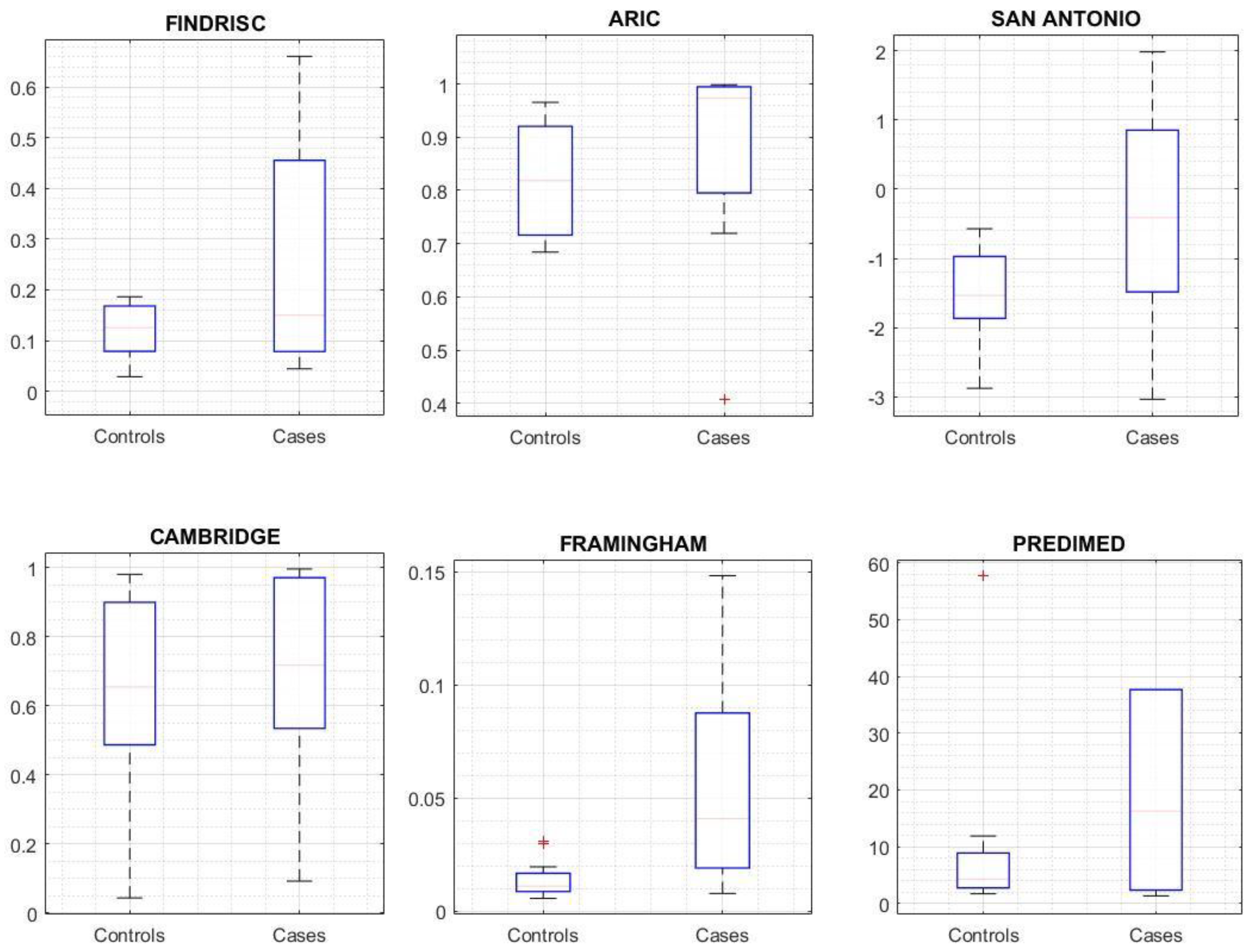
3.1. Evaluation of Prediction Risk Scores for T2DM Performance
3.2. Support on T2DM Screening
3.3. Missing Data Influence on Risk Score Outcome
3.3.1. Prediction Analysis
3.3.2. Detection Analysis
3.4. Clinical Advice for High-Risk Subjects
4. Discussion
4.1. Advancing the Prediction and Diagnosis of T2DM
4.2. Prediction and Detection of T2DM in Clinical Settings
4.3. Limitations of the Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FINDRISC | ARIC | San Antonio | PREDIMED | Framingham | CAMBRIDGE | |
|---|---|---|---|---|---|---|
| Intercept | −5.51 | −9.981 | −13.415 | −18.607 | −6.322 | |
| Age (years) | 45–54: 0.63 55–64: 0.89 | 0.0173 | 0.028 | 50–64: −0.010 ≥65: −0.2107 | 0.063 | |
| Gender | Female: 0.661 | Male: 0.4308 | Female: −0.879 | |||
| Ethnicity | African-American: 0.443 | Hispanic: 0.44 | ||||
| Anti-hypertensive medication | 0.71 | 0.838 | 0.336 | 1.222 | ||
| Fasting glucose (mg/dL) | >110: 2.14 * | 0.088 | 0.079 | ≥100: 1.929 | 0.1398 | |
| BMI (kg/m2) | 25–30: 0.17 >30: 1.10 | 0.070 | ≥27: 0.315 | 0.03922 | 25–27.49: 0.6 9927.50–30: 1.970 >30: 2.518 | |
| HDL | 0.0012 | 0.039 | −0.0488 | |||
| Triglyceride | 0.00271 | ≥150: 0.405 | ||||
| Blood pressure (mmHg) | Systolic: 0.0111 | Systolic: 0.018 | 130/85 *** | Systolic: 0.001 | ||
| Family history of diabetes | 0.498 | 0.481 | 0.506 | 0.4383 | 0.728 ** | |
| Smoker | 0.547 | 0.855 ** | ||||
| Alcohol | 0.427 | |||||
| Waist circumference (cm) | Men 94–102 Women 80–88 0.86 Men ≥102 Women ≥ 88 1.35 | 0.0273 | 0.0488 | |||
| Height (cm) | 0.0326 |
Appendix B
| Risk Score Name and Validation Study | Population Characteristics for Internal Validation | Population Characteristics for External Validation | Mathematical Model | T2DM Diagnosis Criteria |
|---|---|---|---|---|
| FINDRISC [1,2] | NS | North European, Dutch, Australian, African | Logistic regression | WHO (FPG or 2h-PG) |
| Ages: 35–64 | Ages: 35.2–71 | |||
| Follow-up: 5 years | Follow-up: 5 Years | |||
| ARIC [3,4] | United States Communities (85% white; 15% African-American) | United States Communities | Logistic regression | WHO criteria or clinical diagnosis or diabetic treatment |
| Ages: 45–64 | Ages: 45–84 | |||
| Follow-up: 9 years | Follow-up: 4.75 years | |||
| San Antonio Internal [5] | Mexican-Americans and Random Sample | Finland and Sweden | Linear regression | ADA criteria (FPG or 2h-PG only) |
| Ages: NS | Ages: 44–55 | |||
| Follow-up: 7.5 years | Follow-up: 7.5 years | |||
| QDScore Internal [7,8] | Caucasian | Caucasian (93%) and other ethnic groups | Proportional hazards model, multiple imputation | Diagnosis read code for diabetes in EHR |
| Ages: 25–79 | Ages: 25–79 | |||
| Retrospective (15 years) Qresearch Data Base | Retrospective (15 years) THIN DataBase | |||
| Cambridge Internal [9,10] | UK population | UK population | Logistic regression | Diagnostic Code or diabetic medication |
| Ages: 40–79 | Ages: 35–55 | |||
| Follow-up: 5 years | Retrospective data base (11.7 years) | |||
| PREDIMED Internal [11] | Spanish Caucasian | Spanish Caucasian (High Risk) | Multivariate Cox regression | ADA criteria (FPG or 2h-PG only) |
| Ages: 55–80 | Ages: 45–75 | |||
| Follow-up: 3.8 years | Follow-up: 4.2 years | |||
| Framingham Internal [4,12] | Caucasian | Caucasian, African-American, Hispanic, and Chinese-American | Logistic regression | ADA criteria (FPG or 2h-PG only) |
| Ages: 44.2–63.9 | Ages: 45–84 | |||
| Follow-up: 7 years | Follow-up: 4.75 years |
References
- Hemingway, H.; Croft, P.; Perel, P.; Hayden, J.A.; Abrams, K.; Timmis, A.; Briggs, A.; Udumyan, R.; Moons, K.G.; Steyerberg, E.W.; et al. Prognosis research strategy (PROGRESS) 1: A framework for researching clinical outcomes. BMJ 2013, 346, e5595. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.M.Y.; Colagiuri, S. Risk scores for diabetes prediction: The International Diabetes Federation PREDICT-2 project. Diabetes Res. Clin. Pract. 2013, 100, 285–286. [Google Scholar] [CrossRef] [PubMed]
- Collins, G.S.; Ogundimu, E.O.; Altman, D.G. Sample size considerations for the external validation of a multivariable prognostic model: A resampling study. Stat. Med. 2016, 35, 214–226. [Google Scholar] [CrossRef] [PubMed]
- Noble, D.; Mathur, R.; Dent, T.; Meads, C.; Greenhalgh, T. Risk models and scores for type 2 diabetes: Systematic review. BMJ 2011, 343, d7163. [Google Scholar] [CrossRef] [PubMed]
- Asghari, S.; Courteau, J.; Carpentier, A.C.; Vanasse, A. Optimal strategy to identify incidence of diagnostic of diabetes using administrative data. BMC Med. Res. Methodol. 2009, 9, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Chatterton, H.; Younger, T.; Fischer, A.; Khunti, K. Risk identification and interventions to prevent type 2 diabetes in adults at high risk: Summary of NICE guidance. BMJ 2012, 345, e4624. [Google Scholar] [CrossRef] [PubMed]
- Vergouwe, Y.; Steyerberg, E.W.; Eijkemans, M.J.C.; Habbema, J.D. Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J. Clin. Epidemiol. 2005, 58, 475–483. [Google Scholar] [CrossRef]
- Gray, L.J.; Khunti, K. Type 2 diabetes risk prediction-Do biomarkers increase detection? Diabetes Res. Clin. Pract. 2013, 101, 245–247. [Google Scholar] [CrossRef]
- Riley, R.D.; Ensor, J.; Snell, K.I.E.; Debray, T.P.A.; Altman, D.; Moons, K.; Collins, G.S. External validation of clinical prediction models using big datasets from e-health records or IPD meta-analysis: Opportunities and challenges. BMJ 2016, i3140. [Google Scholar] [CrossRef]
- Williams, R.; Kontopantelis, E.; Buchan, I.; Peek, N. Clinical code set engineering for reusing EHR data for research: A review. J. Biomed. Inform. 2017, 70, 1–13. [Google Scholar] [CrossRef]
- Meigs, J.B.; Shrader, P.; Sullivan, L.M.; McAteer, J.B.; Fox, C.S.; Dupuis, J.; Manning, A.K.; Florez, J.C.; Wilson, P.W.; D’Agostino, R.B., Sr.; et al. Genotype Score in Addition to Common Risk Factors for Prediction of Type 2 Diabetes. N. Engl. J. Med. 2008, 359, 2208–2219. [Google Scholar] [CrossRef]
- Bobo, W.V.; Cooper, W.O.; Stein, C.M.; Olfson, M.; Mounsey, J.; Daugherty, J.; Ray, W.A. Positive predictive value of a case definition for diabetes mellitus using automated administrative health data in children and youth exposed to antipsychotic drugs or control medications: A Tennessee Medicaid study. BMC Med. Res. Methodol. 2012, 12, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Hippisley-Cox, J.; Coupland, C.; Robson, J.; Sheikh, A.; Brindle, P. Predicting risk of type 2 diabetes in England and Wales: Prospective derivation and validation of QDScore. BMJ 2009, 338, b880. [Google Scholar] [CrossRef]
- Guariguata, L.; Whiting, D.R.; Hambleton, I.; Beagley, J.; Linnenkamp, U.; Shaw, J.E. Global estimates of diabetes prevalence for 2013 and projections for 2035. Diabetes Res. Clin. Pract. 2014, 103, 137–149. [Google Scholar] [CrossRef] [PubMed]
- Knowler, W.C. Reduction in the Incidence of Type 2 Diabetes with Lifestyle Intervention or Metformin. N. Engl. J. Med. 2002, 346, 393–403. [Google Scholar] [CrossRef] [PubMed]
- Selvin, E.; Wang, D.; Lee, A.K.; Bergenstal, R.M.; Coresh, J. Identifying Trends in Undiagnosed Diabetes in U.S. Adults by Using a Confirmatory Definition. Ann. Intern Med. 2017, 167, 769–776. [Google Scholar] [CrossRef] [PubMed]
- Sattar, N.; Preiss, D.; Murray, H.M. Statins and risk of incident diabetes: A collaborative meta-analysis of randomised statin trials. Rev. Port. Cardiol. 2010, 29, 1077–1078. [Google Scholar] [CrossRef]
- Paprott, R.; Mühlenbruch, K.; Mensink, G.B.M.; Thiele, S.; Schulze, M.B.; Scheidt-Nave, C.; Heidemann, C. Validation of the German Diabetes Risk Score among the general adult population: Findings from the German Health Interview and Examination Surveys. BMJ Open Diabetes Res. Care 2016, 4, e000280. [Google Scholar] [CrossRef] [PubMed]
- Lindstrom, J.; Tuomilehto, J. The Diabetes Risk Score: A practical tool to predict type 2 diabetes risk. Diabetes Care 2003, 26, 725–731. [Google Scholar] [CrossRef] [PubMed]
- Hippisley-Cox, J.; Coupland, C. Development and validation of QDiabetes-2018 risk prediction algorithm to estimate future risk of type 2 diabetes: Cohort study. BMJ 2017, j5019. [Google Scholar] [CrossRef]
- Martinez-Millana, A.; Bayo-Monton, J.-L.; Argente-Pla, M.; Fernandez-Llatas, C.; Merino-Torres, J.F.; Traver-Salcedo, V. Integration of Distributed Services and Hybrid Models Based on Process Choreography to Predict and Detect Type 2 Diabetes. Sensors 2017, 18, 79. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association (ADA). Classification and Diagnosis of Diabetes. Diabetes Care 2016, 40, S11–S24. [Google Scholar] [CrossRef]
- Valdés, S.; Botas, P.; Delgado, E.; Alvarez, F.; Cadórniga, FD. Population-based incidence of type 2 diabetes in Northern Spain. Diabetes Care 2007, 30, 2258–2263. [Google Scholar] [CrossRef] [PubMed]
- Kenny, D.A. Statistics for the Social and Behavioral Sciences; Little, Brown and Company: Boston, MA, USA, 1987. [Google Scholar]
- Sambo, F.; Di, C.B.; Franzin, A.; Facchinetti, A.; Hakaste, L.; Kravic, J.; Fico, G.; Tuomilehto, J.; Groop, L.; Gabriel, R.; et al. A Bayesian Network analysis of the probabilistic relations between risk factors in the predisposition to type 2 diabetes. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Buijsse, B.; Simmons, R.K.; Griffin, S.J.; Schulze, M.B. Risk Assessment Tools for Identifying Individuals at Risk of Developing Type 2 Diabetes. Epidemiol. Rev. 2011, 33, 46–62. [Google Scholar] [CrossRef] [PubMed]
- Rydén, L.; Grant, P.J.; Anker, S.D.; Berne, C.; Cosentino, F.; Danchin, N.; Deaton, C.; Escaned, J.; Hammes, H.-P.; Huikuri, H.; et al. ESC Guidelines on diabetes, pre-diabetes, and cardiovascular diseases developed in collaboration with the EASD. Eur. Heart J. 2013, 34, 3035–3087. [Google Scholar] [CrossRef] [PubMed]
- Reilly, B.M. Translating Clinical Research into Clinical Practice: Impact of Using Prediction Rules to Make Decisions. Ann. Intern Med. 2006, 144, 201. [Google Scholar] [CrossRef]
- Collins, G.S.; Moons, K.G.M. Comparing risk prediction models. BMJ 2012, 344, e3186. [Google Scholar] [CrossRef]
- Guasch-Ferré, M.; Bulló, M.; Costa, B.; Martínez-Gonzalez, M.Á.; Ibarrola-Jurado, N.; Estruch, R.; Barrio, F.; Salas-Salvadó, J.; PREDI-PLAN Investigators. A Risk Score to Predict Type 2 Diabetes Mellitus in an Elderly Spanish Mediterranean Population at High Cardiovascular Risk. PLoS ONE 2012, 7, e33437. [Google Scholar] [CrossRef]
- Alssema, M.; Vistisen, D.; Heymans, M.W. The Evaluation of Screening and Early Detection Strategies for Type 2 Diabetes and Impaired Glucose Tolerance (DETECT-2) update of the Finnish diabetes risk score for prediction of incident type 2 diabetes. Diabetologia 2010, 54, 1004–1012. [Google Scholar] [CrossRef]
- Schmidt, M.I.; Duncan, B.B.; Bang, H.; Pankow, J.S.; Ballantyne, C.M.; Golden, S.H.; Folsom, A.R.; Chambless, L.E.; Atherosclerosis Risk in Communities Investigators. Identifying Individuals at High Risk for Diabetes: The Atherosclerosis Risk in Communities study. Diabetes Care 2005, 28, 2013–2018. [Google Scholar] [CrossRef]
- Mann, D.M.; Bertoni, A.G.; Shimbo, D.; Carnethon, M.R.; Chen, H.; Jenny, N.S.; Muntner, P. Comparative Validity of 3 Diabetes Mellitus Risk Prediction Scoring Models in a Multiethnic US Cohort: The Multi-Ethnic Study of Atherosclerosis. Am. J. Epidemiol. 2010, 171, 980–988. [Google Scholar] [CrossRef]
- Stern, M.P. Identification of Persons at High Risk for Type 2 Diabetes Mellitus: Do We Need the Oral Glucose Tolerance Test? Ann. Intern Med. 2002, 136, 575. [Google Scholar] [CrossRef]
- Abdul-Ghani, M.A.; Abdul-Ghani, T.; Stern, M.P.; Karavic, J.; Tuomi, T.; Bo, I.; Defronzo, R.A.; Groop, L. Two-Step Approach for the Prediction of Future Type 2 Diabetes Risk. Diabetes Care 2011, 34, 2108–2112. [Google Scholar] [CrossRef]
- Collins, G.S.; Altman, D.G. External validation of QDSCORE® for predicting the 10-year risk of developing Type 2 diabetes. Diabet. Med. 2011, 28, 599–607. [Google Scholar] [CrossRef]
- Rahman, M.; Simmons, R.K.; Harding, A.-H.; Wareham, N.J.; Griffin, S.J. A simple risk score identifies individuals at high risk of developing Type 2 diabetes: A prospective cohort study. Fam. Pract. 2008, 25, 191–196. [Google Scholar] [CrossRef]
- Talmud, P.J.; Hingorani, A.D.; Cooper, J.A.; Marmot, M.G.; Brunner, E.J.; Kumari, M.; Kivimäki, M.; Humphries, S.E. Utility of genetic and non-genetic risk factors in prediction of type 2 diabetes: Whitehall II prospective cohort study. BMJ 2010, 340, b4838. [Google Scholar] [CrossRef]
- Wilson, P.W.F. Prediction of Incident Diabetes Mellitus in Middle-aged Adults. Arch. Intern Med. 2007, 167, 1068. [Google Scholar] [CrossRef] [PubMed]
- Rubin, D.B. Multiple imputation after 18+ years. J. Am. Stat. Assoc. 1996, 91, 473–489. [Google Scholar] [CrossRef]
- Pyykkonen, A.-J.; Raikkonen, K.; Tuomi, T.; Eriksson, J.G.; Groop, L.; Bo, I. Depressive Symptoms, Antidepressant Medication Use, and Insulin Resistance: The PPP-Botnia Study. Diabetes Care 2011, 34, 2545–2547. [Google Scholar] [CrossRef] [PubMed]
- Franzin, A.; Sambo, F.; Di Camillo, B. bnstruct: An R package for Bayesian Network structure learning in the presence of missing data. Bioinformatics 2016, btw807. [Google Scholar] [CrossRef]
- Collins, G.S.; Reitsma, J.B.; Altman, D.G.; Moons, K.G.M. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): The TRIPOD Statement. Ann. Intern Med. 2015, 162, 55. [Google Scholar] [CrossRef]
- Collins, D.; Lee, J.; Bobrovitz, N.; Koshiaris, C.; Ward, A.; Heneghan, C. Simple and adaptable R implementation of WHO/ISH cardiovascular risk charts for all epidemiological subregions of the world. F1000Research 2016, 5, 2522. [Google Scholar] [CrossRef] [PubMed]
- Lindström, J.; Ilanne-Parikka, P.; Peltonen, M.; Aunola, S.; Eriksson, J.G.; Hemiö, K.; Hämäläinen, H.; Härkönen, P.; Keinänen-Kiukaanniemi, S.; Laakso, M.; et al. Sustained reduction in the incidence of type 2 diabetes by lifestyle intervention: Follow-up of the Finnish Diabetes Prevention Study. Lancet 2006, 368, 1673–1679. [Google Scholar] [CrossRef]
- Montonen, J.; Knekt, P.; Järvinen, R.; Aromaa, A.; Reunanen, A. Whole-grain and fiber intake and the incidence of type 2 diabetes. Am. J. Clin. Nutr. 2003, 77, 622–629. [Google Scholar] [CrossRef] [PubMed]
- Ley, S.H.; Hamdy, O.; Mohan, V.; Hu, F.B. Prevention and management of type 2 diabetes: Dietary components and nutritional strategies. Lancet 2014, 383, 1999–2007. [Google Scholar] [CrossRef]
- Lin, C.-C.; Li, C.-I.; Liu, C.-S.; Lin, W.-Y.; Lin, C.-H.; Yang, S.-Y.; Li, T.-C. Development and validation of a risk prediction model for end-stage renal disease in patients with type 2 diabetes. Sci. Rep. 2017, 7, 10177. [Google Scholar] [CrossRef] [PubMed]
- Gillies, C.L.; Abrams, K.R.; Lambert, P.C.; Cooper, N.J.; Sutton, A.J.; Hsu, R.T.; Khunti, K. Pharmacological and lifestyle interventions to prevent or delay type 2 diabetes in people with impaired glucose tolerance: Systematic review and meta-analysis. BMJ 2007, 334, 299. [Google Scholar] [CrossRef]
- Gray, L.J.; Taub, N.A.; Khunti, K.; Gardiner, E.; Hiles, S.; Webb, D.R.; Srinivasan, B.T.; Davies, M.J. The Leicester Risk Assessment score for detecting undiagnosed Type 2 diabetes and impaired glucose regulation for use in a multiethnic UK setting. Diabet. Med. 2010, 27, 887–895. [Google Scholar] [CrossRef]





| Risk Score | Sample Size | Incident Cases of T2DM | Cut-Off Point | S | Sp | PPV | NPV | AUC |
|---|---|---|---|---|---|---|---|---|
| FINDRISC Internal [19] | 4586 | 182 | ≥9 | 0.78 | 0.77 | 0.13 | 0.99 | 0.85 |
| FINDRISC External [31] | 18,301 | 844 | ≥7 | 0.76 | 0.63 | 0.11 | NA | 0.76 |
| ARIC Internal [32] | 7915 | 1292 | ≥0.18 | 0.67 | 0.77 | 0.36 | 0.92 | 0.80 |
| ARIC External [33] | 5329 | 446 | NS | NS | NS | NS | NS | 0.84 * |
| San Antonio Internal [34] | 2903 | 275 | NA | NS | NS | NS | NS | 0.84 |
| San Antonio External [35] | 2395 | 124 | >0.0065 | 0.75 | 0.72 | 0.119 | NS | 0.83 * |
| QDScore Internal [36] | 3,773,585 | 115,616 | NS | NS | NS | NS | NS | 0.83 men 0.85 women |
| QDScore External [36] | 2,396,392 | 72,986 | NS | NS | NS | NS | NS | 0.80 men 0.81 women |
| Cambridge Internal [37] | 24,495 | 323 | >0.37 | 0.55 | 0.80 | NS | NS | 0.75 |
| Cambridge External [38] | 5135 | 302 | >0.37 | NS | NS | NS | NS | 0.72 |
| PREDIMED Internal [30] | 1381 | 155 | ≥6 | 0.72 | 0.72 | 0.25 | 0.95 | 0.78 |
| PREDIMED External [30] | 552 | 124 | ≥6 | 0.85 | 0.26 | 0.25 | 0.86 | 0.66 |
| Framingham Internal ** [39] | 3140 | 160 | NS | NS | NS | NS | NS | 0.84 |
| Framingham External ** [33] | 5329 | 446 | NS | NS | NS | NS | NS | 0.83 * |
| S | Sp | PPV | NPV | AUC | Cut-off | HL Score | p-Value | |
|---|---|---|---|---|---|---|---|---|
| FINDRISC | 0.38 | 1 | 1 | 0.6 | 0.69 | 0.180 | 0.003 | 0.043 |
| ARIC | 0.53 | 1 | 1 | 0.67 | 0.73 | 0.821 | 0.271 | 0.397 |
| SAN ANT | 0.61 | 1 | 1 | 0.71 | 0.76 | 0.065 | 0.018 | 0.107 |
| PREDIMED | 0.54 | 0.91 | 0.83 | 0.57 | 0.66 | 16.297 | 0.049 | 0.175 |
| CAMBRIDGE | 0.76 | 0.33 | 0.55 | 0.57 | 0.53 | 0.345 | 0.288 | 0.408 |
| FRAMINGHAM | 0.85 | 0.83 | 0.84 | 0.83 | 0.875 | 0.034 | <0.001 | 0.020 |
| VARIABLE | CONTROLS (n = 13) | CASES (n = 12) | p Value | MISSING DATA (%) | ||
|---|---|---|---|---|---|---|
| Gender | 4 M/9 F | 5 M/7 F | ||||
| Mean | SD | Mean | SD | |||
| Age | 65.76 | 8.20 | 59.41 | 9.28 | 0.082 | 0 |
| Body Mass Index | 28.78 | 5.20 | 32.16 | 8.46 | 0.433 | 56 |
| Waist | 98.66 | 5.13 | 92.00 | 0.00 | 0.377 | 84 |
| Systolic Blood Pressure | 130.00 | 12.94 | 136.67 | 21.82 | 0.451 | 36 |
| Diastolic Blood Pressure | 75.30 | 9.86 | 89.83 | 12.30 | 0.020 | 36 |
| Pulse | 70.85 | 8.78 | 74.00 | 12.20 | 0.613 | 52 |
| Cholesterol | 198.31 | 48.62 | 208.50 | 31.53 | 0.544 | 0 |
| Triglyceride | 149.23 | 60.63 | 175.75 | 61.96 | 0.290 | 0 |
| High-Density Lipoprotein (HDL) | 45.58 | 17.16 | 49.11 | 13.67 | 0.618 | 16 |
| Fasting Glucose | 101.55 | 12.34 | 98.27 | 10.51 | 0.510 | 12 |
| HbA1C | 5.89 | 0.37 | 5.58 | 0.40 | 0.132 | 32 |
| VARIABLE | CONTROLS (n = 25) | CASES (n = 23) | p Value | MISSING DATA (%) | ||
|---|---|---|---|---|---|---|
| Gender | 12 M/13 F | 13 M/10 F | ||||
| Mean | SD | Mean | SD | |||
| Age | 61.6 | 8.98 | 62.35 | 11.18 | 0.800 | 0.00 |
| Body Mass Index | 29.22 | 6.14 | 32.13 | 7.87 | 0.319 | 45.80 |
| Waist | 96 | 6.10 | 115 | 24.95 | 0.262 | 85.40 |
| Systolic Blood Pressure | 135.41 | 18.514 | 128 | 16.749 | 0.237 | 31.25 |
| Diastolic Blood Pressure | 82.41 | 12.76 | 79.5 | 9.07 | 0.020 | 36.00 |
| Pulse | 71.25 | 10.83 | 81.92 | 12.62 | 0.030 | 45.83 |
| Cholesterol | 204.76 | 41.43 | 203.23 | 41.75 | 0.900 | 2.08 |
| Triglyceride | 177.52 | 94.29 | 195.9 | 68.36 | 0.290 | 0.00 |
| HDL | 45.58 | 17.16 | 49.11 | 13.67 | 0.643 | 4.16 |
| Fasting Glucose | 100.82 | 11.083 | 108.13 | 8.95 | <0.05 | 6.00 |
| HbA1C | 5.75 | 0.41 | 6.17 | 0.19 | <0.05 | 54.00 |
| Gender | Male(2)/Female (6) | |
| Age (Years) | 42 ± 13 | |
| Professional Experience (years) | 14 ± 10 | |
| IT Literacy (Self-reported) | High = 3; Medium = 3; Low = 2 | |
| Patients assisted (number of) | Overall | 319.33 ± 247.66 |
| TD2M Patients | 127.44 ± 75.22 | |
| High Risk of developing T2DM | 48.00 ± 33.79 | |
| Recommendation | Risk Outcome | Statistical Analysis | ||
|---|---|---|---|---|
| LOW RISK | HIGH RISK | p | Chi2 | |
| Order an 2h-OGTT for this patient | 4 | 6 | 0.654 | 0.20 |
| Order an HbA1c test for this patient | 15 | 19 | 0.466 | 0.52 |
| Refer to General endocrinologist | 1 | 2 | - | - |
| Refer to General Practitioner | 11 | 12 | - | - |
| Start Pharmacological Treatment | 1 | 8 | 0.004 | 8.00 |
| Start Dietary Habits | 5 | 12 | 0.039 | 4.23 |
| Start Moderate Physical Activity Habits | 6 | 11 | 0.170 | 1.88 |
| Counsel about healthy lifestyle | 15 | 11 | 0.405 | 0.69 |
| Counsel about diet, physical activity, and weight control | 6 | 11 | 0.170 | 1.88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez-Millana, A.; Argente-Pla, M.; Valdivieso Martinez, B.; Traver Salcedo, V.; Merino-Torres, J.F. Driving Type 2 Diabetes Risk Scores into Clinical Practice: Performance Analysis in Hospital Settings. J. Clin. Med. 2019, 8, 107. https://doi.org/10.3390/jcm8010107
Martinez-Millana A, Argente-Pla M, Valdivieso Martinez B, Traver Salcedo V, Merino-Torres JF. Driving Type 2 Diabetes Risk Scores into Clinical Practice: Performance Analysis in Hospital Settings. Journal of Clinical Medicine. 2019; 8(1):107. https://doi.org/10.3390/jcm8010107
Chicago/Turabian StyleMartinez-Millana, Antonio, María Argente-Pla, Bernardo Valdivieso Martinez, Vicente Traver Salcedo, and Juan Francisco Merino-Torres. 2019. "Driving Type 2 Diabetes Risk Scores into Clinical Practice: Performance Analysis in Hospital Settings" Journal of Clinical Medicine 8, no. 1: 107. https://doi.org/10.3390/jcm8010107
APA StyleMartinez-Millana, A., Argente-Pla, M., Valdivieso Martinez, B., Traver Salcedo, V., & Merino-Torres, J. F. (2019). Driving Type 2 Diabetes Risk Scores into Clinical Practice: Performance Analysis in Hospital Settings. Journal of Clinical Medicine, 8(1), 107. https://doi.org/10.3390/jcm8010107