1. Introduction
Global trends indicate a rising prevalence of total hip arthroplasties (THA). Similarly, revision arthroplasties will increase, which are more expensive and are associated with poorer outcomes and more complications [
1,
2,
3]. THA procedures in the United States are estimated to grow by 174% until the year 2030, while the number of THA revisions will double by 2026 [
4].
These findings suggest that the identification of patients at risk for revision is crucial for the individual patient as well as for health care providers in regard to the expected unsustainable expenditures. Hence, risk stratification models have been developed to face this problem. However, current risk analysis tools in arthroplasty have been moderately accurate so far in predicting adverse outcomes [
5]. A major problem with these existing risk stratification models is that they do not sufficiently include specific risk factors in arthroplasty, which together may significantly contribute to the failure of the arthroplasty. However, it is hard to quantify such a revision probability as multilinear correlations are difficult to realize in conventional risk stratification models. Therefore, more comprehensive and specific risk analysis tools are urgently needed.
Machine Learning (ML) evolved from learning theory and is capable of detecting multilinear correlations in complex datasets [
6]. ML applications in arthroplasty are gaining popularity as they may potentially improve preoperative decision making [
7].
Shah et al. investigated administrative data from 89,986 adults who underwent primary THA to predict major complications after primary THA by comparing different ML algorithms and logistic regression models [
8]. Although the authors concluded superior discriminative ability of a ML approach, they concluded that the predictive performance was not sufficient for clinical applicability. They further indicated that the most important variables for their algorithm were malnutrition, dementia and cancer. The investigated administrative database, however, does not provide arthroplasty-specific variables. It is therefore obvious that no arthroplasty-specific variables were considered relevant by their algorithm. Hence, the relevance of malnutrition, dementia and cancer as the most relevant parameters for major complications after primary THA must be further discussed, especially in view of the clinical applicability of such prediction models. The prediction of clinically relevant outcomes such as the occurrence of revisions or complications is intricate as predicting seldom outcomes is not just limited by the amount, but also by the complexity of the applied data. Hence, the prediction of rare outcomes such as adverse events in arthroplasty might not be feasible using only administrative data. We therefore consider the implementation of parameters specific to arthroplasty to be crucial.
Our hypothesis is that an accurate prediction model must have a balanced calibration of specific input data, the algorithm and the outcome labels. We assume that a close collaboration between data scientists and orthopedic surgeons is crucial in this context as extensive knowledge of data science methodology and arthroplasty procedures is necessary. Hence, in this study, we evaluate a ML approach applying data from two German arthroplasty-specific registries to predict adverse outcomes after THA after careful evaluations of ML algorithms, outcome and input variables by an interdisciplinary team of data scientists and surgeons.
3. Results
Overall, 1217 patients with a median age of 67 (13, 97) were included in this study. In total, 672 (55.2%) patients were female and 545 (44.8%) were male. The median BMI was at 23 with a standard deviation of 11.7. Indications for THA were classified as primary osteoarthritis (817, 67.1%), dysplasia (129, 10.6%), fracture (16, 1.3%), femoral head necrosis (80, 6.6%), posttraumatic osteoarthritis (46, 3.8%) and tumor/metastasis (129, 10.6%). The surgeries were performed by 17 different main surgeons with a share of 0.1% up to 26.0% of all surgeries. The experience level of surgeons specified by the EndoCert initiative was distributed from 1.4% (level 1), 9.1% (level 2), 0.1% (level 3), 16.4% (level 4) to 73.0% (level 5). In total, 225 complications in 161 cases occurred (41 cases with multiple complications): inclination > 50° (66/29.3%), infection (41/18.2%), dislocation (8/3.6%), fracture of greater trochanter (23/10.2%), periprosthetic fracture (22/9.8%), revision surgery 40/17.8%, thromboembolism (10/4.4%), mortality (8/3.6%) and neurologic complications (7/3.1%). Surgery duration lasted from 38 to 339 min. The distribution of the outcome labels is summarized in
Table 2.
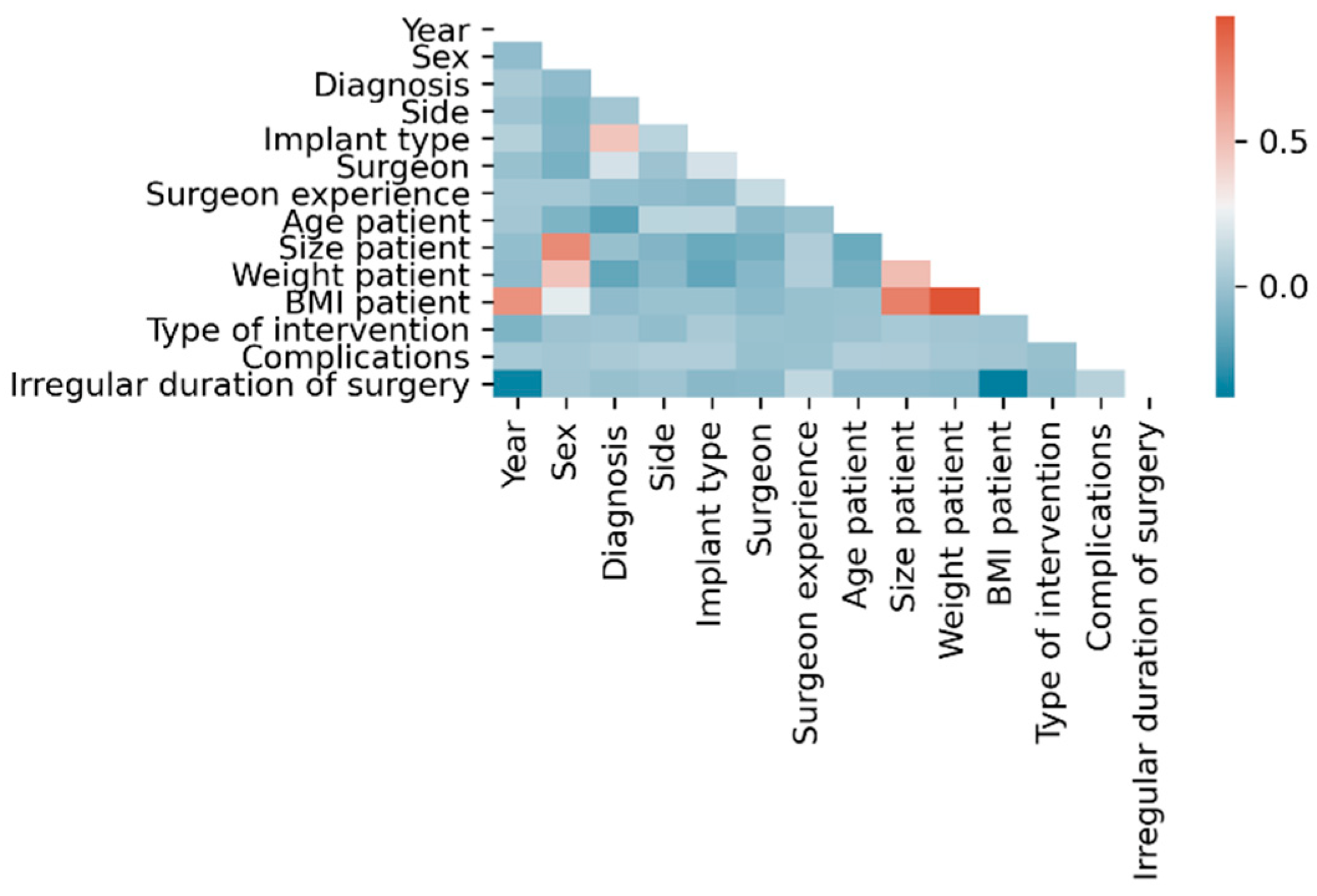
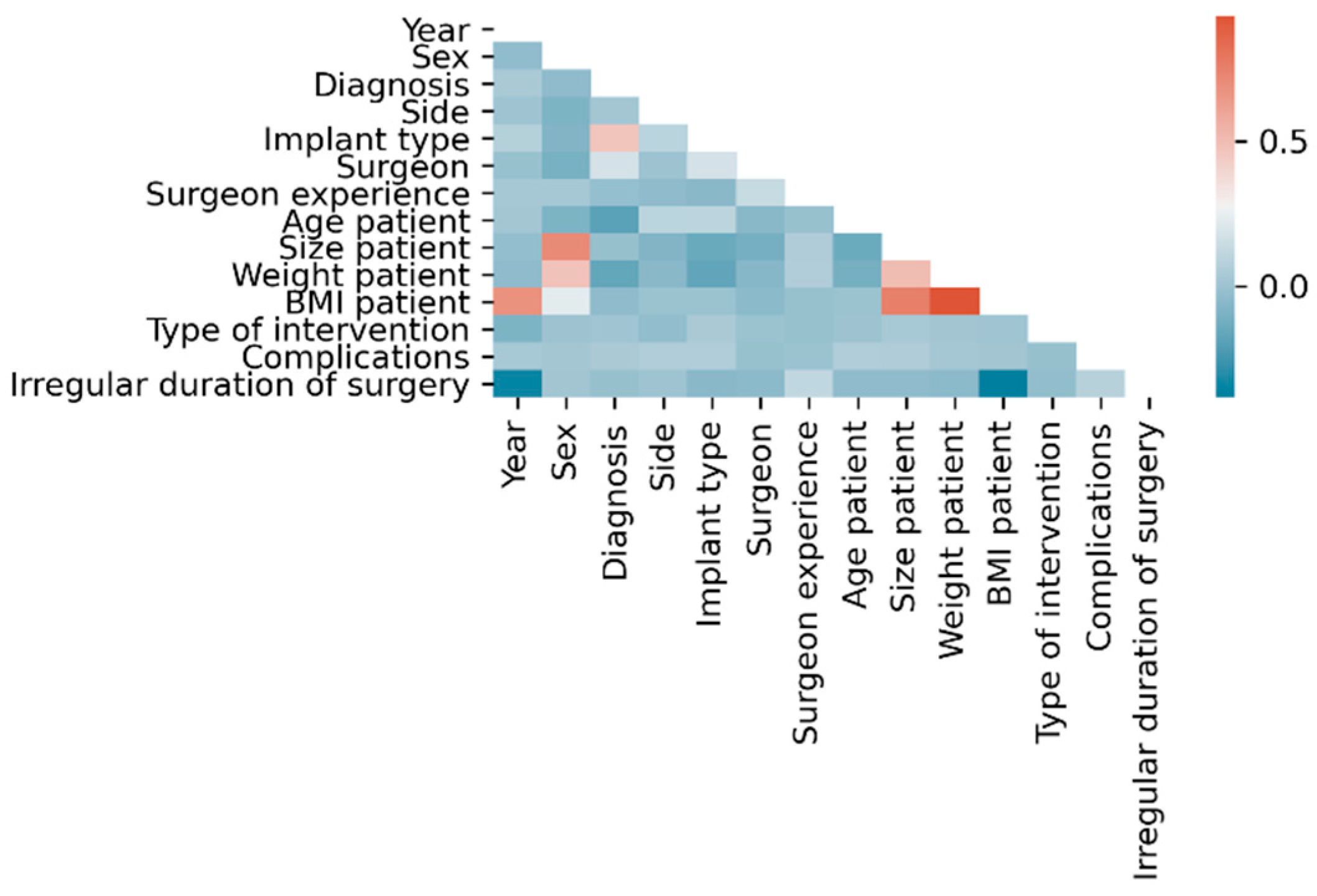
Within the dataset, the following linear correlations were found using classical statistical methods considering |ρ| > 0.5 as statistically relevant: BMI with each year (ρ = 0.68), height (ρ = 0.75) and weight (ρ = 0.93), height with sex (ρ = −0.71) and weight with height (ρ = 0.51) (
Figure 2).
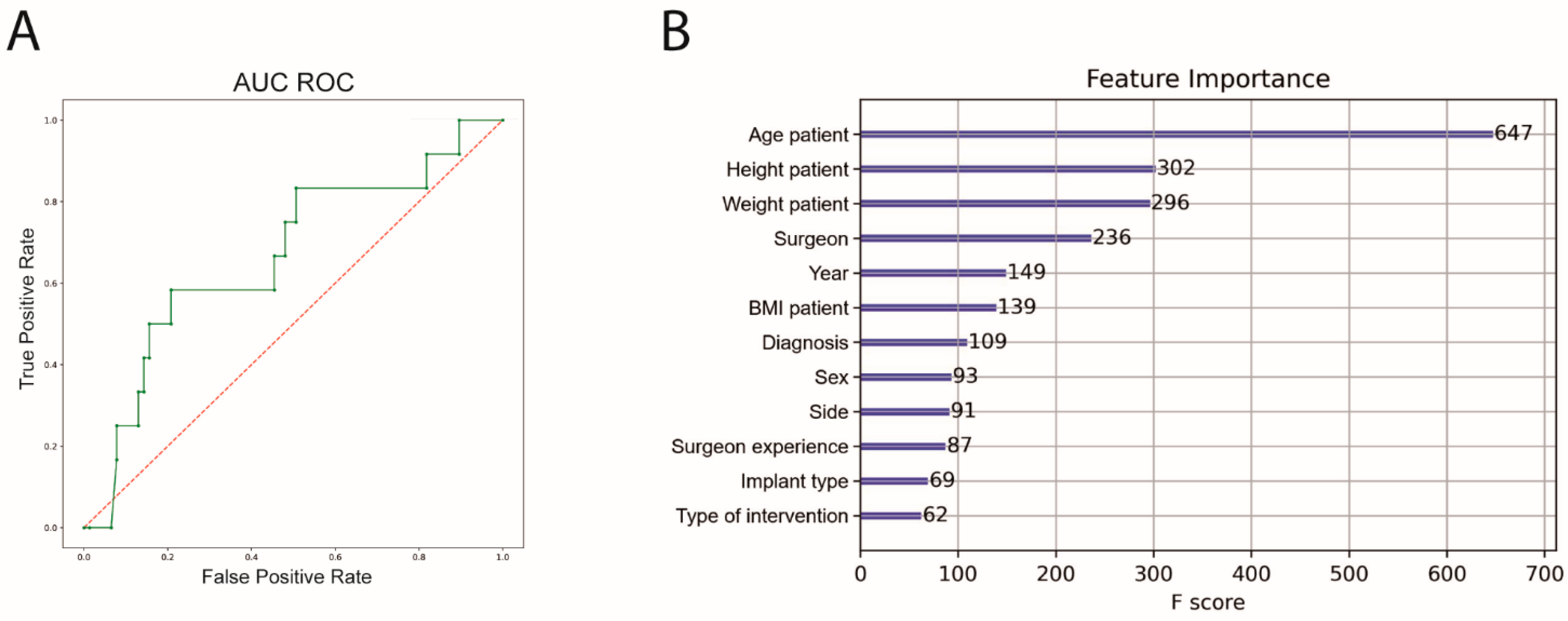
For ML, cross-validation with an 8-fold split was performed (training
n = 1065, test
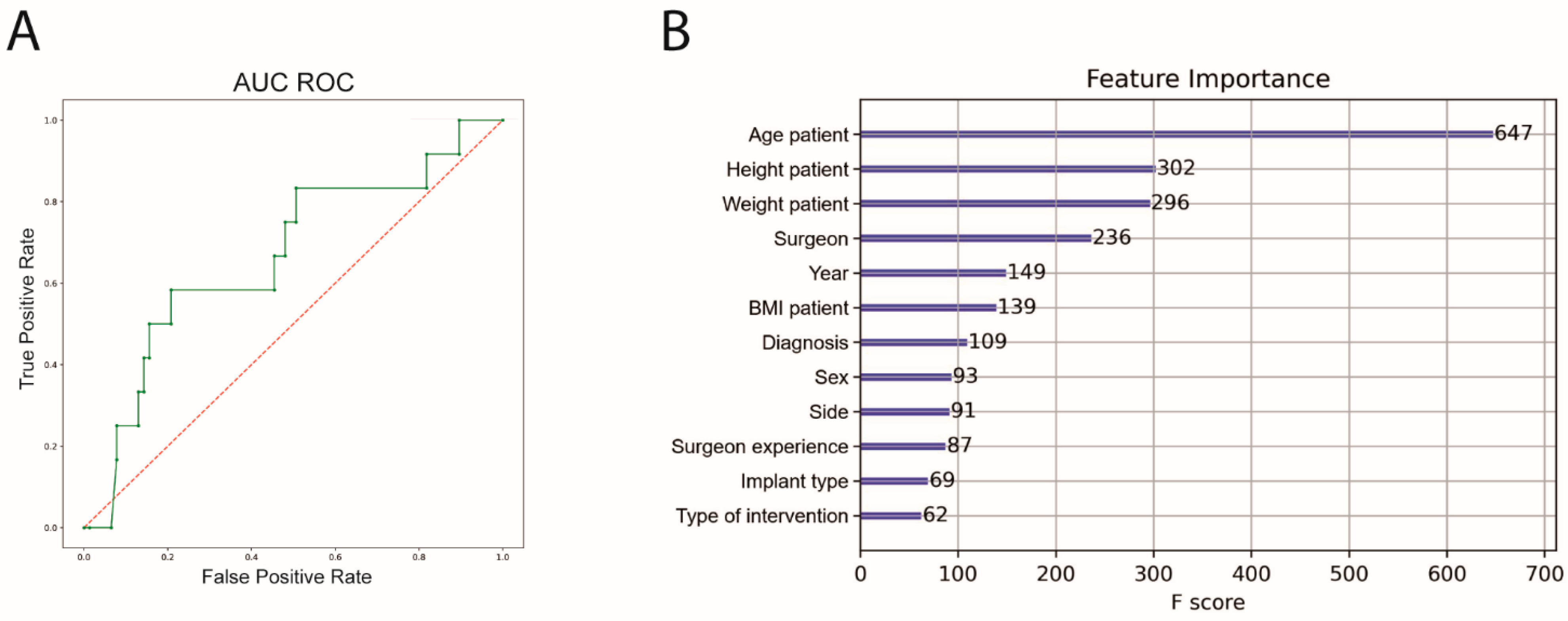
n = 152). The performance of the ML algorithm for predicting complications showed a sensitivity of 31.0%, a specificity of 89.4%, an accuracy of 80.3% and an area under the receiver operating curve (AUC ROC) of 64.1%. Feature importance was subsequently calculated. The highest feature importance for predicting complications was patient age, height and weight before surgeon (
Figure 3).
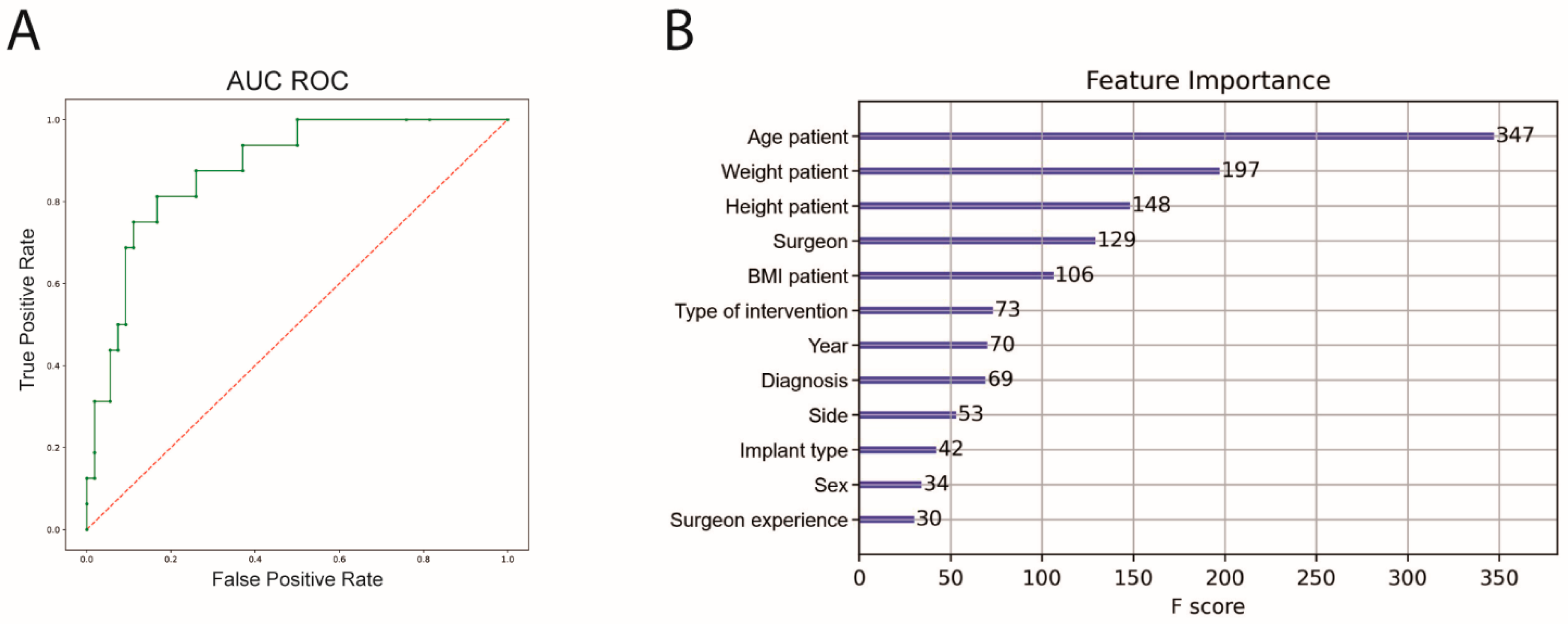
An 8-fold cross-validation was also performed for the prediction of irregular surgery duration. The performance of the ML algorithm showed a sensitivity of 58.2%, a specificity of 91.6%, an accuracy of 81.7% and an AUC ROC of 89.1%. Patient age, weight and height before intervention had the highest significance for predicting complications (
Figure 4). The outcome metrics for both prediction models are summarized in
Table 3.
4. Discussion
Current risk stratification tools do not provide actionable intelligence in clinical practice as their results cannot be directly transferred to clinical cases. Therefore, ML approaches capable of improving preoperative decision making are gaining popularity. However, no clinically applicable models have been developed yet, as predictive performances were heterogeneously reported [
8,
13,
14]. The most important finding of this study is that a feasible ML model was developed for the prediction of complications and irregular surgical durations in primary THA with a high accuracy by using data from two arthroplasty registries. In this context, we highlight our novel methodological approach: input parameters, algorithm and output variables were carefully balanced by an orthopedic surgeon and a data scientist. The most immediate consequence for everyday clinical practice is that a data scientist should be involved in clinical processes.
ML models have predictive power, meaning they can correctly predict outcomes over the course of time as they respond and adapt to complex data inputs. The aspect of learning is achieved by function optimization: the algorithm seeks to determine the best parameter constellations that will minimize the error when confronted with a novel dataset. This training process relies on sufficient data that are complex enough to reveal specific parameter constellations. In data science, the lack of data complexity may be countered by large data volumes. Hence, most of ML applications in orthopedics utilize imaging data [
6]. Conversely, data concerning the outcomes of THA are stored in tabular form which, however, has a significantly lower information density than imaging data, even compared to extensive administrative data available in registries and hospital information systems.
Hence, the outcome to be predicted and the ML algorithm should be suited to the applied dataset. Current tabular data volumes concerning THA forbid more complex applications such as deep learning. Hence, even if arthroplasty-specific data are considered, it does not necessarily imply that the prediction of multifactorial events such as revision must be feasible. We assume that simpler surrogates are easier to predict with less extensive datasets. Furthermore, the selection of a ML algorithm has a significant influence on the model performance [
15]. A variety of algorithms for specific tasks exists and the choice of a suitable algorithm is difficult.
Noteworthy, a high number of different input parameters do not necessarily improve the performance of a ML algorithm. Quite the contrary, feature selection techniques exist to avoid overfitting and improve model performance by restricting the amount of input parameters (i.e., cross-validation, data augmentation, L1/L2 regularization or removal of layers) [
16]. From these methodological considerations, we hypothesized that a ML application intended to predict specific outcomes based on tabular data in orthopedics requires well-considered, specific input data. Hence, we assume that the methodological and substantial discussion regarding the outcomes a priori to the computation of the ML algorithm is mandatory in order to obtain meaningful results that seem clinically and methodologically plausible. For this reason, complications in total were chosen as the outcome label, since in our dataset single complications as listed by EndoCert occurred too rarely. Hence, a representative prediction of specific complications was not technically feasible. Similarly, the low data density for irregular surgery durations forbids the definition of a cut-off value applying continuous variables. Hence, a binary classification into regular and irregular durations was established, with which accurate results could finally be derived.
Interestingly, the prediction of complications yielded worse AUC and sensitivity compared to the duration prediction. This is most likely due to the fact that irregular durations were found almost twice as often as complications (13.2% vs. 21.9%). Hence, a greater class imbalance of cases with and without complications was present so that a highly sensitive prediction in the limited test set of only 152 cases was not achieved.
A particular challenge in the application of ML is that the decisions made by the algorithm are not intelligible in retrospect. Such algorithms are referred to as black box models, whose predications are based on a combination of variables from complex functions which cannot be reproduced from neither the code nor the results. Black box models have high predictive power, but if black box models are superior to interpretable models is currently the subject of scientific research in the field of data science [
17]. In this context, the feature importance indicates to which extent a variable has been weighted by the ML model without indicating a causal relationship nor unbiased associations. An interpretation of the results and an evaluation of significant correlations have to be performed subsequently. In this study, the highest feature importance for both complication and duration prediction was age, height and weight. Younger patient age and obesity have previously been described as risk factors in primary THA [
18,
19,
20]. However, a significant finding of this study is that these results were derived from the ML algorithm and have not been found by classic statistical analysis using a logistic function model in this dataset, indicating the successful feasibility of this approach.
Interestingly, the particular surgeon showed the fourth highest feature importance in both prediction models. It is reasonable to assume that the individual surgeon has an impact on the success of the procedure. However, it has been difficult to incorporate a surrogate for the individual expertise of a surgeon into more conventional risk stratification models so far. One of the strengths of ML is its ability to compute such daily clinical data. However, even if the results are clinically comprehensible, they must be analyzed with a data scientist for confounding and systemic errors. In this study, out of 17 surgeons, 3 surgeons performed 58% of the operations. Ten surgeons performed less than 10% and eight surgeons performed less than 2% of the operations, respectively, resulting in a relevant class imbalance. Complications occurring in cases of the latter surgeons are weighted far greater and therefore most likely contribute to the high feature importance. However, whether this result means that an experienced surgeon contributes significantly to fewer complications and regular surgery times or that the presence of various inexperienced surgeons biases this result by raising the feature importance, cannot be finally assessed as the inherent decisions of the ML algorithm cannot be retrieved. In this context, it is interesting to note that the experience of the surgeon as classified by EndoCert has only a poor feature importance in this study. However, this finding has clinical relevance as the surgeon and his experience should be included in further clinical evaluations of risk factors in THA. Hence, these results are reason to (1) further investigate this correlation with conventional statistical models and (2) to tackle the problem of class imbalance in ML applications in arthroplasty. The latter may be assessed by external validation of the algorithm with larger datasets. However, it is highly unlikely that class imbalance will be fully resolved in medicine, since the occurrence of adverse events will naturally always be more seldom than the number of successful treatments. This is a desirable scenario from a statistical point of view, since it corresponds to a Gaussian distribution and does not induce a bias to the dataset. From a data science perspective, however, a class imbalance impedes an increase in the results and has to be tackled through larger datasets so that the class imbalance becomes less impactful and the algorithm can still learn patterns from the data at hand. We therefore conclude that a profound discussion of the dataset and the derived outcomes is critical, especially regarding the outlook of possible ML applications as decision support systems in orthopedics, where decisions are at high stakes and the data basis is rather small from a data science perspective.
Interestingly, diagnosis and implant type had low feature importance, although we assumed otherwise. Whether substantive or methodological causes account for the missing impact of these parameters in both ML algorithms remains unclear due to the black box model. The most common diagnosis was primary osteoarthritis with 67.1% and the most common implant type was primary implants with 76.6%. A potential impact of these parameters for the outcome prediction has to be revaluated with either a more balanced dataset or by a detailed analysis of the various diagnoses and implant types in separate datasets.
This study has several limitations. The first and utmost relevant limitation is the low data volume from a data science perspective. The data preparation as described above resulted in an aggregation of data in categorical variables. This results in the loss of potentially relevant information through the simplification of the dataset. Elaborate information such as implant components differentiated by a manufacturer could not be adequately addressed by this approach because there simply were not enough separate datasets available. The generalization of these data may have led to a selection bias. Second, the availability of data in both arthroplasty-specific registries was restricted. Weight and height were only available in the registry since 2017. As both parameters demonstrated relevant results in this study, we did not exclude them from the analysis despite the missing data points. For this reason, however, we chose a ML algorithm capable of handling missing data points. Although no relevant deviations are expected in the missing weight and height data, the results may theoretically differ after inclusion. Third, the results of this study are not generalizable as the algorithm is not externally validated. However, we applied several statistical measures (e.g., cross validation, data split) to provide significance. In this context, we highlight that we aimed to conduct a feasibility study with single-center data. The results must therefore be interpreted under these circumstances.
In conclusion, after thorough calibration of input and output data as well as the definition of outcome labels by an orthopedic surgeon and a data scientist, we were able to build an accurate ML model for the prediction of complications and irregular surgery durations for primary THA. Age, height, weight and the performing surgeon showed the highest feature importance for both complication and duration prediction. These parameters, however, were not assessed by conventional statistical evaluations. Therefore, we recommend assessing arthroplasty-specific data in future clinical practice to build an in-depth database for the clinical application of ML prediction models. For the successful implementation of these data in ML applications, a data scientist should be directly involved in the clinical workflows. Interdisciplinary analysis by a data scientist and an orthopedic surgeon to comprehend the significance of identified parameters outside the scope of the presented ML model is crucial to allow for accurate prediction models.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}