
Common Laboratory Parameters Are Useful for Screening for Alcohol Use Disorder: Designing a Predictive Model Using Machine Learning

 , ,
, ,  ,
,
Abstract
1. Introduction
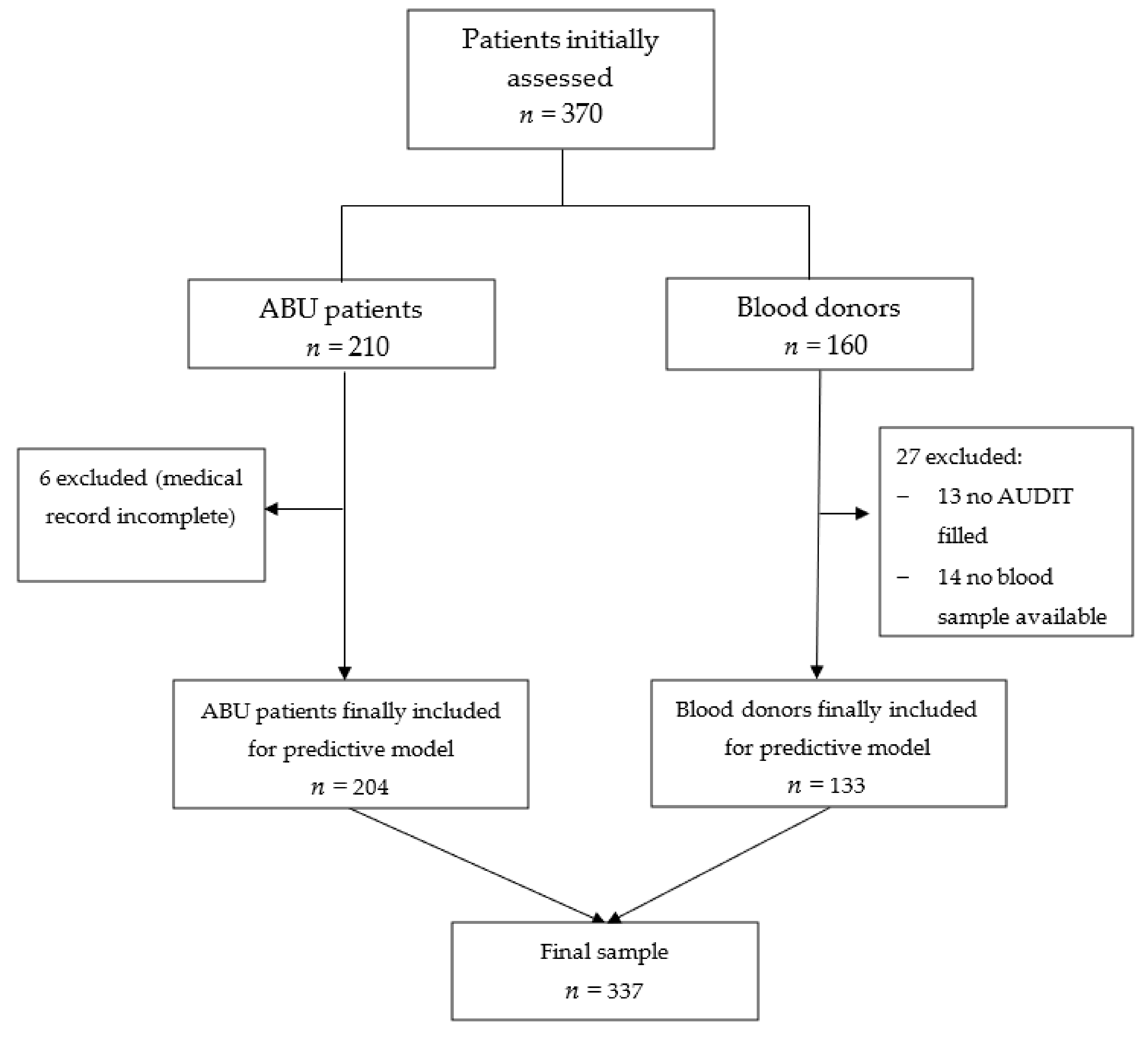
2. Materials and Methods
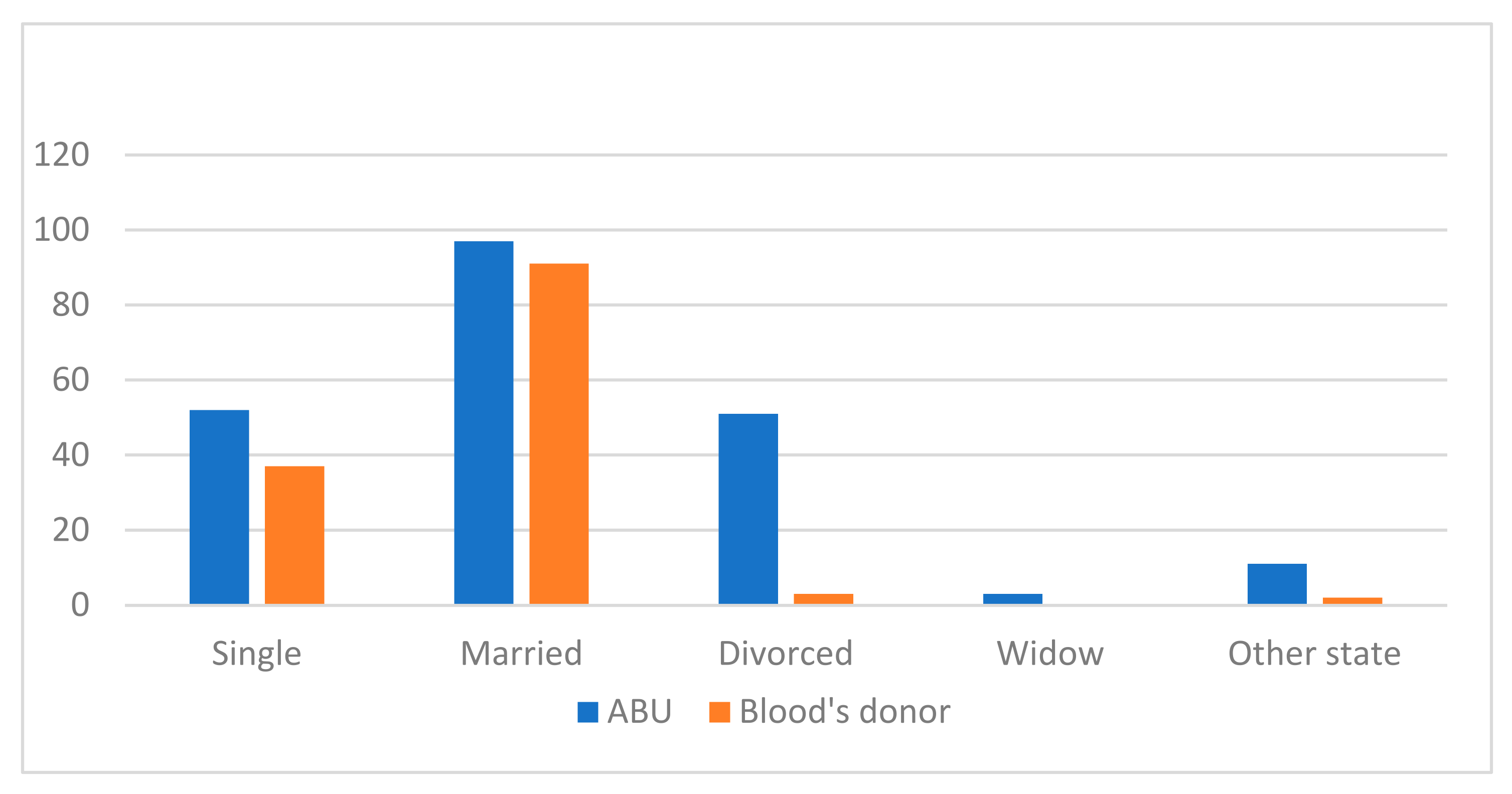
3. Results
3.1. Logistic Regression
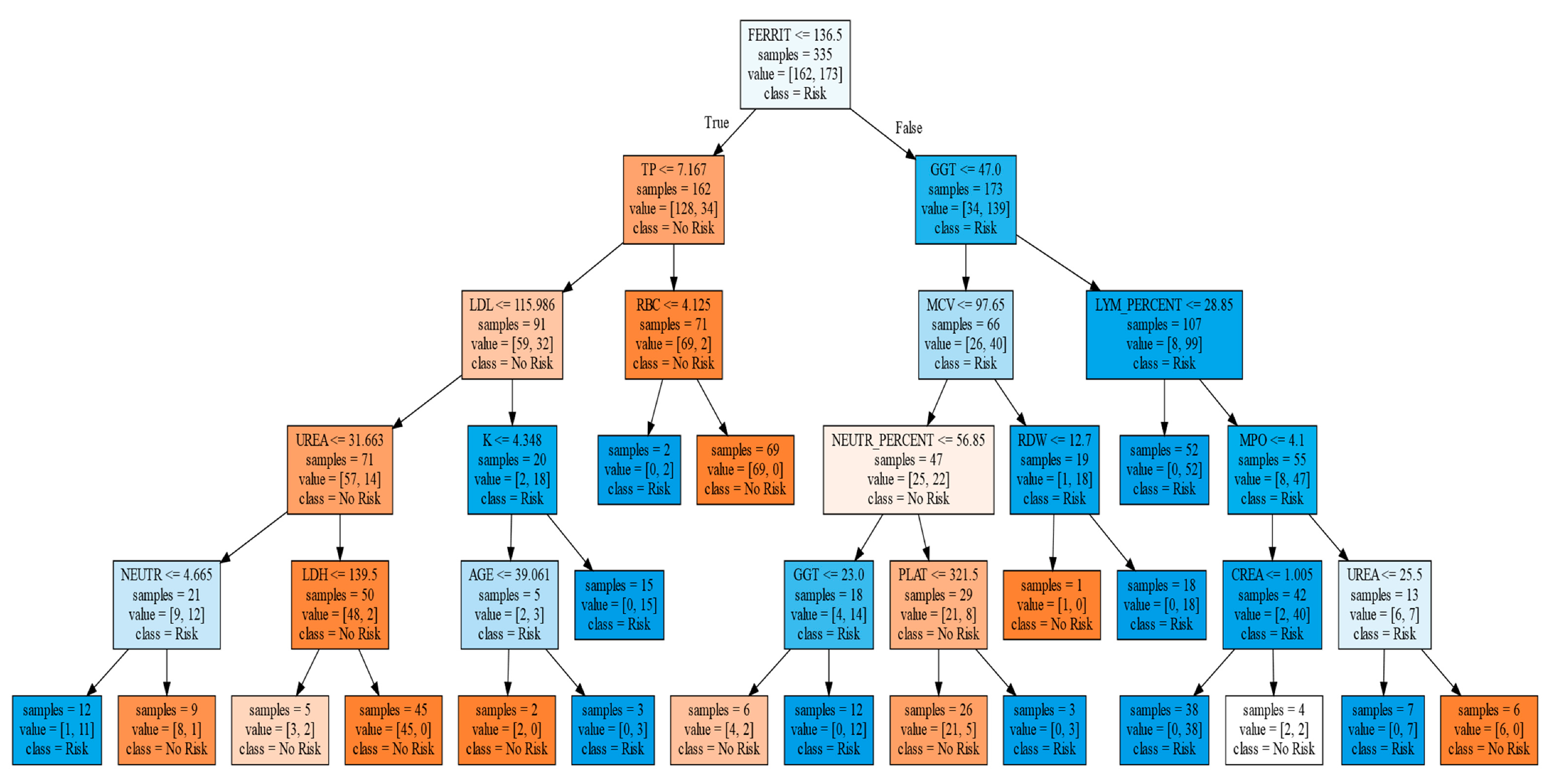
3.2. Classification Tree
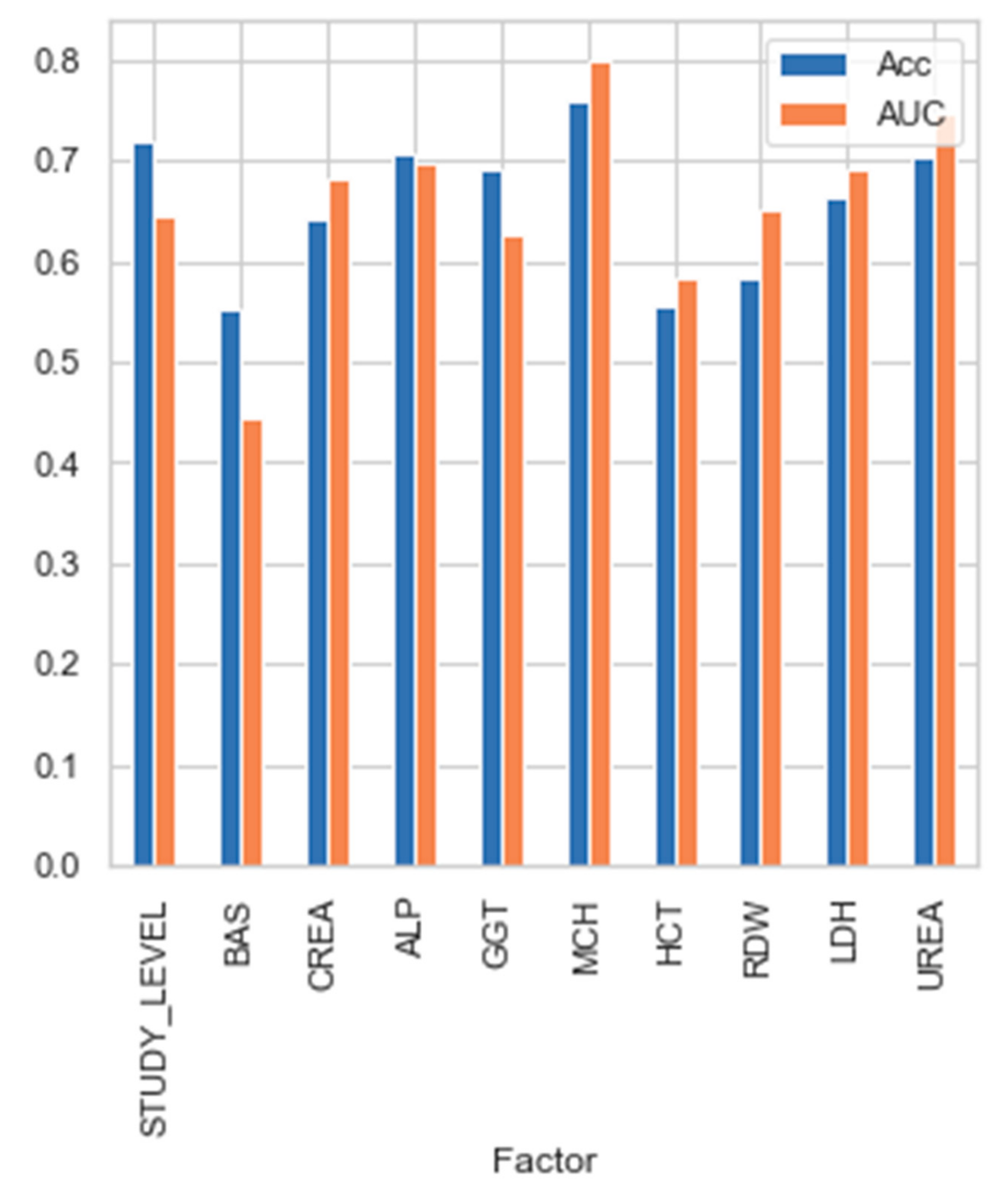
3.3. Bayesian Network
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Friedmann, P.D. Alcohol use in adults. N. Engl. J. Med. 2013, 368, 365–373. [Google Scholar] [CrossRef] [PubMed]
- Benítez-Villa, J.L.; Fernández-Cáceres, C. Comorbilidad Médica Asociada al Abuso y Dependencia de Alcohol. Revisión Documental. Revista Internacional de Investigación en Adicciones. Medical Comorbidity Associated with Alcohol Abuse and Dependence. Document Review. Int. J. Addict. Res. 2019. Available online: http://riiad.org/index.php/riiad/article/view/riiad.2019.1.06/269#toc (accessed on 16 October 2021).
- International Agency for Research on Cancer. Report of the Advisory Group to Recommend Priorities for the IARC Monographs during 2020–2024. IARC Monogr Eval Carcinog Risks to Humans. 2020, (April 2014):i-ix+1-390. Available online: http://monographs.iarc.fr/ENG/Monographs/vol83/mono83-1.pdf (accessed on 16 October 2021).
- Loftfield, E.; Stepien, M.; Viallon, V.; Trijsburg, L. Novel Biomarkers of Habitual Alcohol Intake and Associations with Risk of Pancreatic and Liver Cancers and Liver Disease Mortality; Oxford University Press: Oxford, UK, 2021; pp. 1–33. [Google Scholar]
- Esser, M.B.; Sherk, A.; Liu, Y.; Naimi, T.S.; Stockwell, T.; Stahre, M. Deaths and Years of Potential Life Lost From Excessive Alcohol Use—United States, 2011–2015. Morb. Mortal. Wkly. Rep. 2020, 69, 981. [Google Scholar] [CrossRef] [PubMed]
- Whitty, M.; Nagel, T.; Jayaraj, R.; Kavanagh, D. Development and evaluation of training in culturally specific screening and brief intervention for hospital patients with alcohol-related injuries. Aust. J. Rural Health 2016, 24, 9–15. [Google Scholar] [CrossRef] [PubMed]
- Parsley, I.C.; Dale, A.M.; Fisher, S.L.; Mintz, C.M.; Hartz, S.M.; Evanoff, B.A.; Bierut, L.J. Association Between Workplace Absenteeism and Alcohol Use Disorder From the National Survey on Drug Use and Health, 2015–2019. JAMA Netw. Open. 2022, 5, e222954. [Google Scholar] [CrossRef]
- Gakh, M.; Coughenour, C.; Assoumou, B.O.; Vanderstelt, M. The Relationship between School Absenteeism and Substance Use: An Integrative Literature Review. Subst. Use Misuse 2020, 55, 491–502. [Google Scholar] [CrossRef]
- Van Loon, M.; Van Der Mast, R.C.; Van Der Linden, M.C.; Van Gaalen, F.A. Routine alcohol screening in the ED: Unscreened patients have an increased risk for hazardous alcohol use. Emerg. Med. J. 2019, 37, 206–211. [Google Scholar] [CrossRef]
- Nowakowska-Domagała, K.; Jabłkowska-Górecka, K.; Mokros, Ł.; Koprowicz, J.; Pietras, T. Differences in the verbal fluency, working memory and executive functions in alcoholics: Short-term vs. long-term abstainers. Psychiatry Res 2017, 249, 1–8. [Google Scholar] [CrossRef]
- Torrens, M.; Domingo-salvany, A. Patología dual: Una perspectiva europea Dual diagnosis: An European perspective. Adicciones 2017, 29, 2016–2018. [Google Scholar] [CrossRef]
- Rehm, J.; Anderson, P.; Manthey, J.; Shield, K.D.; Struzzo, P.; Wojnar, M.; Gual, A. Alcohol Use Disorders in Primary Health Care: What Do We Know and Where Do We Go? Alcohol Alcohol. 2015, 51, 422–427. [Google Scholar] [CrossRef]
- Knightly, R.; Tadros, G.; Sharma, J.; Duffield, P.; Carnall, E.; Fisher, J.; Salman, S. Alcohol screening for older adults in an acute general hospital: FAST v. MAST-G assessments. BJPsych Bull. 2016, 40, 72–76. BJPsych Bull. 2016, 40, 72–76. [Google Scholar] [CrossRef]
- Rosón, B.; Corbella, X.; Perney, P.; Santos, A.; Stauber, R.; Lember, M.; Arutyunov, A.; Ruza, I.; Vaclavik, J.; García, L.; et al. Prevalence, Clinical Characteristics, and Risk Factors for Non-recording of Alcohol Use in Hospitals across Europe: The ALCHIMIE Study. Alcohol Alcohol. 2016, 51, 457–464. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Brime, N.G.B. Observatorio Español de las Drogas y las Adicciones. Informe 2021. Alcohol, Tabaco y Drogas Ilegales en España; Spanish Observatory of Drugs and Addictions. Report 2021. Alcohol, Tobacco and Illegal Drugs in Spain; Ministry of Health, Government Delegation for the National Plan on Drugs: Madrid, Spain, 2021; pp. 6–65. [Google Scholar]
- Marcos Martín, M.; Pastor Encinas, I.; Laso, F.J. Marcadores biológicos del alcoholismo. [Alcoholism’s biomarkers]. Rev. Clín. Esp. 2005, 205, 443–445. [Google Scholar] [CrossRef] [PubMed]
- Chaudhari, R.; Moonka, D.; Nunes, F. Using biomarkers to quantify problematic alcohol use. J. Fam. Pract. 2021, 70, 474–481. [Google Scholar] [CrossRef] [PubMed]
- Tavakoli, H.R.; Hull, M.; Okasinski, L.M. Review of current clinical biomarkers for the detection of alcohol dependence. Innov. Clin. Neurosci. 2011, 8, 26–33. [Google Scholar]
- Hurme, L.; Seppä, K.; Rajaniemi, H.; Sillanaukee, P. Chromatographically identified alcohol-induced haemoglobin adducts as markers of alcohol abuse among women. Eur. J. Clin. Investig. 1998, 28, 87–94. [Google Scholar] [CrossRef]
- Israel, Y.; Hurwitzt, E.; Niemela, O.; Arnont, R. Monoclonal and polyclonal antibodies against acetaldehyde–containing epitopes in acetaldehyde-protein adducts. Proc. Natl. Acad. Sci. USA 1986, 83, 7923–7927. [Google Scholar] [CrossRef]
- Koivisto, H.; Hietala, J.; Anttila, P.; Niemelä, O. Co-Occurrence of IgA Antibodies Against Ethanol Metabolites and Tissue Transglutaminase in Alcohol Consumers: Correlation with Proinflammatory Cytokines and Markers of Fibrogenesis. Dig. Dis. Sci. 2008, 53, 500–505. [Google Scholar] [CrossRef]
- Harris, J.C.; Leggio, L.; Farokhnia, M. Blood Biomarkers of Alcohol Use: A Scoping Review. Curr. Addict Rep. 2021, 8, 500–508. [Google Scholar] [CrossRef]
- Silczuk, A.; Habrat, B. Alcohol-induced thrombocytopenia: Current review. Alcohol 2020, 86, 9–16. [Google Scholar] [CrossRef]
- Sillanaukee, P. The diagnostic Value of a Discriminant Score in the Detection of Alcohol Use. Arch. Pathol. Lab. Med. 1992, 116, 924–929. [Google Scholar]
- Hartz, A.J.; Guse, C.; Kajdacsy-Balla, A. Identification of heavy drinkers using a combination of laboratory tests. J. Clin. Epidemiol. 1997, 50, 1357–1368. [Google Scholar] [CrossRef]
- Harasymiw, J.; Bean, P. The combined use of the early detection of alcohol consumption (EDAC) test and carbohydrate-deficient transferrin to identify heavy drinking behaviour in males. Alcohol Alcohol. 2001, 36, 349–353. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Anton, R.F.; Moak, D.H. Carbohydrate-Deficient Transferrin and γ-Glutamyltransferase as Markers of Heavy Alcohol Consumption: Gender Differences. Alcohol. Clin. Exp. Res. 1994, 18, 747–754. [Google Scholar] [CrossRef]
- van Pelt, J.; Leusink, G.L.; van Nierop, P.W.N.; Keyzer, J.J. Carbohydrate- Deficient Transferrin and gammaglutamyltransferase in alcohol-using perimenopausal women. Alcohol. Clin. Exp. Res. 2000, 24, 176–179. [Google Scholar] [CrossRef] [PubMed]
- Mundle, G.; Munkes, J.; Ackermann, K.; Mann, K. Sex Differences of Carbohydrate-Deficient Transferrin, gamma-Glutamyltransferase, and Mean Corpuscular Volume in Alcohol-Dependent Patients. Alcohol. Clin. Exp. Res. 2000, 24, 1400–1405. [Google Scholar] [CrossRef] [PubMed]
- Hermansson, U.; Helander, A.; Brandt, L.; Huss, A.; Rönnberg, S. The alcohol use disorders identification test and carbohydrate-deficient transferrin in alcohol-related sickness absence. Alcohol. Clin. Exp. Res. 2002, 26, 28–35. [Google Scholar] [CrossRef]
- Bean, P.; Harasymiw, J.; Peterson, C.M.; Javors, M. Innovative technologies for the diagnosis of alcohol abuse and monitoring abstinence. Alcohol. Clin. Exp. Res. 2001, 25, 309–316. [Google Scholar] [CrossRef]
- Multivariate, A.; Analysis, S.; Johnson, R.A.; Wichern, D.W. Reviewed Work: Applied Multivariate Statistical Analysis. Biometrics 1998, 54, 1203. [Google Scholar]
- Ministerio de Sanidad. Límites de Consumo de Bajo Riesgo de Alcohol; [Ministry of Health. Low-Risk Alcohol Consumption]; Ministry of Health: Madrid, Spain, 2020.
- Ángel, M.; Carretero, G.; Pedro, J.; Ruiz, N.; Martínez, J.M.; González, C.O.F. Validation of the Alcohol Use Disorders Identification Test in university students: AUDIT and AUDIT-C Validación del test para la identificación de trastornos por uso de alcohol en población universitaria: AUDIT y AUDIT-C. Adicciones 2016, 4, 194–204. [Google Scholar]
- Stockwell, T.; Chikritzhs, T.; Holder, H.; Single, E.; Elena, M.; Jernigan, D. International Guide for Monitoring Alcohol Consumption and Harm; World Health Organization: Geneva, Switzerland, 2000; pp. 1–193. Available online: http://apps.who.int/iris/bitstream/10665/66529/1/WHO_MSD_MSB_00.4.pdf (accessed on 24 January 2021).
- Gual, A.; Martos, A.R.; Lligoña, A.; Llopis, J.J. Does the concept of a standard drink apply to viticultural societies? Alcohol Alcohol. 1999, 34, 153–160. [Google Scholar] [CrossRef]
- Bac, J.; Mirkes, E.M.; Gorban, A.N.; Tyukin, I.; Zinovyev, A. Scikit-dimension: A python package for intrinsic dimension estimation. Entropy 2021, 23, 1368. [Google Scholar] [CrossRef] [PubMed]
- Weka 3—Data Mining with Open Source Machine Learning Software in Java. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 28 November 2021).
- Silczuk, A.; Habrat, B.; Lew-Starowicz, M. Thrombocytopenia in Patients Hospitalized for Alcohol Withdrawal Syndrome and Its Associations to Clinical Complications. Alcohol Alcohol. 2019, 54, 503–509. [Google Scholar] [CrossRef] [PubMed]
- Gowin, J.L.; Manza, P.; Ramchandani, V.A.; Volkow, N.D. Neuropsychosocial Markers of Binge Drinking in Young Adults. Mol. Psychiatry 2021, 26, 4931–4943. [Google Scholar] [CrossRef]
- Kinreich, S.; Meyers, J.L.; Maron-Katz, A.; Kamarajan, C.; Pandey, A.K.; Chorlian, D.B.; Zhang, J.; Pandey, G.; de Viteri, S.S.-S.; Pitti, D.; et al. Predicting risk for Alcohol Use Disorder using longitudinal data with multimodal biomarkers and family history: A machine learning study. Mol. Psychiatry 2021, 26, 1133–1141. [Google Scholar] [CrossRef] [PubMed]
- Gowin, J.L.; Sloan, M.E.; Stangl, B.L.; Vatsalya, V.; Ramchandani, V.A. Vulnerability for alcohol use disorder and rate of alcohol consumption. Am. J. Psychiatry 2017, 174, 1094–1101. [Google Scholar] [CrossRef] [PubMed]
- Bonnell, L.N.; Littenberg, B.; Wshah, S.R.; Rose, G.L. A Machine Learning Approach to Identification of Unhealthy Drinking. J. Am. Board Fam. Med. 2020, 33, 397–406. [Google Scholar] [CrossRef]
- Ebrahimi, A.; Wiil, U.K.; Schmidt, T.; Naemi, A.; Nielsen, A.S.; Shaikh, G.M.; Mansourvar, M. Predicting the Risk of Alcohol Use Disorder Using Machine Learning: A Systematic Literature Review. IEEE Access 2021, 9, 151697–151712. [Google Scholar] [CrossRef]
- Pérez-Milena, A.; Redondo-Olmedilla, M.d.D.; Martínez-Fernández, M.L.; Jiménez-Pulido, I.; Mesa-Gallardo, I.; Leal-Helmling, F.J. Changes in hazardous drinking in Spanish adolescent population in the last decade (2004–2013) using a quantitative and qualitative design. Aten. Primaria 2017, 49, 525–533. [Google Scholar] [CrossRef]
- Choe, Y.M.; Lee, B.C.; Choi, I.G.; Suh, G.H.; Lee, D.Y.; Kim, J.W. Combination of the CAGE and serum gamma-glutamyl transferase: An effective screening tool for alcohol use disorder and alcohol dependence. Neuropsychiatr. Dis. Treat. 2019, 15, 1507–1515. [Google Scholar] [CrossRef]
- Hietala, J.; Koivisto, H.; Anttila, P.; Niemelä, O. Comparison of the combined marker GGT-CDT and the conventional laboratory markers of alcohol abuse in heavy drinkers, moderate dinkers and abstainers. Alcohol Alcohol. 2006, 41, 528–533. [Google Scholar] [CrossRef]
- Bataille, V.; Ruidavets, J.B.; Arveiler, D.; Amouyel, P.; Ducimetière, P.; Perret, B.; Ferrières, J. Joint use of clinical parameters, biological markers and cage questionnaire for the identification of heavy drinkers in a large population-based sample. Alcohol Alcohol. 2003, 38, 121–127. [Google Scholar] [CrossRef] [PubMed]
- Aboutara, N.; Müller, A.; Jungen, H.; Szewczyk, A.; van Rüth, V.; Bertram, F.; Püschel, K.; Heinrich, F.; Iwersen-Bergmann, S. Investigating the use of PEth, CDT and MCV to evaluate alcohol consumption in a cohort of homeless individuals—A comparison of different alcohol biomarkers. Forensic Sci. Int. 2022, 331, 111147. [Google Scholar] [CrossRef] [PubMed]
- Hofmann, V.; Sundermann, T.R.; Schmitt, G.; Bartel, M. Development and validation of an analytical method for the simultaneous determination of the alcohol biomarkers ethyl glucuronide, ethyl sulfate, N-acetyltaurine, and 16:0/18:1-phosphatidylethanol in human blood. Drug Test. Anal. 2022, 14, 92–100. [Google Scholar] [CrossRef] [PubMed]
- Ortega-Alonso, A.; Stephens, C.; Lucena, M.I.; Andrade, R.J. Case characterization, clinical features and risk factors in drug-induced liver injury. Int. J. Mol. Sci. 2016, 17, 714. [Google Scholar] [CrossRef] [PubMed]
- Fagan, K.J.; Irvine, K.M.; Mcwhinney, B.C.; Fletcher, L.M.; Horsfall, L.U.; Johnson, L.; O’Rourke, P.; Martin, J.; Scott, I.; Pretorius, C.J.; et al. Diagnostic sensitivity of carbohydrate deficient transferrin in heavy drinkers. BMC Gastroenterol. 2014, 14, 97. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Coefficient | Confidence Interval (95%) | p Value | |
|---|---|---|---|---|
| Constant | 0.826 | 0.084 | 1.569 | 0.029 |
| Study level | −0.424 | −0.973 | 0.125 | 0.130 |
| Age | −0.191 | −0.746 | 0.364 | 0.499 |
| Albumin | 0.497 | −1.215 | 2.209 | 0.570 |
| Uric acid | −0.057 | −0.635 | 0.521 | 0.846 |
| Basophils | −1.907 | −4.863 | 1.050 | 0.206 |
| Basophils % | 1.898 | −0.766 | 4.562 | 0.163 |
| Total bilirubin | 0.283 | −0.921 | 1.487 | 0.645 |
| Calcium | 0.284 | −0.493 | 1.061 | 0.474 |
| MCHC 1 | −8.259 | −15.893 | −0.625 | 0.034 * |
| Chlorine | 1.029 | 0.320 | 1.737 | 0.004 * |
| Cholesterol | 0.826 | −0.614 | 2.267 | 0.261 |
| Creatinine | −0.608 | −1.322 | 0.106 | 0.095 |
| Eosinophils | −12.068 | −23.030 | −1.106 | 0.031 * |
| Eosinophils % | 11.639 | −3.425 | 26.702 | 0.130 |
| Red blood cells | −2.775 | −10.355 | 4.804 | 0.473 |
| Alkaline phosphatase | 1.125 | 0.244 | 2.006 | 0.012 * |
| Ferritin | 1.872 | 0.268 | 3.477 | 0.022 * |
| Gamma glutamyl transferase | −0.044 | −2.222 | 2.134 | 0.968 |
| Globulins | 0.533 | −1.112 | 2.177 | 0.526 |
| Glucose | −0.483 | −1.082 | 0.115 | 0.114 |
| Aspartate aminotransferase | 0.423 | −1.778 | 2.624 | 0.706 |
| Alanine aminotransferase | 0.503 | −0.554 | 1.559 | 0.351 |
| Haemoglobin | −8.424 | −21.414 | 4.566 | 0.204 |
| Mean corpuscular haemoglobin | 23.651 | 7.540 | 39.762 | 0.004 * |
| Hematocrit | 11.208 | −2.673 | 25.089 | 0.114 |
| HDL- cholesterol | −1.033 | −2.066 | 0.001 | 0.050 |
| Red blood cells distribution width | 0.818 | 0.158 | 1.477 | 0.015 * |
| Platelet distribution width | 0.491 | −0.176 | 1.158 | 0.149 |
| Potassium | 0.636 | 0.014 | 1.259 | 0.045 * |
| Lactate dehydrogenase | 0.412 | −0.193 | 1.016 | 0.182 |
| LDL-cholesterol | 0.310 | −0.869 | 1.489 | 0.607 |
| White blood cells | 205.737 | 15.672 | 395.801 | 0.034 * |
| Lymphocytes | −59.007 | −113.951 | −4.063 | 0.035 * |
| % Lymphocytes | 50.220 | −20.111 | 120.550 | 0.162 |
| % Large Unstained Cells | 17.875 | −9.300 | 45.049 | 0.197 |
| Large Unstained Cells | −20.052 | −42.138 | 2.034 | 0.075 |
| Monocytes | −14.328 | −26.135 | −2.521 | 0.017 * |
| % Monocytes | 12.3017 | −2.676 | 27.280 | 0.107 |
| Myeloperoxidase index | −0.180 | −0.757 | 0.397 | 0.541 |
| Neutrophils | −185.847 | −358.363 | −13.331 | 0.035 * |
| % Neutrophils | 60.0477 | −22.608 | 142.704 | 0.154 |
| Phosphorus | −0.422 | −1.032 | 0.188 | 0.175 |
| Platelets | −0.114 | −0.790 | 0.563 | 0.742 |
| Total Proteins | −1.113 | −2.745 | 0.519 | 0.181 |
| Triglycerides | −0.603 | −1.554 | 0.348 | 0.214 |
| Transferrin | 0.143 | −0.582 | 0.869 | 0.698 |
| Urea | −1.238 | −2.050 | −0.426 | 0.003 * |
| Mean Corpuscular Volume | −22.442 | −36.694 | −8.190 | 0.002 * |
| Mean Platelet Volume | −0.463 | −1.174 | 0.249 | 0.202 |
| Sodium | −1.553 | −2.430 | −0.677 | 0.001 * |
| SEX_woman | −0.278 | −1.021 | 0.464 | 0.462 |
| Variable | Coefficient | Confidence Interval (95%) | p Value | |
|---|---|---|---|---|
| Constant | 0.7079 | 0.263 | 1.153 | 0.002 |
| Mean corpuscular haemoglobin | 1.3679 | 0.944 | 1.791 | 0 |
| Gamma glutamyl transferase | 2.78 | 1.112 | 4.448 | 0.001 |
| Red blood cells distribution width | 1.0657 | 0.663 | 1.469 | 0 |
| Creatinine | −0.7371 | −1.089 | −0.385 | 0 |
| Total bilirubin | 0.4942 | −0.173 | 1.161 | 0.146 |
| Mean Platelet Volume | −0.1804 | −0.479 | 0.118 | 0.236 |
| Large Unstained Cells | 0.4084 | −0.938 | 1.755 | 0.552 |
| HDL-cholesterol | −0.676 | −1.093 | −0.259 | 0.002 |
| Variable | Value | Risk | No risk |
|---|---|---|---|
| Gamma glutamyl transferase | ≤46.5 | 0.572 | 0.929 |
| >46.5 | 0.428 | 0.071 | |
| Mean corpuscular haemoglobin | <31.3 | 0.25 | 0.8 |
| ≥31.3 | 0.75 | 0.2 | |
| Educational level | 1 | 0.020 | 0.003 |
| 2 | 0.202 | 0.033 | |
| 3 | 0.526 | 0.282 | |
| 4 | 0.122 | 0.245 | |
| 5 | 0.082 | 0.312 | |
| 6 | 0.048 | 0.124 | |
| Basophils | ≤0.01 | 0.009 | 0.107 |
| (0.01–0.015] | 0.077 | 0.027 | |
| (0.015–0.02] | 0.003 | 0.216 | |
| >0.02 | 0.911 | 0.649 | |
| Creatinine | ≤1.025 | 0.871 | 0.598 |
| >1.025 | 0.129 | 0.402 | |
| Alkaline phosphatase | ≤34 | 0.003 | 0.131 |
| (34–84.5] | 0.771 | 0.810 | |
| >54.5 | 0.226 | 0.058 | |
| Hematocrit | ≤47.09 | 0.618 | 0.850 |
| >47.09 | 0.382 | 0.150 | |
| Red blood cells distribution width | ≤13.05 | 0.141 | 0.469 |
| >13.05 | 0.859 | 0.531 | |
| Lactate Dehydrogenase | ≤256.5 | 0.836 | 0.985 |
| >256.5 | 0.164 | 0.015 | |
| Urea | ≤23.5 | 0.415 | 0.070 |
| (23.5–40.5] | 0.519 | 0.566 | |
| >40.5 | 0.066 | 0.364 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinar-Sanchez, J.; Bermejo López, P.; Solís García Del Pozo, J.; Redondo-Ruiz, J.; Navarro Casado, L.; Andres-Pretel, F.; Celorrio Bustillo, M.L.; Esparcia Moreno, M.; García Ruiz, S.; Solera Santos, J.J.; et al. Common Laboratory Parameters Are Useful for Screening for Alcohol Use Disorder: Designing a Predictive Model Using Machine Learning. J. Clin. Med. 2022, 11, 2061. https://doi.org/10.3390/jcm11072061
Pinar-Sanchez J, Bermejo López P, Solís García Del Pozo J, Redondo-Ruiz J, Navarro Casado L, Andres-Pretel F, Celorrio Bustillo ML, Esparcia Moreno M, García Ruiz S, Solera Santos JJ, et al. Common Laboratory Parameters Are Useful for Screening for Alcohol Use Disorder: Designing a Predictive Model Using Machine Learning. Journal of Clinical Medicine. 2022; 11(7):2061. https://doi.org/10.3390/jcm11072061
Chicago/Turabian StylePinar-Sanchez, Juana, Pablo Bermejo López, Julián Solís García Del Pozo, Jose Redondo-Ruiz, Laura Navarro Casado, Fernando Andres-Pretel, María Luisa Celorrio Bustillo, Mercedes Esparcia Moreno, Santiago García Ruiz, Jose Javier Solera Santos, and et al. 2022. "Common Laboratory Parameters Are Useful for Screening for Alcohol Use Disorder: Designing a Predictive Model Using Machine Learning" Journal of Clinical Medicine 11, no. 7: 2061. https://doi.org/10.3390/jcm11072061
APA StylePinar-Sanchez, J., Bermejo López, P., Solís García Del Pozo, J., Redondo-Ruiz, J., Navarro Casado, L., Andres-Pretel, F., Celorrio Bustillo, M. L., Esparcia Moreno, M., García Ruiz, S., Solera Santos, J. J., & Navarro Bravo, B. (2022). Common Laboratory Parameters Are Useful for Screening for Alcohol Use Disorder: Designing a Predictive Model Using Machine Learning. Journal of Clinical Medicine, 11(7), 2061. https://doi.org/10.3390/jcm11072061