
The Sound of Emotion: Pinpointing Emotional Voice Processing Via Frequency Tagging EEG

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Vocal Emotion Processing as a Gateway to Social Communication
1.2. Frequency Tagging EEG to Pinpoint Differences in Socio-Communicative Abilities
2. Materials and Methods
2.1. Participants
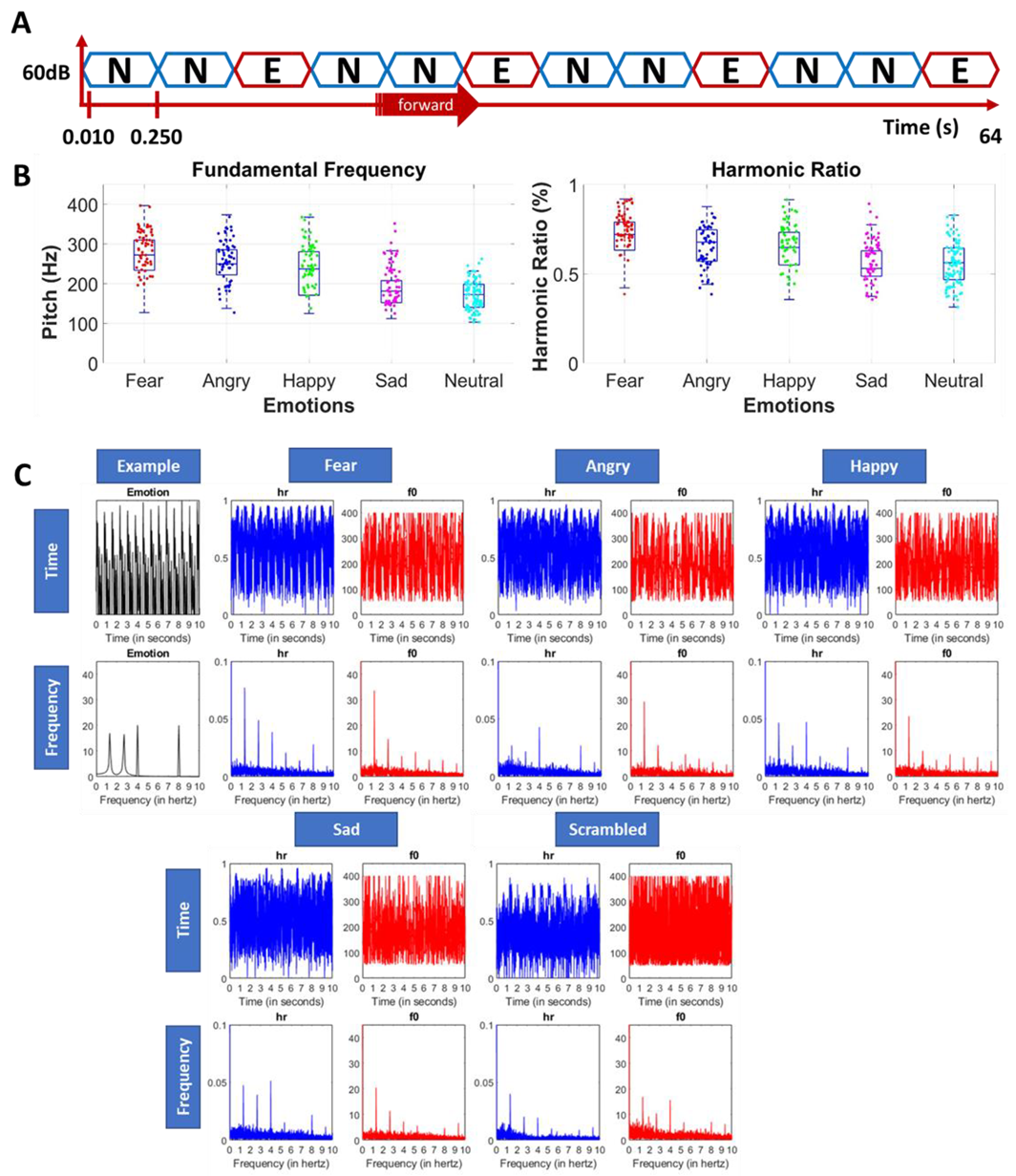
2.2. Stimuli: Design of the Emotional Voices and Identity Database (EVID)
2.3. Procedure and Equipment
2.4. EEG Analysis
2.4.1. Pre-Processing
2.4.2. Frequency-Domain Analysis
2.4.3. Statistical Analyses
3. Results
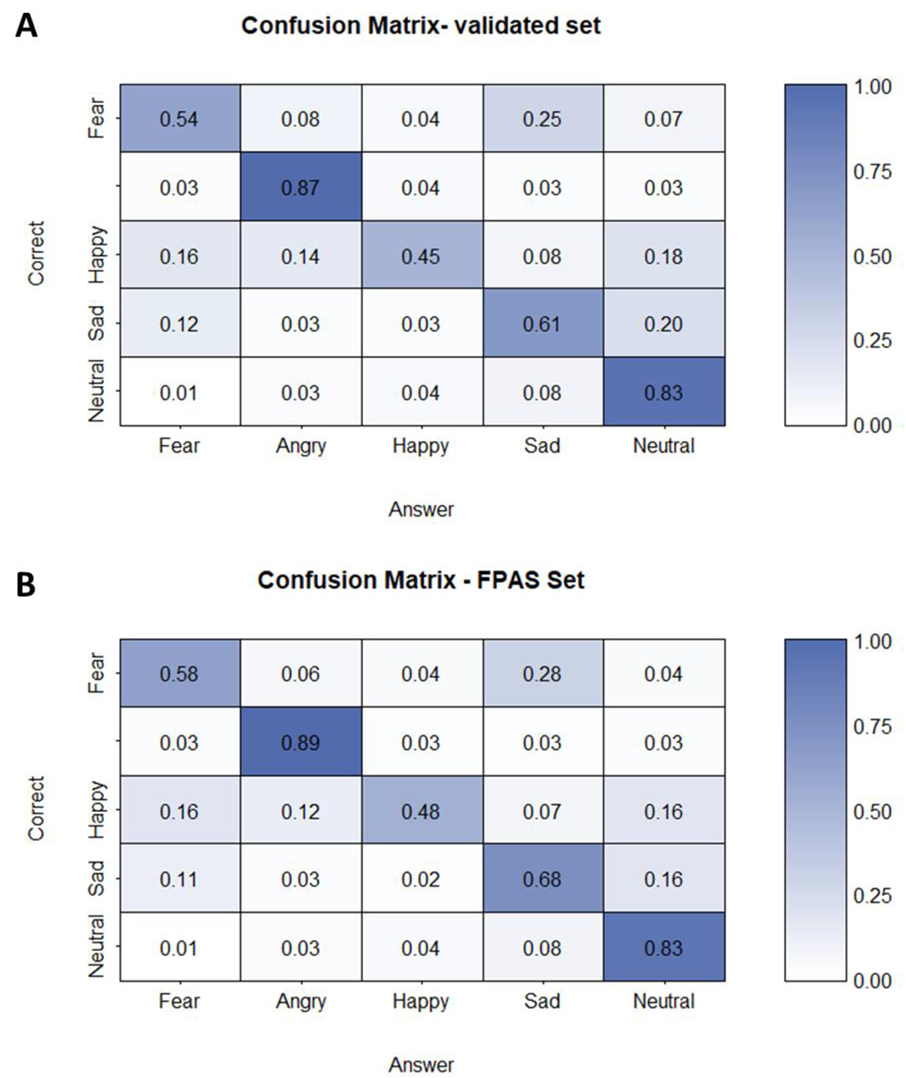
3.1. Orthogonal Task
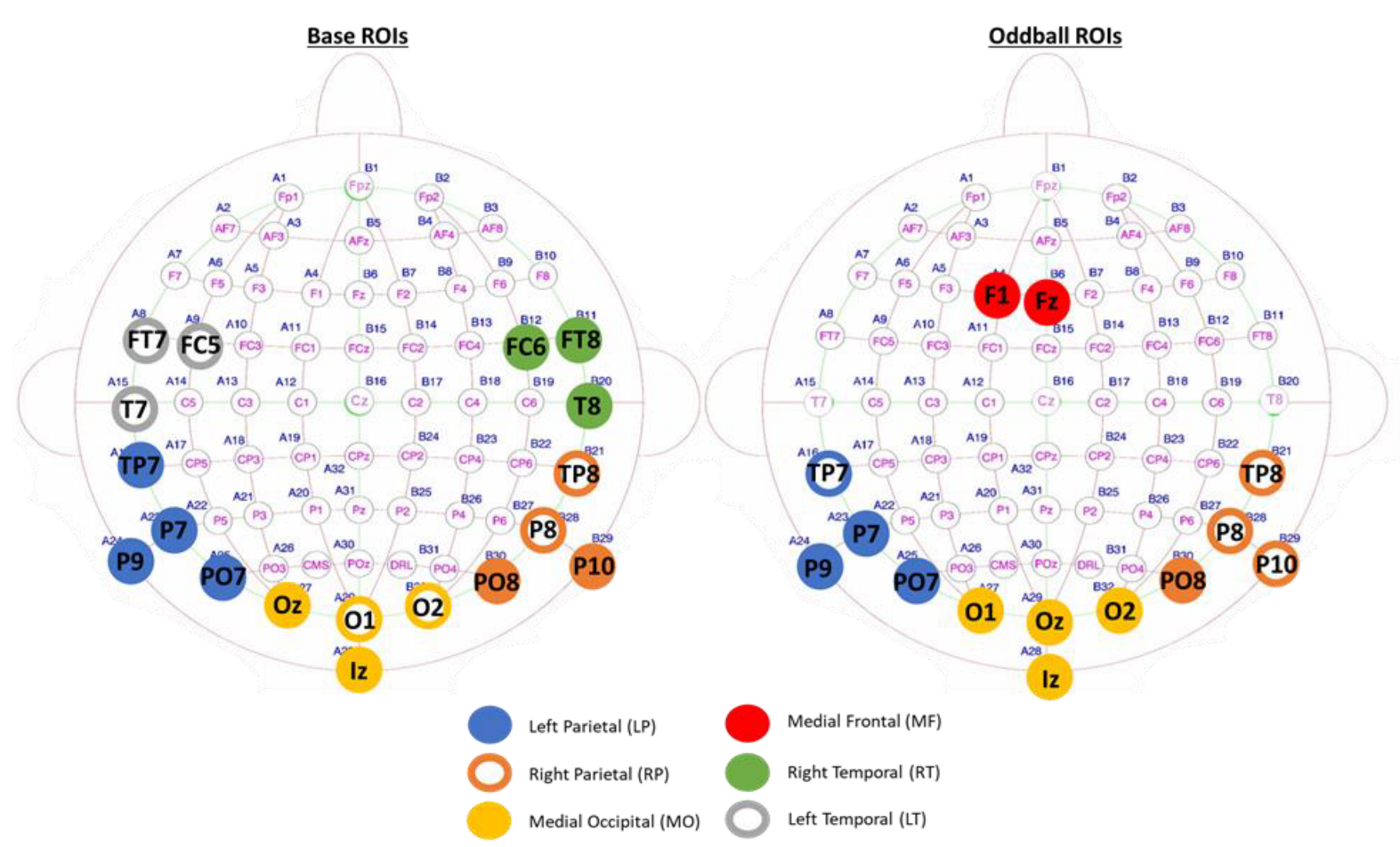
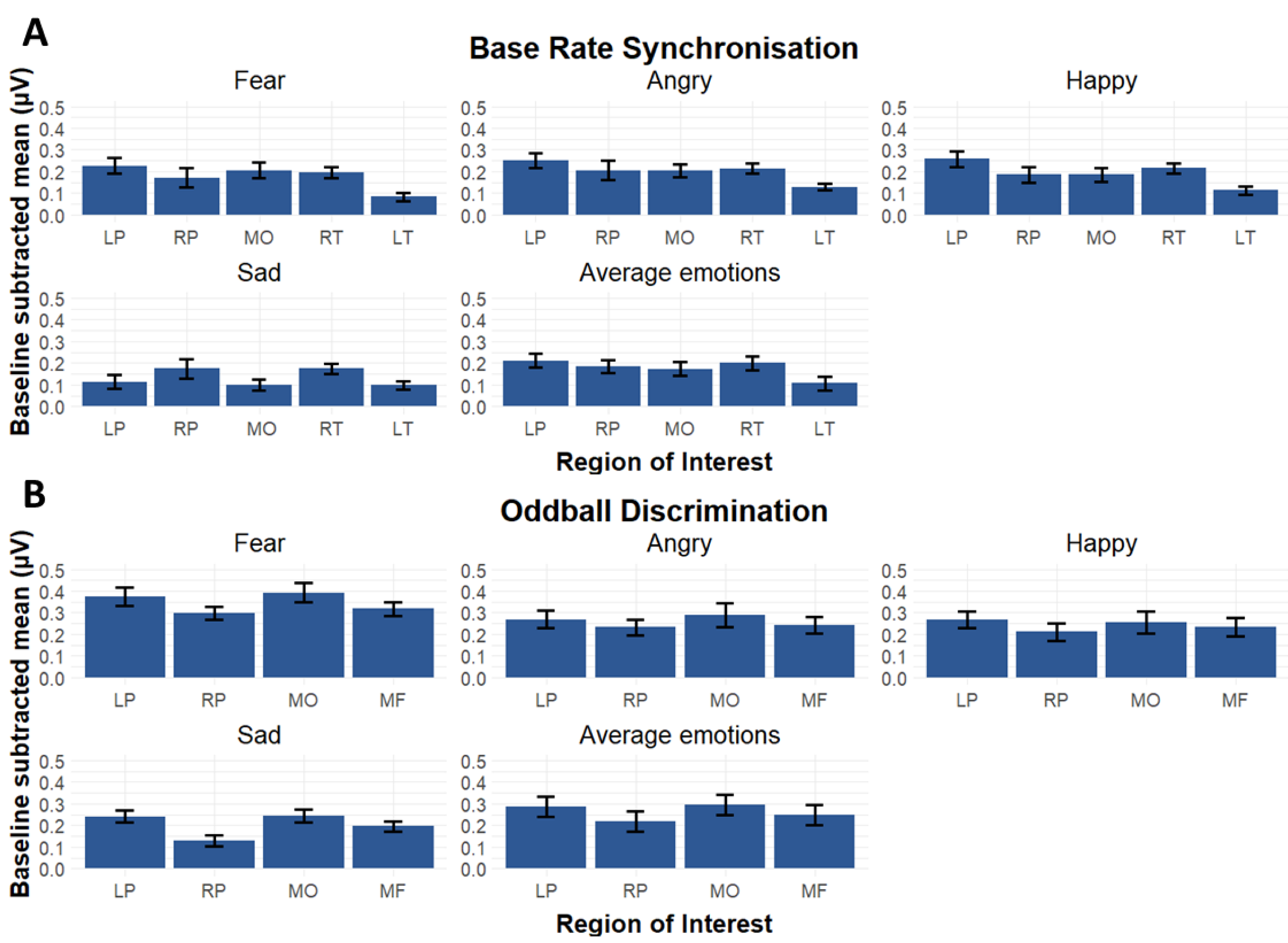
3.2. Region of Interests
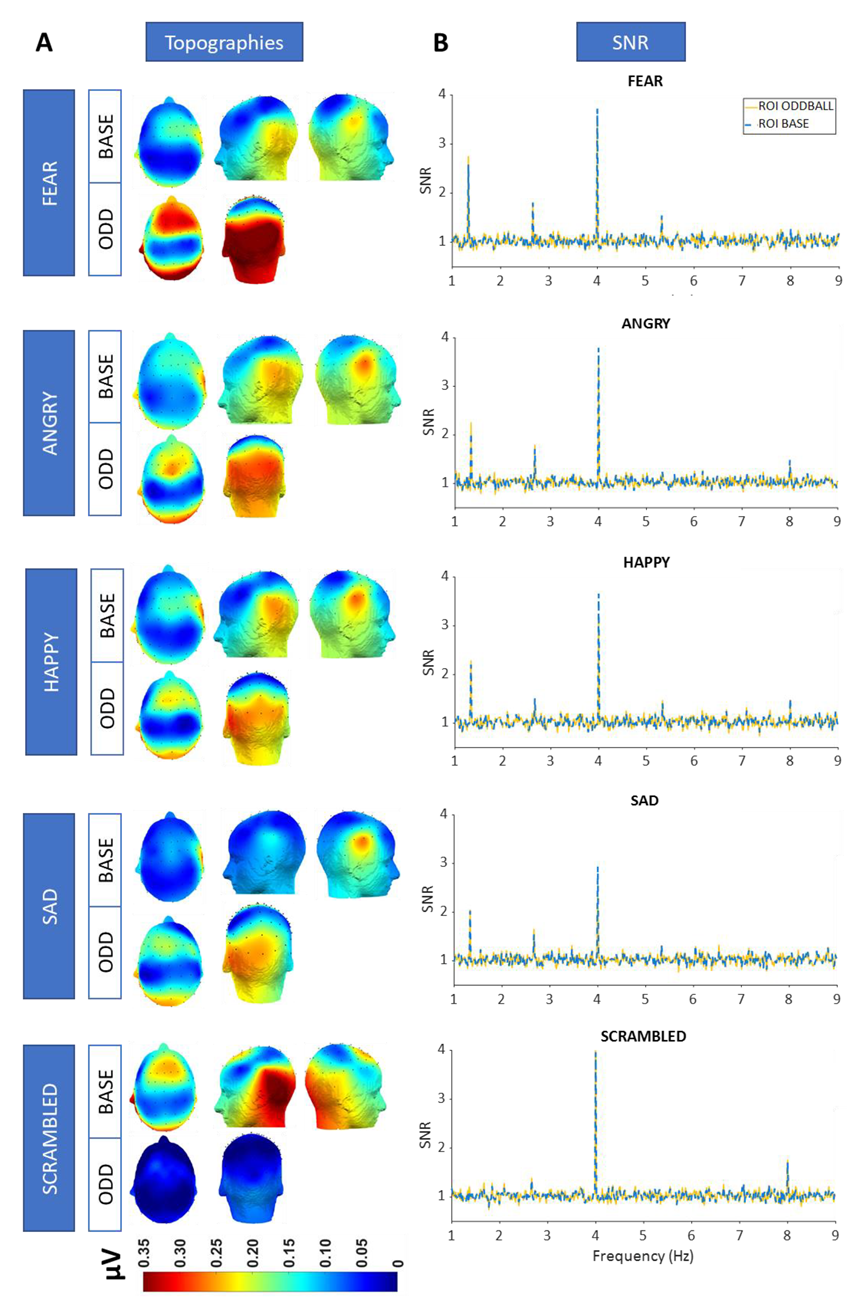
3.3. SNR and Topographies
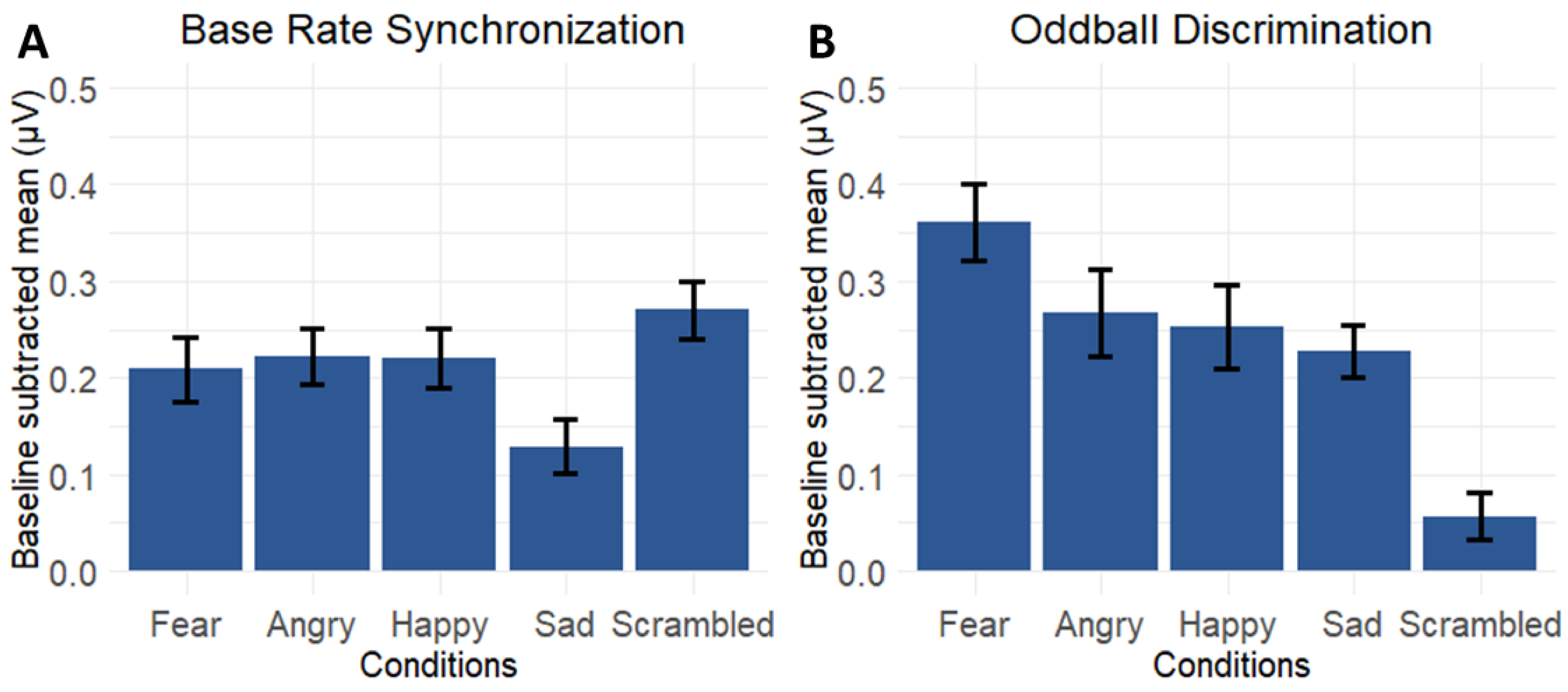
3.4. Contrasting Emotion-Specific Responses Versus Responses for the Scrambled Condition
3.5. Investigating Lateralisation Patterns of Emotion-Specific Responses
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Belin, P. Voice processing in human and non-human primates. Philos. Trans. R. Soc. B Biol. Sci. 2006, 361, 2091–2107. [Google Scholar] [CrossRef] [PubMed]
- Belin, P.; Fecteau, S.; Bédard, C.; Bé, C.; Bédard, C. Thinking the voice: Neural correlates of voice perception. Trends Cogn. Sci. 2004, 8, 129–135. [Google Scholar] [CrossRef] [PubMed]
- Grandjean, D.; Sander, D.; Pourtois, G.; Schwartz, S.; Seghier, M.L.; Scherer, K.R.; Vuilleumier, P. The voices of wrath: Brain responses to angry prosody in meaningless speech. Nat. Neurosci. 2005, 8, 145–146. [Google Scholar] [CrossRef] [PubMed]
- Honorof, D.N.; Whalen, D.H. Identification of speaker sex from one vowel across a range of fundamental frequencies. J. Acoust. Soc. Am. 2010, 128, 3095–3104. [Google Scholar] [CrossRef]
- Krauss, R.M.; Freyberg, R.; Morsella, E. Inferring speakers’ physical attributes from their voices. J. Exp. Soc. Psychol. 2002, 38, 618–625. [Google Scholar] [CrossRef]
- Mohammadi, G.; Vinciarelli, A.; Mortillaro, M. The voice of personality: Mapping nonverbal vocal behavior into trait attributions. In Proceedings of the Proceedings of the 2nd International Workshop on Social Signal Processing, Firenze, Italy, 29 October 2010. [Google Scholar] [CrossRef]
- Rakić, T.; Steffens, M.C.; Mummendey, A. When it matters how you pronounce it: The influence of regional accents on job interview outcome. Br. J. Psychol. 2011, 102, 868–883. [Google Scholar] [CrossRef]
- Batty, M.; Taylor, M.J. Early processing of the six basic facial emotional expressions. Cogn. Brain Res. 2003, 17, 613–620. [Google Scholar] [CrossRef]
- Sauter, D.A.; Eisner, F.; Ekman, P.; Scott, S.K. Cross-cultural recognition of basic emotions through nonverbal emotional vocalizations. Proc. Natl. Acad. Sci. USA 2010, 107, 2408–2412. [Google Scholar] [CrossRef]
- Vytal, K.; Hamann, S. Neuroimaging Support for Discrete Neural Correlates of Basic Emotions: A Voxel-based Meta-analysis. J. Cogn. Neurosci. 2010, 22, 2864–2885. [Google Scholar] [CrossRef]
- Pell, M.D.; Skorup, V. Implicit processing of emotional prosody in a foreign versus native language. Speech Commun. 2008, 50, 519–530. [Google Scholar] [CrossRef]
- Paulmann, S.; Kotz, S.A. An ERP investigation on the temporal dynamics of emotional prosody and emotional semantics in pseudo- and lexical-sentence context. Brain Lang. 2008, 105, 59–69. [Google Scholar] [CrossRef]
- Castiajo, P.; Pinheiro, A.P. Decoding emotions from nonverbal vocalizations: How much voice signal is enough? Motiv. Emot. 2019, 43, 803–813. [Google Scholar] [CrossRef]
- Falagiarda, F.; Collignon, O. Time-resolved discrimination of audio-visual emotion expressions. Cortex 2019, 119, 184–194. [Google Scholar] [CrossRef] [PubMed]
- Pell, M.D.; Kotz, S.A. On the Time Course of Vocal Emotion Recognition. PLoS ONE 2011, 6, e27256. [Google Scholar] [CrossRef] [PubMed]
- Briefer, E.F. Vocal contagion of emotions in non-human animals. Proc. Royal Soc. B Biol. Sci. 2018, 285, 20172783. [Google Scholar] [CrossRef] [PubMed]
- Pell, M.D.; Paulmann, S.; Dara, C.; Alasseri, A.; Kotz, S.A. Factors in the recognition of vocally expressed emotions: A comparison of four languages. J. Phon. 2009, 37, 417–435. [Google Scholar] [CrossRef]
- Coutinho, E.; Cangelosi, A. Musical emotions: Predicting second-by-second subjective feelings of emotion from low-level psychoacoustic features and physiological measurements. Emotion 2011, 11, 921–937. [Google Scholar] [CrossRef] [PubMed]
- Sauter, D.A.; Eisner, F.; Calder, A.J.; Scott, S.K. Perceptual Cues in Nonverbal Vocal Expressions of Emotion. Q. J. Exp. Psychol. 2010, 63, 2251–2272. [Google Scholar] [CrossRef] [PubMed]
- Ethofer, T.; Anders, S.; Wiethoff, S.; Erb, M.; Herbert, C.; Saur, R.; Grodd, W.; Wildgruber, D. Effects of prosodic emotional intensity on activation of associative auditory cortex. Neuroreport 2006, 17, 249–253. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Lee, S.Y.; Chen, H.Y.; Wang, P.Y.; Decety, J. Voice and Emotion Processing in the Human Neonatal Brain. J. Cogn. Neurosci. 2012, 24, 1411–1419. [Google Scholar] [CrossRef]
- Burra, N.; Kerzel, D.; Munoz Tord, D.; Grandjean, D.; Ceravolo, L. Early spatial attention deployment toward and away from aggressive voices. Soc. Cogn. Affect. Neurosci. 2019, 14, 73–80. [Google Scholar] [CrossRef]
- Belin, P.; Zatorre, R.J.; Lafaille, P.; Ahad, P.; Pike, B.G. Voice-selective areas in human auditory cortex. Nature 2000, 403, 309–312. [Google Scholar] [CrossRef] [PubMed]
- Beaucousin, V.; Lacheret, A.; Turbelin, M.-R.; Morel, M.; Mazoyer, B.; Tzourio-Mazoyer, N. FMRI Study of Emotional Speech Comprehension. Cereb. Cortex 2007, 17, 339–352. [Google Scholar] [CrossRef]
- Ethofer, T.; Van De Ville, D.; Scherer, K.; Vuilleumier, P. Decoding of emotional information in voice-sensitive cortices. Curr. Biol. 2009, 19, 1028–1033. [Google Scholar] [CrossRef] [PubMed]
- Kotz, S.A.; Meyer, M.; Alter, K.; Besson, M.; Von Cramon, D.Y.; Friederici, A.D. On the lateralization of emotional prosody: An event-related functional MR investigation. Brain Lang. 2003, 86, 366–376. [Google Scholar] [CrossRef] [PubMed]
- Luo, H.; Poeppel, D. Cortical Oscillations in Auditory Perception and Speech: Evidence for Two Temporal Windows in Human Auditory Cortex. Front. Psychol. 2012, 3, 170. [Google Scholar] [CrossRef]
- Poeppel, D. The analysis of speech in different temporal integration windows: Cerebral lateralization as ‘asymmetric sampling in time’. Speech Commun. 2003, 41, 245–255. [Google Scholar] [CrossRef]
- Zatorre, R.J.; Belin, P.; Penhune, V.B. Structure and function of auditory cortex: Music and speech. Trends Cogn. Sci. 2002, 6, 37–46. [Google Scholar] [CrossRef]
- Kamiloğlu, R.G.; Fischer, A.H.; Sauter, D.A. Good vibrations: A review of vocal expressions of positive emotions. Psychon. Bull. Rev. 2020, 27, 237–265. [Google Scholar] [CrossRef]
- Edwards, J.; Jackson, H.J.; Pattison, P.E. Emotion recognition via facial expression and affective prosody in schizophrenia. Clin. Psychol. Rev. 2002, 22, 789–832. [Google Scholar] [CrossRef]
- Jáni, M.; Kašpárek, T. Emotion recognition and theory of mind in schizophrenia: A meta-analysis of neuroimaging studies. World J. Biol. Psychiatry 2018, 19, S86–S96. [Google Scholar] [CrossRef] [PubMed]
- Leppänen, J.M. Emotional information processing in mood disorders: A review of behavioral and neuroimaging findings. Curr. Opin. Psychiatry 2006, 19, 34–39. [Google Scholar] [CrossRef] [PubMed]
- Leung, F.Y.N.; Sin, J.; Dawson, C.; Ong, J.H.; Zhao, C.; Veić, A.; Liu, F. Emotion recognition across visual and auditory modalities in autism spectrum disorder: A systematic review and meta-analysis. Dev. Rev. 2022, 63, 101000. [Google Scholar] [CrossRef]
- Bänziger, T.; Grandjean, D.; Scherer, K.R. Emotion Recognition From Expressions in Face, Voice, and Body: The Multimodal Emotion Recognition Test (MERT). Emotion 2009, 9, 691–704. [Google Scholar] [CrossRef] [PubMed]
- Bänziger, T.; Mortillaro, M.; Scherer, K.R. Introducing the Geneva Multimodal expression corpus for experimental research on emotion perception. Emotion 2012, 12, 1161–1179. [Google Scholar] [CrossRef]
- Schlegel, K.; Scherer, K.R. Introducing a short version of the Geneva Emotion Recognition Test (GERT-S): Psychometric properties and construct validation. Behav. Res. Methods 2016, 48, 1383–1392. [Google Scholar] [CrossRef]
- Harms, M.B.; Martin, A.; Wallace, G.L. Facial Emotion Recognition in Autism Spectrum Disorders: A Review of Behavioral and Neuroimaging Studies. Neuropsychol. Rev. 2010, 20, 290–322. [Google Scholar] [CrossRef]
- Stewart, M.E.; McAdam, C.; Ota, M.; Peppé, S.; Cleland, J. Emotional recognition in autism spectrum conditions from voices and faces. Autism 2013, 17, 6–14. [Google Scholar] [CrossRef]
- Schirmer, A.; Striano, T.; Friederici, A.D. Sex differences in the preattentive processing of vocal emotional expressions. Neuroreport 2005, 16, 635–639. [Google Scholar] [CrossRef]
- Lindström, R.; Lepistö-Paisley, T.; Makkonen, T.; Reinvall, O.; Nieminen-von Wendt, T.; Alén, R.; Kujala, T. Atypical perceptual and neural processing of emotional prosodic changes in children with autism spectrum disorders. Clin. Neurophysiol. 2018, 129, 2411–2420. [Google Scholar] [CrossRef]
- Mcgee, T.J.; King, C.; Tremblay, K.; Nicol, T.G.; Cunningham, J.; Kraus, N. Long-term habituation of the speech-elicited mismatch negativity. Psychophysiology 2001, 38, 653–658. [Google Scholar] [CrossRef] [PubMed]
- Dzhelyova, M.; Jacques, C.; Rossion, B. At a Single Glance: Fast Periodic Visual Stimulation Uncovers the Spatio-Temporal Dynamics of Brief Facial Expression Changes in the Human Brain. Cereb. Cortex 2016, 27, 4106–4123. [Google Scholar] [CrossRef] [PubMed]
- Liu-Shuang, J.; Norcia, A.M.; Rossion, B. An objective index of individual face discrimination in the right occipito-temporal cortex by means of fast periodic oddball stimulation. Neuropsychologia 2014, 52, 57–72. [Google Scholar] [CrossRef] [PubMed]
- Leleu, A.; Favre, E.; Yailian, A.; Fumat, H.; Klamm, J.; Amado, I.; Baudouin, J.-Y.; Franck, N.; Demily, C. An implicit and reliable neural measure quantifying impaired visual coding of facial expression: Evidence from the 22q11.2 deletion syndrome. Transl. Psychiatry 2019, 9, 67. [Google Scholar] [CrossRef]
- Van der Donck, S.; Dzhelyova, M.; Vettori, S.; Thielen, H.; Steyaert, J.; Rossion, B.; Boets, B. Fast Periodic Visual Stimulation EEG Reveals Reduced Neural Sensitivity to Fearful Faces in Children with Autism. J. Autism Dev. Disord. 2019, 49, 4658–4673. [Google Scholar] [CrossRef]
- Van der Donck, S.; Dzhelyova, M.; Vettori, S.; Mahdi, S.S.; Claes, P.; Steyaert, J.; Boets, B. Rapid neural categorization of angry and fearful faces is specifically impaired in boys with autism spectrum disorder. J. Child Psychol. Psychiatry Allied Discip. 2020, 61, 1019–1029. [Google Scholar] [CrossRef]
- Vettori, S.; Dzhelyova, M.; Van der Donck, S.; Jacques, C.; Steyaert, J.; Rossion, B.; Boets, B. Reduced neural sensitivity to rapid individual face discrimination in autism spectrum disorder. NeuroImage Clin. 2019, 21, 101613. [Google Scholar] [CrossRef]
- Barbero, F.M.; Calce, R.P.; Talwar, S.; Rossion, B.; Collignon, O. Fast Periodic Auditory Stimulation Reveals a Robust Categorical Response to Voices in the Human Brain. eNeuro 2021, 8, ENEURO.0471-20.2021. [Google Scholar] [CrossRef]
- Norcia, A.M.; Appelbaum, L.G.; Ales, J.M.; Cottereau, B.R.; Rossion, B. The steady-state visual evoked potential in vision research: A review. J. Vis. 2015, 15, 4. [Google Scholar] [CrossRef]
- Lausen, A.; Schacht, A. Gender differences in the recognition of vocal emotions. Front. Psychol. 2018, 9, 882. [Google Scholar] [CrossRef]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. CREMA-D: Crowd-sourced Emotional Multimodal Actors Dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [PubMed]
- Dormal, G.; Pelland, M.; Rezk, M.; Yakobov, E.; Lepore, F.; Collignon, O. Functional Preference for Object Sounds and Voices in the Brain of Early Blind and Sighted Individuals. J. Cogn. Neurosci. 2018, 30, 86–106. [Google Scholar] [CrossRef]
- Van Rinsveld, A.; Guillaume, M.; Kohler, P.J.; Schiltz, C.; Gevers, W.; Content, A. The neural signature of numerosity by separating numerical and continuous magnitude extraction in visual cortex with frequency-tagged EEG. Proc. Natl. Acad. Sci. USA 2020, 117, 5726–5732. [Google Scholar] [CrossRef] [PubMed]
- Polich, J. Habituation of P300 from auditory stimuli. Psychobiology 1989, 17, 19–28. [Google Scholar] [CrossRef]
- Schirmer, A.; Kotz, S.A. Beyond the right hemisphere: Brain mechanisms mediating vocal emotional processing. Trends Cogn. Sci. 2006, 10, 24–30. [Google Scholar] [CrossRef]
- Boraston, Z.; Blakemore, S.-J.; Chilvers, R.; Skuse, D. Impaired sadness recognition is linked to social interaction deficit in autism. Neuropsychologia 2007, 45, 1501–1510. [Google Scholar] [CrossRef] [PubMed]
- Namba, S.; Kabir, R.S.; Miyatani, M.; Nakao, T. Dynamic Displays Enhance the Ability to Discriminate Genuine and Posed Facial Expressions of Emotion. Front. Psychol. 2018, 9, 672. [Google Scholar] [CrossRef]
- Jürgens, R.; Grass, A.; Drolet, M.; Fischer, J. Effect of Acting Experience on Emotion Expression and Recognition in Voice: Non-Actors Provide Better Stimuli than Expected. J. Nonverbal Behav. 2015, 39, 195–214. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vos, S.; Collignon, O.; Boets, B. The Sound of Emotion: Pinpointing Emotional Voice Processing Via Frequency Tagging EEG. Brain Sci. 2023, 13, 162. https://doi.org/10.3390/brainsci13020162
Vos S, Collignon O, Boets B. The Sound of Emotion: Pinpointing Emotional Voice Processing Via Frequency Tagging EEG. Brain Sciences. 2023; 13(2):162. https://doi.org/10.3390/brainsci13020162
Chicago/Turabian StyleVos, Silke, Olivier Collignon, and Bart Boets. 2023. "The Sound of Emotion: Pinpointing Emotional Voice Processing Via Frequency Tagging EEG" Brain Sciences 13, no. 2: 162. https://doi.org/10.3390/brainsci13020162
APA StyleVos, S., Collignon, O., & Boets, B. (2023). The Sound of Emotion: Pinpointing Emotional Voice Processing Via Frequency Tagging EEG. Brain Sciences, 13(2), 162. https://doi.org/10.3390/brainsci13020162