Obtaining Human Experience for Intelligent Dredger Control: A Reinforcement Learning Approach


Abstract
:Featured Application
Abstract

1. Introduction
2. Cutting Process Analysis
2.1. General Layout of a CSD
2.2. Problem Statement
2.3. Problem Formulation
- S denotes the finite set of state spaces,
- A denotes the finite set of action space,
- represents the conditional transition probability that defines the probability of arriving at the next state after performing action in state ,
- specifies the expected immediate reward after executing action in state at the next state , and
- is the discount factor that determines the importance of future rewards.
3. Neural Network Model to Construct Virtual Environment
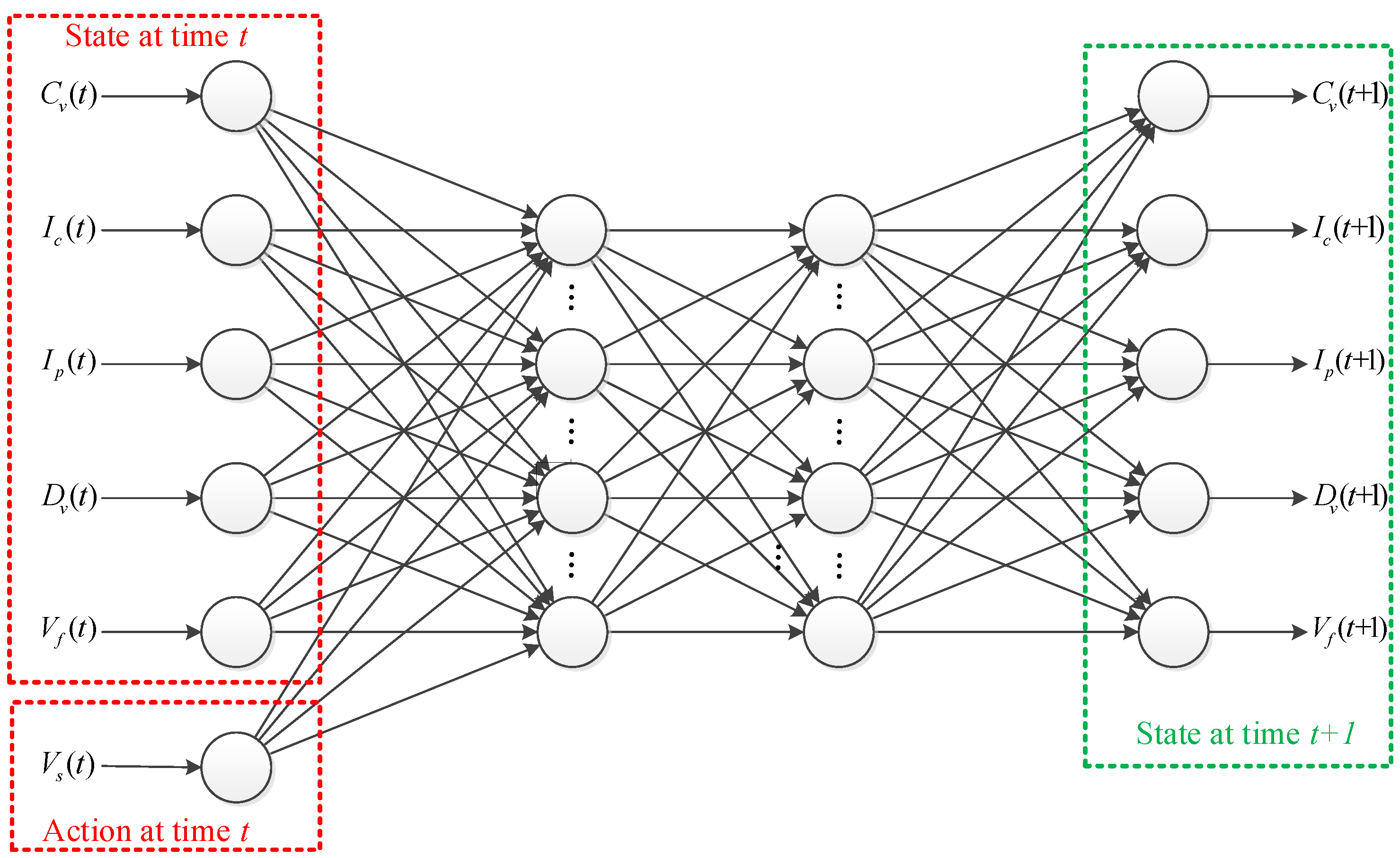
3.1. Representation of State Space
- Swing speed, denoted by , can indicate the among of the soils that are dredged in a swing movement along an arc trajectory. In such a swing, the CSD rotates around the working pole by slacking (or pulling) the cable of the starboard anchor (or the port side anchor). Those anchor cables are connected to the deck winches via the sheaves on both side of the cuter head. Thus, when the deck winches pull or slack the cables for the swing movement, it also produces a reaction force on the cutter head.
- Motor current of the cutter head, denoted by , indicates the reaction forces on the cutter head. The reaction forces are mainly affected by the soil type, as well as the rotation and swing movements of the cutter head. Even if the swing speed remains the same, the reaction forces of the clockwise rotation and the counterclockwise rotation must be different. As mentioned above, the swing movement also produces a reaction force on the cutter head via the anchor cables.
- Motor current of the underwater pump, denoted by , can indicate the extent to which the dredged soil is sucked up by the underwater pump. If the slurry density between the cutter head and the underwater pump remains at a high level, more torque is needed to drive the impeller of the pump for rotating, which results in the increase of the motor current of the underwater pump.
- Degree of suction vacuum, denoted by , can also indicate the extent to which the dredged soil is sucked up by the underwater pump, but this parameter is different from the motor of the underwater pump. Here the reason is that the slurry with high density requires more power to be sucked up, and the degree of the suction vacuum must be maintained at a high level to pump the dredged soil from the inlet of the cutter head.
- Flow velocity, denoted by , can reflect the among of sediment particles in the pipeline. Usually, the rotating speed of the pump(s) is not adjusted frequently, so the changes of the flow velocity are directly related to the slurry density in the pipeline. If the slurry density drops, it will be easier to transport the sediment particles in the pipeline, which will result in the increase of the flow velocity.
3.2. Representation of Action Space
3.3. State Transitions in Neural Networks
4. Reinforcement Learning to Find Optimal Control Policy
4.1. Reward Scheme
4.2. Model-Free Learning Algorithm
5. Evaluation and Results
5.1. Prediction of the Dynamics of the Environment
5.2. Intelligent Control of the Cutting Process
5.2.1. Results and Analysis
- Slurry Density.
- As the objective of the cutting process control is to maintain a high production rate (i.e., slurry density) in the pipeline, the intelligent control models should try to maximize this value. However, according to the reward scheme defined in Equation (7), the action selection should consider the restriction of the other states. In general, Figure 6 demonstrates that the slurry density of the Q-learning, SARSA, and SARSA() change more gently and keep at higher levels of slurry density than the human. Among the intelligent control models, the SARSA() can lead to the highest level of the slurry density. Thus, we can say that the intelligent control models enable the slurry density to be maintained at a consistently high level.The main reason can be explained by the reward scheme, in which we allow the learning agent to receive a big positive reward, i.e., if the slurry density is greater than , so the agent will always try to maximize the slurry density. It should be noted that the reason the slurry density cannot always maintain a high level is because of the environmental uncertainties, e.g., the terrains of the water bed. Nevertheless, we can conclude that the intelligent control models can outperform the experienced human operator with respect to the slurry density, as the intelligent control models have the inherent advantage of maximizing its rewards by selecting the optimal actions in dynamic situations.
- Swing Speed.
- In Figure 6, we have observed that the slurry density of three intelligent control models changes more gently than human operation. The deeper reason is that the intelligent control models can make quicker responses to the changes of uncertain terrains than the human. The phenomena can also be observed in Figure 6, where the learning agent can flexibly adjust its swing speed to cope with environmental uncertainties. In other words, the learning agent can select the action that can maximize the expected return based on the evaluation of the current states.Time delay is the underlying reason it is difficult for the human operator to make real-time response to the dynamic environment. For example, the operator has begun to reduce the swing speed at time-step 400, but the measured slurry density still maintained at a high level, as shown in Figure 6. This is because the slurry density measured by a nuclear-based gamma densitometer is installed at the stern of the CSD, so there is a time lag between the swing operation and the measured data. Thus, the operator cannot accurately predict the trend of the slurry density, and, as a result, he continues to decrease the swing speed at around time-step 405, which results in a sharp decline in the subsequent slurry density at around time-step 425. We can conclude that the intelligent control models can outperform the human in a way that can take future rewards into consideration. Comparatively, the decision-making of the human operator mainly depends on the currently collected data, and it will be hard to solve long time lag problems, i.e., the measured slurry density cannot reflect the change of the swing speed in time.In this work, when the learning agent explores the environment, we do not explicitly provide the information about the time lag problem, and the virtual environment is built up based on historical dredging data. All the data are collected when experienced human operators manipulates the CSD, so the data also contains many samples of unreasonable manipulations. However, from the results we can conclude that the intelligent control methods can learn from the experience of the human operator, and, in addition, improve the performance to avoid unreasonable manipulations.
- Motor Current.
- When we look at the motor current of the cutter head and the motor current of the pump, we can also find that the curves of the Q-learning, SARSA, and SARSA() change more gently then the curve of the human operation. The motor current of the cutter head reflects the cutting forces and the type of soil to be dredged, while the motor current of the pump indicates the slurry density between the cutter head and the underwater pump. In practice, it is hoped that the change of the motor current does not fluctuate too much and can be stabilized within the rated voltage range. However, it is a challenge task even for the experienced operator to achieve such a goal, as can be seen in Figure 6. Comparatively, all the intelligent control models can ensure that the change of the motor current will be stable and gentle, which is conducive to the safe operation of the motor and improve the service life of the motor. The reason the intelligent control models can keep the motor current stable in uncertain environments is also because of the ability of quick responses. Thus, we can conclude that the reward scheme designed in Equation (7) is effective to ensure the safe operation of the motors of the cutter head and the pump.
- Suction Vacuum.
- The degree of suction vacuum can indicate the pipeline concentration between the cutter head and the underwater pump, and if the value is too low, it is hard for the underwater pump to suck up the dredged slurry. In this case, the human operator or the intelligent control models should decrease the swing speed. Otherwise, the low vacuum can result in cavitation in the pipeline, which will affect the normal operation of the underwater pump. Thus, in Figure 6 we can see that all the intelligent control models are able to guarantee that the degree of suction vacuum will be kept with the range of −68 to −38 bar. Comparatively, the curve of the suction vacuum produced by the human violently oscillates between −81 to −28 bar. Thus, we can conclude that the adjustment of the swing speed of the intelligent control models takes account of the degree of suction vacuum and ensures that the value will be kept within a suitable range.
- Flow Velocity.
- As mentioned before, the flow velocity in the pipeline can also indicate the slurry density, and it is considered to be the key indicator for the prevention of blockage. In other words, if the flow velocity is too low, the solids level in the pipeline must be high, and the pipeline will be in danger of being blocked. Thus, the flow velocity must be maintained within a reasonable range. In Figure 6, we can see that all the intelligent control models can maintain the flow velocity at a relatively stable range, while the flow velocity of the human operation varies widely. Hence, we can say that the reward scheme designed in Equation (7) is effective to stabilize the flow velocity. Such a stabilization is achieved by adjusting the swing speed in quick responses, so the flow velocity can be kept with a safety range to avoid the risk of blockage.
5.2.2. Comparison of Production
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tang, J.Z.; Wang, Q.F.; Bi, Z.Y. Expert system for operation optimization and control of cutter suction dredger. Expert Syst. Appl. 2008, 34, 2180–2192. [Google Scholar] [CrossRef]
- Yuan, X.; Wang, X.; Zhang, X. Long distance slurry pipeline transportation slurry arrival time prediction based on multi-sensor data fusion. In Proceedings of the 29th Chinese Control And Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 3577–3581. [Google Scholar]
- Vogt, C.; Peck, E.; Hartman, G. Dredging for Navigation, for Environmental Cleanup, and for Sand/Aggregates. In Handbook on Marine Environment Protection; Springer: Berlin/Heidelberg, Germany, 2018; pp. 189–213. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Littman, M.L. Reinforcement learning improves behaviour from evaluative feedback. Nature 2015, 521, 445. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef] [PubMed]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Arzate Cruz, C.; Ramirez Uresti, J. HRLB2: A Reinforcement Learning Based Framework for Believable Bots. Appl. Sci. 2018, 8, 2453. [Google Scholar] [CrossRef]
- Kretzschmar, H.; Spies, M.; Sprunk, C.; Burgard, W. Socially compliant mobile robot navigation via inverse reinforcement learning. Int. J. Robot. Res. 2016, 35, 1289–1307. [Google Scholar] [CrossRef]
- Fathinezhad, F.; Derhami, V.; Rezaeian, M. Supervised fuzzy reinforcement learning for robot navigation. Appl. Soft Comput. 2016, 40, 33–41. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Fox, D.; Rasmussen, C.E. Gaussian processes for data-efficient learning in robotics and control. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 408–423. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Li, W.; Xu, K.; Zahid, T.; Qin, F.; Li, C. Energy management strategy for a hybrid electric vehicle based on deep reinforcement learning. Appl. Sci. 2018, 8, 187. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Y.; Xiong, W.; Yao, Z.; Moniz, K.; Zahir, A. Pareto Optimal Solutions for Network Defense Strategy Selection Simulator in Multi-Objective Reinforcement Learning. Appl. Sci. 2018, 8, 136. [Google Scholar] [CrossRef]
- Lample, G.; Chaplot, D.S. Playing FPS Games with Deep Reinforcement Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017; pp. 2140–2146. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Hung, S.M.; Givigi, S.N. A q-learning approach to flocking with uavs in a stochastic environment. IEEE Trans. Cybern. 2017, 47, 186–197. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Gao, H.; Qiu, J. A Combined Adaptive Neural Network and Nonlinear Model Predictive Control for Multirate Networked Industrial Process Control. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 416–425. [Google Scholar] [CrossRef] [PubMed]
- Haykin, S.S.; Haykin, S.S.; Haykin, S.S.; Haykin, S.S. Neural Networks And Learning Machines; Pearson: Upper Saddle River, NJ, USA, 2009; Volume 3. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Wiering, M.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 51. [Google Scholar]
- Wang, Y.H.; Li, T.H.S.; Lin, C.J. Backward Q-learning: The combination of Sarsa algorithm and Q-learning. Eng. Appl. Artif. Intell. 2013, 26, 2184–2193. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| neurons of the input layer | 6 |
| neurons of two hidden layers | 50, 50 |
| activation function of two hidden layers | ReLU, ReLU |
| neurons of the output layer | 5 |
| activation function of the output layer | Linear |
| learning rate | 0.1 |
| training episodes | 500 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Ni, F.; Chen, X. Obtaining Human Experience for Intelligent Dredger Control: A Reinforcement Learning Approach. Appl. Sci. 2019, 9, 1769. https://doi.org/10.3390/app9091769
Wei C, Ni F, Chen X. Obtaining Human Experience for Intelligent Dredger Control: A Reinforcement Learning Approach. Applied Sciences. 2019; 9(9):1769. https://doi.org/10.3390/app9091769
Chicago/Turabian StyleWei, Changyun, Fusheng Ni, and Xiujing Chen. 2019. "Obtaining Human Experience for Intelligent Dredger Control: A Reinforcement Learning Approach" Applied Sciences 9, no. 9: 1769. https://doi.org/10.3390/app9091769
APA StyleWei, C., Ni, F., & Chen, X. (2019). Obtaining Human Experience for Intelligent Dredger Control: A Reinforcement Learning Approach. Applied Sciences, 9(9), 1769. https://doi.org/10.3390/app9091769