Abstract Text Summarization with a Convolutional Seq2seq Model


Abstract
:1. Introduction
- We apply a convolutional seq2seq model to realize the text summarization which could help improve the model efficiency. And we also equip the CNN model with GLU and residual connections;
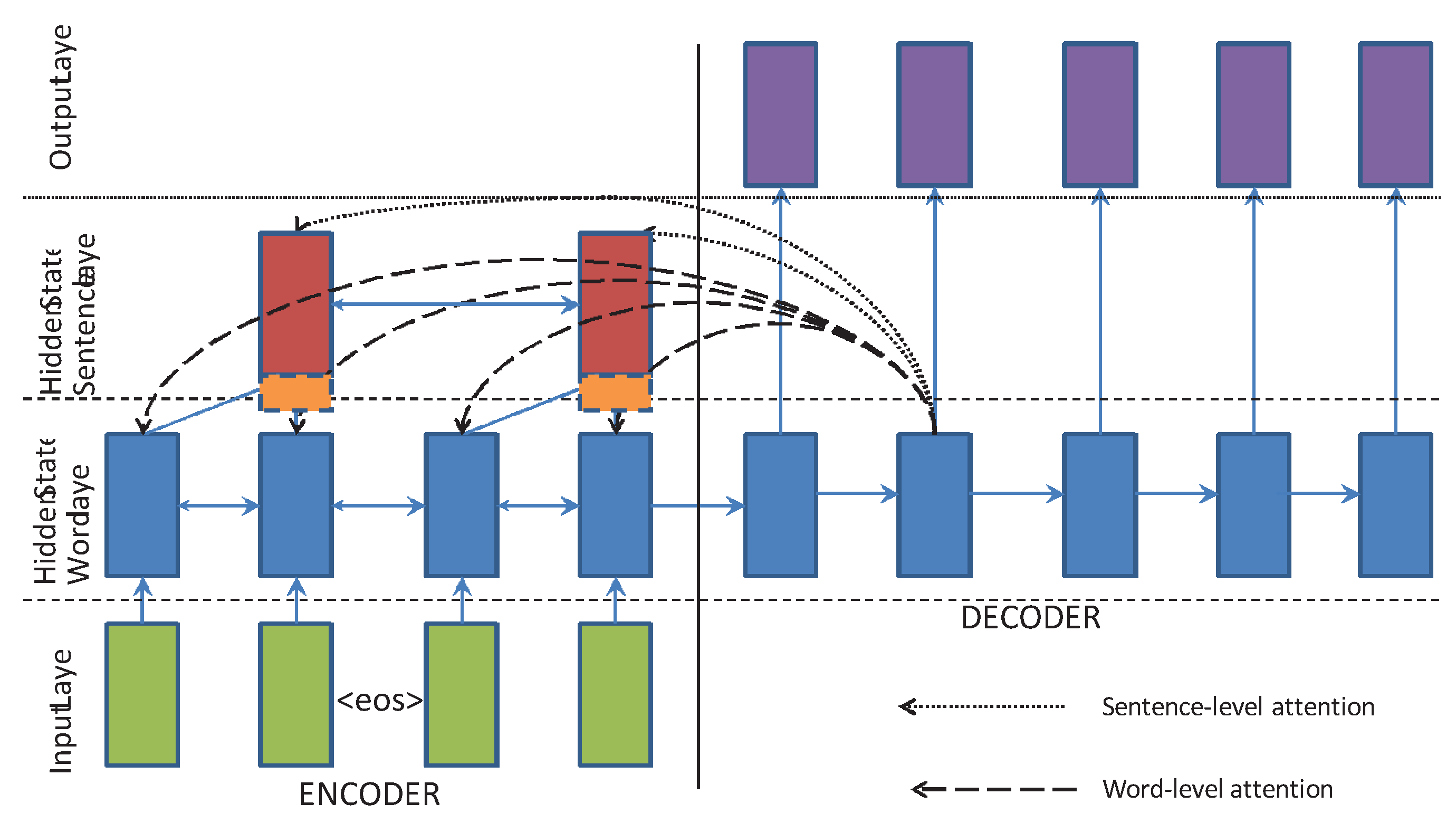
- We adopt a hierarchical attention mechanism to generate the keywords and the key sentences simultaneously. And we also introduce a copying mechanism to extract OOV words from source text.
- We evaluate our model on real-life datasets with other existing models. The experiment results on text summarization prove that our model has better performance than other advanced alternatives consistently and statistically significantly.
2. Related Work
2.1. Automatic Text Summarization
2.2. Seq2seq Model
3. Model Description
3.1. Problem Definition
3.2. Position Embeddings
3.3. Convolutional Seq2seq Model
3.4. Copying Mechanism
3.5. Hierarchical Attention Mechanism
4. Experiments and Results
4.1. Training Datasets
4.2. Experiment Setup
4.3. Evaluation Metrics
4.4. Variants of Our Model
4.5. Experimental Results
4.6. Computation Cost
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Y.; Zincir-Heywood, A.N.; Milios, E.E. World Wide Web site summarization. Web Intell. Agent Syst. 2004, 2, 39–53. [Google Scholar]
- Berend, G. Opinion Expression Mining by Exploiting Keyphrase Extraction. In Proceedings of the Fifth International Joint Conference on Natural Language Processing, IJCNLP 2011, Chiang Mai, Thailand, 8–13 November 2011; pp. 1162–1170. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar] [CrossRef]
- Venugopalan, S.; Rohrbach, M.; Donahue, J.; Mooney, R.J.; Darrell, T.; Saenko, K. Sequence to Sequence—Video to Text. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 4534–4542. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Nallapati, R.; Zhou, B.; dos Santos, C.N.; Gülçehre, Ç.; Xiang, B. Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, 11–12 August 2016; pp. 280–290. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Zhang, Y.; Fang, Y.; Xiao, W. Deep keyphrase generation with a convolutional sequence to sequence model. In Proceedings of the 4th International Conference on Systems and Informatics, ICSAI 2017, Hangzhou, China, 11–13 November 2017; pp. 1477–1485. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O.K. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Berlin, Germany, 7–12 August 2016; Volume 1. Long Papers. [Google Scholar]
- Neto, J.L.; Freitas, A.A.; Kaestner, C.A.A. Automatic Text Summarization Using a Machine Learning Approach. In Proceedings of the 16th Brazilian Symposium on Artificial Intelligence, SBIA 2002, Porto de Galinhas/Recife, Brazil, 11–14 November 2002; pp. 205–215. [Google Scholar] [CrossRef]
- Colmenares, C.A.; Litvak, M.; Mantrach, A.; Silvestri, F. HEADS: Headline Generation as Sequence Prediction Using an Abstract Feature-Rich Space. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2015, The Denver, CO, USA, 31 May–5 June 2015; pp. 133–142. [Google Scholar]
- Riedhammer, K.; Favre, B.; Hakkani-Tür, D. Long story short - Global unsupervised models for keyphrase based meeting summarization. Speech Commun. 2010, 52, 801–815. [Google Scholar] [CrossRef]
- Ribeiro, R.; Marujo, L.; de Matos, D.M.; Neto, J.P.; Gershman, A.; Carbonell, J.G. Self reinforcement for important passage retrieval. In Proceedings of the 36th International ACM SIGIR conference on research and development in Information Retrieval, SIGIR ’13, Dublin, Ireland, 28 July–1 August 2013; pp. 845–848. [Google Scholar] [CrossRef]
- David Zajic, B.J.D.; Schwartz, R. Bbn/umd at duc-2004: Topiary. In Proceedings of the North American Chapter of the Association for Computational Linguistics Workshop on Document Understanding, Boston, MA, USA, 2–7 May 2004; pp. 112–119. [Google Scholar]
- Banko, M.; Mittal, V.O.; Witbrock, M.J. Headline Generation Based on Statistical Translation. In Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics, Hong Kong, China, 1–8 October 2000. [Google Scholar]
- Cohn, T.; Lapata, M. Sentence Compression Beyond Word Deletion. In Proceedings of the 22nd International Conference on Computational Linguistics, Proceedings of the Conference, COLING 2008, Manchester, UK, 18–22 August 2008; pp. 137–144. [Google Scholar]
- Woodsend, K.; Feng, Y.; Lapata, M. Title Generation with Quasi-Synchronous Grammar. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, EMNLP 2010, Cambridge, MA, USA, 9–11 October 2010; pp. 513–523. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P.P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Chopra, S.; Auli, M.; Rush, A.M. Abstractive Sentence Summarization with Attentive Recurrent Neural Networks. In Proceedings of the The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2016, San Diego, CA, USA, 12–17 June 2016; pp. 93–98. [Google Scholar]
- Sankaran, B.; Mi, H.; Al-Onaizan, Y.; Ittycheriah, A. Temporal Attention Model for Neural Machine Translation. arXiv 2016, arXiv:1608.02927. [Google Scholar]
- Hu, B.; Chen, Q.; Zhu, F. LCSTS: A Large Scale Chinese Short Text Summarization Dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; pp. 1967–1972. [Google Scholar]
- Nallapati, R.; Xiang, B.; Zhou, B. Sequence-to-Sequence RNNs for Text Summarization. arXiv 2016, arXiv:1602.06023. [Google Scholar]
- Rekabdar, B.; Mousas, C.; Gupta, B. Generative Adversarial Network with Policy Gradient for Text Summarization. In Proceedings of the 13th IEEE International Conference on Semantic Computing, ICSC 2019, Newport Beach, CA, USA, 30 January–1 February 2019; pp. 204–207. [Google Scholar] [CrossRef]
- Zhang, H.; Gong, Y.; Yan, Y.; Duan, N.; Xu, J.; Wang, J.; Gong, M.; Zhou, M. Pretraining-Based Natural Language Generation for Text Summarization. arXiv 2019, arXiv:1902.09243. [Google Scholar]
- Alguliyev, R.M.; Aliguliyev, R.M.; Isazade, N.R.; Abdi, A.; Idris, N. COSUM: Text summarization based on clustering and optimization. Expert Syst. 2019, 36, e12340. [Google Scholar] [CrossRef]
- Song, S.; Huang, H.; Ruan, T. Abstractive text summarization using LSTM-CNN based deep learning. Multimed. Tools Appl. 2019, 78, 857–875. [Google Scholar] [CrossRef]
- Goularte, F.B.; Nassar, S.M.; Fileto, R.; Saggion, H. A text summarization method based on fuzzy rules and applicable to automated assessment. Expert Syst. Appl. 2019, 115, 264–275. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- van den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, 19–24 June 2016; pp. 1747–1756. [Google Scholar]
- Mousas, C.; Anagnostopoulos, C.N. Learning Motion Features for Example-Based Finger Motion Estimation for Virtual Characters. 3d Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]

{kind=link}
| Metric | Rouge-1 | Rouge-2 | Rouge-L | Src. Copy Rate |
|---|---|---|---|---|
| RNN-1sent | 34.83 | 17.07 | 32.55 | 75.77 |
| RNN-2sent | 35.68 | 17.34 | 32.64 | 76.48 |
| CNN-1sent | 35.02 | 17.23 | 33.25 | 75.21 |
| CNN-2sent | 35.87 | 17.38 | 33.36 | 76.53 |
| CNN-2sent-copy | 36.32 | 18.03 | 33.87 | 84.12 |
| CNN-2sent-hie | 36.02 | 17.74 | 33.57 | 75.49 |
| CNN-2sent-hieco | 37.02 | 18.21 | 34.07 | 80.03 |
| CNN-2sent-hieco-RBM | * 37.95 | * 18.64 | * 35.11 | 80.74 |
| ABS+ | 29.89 | 11.94 | 27.05 | 92.06 |
| RASElman | 36.26 | 17.92 | 33.91 | 83.25 |
| GAN | 36.88 | 17.54 | 34.05 | 76.54 |
| BERT | 36.97 | 17.96 | 33.87 | 74.51 |
| Metric | Rouge-1 | Rouge-2 | Rouge-L | |
|---|---|---|---|---|
| ABS | 26.58 | 7.11 | 22.03 | |
| ABS+ | 28.17 | 8.51 | 23.85 | |
| RASELman | 29.02 | 8.34 | 24.07 | |
| CNN-1sent-hieco | 29.12 | 9.35 | 25.11 | |
| CNN-1sent-hieco-RBM | * 29.74 | * 9.85 | * 25.81 | |
| GAN | 29.05 | 8.27 | 24.69 | |
| BERT | 28.97 | 9.21 | 24.89 |
| Metric | Rouge-1 | Rouge-2 | Rouge-L |
|---|---|---|---|
| ABS | 35.68 | 16.47 | 34.14 |
| ABS+ | 36.74 | 16.89 | 35.01 |
| RASELman | 39.65 | 18.25 | 37.24 |
| CNN-2sent-hieco | 41.87 | 19.64 | 39.35 |
| CNN-2sent-hieco-RBM | * 42.04 | * 19.77 | * 39.42 |
| GAN | 37.87 | 15.71 | 39.20 |
| BERT | 41.71 | 19.49 | 38.79 |
| Model | Times |
|---|---|
| ABS | 3211 |
| ABS+ | 3865 |
| RASELman | 4573 |
| GAN | 6587 |
| BERT | 7432 |
| RNN-1sent | 7753 |
| CNN-1sent | 1681 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, D.; Wang, Y.; Fang, Y.; Xiao, W. Abstract Text Summarization with a Convolutional Seq2seq Model. Appl. Sci. 2019, 9, 1665. https://doi.org/10.3390/app9081665
Zhang Y, Li D, Wang Y, Fang Y, Xiao W. Abstract Text Summarization with a Convolutional Seq2seq Model. Applied Sciences. 2019; 9(8):1665. https://doi.org/10.3390/app9081665
Chicago/Turabian StyleZhang, Yong, Dan Li, Yuheng Wang, Yang Fang, and Weidong Xiao. 2019. "Abstract Text Summarization with a Convolutional Seq2seq Model" Applied Sciences 9, no. 8: 1665. https://doi.org/10.3390/app9081665
APA StyleZhang, Y., Li, D., Wang, Y., Fang, Y., & Xiao, W. (2019). Abstract Text Summarization with a Convolutional Seq2seq Model. Applied Sciences, 9(8), 1665. https://doi.org/10.3390/app9081665