Automatic Spatial Audio Scene Classification in Binaural Recordings of Music †



Abstract
1. Introduction
1.1. Background
1.2. Aims of the Study
2. Materials and Methods
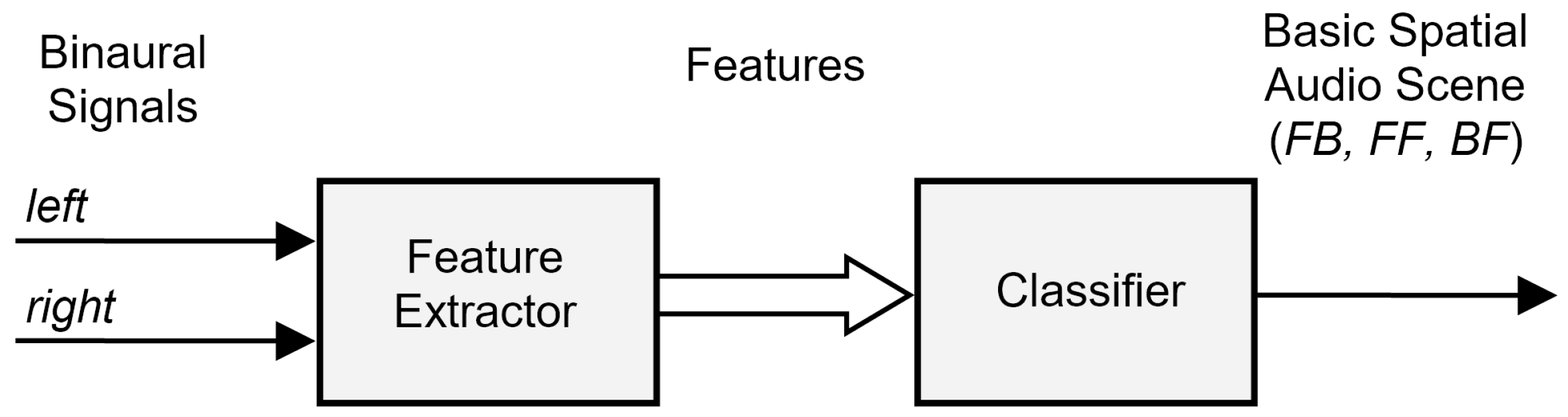
2.1. Method Overview
2.2. Corpus of Binaural Audio Recordings
2.2.1. Raw Audio Material
2.2.2. Database of Binaural Room Impulse Responses
2.2.3. Synthesis of Binaural Recordings
2.3. Feature Extraction
2.3.1. Root Mean Square (RMS) Features
2.3.2. Binaural Cues
- (1)
- means and standard deviations of the ILD values calculated separately for each of the 42 gammotone filters (2 × 42 features),
- (2)
- means and standard deviations of the ITD values calculated separately for each of the 42 gammotone filters (2 × 42 features),
- (3)
- means and standard deviations of the IC values calculated separately for each of the 42 gammotone filters (2 × 42 features),
2.3.3. Spectral Features
- (1)
- means and standard deviations of 14 spectral features calculated for x signal (2 × 14 features),
- (2)
- means and standard deviations of 14 spectral features calculated for y signal (2 × 14 features),
- (3)
- means and standard deviations of 14 spectral features calculated for m signal (2 × 14 features),
- (4)
- means and standard deviations of 14 spectral features calculated for s signal (2 × 14 features).
2.3.4. Mel-Frequency Cepstral Coefficient (MFCC) Features
- (1)
- means and standard deviations of the 40 MFCCs derived from x signal (2 × 40 features),
- (2)
- means and standard deviations of the 40 MFCCs derived from y signal (2 × 40 features),
- (3)
- means and standard deviations of the 40 MFCCs derived from m signal (2 × 40 features),
- (4)
- means and standard deviations of the 40 MFCCs derived from s signal (2 × 40 features).
2.4. Classification Algorithm
3. Results
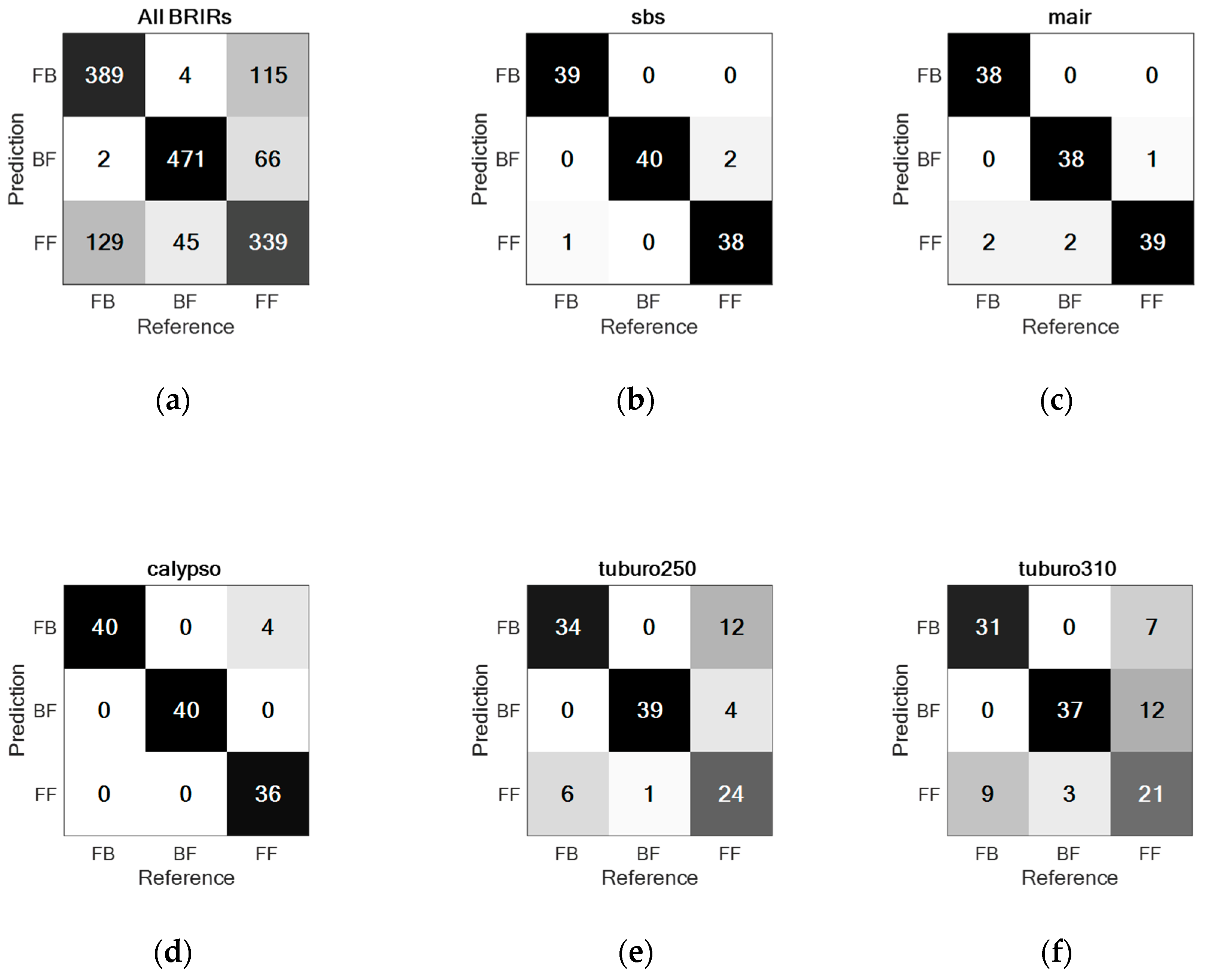
3.1. Experiment 1
3.2. Experiment 2
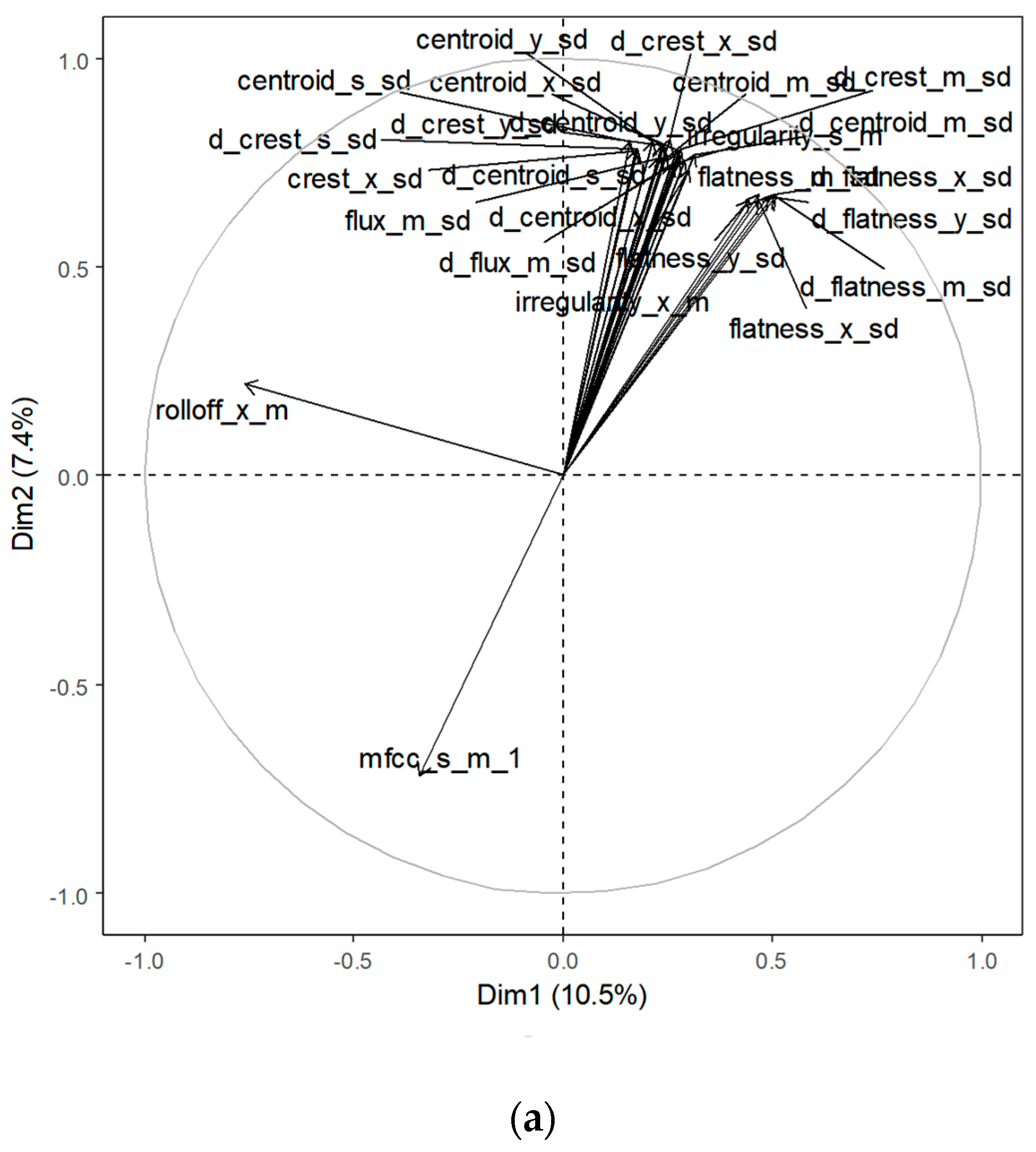
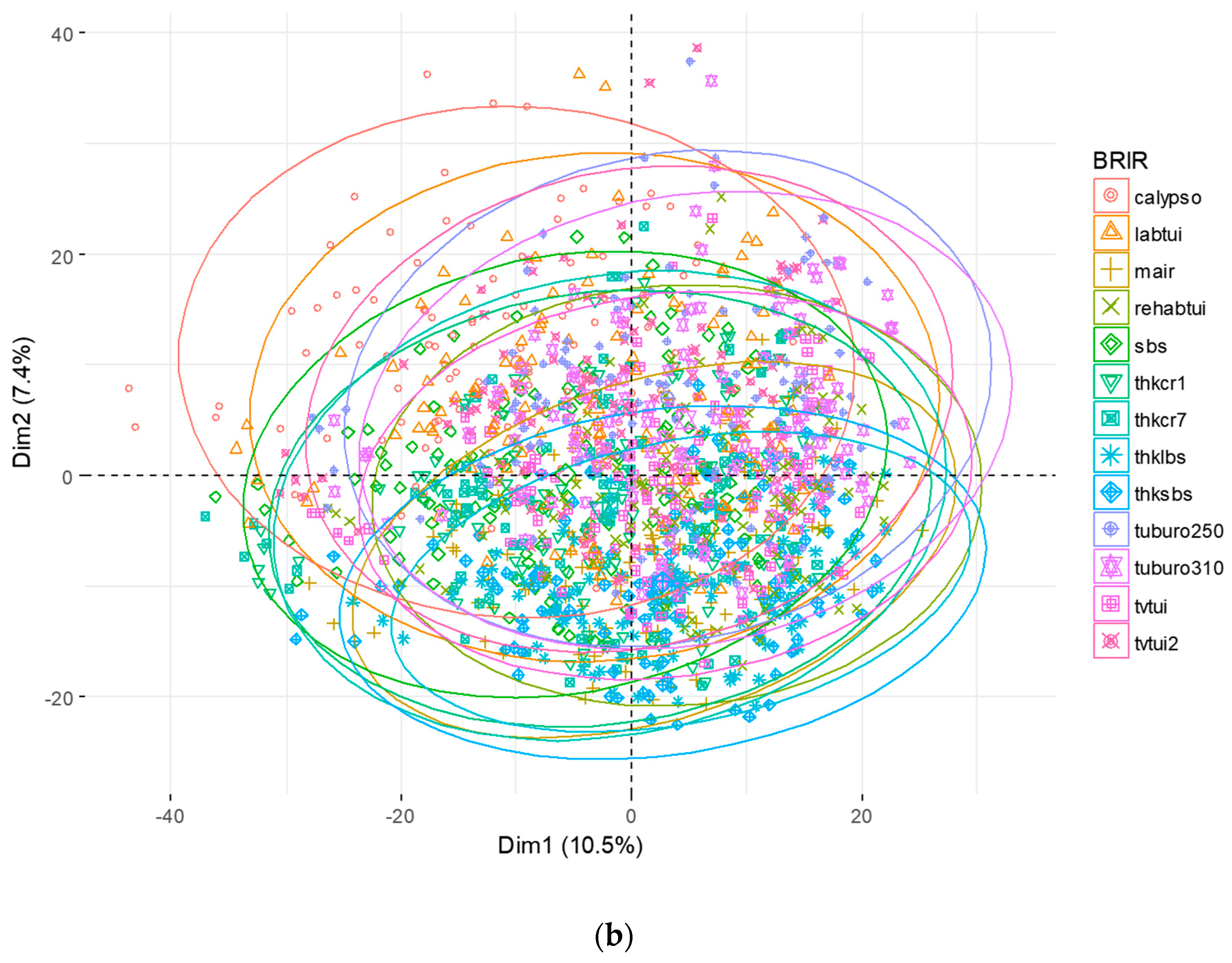
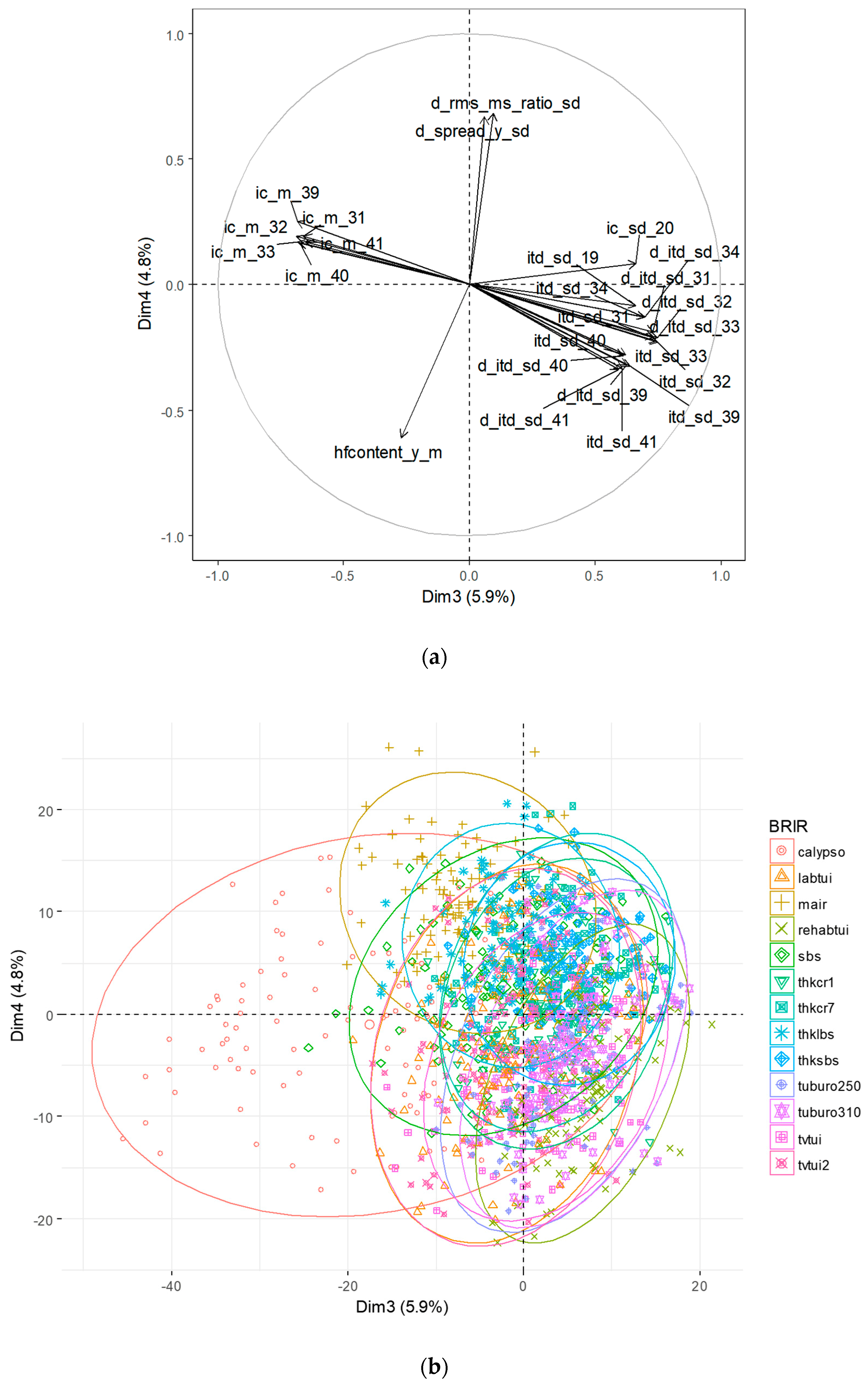
3.3. Principal Component Analysis
4. Discussion
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Kelion, L. YouTube Live-Streams in Virtual Reality and Adds 3D Sound, BBC News. Available online: http://www.bbc.com/news/technology-36073009 (accessed on 18 April 2016).
- Parnell, T. Binaural Audio at the BBC Proms. Available online: https://www.bbc.co.uk/rd/blog/2016-09-binaural-proms (accessed on 14 July 2017).
- Omnitone: Spatial Audio on the Web, Google, USA. Available online: https://opensource.googleblog.com/2016/07/omnitone-spatial-audio-on-web.html (accessed on 25 July 2016).
- Blauert, J. The Technology of Binaural Listening; Springer: Berlin, Germany, 2013. [Google Scholar]
- Rumsey, F. Spatial quality evaluation for reproduced sound: Terminology, meaning, and a scene-based paradigm. J. Audio Eng. Soc. 2002, 50, 651–666. [Google Scholar]
- May, T.; Ma, N.; Brown, G.J. Robust localisation of multiple speakers exploiting head movements and multi-conditional training of binaural cues. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- Ma, N.; Brown, G.J. Speech localisation in a multitalker mixture by humans and machines. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Ma, N.; Gonzalez, J.A.; Brown, G.J. Robust Binaural Localization of a Target Sound Source by Combining Spectral Source Models and Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process 2018, 26, 2122–2131. [Google Scholar] [CrossRef]
- Benaroya, E.L.; Obin, N.; Liuni, M.; Roebel, A.; Raumel, W.; Argentieri, S. Binaural Localization of Multiple Sound Sources by Non-Negative Tensor Factorization. IEEE/ACM Trans. Audio Speech Lang. Process 2018, 26, 1072–1082. [Google Scholar] [CrossRef]
- Lovedee-Turner, M.; Murphy, D. Application of Machine Learning for the Spatial Analysis of Binaural Room Impulse Responses. Appl. Sci. 2018, 8, 105. [Google Scholar] [CrossRef]
- Jeffress, L.A. A place theory of sound localization. J. Comp. Physiol. Psychol. 1948, 41, 35–39. [Google Scholar] [CrossRef] [PubMed]
- Breebaart, J.; van de Par, S.; Kohlrausch, A. Binaural processing model based on contralateral inhibition. I. Model structure. J. Acoust. Soc. Am. 2001, 110, 1074–1088. [Google Scholar] [CrossRef]
- Han, Y.; Park, J.; Lee, K. Convolutional neural networks with binaural representations and background subtraction for acoustic scene classification. In Proceedings of the Conference on Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017. [Google Scholar]
- Blauert, J. Spatial Hearing. The Psychology of Human Sound Localization; The MIT Press: London, UK, 1974. [Google Scholar]
- Käsbach, J.; Marschall, M.; Epp, B.; Dau, T. The relation between perceived apparent source width and interaural cross-correlation in sound reproduction spaces with low reverberation. In Proceedings of the DAGA 2013, Merano, Italy, 18–21 March 2013. [Google Scholar]
- Zonoz, B.; Arani, E.; Körding, K.P.; Aalbers, P.A.T.R.; Celikel, T.; Van Opstal, A.J. Spectral Weighting Underlies Perceived Sound Elevation. Nat. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Raake, A. A Computational Framework for Modelling Active Exploratory Listening that Assigns Meaning to Auditory Scenes—Reading the World with Two Ears. Available online: http://twoears.eu (accessed on 8 March 2019).
- Ibrahim, K.M.; Allam, M. Primary-ambient source separation for upmixing to surround sound systems. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 15–20 April 2018. [Google Scholar]
- Hummersone, C.H.; Mason, R.; Brookes, T. Dynamic Precedence Effect Modeling for Source Separation in Reverberant Environments. IEEE Trans. Audio Speech Lang. Process 2010, 18, 1867–1871. [Google Scholar] [CrossRef]
- Zieliński, S.K.; Lee, H. Feature Extraction of Binaural Recordings for Acoustic Scene Classification. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems (FedCSIS), Poznań, Poland, 9–12 September 2018. [Google Scholar]
- Sturm, B.L. A Survey of Evaluation in Music Genre Recognition. In Adaptive Multimedia Retrieval: Semantics, Context, and Adaptation; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Zieliński, S.; Rumsey, F.; Kassier, R. Development and Initial Validation of a Multichannel Audio Quality Expert System. J. Audio Eng. Soc. 2005, 53, 4–21. [Google Scholar]
- Zieliński, S.K. Feature Extraction of Surround Sound Recordings for Acoustic Scene Classification. In Artificial Intelligence and Soft Computing, Proceedings of the ICAISC 2018; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zieliński, S.K. Spatial Audio Scene Characterization (SASC). Automatic Classification of Five-Channel Surround Sound Recordings According to the Foreground and Background Content. In Multimedia and Network Information Systems, Proceedings of the MISSI 2018; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Beresford, K.; Zieliński, S.; Rumsey, F. Listener Opinions of Novel Spatial Audio Scenes. In Proceedings of the 120th AES Convention, Paris, France, 20–23 May 2006. [Google Scholar]
- Lee, H.; Millns, C. Microphone Array Impulse Response (MAIR) Library for Spatial Audio Research. In Proceedings of the 143rd AES Convention, New York, NY, USA, 21 October 2017. [Google Scholar]
- Zieliński, S.; Rumsey, F.; Bech, S. Effects of Down-Mix Algorithms on Quality of Surround Sound. J. Audio Eng. Soc. 2003, 51, 780–798. [Google Scholar]
- Szabó, B.T.; Denham, S.L.; Winkler, I. Computational models of auditory scene analysis: A review. Front. Neurosci. 2016, 10, 1–16. [Google Scholar] [CrossRef]
- Alinaghi, A.; Jackson, P.J.B.; Liu, Q.; Wang, W. Joint Mixing Vector and Binaural Model Based Stereo Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process 2014, 22, 1434–1448. [Google Scholar] [CrossRef]
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic scene classification: Classifying environments from the sounds they produce. IEEE Signal. Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Pätynen, J.; Pulkki, V.; Lokki, T. Anechoic Recording System for Symphony Orchestra. Acta Acust united Ac. 2008, 94, 856–865. [Google Scholar] [CrossRef]
- D’Orazio, D.; De Cesaris, S.; Garai, M. Recordings of Italian opera orchestra and soloists in a silent room. Proc. Mtgs. Acoust. 2016, 28, 015014. [Google Scholar]
- Mixing Secrets for The Small Studio. Available online: http://www.cambridge-mt.com/ms-mtk.htm (accessed on 8 March 2019).
- Bittner, R.; Salamon, J.; Tierney, M.; Mauch, M.; Cannam, C.; Bello, J.P. MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research. In Proceedings of the 15th International Society for Music Information Retrieval Conference, Taipei, Taiwan, 27 October 2014. [Google Scholar]
- Studio Sessions. Telefunken Elektroakustik. Available online: https://telefunken-elektroakustik.com/multitracks (accessed on 8 March 2019).
- Satongar, D.; Lam, Y.W.; Pike, C.H. Measurement and analysis of a spatially sampled binaural room impulse response dataset. In Proceedings of the 21st International Congress on Sound and Vibration, Beijing, China, 13–17 July 2014. [Google Scholar]
- Stade, P.; Bernschütz, B.; Rühl, M. A Spatial Audio Impulse Response Compilation Captured at the WDR Broadcast Studios. In Proceedings of the 27th Tonmeistertagung—VDT International Convention, Cologne, Germany, 20 November 2012. [Google Scholar]
- Wierstorf, H. Binaural Room Impulse Responses of a 5.0 Surround Setup for Different Listening Positions. Zenodo. Available online: https://zenodo.org (accessed on 14 October 2016).
- Lee, H. Sound Source and Loudspeaker Base Angle Dependency of Phantom Image Elevation Effect. J. Audio Eng. Soc. 2017, 65, 733–748. [Google Scholar] [CrossRef][Green Version]
- Werner, S.; Voigt, M.; Klein, F. Dataset of Measured Binaural Room Impulse Responses for Use in an Position-Dynamic Auditory Augmented Reality Application. Zenodo. Available online: https://zenodo.org (accessed on 26 July 2018).
- Klein, F.; Werner, S.; Chilian, A.; Gadyuchko, M. Dataset of In-The-Ear and Behind-The-Ear Binaural Room Impulse Responses used for Spatial Listening with Hearing Implants. In Proceedings of the 142nd AES Convention, Berlin, Germany, 20–23 May 2017. [Google Scholar]
- Erbes, V.; Geier, M.; Weinzierl, S.; Spors, S. Database of single-channel and binaural room impulse responses of a 64-channel loudspeaker array. In Proceedings of the 138th AES Convention, Warsaw, Poland, 7–10 May 2015. [Google Scholar]
- Pulkki, V. Virtual Sound Source Positioning Using Vector Base Amplitude Panning. J. Audio Eng. Soc. 1997, 45, 456–466. [Google Scholar]
- Politis, A. Vector-Base Amplitude Panning Library. Available online: https://github.com (accessed on 1 January 2015).
- Wierstorf, H.; Spors, S. Sound Field Synthesis Toolbox. In Proceedings of the 132nd AES Convention, Budapest, Hungary, 26–29 April 2012. [Google Scholar]
- Rabiner, L.; Juang, B.-H.; Yegnanarayana, B. Fundamentals of Speech Recognition; Pearson India: New Delhi, India, 2008. [Google Scholar]
- Dau, T.; Püschel, D.; Kohlrausch, A. A quantitative model of the “effective” signal processing in the auditory system. I. Model structure. J. Acoust. Soc. Am. 1996, 99, 3615. [Google Scholar] [CrossRef]
- Brown, G.J.; Cooke, M. Computational auditory scene analysis. Comput. Speech Lang. 1994, 8, 297–336. [Google Scholar] [CrossRef]
- George, S.; Zieliński, S.; Rumsey, F.; Jackson, P.; Conetta, R.; Dewhirst, M.; Meares, D.; Bech, S. Development and Validation of an Unintrusive Model for Predicting the Sensation of Envelopment Arising from Surround Sound Recordings. J. Audio Eng. Soc. 2010, 58, 1013–1031. [Google Scholar]
- Conetta, R.; Brookes, T.; Rumsey, F.; Zieliński, S.; Dewhirst, M.; Jackson, P.; Bech, S.; Meares, D.; George, S. Spatial audio quality perception (part 2): A linear regression model. J. Audio Eng. Soc. 2014, 62, 847–860. [Google Scholar] [CrossRef][Green Version]
- Lerch, A. An Introduction to Audio Content Analysis Applications in Signal. Processing and Music Informatics; IEEE Press: Berlin, Germany, 2012. [Google Scholar]
- Peeters, G.; Giordano, B.; Susini, P.; Misdariis, N.; McAdams, S. Extracting audio descriptors from musical signals. J. Acoust. Soc. Am. 2011, 130, 2902–2916. [Google Scholar] [CrossRef]
- Jensen, K.; Andersen, T.H. Real-time beat estimation using feature extraction. In Computer Music Modeling and Retrieval; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2004. [Google Scholar]
- Scheirer, E.; Slaney, M. Construction and evaluation of a robust multifeature speech/music discriminator. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997. [Google Scholar]
- McCree, A.; Sell, G.; Garcia-Romero, D. Extended Variability Modeling and Unsupervised Adaptation for PLDA Speaker Recognition. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Shen, Z.; Yong, B.; Zhang, G.; Zhou, R.; Zhou, Q. A Deep Learning Method for Chinese Singer Identification. Tsinghua Sci. Technol. 2019, 24, 371–378. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2012, 36, 27–46. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: London, UK, 2017. [Google Scholar]
- Kuhn, M. The Caret Package. Available online: https://topepo.github.io/caret (accessed on 26 May 2018).
- Wightman, F.; Kistler, D. Resolution of Front–Back Ambiguity in Spatial Hearing by Listener and Source Movement. J. Acoust. Soc. Am. 1999, 105, 2841–2853. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
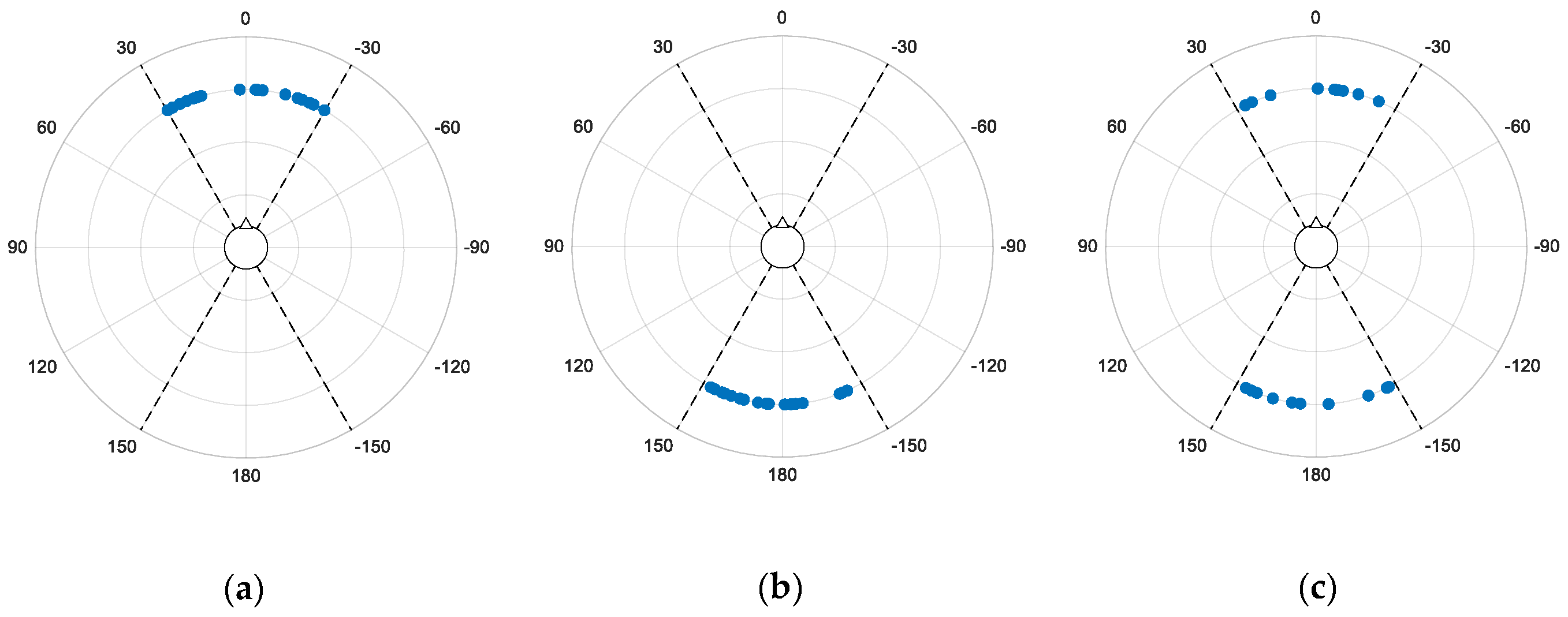
| Acoustic Scene | Description |
|---|---|
| Foreground–Background (FB) | A listener perceives foreground audio content in the front and background content behind the head. |
| Background–Foreground (BF) | A listener perceives background audio content in the front and foreground content behind the head. |
| Foreground–Foreground (FF) | A listener is surrounded by foreground audio content. |
| No. | Acronym | Description | Dummy Head | RT60 (s) |
|---|---|---|---|---|
| 1 | sbs | Salford, British Broadcasting Corporation (BBC)–Listening Room [36] | B&K HATS Type 4100 | 0.27 |
| 2 | mair | Huddersfield–Concert Hall [26] | Neumann KU100 | 2.1 |
| 3 | thkcr1 | Westdeutscher Rundfunk (WDR) Broadcast Studios–Control Room 1 [37] | Neumann KU100 | 0.23 |
| 4 | thkcr7 | WDR Broadcast Studios–Control Room 7 [37] | Neumann KU100 | 0.27 |
| 5 | thksbs | WDR Broadcast Studios–Small Broadcast Studio (SBS) [37] | Neumann KU100 | 1.0 |
| 6 | thklbs | WDR Broadcast Studios–Large Broadcast Studio (LBS) [37] | Neumann KU100 | 1.8 |
| 7 | calypso | Technische Universität (TU) Berlin–Calypso Room [38] | KEMAR 45BA | 0.17 |
| 8 | tvtui | TU Ilmenau–TV Studio (distance of 3.5m) [40] | KEMAR 45BA | 0.7 |
| 9 | tvtui2 | TU Ilmenau–TV Studio (distance of 2m) [41] | KEMAR 45BA | 0.7 |
| 10 | labtui | TU Ilmenau–Listening Laboratory [41] | KEMAR 45BA | 0.3 |
| 11 | rehabtui | TU Ilmenau–Rehabilitation Laboratory [41] | KEMAR 45BA | NA |
| 12 | tuburo250 | University of Rostock–Audio Laboratory (additional absorbers) [42] | KEMAR 45BA | 0.25 |
| 13 | tuburo310 | University of Rostock–Audio Laboratory (all broadband absorbers) [42] | KEMAR 45BA | 0.31 |
| Spatial Features | Spectro-Temporal Features | |||
|---|---|---|---|---|
| Feature Acronym | Root Mean Square (RMS) | Binaural Cues | Spectral Features | Mel-Frequency Cepstral Coefficient (MFCC) |
| Number of Features | 8 | 504 | 224 | 640 |
| Dataset | RMS | Binaural | MFCC | Spectral | RMS + Binaural | MFCC + Spectral | All Features |
|---|---|---|---|---|---|---|---|
| Training | 38.2 | 72.9 | 74.9 | 50.0 | 73.1 | 75.1 | 81.2 |
| Testing | 39.9 | 73.1 | 69.0 | 52.2 | 73.6 | 67.8 | 76.9 |
| ID | BRIR | RMS | Binaural | MFCC | Spectral | RMS + Binaural | MFCC + Spectral | All Features |
|---|---|---|---|---|---|---|---|---|
| 1 | sbs | 43.9 | 91.5 | 88.5 | 49.5 | 91.5 | 88.0 | 91.7 |
| 2 | mair | 48.5 | 91.8 | 85.9 | 51.6 | 91.8 | 84.9 | 92.2 |
| 3 | thkcr1 | 46.3 | 96.8 | 82.1 | 42.1 | 96.8 | 81.6 | 96.2 |
| 4 | thkcr7 | 37.9 | 94.8 | 84.2 | 48.2 | 94.9 | 83.8 | 94.7 |
| 5 | thksbs | 35.9 | 87.9 | 72.5 | 42.5 | 87.9 | 72.4 | 87.6 |
| 6 | thklbs | 50.2 | 85.4 | 68.8 | 47.7 | 85.3 | 68.1 | 85.7 |
| 7 | calypso | 69.3 | 97.5 | 95.2 | 82.7 | 97.5 | 95.6 | 97.8 |
| 8 | tvtui | 48.3 | 88.6 | 74.0 | 58.7 | 88.6 | 73.8 | 87.7 |
| 9 | tvtui2 | 45.6 | 85.3 | 80.2 | 47.2 | 85.1 | 79.9 | 86.9 |
| 10 | labtui | 40.7 | 79.1 | 71.2 | 44.6 | 79.4 | 70.4 | 78.9 |
| 11 | rehabtui | 46.3 | 84.2 | 73.4 | 44.6 | 84.3 | 72.4 | 85.4 |
| 12 | tuburo250 | 38.3 | 66.7 | 72.2 | 58.6 | 66.7 | 72.0 | 71.0 |
| 13 | tuburo310 | 40.4 | 66.2 | 71.5 | 56.9 | 66.6 | 70.6 | 73.6 |
| ID | BRIR | RMS | Binaural | MFCC | Spectral | RMS + Binaural | MFCC + Spectral | All Features |
|---|---|---|---|---|---|---|---|---|
| 1 | sbs | 50.8 | 95.8 | 93.3 | 56.7 | 95.8 | 93.3 | 97.5 |
| 2 | mair | 54.2 | 94.2 | 84.2 | 47.5 | 94.2 | 81.7 | 95.8 |
| 3 | thkcr1 | 50.8 | 98.3 | 85.0 | 45.8 | 98.3 | 83.3 | 98.3 |
| 4 | thkcr7 | 37.5 | 95.8 | 90.8 | 60.0 | 95.8 | 91.7 | 96.7 |
| 5 | thksbs | 42.5 | 84.2 | 75.0 | 48.3 | 84.2 | 75.0 | 84.2 |
| 6 | thklbs | 50.8 | 85.8 | 73.3 | 53.3 | 85.8 | 75.0 | 85.8 |
| 7 | calypso | 69.2 | 97.5 | 97.5 | 75.8 | 97.5 | 97.5 | 96.7 |
| 8 | tvtui | 50.8 | 85.0 | 72.5 | 61.7 | 85.0 | 73.3 | 86.7 |
| 9 | tvtui2 | 46.7 | 89.2 | 78.3 | 53.3 | 90.0 | 76.7 | 90.8 |
| 10 | labtui | 40.8 | 79.2 | 83.3 | 45.8 | 78.3 | 85.0 | 84.2 |
| 11 | rehabtui | 40.8 | 81.7 | 79.2 | 40.8 | 81.7 | 78.3 | 88.3 |
| 12 | tuburo250 | 43.3 | 65.0 | 80.8 | 55.8 | 65.0 | 81.7 | 80.8 |
| 13 | tuburo310 | 35.8 | 70.8 | 75.0 | 52.5 | 70.8 | 75.0 | 74.2 |
| Reverberation Time | RT60 | BRIRs Used for Training | BRIRs Used for Testing | Test Accuracy (%) |
|---|---|---|---|---|
| Short | 0.17−0.31 s | sbs, thkcr1, calypso, labtui, tuburo310 | thkcr7, tuburo250 | 65.4 (59.0, 71.4) |
| Medium | 0.7−1.0 s | thksbs, tvtui | tvtui2 | 51.7 (42.4, 60.9) |
| Long | 1.8−2.1 s | thklbs | mair | 40.0 (31.2, 49.3) |
| No. | BRIR Set Left-Out | Training Accuracy (%) | Testing Accuracy (%) |
|---|---|---|---|
| 1 | sbs | 80.8 | 44.2 (35.1, 53.5) |
| 2 | mair | 80.8 | 56.7 (47.3, 65.7) |
| 3 | thkcr1 | 81.5 | 45.8 (36.7, 55.2) |
| 4 | thkcr7 | 80.6 | 65.0 (55.8, 73.5) |
| 5 | thksbs | 81.1 | 65.0 (55.8, 73.5) |
| 6 | thklbs | 82.0 | 50.0 (40.7, 59.3) |
| 7 | calypso | 80.6 | 37.5 (28.8, 46.8) |
| 8 | tvtui | 80.8 | 55.8 (46.5, 64.9) |
| 9 | tvtui2 | 81.1 | 79.2 (70.8, 86.0) |
| 10 | labtui | 81.7 | 65.8 (56.6, 74.2) |
| 11 | rehabtui | 81.9 | 35.8 (27.3, 45.1) |
| 12 | tuburo250 | 81.6 | 64.2 (54.9, 72.7) |
| 13 | tuburo310 | 81.0 | 73.3 (64.5, 81.0) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zieliński, S.K.; Lee, H. Automatic Spatial Audio Scene Classification in Binaural Recordings of Music. Appl. Sci. 2019, 9, 1724. https://doi.org/10.3390/app9091724
Zieliński SK, Lee H. Automatic Spatial Audio Scene Classification in Binaural Recordings of Music. Applied Sciences. 2019; 9(9):1724. https://doi.org/10.3390/app9091724
Chicago/Turabian StyleZieliński, Sławomir K., and Hyunkook Lee. 2019. "Automatic Spatial Audio Scene Classification in Binaural Recordings of Music" Applied Sciences 9, no. 9: 1724. https://doi.org/10.3390/app9091724
APA StyleZieliński, S. K., & Lee, H. (2019). Automatic Spatial Audio Scene Classification in Binaural Recordings of Music. Applied Sciences, 9(9), 1724. https://doi.org/10.3390/app9091724