Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation



Abstract
:1. Introduction
- We develop new non-convex tensor rank approximation functions that can be used as desirable regularization for the optimization process, which appears to be more effective than current existing approaches in literature.
- An efficient algorithm based on the alternating direction method of multipliers (ADMM) is developed to solve the equivalent optimization problem in the Fourier domain, which is also suitable for general TRPCA problem. In addition, we provided the convergent analysis of the augmented Lagrange multiplier based optimization algorithm.
- Extensive evaluation of the proposed approach on several benchmark data sets has been conducted, and detailed comparison with most recent approaches are provided. Experimental results demonstrate that our proposed approach yields superior performance for image recovery and video background modeling.
2. Related Works
3. Notations and Definitions
4. Tensor Robust Principal Component Analysis with Non-Convex Regularization
| Algorithm 1 Solve the non-convex TRPCA model (5) by ADMM. |
| Input: The observed tensor , the set of index of observed entries , parameter , stopping criterion . Initialize: , , , , .
|
5. Experiments
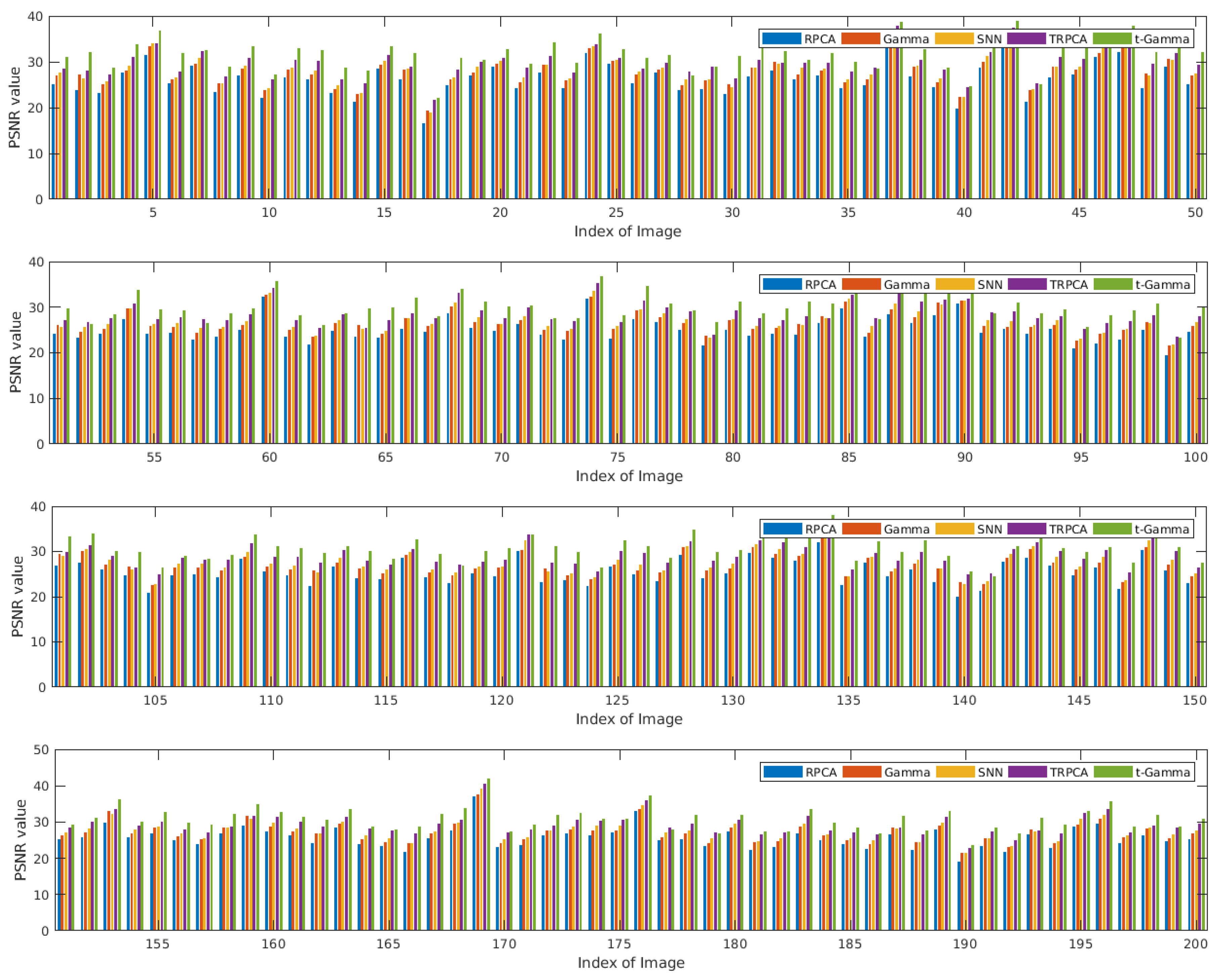
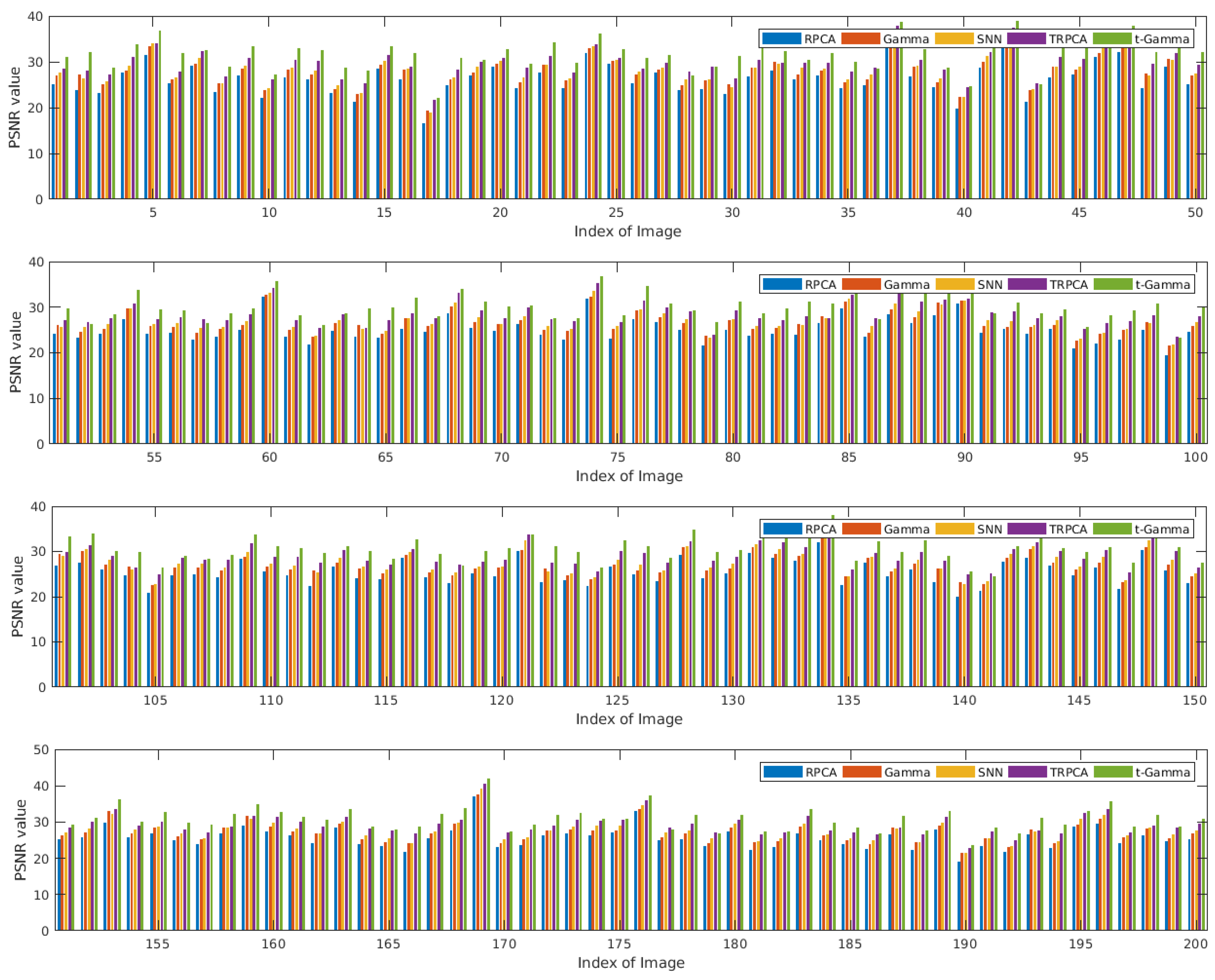
5.1. Image Recovery
5.2. Video Background Modeling
5.2.1. Qualitative Experiments
5.2.2. Quantitative Experiments
6. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Landsberg, J. Tensors: Geometry and Applications; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 2012. [Google Scholar]
- Bro, R. Multi-Way Analysis in the Food Industry: Models, Algorithms, and Applications. Ph.D. Thesis, University of Amsterdam (NL), Amsterdam, The Netherlands, 1998. [Google Scholar]
- Yang, M.; Li, W.; Xiao, M. On identifiability of higher order block term tensor decompositions of rank Lr⊗ rank-1. Linear Multilinear Algebra 2018, 1–23. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, USA, 7–10 December 2009; pp. 2080–2088. [Google Scholar]
- Kang, Z.; Pan, H.; Hoi, S.C.H.; Xu, Z. Robust Graph Learning From Noisy Data. IEEE Trans. Cybern. 2019, 1–11. [Google Scholar] [CrossRef]
- Peng, C.; Kang, Z.; Cai, S.; Cheng, Q. Integrate and Conquer: Double-Sided Two-Dimensional k-Means Via Integrating of Projection and Manifold Construction. ACM Trans. Intell. Syst. Technol. 2018, 9, 57. [Google Scholar] [CrossRef]
- Sun, P.; Qin, J. Speech enhancement via two-stage dual tree complex wavelet packet transform with a speech presence probability estimator. J. Acoust. Soc. Am. 2017, 141, 808–817. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, N.; Bouwmans, T.; Javed, S.; Narayanamurthy, P. Robust subspace learning: Robust PCA, robust subspace tracking, and robust subspace recovery. IEEE Signal Process. Mag. 2018, 35, 32–55. [Google Scholar] [CrossRef]
- Bouwmans, T.; Zahzah, E.H. Robust PCA via principal component pursuit: A review for a comparative evaluation in video surveillance. Comput. Vis. Image Underst. 2014, 122, 22–34. [Google Scholar] [CrossRef]
- Bouwmans, T.; Javed, S.; Zhang, H.; Lin, Z.; Otazo, R. On the applications of robust PCA in image and video processing. Proc. IEEE 2018, 106, 1427–1457. [Google Scholar] [CrossRef]
- Cichocki, A.; Lee, N.; Oseledets, I.; Phan, A.H.; Zhao, Q.; Mandic, D.P. Tensor networks for dimensionality reduction and large-scale optimization: Part 1 low-rank tensor decompositions. Found. Trends® Mach. Learn. 2016, 9, 249–429. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef]
- Hao, N.; Kilmer, M.E.; Braman, K.; Hoover, R.C. Facial recognition using tensor-tensor decompositions. SIAM J. Imaging Sci. 2013, 6, 437–463. [Google Scholar] [CrossRef]
- Zhang, Z.; Ely, G.; Aeron, S.; Hao, N.; Kilmer, M. Novel methods for multilinear data completion and de-noising based on tensor-SVD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3842–3849. [Google Scholar]
- Signoretto, M.; De Lathauwer, L.; Suykens, J.A. Nuclear norms for tensors and their use for convex multilinear estimation. Linear Algebra Appl. 2010, 43. Available online: ftp://ftp.esat.kuleuven.be/sista/signoretto/Signoretto_nucTensors2.pdf (accessed on 3 April 2019).
- Cichocki, A. Era of big data processing: A new approach via tensor networks and tensor decompositions. arXiv, 2014; arXiv:1403.2048. [Google Scholar]
- Grasedyck, L.; Kressner, D.; Tobler, C. A literature survey of low-rank tensor approximation techniques. GAMM-Mitteilungen 2013, 36, 53–78. [Google Scholar] [CrossRef]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Tensors via Convex Optimization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5249–5257. [Google Scholar]
- Lu, C.; Feng, J.; Chen, Y.; Liu, W.; Lin, Z.; Yan, S. Tensor Robust Principal Component Analysis with A New Tensor Nuclear Norm. arXiv, 2018; arXiv:1804.03728. [Google Scholar] [CrossRef] [PubMed]
- Semerci, O.; Hao, N.; Kilmer, M.E.; Miller, E.L. Tensor-based formulation and nuclear norm regularization for multienergy computed tomography. IEEE Trans. Image Process. 2014, 23, 1678–1693. [Google Scholar] [CrossRef]
- Ciccone, V.; Ferrante, A.; Zorzi, M. Robust identification of “sparse plus low-rank” graphical models: An optimization approach. In Proceedings of the 2018 IEEE Conference on Decision and Control (CDC), Miami Beach, FL, USA, 17–19 December 2018; pp. 2241–2246. [Google Scholar]
- Ciccone, V.; Ferrante, A.; Zorzi, M. Factor Models with Real Data: A Robust Estimation of the Number of Factors. IEEE Trans. Autom. Control 2018. [Google Scholar] [CrossRef]
- Fazel, S.M. Matrix Rank Minimization with Applications. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2003. [Google Scholar]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Kang, Z.; Peng, C.; Cheng, Q. Robust PCA Via Nonconvex Rank Approximation. In Proceedings of the 2015 IEEE International Conference on Data Mining (ICDM), Atlantic City, NJ, USA, 14–17 November 2015; pp. 211–220. [Google Scholar]
- Lewis, A.S.; Sendov, H.S. Nonsmooth analysis of singular values. Part I: Theory. Set-Valued Anal. 2005, 13, 213–241. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, L.; Zhu, C. Improved Robust Tensor Principal Component Analysis via Low-Rank Core Matrix. IEEE J. Sel. Top. Signal Process. 2018, 12, 1378–1389. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, S.; Zhou, Y. Tensor Nuclear Norm-Based Low-Rank Approximation With Total Variation Regularization. IEEE J. Sel. Top. Signal Process. 2018, 12, 1364–1377. [Google Scholar] [CrossRef]
- Kong, H.; Xie, X.; Lin, Z. t-Schatten-p Norm for Low-Rank Tensor Recovery. IEEE J. Sel. Top. Signal Process. 2018, 12, 1405–1419. [Google Scholar] [CrossRef]
- Tarzanagh, D.A.; Michailidis, G. Fast Monte Carlo Algorithms for Tensor Operations. arXiv, 2017; arXiv:1704.04362. [Google Scholar]
- Driggs, D.; Becker, S.; Boyd-Graber, J. Tensor Robust Principal Component Analysis: Better recovery with atomic norm regularization. arXiv, 2019; arXiv:1901.10991. [Google Scholar]
- Sobral, A.; Baker, C.G.; Bouwmans, T.; Zahzah, E.H. Incremental and multi-feature tensor subspace learning applied for background modeling and subtraction. In Proceedings of the International Conference Image Analysis and Recognition, Vilamoura, Portugal, 22–24 October 2014; pp. 94–103. [Google Scholar]
- Sobral, A.; Javed, S.; Ki Jung, S.; Bouwmans, T.; Zahzah, E.H. Online stochastic tensor decomposition for background subtraction in multispectral video sequences. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 106–113. [Google Scholar]
- Bouwmans, T.; Sobral, A.; Javed, S.; Jung, S.K.; Zahzah, E.H. Decomposition into low-rank plus additive matrices for background/foreground separation: A review for a comparative evaluation with a large-scale dataset. Comput. Sci. Rev. 2017, 23, 1–71. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef]
- Tyrtyshnikov, E.E. A Brief Introduction to Numerical Analysis; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Marc Peter Deisenroth, A.A.F.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Moreau, J.J. Proximité et dualité dans un espace hilbertien. Bull. Soc. Math. France 1965, 93, 273–299. [Google Scholar] [CrossRef]
- Dong, W.; Shi, G.; Li, X.; Ma, Y.; Huang, F. Compressive Sensing via Nonlocal Low-Rank Regularization. IEEE Trans. Image Process. 2014, 23, 3618–3632. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Lin, Y. Lectures in Functional Analysis; Peking University Press: Beijing, China, 1987. [Google Scholar]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Lu, H.; Plataniotis, K.; Venetsanopoulos, A. Multilinear Subspace Learning: Dimensionality Reduction of Multidimensional Data; Chapman & Hall/CRC Machine Learning & Pattern Recognition Series; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Zhang, Z.; Aeron, S. Exact Tensor Completion Using t-SVD. IEEE Trans. Signal Process. 2017, 65, 1511–1526. [Google Scholar] [CrossRef]
- Luenberger, D.G. Optimization by Vector Space Methods; John Wiley & Sons: New York, NY, USA, 1997. [Google Scholar]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision ( ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, B.; Mu, C.; Goldfarb, D.; Wright, J. Provable models for robust low-rank tensor completion. Pac. J. Optim. 2015, 11, 339–364. [Google Scholar]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection.net: A new change detection benchmark dataset, 2012. In Proceedings of the IEEE Workshop on Change Detection (CDW-2012) at CVPR-2012, Providence, RI, USA, 16–21 June 2012. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | RPCA | Gamma | SNN | TRPCA | t-Gamma |
|---|---|---|---|---|---|
| Average PSNR | 25.5843 | 27.0762 | 27.6329 | 29.1157 | 30.7896 |
| Dataset | RPCA | Gamma | SNN | TNN | t-Gamma | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Precision | F-Measure | Recall | Precision | F-Measure | Recall | Precision | F-Measure | Recall | Precision | F-Measure | Recall | Precision | F-Measure | |
| highway | 0.8642 | 0.9109 | 0.8869 | 0.8837 | 0.9067 | 0.895 | 0.6982 | 0.9041 | 0.7879 | 0.8235 | 0.902 | 0.861 | 0.8835 | 0.909 | 0.8961 |
| pedestrians | 0.9983 | 0.9419 | 0.9692 | 0.9982 | 0.9275 | 0.9616 | 0.9955 | 0.9285 | 0.9608 | 0.9983 | 0.9258 | 0.9607 | 0.9982 | 0.9309 | 0.9634 |
| PETS2006 | 0.8151 | 0.7131 | 0.7607 | 0.8326 | 0.7678 | 0.7989 | 0.288 | 0.6974 | 0.4077 | 0.8033 | 0.6853 | 0.7396 | 0.8301 | 0.7805 | 0.8045 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, S.; Luo, Q.; Yang, M.; Li, W.; Xiao, M. Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation. Appl. Sci. 2019, 9, 1411. https://doi.org/10.3390/app9071411
Cai S, Luo Q, Yang M, Li W, Xiao M. Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation. Applied Sciences. 2019; 9(7):1411. https://doi.org/10.3390/app9071411
Chicago/Turabian StyleCai, Shuting, Qilun Luo, Ming Yang, Wen Li, and Mingqing Xiao. 2019. "Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation" Applied Sciences 9, no. 7: 1411. https://doi.org/10.3390/app9071411
APA StyleCai, S., Luo, Q., Yang, M., Li, W., & Xiao, M. (2019). Tensor Robust Principal Component Analysis via Non-Convex Low Rank Approximation. Applied Sciences, 9(7), 1411. https://doi.org/10.3390/app9071411