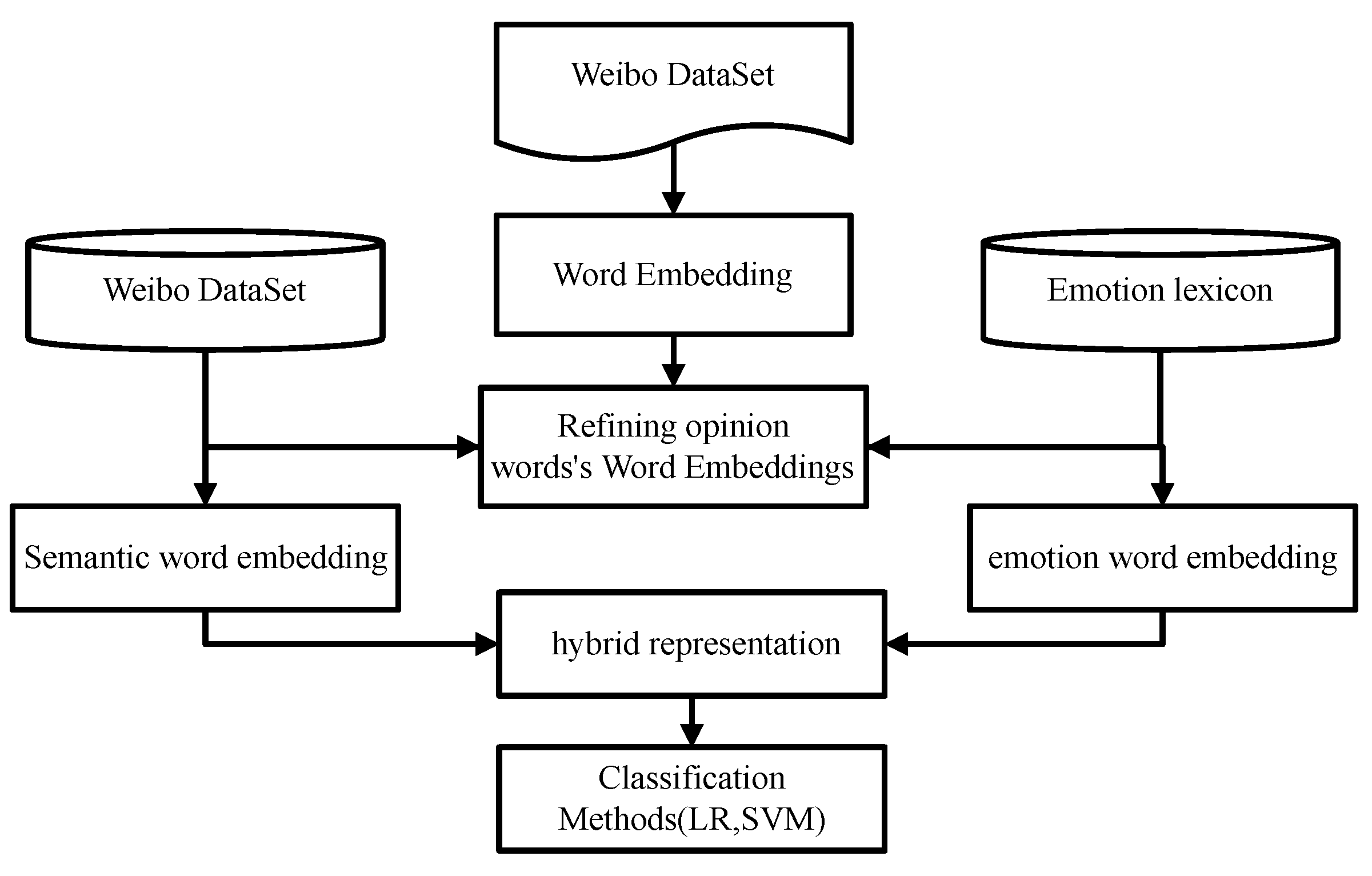
Constructing an effective features vector to represent text is a basic component in the NLP tasks. In view of the specific emotion classification task, we propose the sentiment-aware word embedding based on the construction of a hybrid word vector method containing emotional information.
The method comprises three main components: (1) the construction of semantic word vectors based on Word2Vec; (2) the construction of emotional word vectors based on the emotional lexicon; and (3) the construction of hybrid sentiment-aware word representations. The third step is based on the results of the previous two steps.
3.2. Constructed Emotional Word Vector Based on the Emotional Lexicon
After the preprocessing step, every word in each sentence is converted into a vector. The obtained vectors are then compared based on their cosine similarity degree with the vectors of the emotional words. The emotional word vectors with high similarity scores are selected to be combined. The proposal helps to increase the “semantic power” of traditional semantic space models for emotional analysis by combining different sources of semantic evidence. The hybrid sentiment-aware word embedding is inputted as the experimental model, showing that two kinds of semantic evidence can complement each other, and the mix of them can identify the correct emotion.
The lexicon-based feature extraction method is promising due to the existence of the emotional lexicon. Typically, an emotional lexicon consists of a set of language-specific words, which include information about the emotional category to which it belongs, the polarity intensity, and so on. A fine-grained multi-emotional polarity lexicon can improve the classification accuracy in emotional analysis tasks compared to simple emotional dictionaries [
37].
A set of documents and emotional lexicons is given to build the model and generate the emotional word vectors. A corpus, D, consists of a set of texts, , and the vocabulary, , which are unique terms extracted from D. The word representation of the terms are mapped from the Word2Vec model, and then a set of word representations of all words in the vocabulary is derived, i.e., , where m is the size of the vocabulary, and d represents the dimensions of the vector space.
The core of this method is to construct emotional word vectors representing the emotional information for each word in the vocabulary, but most of them express some emotions that are not typical opinion words, so the paper introduces the lexicon-based method. In order to construct the emotional word vectors, the method utilizes all emotional words in the lexicon as the emotional vocabulary, , and gets their word representations, . Due to the scale problem of word embedding the model by training the corpus, there is a low degree of the coverage problem, that is, there are some words that are in the emotional vocabulary but not in the vector spaces learned from Word2Vec. Thus, these words can be ignored and deleted in subsequent processing.
The word embedding model captures the semantic relationships in the corpus text, and the contexts of words with the same emotional polarity are identical. Therefore, the similarity between two items is estimated by calculating the cosine similarity between the vectors represented by V and E, that is,
, defined as
where V and E are the vectors of length
d.
For each item in T, the similarity to all items in E is calculated and then the similarity results are collected into the matrix , where m is the length of the text glossary, k is the length of the emotional vocabulary, and indicates the cosine similarity between the lexical item i and the emotion j. Based on matrix Y, the top n emotional words, , are selected by setting the threshold. For words in , they are the nearest neighbors to the item in T as determined by distinguishing their sentimental differences.
Similarity in Y means that an item in E and an item in T have the same context; meanwhile, the emotional intensity provided in the dictionary represents the emotional information of the item in E and constructs the emotion vector for all items in T by combining the two kinds of information.
The emotional word vector for each word is calculated as a weighted sum rather than a simple average operation:
Then, Formula (3) is used to compute the weight of every word; based on this formula, the higher ranked nearest neighbors will receive higher weights:
The Dalian University of Technology Information Retrieval (DUTIR) is used to represent sentiment lexicon in this study, which is a Chinese ontology resource labeled by the Dalian University of Technology Information Retrieval Laboratory [
38]. It contains 27,466 words, and each word is associated with a real-valued score of 1, 3, 5, 7, or 9. The score represents the degree of sentiment, where 9 indicates the maximum strength, and 1 is the minimum strength. Then, we rank the emotional words in
by strength scores. The
is defined as the reciprocal rank of
in the
, that is
where
denotes the rank of
generated by the intensity-based ranking process.
The weights have to be normalized to sum to one. This can be obtained with the following relation:
In the process of constructing the emotional word vector of words, the shortcomings of the context-based word embedding result in words with opposite sentiment polarity having a fairly high cosine similarity in the vector space. There are great errors generated in the construction of emotional word vectors using word embedding mapping and cosine similarity, so sentimental lexicons are used to correct the word representations mapping from the word embedding space. It is a good way to optimize existing word vectors by using real-valued sentiment intensity scores provided by the emotional lexicons and word vector refinement model. In this way, the words are closer to semantically and emotionally similar words in the dictionary (that is, those with similar intensity scores) and stay away from words that are not emotionally similar but are similar in semantics.
3.3. Constructing Hybrid Sentiment-Aware Word Embedding
In this work, sentiment-aware word embedding is constructed to represent each word by connecting the emotional word vectors based on the lexicon and the semantic word vectors based on the Word2Vec model. Sentiment-aware word embedding can capture the emotional orientation of words, which is the word representation method strictly based on word embedding. In addition, it also makes the most of the contextual and semantic expression ability of the word embedding model.
The sentiment-aware word embedding combines the emotional word vectors with semantic word embedding to simplify combinatorial functions, which indicates that the advantages of the two models can be combined in a single mixed representation. This paper explores different methods of vector combination and experiments with the proposed vector combination method in
Section 4. In particular, in order to compare the advantages and limitations of various methods, a comparative study of the two combination methods is conducted.
The first method combines the emotional word vectors with semantic words of a given word directly, which allows two vector representations with different dimension representations:
where
(
) represents the emotional word vector, (semantic word embedding).
Two vectors,
and
, form by linking the corresponding vectors from the original space
with
,
, and
as well. Cosine similarity is used to estimate the similarity between two items, and the key factor for cosine similarity is the dot product, i.e.,
Thus, the cosine similarity in cascade space is determined by the linear combination of the dot products of the vector component. Therefore, the semantic relations and emotional relations between two words are distinguished as features.
The second method is to combine these representational spaces by addition, which requires the two spaces to have the same dimensions, and it can be realized using simple vector addition. The value for each word in the new space is the normalized sum of its two component spaces, i.e.,
From the dot product result of the vector, the direct superposition of the two vectors which combine the characteristic components of them increases the distinction between different emotional features.
No matter whether vector connection or vector overlay is used, the experimental results show that the advantages of the two models can be combined in a single mixed representation by combining word vector components generated in different ways with simple combinatorial functions.





{kind=link}