Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks



Abstract
:1. Introduction
2. Proposed Method
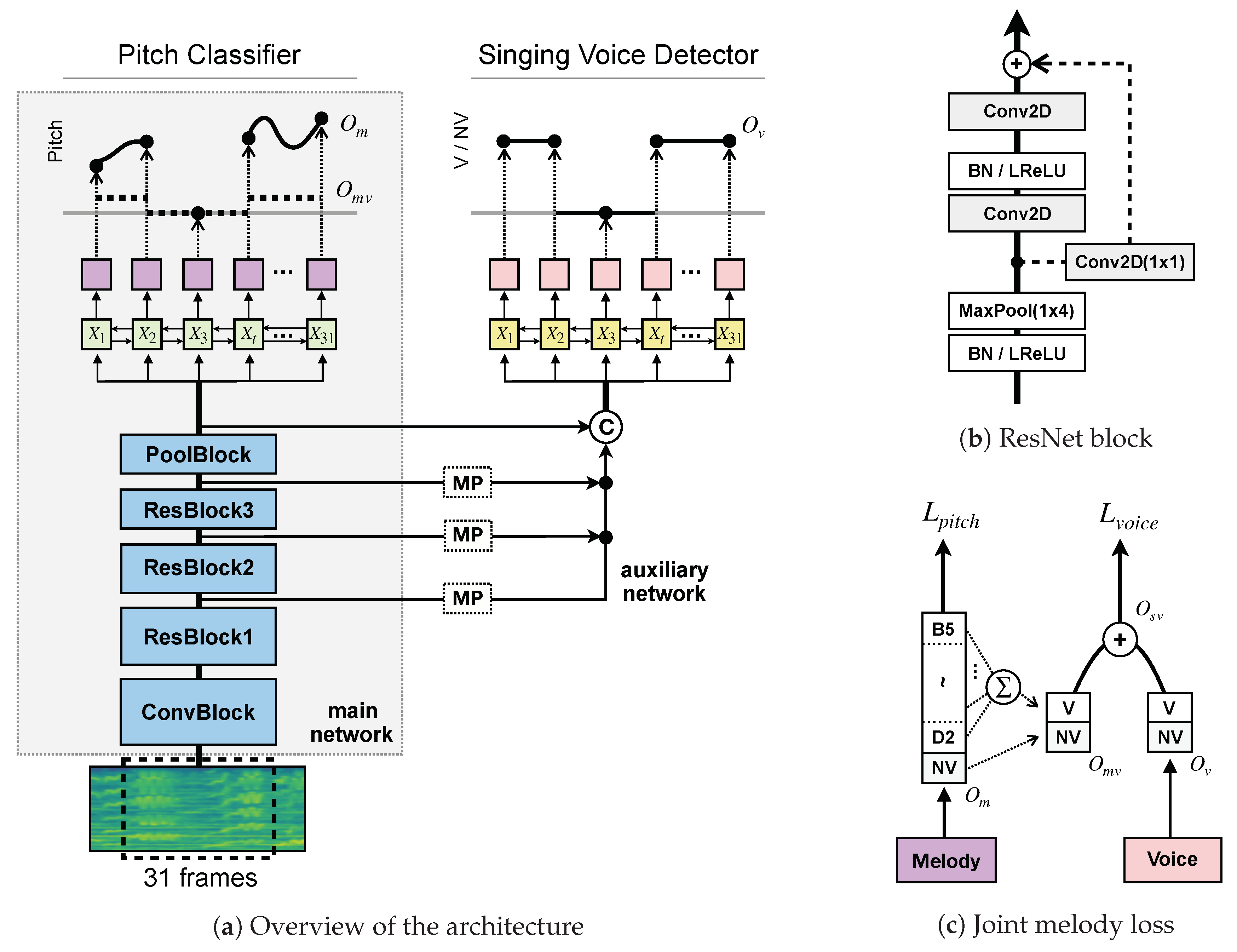
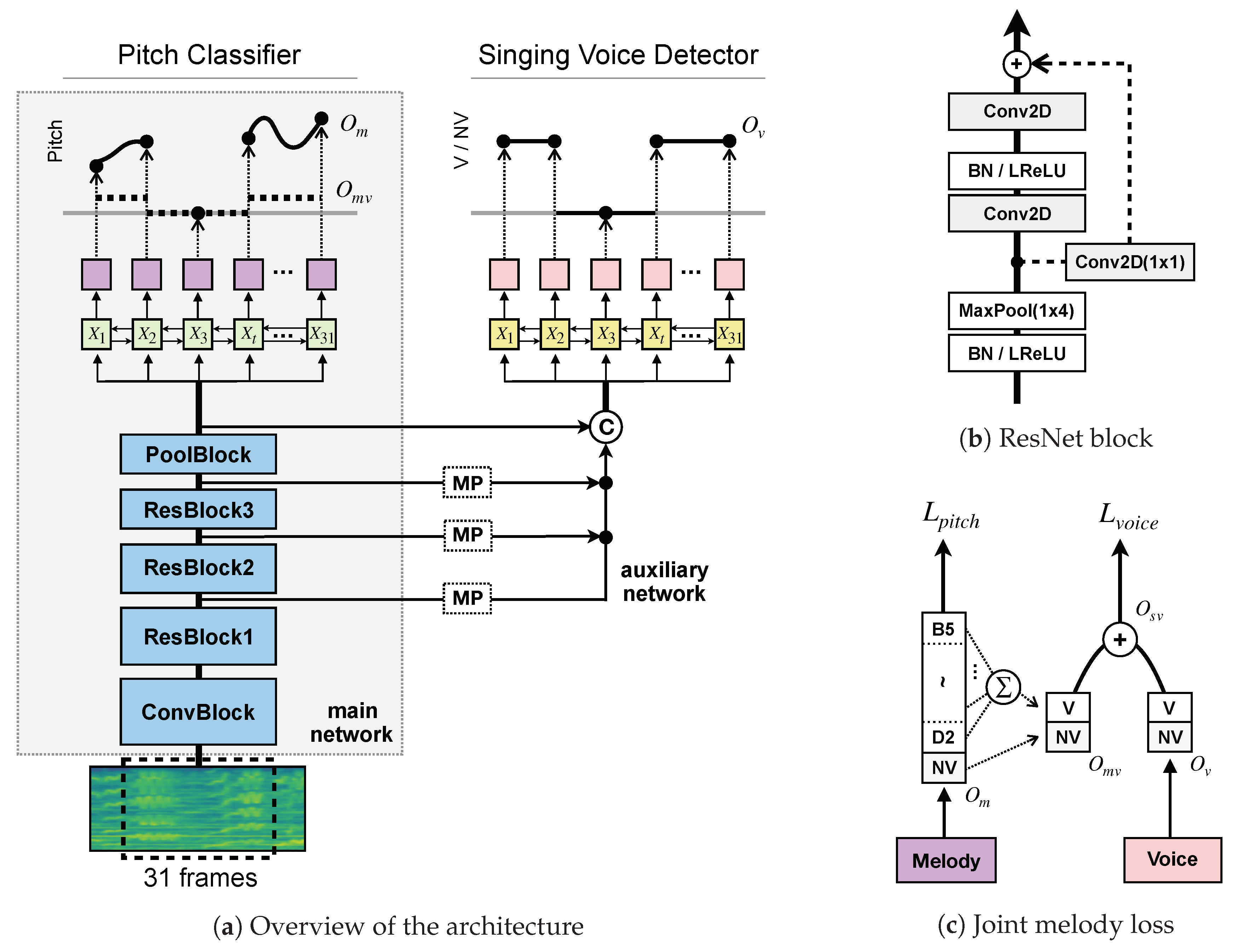
2.1. The Main Network
2.1.1. Architecture
2.1.2. Loss Function
2.2. Joint Detection and Classification Network
2.2.1. Architecture
2.2.2. Joint Loss Function
3. Experiments
3.1. Datasets
3.1.1. Train Datasets
- RWC [35]: 80 Japanese popular songs and 20 American popular songs with singing voice melody annotations. We divided the dataset into three splits: 70 songs for training, 15 songs for validation, and the remaining 15 songs for testing.
- MedleyDB [36]: 122 songs with a variety of musical genres. Among them, we chose 61 songs that are dominated by vocal melody. We divided the dataset into three splits: 37 songs for training, 10 songs for validation and 12 songs for testing. For a comparison of results under the same conditions, we selected the training sets according to [18].
- iKala [37]: 262 Chinese songs clips of 30 s performed by six professional singers. We divided the dataset into two splits: 235 songs for training and 27 songs for validation.
3.1.2. Test Datasets
- ADC04: 20 excerpts of 20 s that contain pop, jazz, and opera songs, as well as synthesized singing and audio from MIDI files. Jazz and MIDI songs were excluded from the evaluation.
- MIREX05: 13 excerpts that contain rock, R&B, pop, and jazz songs, as well as audio generated from a MIDI file. We used 12 songs out of a total of 20, excluding jazz and MIDI files for evaluation.
- MedleyDB: 12 songs not included in the training set. For a comparison of results under the same conditions, we selected the test sets according to [18].
- RWC: 15 songs not included in the training set. This was used internally to evaluate the performance of the proposed models.
- Jamendo: 93 songs designed for the evaluation of singing voice detection. Among them, only 16 songs designated as a test set to measure the performance of singing voice detection were used.
3.2. Evaluation
3.3. Training Detail
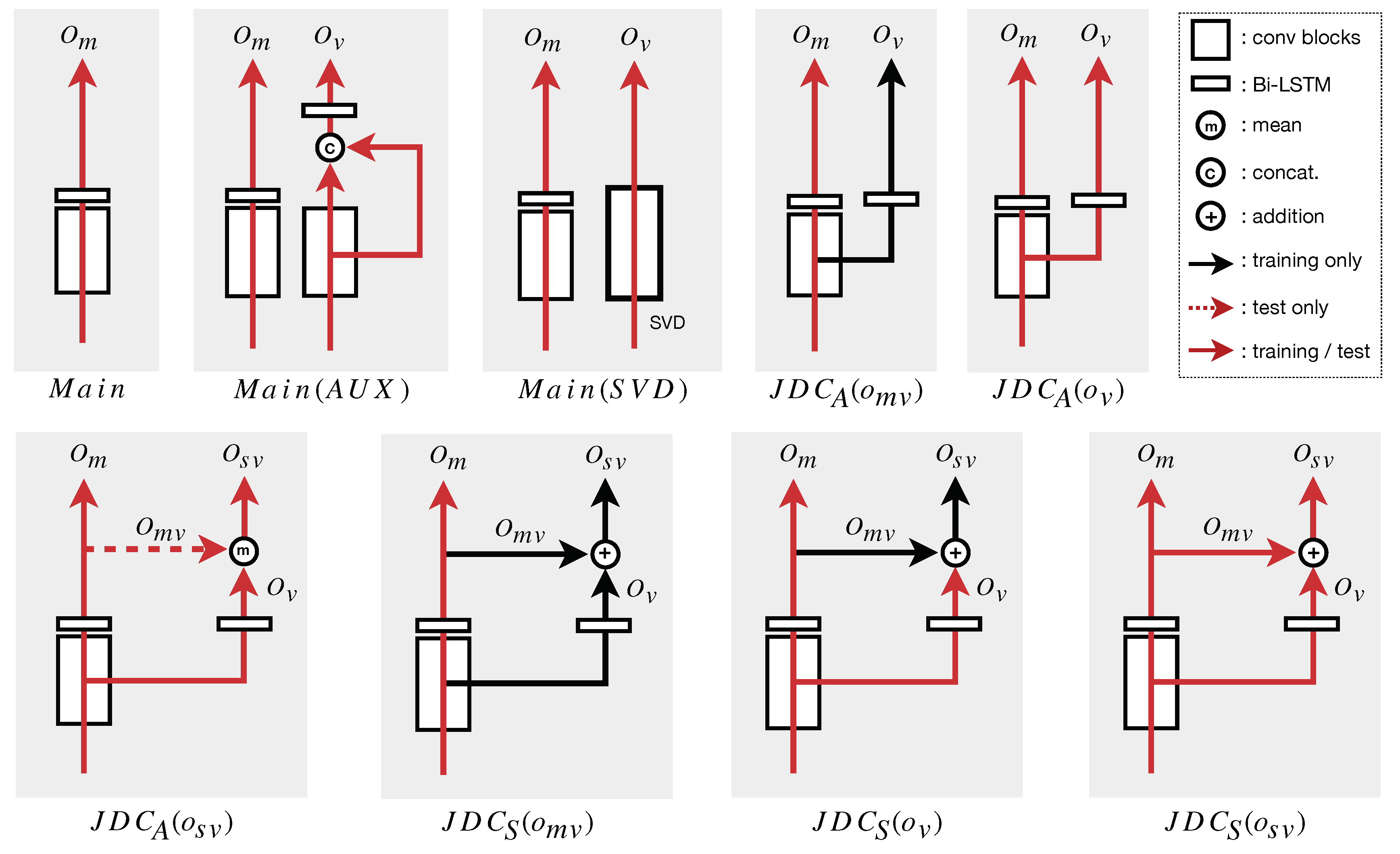
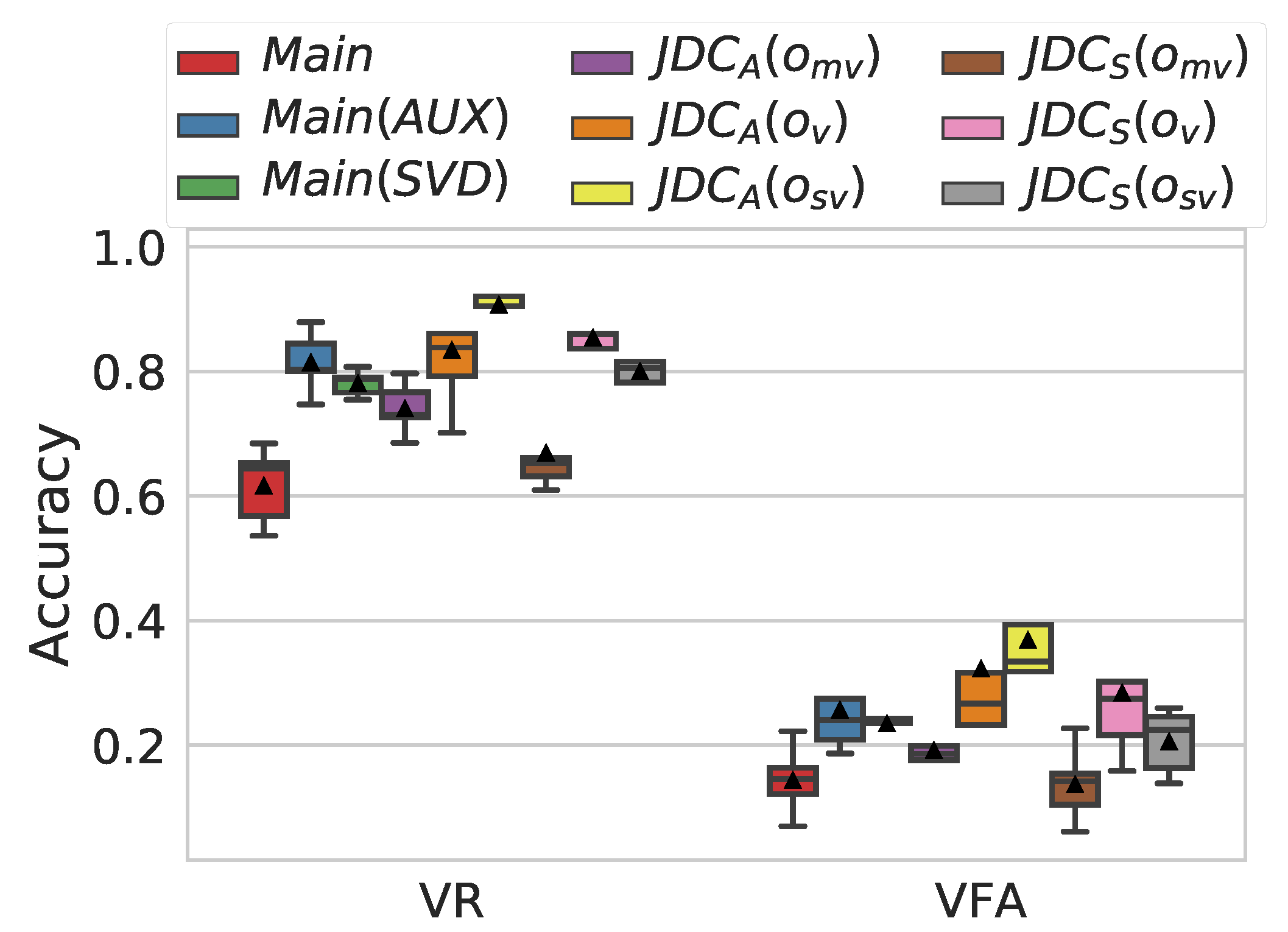
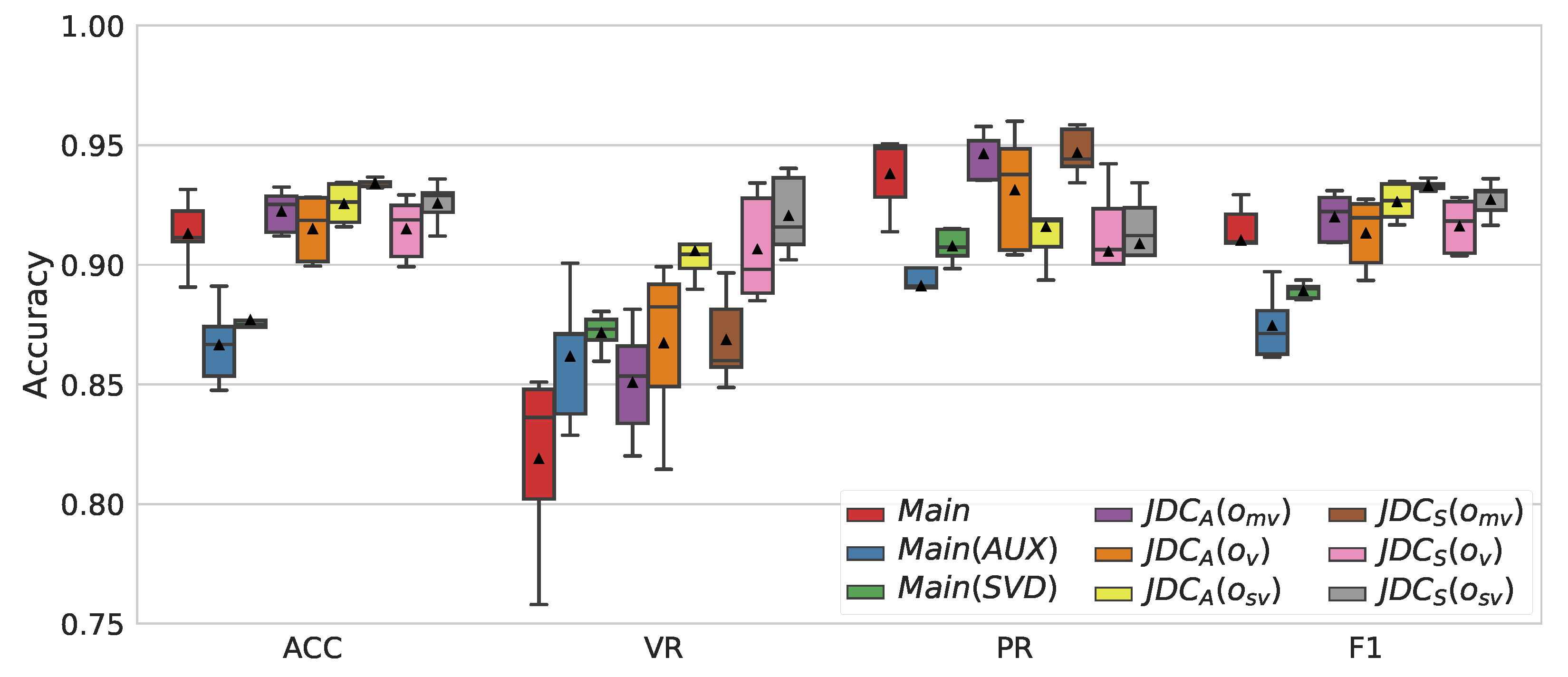
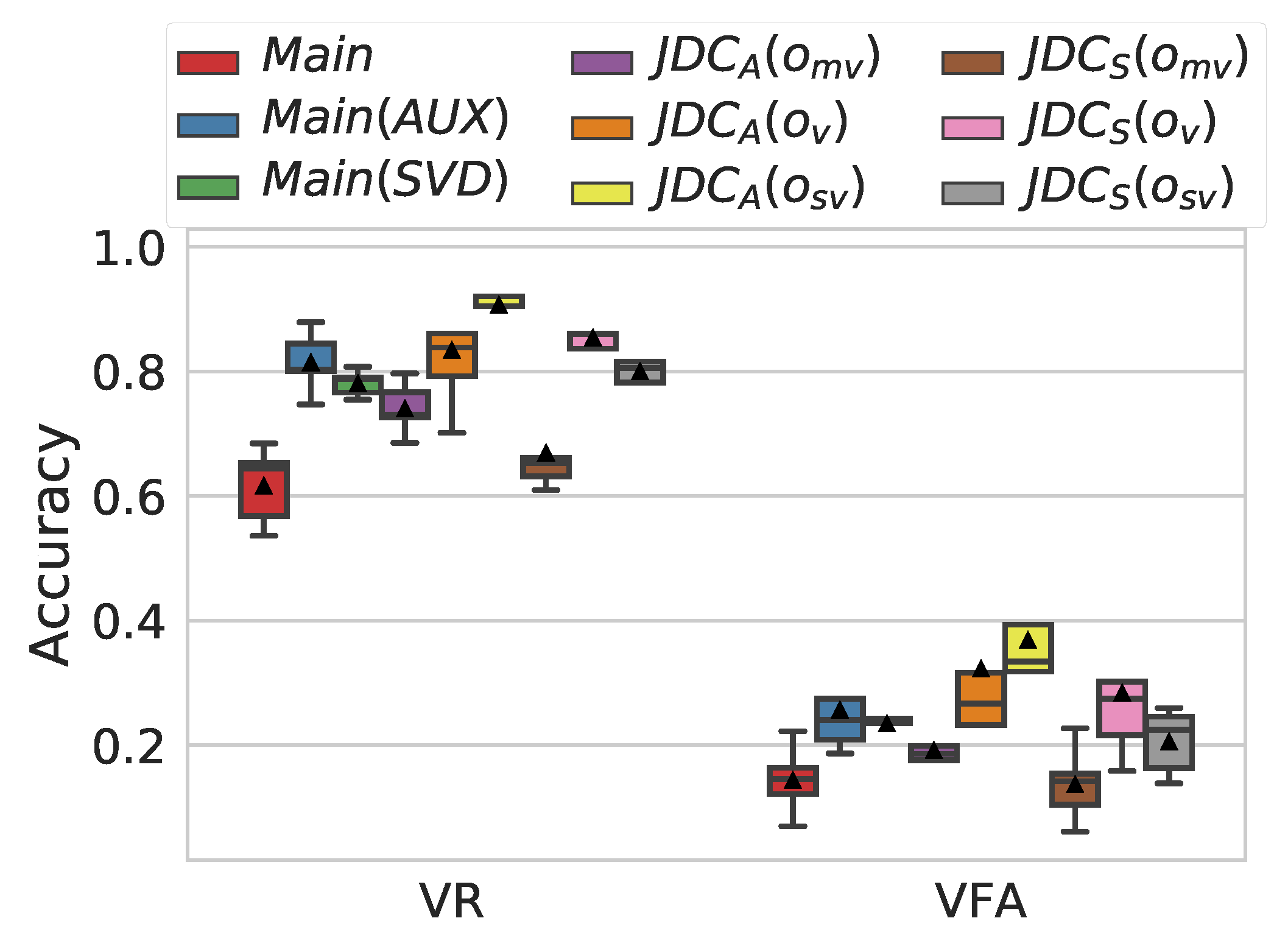
3.4. Ablation Study
- The effect of the auxiliary network: The proposed JDC network model was compared to the main network only (without the auxiliary network). They are denoted by and , respectively.
- The effect of the combined voice detection in calculating the loss function: The proposed model used the sum of the outputs from both the main and auxiliary networks (Equation (3)) in calculating the voice loss function. This was compared to the case where only the output of auxiliary network, , was used in calculating the loss function, which is denoted by .
- The effect of the combined voice detection in predicting singing voice: The JDC network can detect singing voice with three possibilities in the test phase: from the main network, from the auxiliary network, and the sum of the two outputs. We compared the performance of the three melody extraction outputs and evaluated them for each of the two loss functions above. As a result, we had a total of six outputs, which are denoted by , , , , , and .
4. Results and Discussion
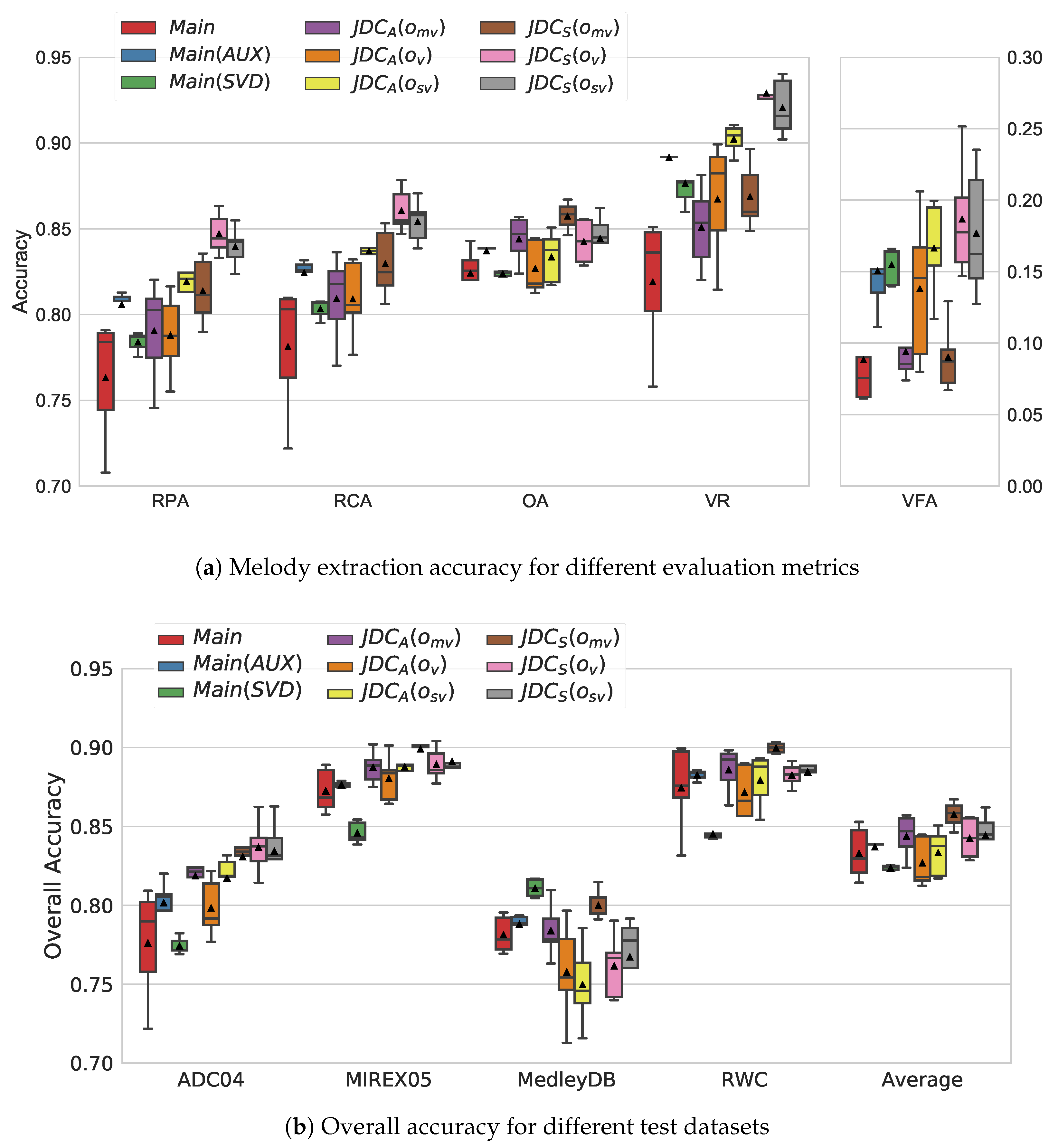
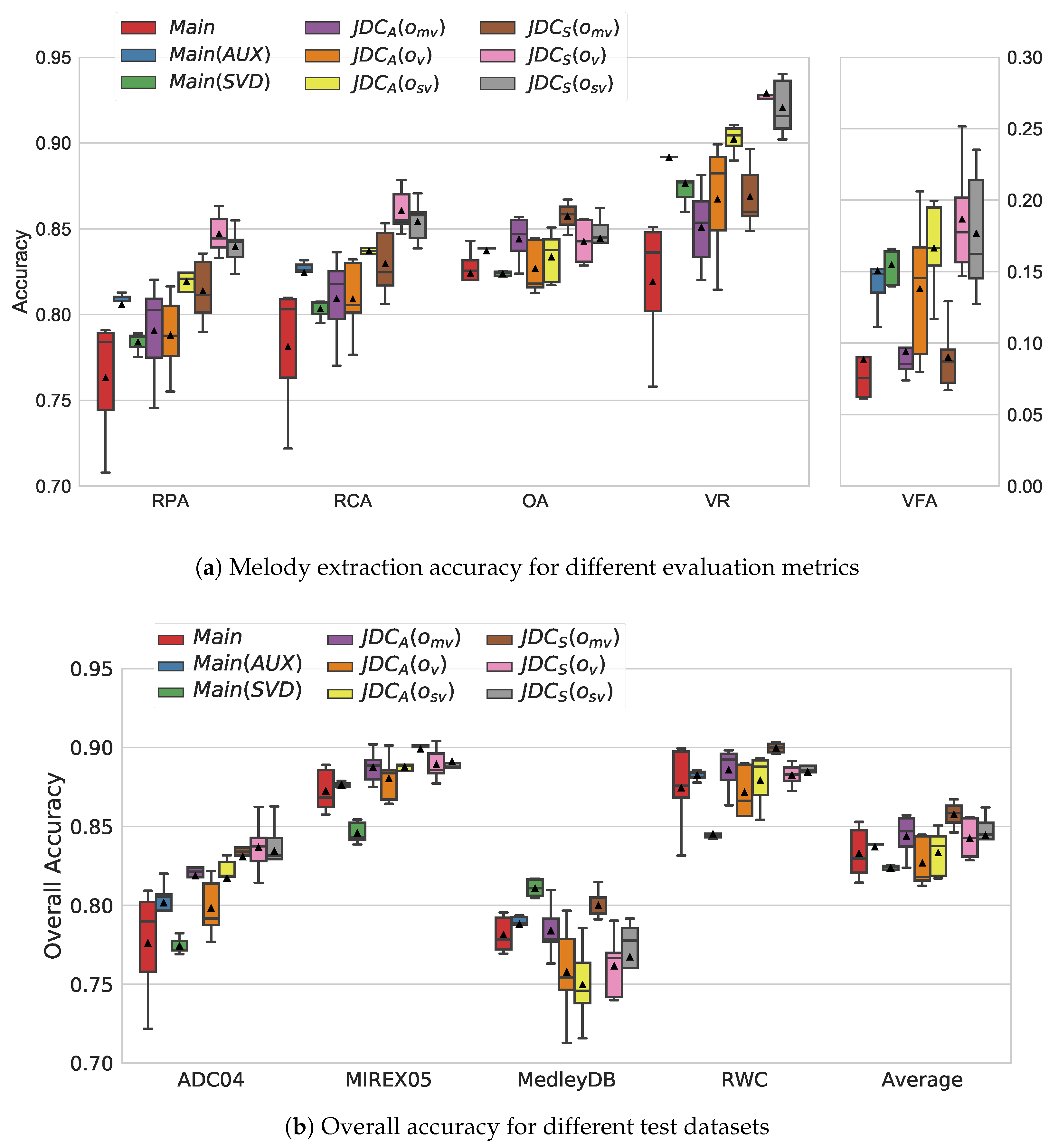
4.1. Comparison of Melody Extraction Performance
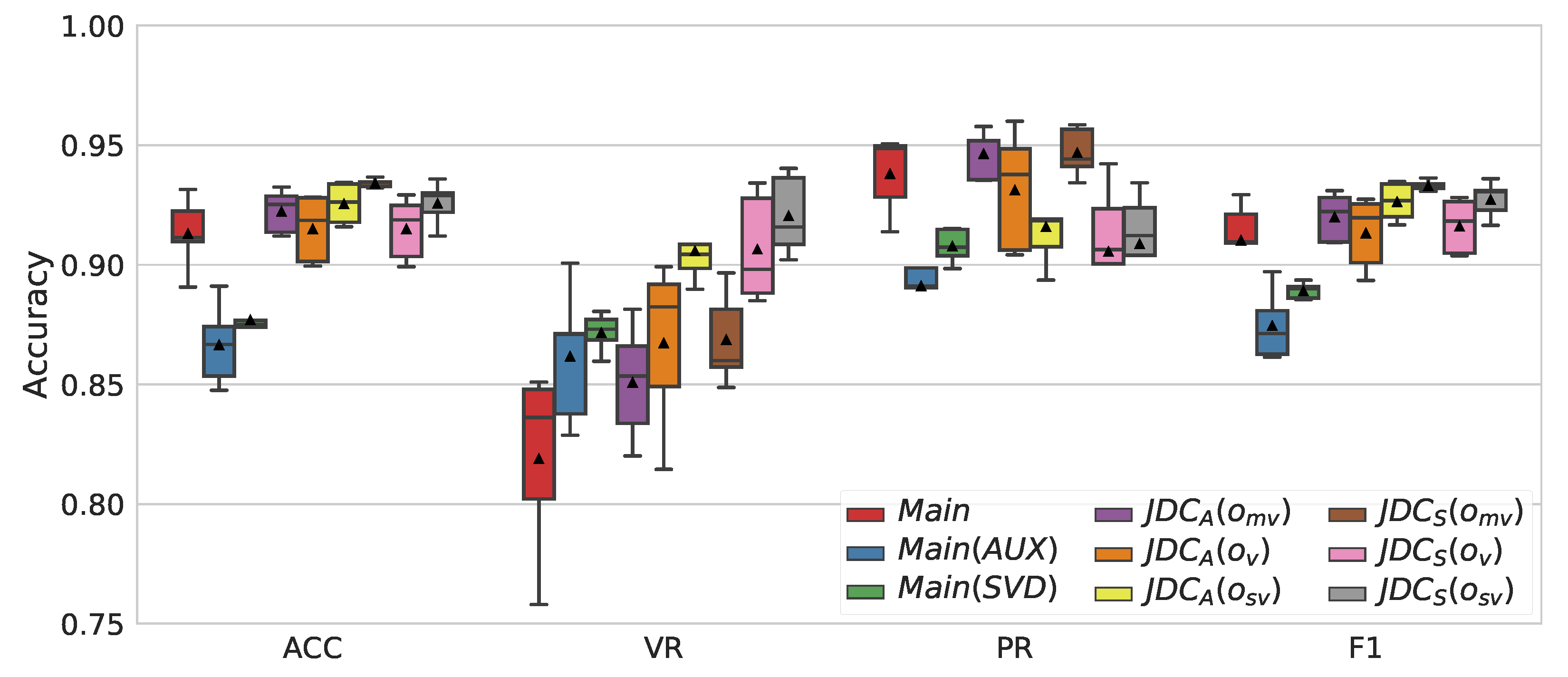
4.2. Comparison of Voice Detection Performance
4.3. Comparison with State-of-the-Art Methods for Melody Extraction
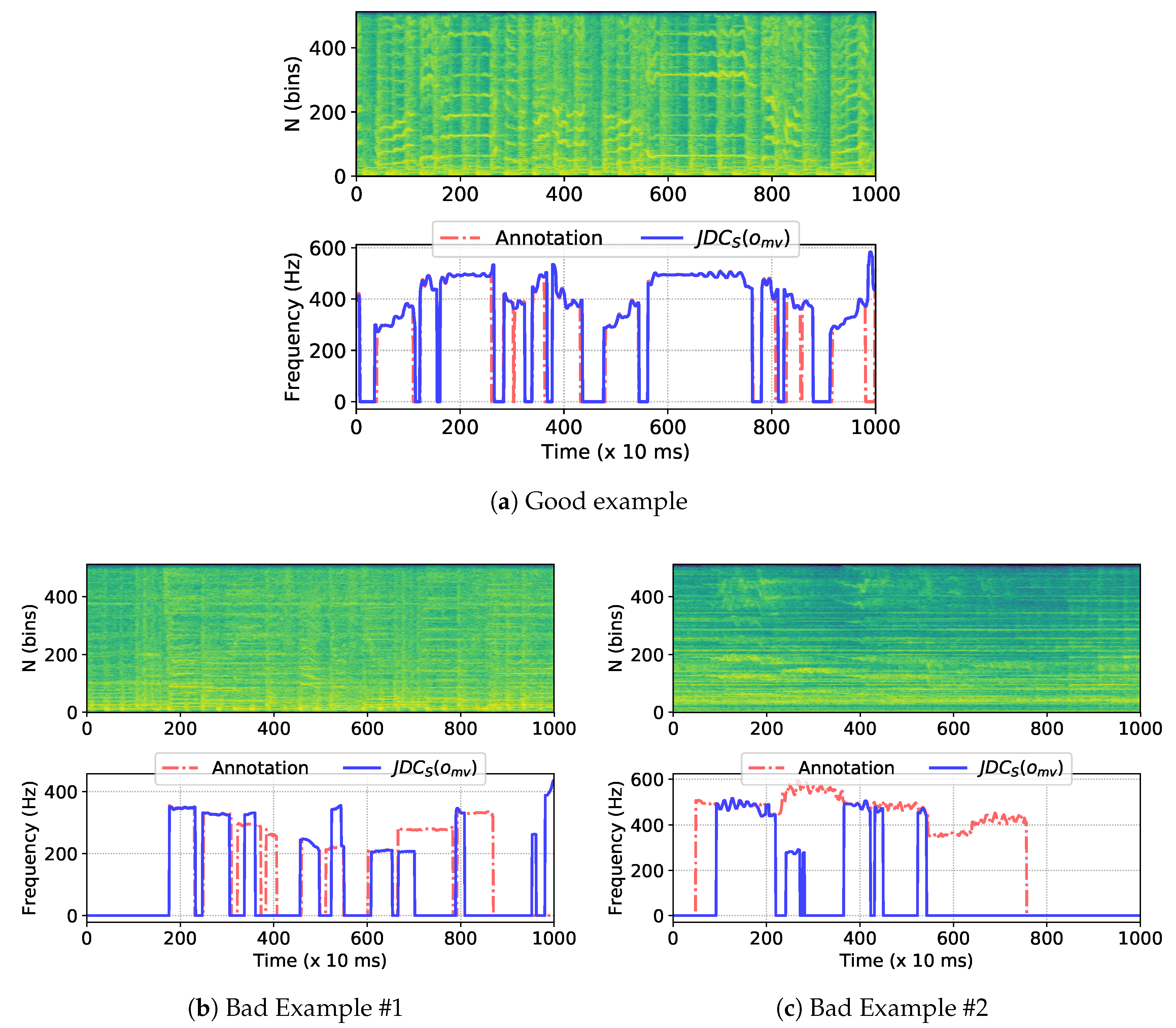
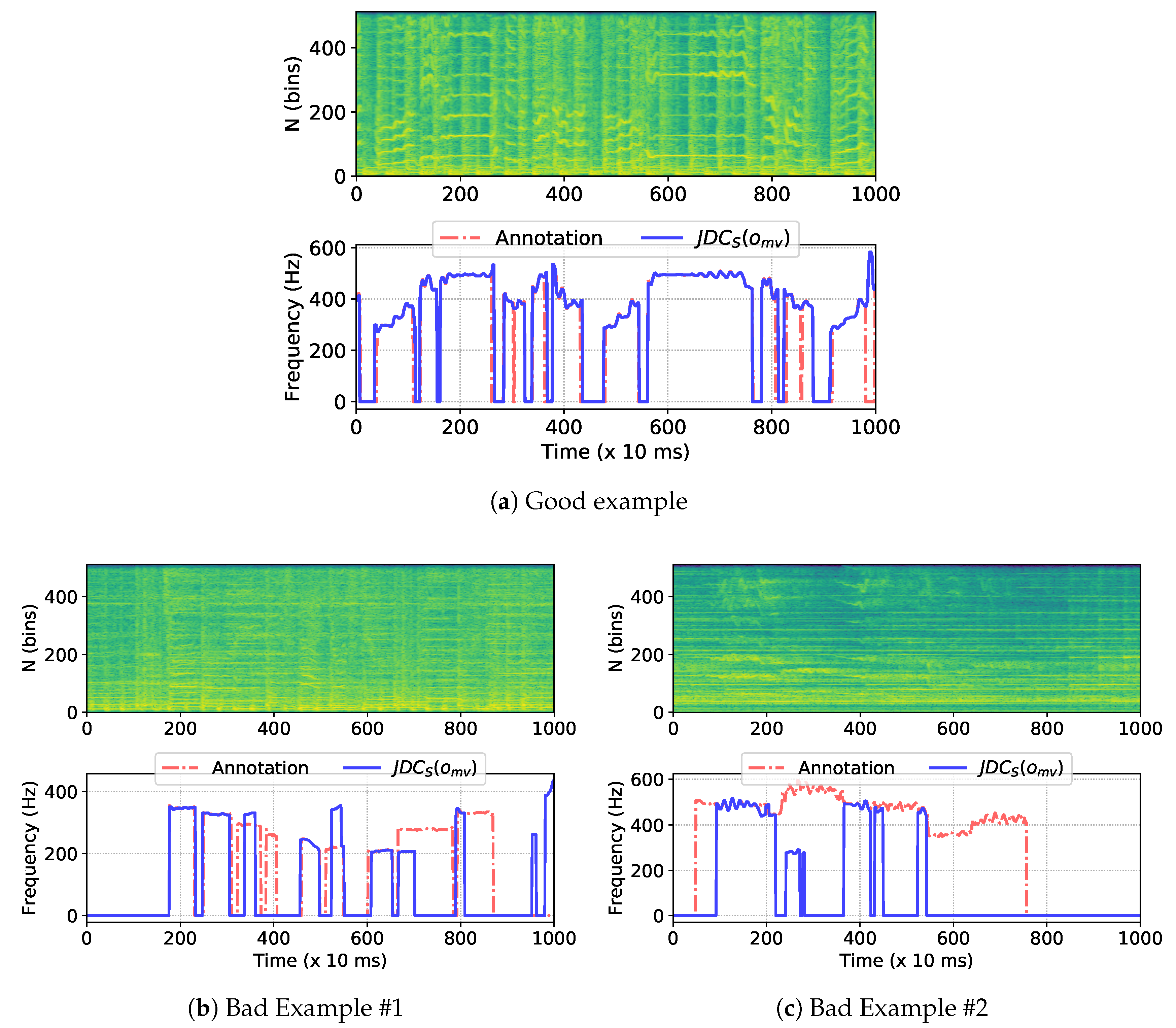
4.4. Case Study of Melody Extraction on MedleyDB
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Molina, E.; Tardón, L.J.; Barbancho-Perez, I.; Barbancho-Perez, A.M. The importance of F0 tracking in query-by-singing-humming. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Taipei, Taiwan, 27–31 October 2014. [Google Scholar]
- Serra, J.; Gómez, E.; Herrera, P. Audio cover song identification and similarity: Background, approaches, evaluation, and beyond. Adv. Music Inf. Retr. 2010, 274, 307–332. [Google Scholar]
- Salamon, J.; Rocha, B.; Gómez, E. Musical genre classification using melody features extracted from polyphonic music signals. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 81–84. [Google Scholar]
- Kako, T.; Ohishi, Y.; Kameoka, H.; Kashino, K.; Takeda, K. Automatic identification for singing style based on sung melodic contour characterized in phase plane. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Kobe, Japan, 26–30 October 2009; pp. 393–398. [Google Scholar]
- Schlüter, J.; Lehner, B. Zero-Mean Convolutions for Level-Invariant Singing Voice Detection. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR 2018), Paris, France, 23–27 September 2018. [Google Scholar]
- Dressler, K. An Auditory Streaming Approach for Melody Extraction from Polyphonic Music. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Miami, FL, USA, 24–28 October 2011; pp. 19–24. [Google Scholar]
- Salamon, J.; Gómez, E.; Ellis, D.P.; Richard, G. Melody extraction from polyphonic music signals: Approaches, applications, and challenges. IEEE Signal Process. Mag. 2014, 31, 118–134. [Google Scholar] [CrossRef]
- Bosch, J.J.; Bittner, R.M.; Salamon, J.; Gómez, E. A comparison of melody extraction methods based on source-filter modelling. In Proceedings of the International Society for Music Information Retrieval (ISMIR), New York, NY, USA, 7–11 August 2016; pp. 571–577. [Google Scholar]
- Reddy, M.G.; Rao, K.S. Predominant melody extraction from vocal polyphonic music signal by time-domain adaptive filtering-based method. Circuits Syst. Signal Process. 2017, 37, 2911–2933. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, Z.; Yin, F.; Zhang, Q. Melody extraction from polyphonic music using particle filter and dynamic programming. IEEE/ACM Trans. Audio, Speech Lang. Process. (TASLP) 2018, 26, 1620–1632. [Google Scholar] [CrossRef]
- Durrieu, J.L.; Richard, G.; David, B.; Févotte, C. Source/filter model for unsupervised main melody extraction from polyphonic audio signals. IEEE/ACM Trans. Audio, Speech Lang. Process. (TASLP) 2010, 18, 564–575. [Google Scholar] [CrossRef]
- Tachibana, H.; Ono, T.; Ono, N.; Sagayama, S. Melody line estimation in homophonic music audio signals based on temporal-variability of melodic source. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 425–428. [Google Scholar]
- Ikemiya, Y.; Itoyama, K.; Yoshii, K. Singing voice separation and vocal F0 estimation based on mutual combination of robust principal component analysis and subharmonic summation. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2016, 24, 2084–2095. [Google Scholar] [CrossRef]
- Poliner, G.E.; Ellis, D.P.; Ehmann, A.F.; Gómez, E.; Streich, S.; Ong, B. Melody transcription from music audio: Approaches and evaluation. IEEE/ACM Trans. Audio, Speech Lang. Process. (TASLP) 2007, 15, 1247–1256. [Google Scholar] [CrossRef]
- Kum, S.; Oh, C.; Nam, J. Melody extraction on vocal segments using multi-column deep neural networks. In Proceedings of the International Society for Music Information Retrieval (ISMIR), New York, NY, USA, 7–11 August 2016; pp. 819–825. [Google Scholar]
- Rigaud, F.; Radenen, M. Singing voice melody transcription using deep neural networks. In Proceedings of the International Society for Music Information Retrieval (ISMIR), New York, NY, USA, 7–11 August 2016; pp. 737–743. [Google Scholar]
- Bittner, R.M.; McFee, B.; Salamon, J.; Li, P.; Bello, J.P. Deep salience representations for f0 estimation in polyphonic music. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Suzhou, China, 23–27 October 2017. [Google Scholar]
- Su, L. Vocal melody extraction using patch-based CNN. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 371–375. [Google Scholar]
- Park, H.; Yoo, C.D. Melody extraction and detection through LSTM-RNN with harmonic sum loss. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2766–2770. [Google Scholar]
- Basaran, D.; Essid, S.; Peeters, G. Main melody extraction with source-filter NMF and CRNN. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Paris, France, 23–27 September 2018; pp. 82–89. [Google Scholar]
- Lu, W.T.; Su, L. Vocal melody extraction with semantic segmentation and audio-symbolic domain transfer learning. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Paris, France, 23–27 September 2018; pp. 521–528. [Google Scholar]
- Hsieh, T.H.; Su, L.; Yang, Y.H. A Streamlined Encoder/Decoder Architecture for Melody Extraction. arXiv, 2018; arXiv:1810.12947. [Google Scholar]
- Chou, H.; Chen, M.T.; Chi, T.S. A hybrid neural network based on the duplex model of pitch perception for singing melody extraction. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 381–385. [Google Scholar]
- Zhang, X.; LeCun, Y. Universum prescription: Regularization using unlabeled data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; pp. 2907–2913. [Google Scholar]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv, 2017; arXiv:1706.05098. [Google Scholar]
- Huang, P.S.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Trans. Audio, Speech Lang. Process. (TASLP) 2015, 23, 2136–2147. [Google Scholar] [CrossRef]
- Stoller, D.; Ewert, S.; Dixon, S. Jointly detecting and separating singing voice: A multi-task approach. In Proceedings of the International Conference on Latent Variable Analysis and Signal Separation, Guildford, UK, 2–5 July 2018; Springer: Berlin, Germany, 2018; pp. 329–339. [Google Scholar]
- Kong, Q.; Xu, Y.; Plumbley, M.D. Joint detection and classification convolutional neural network on weakly labelled bird audio detection. In Proceedings of the Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 1749–1753. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013; Volume 30. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 630–645. [Google Scholar]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 550–558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Kim, J.W.; Salamon, J.; Li, P.; Bello, J.P. CREPE: A Convolutional representation for pitch estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Goto, M.; Hashiguchi, H.; Nishimura, T.; Oka, R. RWC music database: Popular, classical and jazz music databases. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Paris, France, 13–17 October 2002; pp. 287–288. [Google Scholar]
- Bittner, R.M.; Salamon, J.; Tierney, M.; Mauch, M.; Cannam, C.; Bello, J.P. MedleyDB: A multitrack dataset for annotation-intensive MIR research. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Taipei, Taiwan, 27–31 October 2014; pp. 155–160. [Google Scholar]
- Chan, T.S.; Yeh, T.C.; Fan, Z.C.; Chen, H.W.; Su, L.; Yang, Y.H.; Jang, R. Vocal activity informed singing voice separation with the iKala dataset. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Queensland, Australia, 19–24 April 2015; pp. 718–722. [Google Scholar]
- Schlüter, J.; Grill, T. Exploring data augmentation for improved singing voice detection with neural networks. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Malaga, Spain, 26–30 October 2015; pp. 121–126. [Google Scholar]
- Laroche, J. Time and pitch scale modification of audio signals. In Applications of Digital Signal Processing to Audio and Acoustics; Springer: Boston, MA, USA, 2002; pp. 279–309. [Google Scholar]
- Ramona, M.; Richard, G.; David, B. Vocal detection in music with support vector machines. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas, ND, USA, 30 March–4 April 2008; pp. 1885–1888. [Google Scholar]
- Raffel, C.; McFee, B.; Humphrey, E.J.; Salamon, J.; Nieto, O.; Liang, D.; Ellis, D.P.; Raffel, C.C. mir_eval: A transparent implementation of common MIR metrics. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Taipei, Taiwan, 27–31 October 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 29 March 2019).
- Lehner, B.; Widmer, G.; Bock, S. A low-latency, real-time-capable singing voice detection method with LSTM recurrent neural networks. In Proceedings of the Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 21–25. [Google Scholar]
- Leglaive, S.; Hennequin, R.; Badeau, R. Singing voice detection with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Queensland, Australia, 19–24 April 2015; pp. 121–125. [Google Scholar]
- Lee, K.; Choi, K.; Nam, J. Revisiting singing voice detection: A quantitative review and the future outlook. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Paris, France, 23–27 September 2018; pp. 506–513. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Output Size | |||
|---|---|---|---|---|
| Main | Main + AUX | Main | Main + AUX | |
| Input | - | 31 × 513 | ||
| Conv block | [3 × 3, 64] × 2 | 31 × 513, 64 | ||
| ResNet Block 1 | [3 × 3, 128] × 2 | 31 × 128, 128 | ||
| ResNet Block 2 | [3 × 3, 192] × 2 | 31 × 32, 192 | ||
| ResNet Block 3 | [3 × 3, 256] × 2 | 31 × 8, 256 | ||
| Pool block | - | 31 × 2, 256 | ||
| Bi-LSTM | 256 | 256 + 32 | 31 × 512 | 31 × (512 + 64) |
| FC | 722 | 722 + 2 | 31 × 722 | 31 × (722 + 2) |
| Accuracy | VR | Precision | F1 Score | |
|---|---|---|---|---|
| Lehner [44] | 87.9 | 91.7 | 83.8 | 87.6 |
| Schlüter [38] | 86.8 | 89.1 | 83.7 | 86.3 |
| Leglaives [45] | 87.5 | 87.2 | 86.1 | 86.6 |
| 77.4 | 79.7 | 76.2 | 78.3 | |
| 80.0 | 80.2 | 79.1 | 79.2 |
| (a) ADC04 (Vocal) | |||||
| Method | VR | VFA | RPA | RCA | OA |
| Bittner et al. [17] | 92.9 | 50.5 | 77.1 | 78.8 | 70.8 |
| Su [18] | 90.1 | 41.3 | 74.7 | 75.7 | 72.4 |
| Lu and Su [21] | 73.8 | 3.0 | 71.7 | 74.8 | 74.9 |
| Hsieh et al. [22] | 91.1 | 19.2 | 84.7 | 86.2 | 83.7 |
| Proposed | 88.9 | 11.4 | 85.0 | 87.1 | 85.6 |
| (b) MIREX05 (Vocal) | |||||
| Method | VR | VFA | RPA | RCA | OA |
| Bittner et al. | 93.6 | 42.8 | 76.3 | 77.3 | 69.6 |
| Su | 95.1 | 41.1 | 83.1 | 83.5 | 74.4 |
| Lu & Su. | 87.3 | 7.9 | 82.2 | 82.9 | 85.8 |
| Hsieh et al. | 84.9 | 13.3 | 75.4 | 76.6 | 79.5 |
| Proposed | 90.9 | 2.4 | 87.0 | 87.5 | 90.7 |
| (c) MedleyDB (Vocal) | |||||
| Method | VR | VFA | RPA | RCA | OA |
| Bittner et al. | 88.4 | 48.7 | 72.0 | 74.8 | 66.2 |
| Su | 78.4 | 55.1 | 59.7 | 63.8 | 55.2 |
| Lu & Su | 77.9 | 22.4 | 68.3 | 70.0 | 70.0 |
| Hsieh et al. | 73.7 | 13.3 | 65.5 | 68.9 | 79.7 |
| Proposed | 80.4 | 15.6 | 74.8 | 78.2 | 80.5 |
| (d) RWC | |||||
| Method | VR | VFA | RPA | RCA | OA |
| Proposed | 92.4 | 5.4 | 85.4 | 86.2 | 90.0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kum, S.; Nam, J. Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks. Appl. Sci. 2019, 9, 1324. https://doi.org/10.3390/app9071324
Kum S, Nam J. Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks. Applied Sciences. 2019; 9(7):1324. https://doi.org/10.3390/app9071324
Chicago/Turabian StyleKum, Sangeun, and Juhan Nam. 2019. "Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks" Applied Sciences 9, no. 7: 1324. https://doi.org/10.3390/app9071324
APA StyleKum, S., & Nam, J. (2019). Joint Detection and Classification of Singing Voice Melody Using Convolutional Recurrent Neural Networks. Applied Sciences, 9(7), 1324. https://doi.org/10.3390/app9071324