1. Introduction
Contemporary data-intensive applications necessitate the persistent increment in the power of computing resources and the volume of storage devices which are in many real-life use cases essential on-demand for a specific operation in data lifecycle such as data collection, extraction, processing, and reporting. Additionally, it needs to be elastically scaled up and down according to the incoming workload. Cloud computing [
1] delivers platforms and environments for data-intensive applications and facilitates the effective use of big data technologies and distributed resources [
2]. Given the large volume of data to be transmitted and processed, each phase of the data-intensive applications is bringing new challenges to the underlying networking architecture and services.
Distributed batch processing systems like MapReduce [
3] and Hadoop [
4] still serve an essential function in the processing of static and historical datasets. However, MapReduce and Hadoop are not suitable for streaming data applications, because they were designed with the philosophy of offline batch processing of static data in focus, in which all the input data need to be stored in a distributed file system in advance. Streaming data processing systems gained significant attention due to the reason that processing a large volume of data in the batch is often not sufficient in use cases where new data has to be processed fast to quickly adapt and react to changes, such as intrusion detection, fraud detection, and Web analytics systems. Ideally, streaming engines must be capable of handling vast; ever-changing data streams in real-time and of conveying results to potential clients with a minimum delay. Several steaming engines including Storm [
5], Spark [
6], Samza [
7], Google Data Flow [
8], and Flink [
9] have been developed for this very purpose; to support the dynamic analytics of the streaming datasets. These distributed processing systems handle both the batch and real-time analytics which represent the core of modern big data applications. These frameworks orchestrate numerous nodes structured in a cluster and distribute the workload through communication using different messing techniques.
Flink is an open-source, distributed, dynamic streaming engine, designed to process valid and limitless data streams in a user-friendly environment [
9]. Flink is unique in that it does a lot for stream processing what Hadoop has done for batch processing [
10]. Flink was founded on the belief that the various functions of data processing applications, such as dynamic stream analytics, continuous data pipelines, batch processing of historic data, and iterative algorithms, such as machine learning and graph analysis, can all be performed through utilizing fault-tolerant data streams. Regardless of the fact that recent streaming engines have solved a majority of the issues plaguing big data analytics [
11], there are still a few difficult hurdles to overcome, namely, window correctness and buffer timeout. In retrospect, some of the recent streaming engines provide a level of support for the latency and throughput of the system, and the reliability of the results produced, but none have come close to providing a quick runtime.
The default Flink framework, as well as other streaming engines, have presented some inventive challenges for both the academic and industrial communities. Firstly, there’s always either a stagnant configuration procedure or no established procedure to set the maximum out-of-order capacity for any incoming window, as well as a fixed technique for the task tracker’s buffering timeout, all of which are crucial towards the execution of any streaming processing system. Secondly, the majority of these frameworks are incapable of maintaining the latency of these tasks at runtime, causing all manner of problems for the performance of many sensitive and critical applications, such as fraud detection in a banking system, online traffic checking, and so on. Thirdly, default topologies are always mapped to the nodes, whether the knowledge of the workloads is known or not, creating an overhead and resulting in a dip in performance, not only at the task at hand but also in the system as a whole. To rectify these challenges, we propose and extend the idea of our previous work [
12] that has the aptitude of utilizing a variety of different metrics such as late element frequency in the incoming workload, as well as both currently recorded throughput of the system and the runtime measured latency value to control the inherent latency problem as quickly and as efficiently as possible. Unlike the default system, it makes the task tracker’s buffering timeout and max out-of-order-ness dynamic, which can be changed and maintained according to the Service Level Agreements (SLAs) with the users. We propose three varying modes: automated, semi-automated, and manual, to successfully maintain the trade-off between latency and throughput using max-out-of-order-ness and window correctness. In case of manual mode, the system require the administrator to provide target latency, priority proportion of throughput and correctness, lower limit of throughput, and lower limit of window correctness to decide and forward the decision to the streaming environment. Semi-automate mode requires the administrator to provide target latency and preferred throughput, while in automated mode the system only needs target latency as an input.
Following suit from our proposal,
Section 2 highlights the aforementioned problem we must handle, and
Section 3 introduces our proposed system.
Section 4 explains a detailed use-case scenario,
Section 5 offers a thorough evaluation of our work,
Section 6 describes some similar projects, and
Section 7 concludes the paper.
2. Use Case Scenario: Fraud Detection
With the increase of online merchants and e-commerce, fraud becomes a trillion dollar problem for the global economy with the loss of 3.5 to 4 trillion dollars per year, which makes about 5% of global GDP [
13]. Several fraud detections and prevention companies are working to detect and prevent such fraud on time including BankCard USA, Kount, Ingenico, and fraud.net.
The system of fraud.net is one of the world’s leading peer production-based fraud prevention framework which aggregate and analyze large amounts of fraud data from thousands of online merchant in real time. This collaborative program is the largest merchant-led effort to combat online payment fraud costing US merchants an estimated amount of 20 billion dollars annually. It protects more than 2% of all the US-based e-commerce, and its clientele is growing very fast each year recently. This framework saves up to one million dollars a week for its customers by helping them detect and prevent fraud.
The primary challenge of such platforms is to build and train a more significant number of more targeted and precise machine learning models to counter the effect of increasingly different and evolving forms of fraud. As the fraudster’s strategy changes with time, the system should be able to evolve itself with the fraud evolution. There might be 100 different fraud schemes and each one with 100 different variations at any given day. To tackle these issues, the platform needs to have machine learning models and capabilities to identify and handle a new fraud scheme, as it pops up including its different variations.
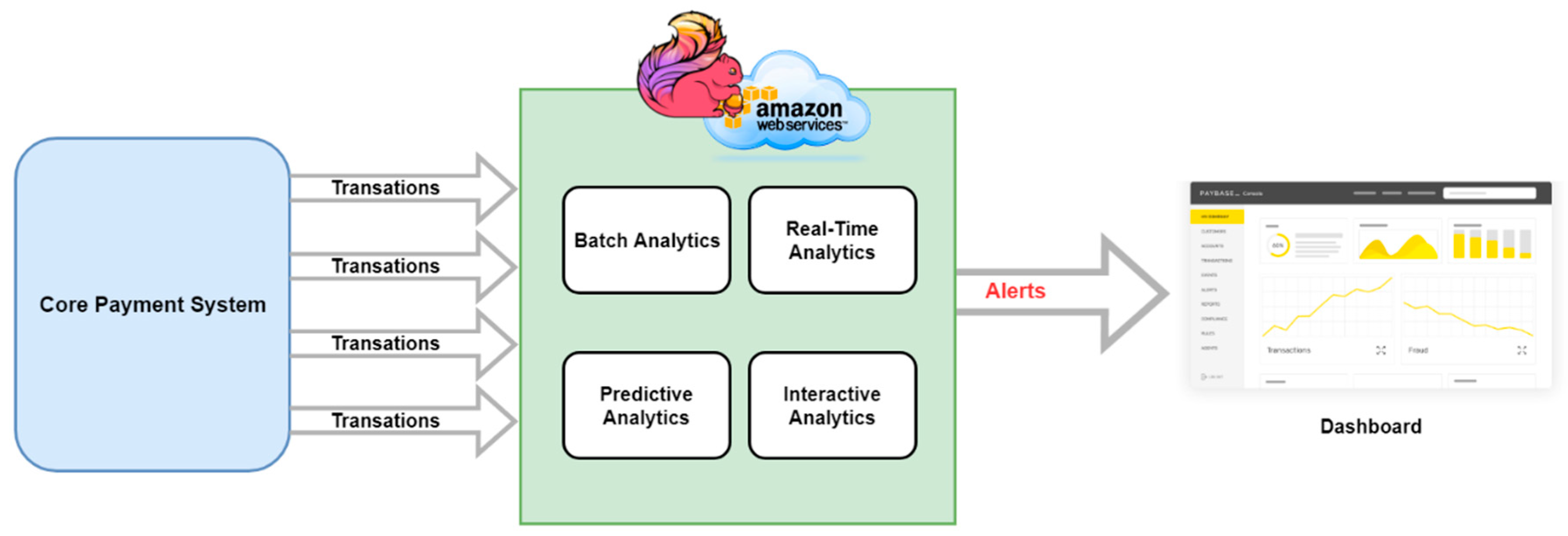
Latency-sensitive applications like fraud detection, traffic analysis, and media streaming need to adapt these capabilities and achieve a better tradeoff between lower latency and higher throughput. With this the goal of the system, the proposed system has different variations of the algorithm to achieve a better tradeoff between these, while taking SLA agreement into consideration. A generic fraud detection and prevention system architecture is shown in
Figure 1. The core payment system process all the transaction and pass it to the main detection and prevention system. The system contains batch analytics, real-time analytics, predictive analytics, and interactive analytics modules which process the transactional data and produce alerts based on the analysis of the incoming workload. The alerts are then portrayed to the dashboard, and the system admin takes actions accordingly.
4. Proposed System
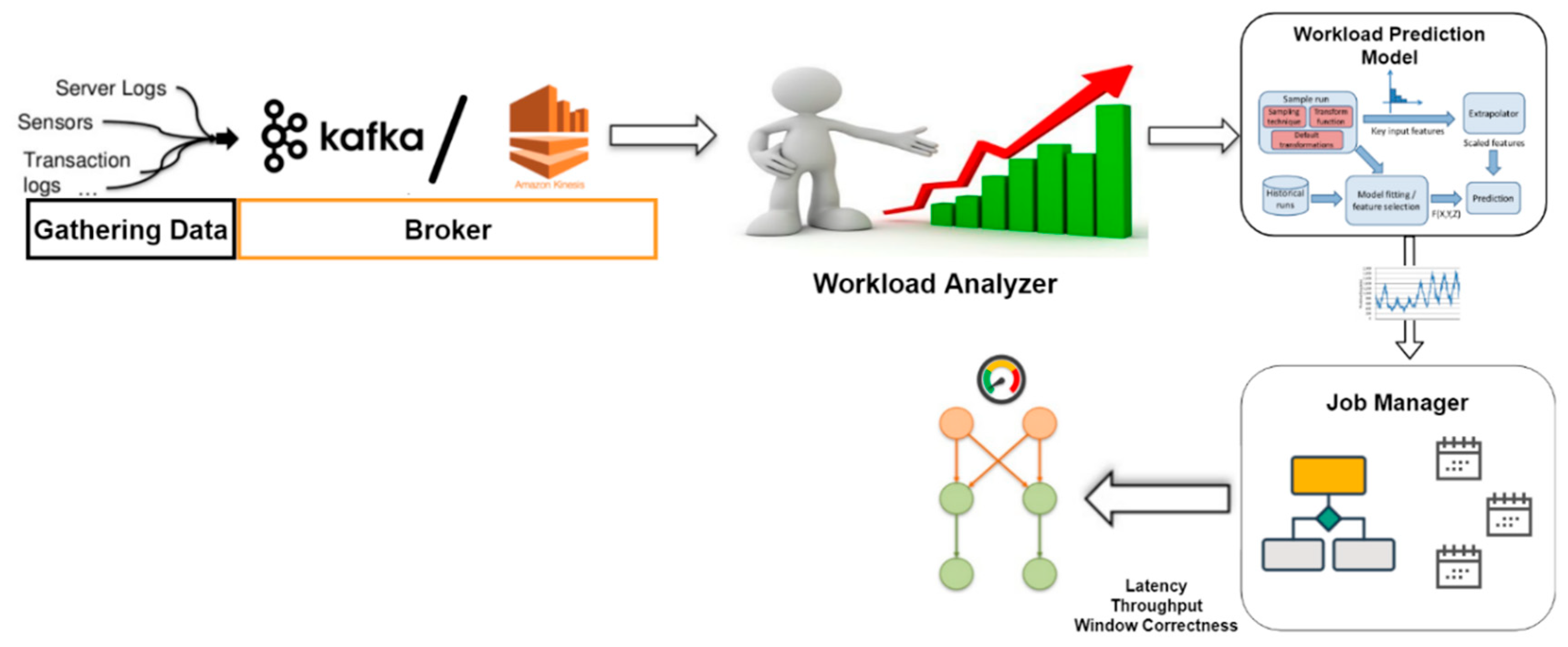
The proposed streaming data processing system is an extended version of our preliminary research work [
12], containing brokering module, workload analyzer, and job manager latency controller. Whereas the extended work in this article is composed of input gathering module, brokering module, workload analyzer, a workload prediction module, and job manager’s latency-throughput controller module as shown in
Figure 9. The input gathering module is the data and event entry point to the system. It collects data from a variety of sources, like sensors, sensor logs, transaction logs, and the like, which are then passed on to a data broker, such as Kafka or Amazon Kinesis. The data broker backup the data streams in varieties of ways, offer the streams for consumption by the engine, as well as provide the stream recovery mechanism. It also has the role to pipeline this newly acquired data stream to the workload analyzer module. This module uses the incoming workload to analyze and measure the metric values used in the analytic algorithms of the system. It also has the ability to analyze and correlate streams, create derived streams and states. The workload analyzer then passes the resultant metrics and calculated information to the workload prediction module and other upstream modules. The workload prediction module is designed based around machine learning algorithms and previous research on the subject for any multi-tier architecture system [
15,
16]. This module gives the system a sense of the incoming workload to make the Job Manager ready and help keeps the system from breaching the SLA agreement. The job manager then takes this collective information, along with the incoming prediction from the previous module and the decision algorithm, to calculate an improved performance enhancement. The system can then increase or decrease both throughput and latency accordingly (using any of the target latency modes described in Section IV-D). Once the system reaches the necessary SLA requirement (if possible), the algorithm will steadily reduce
maxOutOfOrderness and
bufferTimeOut, until a status queue between latency and throughput is established. Furthermore, we have designed an adaptive topology refinement scheme to get the benefit of topological changes needed to be made by the system at runtime while taking the incoming workload into account, which is not in the scope of this paper and will be discussed in our upcoming article.
To this end, we propose a complex adaptive system (CAS), an adaptive watermark and buffer time-out mechanism designed for the efficient optimization of the Flink engine. In the upcoming section, we will briefly highlight the metrics used for our proposed optimization of Flink, as well as explain our aimed latency-bound algorithm. Furthermore, we will also elaborate on the concept surrounding the dynamic buffering timeout and the various target latency techniques we have used throughout the project.
4.1. Performance Metrics
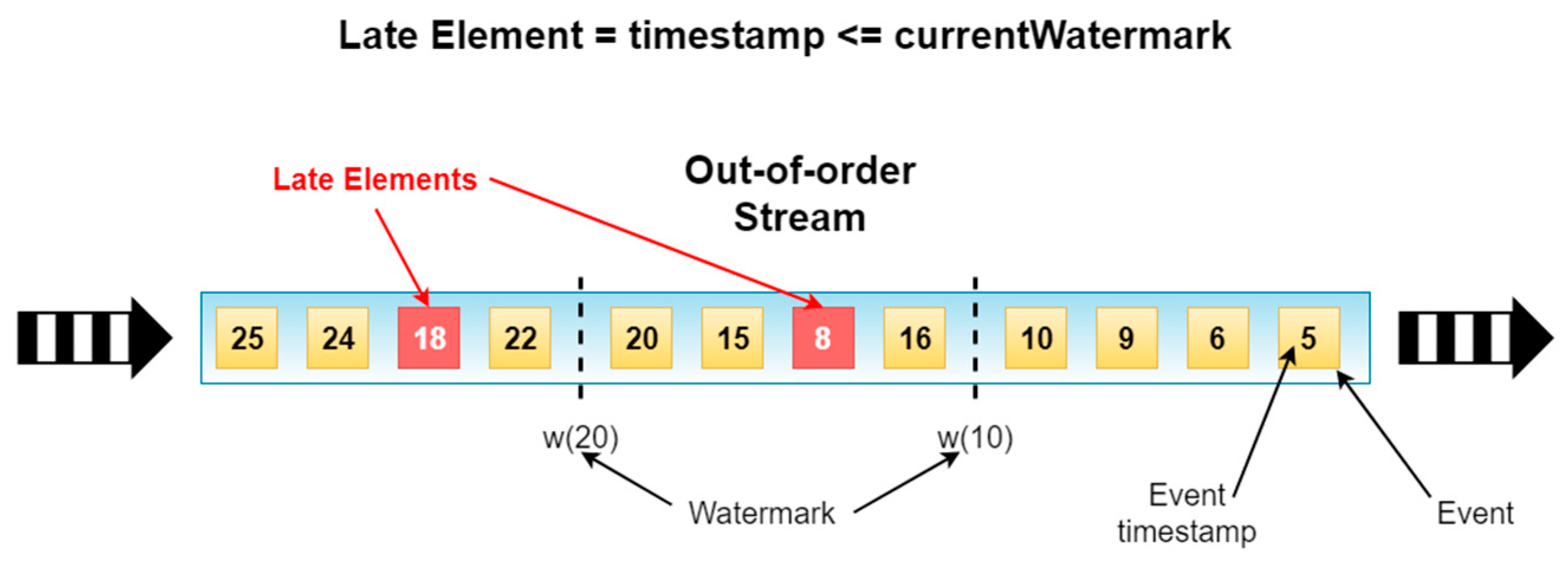
4.1.1. Late Elements Frequency
Within the window operators, whenever a subtask receives any late elements, the operator will alert the master, which in this case is the Job Manager, of the arrival of such elements. The master will then compile the number of late elements of the system, including the recent arrivals, and use them, later on, to help determine the tradeoff mentioned at the beginning of the section between latency and throughput.
4.1.2. Throughput
Flink bestows all users with a rich metric API set. Using
Operator.numRecordsOut(the number of accumulated records) at the sink operator to compute the average throughput per second by dividing the result of the
numRecordsOut function of Operator class by the time passed in seconds as in Equation (1):
where
Ň is the result of the
Operator.numRecordsOut, while
T is the time in seconds.
4.1.3. Latency
It is genuinely challenging to gather the latency in the entire stream as it is a complex metric. Therefore, it is achieved through sample slicing off some of the records from the incoming stream, followed by an appropriate estimation. Records sampling is completed as well, to prevent any potential degradation of performance in the system, and specific records are marked from the source location, enabling the sink operator to identify them during calculation, as these records are the only ones required.
Marking can be done randomly (through random selection algorithm), or at specified times depending on circumstance. This way, the sink operator know the exact records to use in latency calculations. The Job Manager (master node) calculate the latency through following Equation (2).
where
is the finish time of the marked sample and
is the entering time of the sample record in the execution pipeline.
4.2. Latency Control Mechanism
Latency control mechanism acts as an addition towards the Job Manager’s ability to find the suboptimal balance between latency, throughput and window correctness, through considering a variety of metrics in the process of achieving the objective of minimalizing latency while maximizing throughput as much as possible. Latency is decreased when the number of out-of-order events that reach the system also decreases, while throughput increases based on the value of the buffering timeout. The main concern here was to sub-optimally decide the tradeoff between latency, window correctness and buffering timeout, to ensure that the system would be able to maintain its functioning without the breach of SLA agreement. We focus on the tradeoff as an increase of throughput can cause latency to be a breach of SLA, or it can also hurt window correctness (as correctness is sometimes more about timely getting the result than only getting the accurate results).
Through using our proposed metric system, as seen in section III-B, the Job Manager now has an educated estimation of the appearance rate of late elements and a vision of the system as a whole in real-time. The master then triggers the algorithm in
Figure 10 upon the overflow of the user’s
targetLatencyBound.
The algorithm in
Figure 10 is self-explanatory, and it controls the latency and throughput of the cluster on run time. The algorithm first uses the allowed range of
maximumOfOrderness to control latency of the system and confirms whether the
maxOutOfOrderness can be reduced or not, which could result in one of two possible outcomes. The first possible outcome, if the system is using
ascendingTimeStampExtractor or the limitation of the correctness value declared by the user is the same as
maxOutOfOrderness, then the reduction is no longer possible, and this step is then bypassed. The second outcome happens if the system can reduce
maxOutOfOrderness, in which case
maxOutOfOrderness will steadily decline until
currentLatency of the system reaches the
(targetLatency–currentLatency) * allowed percentage of hurting correctness. In the event that the system could not decrease
maxOutOfOrderness, and the impact on correctness is higher than zero in percentage terms, then the user is alerted, and the process ends.
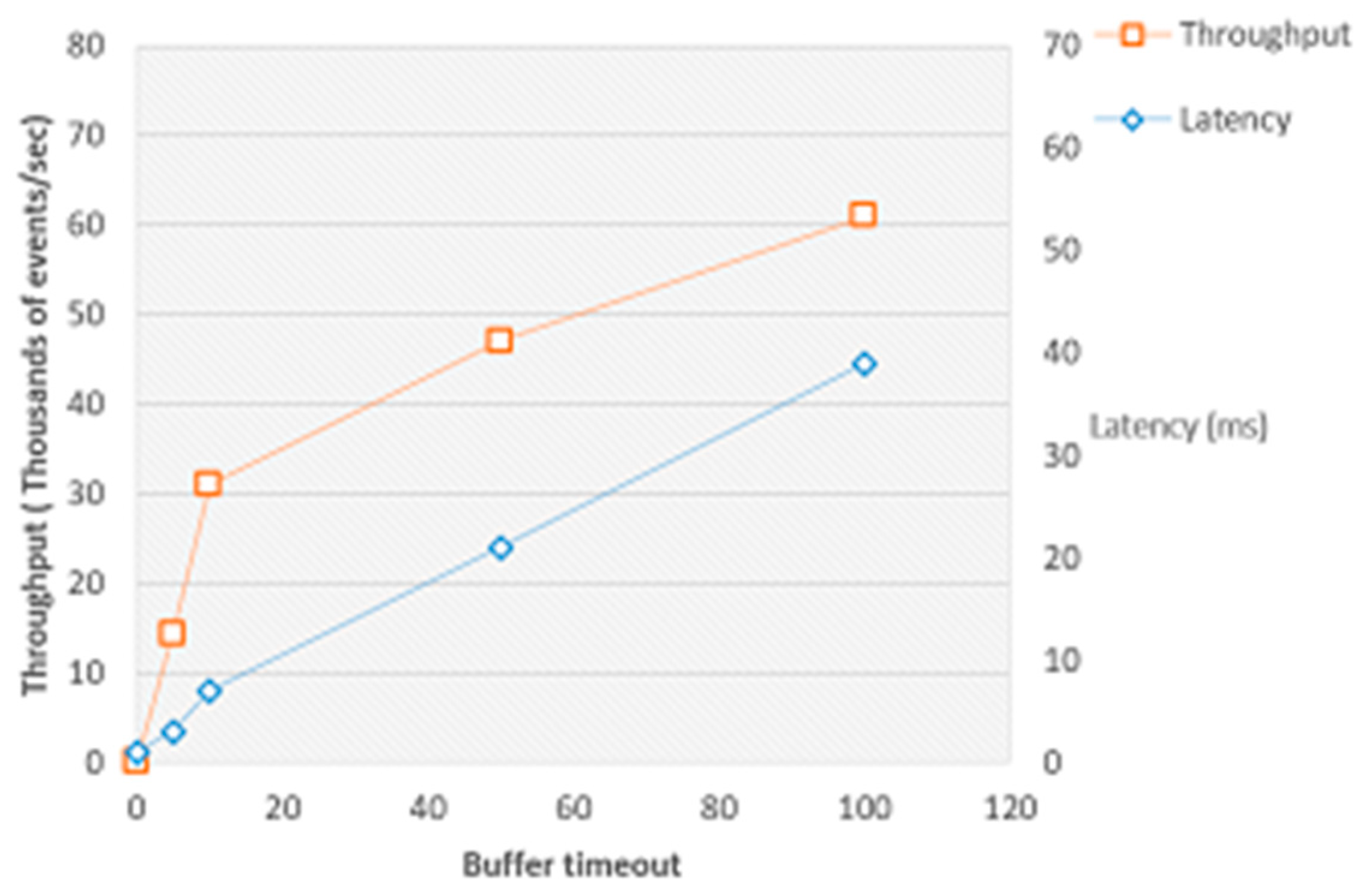
Next, throughput is controlled using bufferTimeout, that is, the throughput of the system is checked to see if a decline can occur to ensure that the best tradeoff can happen automatically. In case the bufferTimeout is already zero or currentThroughput of the system reached its lower limit according to the user configuration, throughput cannot be decreased any further. Thus, it will return from the process. However, if the percentage of hurting throughput is greater than zero, then the system will notify the user before returning. When the system is able to reduce the throughput, it will reduce the bufferTimeout until the current throughput value reaches (targetLatency–current latency) * allowed percentage of hurting throughput.
4.3. Dynamic maxOutOfOrderness and Task Tracker’s bufferingTimeout
Most frameworks have no capabilities that enable them to select the out-of-order ness of all incoming events at system runtime, and likewise, these systems often suffer from the static configuration of the buffering time-out. This absence of such features usually results in the breaching of the SLA agreements dealing with the reliable estimation of outcomes, guaranteed throughput (in case of throughput-intensive applications), some forms of manual end-to-end latency for specific systems (in case of response time-sensitive applications such as financial fraud detection, security systems etc.), and so on.
As opposed to the offered Flink framework, we propose an innovative framework model by making the maxOutOfOrderness and task tracker’s buffering timeout more flexible and dynamic at runtime, providing the system with a sense of control, and adaptable at runtime to any manually defined SLAs. The target values of the two are sent to, and maintained in every node, as follows:
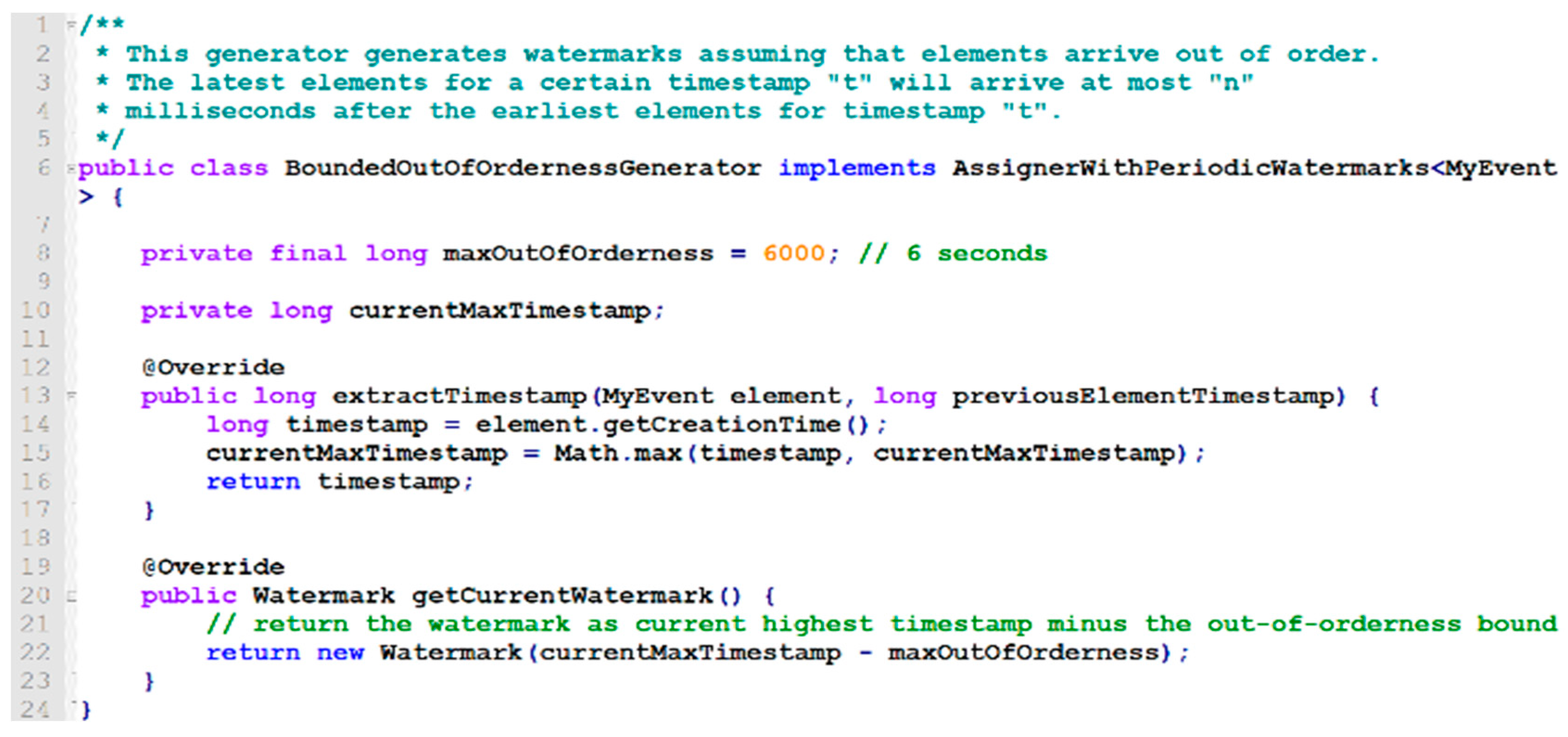
4.3.1. Dynamic maxOutOfOrderness
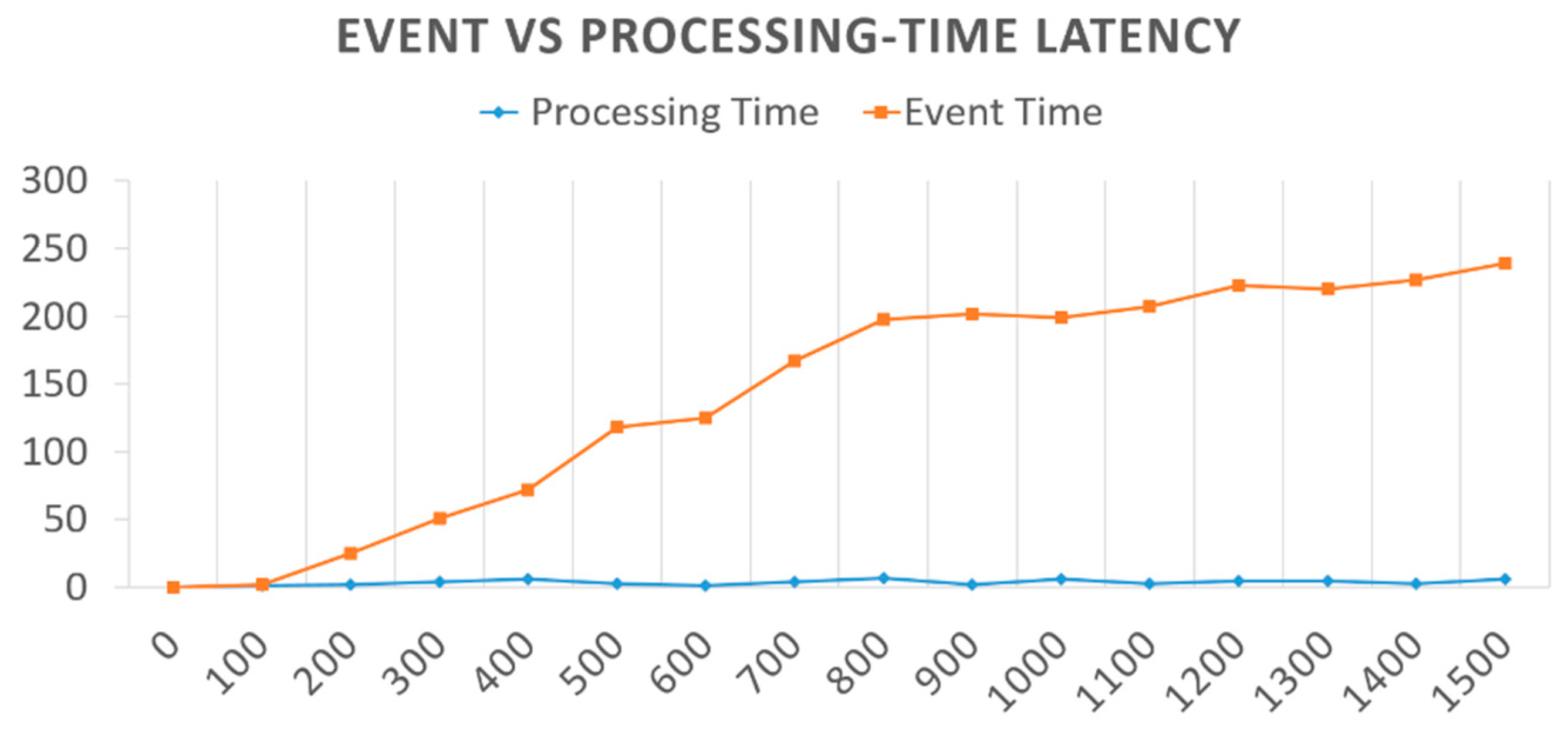
The getCurrentWatermark procedure is used to get the current watermark of the data stream to keep track of the event and processing time of the system. In every iteration, the getCurrentWatermark() method in the run() method of the timestamp and watermark generator’s thread is invoked, our proposed system will call for the master whether the maxOutOfOrderness value was changed or otherwise and will go through with the selected path using the dynamic latency control mechanism accordingly. The proposed system uses a custom-based API to handle the runtime alteration of the out-of-orderness of events in the incoming workload following the procedure and guidelines of the Latency-Throughput control algorithm. In order to avoid the communication overhead from messaging, the communication with the master will be periodic or as necessary. If the maxOutOfOrderness has been altered, the system will change the local variable in the timestamp and watermark generator thread accordingly.
4.3.2. DYNAMIC bufferingTimeout
The connection manager of every node’s task manager sends a request to the master node about the buffer timeout value periodically. Should there have been any changes, then the connection manager will update its local buffer timeout values as needed, while the current ongoing buffer will contain all previous values before the update, and the system will provide the updated value for any generated buffers down the line. The recorded task manager’s value for the buffer timeout is the one changed through custom-based API of the proposed system following the rules and guidelines of the Latency-Throughput control algorithm as shown in
Figure 10 and detailed in
Section 4.2.
4.4. Target Latency Modes
We propose the following three modes of operations to achieve the target latency of the system: fully automated mode, semi-automated mode, and manual mode.
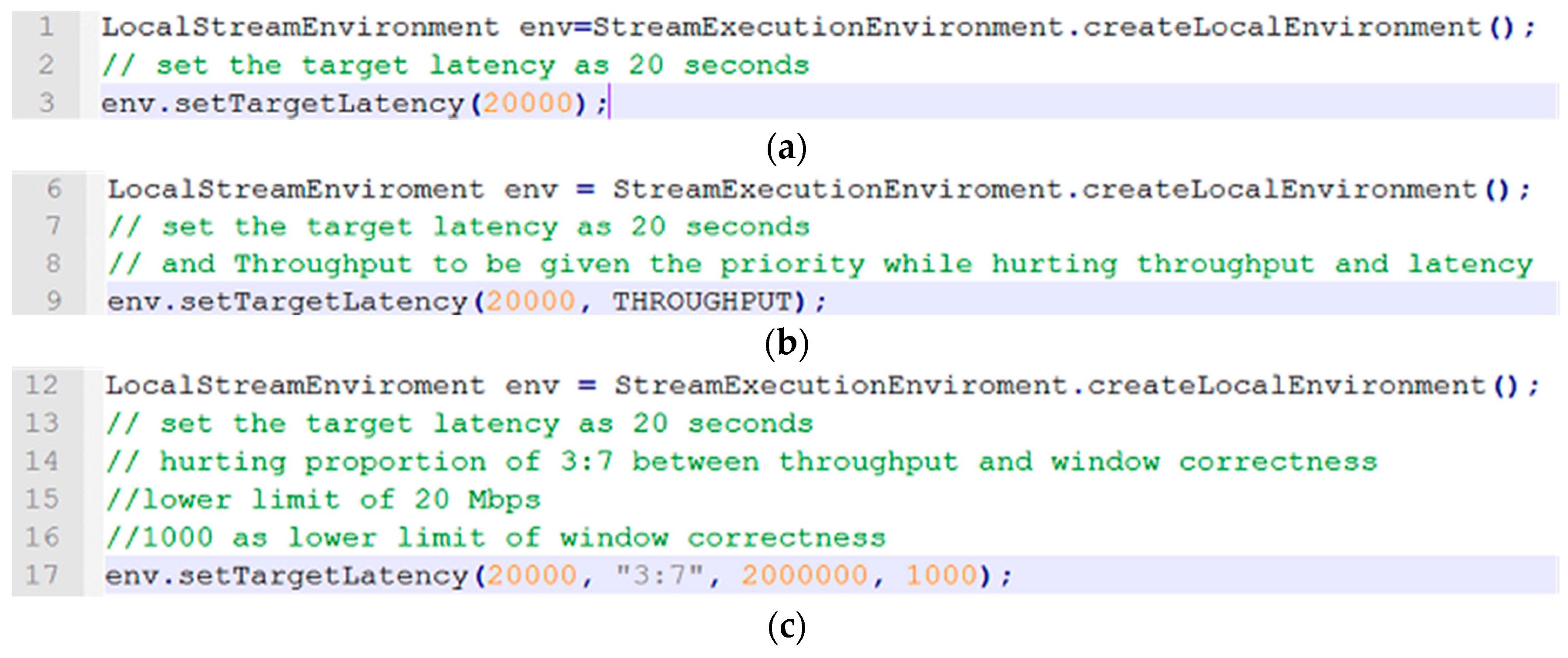
4.4.1. Fully Automated Mode: setTargetLatency(target latency value)
Fully automated mode in the proposed system will automatically provide a sub-optimized ratio between throughput and window correctness of any given workload based on the target latency provided by the user. Based on that, the modified module of the Job Manager will decide the tradeoff between throughput and window correctness, then enforce it at runtime. We utilize a machine learning algorithm which analyzes different workloads and improves the relations between latency, throughput, and window correctness while taking the workload into account. The workloads must be normalized, as the kind of workloads differ.
To elaborate, let us assume we set the target latency of the system to 20 seconds as shown in
Figure 11a. Upon detection that the current latency of the system is overflowed 20 seconds by the Flink framework, it will find an optimized tradeoff between throughput and window correctness automatically, all the while factoring the nature of the workload into account.
4.4.2. Semi-Automated Mode: setTargetLatency(target Latency, priority of hurting throughput and window correctness)
In the semi-automated mode, users will establish the value for the target latency and prioritize which of the two, throughput or window correctness, must be sacrificed in a higher capacity, while calculating the sub-optimized solution for the tradeoff between both.
Again, to elaborate, let us assume a user has set the target latency of the system to 20 s and selected throughput as the defining factor over windowing correctness when one has to be chosen as shown in
Figure 11b. After Flink determines that the current latency overflew 20 s, it will find an optimized tradeoff between throughput and correctness automatically with the intention of favoring throughput rather than correctness.
4.4.3. Manual Mode: setTargetLatency(target latency, hurting proportion between throughput and window correctness, low limit for throughput, low limit for window correctness)
For manual mode, the user will have to supply the required target latency, which affects the ratio between throughput and window correctness, providing a lower limit for affecting throughput for the sack of latency, and a lower limit for affecting window correctness, allowing the system to calculate the tradeoff between both.
To elaborate, suppose a user sets the target latency of the system to 20 s, resulting in a proportion of 3:7 between throughput and window correctness, low limit of 20 Mbps, and 1000 as the low limit of window correctness as in
Figure 11c. After Flink detects that current latency overflew 20 s, it will hurt throughput and window correctness according to 3:7 proportion of throughput and correctness, while taking into account low bound for hurting throughput and the low limit value for hurting window correctness according to the given arguments. If the system cannot fulfill these conditions, it alerts the user about the situation.
In brief, all these operating modes i.e. fully automated mode, semi-automated mode, and manual mode are the variation of a core API function defined in our extension of the original open source framework called “setTargetLatency”. This function is called through the execution environment variable in order for the system to communicate with the system administrator. These functions allows administrators and users to define their SLAs and communicate it to the system in a seamless manner.
6. Related Research
The increasing relevance of streaming engines has resulted in a number of projects focused on exploiting parallelism in stream processing and scale-out. Apache S4 [
28], Strom [
5], and Flink [
9] represent queries and programs as directed acyclic graphs (DAGs) with parallel operators. S4 schedules parallel instances of operators at the cost of being able to control such operators. Storm allows users to stipulate a parallelization level and supports stream partitioning based on key intervals, but it ignores states of operators and has minimal ability to scale at runtime. System S [
29] from IBM supports intra-query parallelism through a fine-grained subscription model that has the ability to describe any and all stream connections. This system has no automated manager for the said mechanism. Hizrel [
30] proposed a MatchRegex operator for System S to detect tuple pattern in parallel. This approach does not consider dynamic repartitioning and state is specific to automata-based pattern detection. Stromy [
31] uses consistent hashing and a logical ring to accommodate new nodes upon scale out. It does not take congestion into account, while our proposed system does. Zeitler and Risch [
32] proposed the
parasplit operator for a partitioning stream statically based on a cost model, allowing for a customized stream splitting for the scalable execution of continuous queries over massive data streams. Instead, our take on this decides the parallelization level at runtime, based on performance metrics.
StreamCloud [
33] constructs elasticity into Borealis Stream Processing Engine [
34]. StreamCloud uses a query compiler to synthesize high-level queries into graphs of relational algebra operators. It uses hash-based parallelization, which is geared towards the semantics of joins and aggregates. It modifies the parallelism level through splitting queries into subqueries and uses rebalancing to adjust resource usage. Our proposed approach CASE-Flink reconfigures the out-of-orderness in the input events occurrences and buffering timeout while complying with user-defined SLA agreement. Backman et al. [
35] partition and distribute operators across nodes within the stream processing system to reduce the amount of processing latency through load balancing according to the simulated estimation of latency. They achieve latency-minimization goals through parallelism model encouraged by latency-oriented operator scheduling policy coupled with the diversification of computing node responsibilities. In contrast, our method of the operator over the cluster nodes is done when needed to remove the processing bottlenecks and achieve low latency.
SEEP [
36] proposed an elastic approach based on operators state management. It exposes internal operator state explicitly to the stream processing system through a set of state management primitives. Based on these primitives, it describes an integrated approach to dynamically scale and recover stateful operators through periodic checkpointing of externalized operator state by streaming processing systems and backed up to upstream VMs. It offers mechanisms to backup, restores, and partition operator’s states in order to achieve short recovery time. Auto-parallelization [
37] addresses the profitability problem associated with automatic parallelization of general purpose distributed data stream processing applications. Their proposed solution can dynamically adjust the numbers of channels used to achieve high throughput and high resource utilization as well as handle partitioned stateful operators through run-time state migration. In contrast, our approach takes workload into account and adjusts the configuration of anticipated metrics at runtime to meet the SLA requirements.
Twitter’s Heron [
38] improves Strom’s congestion handling mechanism by using back pressure. However, it fails to address the elasticity and reconfiguration of topologies specifically. Heinze et al. [
39] proposed an online parameter optimization approach allowing the system to trade a monetary cost in exchange for the offered QoS. It focused on latency and policy, rather than throughput and mechanism. Reactive-Scaling [
40] presents a flexible elastic strategy for enforcing constraints over latencies in a scalable streaming engine while minimizing resource footprints. Their queuing theoretic latency model provides a latency guarantee by tuning the task-wise level of parallelism in a fixed size cluster. It should be pointed out that our proposed mechanisms can be used as a black box within both systems [
39,
40].
7. Concluding Remarks and Future Directions
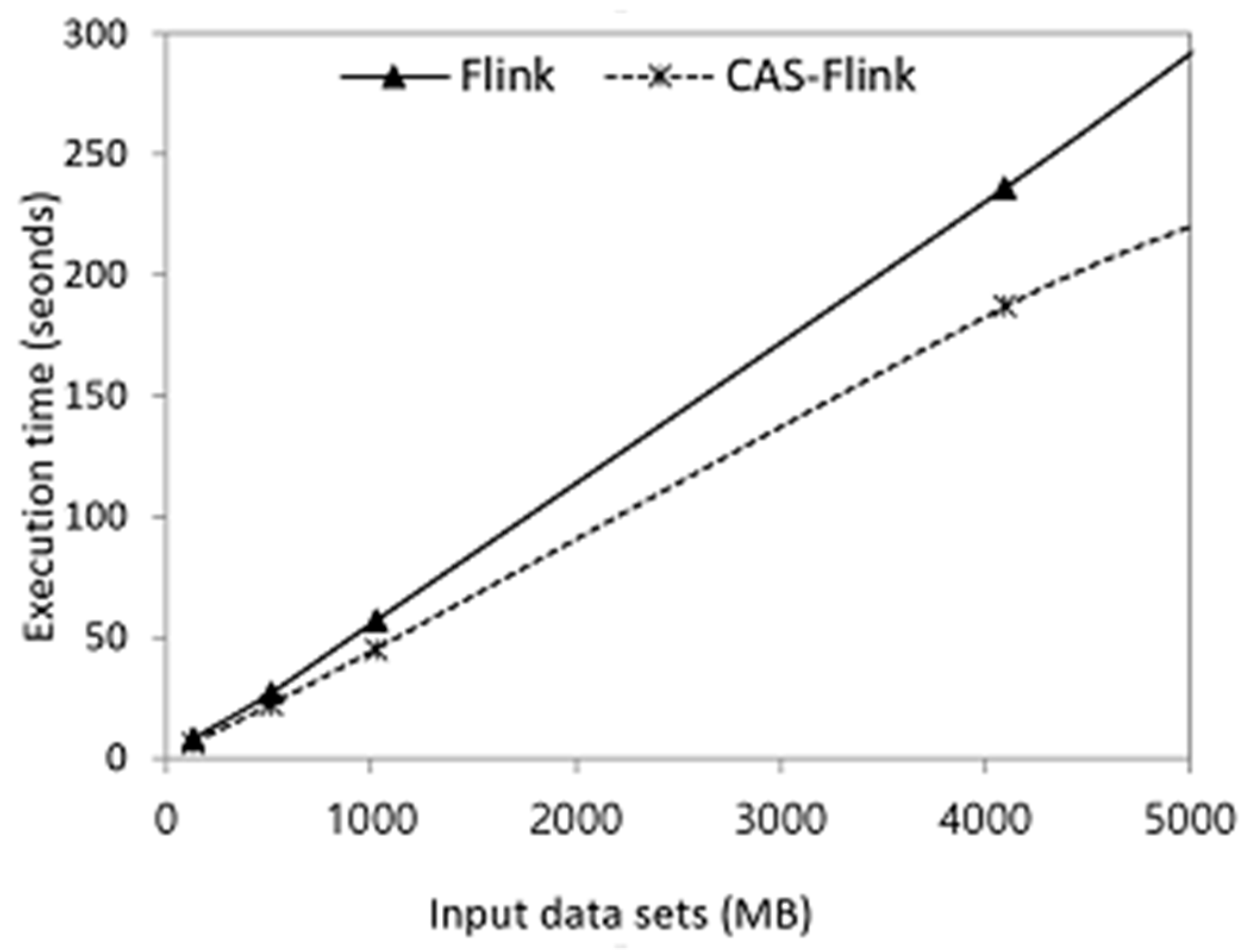
The growing popularity of the Flink framework is due to the wide range of use cases for this platform and its capability to handle both batch and streaming applications and data in a fault-tolerant and efficient way. As an evolving open source framework in the field of big data analytics and distributed computing, Apache Flink has the competency of processing distributed data streams in a reliable and real-time fashion. We proposed an efficient, adaptive watermarking and dynamic buffering timeout mechanism for Apache Flink. It is designed to increase the overall throughput by making the watermarks of the system adaptive based on the workload, while also providing a dynamically updated buffering timeout for every task tracker instantly, all the while maintaining the SLA based end-to-end latency of the system. The main focus of this work is on tuning the parameters of the system based on the incoming workloads and assesses whether a given workload will breach an SLA using output metrics including latency, throughput, and window correctness. Our experimental results show that CAS-Flink outperforms existing distributed stream processing engines.
We plan to investigate more efficient workload analysis methods like Markov Model, and Markov Hidden Model. We believe by introducing such models, and we will be able to fully automatize the system with the inclusion of topology refining scheme to the current model, which will lead the system to be more robust and load balanced within the limits of its SLA agreements and without hurting the QoS accordingly.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}