Abstract
Several phenomena are represented by directional—angular or periodic—data; from time references on the calendar to geographical coordinates. These values are usually represented as real values restricted to a given range (e.g., ), hiding the real nature of this information. In order to handle these variables properly in supervised classification tasks, alternatives to the naive Bayes classifier and logistic regression were proposed in the past. In this work, we propose directional-aware support vector machines. We address several realizations of the proposed models, studying their kernelized counterparts and their expressiveness. Finally, we validate the performance of the proposed Support Vector Machines (SVMs) against the directional naive Bayes and directional logistic regression with real data, obtaining competitive results.
1. Introduction
Several phenomena and concepts in real-life applications are represented by angular data or, as they are referred to in the literature, directional data. Examples of data that may be regarded as directional include temporal periods (e.g., time of day, week, month, year, etc.), compass directions, dihedral angles in molecules, orientations, rotations, and so on. The application fields include the study of wind direction as analyzed by meteorologists and magnetic fields in rocks studied by geologists.
The fact that zero degrees and 360 degrees are identical angles, so that for example 180 degrees is not a sensible mean of two degrees and 358 degrees, provides one illustration that special methods are required for the analysis of directional data.
Directional data have been traditionally modeled with a wrapped probability density function, like a wrapped normal distribution, wrapped Cauchy distribution, or von Mises circular distribution. Measures of location and spread, like mean and variance, have been conveniently adapted to circular data.
The design of pattern recognition systems fed with directional data has either relied completely on these probabilistic models or just ignored the circular nature of the data.
In this work, we formulate for the first time a non-probabilistic model for directional data classification. We adopt the max-margin principle and the hinge loss, yielding a variant of the support vector machine model.
The theoretical properties of the model analyzed in the paper, together with the robust behavior shown experimentally, reveal the potential of the proposed method.
2. State-of-the-Art
Classical methods for method design include probabilistic and non-probabilistic approaches. Probabilistic approaches come in two flavors, generative modeling of the joint distribution and discriminant modeling of the conditional probabilities of the classes given the input. Non-probabilistic approaches directly model the boundaries of the input space or, equivalently, model the partition of the input space in decision regions.
Directional data classifiers have been typically approached [1,2,3] with generative models based on the von Mises distribution. The von Mises probability density function for the angle is given by:
where is the modified Bessel function of order zero, is the concentration parameter, and the mean angle.
Analyzing the posterior probability of the classes,
under the von Mises model for the likelihood, it is trivial to conclude that:
where , , and are functions of the mean and concentrations parameters. Recently [4], a directional logistic regression has been proposed that fits Model Equation (3) directly from data. In there, the multidimensional setting was naturally extended to:
where and is the ith element in vector .
Noting that:
where and are obtained from and , the directional logistic regression model is favorably written as:
enabling the learning task to be solved with conventional logistic regression, by first applying a feature transformation, where each input feature yields two features, and .
3. Support Vector Machine
For an intended output and a classifier score , the hinge loss of the prediction is defined as , where is the input and is the vector of parameters of the model. The Support Vector Machine (SVM) model solves the problem:
where is a regularization parameter. In standard spaces, the model is set to the affine form, , and the previous equation can be equivalently written as:
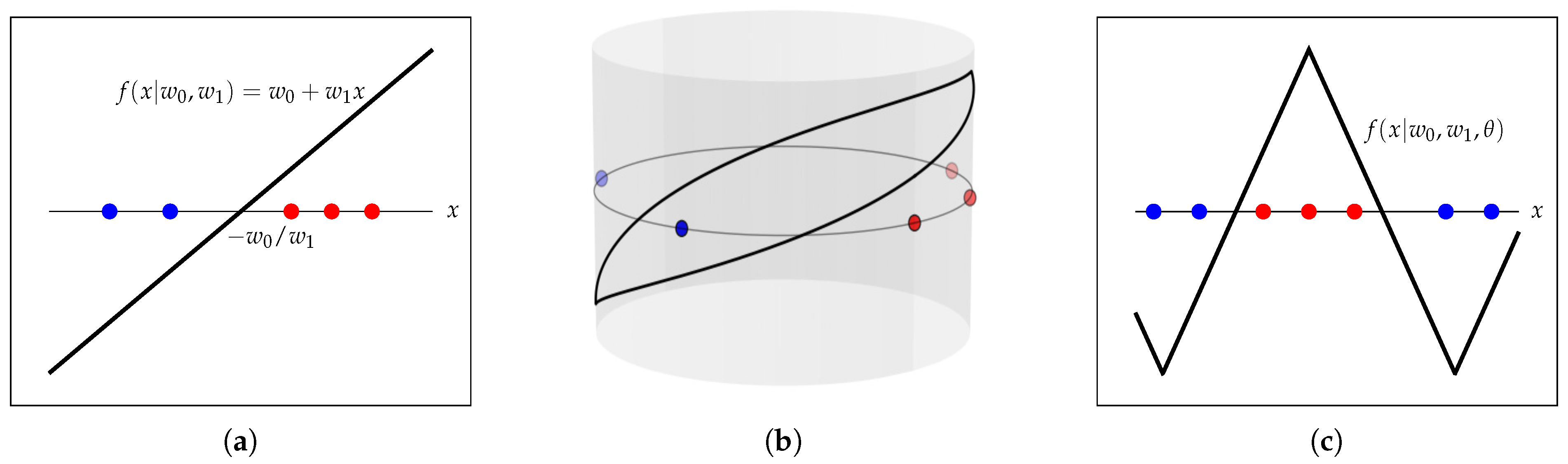
In the trivial unidimensional space, the model boils down to , and the partition of the input space is defined by a single threshold; see Figure 1a.
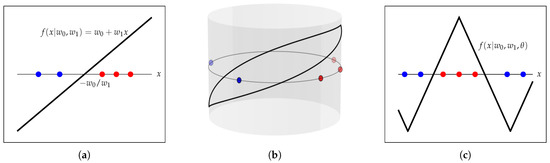
Figure 1.
Toy examples of Support Vector Machine (SVM) in and in the unit circle. (a) Standard linear model. (b) Piecewise linear model in the unit circle. (c) Unfolding the piecewise linear model in the unit circle.
In the following, to avoid unnecessarily cluttering the presentation, we will stay in the unidimensional space, returning only in the end to the multi-dimensional problem. We will also assume the period for the directional data.
4. Symmetric Directional SVM
For directional data, the model has to be adapted, as it should be periodic, continuous, and naturally take positive and negative values in the circular domain (so it can aim to label positive and negative examples correctly). Arguably, the most natural extension of the linear model in is the piecewise linear model in ; see Figure 1b,c. Note that, now, the partition of the input space requires two thresholds.
Motivated by this observation, we explore models of the form:
where we start by investigating the following specific realizations for :
- , where is the triangle wave with unitary amplitude, period , and maxima at . This function is piecewise linear, and so, it is close to the linear version in the standard domain.
- , where . This option can be seen as a rough approximation to the intuitive choice , but as we will see, analytically more tractable.
4.1. Expressiveness of
While in the standard domain, the linear model is able to express (learn) an arbitrary threshold in the input domain, in the directional domain, we need the ability to express any two thresholds. It is easy to conclude that, when instantiated with or , the model is able to express two thresholds in the circular domain, whatever their positions are, as formally stated and proven in Proposition 1.
Proposition 1.
Let be an even periodic function with period . For any distinct and in , there exists a θ in such that is zero at and .
Proof.
Set and . Note that , and . Now, setting , , and yields a model with the desired zeros. □
For the option, using Equation (5), can be equivalently written as , where . Therefore, we consider the following equivalent model:
Similar to the result obtained with the directional logistic regression, the optimization problem in Equation (7) can be efficiently solved by first transforming each directional feature x into two new features, and , and then relying on efficient methods for the conventional primal SVM, such as Pegasos [5].
Unfortunately, the analogous equivalence does not hold for the triangle wave . For , cannot be written as , where . Still, we could be led to assume the decomposition Equation (10) as a good approximation, when instantiated with and use it in practice, with the benefit of using standard SVM toolboxes in pre-processed data. However, the expressiveness of this model is quite limited. For instance, the model is unable to learn two thresholds in . Since this model is linear in this interval, the result follows.
As such, for , we solve the learning task defined by Equation (7) using sub-gradient methods.
5. Kernelized Symmetric Directional SVM
By the representer theorem, the optimal in Equation (8) has the form:
where k is a positive-definite real-valued kernel and . Benefiting from the decomposition of each directional feature in two, this formulation is directly applicable to the primal, fixed margin, directional SVM, when using . As such, all the conventional kernels can be applied in this extended space.
When the model is instantiated with , x is mapped in a two-dimensional feature vector, , and the inner product between and becomes . As such, the feature transformation can be avoided by setting as the kernel the cosine of the angular difference, .
As seen before, in the case of , a similar conclusion does not hold. However, the result for suggests also investigating the interest of using the function as a kernel. We start by presenting Theorem 1, where we show that a broad family of functions, which includes both and , may be used to construct formally-valid kernels.
Theorem 1.
Let be a periodic function with period T and absolutely integrable over one period. Define as the autocorrelation of h, i.e.:
Then, is a kernel function, i.e., there exists a mapping ϕ from to a feature space such that .
Proof.
See Appendix A.1. □
Remark 1.
The triangle wave is the autocorrelation, as defined in this paper, of a square wave with amplitude and period .
Having proven the validity of as a kernel, we now focus on investigating the expressiveness of the resulting SVM. The note made in Section 4.1 supports that the sum of triangle functions centered in fixed positions is not expressive enough since it cannot place the decision boundaries in arbitrary positions. However, the kernelized version in Equation (11) can still be appealing, since now, the models are centered in the training observations, and, as such, adapted in number and phase to the training data. For the purpose of this analysis, the notion of the Vapnik–Chervonenkis (VC) dimension [6], given in Definition 1, will be useful.
Definition 1.
A parametric binary classifier , with parameters , is said to shatter a dataset if, for any label assignment , there exist parameters such that classifies correctly every data point in . The VC dimension of is the size N of the largest dataset that is shattered by such a classifier.
Thus, the VC dimension of a classifier provides a measure of its expressive power. In Theorem 2, we establish a result that determines the VC dimension of the kernelized SVMs we are considering.
Theorem 2.
Let be a kernel function where g is defined as in Theorem 1. Furthermore, suppose that g has zero mean value and its Fourier series has exactly N non-zero coefficients. Then, the VC dimension of the classifier:
equals .
Proof.
See Appendix A.2. □
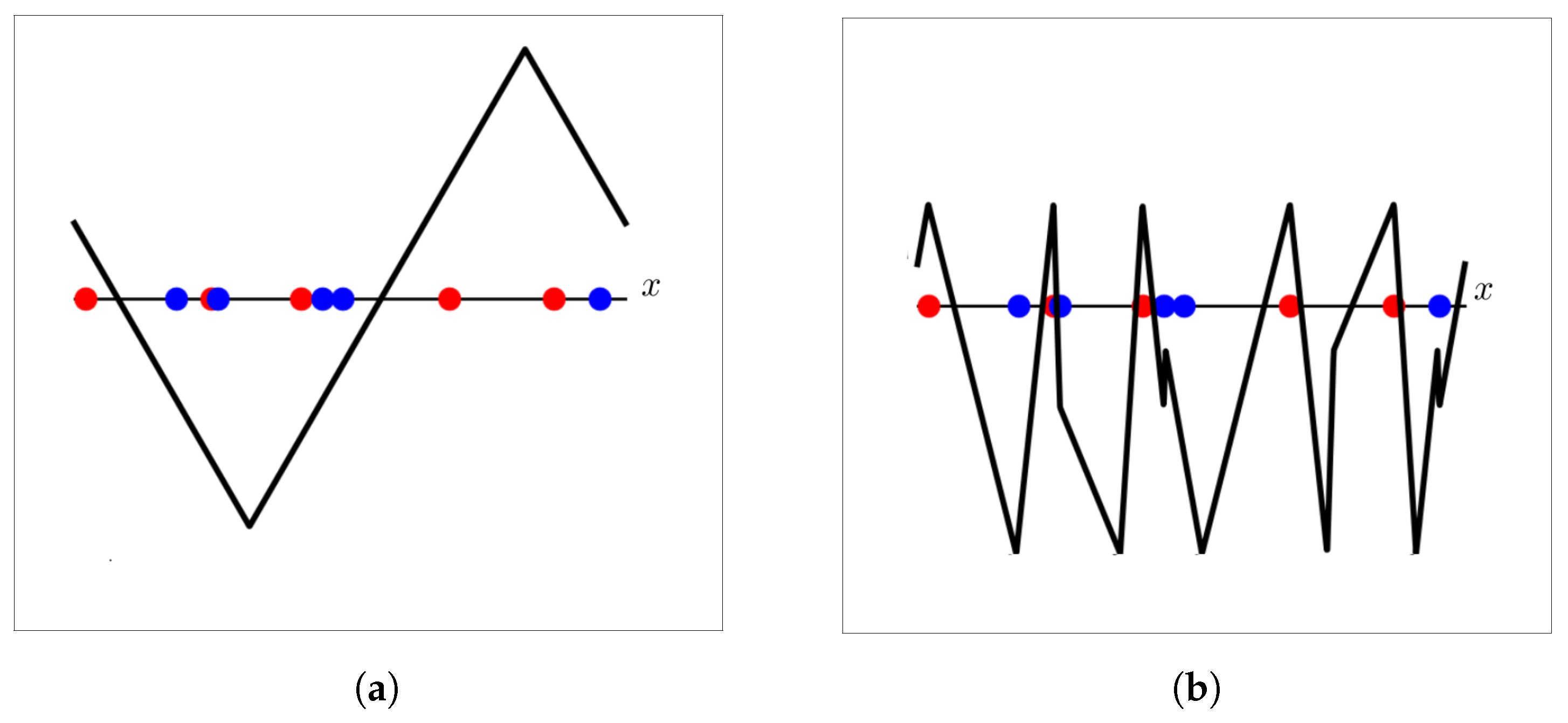
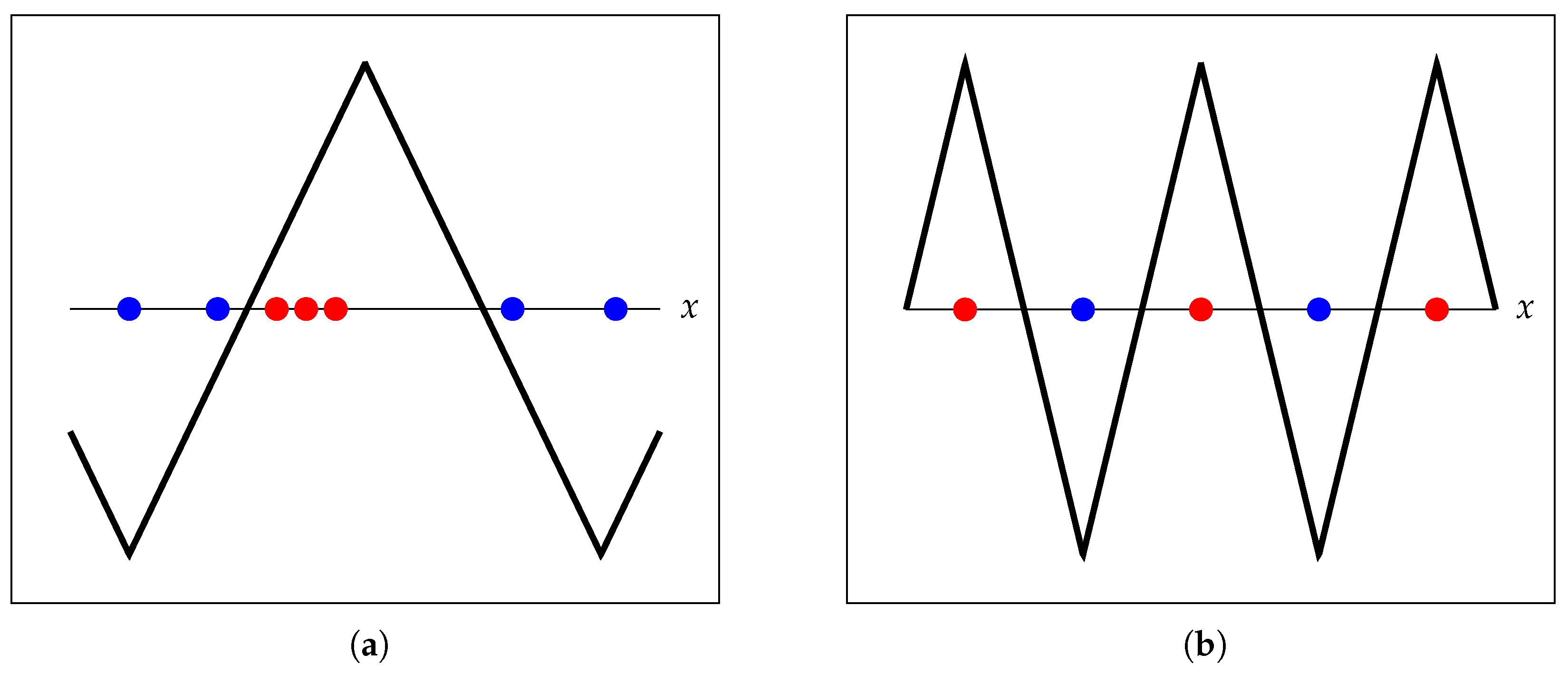
The Fourier series of the triangle wave has an infinite number of non-zero coefficients, and therefore, the classifier instanced with the triangle wave kernel has infinite VC dimension. On the other hand, the VC dimension of the classifier instanced with the cosine kernel equals three. Consequently, the SVM with the triangle wave kernel is able to express an arbitrary number of thresholds in the circular domain, unlike the SVM with the cosine kernel or with the triangle wave in the primal form, which, as proven before, can only express two thresholds in . Figure 2 illustrates these differences.
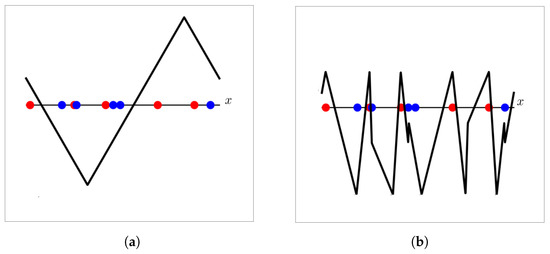
Figure 2.
Example illustrating the benefits of the triangle wave kernel. (a) The SVM with the triangle wave in the primal form cannot learn more than two thresholds; therefore, some training points in this toy dataset are misclassified. (b) The SVM with the triangle wave kernel can learn an arbitrary number of thresholds, classifying every training point in this toy dataset correctly.
However, depending on the relative position of the data points, even the SVM with the triangle wave kernel may fail to assign the correct label to all of them. In order to overcome this limitation, composite kernels, constructed from this baseline, can be explored. Typical cases include the polynomial directional kernel, , where d is the polynomial degree and the directional RBF kernel, (while the standard RBF kernel relies on the Gaussian expression, the directional RBF kernel relies on the expression of the von Mises distribution).
Figure 3a shows a simple training set that is correctly learned both with the primal and kernel triangle wave formulations. On the other hand, it should be clear that the setting in Figure 3b cannot be correctly learned by these same models. In this case, setting the SVM with the kernel achieves the correct labeling.
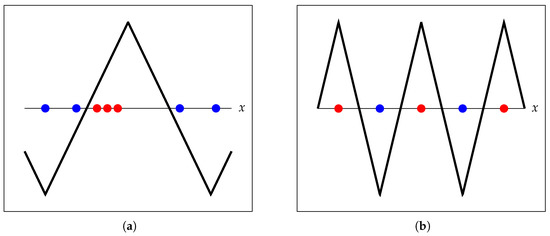
Figure 3.
Example illustrating the benefits of composite kernels. (a) Toy example correctly solved by the primal and the kernel formulation (using the directional kernel ). (b) Toy example not solved correctly by the primal, nor the kernel with . Solved correctly with polynomial directional kernel of degree two.
It is important to note that standard, off-the-shelf, toolboxes can be used to solve the kernelized directional SVM directly. One just needs to properly define the kernel as discussed before.
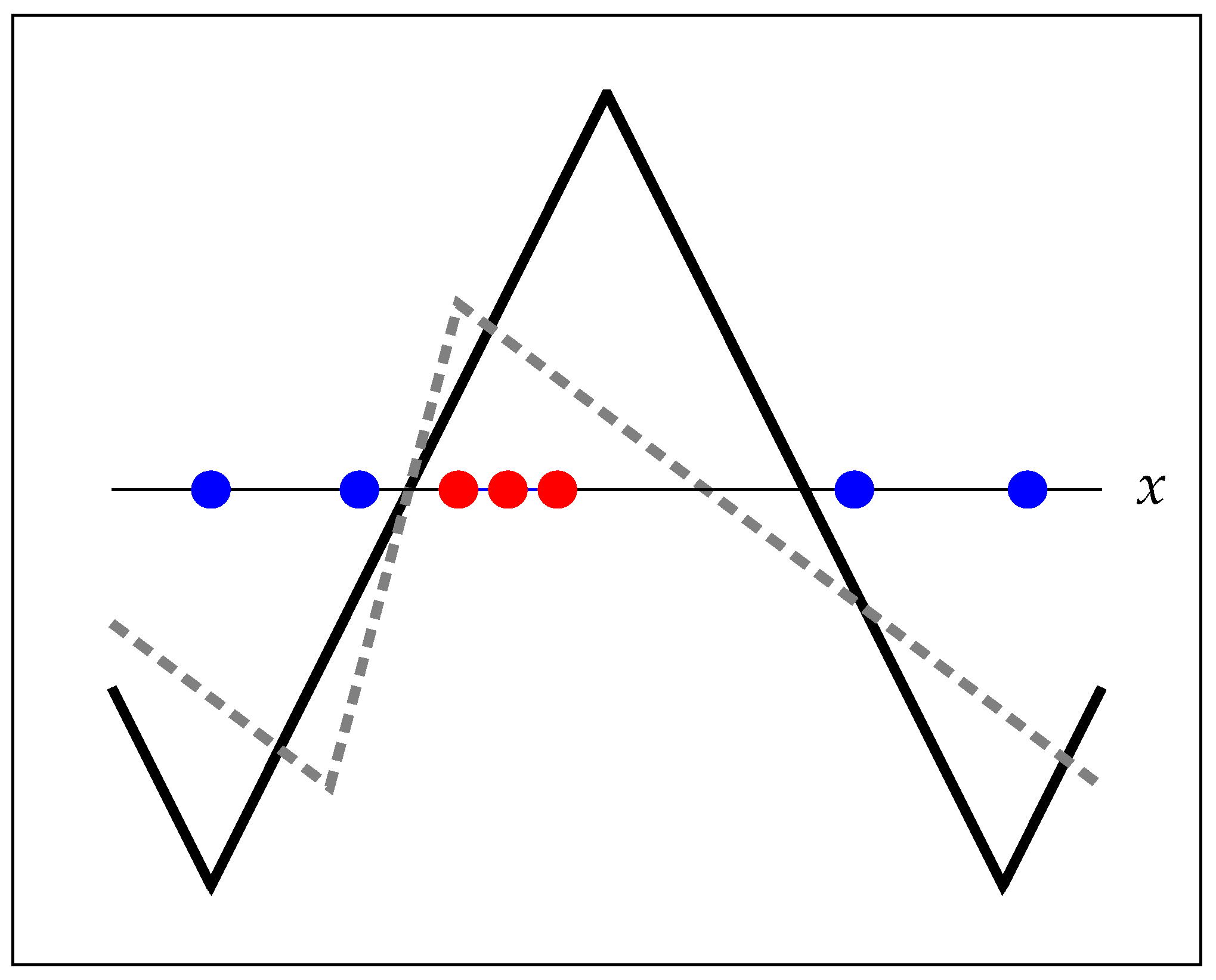
6. Asymmetric Directional SVM
In Figure 4, we portray a toy dataset together with the model that optimizes Equation (7) using in the model . As observed, the margin is determined by the “worst case” transition between positive and negative examples. It is reasonable to assume that a model placing the second threshold centered in the gap between positive and negative examples would generalize better. Shashua and Levin [7] faced a problem with similar characteristics when addressing ordinal data classification in . Similar to them, we propose to maximize the sum of the margins around the two threshold points. Towards that goal, we only need to generalize the model to allow independent slopes in the two parts of the triangle wave, setting , where:
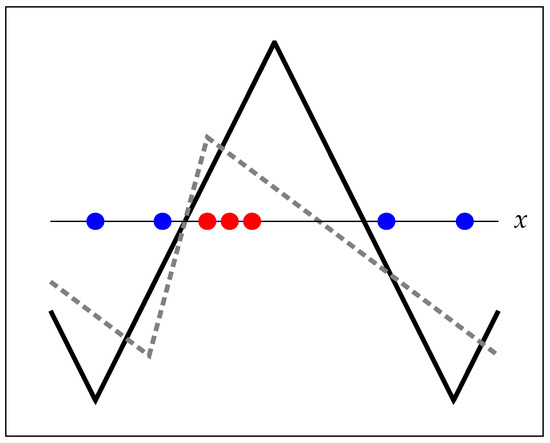
Figure 4.
Toy example where the fitted symmetric model does not provide an appealing solution.
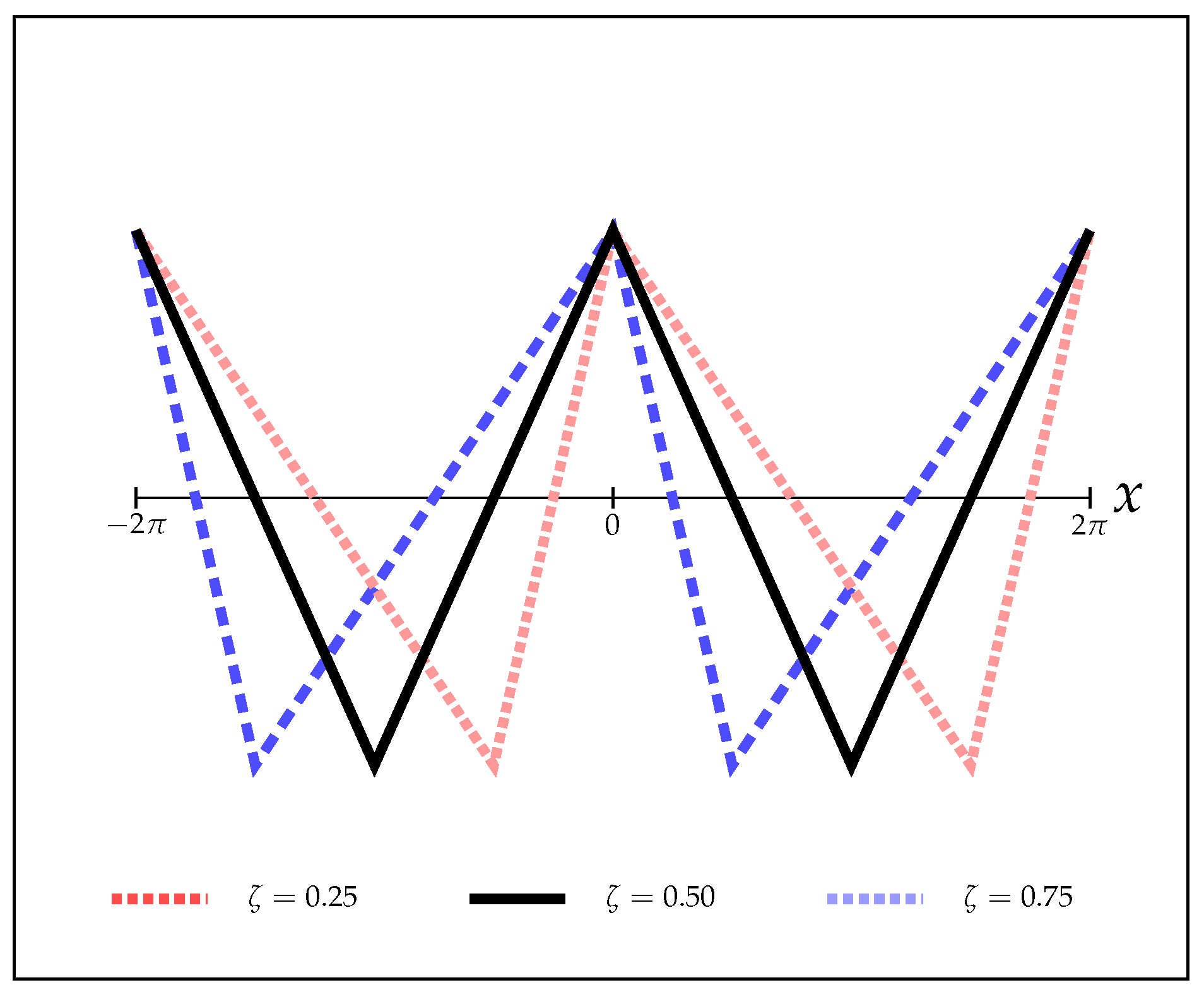
Here, controls the asymmetry of the wave: if , the wave has infinite ascending slope; if , the wave has infinite descending slope, and for , it coincides with the symmetric case, . The wave is depicted in Figure 5 for some values of .
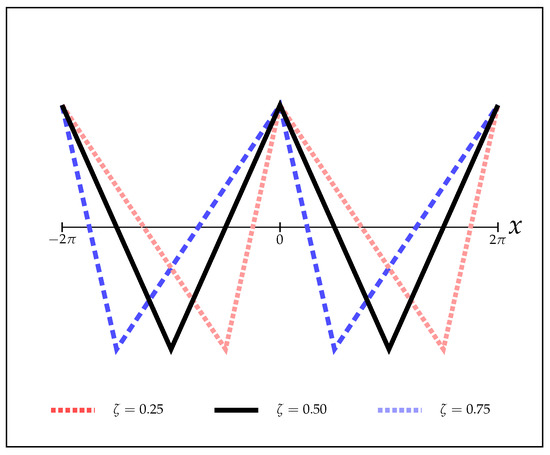
Figure 5.
Asymmetric model , for . This model allows the maximization of the sum of the margins.
It should be clear that the model instanced with retains the same expressiveness as before, being able to express two thresholds (and not more than two) in any position in .
As before with , it is not possible to solve the optimization problem as a conventional setting, and we again directly optimize the goal function using sub-gradient methods.
7. Kernelized Asymmetric Directional SVM
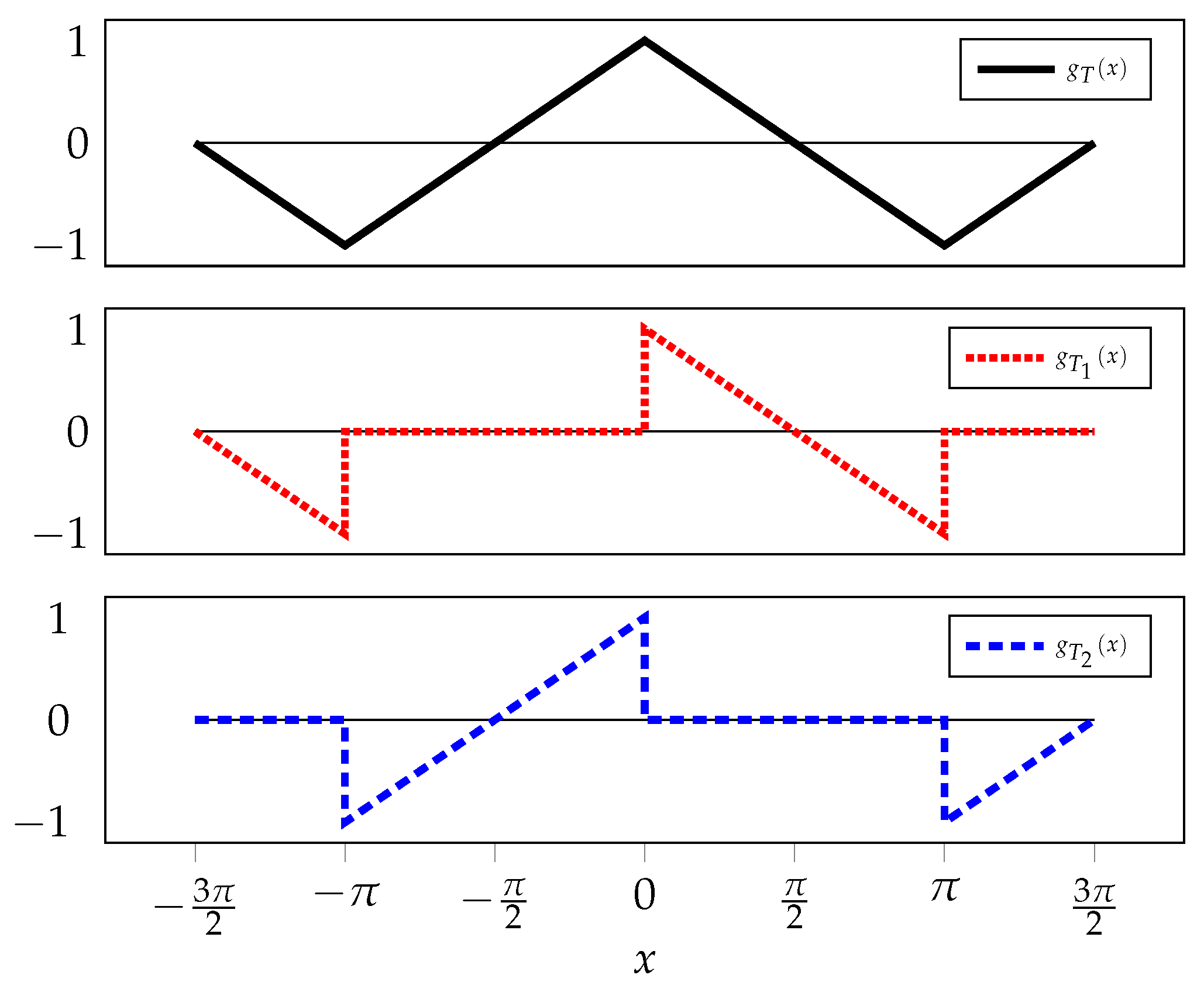
Before, motivated by the behavior with and the representer theorem, we explored models of the form . Using the decomposition depicted in Figure 6, , we can rewrite the model as . We can now gain independence in the two slopes of the model by extending it to , where and are two independent parameters to be optimized from the training set.
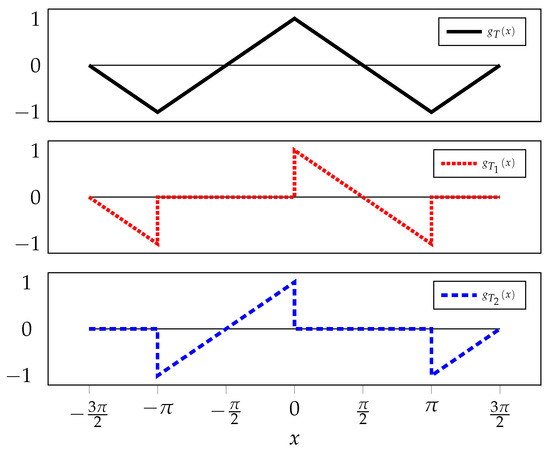
Figure 6.
Decomposition of the triangle wave.
Since , the model equals:
8. The Multi-Dimensional Setting
The extension of the ideas presented before to the multi-dimensional setting is easy. For this purpose, assume our data consist of both directional and non-directional components. This allows each data example to be represented as a vector , where represents the directional components and represents the non-directional ones. Suppose we wish to represent the ith directional component in a feature space , through a mapping , and the non-directional ones in a feature space , through a mapping . Then, our model becomes:
where . Therefore, in the standard setting where the feature spaces are fixed and possibly infinite dimensional, but the respective inner products have a closed form, we may use the kernel trick to solve the optimization problem. Such kernel is an inner product in the joint feature space and equals the sum of the individual kernels:
where and .
If the feature mappings are finite dimensional functions that depend also on parameters to be optimized, like, for instance, in the case of , the kernel itself becomes dependent on such parameters. In this setting, we opted to plug Equation (16) directly into Equation (7), solving the problem directly in its primal form using gradient-based optimization.
For simplicity, we set to the identity in our experiments, inducing the usage of the linear kernel for all the non-directional components.
9. Experiments
In this section, we detail the experimental evaluation of the proposed directional support vector machines against two state-of-the-art directional classifiers: the von Mises naive Bayes [8] and the directional logistic regression [4]. Following [4], the parameter of the von Mises distribution was approximated by 100 iterations (a much larger number of iterations than required to have good convergence values) of Newton’s method proposed by Sra [9].
The SVM regularization constant was chosen using a stratified 3-fold cross-validation strategy. The range of explored values was . The concentration parameter of the directional RBF kernel was also selected through 3-fold cross-validation in the range . The primal directional SVM with fixed margin was randomly initialized and optimized using Adam [10] for 500 iterations. On the other hand, we initialized the asymmetric primal SVM with the fixed margin margin parameters after 400 iterations. Then, all the parameters were fine-tuned for an additional 100 iterations. Using pre-trained parameters for the SVM with an asymmetric margin facilitates convergence given the coupled effect of the and parameters. The kernelized directional version with cosine and triangular kernels was optimized using the standard libsvm [11], which implements an SMO-type algorithm proposed in [12]. For the asymmetric kernel, we used the aforementioned fine-tuning approach in order to fine-tune the coefficients obtained by the standard toolkit.
We validated the advantages of the proposed approach using 12 publicly-available datasets: Arrhythmia [13], Behavior [14], Characters [15], Colposcopy, Continents, eBay [16], MAGIC [17], Megaspores [18], OnlineNews [19], Temperature1, Temperature2, and Wall [20]. Relevant properties about these datasets (e.g., number of directional and non-directional features, number of classes, dimensionality) are presented in Appendix B. Experiments in previous works [4,8] have shown that directional classifiers outperform traditional ones in these datasets, proving that directionality is an important attribute to exploit. Further details about the datasets, including their acquisition and preprocessing, were presented in [4]. Additionally, in order to facilitate the convergence of the SVM-based models, all the non-directional features were scaled to the range 0–1.
Multiclass instances were handled using a one-versus-one approach for all the binary models (i.e., logistic regression and support vector machines). All the experiments detailed below were executed with a 3-fold stratified cross-validation technique (i.e., by preserving the percentage of samples for each class), selecting the best model in terms of accuracy, and the results of 30 different runs were averaged. Specifically, for each model and dataset, we have evaluated the accuracy and the macro F-score, which corresponds to the unweighted mean value of the individual F-scores of each class. Results of these experiments are summarized in Table 1 and Table 2, exhibiting average accuracy and macro F-score, respectively, for 30 independent runs. The best results for each dataset are marked in bold. For reproducibility purposes, the source code and the training-testing partitions are made available (https://github.com/dpernes/dirsvm). The results achieved by the von-Mises naive Bayes (vMNB) and directional Logistic Regression (dLR) align with the results reported in the literature [4].

Table 1.
Average accuracy and standard deviation per model on 30 runs for 12 datasets, which are presented in increasing order of their respective cardinality. The evaluated models are: Naive Bayes with von Mises distribution (vMNB), directional Logistic Regression (dLR), Multilayer Perceptron (MLP), SVM with directional RBF kernel (dRBF-SVM), SVM with cosine kernel (cos-SVM), primal SVM with triangle wave (t-SVM), SVM with Triangle wave kernel (T-SVM), primal SVM with asymmetric triangle wave (a-SVM), and SVM with Asymmetric triangle wave kernel (A-SVM). Best results are given in bold.
Table 2.
Average macro F-score and standard deviation in the same setting as described in Table 1. Best results are given in bold.
Hereafter, we will denote by non-Kernelized directional SVMs (nK-dSVM) the subset of proposed SVM variations with VC dimension equivalent to the one induced by the directional logistic regression; namely, the primal fixed-margin directional SVM with triangle (symmetric and asymmetric) and cosine waves. The remaining models (i.e., directional RBF, symmetric, and asymmetric kernels) will be referred to as Kernelized directional SVMs (K-dSVM).
Although some datasets used here are considerably imbalanced, accuracy and macro F-score values were fairly consistent with each other, in the sense that the best model in terms of accuracy was the top-1 model in terms of macro F-score in 10 of 12 datasets and was among the top-2 models in all datasets. While the dLR achieved a competitive general performance, it was surpassed by at least one of the proposed SVM alternatives in most cases. nK-dSVM performed better than dLR on small datasets, given the margin regularization imposed by the SVM loss function. For larger datasets, dLR performed better since the generalization induced by the nK-dSVM margin became less relevant. However, for large datasets, K-dSVM surpassed dLR and their non-kernelized counterparts in most cases. In general, dSVM with asymmetric margins (kernelized and non-kernelized) attained the best results, obtaining the best average performance on half of the datasets.
As shown in Section 5, kernels involving the triangle wave correspond to inner products in an infinite-dimensional feature space. The same is also true for the directional RBF kernel. Non-kernelized methods, on the other hand, are constructed by explicitly defining the feature transformation, having a necessarily finite VC dimension. Therefore, the former produce models with higher capacity, which may lead to overfitting in small datasets, but better accuracy for large ones. This is confirmed by our experiments: the non-kernelized models achieved the best results in small datasets, while kernelized models built on top of the triangle wave and directional RBF kernel attained the best results in large datasets. The performance gains of kernelized models on the larger datasets were small, however, which may be explained by the unimodal distribution of the angular variables. On datasets with a multi-modal distribution of the directional variables, it is expected to observe higher gains by K-dSVM.
Towards Deep Directional Classifiers
Deep neural networks have achieved remarkable results in multiple machine learning problems and, particularly, in supervised classification. SVMs, on the one hand, typically decouple the data representation problem from the learning problem, by first projecting the data into a prespecified feature space and then learning a hyperplane that separates the two classes. Deep networks, on the other hand, jointly learn the data representation and the decision function, exhibiting superior performance mostly when trained on large datasets. In the context of directional data, we argue that significant performance improvements might be attained by combining the angular awareness of directional feature transformations or kernels with the representation learning provided by deep neural networks.
In order to evaluate the potential of deep classifiers for directional data, we present two further experiments in this section. Specifically, we have trained two Multilayer Perceptrons (MLPs), which were essentially identical, except for one important difference: one of them (denoted by rMLP) was trained on top of raw angle values (normalized to lie in a single period); the other one (denoted by dMLP) was trained on top of the feature transformation , which defines the cosine kernel, applied to all angular components. The latter was a first attempt towards deep directional classifiers, while the former was completely unaware of the directionality of the data. Each hidden layer in the MLPs had the following structure: fully-connected transformation (dense layer) with 256 output neurons + batch normalization [21] + ReLU + dropout [22]. The output layer is a standard fully-connected transformation followed by a sigmoid, in the case of binary classification, or a softmax, when there are more than two classes. The models were trained to minimize the usual cross-entropy loss with regularization. The total number of layers was chosen between 4 and 5 using 3-fold cross-validation, together with the remaining hyperparameters (dropout rate, regularization weight, and learning rate). Training was performed for 200 epochs or until the loss plateaued. The training protocol, including the evaluated datasets, the number of runs for each dataset, and the evaluated metrics, was exactly the same as in the previous set of experiments.
Results are in Table 3a,b, where we show again the values of our most accurate SVM (denoted by best-SVM) in each dataset for easier comparison. Like before, we observed high consistency between the accuracy and macro F-score values. As expected, rMLP had the worst overall performance, and this effect was mostly apparent in small datasets where the number of directional features was in the same order of magnitude as the number of non-directional ones, like Colposcopy and eBay (see Appendix B). In larger datasets and in those where the number of non-directional features was much larger than the number of directional ones (e.g., Behavior, OnlineNews), rMLP achieved more competitive results. The exception was the MAGIC dataset, where the single directional feature seemed to have a high discriminative power, and so, rMLP achieved the lowest performance among the three models. Contrary to what we just observed for rMLP, the gains of dMLP were highly encouraging. This model, built on top of a directional feature transformation, generally outperformed best-SVM in larger datasets and achieved competitive results even in smaller ones. This observation reinforces the role of directionality in these datasets and, more importantly, motivates the importance of further research to merge directional feature transformations and/or kernels with deep neural networks, which we plan to develop as future work.
Table 3.
Average performance and standard deviation per model on 30 runs for 12 datasets, which are presented in increasing order of their respective cardinality. The evaluated models are: directional SVM with highest average accuracy (best-SVM), MLP trained on top of raw angle values (rMLP), and MLP trained on top of the feature transformation (dMLP). Best results are given in bold.
10. Conclusions
Several concepts in real-life applications are represented by directional variables; from periodic time representation on calendars to compass directions. Traditional classifiers, which are unaware of the angular nature of these variables, might not properly model the data. Thereby, the study of directional classifiers is relevant for the machine learning community. Previous attempts to address classification tasks with directional variables focused on generative models [8] and discriminative linear models (logistic regression) [4].
In this work, we proposed several instantiations of directional-aware support vector machines. First, we modified the SVM decision function by considering parametric periodic mappings of the directional variables using cosine and triangle waves. Then, we proposed an extension of the model with triangular waves in order to allow asymmetric margins on the circle. The kernelized versions of these models were proposed as well. Furthermore, we analyzed and demonstrated the expressiveness of each proposed alternative.
In the experimental assessment, the relevance of the proposed models was evaluated, being able to achieve competitive results in most datasets. As expected, when compared to other shallow directional classifiers, kernelized models built on top of the triangle wave attained the best results in larger datasets, due to their large expressive power, which we have proven theoretically. One extra experiment combining a directional feature transformation and a deep neural network showed very promising results and clearly motivates further research.
Since the additional parameters involved in our asymmetric SVMs (in both kernelized and non-kernelized versions) have a periodic impact on the decision boundary or are constrained to a specific domain, using gradient-based optimization techniques may result in sub-optimal models. While this problem was circumvented by using fine-tuning from simpler models, there is research room for the design and exploration of optimization techniques specific for these models. Furthermore, deep multiple kernel learning [23] is an unexplored research line in directional data settings that may lead to a unified framework combining directional kernel machines and deep neural networks.
Author Contributions
K.F. and J.S.C. motivated the problem and designed the proposed models; D.P. conceived the mathematical proofs in the Appendix and wrote most parts of the paper; D.P. and K.F. conducted the experiments; J.S.C. supervised the work.
Funding
This work was partially financed by the ERDF (European Regional Development Fund) through the Operational Programme for Competitiveness and Internationalisation (COMPETE) 2020 Programme and by National Funds through the Portuguese funding agency, FCT (Fundação para a Ciência e a Tecnologia) within project “POCI-01-0145-FEDER-028857” and also by Fundação para a Ciência e a Tecnologia within Ph.D. Grant Numbers SFRH/BD/93012/2013 and SFRH/BD/129600/2017.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| dLR | directional Logistic Regression |
| MLP | Multilayer Perceptron |
| SVM | Support Vector Machine |
| vMNB | von-Mises Naive Bayes |
| dSVM | directional SVM |
| K-dSVM | Kernelized directional SVM |
| nK-dSVM | non-Kernelized directional SVM |
| cos-SVM | SVM with cosine kernel |
| dRBF-SVM | SVM with directional RBF kernel |
| a-SVM | primal SVM with asymmetric triangle wave |
| A-SVM | SVM with Asymmetric triangle wave kernel |
| t-SVM | primal SVM with triangle wave |
| T-SVM | SVM with Triangle wave kernel |
Appendix A. Kernelized Symmetric Directional SVM
Appendix A.1. Kernel Validity: Proof of Theorem 1
From the definition of g, we may verify that it is an even function:
Because g is also periodic with period T, it may be expressed in a Fourier series of the form:
Thus,
where:
Therefore, if and are real vectors, the product is an inner product, and so, is a kernel function. Clearly, and are real vectors if and only if , which can be proven to be true, concluding the proof:
and, for ,
Appendix A.2. VC Dimension: Proof of Theorem 2
Before going into the details of the proof of Theorem 2, we need the result presented in Lemma A1.
Lemma A1.
Let be a set of square integrable and non-zero functions , where is an interval, that satisfy:
There exists a vector such that the matrix:
has full rank.
Proof.
We shall prove by contradiction that such actually exists. Suppose that is rank deficient for all . Then, there exists a function such that:
Due to the orthogonality of the functions in , no non-trivial linear combination of them vanishes identically in , and consequently, may not be a constant function. However, if is not constant, there exist distinct vectors with dimension N such that no non-zero vector belongs to the null spaces of all the matrices . This means that the space generated by the rows of these matrices stacked altogether has dimension N, so we may choose N linearly-independent rows from this stacked matrix. Since each row is defined by a single element in one of the vectors , choosing N linearly-independent rows corresponds to finding a dataset with size N such that has full rank, contradicting the initial hypothesis. □
Now, we may proceed to the proof of Theorem 2. Let denote the VC dimension of the class of classifiers l. Firstly, we are going to prove that . If we proceed as in the proof of Theorem 1, may be defined as a feature space over , by suppressing all components whose coefficients are zero. Therefore, f becomes a hyperplane in , and so, it cannot shatter more than data points.
Now, it suffices to prove that . Let us denote the period of g by T and consider a dataset with examples, namely , where . Like before, we obtain as in the proof of Theorem 1, and we build the matrix , defined as:
By further defining , the following equality is straightforward to check:
where ⊕ denotes the operation of summing the scalar on the left-hand side to every element of the vector on the right-hand side. Let us denote the ground truth label of each as . Because the elements of form a set of orthogonal functions, we know from Lemma A1 that there exists a dataset such that has full rank. Thus, from now on, assume this condition holds. This assumption ensures that, for all possible combinations of values, there exists a that satisfies:
Clearly, using this , the classifier labels all data points correctly provided that . Now, suppose we have one more data point , with ground truth label . Assume, furthermore, that is such that . The existence of such is guaranteed, since the elements of are continuous functions with zero mean value. By setting , for any arbitrary , the classifier labels all data points correctly. Thus, .
Appendix B. Summary of the Datasets
We give a summary of the main characteristics of the datasets used in this work, including number of features per type (i.e., Directional (Dir), Linear (Lin), Discrete (Disc)) and the number of samples per dataset (#).
Table A1.
Number of variables, number of classes and cardinality of each dataset. Variables are divided into the respective types: directional (Dir), linear (Lin) and discrete (Disc).
Table A1.
Number of variables, number of classes and cardinality of each dataset. Variables are divided into the respective types: directional (Dir), linear (Lin) and discrete (Disc).
| Dataset | Number of Variables | Class | # | ||
|---|---|---|---|---|---|
| Dir | Lin | Disc | Values | ||
| Colposcopy | 3 | 6 | 0 | 3 | 150 |
| Behavior [14] | 140 | 426 | 20 | 4 | 261 |
| Arrhythmia [13] | 4 | 191 | 66 | 2 | 430 |
| eBay [16] | 1 | 2 | 0 | 11 | 528 |
| Megaspores [18] | 1 | 0 | 0 | 2 | 960 |
| Characters [15] | 5 | 31 | 0 | 10 | 1000 |
| OnlineNews [19] | 1 | 12 | 0 | 2 | 1000 |
| Continents | 2 | 0 | 0 | 5 | 3481 |
| Wall [20] | 6 | 6 | 0 | 4 | 5456 |
| Temperature1 | 2 | 1 | 0 | 3 | 8764 |
| Temperature2 | 5 | 1 | 0 | 3 | 8764 |
| MAGIC [17] | 1 | 10 | 0 | 2 | 19,020 |
References
- Mooney, J.A.; Helms, P.J.; Jolliffe, I.T. Fitting mixtures of von Mises distributions: A case study involving sudden infant death syndrome. Comput. Stat. Data Anal. 2003, 41, 505–513. [Google Scholar] [CrossRef]
- Banerjee, A.; Dhillon, I.; Ghosh, J.; Sra, S. Clustering on the Unit Hypersphere using von Mises-Fisher Distributions. J. Mach. Learn. Res. 2005, 6, 1345–1382. [Google Scholar]
- Mardia, K.V.; Kent, J.T.; Zhang, Z.; Taylor, C.C.; Hamelryck, T. Mixtures of concentrated multivariate sine distributions with applications to bioinformatics. J. Appl. Stat. 2012, 39, 2475–2492. [Google Scholar] [CrossRef]
- Fernandes, K.; Cardoso, J.S. Discriminative Directional Classifiers. Neurocomputing 2016, 141–149. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Singer, Y.; Srebro, N. Pegasos: Primal Estimated sub-GrAdient SOlver for SVM. In Proceedings of the 24th International Conference on Machine Learning (ICML’07), Corvalis, OR, USA, 20–24 June 2007; pp. 807–814. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. In Measures of Complexity; Springer: Berlin, Germany, 2015; pp. 11–30. [Google Scholar]
- Shashua, A.; Levin, A. Ranking with Large Margin Principle: Two Approaches. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2003. [Google Scholar]
- López-Cruz, P.L.; Bielza, C.; Larrañaga, P. Directional naive Bayes classifiers. Pattern Anal. Appl. 2015, 18, 225–246. [Google Scholar] [CrossRef]
- Sra, S. A short note on parameter approximation for von Mises-Fisher distributions: and a fast implementation of I s (x). Comput. Stat. 2012, 27, 177–190. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 27. [Google Scholar] [CrossRef]
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working Set Selection Using Second Order Information for Training Support Vector Machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Guvenir, H.A.; Acar, B.; Demiroz, G.; Cekin, A. A supervised machine learning algorithm for arrhythmia analysis. Comput. Cardiol. 1997, 433–436. [Google Scholar]
- Pereira, E.M.; Ciobanu, L.; Cardoso, J.S. Social signaling descriptor for group behaviour analysis. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Santiago de Compostela, Spain, 17–19 June 2015; Springer: Berlin, Germany, 2015; pp. 13–22. [Google Scholar]
- Guvenir, H.A.; Acar, B.; Muderrisoglu, H. UCI Machine Learning Repository; 1992; Available online: https://archive.ics.uci.edu/ml/datasets/Artificial+Characters (accessed on 8 November 2018).
- Van de Weijer, J.; Schmid, C. Applying color names to image description. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2007), San Antonio, TX, USA, 16–19 September 2007; Volume 3, pp. 493–496. [Google Scholar]
- Bock, R.; Chilingarian, A.; Gaug, M.; Hakl, F.; Hengstebeck, T.; Jiřina, M.; Klaschka, J.; Kotrč, E.; Savickỳ, P.; Towers, S.; et al. Methods for multidimensional event classification: A case study using images from a Cherenkov gamma-ray telescope. Nuclear Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 2004, 516, 511–528. [Google Scholar] [CrossRef]
- Kovach, W.L. Quantitative methods for the study of lycopod megaspore ultrastructure. Rev. Palaeobot. Palynol. 1989, 57, 233–246. [Google Scholar] [CrossRef]
- Fernandes, K.; Vinagre, P.; Cortez, P. A proactive intelligent decision support system for predicting the popularity of online news. In Proceedings of the Portuguese Conference on Artificial Intelligence, Coimbra, Portugal, 8–11 September 2015; Springer: Berlin, Germany, 2015; pp. 535–546. [Google Scholar]
- Freire, A.L.; Barreto, G.A.; Veloso, M.; Varela, A.T. Short-term memory mechanisms in neural network learning of robot navigation tasks: A case study. In Proceedings of the IEEE 2009 6th Latin American Robotics Symposium (LARS), Valparaiso, Chile, 29–30 October 2009; pp. 1–6. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Strobl, E.V.; Visweswaran, S. Deep multiple kernel learning. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 4–7 December 2013; Volume 1, pp. 414–417. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).