A 3D Object Detection Based on Multi-Modality Sensors of USV

Abstract
:1. Introduction
2. Related Work
2.1. Point-Cloud-Based Method vs. View-Based Method
2.2. Two-Stage Detection Network vs. Single-Stage Detection Network
2.3. Deep Fusion Network
3. Method
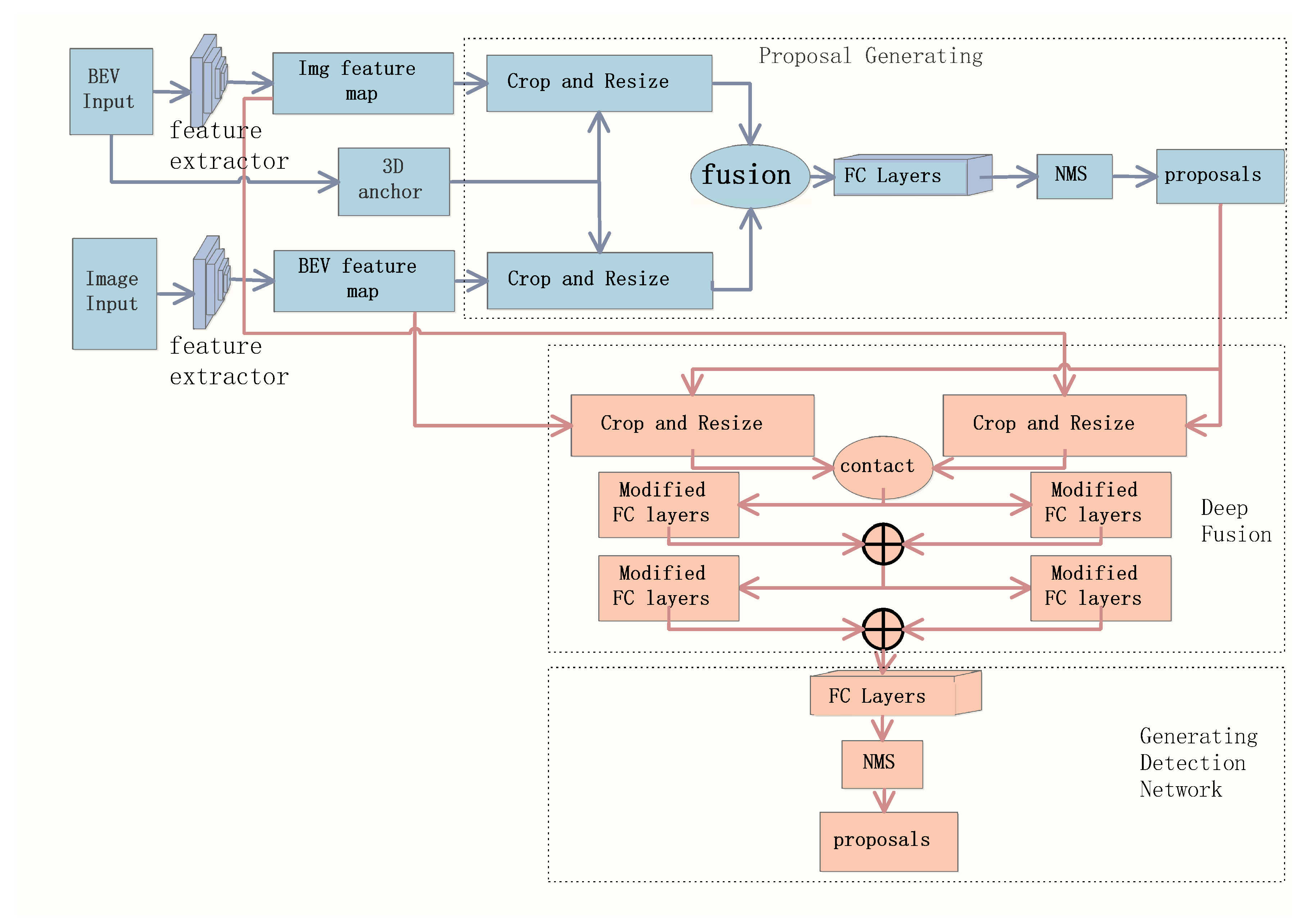
3.1. The Object Detection Architecture
3.2. Proposal Generation Network
3.2.1. Bird’s Eye View Generating
3.2.2. Feature Map Extraction
3.2.3. Proposal Generating
- 3D Box Description: In two-stage 2D object detection, the proposal is generated from a series of prior boxes. In [6,12], an encoding method of 3D prior boxes is proposed. Each 3D prior box is parameterized to (x,y,z,l,w,h,r), where (x,y,z) is the center of the mass coordinate of box, (l,w,h) is the size of box, and (r) is the direction of the box. The prior box is generated from BEV. The sampling interval (x, y) is 0.5 m, while the ground height of the sensor determines parameter z.
- Crop and Resize Instead of Roi Pooling: We chose to use crop and resize [12,29] to extract the box’s corresponding feature map from a particular view instead of the ROI-pooling. Because ROI-pooling uses nearest neighbor interpolation, it may lose spatial symmetry. nearest neighbor interpolation means that ROI-pooling adopts rounding, which is equivalent to selecting the Nearest point to the target point when the scaled coordinate cannot be an exact integer. To keep the symmetry of the space, crop and resize uses bilinear interpolation to resample an image to a fixed size.
- Drop Path: In the fusion of RPN stage, we added the drop path method. The extracted feature channel is randomly discarded. Then, the elements were evenly fused. fractalnet used drop path method to normalize collaborative adaptiveneutron paths in fractal structures Larsson et al. [26]. Through this normalization, it is able to prove that the answer given by the shallow subnetwork is faster, while the answer given by the deep subnetwork is more accurate.
- 3D Proposal Generating: We used 1 × 1 convolution instead of the full connection layer and then used a multi-task loss to classify the object/background and computed the regression of proposal boxes. To sort out the background/object, we used cross-entropy loss, while, for the regression loss of the proposal boxes, we selected smooth L1 loss. When computing boxes regression, we ignored the background anchor point. The background anchor point is determined by the IoU overlap between ground truth and the anchor point in BEV. Overlap above 0.7 is considered as the background. If the overlap is less than 0.5, it is considered as the target. To to redundancy, Non-Maximum Suppression (NMS) is applied in BEV with a threshold of 0.8.
3.3. Deep Fusion Detection Network
3.3.1. Deep Fusion
3.3.2. Generating Detection Network
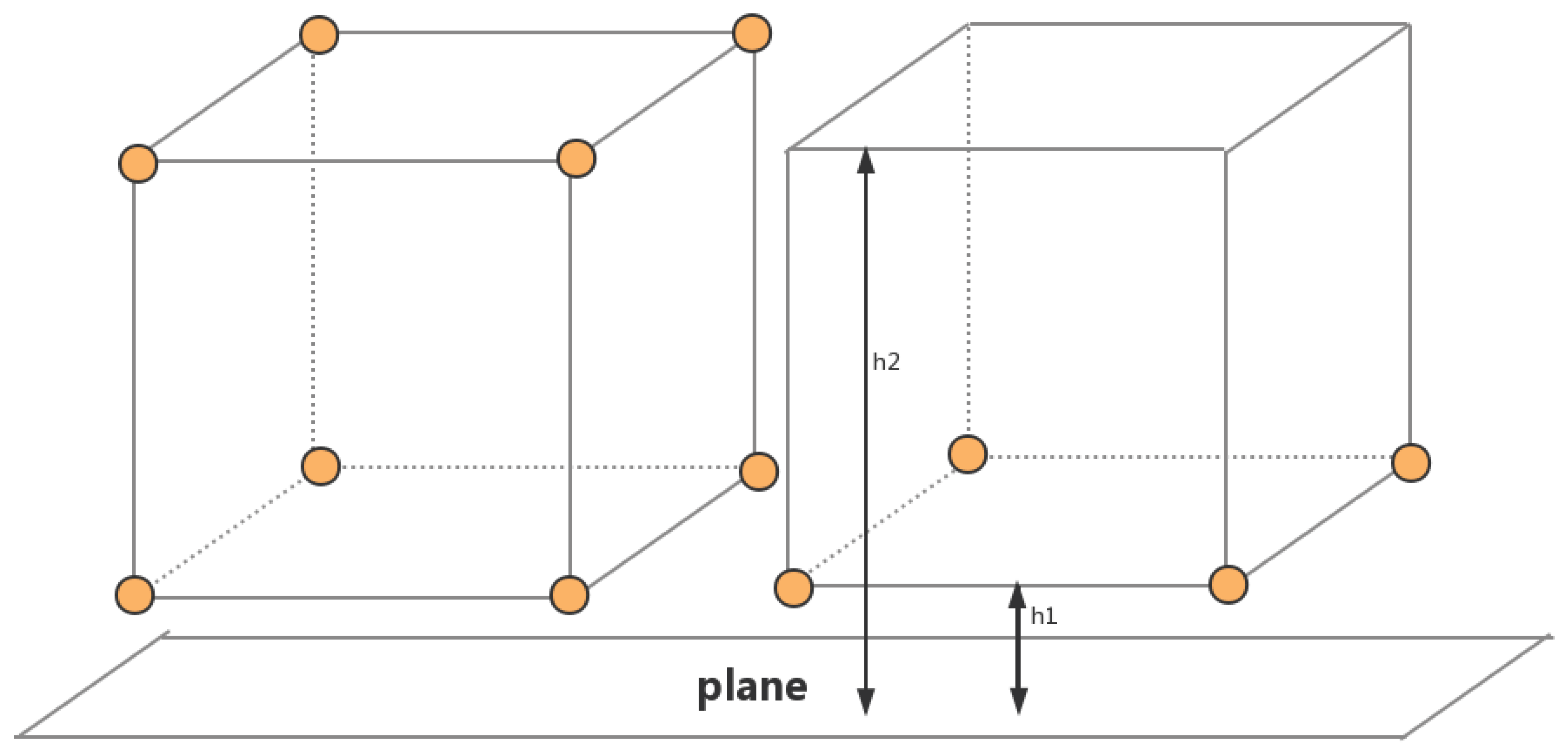
- 3D Bounding Box Regression: As shown in Figure 4, traditional axis aligned coding uses centers of mass and axes. Chen et al. [6] used eight-corner box coding. We used a more simplified four-corner coding. Considering that the bottom four corners must be aligned with the top, the physical constraint of the 3D bounding box is added. We encoded the border as four corners and two heights. Thus, the original regression target of the 24-dimensional vector of the eight-corner box is changed to (x1… x2. y1… y2. h1, h2). To reduce the amount of calculation and to improve the speed of calculation, we selected the four-corner encoding and introduced orientation estimation. From the orientation estimation, we extracted four possible directions of the border box and explicitly computed the box regression loss.
- Generating Detection: The fused features are input to the full connection layer. Box regression and classification operation are carried out after the three fully-connected layers of size 2048. Similarly, Smooth L1 loss is still used for box regression, and cross-entropy loss is used for classification. To eliminate overlap, we used IoU threshold of 0.01 for NMS.
3.4. Training
4. Experiments and Results
4.1. Evaluation on the KITTI Validation Set
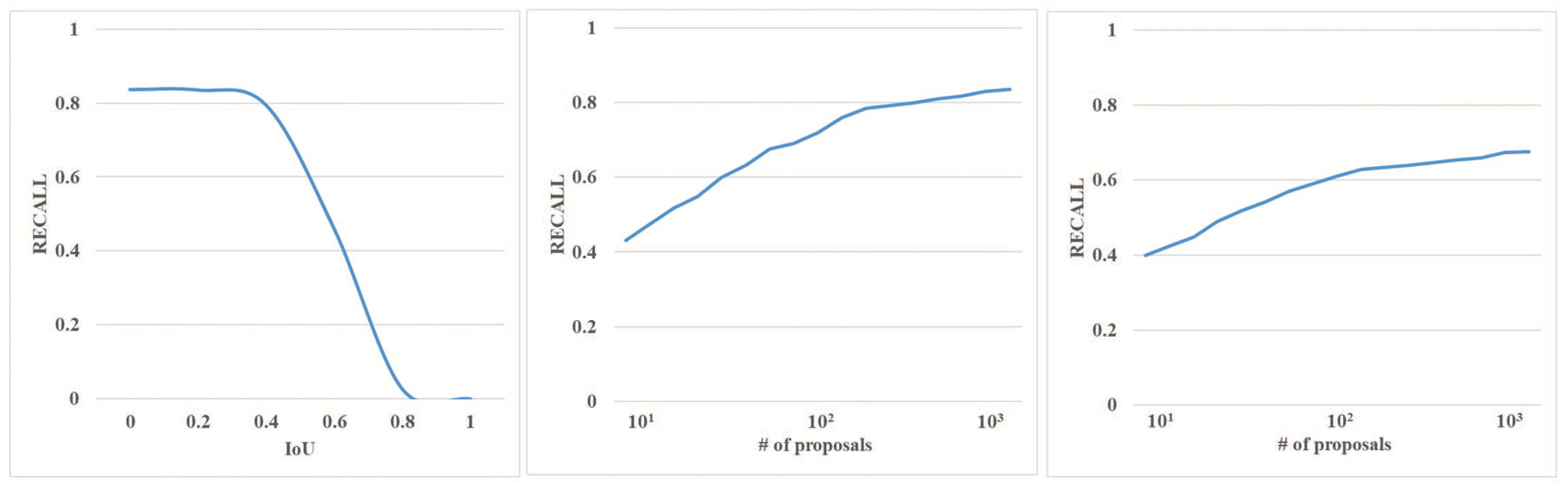
- Evaluation of Object DetectionFor 3D overlap standard, in the radar-based method, we used the IoU threshold of 0.7 to conduct the 3D object detection. Because our model focuses on BEV and images, we also compared it with f-point net, while comparing MV3D and AVOD. The results are shown in Table 1. The results are significantly more than 10% higher than MV3D in terms of average precision. The results are also superior to AVOD in the easy and moderate mode. On the hard mode, however, the results are weaker. However, it can be tolerated in practice.We also carried out 3D detection in the BEV, and the results are shown in Table 2. AVOD did not release its results, thus we could not compare our results with AVOD’s results. Our model was superior to MV3D in all aspects. Our model also performed better than f-point net in easy and hard mode.Inspired by AVOD, we also included orientation estimation in the network. We compared the Average Orientation Similarity (AOS). In AVOD, they are called Average Heading Similarity (AHS). As shown in Table 3, our model had better results than AVOD.
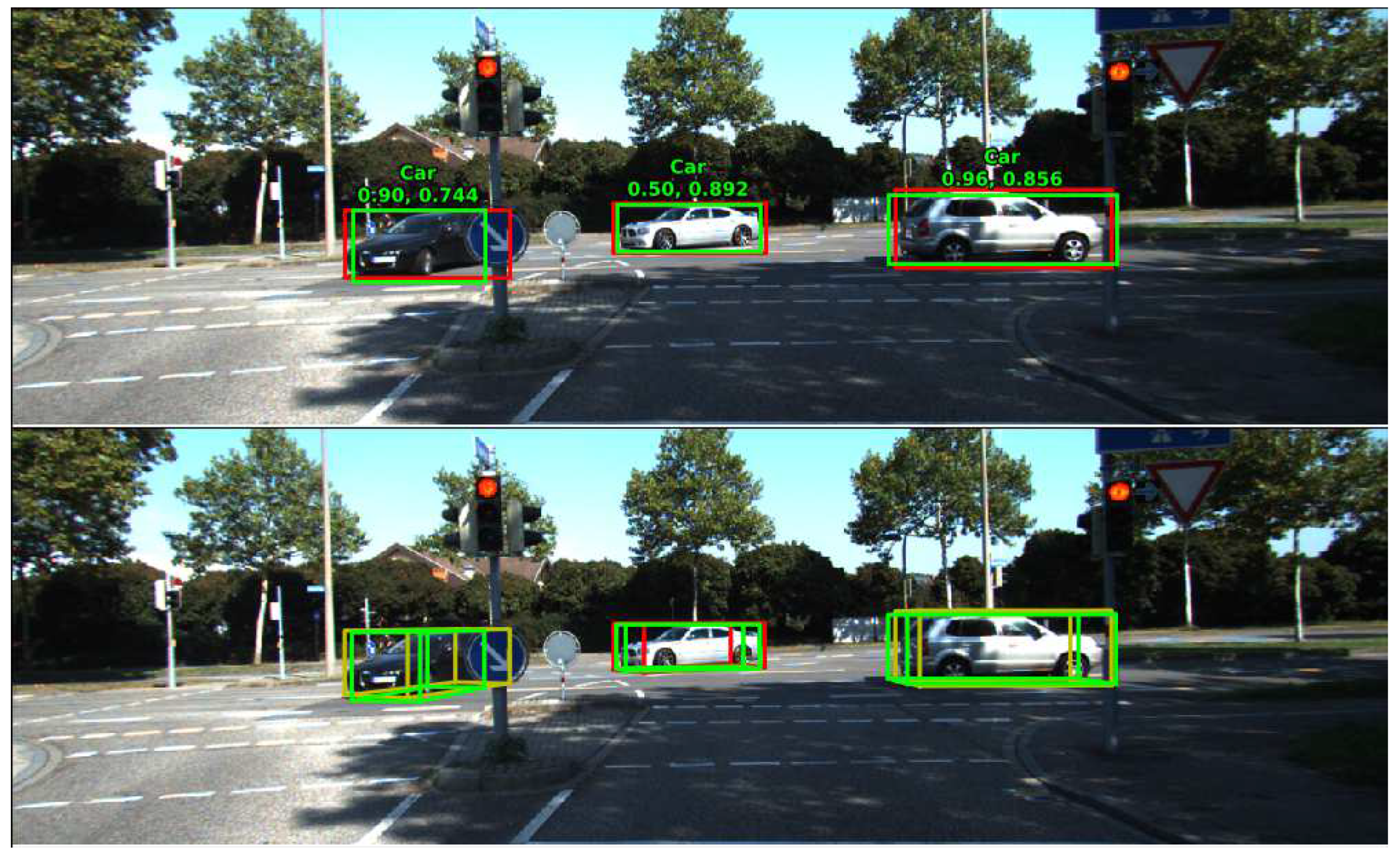
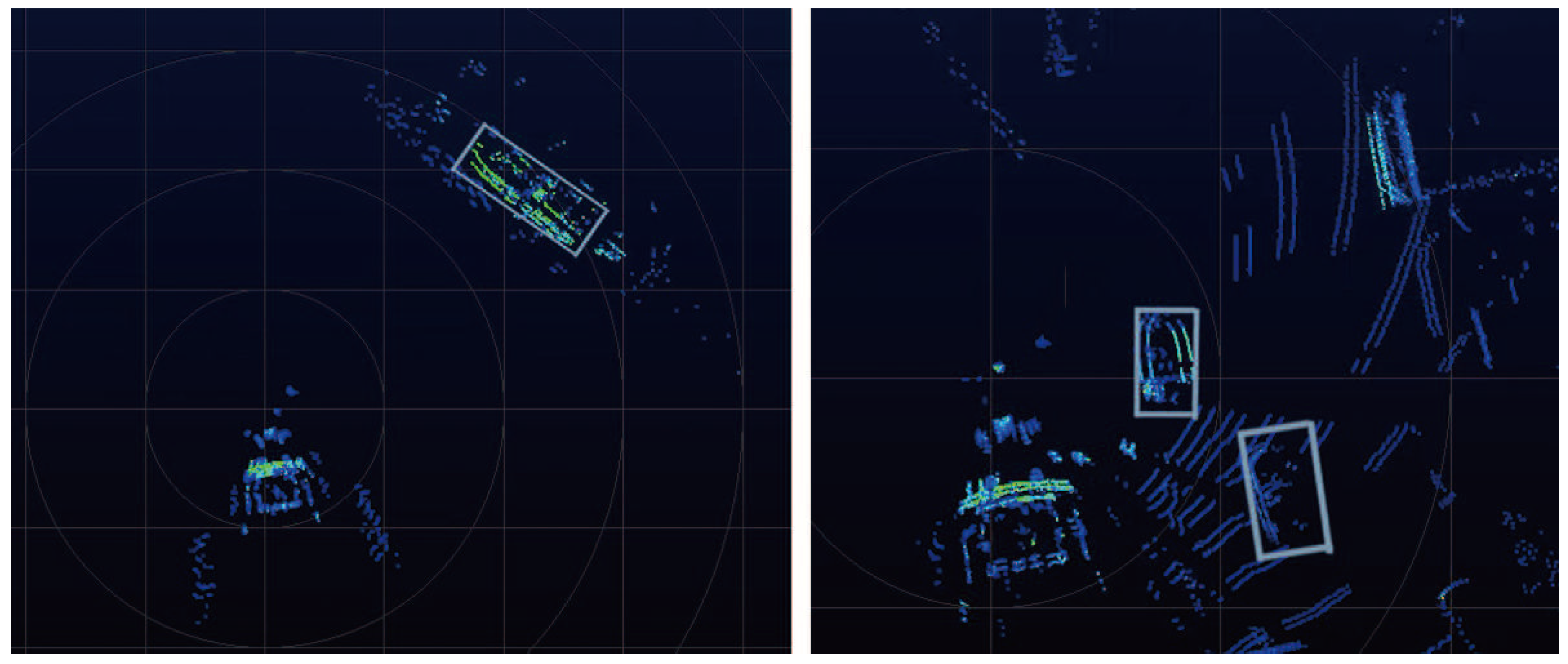
- Analysis of Detection ResultsFigure 5 shows the detection results in the six channels of BEV. Our model worked well in medium- and short-range cars. Although the longer distance cars have fewer points, our model still performed well. We were surprised to find that the car’s directional regression was also excellent. These results prove the effectiveness of our model. Figure 6 demonstrates the detection results projected onto the 2D images.
- Runtime and Memory RequirementsWe used several parameters to assess the computational efficiency and the memory requirements of the proposed network. Our object detection architecture employed roughly 52.04 million parameters. We significantly reduced the number of parameters compared with the method in [6], the second stage detection network of which has three fully connected layers. Because we chose the Resnet-50 with more layers, our parameter number was higher than the method in [12]. Each frame was processed in 0.14 s on Titan X and 0.12 s in 2080TI. The inference time of the network for each picture was 90 ms at 2080TI.
- Ablation StudiesAs shown in Table 4 and Table 5, we first compared our proposed Deep Fusion Detection Network with early fusion method. In the same case that our modified Resnet-50 feature extractor was used, the average precision of our Deep Fusion Detection Network in 3D boxes and BEV boxes was higher than that of the earlier fusion method. Especially in BEV boxes, our networks performed best, about 10% better. To study the contribution of our proposed feature extractor, we replaced the Resnet-50 with the VGG16 used in [6,12] for comparison. Our test results were also slightly higher than VGG16.
4.2. Evaluation on the Offshore Marine Environments Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Manley, J.E. Unmanned surface vehicles, 15 years of development. In Proceedings of the OCEANS 2008, Quebec City, QC, Canada, 15–18 September 2008; pp. 1–4. [Google Scholar]
- Sinisterra, A.J.; Dhanak, M.R.; Von Ellenrieder, K. Stereovision-based target tracking system for USV operations. Ocean Eng. 2017, 133, 197–214. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Wolf, M.T.; Assad, C.; Kuwata, Y.; Howard, A.; Aghazarian, H.; Zhu, D.; Lu, T.; Trebi-Ollennu, A.; Huntsberger, T. 360-degree visual detection and target tracking on an autonomous surface vehicle. J. Field Robot. 2010, 27, 819–833. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 354–370. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. IEEE CVPR 2017, 1, 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Qi, C.R.; Guibas, L.J. Fpnn: Field probing neural networks for 3d data. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 307–315. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 652–660. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. arXiv, 2017; arXiv:1711.06396. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S. Joint 3d proposal generation and object detection from view aggregation. arXiv, 2017; arXiv:1712.02294. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Hegde, V.; Zadeh, R. Fusionnet: 3d object classification using multiple data representations. arXiv, 2016; arXiv:1607.05695. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 945–953. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. arXiv, 2016; arXiv:1608.07916. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Multi-classification approaches for classifying mobile app traffic. J. Netw. Comput. Appl. 2018, 103, 131–145. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Traffic Classification of Mobile Apps through Multi-classification. In Proceedings of the GLOBECOM 2017-2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- González, A.; Vázquez, D.; López, A.M.; Amores, J. On-board object detection: Multicue, multimodal, and multiview random forest of local experts. IEEE Trans. Cybern. 2017, 47, 3980–3990. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wei, Z.; Zhang, T.; Zeng, W. Deeply-fused nets. arXiv, 2016; arXiv:1605.07716. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Fractalnet: Ultra-deep neural networks without residuals. arXiv, 2016; arXiv:1605.07648. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. IEEE CVPR 2017, 4, 3296–3297. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3d object proposals for accurate object class detection. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 424–432. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| MV3D | 71.29 | 62.68 | 56.56 |
| F-Point | 83.76 | 70.92 | 63.65 |
| AVOD | 84.41 | 74.44 | 68.65 |
| Ours | 88.19 | 74.54 | 65.86 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| MV3D | 86.55 | 78.10 | 76.67 |
| F-Point | 88.16 | 84.02 | 76.44 |
| Ours | 88.73 | 79.07 | 77.89 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| Deep3DBox | 5.84 | 4.09 | 3.83 |
| MV3D | 52.74 | 43.75 | 39.86 |
| AVOD | 84.19 | 74.11 | 68.28 |
| Ours | 84.62 | 74.66 | 72.69 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| Modified Resnet-50 +early | 85.43 | 72.22 | 57.79 |
| VGG16+ Deep Fusion | 84.37 | 73.09 | 57.78 |
| Modified Resnet-50+Deep Fusion | 88.19 | 74.54 | 65.86 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| Modified Resnet-50 +early | 75.55 | 66.41 | 58.77 |
| VGG16+ Deep Fusion | 88.29 | 77.49 | 76.41 |
| Modified Resnet-50+Deep Fusion | 88.73 | 79.07 | 77.89 |
| Method | Accuracy | Time |
|---|---|---|
| DPM | 54% | 16 s |
| Ours | 78% | 120 ms |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Qin, H.; Liu, T.; Liu, H.; Wei, Z. A 3D Object Detection Based on Multi-Modality Sensors of USV. Appl. Sci. 2019, 9, 535. https://doi.org/10.3390/app9030535
Wu Y, Qin H, Liu T, Liu H, Wei Z. A 3D Object Detection Based on Multi-Modality Sensors of USV. Applied Sciences. 2019; 9(3):535. https://doi.org/10.3390/app9030535
Chicago/Turabian StyleWu, Yingying, Huacheng Qin, Tao Liu, Hao Liu, and Zhiqiang Wei. 2019. "A 3D Object Detection Based on Multi-Modality Sensors of USV" Applied Sciences 9, no. 3: 535. https://doi.org/10.3390/app9030535
APA StyleWu, Y., Qin, H., Liu, T., Liu, H., & Wei, Z. (2019). A 3D Object Detection Based on Multi-Modality Sensors of USV. Applied Sciences, 9(3), 535. https://doi.org/10.3390/app9030535