2.1. Pre-Processing and LEPA-Processing
Scale-invariant feature transform feature detection is a very effective method for extracting regions of interest (ROIs) [
16,
17,
18]. A large amount of research on SIFT algorithm is used for extraction of targets, such as airports [
19], vehicles [
20], and robots [
21]. However, the classical SIFT feature detection algorithm is not suitable for extracting the ROIs of remote-sensing images due to the high resolution and complex background [
22]. In order to improve the extraction of SIFT keypoints and reduce the computational complexity and interference from complex textures, we use two methods: First, the SIFT detection method usually extracts keypoints in grayscale, so we convert the original image from RGB space to CIE Lab [
23]. Then we use the luminance channel L of Lab to extract the SIFT keypoints. Next, image downsampling is used to reduce the number of pixels. I
2 represents an image which resulted from downsampling the original image I by 2
2, and we used the original image I(x, y) and the downsampling image I
2(x, y) as input images for post-processing.
After preprocessing, the next step is to process the edges of the images. Some previous algorithms mainly do image segmentation based on local information [
24], whereas others do some edge smoothing to reduce the detail information [
25,
26]. However, the former cannot effectively reduce the computational complexity of the feature extraction algorithm, and the latter reduces both useful edge information and useless edge information, which is not the results we hoped for. Therefore, we propose a local edge preservation algorithm (LEPA), which can reduce the edge information of the background and retain the useful edge information. For the harbor target extraction algorithm, we regard small targets (such as ships, rocks, buildings) as backgrounds; reducing their edge information helps us to remove some useless feature points. Next, we introduce this algorithm in detail.
In order to achieve the above objectives, we have improved the image segmentation method. First, we divide the original image
R into n sub-regions
R1, R2, …, Rn. Then we use regional growth method to achieve image segmentation; we set a threshold variable SCOPE when the size of the region
Ri is smaller than the threshold SCOPE; we think that region
Ri needs to grow, otherwise region
Ri stops growing. Finally, we repeat this cycle until the image is split. For the region growth method, we use a function
DIFF to achieve the two most similar regions merged; we use a threshold variable MD when the value of the function
DIFF is larger than MD, and the size of the region
Ri is smaller than SCOPE; it is considered that this region
Ri is a small ground target (for example, a small building), so it can be regarded as a background region; we can use the surrounding background region instead of this region because its details are useless. The function
DIFF consists of two parts. The first part
FD is defined as the difference in characteristics between
Ri and
Rj, and it is defined as:
where
A,
B represent the two image regions,
and
are the feature vector sets of two image regions
A and
B, respectively,
n is the number of selected feature vectors for the region, and
Wi is the weight of
T.
The second part
VAR is defined as the difference in regional variance function, and it is defined as:
Where
varA and
varB are the variance of
A and
B, respectively.
The reason we add VAR to the DIFF function is that some regions have shadows due to occlusion; this may affect regional segmentation and the determination of small ground targets. For this reason, it is important to use the constraints of variance to increase the reliability of LEPA.
According to the above introduction, the flow of the algorithm is shown in
Figure 1.
The specific process of LEPA is as follows:
- (I)
We assume that the original image has M × N pixels, we use each pixel as the initial target region Ri, where 0 ≤ i ≤ M × N;
- (II)
Set a variable SCOPE to determine if the target region needs to be grown: if the size of Ri is larger than SCOPE, the growth of the Ri is terminated;
- (III)
If the size of
Ri is smaller than SCOPE, we use the function
DIFF to calculate the difference between
Rj and every adjacent region
Rj.
where
WFD and
WVAR are the weight for
FD and
VAR, respectively, with 0 ≤
WFD ≤ 1, 0 ≤
WVAR ≤ 1,
WFD +
WVAR = 1;
- (VI)
Get the smallest DIFF value DIFFk; for all DIFFk, we compare the value of DIFFk and MD. If DIFFk is larger than MD, Ri is considered a small target, and it will be adjusted to the background region around it. If DIFFk is smaller than MD, Ri will be merged into the most similar region Rk;
- (V)
Perform the above calculations for all regions Ri and then the method continues to the next cycle until all target regions are larger than SCOPE, then the LEPA ends.
A typical remote-sensing image containing the harbor as a test image of the proposed method, the image processing results and other smoothing algorithms processing results are compared as shown in
Figure 2. In this experiment, the value of SCOPE is 150, and the value of MD is 10.
As can be seen, the processing result of our algorithm is better than the general smoothing algorithm and other edge-preserving filtering algorithms. The useless edges in the bilateral filter and guided filter are larger than our method, and the useful edges are less than our method. These results show that our method meets the expected requirements and does not lose too much useful edge information.
2.2. Harbor Candidate Extraction
After image preprocessing, we will extract the candidate regions of the harbors. For a given high-resolution broad-area remote-sensing image, the main characteristics of the harbor are as follows:
- (1)
Overall shape of the harbor region is semi-closed and it contains some strip-shaped targets of a certain length (i.e., the jetty, including the breakwater and the code head); the strip-shaped targets are surrounded by water on both sides;
- (2)
The gray value of water in the remote-sensing image is generally low and the gray value distribution is uniform (the variance is relatively small), while the gray value and variance of the land are larger than those values of the water, so there is a clear boundary between the water and the land;
- (3)
There are more than two jetties in the same harbor, the jetties are adjacent, and two or more jetties are overlapping;
- (4)
The container yard around the dock has obvious aspect ratio and has obvious geometric features.
In order to use of the above characteristics of the harbor target and increase the extraction efficiency, we have proposed EC-SIFT, which can remove redundant SIFT keypoints to further reduce the required calculations.
Scale-invariant feature transform is a successful local feature descriptor, which is widely used in template matching of various images. The traditional SIFT algorithm implementation has the following steps: First, extracting SIFT keypoints from the template images and the target images respectively; secondly, describing each SIFT keypoint separately, and it can form a 128-dimensonal keypoint vector for each keypoint; finally, the target extraction results are obtained by matching the keypoint vectors of the target images and the template images. However, when the traditional SIFT algorithm is applied to remote-sensing images, there will be a large number of non-target keypoints; moreover, it is difficult to get all types of harbor templates. Therefore, the keypoints matching for harbor targets may be inaccurate, which directly leads to an increase in the false detection rate of harbor extraction results.
In order to solve these problems, we propose EC-SIFT algorithm to reduce the false detection rate and the number of redundant matching keypoints. The EC-SIFT algorithm combines EC feature and clustering information in the SIFT feature extraction and matching process; we can accurately extract and detect complete harbor candidates. In this part of the article, EC-SIFT algorithm can reduce the redundant keypoints of images. Then, under the guidance of the clustering information, we use the QT algorithm to get the complete harbor candidates. The next section will describe these algorithms in detail.
2.2.1. SIFT Keypoints Extraction Method Based on Edge Categories
The traditional SIFT algorithm takes the extreme points searched in the entire scale space as keypoints, and it will generate a lot of redundant keypoints. Therefore, we propose a keypoint location strategy instead of searching extreme points in the entire scale space. First, we use the geometric invariant moment to extract the EC of images, and then we search for the extreme points corresponding to the EC in the scale space. The flow of the EC-SIFT algorithm is shown in
Figure 3.
The EC is defined as a collection of regions containing image edge information, so we look for EC in the image sub-block, and we split the images into image sub-blocks of the same size. In order to make the moment of image sub-blocks have the characteristics of translation, rotation and scale invariance, we use a moment invariant of the Hu moment [
27]. It is defined as follows:
where
x, y are the subscripts of the image sub-blocks.
ηpq represents the normalized center moment; the formula is as follows:
where
upq is the central moment, it is defined as follows:
x0,
y0 is the centroid coordinate of the image sub-block region. It is defined as follows:
mpq is the origin moment, and it is defined as follows:
The idea of EC extraction is to use image sub-blocks corresponding to local invariant moments whose adjacent moments value jump larger as EC of the images. Therefore, we need to use the moments of adjacent image sub-blocks to calculate the gradient values for the moments of each image sub-block. After the gradient is taken, we set a jump threshold
T, and the gradient value of the image sub-block smaller than the threshold
T is zeroed; other image sub-blocks are adjusted as EC of the images. The gradient calculation formula of the image sub-block is defined as follows:
The local brightness values of the entire image may not be an order of magnitude; thus, if a fixed threshold
T is used for all gradient values, a part of the edge regions will be missed when
T is too large, and false edge regions will appear when
T is too small. We can solve this problem with adaptive threshold
T, which is defined as follows:
The above formula determines the threshold T based on the local luminance information, which can distinguish the brightness jumps of different orders of magnitude.
When we segment the image, the image sub-blocks of the edge regions do not all cross the edge line of the image; many image sub-blocks are offset, and some of them even use the image edge lines as the boundary of the image sub-block. If such sub-block is used as the EC region of the image, we will lose a lot of edge information. Therefore, we need to make adjustment to the reserved image sub-blocks, so that the image sub-blocks cross the edge lines as much as possible; in this way, we can ensure that EC contains most of the edge information. We use the adaptive
F(
x, y) to adjust the starting coordinate of
F(
x, y) and use the following formula as the condition to terminate the adjustment:
After the above algorithm, we have extracted the EC of images, and the detection of the extreme points will be performed in the corresponding regions of the original images.
Figure 4 shows the comparison between keypoints extraction of traditional SIFT algorithm and keypoints extraction of EC-SIFT algorithm in this article. The results show that the EC-SIFT algorithm can improve the traditional SIFT algorithm in two aspects:
- (1)
The redundant keypoints are greatly reduced, so that the search speed of SIFT keypoints is increased;
- (2)
The search range of the extreme points is reduced, so that the SIFT keypoints are concentrated in the edge regions, which improves the accuracy of the subsequent extraction algorithm.
2.2.2. Harbor Candidate Extraction
After extracting keypoints of SIFT, we will extract harbor candidates. It is a common method to use SIFT keypoints to match template images and target images [
28], so we will use this method. Because the breakwaters of harbors are semi-closed and are also prominent in the sea, we use the breakwaters as the main keypoints of matching. First, we use the matching results between the template images and the test image to get the matched keypoints. In the traditional SIFT algorithm, each SIFT keypoint is described by a vector
ν=(θ, σ, x, y), where
θ is the direction of the feature vector,
σ is the scale,
x, y are the spatial coordinates of the keypoint. In order to increase the robustness of keypoints matching, we use the gradient orientation modification SIFT (GOM-SIFT) algorithm and the scale restriction criteria algorithm, which are proposed by Z. Yi [
29] to improve the matching rate. In this method, we are going to improve the gradient orientations: when the SIFT descriptor samples the image gradient orientations around the keypoints, we found that the grayscale intensities in the same region of some images were completely different, even that the intensity was opposite, so we use GOM-SIFT to modify the gradient direction. The following formula shows the process of modification:
where
α is gradient orientation and
β is modified gradient orientation. However, GOM-SIFT can only remove some incorrect matched keypoints when the image is self-similitude, so we use scale restriction criteria to remove more mismatched keypoints. The definition of scale difference is as follows:
We assume that the spatial transformation between pairs of images is affine, and the dimensions of the corresponding local regions are equal, so the
SD value of the correct matched pairs should be close to a constant, which means that the
SD’s standard deviation of the correct matched pairs should be smaller than the incorrect matched pairs. According to the above principles, we propose scale restriction criteria:
If a matched pair does not accord with the scale restriction criteria, this matched pair will be rejected. To determine the value of a and b, we form a histogram of all SD values of matched pairs, the peak in the histogram of SD values is recorded as PSD, and then the values of a and b are obtained by PSD-W and PSD+W, respectively, where W is a constant.
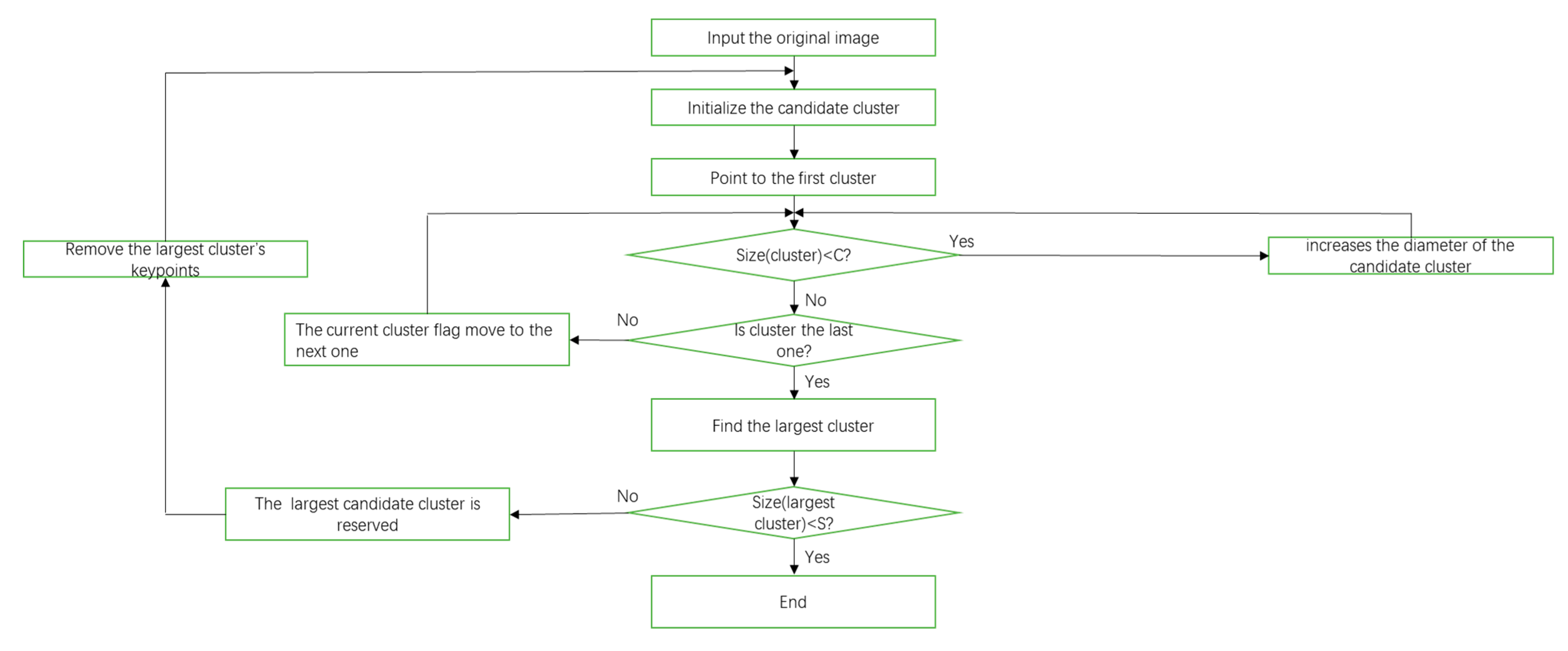
After getting the matched keypoints through GOM-SIFT and scale restriction criteria, we remove some mismatched keypoints. Next, we will use the matched keypoints to extract harbor candidates. Since a harbor is a semi-closed structure, which is composed of regions such as breakwaters and docks, the matched keypoints belonging to the harbor regions should stay within a certain range. Therefore, we get some harbor candidates by dividing the matched keypoints into several groups based on their spatial location. In order to achieve it, we use a quality threshold (QT) clustering method [
30], and the flow of the QT algorithm is shown in
Figure 5. Quality threshold is an algorithm that classifies matched keypoints into high quality clusters; it ensures high quality clusters by limiting the diameter of the clusters. This method prevents dissimilar keypoints from being forced under the same cluster and ensures that only high-quality clusters are formed. The specific method is implemented as follows:
- (1)
Forming a candidate cluster from a single matched keypoint, the growth of the cluster is achieved by adding the matched keypoint around a cluster one by one;
- (2)
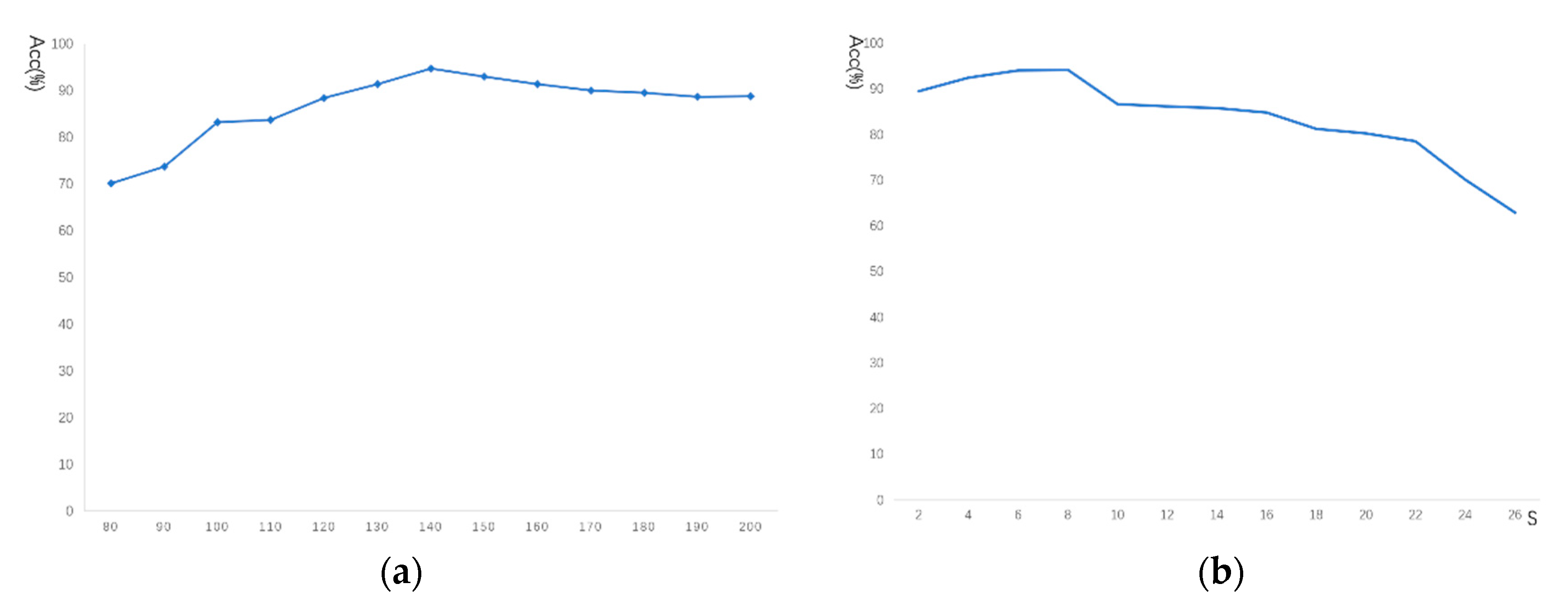
The addition of each associated matched keypoint will increase the diameter of the candidate cluster. We set a maximum diameter threshold C, when the diameter of the cluster exceeds this threshold after increasing the associated matched keypoints, we will stop growing this cluster;
- (3)
Subsequent formation of candidate clusters repeats the above process. When forming the candidate clusters, we retain the previous matched keypoints, so we will get the number of candidate clusters with the same number of matched keypoints;
- (4)
The largest candidate cluster is reserved, and all the matched keypoints that it contains are removed from the next calculation;
- (5)
Repeat the above calculation process;
- (6)
Setting a minimum cluster size threshold S. When the diameter of the remaining maximum cluster is smaller than the threshold S, the entire calculation process will stop.
The candidate regions extracted by QT algorithm are shown in
Figure 6. These resulting regions are referred to as regions containing the harbor.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}