Analysis of Methanol Gasoline by ATR-FT-IR Spectroscopy


Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Collection of ATR-FTIR Spectra
2.3. Multivariate Data Analysis
2.3.1. Principal Component Analysis
2.3.2. Classification for Adulteration Category
2.3.3. Regression for Adulteration Content
2.3.4. Variables Selection for Significant Information
2.3.5. Evaluation of the Model’s Performance
3. Result and Discussion
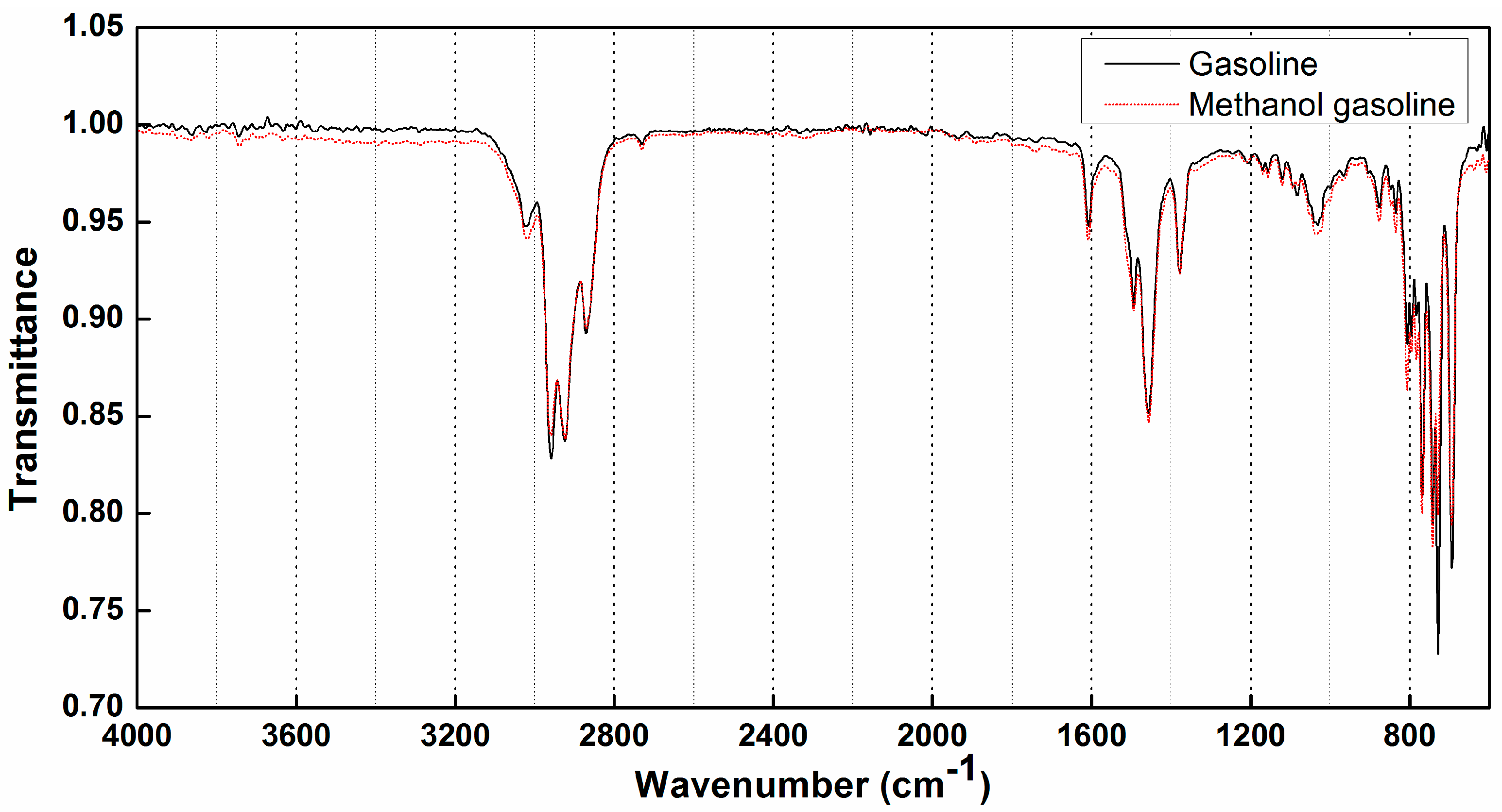
3.1. Analysis of ATR-FTIR Spectral Feature of Gasoline
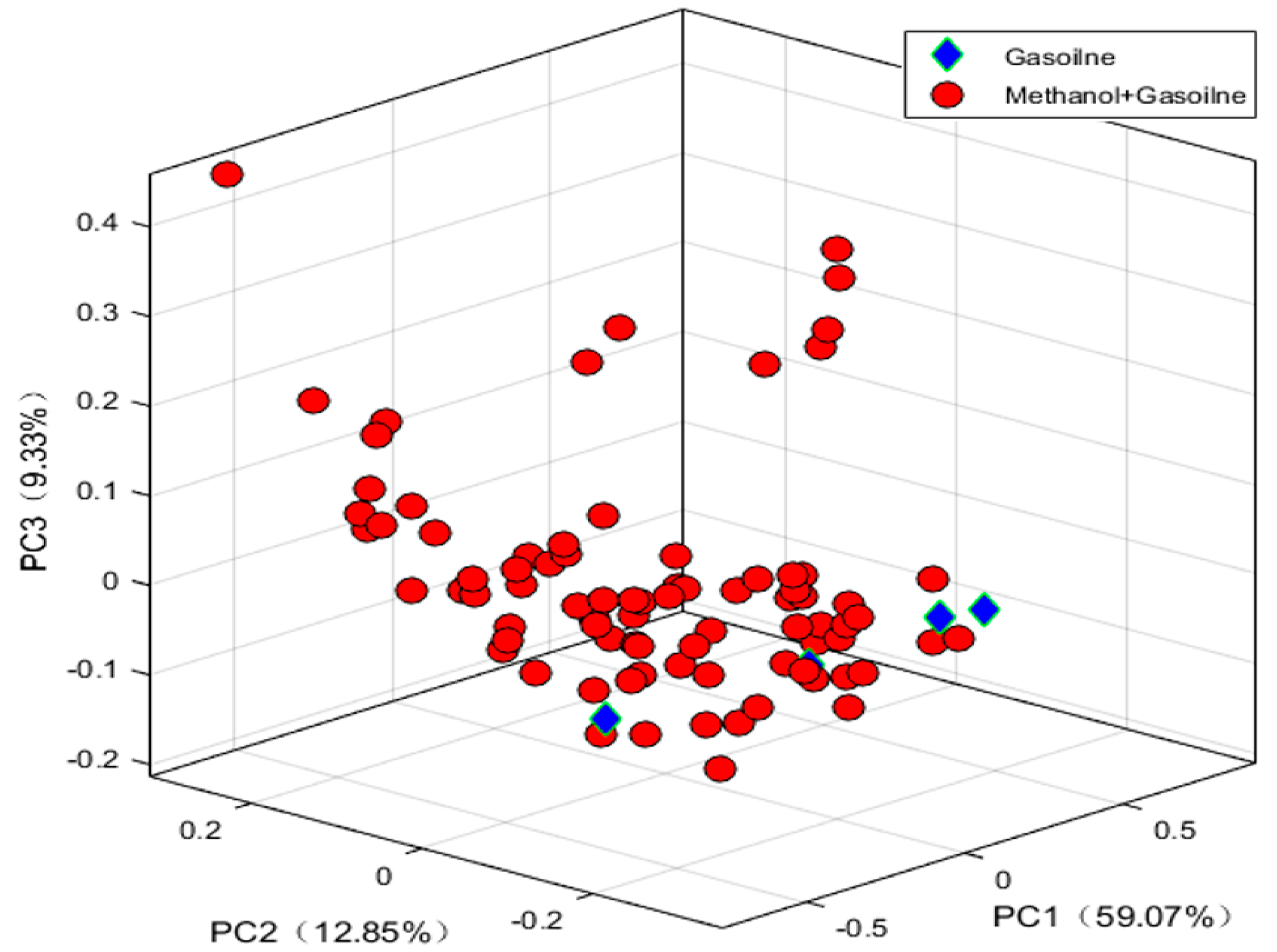
3.2. Exploratory Analysis
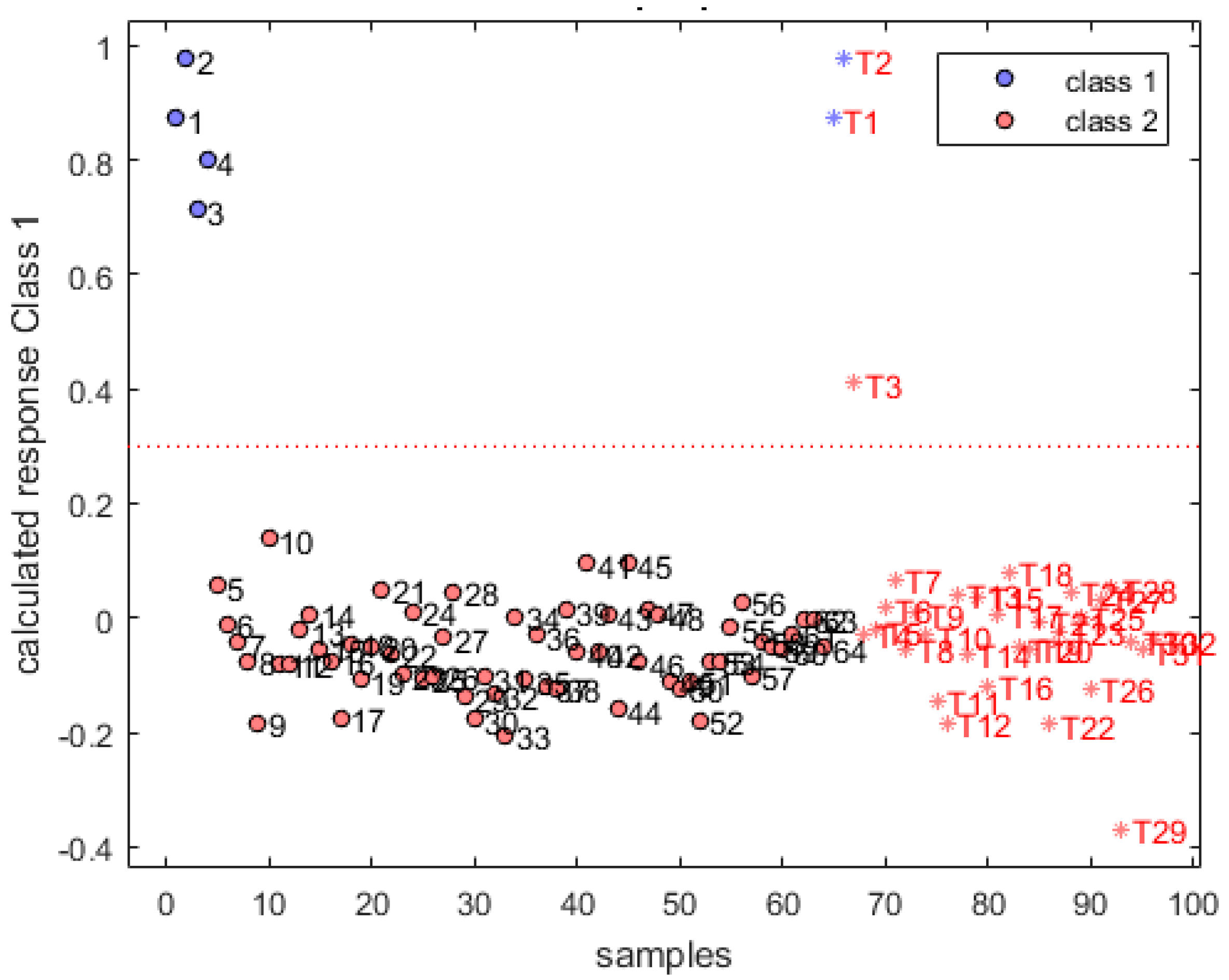
3.3. Qualitative Analysis of Gasoline
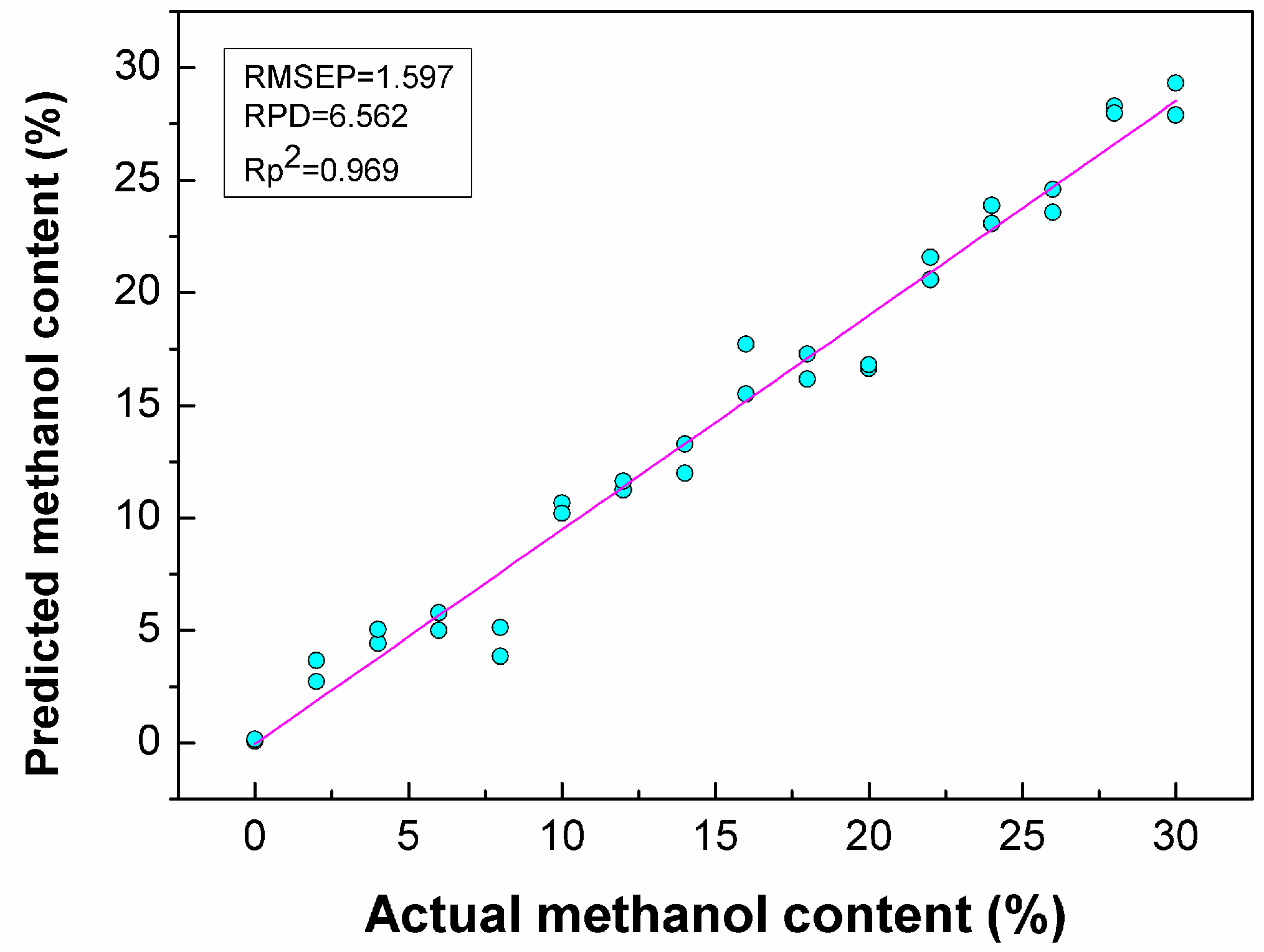
3.4. Quantitative Analysis of Methanol in Gasoline
3.5. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wiedemann, L.; d’Avila, L.; Azevedo, D. Adulteration detection of Brazilian gasoline samples by statistical analysis. Fuel 2005, 84, 467–473. [Google Scholar] [CrossRef]
- Song, M.; Zheng, W.; Wang, Z. Environmental efficiency and energy consumption of highway transportation systems in China. Int. J. Prod. Econ. 2016, 181, 441–449. [Google Scholar] [CrossRef]
- Valera, H.; Agarwal, A.K. Methanol as an Alternative Fuel for Diesel Engines; Methanol and the Alternate Fuel Economy; Springer: Berlin, Germany, 2019; pp. 9–33. [Google Scholar]
- Yilmaz, İ.; Taştan, M. Investigation of hydrogen addition to methanol-gasoline blends in an SI engine. IJHE 2018, 43, 20252–20261. [Google Scholar] [CrossRef]
- Liu, F.; Hua, Y.; Wu, H.; Lee, C.-F.; Shi, Z. Experimental and kinetic studies of soot formation in methanol-gasoline coflow diffusion flames. J. Energy Inst. 2017, 92, 38–50. [Google Scholar] [CrossRef]
- Khanmohammadi, M.; Garmarudi, A.B.; de la Guardia, M. Characterization of petroleum-based products by infrared spectroscopy and chemometrics. TrAC Trends Anal. Chem. 2012, 35, 135–149. [Google Scholar] [CrossRef]
- Teixeira, L.S.; Oliveira, F.S.; dos Santos, H.C.; Cordeiro, P.W.; Almeida, S.Q. Multivariate calibration in Fourier transform infrared spectrometry as a tool to detect adulterations in Brazilian gasoline. Fuel 2008, 87, 346–352. [Google Scholar] [CrossRef]
- Balabin, R.M.; Safieva, R.Z. Gasoline classification by source and type based on near infrared (NIR) spectroscopy data. Fuel 2008, 87, 1096–1101. [Google Scholar] [CrossRef]
- da Silva, M.P.F.; e Brito, L.R.; Honorato, F.A.; Paim, A.P.S.; Pasquini, C.; Pimentel, M.F. Classification of gasoline as with or without dispersant and detergent additives using infrared spectroscopy and multivariate classification. Fuel 2014, 116, 151–157. [Google Scholar] [CrossRef]
- Mabood, F.; Gilani, S.A.; Albroumi, M.; Alameri, S.; Al Nabhani, M.M.; Jabeen, F.; Hussain, J.; Al-Harrasi, A.; Boqué, R.; Farooq, S.; et al. Detection and estimation of Super premium 95 gasoline adulteration with Premium 91 gasoline using new NIR spectroscopy combined with multivariate methods. Fuel 2017, 197, 388–396. [Google Scholar] [CrossRef]
- Balabin, R.M.; Safieva, R.Z.; Lomakina, E.I. Gasoline classification using near infrared (NIR) spectroscopy data: Comparison of multivariate techniques. Anal. Chim. Acta 2010, 671, 27–35. [Google Scholar] [CrossRef]
- Kardamakis, A.A.; Pasadakis, N. Autoregressive modeling of near-IR spectra and MLR to predict RON values of gasolines. Fuel 2010, 89, 158–161. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Orecchio, S.; Fiore, M.; Barreca, S.; Vara, G. Volatile profiles of emissions from different activities analyzed using canister samplers, and gas chromatography-mass spectrometry, (gc/ms) analysis: A case study. Int. J. Environ. Res. Public Health 2017, 142, 195. [Google Scholar] [CrossRef] [PubMed]
- Orecchio, S.; Bianchini, F.; Bonsignore, R.; Blandino, P.; Barreca, S.; Amorello, D. Profiles and sources of pahs in sediments from an open-pit mining area in the Peruvian andes. Polycycl. Aromat. Compd. 2016, 36, 429–451. [Google Scholar] [CrossRef]
- Amorello, D.; Orecchio, S.; Pace, A.; Barreca, S. Discrimination of almonds (prunus dulcis) geographical origin by minerals and fatty acids profiling. Nat. Prod. Lett. 2016, 3018, 2107–2110. [Google Scholar] [CrossRef]
- Chen, X.; Ding, H.; Yuan, L.M.; Cai, J.R.; Chen, X.; Lin, Y. New approach of simultaneous, multi-perspective imaging for quantitative assessment of the compactness of grape bunches. Aust. J. Grape Wine Res. 2018, 244, 413–420. [Google Scholar] [CrossRef]
- Kutsanedzie, F.Y.H.; Chen, Q.S.; Hassan, M.M.; Yang, M.; Sun, H.; Rahman, M.H. Near infrared system coupled chemometric algorithms for enumeration of total fungi count in cocoa beans neat solution. Food Chem. 2018, 240, 231–238. [Google Scholar] [CrossRef]
- Lee, L.C.; Liong, C.-Y.; Jemain, A.A. Partial least squares-discriminant analysis (PLS-DA) for classification of high-dimensional (HD) data: A review of contemporary practice strategies and knowledge gaps. Analyst 2018, 143, 3526–3539. [Google Scholar] [CrossRef]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Höskuldsson, A. PLS regression methods. J. Chemom. 1988, 2, 211–228. [Google Scholar] [CrossRef]
- Huang, L.; Meng, L.; Zhu, N.; Wu, D. A primary study on forecasting the days before decay of peach fruit using near-infrared spectroscopy and electronic nose techniques. Postharvest Biol. Technol. 2017, 133, 104–112. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- Cai, W.; Li, Y.; Shao, X. A variable selection method based on uninformative variable elimination for multivariate calibration of near-infrared spectra. Chemom. Intell. Lab. Syst. 2008, 90, 188–194. [Google Scholar] [CrossRef]
- Ye, S.; Wang, D.; Min, S. Successive projections algorithm combined with uninformative variable elimination for spectral variable selection. Chemom. Intell. Lab. Syst. 2008, 91, 194–199. [Google Scholar] [CrossRef]
- Mehmood, T.; Liland, K.H.; Snipen, L.; Sæbø, S. A review of variable selection methods in partial least squares regression. Chemom. Intell. Lab. Syst. 2012, 118, 62–69. [Google Scholar] [CrossRef]
- Zhu, N.; Nie, Y.; Wu, D.; He, Y.; Chen, K. Feasibility study on quantitative pixel-level visualization of internal quality at different cross sections inside postharvest loquat fruit. Food Anal. Meth. 2017, 10, 287–297. [Google Scholar] [CrossRef]
- Huang, L.; Zhou, Y.; Meng, L.; Wu, D.; He, Y. Comparison of different CCD detectors and chemometrics for predicting total anthocyanin content and antioxidant activity of mulberry fruit using visible and near infrared hyperspectral imaging technique. Food Chem. 2017, 224, 1–10. [Google Scholar] [CrossRef]
- Corsetti, S.; Zehentbauer, F.M.; McGloin, D.; Kiefer, J. Characterization of gasoline/ethanol blends by infrared and excess infrared spectroscopy. Fuel 2015, 141, 136–142. [Google Scholar] [CrossRef]
- Noor, P.; Khanmohammadi, M.; Roozbehani, B.; Yaripour, F.; Garmarudi, A.B. Determination of reaction parameters in methanol to gasoline (MTG) process using infrared spectroscopy and chemometrics. J. Clean. Prod. 2018, 196, 1273–1281. [Google Scholar] [CrossRef]
- Li, H.D.; Liang, Y.Z.; Xu, Q.S.; Cao, D.S. Model population analysis for variable selection. J. Chemom. 2010, 24, 418–423. [Google Scholar] [CrossRef]
- Wu, D.; Shi, H.; He, Y.; Yu, X.; Bao, Y. Potential of hyperspectral imaging and multivariate analysis for rapid and non-invasive detection of gelatin adulteration in prawn. J. Food Eng. 2013, 119, 680–686. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Al-Walaan, N. Glucose adulteration in Saudi honey with visible and near infrared spectroscopy. Int. J. Food Prop. 2014, 17, 2263–2274. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Variable Selection | Number of Variables | LVs | Calibration Set | Prediction Set | ||||
|---|---|---|---|---|---|---|---|---|---|
| R2c | RMSEC | R2p | RMSEP | RPD | ABS | ||||
| PLSR | / | 1762 | 15 | 0.998 | 0.405 | 0.968 | 1.658 | 6.124 | 1.253 |
| LS-SVM | / | 1762 | / | 0.998 | 0.395 | 0.968 | 1.661 | 5.886 | 1.266 |
| PLSR | CARS | 48 | 11 | 0.97 | 0.426 | 0.969 | 1.597 | 6.563 | 1.171 |
| LS-SVM | CARS | 48 | / | 0.998 | 0.404 | 0.968 | 1.636 | 6.373 | 1.232 |
| PLSR | UVE | 479 | 10 | 0.994 | 0.699 | 0.972 | 1.545 | 6.420 | 0.847 |
| LS-SVM | UVE | 479 | / | 0.998 | 0.395 | 0.964 | 1.742 | 5.555 | 1.347 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
XIA, Q.; YUAN, L.-m.; CHEN, X.; MENG, L.; HUANG, G. Analysis of Methanol Gasoline by ATR-FT-IR Spectroscopy. Appl. Sci. 2019, 9, 5336. https://doi.org/10.3390/app9245336
XIA Q, YUAN L-m, CHEN X, MENG L, HUANG G. Analysis of Methanol Gasoline by ATR-FT-IR Spectroscopy. Applied Sciences. 2019; 9(24):5336. https://doi.org/10.3390/app9245336
Chicago/Turabian StyleXIA, Qi, Lei-ming YUAN, Xiaojing CHEN, Liuwei MENG, and Guangzao HUANG. 2019. "Analysis of Methanol Gasoline by ATR-FT-IR Spectroscopy" Applied Sciences 9, no. 24: 5336. https://doi.org/10.3390/app9245336
APA StyleXIA, Q., YUAN, L.-m., CHEN, X., MENG, L., & HUANG, G. (2019). Analysis of Methanol Gasoline by ATR-FT-IR Spectroscopy. Applied Sciences, 9(24), 5336. https://doi.org/10.3390/app9245336