1. Introduction
Currency crises can have a catastrophic impact on the real economy in a short space of time. In general, they occur when there is a sudden devaluation in a currency, often resulting in a speculative attack on the international currency market. Currency crises can also occur as a result of high balance of payments deficits or when governments are unable to restore the value of their currency after a fall in its price in the markets.
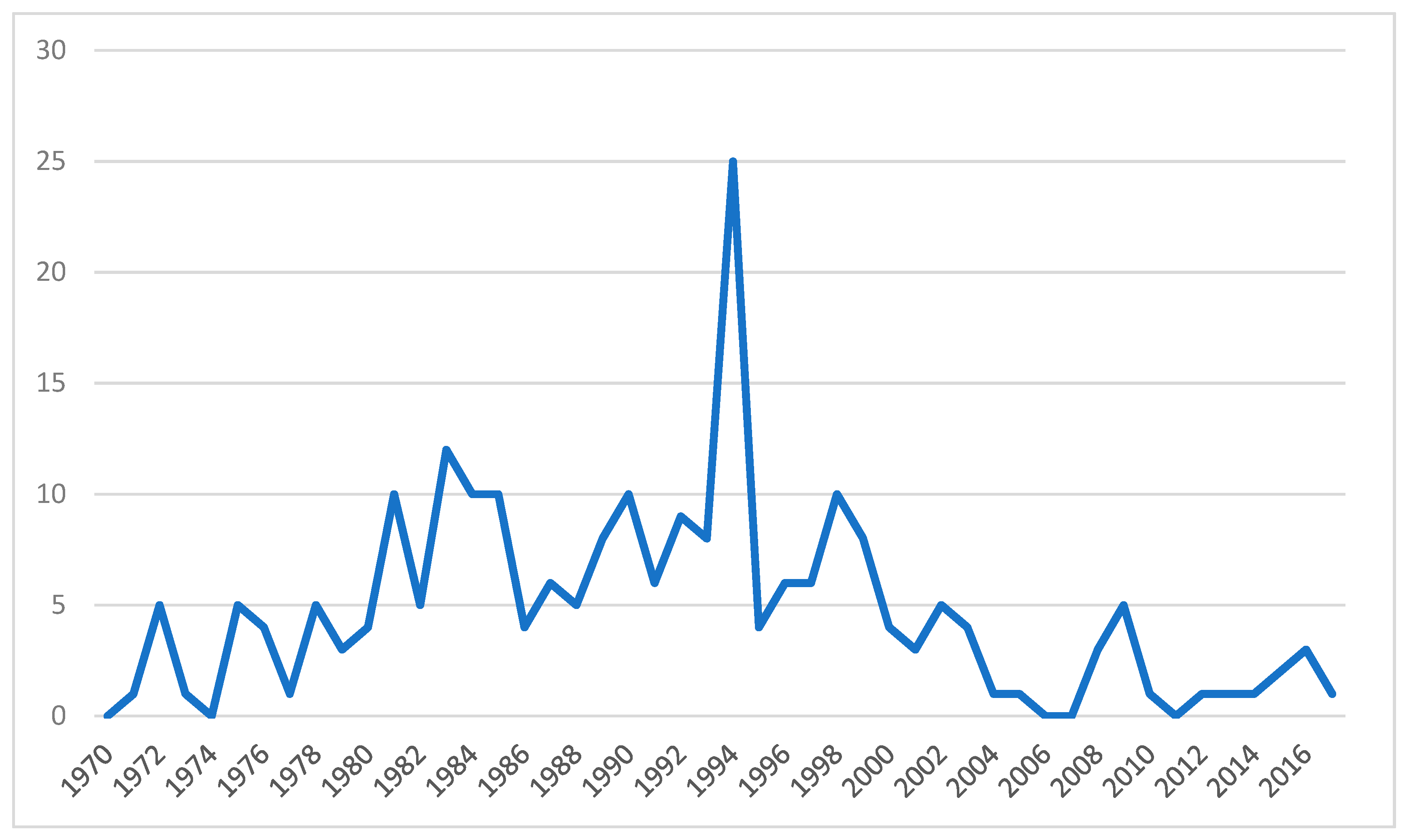
One of the first currency crises occurred in 1992 when many European countries faced a crisis as part of the Exchange Rate Mechanism (ERM). Another episode was the currency crisis suffered by the Mexican peso in December 1994. This crisis began with an abrupt decision by the Mexican government to devalue its currency, causing a crash in the peso days later and an economic crisis that resulted in a sharp drop in GDP. However, the biggest event has been the Asian Financial Crisis in 1997. The crisis began with the sharp devaluation of the Thai baht and was the first to show the effect of contagion on other countries. However, the event was about more than just speculation on the Thai currency and saw the collapse of Asian stock markets. The financial crisis that began with the devaluation of the Thai baht exchange rate resulted in a sharp increase in interest rates and the collapse of many companies, as well as an increase in the cost of credit and a general fall in GDP in the region [
1]. This resulted in foreign and national investors pulling out investment. Not only did this crisis affect Asian countries, but it also had a negative impact on other emerging economies, especially in Latin America, showing that currency crises are not limited to a specific economy. Globalization can increase the economic difficulties of societies and affect the structure of national economies after the real economy has suffered a damaging impact [
2].
Figure 1 shows the number of currency crises per year at the international level.
On the other hand, it is interesting to influence the economic consequences that currency crises can cause. Reference [
3] demonstrated that a currency crisis makes it difficult to design an optimal monetary policy, making the setting of the interest rate a dilemma; since, if it increases, it makes it difficult to lend money to companies, and, if it decreases, it devalues the debt denominated in foreign currency. They concluded that the best decision is to reduce the interest rate, thanks to the continuous international financial development and the increase in credit flows. Following this argument, some works indicated that currency crises deteriorate the balance sheets of companies based on the fact that, if prices are rigid, a depreciation of the currency leads to an increase in the obligations of payment of the debt in the foreign currency of companies, causing a fall in their profits [
4,
5]. This reduces the borrowing capacity of companies and, therefore, investment and production in an economy with credit limitations which, in turn, reduces the demand for the national currency and leads to depreciation. Other authors presented a general equilibrium model of currency crises and how they are driven by credit restrictions and rigidity of nominal prices [
6,
7,
8]. They showed that an increase in the interest rate to support the currency in crisis may not be effective, but that relaxation of short-term loan facilities can make this policy effective by mitigating the increase in interest rates for companies [
9]. In addition to interest rate policy being an instrument to end a currency crisis, intervention in the foreign exchange market is also a measure to stabilize inflation and production as a result of this type of crisis. They demonstrated how intervention in the foreign exchange market improves the situation of the economy, regardless of the exchange rate regime chosen by the country. It can achieve great results if the economy encounters imperfect capital mobility/asset substitutability movements, producing the same result as discretionary monetary policy and without jeopardizing the inflation target [
9,
10,
11].
To avoid future crises, researchers have tried to identify common factors underlying exchange rate instability and develop predictive models. However, despite impressive results for in-sample, the existing early warning models encounter difficulties when it comes to predicting crises outside it [
12,
13,
14].
In recent years, there has been considerable research on currency crises, mainly on the application of computational techniques for emerging economies. Statistical methods have also been used, albeit with limited success. For example, Reference [
12] applied extreme value theory, obtaining an accuracy of 44%. Reference [
15] developed a discrete choice early warning system considering the persistence of the phenomenon of the crisis. Their logistic regression system used a maximum likelihood estimation method both country-by-country and in a panel framework. The model obtained predictive capacity that significantly improved the existing static models, both inside and outside the sample (89.8% and 90.2%, respectively).
Reference [
1] used computational combinations with support vector machine (SVM), logistic regression, and logical analysis of data tree (LADTree), based on the k-nearest neighbor. The results showed that the computational classifiers were more accurate than the traditional statistical methods, obtaining a level above 90%. Reference [
2] individually used SVM for the currency crisis in Argentina, obtaining a high level of robustness. Similarly, Reference [
13] studied currency crises in developed countries using the classification and regression tree methodology (CART) and random forest (RF). Their findings determined that significant factors included high short-term domestic interest rates and overvalued exchange rates. Reference [
16] compared logistic regression, neural networks (NNs), and decision trees (DTs) to predict the currency crisis in Turkey, with NNs achieving the highest level of accuracy. Also for Turkey, Reference [
17] used logistic regression to analyze the determinants of the currency and banking crisis. The study found that currency crises are caused by an excessive fiscal deficit, short-term increases in external debt, overvaluation of the Turkish lira, and adverse external shocks, confirming the results obtained by other studies based on the experiences of emerging countries [
18,
19].
This study attempted to build more accurate models for predicting currency crises. To do so, we developed models for four regions of the world (i.e., Latin America, Asia, Africa, and the Middle East and Europe) together with a global model for all world regions. This study thus sought to address a gap in the literature, which requires broader models that can provide powerful and homogeneous empirical tools for public institutions in different countries. It did this using the deep neural decision trees (DNDTs) methodology, developed in Reference [
20], which allows for solutions to forecasting problems involving data outside of a sample, also one of the least resolved aspects in the existing literature. We compared this novel method in terms of accuracy with other popular methodologies used in time-series prediction such as regression logistic, neural networks, support vector machines, and AdaBoost.
The rest of this article is organized as follows:
Section 2 describes the DNDTs algorithm, and
Section 3 summarizes the data and variables used as possible predictors. The results and their comparison with the existing literature are provided in
Section 4. Finally,
Section 5 summarizes the main conclusions.
2. Methodology
As already stated above, the DNDT algorithm was applied to solve the research question raised, but we have also used different methods in the construction of the currency crisis prediction model. The use of different methods aimed to achieve a robust model which is contrasted not only through a classification technique but also by applying all those that have shown success in the previous literature [
1,
2,
12,
13,
14]. Specifically, logistic regression, artificial neural networks, support vector machines, and AdaBoost were used. A synthesis of the methodological aspects of each of these classification techniques appears below.
2.1. Logistic Regression
The logistic regression model (Logit) is a non-linear classification model, although it contains a linear combination of parameters and observations of the explanatory variables [
21]. The logistic function is bounded between 0 and 1, thus providing the probability that an element is in one of the two established groups. From a dichotomous event, the Logit model predicts the probability that the event will or will not take place. If the probability estimate is greater than 0.5, then the prediction is that it does belong to that group, otherwise it would assume that it belongs to the other group considered. To estimate the model, we started from the quotient between the probability that an event will occur and the probability that it will not occur. The probability of an event occurring is determined by Expression (1).
where
β0 is the constant term of the model and
β1, …,
βk are the coefficients of the variables.
2.2. Support Vector Machines
Support vector machines (SVMs) have been shown to achieve good generalization performance over a wide variety of classification problems, where it is seen that SVM tends to minimize generalization errors, that is, classifier errors over new instances. In geometric terms, SVM can be seen as the attempt to find a surface (
σi) that separates positive examples from negative ones by the widest possible margin [
22,
23,
24].
The search that meets the minimum distance between it and an example of training is the maximum and is performed across all surfaces (σ1, σ2…) in the A-dimensional space that separates the positive examples from the negative in the training set (known as decision surfaces). To better understand the idea behind the SVM algorithm, we take the case in which the positive and negative examples are linearly separable; therefore, the decision surfaces are |A|-1-hyperplanes. For example, in the case of two dimensions, several lines can be taken as decision surfaces. In this circumstance, the SVM method chooses the middle element of the widest set of parallel lines, that is, from the set in which the maximum distance between two of its elements is the greatest. It should be noted that the best decision surface is determined only by a small set of training examples, called support vectors.
An important advantage of SVM is that it allows the construction of non-linear classifiers, that is, the algorithm represents non-linear training data in a high-dimensional space (called the characteristic space) and builds the hyperplane that has the maximum margin. In addition, due to the use of a kernel function to perform the mapping, it is possible to calculate the hyperplane without explicitly representing the feature space.
In the present work, the method of minimum sequential optimization (SMO) was used to train the SVM algorithm. In general, SMO divides a large number of quadratic programming (QP) problems that need to be solved in the SVM algorithm by a series of smaller QP problems.
2.3. Artificial Neural Networks (Multilayer Perceptron)
A multilayer perceptron (MLP) is a feedforward artificial neural network model of supervised learning which is composed of a layer of input units (sensors), another output layer, and a certain number of intermediate layers, called hidden layers, in so much that they have no connections with the outside. Each input sensor is connected to the units of the second layer and these in turn with those of the third layer, etc. The network aims to establish a correspondence between a set of input data and a set of desired outputs.
Reference [
25] confirmed that learning in MLP is a special case of functional approximation, where there is no assumption about the model underlying the analyzed data. This process involves finding a function that correctly represents the learning patterns, in addition to carrying out a generalization process that allows to efficiently treat individuals not analyzed during said learning [
26]. For this, we proceed to the adjustment of weights,
W, from the information from the sample set, considering that both the architecture and the connections of the network are known, being the objective to obtain those weights that minimize the learning error. Given, then, a set of pairs of learning patterns {(
x1,
y1), (
x2,
y2) … (
xp,
yp)} and an error function
ε (
W,
X,
Y), the training process implies the search for the set of weights that minimizes the learning error
E(
W) [
27], as expressed in Equation (2).
2.4. AdaBoost
AdaBoost is a meta-algorithm learning machine that can be used in conjunction with many other types of learning algorithms to improve its performance. The output of the other learning algorithms of the “weak” classifiers is combined in a weighted sum representing the final output of the driven classifier. AdaBoost is adaptive in the sense that weak posterior classifiers are adjusted in favor of those cases poorly classified by previous classifiers. AdaBoost is sensitive to noisy data and outliers. In some problems, however, it may be less susceptible to problems than other learning algorithms [
28].
While each learning algorithm tends to adapt to some types of problems better than others, and usually has many different parameters and configurations to adjust before achieving optimal performance in a data set, AdaBoost (with decision trees such as weak classifiers) is often referred to as the best classifier outside the sample. Unlike neural networks and SVMs, the AdaBoost training process selects only those characteristics known to improve the predictability of the model, reduce dimensionality, and, potentially, improve the execution time of functions as irrelevant that do not need to be calculated.
AdaBoost refers to a method of training a driven classifier [
29]. A boost classifier is designed as follows:
where each
ft is a weak learner that takes an object
x as input and returns a result of real value that indicates the class of the object. The weak classifier output signal identifies the predicted object class and the absolute value gives confidence in that classification. Similarly, the
T of the layer classifier will be positive if the sample is believed to be in the positive and negative class in another way.
Each weak classifier produces an output, the hypothesis
h(
xi), for each sample in the training set. In each iteration
t, a weak learner is selected and assigned a coefficient
αt such that the training error sum
Et of the resultant t of the classifying pulse is minimized.
where
Ft−1 is the driven classifier that has been built up to the previous stage of the formation,
E(
F) is the error function, and
ft (
x)
= αth(
x) is the weak beginner being considered for the addition to the final classifier.
2.5. Deep Neural Decision Trees (DNDTs)
Deep neural decision trees are DT models executed by deep-learning NNs, where a configuration of DNDT weightings corresponds to a specific decision tree and is thus interpretable [
20]. Nevertheless, as DNDT is performed by the NN, it has several different properties of conventional DTs: DNDTs can be implemented from the NN structure in software such as Python (Pytorch). All parameters are optimized simultaneously with stochastic gradient descent (SGD) instead of a complex greedy splitting procedure; this allows large-scale processing with mini-batch-based learning and can be connected to any larger NN model for end-to-end learning with backward propagation. Continuing with this explanation, conventional DTs learn through a greedy and recursive division of characteristics [
30]. This may have benefits with respect to the selection of functions; however, this greedy search may become inefficient [
31]. Some recent work explores alternative approaches to train decision trees that aim to achieve better performance, for example, with a latent variable structured prediction [
31]. On the other hand, a DNDT is much simpler, but we can still find the best solutions compared to conventional DT inductors when looking for the structure and parameters of the tree with SGD. Finally, while conventional DT inductors only use binary divisions to simplify, DNDT can also work with arbitrary cardinality divisions which can sometimes generate more interpretable trees. The algorithm begins by implementing a soft binning function to calculate the error rate for each node, making it possible to make decisions divided into DNDTs [
32]. In general, the input of a binning function is a real scalar x which generates an index of the containers to which x belongs. Assuming x is a continuous variable, group it into
n + 1 intervals. This requires
n cut-off points which are trainable variables in this context. The cut-off points are denoted as (β
1, β
2, …, β
n) and are strictly ascending such that β
1 < β
2 < … < β
n.
The activation function of the DNDT algorithm is implemented based on the NN defined in Equation (1).
where w is a constant with value w = [1, 2, …,
n + 1], τ > 0 is a temperature factor, and b is defined in Equation (6).
The NN defined in Equation (1) gives a coding of the binning function x. Additionally, if τ tends to 0 (often the most common case), the vector sampling is implemented using the Straight-Through (ST) Gumbel–Softmax method [
33].
Given the binning function described above, the key idea is to build the DT using the Kronecker product. Assuming we have an input instance
x ∈ RD with D characteristics. Associating each characteristic
xd with its own NN f
d (x
d), we can determine all the final nodes of the DT, in line with Equation (7).
where z is now also a vector that indicates the index of the leaf node reached by instance x. We assume that a linear classifier on each leaf z classifies the instances that reach it. The number of cut points per feature is the complexity parameter of the model. The cut-off point values are not limited, which means that some of them may be inactive. For example, they are smaller than the minimum x
d or greater than the maximum x
d.
With the method described so far, we can route the input instances to the leaf nodes and classify them. Therefore, training a decision tree becomes a matter of training the cut-off points of the container and the sheet sorters. Since all steps forward are differentiable, all parameters can be trained directly and simultaneously with SGD.
The DNDT scales well with the number of inputs due to the training of the mini-batches of the NN. However, the main drawback of the design is the use of the Kronecker product, which means it is not scalable in terms of the number of characteristics. In our current implementation, we avoided this problem by using broad datasets, training a forest with a random subspace [
34]. This involved introducing multiple trees and training each with a subset with random characteristics. A better solution that does not require a forest of hard interpretability involves exploiting the dispersion of the binning function during the learning since the number of non-empty leaves grows much slower than the total.
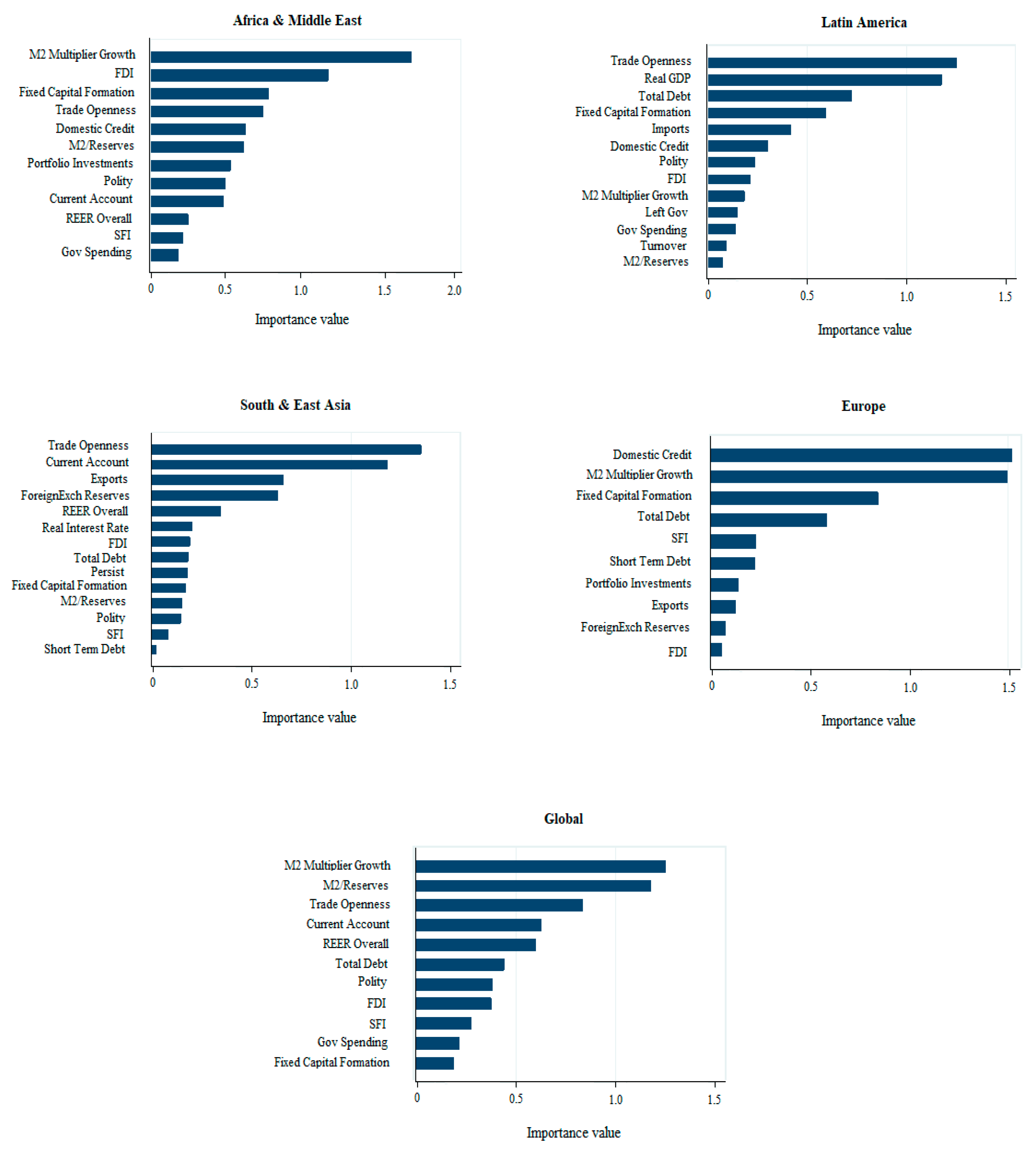
2.6. Sensitivity Analysis
While DTs have a high explanatory capacity, when numerous exploratory variables are used, we need indicators to show the determined impact of these variables. Sensitivity analysis is used for this purpose, allowing the quantification of the relative significance of the independent variables related to the dependent variable [
35]. The DT models used in this study build an appropriate measure of significance as shown in
Table A3. The sensitivity analysis is also used to reduce the models to the most significant variables, eliminating or ignoring those of lesser significance. A variable is considered more significant than another if it increases the variance compared to the set of variables of the model. Each DT model generates significance scores for each independent variable. This is done using the Sobol method [
36], which decomposes the variance of the total output
V(
Y) in line with the equations in Equation (8).
where
and
.
The sensitivity indexes are determined by Si = Vi/V and Sij = Vij/V, where Sij indicates the effect of the interaction between two factors. The Sobol decomposition allows the estimation of a total sensitivity index STi which measures the sum of all the sensitivity effects involved in the independent variables.
2.7. Research Steps
The empirical research for predicting currency crises involved five steps: Creating the sample, data preprocessing, model construction, accuracy assessment, and classification and prediction as shown in
Figure 2. The first step (sample creation) was based on obtaining the relevant data from the data sources such as information published by international economic bodies. The attributes of the dataset include measurements of exposure to debt, the external sector, domestic macroeconomic factors, the banking sector, and political attributes. The data preprocessing step involved making the attributes with continuous values discreet, generalizing data and analysis of the relativity of the attributes, and eliminating outlier values. Regarding outliers values, since the deletion of elements of the sample implies a loss of information, only the ends that do not belong to the interval have been suppressed:
where Q
1 is the first quartile, Q
3 is the third quartile, and R
Q is interquartile range.
The step of constructing the model was based on inductively learning from the preprocessed data using the DNDT algorithm defined in
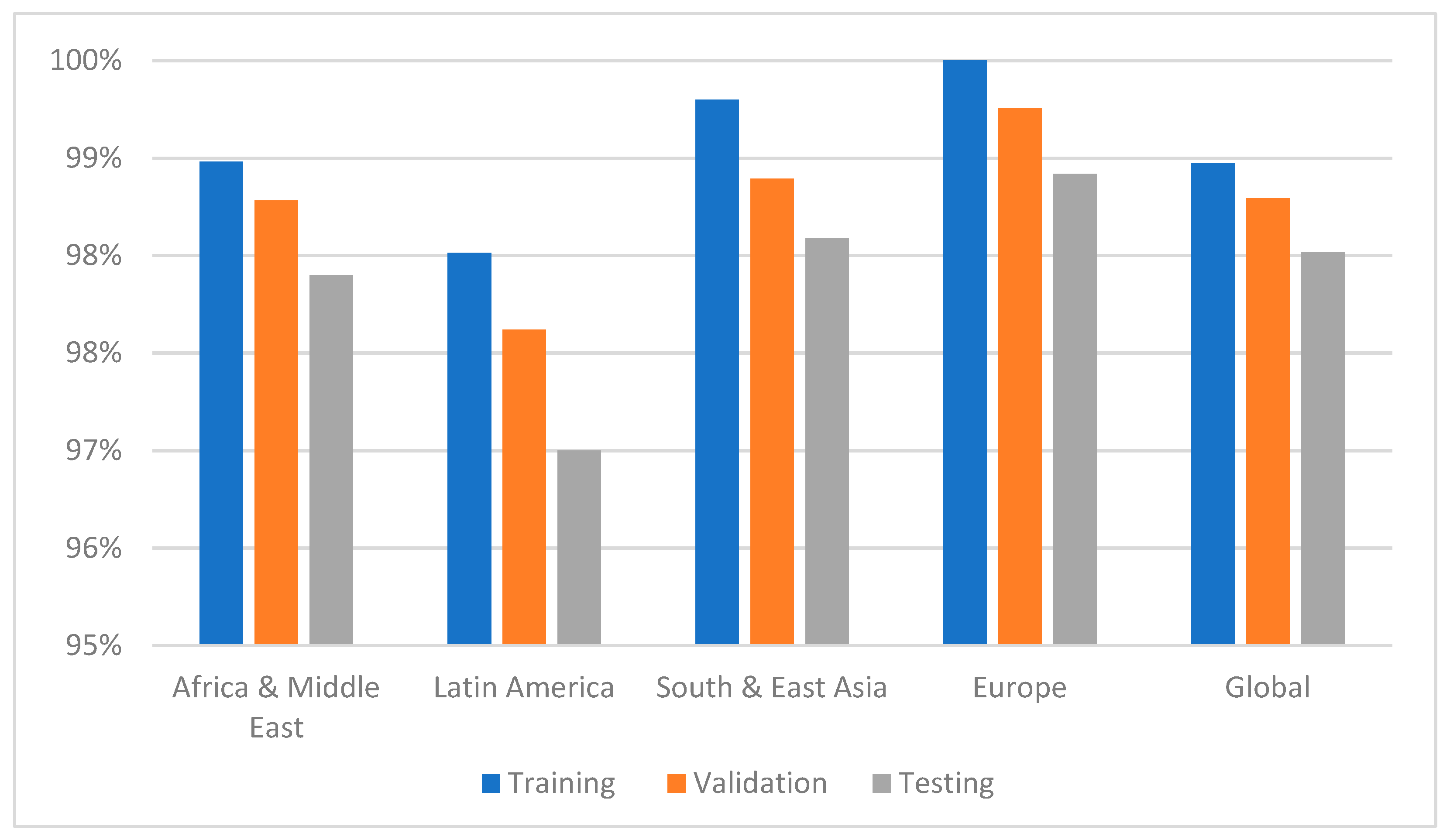
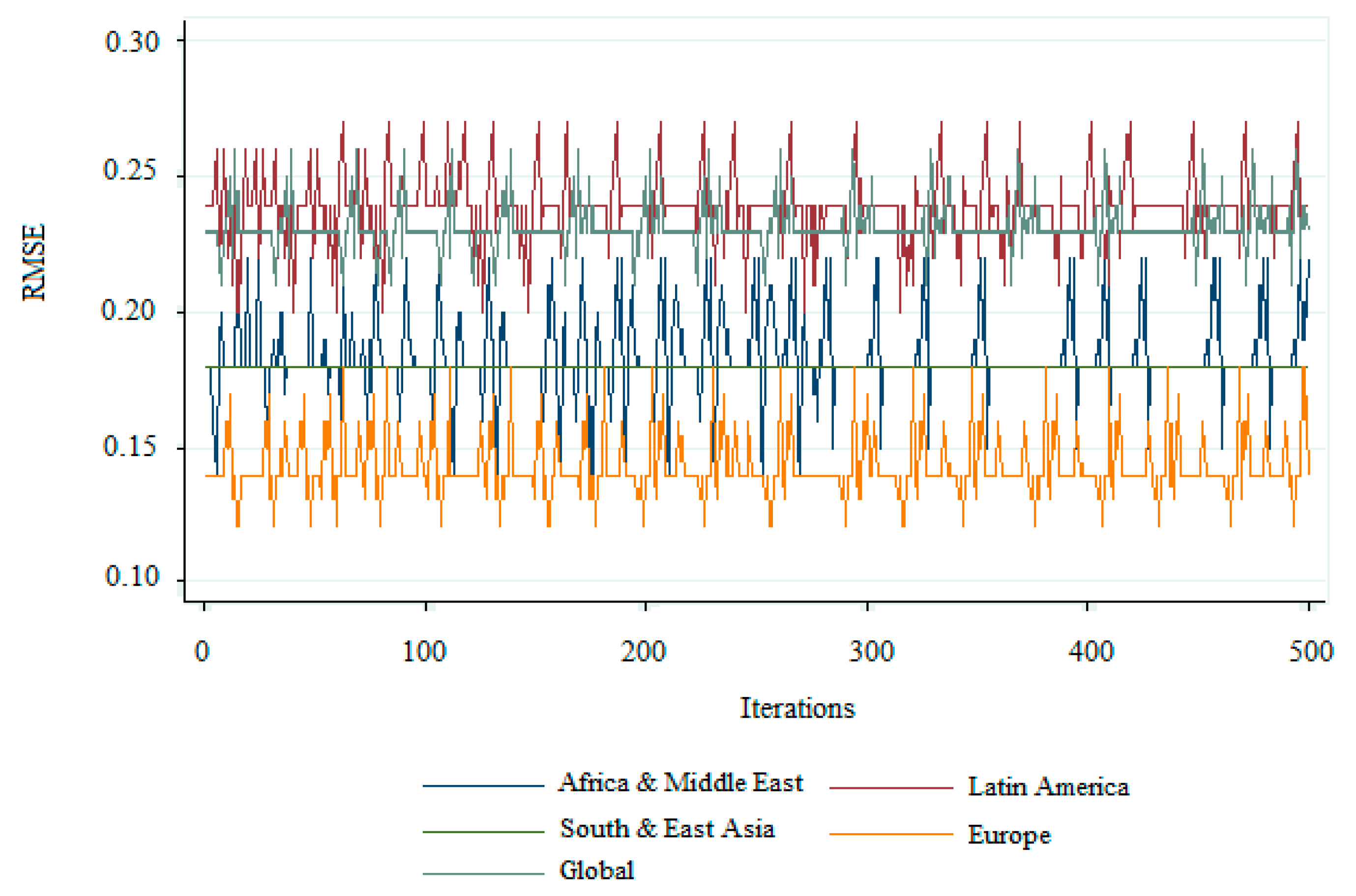
Section 2 and choosing the significant independent variables via the proposed sensitivity analysis. To do so, the sample was randomly divided into three mutually exclusive datasets: Training (70%), validation (10%), and testing (20%). This process used the 10 fold cross-validation method with 500 iterations to estimate error ratios [
37]. The first subset of data was used to train the models and estimating the parameters. The second subset was used for model selection. Finally, the third dataset (testing) was used to evaluate the predictive accuracy of the model in the accuracy assessment step. This was complemented by the analysis of the model’s robustness and its predictive capacity for currency crises at the global level in the classification and prediction step. All variables used in this study were considered in every dataset of training, validation, and testing data
3. Data and Variables
The sample used in this study comprised 162 developed, emerging, and developing countries with information for the period 1970–2017 (
Appendix A). The granularity of the data was annual, following the format data of previous works [
1,
12,
38]. The dataset of the present study had 7708 observations, being 236 crisis observations. Specifically, a set of 32 explanatory variables chosen from the existing literature on the prediction of currency crises was obtained. Of these, 23 corresponded to factors related to debt exposure, the external sector, domestic macroeconomy, and the banking sector [
1,
14,
15,
17,
19]. This information was sourced from the International Monetary Fund (IMF) International Financial Statistics, World Bank Development Indicators, World Economic Outlook, and the World Bank Global Financial Database. The nine remaining variables refer to political factors and have been extracted from the database of the Polity IV Project of Center for Systemic Peace, selecting the variables used in Reference [
39]. The dependent variable was constructed based on the definition in Reference [
38]: “a currency crisis is defined as a nominal depreciation of the currency with respect to the US dollar by at least 30% and at least 10 percentage points higher than the depreciation rate for the previous year”. This dependent variable was 1 for the years in which currency crises occurred and 0 otherwise. The choice of countries was mainly guided by the availability of data, covering four main regions: Africa and the Middle East, South and East Asia, Latin America, and Europe.
Table 1 shows the independent variables used in this research.
5. Conclusions
Currency crises constitute an area of international concern that has received interest from macroeconomic researchers and public policymakers in recent decades. Our results show that DNDTs improve the accuracy of predictive models for currency crises. They also improve the quality of information for policymakers in the regions under consideration who require empirical tools to mitigate and resolve the impact of a sharp fall in the value of their currency and the negative effects. Our models may also be of particular relevance to financial institutions, such as rating agencies and central banks, which need to control the risk of a potential imminent crisis.
The DNDT algorithm exhibited high predictive capacity in the case analyzed as a result of using NNs to implement DTs. The algorithm also improved the interpretation of results and the quality of information. The results are more accurate than in the existing literature, taking into account the requirement of the samples used in this study.
The results of this study have also suggested a new set of variables to predict currency crises. In this respect, the significance of variables for the external sector and domestic macroeconomy stands out, suggesting they are the best indicators to predict a currency crisis at the global level. There are also a number of other variables for models adapted to the specific circumstances of Asia and Europe, and Africa and Latin America, in which the political and domestic credit variables stand out.
Given the significance of the issue addressed in this study, presenting a global forecasting model to address a gap in the existing literature and obtaining accuracy in the testing sample of over 96% represents significant progress in the challenging task of forecasting future currency crises. It also provides a unique international experience, simplifying and reducing the resources and effort for creating different models for predicting currency crises.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






