1. Introduction
Given two scientific articles
a1 and
a2, bibliographic coupling (BC) is a measure to estimate the similarity between
a1 and
a2 by considering how
a1 and
a2 cite a similar set of references [
1]. BC works based on an expectation that two articles with a similar set of references may focus on related (or even the same) research issues. The expectation is justified in practice, as BC has been an effective measure for many literature analysis and mapping tasks, such as classification [
2] and clustering [
3,
4] of scientific articles, as well as clustering of scientific journals [
5]. Moreover, BC can be applied to more scientific articles, because it works on the references cited by two articles
a1 and
a2, and the
titles of these references are more publicly available than other kinds of information about
a1 and
a2, including full texts of
a1 and
a2, as well as how
a1 and
a2 are cited by others (many articles are even not cited by any article). BC is thus an effective measure to retrieve similar legal judgments [
6] and detect plagiarism [
7] as well. It can also be integrated with different similarity measures, such as those that work on main contents (titles, abstracts, and/or full texts) of articles to cluster articles and map research fields [
3,
8].
Therefore, further improvement of BC is of practical and technical significance. An improved version of BC can be a fundamental component for the scientometric applications noted above. Equation (1) defines BC similarity between two articles
a1 and
a2, where R
a1 and R
a2 are the sets of references cited by
a1 and
a2 respectively. Therefore, the main weaknesses of BC include: (1) two related articles may still cite different references; and conversely, (2) two unrelated articles may happen to cite the same references. Many techniques have been developed to tackle the weaknesses by collecting additional information from different sources, including titles of the references cited by
a1 and
a2 [
9,
10] and full texts of
a1 and
a2 [
11,
12]); however, full texts of many articles are not publicly available.
In this paper, we aim at improving BC by tackling the first weakness noted above (i.e., two related articles may cite different references) without relying on full texts of the articles. A different kind of information is considered: category-based cocitation (category-based CC), which measures how a1 and a2 cite those references that are cited by articles in the same categories about specific topics. A category contains a set of articles that focus on the same research topic (e.g., association between specific entities or events). As articles in the same category are highly related to each other, the references cited by these articles may be related to each other as well, and hence if a1 and a2 cite these references, the similarity between a1 and a2 can be increased, even though these references have different titles. The enhanced version of BC is thus named BCCCC (Bibliographic Coupling with Category-based Cocitation). Experimental results will show that BCCCC performs significantly better than several state-of-the-art variants of BC that worked on references and their titles, which are more publicly available than full texts of articles.
The intended application of BCCCC is the identification of
highly related articles. Two articles are highly related only if they
focus on the
same specific research issues. Researchers often routinely strive to analyze highly related articles on specific research issues that are in their own interest. A typical example of such applications is the identification of articles that report conclusive results on associations of specific biomedical entities. Many databases are built and maintained to include the associations already published in biomedical literature. Examples of such databases are CTD (Comparative Toxicogenomics Database, available at
http://ctdbase.org), GHR (Genetic Home Reference, available at
https://ghr.nlm.nih.gov), and OMIM (Online Mendelian Inheritance in Human, available at
https://www.omim.org). However, maintenance of the databases is quite costly, as it requires a large number of domain experts to routinely collect and analyze highly related articles to curate the databases [
13,
14,
15]. BCCCC is a better tool for the domain experts to prioritize those articles that report conclusive results on the same associations. The article prioritization service provided by BCCCC can also be used to improve those bibliometric techniques that analyze articles about specific topics obtained by a keyword-based search (e.g., using the topic names and their related terms as keywords to get articles about equipment maintenance [
4], pavement management [
16], and pollution by particulate matter [
17]). With the keyword-based search, many articles that do not focus on the topics may be retrieved, and conversely, many articles that focus on the topics may not be retrieved. BCCCC can be used to identify those articles that are highly related to the specific topics.
Moreover, as BCCCC is an enhanced version of BC, it can be used to improve those techniques that relied on BC in various domains (e.g., computer science [
2], biomedicine [
3], legal judgments [
6], smart cities [
18], and mapping of multiple research fields [
5]). BCCCC can also be an improved measure for article clustering, which is a fundamental task of scientometrics studies in various domains (e.g., Internet of things [
19] and smart cities [
20]).
3. Development of BCCCC
The main ideas of BCCCC are illustrated in
Figure 1, which also highlights main ideas of BC and its two variants IBS (Issue-Based Similarity [
9]) and DBC (DescriptiveBC [
10]). BC estimates the similarity between two articles
a1 and
a2 by considering whether they cite the
same references, i.e., Type I similarity in
Figure 1. For example, in
Figure 1,
r1m cited by
a1 is simply
r23 cited by
a2, and hence BC may increase the similarity between
a1 and
a2. Both IBS and DBC estimate the similarity by considering how
a1 and
a2 cite
references with similar titles, i.e., Type II similarity in
Figure 1. For example, in
Figure 1,
r13 (cited by
a1) and
r22 (cited by
a2) have similar titles (even though they are different references), and hence IBS and DBC may increase the similarity between
a1 and
a2. In addition to the above two types of similarity (i.e., Type I and Type II), BCCCC also considers how
a1 and
a2 cite those references that are cited by articles in the same
categories (i.e., Type III similarity, which is measured by category-based CC). For example, in
Figure 1,
r11 (cited by
a1) and
r21 (cited by
a2) are cited by two articles in the same category (even though the two citing articles are different articles), and hence BCCCC may increase the similarity between
a1 and
a2.
More specifically, the similarity between two references r1 and r2 is composed of two parts: (1) text-based similarity (for Type I similarity and Type II similarity noted above); and (2) citation-based similarity (for Type III similarity noted above). Equation (2) defines the text-based similarity, which is 1.0 if r1 and r2 are the same reference; otherwise it is estimated based on the percentage of the terms shared by titles of r1 and r2. When computing the percentage of the shared terms, each term has a weight measured by its IDF (inverse document frequency, see Equation (3). IDF of a term t measures how rarely t appears in the titles of the references of articles. If fewer articles with references mentioning t in their titles, t will get a larger IDF value. Two references will have larger text-based similarity if their titles share many terms with larger IDF values.
The citation-based similarity between two references r1 and r2 is defined in Equation (4), where CategorySpaceVec is a vector with C dimensions (C is the number of categories), and CosineSim is the cosine similarity between two vectors (i.e., cosine of the angle of the two vectors). Each dimension in CategorySpaceVec(r) corresponds to a category, and the value on the dimension is the number of articles (in the category) that cite r. Therefore, references r1 and r2 will have large citation-based similarity if they are cited by articles in a similar set of categories. In that case, r1 and r2 are actually cited by articles with a similar set of research focuses, and hence may be related to each other.
By integrating the two kinds of similarity (i.e., the text-based similarity and the citation-based similarity), the similarity between two references
r1 and
r2 can be estimated. The two kinds of similarity are integrated in a linear way (see Equation (5)), with the text-based similarity having a larger weight because when the text-based similarity is quite high (e.g., it is 1.0 if
r1 and
r2 are the same reference), the similarity between
r1 and
r2 should be high as well, no matter whether the citation-based similarity is large or not. Therefore, the weight of the text-based similarity is set to 1.0, while the citation-based similarity (i.e., parameter
k in Equation (5) may be set to 0.5. We also expect that proper setting for
k should not be a difficult task (the expectation will be justified by experimental results in
Section 4.6).
Based on the similarity between references, the similarity between two articles a1 and a2 is defined in Equation (6), where Ra is the set of references cited by article a. The similarity is estimated by considering how a1 cites those references that are similar to the ones cited by a2, and vice versa. Therefore, for each reference r in Ra1 (Ra2), BCCCC identifies its most similar reference rmax in Ra2 (Ra1). The similarity between each r and its rmax is the basis on which the similarity between a1 and a2 is estimated. Two articles are similar to each other if they cite references that are assessed (by Equation (5)) to be similar to each other. In that case, the two articles may be related to each other as they cite those references that are related to each other.
4. Experiments
4.1. Experimental Data
Development of BCCCC is motivated by the need of researchers who routinely collect new research results on specific associations between biomedical entities, such as genes, diseases, and chemicals. The experimental data was thus collected from CTD, which recruits biomedical experts to curate associations to support biomedical professionals to do further research on the associations already published in literature [
36,
37]. The associations are of three types: <chemical, gene>, <chemical, disease>, and <gene, disease>. All the associations in CTD were downloaded in August 2017. As in [
9], we exclude those associations that are not supported by direct evidence (i.e., those diseases that have no ‘marker/mechanism’ or ‘therapeutic’ relations to chemicals or genes). Each association has scientific articles that have been confirmed (by CTD experts) to be focusing on the association. Therefore, an association can thus be seen as a
category of articles that are
highly related to each other (i.e., they report conclusive findings on the same association, rather than a single entity). Given a target article
aT, a better system should be able to rank higher those articles that are highly related to
aT (i.e., those that are in the same category of
aT). Such a system is essential for researchers (including CTD experts and biomedical professionals) to retrieve, validate, and curate conclusive findings on specific topics reported in literature.
As we are investigating whether BCCCC is an improved version of BC, those articles whose references cannot be retrieved from PubMed Central are removed (PubMed Central is available at
https://www.ncbi.nlm.nih.gov/pmc). Categories (associations) without multiple articles are removed, and categories with the same set of articles are treated as a category. There are 16,273 categories, within which there are 12,677 articles for experimentation. The data items are available as
Supplementary Materials, see
Tables S1–S3 for the three types of categories, respectively. Titles of the references in the articles are preprocessed by removing stop words with a stop word list provided by PubMed (available at
https://www.ncbi.nlm.nih.gov/books/NBK3827/table/pubmedhelp.T.stopwords). To process synonyms properly, MetaMap (available at
https://metamap.nlm.nih.gov) is employed to replace biomedical entities in the titles with their concept IDs.
The 12,677 articles are then randomly and evenly split into 20 parts so that we can conduct 20-fold cross validation: each fold is selected as a
test fold exactly one time and the other folds are used to collect category-based CC information for BCCCC to rank the articles in the test fold, and the process repeats twenty times. In the experiment on a test fold
f, each article
aT in
f is selected as the
target article exactly one time. BCCCC and all the baseline systems (see
Section 4.2) rank the other articles in
f based on how these articles are similar to
aT. To objectively evaluate BCCCC, no information should be available to indicate the categories of the articles in a test fold (i.e., these articles should be treated as “new” articles for which category information is
not provided). Therefore, when BCCCC collects category-based CC information to rank the articles in a test fold, category information of these articles is removed.
As noted above, each article
aT in a test fold
f is selected as the target article exactly one time. Among the articles in a test fold
f to be ranked, those that belong to the same categories of
aT are
highly related to
aT, and hence should be ranked higher. Performance of each system can be evaluated by measuring how the systems rank the highly related articles for each target article (those target articles without highly related articles in
f are excluded in the experiment). Average performance on the target articles is then reported (see the evaluation criteria defined in
Section 4.3).
4.2. Baseline Systems for Performance Comparison with BCCCC
Table 1 lists the baseline systems in the experiments. The first three baselines are BC and its variants: IBS (Issue-Based Similarity [
9]) and DBC (DescriptiveBC [
10]). They are the main baselines in the experiments, as BCCCC aims at being an improved version of BC. Instead of relying on full texts of articles that may not be publicly available [
11,
12], IBS and DBC improve BC by references in the articles. Therefore, performance comparison with BC and the two variants can identify the contribution of BCCCC to further improvement of BC, which has been a fundamental technique for literature retrieval, analysis, and mapping.
To estimate the similarity between two articles
a1 and
a2, the three baselines consider the references cited by
a1 and
a2. The key difference is that BC treats each reference in an “object-based” manner, because the similarity between
a1 and
a2 is increased only when they cocite the same objects (i.e., references, ref. Equation (1)). On the other hand, IBS and DBC were developed to improve BC by “title-based” similarity estimation, in which the similarity between
a1 and
a2 can be increased if they cite references with
similar titles, even though these references are
different from each other. IBS estimates the similarity between two articles based on a certain number of
most-similar references titles in the articles, while DBC estimates the similarity based on
all references’ titles in the articles. It was shown that, by considering the title-based similarity, IBS and DBC performed significantly better than BC in article clustering [
9] and article ranking [
10]. Therefore, BC and the two state-of-the-art variants (IBS and DBC) can be the main baselines to verify whether BCCCC is a further improved version of BC. For more detailed definitions for IBS and DBC, the readers are referred to [
9] and [
10], respectively.
Moreover, to evaluate BCCCC more comprehensively, BM25ref is implemented as a baseline as well. This baseline represents a way that ranks articles by text-based similarity on reference titles. As noted in
Section 2, BM25 [
21] was one of the best text-based techniques to identify related scientific articles [
22]. We apply BM25 to estimating the similarity between
concatenated reference titles (CRTs) of articles. For each article, a CRT is constructed by concatenating all titles of the references cited by the article. The similarity between a target article
aT and another article
ax is simply the BM25 similarity between their CRTs (denoted by CRT
T and CRT
x, respectively). BM25ref similarity is defined in Equation (7), where
k1 and
b are two parameters,
|CRT| is the number of terms in
CRT (i.e., length of
CRT),
avglen is the average length of CRTs (following several previous studies [
10,
22], the two parameters
k1 and
b of BM25ref are set to 2 and 0.75 respectively).
Therefore, BM25ref is not a version of BC, although it relies on the references cited by articles as well. It is thus actually not the main baseline in the experiments. However, comparison of BCCCC and BM25ref can provide additional evidence to further validate whether BCCCC can perform better than a typical text-based approach, which works on reference titles as well. BCCCC can be an enhanced version of BC only if it performs significantly better than all the baselines.
4.3. Evaluation Criteria
As noted above, each article will be a target article exactly one time. Therefore, for each target article, we evaluate how the systems rank its highly related articles (i.e., those that are judged by CTD experts to be focusing on the same research topic as the target article). Two evaluate criteria that are commonly employed by previous studies (e.g., [
10]) are employed to evaluate the systems. The first criterion is Mean Average Precision (MAP), which measures how highly related articles are ranked at higher positions. MAP is defined in Equation (8), where
T is the set of target articles, and AvgPrecision(
i) is the average precision for the
ith target article. MAP is thus the average of the AvgPrecision values for all the target articles.
For each target article, AvgPrecision is defined in Equation (9), where Hi is the number of articles that are highly related to the ith target article, and Ranki,j is the rank of the jth highly related article of the ith target article. As the system being evaluated aims at ranking articles, Ranki,j is determined by the system, and hence Ranki,j is actually the number of articles that readers have read when the jth highly related article is recommended by the system. The ratio j/Ranki,j can thus be seen as the precision (achieved by the system) when the jth highly related article is shown. AvgPrecision(i) is simply the average of the precision values on all highly related articles of the ith target article. It is in the range [0–1], and it will be 1.0 when all the highly related articles are ranked at top-Hi positions.
Therefore, MAP is concerned with how all highly related articles are ranked at higher positions. In some practical cases, readers may only care about how highly related articles are ranked at top positions (e.g., readers only read a certain number of articles at top positions). Therefore, another evaluation criterion average P@X is employed as well. This criterion considers those articles that are ranked at top-X positions only. It is defined in Equation (10), where P@X(i) is the precision when top-X articles are shown to the readers for the ith target article (as defined in Equation (11)). As readers often care about a limited number of top positions only, X should be set to a small value, and hence we investigate performance of the systems when X is set to 1, 3, 5, and 10.
By simultaneously measuring performance of the systems in both MAP and average P@X, we can comprehensively evaluate how the systems rank all highly related articles, as well as how highly related articles are ranked at top positions. A better system should be able to perform significantly better than others in both evaluation criteria.
4.4. Performance of BCCCC and the Baselines
Figure 2 shows performance of all systems. To verify whether differences of the performance of BCCCC and the baselines are
statistically significant, a two-tailed and paired
t-test with 99% confidence level is conducted. The results show that BCCCC performs significantly better than each baseline in all evaluation criteria MAP and Average P@X (X = 1, 3, 5, and 10). When compared with the best baseline DBC, BCCCC contributes 10.2% improvement in MAP (0.5708 vs. 0.5180), indicating that it is more capable of ranking highly related articles at higher positions. When only the top positions are considered, BCCCC yields a 7.1% improvement in Average P@1 (0.5383 vs. 0.5025), 9.8% improvement in Average P@3 (0.3620 vs. 0.3297), 9.3% improvement in Average P@5 (0.2850 vs. 0.2607), and 10.4% improvement in Average P@10 (0.1967 vs. 0.1782).
The results justify the contribution of category-based CC to BC. The best baselines, DBC and IBS, improve BC by considering text-based similarities between reference titles. BCCCC performs significantly better than them by considering category-based CC. BCCCC is thus a further improved version of BC, which is a critical method routinely used to retrieve, cluster, and classify scientific literature. Development of BCCCC can thus significantly advance the state of the art of literature analysis.
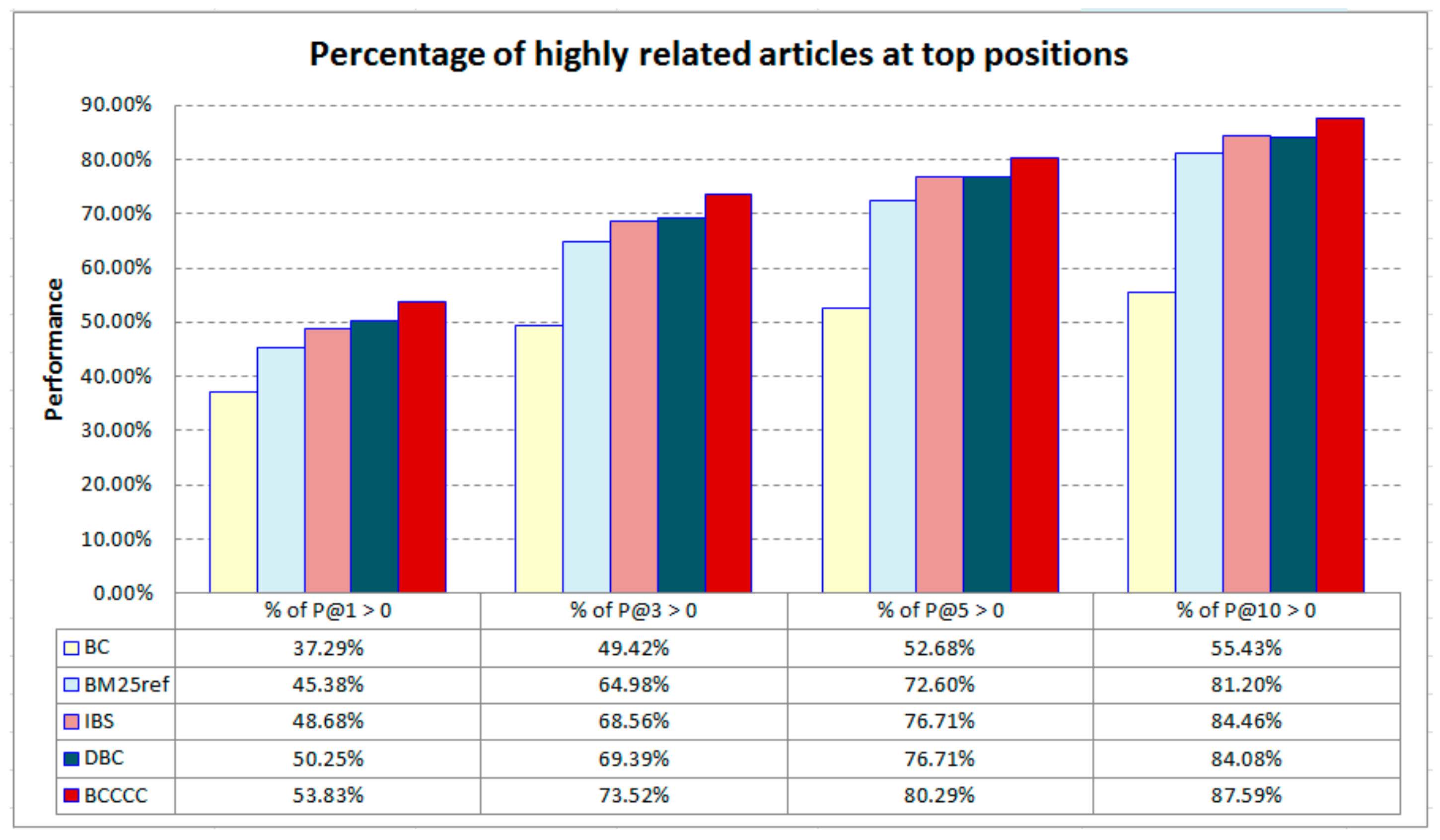
We further measure the percentage of the target articles that have highly related articles ranked at top-X positions (X = 1, 3, 5, and 10). A higher percentage indicates that the system performs more stably in identifying highly related articles for different target articles, making the system more helpful in practice.
Figure 3 shows the results. BCCCC achieves the best performance again. When compared with the best baseline, DBC, it yields a 7.1% improvement when X = 1 (53.83% vs. 50.25%), 6.0% improvement when X = 3 (73.52% vs. 69.39%), 4.7% improvement when X = 5 (80.29% vs. 76.71%), and 4.2% improvement when X = 10 (87.59% vs. 84.08%). BCCCC contributes larger improvements when X is smaller, indicating that it is more capable in ranking highly related articles at top positions for more articles.
4.5. A Case Study
We conduct a case study on a target article (PubMed ID: 22707478 [
38]) to further analyze the contribution of BCCCC, as seen in
Figure 4. Based on the curation by CTD experts, the article focuses on associations of the chemical Bisphenol A with several genes such as ESRRG and ESR1 (i.e., associations <Bisphenol A, ESRRG> and <Bisphenol A, ESR1>). Bisphenol A is a synthetic compound that exhibits estrogen-mimicking properties. ESRRG (Estrogen Related Receptor Gamma) and ESR1 are two genes that respectively encode estrogen receptor-related receptors and Estrogen Receptor α (ERα).
As a test article, article 18197296 [
39] focuses on associations of the gene ESRRG with two chemicals including Bisphenol A (i.e., association <Bisphenol A, ESRRG>). This article is thus highly related to the target article (i.e., article 22707478 noted above), with the association <Bisphenol A, ESRRG> as their common research focus. Another test article is article 17850458 [
40]. It focuses on associations of the chemical Estradiol with two genes ESR1 and ESR2 (i.e., associations <Estradiol, ESR1> and <Estradiol, ESR2>). Estradiol is a female sex hormone, while ESR2 is a gene that encodes Estrogen Receptor β (ERβ). Therefore, although this article and the target article (22707478) have a common focus on the gene ESR1, they are
not highly related, as they actually focus on associations of ESR1 with
different chemicals (article 17850458 focuses on <Estradiol, ESR1>, but article 22707478 focuses on <Bisphenol A, ESR1>).
Therefore, given article 22707478 as a target, article 18197296 is a highly related article, while article 17850458 is a less related article, as seen in
Figure 4, and hence the former should be ranked higher than the latter. However, better baselines in the experiment fail to do so. They prefer article 17850458 to article 18197296 by ranking article 17850458 at the top three positions (DBC: top position; IBS: top position; BM25ref: the 3rd position; BC: the 3rd position), but article 18197296 after the 11th position. BCCCC successfully ranks the less related article at the lower position (the 7th position) and the highly related article at the top position.
We further analyze why BCCCC can rank the highly related article (i.e., article 18197296) at the top position for the target article (i.e., article 22707478). References cited by the two articles tend to have low text-based similarities in their titles (i.e.,
TextSimref is low), while many of these references have high citation-based similarities (i.e.,
CitationSimref is high). Only 15 pairs of the references have TextSimref 0.15, but 67 pairs of the references have CitationSimref 0.5. This is the reason why BCCCC can successfully rank article 18197296 high, but the baselines cannot.
Figure 5 shows an example to illustrate the analysis. Article 22707478 (the target article) and article 18197296 (the highly related article) respectively cite articles 22101008 [
41] and 12185669 [
42] as references (see
r1 and
r2 in
Table 2). The two references share no terms in their titles, and hence their text-based similarity (
TextSimref) is 0. On the other hand, although the two references are
not cocited by any articles, they are cited by
different articles in the same categories (see categories
c1 to
c3 in
Figure 5). Therefore, by category-based cocitation,
CitationSimref between the two references is high (0.647), indicating that the two references may be highly related, and hence BCCCC similarity between the target article and the highly related article can be increased.
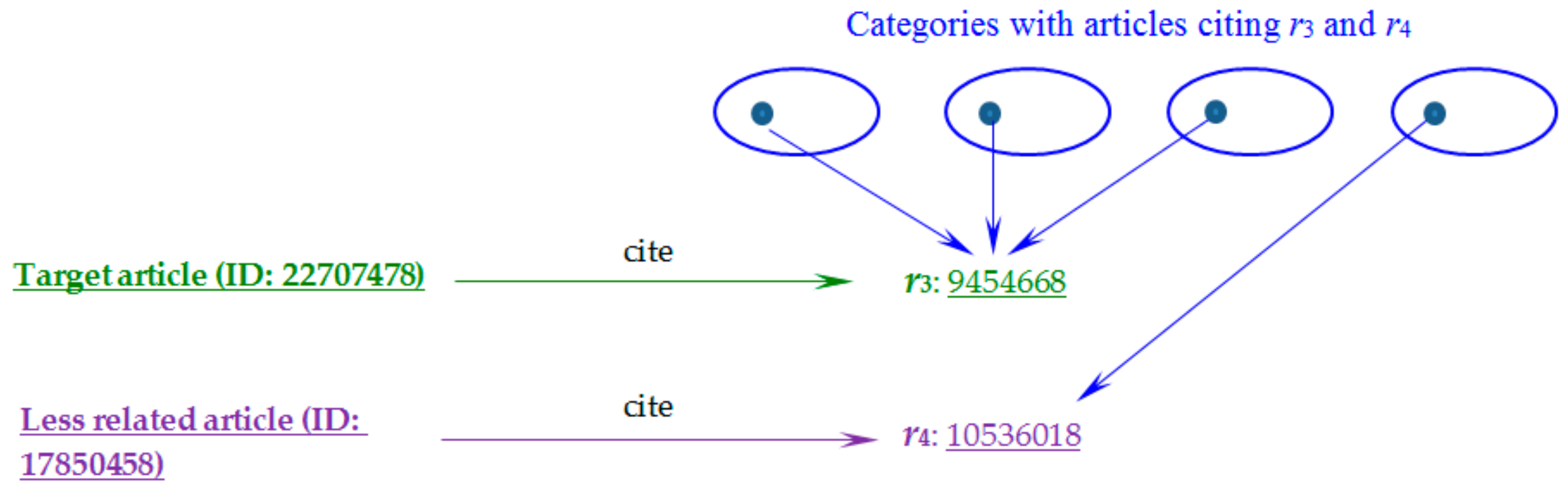
We then analyze why BCCCC can rank the less related article (i.e., article 17850458) at a lower position (the 7th position) for the target article (i.e., article 22707478). Many references cited by the two articles have high text-based similarities, but a smaller number of them have high citation-based similarities (49 pairs of the references have TextSimref 0.15, and 39 pairs of the references have CitationSimref 0.5). This is the reason why BCCCC can successfully rank article 17850458 lower, but the baselines cannot.
Figure 6 shows an example to illustrate the analysis. Article 22707478 (the target article) and article 17850458 (the less related article) respectively cite articles 9454668 [
43] and 10536018 [
44] as references, see
r3 and
r4 in
Table 2. The two references share many terms in their titles (e.g., ‘behavior’, ‘estrogen receptor’, ‘gene’, ‘male’, ‘female mice’), and hence their text-based similarity (
TextSimref) is high (0.21). However, they are not cited by any article in the same categories
, as illustrated in
Figure 6, and hence their citation-based similarity (
CitationSimref) is 0.
Detailed analysis also justifies that the two references actually focus on different issues. As noted in their titles, see
r3 and
r4 in
Table 2, they actually focus on ERα and ERβ, respectively. Estrogen receptors modulate many different biological activities (e.g., reproductive organ development, cardiovascular systems, and metabolism), and ERα and ERβ are encoded by different genes and have different biological functions [
45]. Therefore, term overlap in titles of references (as considered by DBC and IBS) may not be reliable in measuring the similarity between the references. BCCCC considers category-based CC to collect additional information to further improve the similarity estimation.
4.6. Effects of Different Settings for BCCCC
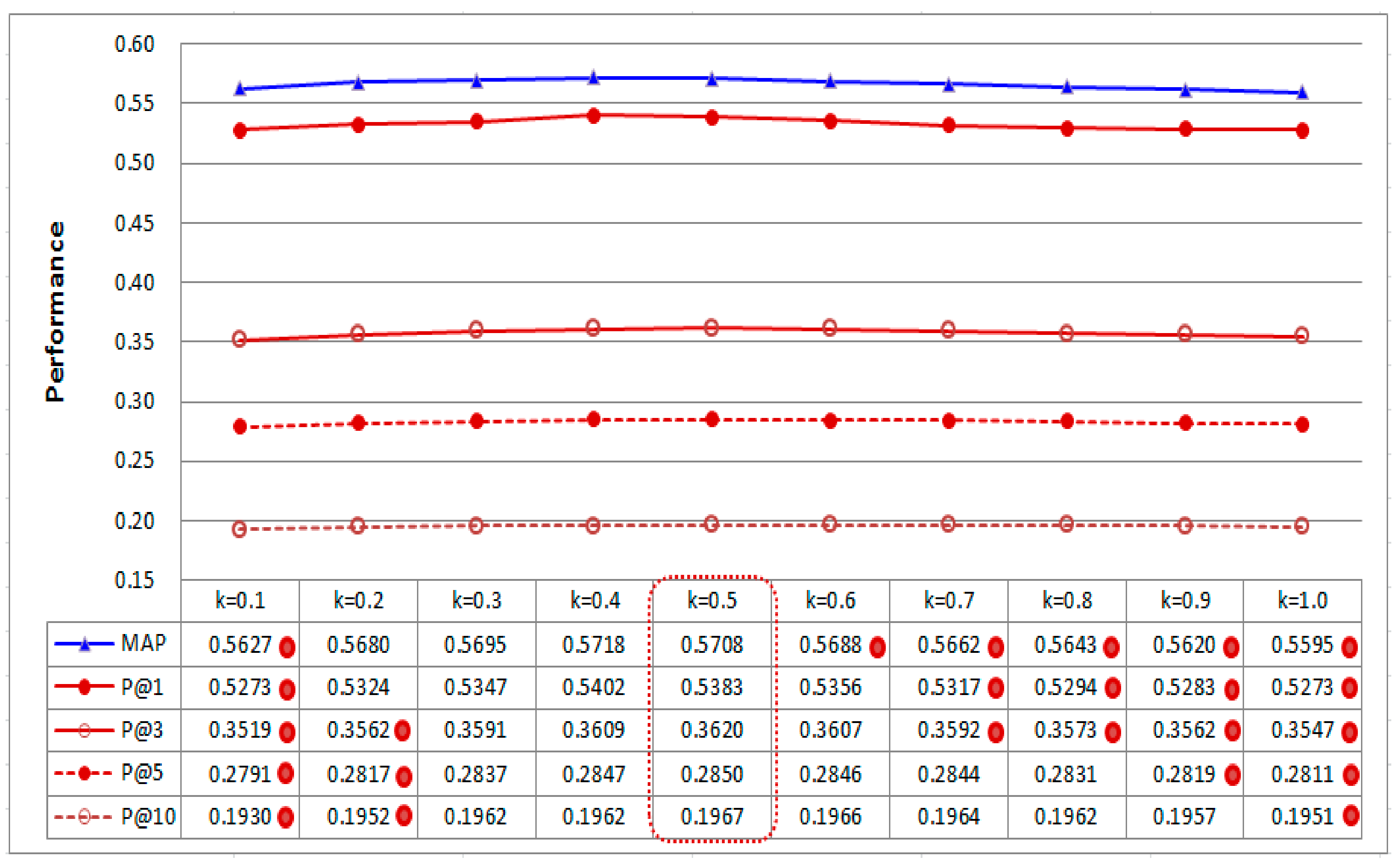
We further investigate the effects of different settings for BCCCC. There is a parameter k that governs the relative weight of the category-based CC component of BCCCC (see Equation (5)). In the above experiments, k is set to 0.5. It is interesting to investigate whether this parameter is difficult to set (i.e., whether performance of BCCCC changes dramatically for different settings for k).
Figure 7 shows performance of BCCCC with ten different settings for
k in [0.1–1.0]. It is interesting to note that performance in each evaluation criterion (i.e., MAP, and Average P@X) does not change dramatically. BCCCC with
k = 0.5 does not have significantly different performance than BCCCC with some of the other settings for
k, especially, when
k is in [0.3–0.5], all performance differences are not statistically significant. Therefore, it is not a difficult task to set the parameter
k in practice. Setting
k as [0.3–0.5] may be good for BCCCC.
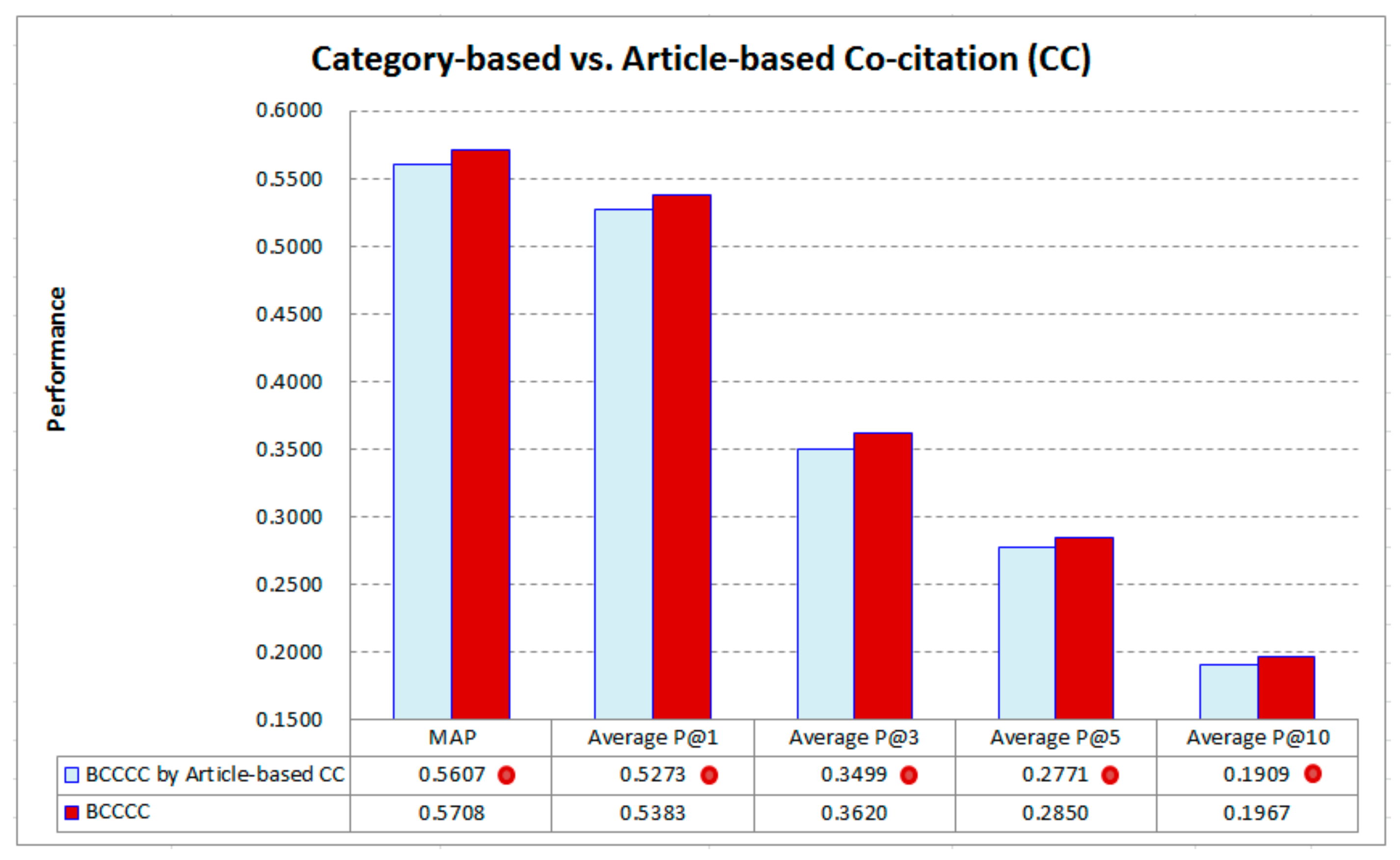
Another different setting for BCCCC is the way to compute the citation-based similarity. In the above experiments, BCCCC employs category-based CC (see Equation (4)). Another setting for BCCCC is to replace Equation (4) with
article-based cocitation (i.e., article-based CC), which is a traditional cocitation measure defined in Equation (12) [
2,
29], where
Ia1 and
Ia2 are the sets of articles that cite articles
a1 and
a2, respectively (i.e., in-link citations of
a1 and
a2, respectively).
Therefore, article-based CC can be seen as a “constrained” version of category-based CC, as cocitation is counted only if two references are cited by the same article (rather than articles in the same category).
Figure 8 shows the performance of the different settings. BCCCC with category-based CC performs significantly better than BCCCC with article-based CC in all evaluation criteria. The results justify the contribution of category-based CC, which provides additional helpful information even when two references are not cocited by the same article. It is also interesting to note that, as BCCCC with article-based CC still performs better than the baselines, as seen in
Figure 2 and
Figure 8, it can be a good version as well, especially when no categories of articles are provided in practice.
4.7. Potential Application of BCCCC to Biomedical Search Engines
We further investigate the potential application of BCCCC to biomedical search engines by comparing its performance with PMS (a PubMed service), which is a service provided by PubMed to recommend related articles for a given article. As noted in
Section 2, PubMed is a popular search engine for biomedical professionals, and PMS integrates several kinds of well-known indicators [
23,
24]. These indicators are routinely employed in information retrieval systems as well. PMS was also one of the best to cluster scientific articles as well [
22]. Therefore, by comparing how BCCCC and PMS identify highly related articles, the potential contribution of BCCCC to biomedical article recommendation can be evaluated.
For each target article, related articles recommended by PubMed were collected on 18 October and 19 October 2019. We focused on those target articles for which the numbers of recommended articles were less than 200. Some of the articles recommended for a target article aT may not be the test articles in the experiments, and hence there is no conclusive information to validate whether these articles are highly related to aT. Therefore, to conduct objective performance comparison, these articles are excluded so that both BCCCC and PMS can work on the same set of test articles whose relatedness to aT has been validated by CTD experts.
More specifically, given a target article aT, let PT be the set of articles that are recommended by PubMed and included in the test articles judged by CTD experts. Let l be the lowest rank of the articles (in PT) in the ranked list produced by BCCCC, and BT be the set of articles that BCCCC ranks at the 1st to the lth positions. Therefore, BT includes articles in PT, as well as those that are ranked higher by BCCCC. Articles in BT thus fall into two types: (1) those that are recommended by both BCCCC and PMS (i.e., the set PT); and (2) those that are recommended by BCCCC but not PMS (i.e., the difference set BT−PT). With this experimental setting, it is reasonable to expect that PMS actually prefers the former (i.e., articles in PT) to the latter (i.e., articles in BT−PT).
Performance of PMS and BCCCC can be compared by measuring their precision and recall on PT and BT, respectively. Precision of PMS is the percentage of highly related articles in PT, while precision of BCCCC is the percentage of highly related articles in BT (see Equations (13) and (15)). Computation of recall requires the number of highly related articles that should be retrieved. This number can be seen as the highly related articles in BT (see denominators of Equations (14) and (16), and if there is no highly related articles in BT, the target article aT is excluded from the experiment), because BCCCC recommends all articles in BT, while PMS may only recommend some of them (as noted above). Recall of BCCCC is thus always 1.0 (see Equation (16)), and we are investigating whether this is at the cost of recommending more articles and thus possibly reducing its precision.
Therefore, there often exist tradeoffs between precision and recall, and hence the F1 measure is computed. F1 is a measure commonly used in information retrieval studies to harmonically integrate precision and recall (see Equation (17)).
The results show that the average F1 values of PMS and BCCCC are 0.7786 and 0.8420, respectively, indicating that BCCCC performs 8.1% better than PMS. A significance test (two-tailed and paired t-test) also shows that the performance difference is statistically significant (p < 0.01). PMS performs worse as it cannot recommend many highly related articles that are recommended by BCCCC. As PMS is a practical system that recommends scientific articles based on titles and abstracts of articles, it is helpful for the article recommendation services to consider the citation-based information collected by BCCCC, especially when the system aims at recommending highly related articles.
5. Conclusions and Future Work
BC is a similarity measure applicable to scientific articles that cite references, because it estimates the similarity between two articles by measuring how the two articles cite a similar set of references. BC is thus an effective and fundamental measure for retrieval, analysis, and mapping of scientific literature. However, BC has a main weakness: two related articles may still cite different references. The proposed new measure, BCCCC, tackles the weakness of category-based CC, which estimates how these different references are related to each other. Development of category-based CC is based on the assumption that two different references may be related if they are cited by articles in the same categories about specific topics.
The performance of BCCCC is evaluated by experiments and validated in a case study. The results show that BCCCC is an improved version of BC, as it performs significantly better than state-of-the-art variants of BC. The contribution of category-based CC to BC is thus justified. Moreover, effects of different settings for BCCCC are investigated as well. The results show that setting a proper parameter for BCCCC is not a difficult task, and article-based CC may still be helpful, although it is less helpful than category-based CC. We also investigated the potential contribution of BCCCC to biomedical search engines. The results show that BCCCC performs significantly better than the article recommendation service provided by PubMed, which is a popular search engine routinely employed by biomedical professionals. BCCCC can thus provide a different kind of helpful information to further improve the search engine, especially in recommending articles that are highly related to each other (i.e., focusing and reporting conclusive results on the same specific topics).
An application of BCCCC is the identification of highly related articles. As noted above, BCCCC can be used to improve PubMed in recommending highly related articles, which is a service required by biomedical professionals, who often routinely analyze highly related articles on specific research issues. Identification of highly related articles is also required by domain experts that strive to maintain online databases of the associations already published in biomedical literature (e.g., CTD, GHR, and OMIM noted in
Section 1). Maintenance of these databases is quite costly, as the domain experts need to routinely collect and analyze highly related articles to curate the databases. The associations already in the databases can be treated as categories for BCCCC to employ category-based CC to prioritize new articles that report conclusive results on the same associations. With the support of BCCCC, curation of new associations can be done in a more timely and comprehensive manner. The bibliographic coupling information provided by BCCCC may be used to improve other search engines in different domains as well.
Another application of BCCCC is the improvement of scientometric techniques that have been used in various domains. BCCCC can be used to improve these techniques in retrieval, clustering, and classification of scientific literature. Moreover, BCCCC is an enhanced version of BC, which is often integrated with different measures. It is thus reasonable to expect that these measures can be further improved by incorporating the idea of BCCCC.
BCCCC improves BC by category-based CC (i.e., CitationSimref, see Equation (4)), which is integrated with a similarity component working on the titles of the references (i.e., TextSimref, ref. Equation (2)). It is thus interesting to investigate how category-based CC can work with other kinds of text-based similarity components so that identification of highly related articles can be further improved. For example, text-based similarity can be measured by considering the abstracts of the references, rather than only the titles of the references. The abstract of a reference is often a commonly available part describing the goal of the reference, and hence text-based similarity based on the abstract may be helpful to further improve BCCCC. It is thus interesting to develop methods to (1) recognize the main research focus of a reference from its abstract; (2) estimate the similarity between two references based on their research focuses; and (3) integrate BCCCC with the abstract-based similarity.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}