1. Introduction
Damage detection and Structural Health Monitoring (SHM) indicate the field of engineering that is involved in the assessment of the structural integrity for civil, mechanical, and aerospace applications, among others [
1]. More specifically, vibration-based SHM [
2] deals with the structural response, as recorded by means of a sensor network, to extract damage-related features from its free or forced oscillations. In this context, recent years have seen a continuous surge of interest in Machine Learning (ML) algorithms, as they are perfectly suited for damage detection [
3], if this is seen from a Pattern Recognition/Novelty Detection standpoint [
4]. The concept is simple: by knowing the current state of a system (which is usually undamaged, but can be indistinctly previously damaged, as long as it is stable and not dramatically changing under “normal” conditions), a baseline can be defined. This is performed by training a “normality” model via ML techniques over the features that were extracted from the known set of data. Subsequently, the structural response from other scenarios can be labelled as divergent from this model or not by regarding the value of a distance metric between its current response and the baseline model. One can refer to the previously cited book of Farrar & Worden for a detailed description of the basics of ML for SHM [
1].
Some damage-related features (also known as damage sensitive features, DSFs) are needed for training and testing a Machine Learning algorithm. Eventually, DSFs need to be as low in dimensionality as possible, since a very large number of cases is required for the training phase, preserving the relevant information while discarding unrelated effects. However, feature selection is a concern much broader than its SHM applications. One of the fields where it has seen a major development is in speech, speaker, and language recognition.
Virtual assistants, human-like speech synthesis, and audio indexing are all examples of ML applied to Speech Processing for Artificial Intelligence (AI) purposes. Other applications are countless: automatic transcription to text and conversational human-machine interfaces are the most obvious uses of speech recognition. Speaker recognition, i.e., the process of automatically predicting the identity of the speaker by a given utterance, is used for voice biometric authentication, telephone-based services, speaker diarisation, and forensic activities. Finally, language recognition finds its main applications in emergency call routing, spoken language translation, and audio surveillance, to cite a few. Speaker and language recognition rely on similar techniques, as they mostly share the same problems: preprocessing the signal, extracting its relevant features, and representing them by means of statistical models.
There are no conceptual impediments for the application of the related techniques for vibration-based SHM if acceleration time histories (THs) from the structure of interest are considered instead of audio samples. As for speaker recognition, distinctive traits, related to specific phenomena of interest, have to be spotted and discerned from uninteresting effects. On the one hand, mechanical vibrations and biomedical signals show the same issues, such as changing content along time (both frequency- and amplitude-wise) during dynamic excitation, which cannot be properly depicted by means of Discrete Fourier Transform (DFT) [
5], and thus require joint time-frequency analysis techniques for a two-dimensional, time-vs-frequency representation [
6,
7], such as the one obtained via wavelet analysis [
8,
9,
10,
11]. On the other hand, speech signals present some difficulties—such as different duration between samples, unknown input, and high level of non-stationarity—which are generally much less impelling for civil and mechanical structures rather than in biological systems [
12]. Indeed, it is possible to figure the human speech production system out as a control system, where the plant dynamics are related to the vocal tract characteristics, while the constriction and airflow mechanisms are the biological counterparts of the controller. In this sense, the analogy with structural vibrations is straightforward. Some other examples of contamination between the speech processing techniques and structural health monitoring include some recent works on Wavelet Levels (WLs), on Hilbert-Huang Transform (HHT), and on Empirical Mode Decomposition (EMD) [
13,
14]. Other proposals include well-known techniques, such as the Continuous Wavelet Transform (CWT), the Unscented Kalman Filter (UKF), and the Blind Source Separation (BSS) [
5].
By far, the cepstrum [
15] has been the main contribution to the field, being often coupled with other techniques, such as autoregressive moving-average (ARMA) models [
16] or directly applied for the cepstral editing of signals [
17,
18]; an extensive review of the uses of cepstral features for the monitoring of mechanical (non-biological) vibrations can be found in [
19].
Mel-Frequency Cepstral Coefficients (MFCCs) are an example of low-dimensional, fixed dimension feature vectors defined into a cepstral framework, which are very effective in speech processing and already successfully tested as DSFs for mechanical systems [
20,
21] and subsequently refined [
22]. MFCCs proved to be apt in detecting damage in experimental and numerically simulated data for simpler structural elements and in more complex cases, such as historic masonry buildings. However, this feature is not free of issues; one of the major problems of MFCCs is how they can be swayed by additive noise with relative ease. Indeed, log-mel-amplitudes are influenced by the low-energy component of the signal and this is more strongly evident in the first MF cepstral coefficient.
Similarly to the MFCCs, the Teager-Kaiser Energy Cepstral Coefficients (TECCs) were first introduced in the ambit of Speech Recognition in 2005 by Dimitriadis et al. [
23], relying on the Kaiser definition of the Teager Energy Operator [
24]. The process for their extraction is two-stepped. Firstly, the signal is filtered through a dense non-constant-Q Gammatone filterbank (details will follow shortly), which replaces the triangular filters utilised in the standard MFCCs approach. This initial step is shared with other closely related alternatives, such as, specifically, the Gammatone Cepstral Coefficients (GTCCs) [
25], which have also been tested here in this work. Secondly, the short-time average of the output of the previously mentioned Teager-Kaiser Energy (TKE) Operator is computed. A deeper discussion for both MFCCs and TECCs is postposed to the respective subsections; it is important to remark here how the proposed TECC-based method relies on the TKE operator, which, in turn, is the basis of several time-frequency analysis approaches for the estimation of instantaneous amplitude and frequency [
26]. These techniques already proved to be efficient in other fields of signal processing apart speech analysis and very recently they have been successfully applied to Structural Health Monitoring. For instance, the TKE has been combined with deep belief networks for the fault diagnosis of reciprocating compressor valves [
27] and with least-squares support vector machine (LS-SVM) classifiers to detect bearing fault [
28]. Nevertheless, its use is still very limited and few applications are reported in the literature.
The proposed TECC-based approach has been tested on two numerical and one experimental case studies. The first numerical case is a Finite Element (FE) model that represents the Santa Maria and San Giovenale Cathedral bell tower in Fossano, Italy, which is a structure of relevant importance for cultural heritage and it has been deeply investigated in the literature (for instance, see [
29]). This is representative of historical masonry buildings, which noteworthy often present several structural problematics and require proper monitoring [
30], especially in the case of high-rise medieval structures [
31,
32]. The second case study regards the spar of the high-aspect-ratio (HAR) prototype wing XB-1 studied in [
33]. This case also presents its own difficulties, arising from the high flexibility of the cantilevered structure. The experimental data that are described in [
21] have also been used for comparison. In this last case study, the damage is modelled as a breathing crack mechanism, introducing a source of nonlinearities often encountered in damaged structures, where the presence of crack often results in nonlinear behaviour [
34,
35]. As a benchmark, the original five alternative methods that were proposed in [
21] and the six new closely-related variants described in [
22] have also been applied to the numerical and experimental data; the results show interesting improvements.
It is important to stress how the choice of different structural systems, materials, and damage mechanisms for this methodology’s validation is intended to show its reliability for novelty detection in a wide range of applications and conditions, as “damage” (in the broader sense possible) might manifest itself in many different ways, also depending on the specific constructional material [
36], and these different occurrences may not be all similarly easy to detect—especially in larger structures with complicated geometries.
The outline of this paper is as following: in
Section 2, the needed background for a full comprehension of the context is recalled. The algorithm that is utilised for damage detection is described in
Section 3. In
Section 4, the numerical case studies are presented.
Section 5 briefly describes the experimental data used for further validation. A comparison with previous works and similar alternatives is also proposed in the Results Section, and Conclusions follow.
3. Damage Detection Algorithm
The chosen feature, the TEC coefficients, has been used to train a machine learning (ML) algorithm, obtaining a model of the structural response of interest on unaltered conditions. The algorithm applied is essentially the one that is described in [
21], being the proposed DSF, and not the ML procedure utilised, the novelty of this paper; the procedure is only briefly restated for completeness.
As for any ML approach, two phases exist—training and testing—where the former can be executed offline, while the latter may be performed online. During the training phase, the pattern of the DSF coming from the baseline model is ‘learnt’ by the algorithm, which builds a statistical model out of it. This model is then used as a comparison for the same feature when extracted from the structural response under unknown conditions. A metric of distance between any test case and the reference model is then utilised to discern whether these conditions under inspection correspond to a structural change that is substantial enough to be linked with damage. This threshold value, as will be better explained later, is derived via statistical means. This classic statistical framework is well described in [
59].
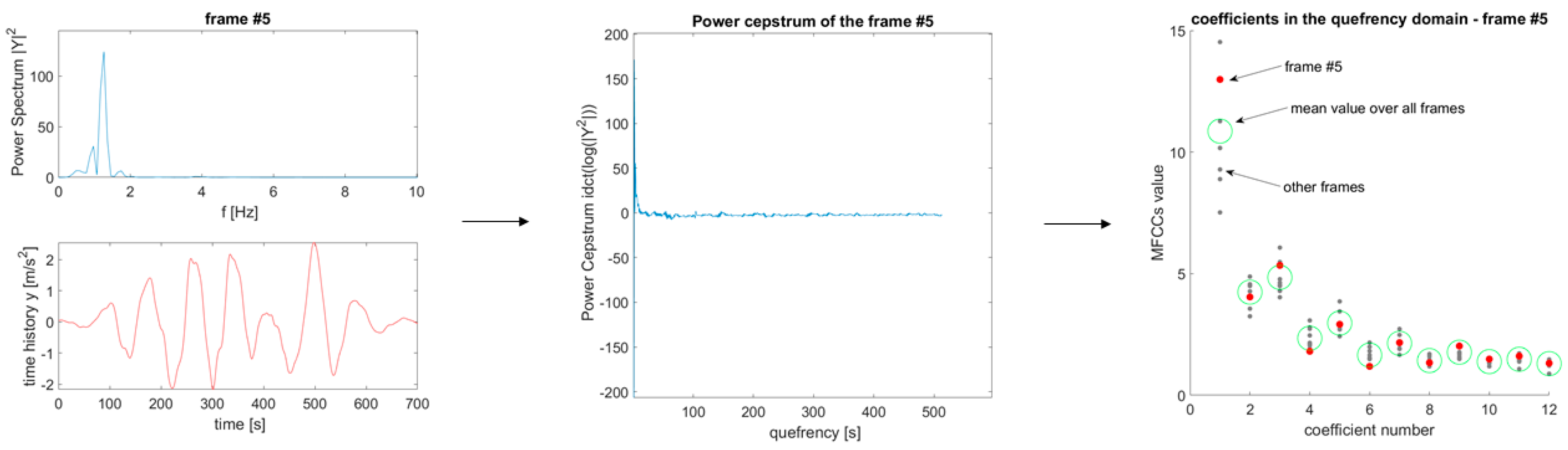
Signal pre-processing on the acceleration THs was executed, as indicated in [
22]. For
acquisition channels,
realisation and thus
THs for training the ML algorithm, it is then possible to extract
feature vectors, i.e.,
, where
represents the
-th vectors of
CCs, where
has been arbitrarily chosen and set equal for all of the alternatives tested here (both numerically and experimentally) to enforce comparability; note that the size
derives from the first CC,
, being always discarded to mitigate the DC component and other input-specific effects [
20].
The following hypotheses have been made. First, the cepstral features are assumed to follow a Gaussian multi-variate distribution (which is reasonable for a large enough training set and very commonly used for ML); therefore, all
are considered as being practically uncorrelated and thus independent identically distributed (i.i.d.) vectors. This is necessary to completely define the ‘normality’ model (i.e., the baseline model of the unaltered reference situation) by means of its sample covariance matrix
and the sample mean vector
alone. These can be computed, respectively, as
and
The Squared Mahalanobis Distance (SMD) of a
-dimensional point
from the baseline model is used as a damage metric;
corresponds to one element of the test set, i.e., to a single test feature vector
. The physical meaning behind the use of SMD is that features coming from more different structural conditions will be more distant in the feature space; the advantages of this approach, which is the favourite (and often the default) option for outlier detection, are well-known and properly described in [
21]. Basically, it relies on the sample covariance matrix
; this allows for accounting for feature variability under confounding factors, such as temperature variation, wind speed, or operational conditions, as long as the given samples are measured during these different, non-damage-related external conditions. The SMD can be analytically defined as
and the procedure can be easily extended and generalized to multiple elements in the test set. As a Damage Index (DI),
needs a threshold (hereinafter,
) to discern actual outliers—hopefully, linked to damaged conditions—to statistical fluctuations of the normality model; it is, essentially, a lower limit of discordancy to call for novelty.
is defined here by exploiting a known property of the inspected distribution. The distribution of the SMD of a
-variate point
follows a scaled
-distribution [
60], defined by two degrees of freedom, the dimension of the scalar
and the number of observations in the statistical population used to define the model. In this specific case, they take the form of
and
, which leads to
where
can be directly compared to the
F-distribution after being properly scaled. Noteworthy, this is valid as long as
, which belongs to the test set, has not been used to define the sample statistics’ estimators.
is then simply defined correspondingly to the
quantile of
, with
arbitrarily set to 1%. Moreover, it is mandatory that the total number of training data is larger than the degrees of freedom of the system analysed (i.e., of the product between the number of cepstral coefficients per channel and the number of channels) to produce the needed statistics.
5. The Experimental Case Study (Frame Behaving Nonlinearly)
For the experimental validation, a laboratory three-story frame, which behaves nonlinearly due to damage occurrence, has been investigated; this is the same case studied by [
21], again to ensure the comparison of the results, and proposed by [
3]. Please note that this is quite different from the two numerical cases, where the structural damage was not a source of nonlinearity. This is due to the goal of this experimental setup being to mimic breathing crack behaviour [
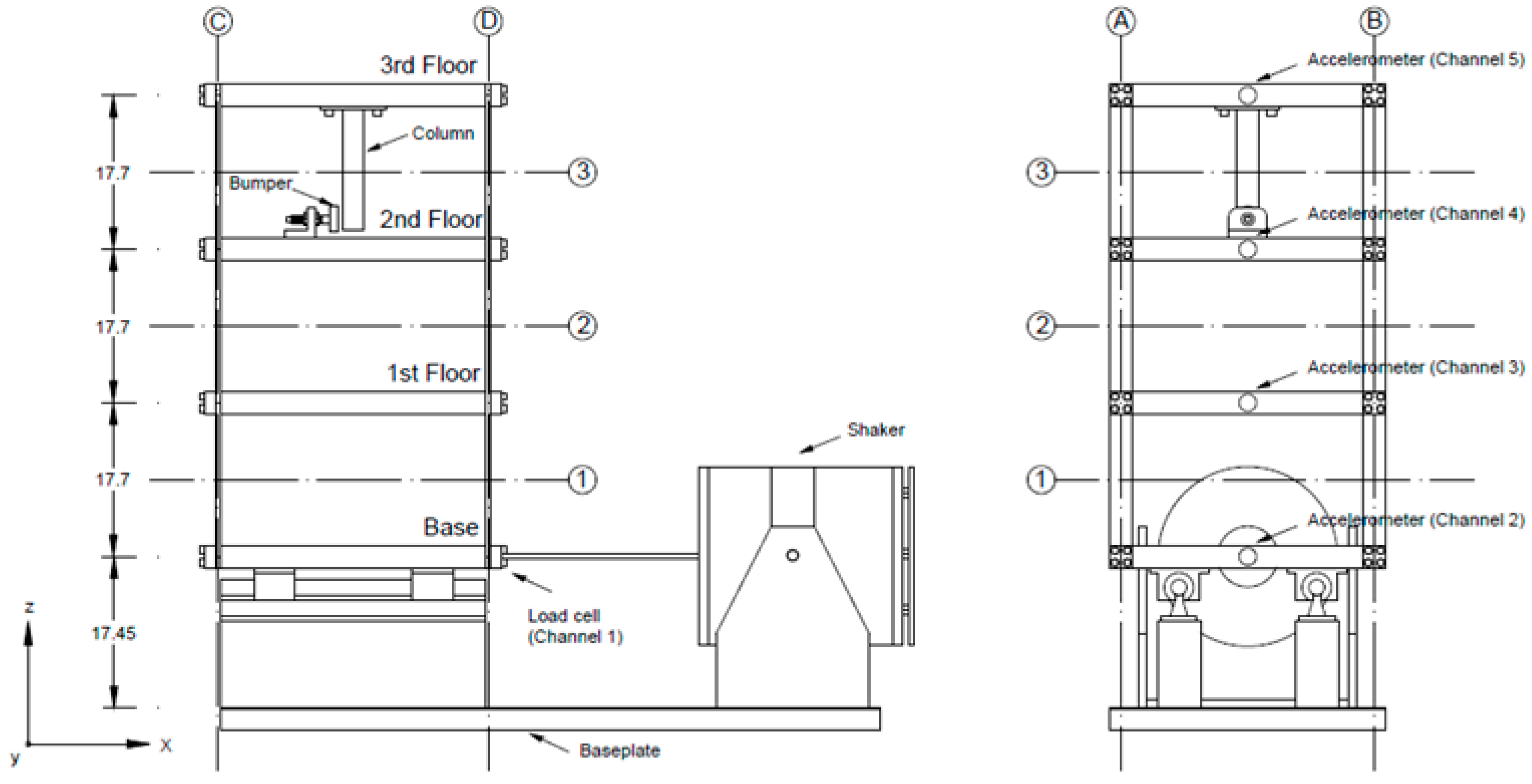
63]. A bumper–column bilinear mechanism achieves this: the column, hanging from the third floor, meets the bumper at the second story. This mechanism generates a directional nonlinear response, with stiffness increasing when the two are touching and pushing against each other. A scheme of the test structure is reported in
Figure 8; the shaker and the four sensors’ locations are highlighted. A detailed description of the experimental setup and procedure is provided in [
59]. The severity of the damage is modelled by moving closer or farther the column’s tip—when they are closer, the two elements come in touch for lower amplitudes of the driving force, thus causing major nonlinearities in the recorded response. The experimental THs have a total duration of 25.6 s, with
Hz. The dynamic input is a band-limited excitation (ranging 20–150 Hz), as defined in [
3]. The 17 states (nine undamaged and eight damaged, with the first nine configurations being intended to emulate different operational and environmental conditions) were used for this investigation; they are summarized in
Table 6. All the output channels were used for the sensor setup considered. The test set was made up of 10 realisations for each scenario, totalling 180 simulated THs.
As for the second numerical case study, the definitions of ECO- and MO-MMFCCs have been changed to fit the structure of interest. For ECO-MMFCCs, the 90% bound of
is approximately 78 Hz (averaging over the channels 3, 4, and 5 for the 50 realisations of Case 1); the
limit of LO-MMFCCs becomes 160 Hz. The array of the centre frequencies for MO-MMFCCs underwent some major rethinking. Being the structure basically assimilable to a three degrees-of-freedom oscillator (floor level does not count as it is subject to the input-induced rigid motion), only the first three frequencies have been retained. The remaining seven filters have been linearly spaced up to
, i.e., 160 Hz, thus resulting in
6. Results
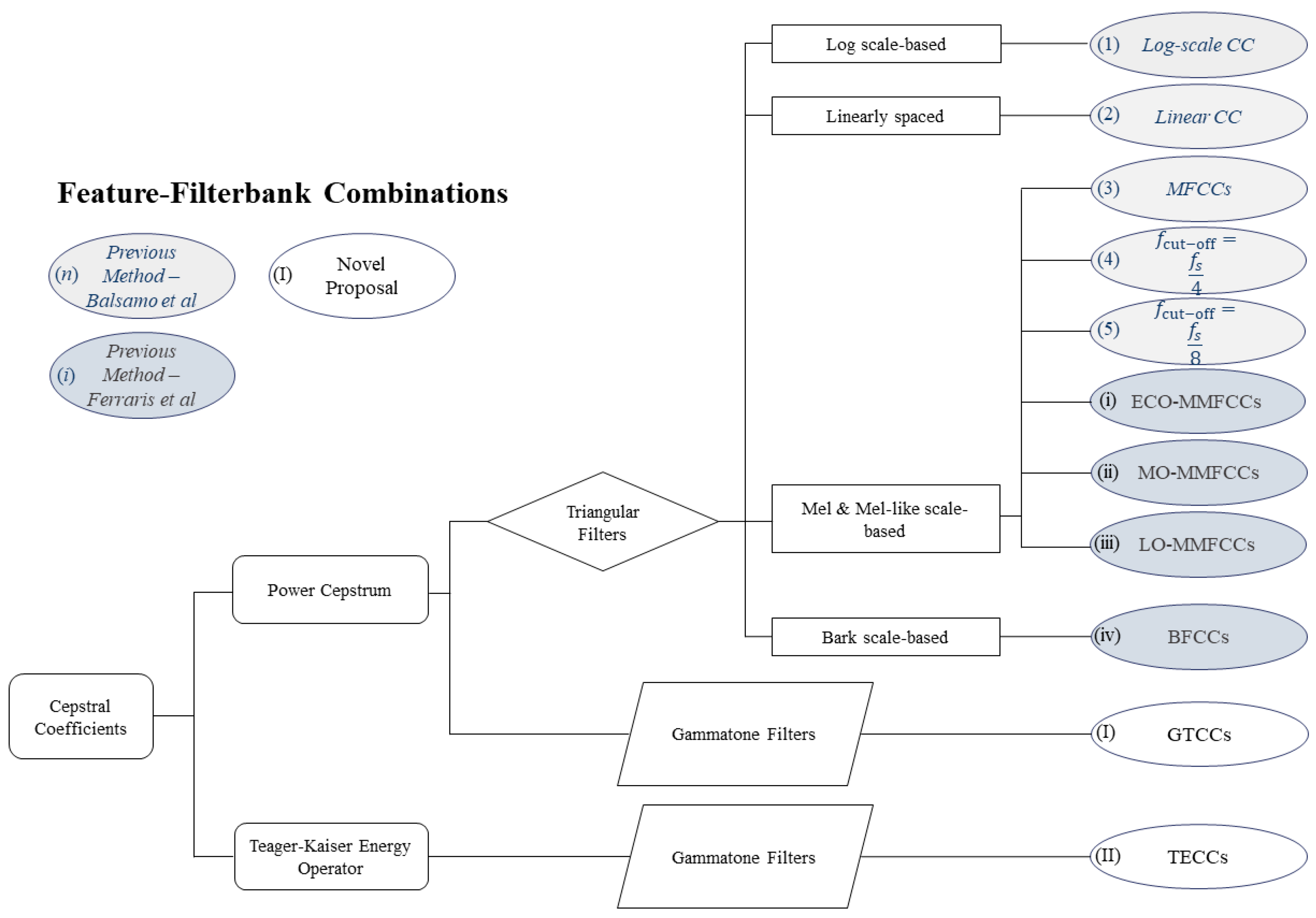
The results from previous works are reported for direct comparison. The methods applied are, by following the same nomenclature (see also
Figure 2), (1) the log-scale CCs; (2) the linear CCs; (3) the classic definition of MFCCs; (4) the MFCCs with a cut-off frequency
; and, (5) the MFCCs with a cut-off frequency
from [
21]; the three proposed Mel-Modified Cepstral Coefficients (MMFCCs), i.e., the so-called (i) ECO-MMFCCs; (ii) MO-MMFCCs; and, (iii) LO-MMFCCs, from [
22], plus the Bark-scale based (iv) BFCCs; finally, the novel features here presented, (I) the GTCCs and (II) the TECCs.
For better readability, this Section is split between the numerical and the experimental data. All the results are expressed in terms of type 1 (false positives, i.e., false alarms) and type 2 (false negatives or false acceptance) errors. In the latter case, the system is declared healthy while not being so; the opposite happens for false alarms. Being life-safety the main aim of any SHM procedure, type 1 errors are generally overlooked respect to their type 2 counterparts. Nevertheless, economical, practical, and psychological concerns make these as valuable as the other ones. A simple yet effective reasoning is that an alarm system constantly affected by false alarm will most probably be ignored when actual damage is effectively spotted. This nullifies any possible gain from the deployment of the SHM apparatus.
6.1. Results from the Numerical Simulations
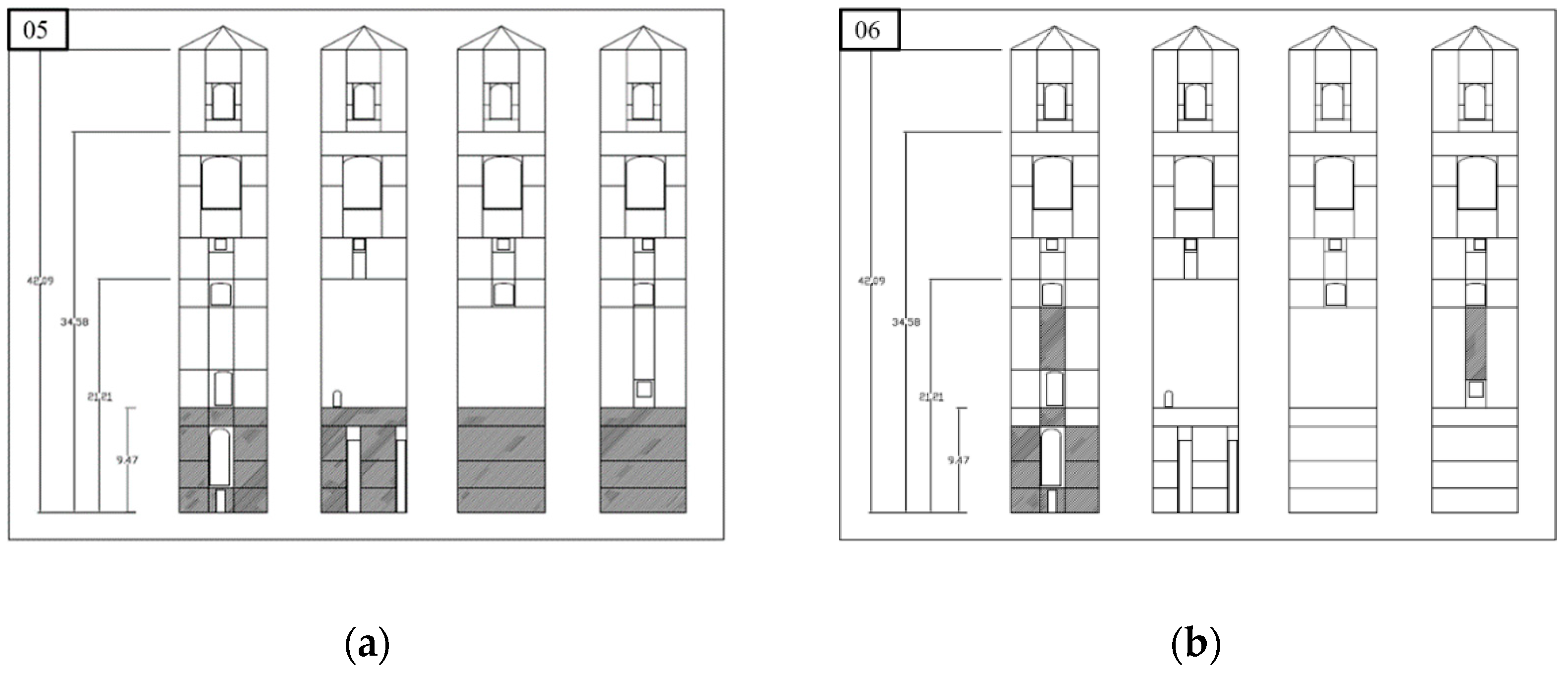
Regarding the first numerical case study (the Fossano bell tower), cases 00 to 04—i.e., the baseline and the story-uniform damage cases—are visually compared in
Figure 9 to prove the algorithms capability to discern simpler configurations and widely extended damage from the normality model.
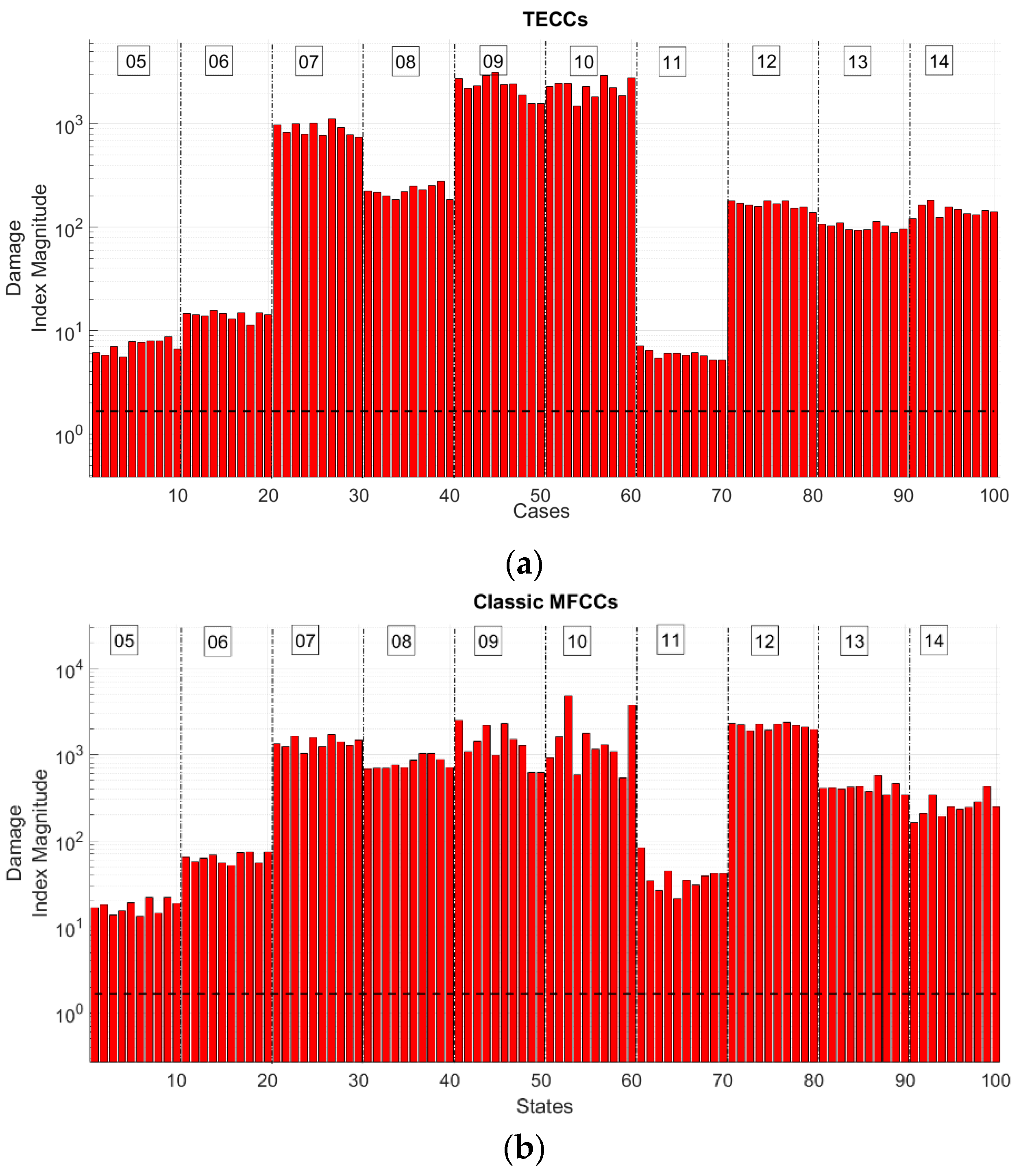
Figure 10 shows the results for cases 05 to 10 (realistic damage scenarios). To estimate the robustness of each MFCC-based variant to false alarms, cases 15 to 18 (i.e., the scenarios with small fluctuations of the Young’s modulus respect to the baseline) are presented in
Figure 11. Apart from the Teager-Kaiser Energy Cepstral Coefficients, the standard definition of MFCCs is also shown for comparison.
Table 7 reports all results. In all figures, the black dashed line represents the defined threshold; bars exceeding it are coloured in red and they stand for the realisations labelled as damaged, while blue bars indicate values of DI under the prescribed threshold. From a statistical pattern recognition standpoint, this means that the cepstral features that correspond to that specific realisation have not departed considerably enough from their respective values for the reference baseline and are therefore labelled as undamaged.
As can be inferred from the first two columns of
Table 7, the GTCCs, the Logarithmic Scale CCs, and the three Mel-Modified Scales (ECO-, MO-, and LO-MMFCCs) have all relatively low type 1 errors. The Damage Index values inside any given damage case are quite similar; that is a valuable proof of the robustness of the method. Bark-scale based CCs wrongly labelled as damaged 60% of the undamaged inputs coming from the same scenario used for the training. The TECCs were the most performing feature; in
Figure 9.a one can clearly see that two out of the three mislabeled realisations for TECCs fall very short of the threshold. The third column in
Table 7 (cases 05–14) shows that all algorithms work effectively in terms of damage detection. The classic definition of the Mel-Scale, the Bark-Scale, and the linear Scale nevertheless present some relatively larger fluctuations along the ten realisations of the same damage scenario with different inputs. The Log-Scale and the Mel-modified Scales provide more stable results, with a flat trend inside each damage scenario. This seems to indicate that a kind of nonlinear scale performs better than the constantly spaced filters. The filter shape might be even more incisive, as GTCCs and TECCs are all spaced according to the Bark Critical Bands yet perform better than triangular filters-based options both in terms of type I and II errors. Most of the algorithms recognise substantial gaps (
Figure 8 and
Figure 9) between different scenarios, which reflect the difference of damage extension; this seems to indicate a possibility to also exploit them for instances of damage severity assessment. Finally, the last column of
Table 7 (cases 15 to 18) evidently portrays how only the TECCs correctly label all the proposed cases as unmodified respect to the baseline; the other features proved to be quite unsatisfactory, especially the Mel-Scale and Bark-Scale. That seems to once more validate the assumption that the straight application of the original definition of the mel-scale, tuned for speech processing aims, is not well-performing and proper corrections are needed. In particular, the scenarios with a variation in the material properties of ±0.25% are most often correctly labelled as healthy; otherwise, the ±1.00% deviation of the Young’s modulus provides DI values above the threshold. This phenomenon could be justified by the fact that even a relatively small difference between the pristine and modified mechanical properties of the model’s material cause a greater variation in the power spectrum of the structure, which is also reflected in the power and is wrongly seen as damage-induced. This aspect is not helpful in the damage detection process; the TKE operator seems to be more resilient to these slight changes. By summing up all of the damage scenarios of this first case, it turns out that of all features, the TECCs are the only one always correctly labelling the cases with realistic damage patterns (05–14) and the ones with global, small fluctuations of
E, unrelated to damage (15–18). Indeed, the TECCs fall short of a perfect score for only three mislabeled realisations (out of 10) in case 01, which was also the most demanding scenario due to the proximity of the damage to the fixed end.
Table 8 reports the results for the second case study (the highly flexible prototype wing);
Figure 12 graphically illustrates them. It can be inferred that, in this case, the exact detection of damage was more difficult. MFCCs and similar variants proved to be able to spot everywhere the damage but at the cost of not actually discerning it from the two cases with small perturbations. The TECCs, on the other hand, did not perform perfectly, yet they avoided all but one false alarm and were able to discern the damaged conditions decently in the inspected scenarios. If one does not take into account Case 07, which presents an imperceptible decrease of 0.03 Hz and went completely unnoticed by the trained algorithm, the type 2 error percentage drops to 7.50%, with two errors in Case 04, no one in Case 05, and a single mislabeled element in Case 06.
As in the previous case of the Fossano bell tower, this seems to point out the larger robustness of the TECCs feature to small changes, assumed here as statistical variations of the structural parameters and not directly linked to damage occurrence. A possible explanation comes from the TKE Operator being notably sensitive to frequency and amplitude changes, while much more robust than MFCCs to noise and minimal variations in the field of speech recognition accuracy.
6.2. Results from the Experimental Data
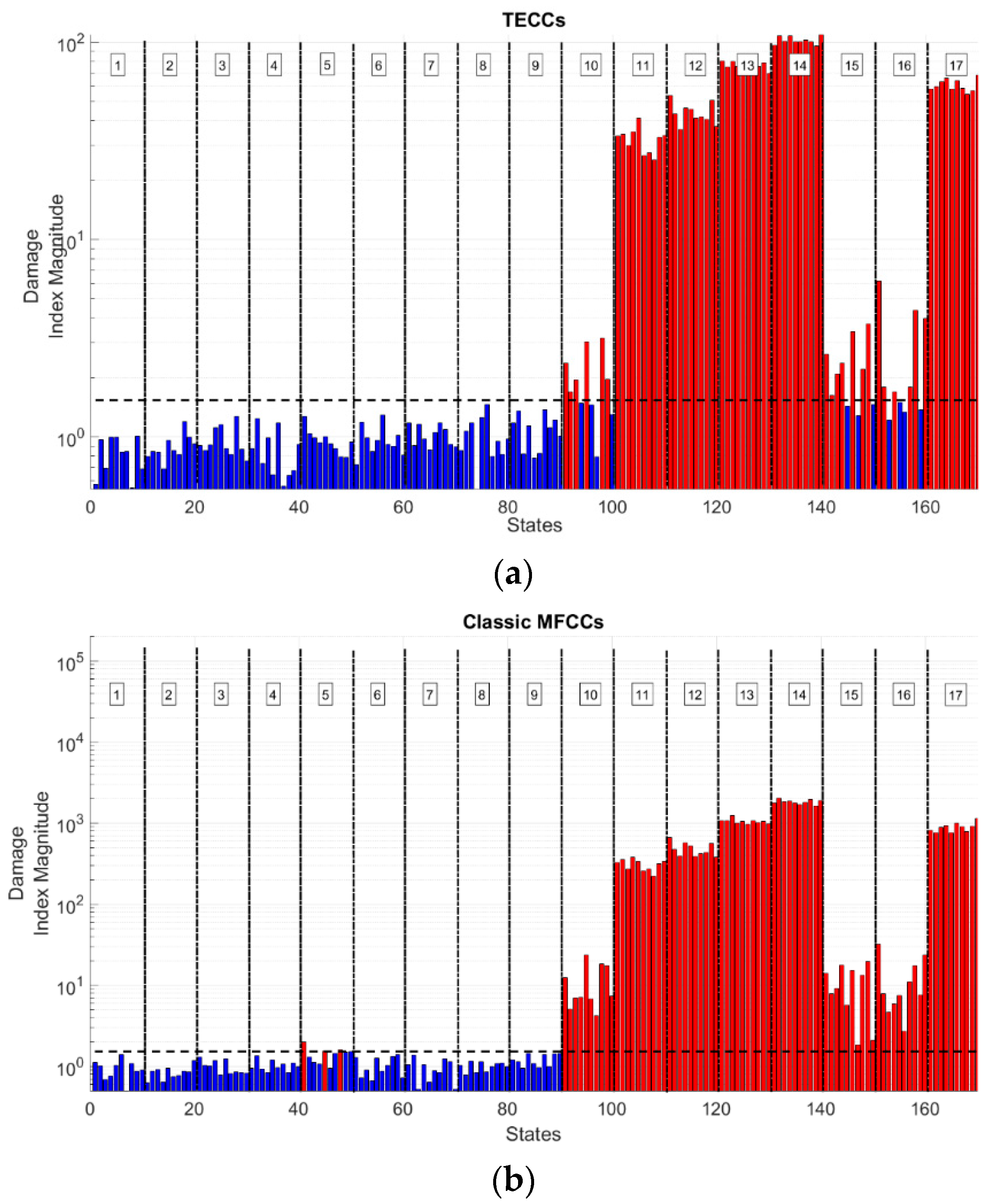
The results from experimental data are displayed here in
Figure 13. As before, TECCs and classic MFCCs are only depicted due to space constraints.
Table 9 summarises the results, in terms of percentage of type 1 and 2 errors.
In interpreting the data, one must consider the different definition of ‘damage’ between the two numerical and the experimental case studies. The Fossano bell tower and the HAR prototype wing behave linearly in both damaged and pristine conditions; again, the difference between the two is only a matter of shifting natural frequencies. The experimental data have a completely different ‘meaning’ of damage, as here, differences in mass and stiffness are accounted as different operational conditions and the distinction between damaged and undamaged response lies solely on the presence of nonlinearities. In this latter case, the TECCs proved to be the only feature able to reach a 0% type 1 error in the test set, but only in spite of a relatively high type 2 error percentage, only surpassed by the recently proposed MO- and LO-MMFCCs. Nevertheless, a closer inspection of the several damaged and undamaged configurations allows for highlighting that this error is clustered in only three scenarios, respectively, cases 10, 15, and 16. Case 10 is the one with the slightest nonlinearity and, thus, is the most challenging to detect. The algorithm also struggled for cases 15 and 16, where changes in the frame’s mass are involved. On the other hand, all of the undamaged scenarios are recognised as such by means of the TECCs, while classic MFCCs generate some misclassifications for case 5 (which is the one with the largest stiffness reduction close to the base of the frame, where such structural changes have the most impact in the vibrational response).
Therefore, experimental results seem to validate what is expected from numerical simulations, that is to say: (i) a greater generalisation capability of the TECCs feature over closely-related alternatives; (ii) a strong robustness to false alarms but at the cost of some false negatives; and, (iii) a sensibility to shifts in the frequency content higher or at least comparable to MFCCs in its original form and proposed variants. On the other hand, the TECCs proved to be less sensitive to the presence of limited nonlinearities during changing operational conditions than to mass changes respect to the MFCCs and similar features; but this outcome might be specific of the experimental data utilised here.
6.2.1. Further Analysis of the Experimental Data
Some further tests were performed to better define the advantages of the proposed TECCs feature. For brevity sake, only the results for experimental data are reported; the same findings were observed for numerical data.
Firstly, the number and distribution of output channels were investigated. Four setups have been considered: setup #0, including all channels (numbered 2 to 5, see
Figure 8), for which the results are already reported in
Figure 13 and
Table 9; setup #1 (channels 3, 4, and 5); setup #2 (channels 3 and 4); and finally, setup #3 (constituted by channels 4 and 5).
Table 10 enlists the results for these last three setups. Remarkably, this test evidenced what was already observed in [
21], that is to say, MFCCs and similar features produce less accurate results when all of the acquisition channels are considered. This point was confirmed here for type 1 errors in two out of the three new setups considered. The same effects were encountered here for TECCs as well, with the same conditions: MFCCs systematically fail in labelling case 5 as undamaged, due to its relatively large shift in frequency, while TECCs struggle in classifying cases 10, 15, and 16 as damaged due to their lower level of nonlinear distortion.
Secondly, a comparison with a non-cepstral feature, the aforementioned AR coefficients, was also performed and reported in
Table 10. The AIC approach was applied similarly to what done in [
21]. An order of 12 was used for sensor setup #1 and #2; order 10 was applied instead for the sensor setup #3. It can be seen that the percentage of type 1 error is generally higher than most of the cepstral features that are proposed here.
The Central Processing Unit (CPU) time that was required for the training phase was then evaluated for all types of DSFs on non-optimised (yet comparable) versions of the code. This was tested by means of the Matlab
® stopwatch timer tic–toc;
Table 11 reports the results. One can clearly see that the computational time is comparable over the several sensor setups considered. Note that the timing accounts for training operations (feature extraction and population statistics estimation) and for threshold definition; the time required for data preprocessing, differently from what done in [
21], was not considered, as it is identical for all features. This returns some faster results with respect to what is reported there. Moreover, the codes were run 10 times to avoid any computational variability; the average result is reported. As expected, the difference between MFCCs, similar variants, GTCCs and TECCs are minimal. It can be observed that GTCCs takes slightly longer than MFCCs (in the order of some fractions of a second), since there it is needed to build up the more complexly shaped gammatone filterbank. The TECCs require that additional time plus a bit more to compute the TKE operator out of the provided time arrays. In the case with all acquisition channels considered, these two operations make the code run in almost 30% more time (0.43 s on average). However, this delay is basically irrelevant if compared to the one that is needed to extract other features, such as the Auto-Regressive (AR) model coefficients [
21].
Lastly, the standard deviation is proposed as a metric of dispersion for the results of the several realisations that belong to the same damage case, to quantitatively express the robustness of the classification.
Table 12 enlists the results for all 17 cases. Only the values for the sensor setup #0 and for MFCCs, log-scale CCs, linear CCs, BFCCs, GTCCs, and TECCs are reported here due to space constraints. The same behaviour was observed for the other setups as well. By considering ten realisations per investigated case, it can be observed that the use of TECCs as a DSF produce a much smaller scattering of the results, with the standard deviation never exceeding
, while the same measure goes well over 50 or even 70 for MFCCs in some cases.
7. Conclusions
Any Structural Health Monitoring system relies on data, almost always pre-processed, and on features extrapolated from them. Mel-Frequency Cepstral Coefficients (MFCCs) have recently been proven to be effective in damage detection, relying on the cepstrum of the recorded structural response, even if margins for improvements were evident. The Teager-Kaiser Energy (TKE) operator has been proposed here as the basis for a similar feature, less subject to false positive mislabeling when used for Machine Learning. That is adherent to what is encountered for speech signals and well-known in the field of speaker and speech recognition. The investigation reported here spans over different structures, with different input and very different setups—varying acquisition parameters, such as the number of the output channels, the sampling frequency, and so on. Moreover, in the first and in the second numerical study, the damage was modelled as a linear reduction of stiffness inserted in a linear system, while the experimental case emulated the damage as a pointwise source of nonlinearity in an otherwise linear system and stiffness local reduction was intended as a change in the operational conditions that were unrelated to damage. This shows the excellent capability of generalisation of this approach.
The proposed damage sensitive feature, the Teager-Kaiser Energy Cepstral Coefficients (TECCs), has been benchmarked against the MFCCs and some similar variants. Interesting numerical and experimental results were achieved for both the linear and nonlinear models of damage.
The main conclusions are the following:
the TECCs, MFCCs, and similar features perform efficiently both with damage emulated by a reduction of the Young’s modulus E or by the presence of nonlinearities, even if the signal is noisy;
the Mel-Scale performed similarly to other nonlinear scales such as the Bark Scale or logarithmic spacing, with no clear best option among all the investigated case studies;
the algorithms that resort to a Gammatone filterbank generally produced better results than the ones with triangular filters; even if the TECCs still outperforms the GTCCs;
the TECCs present a strong reduction of the order of magnitude of the Damage Index (DI) with respect to MFCCs and similar options, in absolute terms; this does not affect the damage detection algorithm, as the relative distance between the ‘normality’ model and the damaged cases remains and seems even to increase;
the Teager-Kaiser Energy Cepstral Coefficients outperforms all the competitors in terms of little or no type 1 errors, but it is slightly more prone to type 2 errors respect to MFCCs and derived features;
with respect to non-cepstral features, such as the AR coefficients, the main benefits lie in the less computational cost and greater robustness to noise and to confounding influences, such as environmental and operational effects, unrelated to damage.
The outcomes of this research leave plenty of room for improvements. Indeed, apart from the TECCs and other cepstral-based alternatives, wavelet-based alternatives are of great interest. The Mel-Frequency Discrete Wavelet Coefficients may be a relevant alternative. Thanks to the Discrete Wavelet Transform, the filter spacing issue is by-passed; filter shaping is reduced to the selection of the mother wavelet. The Authors are committed to pursuing further studies in this direction.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}