Semantic Data Management for a Virtual Factory Collaborative Environment

 ,
,  ,
, 
Abstract
Featured Application
Abstract
1. Introduction
- Which tools and approaches can contribute to the improvement of semantic interoperability of heterogeneous data?
- How can the import and combination of various data models and ontologies help to enrich the mapping process?
- How does a collaborative approach contribute to forming the knowledge base and improving the mapping process?
2. Related Literature
- it can be used to represent order and structural features of the considered topic;
- it allows decomposition of complex topics and representation of interdependencies among subtopics;
- it allows hierarchical representation of topics, features, and so on; and
- it offers pattern detection capabilities.
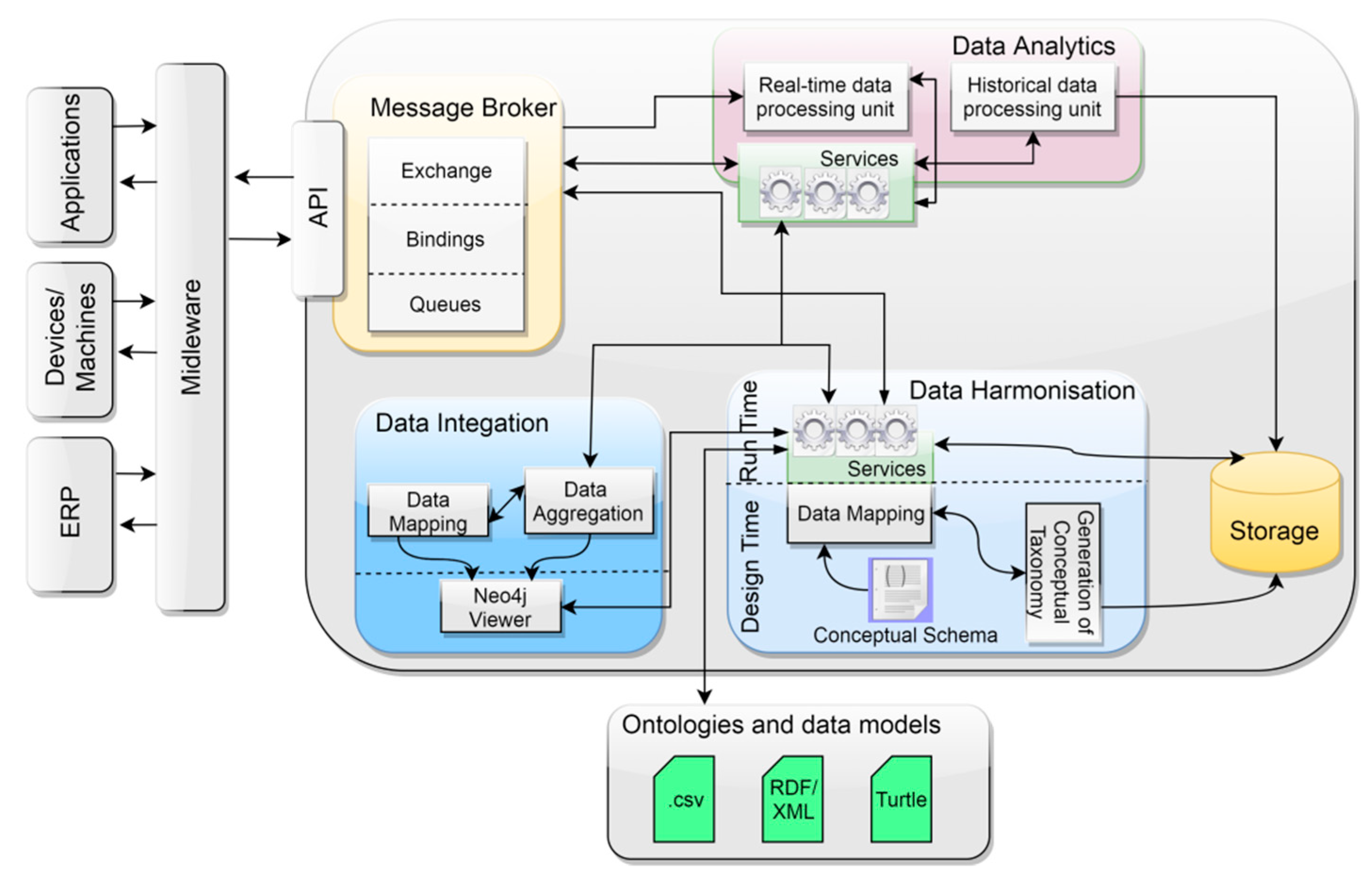
3. Relation to vf-OS
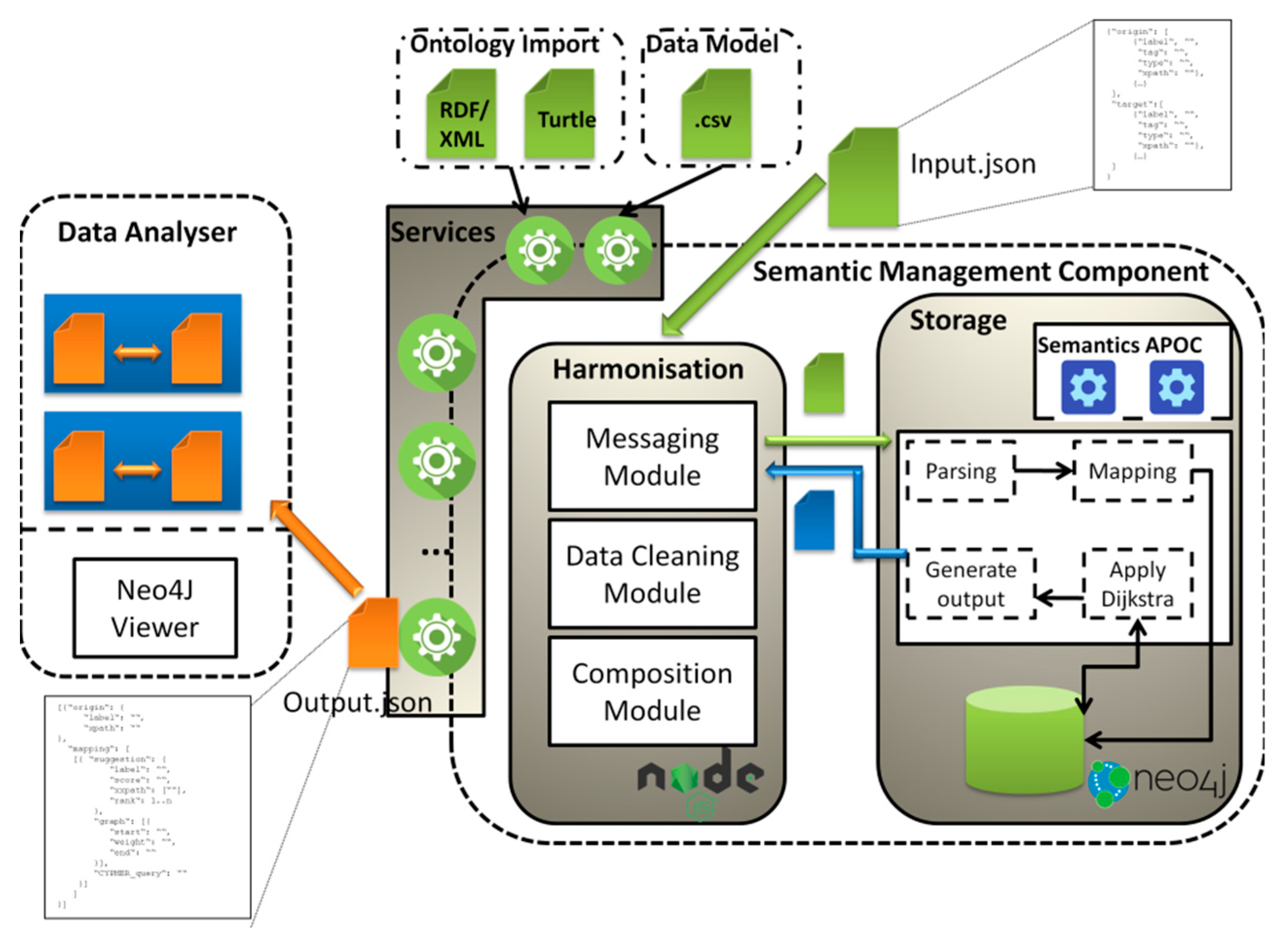
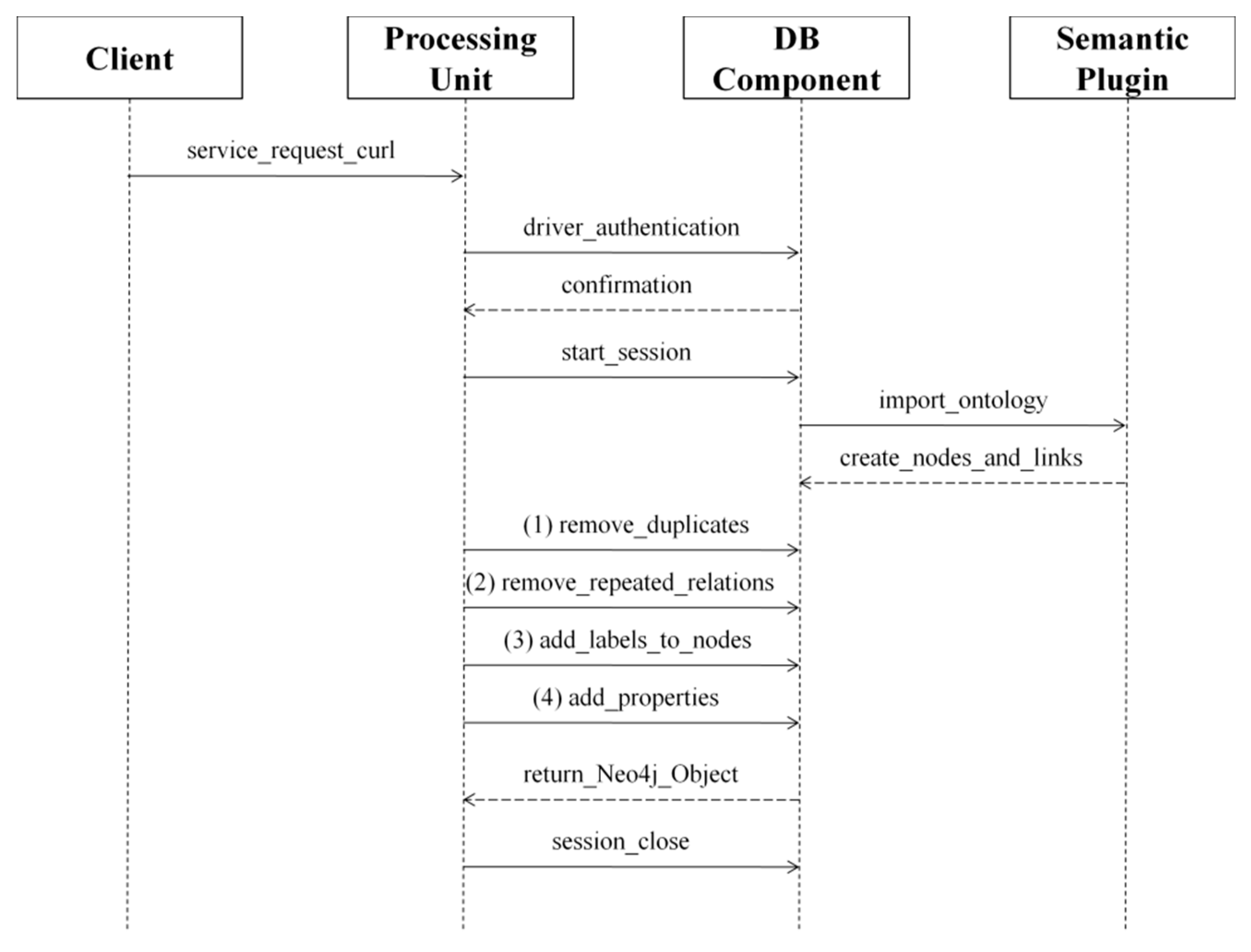
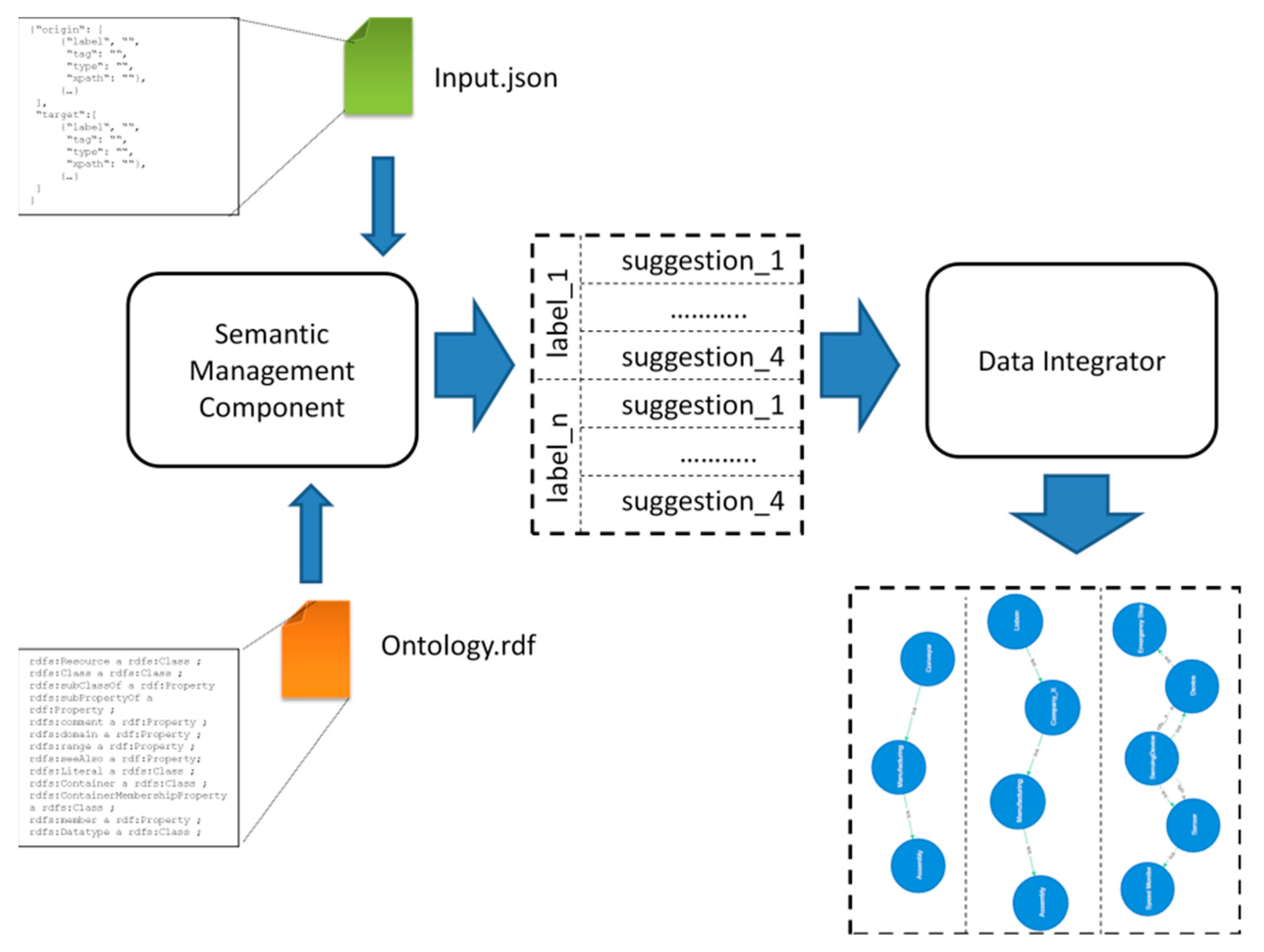
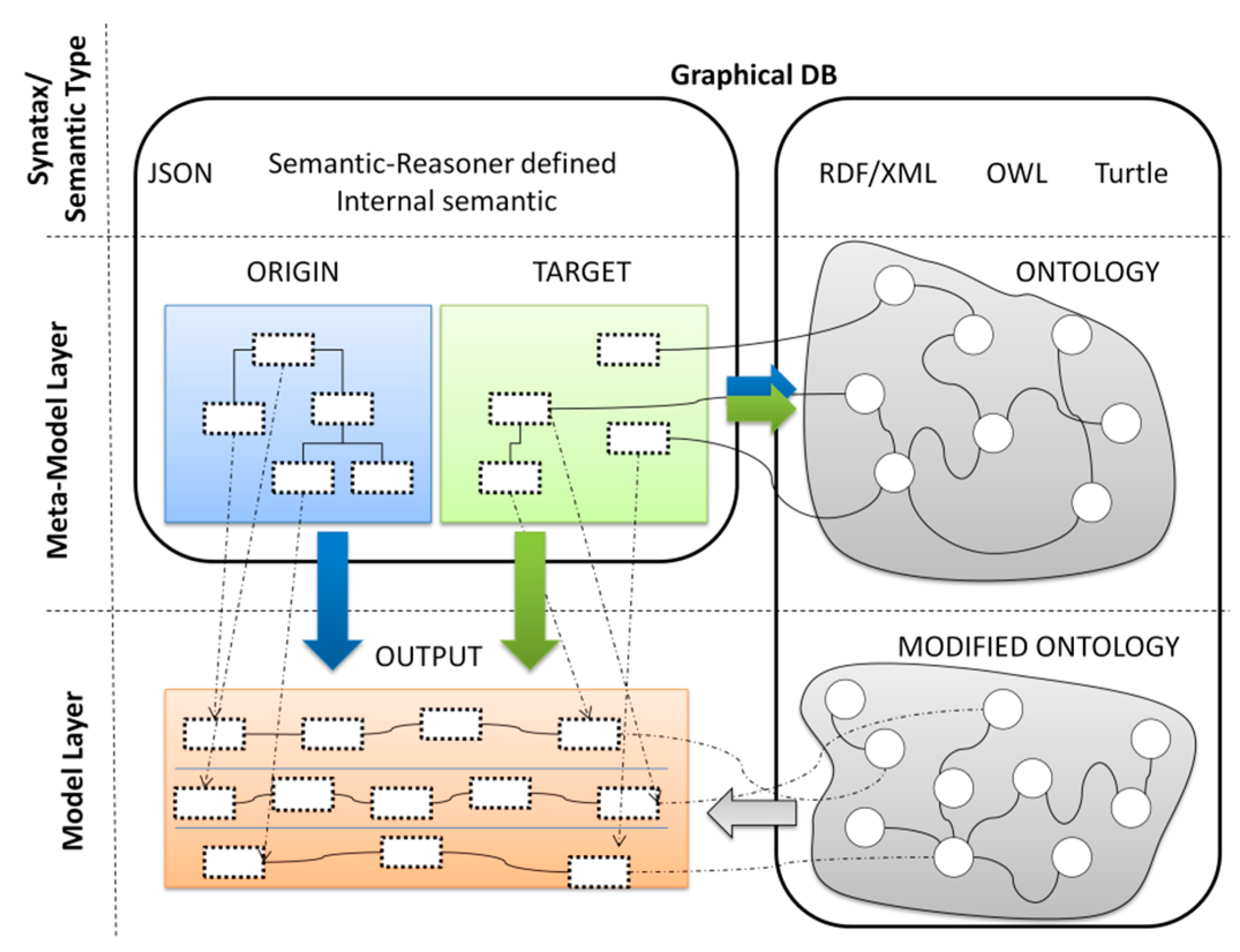
4. Semantic Management Component
- The messaging module is responsible for maintaining communication between the storage and harmonization components. Moreover, it provides a Representational State Transfer (REST)-based interface for outer applications. Between the harmonization and storage components, communication is accomplished through bolt connectivity, which is the network protocol running over a Transmission Control Protocol (TCP) connection. In other words, the messaging module allows requests to be received from outer applications, following the REST architectural approach, and retranslates them to storage in a bolt-compatible format.
- The data cleaning module is needed to cope with complex output objects returned after the storage component processes a request. Neo4j-returned objects are parsed, and the required data are extracted.
- The composition module is used to align the data that was prepared by the data cleaning module with the output format and to generate a Cypher query which can be visualized in the Neo4j viewer environment to represent the output in a human-friendly format. However, this module, as well as the data cleaning one, is only needed for some of the services, as not all of them are assumed to return a JSON output.
4.1. Get MappingSuggestion Service
- “label”—which introduces the name of the capillary/single concept;
- “tag”—this field can be used to identify the attributes of the concept. The inspiration for introducing the “tag” field came from the topic of folksonomy, described in [43], where a collaborative tagging system is presented that is composed of three core entities: users, resources, and tags. Tags, compared to, for instance, resources, are in no way limited by predefined vocabulary [44]. In this work, tags are used to describe the concepts that, to some extent, can be compared with resources in folksonomy;
- “xpath”—is used to show the parent concepts of the capillary/single concept. This field allows expressing the hierarchy of concepts from a specific concept to the root;
- “type”—used to express the type of the concept, for instance: string.
| Algorithm 1 Suggestion building for each concept in the origin model |
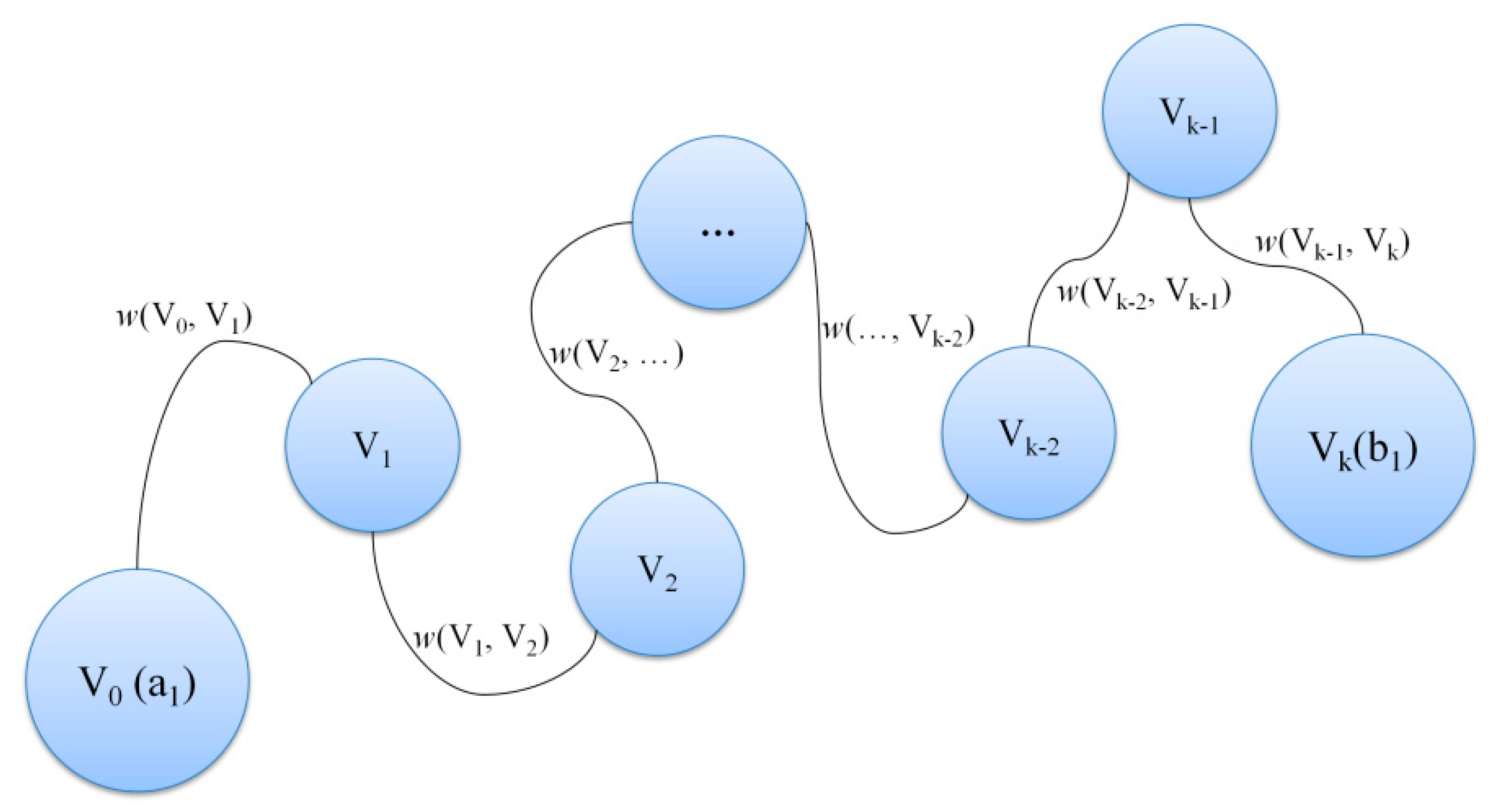
| INPUT: origin and target labels A and B, nondirected graph G = (V, E, w), with relationships weights for all , source and target concepts for each a in A do define all possible paths from a to each b in B if there is a path p form a to b in G then apply Dijkstra’s algorithm to all a-b pairs order resulting paths by distance (or semantic distance) if the number of resulting paths < 4 then collect number shortest paths else collect 4 shortest paths end if else assign nil end if end for each OUTPUT: number ordered paths with assigned distance |
- “origin”—which contains the subfields “label” for the name of the concept and “XPath” containing the parent nodes;
- “mapping”—represents mapping the origin and target data models, containing all suggestions for each specific concept. The subfields are:
- “suggestion”, with “label” naming the target concept, “score” reflecting the importance or weight of the path between “origin” and “target” concepts, “XPath” for the parent concepts, and “rank”, which serves to identify which suggestion is the closest one;
- “graph”—representing the full path from the “origin” to the “target” concept in a segmental way, being composed of triples of the form “start” -> “weight” -> “end”; and
- “CYPHER query”—a field that contains the generated Cypher query, which can be used for visualizing and checking the suggested path.
4.2. Import Data Model Service
4.3. Import Ontology Service
- reusability, when the concepts introduced in existing reliable ontologies can be reused;
- semantic alignment, referring mainly to ontology interoperability, to integrate concepts from imported ontologies, as well as newly created concepts into an existing structure;
- ontology design pattern usage, to ensure that the concept generation procedure can be applied not only to a single concept but to a group of concepts; and
- community extensibility, assuming a collaborative perspective when one ontology, covering few use-cases, can be extended by other users of a community and, thus, be applied to more use-cases.
| Algorithm 2 Suggestion building for each concept in the origin model |
| INPUT: nondirected graph Ginit=(Vinit, Einit, w), with edges and , vertices and edge weights for all , nondirected graph Gimp=(Vimp, Eimp), with edges and vertices for each einit in Einit do if then imported edge exists in the initial model → skip else end if end for each for each do if then imported vertices exist in this initial model → skip else end if end for each OUTPUT: Gres |
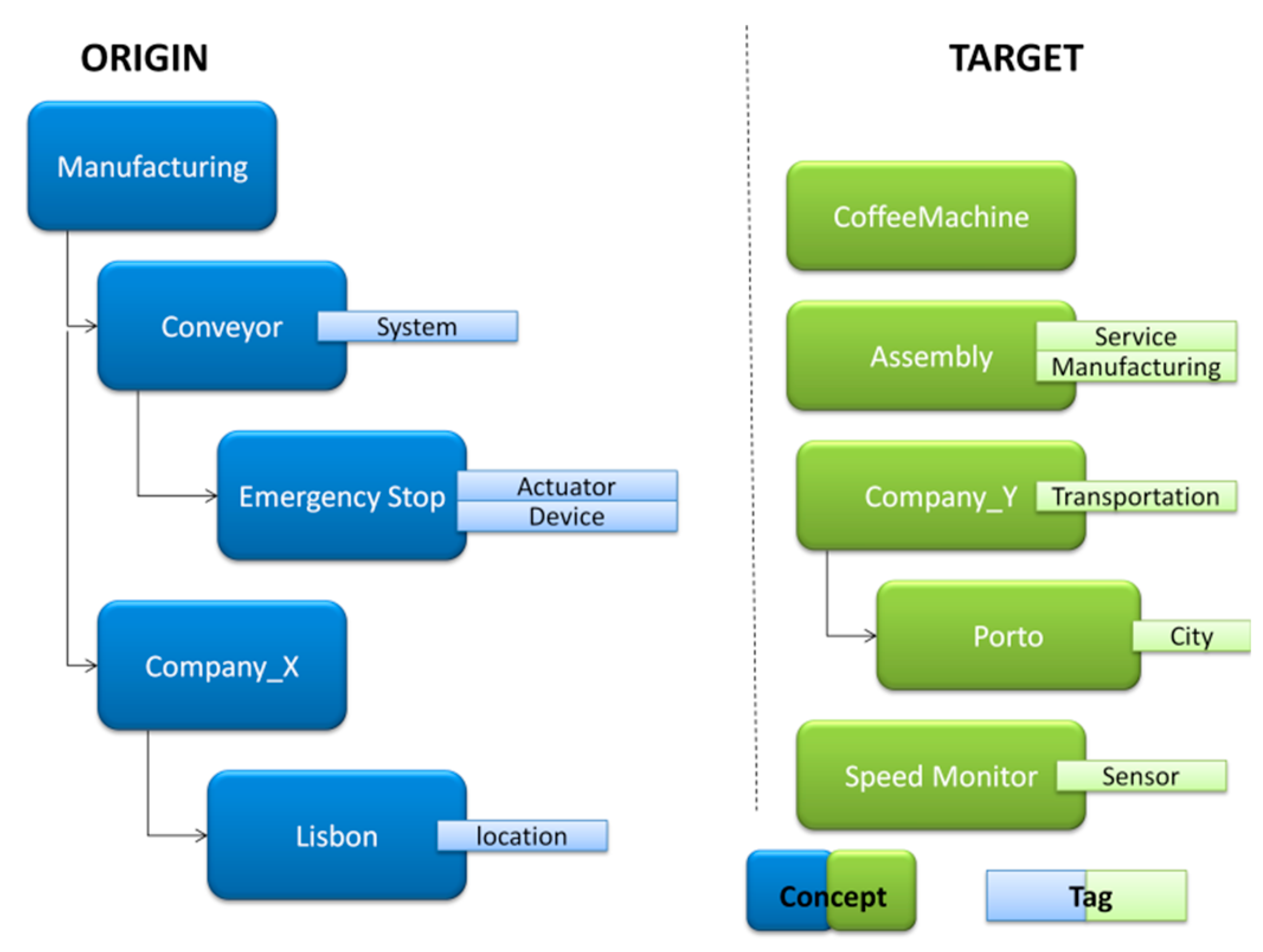
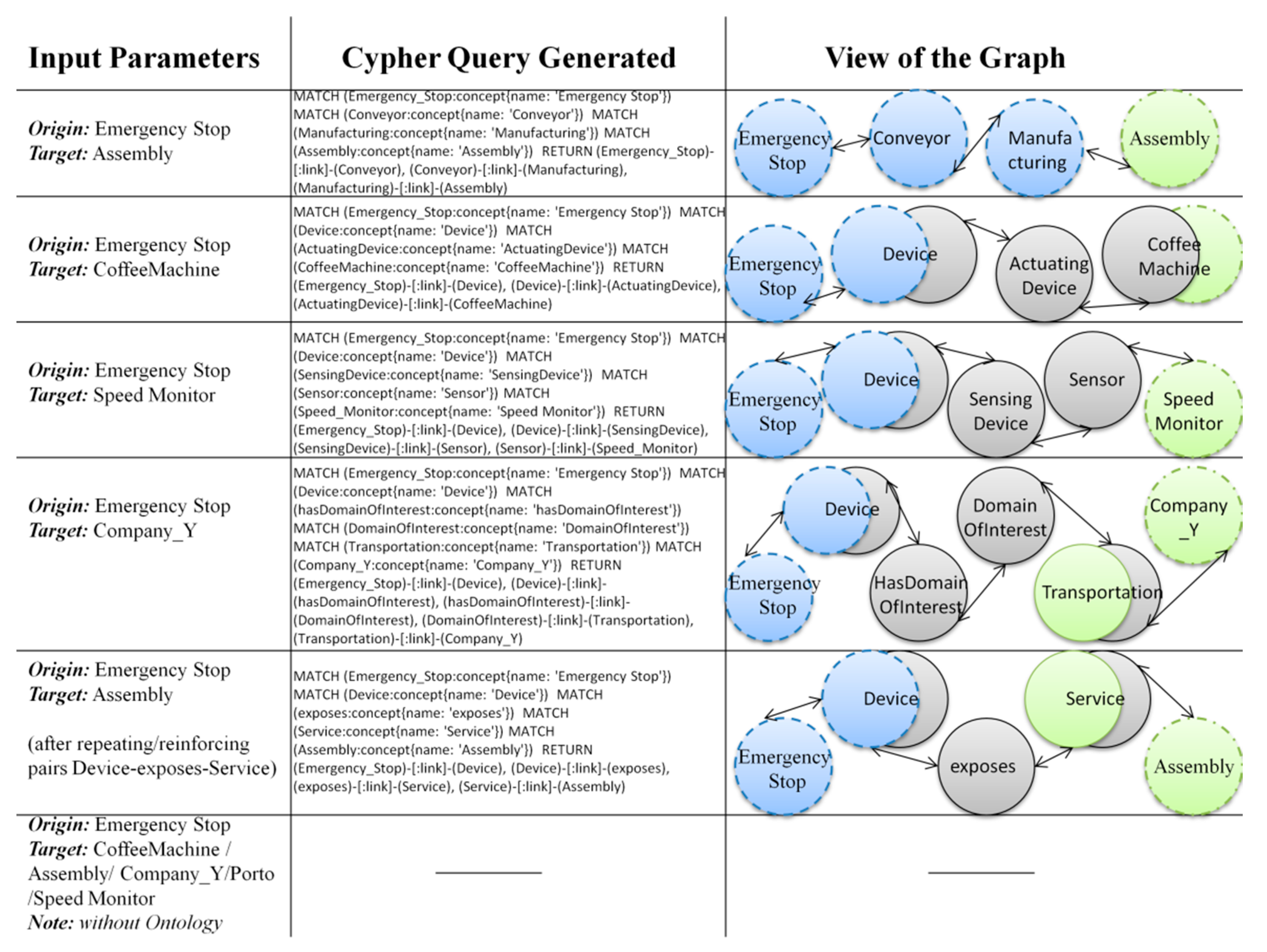
5. Test Case Scenario and Discussion
(Manufacturing,Company_Y),(Manufacturing,Porto),(Manufacturing,
Speed Monitor),…,(Lisbon,CoffeeMachine),(Lisbon,Assembly),
(Lisbon,Company_Y),(Lisbon,Porto),(Lisbon,Speed Monitor)}.
ActuatingDevice,CoffeeMachine,SensingDevice,Sensor,Speed Monitor,
HasDomainOfInterest,DomainOfInterest,Transportation,Company_Y}.
(Manufacturing,Assembly)},{(Emergency Stop,Device),
(Device,ActuatingDevice),(ActuatingDevice,CoffeeMachine)},
{(Emergency Stop,Device),(Device,SensingDevice),(SensingDevice,Sensor),
(Sensor,Speed Monitor)},{(Emergency Stop,Device),
(Device,HasDomainOfInterest),(HasDomainOfInterest,DomainOfInterest),
(DomainOfInterest,Transportation),(Transportation,Company_Y}},
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lee, J.; Azamfar, M.; Singh, J. A blockchain enabled Cyber-Physical System architecture for Industry 4.0 manufacturing systems. Manuf. Lett. 2019, 20, 34–39. [Google Scholar] [CrossRef]
- Ancarani, A.; Di Mauro, C.; Mascali, F. Backshoring strategy and the adoption of Industry 4.0: Evidence from Europe. J. World Bus. 2019, 54, 360–371. [Google Scholar] [CrossRef]
- Kavakli, E.; Buenabad-Chavez, J.; Tountopoulos, V.; Loucopoulos, P.; Sakellariou, R. WiP: An Architecture for Disruption Management in Smart Manufacturing. In Proceedings of the IEEE International Conference on Smart Computing, Taormina, Italy, 18–20 June 2018; pp. 279–281. [Google Scholar] [CrossRef]
- Fraile, F.; Tagawa, T.; Poler, R.; Ortiz, A. Trustworthy Industrial IoT Gateways for Interoperability Platforms and Ecosystems. IEEE Internet Things J. 2018, 5, 2506–4514. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Wang, L.; Nee, A.Y.C. Digital Twins and Cyber-Physical Systems toward Smart Manufacturing and Industry 4.0: Correlation and Comparison. Engineering 2019, 5, 653–661. [Google Scholar] [CrossRef]
- Wermann, J.; Colombo, A.W.; Pechmann, A.; Zarte, M. Using an interdisciplinary demonstration platform for teaching Industry 4.0. Procedia Manuf. 2019, 31, 302–308. [Google Scholar] [CrossRef]
- Nazarenko, A.; Camarinha-Matos, L.M. Basis for an Approach to Design Collaborative Cyber-Physical Systems. In DoCEIS 2019: Technological Innovation for Industry and Service Systems; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef]
- Camarinha-Matos, L.M.; Fornasiero, R.; Afsarmanesh, H. Collaborative Networks as a Core Enabler of Industry 4.0. In PRO-VE 2017: Collaboration in a Data-Rich World; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Wei, W.; Guo, C. A text semantic topic discovery method based on the conditional co-occurrence degree. Neurocomputing 2019, 368, 11–24. [Google Scholar] [CrossRef]
- Dai, W.; Vyatkin, V. Transformation from PLC to Distributed Control using Ontology Mapping. In Proceedings of the IEEE 10th International Conference on Industrial Informatics, Beijing, China, 25–27 July 2012; pp. 436–441. [Google Scholar] [CrossRef]
- Xia, H.; Hu, C.; Xiao, F.; Cheng, X.; Pan, Z. An Efficient Social-Like Semantic-Aware Service Discovery Mechanism for Large-Scale Internet of Things. Comput. Netw. 2019, 152, 210–220. [Google Scholar] [CrossRef]
- Louge, T.; Karray, M.H.; Archimede, B.; Maamar, Z.; Mrissa, M. Semantic Web Services Composition in the astrophysics domain: Issues and solutions. Future Gener. Comput. Syst. 2019, 90, 185–197. [Google Scholar] [CrossRef]
- Alshammari, M.; Nasraoui, O.; Sanders, S. Mining Semantic Knowledge Graphs to Add Explainability to Black Box Recommender Systems. IEEE Access 2019, 7, 110563–110579. [Google Scholar] [CrossRef]
- Cousin, P.; Serrano, M.; Soldatos, J. Internet of Things Research on Semantic Interoperability to Address Manufacturing Challenges. In Enterprise Interoperability: Interoperability for Agility, Resilience and Plasticity of Collaborations: IESA’14 Proceedings; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 21–30. [Google Scholar] [CrossRef]
- Willner, A.; Diedrich, C.; Ben Younes, R.; Hohmann, S.; Kraft, A. Semantic communication between components for smart factories based on oneM2M. In Proceedings of the 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Limassol, Cyprus, 12–15 September 2017. [Google Scholar] [CrossRef]
- Borch, N.T. Improving Semantic Routing Efficiency. In Proceedings of the Second International Workshop on Hot Topics in Peer-to-Peer Systems, San Diego, CA, USA, 21 July 2015. [Google Scholar] [CrossRef]
- Zhao, Z.; Liao, X.; Martin, P.; Maduro, J.; Thijsse, P.; Schaap, D.; Stocker, M.; Goldfarb, D.; Magagna, B. Knowledge-as-a-Service: A Community Knowledge Base for Research Infrastructures in Environmental and Earth Sciences. In Proceedings of the IEEE World Congress on Services (SERVICES), Milan, Italy, 8–13 July 2019; pp. 127–132. [Google Scholar] [CrossRef]
- Mistry, S.K.; Kamal, M.H.; Mistry, D. Semantic Discovery of Web Services through Social Learning. Procedia Technol. 2012, 3, 167–177. [Google Scholar] [CrossRef]
- Moeini, H.; Yen, I.-L.; Bastani, F. Service Specification and Discovery in IoT Networks. In Proceedings of the IEEE International Conference on Web Services (ICWS), Milan, Italy, 8–13 July 2019. [Google Scholar] [CrossRef]
- Tsang, V.; Stevenson, S. A Graph-Theoretic Framework for Semantic Distance. Comput. Linguist. 2010, 36, 31–69. [Google Scholar] [CrossRef]
- Quevedo, J.; Antunes, M.; Corujo, D.; Gomes, D.; Aguiar, R.L. On the application of contextual IoT service discovery in Information Centric Networks. Comput. Commun. 2016, 89–90, 117–127. [Google Scholar] [CrossRef]
- Gries, S.; Hesenius, M.; Gruhn, V. Tracking Information Flow in Cyber-Physical Systems. In Proceedings of the IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 2589–2590. [Google Scholar] [CrossRef]
- Smirnov, A.; Kashevnik, A.; Shilov, N. Cyber-Physical-Social System Self-Organization: Ontology-Based Multi-Level Approach and Case Study. In Proceedings of the IEEE 9th International Conference on Self-Adaptive and Self-Organizing Systems, Cambridge, MA, USA, 21–25 September 2015; pp. 168–169. [Google Scholar] [CrossRef]
- Goncalves, R.; Sarraipa, J.; Agostinho, C.; Panetto, H. Knowledge framework for intelligent manufacturing systems. J. Intell. Manuf. 2011, 22, 725–735. [Google Scholar] [CrossRef]
- Cristani, M.; Demrozi, F.; Tomazzoli, C. ONTO-PLC: An ontology-driven methodology for converting PLC industrial plants to IoT. Procedia Comput. Sci. 2018, 126, 527–536. [Google Scholar] [CrossRef]
- Martinez-Gil, J. An overview of textual semantic similarity measures based on web intelligence. Artif. Intell. Rev. 2014, 42, 935–943. [Google Scholar] [CrossRef]
- Miller, G.A.; Charles, W.G. Contextual Correlates of Semantic Similarity. Lang. Cogn. Process. 1991, 6, 1–28. [Google Scholar] [CrossRef]
- Song, S.; Lin, Y.; Guo, B.; Di, Q.; Lv, R. Scalable Distributed Semantic Network for knowledge management in cyber physical system. J. Parallel Distrib. Comput. 2018, 118, 22–33. [Google Scholar] [CrossRef]
- Henkel, R.; Wolkenhauer, O.; Waltemath, D. Combining computational models, semantic annotations and simulation experiments in a graph database. Database 2015, 2015, bau130. [Google Scholar] [CrossRef]
- Abay, N.C.; Mutlu, A.; Karagoz, P. A Path-finding Based Method for Concept Discovery in Graphs. In Proceedings of the 6th International Conference on Information, Intelligence, Systems and Applications (IISA), Corfu, Greece, 6–8 July 2015. [Google Scholar] [CrossRef]
- Hoppen, M.; Rossmann, J.; Stapelbroek, A.-M.; Hiester, S. Managing Semantic World Models for eRobotics Applications Two Approaches Based on Object-Relational Mapping and on a Graph Database. Int. J. Adv. Softw. 2017, 10, 79–95. Available online: http://www.iariajournals.org/software/ (accessed on 7 September 2019).
- Hor, A.-H.; Sohn, G.; Claudio, P.; Jadidi, M.; Afnan, A. A Semantic Graph Database for BIM-GIS Integrated Information Model for an Intelligent Urban Mobility Web Application. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 89–96. [Google Scholar] [CrossRef]
- Song, S.; Sun, Y.; Di, Q. Multiple order semantic relation extraction. Neural Comput. Appl. 2019, 31, 4563–4576. [Google Scholar] [CrossRef]
- Hristovski, D.; Kastrin, A.; Rindflesch, T.C. Semantics-Based Cross-domain Collaboration Recommendation in the Life Sciences. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 15), Paris, France, 25–28 August 2015. [Google Scholar] [CrossRef]
- Kivikangas, P.; Ishizuka, M. Improving Semantic Queries by Utilizing UNL Ontology and a Graph Database. In Proceedings of the IEEE Sixth International Conference on Semantic Computing, Palermo, Italy, 19–21 September 2012. [Google Scholar] [CrossRef]
- Malliaros, F.D.; Skianis, K. Graph-Based Term Weighting for Text Categorization. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 15), Paris, France, 25–28 August 2015. [Google Scholar] [CrossRef]
- Nguyen, S.H.; Yao, Z.; Kolbe, T.H. Spatio-Semantic Comparison of Large 3D City Models in CITYGML Using a Graph Database. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 99–106. [Google Scholar] [CrossRef]
- Rashidy, R.A.H.E.L.; Hughes, P.; Figueres-Esteban, M.; Harrison, C.; Van Gulijk, C. A big data modeling approach with graph databases for SPAD risk. Saf. Sci. 2017, 110, 75–79. [Google Scholar] [CrossRef]
- Dai, W.; Dubinin, V.N.; Vyatkin, V. Migration from PLC to IEC 61499 Using Semantic Web Technologies. IEEE Trans. Syst. Man Cybern. 2014, 44, 277–291. [Google Scholar] [CrossRef]
- Kibria, M.G.; Ali, S.; Jarwar, M.A.; Chong, I. A Framework to Support Data Interoperability in Web Objects Based IoT Environments. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 18–20 October 2017; pp. 29–31. [Google Scholar] [CrossRef]
- Pape, D.; Hinz, T.; Perales, O.G.; Fraile, F.; Flores, J.L.; Rubio, O.J. vf-OS Architecture in Enterprise Interoperability: Smart Services and Business Impact of Enterprise Interoperability; Zelm, M., Jaekel, F.-W., Doumeingts, G., Wollschlaeger, M., Eds.; ISTE Ltd.: London, UK, 2018; pp. 77–82. [Google Scholar] [CrossRef]
- Nazarenko, A.A.; Giao, J.; Sarraipa, J.; Saiz, O.J.; Perales, O.G.; Jardim-Gonçalves, R. Data Management Component for Virtual Factories Systems. In Enterprise Interoperability: Smart Services and Business Impact of Enterprise Interoperability; Zelm, M., Jaekel, F.-W., Doumeingts, G., Wollschlaeger, M., Eds.; ISTE Ltd.: London, UK, 2018; pp. 99–106. [Google Scholar] [CrossRef]
- Xie, M.; Lu, J.; Chen, G.; Wu, M.-Y. Folksonomy-Based Internet Object Profiling and Relation Extracting. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Singapore, 4–8 December 2017. [Google Scholar] [CrossRef]
- Solskinnsbakk, G.; Gulla, J.A.; Haderlein, V.; Myrseth, P.; Cerrato, O. Quality of hierarchies in ontologies and folksonomies. Data Knowl. Eng. 2012, 74, 13–25. [Google Scholar] [CrossRef]
- Neo4j Labs. Available online: https://neo4j.com/docs/labs/apoc/3.4/overview/ (accessed on 25 July 2019).
- Berkeley EECS. Available online: https://people.eecs.berkeley.edu/~nirkhe/cs38notes/graph.pdf (accessed on 3 September 2019).
- Dietsel, R. Graph Theory; Electronic Edition; Springer: New York, NY, USA, 2000; Available online: http://www.esi2.us.es/~mbilbao/pdffiles/DiestelGT.pdf (accessed on 3 September 2019).
- Common Format and MIME Type for Comma-Separated Values (CSV) Files, Network Working Group, Request for Comments: 4180, 2005. Available online: https://tools.ietf.org/html/rfc4180 (accessed on 7 August 2019).
- Xiang, Y.; He, Z.; Zheng, J.; Lin, Y.; Overton, J.A.; Ong, E. The eXtensible ontology development (XOD) principles and tool implementation to support ontology interoperability. J. Biomed. Semant. 2018, 9, 3. [Google Scholar] [CrossRef]
- Panagiotopoulos, I.; Kalou, A.; Pierrakeas, C.; Kameas, A. An Ontological Approach for Domain Knowledge Modeling and Management in E-Learning Systems. In Proceedings of the 8th International Conference on Artificial Intelligence Applications and Innovations (AIAI), Halkidiki, Greece, 27–30 September 2012; pp. 95–104. [Google Scholar] [CrossRef]
- Arnold, P.; Rahm, E. Enriching ontology mappings with semantic relations. Data Knowl. Eng. 2014, 93, 1–18. [Google Scholar] [CrossRef]
- Annane, A.; Bellahsene, Z.; Azouaou, F.; Jonquet, C. Building an effective and efficient background knowledge resource to enhance ontology matching. J. Web Semant. 2018, 51, 51–68. [Google Scholar] [CrossRef]
- Agarwal, R.; Gomez Fernandez, D.; Elsaleh, T.; Gyrard, A.; Lanza, J.; Sanchez, L.; Georgantas, N.; Issarny, V. Unified IoT Ontology to Enable Interoperability and Federation of Testbeds. In Proceedings of the IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 70–75. [Google Scholar] [CrossRef]
- W3C Working Group Note. 24 June 2014. Available online: http://www.w3.org/TR/2014/NOTE-rdf11-primer-20140624/ (accessed on 23 June 2019).
- OWL Web Ontology Language, Reference W3C Recommendation. 10 February 2004. Available online: https://www.w3.org/TR/owl-ref/ (accessed on 23 June 2019).
- Barrasa, J. Building a Semantic Graph in NEO4J. April 2016. Available online: https://jbarrasa.com/2016/04/06/building-a-semantic-graph-in-neo4j/ (accessed on 15 June 2019).
- Hinkelmann, K.; Gerber, A.; Karagiannis, D.; Thoenssen, B.; van der Merwe, A.; Woitsch, R. A new paradigm for the continuous alignment of business and IT: Combining enterprise architecture modelling and enterprise ontology. Comput. Ind. 2016, 79, 77–86. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Henkel et al., 2015 | Kivikangas & Ishizuka, 2012 | Hoppen et al., 2017 | Hor et al., 2018 | Nguyen et al., 2017 | Hristovski et al., 2015 | Song et al., 2018 | Malliaros & Skianis, 2015 | Abay et al., 2015 | Rashidy et al., 2018 | Xia et al., 2019 | Alshammari et al., 2019 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ontology or Data Model import | x | x | x | x | x | |||||||
| Delivering concept “relatedness” | x | x | x | x | x | x | ||||||
| Generation of Queries for further discovery and visualization | x | |||||||||||
| Mapping of data models and ontologies | x | x | x | x | x | x | ||||||
| Consideration of weighted edges | x |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nazarenko, A.A.; Sarraipa, J.; Camarinha-Matos, L.M.; Garcia, O.; Jardim-Goncalves, R. Semantic Data Management for a Virtual Factory Collaborative Environment. Appl. Sci. 2019, 9, 4936. https://doi.org/10.3390/app9224936
Nazarenko AA, Sarraipa J, Camarinha-Matos LM, Garcia O, Jardim-Goncalves R. Semantic Data Management for a Virtual Factory Collaborative Environment. Applied Sciences. 2019; 9(22):4936. https://doi.org/10.3390/app9224936
Chicago/Turabian StyleNazarenko, Artem A., Joao Sarraipa, Luis M. Camarinha-Matos, Oscar Garcia, and Ricardo Jardim-Goncalves. 2019. "Semantic Data Management for a Virtual Factory Collaborative Environment" Applied Sciences 9, no. 22: 4936. https://doi.org/10.3390/app9224936
APA StyleNazarenko, A. A., Sarraipa, J., Camarinha-Matos, L. M., Garcia, O., & Jardim-Goncalves, R. (2019). Semantic Data Management for a Virtual Factory Collaborative Environment. Applied Sciences, 9(22), 4936. https://doi.org/10.3390/app9224936