Abstract
This paper presents a new intelligent monitoring and event management method for data center physical infrastructure based on multilayer node event processing. The priorities of highly classified data centers are not only the maintenance of the highest level of reliability and availability of the operation, but also fast, specific event identification and energy consumption monitoring, which altogether improve the level of energy efficiency. The new method, using a tree node for each device, improves information about the events in a specific node. Its major advantage is that in the case of a large number of nodes, it considerably reduces the number of identified events (alarms/alerts) that might be the main cause. Fast event processing lowers data center physical infrastructure operating costs, improving at the same time the level of energy efficiency. The experimental results show that the use of tree nodes significantly reduces the number of unexpected events, the time needed for the main event identification, and the maintenance response time to events. By using event entities processing, multilayer nodes have a significant impact on the efficient operation of data center physical infrastructure.
1. Introduction
Intelligent monitoring in today’s data centers has increased significantly in recent years. In order to maintain high availability of data, all components of the data center infrastructure must carry out their assigned tasks, including adequate energy support without excessive energy consumption. All physical infrastructure failures, regardless of the level at which they occur, have a significant impact on the effectiveness of information technology (IT) services [1,2]. Therefore, monitoring and control is important for all existing component parameters in the data center infrastructure system, including energy consumption management, which have become crucial in recent years due to their high economic and environmental impact. The cooling infrastructure consumes a large amount of data center energy. In terms of consumption, it is followed by servers, storage, and other infrastructure elements [3]. A typical data center can consume as much energy as 25,000 households. For instance, data center spaces can consume 100 to 200 times more electricity than standard office spaces. The use of energy in data centers also causes over-heating of the environment [4]. A study by Van Heddeghem et al. [5] showed that in 2014, data centers consumed 270 TWh of energy worldwide, and that this consumption will have a combined annual growth rate (CAGR) of 5% in the future. For these reasons, data center energy reduction is now regarded as the main concern for data center operators, equally important to (if not more so than) the traditional aspects of availability and security [2,6,7]. The basic goals of past research were to clearly define and monitor all processes of data center operation. When such processes are not effectively implemented, inconsistencies in the operation and maintenance of the systems are inevitable, leading to unexpected downtime. The cost of downtime depends on the industry, reaching thousands of dollars per minute. The average cost associated with data center downtime for an unplanned outage is $8851 per minute [8].
Recently, a number of studies on event monitoring and management have been published. Surveys [4,9] showed the control of alarms in electricity distribution. The basis of these research works was the concept of ontology. On the second ontological level there is an expert system with professional, if–then rules. The determination of rules is based on professional knowledge, which is a complex task aiming to turn knowledge into both intelligible and logical rules. In [5,10], soft conclusions were used with Petri’s network, but it had limitations in more complex systems. This method was used to detect the location of an event in a distribution network of electricity. For each part of the network, there was a model based on expertise with possible causes of events or failures. In these models, it is a matter of establishing retroactively the cause of events with probability values. In [11], tools with integrated processes, called data center infrastructure management (DCIM), were discussed, highlighting the system connectivity and interconnectivity between the operations of the system support and system for data center operators. Different communication technologies were presented as models for use in the design of data center communication paths. These models can reduce the network operating costs, improve energy efficiency, and increase operational efficiency. DCIM in [12] used tools that monitor, measure, manage, and control the resources and energy consumption of both a data center’s IT equipment (servers, storage devices) and its infrastructure components (power distribution units (PDUs), air conditioners, etc.). Event management is a part of DCIM’s philosophy, where users have to manually set alarms and prioritize them. In [13,14], the emphasis is on the general philosophy of event processing, availability, and shortened mean time to repair (MTTR) the system.
This paper presents a new intelligent monitoring method for data center physical infrastructure parameters, based on multilayer node and event entities processing. The method highly improves information about the events in a specific node. Its major advantage is that in the case of a large number of nodes, it considerably reduces the number of identified events (alarms/alerts) that might be the main cause. The importance of this research lies in the fast and more detailed intelligent analysis of all parameters of the physical infrastructure, including events that may affect energy overconsumption. When designing a computer data center it is vital to ensure the necessary main and backup energy supplies, an uninterruptible power supply (UPS), energy support for the system and communication cabinets, and cooling device power supplies, because costs are an important factor when designing the support infrastructure [11,12]. Compared to other approaches [15,16], the proposed method quickly provides filtered information about individual events in nodes and fast main event identification, as well as comprehensive monitoring of the IT data center infrastructure [17,18].
2. Data Center Physical Infrastructure
The priorities of highly classified data centers are not only to maintain the highest level of reliability and availability of the operation, but also fast, specific event identification and energy consumption monitoring, which altogether improve the level of energy efficiency. Monitoring functions include technological components and their control, optimal energy support, alarm and event reporting, and further data reporting to the central control component. Data acquired from the distributed modules and components are then real-time data for central servers at the level of the main control.
Event processing is difficult because the system’s availability level must remain within the required limits. Event information must be accurate and timely so that the appropriate intervention measures can be triggered. During data center operation, many events take place, and these events must be filtered from actual alarms [9,18]. Some events have other consequences as a result of a chain reaction. In order to successfully eliminate all the consequences, the causes of the problem should be found based on the appropriate philosophy of cause and effect and their filtering [17]. In the event of a component failure, all corrective measures must be taken to establish the previous state of process availability within the required time period. During active data center operation, there is no time available to manually perform an analysis of the cause or to determine the percentage chance that the event that actually occurred was the main cause of the error. A manual analysis approach always requires expertise [19].
An information center requires a high degree of availability of the system [20]. On the other hand, there must be a balance between the system availability requirements and energy efficiency, operating costs, and, in a later stage, maintenance costs. A well-known characterization of this is the classification of the levels of availability of data centers (Tier I to Tier IV) by the Uptime Institute [21]. The classification describes and differentiates data centers according to their degree of availability and represents the four levels of requirements to be taken into account [22,23]. The development of standards for these requirements was provided by ANSI/TIA-942—the standard for telecommunications infrastructure for data centers issued by the Telecommunications Industry Association (TIA) [24]. In this series of standards, the data center class Tier I has non-redundant capacity components and non-redundant paths to distribute paths that serve the site’s computer equipment. The data center has cooling of computer rooms and energy distribution. It can also have (or not) a UPS and/or an engine generator. The data center should be closed for annual scheduled maintenance work and repairs. Repair maintenance may require additional shutdowns. Mistakes or spontaneous faults in the infrastructure components will cause disturbances in the data center. Thus, for instance, a Tier I data center is suitable for small businesses where IT is dedicated to internal business processes. A Tier II data center has redundant performance components and individual non-redundant distribution channels that serve the computer equipment of a particular site. They have a UPS and generators, but a route redundancy plus one (N + 1) is required. Maintenance of critical energy routes and other parts of the infrastructure of a particular place requires the shutdown of computer processes. A Tier II data center could be suitable for internet-based businesses without any serious financial penalties for service quality. A Tier III data center is maintenance-free and has excessive performance components and several distribution channels that serve the computer equipment of an individual part of the data center. In this case, the computer equipment uses only one distribution path at any time. This topology allows any planned activity of the site’s infrastructure without interfering with the operation of computer systems in any way. Tier III would, for example, include companies operating in several time zones or whose IT resources support automated business processes, and where the data center is tolerant of errors and has redundant capacity capabilities and several distribution channels that simultaneously serve the site’s computer equipment. All IT equipment is duplicated and connected so that it is compatible with the topology of the data center architecture. Examples of Tier IV include companies that have high availability requirements for current transactions, such as e-commerce, market transactions, or financial settlement procedures [25,26].
3. Results
3.1. Monitoring of Data Center Physical Infrastructure
Figure 1 shows the typical data center technical infrastructure with diesel generators, power supplies, redundant power supplies, UPSs, a cooling system, an air-conditioned system, and technical safety. The status of individual devices in the data center technical infrastructure is obtained via various interfaces and sensors. Data are captured using a programmable logic controller (PLC) through various data capture interfaces (such as Ethernet, Wi-Fi, analog and digital interfaces) and stored in a database. In Figure 1, CcA and CcB represent air conditioners. The purpose of the thermal management is to keep the temperatures in all room spaces below the upper limits required in the standard with the lowest energy consumption [27]. The temperature for the A1 class should be in the range of 15–32 °C and the relative humidity should be between 20% and 80%, as shown in Table 1 [28]. To accurately measure the moisture and temperature in the data center technical infrastructure rooms, industrial humidity probes and sensors are used.
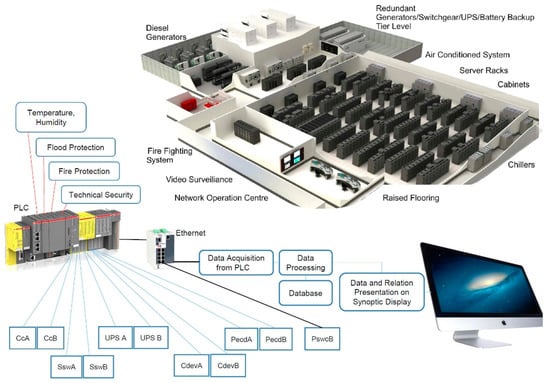
Figure 1.
Data center technical infrastructure monitoring.

Table 1.
American Society of Heating, Refrigerating, and Air-Conditioning Engineers (ASHRAE) thermal guidelines for data centers [29,30,31].
SswA and SswB are static transfer switches that have the task of transferring the power from UPS A to (UPS B) in the event of failure of the UPS A. CdevA and CdevB are cooling devices in which the chilled water temperature is allowed in range of 7.3–25.6 °C in accordance with the maximum allowed IT inlet air temperature, which was, in addition, used to calculate the chilled water temperature.
PecdA and PecdB represent cooling device power supplies, and PswcB is an interface for capturing the state of IT equipment power switches and circuit breakers.
Experimental equipment (Tier IV):
- -
- 6 EMERSON chillers (300 KW of cooling capacity each)—periodic autorotation of active versus
- -
- standby (N + 2 redundancy), integrated free cooling;
- -
- 2 EuroDiesel rotary diesel UPSs (1340 KW) (3–5 days autonomy);
- -
- 1 standard diesel generator (1250 KVA) which can be used for emergency power or non-IT
- -
- equipment (e.g., chillers);
- -
- 3 transformers (1 reserve), 2.5 MW (2 separated 400 A);
- -
- 3 static transfer switches;
- -
- 5 power switches and circuit breakers.
Room 1:
- -
- 44 racks (10 KW each);
- -
- 12 “Schneider APC StruxureWare ” InRow redundant powers (RPs) (IRP), precision cooling with two-way valves;
- -
- 3 fans and humidity controls of 50 kW cooling capacity each;
- -
- 4 redundant power distribution lines of 400 A.
Room 2:
- -
- 76 racks (20 KW each);
- -
- 32 APC InRow RPs (IRP), precision cooling with two-way valves;
- -
- 3 fans and humidity controls of 50 kW cooling capacity each;
- -
- 16 redundant power distribution lines of 400 A;
- -
- 300 different electric IT devices.
Altogether, there were 510 elements of infrastructure used.
Table 2 displays the range limits and their monitoring, as well as the on/off states of individual devices. In particular, the temperature ranges that need to be within the specified limits are of special importance.
Table 2.
Device state detection (1, on; 0, off) [32,33].
The starting point for monitoring a physical infrastructure is to build a common block diagram for all layers of the data center infrastructure. A heuristic professional approach is needed to create a constructive diagram. Based on the basic processes, individual block sub-diagrams were designed for the following layers: power supply, technical cooling, air conditioning, control and management, and technical protection. Other layers can be added according to the design and additional requirements of the data center (DC) power supply.
The data model was implemented in a database management system (DBMS) from the node tree diagram, where all nodes and events in the procedure must be defined. The software used was the CODESYS software language standard [34] (developed by the German (Kempten) software company 3S-Smart Software Solution). The software tool covers different aspects of industrial automation technology. Each node (Figure 2) contains a combination of possible entities.
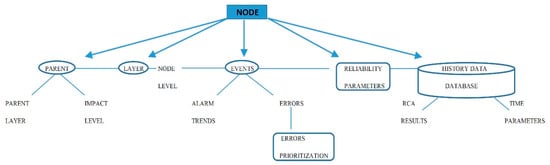
Figure 2.
Possible node model entities.
All nodes and event entities and attributes were stored in databases. Links have to be made between the node and all possible events pointing to the selected node. This also includes definitions of all parents on all layers. All parent nodes have entities with a prioritization value as an impact level. Tree algorithms start in the root nodes and approach the children via parents through the data structure. A child is a node that is directly linked to another node. The parent is a conversational concept of a relationship with a child. Where redundant paths are required, some nodes may have several parents. The number of links between the node and root determines the level of the node. All other nodes are accessible via other links and paths. This approach focuses on the fact that every node in the tree can be understood as the root node of the subordinate roots on this node. In order to minimize the tree graph, internodes were used to rationalize the graph and increase transparency where there were several nodes with several equal parent paths. When searching for the status of the event relatives, it is necessary to check the priority redundancy path. During primary failure, the redundancy path is the secondary path.
3.2. Experimental Power Supply Block as a Node Tree
All the data center’s components and devices in the technical infrastructure block diagram (Figure 1) were converted to nodes. Figure 3 shows an experimental block diagram of a static transfer switch that has the task of transferring power from one UPS to another in the event of a fault or failure of the first UPS.
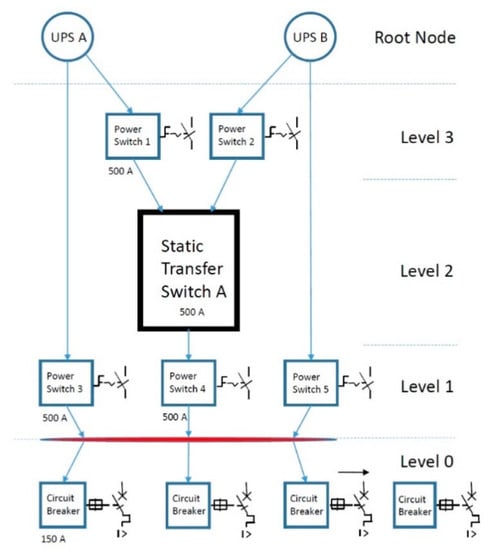
Figure 3.
Node tree diagram with internode of a power supply block.
In the experimental block of the power supply, the two root nodes represent two redundant paths in the node diagram. On these nodes, events and alarms are associated with the program process. The node tree is used to provide more precise and transparent information on the causes and consequences. The theory of tree graphs was used, based on the fact that a tree is a type of non-directional graph in which two or more nodes are connected with exactly one path [35,36]. Node trees are flexible for the processing of mixed real and categorical properties. It is mandatory that data are obtained from all components. When all nodes are defined, they can be easily added and sorted. Sophisticated tree models produced by software can use historical data to perform statistical analysis and predict event probabilities. In Figure 3, the internode (marked with a red line) is a node with information such as links and interconnections and is used anywhere where there is more than one linear path. Once the block diagram is defined for the entire technical infrastructure (Figure 1), the tree nodes with their properties are stored in the database.
3.3. The Root Cause Method
The root cause method (RCM) follows the problem to its source [37,38]. RCM assumes that systems and events are dependent and may be related. An event in one part of the system causes an effect in a second part of the system and then results in an undefined alarm. An event that follows its source can be used to identify the source of the problem and its consequences and subsequent events. Different patterns of negative consequences, hidden deficiencies in the search system, and the events that led to the problem need to be explored. There is a possibility that RCM will disclose more than one cause. RCM first requires the definition of the root cause (RC). The following appropriate definitions can be used:
- -
- RC is a specific cause;
- -
- RCs are those that are logically identified;
- -
- RCs are those that are monitored by system administrators.
The main RCM steps are as follows:
- -
- Data acquisition;
- -
- Graphical display of all root factors (Figure 4);
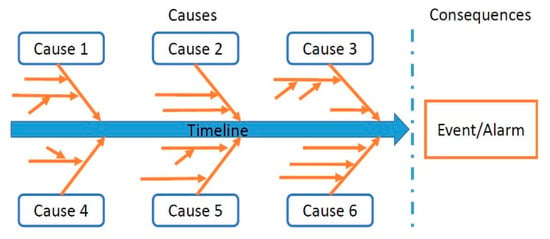 Figure 4. Event cause–consequence diagram.
Figure 4. Event cause–consequence diagram. - -
- RC identification;
- -
- Change proposal generation and implementation.
Once the data are acquired, graphical display of the events and root factors helps us identify the sequence of events and their connection to the circumstances. These events and current circumstances are displayed on a timeline (Figure 4).
The events and conditions proven by facts are displayed along the full line. A graphical display of the events and root factors
- -
- shows the root-cause-based explanation and causes for events;
- -
- helps identify those key areas that represent weak points of system functioning;
- -
- helps guarantee objectivity in cause identification;
- -
- helps prove events and root factors;
- -
- shows multiple cause situations and their mutual dependencies;
- -
- shows the chronology of events;
- -
- shows the basis for helpful changes aimed at preventing the error reappearance in the future;
- -
- is efficient in helping further system design and planning.
The advantages of an event and root factor graphical display are as follows:
- -
- It provides the structure for recording known facts and proof;
- -
- It reveals the gaps in system knowledge through logical connections;
- -
- It enables integration of other software tool results.
Once the root factors are identified, the process of root cause identification starts. The novelty of the RCM method is the use of the event cause–consequence diagram (Figure 4), entity relationship diagram (Figure 5), the node entities model (Figure 2), and the RCM search algorithm (Figure 6). The first diagram structures the sampling procedure, answering the question of why a certain root factor exists/appears. It is followed by a failure root diagram used for possible system failure identification. It is frequently used in the design stage and performs well when we search for possible cause relations. It requires the use of specific data with component failure probability values. Based on the block diagram described in Section 3.3 (Figure 3), the connections between the nodes are defined by entities and attributes for the individual node in question. Figure 5 demonstrates the database model with connections among individual tables. The primary key in the node table is the node name and ID, which is unique for a given node and connected to most of the tables.
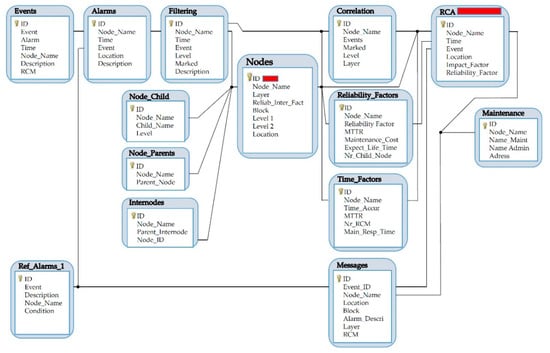
Figure 5.
Tables with the entity relationship diagram (RCM: Root Cause Method, MTTR: Mean Time to Repair system).
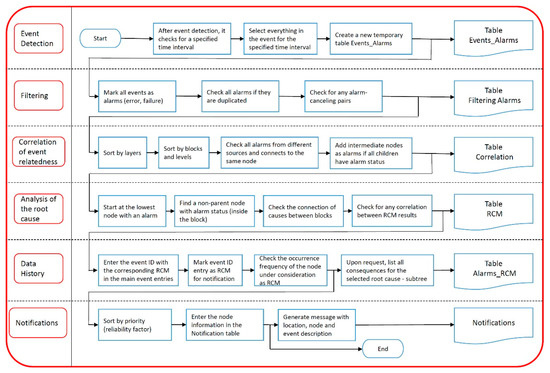
Figure 6.
Key steps of event processing.
With RCM, a query procedure starts with a node with no child. When an internode exists as a parent of a node, all other children from the internodes can be ignored. The steps and RCM procedure were carried out using programming language SQL and a SQL server with event data, saved in the database. Figure 6 shows the key steps of the acquired data processing. More root causes were identified due to the special rules saved with node entities: in the case when the node is the redundant power supply possibility, it always has to be considered as a root cause option.
The backward chaining method was used to find the root cause from the group of related events. RCM theory runs heuristically with experts and usually uses a manual cause-and-effect diagram to determine the reasons why there is a specific causative factor or why it happens for all possible causes and effects. Proposals for corrective actions must then address the causes that have been identified during the analysis process.
3.4. An Overview of Alternative Literature on Big Data Reducing Methods
This section provides an overview of original research and literature on the subject that was gathered through a search of the Web of Science portals.
In the big data methods, new challenges have emerged regarding the computing requirements and strategies for conducting operations management analysis. Data minimizing methods combine statistical and machine learning models, which makes them versatile in dealing with different types of data; however, these methods suffer from the weaknesses of the underlying models [39]. In [40], to better understand processor design decisions in the context of data analytics in data centers, comprehensive evaluations using representative data analytics workloads on representative conventional multi-core and many-core processors were conducted. After a comprehensive analysis of performance, power, and energy efficiency, the authors made the following observation: contrasting with the conventional wisdom that uses wimpy many-core processors to improve energy efficiency, brawny multi-core processors and dynamic overclocking technologies outperformed their counterparts in terms of both execution time and energy efficiency for most of the data analytics workloads in the experiments performed. In [41], the integration and coordination of big data were required to improve the application and network performance of big data applications. While the empirical evaluation and analysis of big data can be one way of observing proposed solutions, it is often impractical or difficult to apply for several reasons, such as the expense, time consumption, and complexity. Thus, simulation tools are preferable options for performing cost-effective, scalable experimentation in a controllable, repeatable, and configurable manner.
Markov chains are stochastic models describing a sequence of events in which the probability of each event depends only on the previous state of the event. In data reduction and reconstruction using Markov Models, higher batch sizes reduce accuracy as the reconstruction does not retain the information which is present in the original dataset. Following a hybrid active/passive approach [42], this paper introduces a family of change-detection mechanisms, differing in the required assumptions and performance. In [43], the authors considered the scenario where the number of virtual CPUs requested by each customer job may be different, and they proposed a hierarchical stochastic modeling approach applicable to performance analysis under such a heterogeneous workload. In [44], the authors addressed the problem of proposing and evaluating large-scale data centers to efficiently reduce bandwidth and storage for telemetry data through real-time modeling using Markov-chain-based methods. Large-scale data centers are composed of thousands of servers organized in interconnected racks to offer services to users. These data centers continuously generate large amounts of telemetry data streams (e.g., hardware utilization metrics) used for multiple purposes, including resource management and real-time analytics.
Article [45] proposed an irregular sampling estimation method to extract the main trend of a time series, in which the Kalman filter was used to remove the noise, missing data, and outliers; then, cubic spline interpolation and averaging methods were used to reconstruct the main trend. In [46], transport protocols such as optical packet switching and optical burst switching allowed a one-sided view of the traffic flow in the network. This resulted in disjointed and uncoordinated decision-making at each node. For effective resource planning, there is a need to consider joining distributed and centralized management, which anticipates the system’s needs and regulates the entire network using Kalman filters. In [47], multisensor data fusion and distributed state estimation techniques that enable local processing of sensor data were the means of choice in order to minimize storage. In particular, a distributed implementation of the optimal Kalman filter was recently developed. A disadvantage of this algorithm is that the fusion center needs access to each node so as to compute a consistent state estimate, which requires full communication each time an estimate is requested.
3.5. Experimental Results of a Reduced Number of Alarms by RCM
The RCM was run on stored data collected between 2016 and 2019 and filtered by a correlation process. The data query starts at a node or a group of nodes without children. Nodes that share the same group of parents have the same internode. The procedure checks the parental status of all nodes in the possible alarm state. If the parent of the observed node is in an alarm state, the repeat loop procedure is performed in the method, checking the state of the next parent until it reaches a parent without further errors. When you follow a parental path up the tree diagram, you need to check the one redundancy path with the highest parental priority. Later, the paths of parents with lower priority factors are checked. After the use of data queries, different RCM results are possible:
- -
- The root event is on the linear path in the tree node diagram with no other parent in the event
- -
- having a malfunction;
- -
- Multiple parents with priority values and all redundant routes are checked to define the main
- -
- current event;
- -
- No connected nodes with the current event;
- -
- A Level 1 event can have a root cause on Level 0;
- -
- The data connections of multiple line paths are checked with possible events;
- -
- The priority classification of alarms due to the reliability of the node is triggered.
When managing and acquiring a great amount of data, data overwrite, data reduplication, missing transfer data, and many other related events can happen. Because of these possible events, data filtering has to be done in the selected time interval. Filtering also enables the same type of event gathered via different types of interfaces to be marked as the same event. This scenario is frequently used when the DC infrastructure is operational, because it is not possible to anticipate all events during the design stage.
During the first experiment, first the data center power supply level was simulated. The same test data were manually inserted into the database in Table 3 and Table 4 (“Events”). Table 3 shows the number of alarms without using RCM, and Table 4 shows that when it was used. The main cause was inserted as a failure of the diesel generator due to a filter failure. All nodes had an alarm event. For a more transparent presentation, the alarm nodes were grouped into parts connected to the same device or cabinets and power devices. For example, a component in the line labeled “DEG” (Table 3 and Table 4) refers to a diesel electric generator. The power supplies of the system cabinets are marked with “Psc 1, 2, 3”. The power distribution units are designated as “Pdu 1, 2” and they are in all IT cabinets. The “UPS A, B” labels represent uninterruptible power supplies and all components related to them. The “Cch A, B” are cooling chillers. “Psc A, B” represent power supplies of the cooling devices. The successive steps in the process from “Events” to “Alerts” were systematically derived as shown in Table 4. The RCM inquiry procedure (Figure 2 and Figure 3) started with a childless node. In the event that the internode existed as the main node, all other children of the internode were ignored. Several specific causes were identified due to special rules stored with node entities. To find the root cause of a group of related events, the reverse method was used. After filtering the data, a correlation process was used to combine the associated alarm events with the same parent group. A correlation step must be performed in order to search for all related events among alarms. Correlation does not imply causation [48,49], which means that one alarm event does not necessarily cause another. It can only be assumed, as to the definitions, that if the events are correlated, that means that a change in one event causes a change in another node. The correlation factor in this approach is related connectivity. If there are any alarm events that have the same parents, they are grouped together, so the node path of these events is checked in the root cause analysis only once.
Table 3.
Comparison of the alert/event number (without root cause method (RCM))—data center power supply level.
Table 4.
Comparison of the alert/event number (with root cause method (RCM))—data center power supply level.
After linking related events to internodes, the correlation method yielded results for each part of the system, as shown in Table 4 in the “Correlation” row. Table 4 shows that the number of alarm events decreased.
For example, in Psc 1, 2, and 3, the system cabinets are all directly connected to power switches. They all have the same parental internal hub and the same power supply group (UPS A, B) (Figure 3). The alarm events of these system cabinets were merged and therefore reduced to the same internal node. Therefore, due to the RCM, the alerts were carried out for the following:
- -
- The diesel generator, which is also the main cause and one redundant power option;
- -
- UPS A and UPS B, which were identified as a root cause because of the redundancy option;
- -
- Cch A and Cch B, which have the same power source as the main network power supply.
From the number of events, it was calculated that the number of saved alarms/alerts decreased to 38%, which means that the average number of all alarms decreased by 62% (Table 4).
Another experiment was performed on data stored in the history on messages sent to administrators. These messages contained all the information about events that had happened in the past. The event data that were stored were compared to the currently detected causes. The messages were gathered by blocks (system functional parts) and by data type in the CODESYS software. Event declarations can be sorted by individual blocks. The connections to nodes to which an event is related can be determined in the list and during event identification. The event origin (device, node, type of event) can be determined for event variables. An example of the table with event declarations and alarm statuses for the cooling cabinets is shown in Table 5 below.
Table 5.
An example of event definition and features for a cooling cabinet (CC_1).
Table 6 shows an example of alarm activation areas with variables for the border regions for the cooling cabinet temperature measurement.
Table 6.
Activation alarm area for increased temperature in cooling devices CC1 and CC2.
With the RCM running on the stored data, the number of events was decreased by ~50% for the period from 2016 to 2019 (Table 7). Table 7, a comparison of the total numbers of all events between 2016 and 2019, shows that when using the RCA method, the number of detected real alarms increased with increasing number of alarms (events). There were no data center downtime periods during the event collection period.
Table 7.
Event comparison.
4. Discussion
The experimental results of the proposed RCM provide more precise information about the node which is the main cause of the events. From a large number of nodes, the number was minimized by identifying the main cause of the event. Another advantage of the method lies in obtaining accurate information about the operation of an individual device by monitoring all the data center’s technical devices. Rapid identification of data center failure is essential to ensuring high-quality service in terms of high availability. The disadvantage of the RCM is that most of the work needs to be done at the design stage in order to achieve a high degree of availability and reduce the data center’s power consumption. The proposed method allows for the addition, removal, and replacement of power supplies, which should be conceived at the data center infrastructure design phase. The design of the software and the sensor system requires critical activities relating to the RCM, where it is necessary to identify all nodes for monitoring and all the parameters that are important for the efficient operation of the data center.
With the RCM, most information about the condition of all devices and indirect information on how to reduce the energy consumption in data centers is gathered from the basic layer (power supplies, cooling systems, etc.). For example, if we look at servers, even when they are in sleep mode, they consume a lot of energy. Great savings can be achieved by changing these servers to standby mode when there is no need for their operation. If we use these and other measures, such as consolidation of the total workload to reduce the consumption of electricity in data centers, availability may be reduced. Therefore, a complex balance is needed between energy savings and high availability of the data center. Electricity consumption and heat valuation metrics play an important role in describing the reduction of electrical and thermal loads on the environment. A well-known metric is the power usage efficiency (PUE) measure, which shows the total energy consumption in the data center per unit of energy consumed by the IT system. In addition to the PUE measurement, other information is vital, such as the carbon utilization efficiency (CUE), the green energy coefficient (GEC), the energy reuse factor (ERF), and renewable energy or the recycling of waste heat in data centers [32,50,51]. Measurements of general energy efficiency were carried out where small data center efficiency in terms of energy and cooling was evaluated using 25 parameters over a period of six weeks during real-time operation. The measured data were then compared with the supply heat index (SHI), rack heat index (RHI), rack cooling index (RCI), rack temperature index (RTI), and PUE. The results of these comparisons demonstrated that server ceilings were over-cooled by more than 25% if the SHI and RHI were 16% and 74%, respectively [33,51]. As a measure of improvement, there was a reduction in the cooling load. The next suggestion was that the data center heat load and the level of server cabinets should be evaluated at the same time, in order to more accurately analyze the overall operation of the cooling system.
It is also important to ensure that the data center maintains an appropriate climate environment (humidity and temperature) to avoid compromising the reliability of computer equipment. In high humidity, water vapor condensation occurs on the computer equipment, and low humidity results in electrostatic discharges. The thermal management of the data center is also important in order to maintain lower temperatures where the data center equipment is located, as required by the standard specifying the lowest energy consumption.
In general, the RCM improves the monitoring of data center operations and the effectiveness of the available data. The method allows objectivity by weighing evidence of alarm events that have already been reported in the past, regardless of the user’s personal reactions. In addition, dynamic monitoring is available through the modularity of the process structure. The results of the measurements stimulate in-depth research of critical events. The method does not ensure the improvement of the data center’s energy efficiency, unless all components are included in the RCM. Based on the data center’s data, event reports about a certain part of the system or device can be searched, and the energy efficiency of a particular manufacturer of individual devices can be checked. Furthermore, RCM has clear positive economic effects for data center functioning. Its fast event identification enables a swift reaction to events (turning off of individual units or changing their functioning to sleep mode to save electricity). It also increases the availability class. Finally, the results of the RCM can help to improve standards for efficient energy management and maintenance measures in data centers.
5. Conclusions
The advanced concept of RCM design and event monitoring in a typical data center was used herein. A new method for monitoring the parameters of a physical data center’s infrastructure and for event management using the multilevel tree node approach was introduced. The RCM brings benefits such as accurate event identification and, thus, potential opportunities to reduce energy and use standardized measures to add and replace equipment. The obtained experimental results show that all the individual steps of this method contribute to the minimization of events (alerts). The administrators are provided with a wider and more accurate overview of data center infrastructure operations. It is suitable for use in small and large data centers and in modular data centers.
Author Contributions
The research work was carried out by V.M., who analyzed the intelligent monitoring of physical data centers and prepared the article; B.B. developed the software for the multilayer event processing and conducted experiments, while M.M. supervised the research.
Funding
The authors are grateful to the Slovenian National Science Foundation for the support of this work through projects under Grant P2-7436.
Acknowledgments
The authors acknowledge the Slovenian National Science Foundation and the University of Maribor, Faculty of Electrical Engineering and Computer Science.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Guerraiche, K.; Rahli, M.; Zeblah, A.; Dekhici, L. Budgetary and redundancy optimization of heterogeneous series-parallel power systems under availability constraints. Energy Procedia 2015, 74, 547–554. [Google Scholar] [CrossRef]
- Ciapessoni, E.; Cirio, D.; Kjolle, G.; Massucco, S.; Pitto, A.; Sforna, M. Probabilistic risk-based security assessment of power systems considering incumbent threats and uncertainties. IEEE Trans. Smart Grid 2016, 7, 2890–2903. [Google Scholar] [CrossRef]
- Alam, M.A. Study and analysis of energy efficient data center for sustainable development of ict. Int. J. Adv. Res. Comput. Sci. 2017, 8, 1486. [Google Scholar]
- Whitehead, B.; Andrews, D.; Shah, A.; Maidment, G. Assessing the environmental impact of data centres part 1: Background, energy use and metrics. Build. Environ. 2014, 82, 151–159. [Google Scholar] [CrossRef]
- Van Heddeghem, W.; Lambert, S.; Lannoo, B.; Colle, D.; Pickavet, M.; Demeester, P. Trends in worldwide ict electricity consumption from 2007 to 2012. Comput. Commun. 2014, 50, 64–76. [Google Scholar] [CrossRef]
- Dayarathna, M.; Wen, Y.; Fan, R. Data center energy consumption modeling: A survey. IEEE Commun. Surv. Tutor. 2016, 18, 732–794. [Google Scholar] [CrossRef]
- Wiboonrat, M. Next generation data center design under smart grid. In Proceedings of the 2012 Fourth International Conference on Ubiquitous & Future Networks (ICUFN), Phuket, Thailand, 4–6 July 2012; pp. 103–108. [Google Scholar]
- Institute_LLC Ponemon. Cost of Data Center Outages; Data Center Performance Benchmark Serie; Institute_LLC Ponemon: North Traverse City, MI, USA, 2016. [Google Scholar]
- Silva, M.J.D.; Pereira, C.E.; Götz, M. Knowledge awareness in alarm system database. IFAC PapersOnLine 2016, 49, 297–302. [Google Scholar] [CrossRef]
- Liu, H.-C.; You, J.-X.; Li, Z.; Tian, G. Fuzzy petri nets for knowledge representation and reasoning: A literature review. Eng. Appl. Artif. Intell. 2017, 60, 45–56. [Google Scholar] [CrossRef]
- Jia, M.; Srinivasan, R.S.; Raheem, A.A. From occupancy to occupant behavior: An analytical survey of data acquisition technologies, modeling methodologies and simulation coupling mechanisms for building energy efficiency. Renew. Sustain. Energy Rev. 2017, 68, 525–540. [Google Scholar] [CrossRef]
- Bostoen, T.O.M.; Mullender, S.; Berbers, Y. Power-reduction techniques for data-center storage systems. ACM Comput. Surv. 2013, 45, 31–38. [Google Scholar] [CrossRef]
- Vojko, M.; Barbara, B. Improved data center energy efficiency and availability with multilayer node event processing. Energies 2018, 11, 2478. [Google Scholar]
- Zhou, D.; Lv, C.; Li, Y.; Guo, Z. A system’s mean time to repair allocation method based on the time factors. Qual. Reliab. Eng. Int. 2014, 30, 247–256. [Google Scholar]
- Bilal, K.; Malik, S.U.R.; Khan, S.U.; Zomaya, A.Y. Trends and challenges in cloud data centers. IEEE Cloud Comput. 2014, 1, 10–20. [Google Scholar] [CrossRef]
- Khatab, A.; Aghezzaf, E.H. Selective maintenance optimization when quality of imperfect maintenance actions is stochastic. Reliab. Eng. Syst. Saf. 2016, 150, 182–189. [Google Scholar] [CrossRef]
- Derringer, C.; Rottman, B.M. How people learn about causal influence when there are many possible causes: A model based on informative transitions. Cogn. Psychol. 2018, 102, 41–71. [Google Scholar] [CrossRef] [PubMed]
- Straka, M.; Lenort, R.; Khouri, S.; Feliks, J. Design of large-scale logistics systems using computer simulation hierarchic structure. Int. J. Simul. Model. 2018, 17, 105–118. [Google Scholar] [CrossRef]
- Prado, R.P.; Hoffmann, F.; Garcı’a-Galán, S.; Muñoz Expósito, J.E.; Bertram, T. On providing quality of service in grid computing through multi-objective swarm-based knowledge acquisition in fuzzy schedulers. Int. J. Approx. Reason. 2012, 53, 228–247. [Google Scholar] [CrossRef]
- Nguyen, T.A.; Kim, D.S.; Park, J.S. Availability modeling and analysis of a data center for disaster tolerance. Future Gener. Comput. Syst. 2016, 56, 27–50. [Google Scholar] [CrossRef]
- Dumsky, D.V.; Isaev, E.A. Data centers for physical research. Phys. Procedia 2015, 71, 298–302. [Google Scholar] [CrossRef]
- Talapko, D. Telecom datacenter power infrastructure availability comparison of dc and ac ups. In Proceedings of the Intelec 2012, Scottsdale, AZ, USA, 30 September–4 October 2012; pp. 1–5. [Google Scholar]
- Govindan, S.; Wang, D.; Chen, L.; Sivasubramaniam, A.; Urgaonkar, B. Modeling and Analysis of Availability of Datacenter Power; IBM Research Zurich: Technical Report; CSE 10-006; The Pennsylvania State University: State College, PA, USA, 2010. [Google Scholar]
- Chille, V.; Mund, S.; Möller, A. Harmonizing Physical and It Security Levels for Critical Infrastructures; Gesellschaft für Informatik e.V.: Bonn, Germany, 2018. [Google Scholar]
- Chen, T.; Gao, X.; Chen, G. The features, hardware, and architectures of data center networks: A survey. J. Parallel Distrib. Comput. 2016, 96, 45–74. [Google Scholar] [CrossRef]
- Siu, S.K.; Lopopolo, J. Compatibility, sizing, and design considerations for generators and upss in tiers i, ii, iii, and iv topologies. IEEE Trans. Ind. Appl. 2011, 47, 2324. [Google Scholar] [CrossRef]
- Fouladi, K.; Wemhoff, A.P.; Silva-Llanca, L.; Abbasi, K.; Ortega, A. Optimization of data center cooling efficiency using reduced order flow modeling within a flow network modeling approach. Appl. Therm. Eng. 2017, 124, 929–939. [Google Scholar] [CrossRef]
- Oró, E.; Depoorter, V.; Garcia, A.; Salom, J. Energy efficiency and renewable energy integration in data centres. Strategies and modelling review. Renew. Sustain. Energy Rev. 2015, 42, 429–445. [Google Scholar] [CrossRef]
- ASHRA. Thermal Guidelines for Data Processing Environments—Expanded Data Center Classes and Usage Guidance; Technical Committee (tc) 9.9; ASHRAE: Atlanta, GA, USA, 2011. [Google Scholar]
- Standard, E. European Standard en 50600-1:2012. Available online: https://shop.bsigroup.com/ProductDetail/?pid=000000000030242880 (accessed on 19 November 2019).
- Standard, E. European Standard en 50600-2-3:2012. Available online: https://shop.bsigroup.com/ProductDetail/?pid=000000000030374953 (accessed on 19 November 2019).
- Yuventi, J.; Mehdizadeh, R. A critical analysis of power usage effectiveness and its use in communicating data center energy consumption. Energy Build. 2013, 64, 90–94. [Google Scholar] [CrossRef]
- Lajevardi, B.; Haapala, K.R.; Junker, J.F. Real-time monitoring and evaluation of energy efficiency and thermal management of data centers. J. Manuf. Syst. 2015, 37, 511–516. [Google Scholar] [CrossRef]
- Stoj, J.; Smolka, I.; Mackowski, M. Determining the usability of embedded devices based on raspberry pi and programmed with codesys as nodes in networked control systems. In Computer Networks, cn 2018; Springer: Cham, Switzerland, 2018; Volume 860, pp. 193–205. [Google Scholar]
- Strawn, G. Don knuth: Mastermind of algorithms [review of “the art of programming”]. IT Prof. 2014, 16, 70. [Google Scholar] [CrossRef]
- Lin, G.; Rajaraman, R. Approximation algorithms for multiprocessor scheduling under uncertainty. Theory Comput. Syst. 2010, 47, 856–877. [Google Scholar] [CrossRef]
- Dhukaram, A.V.; Baber, C. A systematic approach for developing decision aids: From cognitive work analysis to prototype design and development. Syst. Eng. 2016, 19, 79–100. [Google Scholar] [CrossRef]
- Opmanis, R.; ĶIkusts, P.; Opmanis, M. Root cause analysis of large scale application testing results. Informatica 2016, 27, 819–842. [Google Scholar] [CrossRef]
- Choi, T.M.; Wallace, S.W.; Wang, Y. Big data analytics in operations management. Prod. Oper. Manag. 2018, 27, 1868–1883. [Google Scholar] [CrossRef]
- Jia, Z.G.; Gao, W.; Shi, Y.; McKee, S.A.; Ji, Z.; Zhan, J.; Wang, L.; Zhang, L. Understanding processors design decisions for data analytics in homogeneous data centers. IEEE Trans. Big Data 2019, 5, 81–94. [Google Scholar] [CrossRef]
- Alwasel, K.; Calheiros, R.N.; Garg, S.; Buyya, R.; Ranjan, R. Bigdatasdnsim: A simulator for analyzing big data applications in software-defined cloud data centers. arXiv 2019, arXiv:1910.04517. [Google Scholar]
- Roveri, M. Learning discrete-time markov chains under concept drift. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2570–2582. [Google Scholar] [CrossRef] [PubMed]
- Chang, X.; Xia, R.; Muppala, J.K.; Trivedi, K.S.; Liu, J. Effective modeling approach for iaas data center performance analysis under heterogeneous workload. IEEE Trans. Cloud Comput. 2018, 6, 991–1003. [Google Scholar] [CrossRef]
- Iqbal, W.; Berral, J.L.; Erradi, A.; Carrera, D. Real-time data center’s telemetry reduction and reconstruction using markov chain models. IEEE Syst. J. 2019. [Google Scholar] [CrossRef]
- Miao, B.; Dou, C.; Jin, X. Main trend extraction based on irregular sampling estimation and its application in storage volume of internet data center. Comput. Intell. Neurosci. 2016, 9328062. [Google Scholar] [CrossRef]
- Mbous, J.; Tao, J.; Ming, T.; Songnian, F.; Deming, L. Kalman filtering-based traffic prediction for software defined intra-data center networks. Trans. Internet Inf. Syst. 2019, 13, 2964. [Google Scholar]
- Dormann, K.; Noack, B.; Hanebeck, U.D. Optimally distributed kalman filtering with data-driven communication. Sensors 2018, 18, 1034. [Google Scholar] [CrossRef]
- Baumgartner, M. A regularity theoretic approach to actual causation. Erkenntnis 2013, 78, 85. [Google Scholar] [CrossRef]
- Zaki, M.J.; Meira, W., Jr.; Meira, W. Data Mining and Analysis Fundamental Concepts and Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Zhang, K.; Zhang, Y.; Liu, J.; Niu, X. Recent advancements on thermal management and evaluation for data centers. Appl. Therm. Eng. 2018, 142, 215–231. [Google Scholar] [CrossRef]
- Spafford, G. Greening the Data Center: Opportunities for Improving Data Center Energy Efficiency; IT Governance Publishing: Ely, Cambridgeshire, UK, 2009. [Google Scholar]






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).