Deep Neural Network Equalization for Optical Short Reach Communication

 , ,
, , 
Abstract
:1. Introduction
2. Principles of Nonlinear Equalizer
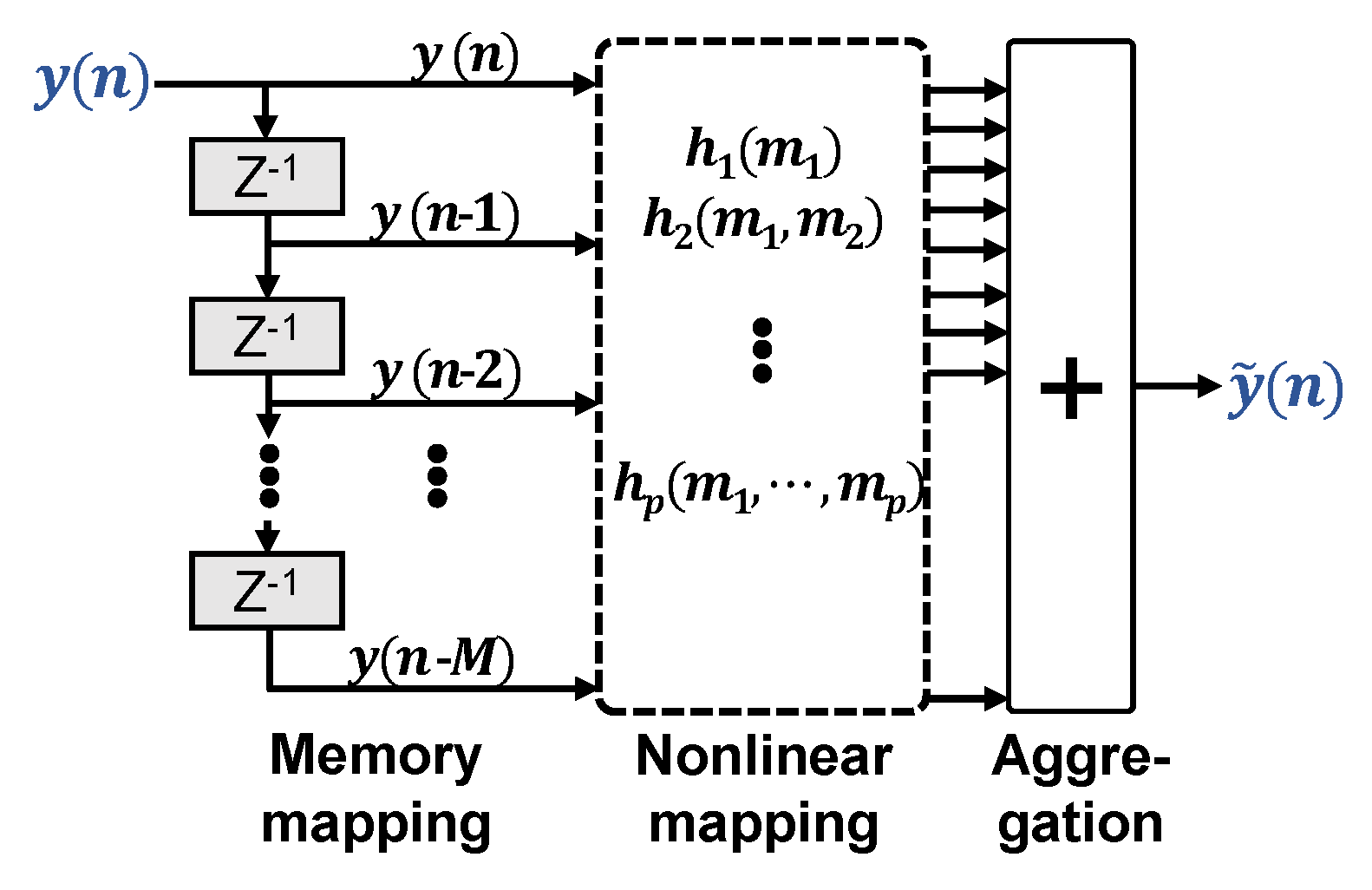
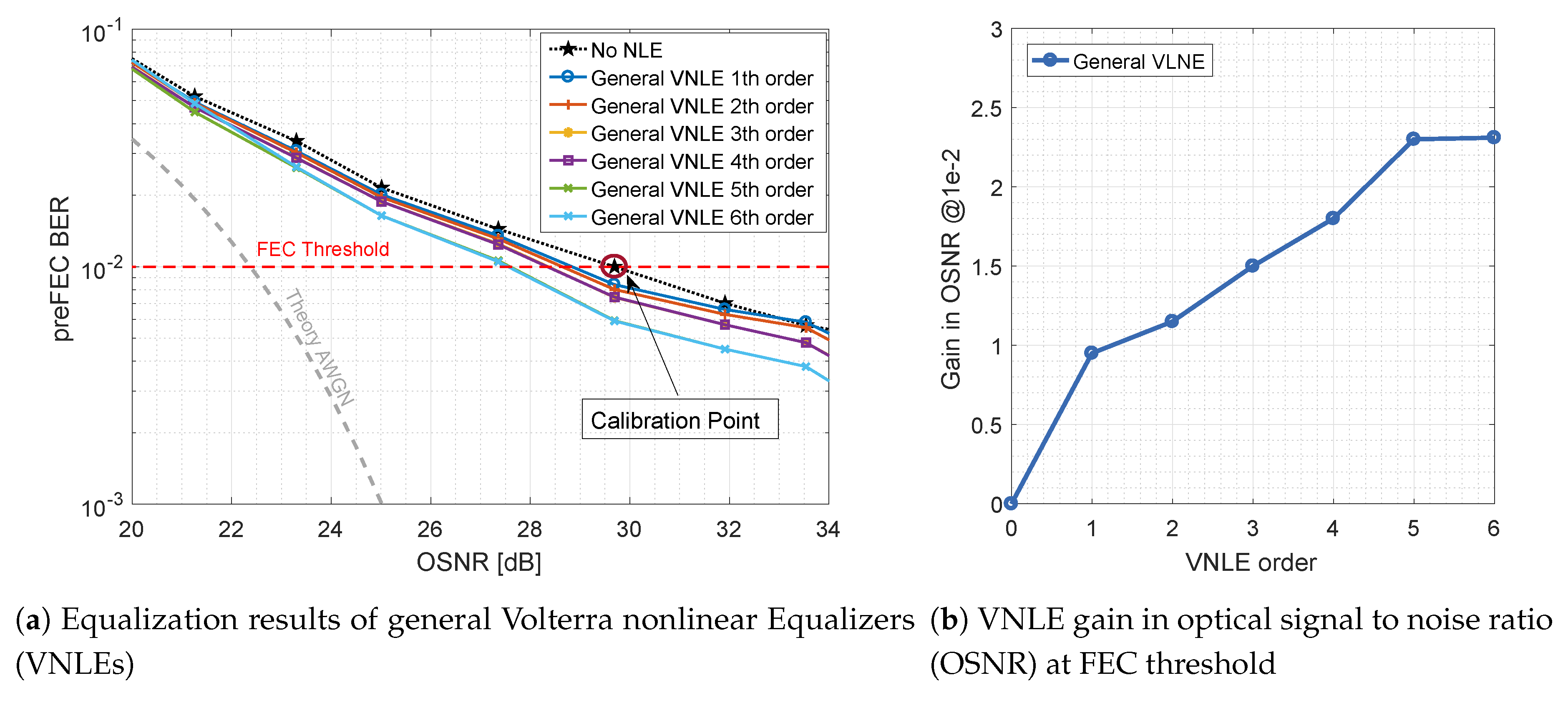
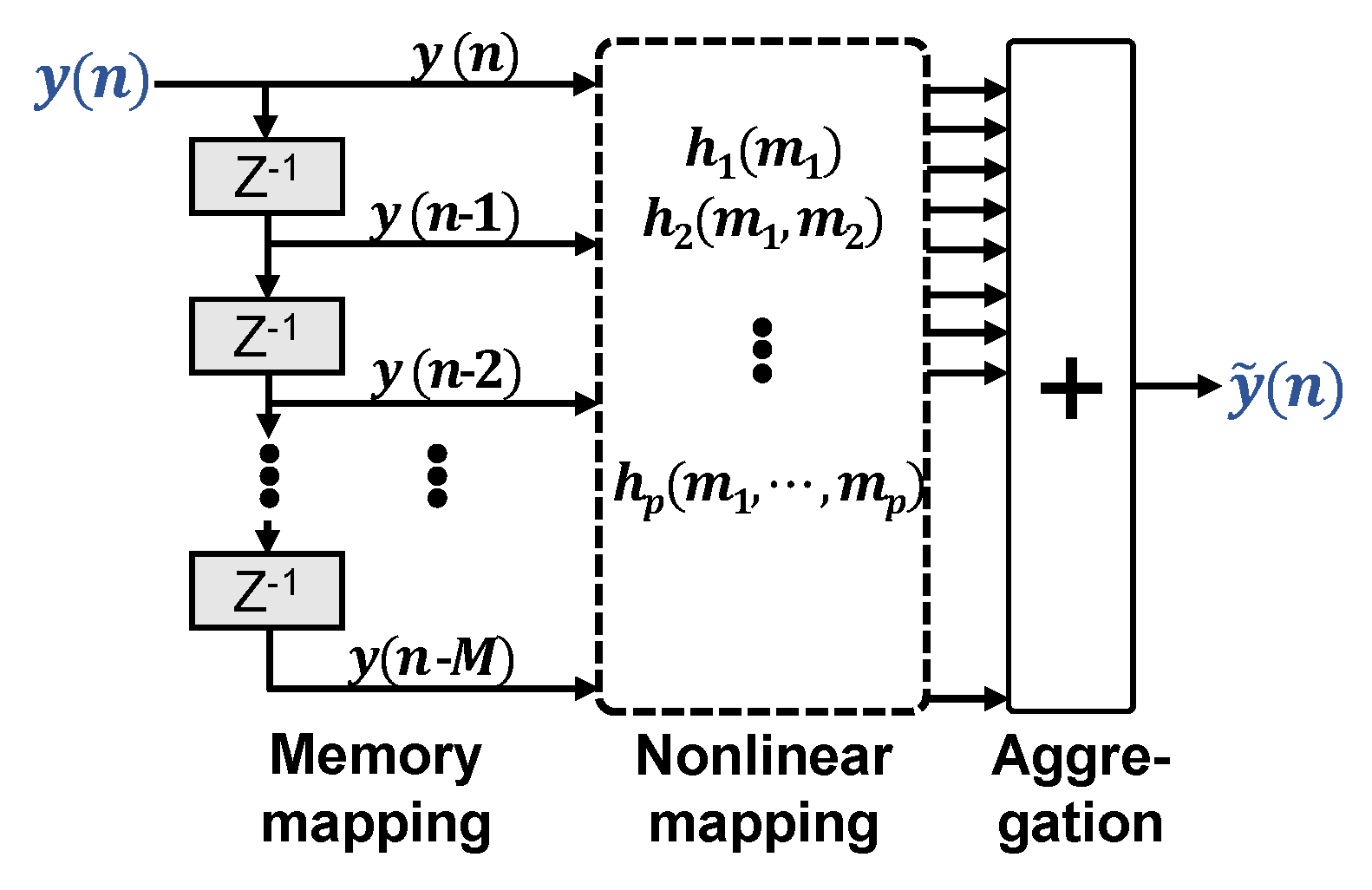
2.1. General Volterra Equalizer
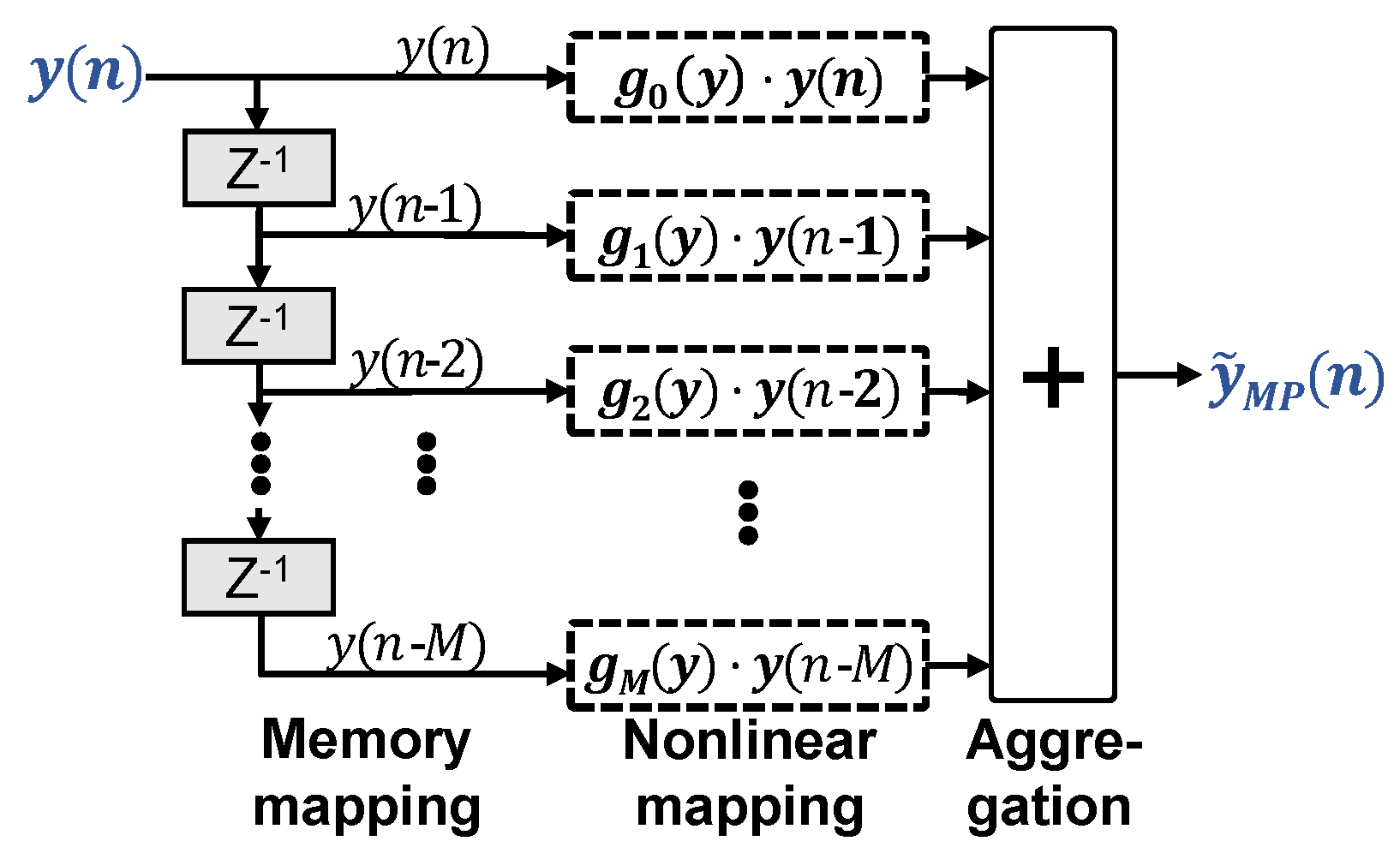
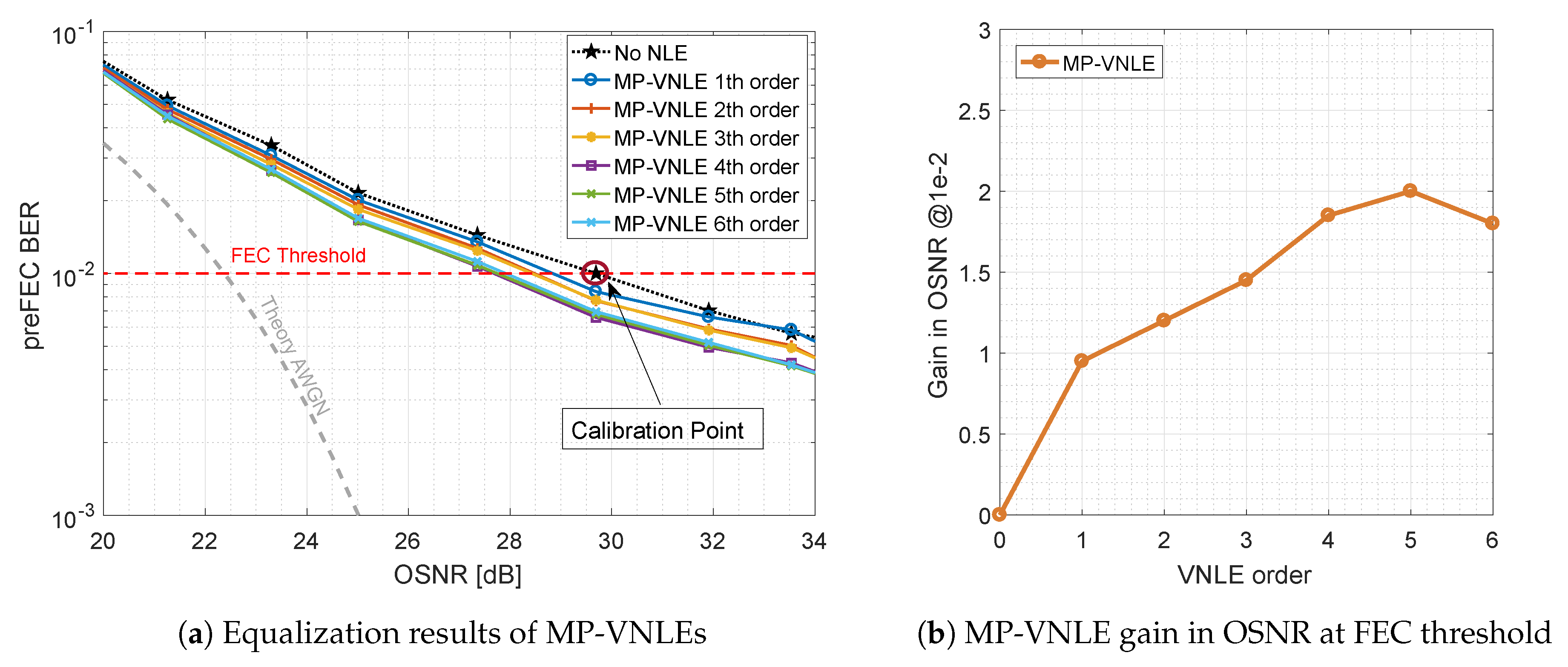
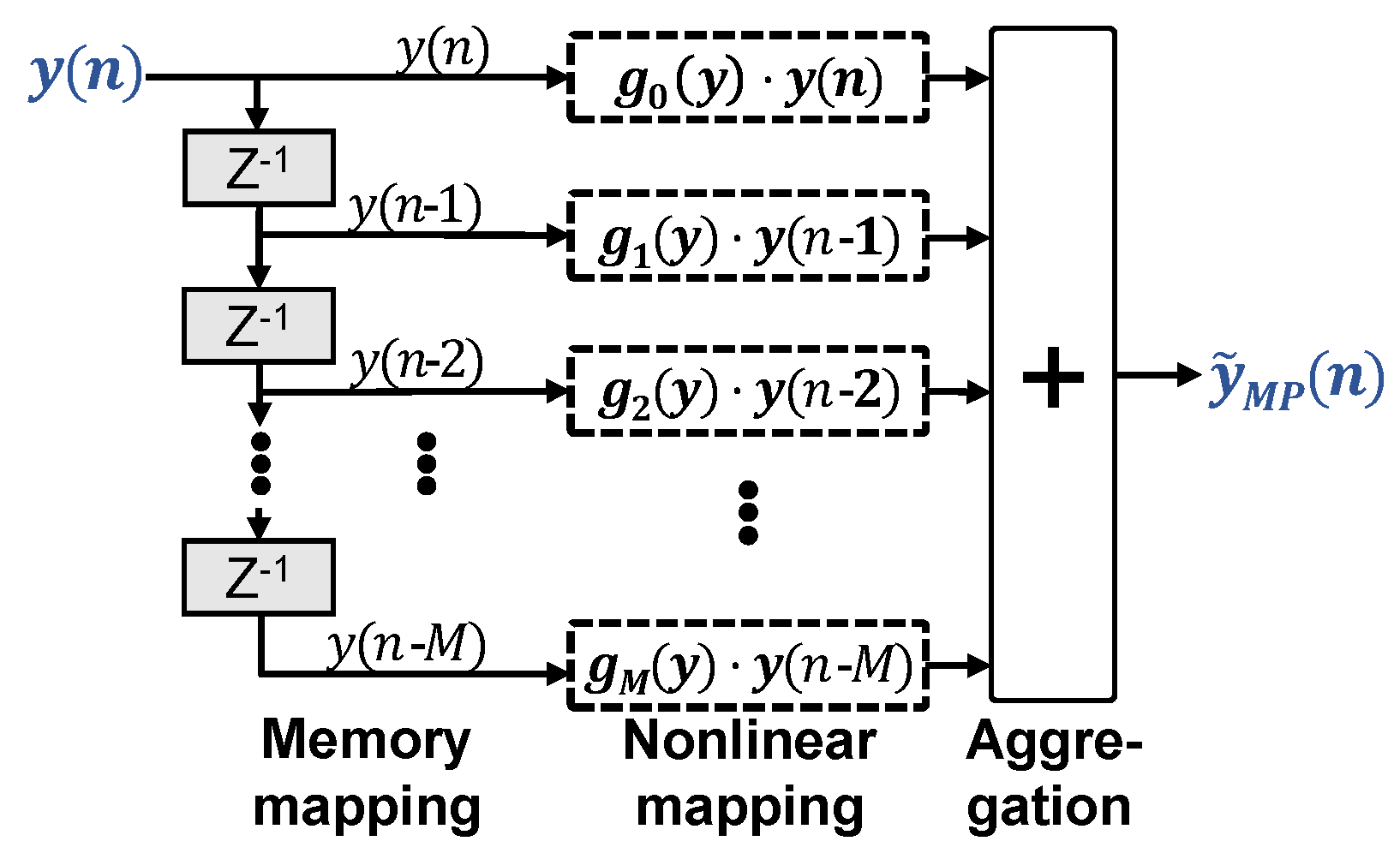
2.2. Memory Polynomial Volterra Equalizer
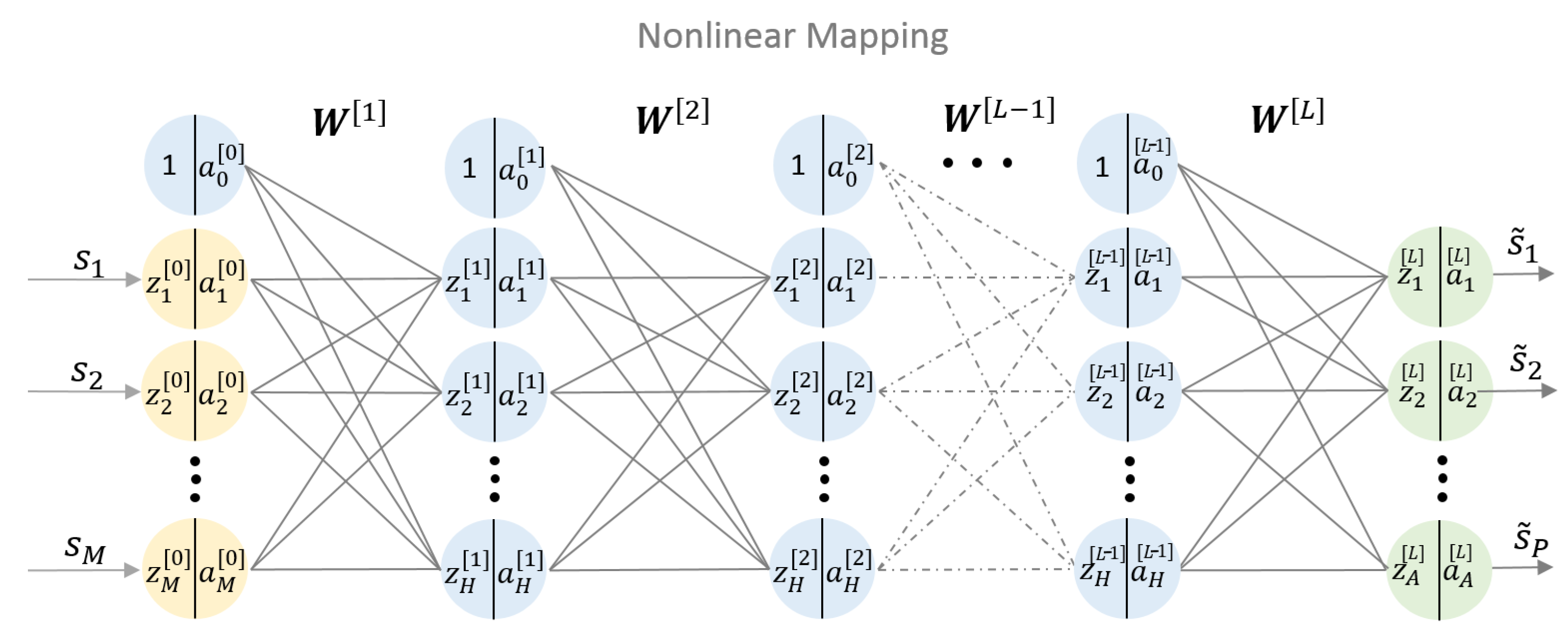
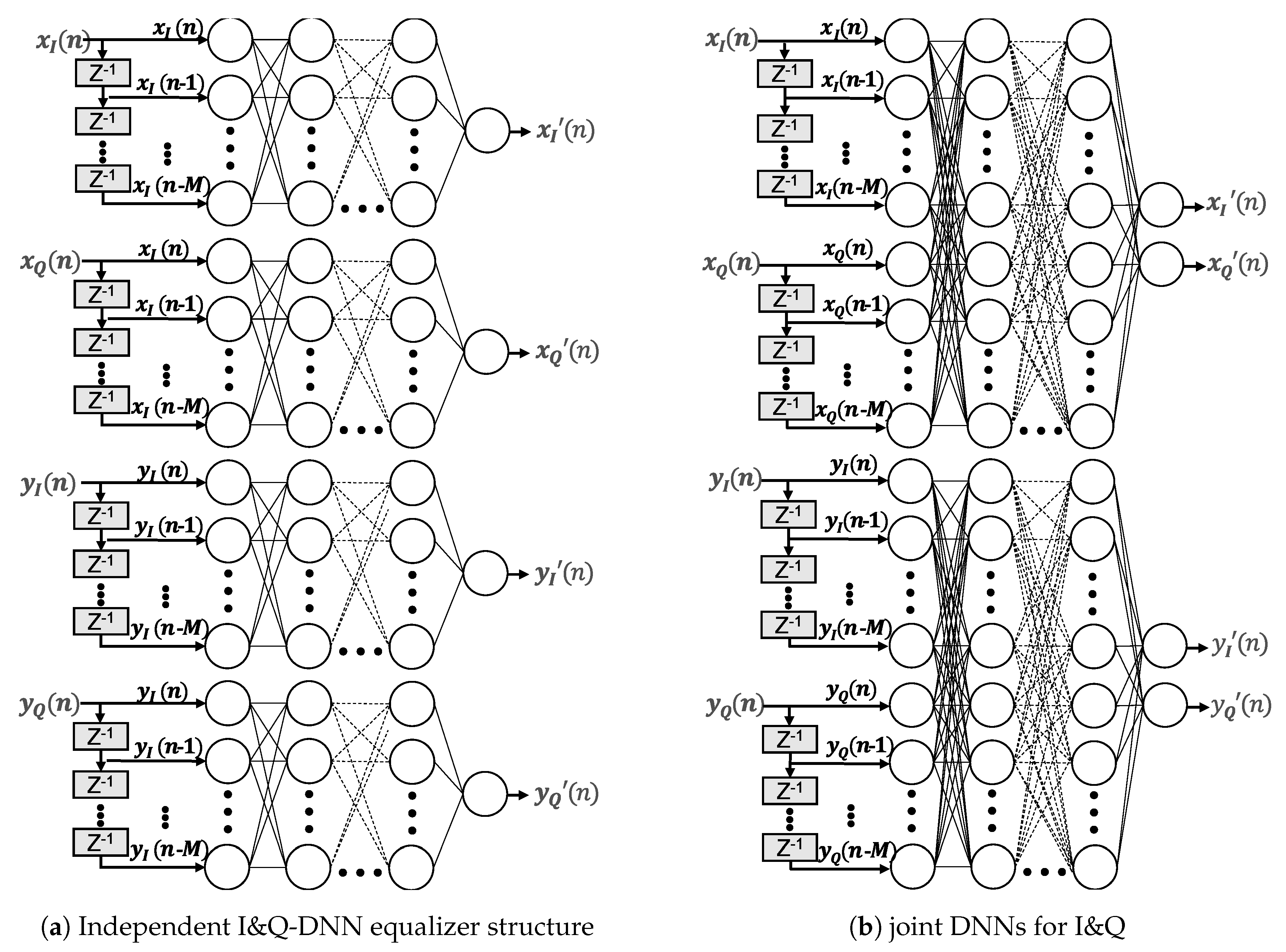
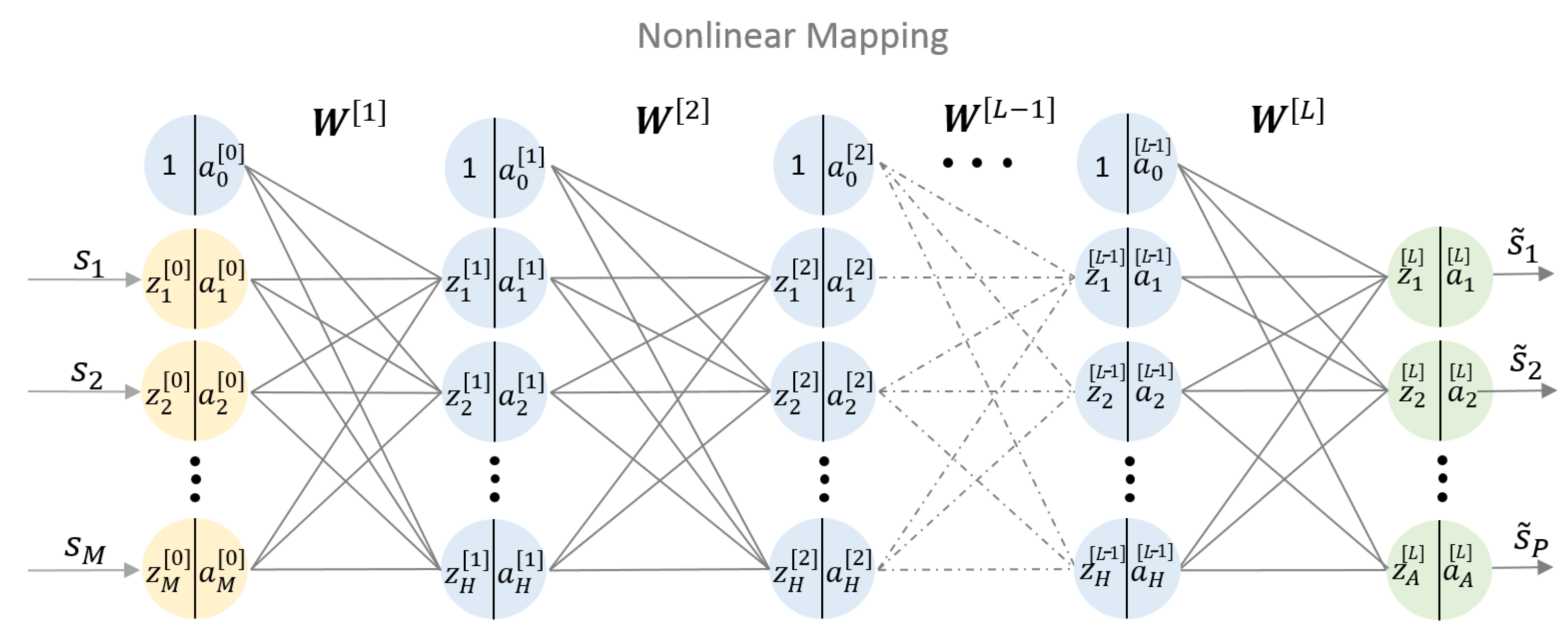
2.3. Deep Neural Network Equalizer
- denotes the input signal,
- denotes the equalized signal,
- denotes a weight matrix (including the bias) between the -th layer to the l-th layer,
- denotes the output of the i-th neuron in the l-th layer,
- denotes the summed up input to the i-th neuron in the l-th layer,
- The activation function is the relation between and of the i-th neuron in the l-th layer,
3. Experimental Verification and Discussion
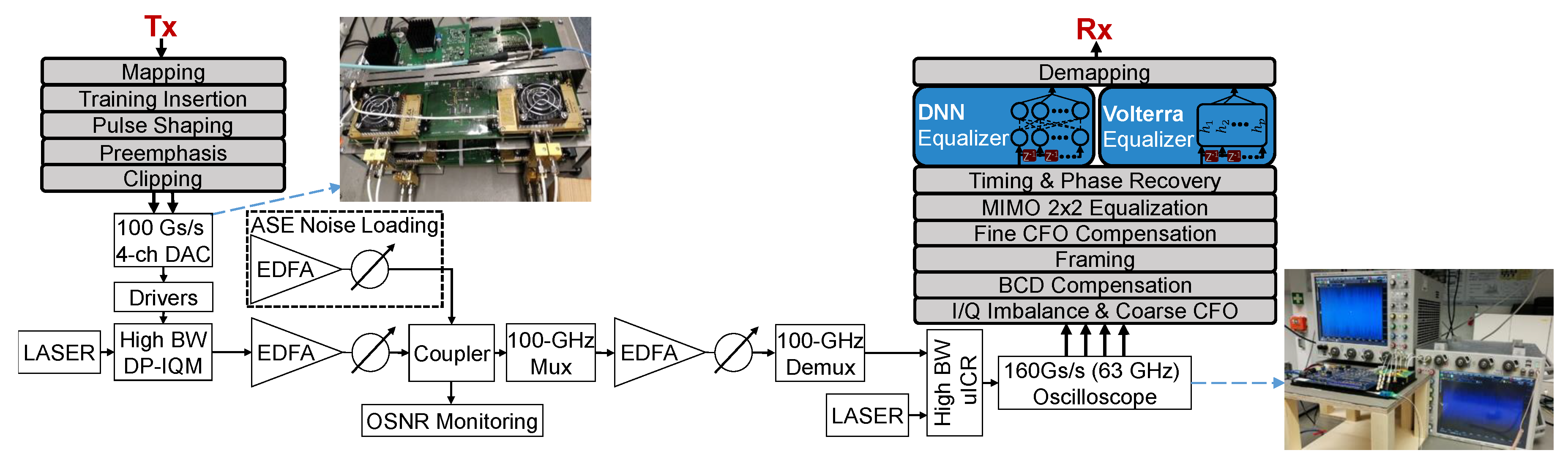
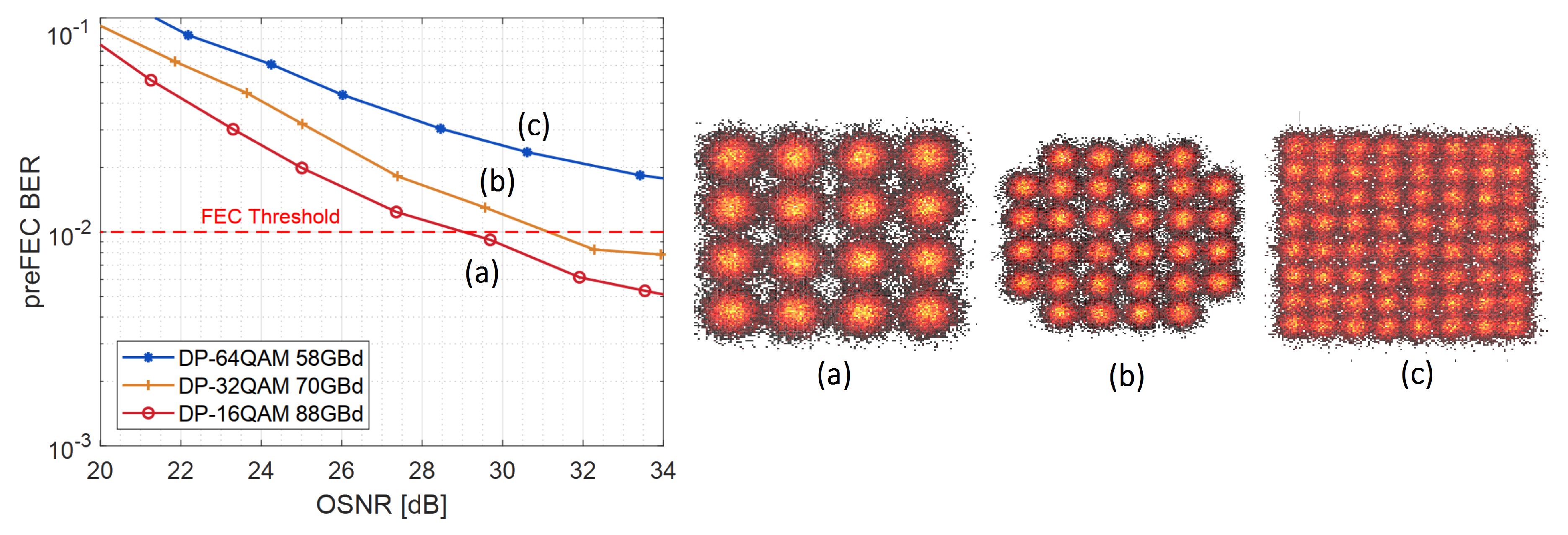
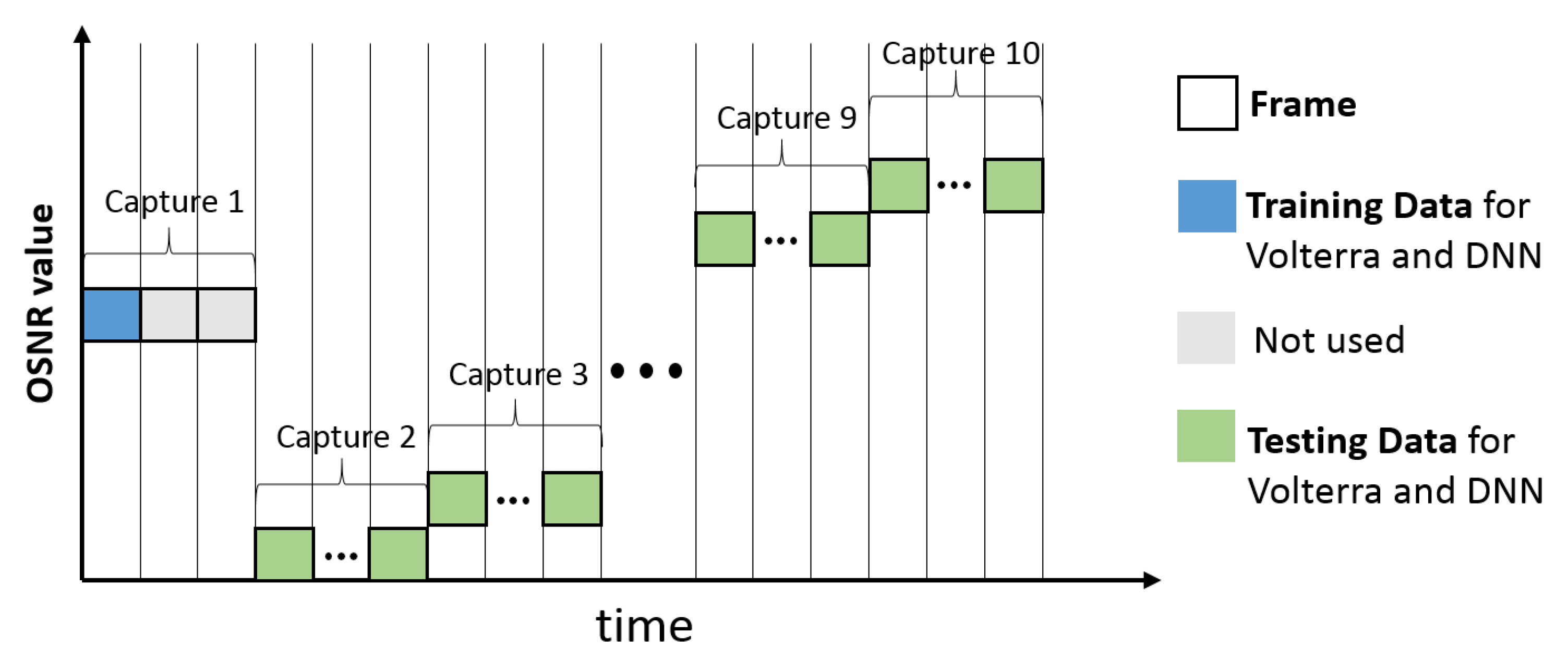
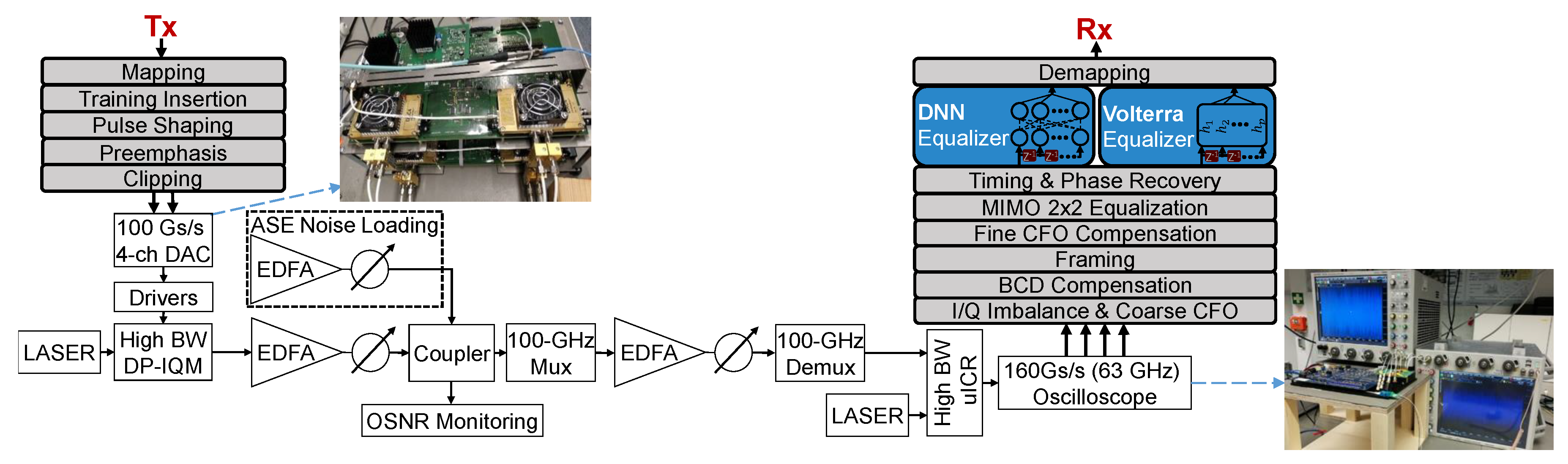
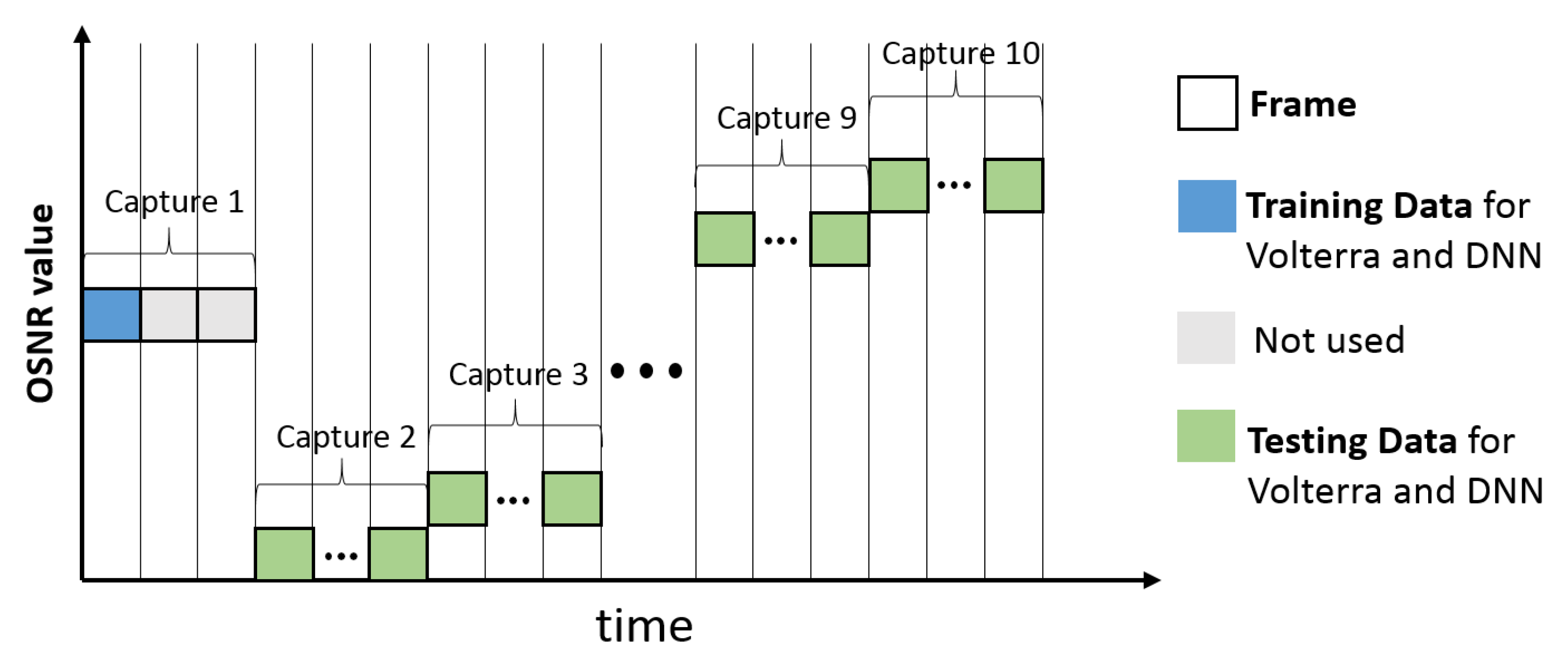
3.1. Measurement Setup
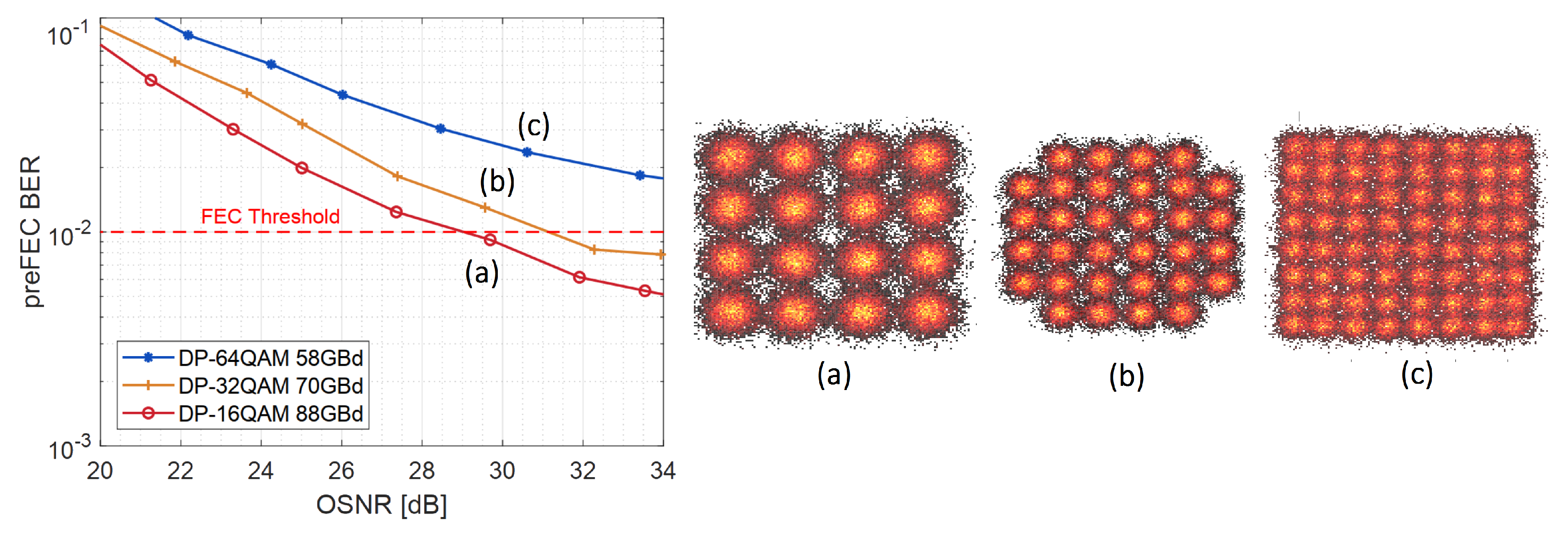
3.2. Measurement Results over an Optical Channel with 600 Gb/s/
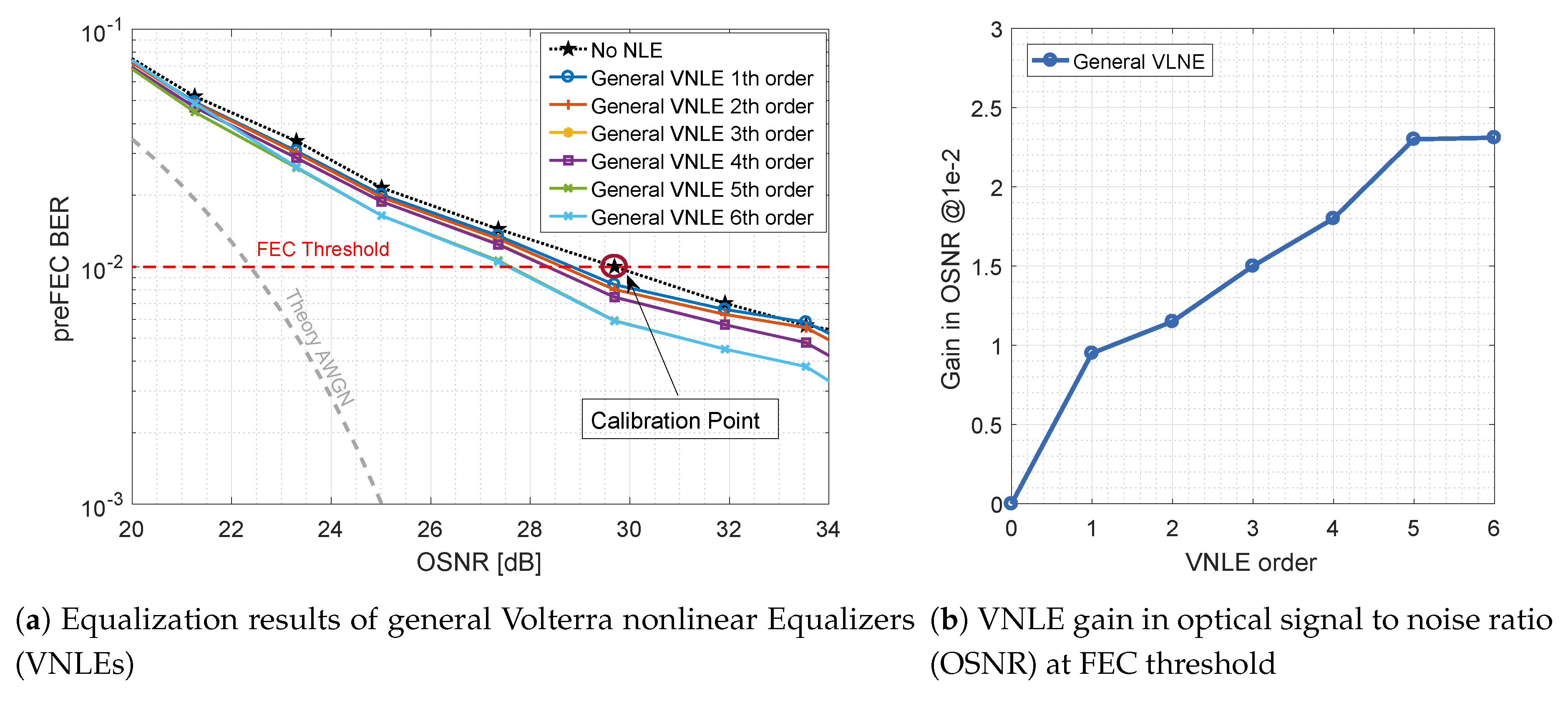
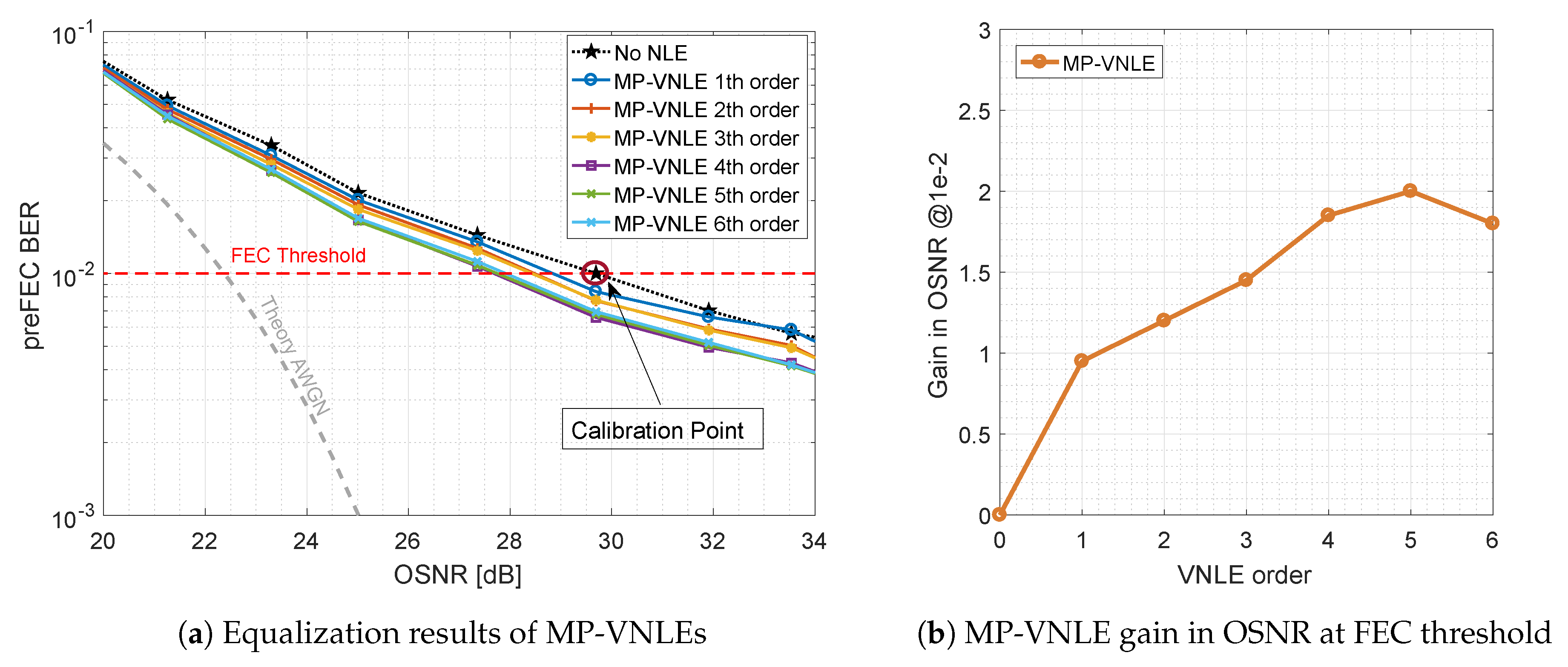
3.2.1. General and Memory Polynomial (MP-) Volterra nonlinear Equalizer (VNLE)
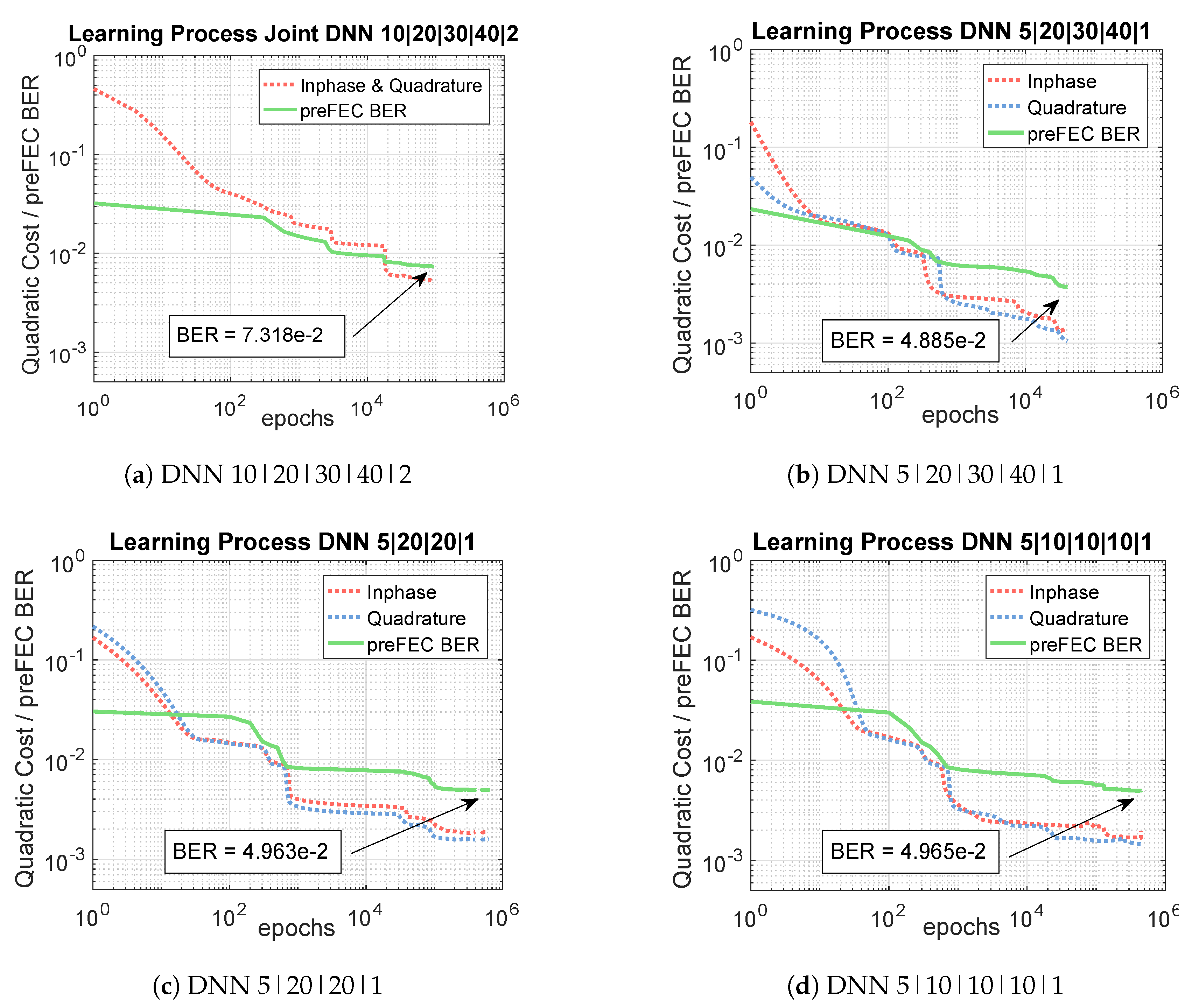
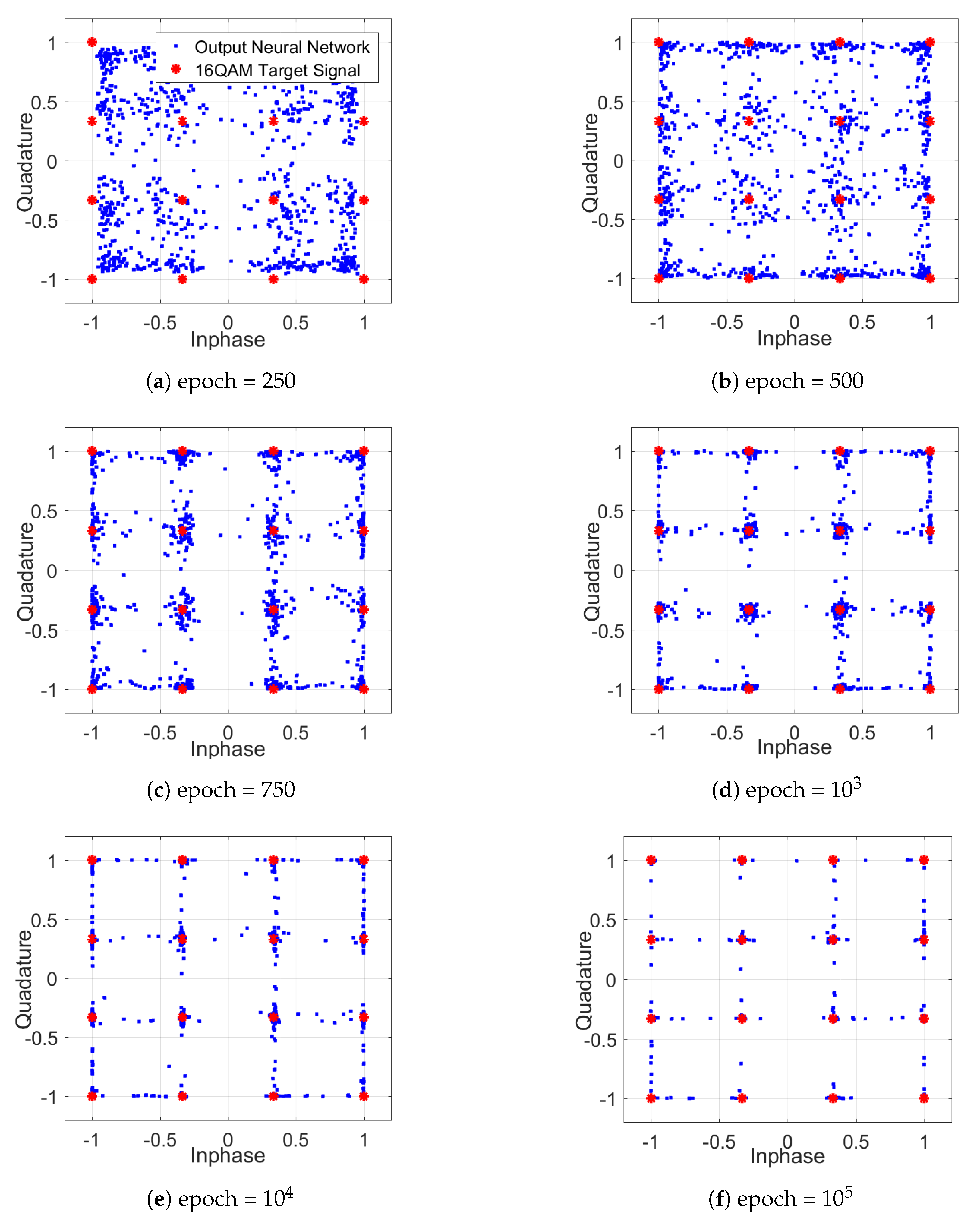
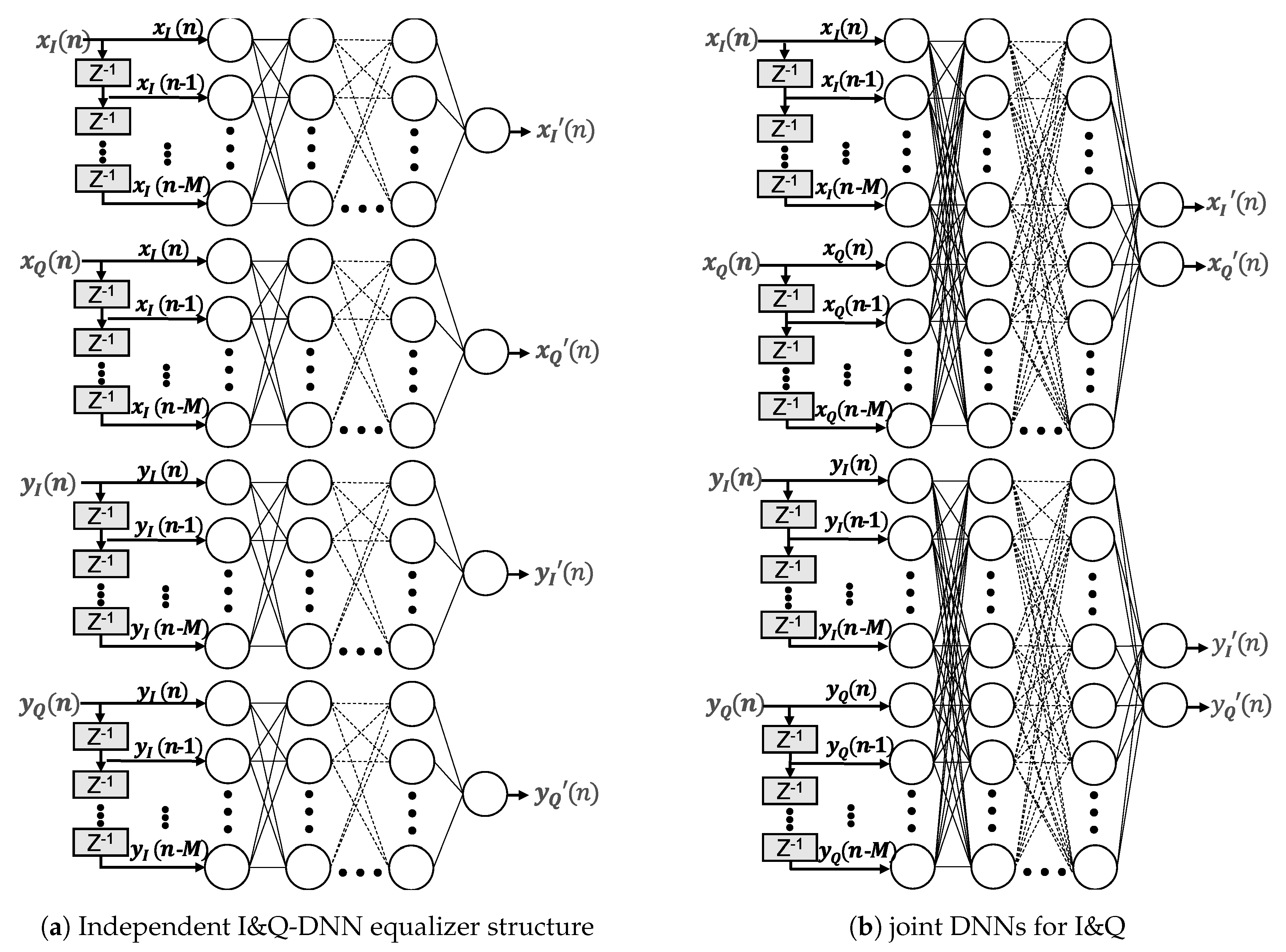
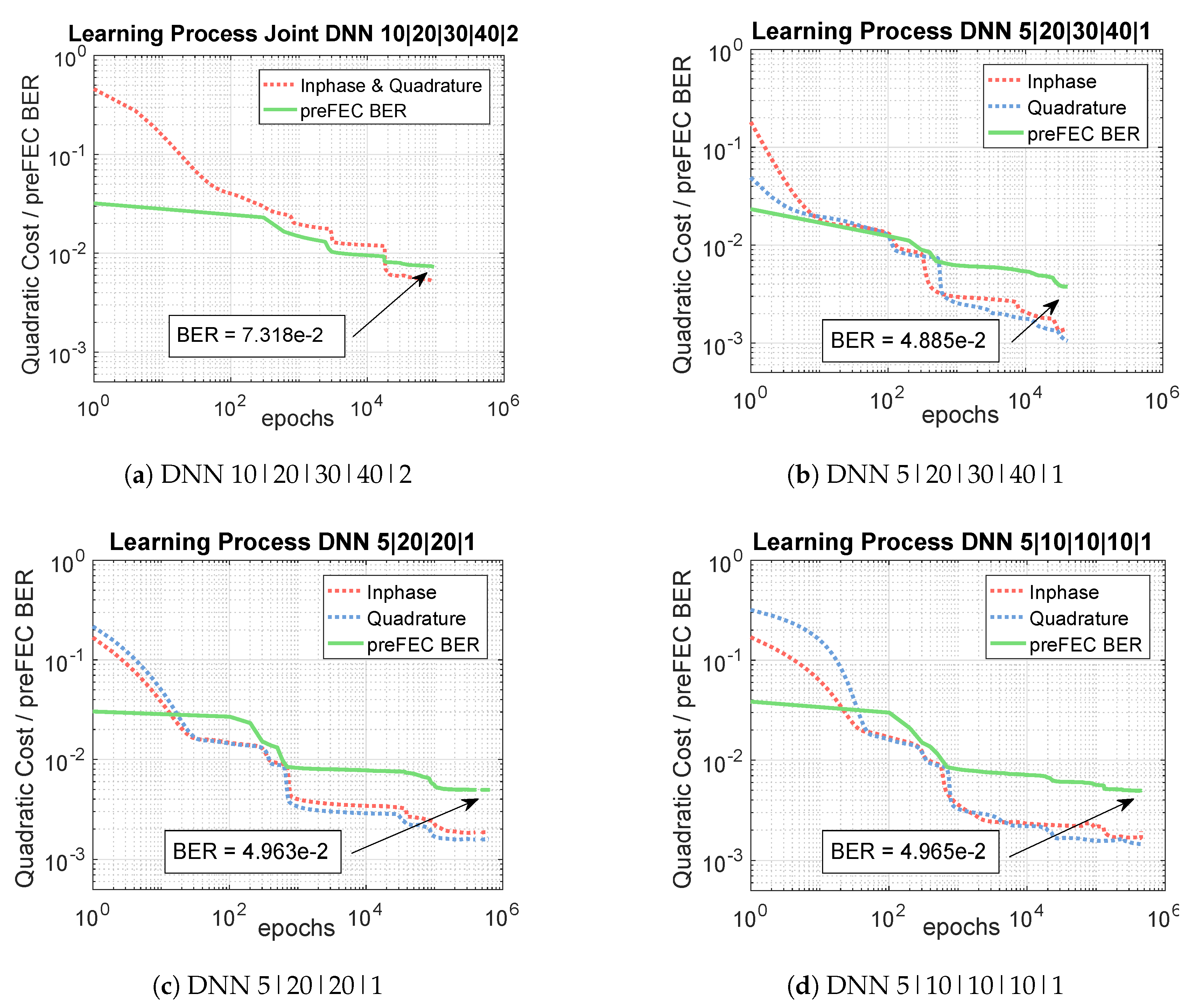
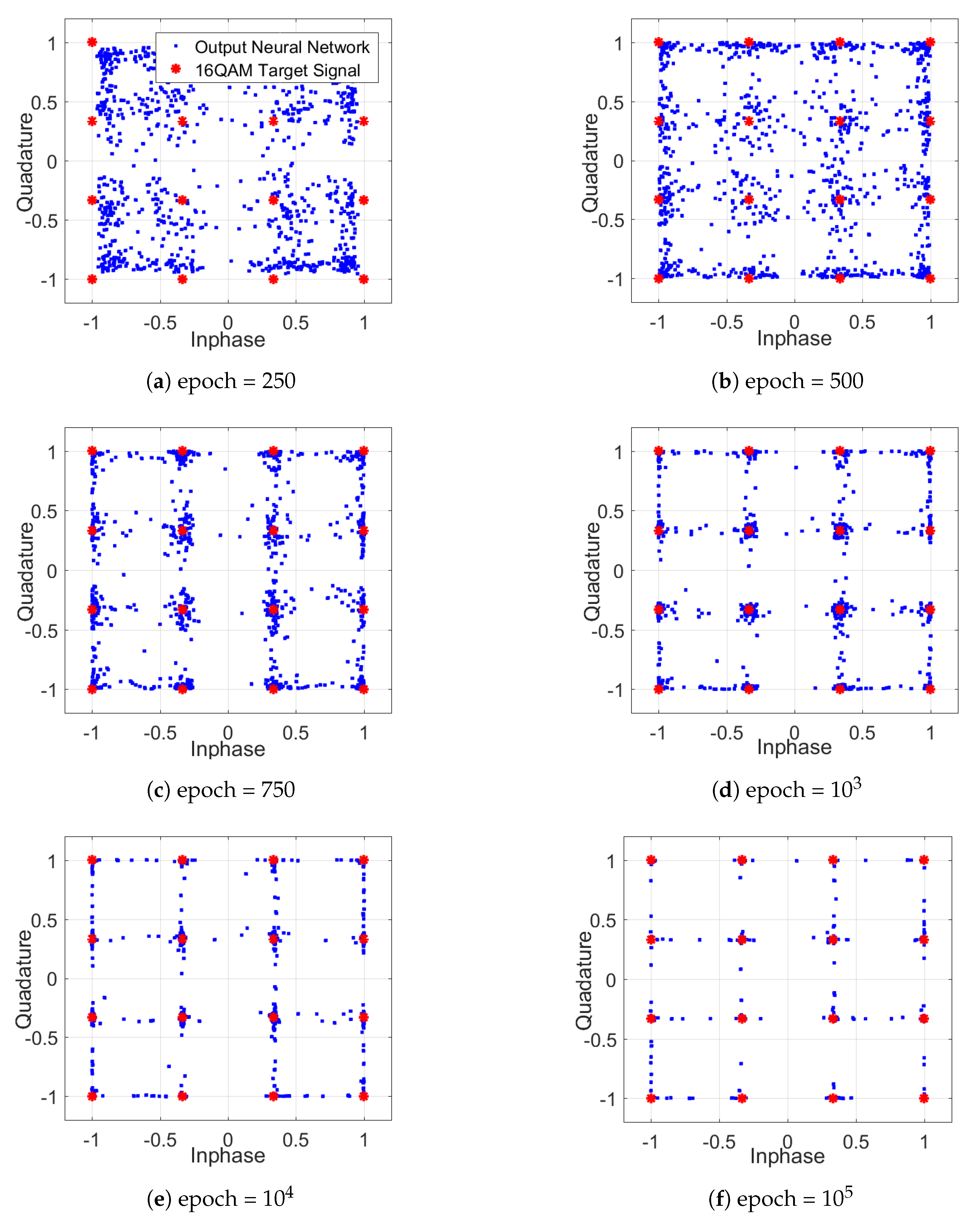
3.2.2. Deep Neural Network Equalizer
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bluemm, C.; Schaedler, M.; Kuschnerov, M.; Pittala, F.; Xie, C. Single Carrier vs. OFDM for Coherent 600Gb/s Data Centre Interconnects with Nonlinear Equalization. In Proceedings of the 2019 Optical Fiber Communications Conference and Exhibition (OFC), San Diego, CA, USA, 3–7 March 2019. [Google Scholar]
- Amari, A.; Dobre, O.A.; Venkatesan, R.; Kumar, O.S.; Ciblat, P.; Jaouen, Y. A survey on fiber nonlinearity compensation for 400 Gb/s and beyond optical communication systems. IEEE Commun. Surv. Tutor. 2017, 19, 3097–3113. [Google Scholar] [CrossRef]
- Rezania, A.; Cartledge, J.C.; Bakhshali, A.; Chan, W.Y. Compensation schemes for transmitter-and receiver-based pattern-dependent distortion. IEEE Photonics Technol. Lett. 2016, 28, 2641–2644. [Google Scholar] [CrossRef]
- Cartledge, J.C. Volterra Equalization for Nonlinearities in Optical Fiber Communications. In Signal Processing in Photonic Communications; Optical Society of America: Washington, DC, USA, 2017. [Google Scholar]
- Schetzen, M. Theory of pth-order inverses of nonlinear systems. IEEE Trans. Circuits Syst. 1976, 23, 285–291. [Google Scholar] [CrossRef]
- Kim, J.; Konstantinou, K. Digital predistortion of wideband signals based on power amplifier model with memory. Electron. Lett. 2001, 37, 1417–1418. [Google Scholar] [CrossRef]
- Kamalov, V.; Jovanovski, L.; Vusirikala, V.; Zhang, S.; Yaman, F.; Nakamura, K.; Inoue, T.; Mateo, E.; Inada, Y. Evolution from 8QAM live traffic to PS 64-QAM with neural-network based nonlinearity compensation on 11000 km open subsea cable. In Proceedings of the Optical Fiber Communication Conference, San Diego, CA, USA, 11–15 March 2018. [Google Scholar]
- Guan, L. FPGA-based Digital Convolution for Wireless Applications; Springer International Publishing: New York, NY, USA, 2017. [Google Scholar]
- Ghannouchi, F.M.; Hammi, O.; Helaoui, M. Behavioral Modeling and Predistortion of Wideband Wireless Transmitters; John Wiley and Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Raich, R.; Zhou, G.T. Orthogonal polynomials for complex Gaussian processes. IEEE Trans. Signal Process. 2004, 52, 2788–2797. [Google Scholar] [CrossRef]
- Musumeci, F.; Rottondi, C.; Nag, A.; Macaluso, I.; Zibar, D.; Ruffini, M.; Tornatore, M. An overview on application of machine learning techniques in optical networks. IEEE Commun. Surv. Tutor. 2018, 21, 1383–1408. [Google Scholar] [CrossRef]
- Khan, F.N.; Fan, Q.; Lu, C.; Lau, A.P.T. An Optical Communication’s Perspective on Machine Learning and Its Applications. J. Light. Technol. 2019, 37, 493–516. [Google Scholar] [CrossRef]
- Schaedler, M.; Kuschnerov, M.; Pachnicke, S.; Bluemm, C.; Pittala, F.; Changsong, X. Subcarrier Power Loading for Coherent Optical OFDM optimized by Machine Learning. In Proceedings of the Optical Fiber Communication Conference, San Diego, CA, USA, 3–7 March 2019. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Academic Press: Cambridge, MA, USA, 1992; pp. 65–93. [Google Scholar]
- Pittalà, F.; Cano, I.N.; Bluemm, C.; Schaedler, M.; Calabrò, S.; Goeger, G.; Brenot, R.; Xie, C.; Shi, C.; Liu, G.N.; et al. 400Gbit/s DP-16QAM Transmission over 40km Unamplified SSMF with Low-Cost PON Lasers. IEEE Photonics Technol. Lett. 2019, 1, 1229–1232. [Google Scholar] [CrossRef]
- Gao, Y.; Lau, A.P.T.; Lu, C.; Wu, J.; Li, Y.; Xu, K.; Li, W.; Lin, J. Low-complexity two-stage carrier phase estimation for 16-QAM systems using QPSK partitioning and maximum likelihood detection. In Proceedings of the 2011 Optical Fiber Communication Conference and Exposition and the National Fiber Optic Engineers Conference, Los Angeles, CA, USA, 6–10 March 2011. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Huang, W.J.; Chang, W.F.; Wei, C.C.; Liu, J.J.; Chen, Y.C.; Chi, K.L.; Wang, C.L.; Shi, J.W.; Chen, J. 93% complexity reduction of Volterra nonlinear equalizer by L 1-regularization for 112-Gbps PAM-4 850-nm VCSEL optical interconnect. In Proceedings of the 2018 Optical Fiber Communications Conference and Exposition (OFC), San Diego, CA, USA, 11–15 March 2018. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Architecture | Design | Multipliers |
|---|---|---|---|
| 1 | joint I&Q | (10 ∗ 20 + 20 ∗ 30 + 30 ∗ 40 + 40 ∗ 2) ∗ 2 = 4160 | |
| 2 | Independent I&Q | (5 ∗ 20 + 20 ∗ 30 + 30 ∗ 40 + 40 ∗ 1) ∗ 2 ∗ 2 = 7760 | |
| 3 | Independent I&Q | (5 ∗ 20 + 20 ∗ 20 + 20 ∗ 1) ∗ 2 ∗ 2 = 2080 | |
| 4 | Independent I&Q | (5 ∗ 10 + 10 ∗ 10 + 10 ∗ 10 + 10 ∗ 1) ∗ 2 ∗ 2 = 1040 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schaedler, M.; Bluemm, C.; Kuschnerov, M.; Pittalà, F.; Calabrò, S.; Pachnicke, S. Deep Neural Network Equalization for Optical Short Reach Communication. Appl. Sci. 2019, 9, 4675. https://doi.org/10.3390/app9214675
Schaedler M, Bluemm C, Kuschnerov M, Pittalà F, Calabrò S, Pachnicke S. Deep Neural Network Equalization for Optical Short Reach Communication. Applied Sciences. 2019; 9(21):4675. https://doi.org/10.3390/app9214675
Chicago/Turabian StyleSchaedler, Maximilian, Christian Bluemm, Maxim Kuschnerov, Fabio Pittalà, Stefano Calabrò, and Stephan Pachnicke. 2019. "Deep Neural Network Equalization for Optical Short Reach Communication" Applied Sciences 9, no. 21: 4675. https://doi.org/10.3390/app9214675
APA StyleSchaedler, M., Bluemm, C., Kuschnerov, M., Pittalà, F., Calabrò, S., & Pachnicke, S. (2019). Deep Neural Network Equalization for Optical Short Reach Communication. Applied Sciences, 9(21), 4675. https://doi.org/10.3390/app9214675