5.1. Spatial Autocorrelation Test for Variables
Establishing whether the candidate variables are spatially autocorrelated is necessary before the GWR model can be implemented. A spatial autocorrelation test can detect the degree of spatial correlation of the variables, which will provide theoretical support for the feasible application of spatial models. Moran’s I, proposed by Patrick Alfred Pierce Moran (1950) [
35], is a correlation coefficient that measures the spatial autocorrelation. The estimated Moran’s I values of the response variables and all of the candidate explanatory variables are higher than the expected I values, indicating that the variables have positive spatial autocorrelations (
Table 3). In the tables, we use the concise expressions weekly_ridership, weekday_ridership, weekend_ridership, evenrush_ridership, and nonrush_ridership to denote the average daily ridership in a week, average weekday ridership, average weekend ridership, evening rush hour ridership, and nonrush hour ridership, respectively. The Moran scatter plot can directly reflect the spatial autocorrelation of variables, and the plot has four quadrants. A strong positive spatial correlation is observed when the values are distributed in the first and third quadrants, and a negative spatial correlation will emerge if they fall in the second and fourth quadrants.
Figure 3 presents the Moran scatter plots of several variables.
None of the Moran’s I values presented in
Figure 3 are 0, indicating that they are not randomly distributed in space. In addition, most belong to the first and third quadrants, which indicates that the variables show significantly positive spatial autocorrelation. The three explanatory variables with the highest Moran’s I values are population, distance to the city center, and days since station opened, as their Moran’s I values are greater than 0.3 [
36]. The results of the Moran’s I test thus provide a theoretical foundation for the rationale of the follow-up study.
5.2. Model Implementation and Results Analysis
Strong spatial autocorrelation is found for all of the variables included in our study. Thus, it is feasible to implement GWR models to explore the association between Shenzhen Metro ridership and its influencing factors. The final selection of explanatory variables derived from the backward stepwise regression method for the five models is given in
Table 4.
Table 4 enables us to find the common explanatory variables among the five models and the individual variables of each model. The common explanatory variables are the major factors impacting metro ridership, including population, betweenness centrality, and days since opening. The different individual variables of the five models indicate that factors affecting station-level ridership differ by the day of the week and time of the day.
The number of offices within the PCA and the distance from the station to the city center are individual variables in the model for average weekday ridership. The number of residences and shopping places within the station catchment area is related to the average weekend ridership. Thus, commuting activities appear to mainly affect the average weekday ridership, while recreational activities related to commercial development such as shopping malls mainly affect the average weekend ridership. Across a single day, the number of schools and the distance to the center mainly affect the evening rush hour ridership, while the number of shopping places and the distance to the center mainly affect the nonrush hour ridership. Thus, passengers from schools (primary schools, high schools, and universities) contribute to the evening rush ridership and noncommuting activities like shopping affect the nonrush hour ridership.
First,
Table 5 shows that the AICc values of all of the GWR models are smaller than those of the corresponding global regression (OLS) models. According to the evaluation criterion proposed by Fotheringham et al. (1996) [
19], if the difference between the AICc values of a GWR model and an OLS model is more than 3, the GWR model can be considered more applicable than the OLS model, even though it is more complex. The adjusted R-squared values of the GWR models are greater than those of the corresponding OLS models, demonstrating that the GWR model has strong explanatory power even when considering model complexity. Likewise, the parameter values (Sigma) indicating the model error of the GWR models are lower, and the residual sum of the squares from the GWR models are smaller than those from the OLS models. Thus, the results show that the GWR models generally perform better in goodness-of-fit measures than the OLS models. ANOVA tests, as shown in
Table 5, are conducted to find out if the global (OLS) regression model and the GWR model have the same statistical performance (the same size of error variance). The results suggest that there is a significant improvement when GWR is used.
In addition, by comparing the results of the five models, the model for nonrush_hour ridership regression is found to perform the best in terms of the R-squared value. We only need the information about population distribution, degree centrality, betweenness centrality, days since opening, the number of shopping places and distance to the city center to use the GWR model to explain 88% of the response variable of nonrush hour ridership. In addition, the relevant data covering the information on the explanatory variables are easily accessible.
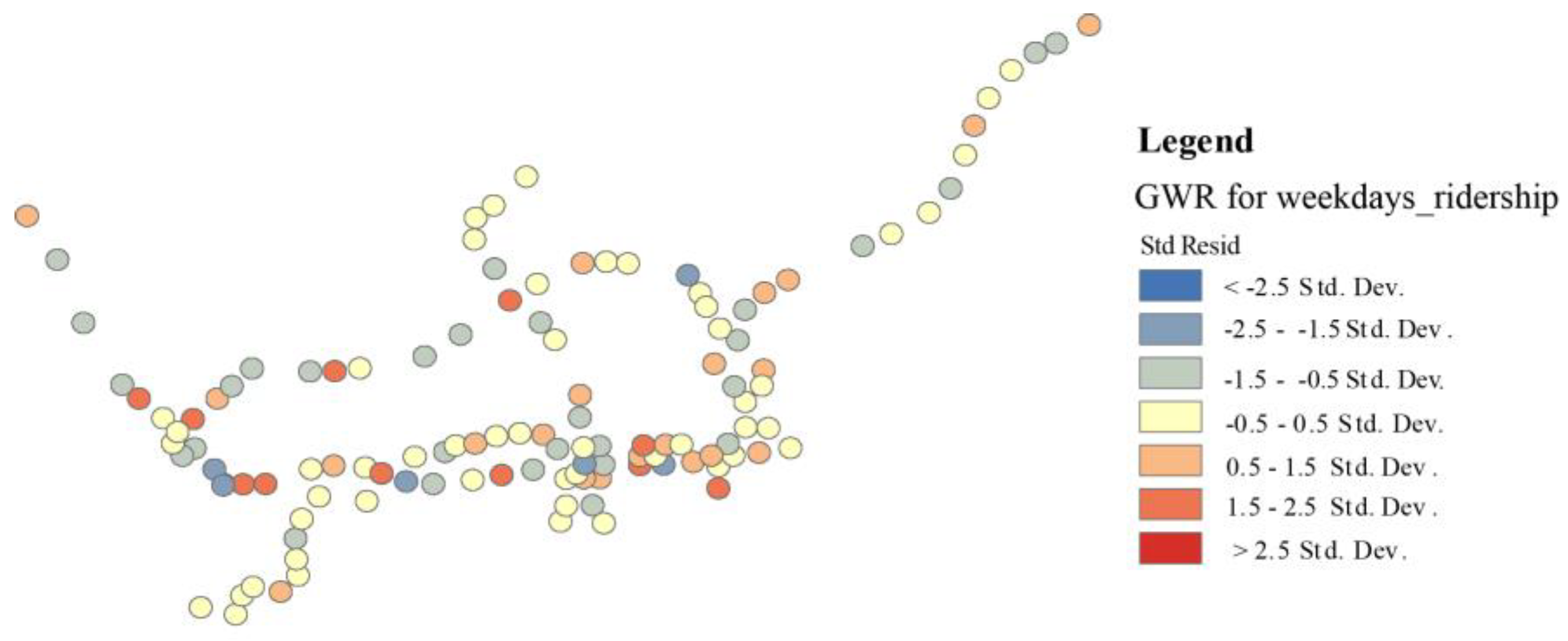
Figure 4 shows the standardized residuals of the GWR model for average weekday ridership, and for most stations these are relatively small, demonstrating the high accuracy of the model. Overpredictions (red bubbles) and underpredictions (blue bubbles) are randomly distributed in
Figure 5, which indicates that our model is well specified. The spatial autocorrelation (Moran’s I) test of the regression residuals helps to ensure that they are spatially random (
Table 6).
The global Moran’s I residuals test of the models for the average ridership over the whole week, shown in
Table 6, demonstrates that GWR surpasses OLS, as the Moran I’s calculation is closer to the expected value in the GWR model. The residuals of the GWR model have a greater likelihood of random distribution (
p-value) and show less variance (z-score). However, the residuals of OLS demonstrate statistically significant clustering characteristics (reflected by the Z-score and
p-value).
The local indicator of spatial association (LISA) was proposed to represent local pockets of nonstationarity, assess the influence of individual locations on the magnitude of the global statistic, and identify “outliers” [
37].
Figure 5 shows the LISA cluster maps of residuals in the OLS and GWR models for average daily ridership over a whole week. The residuals of the OLS model give significantly positive high-value clustering, while in the GWR model almost all of the clusters of residuals are ruled out, implying that GWR makes a significant improvement over OLS in terms of model fitting from the perspective of residuals.
Using the Voronoi algorithm [
38], the Shenzhen Metro coverage area can be divided into several Thiessen polygons according to the locations of the stations. Here, the spatial distribution of the local R-squared and local coefficients is visualized using Thiessen polygons. The values of the local R-squared range between 0 and 1, which indicates the satisfactory fitting of the local regression model. Mapping the local R-squared values can help us to see where GWR has a higher predictive capacity and where it performs poorly.
Figure 6 illustrates the spatial distribution of the local R-squared of Model 2 for average weekday ridership and Model 5 for nonrush hour ridership, enabling us to understand where the model has a stronger explanatory power (local R-squared). Both Model 2 and Model 5 have a higher explanatory power in the central-north and southeast regions than in the other regions. In addition, the local R-squared values of most of the stations are higher than 0.82; these stations are mainly located in Luohu district.
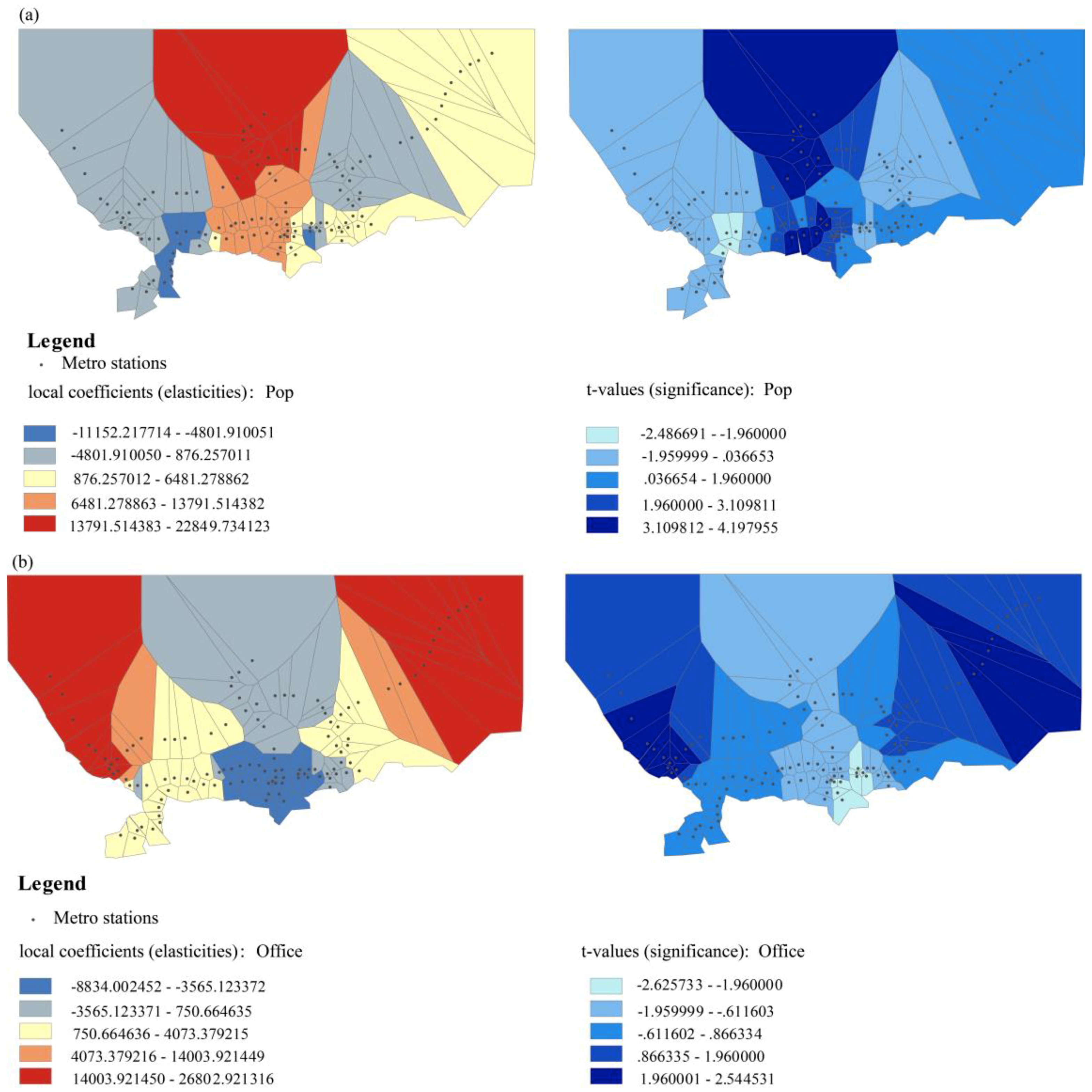
By understanding the spatial distribution of local coefficients (elasticities) and
t-values (significance), we can determine how the relationship between the variables changes spatially (estimated coefficients), and at what level of statistical significance. For example, in Model 2 (see
Figure 7), as a common factor, the mean of the coefficients for the population variable is 3284.89. Thus, for each person within the station’s PCA, the number of trips adds up to 3284.89 each weekday. However, these elasticities are distributed unevenly in space. More trips per capita are expected in the central zone and the mid-north, where commercial and administrative areas and educational institutions are intensively distributed, while elasticity values are lower in the west and east. The
t-value map on the right also shows that the effect of population is more significant in the middle area at a 0.05 level (the absolute value of a
t-value larger than 1.96) (
Figure 7a).
For the individually selected factor in Model 2, the mean of the elasticities for the office variable is 2397.24. Thus, for each new office within the station’s PCA, the number of trips adds up to 2397.24 each weekday. Elasticities are higher (more trips attracted per office) in the east and west than in the middle, whereas the elasticities of the central and north regions are negative and low, indicating that people who go to work in these regions depend more on transport other than the metro. In addition, the t-value map on the right shows that the effect of offices is more significant in the east, west, and mid-south areas at a 0.05 level (the absolute value is larger than 1.96) (
Figure 7b). Thus, in general GWR is shown to have strong spatial explanatory power, based on local analysis of the variation of each coefficient across space (elasticities).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






