1. Introduction
Today, with the rapid growth and the wide application of the Internet and Intranet, computer networks have brought great convenience to people’s life and work. However, at the same time, they also brought a lot of security problems, such as various types of viruses, vulnerabilities and attacks, which cause heavy losses. How can necessary protection and security be provided for computer networks, and their integrity and availability be maintained? This question has become a hot issue in research. Intrusion Detection System (IDS) is an important security device or software application in a network environment. It is widely used to monitor network activities and detect whether the system is subjected to network attacks such as DoS (Denial of Service) attacks. According to the analysis method and detection principle, IDS can be anomaly-based detection or misuse-based detection [
1,
2]. In this work, we focus on misuse-based IDS.
In recent years, many researchers have introduced more and more innovative techniques to detect intrusions, such as machine learning, data mining and swarm intelligence. In the literature, these techniques are divided into three categories. The first category is the anomaly detection methods, which require normal datasets to train the classifier and determine whether the new data sample is in conformity with the model. Examples of these methods include the cluster algorithm [
3], SOM (Self-Organizing Map) [
4] and GMM (Gaussian Mixture Model) [
5]. The second category uses an individual machine learning algorithm to solve intrusion detection problems, such as KNN (K-Nearest Neighbor) [
6,
7], SVM (Support Vector Machines) [
8], ANN (Artificial Neural Network) [
9], DT (Decision Tree) [
10], etc. The last category uses various ensemble and hybrid techniques, combined with various machine learning techniques to improve detection performance. These methods include Bagging, Boosting, Stacking, and combined classifier methods [
11]. RF (Random Forest) [
12] is an ensemble learning method based on bagging, which builds a classification model from a multitude of decision trees. AdaBoost (Adaptive Boosting) [
13] is a popular boosting method that has the ability to adapt to errors associated with weak hypotheses. The idea of Stacking is that the output of a set of classifiers is used as the input of another classifier [
14].
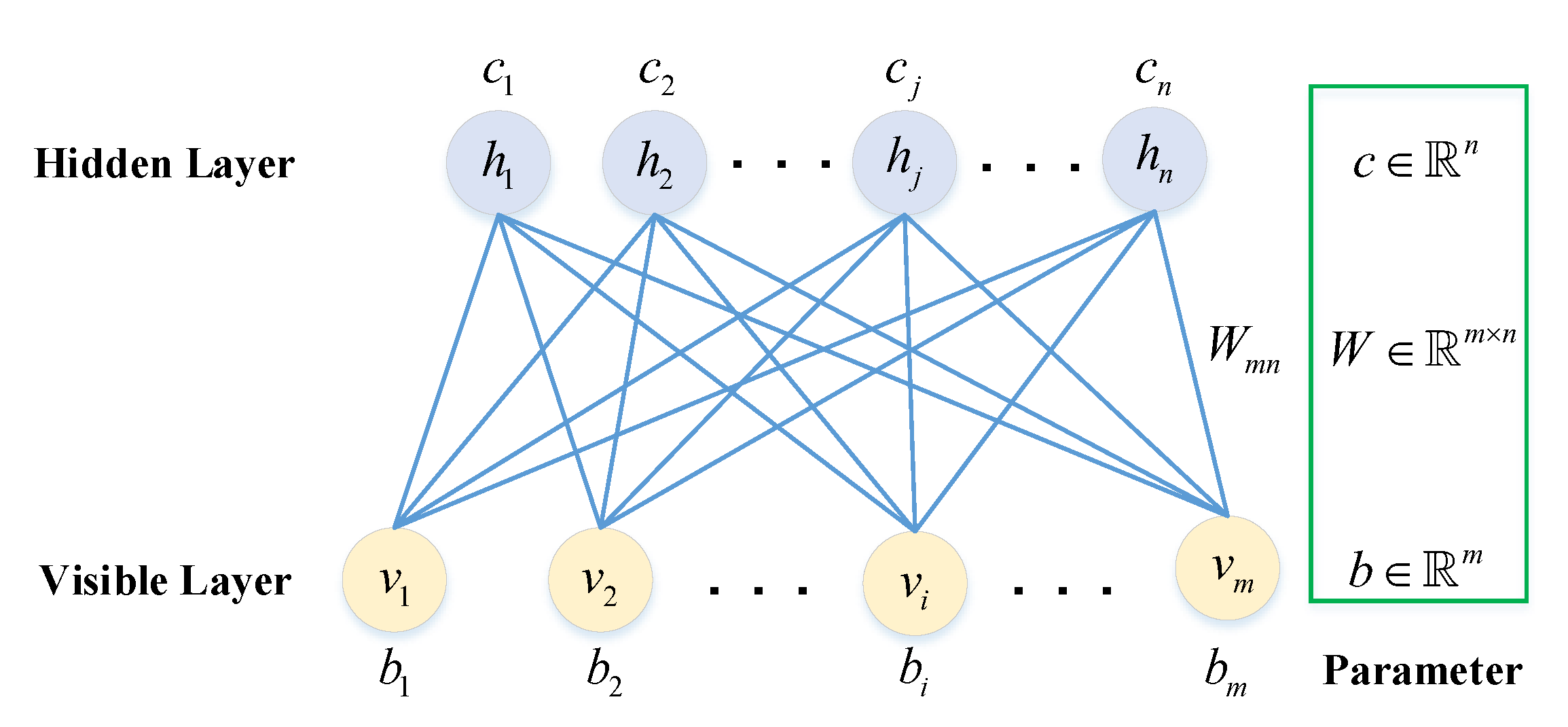
In 2006, Hinton proposed Deep Belief Networks (DBNs) [
15,
16], which made deep learning the meteoric rise in the field of machine learning. In recent years, deep learning has become a hot research topic, and has achieved great success in extracting high-level latent features from data samples. Deep learning can reconstruct the approximate compression of the original features and has been successfully used in many applications such as speech recognition, natural language processing, image processing, network security detection [
17,
18], and so on. DBNs are probabilistic generative neural network composed by several layers of RBMs (Restricted Boltzmann Machines) and a single layer of BP (Back Propagation) neural network. RBMs are used to initialize the neural network through a pre-training process, which can make the initialization parameters of neural network closer to the global optimal value, and make the network training easier to achieve global optimization. Huda et al. [
19] used optimal deep belief networks to detect malware behaviors.
However, there are still many problems with intrusion detection systems. First, different types of network traffic in a real network environment are imbalanced, and network intrusion records are less than normal records. As a result, unbalanced network traffic greatly compromises the detection performance of most classifiers. The classifier is biased towards the more frequently occurring records, which reduces the detection rate of small attack records such as U2R and R2L records. Second, due to the high dimensionality of network data, the feature selection methods in many intrusion models are first considered as one of the preprocessing steps [
20], such as PCA (Principal Component Analysis) and chi-square feature selection. However, these feature selection methods rely heavily on manual feature extraction, mainly through experience and luck, and these algorithms are not effective enough. Third, because of the large amount of network traffic and complex structure, the traditional classifier algorithm cannot achieve higher attack detection rate with lower false positive rate. Fourth, the network operating environment and structure in the real world are changing, for example, the popularity of the Internet of Things and the widespread use of cloud services, as well as various new attacks are emerging. Many unknown attacks do not appear in the training dataset. For example, for the NSL-KDD [
21,
22] dataset, 16.6% of the attack samples in the test dataset did not appear in the training dataset [
23]. As a result, all traditional intrusion detection methods usually perform poorly.
Taking into account the above factors, we propose a novel fuzzy aggregation method called MDPCA-DBN, which combines the modified density peak clustering algorithm (MDPCA) and the deep belief networks (DBNs). The MDPCA divides the original training dataset into several smaller subsets according to the feature similarity of the training samples. These subsets are used to train their respective sub-DBNs classifiers. These sub-DBNs can automatically extract high-level abstract features from the training samples and reduce the dimensions of network traffic data without heuristic rules and manual experience. DBNs integrate feature extraction and classification into a system that extracts high-level features by identifying network traffic and classifies them based on labeled samples. In the test phase, the fuzzy membership weight of each test sample in each sub-DBNs classifier is calculated based on the nearest neighbor criteria of the training sample cluster. Then, each test sample is tested in each trained sub-DBNs classifier. Finally, the output of all sub-DBNs classifiers is aggregated based on the fuzzy membership weights.
The key contributions of this paper are as follows. First, we improve the Euclidean distance calculation method of the density peak clustering algorithm (DPCA) [
24], and use the kernel function to project the original features into the high-dimensional kernel space to better cluster the complex nonlinear inseparable network traffic data. Second, we use MDPCA to extract similar features of complex network data and divide the network dataset into several subsets with different clusters. Compared with the original dataset, these subsets reduce the imbalance of multi-class network data and improve the detection rate of the minority classes. Third, we use DBNs to automatically extract high-level features from massive and complex network traffic data and perform classification. DBNs with several hidden layers initialize network parameters through greedy layer-by-layer unsupervised learning algorithms, and adjust network weights by backpropagation and fine-tuning to better solve the classification problem of complex, large-scale and nonlinear network traffic data. The deep generation model can obtain a better attack classification than the shallow machine learning algorithm, and can solve many nonlinear problems of complex and massive data. Finally, we have evaluated the proposed method on the NSL-KDD [
21,
22] and UNSW-NB15 [
25,
26,
27] datasets. Experimental results show that, compared with the well-known classification algorithms, the proposed method achieved better performance in terms of accuracy, detection rate and false positive rate.
The rest of this paper is organized as follows.
Section 2 introduces intrusion detection related works based on RBM and deep learning. In
Section 3, we detail the MDPCA and DBNs algorithms.
Section 4 presents the proposed hybrid model for intrusion detection and describes how the model works.
Section 5 demonstrates the experimental details and results. Finally, we draw some conclusions and suggest the further work in
Section 6.
2. Related Works
As far as we know, there are no reports on DPCA and DBN hybrid methods for intrusion detection, although related works to DPCA have been done in other areas. Cha et al. [
28] employed the DPCA algorithm for structural damage detection. Li et al. [
29] proposed a hybrid model combining the core ideas of KNN and DPCA for intrusion detection. The model uses the idea of density and the process of the k-nearest neighbors to detect attacks. Ma et al. [
30] presented a hybrid method combining spectral clustering and deep neural networks, named SCDNN. SCDNN uses spectral clustering to divide the training set and test set into several subsets, and then input them into the deep neural network for intrusion detection. They reported an overall accuracy of 72.64% on the NSL-KDD dataset. The clustering algorithm and classifier of SCDNN are spectral clustering (not DPCA) and DNN (not DBN), respectively. Moreover, the output of SCDNN on the test set is only a simple summary, without any integration principle. This is completely different from our proposed method.
The deep learning method integrates high-level feature extraction and classification tasks, overcomes some limitations of shallow learning, and further promotes the progress of intrusion detection systems. Recently, many studies have applied deep learning models to classification in the intrusion detection field. Thing et al. [
31] used stacked autoencoders to detect attacks in IEEE 802.11 networks with an overall accuracy of 98.6%. Naseer et al. [
32] proposed a deep convolutional neural network (DCNN) to detect intrusion. The proposed DCNN uses graphics processing units (GPUs) to train and test on the NSL-KDD dataset. Tang et al. [
33] implemented a Gated Recurrent Unit Recurrent Neural Network (GRU-RNN) intrusion detection system for SDNs with an accuracy of 89%. Shone et al. [
34] implemented a combination of deep and shallow learning, using a stacked Non-symmetric Deep Auto-Encoder (NDAE) for unsupervised feature learning and random forest (RF) as a classifier. Muna et al. [
35] proposed an anomaly detection technique for Internet Industrial Control Systems (IICSs) based on the deep learning model, which uses deep auto-encoder for feature extraction and deep feedforward neural network for classification.
In recent years, many researchers have successfully applied DBN to intrusion detection systems. DBN is an important probabilistically generated model consisting of multi-layer restricted Boltzmann machines (RBMs) with good feature representation and classification functions. Tamer et al. [
36] employed a restricted Boltzmann machine to distinguish between normal and abnormal network traffic. Experimental results on the ISCX dataset show that RBM can be successfully trained to classify normal and abnormal network traffic. Li et al. [
37] proposed a hybrid model (RNN-RBM) to detect malicious traffic. The model combines a recurrent neural network (RNN) with a restricted Boltzmann machine (RBM) that takes byte-level raw data as input without feature engineering. Experimental results show that the RNN-RBM model outperforms the traditional classifier on the ISCX-2012 and DARPA-1998 datasets. Imamverdiyev [
38] used the multilayer deep Gaussian–Bernoulli RBM method to detect denial of service (DoS) attacks. They reported an accuracy of 73.23% for the NSL-KDD dataset.
The above intrusion detection evaluation results are very encouraging, but these classification techniques still have detection defects, low detection rate for unknown attacks and high false positive rate for unbalanced samples. To overcome these problems, we use fuzzy aggregation technology to summarize the output of several classifiers combined with MDPCA and DBN. First, MDPCA divides the original training dataset into several subsets based on feature similarity, thereby reducing sample imbalance. Next, the multi-layer RBM learns and explores the high-level features in an unsupervised, greedy manner, automatically reduces data dimensions, and is used to effectively initialize the parameters of the DBN. We then train the corresponding DBN classifier on each training subset in a supervised manner. Finally, the fuzzy membership of the test data in the nearest neighbor of each cluster is calculated, and the outputs of all classifiers are aggregated according to the fuzzy membership.
4. The Proposed Hybrid Approach for Intrusion Detection
Recent literature surveys have shown that several hybrid methods combining feature selection with classifiers can effectively deal with many common intrusion detection problems. However, when faced with high-dimensional, randomized, unbalanced and complex network intrusion data, they often perform poorly. To solve the above problems, we propose an effective intrusion detection framework based on the modified density peak clustering algorithm and deep belief networks, named MDPCA-DBN, as shown in
Figure 4.
The proposed framework is composed of four main phases: (1) data collection, where network traffic packets are collected; (2) data preprocessing, where each symbol feature of the training and testing data is converted into a numerical value and scaled to the range [0, 1]; (3) training classifier, where the proposed hybrid classification model is trained by using the training dataset; and (4) attack recognition, where the trained classifier is used to detect attacks on test data. Each test datum is input to all trained sub-DBN classifiers, and the results of all sub-classifiers are aggregated according to the fuzzy membership degree. The final classification result is output.
MDPCA can divide the original training dataset into several subsets with similar attributes, thereby reducing the volume of data in each subset. Deep learning based on DBNs can automatically reduce the dimensions of data samples, extract high-level features, and perform classification.
4.1. Data Collection
Network traffic collection is the first and key step in intrusion detection. The location of the network collector plays a decisive role in the efficiency of intrusion detection. To provide the best protection for the target host and network, the proposed intrusion detection model is deployed on the nearest victim’s router or switch to monitor the inbound network traffic. During the training phase, the collected data samples are categorized according to the transport layer and network layer protocol and are labeled based on the domain knowledge. However, the data collected during the test phase are classified according to the trained hybrid model.
4.2. Data Preprocessing
The data obtained during the data collection phase are first processed to generated network features similar to the KDD Cup 99 [
46,
47] dataset, including the basic features of individual TCP connections, content features within a connection suggested by domain knowledge, traffic features computed using a two-second time window, and host features based on the purpose of the TCP connection. This process consists of two main stages shown as follows.
4.2.1. Feature Mapping
The features extracted from network traffic include numerical and symbol features, but machines can only identify numerical values. Therefore, each symbol feature needs to be first converted into numerical values. For example, the NSL-KDD [
21,
22] dataset contains 3 symbol features and 38 numeric features, and the UNSW-NB15 [
25,
26] dataset contains 3 symbol features and 39 numeric features. Symbol features in the NSL-KDD dataset include protocol types (e.g., TCP, UDP, and ICMP), destination network services (e.g., HTTP, SSH, FTP, etc.) and normal or error status of the connection (e.g., OTH, REJ, S0, etc.). In the proposed model, the original training dataset is divided into several subsets using the MDPCA clustering algorithm. To avoid the influence of the discrete attributes on clustering, these symbol features are encoded using a one-hot encoding scheme. For example, the symbol feature “protocol type” in the NSL-KDD dataset has three discrete values, namely TCP, UDP, and ICMP, which can be encoded in a space of three dimensions (with one-hot feature vectors
,
, and
). Since the symbol features “service types” and “flag types” in the NSL-KDD dataset include 70 and 11 discrete attributes, respectively, they can be transformed to 70 and 11 one-hot feature values, respectively. According to this method, the 41-dimensional original features of the NSL-KDD dataset are finally transformed into 122-dimensional features. Similarly, the 42-dimensional features in the UNSW-NB15 dataset are converted to 196-dimensional features.
4.2.2. Data Normalization
Since the network feature values vary greatly, the value of each feature must be normalized to a reasonable range in order to reduce the influence of values between different features. Because DBNs require input data in the range of
, each feature must be normalized by the respective minimum and maximum feature values and fall within the same range of
. The normalization process is also applied to the test data. The most common method of data normalization is the minimum and maximum normalization, often between zero and one. Each feature value should be normalized as follows:
where
is the original feature value and
and
represent the minimum and maximum feature values from the input data
x, respectively. After normalization, all data points are scaled within the range of
.
4.3. Training Classifier
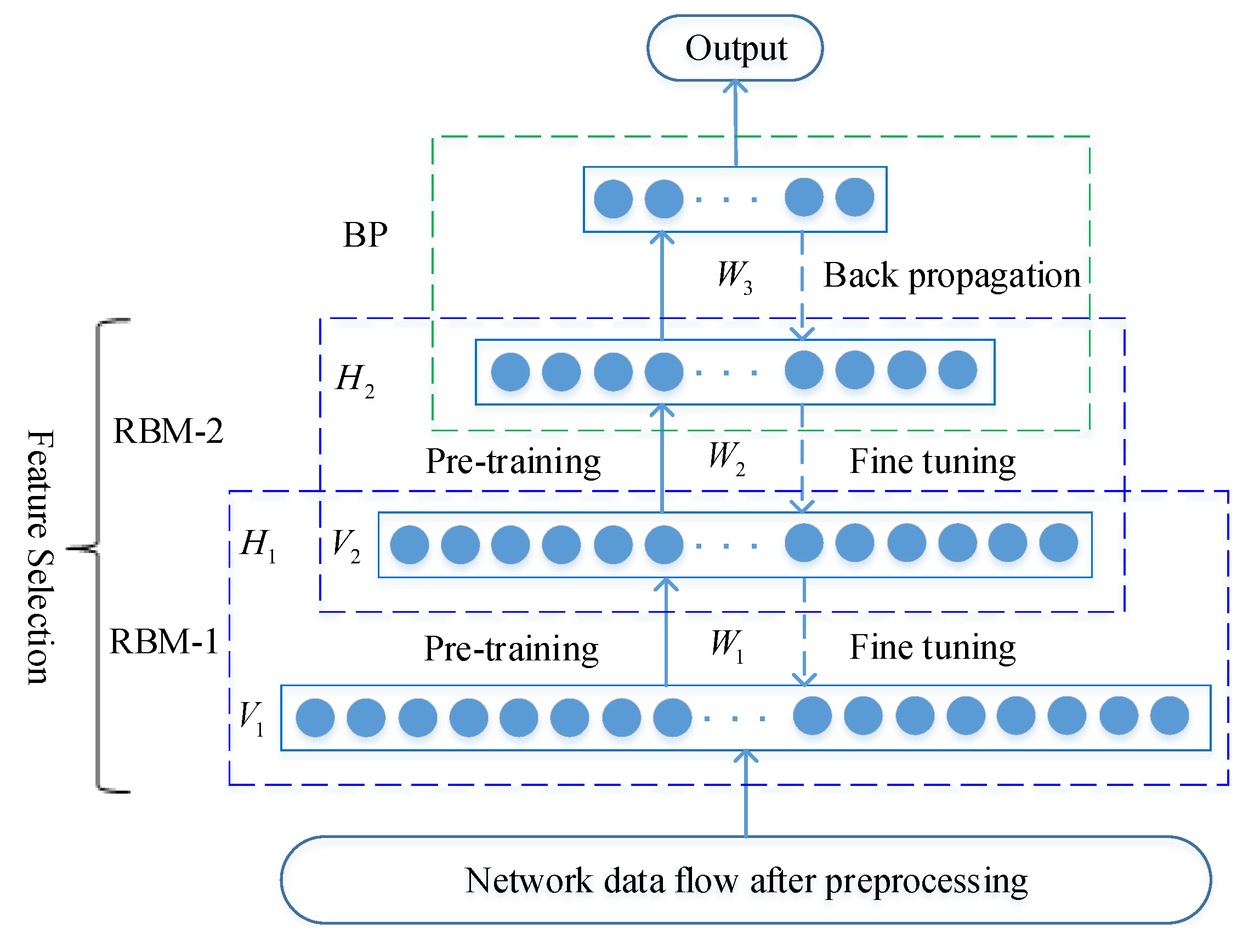
The method for training classifier is a two-phase hybrid approach: unsupervised clustering and supervised learning. First, the unsupervised clustering algorithm MDPCA is utilized to divide the original training dataset into K subsets . Next, the DBNs initialize the network parameters through the unsupervised pre-training of BernoulliRBM, and then use the back-propagation algorithm to fine tune the network connection weights. We use the K subsets from the training dataset to train the K sub-DBN classifiers. Each subset is assigned to train the corresponding . These DBNs are different from each other because they have been trained on different subsets. Each DBN has one input layer, three hidden layers, and one output layer. Three hidden layers automatically learn features from each training subset. The network structures of each DBN in the NSL-KDD and UNSW-NB15 datasets are 122-40-20-10-5 and 196-80-40-20-10, respectively.
4.4. Attack Recognition
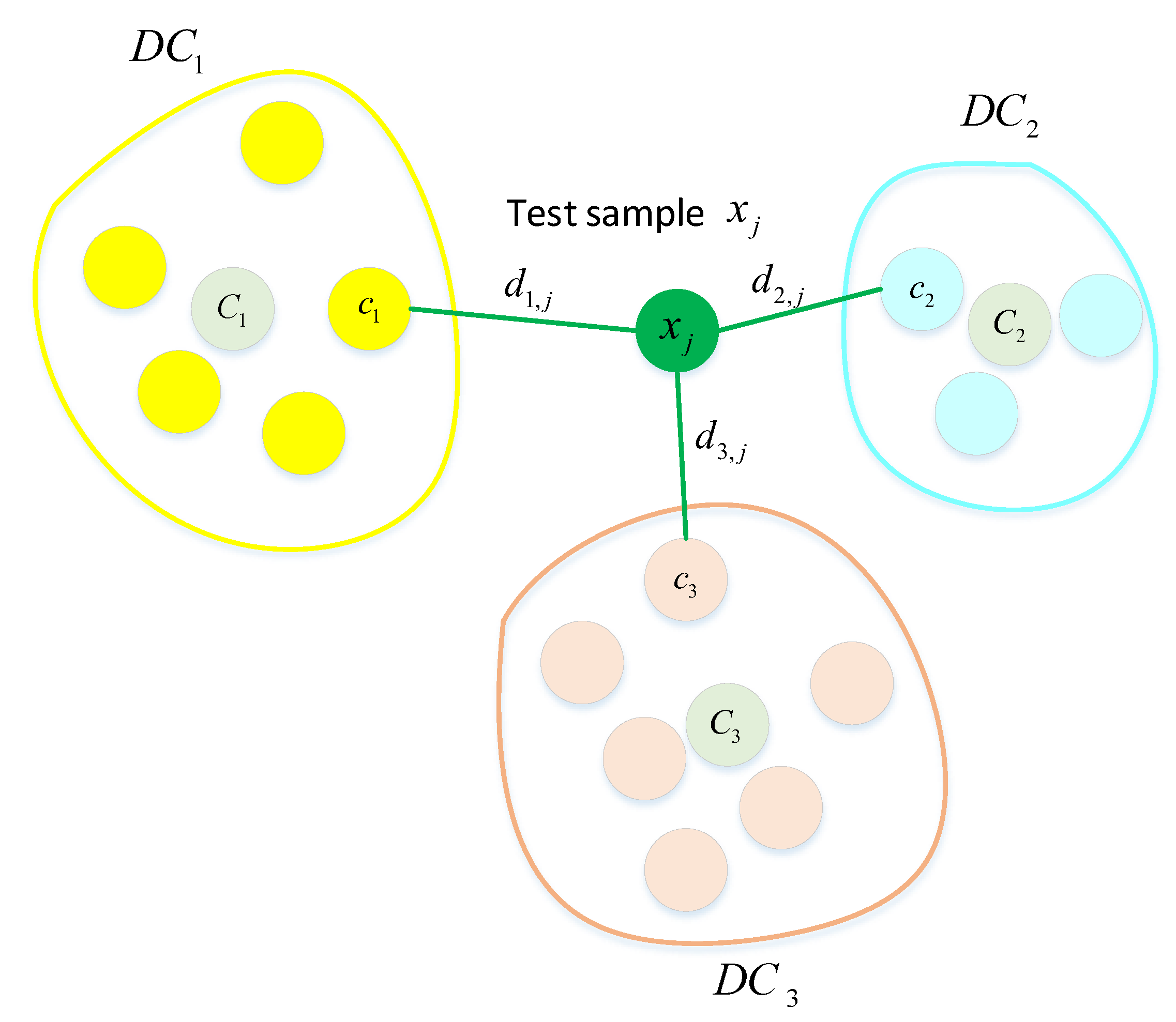
After completing the above steps, we obtain clusters of training datasets, which are divided into
K disjoint subsets
. These clusters are used to calculate the fuzzy membership matrix
of the test samples associated with each cluster. For each test sample
, we use the nearest neighbor sample
of the
ith cluster to calculate the fuzzy membership degree
according to Equation (
14). Once these sub-DBNs classifiers have been trained on their training subsets, the test data are applied to each trained classifier
to detect and identify normal and intrusion network traffic. The predicted values of each sub-
classifier are aggregated according to the fuzzy membership degree
. The output of test sample
in each sub-
classifier is defined as
. The fuzzy aggregate output of each test sample
can be computed as follows:
where
K is the number of clusters and represents the number of sub-DBNs classifiers.
The predictions of these sub-DBNs classifiers are aggregated into the final output of the intrusion detection system and used to detect attack categories. The proposed hybrid approach for intrusion detection is detailed in Algorithm 3.
| Algorithm 3 MDPCA-DBN (Modified Density Peak Clustering Algorithm and Deep Belief Networks) |
| Input: Dataset S, cluster number K, Gaussian kernel parameter . |
| Output: the final classification results. |
| 1: Data collection: a training dataset and a testing dataset. |
| 2: Data preprocessing: feature mapping and data normalization. |
3: According to Algorithm 1, MDPCA is used to divide the original training dataset into K subsets
. |
4: According to Algorithm 2, each training subset is used to train the corresponding classifier
. |
| 5: Caculate the fuzzy membership matrix U of test samples according to Equation (14). |
6: Test sample is tested on each trained classifier. The predictions of these classifiers
are fuzzy aggregated according to Equation (28), and the final classification results are output. |
| 7: return the final classification results. |
6. Conclusions and Future Work
In this paper, we propose a hybrid intrusion detection approach combining modified density peak clustering algorithm (MDPCA) and deep belief networks (DBNs). MDPCA is used to find similar features of complex and large-scale network data. According to the similarity of traffic features, large-scale network data are divided into several training subsets of different clustering centers. To a certain extent, MDPCA breaks the imbalance of multiclass records, reduces the complexity of training subsets, and makes the model achieve the best detection performance. DBN can automatically extract high-level abstract features from each training subset without a lot of heuristic rules and manual experience, and reduce data dimensions to avoid the curse of dimensions. As a deep learning approach, DBNs integrate feature extraction and classification modules into a system that can automatically extract features and classify them. This is an effective way to improve the detection performance. The classification performance of MDPCA-DBN was evaluated on the NSL-KDD (KDDTest+), NSL-KDD (KDDTest-21), and UNSW-NB15 datasets and compared with six well-known classifiers. In addition, the classification performance of MDPCA-DBN was also compared with other state-of-the-art classifiers on theNSL-KDD (KDDTest+), NSL-KDD (KDDTest-21), and UNSW-NB15 datasets. The experimental results show that the classification accuracy, detection rate and false positive rate of MDPCA-DBN are better than those of traditional methods.
Since fewer U2R and R2L attacks in the NSL-KDD dataset are recorded, and nearly half of the unknown attacks on the testing dataset never appear in the training dataset, it is difficult for all classifiers to detect U2R and R2L attacks. For future work, we plan to use the adversarial learning method to synthesize U2R and R2L attacks, thereby increasing training samples for U2R and R2L attacks. Through the adversarial learning method, similar unknown U2R and R2L attack records can be synthesized. As a result, the imbalance of five types of attack records is reduced and the detection accuracy of U2R and R2L attacks is improved. This can further improve the detection performance of the proposed model.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}