1. Introduction
Massive Internet of Things (IoT) has gained great research attention. Its objective is to connect a wide range of devices to share data and information with each other. Massive IoT targets various applications such as smart cities, environmental monitoring, and health-care monitoring systems. Computing Technology Industry Association (CompTIA) has predicted that the number of connected devices will reach over 50 billion units by 2020 and 125 billion by 2030 [
1]. However, the majority of such connected devices have low processing power, limited storage capacity, and energy constraints.
The network congestion becomes an issue as the sheer number of connected devices increases over a network. IoT devices generate enormous traffic on the communication path, which creates network congestion. To manage network congestion, a multi-channel technology is proposed to be applied to the wireless communication network, which can benefit from the parallel transmission and reduced interference. Numerous multi-channel-based algorithms [
2,
3] are proposed to dynamically select channels for communication for improving the IoT network performance. All these related works are proposed based on time-slotted channel hopping (TSCH), which is a mechanism to improve the reliability of an IoT network and included in the IEEE 802.15.4e standard [
4]. The fundamental principle of TSCH is the scheduling of the time slots and channels for each communication in an IoT network, which can simultaneously decrease the frequency of communications and improve the network performance.
However, most of the existing multi-channel algorithms require strict synchronization, an extra overhead for negotiating channel assignment, which poses significant challenges to resource-constrained IoT devices. In addition, the current available IoT devices, especially resource-constrained IoT devices, have only one simple half-duplex radio transceiver, which does not satisfy the strong assumptions of operating on multiple channels simultaneously in most of existing works.
In contrast, to implement self-decision and self-learning in a wireless network system, recently, numerous reinforcement-learning-based approaches have been proposed to improve the wireless communication systems. In [
5], a reinforcement learning solution and simulation analysis were given for heterogeneous cellular networks to select multiple radio access technologies (RAT). Channel assignment schemes were proposed for cognitive radio networks (CRNs) that address the tradeoff of rate maximization and network connectivity in [
6,
7]. The problem of assigning channels has been modeled as a multi-armed bandit (MAB) [
8] problem, and accordingly, the MAB algorithm was proposed to explore and exploit suitable channel assignment.
The work in [
9,
10,
11] proposed an efficient, yet simple MAB algorithm, called the tug-of-war (TOW) dynamics, which could make decisions accurately and rapidly following a change in the environment. The work in [
12,
13] proposed to apply the TOW dynamics to a cognitive radio system and WLAN. In the above-mentioned related work, the experiments showed network performance improvement on the application of the TOW dynamics.
In this paper, a reinforcement-learning-based channel selection algorithm utilizing the TOW dynamics [
9,
10,
11] is proposed. In this proposal, a simple learning procedure for updating the reward estimates only needs to check whether the ACK frame is received or not. Meanwhile, minimal memory and computation capability for the learning procedure are required. Thus, the proposal can run on resource-constrained IoT devices. The proposal only focuses on the medium access control (MAC) layer procedure modification. We prototype the proposed algorithm on a resource-constrained single-board computer (SBC), which is hereafter called the cognitive-IoT prototype. Moreover, evaluation experiments deploying the cognitive-IoT prototype with high density in a frequently-changing radio environment are conducted. The evaluation results show that the cognitive-IoT prototype accurately and adaptively makes decisions to select channels respecting fairness among IoT devices when the real environment regularly varies.
3. Problem Formulation
3.1. Multi-Armed Bandit Problem
MAB [
8] is a statistical model that balances exploration and exploitation to solve recurring decision problems. A common real-world comparison for this problem is a gambler facing a collection of slot machines (“bandits”) at a casino, with each machine having an “arm” to pull. Each machine has an unknown distribution and expected payout, and the goal is to select arms that maximize the winnings by a sequence of lever pulls. After each attempt, the gambler must decide which slot machine to play given the current knowledge about their payouts.
Formally, an MAB is defined with K arms with unknown reward probabilities , which is the fundamental challenge of solving the MAB problem. At each round t, the player plays arm and obtains a reward. Therefore, the player has to play machines strategically to both maximize the reward and discover information about the arm rewards, denoted as . The target is to maximize the accumulated rewards, .
3.2. Channel Selection Problem as an MAB Problem
According to the system model introduced in
Section 2.2, the objective of the distributed channel selection problem for IoT devices is to maximize the total frames successfully transmitted via an optimal channel selection strategy. We assumed distributed channel selection processes for multiple IoT devices with no prior coordination. Each IoT device can select a set
of available channels. Here,
k refers to the index of the channel. For simplicity, we assumed that each IoT device can access one channel at a time. The distributed channel selection problem of IoT device belongs to the class of MAB.
The challenge in distributed channel selection problem is similar to that in the MAB problem: an IoT device (player) has
K channels (slot machines), the
of which has successful frame transmission possibility
(reward probability). The IoT device does not know the values of the
s and must sequentially select a channel to send the data frame (select a machine to play). The target is to maximize the total successful frame transmission (overall gain) for a total of
T transmissions (plays). The distributed channel selection problem and MAB problem share the same concept, which is summarized in
Table 1.
An IoT device selects channel
at current time
t. If the IoT device sends the data frame over a selected channel
successfully, the selected channel,
, receives a reward. We assume that the IoT devices follow a generalized version of the unslotted CSMA/CA algorithm introduced in
Section 2.2 For more details, if channel
is selected, an IoT device will wait the time specified by the generated random number. At the end of the waiting period, the IoT device senses the selected channel again, and if it is found to be busy, it will generate another random number following the CSMA/CA algorithm. It will then detect the selected channel,
, again until reaching the predetermined maximum challenge time. If the selected channel,
, is still found busy when reaching the maximum retry time, the IoT device will discard the data frame and recognize the current data frame transmission as failed.
However, if the selected channel, , is assessed as idle, the data frame will be transmitted by the IoT device. Moreover, if the ACK frame is received successfully from the destination of the data frame transmitted previously, then the IoT device will recognize the transmitted data frame over the selected channel, , as a success. If the ACK frame is not received successfully from the destination of the data frame transmitted previously, then the IoT device will recognize the transmitted data frame over the selected channel, , as failed. Regardless of the success of the current data transmission, the IoT device will enter sleep and possibly select a different channel to access when it wakes up the next time.
The challenge stems from the uncertainty in the successful frame transmission probability, , imposing a trade-off between the exploration learning , and exploitation by selecting the channel with the highest estimated successful frame transmission probability, , based on the currently available information. An IoT device employs a strategy that will select channel to access at current time t according to any possible causal information pattern obtained from the previous observations. This is done to maximize the accumulated reward, , i.e., the total successful frame transmission.
4. TOW Dynamics-Based Strategy
Many algorithms [
15,
16,
17,
18] have been proposed to solve the MAB problem. In this paper, the strategy used to solve the distributed channel selection problem is referred to the tug-of-war (TOW) dynamics [
9,
10,
11,
12]. Despite the simplicity, the high efficiency of TOW dynamics has been analytically validated in making a series of decisions for maximizing the total sum of stochastically-obtained rewards in an environment where the reward probability frequently changes [
9,
10,
11,
12]. The main methodology of [
9,
10,
11,
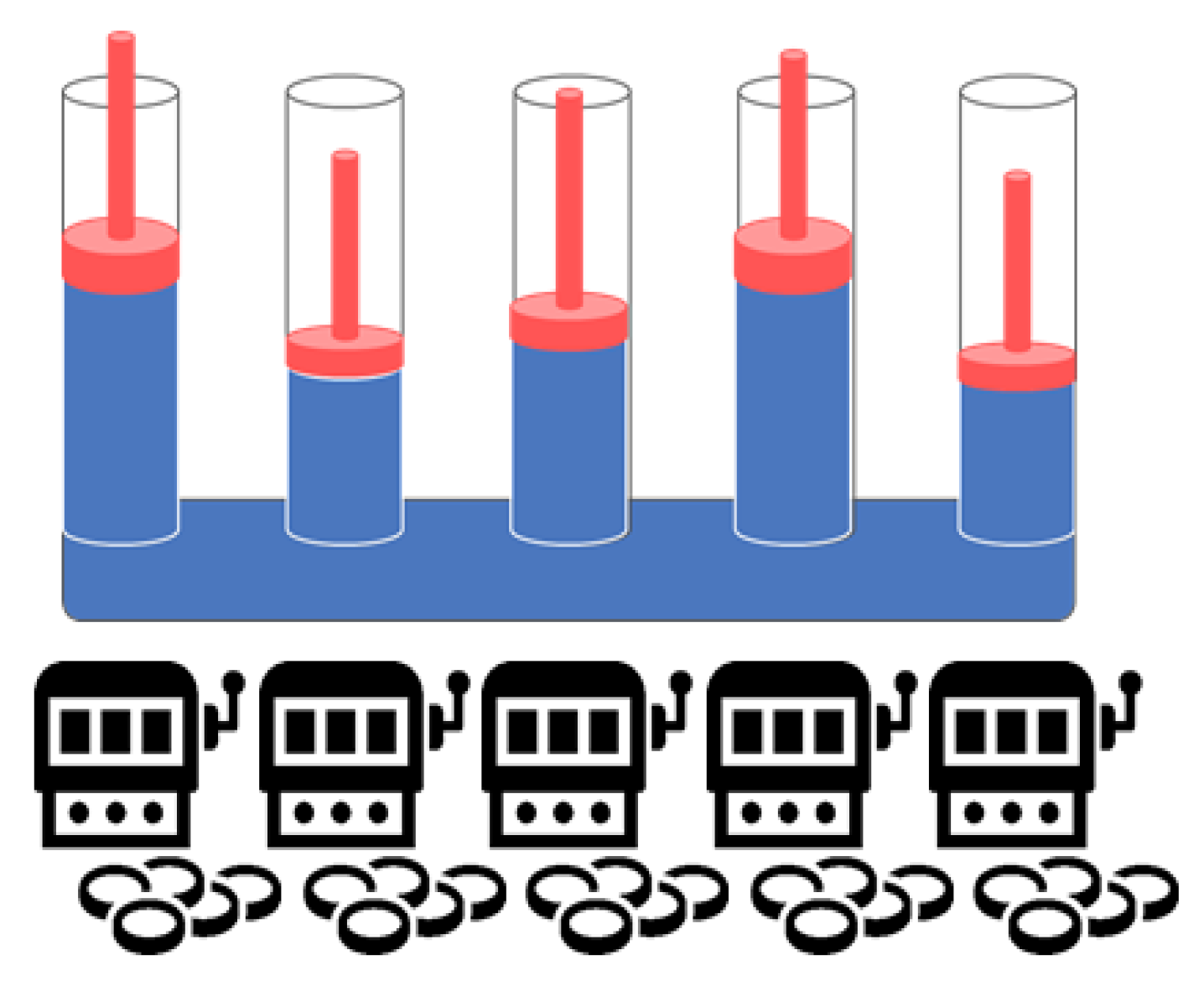
12] is summarized below. The essential element of the TOW dynamics is the consideration of a volume-conserving physical object, e.g., the incompressible liquid (blue) is assumed in a branched cylinder shown in
Figure 3, which implies a non-local correlation between the terminal parts. Specifically, the volume increase in one part is immediately compensated by the volume decrease in the other part(s). Here, the
n-machine MAB is considered. For each machine (branch)
k at time
t, let
correspond to the displacement of machine
k. Thus, the reward estimates of each machine can be obtained by Equation (
1),
where
. Here,
denotes the accumulated counts of selections of machine
k, while
denotes non-rewarded counts of machine
k until time
t.
is given by Equation (
2).
Accordingly, based on the conservation laws in TOW dynamics, the displacement of machine
k can be estimated by Equation (
3),
where
n is the total number of arms. The incompressible liquid oscillates autonomously according to Equation (
4) [
12]. There are many possibilities of adding the oscillations. In [
11], the influence of
on the efficiency of decision making as studied, which is outside of the scope of this paper. For the sake of simplicity, we used
for all machines in this paper.
The estimated reward probability, denoted as
, can be obtained by Equation (
5),
where
counts the number of times of getting rewards when machine
k is played
times until time
t. Consequently, the TOW dynamics-based strategy evolves according to a particular simple rule: if machine
k is played at each time
t,
or
is added to
when rewarded and non-rewarded, respectively. To explore the appropriate weight parameter of
, the expected value of reward estimates of machine
k can be obtained by Equation (
6).
Here, the highest and the second highest estimated reward probability among n machines can be obtained given by Equation (
5), denoted as
and
, respectively. Accordingly, the highest and the second highest expected value of reward estimates among n machines can be obtained by Equation (
6). To achieve always selecting the machine with the highest reward estimates, the following forms could be expressed,
and these expressions can be rearranged into the form:
In other words, the weight parameter
should satisfy the above condition Inequality (
8) so that the selection correctly represents the largest reward estimates. One way of ensuring Inequality (
8) is to take an
that satisfies Equation (
9).
From Equation (
9), we obtain the appropriate value of weight parameter
given by Equation (
10) to use the TOW dynamics-based strategy for selecting the correct machine that maximizes the reward.
It is implied from the above description that the TOW algorithm has an equivalent learning rule for a system that can update the reward estimates simultaneously, which would be able to make decision with high efficiency for a variety of real-world applications. In [
12,
13], the TOW dynamics was proposed to be utilized in wireless cognitive radio and WLAN systems respectively to improve the multi-user channel allocations of the cognitive radio efficiently.
In this paper, the TOW dynamics-based strategy is proposed to solve the distributed channel selection problem in massive IoT, which is modeled as the MAB problem (see
Section 3.2). The objective is to maximize the total successful frame transmissions. The TOW-dynamics-based strategy is applied to explore the appropriate channel selection in the proposal by simply checking the ACK frame reception. The learning rule of the proposal is based on Equation (
1).
Meanwhile, the estimated reward probability
(see Equation (
5)) is actually obtained by Equation (
11) according to the massive IoT system procedure in the proposal.
Then, the appropriate
can be explored as given by Equations (
10) and (
11).
In addition, because the wireless channels are frequently changing, a parameter, denoted as the forgetting ratio
, is used for controlling how much the past experiences influence. Then,
is proposed to be rewritten as Equation (
12).
Above, the closer
is to zero, the fewer estimated
are influenced by the past experiences. In contrast, the closer
is to one, the more estimated
are influenced by the past experiences. Accordingly,
of each available channel can be determined by Equation (
3). Then, the IoT device will select the channel,
, once it wakes up the next time.
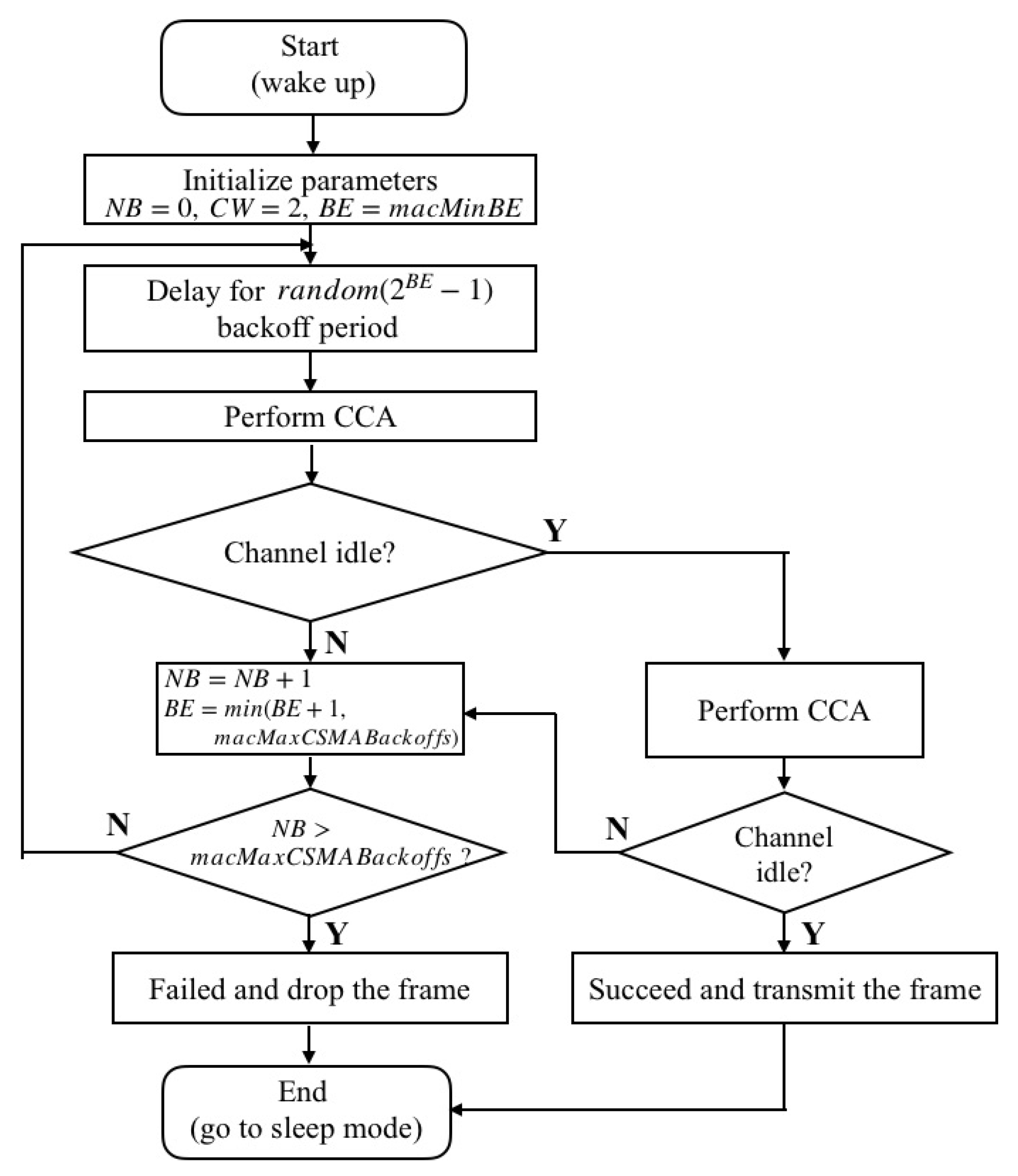
5. Proposal: TOW Dynamics-Based Channel Selection Algorithm and Its IoT Prototype Implementation
In this section, the proposed TOW dynamics-based channel selection algorithm and its prototype implementation are described. The proposed algorithm works extremely simply. Accordingly, only minimal memory and computation capability are necessary to implement the algorithm on a resource-constrained IoT device. The IoT device conducts the proposed channel selection algorithm to update the accumulated reward estimates,
, of the all available channels simultaneously following the learning process described in
Section 4.
Based on the system model and problem formulation introduced in
Section 2.2 and
Section 3.2 respectively, the IoT device initially wakes up and randomly selects a channel from the available
K channels. As mentioned in
Section 3.1, if the IoT device sends the data frame over selected channel
and receives the ACK frame from the destination, then the IoT device will recognize the data transmission as a success over the selected channel,
, which implies that it is rewarded, and
given by Equation (
2) is set as
. Otherwise, if the IoT device does not receive the ACK frame, it will recognize the data transmission over the selected channel,
, as failed, which implies that it is unrewarded, and
is set as
.
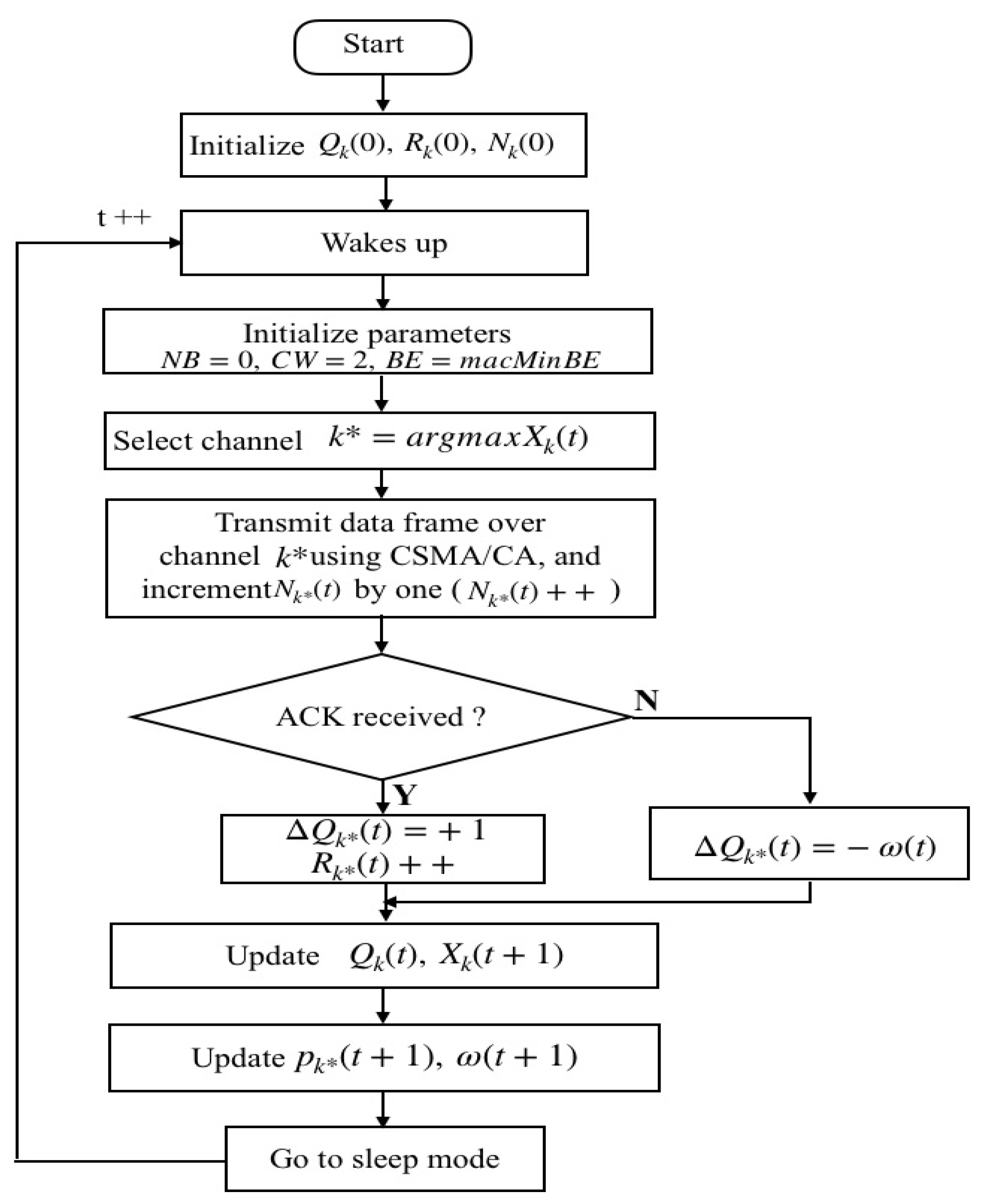
Figure 4 shows the flowchart of the proposed procedure for each IoT device. Essentially, the proposed procedure follows the same procedure as that of the non-beacon-enabled mode of IEEE 802.15.4. Therefore, the IoT device periodically goes to the sleep mode to save power after sending a data frame. Each IoT device initializes
,
, and
at
. Once the IoT device wakes up at
, it sends the data frames over the selected channel
. Because the
is randomly set to the same value for all available channels initially, the IoT device actually randomly selects a channel to send data frames at
. Meanwhile, the count of transmissions over channel
, denoted as
, is incremented by one.
If the IoT device receives the ACK frame successfully, the channel is rewarded, and is added to . Meanwhile, the counts of rewards is incremented by one accordingly. Otherwise, the selected channel is unrewarded, and is added to for updating. Regarding those unselected channels at , . The reward estimates of the unselected channels are given by accordingly.
Then,
of each available channel is updated by Equation (
3) for the next time
. Meanwhile, the reward probability estimate of the selected channel
, i.e.,
, is updated for the next time
according to Equation (
11). In addition, the appropriate value of weight parameter
is also updated adaptively based on Equation (
10) for the next time
Then, the IoT device goes to sleep mode again and wakes up at
to send a data frame over the selected channel with the highest
, which has been calculated at
.
We implemented the proposed channel selection algorithm on an SBC shown in
Figure 5. As described above, the cognitive-IoT prototype only needs to receive the ACK frame to explore the channel selection strategy. Concurrently, the proposed TOW dynamics-based learning process only requires adding one or subtracting
to update the reward estimate. Therefore, to implement the proposal, only addition and subtraction are necessary based on the procedure of the proposal. Thus, minimal memory and computation capability are enough for prototyping the proposed reinforcement-learning-based channel selection algorithm. More details of the processes of the algorithm running on the cognitive-IoT prototype are summarized in Algorithm 1.
| Algorithm 1 TOW dynamics-based channel selection algorithm for the cognitive-IoT prototype . |
- 1:
Initialize . - 2:
while wake time is not expired do - 3:
Initiate channel access parameters, i.e., NB, CW, BE - 4:
Select channel - 5:
while do - 6:
Delay for random - 7:
Perform clear channel assessment (CCA) - 8:
if Channel is assessed as idle then - 9:
Transmit the data frame - 10:
- 11:
if the data frame is transmitted, and the corresponding ACK frame is received then - 12:
Data transmission succeeded - 13:
Set - 14:
Increment by one () - 15:
else - 16:
Data transmission failed - 17:
Set - 18:
end if - 19:
Update given by Equation ( 12) - 20:
Update given by Equation ( 3) - 21:
Update given by Equation ( 11) - 22:
Update given by Equation ( 10) - 23:
else if Channel is assessed as busy then - 24:
Update and - 25:
Continue - 26:
end if - 27:
end while - 28:
Enter sleep mode for 1000 ms - 29:
- 30:
end while
|
The cognitive-IoT prototype was developed on a well-used SBC, Lazurite 920 MHz [
19]. Lazurite is equipped with the IEEE 802.15.4g radio-compatible transceiver supporting a 50-kbps data rate in the 920-MHz band. An ultra-low power 16-bit microcontroller (ML620Q504H) and 64 KB ROM are used in Lazurite. In addition, Lazurite’s operating voltage range is 1.8 V∼5.5 V, while the operating current range is 7 μA∼mA The photographs of the cognitive-IoT prototype are shown in
Figure 5.
6. Performance Evaluation
To validate that the cognitive-IoT prototypes make the decisions to select the suitable channels to transmit adaptively, a series of experiments were conducted. A photograph of the experiment setting is shown in
Figure 6. The cognitive-IoT prototypes (see
Figure 7) were deployed in a 1 m × 1 m area with high density, where they communicated with three gateways (see
Figure 8) operating on different channels with a star topology, following the proposed procedure introduced in
Section 5. The deployment and topology were static throughout the experiments.
In addition, the bandwidth of all three available channels was 200 kHz. Each IoT node had a 1000-ms sleep interval.
was chosen as 0.995 in the experiments.
Table 2 summarizes the experiment parameters.
Furthermore, to validate that the cognitive-IoT prototypes select suitable channels adaptively, the externally-offered loads that were generated by the IEEE 802.15.4e IoT devices were added to evaluate the effectiveness of the cognitive-IoT prototypes in four different test scenarios, which are summarized in
Table 3. The sleeps internal of all the IEEE 802.15.4e IoT devices was set as 100 ms.
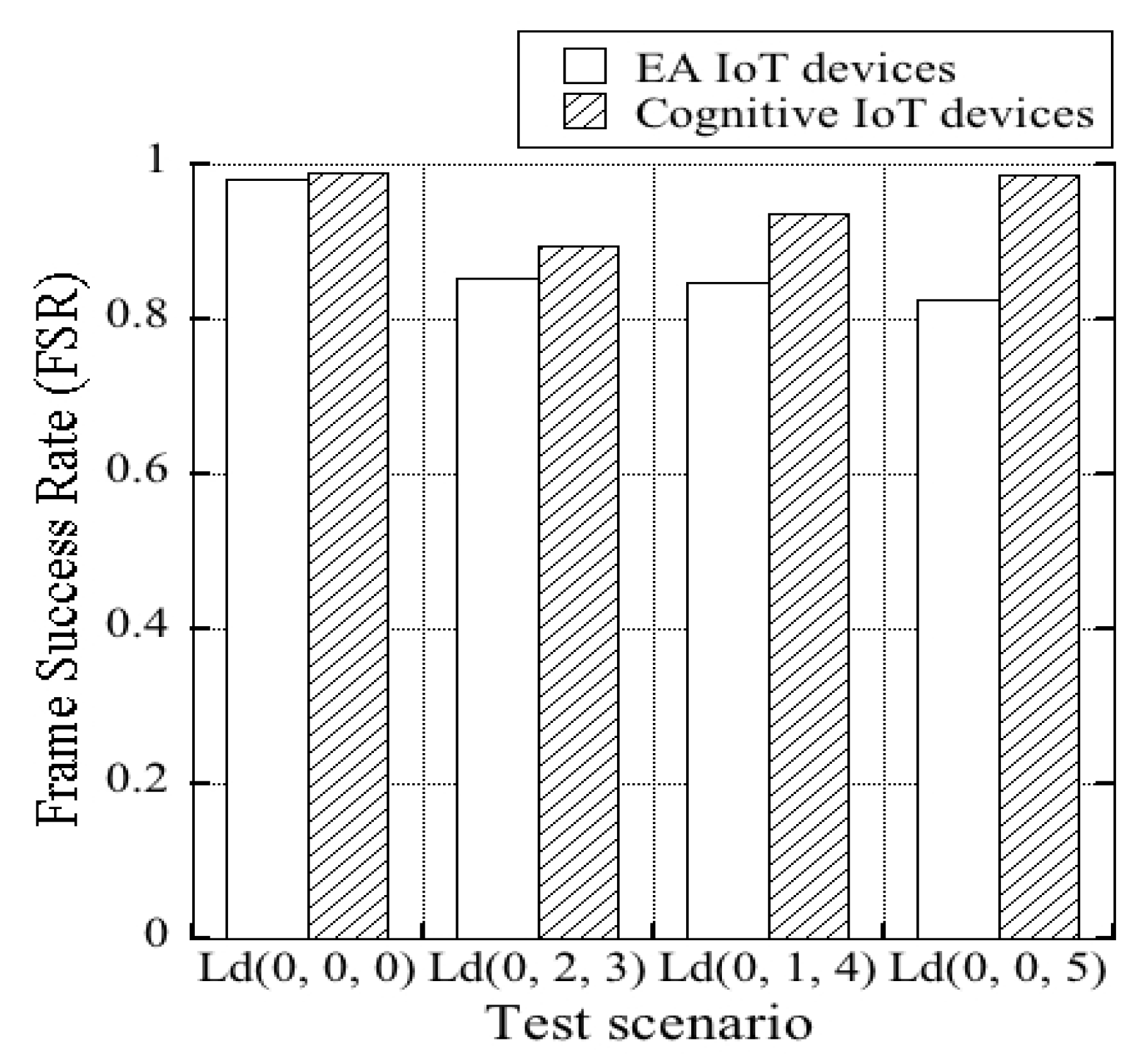
First, to evaluate that the cognitive-IoT prototypes can improve the successful frame delivery of the network by adaptively selecting the suitable channel to send the frame, the Frame Successful Ratio (FSR) (see Equation (
13)) was compared with that of the evenly assigned (EA) IoT devices. Here, the EA IoT devices represent the IEEE 802.15.4e IoT devices on which we implemented the standard procedure of IEEE 802.15.4e on the same SBC with the cognitive-IoT prototype shown in
Figure 5. These EA IoT devices were set up to operate statically on the assigned channels where devices were EA on each available channel. Because the EA IoT devices operated based on the standard procedure of IEEE 802.15.4e, the EA IoT devices were not be able to change their channel once their operating channel was pre-determined. Each EA IoT device periodically went to sleep to save energy, which is the same as the cognitive-IoT prototype. The sleep intervals of all the EA IoT devices were set to the same as those of the cognitive-IoT prototypes, i.e., 1000 ms.
where
M is the number of devices and, accordingly,
j is the index of the device. Meanwhile,
K is the number of available channels, and
i is the index of the available channel. The FSR results are shown in
Figure 9. In the
test scenario, the FSR of the cognitive-IoT prototype was practically the same as that of the EA IoT devices. As for the other test scenarios with an added externally-offered load, i.e.,
, and
, the FSR results of the cognitive-IoT prototypes were typically higher than those of the EA IoT devices. This was because the cognitive-IoT prototypes generally adaptively selected appropriate channels to send the data frames successfully, whereas the EA IoT devices used the assigned channels, which became congested and failed to send the data frames. It can be stated that by employing the proposed TOW-dynamics-based algorithm to select suitable channels adaptively, the cognitive-IoT prototype improved the FSR of the network.
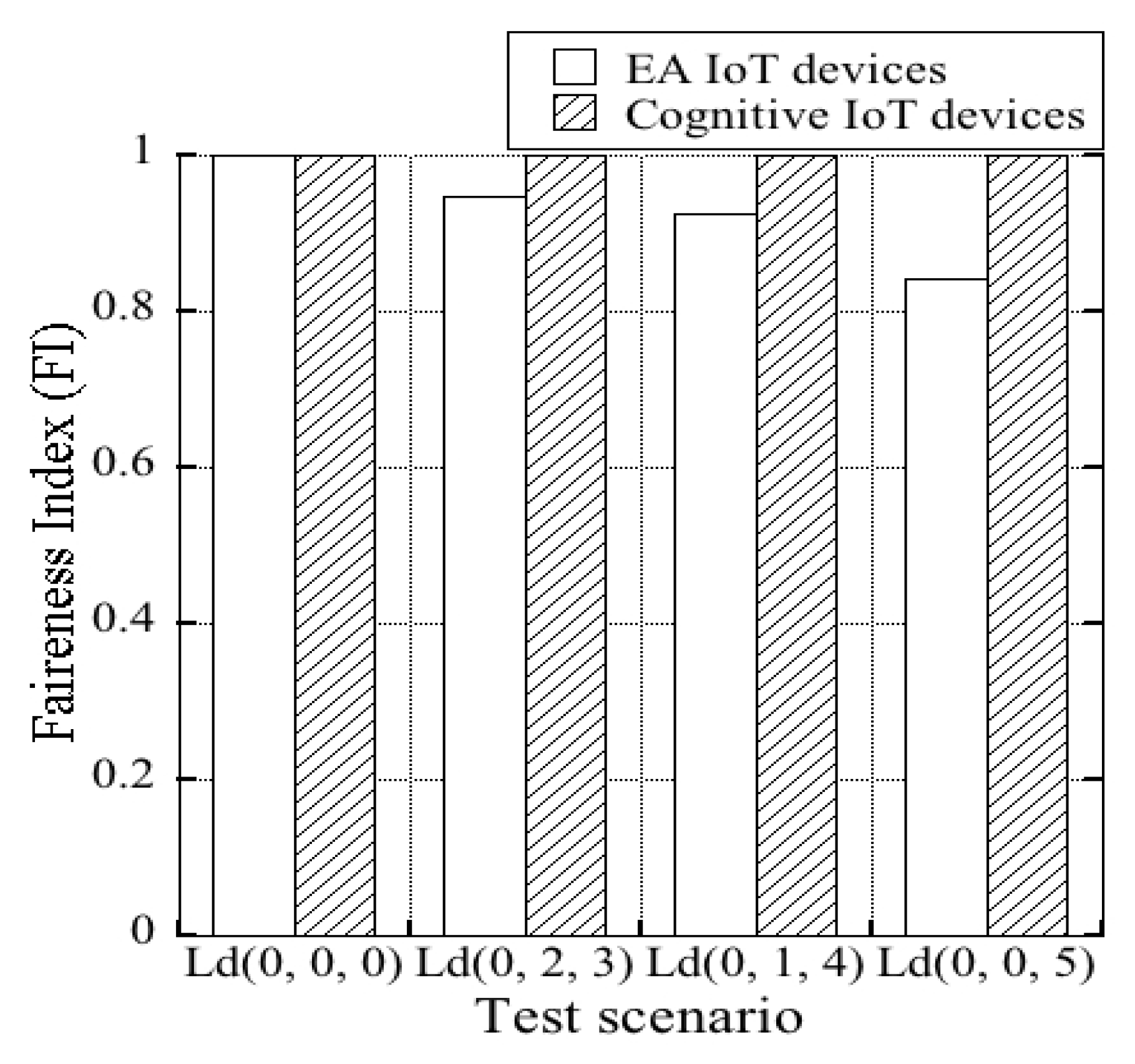
Second, because it was important for the IoT devices to send the data frames unbiasedly, the well-used Jain’s fairness index (FI) (see Equation (
14)) for the data transmission of the IoT devices was measured.
where
M is the number of devices and, accordingly,
j is the index of device, while
, A larger value represents a more reasonable frame transmission achieved by the IoT devices.
Figure 10 shows the results of the FIs of the cognitive-IoT prototypes and EA IoT devices.
As shown in
Figure 10, the FI values of both the cognitive-IoT prototypes and EA IoT devices were nearly one when all the available channels were equivalently “idle”, i.e.,
: (0, 0, 0). However, for the other test scenarios, i.e.,
: (0, 2, 3),
: (0, 1, 4), and
: (0, 0, 5), the FI values of the EA IoT devices decreased because some of the EA IoT devices failed to send the data frames owing to channel congestion, whereas some of them can do this successfully This led to unfairness in the EA IoT devices. By contrast, in all the test scenarios, the FI values of the cognitive-IoT prototypes were typically kept nearly one.
Furthermore, for validating that the cognitive-IoT prototypes adaptively selected the channels, in the experiments, the number of successful frame transmissions over each available channel was observed. We initiated the experiment with test scenario
: (0, 0, 0) and then changed the test scenarios in the middle of the experiment, i.e., testing
: (0, 0, 5) for 10 min,
: (0, 1, 4) for 15 min,
: (0, 2, 3) for 15 min, and
: (0, 0, 0) for 15 min subsequently (see
Figure 11). The results were tracked and are shown in
Figure 11. It can be observed from
Figure 11 that the number of successful frame transmissions over the CH56 decreased to almost zero immediately after the test scenario changed to
: (0, 0, 5) when an externally-offered load was added to CH56. In addition, it is observed from
Figure 11 that the cognitive-IoT prototypes started to select CH56 again when the externally-offered load became lighter, i.e.,
: (0, 1, 4) and
: (0, 2, 3), than before, i.e.,
: (0, 0, 5). It can be stated that the cognitive-IoT prototype achieved selecting the optimal channel accurately and adaptively.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}