Semi-Supervised Convolutional Neural Network for Law Advice Online

Abstract
1. Introduction
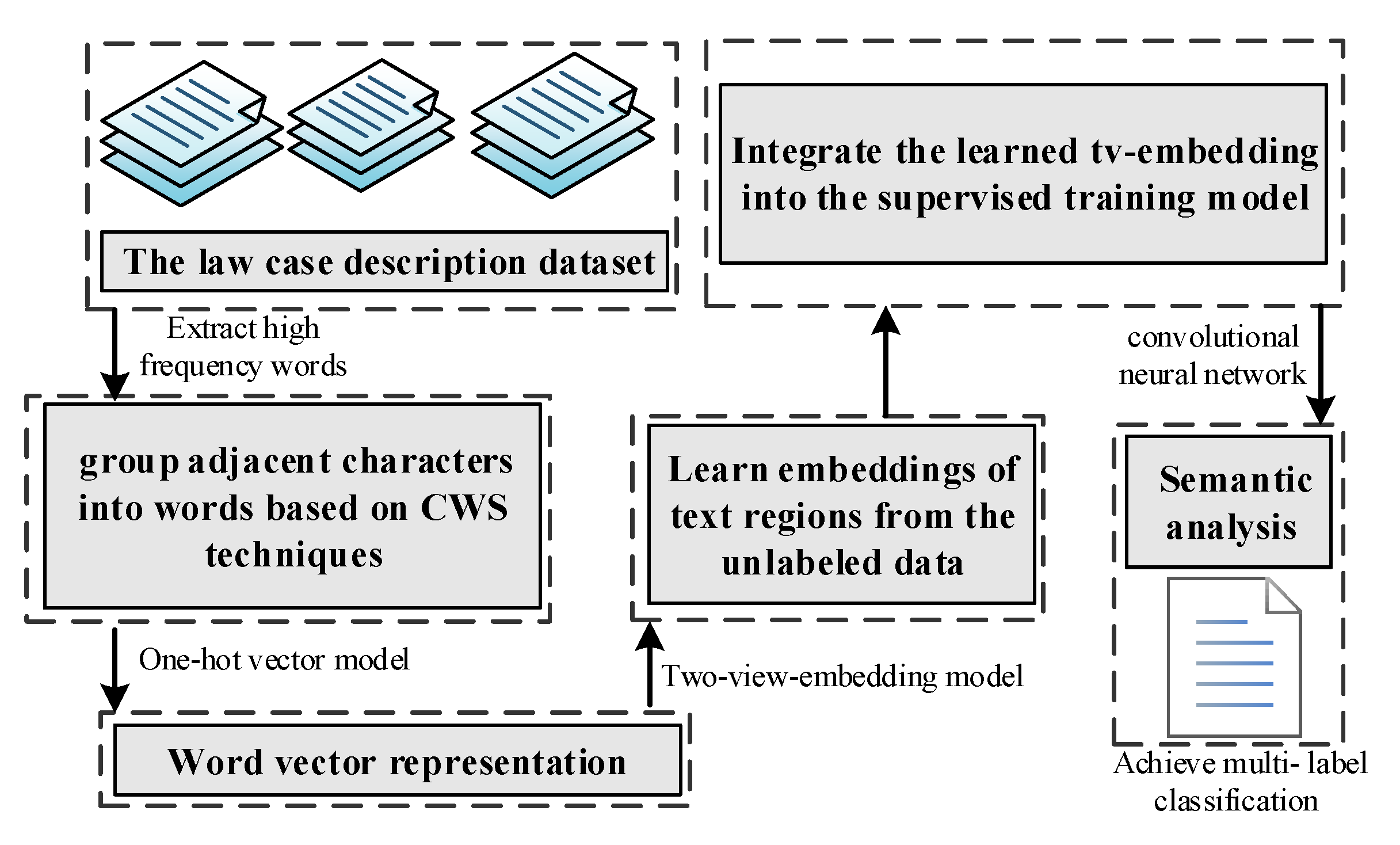
- To solve the data annotation problem, the two-view-embedding model is presented, which learns the embedding of small text regions from unlabeled data to reduce the labor cost and time expenditure, while considering not sacrificing the system performance.
- We propose a novel SSC-based model, with general adaptability and good scalability, to realize the Chinese text classification. Unlike English, there is no obvious division between Chinese words. To apply it to Chinese NLP tasks, firstly, a Chinese sentence needs to be segmented to get words. Then, deeper information of Chinese words is exploited to learn Chinese word vector representation. Finally, the learned word vector is integrated into the SSC model.
- The proposed method is evaluated experimentally subject to a Chinese law case description dataset. On Chinese data, results suggest that compared to SVM, our scheme respectively improves by 7.76%, 7.86%, 9.19% and 2.96% in terms of precision, recall, F-1, and Hamming loss.
2. Related Work
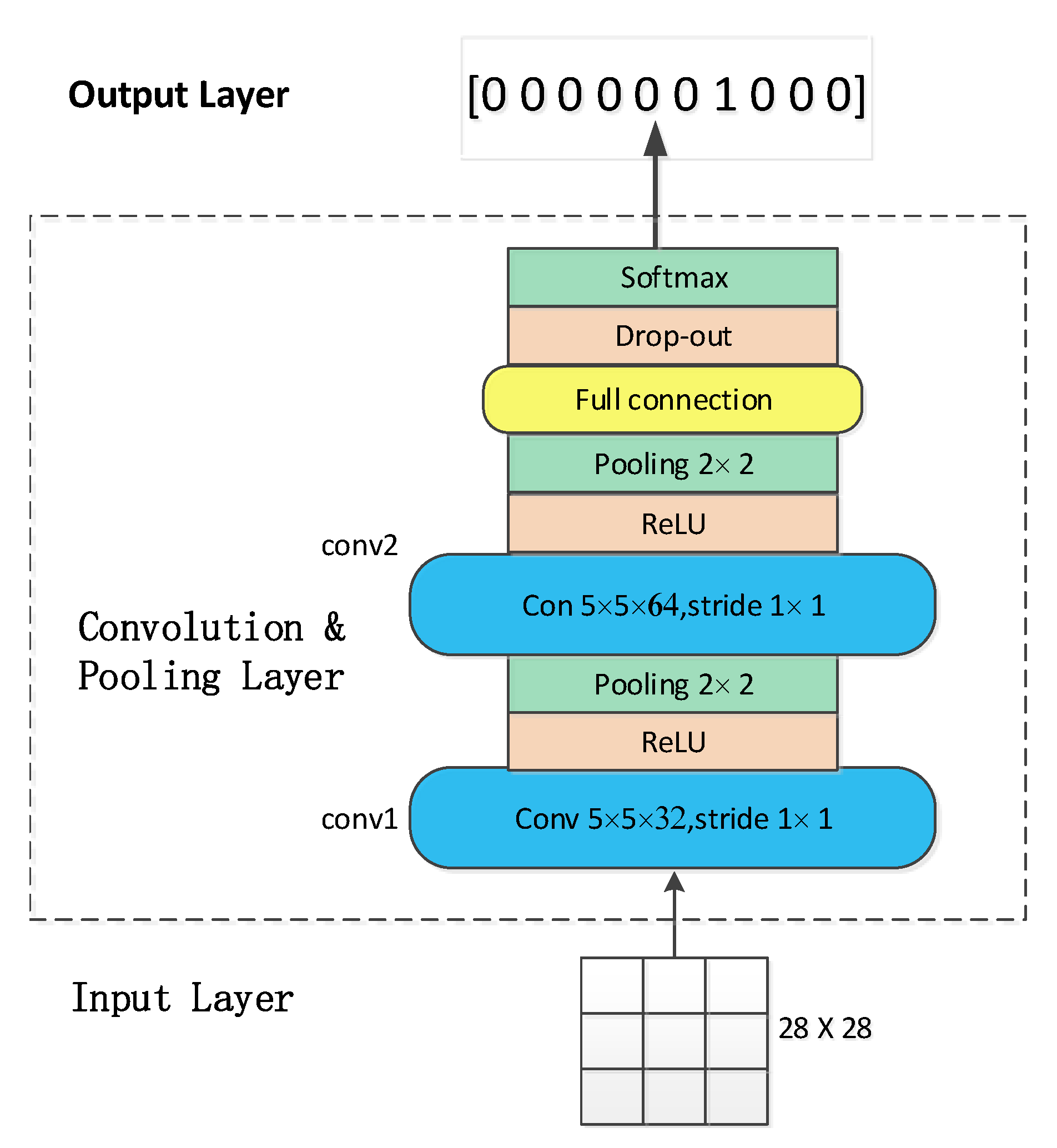
2.1. Fundamentals of CNN
2.2. The Applications of CNN in NLP
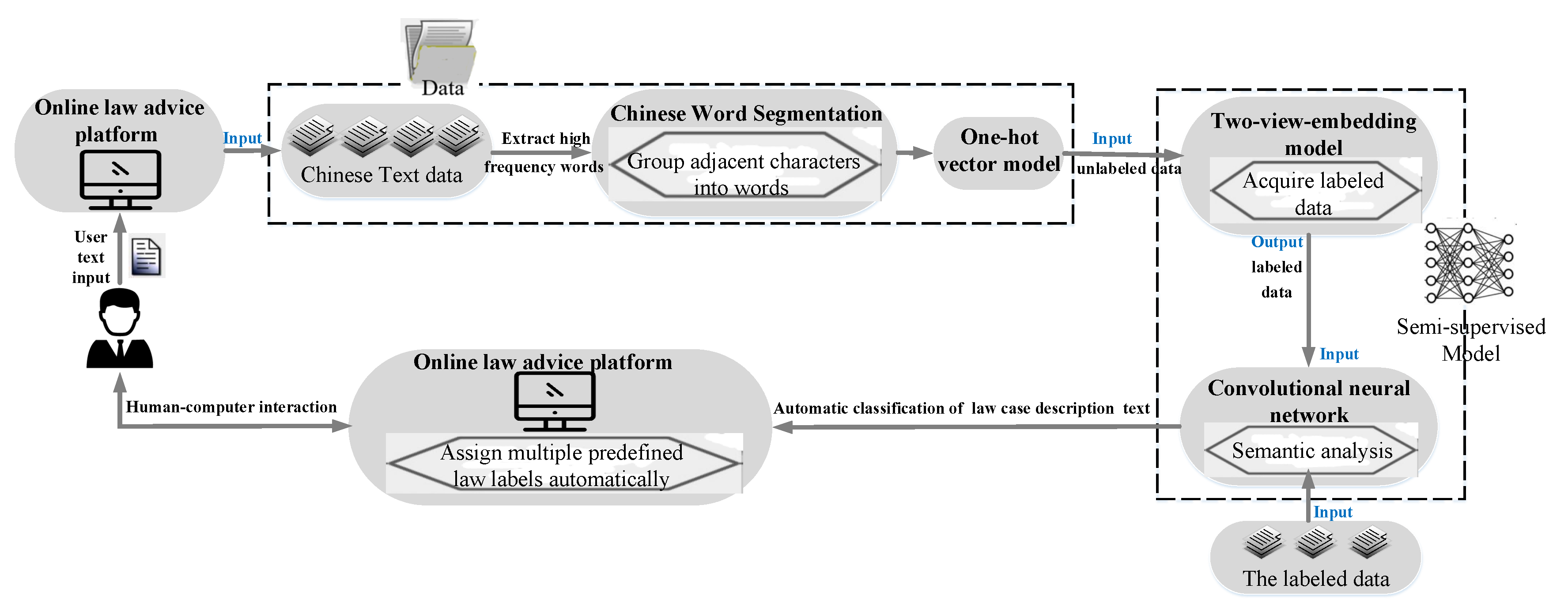
3. Problem Formulation and Challenges
3.1. Problem Description and Solutions
3.2. Scheme
| Algorithm 1: SSC training algorithm. |
| Input: training data T, validation data V and test data E. |
| Output: the classification results R. |
| 1. extract high frequency words from the text data T; |
| 2. group adjacent characters into words based on the Chinese word segmentation (CWS) technique; |
| 3. generate the input data of the tv-embedding model by the bow-one-hot language model; |
| 4. train the tv-embedding model defined as |
| to predict adjacent regions from each small text region; |
| 5. set a threshold ; |
| 6. while the precision P < do |
| 7. for all convolution layers in CNN do |
| 8. integrate the learned tv-embedding into the CNN’s convolution layer calculated as |
| ; |
| 9. the filter performs the convolution operation on the sentence matrix; |
| 10. get different degrees of feature dictionaries D; |
| 11. end for |
| 12. for all pooling layers in CNN do |
| 13. maximum pooling operation; |
| 14. generate a set of univariate feature vectors U; |
| 15. end for |
| 16. for softmax layer in CNN do |
| 17. feature vectors U are used as input to classify the text; |
| 18. end for |
| 19. return the classification results R; |
| 20. end while |
| 21. enter the validation set V, and then, adjust the classifier parameters; |
| 22. enter the test set E and test the classification capacity of the model. |
3.3. Challenges
- For large-scale learning tasks in NLP, the training data need to be manually annotated, which increases the labor and time costs and tremendously limits the general adaptability of NLP.
- It is important to note that while the CNN-based online law consulting system has achieved better intelligent experience than other studies, significant challenges remain on the internal structure of the model, such as fewer network layers to extract text feature.
4. The Implementation of Our Scheme
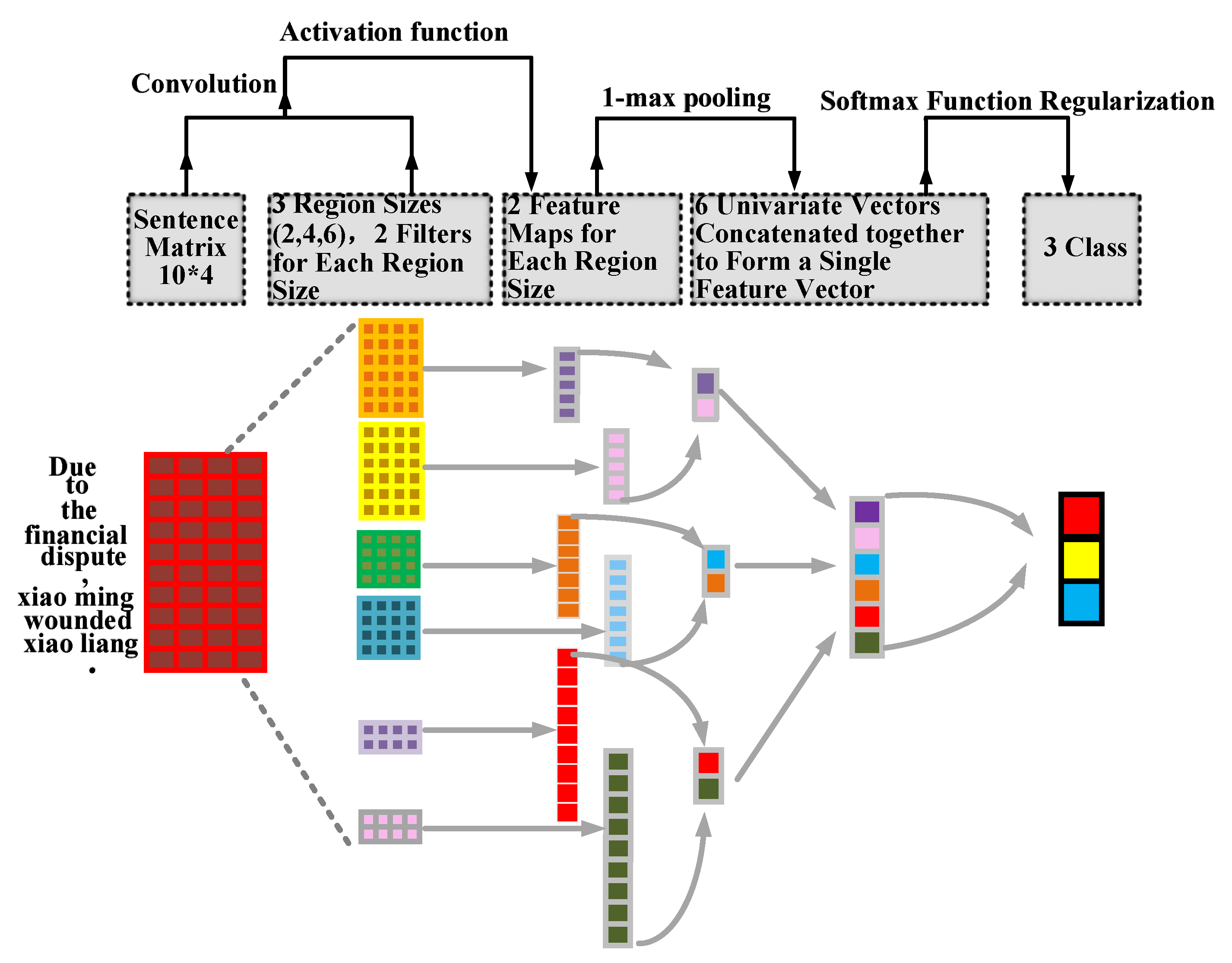
4.1. One-Hot Embedding for Small Text Regions
4.2. tv-Embedding Model
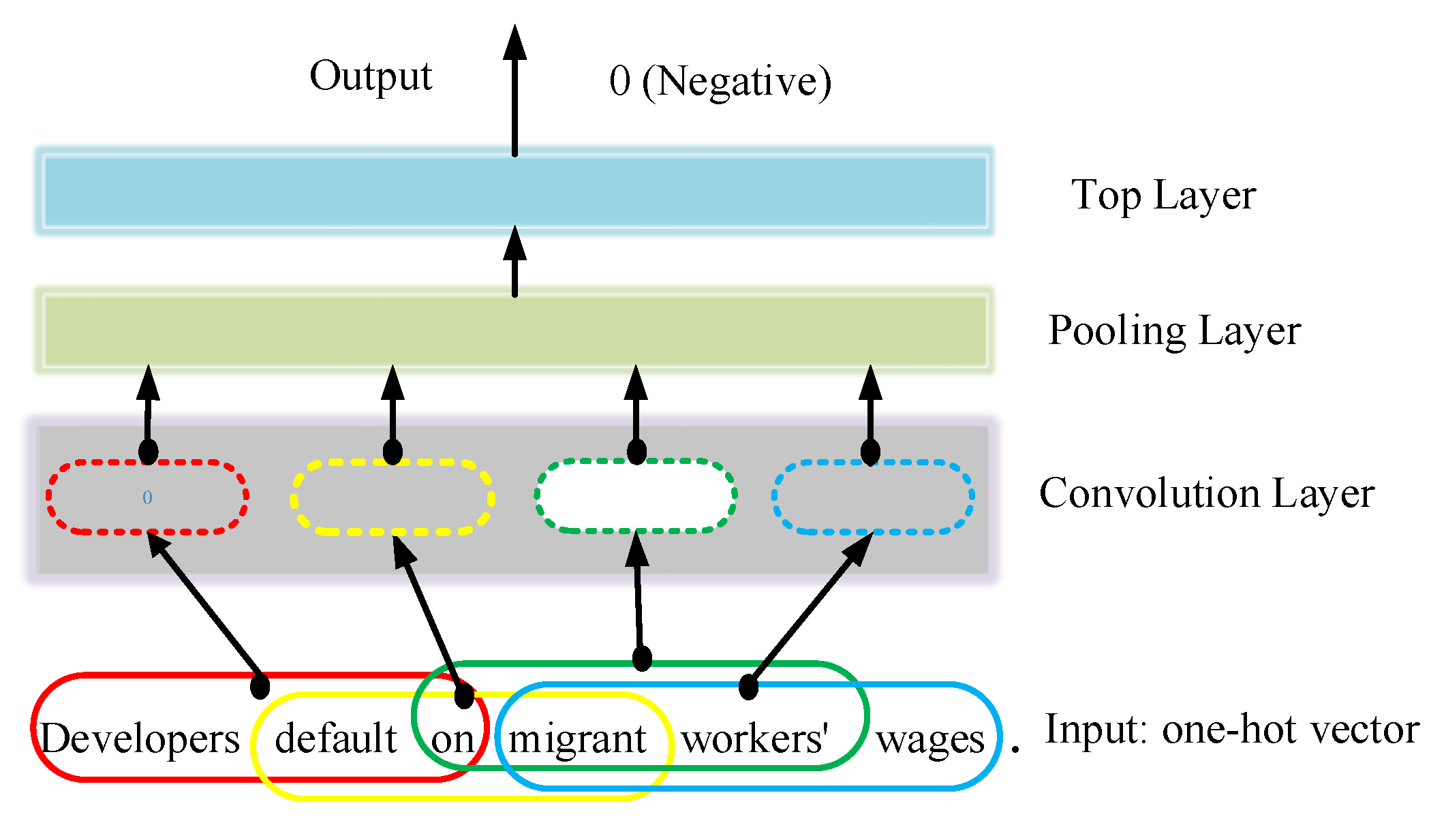
- It implements the goal to predict the adjacent text region from each region of size p. What is more, it can capture the internal information between data.
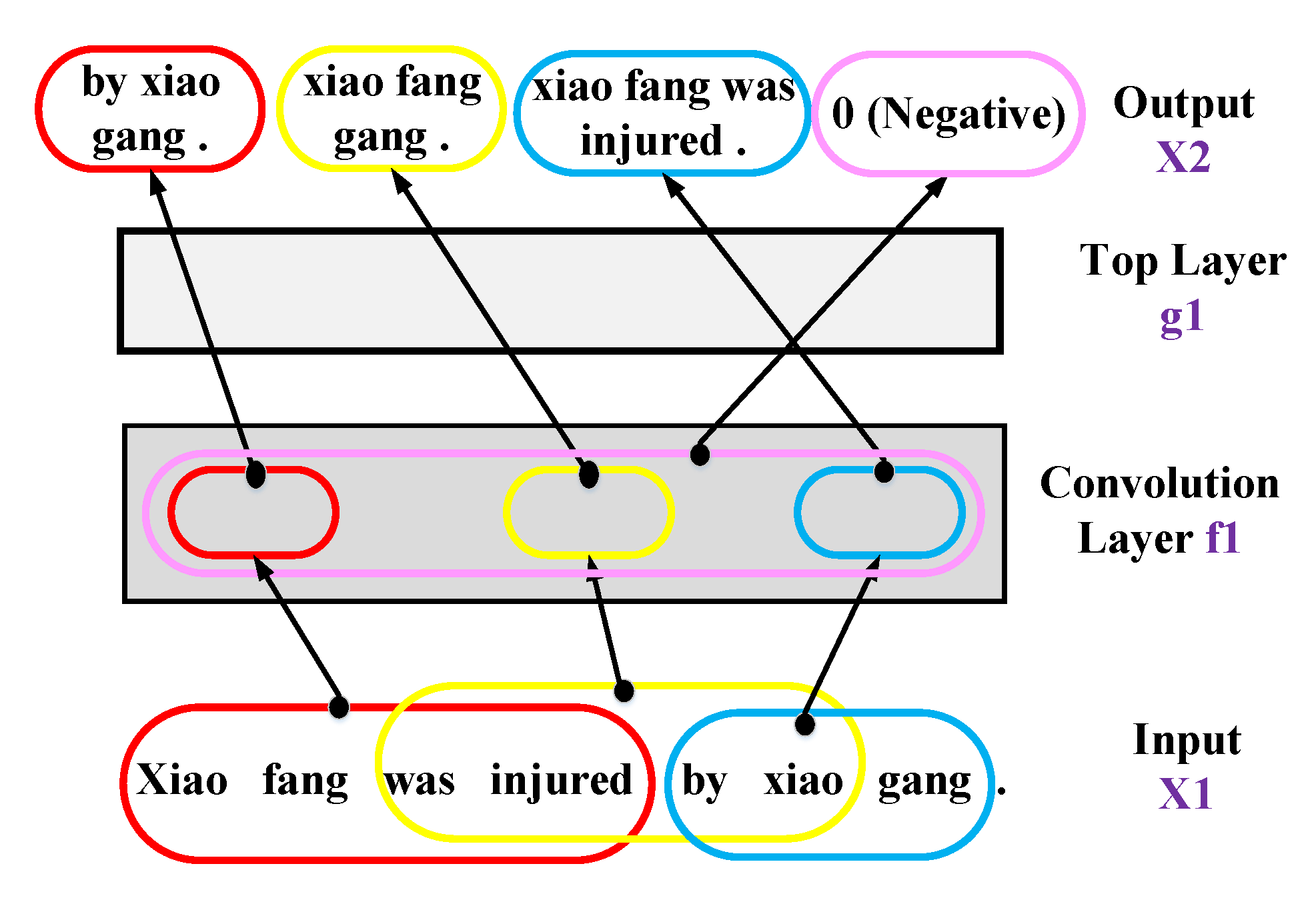
- It can assign a sub-label (e.g., positive/negative) to each small text region of size p. For example, in Figure 5 above, with and , three regions “Xiao fang was injured”, “was injured by Xiao” and “by X Xiao gang” are assigned sub-labels 0, 0, 1, respectively. Note that 1 means positive, 0 means negative. It is worth noting that assigning a sub-label to each small text region of size p is sensible because these small text regions are helpful for making classification.
- It also assigns a total label (e.g., positive/negative) for the entire sentence. For example, the entire sentence “Xiao fang was injured by Xiao gang.” is assigned a total label 0, as illustrated in Figure 5. Note that 1 means positive, 0 means negative. This is sensible because CNN makes classification by analyzing the entire sentence as well.
- A convolution layer learns the embedding of small regions from no-label text data. The high-dimensional feature vectors are converted to the low-dimensional feature vectors; in addition, the predictive structure is preserved.
4.3. Integration of the tv-Embedding into Supervised CNN
5. Performance Evaluation
5.1. The Experiment Platform
5.2. Dataset
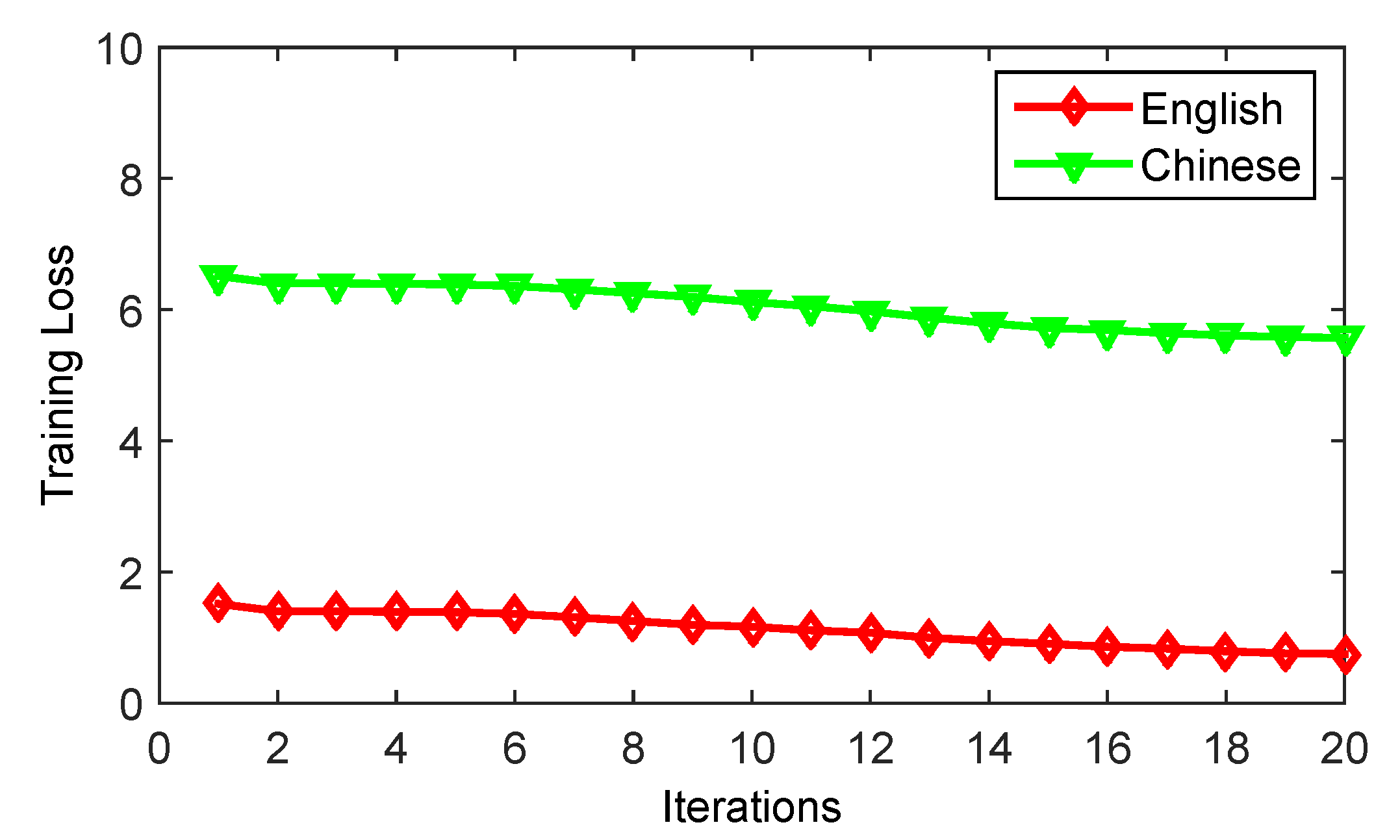
5.3. Evaluation of the Classification Performance
5.4. Experimental Results
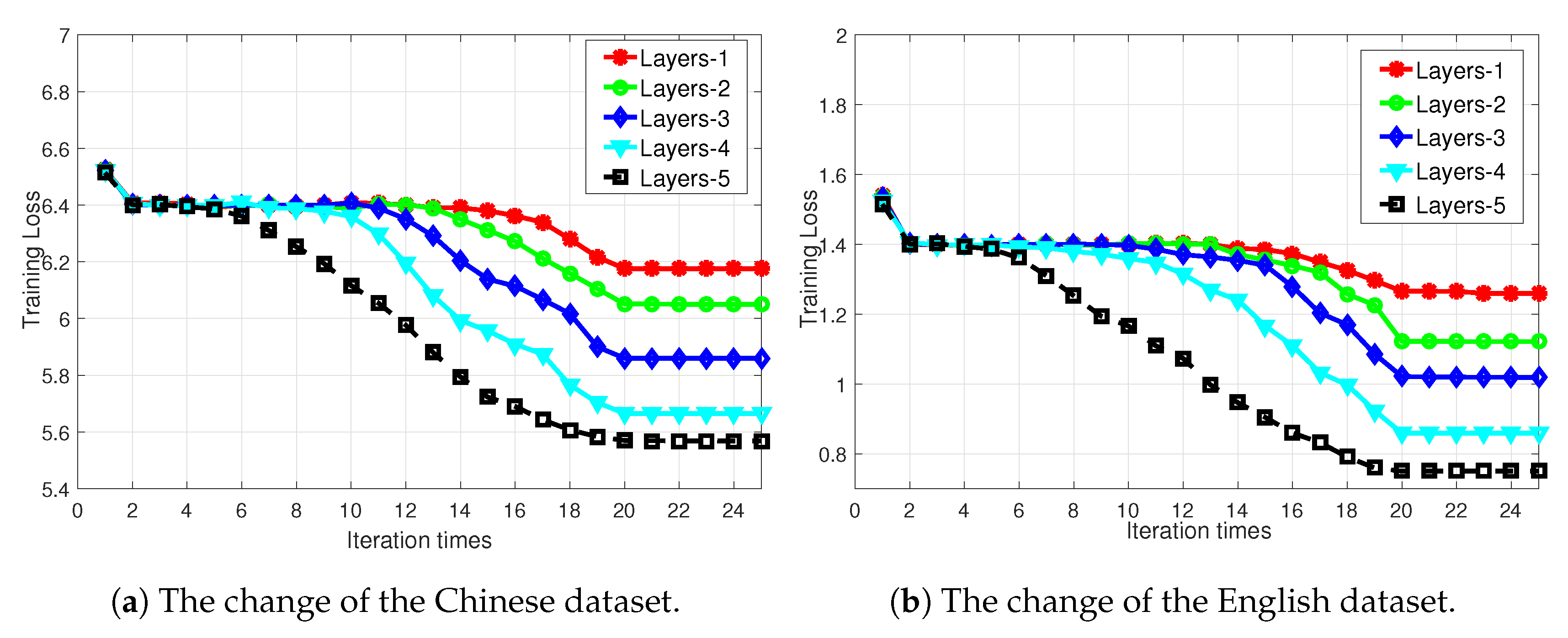
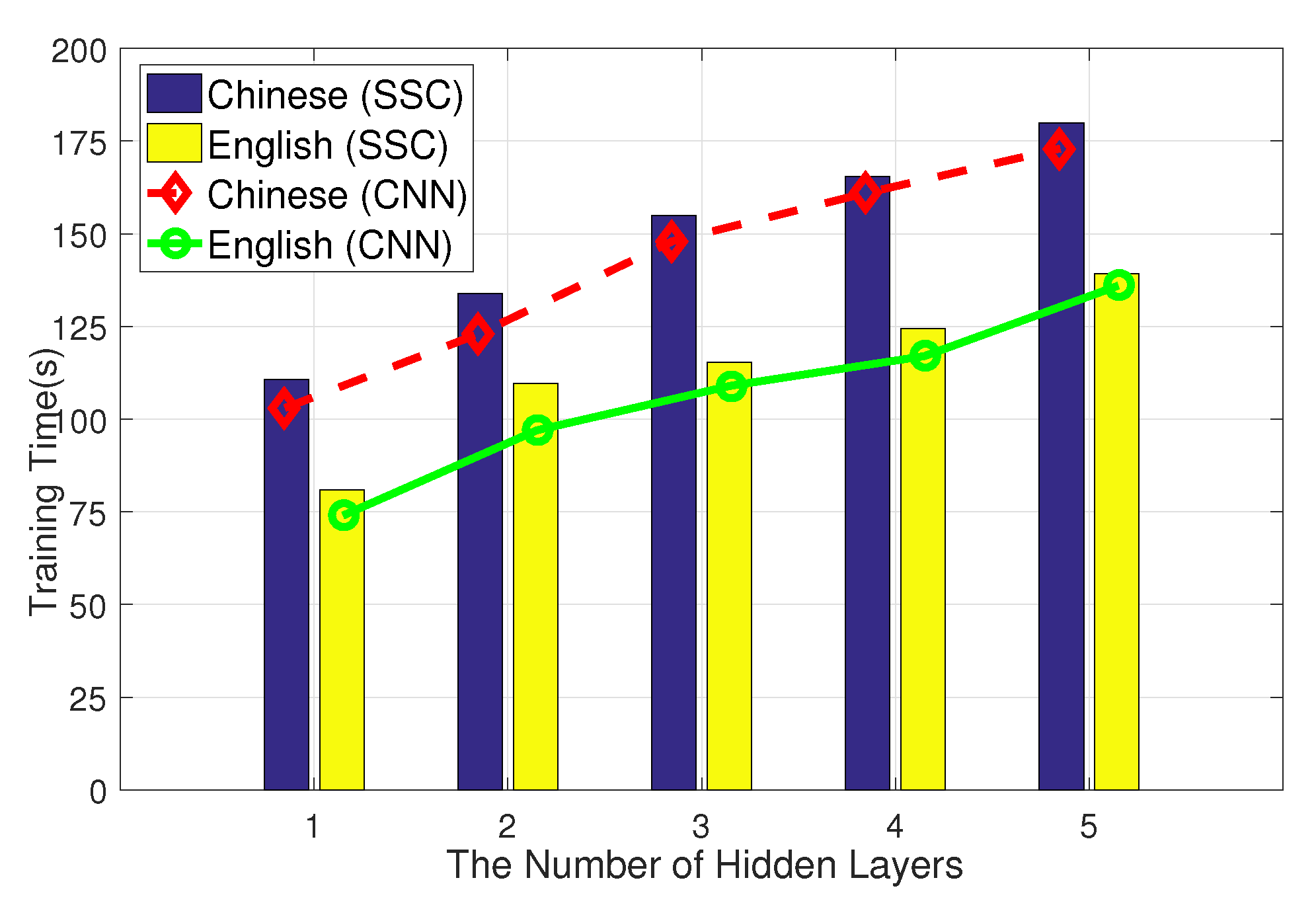
5.4.1. Depth Improves Performance
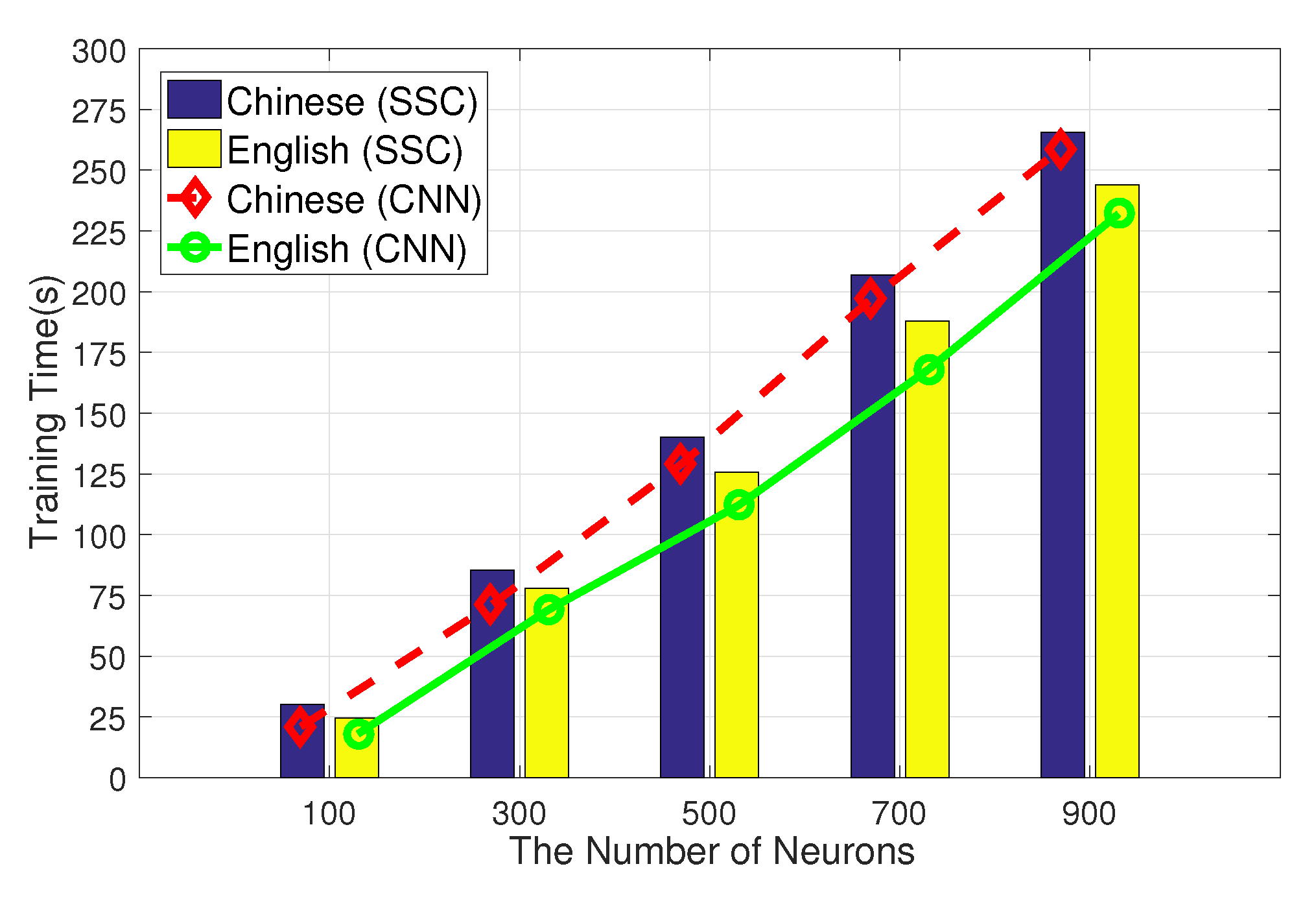
5.4.2. Neurons Improve Performance
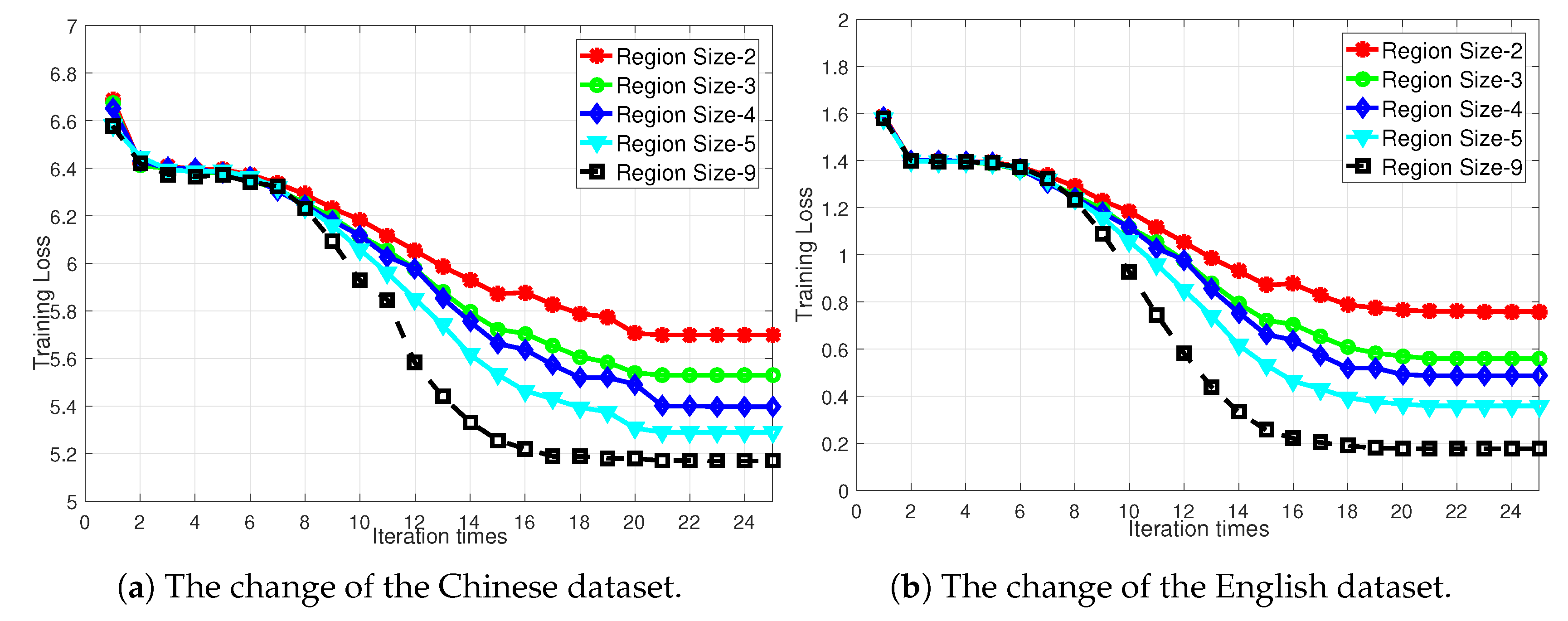
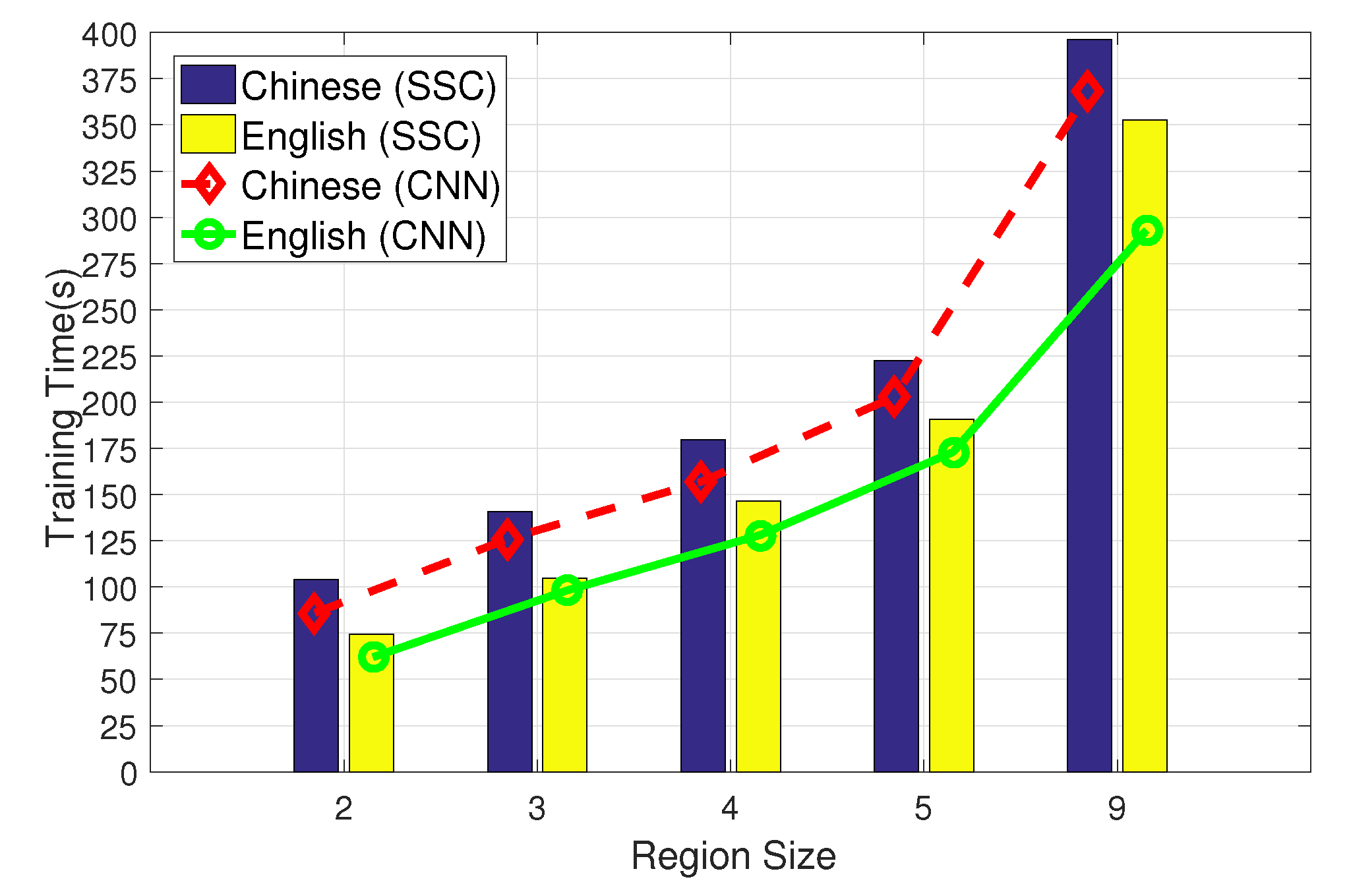
5.4.3. Bigger Region Size Improves Performance
5.4.4. Comparison of Different Datasets
5.4.5. Comparison of Time Consumption
5.4.6. Performance Results of Different Models
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Kirkpatrick, K. Legal advice on the smartphone. Commun. ACM 2016, 59, 19–21. [Google Scholar] [CrossRef]
- Jing, L. Platform Economy in Legal Profession: An Empirical Study on Online Legal Service Providers in China. Soc. Sci. Electron. Publ. 2018, 35, 97–153. [Google Scholar]
- Peressutti, D.; Sinclair, M.; Bai, W.; Jackson, T.; Ruijsink, J.; Nordsletten, D.; Asner, L.; Hadjicharalambous, M.; Rinaldi, C.A.; Rueckert, D. A Framework for Combining a Motion Atlas with Non-Motion Information to Learn Clinically Useful Biomarkers: Application to Cardiac Resynchronisation Therapy Response Prediction. Med. Image Anal. 2017, 35, 669–684. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Zhu, H.; Li, G.; Cui, Z.; Huang, H.; Li, J.; Chen, E.; Xu, G. An efficient Wikipedia semantic matching approach to text document classification. Inf. Sci. 2017, 393, 15–28. [Google Scholar] [CrossRef]
- Eger, S.; Youssef, P.; Gurevych, I. Is it time to swish? comparing deep learning activation functions across NLP tasks. arXiv 2019, arXiv:1901.02671. [Google Scholar]
- Yamada, I.; Ito, T.; Takeda, H.; Takefuji, Y. Linkify: Enhancing Text Reading Experience by Detecting and Linking Helpful Entities to Users. IEEE Intell. Syst. 2019, 33, 37–46. [Google Scholar] [CrossRef]
- Kurita, S.; Kawahara, D.; Kurohash, S. Neural Adversarial Training for Semi-supervised Japanese Predicate-argument Structure Analysis. arXiv 2018, arXiv:1806.00971. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. IEEE Comput. Intell. Mag. 2017, 13, 55–75. [Google Scholar] [CrossRef]
- Desmet, B.; Hoste, V. Online suicide prevention through optimised text classification. Inf. Sci. 2018, 439–440, 61–78. [Google Scholar] [CrossRef]
- Baolin, W.; Tom, A.; David, F.; Walter, M.M.; Gil, M.; Kathryn, S.; David, W.; Kenneth, W.; Hongyu, Z. Comparison of statistical methods for classification of ovarian cancer using mass spectrometry data. Bioinformatics 2003, 19, 1636–1643. [Google Scholar]
- Brodeur, J.; Coetzee, S.; Danko, D.; Garcia, S.; Hjelmager, J. Geographic Information Metadata—An Outlook from the International Standardization Perspective. ISPRS Int. J. Geo-Inf. 2019, 8, 280. [Google Scholar] [CrossRef]
- Mehmood, A.; Jia, S.; Mahmood, R.; Yan, J.; Ahsan, M. Non-Stationary Bayesian Modeling of Annual Maximum Floods in a Changing Environment and Implications for Flood Management in the Kabul River Basin, Pakistan. Water 2019, 11, 1246. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Sun, D.; Zhu, Y.; Xu, H.; He, Y.; Cen, H. Time-Series Chlorophyll Fluorescence Imaging Reveals Dynamic Photosynthetic Fingerprints of sos Mutants to Drought Stress. Sensors 2019, 19, 2649. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.N.; Huang, H.J.; Wong, T.T. Implications of the Dirichlet assumption for discretization of continuous variables in naive Bayesian classifiers. Mach. Learn. 2003, 53, 235–263. [Google Scholar] [CrossRef]
- Chen, W.J.; Shao, Y.H.; Li, C.N.; Deng, N.Y. MLTSVM: a novel twin support vector machine to multi-label learning. Pattern Recognit. 2016, 52, 61–74. [Google Scholar] [CrossRef]
- Wang, A.; Ning, A.; Chen, G.; Lian, L.; Alterovitz, G. Accelerating Incremental Wrapper Based Gene Selection with K-Nearest-Neighbor. In Proceedings of the IEEE International Conference on Bioinformatics & Biomedicine, Belfast, UK, 2–5 Novomber 2015. [Google Scholar]
- Xing, E.P.; Jordan, M.I.; Karp, R.M. Feature Selection for HighDimensional Genomic Microarray Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Kim, H.; Jeong, Y.S. Sentiment Classification Using Convolutional Neural Networks. Appl. Sci. 2019, 9, 2347. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, W.; Luo, R.; Wang, J. Learning text representation using recurrent convolutional neural network with highway layers. arXiv 2016, arXiv:1606.06905. [Google Scholar]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Woźniak, M. Sentiment analysis of Lithuanian texts using traditional and deep learning approaches. Computers 2019, 8, 4. [Google Scholar] [CrossRef]
- Damaševicius, R.; Wei, W. Design of Computational Intelligence-Based Language Interface for Human-Machine Secure Interaction. J. Univ. Comput. Sci 2018, 24, 537–553. [Google Scholar]
- Wen, T.; Zhang, Z. Deep Convolution Neural Network and Autoencoders-Based Unsupervised Feature Learning of EEG Signals. IEEE Access 2018, 6, 25399–25410. [Google Scholar] [CrossRef]
- Ghosh-Dastidar, S.; Adeli, H. A new supervised learning algorithm for multiple spiking neural networks with application in epilepsy and seizure detection. Neural Networks 2009, 22, 1419–1431. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.; Zhang, T. Semi-Supervised Convolutional Neural Networks for Text Categorization via Region Embedding. In Proceedings of the Advances in neural information processing systems, Montreal, QC, Canada, 7–12 December 2015; pp. 919–927. [Google Scholar]
- Qiao, J.; Wang, G.; Li, W.; Li, X. A deep belief network with PLSR for nonlinear system modeling. Neural Networks 2017, 104, S0893608017302496. [Google Scholar] [CrossRef] [PubMed]
- Su, B.; Lu, S. Accurate Recognition of Words in Scenes without Character Segmentation using Recurrent Neural Network. Pattern Recognit. 2017, 63, 397–405. [Google Scholar] [CrossRef]
- Chelba, C.; Norouzi, M.; Bengio, S. N-gram Language Modeling using Recurrent Neural Network Estimation. arXiv 2017, arXiv:1703.10724. [Google Scholar]
- Raghavendra, U.; Fujita, H.; Bhandary, S.V.; Gudigar, A.; Tan, J.H.; Acharya, U.R. Deep Convolution Neural Network for Accurate Diagnosis of Glaucoma Using Digital Fundus Images. Inf. Sci. 2018, 441, S0020025518300744. [Google Scholar] [CrossRef]
- Xu, J.; Xu, B.; Wang, P.; Zheng, S.; Tian, G.; Zhao, J.; Xu, B. Self-Taught convolutional neural networks for short text clustering. Neural Networks 2017, 88, 22–31. [Google Scholar] [CrossRef]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.; Rueckert, D. A Deep Cascade of Convolutional Neural Networks for MR Image Reconstruction. IEEE Trans. Med. Imaging 2017, 37, 491–503. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Visual Saliency Detection Based on Multiscale Deep CNN Features. IEEE Trans. Image Process. 2016, 25, 5012–5024. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2016, 26, 3142–3155. [Google Scholar] [CrossRef]
- Ding, S.H.H.; Fung, B.C.M.; Iqbal, F.; Cheung, W.K. Learning Stylometric Representations for Authorship Analysis. IEEE Trans. Cybern. 2017, 49, 107–121. [Google Scholar] [CrossRef] [PubMed]
- Gomez, L.; Nicolaou, A.; Karatzas, D. Improving patch-based scene text script identification with ensembles of conjoined networks. Pattern Recognit. 2017, 67, 85–96. [Google Scholar] [CrossRef]
- Severyn, A.; Moschitti, A. Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks. In Proceedings of the International Acm Sigir Conference, Santiago, Chile, 9–13 August 2015. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Feng, M.; Wang, Y.; Liu, J.; Zhang, L.; Mian, A. Benchmark Dataset and Method for Depth Estimation from Light Field Images. IEEE Trans. Image Process. 2018, 27, 3586–3598. [Google Scholar] [CrossRef] [PubMed]
- Pakniat, R.; Soltani, M.; Tavassoly, M.K. Considerable improvement of entanglement swapping by considering multiphoton transitions via cavity quantum electrodynamics method. Int. J. Mod. Phys. B 2017, 32, 1850093. [Google Scholar] [CrossRef]
- Zhuang, L.; Zhou, Z.; Gao, S.; Yin, J.; Lin, Z.; Ma, Y. Label Information Guided Graph Construction for Semi-Supervised Learning. IEEE Trans. Image Process. 2017, 26, 4182–4192. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.L.; Hsaio, W.H.; Lee, C.H.; Chang, T.H.; Kuo, T.H. Semi-Supervised Text Classification With Universum Learning. IEEE Trans. Cybern. 2017, 46, 462–473. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Hasan, M.; Esesn, B.C.V.; Awwal, A.A.S.; Asari, V.K. The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Yong, L.I.; Lin, X.Z.; Jiang, M.Y. Facial Expression Recognition with Cross-connect LeNet-5 Network. Acta Autom. Sin. 2018, 44, 176–182. [Google Scholar]
- Bi, N.; Chen, J.; Tan, J. The Handwritten Chinese Character Recognition Uses Convolutional Neural Networks with the GoogLeNet. Int. J. Pattern Recognit. Artif. Intell. 2019, 1940016. [Google Scholar] [CrossRef]
- Jin, K.H.; Mccann, M.T.; Froustey, E.; Unser, M. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed]
- Fei, Y.; Wang, K.C.P.; Zhang, A.; Chen, C.; Li, B. Pixel-Level Cracking Detection on 3D Asphalt Pavement Images Through Deep-Learning-Based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2019, 1–12. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, S.; Huang, X.; Chen, B.; Zhu, C. Hybrid CS-DMRI: Periodic Time-Variant Subsampling and Omnidirectional Total Variation Based Reconstruction. IEEE Trans. Med. Imaging 2017, 36, 2148–2159. [Google Scholar] [CrossRef] [PubMed]
- Xie, G.S.; Zhang, X.Y.; Yang, W.; Xu, M.; Yan, S.; Liu, C.L. LG-CNN: From local parts to global discrimination for fine-grained recognition. Pattern Recognit. 2017, 71, 118–131. [Google Scholar] [CrossRef]
- Roth, W.; Pernkopf, F. Bayesian Neural Networks with Weight Sharing Using Dirichlet Processes. IEEE Trans. Pattern Anal. Mach. Intell. 2018. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Wu, X. Scene Text Detection and Segmentation based on Cascaded Convolution Neural Networks. IEEE Trans. Image Process. 2017, 26, 1509–1520. [Google Scholar] [CrossRef] [PubMed]
- Liu, H. Sentiment Analysis of Citations Using Word2vec. arXiv 2017, arXiv:1704.00177. [Google Scholar]
- Rao, A.; Spasojevic, N. Actionable and Political Text Classification using Word Embeddings and LSTM. arXiv 2016, arXiv:1607.02501. [Google Scholar]
- Johnson, R.; Tong, Z. Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2014. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Wang, P.; Xu, B.; Xu, J.; Tian, G.; Liu, C.L.; Hao, H. Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing 2016, 174, 806–814. [Google Scholar] [CrossRef]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. Learning Semantic Representations Using Convolutional Neural Networks for Web Search. In Proceedings of the International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Liu, J.; Li, D.; Cao, L.; Wang, Z.; Li, Y.; Liu, H.; Chen, G. Elevated preoperative plasma fibrinogen level is an independent predictor of malignancy and advanced stage disease in patients with bladder urothelial tumors. Int. J. Surg. 2016, 36, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.C.; Yin, F.; Liu, C.L. Improving handwritten chinese text recognition using neural network language models and convolutional neural network shape models. Pattern Recognit. 2016, 65, 251–264. [Google Scholar] [CrossRef]
- Yan, S.; Hardmeier, C.; Tiedemann, J.; Nivre, J. Character-based Joint Segmentation and POS Tagging for Chinese using Bidirectional RNN-CRF. arXiv 2017, arXiv:1704.01314. [Google Scholar]
- Lewis, D.D.; Yang, Y.; Rose, T.G.; Fan, L. RCV1: A New Benchmark Collection for Text Categorization Research. J. Mach. Learn. Res. 2004, 5, 361–397. [Google Scholar]
- Zhang, L.; Shah, S.K.; Kakadiaris, I.A. Hierarchical Multi-Label Classification using Fully Associative Ensemble Learning. Pattern Recognit. 2017, 70, 89–103. [Google Scholar] [CrossRef]
- Liu, J.; Chang, W.C.; Wu, Y.; Yang, Y. Deep Learning for Extreme Multi-label Text Classification. In Proceedings of the International Acm Sigir Conference on Research & Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Liu, Y.; Bi, J.W.; Fan, Z.P. A method for multi-class sentiment classification based on an improved one-vs-one (OVO) strategy and the support vector machine (SVM) algorithm. Inf. Sci. 2017, 394–395, 38–52. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Environment Configuration |
|---|---|
| The operating system | Ubuntu 14.04 |
| CPU | i7-6700k |
| GPU | GTX 980 Ti |
| Internal storage | 64 GB |
| Programming language | Python |
| Deep learning framework | theano |
| Training Set | Validation Set | Test Set | Unlabeled Data | Class | Output | |
|---|---|---|---|---|---|---|
| Law text (Chinese) | 16,000 | 2000 | 2000 | 500 K (133 M words) | 25 (multi) | law labels |
| RCV1 (English) | 23,149 | 0 | 781,265 | 781 K (214 M words) | 103 (multi) | Topic |
| RCV1 | Chinese Law Case Description Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F-1 | Hamming Loss | Precision | Recall | F-1 | Hamming Loss | |
| Linear SWM | 89.32% | 84.54% | 86.72% | 9.38% | 87.72% | 84.12% | 84.59% | 10.88% |
| CNN | 93.16% | 88.24% | 90.64% | 7.96% | 91.02% | 86.22% | 88.64% | 8.79% |
| Semi-supervised model | 95.37% | 90.57% | 92.87% | 7.31% | 92.83% | 88.13% | 90.43% | 8.17% |
| Our scheme (SSC) | 96.76% | 93.16% | 94.24% | 6.34% | 95.48% | 91.98% | 93.78% | 7.92% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Li, P.; Li, Y.; Hou, J.; Li, Y. Semi-Supervised Convolutional Neural Network for Law Advice Online. Appl. Sci. 2019, 9, 3617. https://doi.org/10.3390/app9173617
Zhao F, Li P, Li Y, Hou J, Li Y. Semi-Supervised Convolutional Neural Network for Law Advice Online. Applied Sciences. 2019; 9(17):3617. https://doi.org/10.3390/app9173617
Chicago/Turabian StyleZhao, Fen, Penghua Li, Yuanyuan Li, Jie Hou, and Yinguo Li. 2019. "Semi-Supervised Convolutional Neural Network for Law Advice Online" Applied Sciences 9, no. 17: 3617. https://doi.org/10.3390/app9173617
APA StyleZhao, F., Li, P., Li, Y., Hou, J., & Li, Y. (2019). Semi-Supervised Convolutional Neural Network for Law Advice Online. Applied Sciences, 9(17), 3617. https://doi.org/10.3390/app9173617