Cooperative Threads with Effective-Address in Simulated Annealing Algorithm to Job Shop Scheduling Problems


Abstract
Featured Application
Abstract
1. Introduction
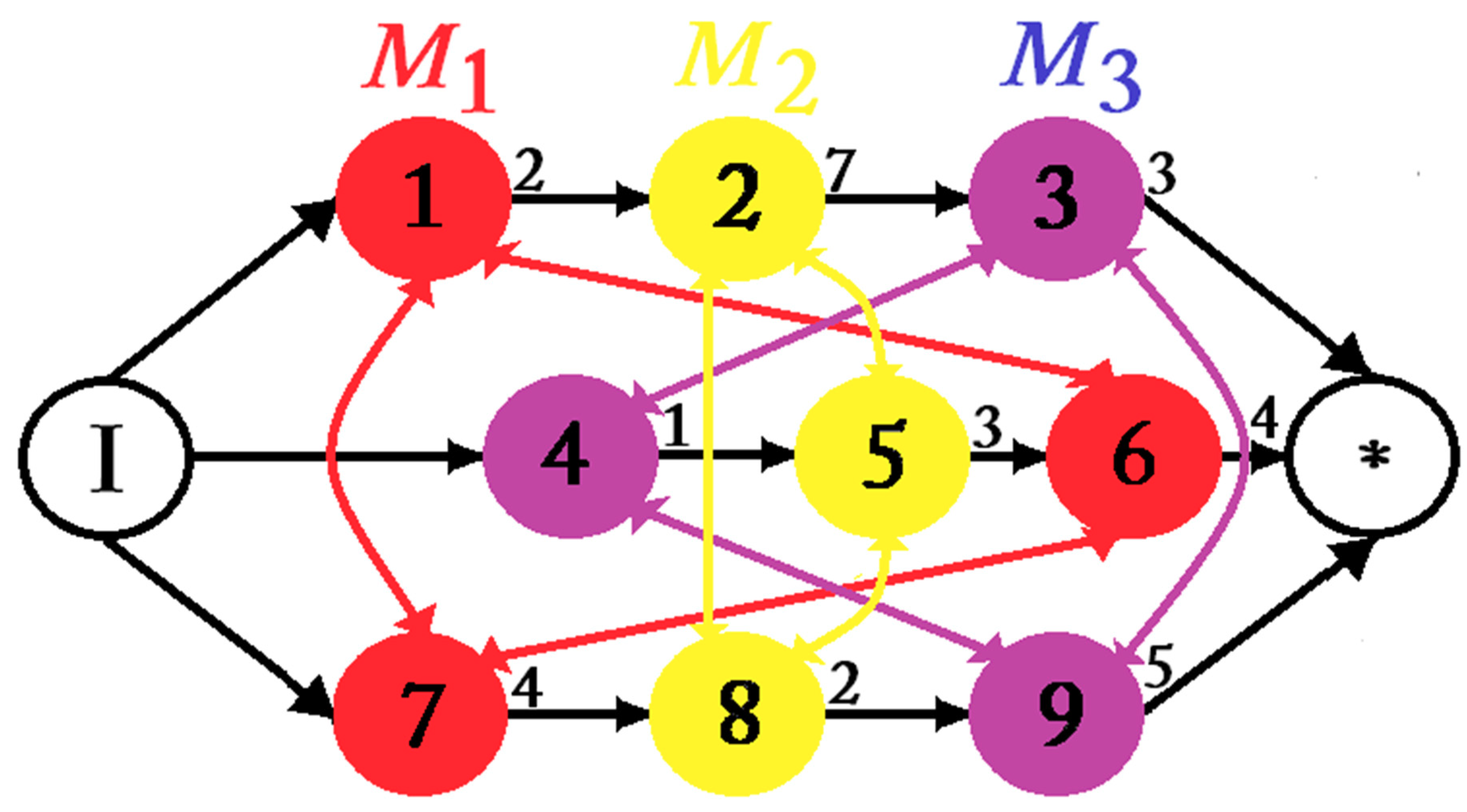
2. Disjunctive Formulation of Job Shop Scheduling Problem
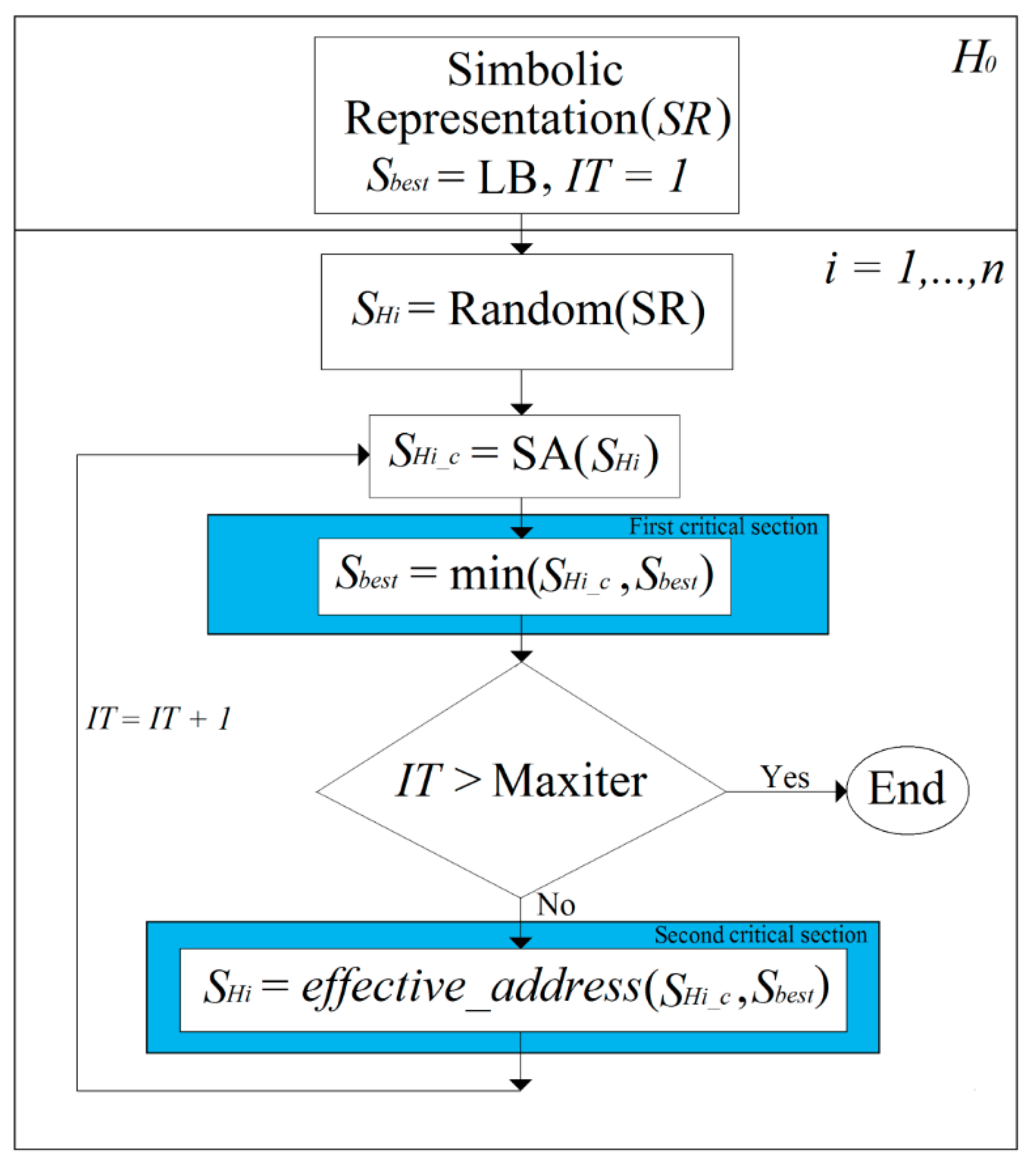
3. Simulated Annealing Algorithm with Cooperative Threads (SACT)
| Algorithm 1 Simulated annealing executed in each generated thread Hi by SACT. |
|
- iter (global variable known in the n threads) is the variable that counts the number of SA executed in SACT. The final control coefficient, Cf, the initial control coefficient (temperature), Co, the control factor α and the best f(SHi_c) (at the beginning this is a very large value) are initialized.
- If the number of SA (iter) for SACT has not been completed (which is indicated with Maxiter), then a new SA is begun using the new solution SHi obtained with the effective-address procedure.
- 3.1.
- Begin the annealing iter.
- 3.2.
- The value of initial control coefficient of the SA is initialized.
- 3.3.
- The external cycle begins, which carries out the decrease in control coefficient (3.3.2) of the SA according to α.
- 3.3.1.
- The internal cycle in annealing begins, which executes the Metropolis algorithm until equilibrium is reached, this depends on the size of the Markov chain (MC) and that for optimization problems is represented by the neighborhood size of a solution of the problem.
- 3.3.1.1.
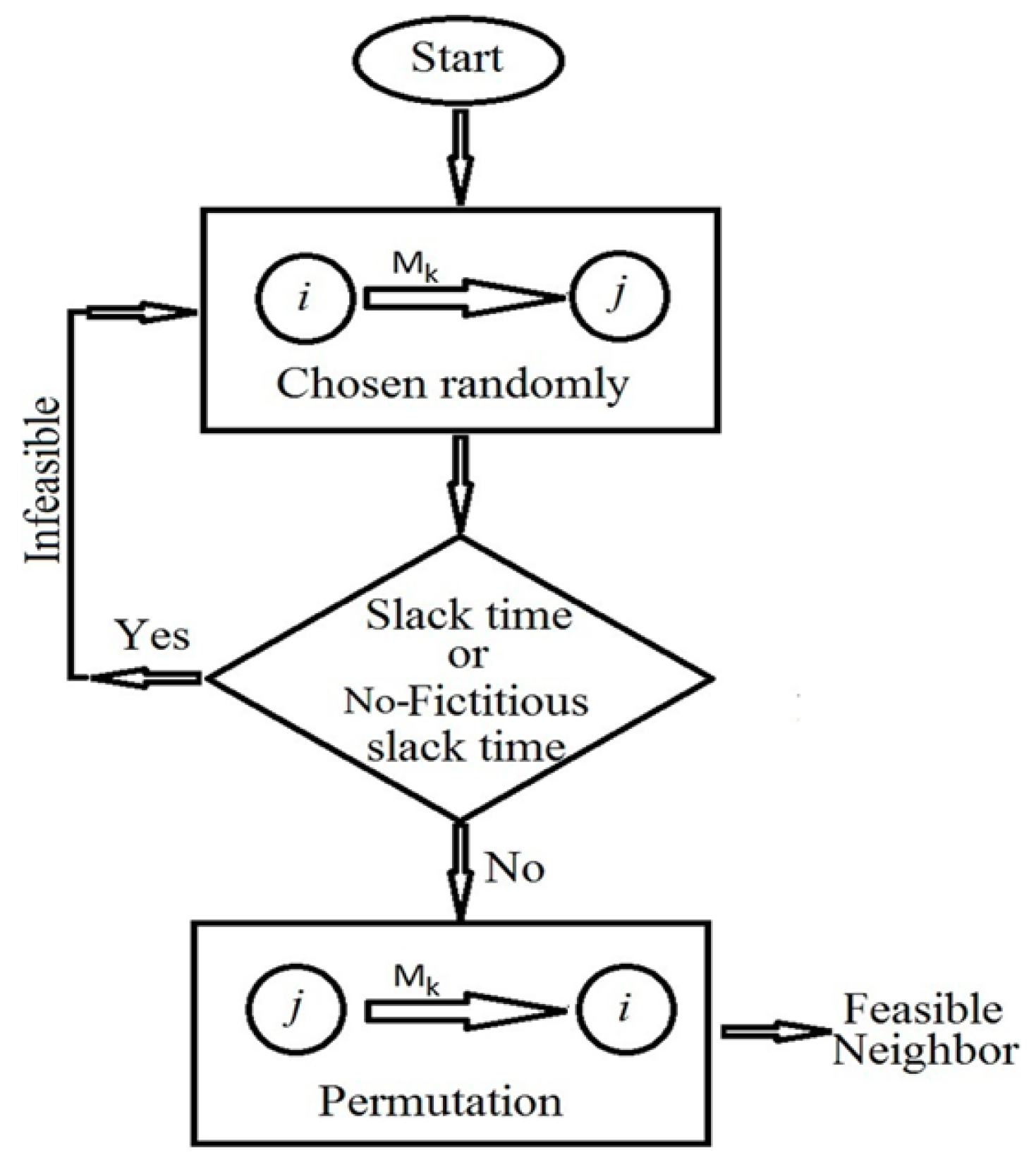
- A neighborhood structure is used (explained later on, Section 3.1). This generates a state in annealing (neighbor S’Hi).
- 3.3.1.2.
- S’Hi is accepted as a new configuration if the energy of the system decreases.
- 3.3.1.3.
- If the energy of the system increases, S’Hi is accepted as a new configuration according to the probability of acceptance Paccept obtained by the function of Boltzmann, and
- 3.3.1.4.
- Comparing this Paccept with ρ, which is a random number uniformly distributed between (0, 1).
- 3.3.1.5.
- If ρ < Paccept the generated state is accepted as the current state.
- 3.3.1.6.
- If the new schedule cost f(SHi) is better than the best schedule cost f(SHi_c) of the thread Hi, then SHi_c is upgraded.
- 3.3.1.7.
- If the new schedule cost f(SHi) is better that the best schedule cost f(Sbest) which has been obtained from all the threads of SACT, then Sbest is upgraded.
- 3.3.2.
- The control coefficient is decreased.
- 3.4.
- Every time that the thread Hi in execution finishes an SA, an effective-address is carried out between the best solution SHi_c obtained from the SA and the best existing solution Sbest in the algorithm SACT. The effective-address mechanism is explained later (Section 3.2).
3.1. Neighborhood Generation Mechanism
3.2. Effective-Address Mechanism
4. Experimental Results
4.1. JSSP Instances and Simmulated Annealing Parameters
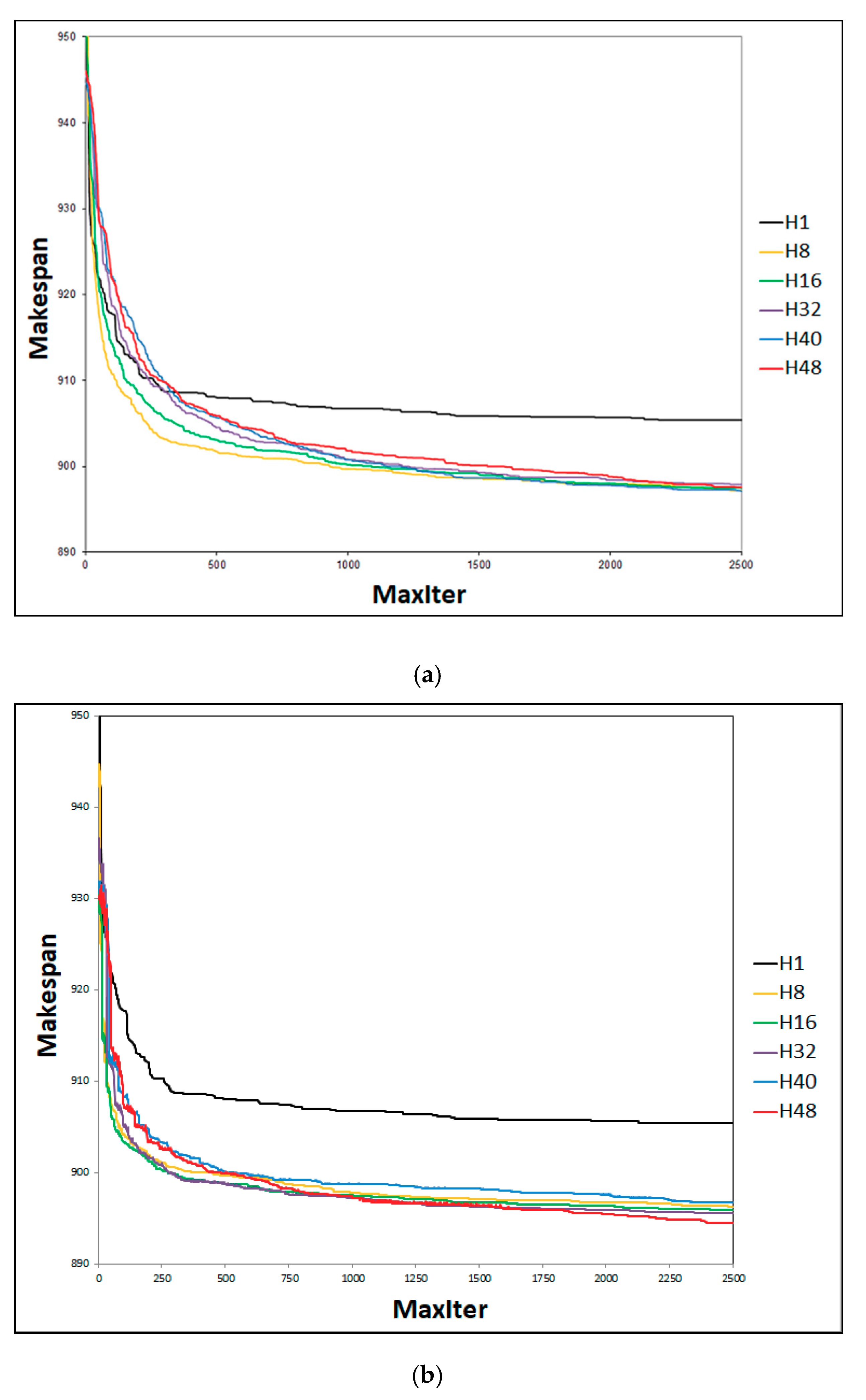
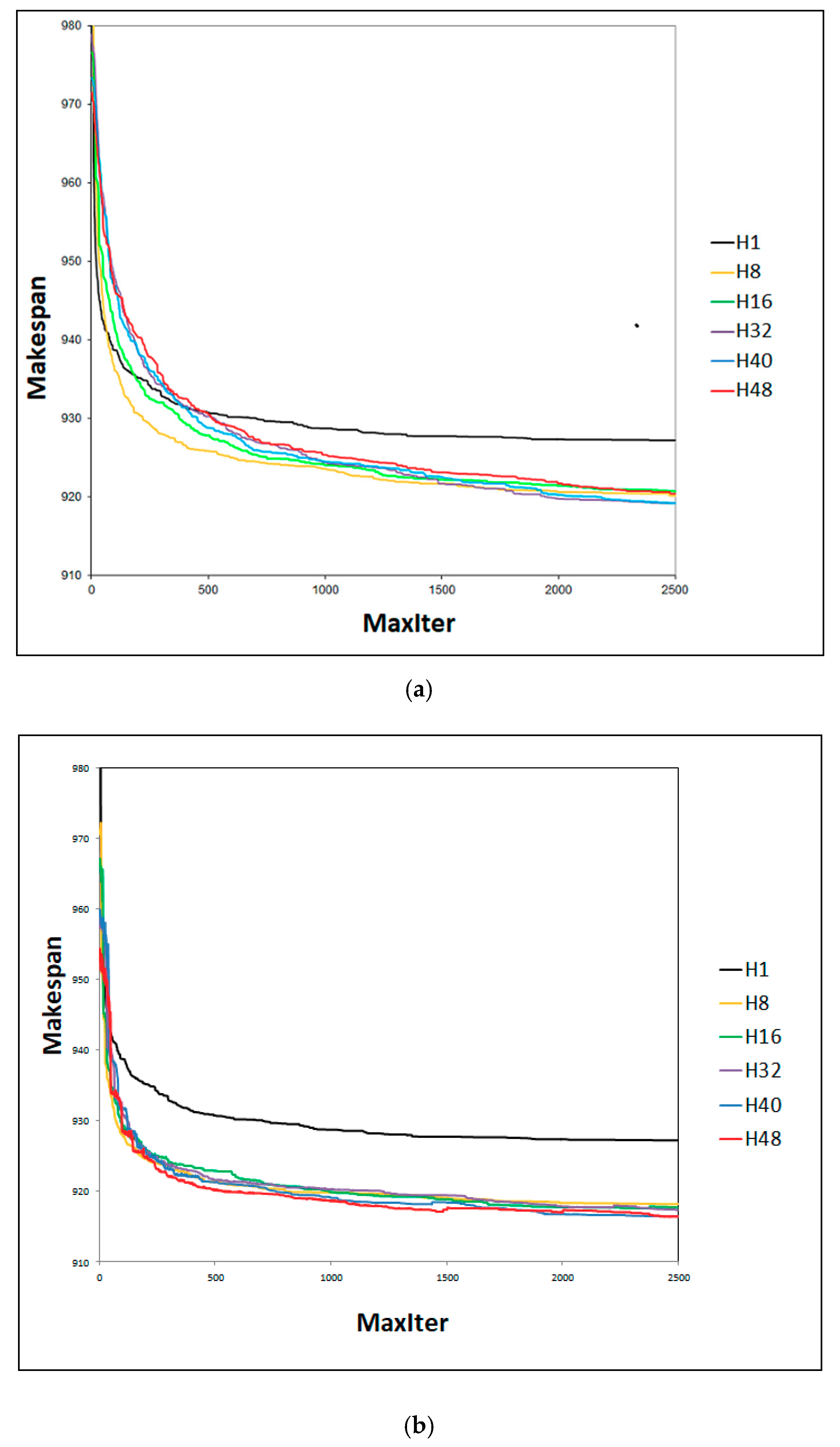
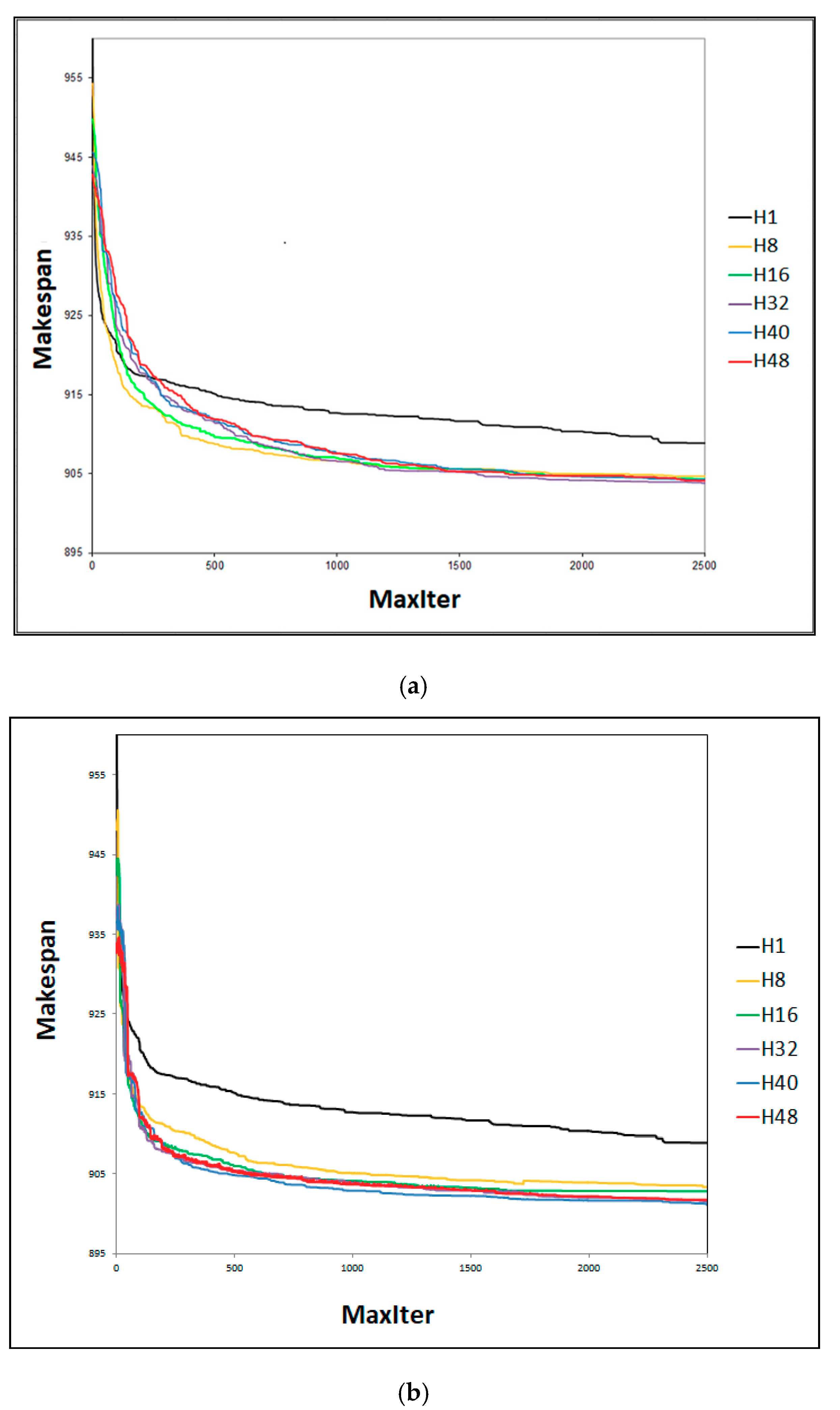
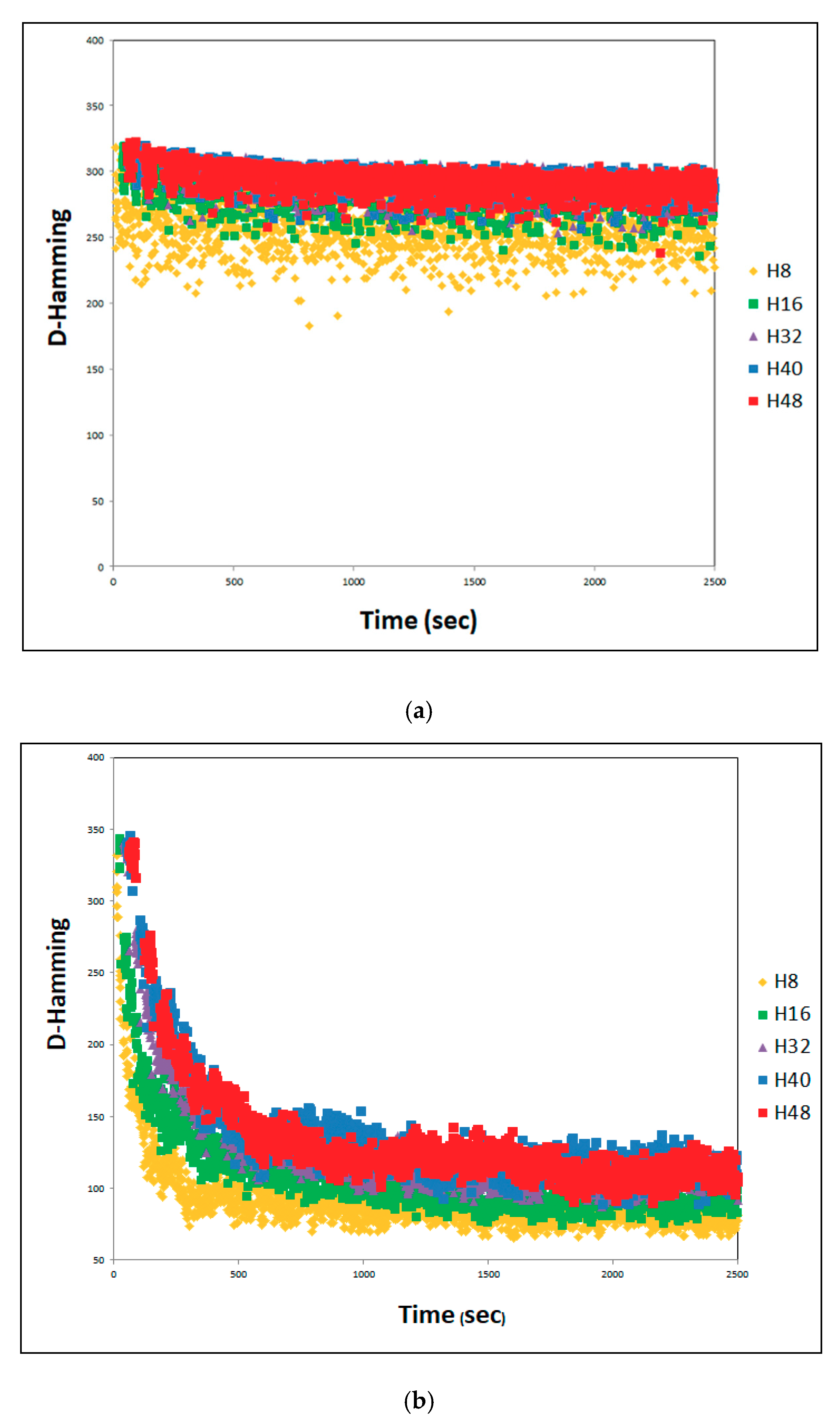
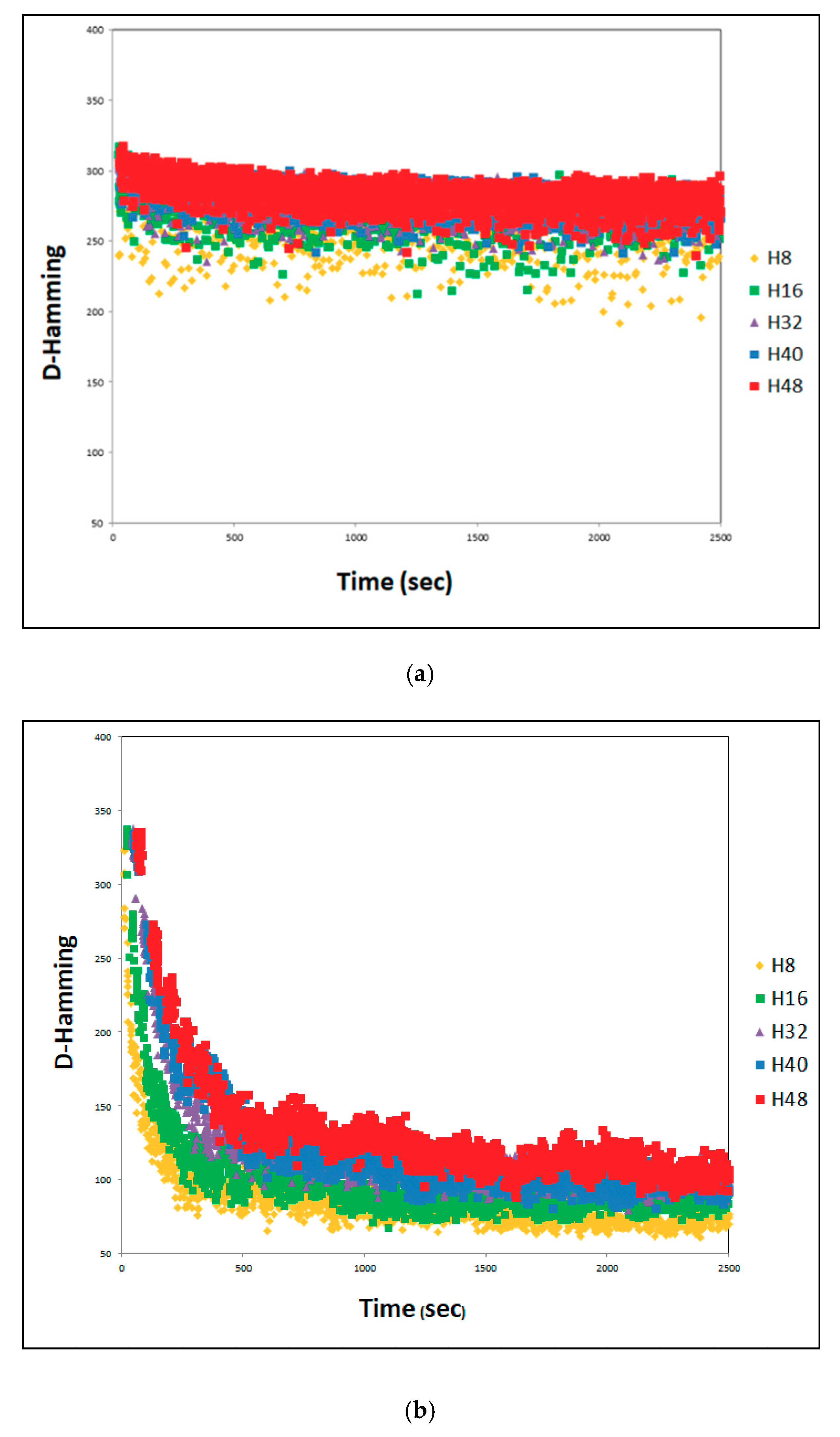
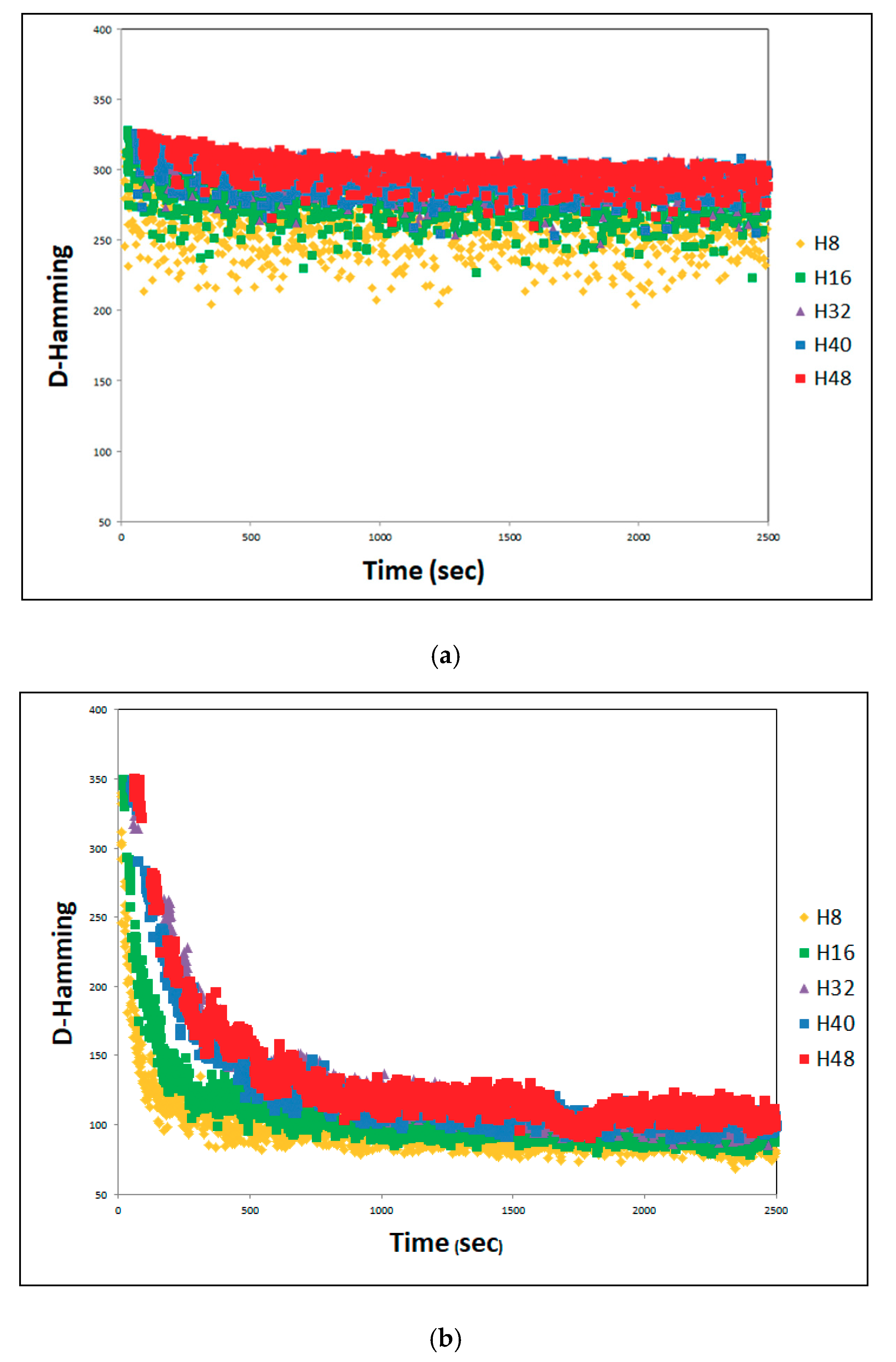
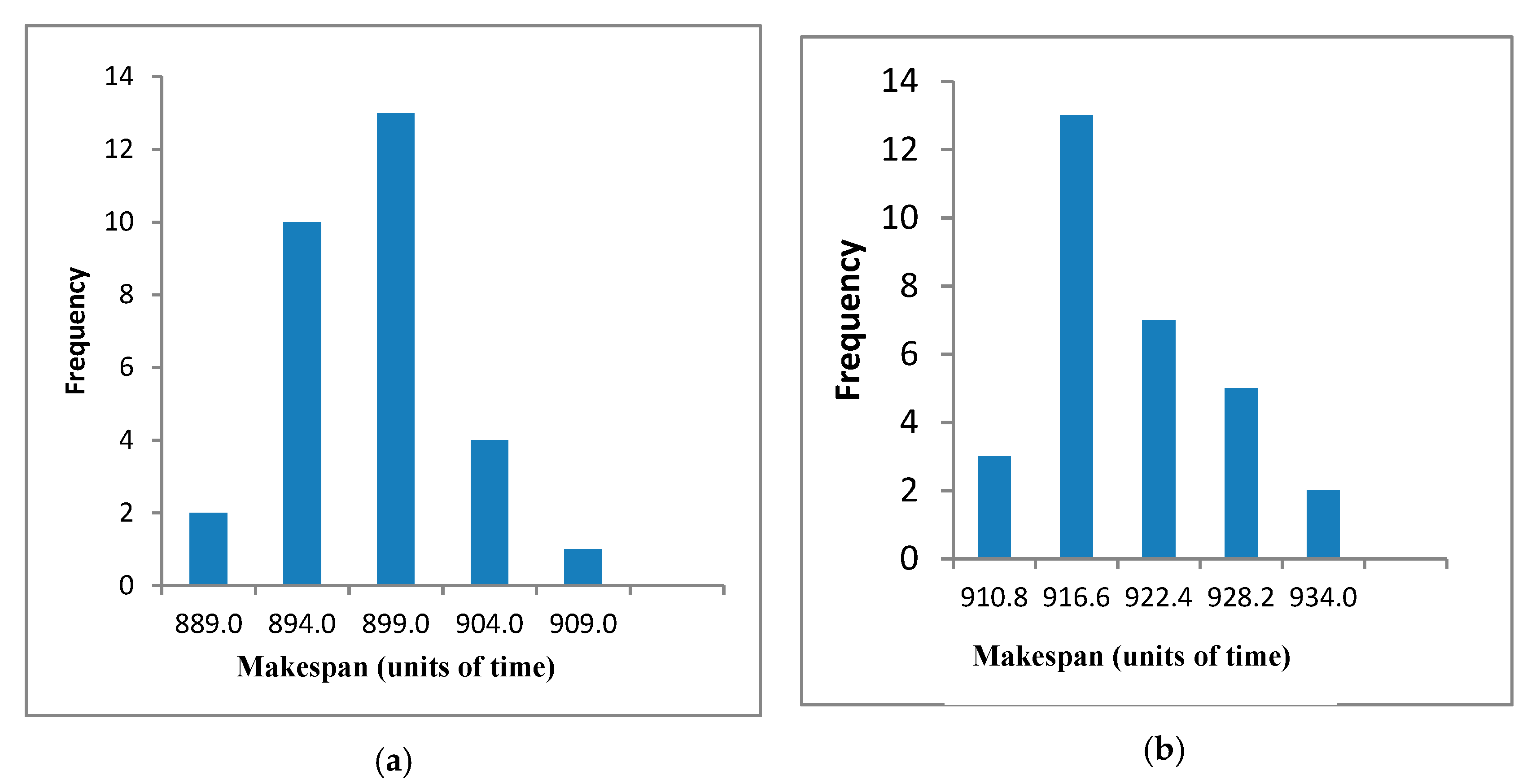
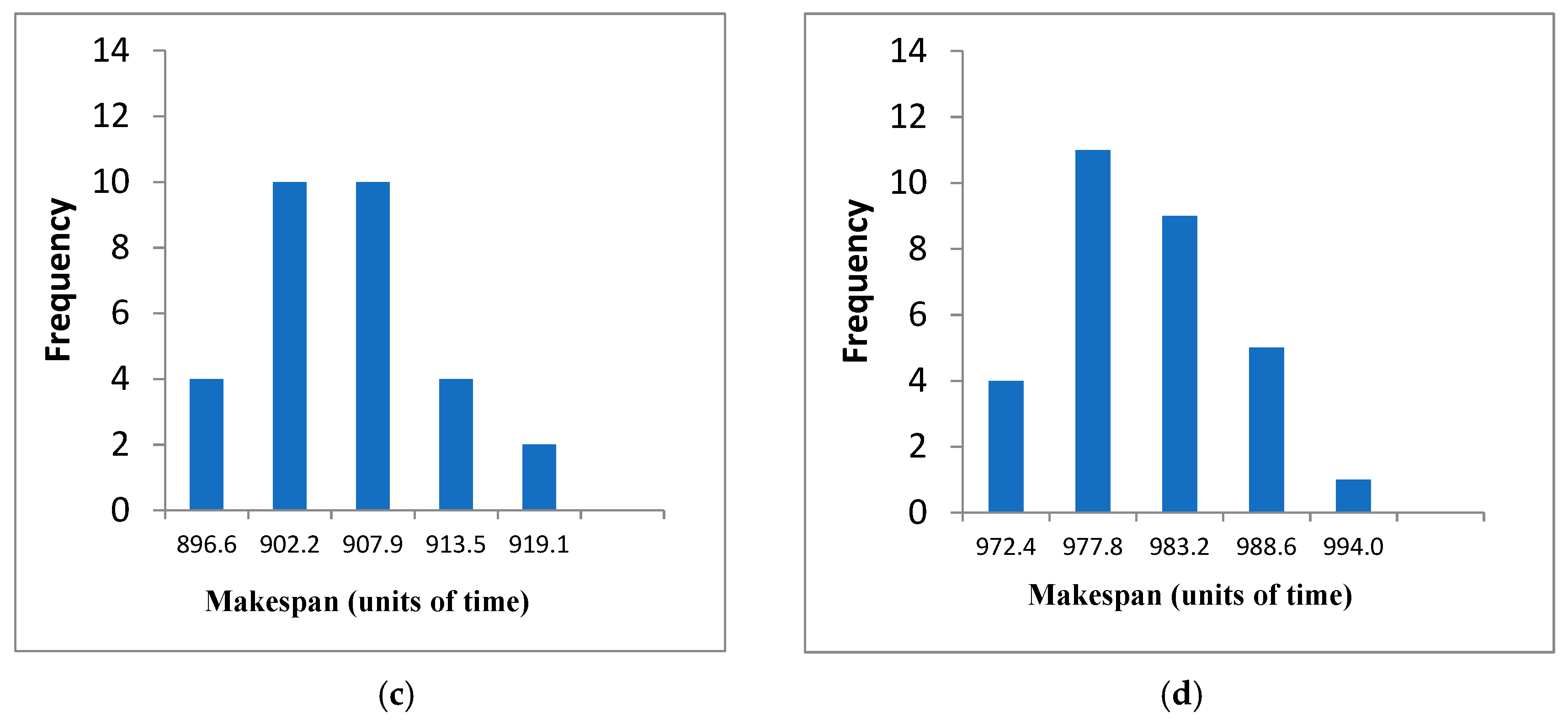
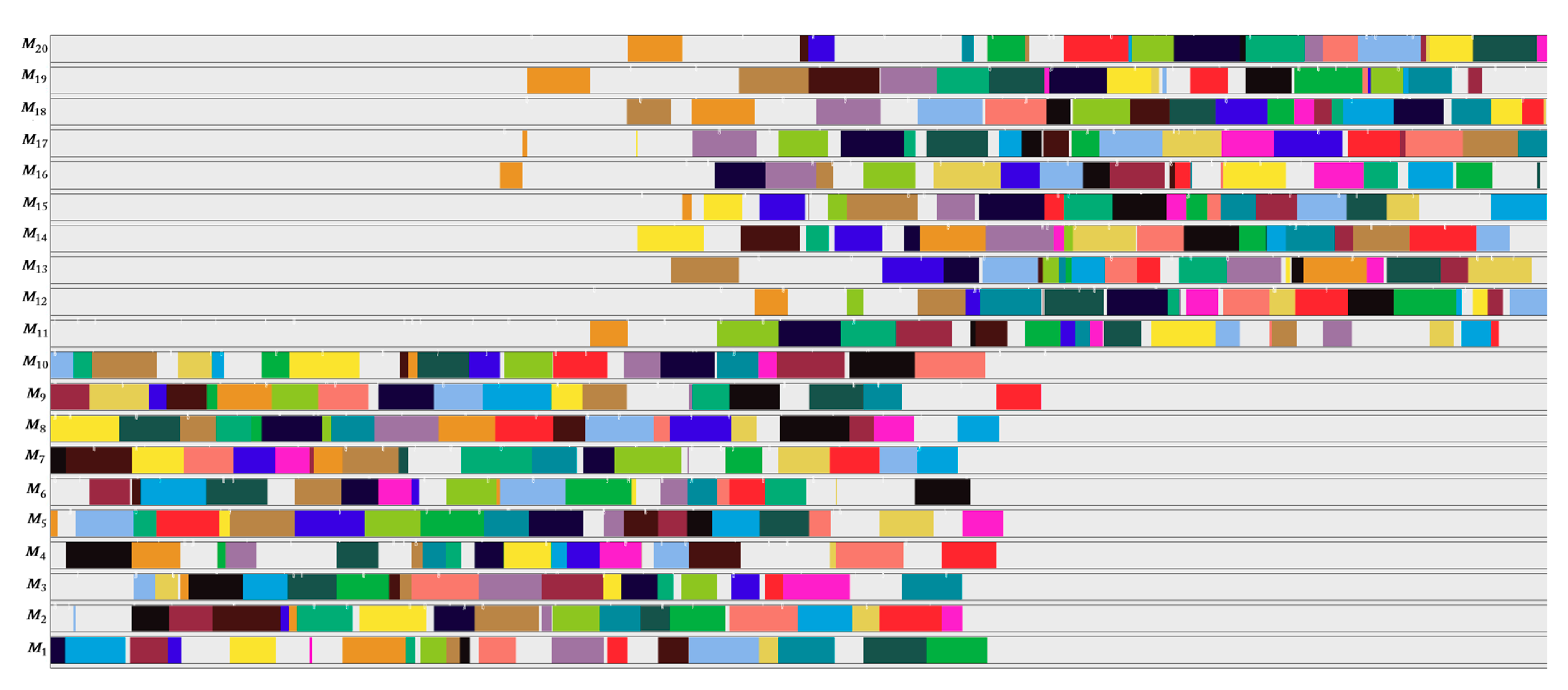
4.2. Effect of Cooperating with Effective-Address
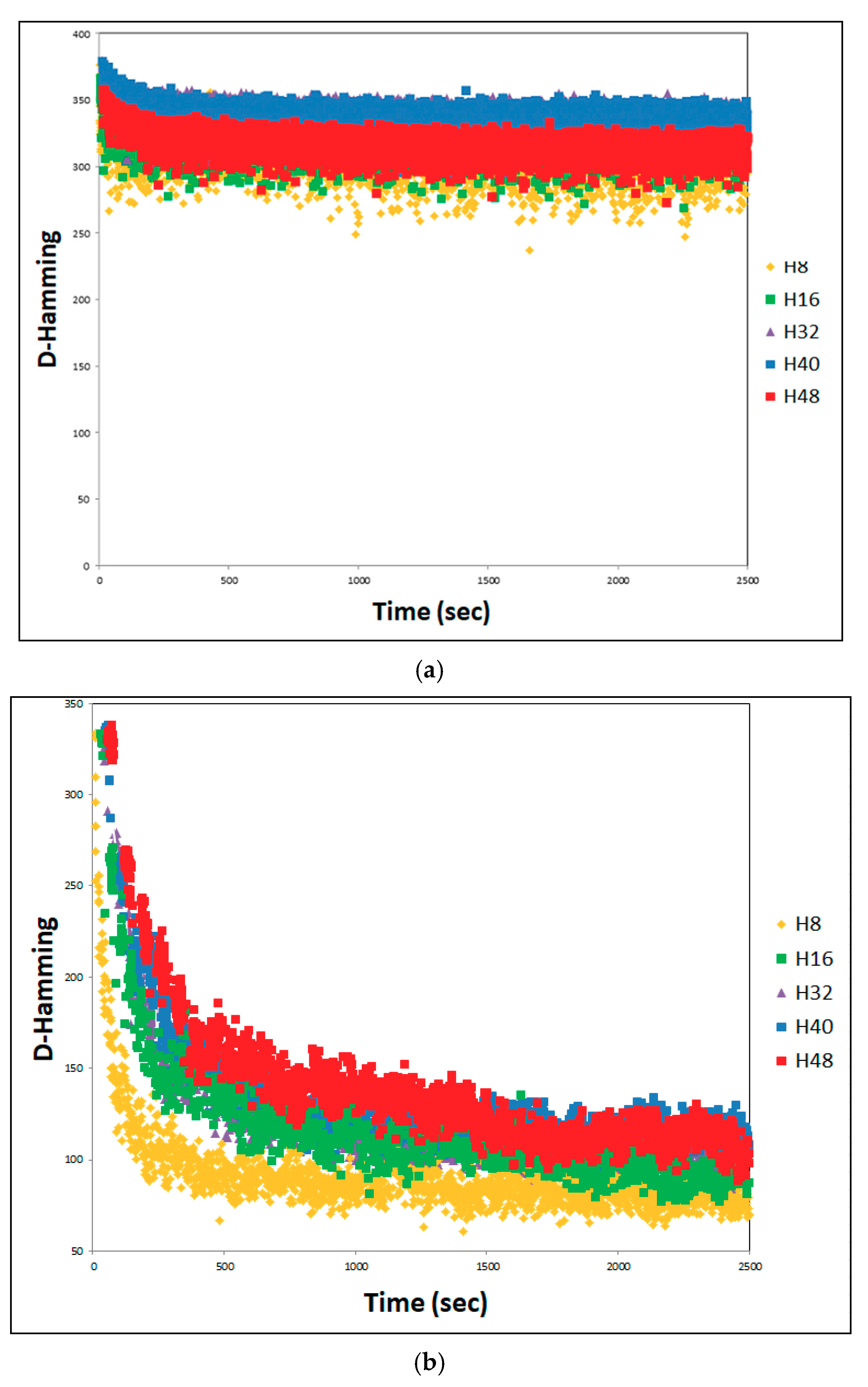
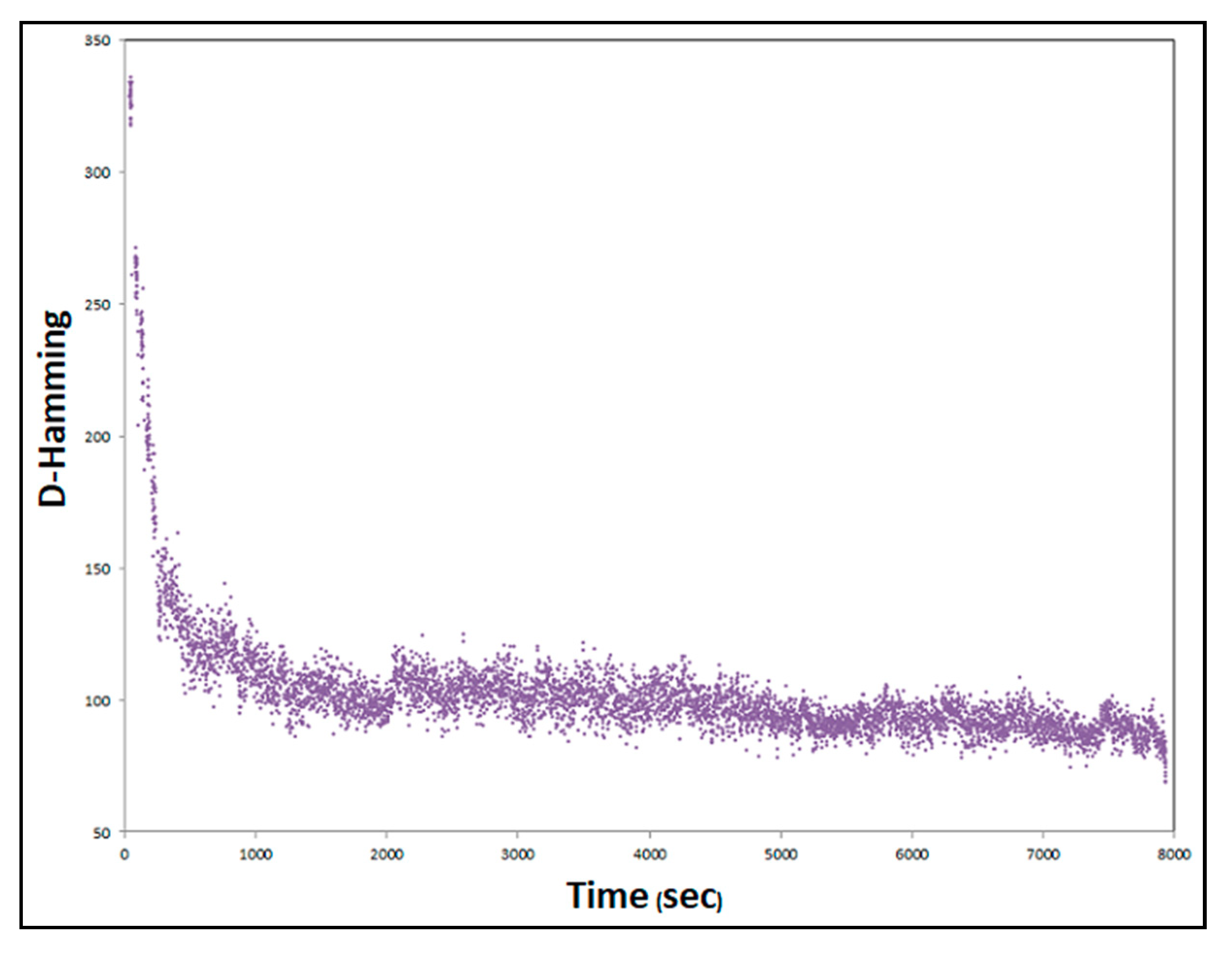
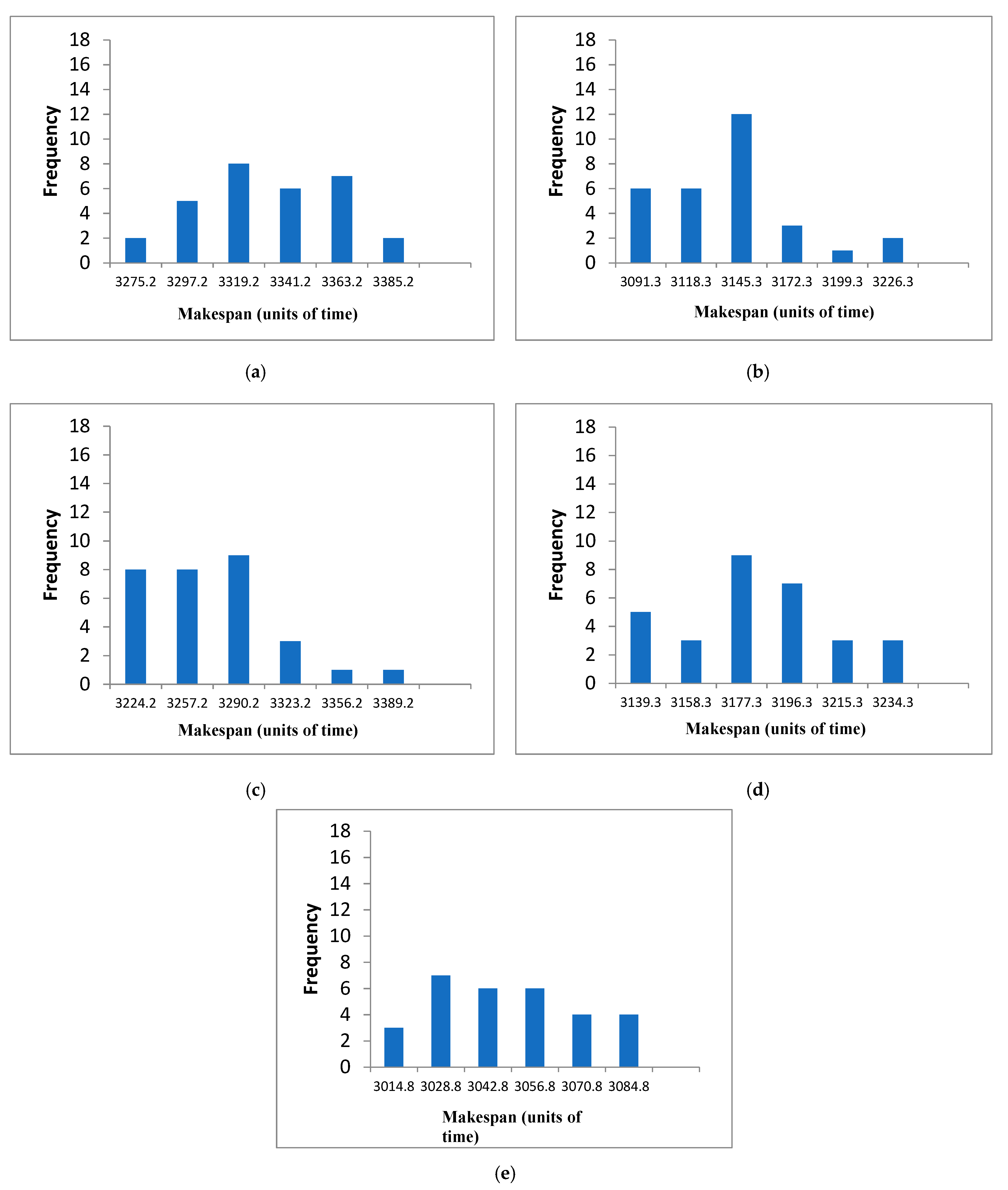
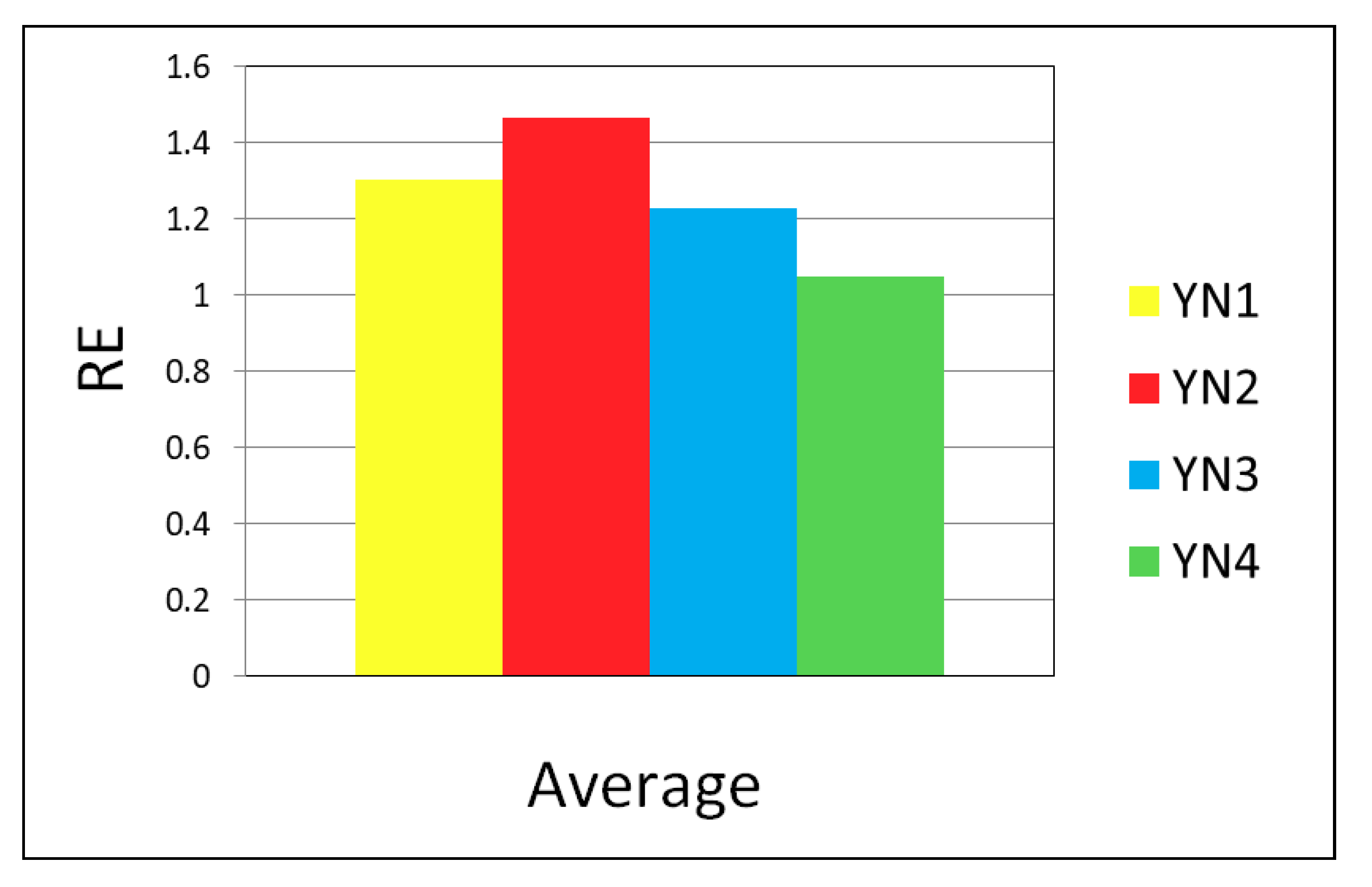
4.3. SACT Statistic Review
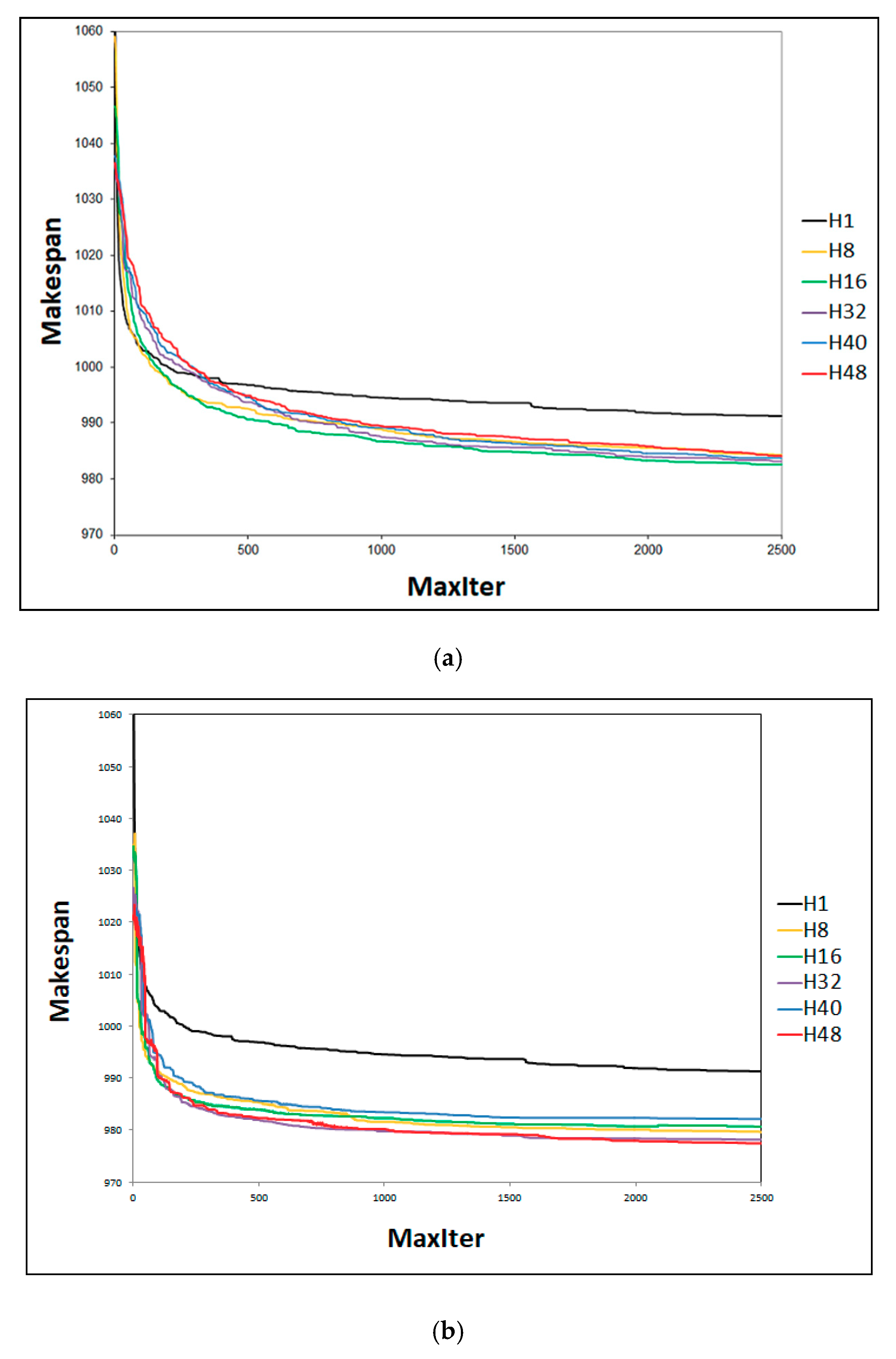
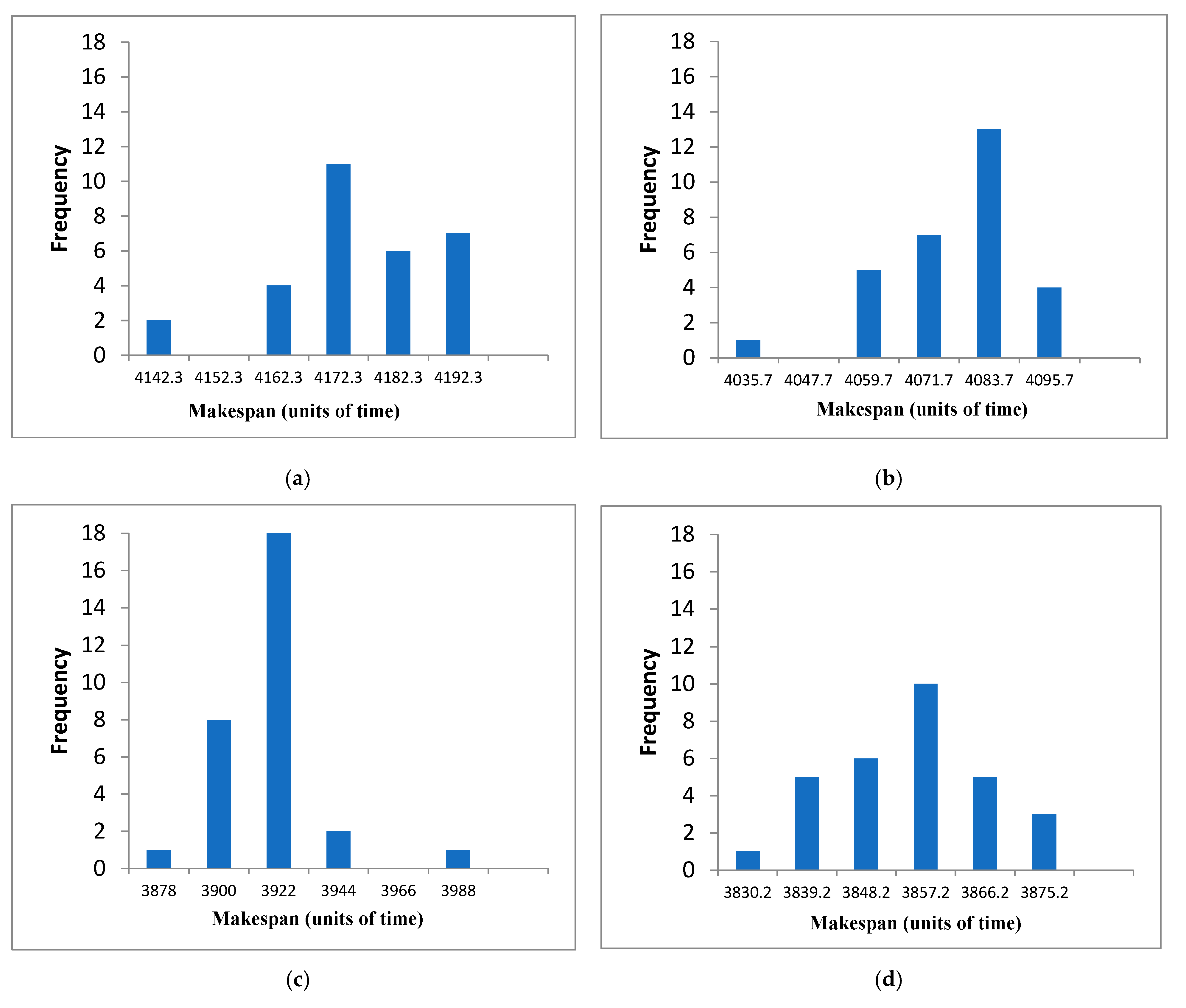
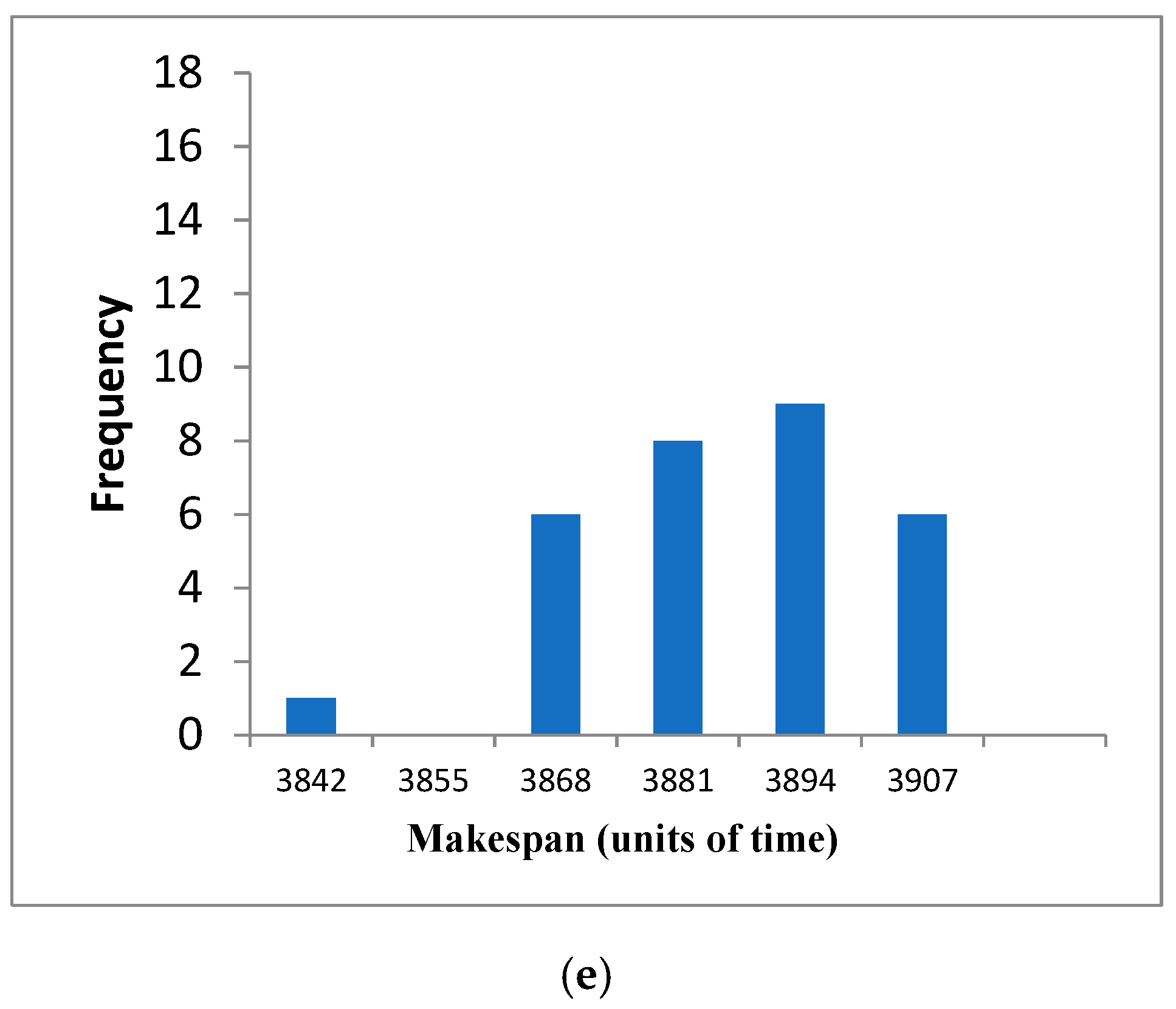
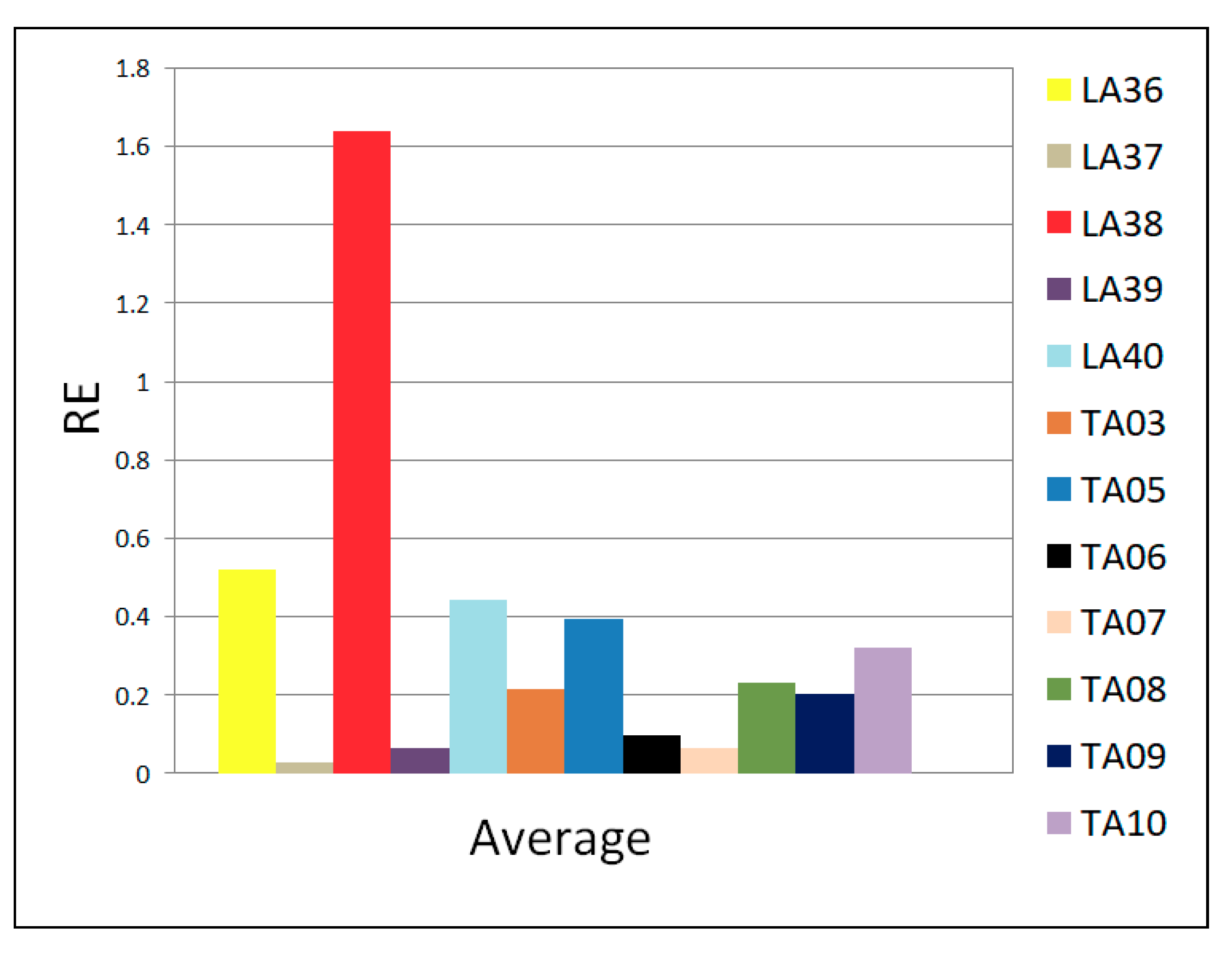
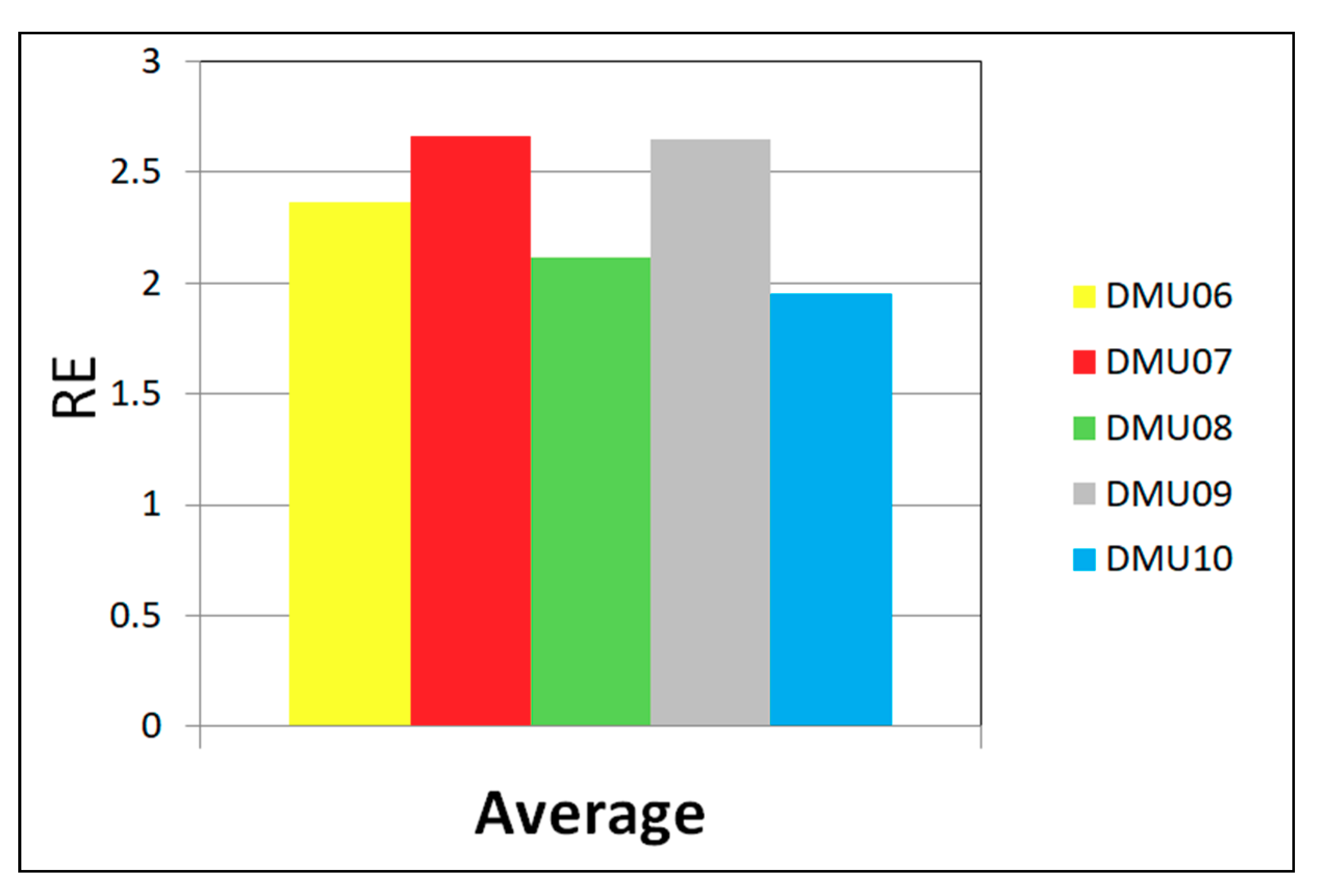
4.4. Behaviour in DMU Benchmarks Scheduling
4.5. Comparision of SACT with Other Algorithms
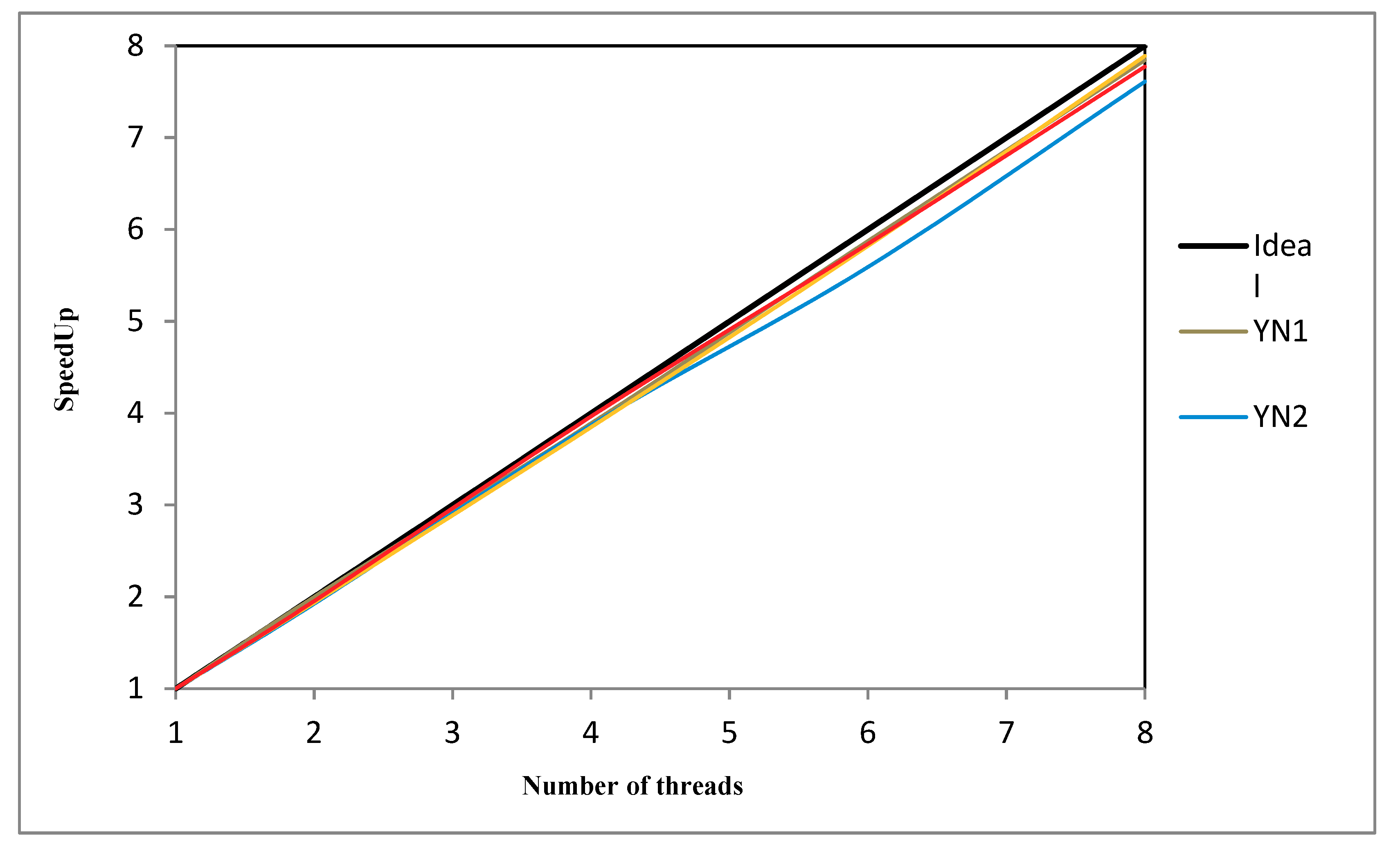
4.6. SACT Computational Efficiency
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | Size | Optimum/UB Units of Time | |
|---|---|---|---|
| Jobs | Machines | ||
| FT6 | 6 | 6 | 55 |
| FT10 | 10 | 10 | 930 |
| LA16 | 10 | 10 | 945 |
| LA17 | 10 | 10 | 784 |
| LA18 | 10 | 10 | 848 |
| LA19 | 10 | 10 | 842 |
| LA20 | 10 | 10 | 902 |
| ORB01 | 10 | 10 | 1059 |
| ORB02 | 10 | 10 | 888 |
| ORB03 | 10 | 10 | 1005 |
| ORB04 | 10 | 10 | 1005 |
| ORB05 | 10 | 10 | 887 |
| ORB06 | 10 | 10 | 1010 |
| ORB07 | 10 | 10 | 397 |
| ORB08 | 10 | 10 | 899 |
| ORB09 | 10 | 10 | 934 |
| ORB10 | 10 | 10 | 944 |
| ABZ5 | 10 | 10 | 1234 |
| ABZ6 | 10 | 10 | 943 |
| LA36 | 15 | 15 | 1268 |
| LA37 | 15 | 15 | 1397 |
| LA38 | 15 | 15 | 1196 |
| LA39 | 15 | 15 | 1233 |
| LA40 | 15 | 15 | 1222 |
| TA01 | 15 | 15 | 1231 |
| TA02 | 15 | 15 | 1244 |
| TA03 | 15 | 15 | 1218 |
| TA04 | 15 | 15 | 1175 |
| TA05 | 15 | 15 | 1224 |
| TA06 | 15 | 15 | 1238 |
| TA07 | 15 | 15 | 1227 |
| TA08 | 15 | 15 | 1217 |
| TA09 | 15 | 15 | 1274 |
| TA10 | 15 | 15 | 1241 |
| TA21 | 20 | 20 | 1642 |
| TA22 | 20 | 20 | 1600 |
| TA23 | 20 | 20 | 1557 |
| TA24 | 20 | 20 | 1646 |
| TA25 | 20 | 20 | 1595 |
| TA26 | 20 | 20 | 1643 |
| TA27 | 20 | 20 | 1680 |
| TA28 | 20 | 20 | 1603 |
| TA29 | 20 | 20 | 1625 |
| TA30 | 20 | 20 | 1584 |
| DMU06 | 20 | 20 | 3244 |
| DMU07 | 20 | 20 | 3046 |
| DMU08 | 20 | 20 | 3188 |
| DMU09 | 20 | 20 | 3092 |
| DMU10 | 20 | 20 | 2984 |
| DMU46 | 20 | 20 | 4035 |
| DMU47 | 20 | 20 | 3942 |
| DMU48 | 20 | 20 | 3763 |
| DMU49 | 20 | 20 | 3710 |
| DMU50 | 20 | 20 | 3729 |
| YN1 | 20 | 20 | 884 |
| YN2 | 20 | 20 | 904 |
| YN3 | 20 | 20 | 892 |
| YN4 | 20 | 20 | 968 |
| Algorithm | Hardware and Software |
|---|---|
| PPSO, [5] | Server and client Machines, Logical ring topology, Java, Windows system |
| HGAPSA, [14] | Server and client Machines |
| cGA-PR, [15] | Workstation Pentium IV, multicore, 2.0GHz, 1GB, Microsoft Visual C++ |
| PaGA, [19] | Computer network with JADE Middleware, Java |
| HIMGA, [20] | PC, 3.4GHz, Intel®, Core(TM), i7-3770 CPU, 8GB, C++ |
| NIMGA. PC, [21] | PC, 3.4GHz, Intel®, Core(TM), i7-3770 CPU, 8GB, C++ |
| IIMMA, PC, [22] | PC, 3.4 GHz, Intel®, Core(TM), i7-3770 CPU, 8GB, C++ |
| Sequential AntGenSA (SGS), Parallel AntGenSA (PGS), [23] | Cluster 4nodes, Intel® Xeon® 2.3 GHz, 64GB, Linux CentOS, C, OpenMP |
| PABC, [24] | Four computers system configuration, JAVA |
| HGACC (HG), [25] | CLUSTER, 48 cores, Xeon 3.06GHz, Linux Centos 5.5, GNU gcc, MPI Library |
| BRK-GA (BG), [36] | AMD Opteron 2.2GHz CPU, Linux Fedora release 12, C++ |
| SAGen (SG), [37] | Pentium 120 (0.12 GHz), Pentium 166 |
| ACOFT-MWR (AM), [38] | PC AMD 1533MHz CPU, 768 MB, Windows XP, Microsoft Visual C++ 6.0 |
| TSSA (TA), [39] | PC Pentium IV 3.0GHz, Visual C++ |
| HPSO (HO), [40] | PC, AMD Athlon 1700+ (1.47 GHz), Visual C++ |
| TGA, [41] | PC 2.2 GHz, 8GB RAM, GNU gcc compiler |
| IEBO (IO), [42] | 2.93 GHz, Intel Xeon X5670, GNU g++ compiler |
| TS/PR, [43] | PC Quad-Core AMD Athlon 3 GHz, 2GB, Windows 7, C++ |
| UPLA, [44] | (UP) Intel CoreTM i5, processor M580 2.67 GHz, 6GB, C# |
| ALSGA (AG), [45] | Intel core 2 duo, 2.93 GHz, 2.0GB, Java Agent DEvelopment platform (JADE) |
| GA-CPG-GT (GT), [46] | PC 3.40 GHz Intel(R) Core (TM) i7-3770, 8GB, C++ |
| SACT (ST), this work | Workstation PowerEdge T320, Intel® Xeon® Processor E5-2470 v2, 10cores, 3.10 GHz each, 24GB, Windows Vista Ultimate 64 bits O.S, Visual C++ 2008, MFC library |
References
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W.H. Freeman and Company: New York, NY, USA, 1990; p. 340. [Google Scholar]
- Perregaard, M.; Clausen, J. Parallel branch-and-bound methods for thejob-shop scheduling problem. Ann. Oper. Res. 1998, 83, 137–160. [Google Scholar]
- Ku, W.-Y.; Beck, J.C. Mixed Integer Programming models for job shop scheduling: A computational analysis. Comput. Oper. Res. 2016, 73, 165–173. [Google Scholar] [CrossRef]
- Dabah, A.; Bendjoudi, A.; El-Baz, D.; AitZai, A. GPU-Based Two Level Parallel B&B for the Blocking Job Shop Scheduling Problem. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Chicago, IL, USA, 23–27 May 2016; pp. 747–755. [Google Scholar]
- AitZai, A.; Boudhar, M. Parallel branch-and-bound and parallel PSO algorithms for job shop scheduling problem with blocking. Int. J. Oper. Res. 2013, 16, 14. [Google Scholar] [CrossRef]
- Der, U.; Steinhöfel, K. A Parallel implementation of a job shop scheduling heuristic. In Applied Parallel Computing. New Paradigms for HPC in Industry and Academia, PARA 2000; Sørevik, T., Manne, F., Gebremedhin, A.H., Moe, R., Eds.; Springer-Verlag: Berlin, Germany, 2001; pp. 215–222. [Google Scholar]
- Steinhöfel, K.; Albrecht, A.; Wong, C. An experimental analysis of local minima to improve neighbourhood search. Comput. Oper. Res. 2003, 30, 2157–2173. [Google Scholar] [CrossRef]
- Aydin, M.E.; Fogarty, T.C. A Distributed Evolutionary Simulated Annealing Algorithm for Combinatorial Optimisation Problems. J. Heuristics 2004, 10, 269–292. [Google Scholar] [CrossRef]
- Skakovski, A.; Jędrzejowicz, P. An island-based differential evolution algorithm with the multi-size populations. Expert Syst. Appl. 2019, 126, 308–320. [Google Scholar] [CrossRef]
- Yamada, T. A genetic algorithm with multi-step crossover for job-shop scheduling problems. In Proceedings of the 1st International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications (GALESIA), Sheffield, UK, 12–14 September 1995; pp. 146–151. [Google Scholar]
- Yamada, T.; Nakano, R. A fusion of crossover and local search. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT'96), Shanghai, China, 2–6 December 1996; pp. 426–430. [Google Scholar]
- Nakano, R.; Yamada, T. Conventional genetic algorithm for job-shop problems. In Proceedings of the 4th International Conference on Genetic Algorithms, San Diego, CA, USA, July 1991; pp. 474–479. [Google Scholar]
- Wendt, O.; König, W. Cooperative Simulated Annealing: How Much Cooperation Is Enough? Research Report; Frankfurt University: Frankfurt, Germany, 1997; pp. 1–19, unpublished. [Google Scholar]
- Rakkiannan, T.; Palanisamy, B. Hybridization of Genetic Algorithm with Parallel Implementation of Simulated Annealing for Job Shop Scheduling. Am. J. Appl. Sci. 2012, 9, 1694–1705. [Google Scholar]
- Spanos, A.C.; Ponis, S.T.; Tatsiopoulos, I.P.; Christou, I.T.; Rokou, E. A new hybrid parallel genetic algorithm for the job-shop scheduling problem. Int. Trans. Oper. Res. 2014, 21, 479–499. [Google Scholar] [CrossRef]
- Yusof, R.; Khalid, M.; Hui, G.T.; Yusof, S.M.; Othman, M.F. Solving job shop scheduling problem using a hybrid parallel micro genetic algorithm. Appl. Soft Comput. 2011, 11, 5782–5792. [Google Scholar] [CrossRef]
- Mùi, N.H.; Hòa, V.D.; Tuyên, L.T. A parallel genetic algorithm for the job shop scheduling problem. In Proceedings of the 2012 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ho Chi Minh City, Vietnam, 12–15 December 2012; pp. 19–24. [Google Scholar]
- Yoo, M.J.; Müller, J.P. Using multi-agent system for dynamic job shop scheduling. In Proceedings of the 4th-ICEIS, Ciudad Real, Spain, 30 January 2002; pp. 1–8. [Google Scholar]
- Asadzadeh, L.; Zamanifar, K. An agent-based parallel approach for the job shop scheduling problem with genetic algorithms. Math. Comput. Model. 2010, 52, 1957–1965. [Google Scholar] [CrossRef]
- Beasley, J.E. OR-Library: Distributing Test Problems by Electronic Mail. J. Oper. Res. Soc. 1990, 41, 1069. [Google Scholar] [CrossRef]
- Demirkol, E.; Mehta, S.; Uzsoy, R. A Computational Study of Shifting Bottleneck Procedures for Shop Scheduling Problems. J. Heuristics 1997, 3, 111–137. [Google Scholar] [CrossRef]
- Watson, J.-P.; Beck, J.; Howe, A.E.; Whitley, L. Problem difficulty for tabu search in job-shop scheduling. Artif. Intell. 2003, 143, 189–217. [Google Scholar] [CrossRef][Green Version]
- Goncalves, J.F.; Resende, M.G.C. An extended akers graphical method with a biased random-key genetic algorithm for job-shop scheduling. Int. Trans. Oper. Res. 2014, 21, 215–246. [Google Scholar] [CrossRef]
- Kolonko, M. Some new results on simulated annealing applied to the job shop scheduling problem. Eur. J. Oper. Res. 1999, 113, 123–136. [Google Scholar] [CrossRef]
- Kuo-Ling, H.; Ching-Jong, L. Ant colony optimization combined with taboo search for the job shop scheduling problem. Comput. Oper. Res. 2008, 35, 1030–1046. [Google Scholar] [CrossRef]
- Sha, D.; Hsu, C.-Y. A hybrid particle swarm optimization for job shop scheduling problem. Comput. Ind. Eng. 2006, 51, 791–808. [Google Scholar] [CrossRef]
- Kurdi, M. A new hybrid island model genetic algorithm for job shop scheduling problem. Comput. Ind. Eng. 2015, 88, 273–283. [Google Scholar] [CrossRef]
- Kurdi, M. An effective new island model genetic algorithm for job shop scheduling problem. Comput. Oper. Res. 2016, 67, 132–142. [Google Scholar] [CrossRef]
- Kurdi, M. An improved island model memetic algorithm with a new cooperation phase for multi-objective job shop scheduling problem. Comput. Ind. Eng. 2017, 111, 183–201. [Google Scholar] [CrossRef]
- Hernández-Ramírez, L.; Frausto-Solis, J.; Castilla-Valdez, G.; González-Barbosa, J.J.; Terán-Villanueva, D.; Morales-Rodríguez, M.L. A hybrid simulated annealing for job shop scheduling problem. Int. J. Comb. Optim. Probl. Inform. 2019, 10, 6–15. [Google Scholar]
- Amirghasemi, M.; Zamani, R.; Amirghasemi, M. An effective asexual genetic algorithm for solving the job shop scheduling problem. Comput. Ind. Eng. 2015, 83, 123–138. [Google Scholar] [CrossRef]
- Nagata, Y.; Ono, I. A guided local search with iterative ejections of bottleneck operations for the job shop scheduling problem. Comput. Oper. Res. 2018, 90, 60–71. [Google Scholar] [CrossRef]
- Peng, B.; Lu, Z.; Cheng, T. A tabu search/path relinking algorithm to solve the job shop scheduling problem. Comput. Oper. Res. 2015, 53, 154–164. [Google Scholar] [CrossRef]
- Cruz-Chávez, M.A. Neighborhood generation mechanism applied in simulated annealing to job shop scheduling problems. Int. J. Syst. Sci. 2015, 46, 2673–2685. [Google Scholar] [CrossRef]
- Aksenov, V. Synchronization Costs in Parallel Programs and Concurrent Data Structures. Distributed, Parallel, and Cluster Computing [cs.DC]. ITMO University. Paris Diderot University. Available online: https://hal.inria.fr/tel-01887505/document (accessed on 4 October 2018).
- Tanenbaum, A.S.; Bos, H. Modern Operating Systems, 4th ed.; Pearson Education: Amsterdan, The Netherlands, 2016; p. 1136. [Google Scholar]
- Visual Studio 2019. MFC Desktop Applications. Available online: https://docs.microsoft.com/es-es/cpp/mfc/mfc-desktop-applications?view=vs-2019 (accessed on 27 July 2019).
- Pongchairerks, P. A Two-Level Metaheuristic Algorithm for the Job-Shop Scheduling Problem. Complexity 2019, 2019, 8683472. [Google Scholar] [CrossRef]
- Asadzadeh, L. A local search genetic algorithm for the job shop scheduling problem with intelligent agents. Comput. Ind. Eng. 2015, 85, 376–383. [Google Scholar] [CrossRef]
- Kurdi, M. An effective genetic algorithm with a critical-path-guided Giffler and Thompson crossover operator for job shop scheduling problem. Int. J. Intell. Syst. Appl. Eng. 2019, 7, 13–18. [Google Scholar] [CrossRef][Green Version]
- Asadzadeh, L. A parallel artificial bee colony algorithm for the job shop scheduling problem with a dynamic migration strategy. Comput. Ind. Eng. 2016, 102, 359–367. [Google Scholar] [CrossRef]
- Cruz-Chávez, M.A.; Cruz-Rosales, M.H.; Zavala-Díaz, J.C.; Hernández-Aguilar, J.A.; Rodríguez-León, A.; Prince-Avelino, J.C.; Luna, M.E.; Salina, O.H. Hybrid Micro Genetic Multi-Population Algorithm with Collective Communication for the Job Shop Scheduling Problem. IEEE Access 2019, 7, 82358–82376. [Google Scholar] [CrossRef]
- Bryson, K. Global HPC Leaders Join to Support New Platform; NVIDIA: Santa Clara, CA, USA, 2019; Available online: https://nvidianews.nvidia.com/news/nvidia-brings-cuda-to-arm-enabling-new-path-to-exascale-supercomputing (accessed on 29 July 2019).
- Lakin, D. How to Use the Same Thread Function for Multiple Threads (Safely). 2019. Available online: https://www.codeproject.com/Articles/1149/How-to-use-the-same-thread-function-for-multiple-t (accessed on 28 May 2001).
- Amirghasemi, M.; Zamani, R. A synergetic combination of small and large neighborhood schemes in developing an effective procedure for solving the job shop scheduling problem. SpringerPlus 2014, 3, 193. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Zhang, C.Y.; Li, P.; Rao, Y.; Guan, Z. A very fast TS/SA algorithm for the job shop scheduling problem. Comput. Oper. Res. 2008, 35, 282–294. [Google Scholar] [CrossRef]























| Problem | Co | Cf | α | MC | UB = f(S) |
|---|---|---|---|---|---|
| Size 6 × 6 | |||||
| FT06 | 800 | 1.0 | 0.98 | 30 | 80 |
| Size 10 × 10 | |||||
| FT10 | 25 | 1.0 | 0.98 | 1000 | 2500 |
| ORB and ABZ | 64,000 | 1.0 | 0.98 | 1000 | 2500 |
| Size 15 × 15 | |||||
| LA16 to LA20 | 64,000 | 1.0 | 0.98 | 1000 | 2500 |
| LA36 to LA40 | 2 | 1 × 10−6 | 0.99 | 300 | 2500 |
| TA01 to TA10 | 25 | 1.0 | 0.98 | 800 | 2500 |
| Size 20 × 20 | |||||
| TA21 to TA30 | 2 | 1 × 10−6 | 0.99 | 300 | 3500 |
| YN | 2 | 1 × 10−6 | 0.99 | 300 | 2000 |
| DMU06 to DMU10 | 2 | 5 × 10−6 | 0.99 | 300 | 9000 |
| DMU46 to DMU50 | 100 | 0.05 | 0.99 | 6000 | 9500 |
| Problem | Threads | |||||
|---|---|---|---|---|---|---|
| YN1 | H40–H16 | H16 | H48 | H8 | H32 | H1 |
| YN2 | H40–H32 | H32 | H8 | H48 | H16 | H1 |
| YN3 | H32 | H48 | H40 | H16 | H8 | H1 |
| YN4 | H16 | H32 | H40 | H48 | H8 | H1 |
| Problem | Threads | |||||
|---|---|---|---|---|---|---|
| YN1 | H48 | H32 | H16 | H8 | H40 | H1 |
| YN2 | H48–H40 | H40 | H32 | H16 | H8 | H1 |
| YN3 | H40–H48 | H48 | H32 | H16 | H8 | H1 |
| YN4 | H48 | H32 | H8 | H16 | H40 | H1 |
| Problem | Optimum Units of Time | Better Units of Time | Worse Units of Time | Mean Units of Time | %RE | σ | t Sec | Median | Mode |
|---|---|---|---|---|---|---|---|---|---|
| FT6 | 55 | 55 | 55 | 55 | 0 | 0.0 | 0.03 | 55 | 55 |
| FT10 | 930 | 930 | 930 | 930 | 0 | 0.0 | 1.05 | 930 | 930 |
| LA16 | 945 | 945 | 945 | 945 | 0 | 0.0 | 5.1 | 945 | 945 |
| LA17 | 784 | 784 | 784 | 784 | 0 | 0.0 | 4.9 | 784 | 784 |
| L18 | 848 | 848 | 848 | 848 | 0 | 0.0 | 4.2 | 848 | 848 |
| LA19 | 842 | 842 | 842 | 842 | 0 | 0.0 | 4.1 | 842 | 842 |
| LA20 | 902 | 902 | 902 | 902 | 0 | 0.0 | 4.34 | 902 | 902 |
| ORB01 | 1059 | 1059 | 1059 | 1059 | 0 | 0.0 | 13.63 | 1059 | 1059 |
| ORB02 | 888 | 888 | 889 | 889 | 0 | 0.4 | 9720 | 889 | 889 |
| ORB03 | 1005 | 1005 | 1021 | 1017 | 0 | 6.9 | 1048 | 1020 | 1021 |
| ORB04 | 1005 | 1005 | 1005 | 1005 | 0 | 0.0 | 155 | 1005 | 1005 |
| ORB05 | 887 | 887 | 890 | 888 | 0 | 1.6 | 1354 | 887 | 887 |
| ORB06 | 1010 | 1010 | 1010 | 1010 | 0 | 0.0 | 59 | 1010 | 1010 |
| ORB07 | 397 | 397 | 397 | 397 | 0 | 0.0 | 4.95 | 397 | 397 |
| ORB08 | 899 | 899 | 899 | 899 | 0 | 0.0 | 10.33 | 899 | 899 |
| ORB09 | 934 | 934 | 934 | 934 | 0 | 0.0 | 5 | 934 | 934 |
| ORB10 | 944 | 944 | 944 | 944 | 0 | 0.0 | 4.84 | 944 | 944 |
| ABZ5 | 1234 | 1234 | 1234 | 1234 | 0 | 0.0 | 12.62 | 1234 | 1234 |
| ABZ6 | 943 | 943 | 943 | 943 | 0 | 0.0 | 4.23 | 943 | 943 |
| Problem | Optimum Units of Time | Better Units of Time | Worse Units of Time | Mean Units of Time | %RE | σ | t Sec | Median | Mode |
|---|---|---|---|---|---|---|---|---|---|
| LA36 | 1268 | 1268 | 1281 | 1275 | 0 | 6.1 | 371.6 | 1278 | 1268 |
| LA37 | 1397 | 1397 | 1399 | 1397 | 0 | 0.9 | 230 | 1397 | 1397 |
| LA38 | 1196 | 1196 | 1245 | 1216 | 0 | 20.6 | 55 | 1218 | 1196 |
| LA39 | 1233 | 1233 | 1237 | 1234 | 0 | 1.8 | 54 | 1233 | 1233 |
| LA40 | 1222 | 1222 | 1234 | 1227 | 0 | 3.4 | 2245 | 1228 | 1229 |
| TA01 | 1231 | 1231 | 1231 | 1231 | 0 | 0.0 | 328 | 1231 | 1231 |
| TA02 | 1244 | 1244 | 1244 | 1244 | 0 | 0.0 | 501 | 1244 | 1244 |
| TA03 | 1218 | 1218 | 1223 | 1221 | 0 | 2.3 | 4373 | 1221 | 1223 |
| TA04 | 1175 | 1175 | 1175 | 1175 | 0 | 0.0 | 301 | 1175 | 1175 |
| TA05 | 1224 | 1224 | 1231 | 1229 | 0 | 2.8 | 2218 | 1230 | 1230 |
| TA06 | 1238 | 1238 | 1240 | 1239 | 0 | 0.8 | 5090 | 1239 | 1239 |
| TA07 | 1227 | 1227 | 1228 | 1228 | 0 | 0.4 | 99 | 1228 | 1228 |
| TA08 | 1217 | 1217 | 1224 | 1220 | 0 | 3.0 | 1986 | 1218 | 1218 |
| TA09 | 1274 | 1274 | 1281 | 1277 | 0 | 3.6 | 1433 | 1274 | 1274 |
| TA10 | 1241 | 1241 | 1253 | 1245 | 0 | 4.6 | 3830 | 1244 | 1244 |
| Problem | UB Units of Time | Better Units of Time | Worse Units of Time | Mean Units of Time | %RE | σ | t Sec | Median | Mode |
|---|---|---|---|---|---|---|---|---|---|
| TA21 | 1642 | 1646 | 1772 | 1683 | 0.24 | 18.1 | 1938 | 1681 | 1665 |
| TA22 | 1600 | 1600 | 1680 | 1637 | 0 | 13.1 | 3476 | 1636 | 1644 |
| TA23 | 1557 | 1560 | 1628 | 1600 | 0.19 | 15.5 | 1681 | 1598 | 1598 |
| TA24 | 1646 | 1651 | 1693 | 1681 | 0.3 | 14.4 | 397 | 1683 | 1670 |
| TA25 | 1595 | 1597 | 1669 | 1633 | 0.13 | 17.9 | 2208 | 1634 | 1649 |
| TA26 | 1643 | 1651 | 1716 | 1684 | 0.49 | 15.6 | 4547 | 1681 | 1680 |
| TA27 | 1680 | 1682 | 1712 | 1701 | 0.12 | 6.5 | 1736 | 1700.5 | 1698 |
| TA28 | 1603 | 1617 | 1639 | 1625 | 0.87 | 6.6 | 1374 | 1623 | 1622 |
| TA29 | 1625 | 1627 | 1642 | 1631 | 0.12 | 4.9 | 4876 | 1628.5 | 1627 |
| TA30 | 1584 | 1584 | 1618 | 1607 | 0 | 6.0 | 6429 | 1608.5 | 1606 |
| DMU06 | 3244 | 3254 | 3381 | 3321 | 0.31 | 30.4 | 267 | 3319 | 3307 |
| DMU07 | 3046 | 3065 | 3223 | 3127 | 0.62 | 37.5 | 3192 | 3122.5 | 3118 |
| DMU08 | 3188 | 3192 | 3385 | 3255 | 0.13 | 41.8 | 1696 | 3253 | 3202 |
| DMU09 | 3092 | 3121 | 3231 | 3174 | 0.94 | 29.5 | 1912 | 3173.5 | 3228 |
| DMU10 | 2984 | 3001 | 3084 | 3042 | 0.57 | 23.1 | 246 | 3041 | 3032 |
| DMU46 | 4035 | 4133 | 4189 | 4171 | 2.43 | 13.9 | 3424 | 4172 | 4176 |
| DMU47 | 3942 | 4024 | 4094 | 4070 | 2.08 | 13.9 | 1244 | 4073.5 | 4074 |
| DMU48 | 3763 | 3856 | 3988 | 3907 | 2.47 | 20.9 | 858 | 3906 | 3908 |
| DMU49 | 3710 | 3822 | 3871 | 3851 | 3.02 | 21.3 | 8301 | 3906 | 3902 |
| DMU50 | 3729 | 3829 | 3907 | 3882 | 2.68 | 16.2 | 5281 | 3881.5 | 3881 |
| YN1 | 884 | 885 | 905 | 896 | 0.11 | 4.5 | 1558 | 895.5 | 896 |
| YN2 | 904 | 906 | 930 | 917 | 0.22 | 6.4 | 3353 | 916 | 913 |
| YN3 | 892 | 892 | 915 | 903 | 0 | 5.9 | 2459 | 903.5 | 904 |
| YN4 | 968 | 968 | 990 | 978 | 0 | 5.8 | 3525 | 977.5 | 974 |
| Prob | Op | ST | t Sec | BG | t Sec | SG | t Sec | AM | t Sec | TA | t Sec | SGS | t Sec | TGA | t Sec | TS/PR | t Sec | UP | t Sec | HO | t Sec | GT | AG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| %RE | |||||||||||||||||||||||
| Size 10 × 10 | |||||||||||||||||||||||
| FT10 | 930 | 0 | 1.05 | 0 | 10.1 | -- | -- | 0 | 64.6 | 0 | 3.8 | 1.8 | 557 | 0 | 0.06 | 0 | 4.75 | 0 | 1208 | 0 | 4.1 | 0.54 | 0 |
| LA16 | 945 | 0 | 5.1 | 0 | 4.6 | 0 | 38.8 | -- | -- | -- | -- | 0 | 304 | 0 | 0.094 | 0 | 0.15 | 0 | 1458 | 0 | 19.9 | 0.11 | 0.10 |
| LA17 | 784 | 0 | 4.9 | 0 | 4.6 | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 0.016 | 0 | 0.08 | 0 | 78 | 0 | 19.9 | 0 | 0 |
| LA18 | 848 | 0 | 4.2 | 0 | 4.6 | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 0.015 | 0 | 0.09 | 0 | 76 | 0 | 19.9 | 0 | 0 |
| LA19 | 842 | 0 | 4.1 | 0 | 4.6 | 0 | 34.6 | -- | -- | 0 | 0.5 | -- | -- | 0 | 0.025 | 0 | 0.16 | 0 | 1130 | 0 | 19.9 | 0 | 1.18 |
| LA20 | 902 | 0 | 4.34 | 0 | 4.6 | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 0.031 | 0 | 0.11 | 0 | 1304 | 0 | 19.9 | 0.55 | 0.55 |
| Size 15 × 15 | |||||||||||||||||||||||
| LA36 | 1268 | 0 | 371.6 | 0 | 21.4 | 0 | 4655 | 0 | 36.6 | 0 | 9.9 | -- | -- | 0 | 0.57 | 0 | 4.5 | 0.79 | 48,387 | 0 | 105 | 3.16 | -- |
| LA37 | 1397 | 0 | 230 | 0 | 21.4 | 0.29 | 4144 | 0 | 879.6 | 0 | 42.1 | -- | -- | 0 | 0.51 | 0 | 26.2 | 0.72 | 49,836 | 0 | 105 | 6.59 | -- |
| LA38 | 1196 | 0 | 55 | 0 | 21.4 | 0.42 | 5049 | 0 | 55.4 | 0 | 47.8 | -- | -- | 0 | 1.25 | 0 | 32.6 | 1.59 | 50,876 | 0 | 105 | 6.61 | -- |
| LA39 | 1233 | 0 | 54 | 0 | 21.4 | -- | -- | 0 | 65.7 | 0 | 28.6 | -- | -- | 0 | 0.5 | 0 | 11.6 | 1.38 | 50,603 | 0 | 105 | 4.62 | -- |
| LA40 | 1222 | 0 | 2245 | 0 | 21.4 | 0.33 | 4544 | 0.16 | 941.4 | 0.16 | 52.1 | -- | -- | 0.16 | 0.86 | 0 | 385 | 0.57 | 50,609 | 0.16 | 105 | 2.46 | -- |
| Problem | Op/UB | ST | t Sec | BG | t Sec | AM | t Sec | TSSA | t Sec | SGS | T Sec | TGA | t Sec | IO | t Sec | TS/PR | t Sec | UP | t Sec | GT | AG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| %RE | |||||||||||||||||||||
| Size 10 × 10 | |||||||||||||||||||||
| ORB01 | 1059 | 0 | 4.34 | 0 | 5.8 | 0 | 56.6 | 0 | 3.5 | 0 | 342 | 0 | 0.06 | -- | -- | 0 | 0.51 | 0 | 2312 | 2.36 | 3.12 |
| ORB02 | 888 | 0 | 9720 | 0 | 5.8 | 0 | 569.3 | 0 | 6.4 | 0.1 | 306 | 0 | 0.06 | -- | -- | 0 | 1.69 | 0.11 | 2393 | 0.23 | 0.68 |
| ORB03 | 1005 | 0 | 1048 | 0 | 5.8 | 0 | 403.7 | 0 | 13.8 | 1.2 | 330 | 0 | 0.15 | -- | -- | 0 | 1.46 | 0 | 2358 | 3.18 | 2.39 |
| ORB04 | 1005 | 0 | 155 | 0 | 5.8 | 0 | 17.9 | 0 | 14.3 | 0 | 306 | 0 | 0.45 | -- | -- | 0 | 3.71 | 0 | 796 | 2.29 | 1.09 |
| ORB05 | 887 | 0 | 1354 | 0 | 5.8 | 0 | 670.3 | 0 | 6.6 | 0 | 366 | 0 | 0.76 | -- | -- | 0 | 7.28 | 0.23 | 2458 | 0.79 | 1.58 |
| ORB06 | 1010 | 0 | 59 | 0 | 5.8 | -- | -- | 0 | 8.5 | -- | -- | 0 | 0.72 | -- | -- | 0 | 1.81 | 0.30 | 2525 | 2.48 | 1.78 |
| ORB07 | 397 | 0 | 4.95 | 0 | 5.8 | -- | -- | 0 | 0.5 | -- | -- | 0 | 0.02 | -- | -- | 0 | 0.13 | 0 | 2096 | 1.76 | 2.02 |
| ORB08 | 899 | 0 | 10.33 | 0 | 5.8 | -- | --- | 0 | 7.2 | -- | -- | 0 | 0.09 | -- | -- | 0 | 3.99 | 0 | 2338 | 4.23 | 1.67 |
| ORB09 | 934 | 0 | 5 | 0 | 5.8 | -- | -- | 0 | 0.4 | -- | -- | 0 | 0.09 | -- | -- | 0 | 0.47 | 0 | 884 | 0.96 | 0.96 |
| ORB10 | 944 | 0 | 4.84 | 0 | 5.8 | -- | -- | 0 | 0.3 | -- | -- | 0 | 0.03 | -- | -- | 0 | 0.09 | 0 | 817 | 2.44 | -- |
| ABZ5 | 1234 | 0 | 12.62 | -- | -- | 0 | 501.9 | -- | -- | -- | -- | 0 | 0.04 | -- | -- | -- | -- | -- | -- | 0.32 | -- |
| ABZ6 | 943 | 0 | 4.23 | -- | -- | 0 | 199.3 | -- | -- | -- | -- | 0 | 0.03 | -- | -- | -- | -- | -- | -- | 0.42 | -- |
| Size 15 × 15 | |||||||||||||||||||||
| TA01 | 1231 | 0 | 328 | 0 | 30.4 | 0 | 1531.4 | 0 | 11.2 | 3.1 | 2782 | -- | -- | 0 | 124 | 0 | 2.93 | -- | -- | -- | -- |
| TA02 | 1244 | 0 | 501 | 0 | 30.4 | 0 | 685.2 | 0 | 30.1 | -- | -- | -- | -- | 0 | 118 | 0 | 38 | -- | -- | -- | -- |
| TA03 | 1218 | 0 | 4373 | 0 | 30.4 | 0.16 | 1833.7 | 0 | 108.5 | -- | -- | -- | -- | 0 | 120 | 0 | 44 | -- | -- | -- | -- |
| TA04 | 1175 | 0 | 301 | 0 | 30.4 | 0 | 1186.2 | 0 | 71.7 | -- | -- | -- | -- | 0 | 117 | 0 | 39 | -- | -- | -- | -- |
| TA05 | 1224 | 0 | 2218 | 0 | 30.4 | 0.33 | 1492.6 | 0 | 10.8 | -- | -- | -- | -- | 0 | 120 | 0 | 11 | -- | -- | -- | -- |
| TA06 | 1238 | 0 | 5090 | 0 | 30.4 | 0 | 1549.1 | 0 | 125.2 | -- | -- | -- | -- | 0 | 113 | 0 | 178 | -- | -- | -- | -- |
| TA07 | 1227 | 0.08 | 99 | 0.081 | 30.4 | 0.08 | 1687 | 0.08 | 138.6 | -- | -- | -- | -- | 0 | 117 | 0.08 | 0.60 | -- | -- | -- | -- |
| TA08 | 1217 | 0 | 1986 | 0 | 30.4 | 0 | 968.4 | 0 | 27.6 | -- | -- | -- | -- | 0 | 108 | 0 | 2.43 | -- | -- | -- | -- |
| TA09 | 1274 | 0 | 1433 | 0 | 30.4 | 0 | 1694.2 | 0 | 61.3 | -- | -- | -- | -- | 0 | 127 | 0 | 19 | -- | -- | -- | -- |
| TA10 | 1241 | 0 | 3380 | 0 | 30.4 | 0 | 1418.2 | 0 | 68 | -- | -- | -- | -- | 0 | 122 | 0 | 42 | -- | -- | -- | -- |
| Size 20 × 20 | |||||||||||||||||||||
| TA21 | 1642 | 0.24 | 1938 | 0 | 143.2 | 0.31 | 4158.4 | 0.12 | 437 | -- | -- | -- | -- | 0 | 408 | 0.12 | 503 | -- | -- | -- | -- |
| TA22 | 1600 | 0 | 3476 | 0 | 143.2 | 0.06 | 3586.4 | 0 | 433.5 | -- | -- | -- | -- | 0 | 395 | 0 | 229 | -- | -- | -- | -- |
| TA23 | 1557 | 0.19 | 1681 | 0 | 143.2 | 0.19 | 4175.7 | 0.19 | 429.4 | -- | -- | -- | -- | 0 | 390 | 0 | 360 | -- | -- | -- | -- |
| TA24 | 1644 | 0.43 | 397 | 0.12 | 143.2 | 0.49 | 3320.2 | 0.12 | 431.6 | -- | -- | -- | -- | 0.12 | 435 | 0.06 | 779 | -- | -- | -- | -- |
| TA25 | 1595 | 0.13 | 2208 | 0 | 143.2 | 0.13 | 3654.3 | 0.13 | 421 | -- | -- | -- | -- | 0 | 414 | 0 | 416 | -- | -- | -- | -- |
| TA26 | 1643 | 0.49 | 4547 | 0 | 143.2 | 0.55 | 3178.8 | 0.24 | 436.2 | -- | -- | -- | -- | 0 | 87 | 0.24 | 268 | -- | -- | -- | -- |
| TA27 | 1680 | 0.12 | 1736 | 0 | 143.2 | 0.36 | 3523.8 | 0 | 447.8 | -- | -- | -- | -- | 0 | 423 | 0 | 255 | -- | -- | -- | -- |
| TA28 | 1603 | 0.87 | 1374 | 0 | 143.2 | 0.94 | 3804.8 | 0 | 431.2 | -- | -- | -- | -- | 0 | 370 | 0.62 | 326 | -- | -- | -- | -- |
| TA29 | 1625 | 0.12 | 4876 | 0 | 143.2 | 0.12 | 3324.9 | 0.12 | 426.2 | -- | -- | -- | -- | 0 | 396 | 0 | 94 | -- | -- | -- | -- |
| TA30 | 1584 | 0 | 6429 | 0 | 143.2 | 0.69 | 4003.5 | 0 | 436.1 | -- | -- | -- | -- | 0 | 429 | 0 | 389 | -- | -- | -- | -- |
| DMU06 | 3244 | 0.31 | 267 | 0 | 145.4 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0.03 | 823 | -- | -- | -- | -- |
| DMU07 | 3046 | 0.62 | 3192 | 0 | 145.4 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 361 | -- | -- | -- | -- |
| DMU08 | 3188 | 0.13 | 1696 | 0 | 145.4 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 296 | -- | -- | -- | -- |
| DMU09 | 3092 | 0.94 | 1912 | 0 | 145.4 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0.07 | 148 | -- | -- | -- | -- |
| DMU10 | 2984 | 0.57 | 246 | 0 | 145.4 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0.03 | 253 | -- | -- | -- | -- |
| DMU46 | 4035 | 2.43 | 3424 | 0 | 187.7 | -- | -- | -- | -- | -- | -- | -- | -- | -- | --- | 0 | 985 | -- | -- | -- | -- |
| DMU47 | 3939 | 2.15 | 1244 | 0 | 187.7 | -- | --- | -- | -- | -- | -- | -- | -- | -- | -- | 0.08 | 829 | -- | -- | -- | -- |
| DMU48 | 3763 | 2.47 | 858 | 0.48 | 187.7 | -- | - | -- | -- | -- | -- | -- | -- | -- | -- | 0.40 | 939 | -- | -- | -- | -- |
| DMU49 | 3710 | 3.02 | 8301 | 0.35 | 187.7 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 634 | -- | -- | -- | -- |
| DMU50 | 3729 | 2.68 | 5281 | 0.08 | 187.7 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 610 | -- | -- | -- | -- |
| YN1 | 884 | 0.11 | 1558 | 0 | 105.2 | -- | -- | 0 | 106.6 | 0.2 | 15,786 | 0.23 | 92.8 | 0 | 190 | 0 | 169 | -- | -- | -- | |
| YN2 | 904 | 0.22 | 3353 | 0 | 105.2 | -- | -- | 0.33 | 110.4 | 4.4 | 14,586 | 0.77 | 13.1 | 0 | 197 | 0 | 202 | -- | -- | -- | -- |
| YN3 | 892 | 0 | 2459 | 0 | 105.2 | -- | -- | 0 | 110.8 | 1.3 | 16,662 | 0.56 | 37.2 | 0 | 212 | 0 | 344 | -- | -- | -- | -- |
| YN4 | 967 | 0.1 | 3525 | 0.1 | 105.2 | -- | -- | 0.21 | 108.7 | 2.17 | 14,752 | 0.83 | 114.1 | 0.10 | --- | 0.10 | 321 | -- | -- | -- | -- |
| Problem | Size | Op/UB | %RE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SACT | PPSO | cGA-PR | PaGA | HGAPSA | HIMGA | NIMGA | IIMMA | PGS | PABC | HG | |||
| FT06 | 6 × 6 | 55 | 0 | -- | -- | 0 | -- | 0 | 0 | 0 | 0 | 0 | -- |
| FT10 | 10 × 10 | 930 | 0 | -- | 0 | 7.2 | -- | 0 | 0 | 0 | 0.9 | 0 | 0 |
| LA16 | 10 × 10 | 945 | 0 | 29 | -- | 5.2 | -- | 0 | 0.11 | 0 | -- | 0 | 0 |
| LA17 | 10 × 10 | 784 | 0 | 33 | -- | 1.2 | -- | 0 | 0 | 0 | -- | 0 | 0 |
| LA18 | 10 × 10 | 848 | 0 | 33 | -- | 1.4 | -- | 0 | 0 | 0 | -- | 0 | 0 |
| LA19 | 10 × 10 | 842 | 0 | 37 | -- | 3.7 | -- | 0 | 0 | 0 | -- | 0 | 0 |
| LA20 | 10 × 10 | 902 | 0 | 32 | -- | 1.1 | -- | 0 | 0.55 | 0 | -- | 0.55 | 0 |
| LA36 | 15 × 15 | 1268 | 0 | 65 | -- | -- | 0.87 | 0 | 1.97 | 0 | -- | -- | 0 |
| LA37 | 15 × 15 | 1397 | 0 | 58 | -- | -- | 0.79 | 0 | 3.01 | 0 | -- | -- | 0 |
| LA38 | 15 × 15 | 1196 | 0 | 68 | 1.0 | -- | 1.92 | 0 | 2.17 | 0 | -- | -- | 0 |
| LA39 | 15 × 15 | 1233 | 0 | 67 | -- | -- | 1.05 | 0 | 2.11 | 0 | -- | -- | 0 |
| LA40 | 15 × 15 | 1222 | 0 | 68 | 1.31 | -- | 1.56 | 0.16 | 1.96 | 0.16 | -- | -- | 0 |
| ORB01 | 10 × 10 | 1059 | 0 | -- | 0 | 8.5 | -- | 0 | 0 | 0 | 0 | -- | 0 |
| ORB02 | 10 × 10 | 888 | 0 | -- | -- | 4.6 | -- | 0 | 0.23 | 0 | 0.1 | -- | 0 |
| ORB03 | 10 × 10 | 1005 | 0 | -- | 0 | 12.3 | -- | 0 | 2.09 | 0 | 0 | -- | 0 |
| ORB04 | 10 × 10 | 1005 | 0 | -- | 0 | 5.7 | -- | 0 | 1.39 | 0 | 0 | -- | 0 |
| ORB05 | 10 × 10 | 887 | 0 | -- | -- | 5.5 | -- | 0 | 0.68 | 0 | 0 | -- | 0 |
| ORB06 | 10 × 10 | 1010 | 0 | -- | -- | 4.0 | -- | 0 | 0.20 | 0 | -- | -- | 0 |
| ORB07 | 10 × 10 | 397 | 0 | -- | -- | 4.8 | -- | 0 | 0 | 0 | -- | -- | 0 |
| ORB08 | 10 × 10 | 899 | 0 | -- | 0 | 12.4 | -- | 0 | 1.11 | 0 | -- | -- | 0 |
| ORB09 | 10 × 10 | 934 | 0 | -- | -- | 6.4 | -- | 0 | 0.86 | 0 | -- | -- | 0 |
| ORB10 | 10 × 10 | 944 | 0 | -- | 0 | -- | -- | 0 | -- | 0 | -- | -- | 0 |
| TA21 | 20 × 20 | 1642 | 0.24 | -- | 0.49 | -- | -- | 0.49 | -- | -- | -- | -- | -- |
| TA22 | 20 × 20 | 1600 | 0 | -- | 0.38 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA23 | 20 × 20 | 1557 | 0.19 | -- | 0.19 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA24 | 20 × 20 | 1646 | 0.3 | -- | 0.36 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA25 | 20 × 20 | 1595 | 0.13 | -- | 0.13 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA26 | 20 × 20 | 1643 | 0.49 | -- | 0.55 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA27 | 20 × 20 | 1680 | 0.12 | -- | 0.36 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA28 | 20 × 20 | 1603 | 0.87 | -- | 0.87 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA29 | 20 × 20 | 1625 | 0.12 | -- | 0.25 | -- | -- | -- | -- | -- | -- | -- | -- |
| TA30 | 20 × 20 | 1584 | 0 | -- | 0 | -- | -- | -- | -- | -- | -- | -- | -- |
| DMU06 | 20 × 20 | 3244 | 0.31 | -- | 0.52 | -- | -- | -- | -- | -- | -- | -- | 0.74 |
| DMU07 | 20 × 20 | 3046 | 0.62 | -- | 1.15 | -- | -- | -- | -- | -- | -- | -- | 0.59 |
| DMU08 | 20 × 20 | 3188 | 0.13 | -- | 0.53 | -- | -- | -- | -- | -- | -- | -- | 0 |
| DMU09 | 20 × 20 | 3092 | 0.94 | -- | 0.13 | -- | -- | -- | -- | -- | -- | -- | 0.59 |
| DMU10 | 20 × 20 | 2984 | 0.57 | -- | 0.84 | -- | -- | -- | -- | -- | -- | -- | 0.10 |
| YN1 | 20 × 20 | 884 | 0.11 | -- | 2.49 | -- | -- | 1.01 | -- | 0.22 | 1.4 | -- | 0.23 |
| YN2 | 20 × 20 | 904 | 0.22 | -- | 1.77 | -- | -- | 0.99 | -- | 0.55 | 1.2 | -- | 0.33 |
| YN3 | 20 × 20 | 892 | 0 | -- | 1.01 | -- | -- | 0.90 | -- | 0.34 | 0.9 | -- | 0 |
| YN4 | 20 × 20 | 967 | 0.1 | -- | 1.45 | -- | -- | 0.93 | -- | 0.21 | 1.76 | -- | 0.21 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cruz-Chávez, M.A.; Peralta-Abarca, J.d.C.; Cruz-Rosales, M.H. Cooperative Threads with Effective-Address in Simulated Annealing Algorithm to Job Shop Scheduling Problems. Appl. Sci. 2019, 9, 3360. https://doi.org/10.3390/app9163360
Cruz-Chávez MA, Peralta-Abarca JdC, Cruz-Rosales MH. Cooperative Threads with Effective-Address in Simulated Annealing Algorithm to Job Shop Scheduling Problems. Applied Sciences. 2019; 9(16):3360. https://doi.org/10.3390/app9163360
Chicago/Turabian StyleCruz-Chávez, Marco Antonio, Jesús del C. Peralta-Abarca, and Martín H. Cruz-Rosales. 2019. "Cooperative Threads with Effective-Address in Simulated Annealing Algorithm to Job Shop Scheduling Problems" Applied Sciences 9, no. 16: 3360. https://doi.org/10.3390/app9163360
APA StyleCruz-Chávez, M. A., Peralta-Abarca, J. d. C., & Cruz-Rosales, M. H. (2019). Cooperative Threads with Effective-Address in Simulated Annealing Algorithm to Job Shop Scheduling Problems. Applied Sciences, 9(16), 3360. https://doi.org/10.3390/app9163360