Deep Learning-Based Classification of Weld Surface Defects


Abstract
1. Introduction
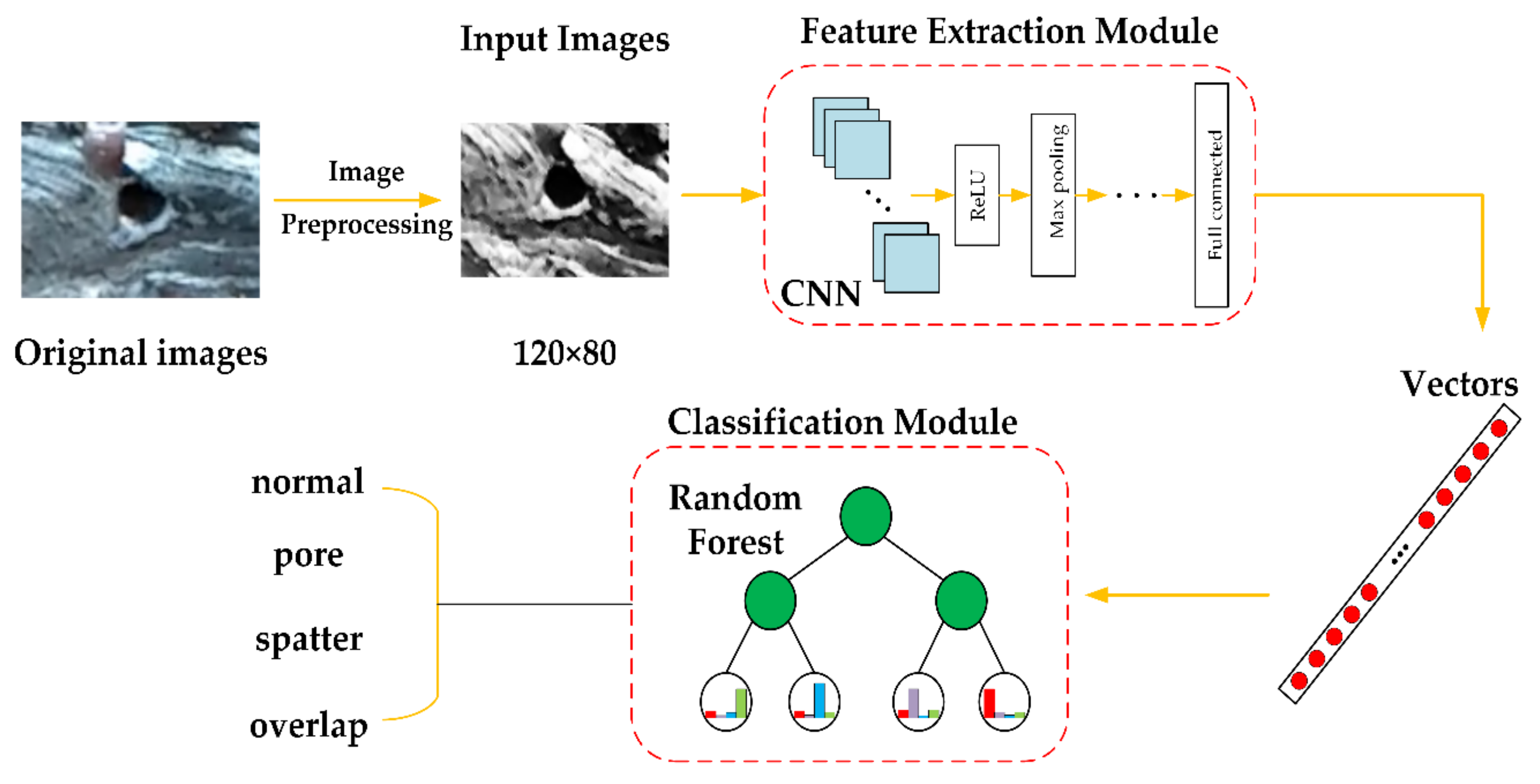
2. CNN-Based Feature Extraction
2.1. Background
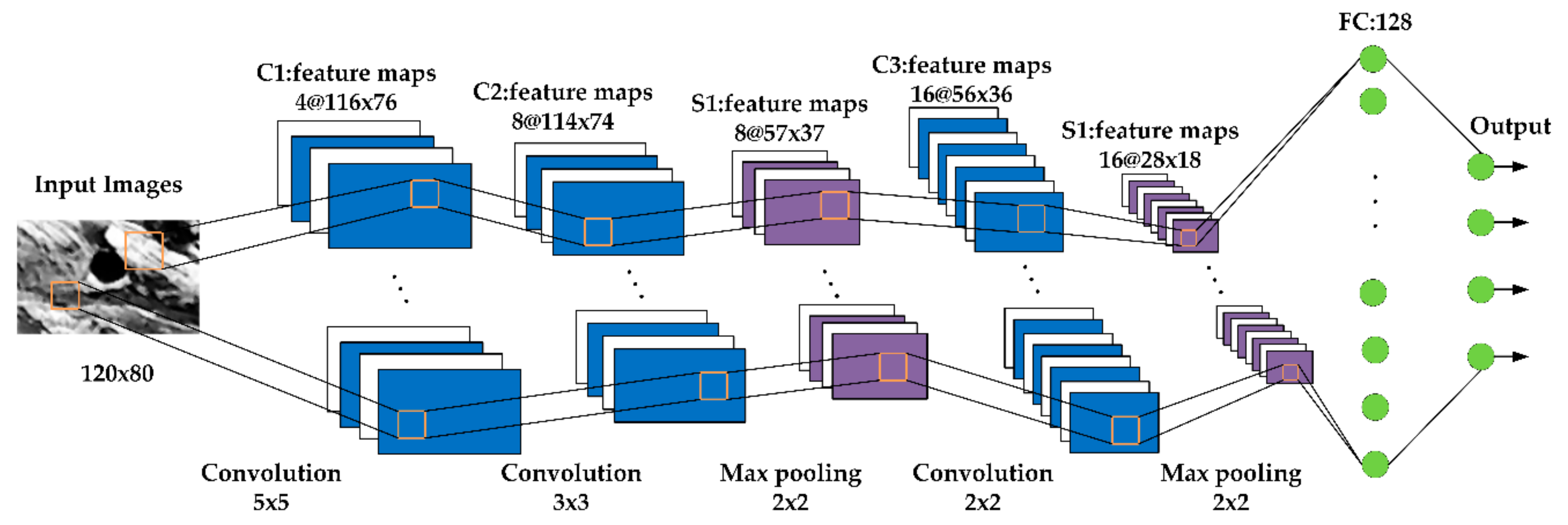
2.2. Feature Extraction Module
3. Classification with Random Forest
3.1. Random Forest Algorithm
3.2. Classification Module
| Algorithm 1 Random Forest for Classification |
| 1: Input: 2: Initialization 3: procedure Random Forest 4: For = 1 to do 5: Draw n bootstrap sample from input data 6: Build a decision tree on by recursively repeating the following steps for each terminal root 7: Select features without replacement from the features 8: Calculate the smallest Gini index of feature attribute among the feature subset based on Equation (5) 9: end procedure 10: Output: the ensemble of trees 11: Classification: 12: |
4. Experimental Results.
4.1. Settings and Experimental Environment
4.2. Image Preprocessing
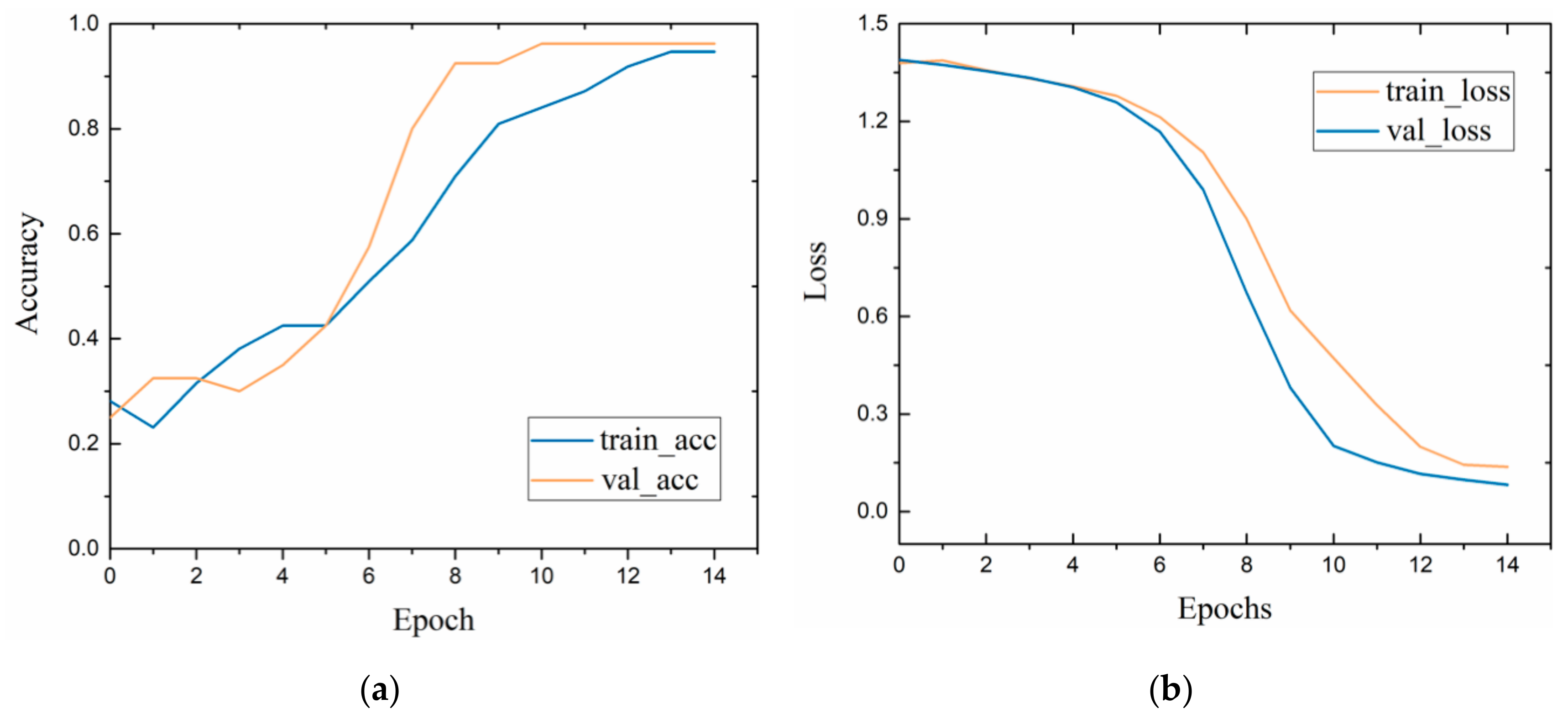
4.3. Evaluation of Feature Extraction Module
4.4. Comparison to Other Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Petcher, P.A.; Dixon, S. Weld defect detection using PPM EMAT generated shear horizontal ultrasound. NDT E Int. 2015, 74, 58–65. [Google Scholar] [CrossRef]
- Zou, Y.R.; Du, D.; Chang, B.H.; Ji, L.H.; Pan, J.L. Automatic weld defect detection method based on Kalman filtering for real-time radiographic inspection of spiral pipe. NDT E Int. 2015, 72, 1–9. [Google Scholar] [CrossRef]
- Dziczkowski, L. Elimination of coil liftoff from eddy current measurements of conductivity. IEEE Trans. Instrum. Meas. 2013, 62, 3301–3307. [Google Scholar] [CrossRef]
- Mery, D.; Arteta, C. Automatic defect recognition in x-ray testing using computer vision. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Sun, J.; Li, C.; Wu, X.J.; Palade, V.; Fang, W. An effective method of weld defect detection and classification based on machine vision. IEEE Trans. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Valavanis, I.; Kosmopoulos, D. Multiclass defect detection and classification in weld radiographic images using geometric and texture features. Expert Syst. Appl. 2010, 37, 7606–7614. [Google Scholar] [CrossRef]
- Yin, Z.Y.; Ye, B.; Zhang, Z.L. A novel feature extraction method of eddy current testing for defect detection based on machine learning. NDT E Int. 2019. [Google Scholar] [CrossRef]
- Boaretto, N.; Centeno, T.M. Automated detection of welding defects in pipelines from radiographic images DWDI. NDT E Int. 2017, 86, 7–13. [Google Scholar] [CrossRef]
- Zapata, J.; Vilar, R.; Ramón, R. Performance evaluation of an automatic inspection system of weld defects in radiographic images based on neuro-classifiers. Expert Syst. Appl. 2011, 38, 8812–8824. [Google Scholar] [CrossRef]
- Zahran, O.; Kasban, H.; El-Kordy, M.; El-Samie, F.E.A. Automatic weld defect identification from radiographic images. NDT E Int. 2013, 57, 26–35. [Google Scholar] [CrossRef]
- Jiang, H.Q.; Zhao, Y.L.; Gao, J.M.; Zhao, W. Weld defect classification based on texture features and principal component analysis. Insight Destruct. Test. Cond. Monit. 2016, 58, 194–200. [Google Scholar] [CrossRef]
- Mu, W.L.; Gao, J.M.; Jiang, H.Q.; Zhao, W. Automatic classification approach to weld defects based on PCA and SVM. Insight Destruct. Test. Cond. Monit. 2013, 55, 535–539. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inform. Proc. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Yang, N.N.; Niu, H.J.; Chen, L.; Mi, G.H. X-ray weld image classification using improved Convolutional Neural Network. AIP Conf. Proc. 2018, 1995. [Google Scholar] [CrossRef]
- Hou, W.H.; Ye, W.; Yi, J.; Zhu, C.A. Deep features based on a DCNN model for classifying imbalanced weld flaw types. Measurement 2019, 131, 482–489. [Google Scholar] [CrossRef]
- Khumaidi, A.; Yuniarno, E.M.; Purnomo, M.H. Welding defect classification based on convolution neural network (CNN) and Gaussian kernel. In Proceedings of the International Seminar on Intelligent Technology and Its Applications, Surabaya, Indonesia, 28–29 August 2017; pp. 261–265. [Google Scholar]
- Liu, B.; Zhang, X.Y.; Gao, Z.Y.; Chen, L. Weld defect images classification with VGG16-Based neural network. In Proceedings of the International Forum on Digital TV and Wireless Multimedia Communications, Shanghai, China, 8–9 November 2017; pp. 215–223. [Google Scholar]
- Hou, W.H.; Wei, Y.; Guo, J.; Jin, Y.; Zhu, C.A. Automatic detection of welding defects using deep neural network. J. Phys. Conf. Ser. 2018, 933, 012006. [Google Scholar] [CrossRef]
- Du, W.Z.; Shen, H.Y.; Fu, J.Z.; Zhang, G.; He, Q. Approaches for improvement of the X-ray image defect detection of automobile casting aluminum parts based on deep learning. NDT E Int. 2019, 107. [Google Scholar] [CrossRef]
- Wang, L.Z.; Zhang, J.B.; Liu, P.; Choo, K.K.R.; Huang, F. Spectral–spatial multi-feature-based deep learning for hyperspectral remote sensing image classification. Soft Comput. 2017, 21, 213–221. [Google Scholar] [CrossRef]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Hinton, G.E.; Osindero, S.; The, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Lee, N.; Sun, J.M.; Hu, J.Y.; Ebadollahi, S. Automatic group sparse coding. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011. [Google Scholar]
- Roux, N.L.; Bengio, Y. Representational power of restricted Boltzmann machines and deep belief networks. Neural Comput. 2008, 20, 1631–1649. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.W.; Fan, Q.F.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 354–370. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lecun, Y.L.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | C1 | C2 | S1 | C3 | S2 |
|---|---|---|---|---|---|
| Details | 4 filters 5 × 5, ReLU, stride 1 × 1 | 8 filters 3 × 3, ReLU, stride 1 × 1 | max pooling, stride 2 × 2 | 16 filters 2 × 2, ReLU, stride 1 × 1 | max pooling, stride 2 × 2 |
| Method | Accuracy |
|---|---|
| CNN + Random Forest | 0.9875 |
| CNN + SVM | 0.95 |
| CNN + Softmax | 0.9469 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Ge, W.; Liu, Z. Deep Learning-Based Classification of Weld Surface Defects. Appl. Sci. 2019, 9, 3312. https://doi.org/10.3390/app9163312
Zhu H, Ge W, Liu Z. Deep Learning-Based Classification of Weld Surface Defects. Applied Sciences. 2019; 9(16):3312. https://doi.org/10.3390/app9163312
Chicago/Turabian StyleZhu, Haixing, Weimin Ge, and Zhenzhong Liu. 2019. "Deep Learning-Based Classification of Weld Surface Defects" Applied Sciences 9, no. 16: 3312. https://doi.org/10.3390/app9163312
APA StyleZhu, H., Ge, W., & Liu, Z. (2019). Deep Learning-Based Classification of Weld Surface Defects. Applied Sciences, 9(16), 3312. https://doi.org/10.3390/app9163312