Aspect-Based Sentiment Analysis Using Aspect Map

Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
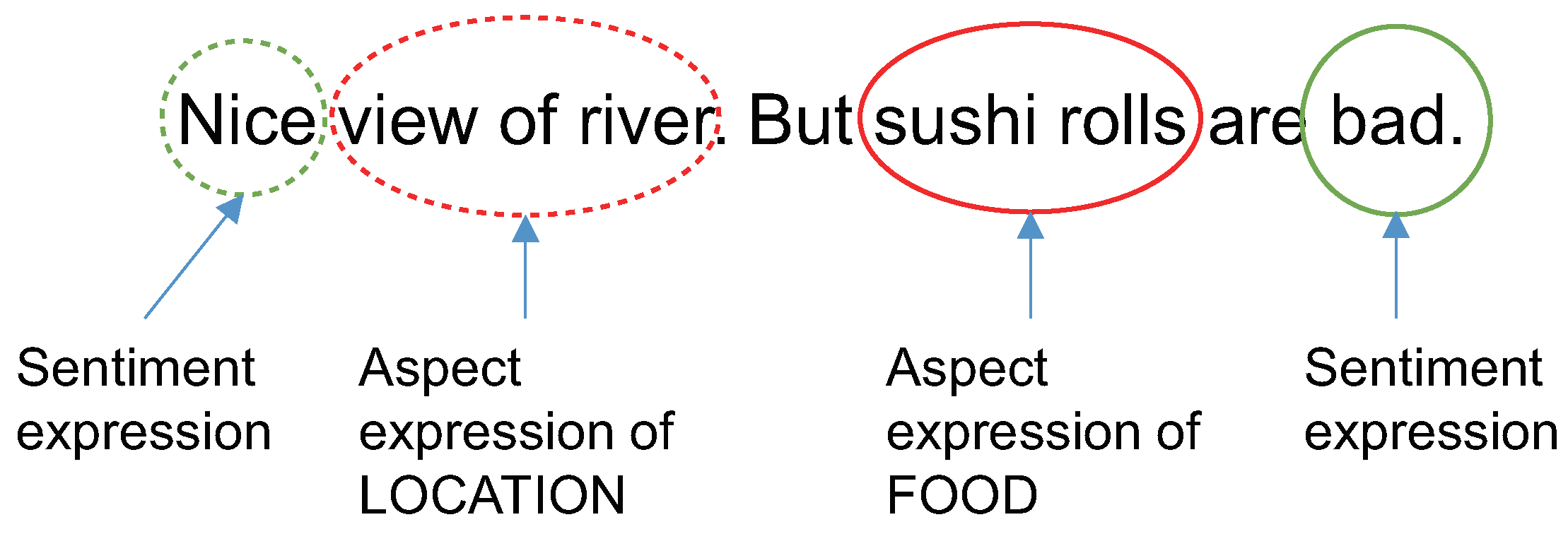
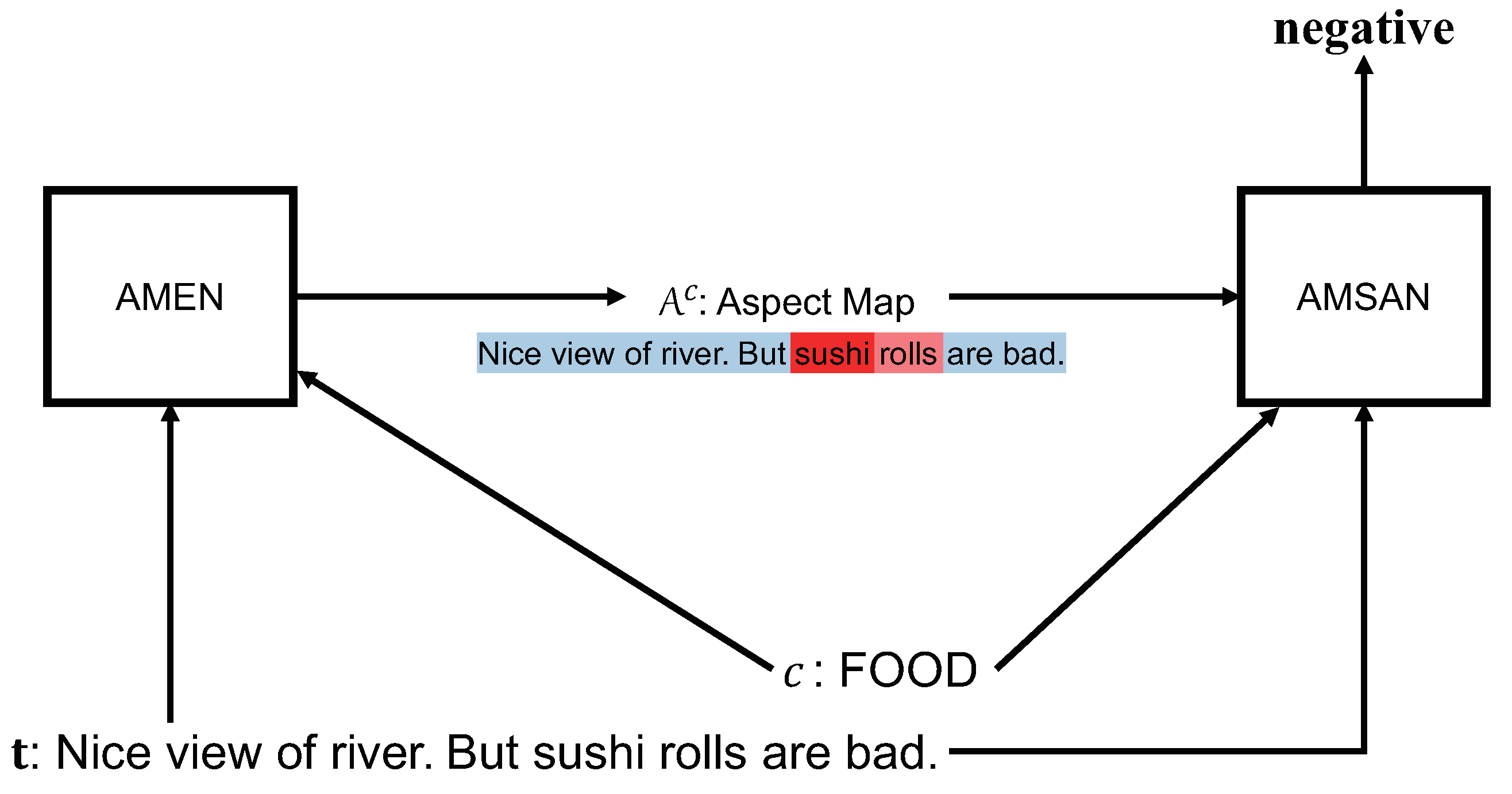
3. Sentiment Analysis Using Aspect Map
4. Learning AMEN and AMSAN
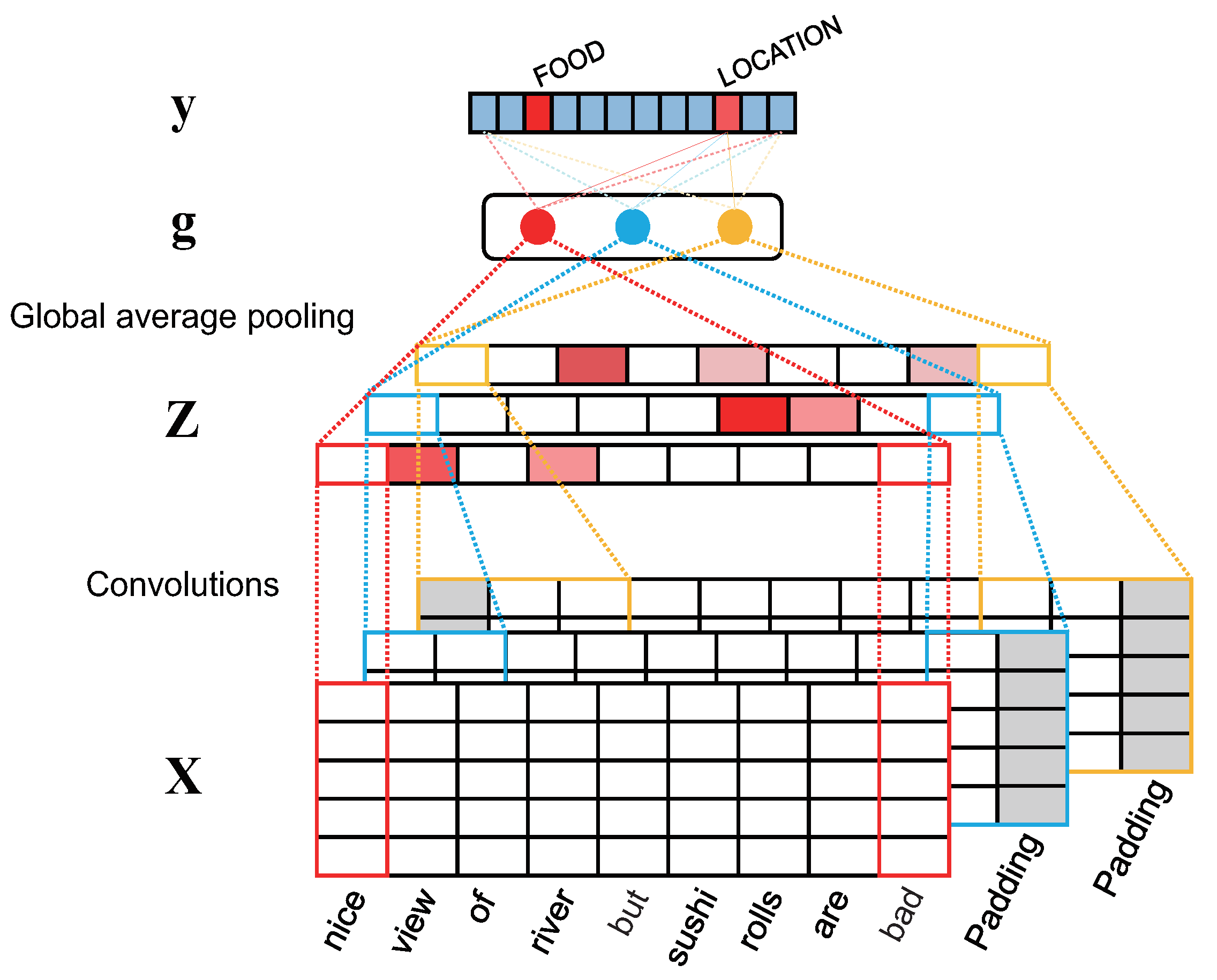
4.1. Aspect-Map Extraction Network (AMEN)
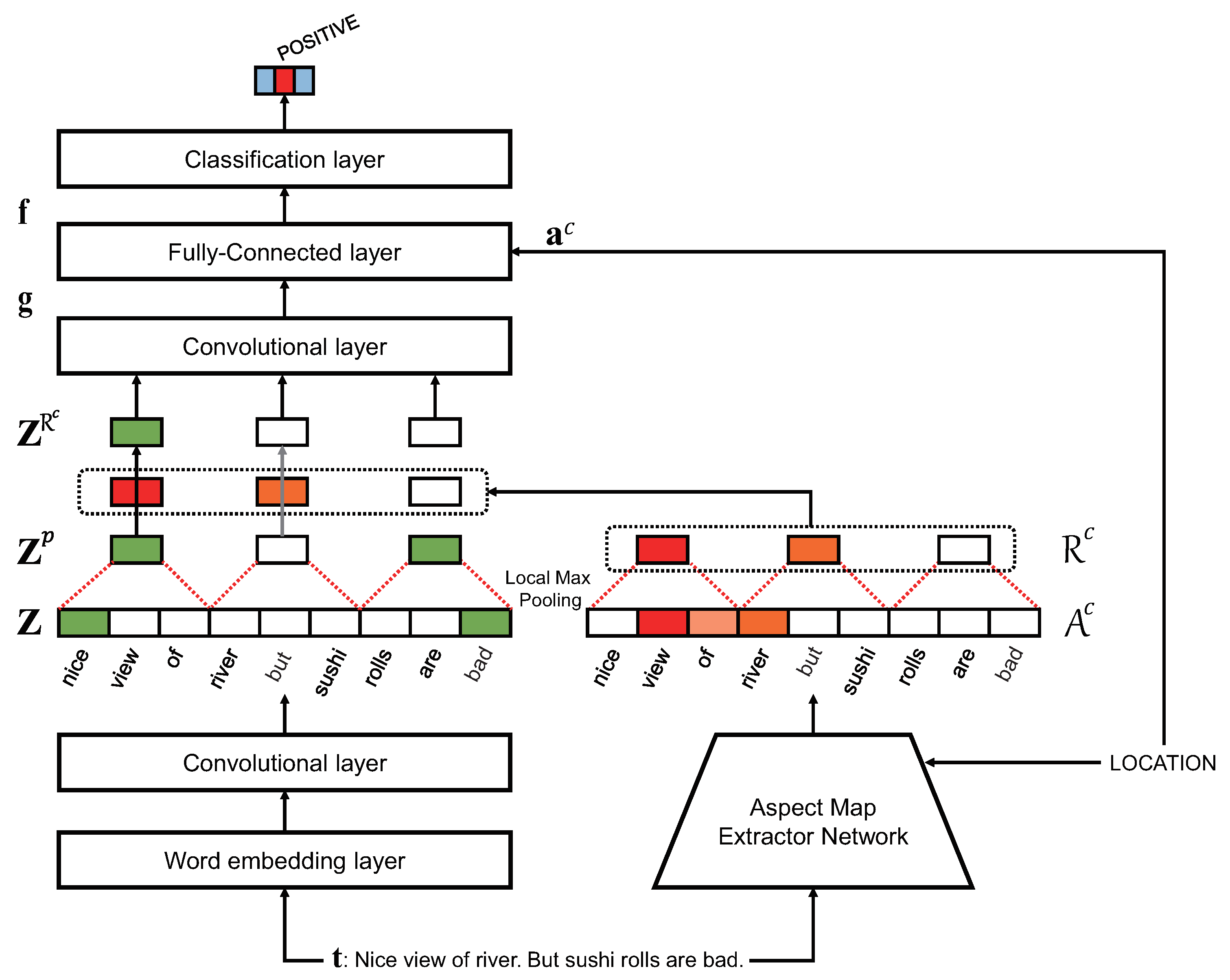
4.2. Aspect Map-Based Sentiment Analysis Network (AMSAN)
5. Experiments
5.1. Dataset
5.2. Model Training
5.3. Experimental Results
- UWB [39]: This is the best model in SemEval 2016 Task 5 for both text-level restaurant and laptop datasets. It uses a large number of hand-crafted features. After representing all sentences in a dataset with a set of hand-crafted features, it classifies the sentiment of every sentence by the maximum entropy classifier. Then, the sentiment of a text is determined by the majority vote of sentence sentiments. Because the datasets for SemEval 2016 are small, top-ranked models in SemEval 2016 seldom adopt a deep learning method. This baseline is only for SemEval-2016 benchmark.
- ATAE-LSTM [22]: This is an attention-based LSTM for ABSA, where the aspect vector for a target aspect is concatenated to all word embeddings in a text. Then, the word embeddings are used as an input of an LSTM and an attention layer is located on the top of the LSTM. Because the performance of ATAE-LSTM is not reported on SemEval 2016 Task 5, we implement it ourselves for comparison with the proposed model.
- GCAE [20]: This is a CNN-based model for ABSA which includes the gated Tanh-ReLU units for capturing aspect-specific sentiment expressions from convolutional layers. The authors open their own code (https://github.com/wxue004cs/GCAE), and thus all experimental results on GCAE below are obtained using the code.
- AMSAN w/o aspect map: Because the aspect vector of a target aspect is fed to the fully connected layer of AMSAN, AMSAN can operate without an aspect map from AMEN. Thus, the impact of the aspect map can be judged by comparing AMSAN without aspect map with the proposed model.
5.4. Quality of Aspect Map
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Petz, G.; Karpowicz, M.; Fürschuß, H.; Auinger, A.; Winkler, S.M.; Schaller, S.; Holzinger, A. On text preprocessing for opinion mining outside of laboratory environments. In International Conference on Active Media Technology; Springer: Berlin, Germany, 2012; pp. 618–629. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Turney, P.D. Thumbs up or Thumbs down? Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 417–424. [Google Scholar]
- Kim, S.; Hovy, E.H. Determining the Sentiment of Opinions. In Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004. [Google Scholar]
- Ding, X.; Liu, B.; Yu, P.S. A holistic lexicon-based approach to opinion mining. In Proceedings of the International Conference on Web Search and Web Data Mining, Palo Alto, CA, USA, 11–12 February 2008; pp. 231–240. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002. [Google Scholar]
- Dave, K.; Lawrence, S.; Pennock, D.M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In Proceedings of the Twelfth International World Wide Web Conference, Budapest, Hungary, 20–24 May 2003; pp. 519–528. [Google Scholar]
- Mullen, T.; Collier, N. Sentiment Analysis using Support Vector Machines with Diverse Information Sources. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 15 January 2004; pp. 412–418. [Google Scholar]
- Jo, Y.; Oh, A.H. Aspect and sentiment unification model for online review analysis. In Proceedings of the Forth International Conference on Web Search and Web Data Mining, Hong Kong, China, 9–12 February 2011; pp. 815–824. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Socher, R.; Pennington, J.; Huang, E.H.; Ng, A.Y.; Manning, C.D. Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; pp. 151–161. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach. In Proceedings of the 28th International Conference on Machine Learning, Omnipress, Bellevue, WA, USA, 28 June–2 July 2011; pp. 513–520. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.J.; Hovy, E.H. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Feldman, R. Techniques and applications for sentiment analysis. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P.P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Guan, Z.; Chen, L.; Zhao, W.; Zheng, Y.; Tan, S.; Cai, D. Weakly-Supervised Deep Learning for Customer Review Sentiment Classification. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3719–3725. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect Level Sentiment Classification with Deep Memory Network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 214–224. [Google Scholar]
- Xue, W.; Li, T. Aspect Based Sentiment Analysis with Gated Convolutional Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2514–2523. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive Attention Networks for Aspect-Level Sentiment Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Cheng, J.; Zhao, S.; Zhang, J.; King, I.; Zhang, X.; Wang, H. Aspect-level Sentiment Classification with HEAT (HiErarchical ATtention) Network. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 97–106. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, À.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Ruder, S.; Ghaffari, P.; Breslin, J.G. INSIGHT-1 at SemEval-2016 Task 5: Deep Learning for Multilingual Aspect-based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 330–336. [Google Scholar]
- Lee, G.; Jeong, J.; Seo, S.; Kim, C.; Kang, P. Sentiment classification with word localization based on weakly supervised learning with a convolutional neural network. Knowl.-Based Syst. 2018, 152, 70–82. [Google Scholar] [CrossRef]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 27–35. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; Clercq, O.D.; et al. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent Attention Network on Memory for Aspect Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A.C. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014; NIPS: Grenada, Spain, 2014; pp. 3320–3328. [Google Scholar]
- Mou, L.; Meng, Z.; Yan, R.; Li, G.; Xu, Y.; Zhang, L.; Jin, Z. How Transferable are Neural Networks in NLP Applications? In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 479–489. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- He, R.; McAuley, J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 7 August 2019).
- Hercig, T.; Brychcín, T.; Svoboda, L.; Konkol, M. UWB at SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 342–349. [Google Scholar]
- Holzinger, A. From machine learning to explainable AI. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Košice, Slovakia, 23–25 August 2018; pp. 55–66. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2014-Restaurant | Train | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| AMEN | 3041 | 800 | ||||||
| (1.22) | (1.28) | |||||||
| AMSAN | Positive | Negative | Neutral | Conflict | Positive | Negative | Neutral | Conflict |
| 2179 | 839 | 500 | 195 | 657 | 222 | 94 | 52 | |
| 2016-Restaurant | Train | Test | ||||||
| AMEN | 335 | 90 | ||||||
| (4.28) | (4.49) | |||||||
| AMSAN | Positive | Negative | Neutral | Conflict | Positive | Negative | Neutral | Conflict |
| 1012 | 327 | 55 | 41 | 286 | 84 | 23 | 11 | |
| 2016-Laptop | Train | Test | ||||||
| AMEN | 395 | 80 | ||||||
| (5.27) | (6.68) | |||||||
| AMSAN | Positive | Negative | Neutral | Conflict | Positive | Negative | Neutral | Conflict |
| 1210 | 708 | 123 | 41 | 330 | 161 | 31 | 13 | |
| Model | Acc. w/ Conflict | Acc. w/o Conflict |
|---|---|---|
| UWB | 81.931 (-) | - |
| ATAE-LSTM | 82.699 (0.996) | 85.496 (0.924) |
| GCAE | 81.640 (0.621) | 83.606 (0.756) |
| AMSAN w/o aspect map | 82.309 (0.546) | 85.394 (0.458) |
| AMEN-AMSAN | 83.936 (0.496) | 86.578 (0.407) |
| Model | Acc. w/ Conflict | Acc. w/o Conflict |
|---|---|---|
| UWB | 75.046 (-) | - |
| ATAE-LSTM | 78.692 (0.747) | 79.685 (1.197) |
| GCAE | 78.659 (0.812) | 80.812 (0.609) |
| AMSAN w/o aspect map | 79.719 (0.920) | 81.797 (1.100) |
| AMEN-AMSAN | 80.399 (0.555) | 82.201 (0.488) |
| Model | Acc. on Whole Test | Acc. on Hard Test |
|---|---|---|
| ATAE-LSTM | 74.87 (1.46) | 49.89 (1.88) |
| GCAE | 74.13 (0.72) | 46.29 (1.93) |
| AMSAN w/o aspect map | 74.59 (0.78) | 46.52 (1.28) |
| AMEN-AMSAN | 75.59 (0.51) | 53.26 (0.41) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noh, Y.; Park, S.; Park, S.-B. Aspect-Based Sentiment Analysis Using Aspect Map. Appl. Sci. 2019, 9, 3239. https://doi.org/10.3390/app9163239
Noh Y, Park S, Park S-B. Aspect-Based Sentiment Analysis Using Aspect Map. Applied Sciences. 2019; 9(16):3239. https://doi.org/10.3390/app9163239
Chicago/Turabian StyleNoh, Yunseok, Seyoung Park, and Seong-Bae Park. 2019. "Aspect-Based Sentiment Analysis Using Aspect Map" Applied Sciences 9, no. 16: 3239. https://doi.org/10.3390/app9163239
APA StyleNoh, Y., Park, S., & Park, S.-B. (2019). Aspect-Based Sentiment Analysis Using Aspect Map. Applied Sciences, 9(16), 3239. https://doi.org/10.3390/app9163239