User Interactions for Augmented Reality Smart Glasses: A Comparative Evaluation of Visual Contexts and Interaction Gestures

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
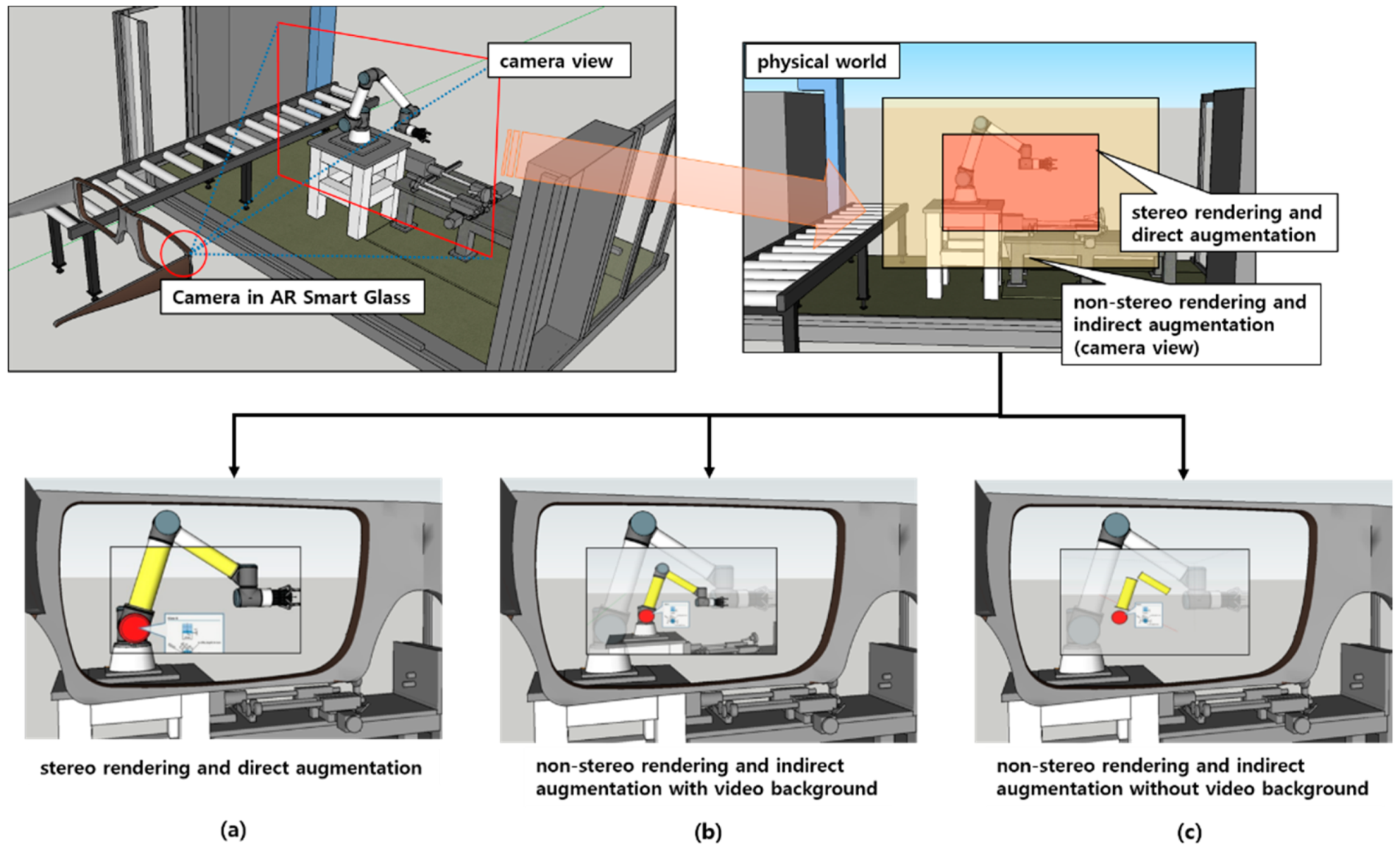
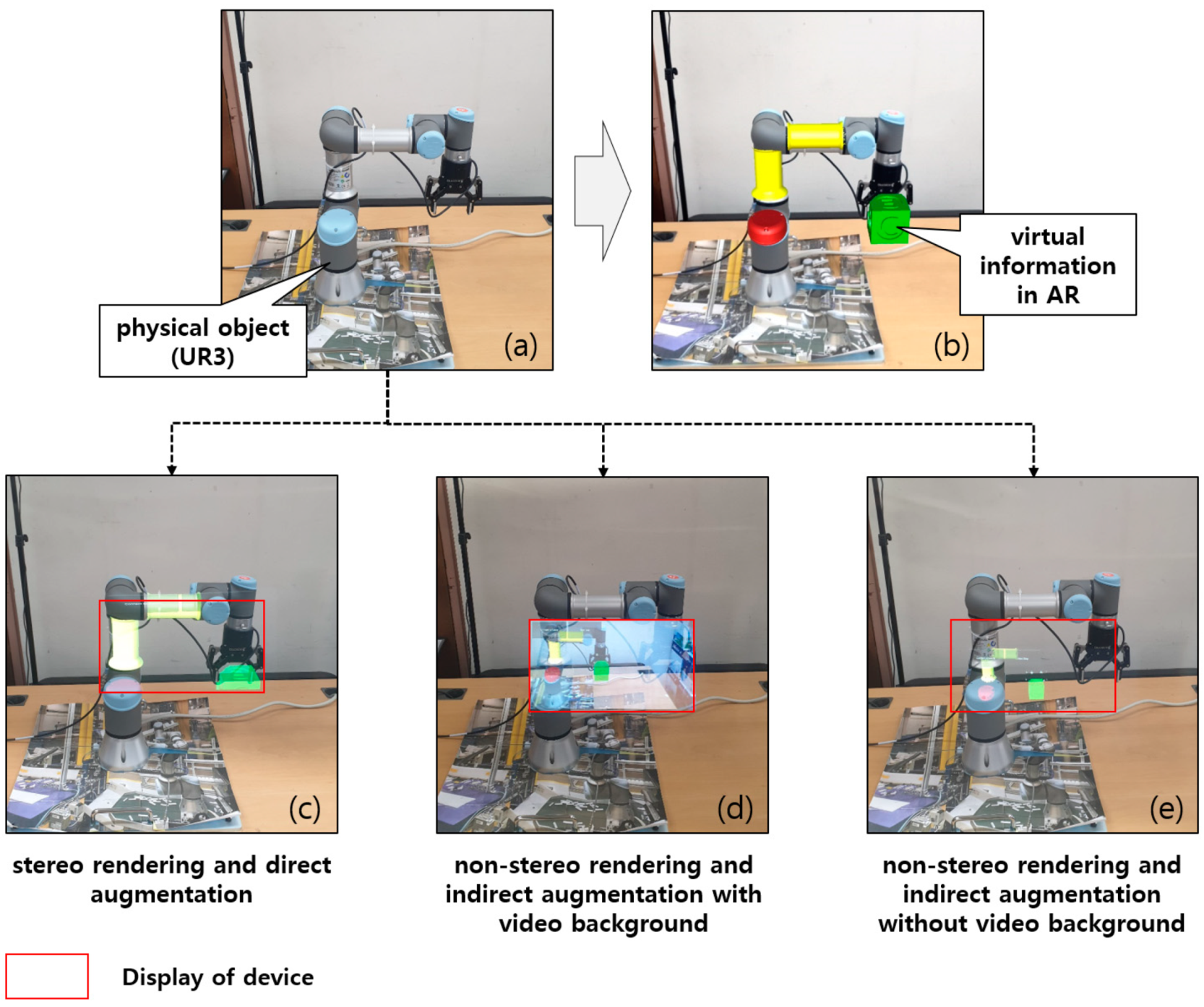
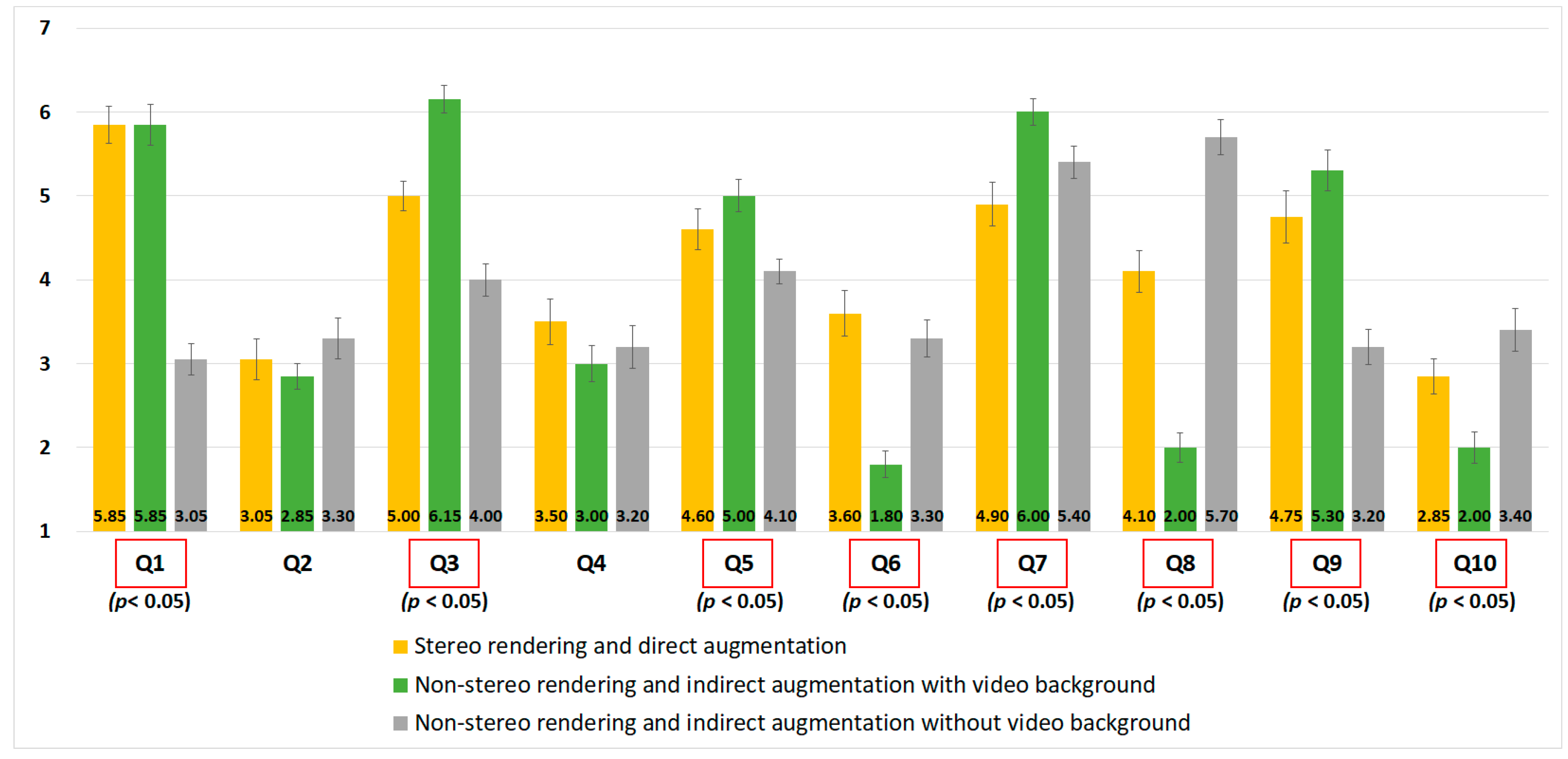
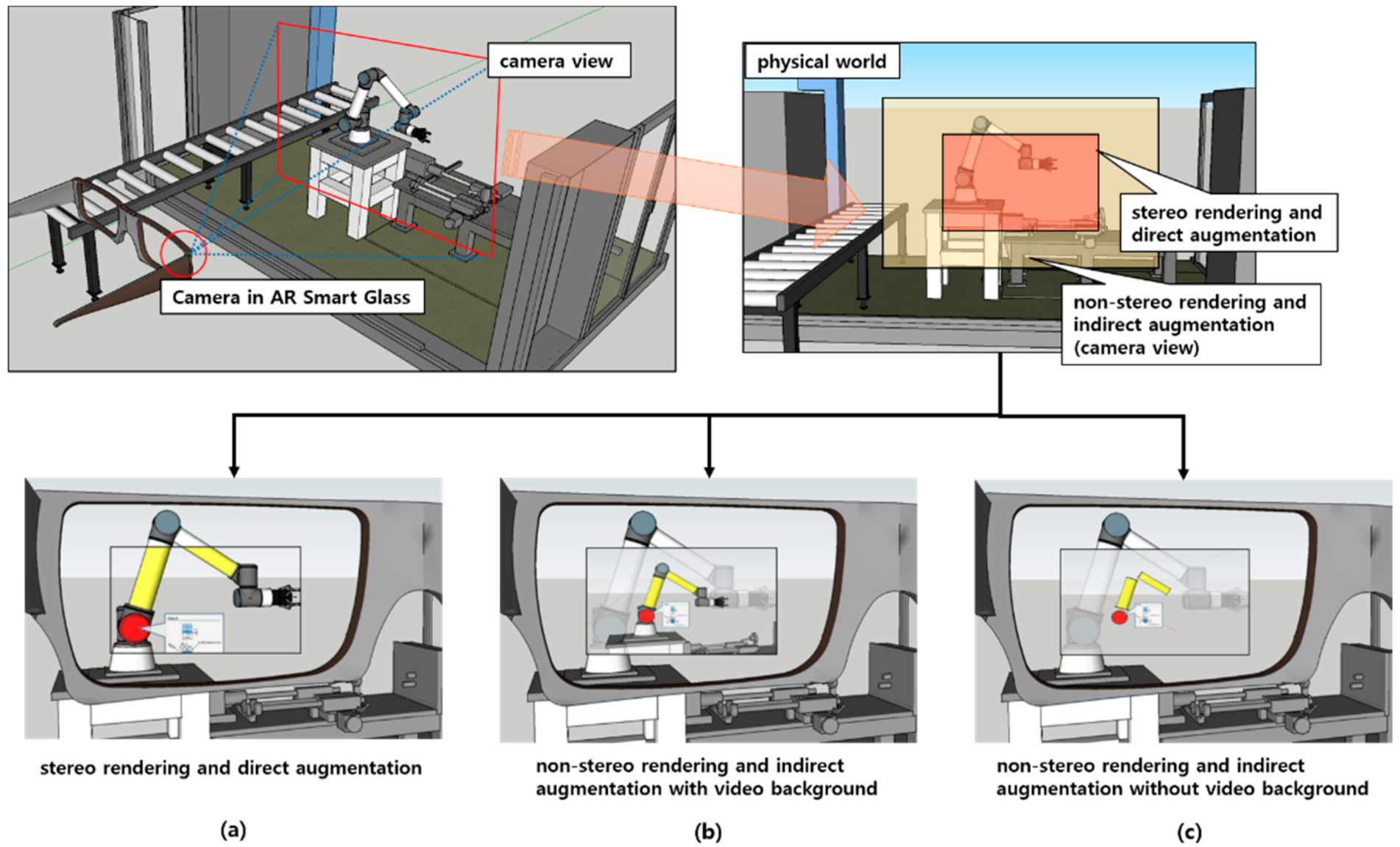
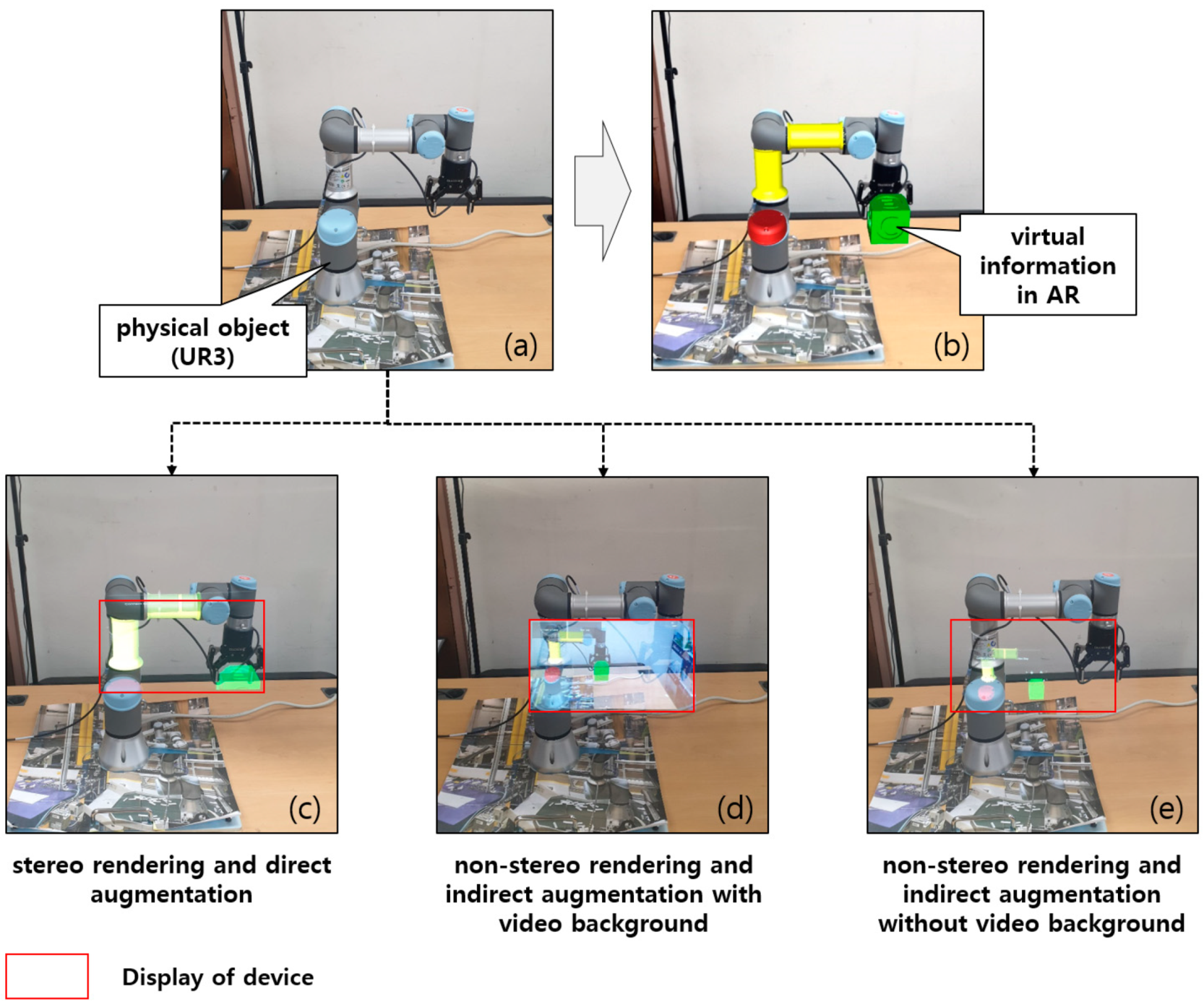
- Stereo rendering and direct augmentation
- Non-stereo rendering and indirect augmentation with video background
- Non-stereo rendering and indirect augmentation without video background
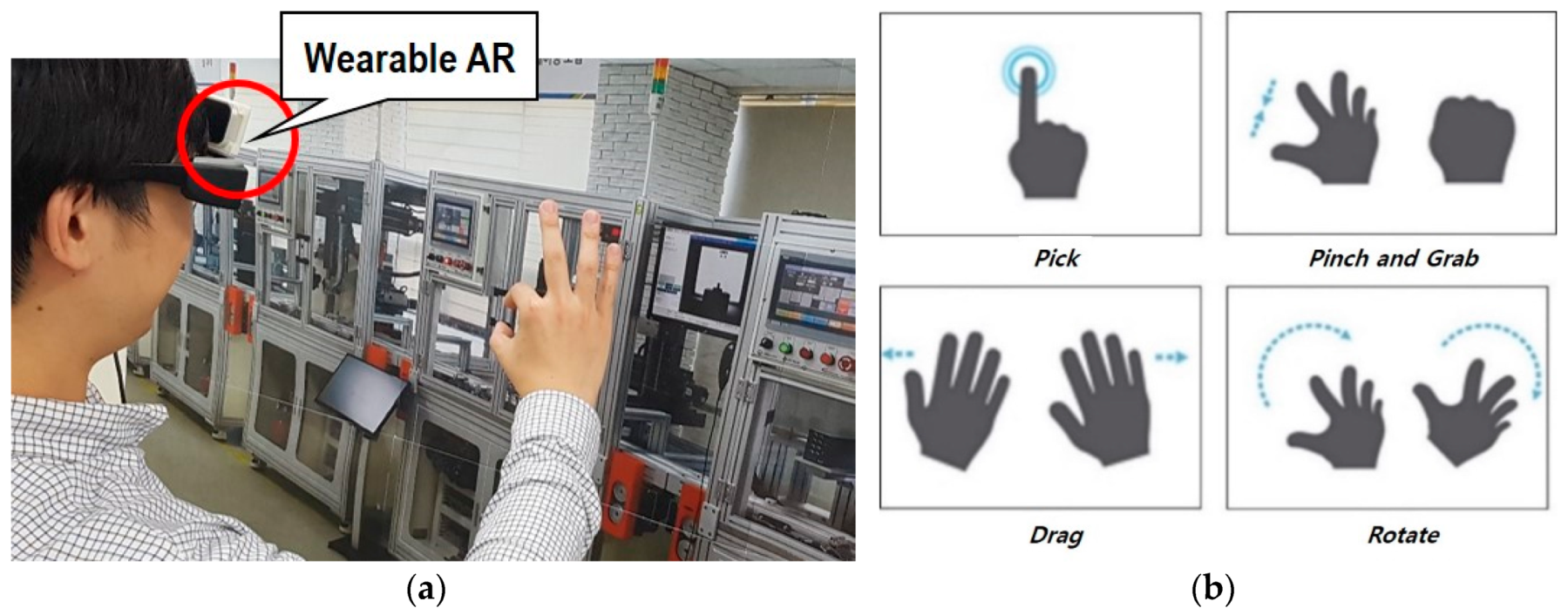
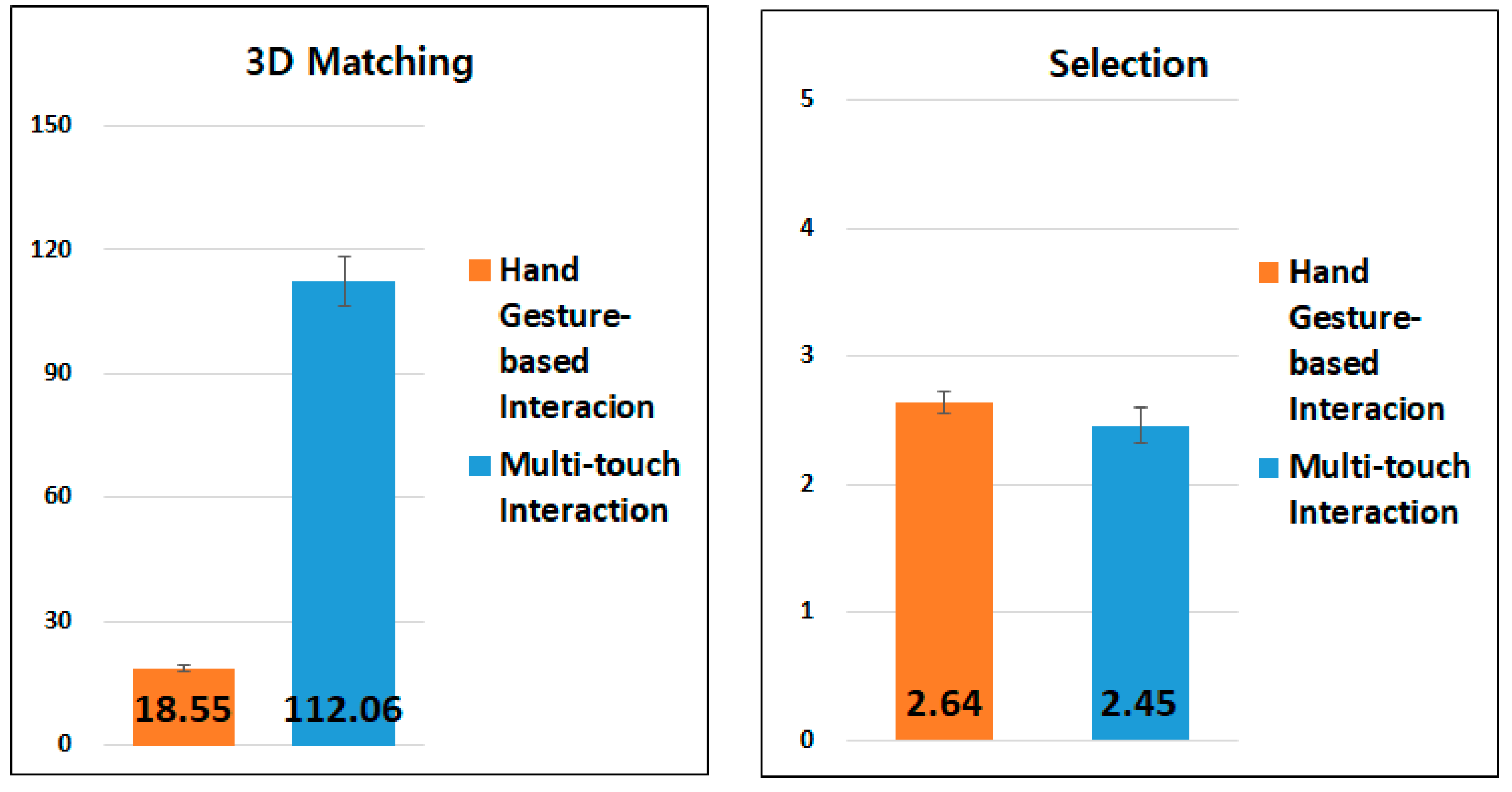
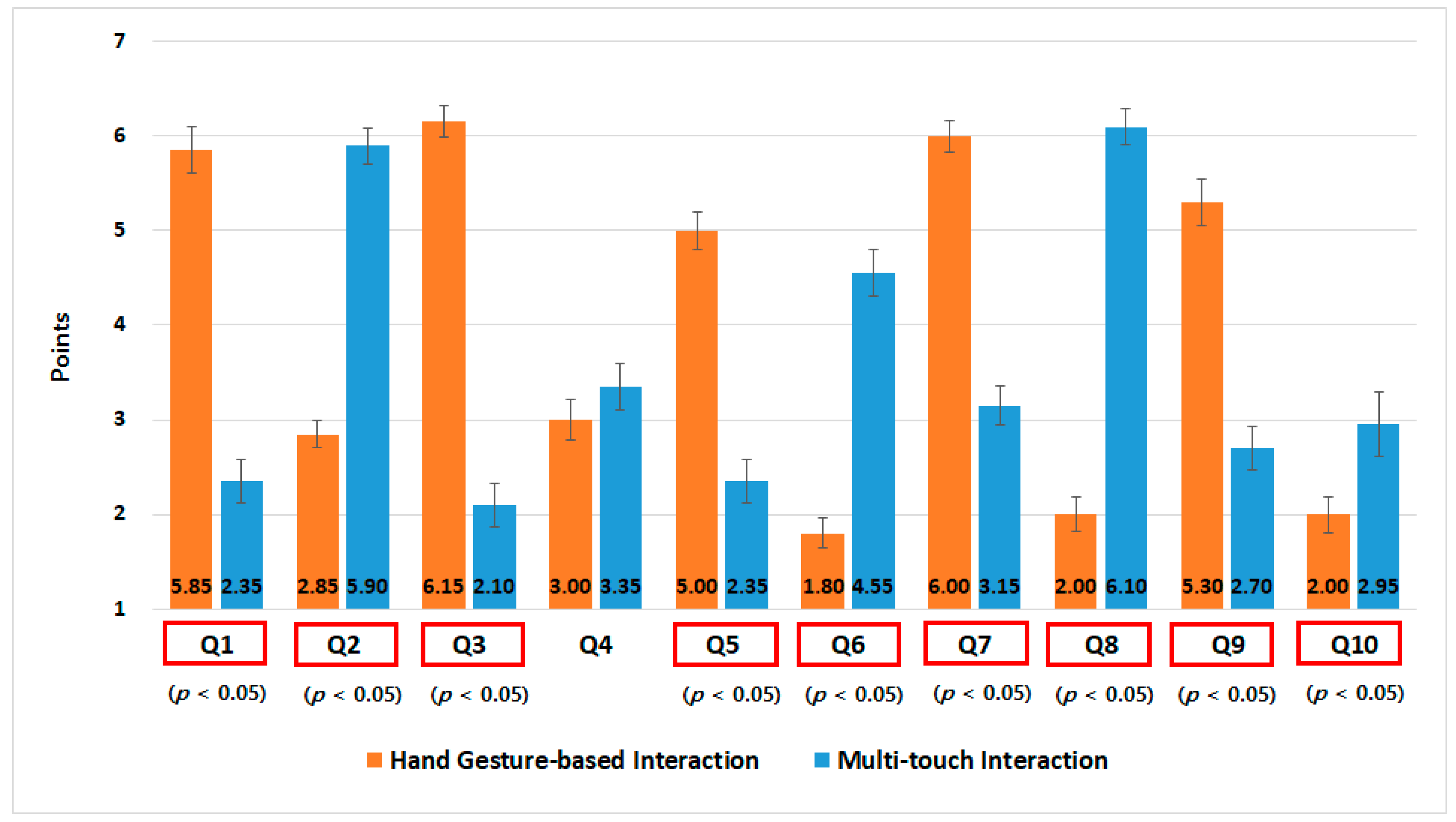
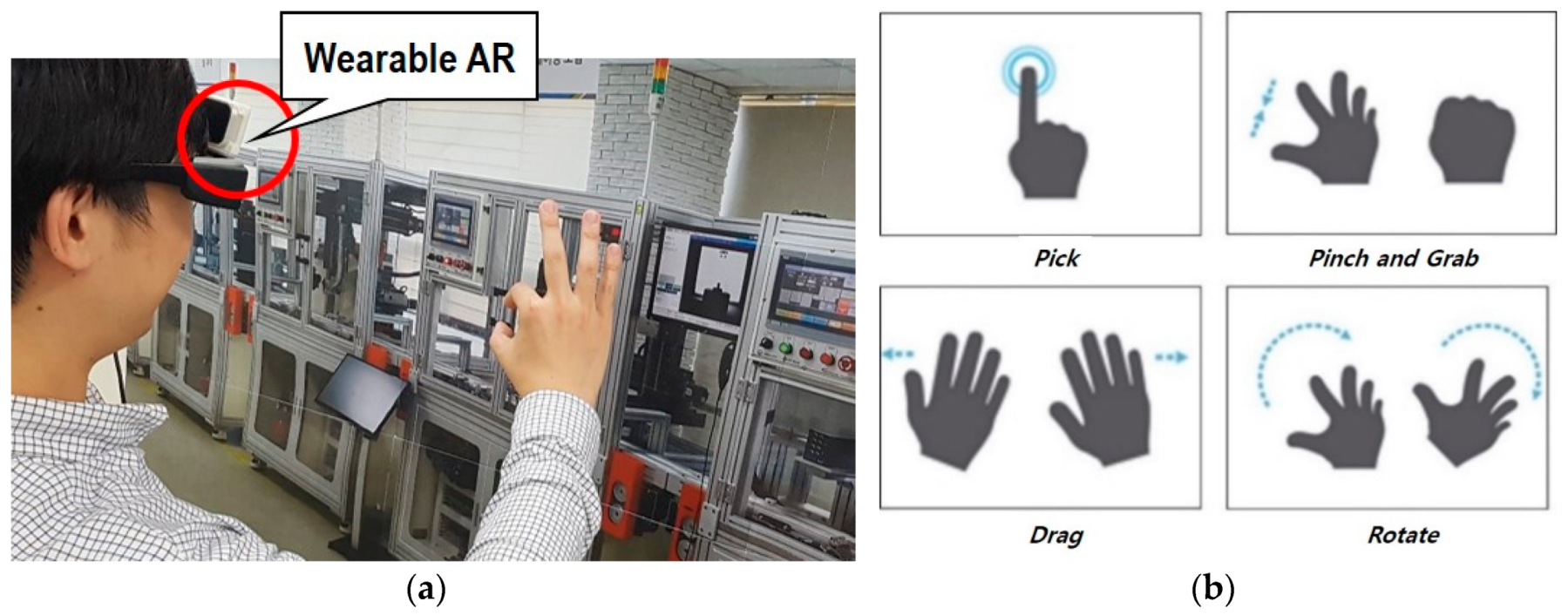
- Hand gesture-based interaction
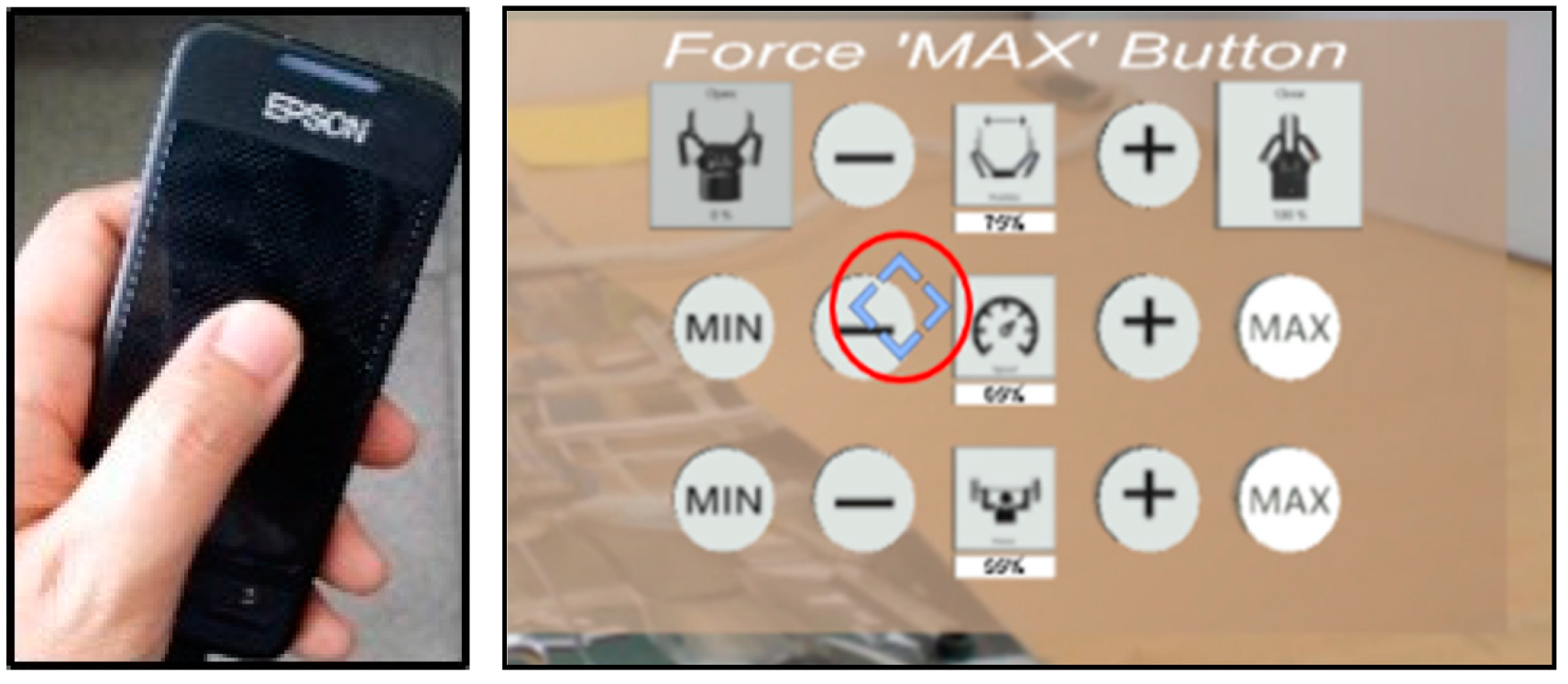
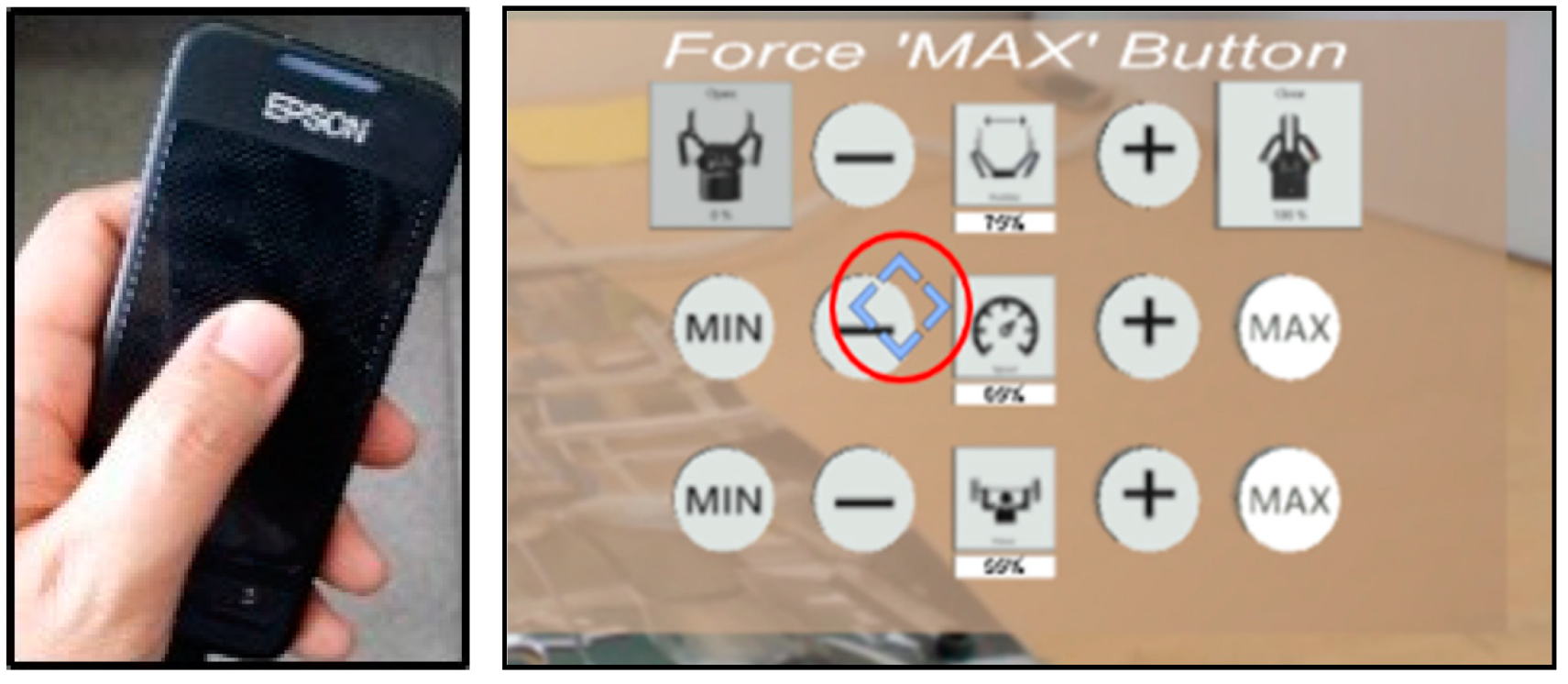
- Multi-touch interaction
- We have conducted a comparative and substantial evaluation of user interactions for AR smart glasses concerning visual contexts and gesture interactions, which suggests new directions for task assistance in wearable AR.
- We have performed quantitative and qualitative experiments to analyze task performance and usability to provide user-centric visualization and interaction.
- Through the experiment, we have found that FOV and visual registration complement each other so that it is necessary to increase the visual focus of the information by calculating degree-of-interest.
- The analysis result was tested by a real use case of industrial workers concerning cognitive load by performing tasks using wearable AR.
2. Related Work
2.1. Visual Context-Based Visualization
2.2. Gesture Interactions
3. Visual Context and Gesture Interaction
3.1. Visual Augmentation Depending on Visual Contexts
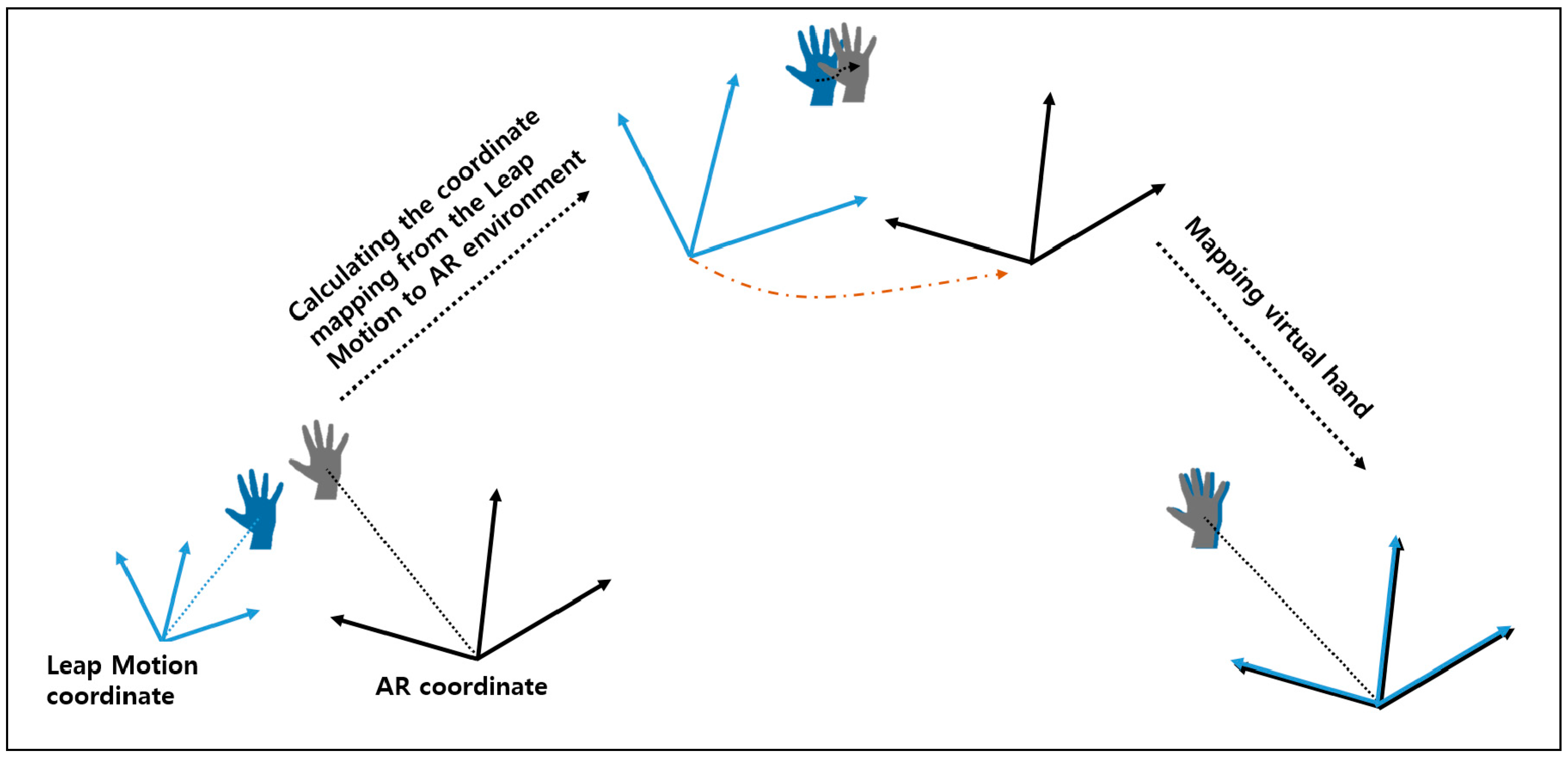
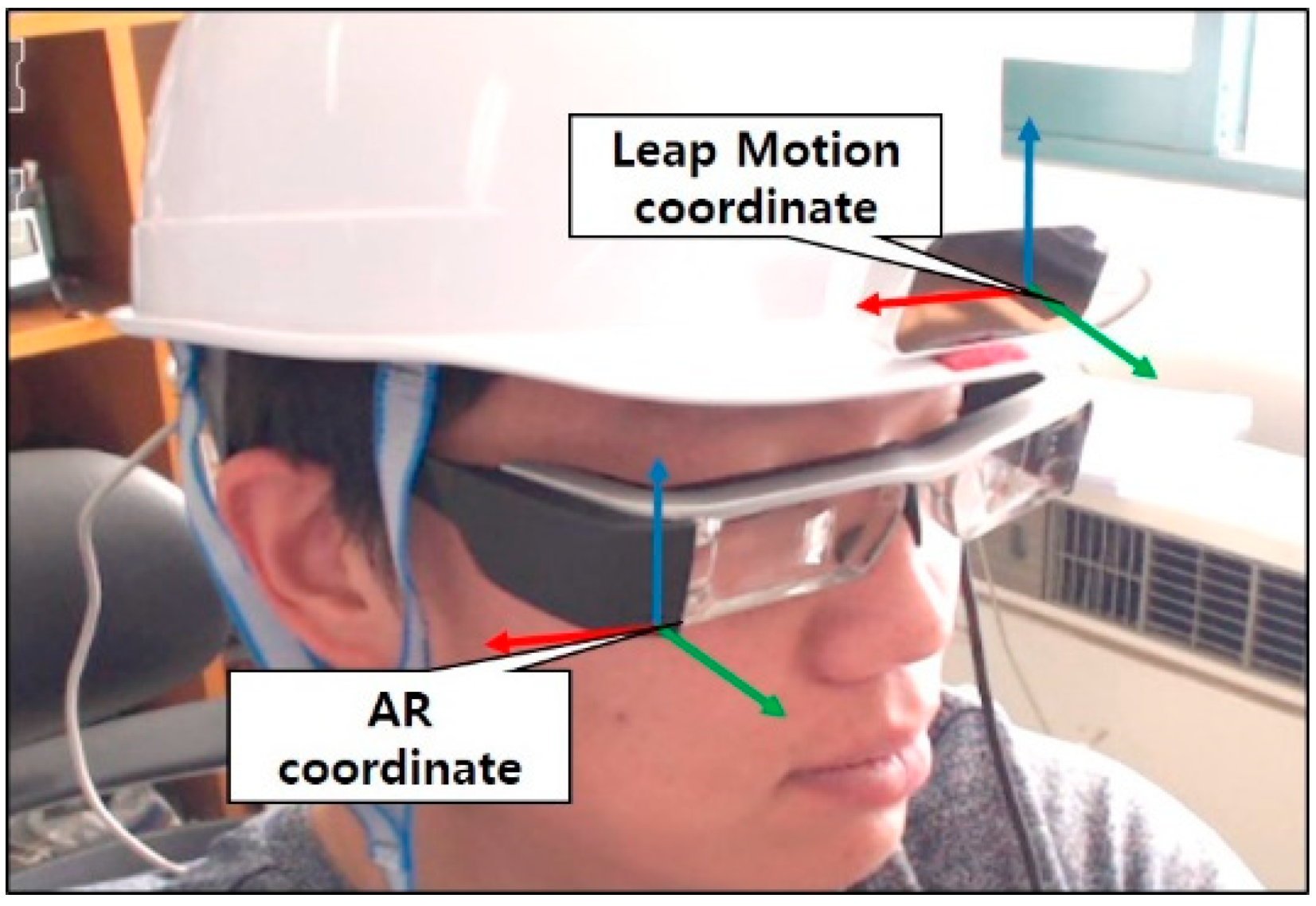
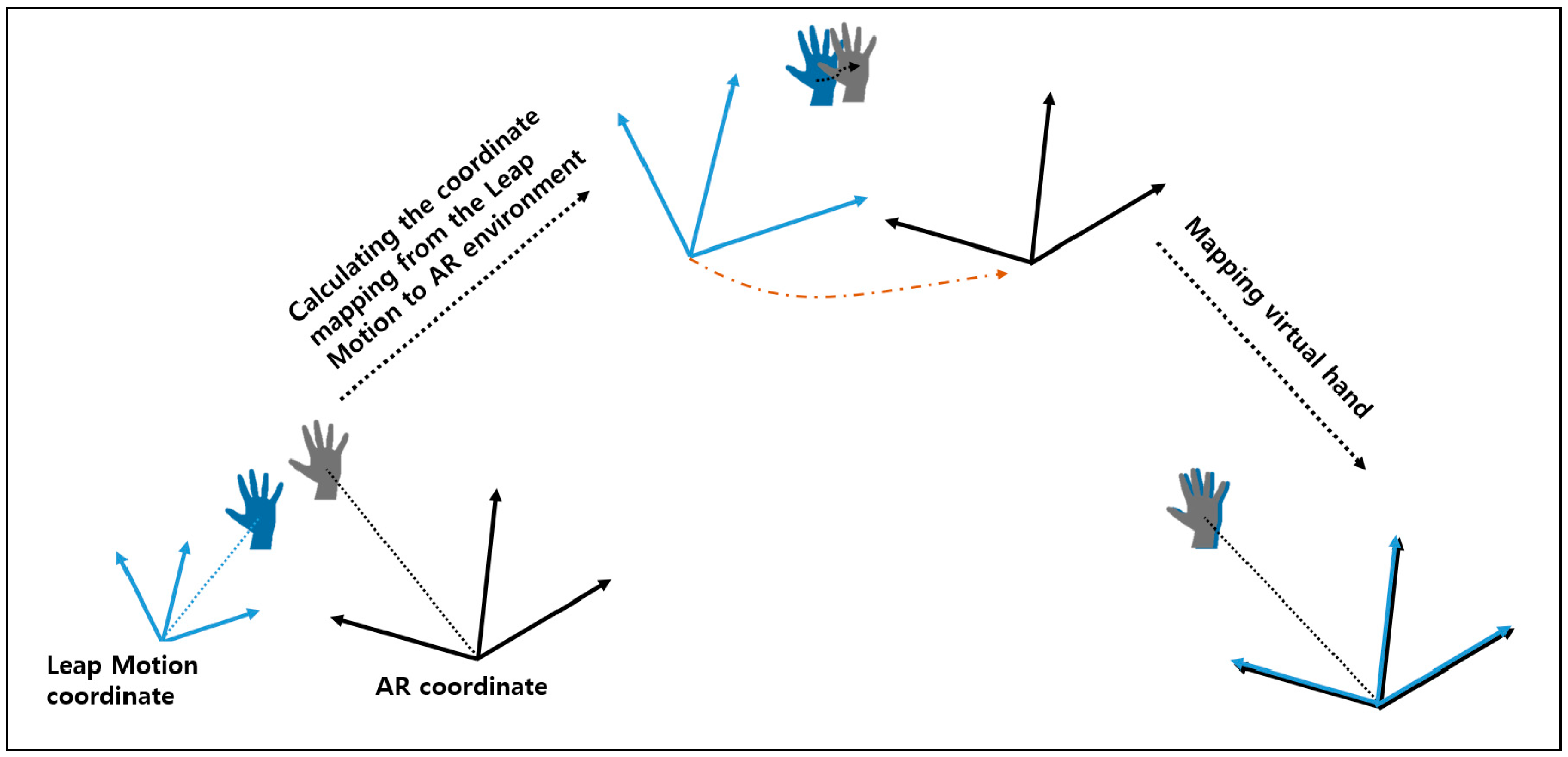
3.2. Gesture Interaction
4. Comparative Evaluation of User Interaction in Wearable AR
4.1. Overview of the Experiment
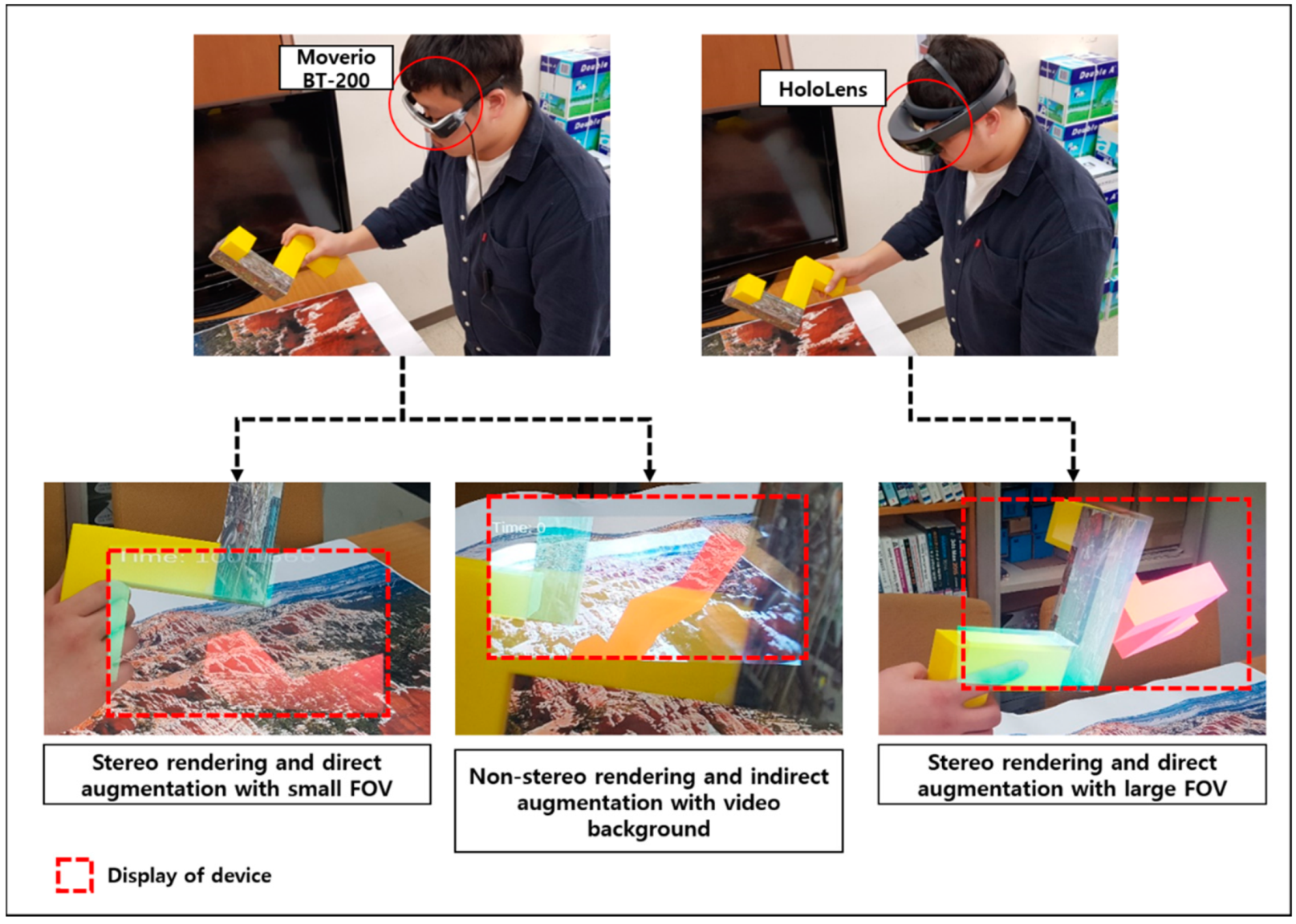
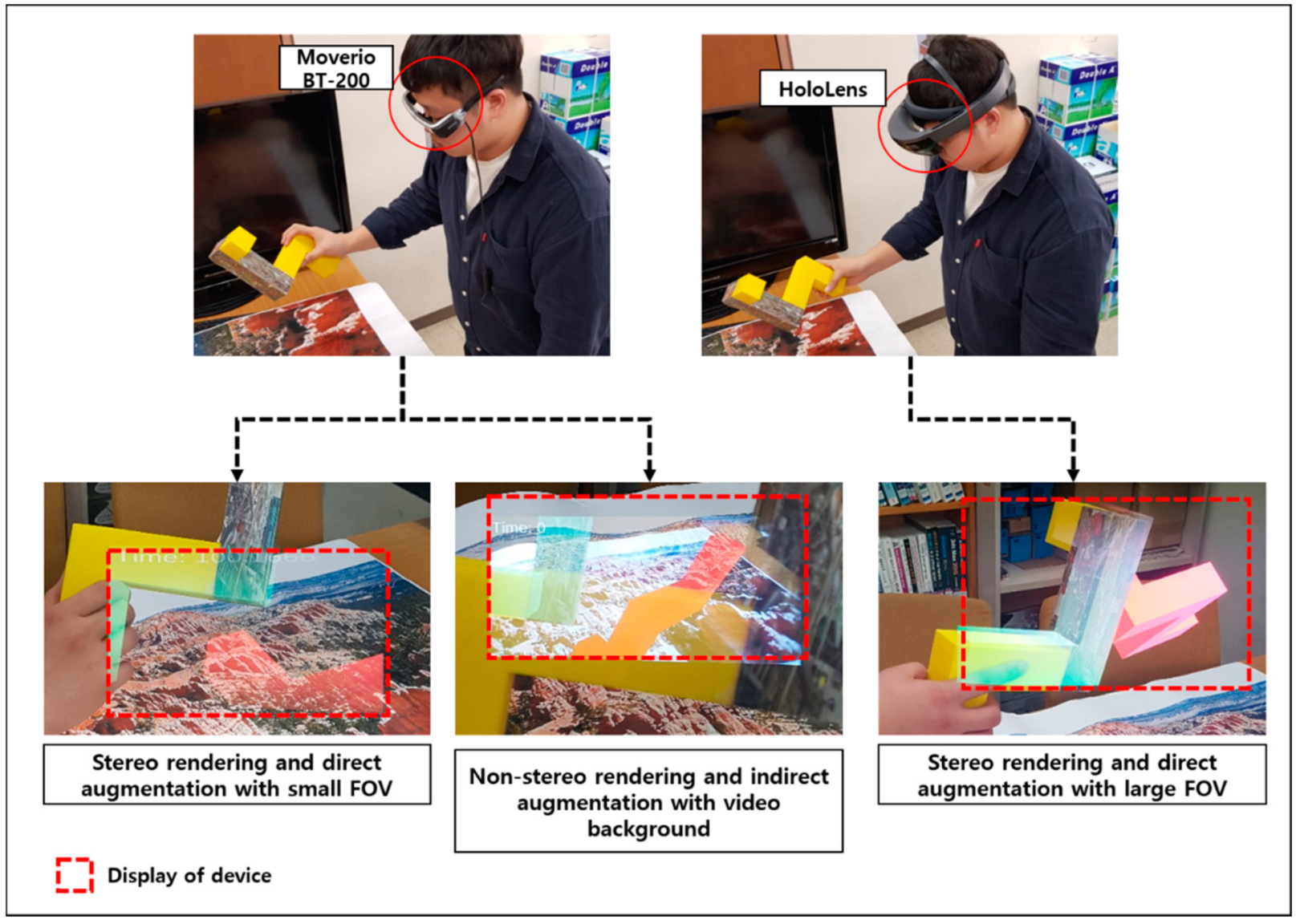
4.2. Experimental Setup
4.3. Experimental Design
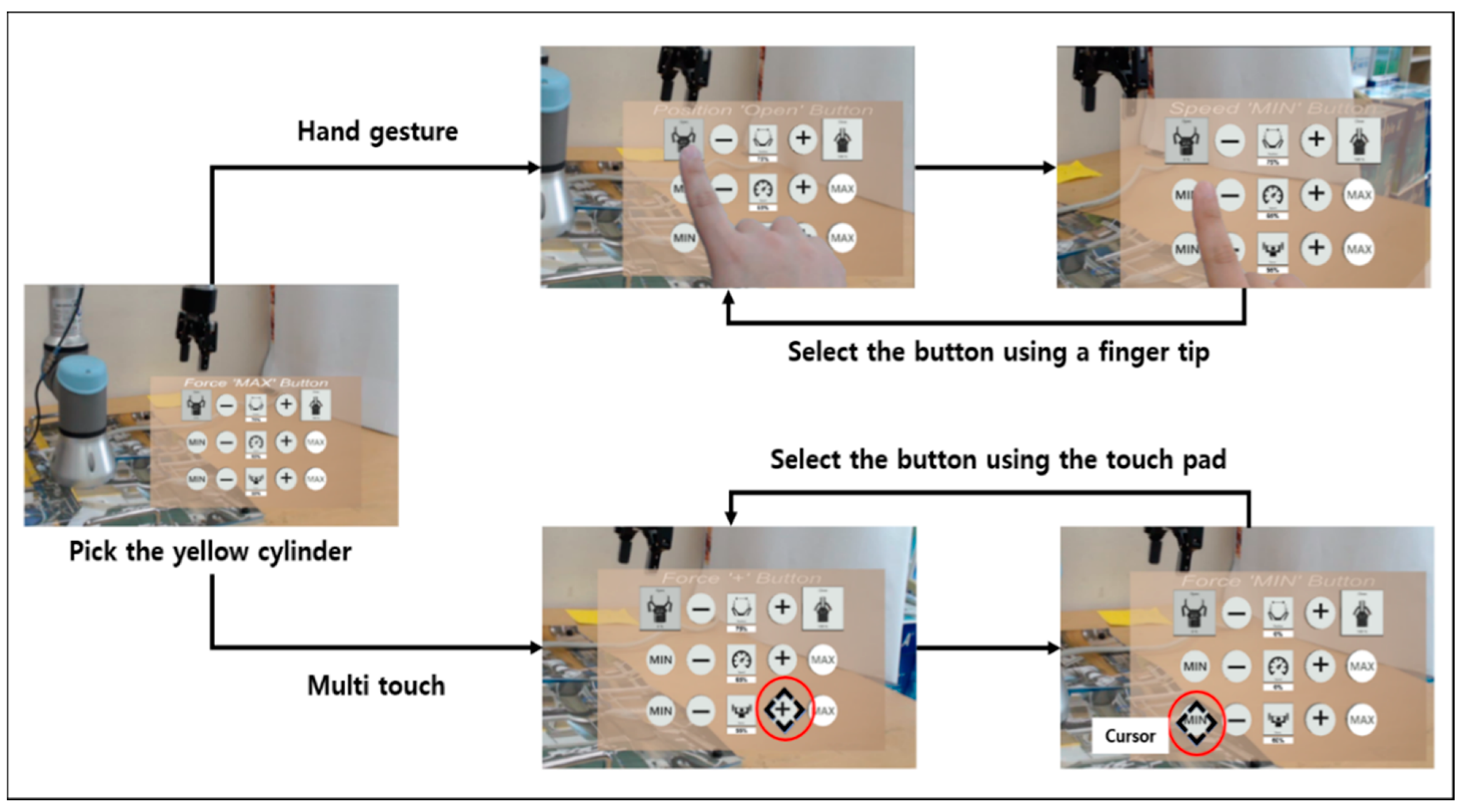
4.3.1. Selection
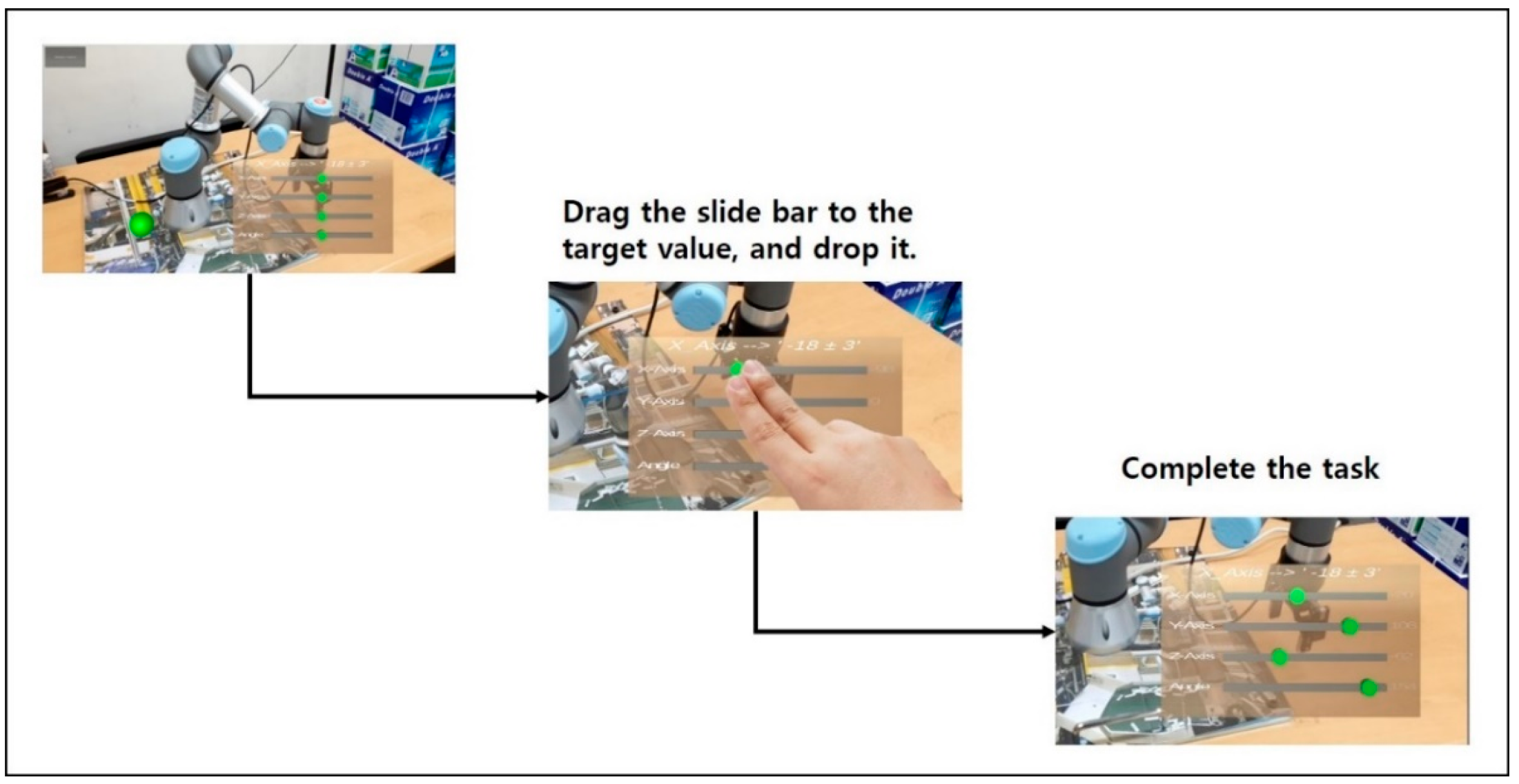
4.3.2. Dragging and Dropping
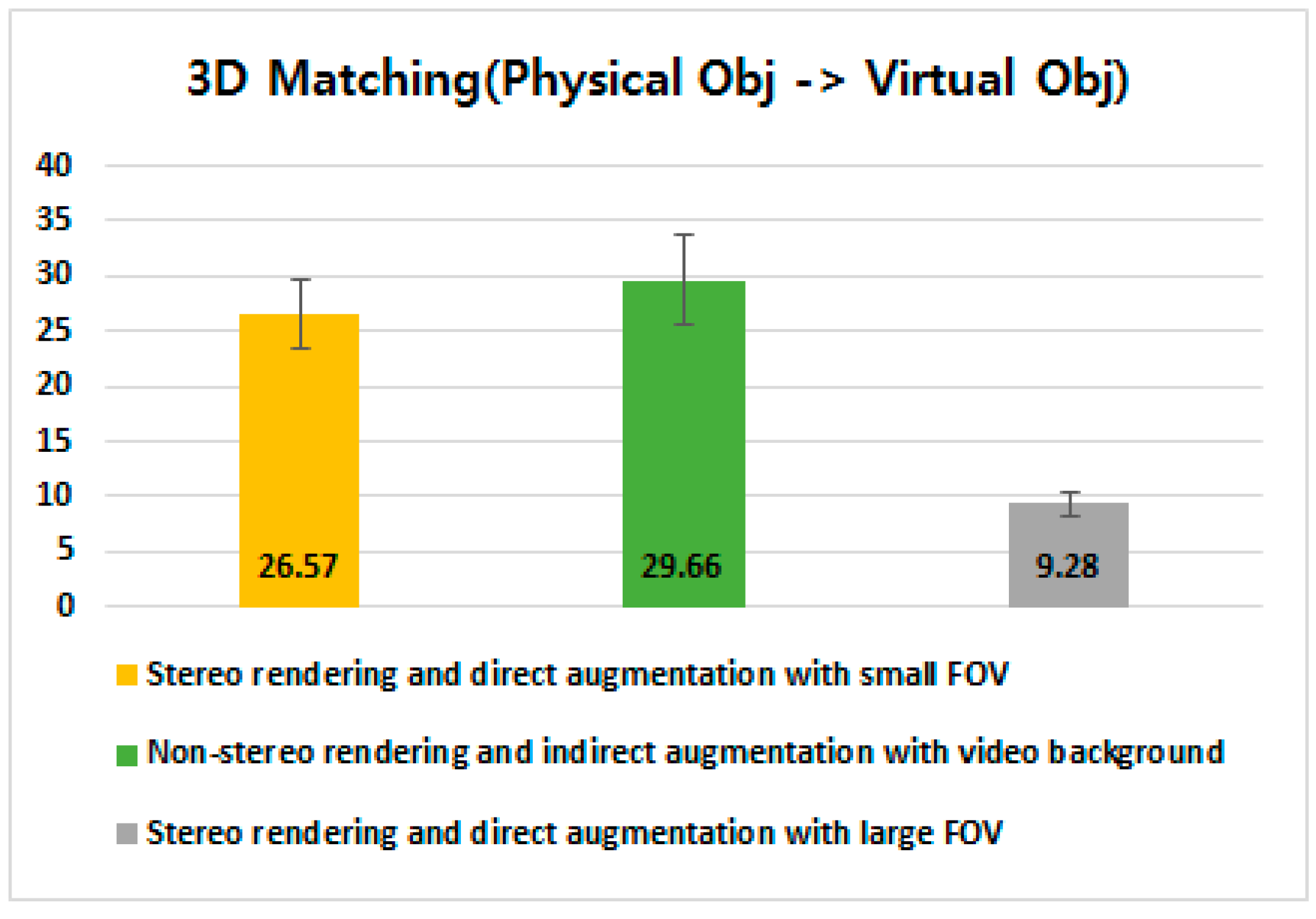
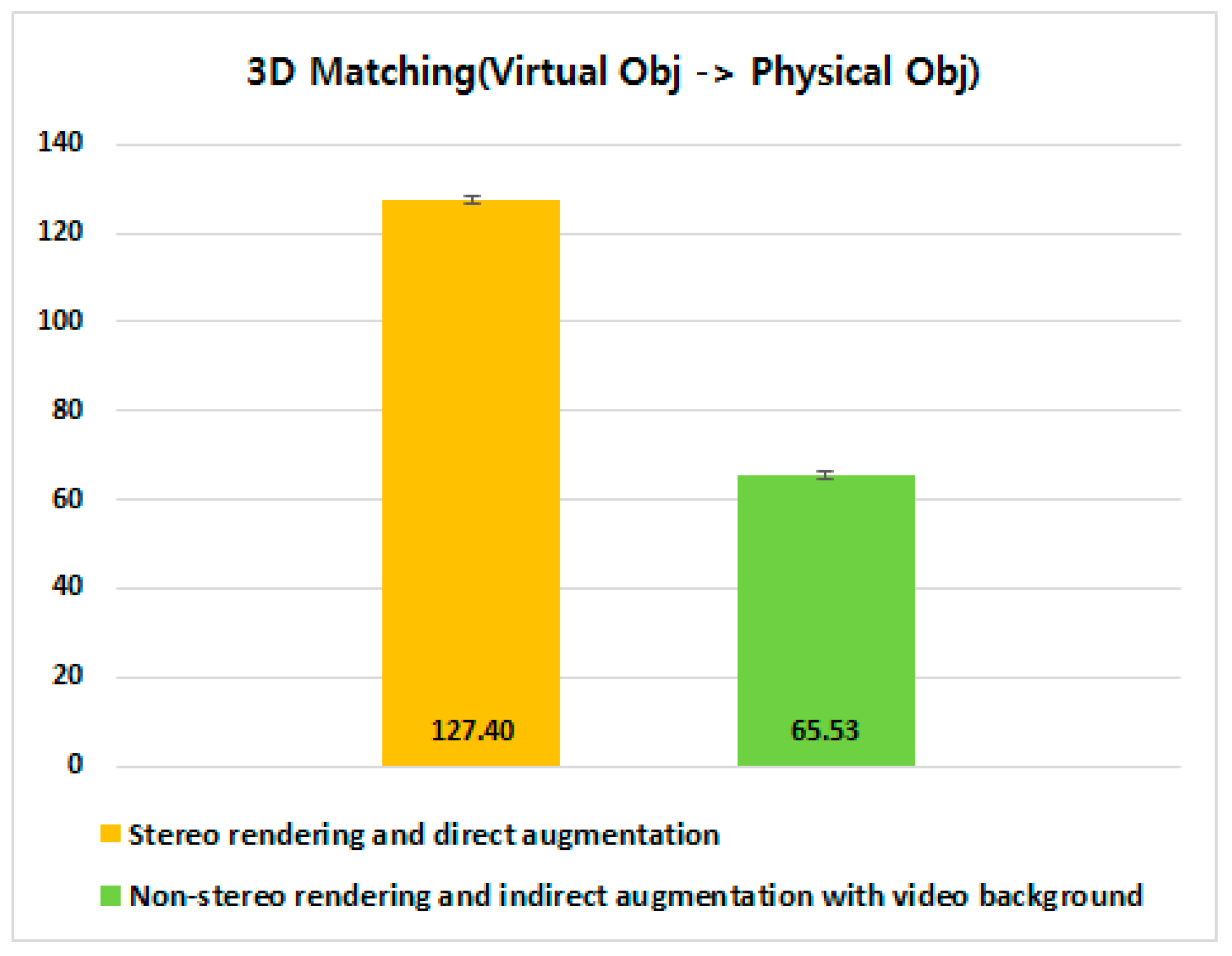
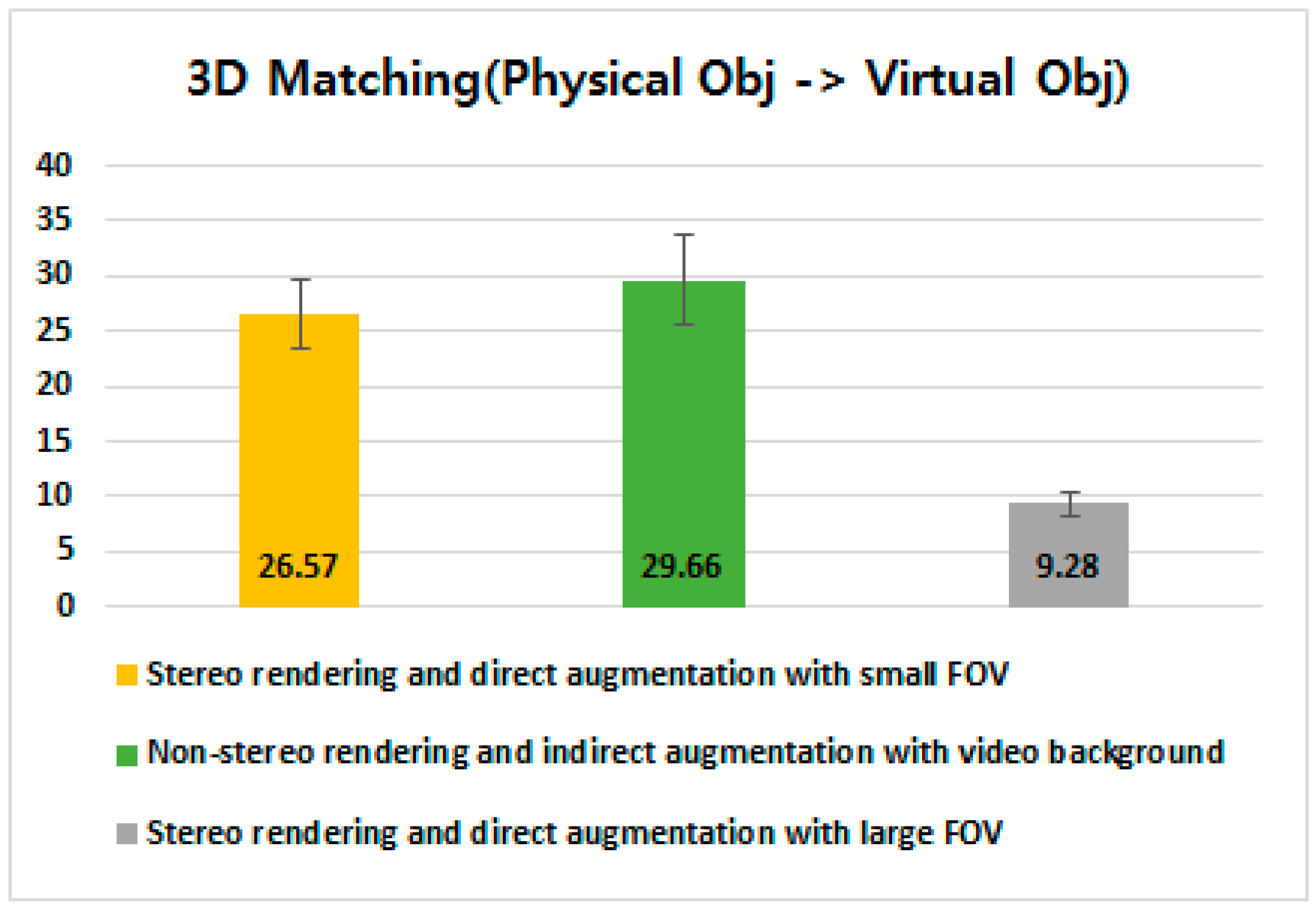
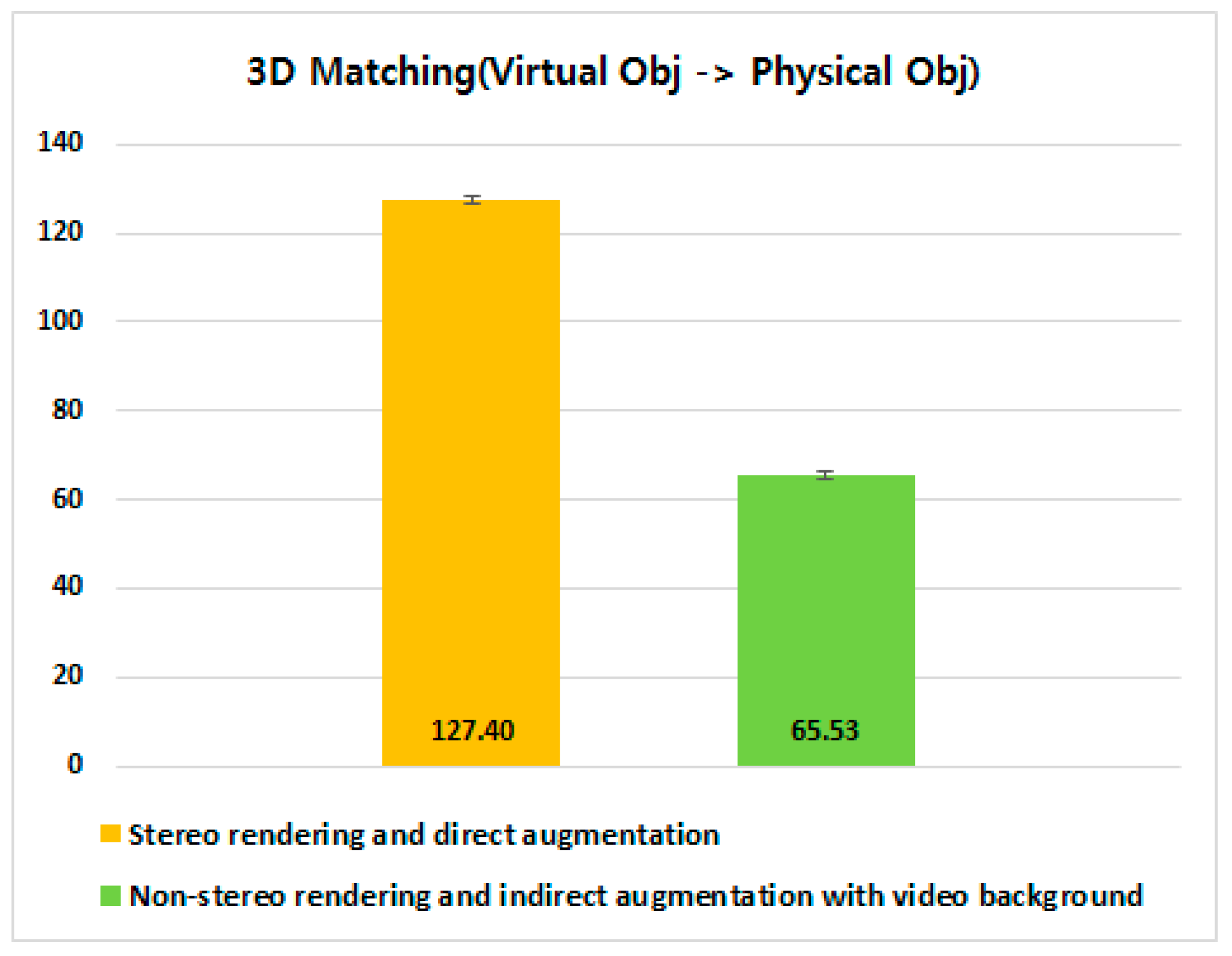
4.3.3. 3D Matching Between a Virtual Object and its Corresponding Physical Object
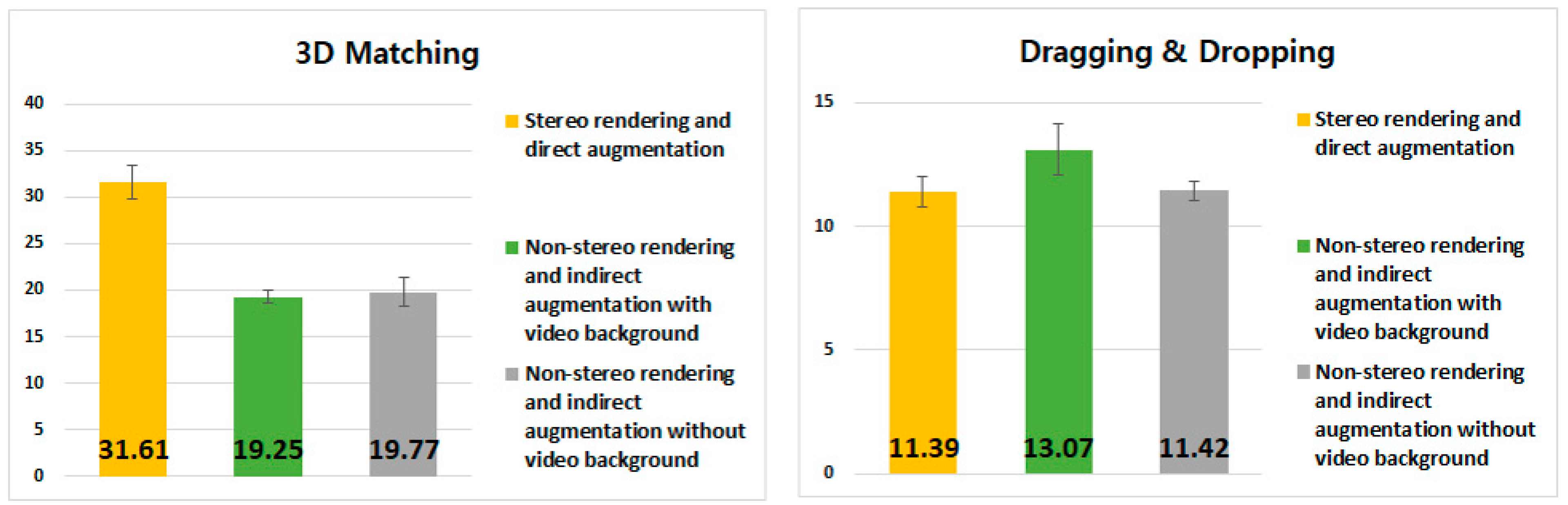
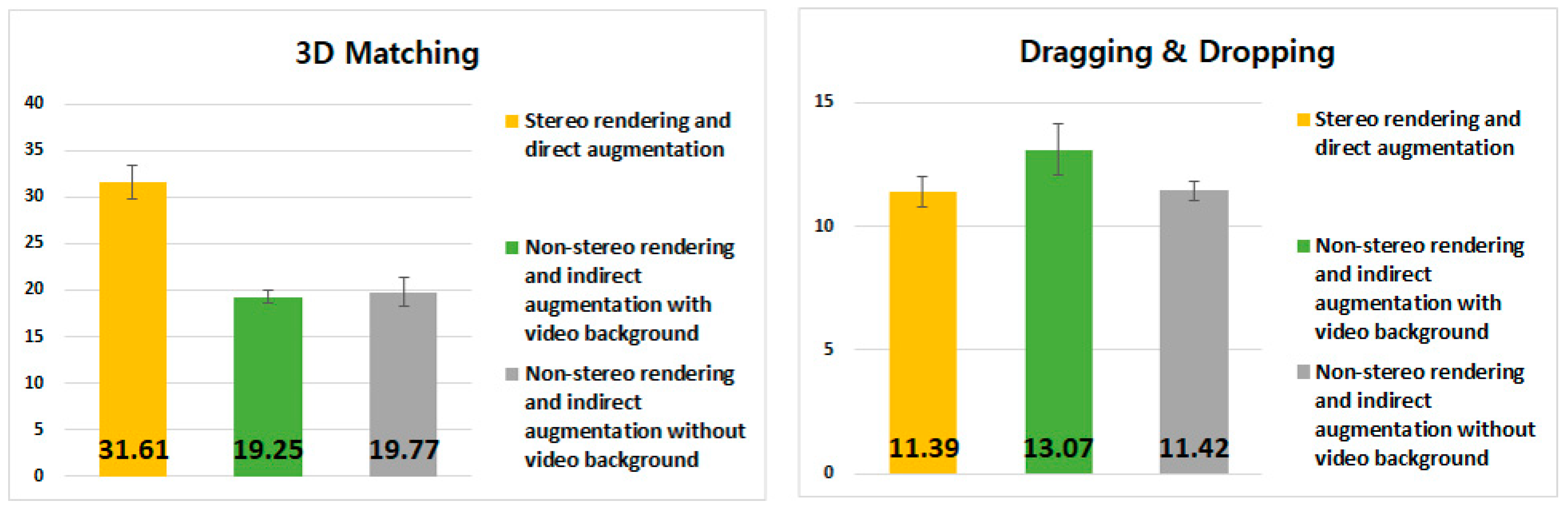
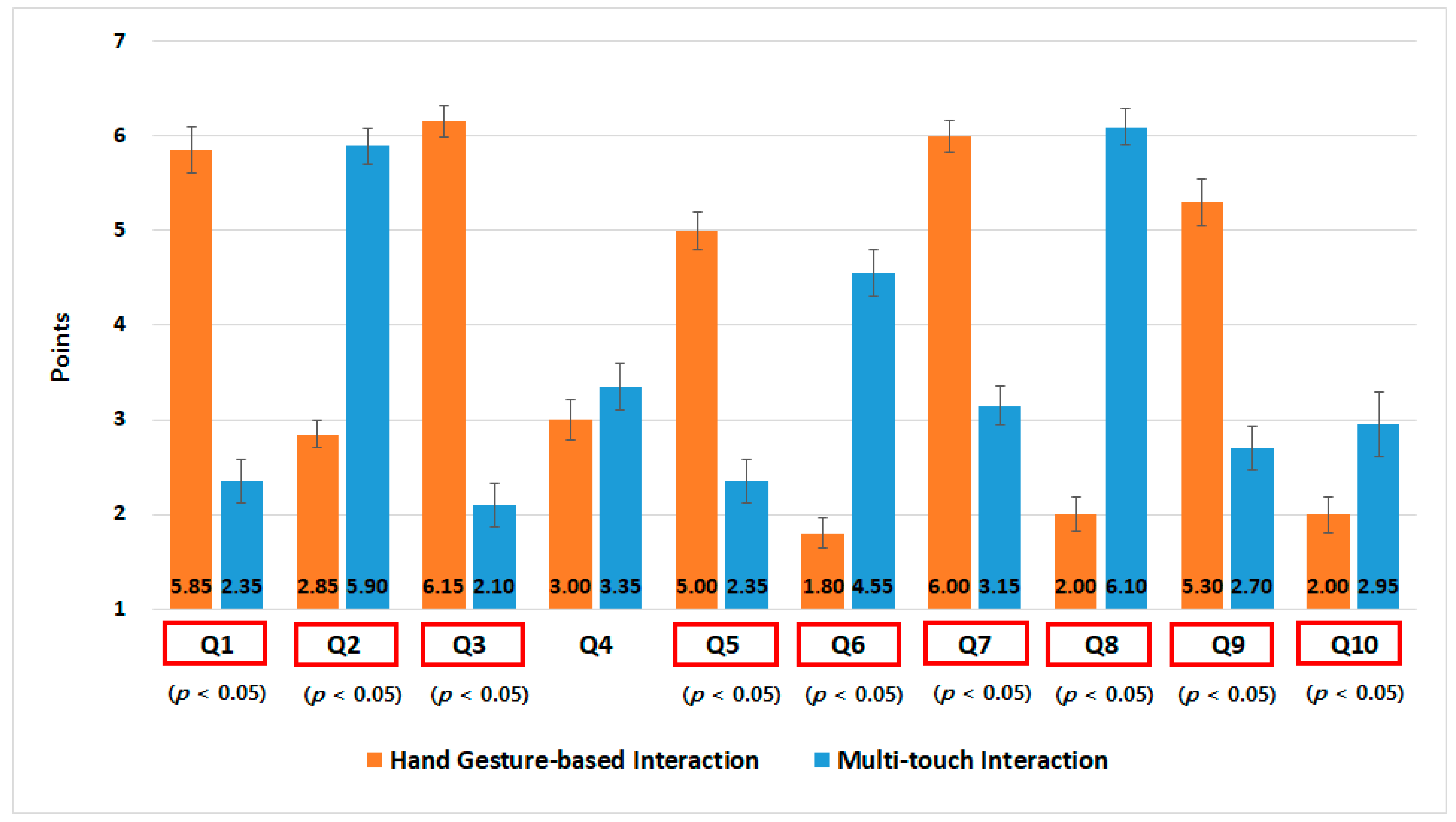
4.4. Experimental Results
5. Comparative Evaluation of Different FOVs
5.1. Experimental Setup and Design
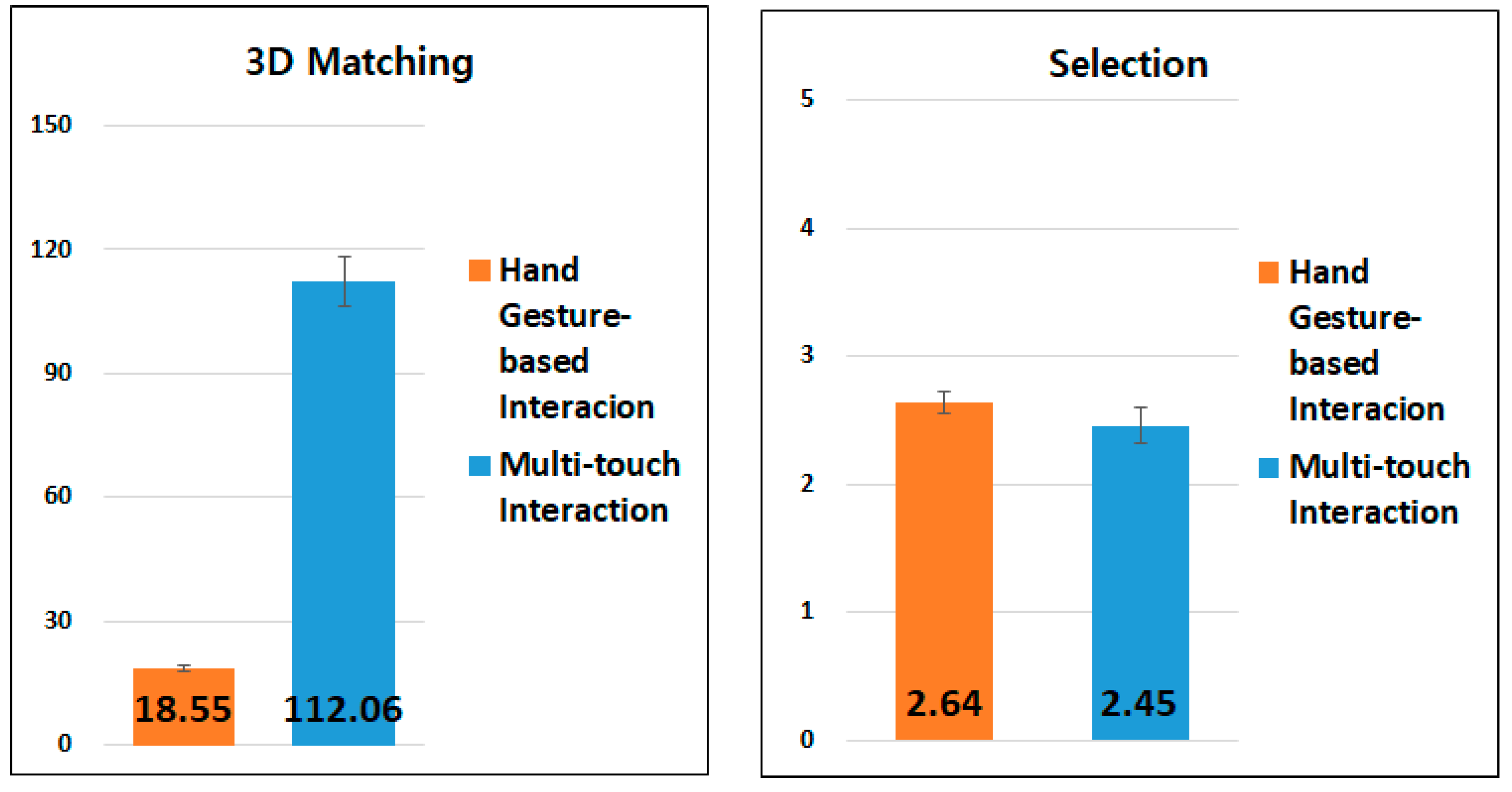
5.2. Experimental Results
5.3. 3D Matching Between Virtual Control and Physical Target Objects (Revisited)
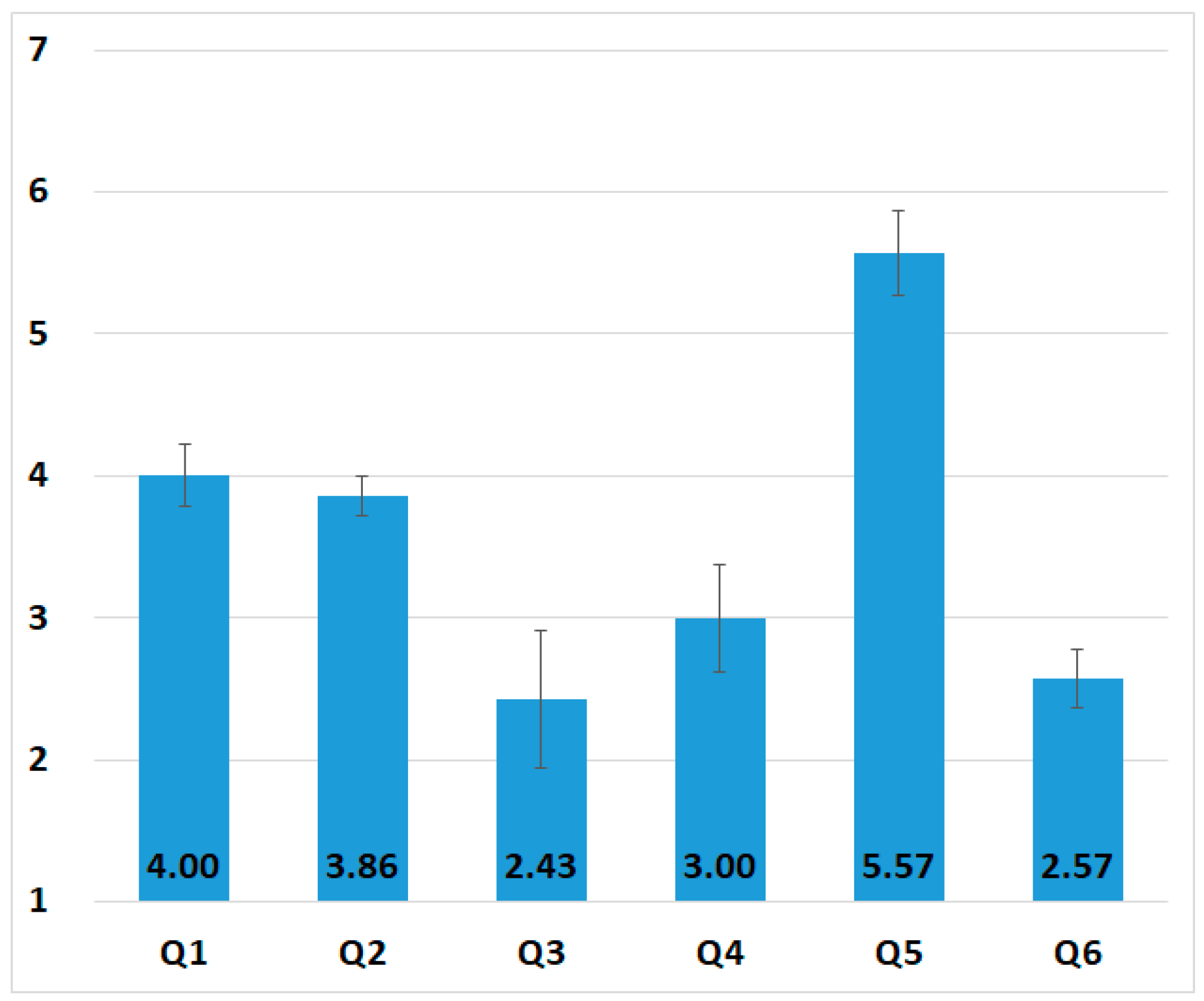
6. Real Use Case Analysis for Industrial Workers
7. Discussion on User Studies and Suggestions for User-Centric Task Assistance
7.1. Discussion on User Studies
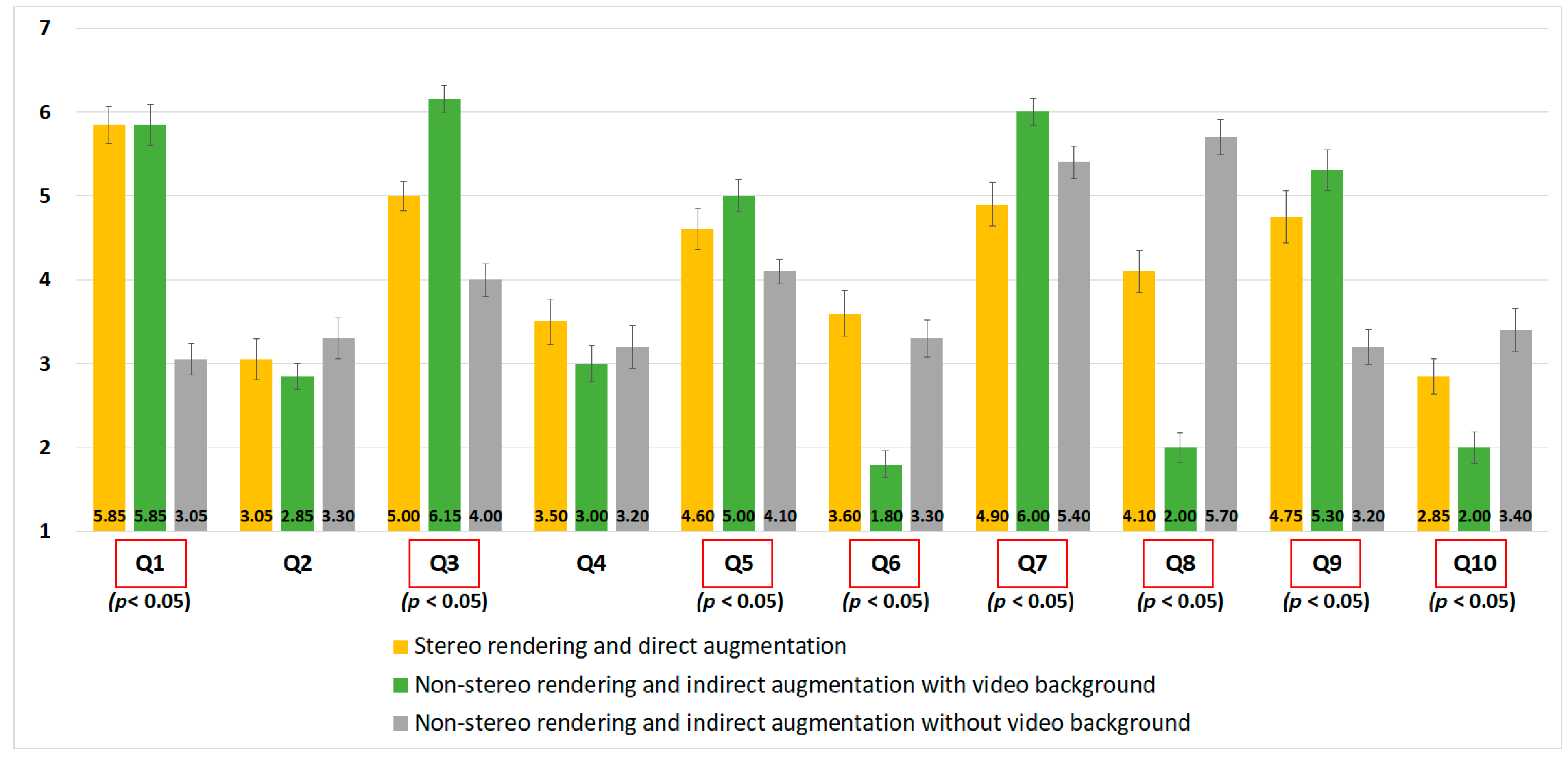
7.1.1. Evaluation for the Visual Context
7.1.2. Evaluation for the Gesture Interaction
7.2. Challenges for Supporting User-Centric Task Assistance
7.2.1. Visual Layout for Cognitive Information Visualization
7.2.2. Hybrid User Interaction
7.2.3. Enhanced Hand Gesture Interaction
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zheng, X.S.; Foucault, C.; Da Silva, P.M.; Dasari, S.; Yang, T.; Goose, S. Eye-wearable technology for machine maintenance: Effects of display position and hands-free operation. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 2125–2134. [Google Scholar]
- Friedrich, W.; Jahn, D.; Schmidt, L. ARVIKA-Augmented reality for development, production and service. In Proceedings of the International Symposium on Mixed and Augmented Reality, Darmstadt, Germany, 1 October 2002; pp. 3–4. [Google Scholar]
- Westerfield, G.; Mitrovic, A.; Billinghurst, M. Intelligent augmented reality training for motherboard assembly. Int. J. Artif. Intell. Educ. 2015, 25, 157–172. [Google Scholar] [CrossRef]
- Kim, M.; Lee, J.Y. Touch and hand gesture-based interactions for directly manipulating 3D virtual objects in mobile augmented reality. Multimed. Tools Appl. 2016, 75, 16529–16550. [Google Scholar] [CrossRef]
- Choi, S.H.; Kim, M.; Lee, J.Y. Situation-dependent remote AR collaborations: Image-based collaboration using a 3D perspective map and live video-based collaboration with a synchronized VR mode. Comput. Ind. 2018, 101, 51–66. [Google Scholar] [CrossRef]
- Syberfeldt, A.; Danielsson, O.; Gustavsson, P. Augmented reality smart glasses in the smart factory: Product evaluation guidelines and review of available products. IEEE Access 2017, 5, 9118–9130. [Google Scholar] [CrossRef]
- Henderson, S.J.; Feiner, S.K. Augmented reality in the psychomotor phase of a procedural task. In Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 191–200. [Google Scholar]
- Khuong, B.M.; Kiyokawa, K.; Miller, A.; La Viola, J.J.; Mashita, T.; Takemura, H. The effectiveness of an AR-based context-aware assembly support system in object assembly. In Proceedings of the IEEE Virtual Reality, Minneapolis, MN, USA, 29 March–2 April 2014; pp. 57–62. [Google Scholar]
- Zhu, Z.; Branzoi, V.; Wolverton, M.; Murray, G.; Vitovitch, N.; Yarnall, L.; Acharya, G.; Samarasekera, S.; Kumar, R. AR-mentor: Augmented reality based mentoring system. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality, Munich, Germany, 10–12 September 2014; pp. 17–22. [Google Scholar]
- Moverio BT-200. Available online: www.epson.com/MoverioBT200 (accessed on 5 April 2017).
- MS HoloLens. Available online: https://www.microsoft.com/en-us/hololens (accessed on 20 March 2018).
- Ergonomics of Human-System Interaction. Available online: https://www.iso.org/obp/ui/#iso:std:iso:9241:-11:ed-2:v1:en (accessed on 10 October 2018).
- Robertson, C.; MacIntyre, B. Adapting to registration error in an intent-based augmentation system. In Virtual and Augmented Reality Applications in Manufacturing, 1st ed.; Ong, S.K., Nee, A.Y.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 147–167. [Google Scholar]
- Robertson, C.M.; MacIntyre, B.; Walker, B.N. An evaluation of graphical context as a means for ameliorating the effects of registration error. IEEE Trans. Vis. Comput. Graph. 2008, 15, 179–192. [Google Scholar] [CrossRef] [PubMed]
- Longo, F.; Nicoletti, L.; Padovano, A. Smart operators in industry 4.0: A human-centered approach to enhance operators’ capabilities and competencies within the new smart factory context. Comput. Ind. Eng. 2017, 113, 144–159. [Google Scholar] [CrossRef]
- Funk, M.; Kritzler, M.; Michahelles, F. HoloCollab: A shared virtual platform for physical assembly training using spatially-aware head-mounted displays. In Proceedings of the Seventh International Conference on the Internet of Things, Linz, Austria, 22–25 October 2017; p. 19. [Google Scholar]
- Benko, H.; Ofek, E.; Zheng, F.; Wilson, A.D. Fovear: Combining an optically see-through near-eye display with projector-based spatial augmented reality. In Proceedings of the 28th Annual ACM Symposium on User Interface Software and Technology, Charlotte, NC, USA, 11–15 November 2015; pp. 129–135. [Google Scholar]
- Nambu, R.; Kimoto, T.; Morita, T.; Yamaguchi, T. Integrating smart glasses with question-answering module in assistant work environment. Procedia Comput. Sci. 2016, 96, 1772–1781. [Google Scholar] [CrossRef]
- Büttner, S.; Funk, M.; Sand, O.; Röcker, C. Using head-mounted displays and in-situ projection for assistive systems: A comparison. In Proceedings of the 9th ACM international Conference on Pervasive Technologies Related to Assistive Environments, Corfu, Island, Greece, 29 June–1 July 2016; p. 44. [Google Scholar]
- Funk, M.; Kosch, T.; Schmidt, A. Interactive worker assistance: Comparing the effects of in-situ projection, head-mounted displays, tablet, and paper instructions. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 934–939. [Google Scholar]
- Ha, T.; Feiner, S.; Woo, W. WeARHand: Head-worn, RGB-D camera-based, bare-hand user interface with visually enhanced depth perception. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality, Munich, Germany, 10–12 September 2014; pp. 219–228. [Google Scholar]
- Wang, X.; Ong, S.K.; Nee, A.Y.C. Real-virtual components interaction for assembly simulation and planning. Robot. Comput. Integr. Manuf. 2016, 41, 102–114. [Google Scholar] [CrossRef]
- Wang, X.; Ong, S.K.; Nee, A.Y.C. Multi-modal augmented-reality assembly guidance based on bare-hand interface. Adv. Eng. Inform. 2016, 30, 406–421. [Google Scholar] [CrossRef]
- Lee, J.Y.; Rhee, G.W.; Seo, D.W. Hand gesture-based tangible interactions for manipulating virtual objects in a mixed reality environment. Int. J. Adv. Manuf. Technol. 2010, 51, 1069–1082. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Hui, P. Ubii: Towards seamless interaction between digital and physical worlds. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Austria, 26–30 October 2015; pp. 341–350. [Google Scholar]
- He, Z.; Yang, X. Hand-based interaction for object manipulation with augmented reality glasses. In Proceedings of the 13th ACM SIGGRAPH International Conference on Virtual-Reality Continuum and its Applications in Industry, Shenzhen, China, 30 November–2 December 2014; pp. 227–230. [Google Scholar]
- Brancati, N.; Caggianese, G.; De Pietro, G.; Frucci, M.; Gallo, L.; Neroni, P. Usability evaluation of a wearable augmented reality system for the enjoyment of the cultural heritage. In Proceedings of the 11th International Conference on Signal-Image Technology and Internet-Based Systems, Bangkok, Thailand, 23–27 November 2015; pp. 768–774. [Google Scholar]
- Hsieh, Y.T.; Jylhä, A.; Orso, V.; Gamberini, L.; Jacucci, G. Designing a willing-to-use-in-public hand gestural interaction technique for smart glasses. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 4203–4215. [Google Scholar]
- Haque, F.; Nancel, M.; Vogel, D. Myopoint: Pointing and clicking using forearm mounted electromyography and inertial motion sensors. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3653–3656. [Google Scholar]
- Dudley, J.J.; Vertanen, K.; Kristensson, P.O. Fast and Precise Touch-Based Text Entry for Head-Mounted Augmented Reality with Variable Occlusion. ACM Trans. Comput. Hum. Int. 2018, 25, 30. [Google Scholar] [CrossRef]
- Ha, T.; Woo, W. ARWand: Phone-based 3d object manipulation in augmented reality environment. In Proceedings of the International Symposium on Ubiquitous Virtual Reality, Jeju, Korea, 1–4 July 2011; pp. 44–47. [Google Scholar]
- Yang, Y.; Shim, J.; Chae, S.; Han, T.D. Interactive Augmented Reality Authoring System using mobile device as input method. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2016; pp. 1429–1432. [Google Scholar]
- Ahn, S.; Heo, S.; Lee, G. Typing on a smartwatch for smart glasses. In Proceedings of the ACM International Conference on Interactive Surfaces and Spaces, Brighton, UK, 17–20 October 2017; pp. 201–209. [Google Scholar]
- Whitmire, E.; Jain, M.; Jain, D.; Nelson, G.; Karkar, R.; Patel, S.; Goel, M. Digitouch: Reconfigurable thumb-to-finger input and text entry on head-mounted displays. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 113:1–113:21. [Google Scholar] [CrossRef]
- Wang, C.Y.; Chu, W.C.; Chiu, P.T.; Hsiu, M.C.; Chiang, Y.H.; Chen, M.Y. PalmType: Using palms as keyboards for smart glasses. In Proceedings of the 17th International Conference on Human-Computer Interaction with Mobile Devices and Services, Copenhagen, Denmark, 24–27 August 2015; pp. 153–160. [Google Scholar]
- Lissermann, R.; Huber, J.; Hadjakos, A.; Nanayakkara, S.; Mühlhäuser, M. EarPut: Augmenting ear-worn devices for ear-based interaction. In Proceedings of the 26th Australian Computer-Human Interaction Conference on Designing Futures: The Future of Design, Sydney, New South Wales, Australia, 2–5 December 2014; pp. 300–307. [Google Scholar]
- Raynal, M.; Gauffre, G.; Bach, C.; Schmitt, B.; Dubois, E. Tactile camera vs. tangible camera: Taking advantage of small physical artefacts to navigate into large data collection. In Proceedings of the 6th Nordic Conference on Human-Computer Interaction: Extending Boundaries, Reykjavik, Iceland, 16–20 October 2010; pp. 373–382. [Google Scholar]
- Terrenghi, L.; Kirk, D.; Sellen, A.; Izadi, S. Affordances for manipulation of physical versus digital media on interactive surfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 22–27 April 2006; pp. 1157–1166. [Google Scholar]
- Unity3D. Available online: http://unity3d.com (accessed on 17 December 2017).
- Vuforia SDK. Available online: https://www.vuforia.com/ (accessed on 18 December 2017).
- Leap Motion. Available online: https://www.leapmotion.com/ (accessed on 27 December 2017).
- Moser, K.R.; Swan, J.E. Evaluation of user-centric optical see-through head-mounted display calibration using a leap motion controller. In Proceedings of the IEEE Symposium on 3D User Interfaces, Greenville, SC, USA, 19–20 March 2016; pp. 159–167. [Google Scholar]
- Umeyama, S. Least-squares estimation of transformation parameters between two point patterns. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 4, 376–380. [Google Scholar] [CrossRef]
- Nielsen, J. Why You Only Need to Test with 5 Users? 2000. Available online: http://www. nngroup.com/articles/why-you-only-need-to-test-with-5-users/ (accessed on 3 December 2018).
- Bangor, A.; Kortum, P.; Miller, J. Determining what individual SUS scores mean: Adding an adjective rating scale. J. Usability Stud. 2009, 4, 114–123. [Google Scholar]
- Welch’s ANOVA Test. Available online: https://www.real-statistics.com/one-way-analysis-of-variance-anova/welchs-procedure/ (accessed on 28 February 2019).
- Shepard, R.N.; Metzler, J. Mental rotation of three-dimensional objects. Science 1971, 171, 701–703. [Google Scholar] [CrossRef] [PubMed]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. Adv. Psychol. 1988, 52, 139–183. [Google Scholar]
- Furnas, G.W. Generalized fisheye views. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 13–17 April 1986; pp. 16–23. [Google Scholar]
- Belkacem, I.; Pecci, I.; Martin, B. Smart Glasses: A semantic fisheye view on tiled user interfaces. In Proceedings of the Federated Conference on Computer Science and Information Systems, Gdańsk, Poland, 11–14 September 2016; pp. 1405–1408. [Google Scholar]
- Lee, L.H.; Hui, P. Interaction methods for smart glasses: A survey. IEEE Access 2018, 6, 28712–28732. [Google Scholar] [CrossRef]










© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Choi, S.H.; Park, K.-B.; Lee, J.Y. User Interactions for Augmented Reality Smart Glasses: A Comparative Evaluation of Visual Contexts and Interaction Gestures. Appl. Sci. 2019, 9, 3171. https://doi.org/10.3390/app9153171
Kim M, Choi SH, Park K-B, Lee JY. User Interactions for Augmented Reality Smart Glasses: A Comparative Evaluation of Visual Contexts and Interaction Gestures. Applied Sciences. 2019; 9(15):3171. https://doi.org/10.3390/app9153171
Chicago/Turabian StyleKim, Minseok, Sung Ho Choi, Kyeong-Beom Park, and Jae Yeol Lee. 2019. "User Interactions for Augmented Reality Smart Glasses: A Comparative Evaluation of Visual Contexts and Interaction Gestures" Applied Sciences 9, no. 15: 3171. https://doi.org/10.3390/app9153171
APA StyleKim, M., Choi, S. H., Park, K.-B., & Lee, J. Y. (2019). User Interactions for Augmented Reality Smart Glasses: A Comparative Evaluation of Visual Contexts and Interaction Gestures. Applied Sciences, 9(15), 3171. https://doi.org/10.3390/app9153171