Fault Diagnosis of Rolling Bearings in Rail Train Based on Exponential Smoothing Predictive Segmentation and Improved Ensemble Learning Algorithm

Abstract
:Featured Application
Abstract
1. Introduction
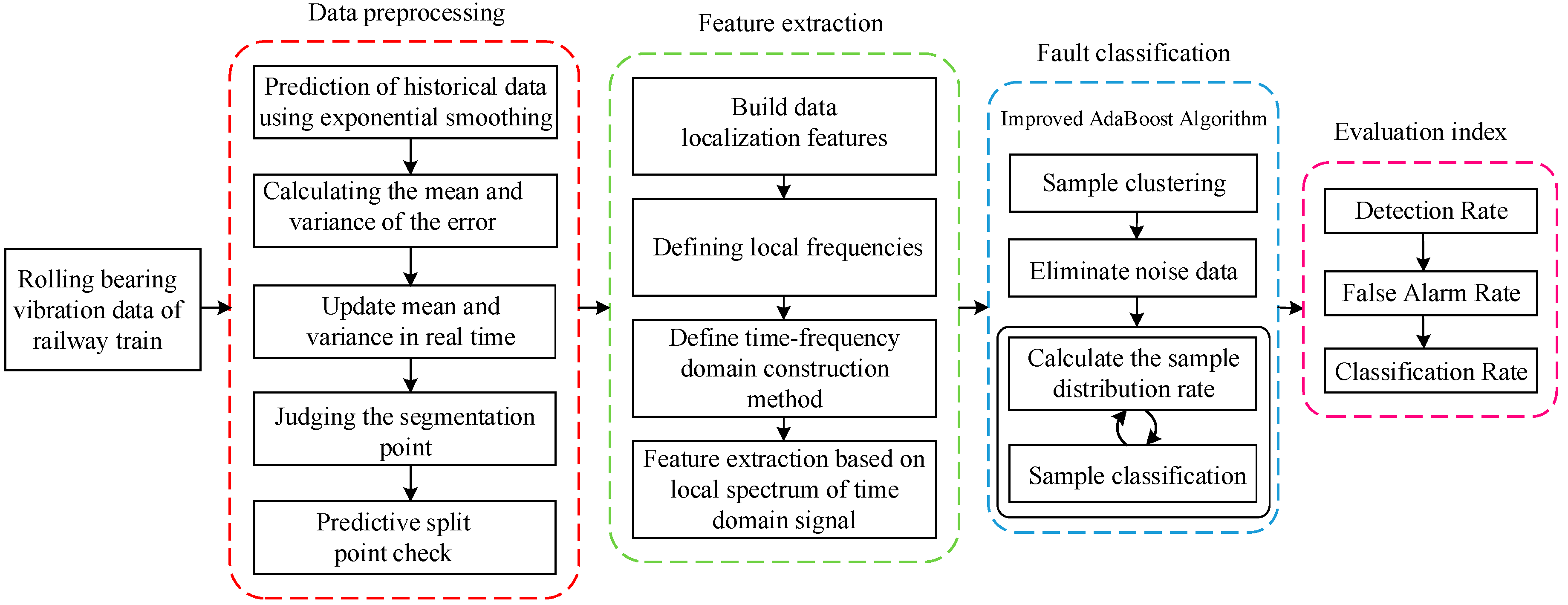
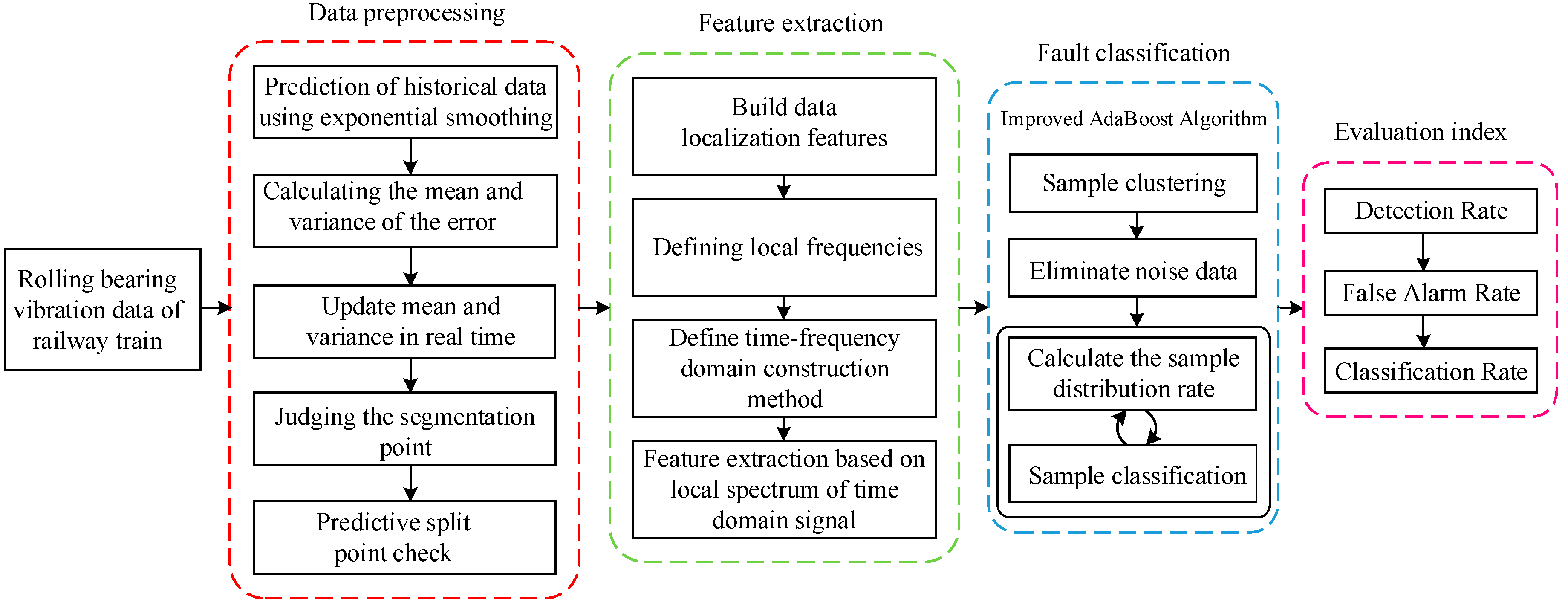
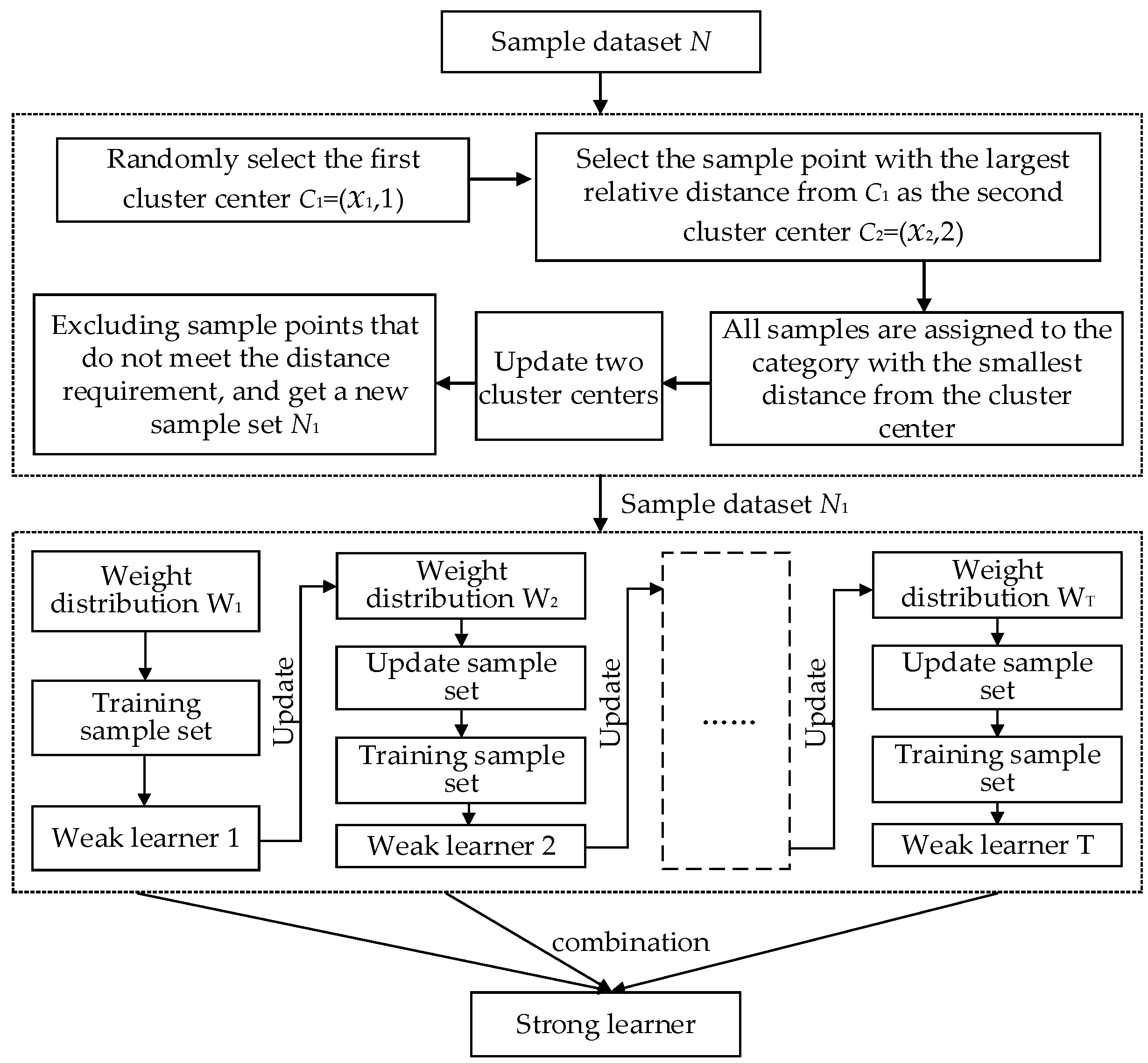
2. Complete Fault Diagnosis Process
- (1)
- Firstly, the data is cleaned, and the data dimension is unified by the method of data visualization; then the exponential smoothing method is used to smooth the sequence to eliminate the random error, and the main trend of the time-series is obtained. The adaptive sliding window model based on the short-term prediction ability of the exponential smoothing method and the statistical characteristics of historical data is used to segment the time-series data, and the relationship between the statistical characteristics of the historical data and the prediction error is used to determine the segmentation point.In the process of detecting data and transmitting data by the sensor, it is possible to be interfered to obtain an unrealized outlier point. Therefore, in the process of detecting the segmentation point, it is necessary to add a verification step to determine that the obtained split point is not an outlier generated due to interference. In the verification step, the method of setting the flag is used, that is, when a certain point of the time-series does not satisfy the historical trend, the point is set as a suspicious segmentation point. Then, check the next point, when the next point also does not satisfy the historical trend, the suspect split point is determined as the split point, and the flag bit is set; otherwise, the suspicious segmentation point is determined to be the outlier point, and the flag bit is cleared.
- (2)
- The nonlinear and non-stationary data characteristics extraction method based on local frequency is designed, which smartly combines the split point obtained from preprocessed data with the spectrum analysis and constructs the localization feature of data. Then, the definition of local frequency and the construction method of time-frequency-domain to proceed with the feature extraction are finalized. This method overcomes the limitation of HHT, only applicable to describe the narrowband signal, while in the meantime, it makes up the setback of Fourier global frequency, which is only worthy for unlimited fluctuating periodical signals.
- (3)
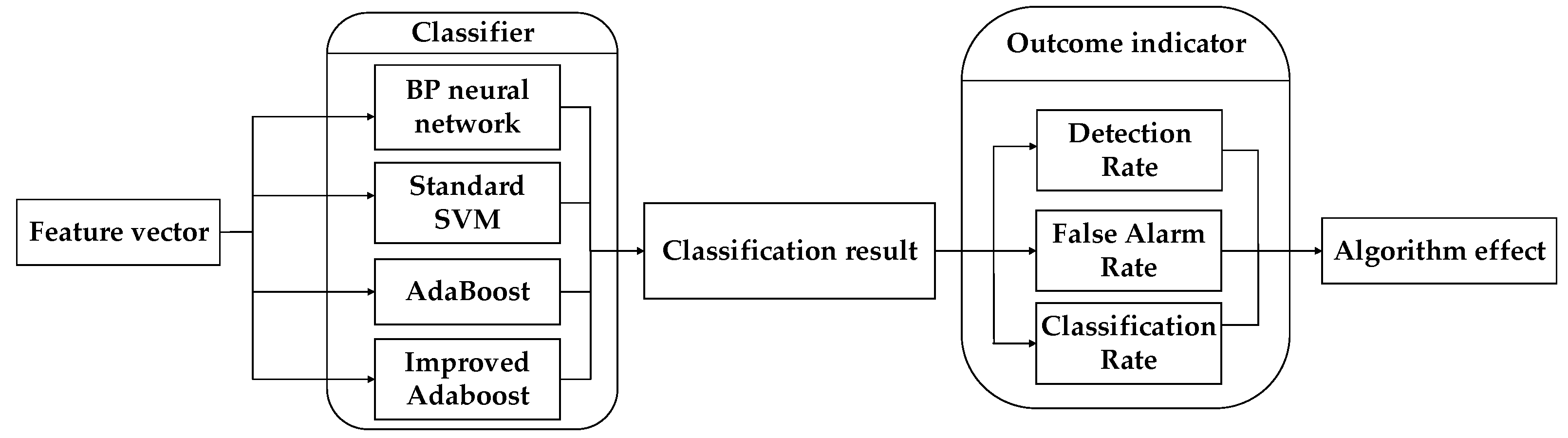
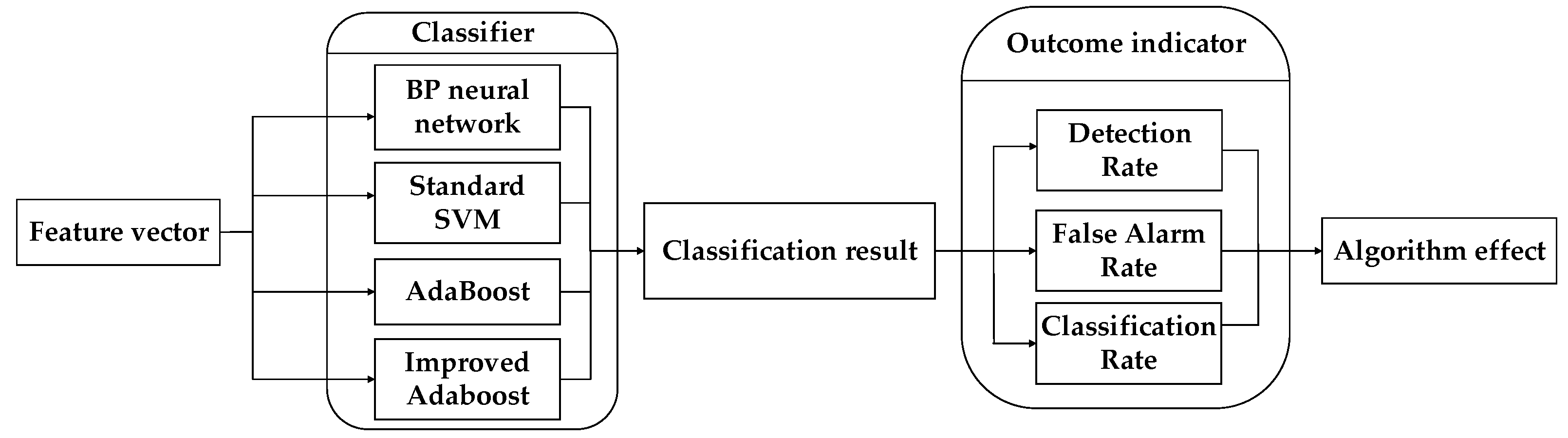
- Aiming at the shortcomings of the AdaBoost algorithm in anti-noise, an Improved AdaBoost Algorithm (IAA) is proposed. The method first clusters the data, filters out the noise data, and then combines AdaBoost for classification experiments which enhances the anti-noise ability and improves the classification accuracy. During the learning of the base classifier, the distribution rate of the sample is continuously calculated, and the samples with excessive sample distribution rate are deleted. The IAA is compared with the current mainstream Back Propagation (BP) neural network, standard SVM, and AdaBoost. The classification results of each classification algorithm are obtained through experiments.
- (4)
- To compare the performance of each classification algorithm, three evaluation indexes, namely Detection Rate (DR), False Alarm Rate (FAR), and Classification Rate (CR), are defined. The classification results of BP neural network, standard SVM network, AdaBoost, and IAA are evaluated, respectively. The superiority of the IAA is reflected by comparison.
3. Fault Diagnosis Method
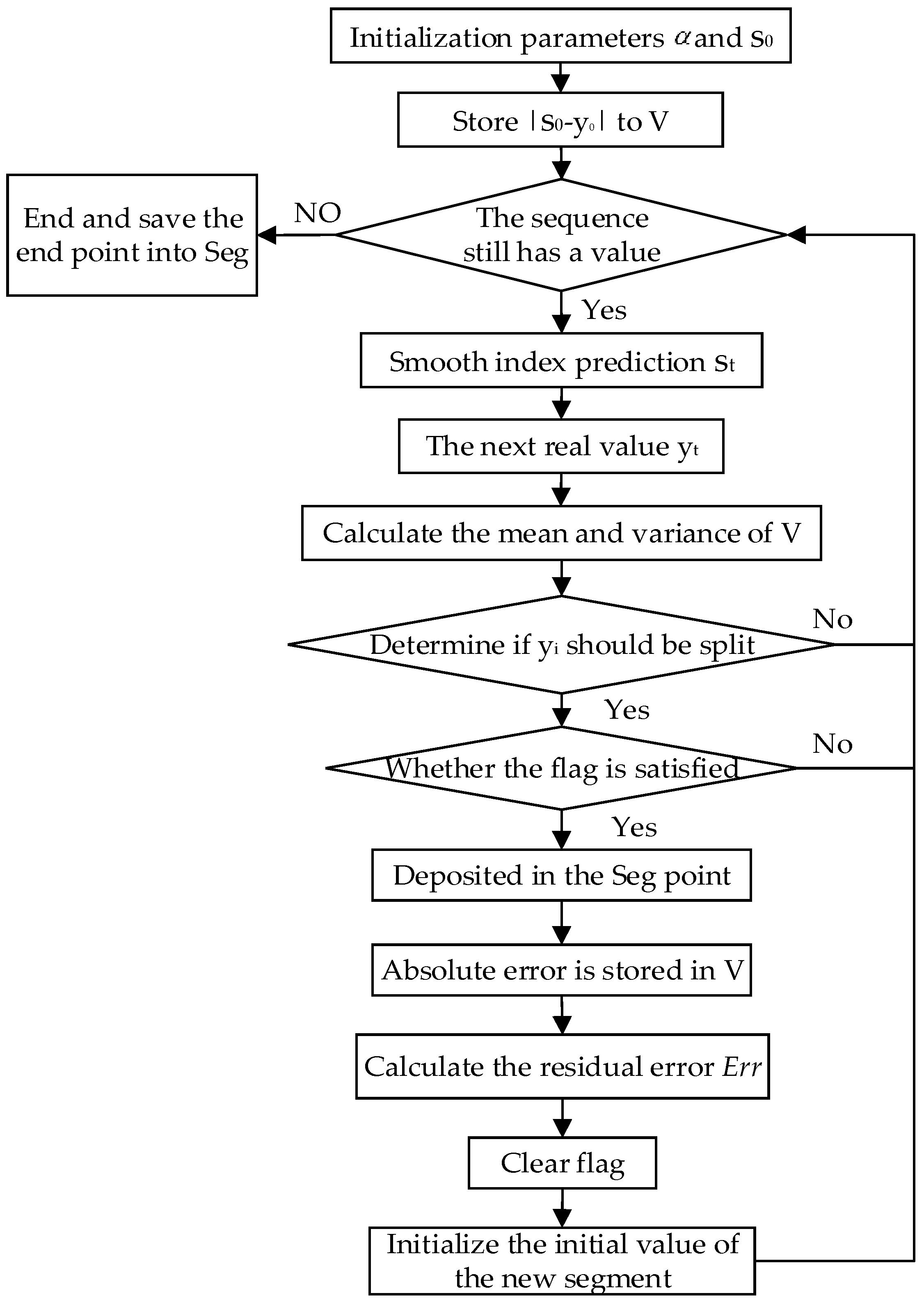
3.1. Time-Series Segmentation
- (a)
- Use a single exponential smoothing method to calculate the smoothed value as the predicted value of the next time point t;
- (b)
- Obtain the true value of the time point t, calculate the prediction error , and store the value in the vector V;
- (c)
- Calculate the mean and standard deviation of V, and the standard deviation and mean are updated in real-time;
- (d)
- Determine whether the point is a split point by Equation (3). If not, continue to loop the next point; if yes, set the flag to cache the point at the same time. If the next point also satisfies the requirements of the split point, the previous point is stored in Seg, and the initial of the split segment is reinitialized to continue the loop.where p is the split compression ratio of the time-series (p needs to be set in advance by user, ), R represents a random variable.
3.2. Feature Extraction Based on Local Spectrum of Time-Domain Signal
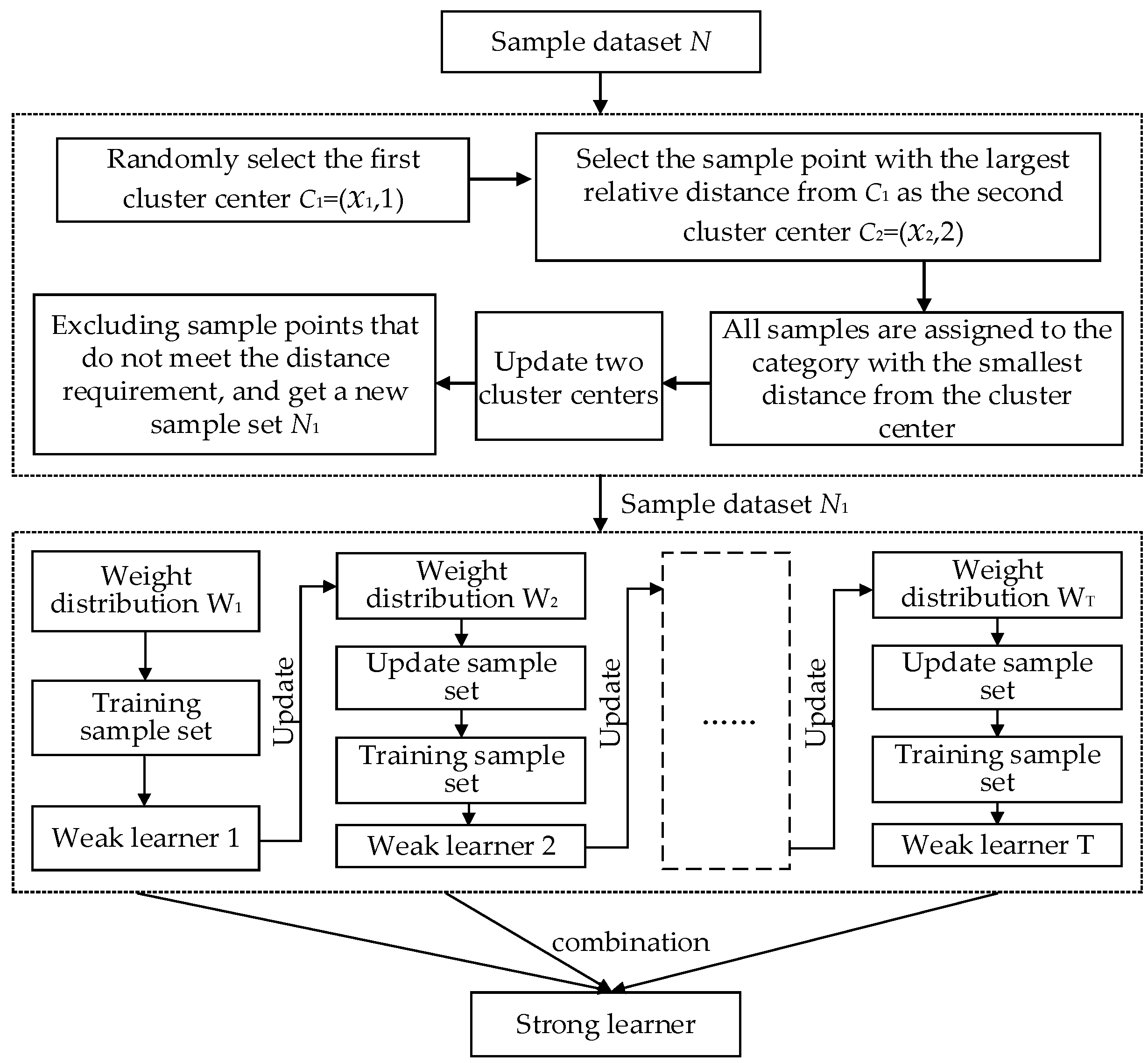
3.3. Improved AdaBoost Algorithm
- (1)
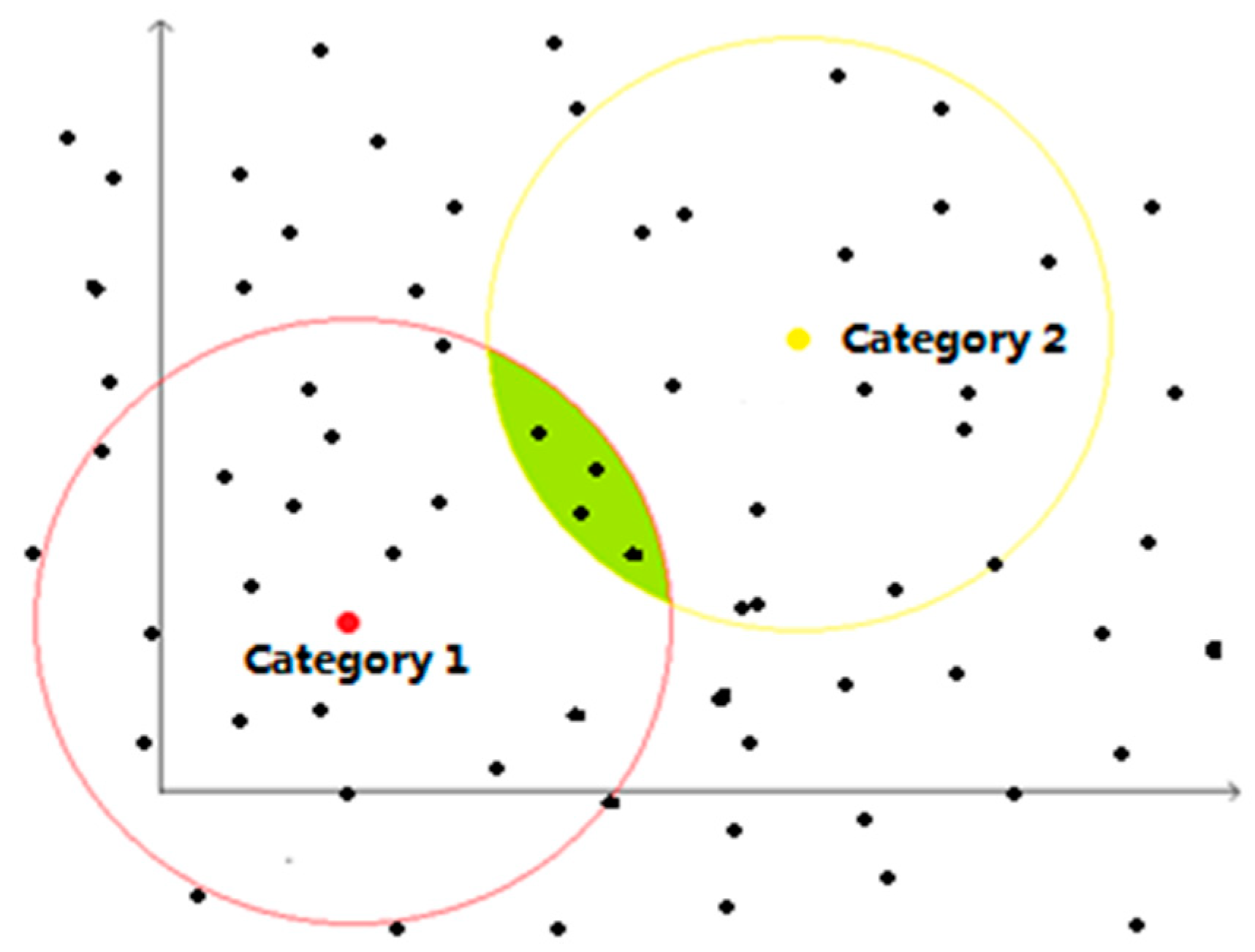
- For a given sample data set, = {, …, }, , , where is the sample data with attributes of r dimensions, is the category to which the sample belongs. The K-means clustering operation is performed on the two types of samples, and the selection of the initial cluster center is optimized. Finally, the cluster center of the two types of samples, and , is obtained.
- (2)
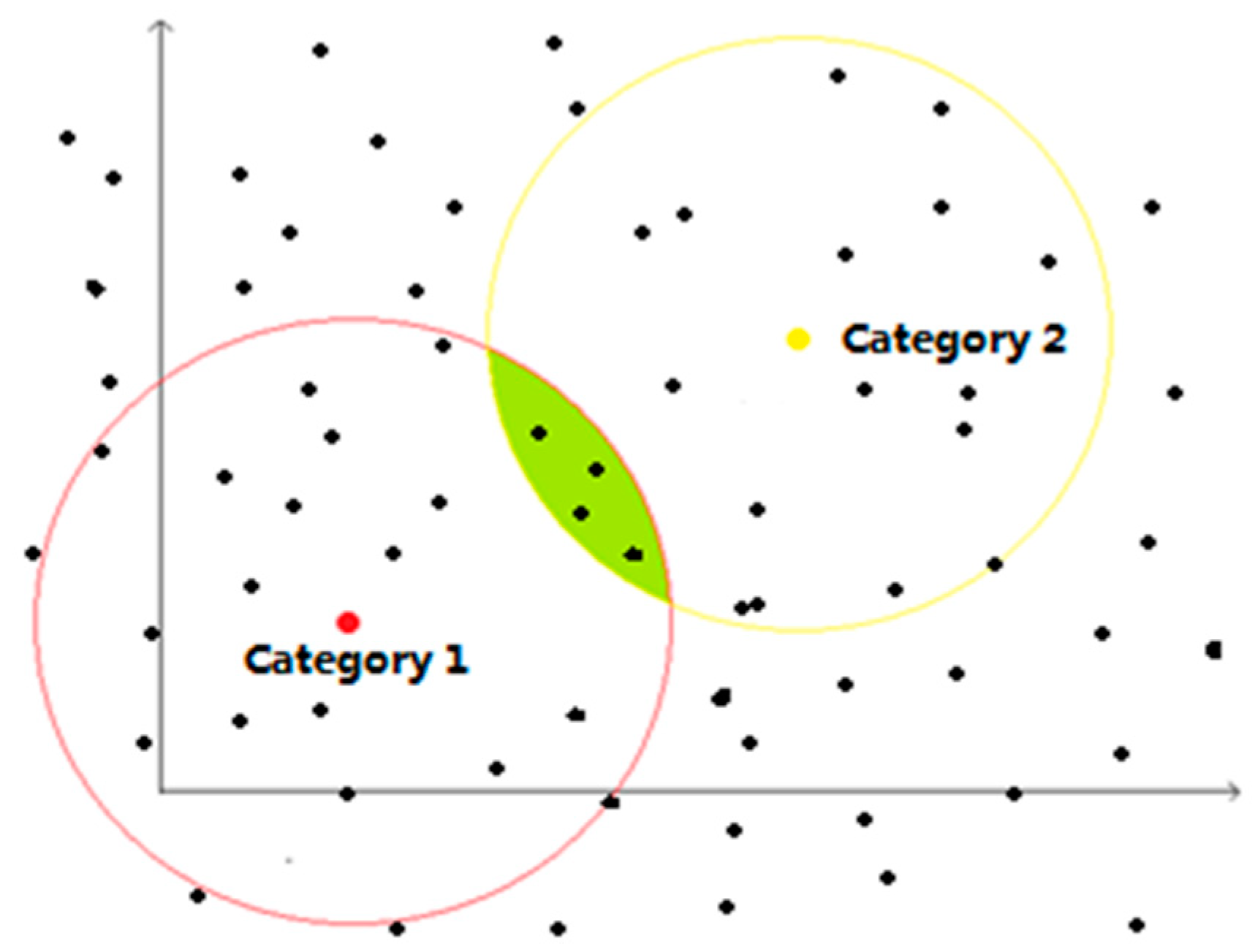
- Traversing all the samples in the sample dataset. All the samples belonging to category “1” are required to have a distance to less than , and the distance to greater than . At the same time, all the samples belonging to category “2” are required to have a distance to less than , and the distance to greater than . Samples that do not meet the requirements are rejected. Then, the new training set is = {, …, }, , , and Figure 3 shows the case when the number of clusters is 2 and 2 dimensions in the sample.
| Algorithm 1. Execution steps of the complete IAA (Improved AdaBoost Algorithm) fault classification method. | |
| Step | Execution Steps |
| Input: | Sample set = { , …, }, , ; Number of cluster categories K; Distance parameter , , …, ; Maximum sample distribution rate F; Number of weak learners T; Base learning algorithm ; sum = 0. |
| Output: | Classification result |
| 1: | Randomly select a point from the sample set as the cluster center |
| 2: | fori = 1 to n |
| 3: | Calculate the shortest Euclidean distance between the sample point and the current existing cluster center |
| 4: | sumsum + , |
| 5: | end for |
| 6: | fori = 1 to n |
| 7: | Calculate the probability that is selected as the next cluster center |
| 8: | Calculate the probability interval of |
| 9: | end for |
| 10: | Generate random numbers “r” between 0 and 1 |
| 11: | The sample corresponding to the interval, to which the random number “r” belongs, is the second cluster center |
| 12: | Repeat steps 2~12 to find the third and fourth cluster centers ~ |
| 13: | fori = 1 to n |
| 14: | Calculate the Euclidean distance from for all cluster centers separately and classify into the category corresponding to the cluster center with the smallest distance |
| 15: | Update cluster center |
| 16: | end for |
| 17: | Samples in the k-th category with a distance greater than from are excluded, samples with a distance less than from and, at the same time, the distance less than from one of ,,…,,,…, are excluded, get a new sample set N1 |
| 18: | fork = 1 to T |
| 19: | Calculate the initial weight distribution of the sample set N1 |
| 20: | Use Wk training sample set to get the k-th weak learner |
| 21: | Calculate the classification error rate of on the sample set N1 |
| 22: | Calculate the weight coefficient of |
| 23: | Update the weight distribution Wk+1 of sample set N1 |
| 24: | Update the sample distribution rate q, eliminate the sample with a sample distribution rate greater than F, update the sample set N1, and count the number of samples n |
| 25: | Strong learner |
| 26: | Calculate sample classification results |
| 27: | end for |
4. Experimental Results and Analysis
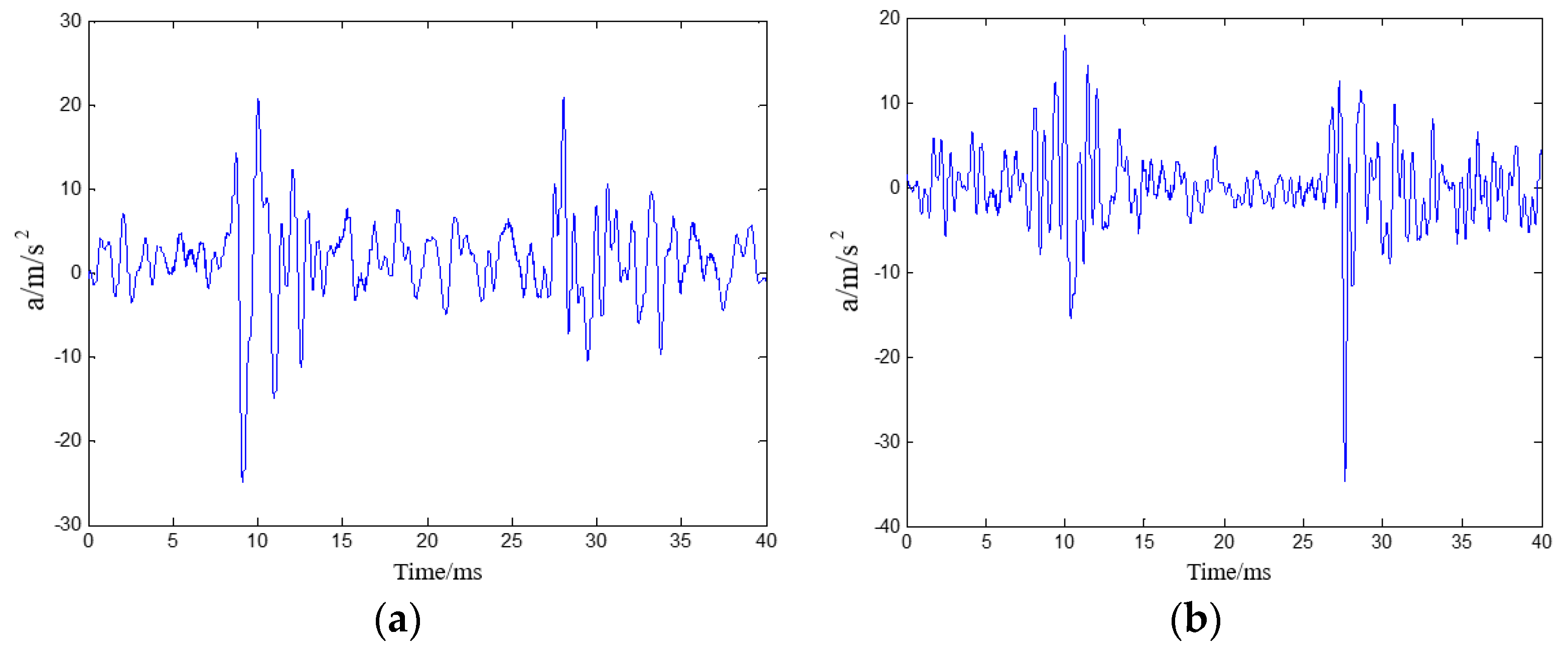
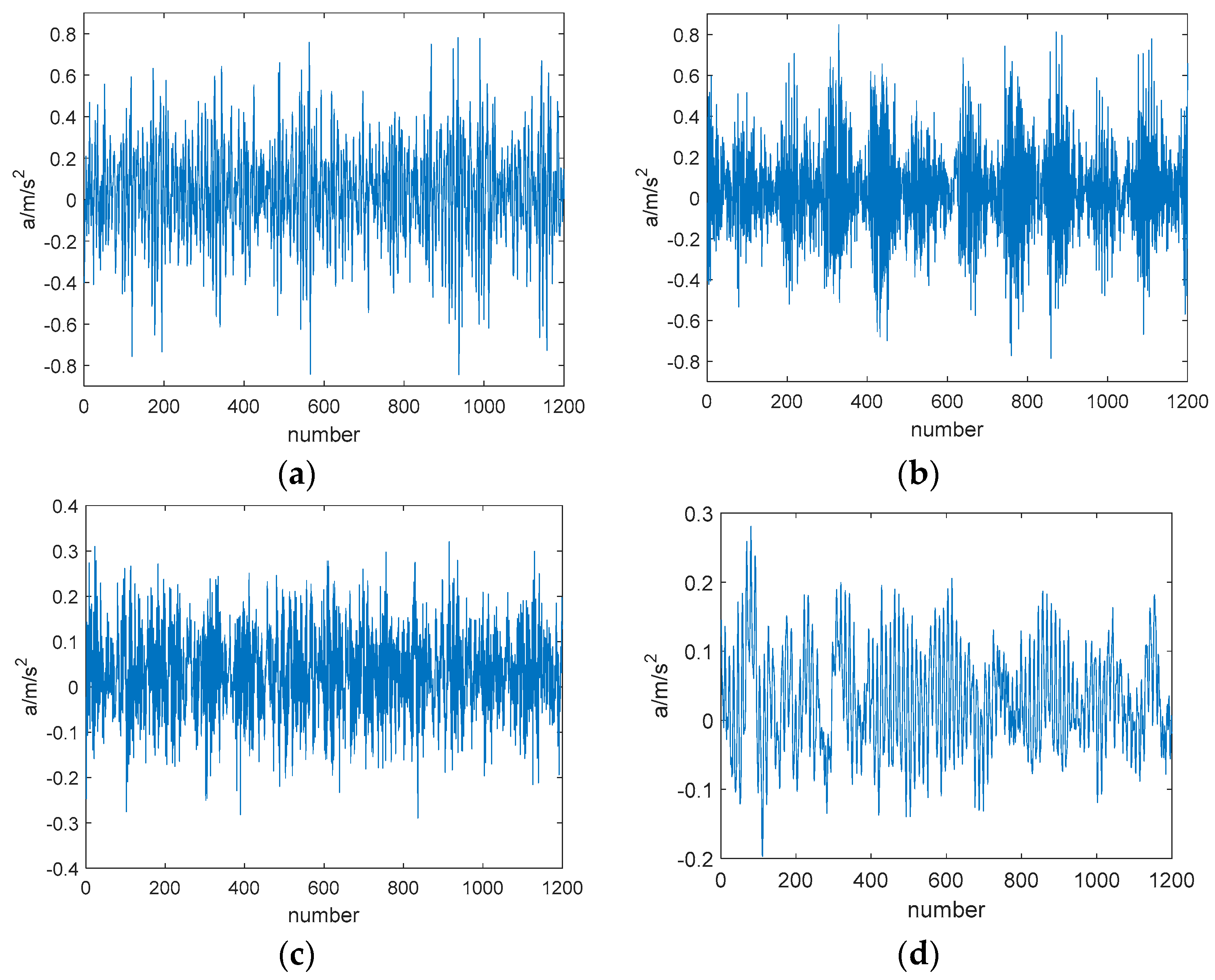
4.1. Experimental Data
4.2. Experimental Target
4.3. Result and Analysis of Experiment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Smith, W.A.; Randall, R.B. Rolling element diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, W.; Glowacz, Z.; Kozik, J. Early fault diagnosis of bearing and stator faults of the single-phase induction motor using acoustic signals. Measurement 2018, 113, 1–9. [Google Scholar] [CrossRef]
- Duan, Z.; Wu, T.; Guo, S.; Shao, T.; Malekian, R.; Li, Z. Development and trend of condition monitoring and fault diagnosis of multi-sensors information fusion for rolling bearings: A review. Int. J. Adv. Manuf. Technol. 2018, 96, 803–819. [Google Scholar] [CrossRef]
- Li, Z.; Jiang, Y.; Hu, C.; Peng, Z. Recent progress on decoupling diagnosis of hybrid failures in gear transmission systems using vibration sensor signal: A. review. Measurement 2016, 90, 4–19. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Z.; Miao, Q.; Zhang, X. Time–frequency analysis based on ensemble local mean decomposition and fast kurtogram for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2018, 103, 60–75. [Google Scholar] [CrossRef]
- Zheng, K.; Luo, J.; Zhang, Y.; Li, T.; Wen, J.; Xiao, H. Incipient fault detection of rolling bearing using maximum autocorrelation impulse harmonic to noise deconvolution and parameter optimized fast EEMD. ISA Trans. 2019, 89, 256–271. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; He, Q.; Zhao, J. Bearing fault diagnosis of a permanent magnet synchronous motor via a fast and online order analysis method in an embedded system. Mech. Syst. Signal Process. 2018, 113, 36–49. [Google Scholar] [CrossRef]
- Peng, K.; Ma, L.; Zhang, K. Review of quality-related fault detection and diagnosis techniques for complex industrial processes. Acta Autom. Sin. 2017, 43, 349–365. [Google Scholar]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S. A Survey of Fault Diagnosis and Fault-Tolerant Techniques Part II: Fault Diagnosis with Knowledge-Based and Hybrid/Active Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef]
- Gusstafsson, H.; Claesson, I.; Nordholm, S. Signal Noise Reduction by Spectral Subtraction Using Linear Convolution and Casual Filtering. U.S. Patent No. 6,175,602, 16 January 2001. [Google Scholar]
- Cheng, M.; Gao, F.; Li, Y. Vibration detection and experiment of PMSM high speed grinding motorized spindle based on frequency domain technology. Meas. Sci. Rev. 2019, 19, 109–125. [Google Scholar] [CrossRef]
- Caesarendra, W.; Tjahjowidodo, T. A review of feature extraction methods in vibration-based condition monitoring and its application for degradation trend estimation of low-speed slew bearing. Machines 2017, 5, 21. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. Application of CSA-VMD and optimal scale morphological slice bispectrum in enhancing outer race fault detection of rolling element bearings. Mech. Syst. Signal Process. 2019, 122, 56–86. [Google Scholar] [CrossRef]
- Glowacz, A. Fault diagnosis of single-phase induction motor based on acoustic signals. Mech. Syst. Signal Process. 2019, 117, 65–80. [Google Scholar] [CrossRef]
- Saravanan, N.; Ramachandran, K.I. Incipient gear box fault diagnosis using discrete wavelet transform (DWT) for feature extraction and classification using artificial neural network (ANN). Expert Syst. Appl. 2010, 37, 4168–4181. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, S.; Zhao, H.; Yang, X. A novel fault diagnosis method based on integrating empirical wavelet transform and fuzzy entropy for motor bearing. IEEE Access 2018, 6, 35042–35056. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Wang, E.; Feng, J.; Kong, X.; Chen, L.; Li, B.; Li, N.-y. Analysis of natural mineral earthquake and blast based on Hilbert–Huang transform (HHT). J. Appl. Geophys. 2016, 128, 79–86. [Google Scholar] [CrossRef]
- Duan, Y.; Wang, C.; Chen, Y.; Liu, P. Improving the accuracy of fault frequency by means of local mean decomposition and ratio correction method for rolling bearing failure. Appl. Sci. 2019, 9, 1888. [Google Scholar] [CrossRef]
- Ding, H.; Wang, Y.; Yang, Z.; Pfeiffer, O. Nonlinear blind source separation and fault feature extraction method for mining machine diagnosis. Appl. Sci. 2019, 9, 1852. [Google Scholar] [CrossRef]
- Xi, X.; Zhao, J.; Liu, T.; Yan, L. Observer-based fault diagnosis of discrete interconnected systems. Chin. J. Sci. Instrum. 2018, 39, 167–178. [Google Scholar]
- Sawalhi, N.; Randall, R.B. Gear parameter identification in a wind turbine gearbox using vibration signals. Mech. Syst. Signal Process. 2014, 42, 368–376. [Google Scholar] [CrossRef]
- Straczkiewicz, M.; Czop, P.; Barszcz, T. Supervised and unsupervised learning process in damage classification of rolling element bearings. Diagnostyka 2016, 17, 71–80. [Google Scholar]
- Glowacz, A.; Glowacz, W. Vibration-based fault diagnosis of commutator motor. Shock Vib. 2018, 2018, 10. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, F.-L.; Wang, S.; Zhao, L.-P. A fault diagnosis approach by D-S fusion theory and hybrid expert knowledge system. Acta Autom. Sin. 2017, 43, 1580–1587. [Google Scholar]
- Qin, A.; Hu, Q.; Lv, Y.; Zhang, Q. Concurrent Fault Diagnosis Based on Bayesian Discriminating Analysis and Time Series Analysis with Dimensionless Parameters. IEEE Sens. J. 2019, 19, 2254–2265. [Google Scholar] [CrossRef]
- Islam, M.R.; Kim, Y.H.; Kim, J.Y.; Kim, J.M. Detecting and Learning Unknown Fault States by Automatically Finding the Optimal Number of Clusters for Online Bearing Fault Diagnosis. Appl. Sci. 2019, 9, 2326. [Google Scholar] [CrossRef]
- Cui, S.; Yu, C.; Su, W.; Cheng, X. One kind of massive real-time series data segmentation algorithm based on exponential smoothing prediction. Appl. Res. Comput. 2016, 33, 2712–2715. [Google Scholar]
- Su, W.; Yang, F.; Yu, C.; Cheng, X.; Cui, S. Rolling bearing fault feature extraction method based on local spectrum. Chin. J. Electron. 2018, 46, 160–166. [Google Scholar]
- Li, G.; Cai, Z.; Kang, X.; Wu, Z.; Wang, Y. A prediction-based algorithm for streaming time series segmentation. Expert Syst. Appl. 2014, 41, 6098–6105. [Google Scholar] [CrossRef]
- Keogh, E.; Selina, C.; David, H.; Pazzani, M. An online algorithm for segmenting time series. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 289–296. [Google Scholar]
- Keogh, E.; Lin, J.; Fu, A. HOT SAX: Efficiently finding the most unusual time series subsequence. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; pp. 226–233. [Google Scholar]
- Smith, J.S. The local mean decomposition and its application to EEG perception data. J. R. Soc. Interface 2005, 2, 443–454. [Google Scholar] [CrossRef]
- Jonathan, M.L.; Sofia, C.O. Bivariate Instantaneous Frequency and Bandwidth. IEEE Trans. Signal Process. 2010, 58, 591–603. [Google Scholar]
- Zhao, Y.; Gong, L.; Zhou, B.; Huang, Y.; Liu, C. Detecting tomatoes in greenhouse scenes by combining Adaboost classifier and colour analysis. Biosyst. Eng. 2016, 148, 127–137. [Google Scholar] [CrossRef]
- Kong, K.K.; Hong, K.S. Design of coupled strong classifiers in Adaboost framework and its application to pedestrian detection. Pattern Recognit. Lett. 2015, 68, 63–69. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | SW | SWAB | SWESSA |
|---|---|---|---|
| NSN | 1 | 0.982 | 1.028 |
| NRES | 1 | 1.052 | 0.978 |
| NTIME | 1 | 2.372 | 0.852 |
| Rolling Velocity | Category | Sampling Frequency | Number of Data Samples |
|---|---|---|---|
| 2 Hz | Normal | 51,200 Hz | 80 |
| Inner fault | 51,200 Hz | 80 | |
| Outer fault | 51,200 Hz | 80 | |
| Rolling fault | 51,200 Hz | 80 | |
| 4 Hz | Normal | 51,200 Hz | 80 |
| Inner fault | 51,200 Hz | 80 | |
| Outer fault | 51,200 Hz | 80 | |
| Rolling fault | 51,200 Hz | 80 | |
| 6 Hz | Normal | 51,200 Hz | 80 |
| Inner fault | 51,200 Hz | 80 | |
| Outer fault | 51,200 Hz | 80 | |
| Rolling fault | 51,200 Hz | 80 | |
| 8 Hz | Normal | 51,200 Hz | 80 |
| Inner fault | 51,200 Hz | 80 | |
| Outer fault | 51,200 Hz | 80 | |
| Rolling fault | 51,200 Hz | 80 |
| Rolling Velocity | Category | Sampling Frequency | Number of Data Samples |
|---|---|---|---|
| 30 Hz | Normal | 12,000 Hz | 80 |
| Inner fault | 12,000 Hz | 80 | |
| Outer fault | 12,000 Hz | 80 | |
| Rolling fault | 12,000 Hz | 80 |
| Serial Number | Normal | Inner Fault | Outer Fault | Rolling Fault |
|---|---|---|---|---|
| 1 | 1202 | 2523 | 4822 | 3104 |
| 2 | 1183 | 2558.5 | 4790 | 3085.5 |
| 3 | 1267.5 | 2570 | 4831 | 3091 |
| 4 | 1256 | 2585 | 4764 | 3169 |
| 5 | 1162.5 | 2506 | 4814.5 | 3064 |
| Fault Type | Feature Vector Dimension | Feature Vector Label |
|---|---|---|
| 4 r/s Normal | 80 × 100 | 0 |
| 4 r/s Inner fault | 80 × 100 | 1 |
| 4 r/s Outer fault | 80 × 100 | 2 |
| 4 r/s Rolling fault | 80 × 100 | 3 |
| Fault Type | Feature Vector Dimension | Feature Vector Label |
|---|---|---|
| Normal | 80 × 100 | 0 |
| Inner fault | 80 × 100 | 1 |
| Outer fault | 80 × 100 | 2 |
| Rolling fault | 80 × 100 | 3 |
| Fault Type | BP | SVM | AdaBoost | IAA |
|---|---|---|---|---|
| 4 r/s Inner fault | 0.85 | 0.76 | 0.81 | 0.83 |
| 4 r/s Outer fault | 0.72 | 0.88 | 0.92 | 0.93 |
| 4 r/s Rolling fault | 0.73 | 0.76 | 0.8 | 0.95 |
| Standard inner fault | 0.81 | 0.82 | 0.89 | 0.85 |
| Standard outer fault | 0.76 | 0.81 | 0.81 | 0.88 |
| Standard rolling fault | 0.80 | 0.90 | 0.92 | 0.95 |
| Mean | 0.78 | 0.82 | 0.86 | 0.90 |
| Fault Type | BP | SVM | AdaBoost | IAA |
|---|---|---|---|---|
| 4 r/s Inner fault | 0.03 | 0.07 | 0.07 | 0.03 |
| 4 r/s Outer fault | 0.04 | 0.03 | 0.03 | 0.04 |
| 4 r/s Rolling fault | 0.03 | 0.05 | 0.04 | 0.03 |
| Standard inner fault | 0.09 | 0.06 | 0.06 | 0.05 |
| Standard outer fault | 0.10 | 0.05 | 0.04 | 0.03 |
| Standard rolling fault | 0.07 | 0.06 | 0.05 | 0.05 |
| Mean | 0.060 | 0.053 | 0.048 | 0.038 |
| Fault Type | BP | SVM | AdaBoost | IAA |
|---|---|---|---|---|
| 4r/s Inner fault | 0.83 | 0.76 | 0.78 | 0.83 |
| 4r/s Outer fault | 0.8 | 0.91 | 0.92 | 0.95 |
| 4r/s Rolling fault | 0.73 | 0.76 | 0.81 | 0.9 |
| Standard inner fault | 0.70 | 0.85 | 0.90 | 0.91 |
| Standard outer fault | 0.84 | 0.83 | 0.83 | 0.88 |
| Standard rolling fault | 0.85 | 0.88 | 0.91 | 0.94 |
| Mean | 0.79 | 0.83 | 0.86 | 0.90 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, L.; Yu, C.; Liu, C.; Qin, Y.; Cui, S. Fault Diagnosis of Rolling Bearings in Rail Train Based on Exponential Smoothing Predictive Segmentation and Improved Ensemble Learning Algorithm. Appl. Sci. 2019, 9, 3143. https://doi.org/10.3390/app9153143
Han L, Yu C, Liu C, Qin Y, Cui S. Fault Diagnosis of Rolling Bearings in Rail Train Based on Exponential Smoothing Predictive Segmentation and Improved Ensemble Learning Algorithm. Applied Sciences. 2019; 9(15):3143. https://doi.org/10.3390/app9153143
Chicago/Turabian StyleHan, Lu, Chongchong Yu, Cuiling Liu, Yong Qin, and Shijie Cui. 2019. "Fault Diagnosis of Rolling Bearings in Rail Train Based on Exponential Smoothing Predictive Segmentation and Improved Ensemble Learning Algorithm" Applied Sciences 9, no. 15: 3143. https://doi.org/10.3390/app9153143
APA StyleHan, L., Yu, C., Liu, C., Qin, Y., & Cui, S. (2019). Fault Diagnosis of Rolling Bearings in Rail Train Based on Exponential Smoothing Predictive Segmentation and Improved Ensemble Learning Algorithm. Applied Sciences, 9(15), 3143. https://doi.org/10.3390/app9153143