A Hybrid Two-Phase Recommendation for Group-Buying E-commerce Applications


Abstract
Featured Application
Abstract
1. Introduction
- -
- To alleviate the data sparsity problem, item features and user behaviors were fully investigated; feature description approaches were designed to construct the feature matrix.
- -
- Based on item clustering, the user-item category tendency was defined to integrate users’ preferences with users’ concern degrees for item category. In addition, a concept of integrating similarity between users is proposed by considering user behaviors and frequencies of these behaviors.
- -
- A parallelized strategy of execution is proposed to improve the capability of dealing with massive data with the recommendation process. To be specific, after item clustering, the rating for new items (not rated) was predicted and taken as supplementation of the feature matrix. Meanwhile, considering item clusters, user clustering was performed on the basis of the integrating similarity and the user-item tendency matrix.
- -
- An improved K nearest neighbors (KNN) method was designed to generate a personalized recommendation list. The key idea was to determine the nearest neighbors by measuring the similarity between the target user and related clusters, which were selected by comparing cluster centers with a predefined similarity threshold.
- -
- The rest of this paper is organized as follows: Section 2 introduces recommendation techniques and the clustering-based two-phase recommendation. Section 3 analyzes the research problem. Section 4 illustrates the proposed HTPR method in detail. Section 5 shows the experimental results, and Section 6 concludes the paper and discusses future work.
2. Literature Review
2.1. Recommendation Techniques
- (1)
- feature input the information that describes the user’s preferences/item features in a specific data structure;
- (2)
- a recommendation engine that combines user’s characteristic analysis and recommendation models building to generate suggestions;
- (3)
- output the information that presents in various forms including rating prediction and Top-N recommendations.
- (1)
- content filtering: recommending services similar to those the user used to like;
- (2)
- social filtering: recommending services similar to those the user’s friends or other users who have similar preferences in the past;
- (3)
- collaborative filtering: finding out the similarity of items, or the similarity of users by mining their historical behaviors, further to generate a recommendation.
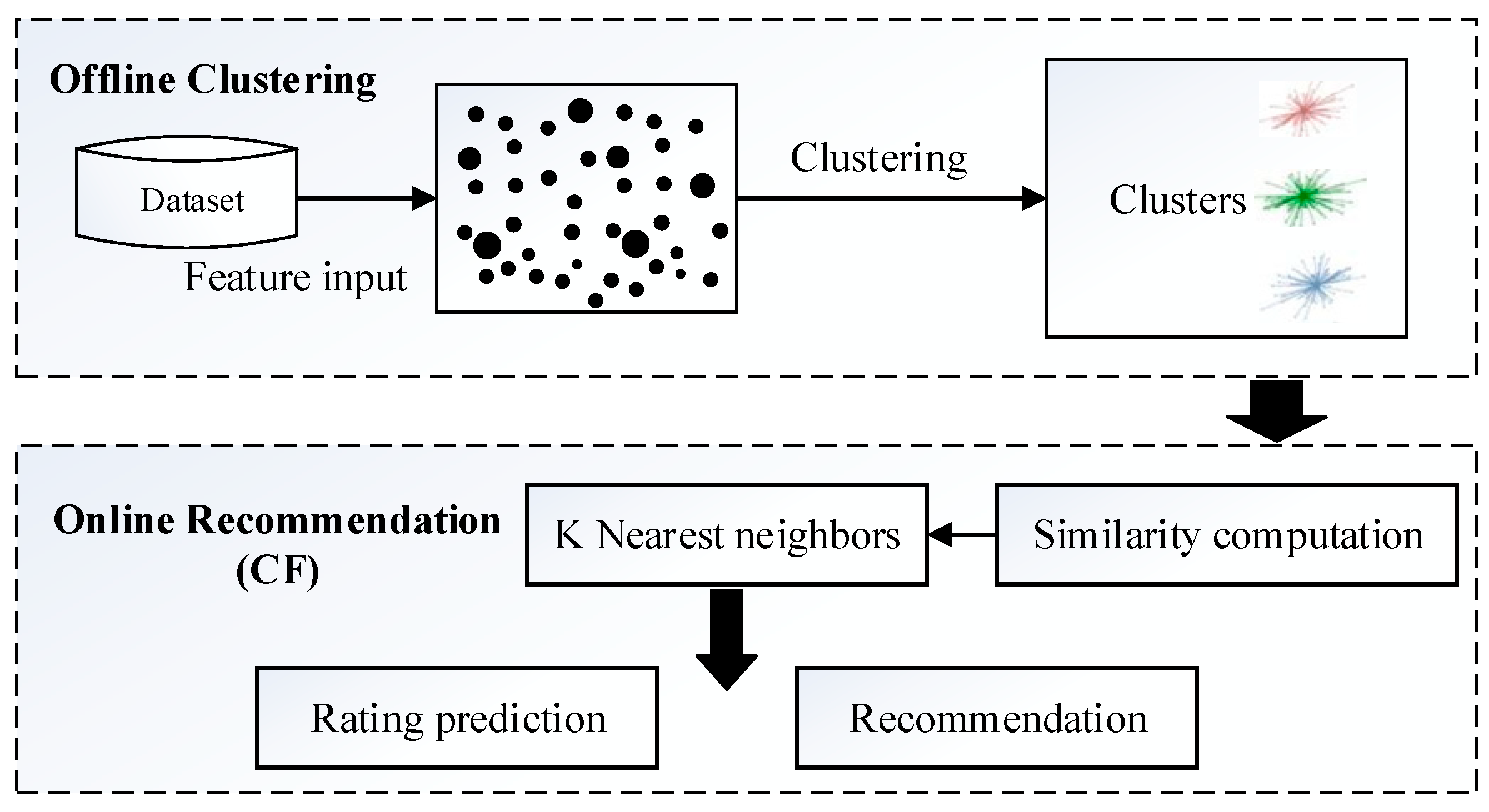
2.2. Clustering Based Two-Phase Recommendation
3. Problem Analysis
3.1. Problem Statement
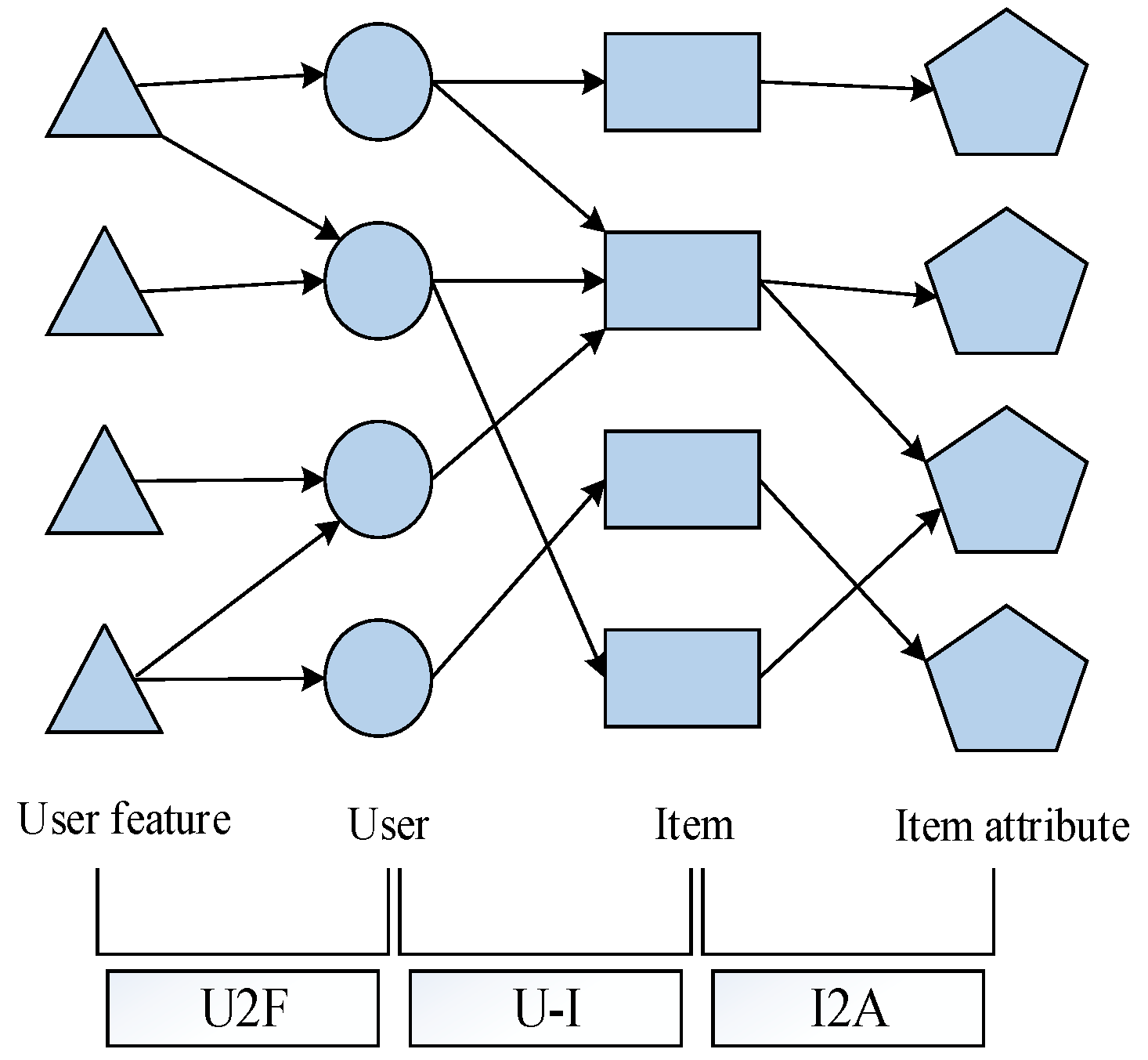
3.2. Feature Description
3.2.1. Feature Description of Item Attribute
3.2.2. Feature Description of User Behavior
4. Proposed HTPR Method
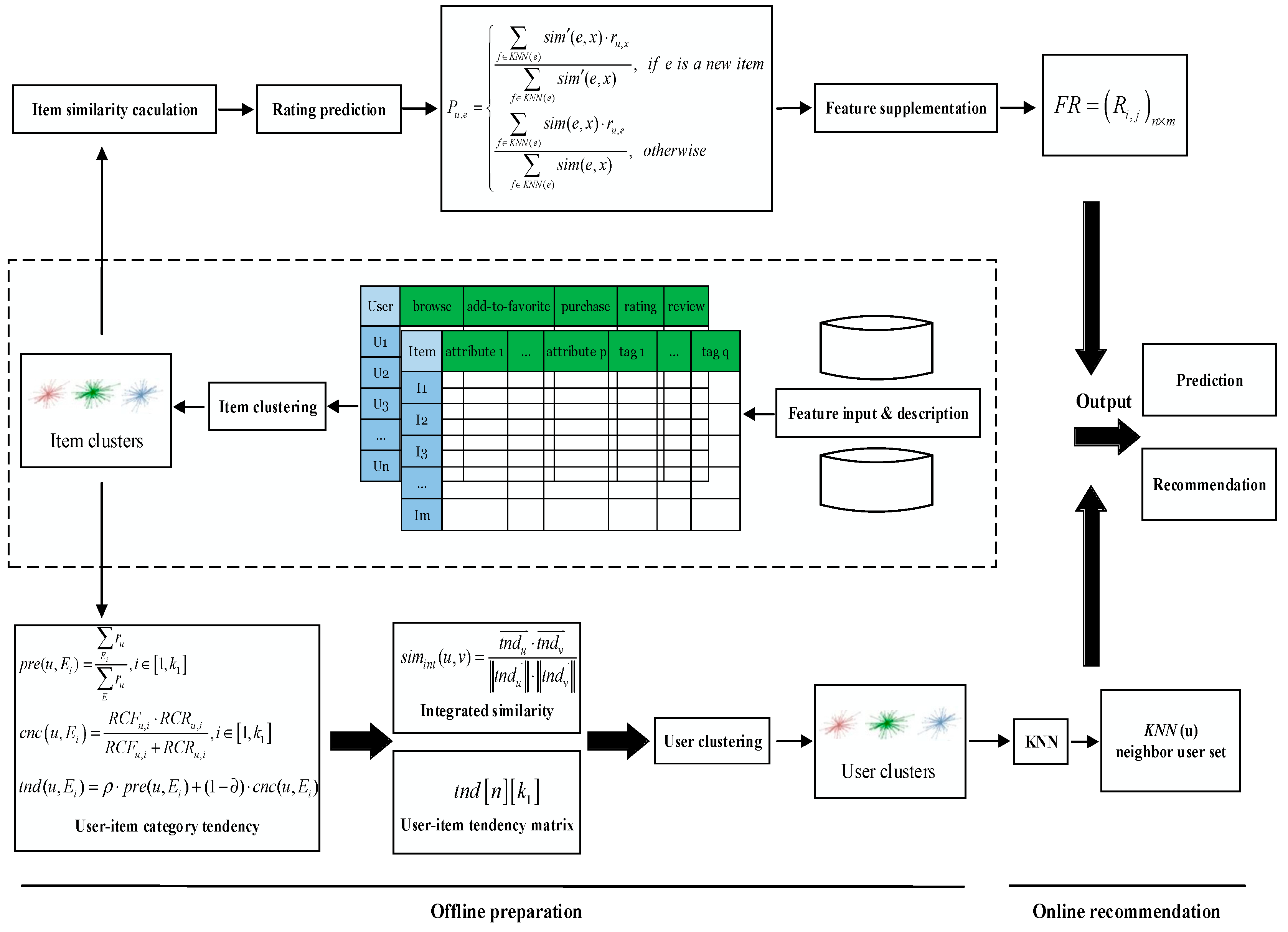
4.1. Overview of the Proposed Solution
- -
- Feature input and description. Feature information was input to the recommendation system after feature description. The input features involved the content of items, i.e., item/attribute matrix and user behaviors including browse, add-to-favorite, purchase, review and rating (described as user-item browse matrix, user-item wish list matrix, user-item purchase matrix, item review tag matrix, and user-item rating matrix respectively).
- -
- Item clustering. After the feature combination of item review tags and item attributes were obtained, item clusters were generated by the K-Means algorithm.
- -
- Feature supplementation. For each item without rating in the user-item rating matrix, the most similar neighbors from its cluster were picked out, and then it was rated based on the rating of its nearest neighbors. In this way, the user-item rating matrix was supplemented.
- -
- Integrating similarity. The preference of a user for an item category was defined based on the results of item clustering, and then the concern degree of the user for the item category was defined based on the user’s historical behaviors. By integrating preference and concern degree, the tendency of the user for the item category could be defined, and the integrating similarity could be calculated.
- -
- User clustering. Clustering users according to the user-item category tendency matrix, and obtaining user clusters and their cluster centers.
- -
- Online recommendation. Selecting some clusters from all user clusters by comparing cluster centers with a predefined similarity threshold, and then obtaining the set of nearest neighbors by measuring the similarity between the target user and users of selected clusters. Next, the rating prediction of all candidate items was made for the target user based on the rating of the nearest neighbors. Finally, a personalized service recommendation list (Top-N list) was generated and the most appropriate items were recommended to the target user.
4.2. Feature Supplementation Based on Item Clustering
| Algorithm 1: Item-Clustering-K-Means |
| Input: The item set The item feature matrix The number of clusters Output: The item clusters The cluster centers 1: select some items whose number is from item set E at random, i.e.,, as the initial cluster centers 2: for each item 3: calculate its similarity with each cluster center, in turn, according to (4), and assign it to the corresponding cluster 4: end for 5: for each cluster 6: adjust the cluster center according to the average value of all items in the cluster, i.e., , where is the number of items for the i-th cluster 7: end for 8: return to step 2 till the square error of the cluster criterion function, i.e., reaches convergence |
4.3. Integrating Similarity Calculation and User Clustering
| Algorithm 2: User-Clustering-K-Means |
The user-item category tendency matrix , The number of user clusters k2 1: select some users whose number is k2 from user set U at random, i.e., as the initial cluster centers 3: calculate its similarity with each cluster center, in turn, according to (14), and assign it to the nearest cluster 4: end for 5: for each cluster 6: adjust the cluster center according to the average value of item category tendency for all users in a cluster, i.e., , where mi is the number of users for the i-th cluster 7: end for 8: return to step 2 till the square error of the cluster criterion function, i.e., reaches convergence |
4.4. Online Recommendation
| Algorithm 3: K-Nearest-Neighbors |
| Input: The target user u The number of nearest neighbor users K The user clusters The cluster centers (here, represents the proxy user for the i-th cluster) The similarity threshold θ Output: The neighbor user set 1: for each cluster center 2: calculate its similarity with the target user according to (15), written as 3: if then 4: calculate the similarity of the user u and every other user of this cluster, e.g., the user v and the target user u 5: end if 6: end for 7: sort the users according to the result of a similarity calculation 8: return the set of nearest neighbor users which is consisted of the users with the Top-K highest similarity |
5. Experimental Results
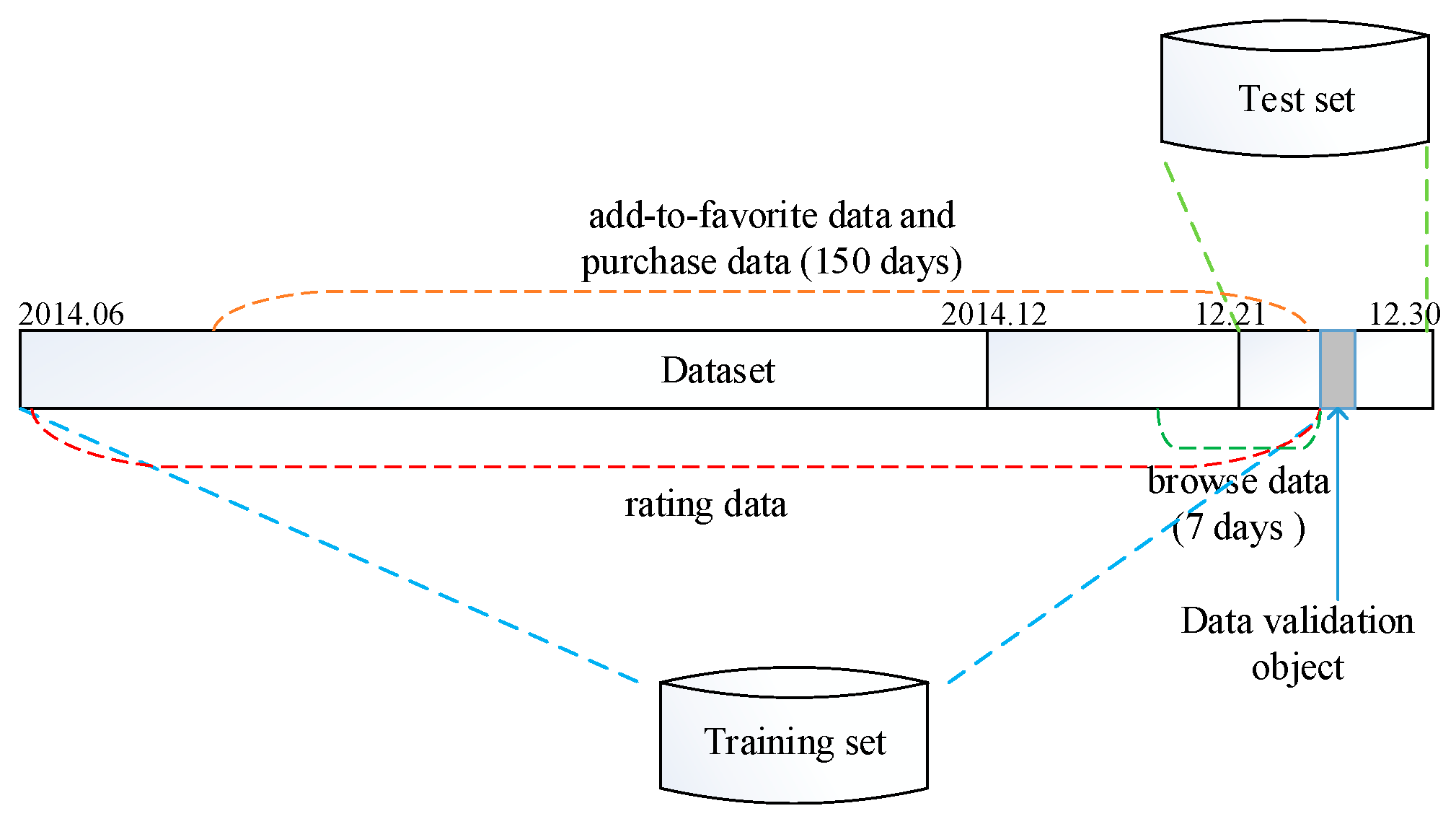
5.1. Experiment Dataset and Metrics
5.2. Experiment Evaluation
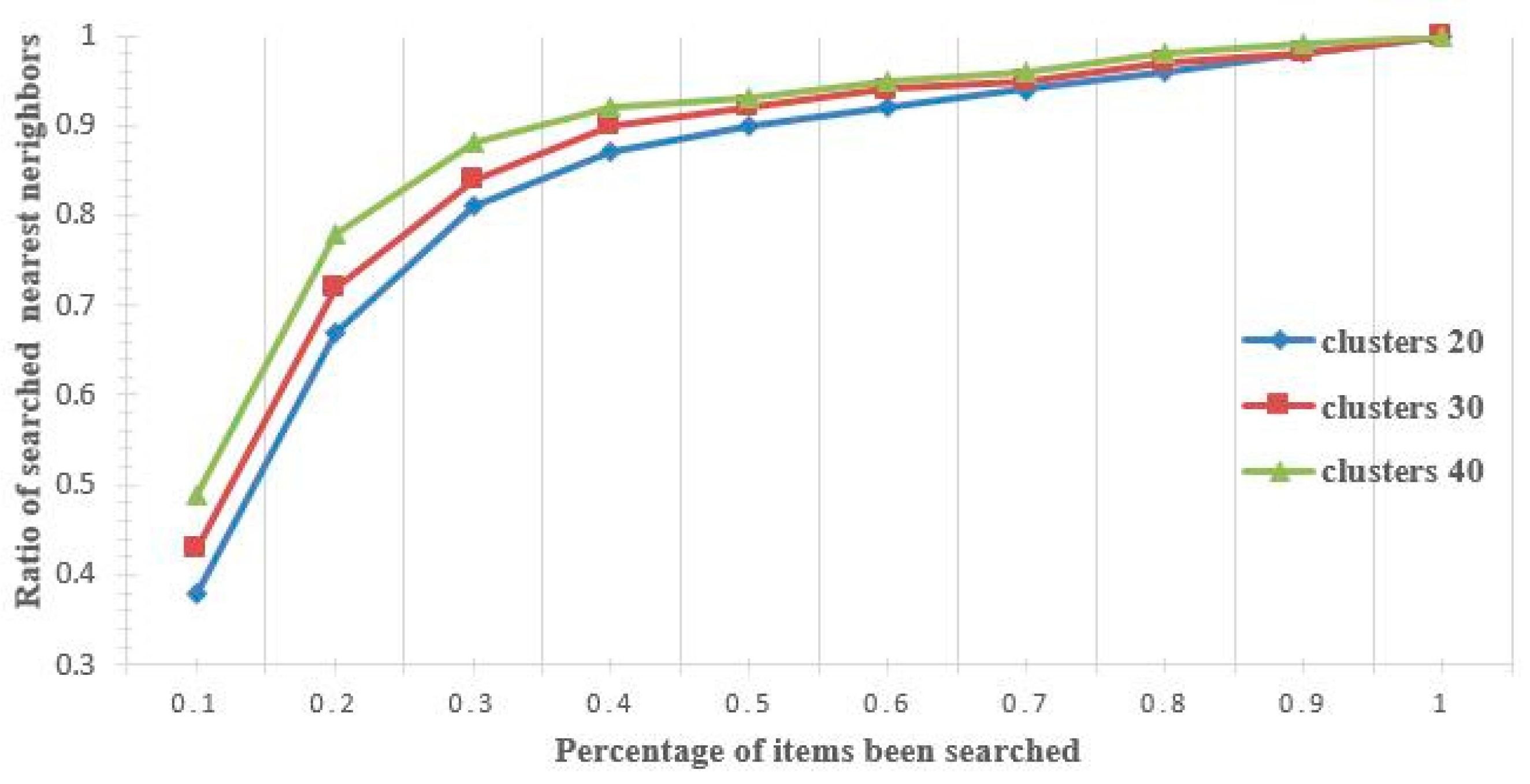
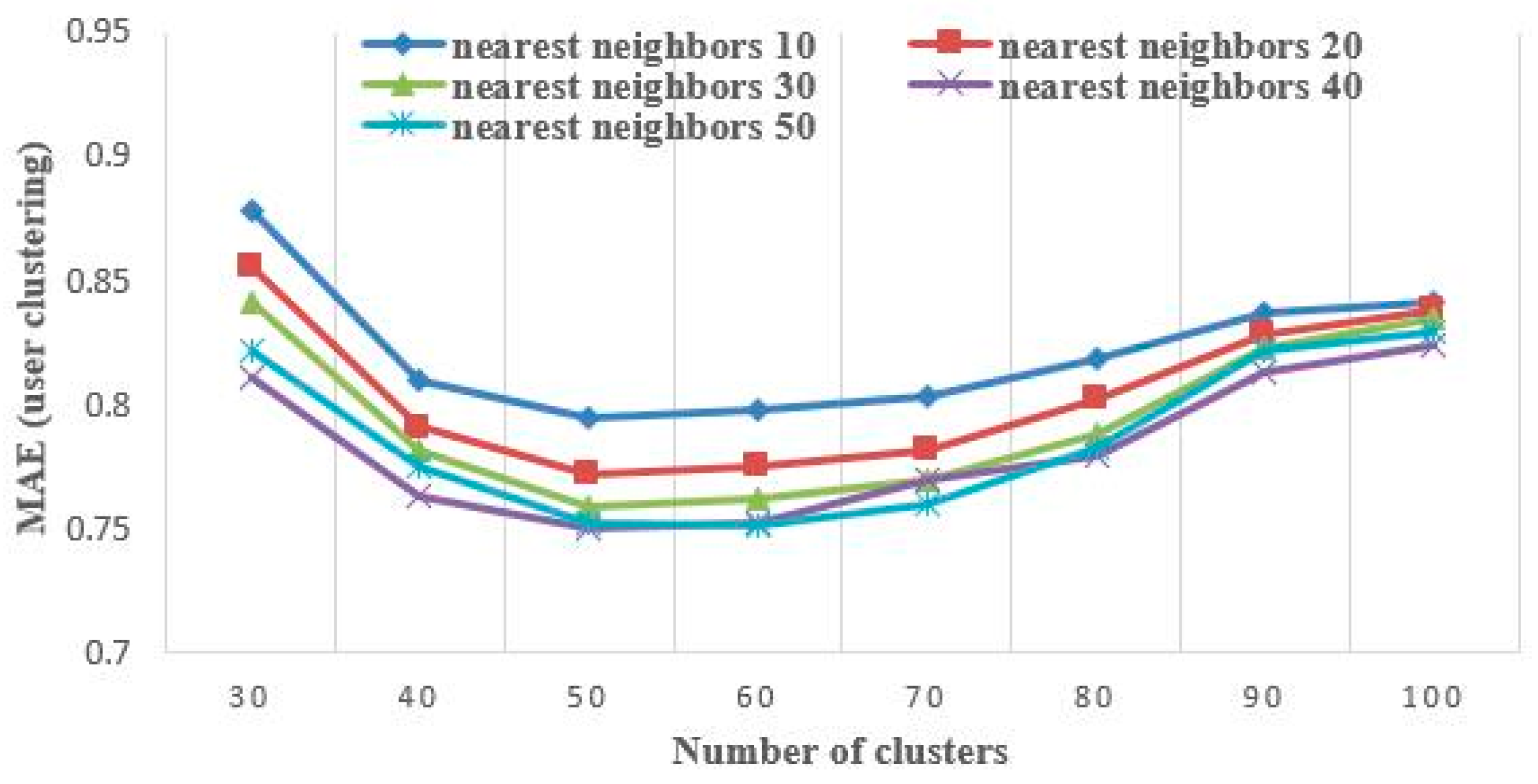
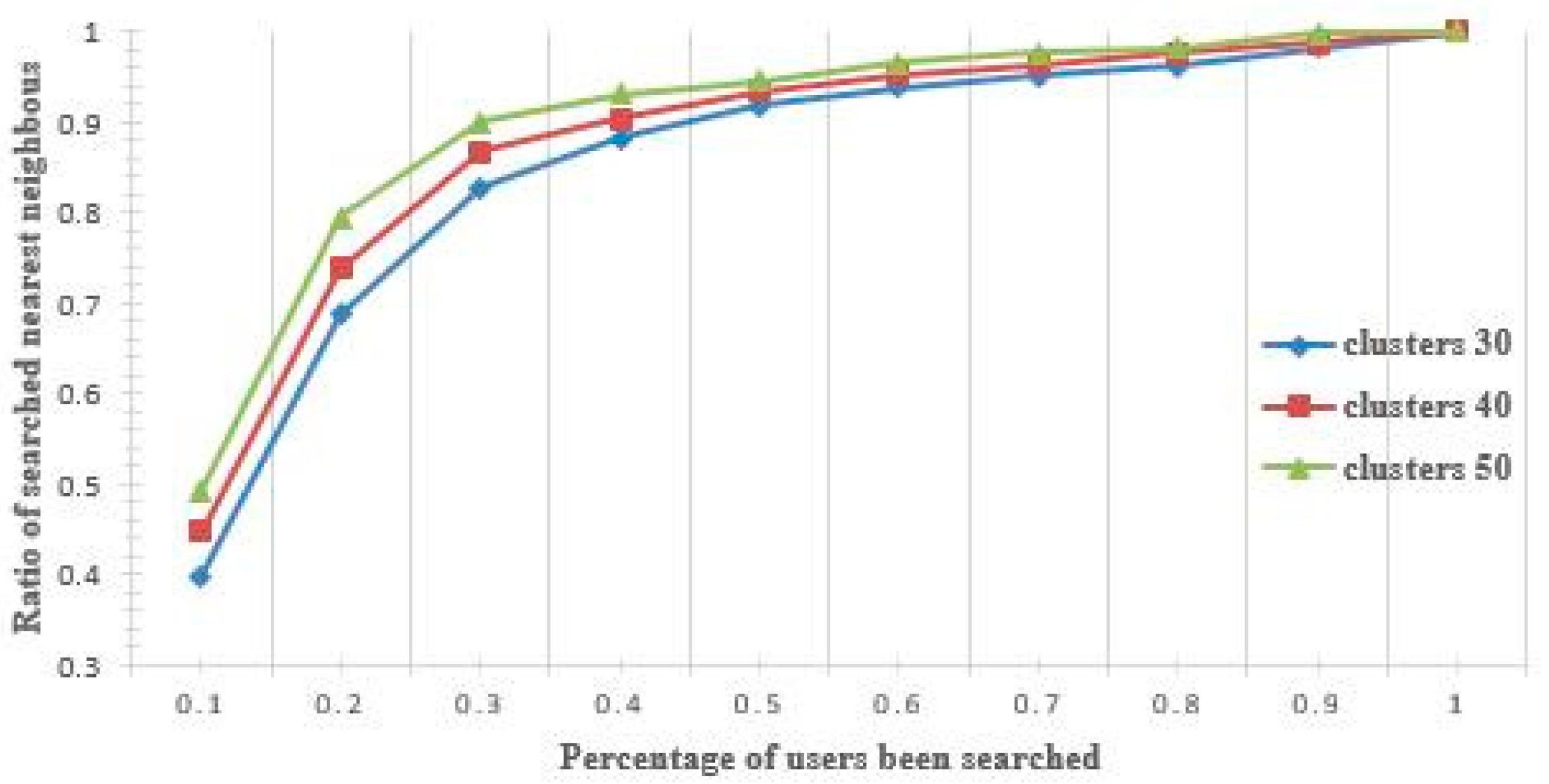
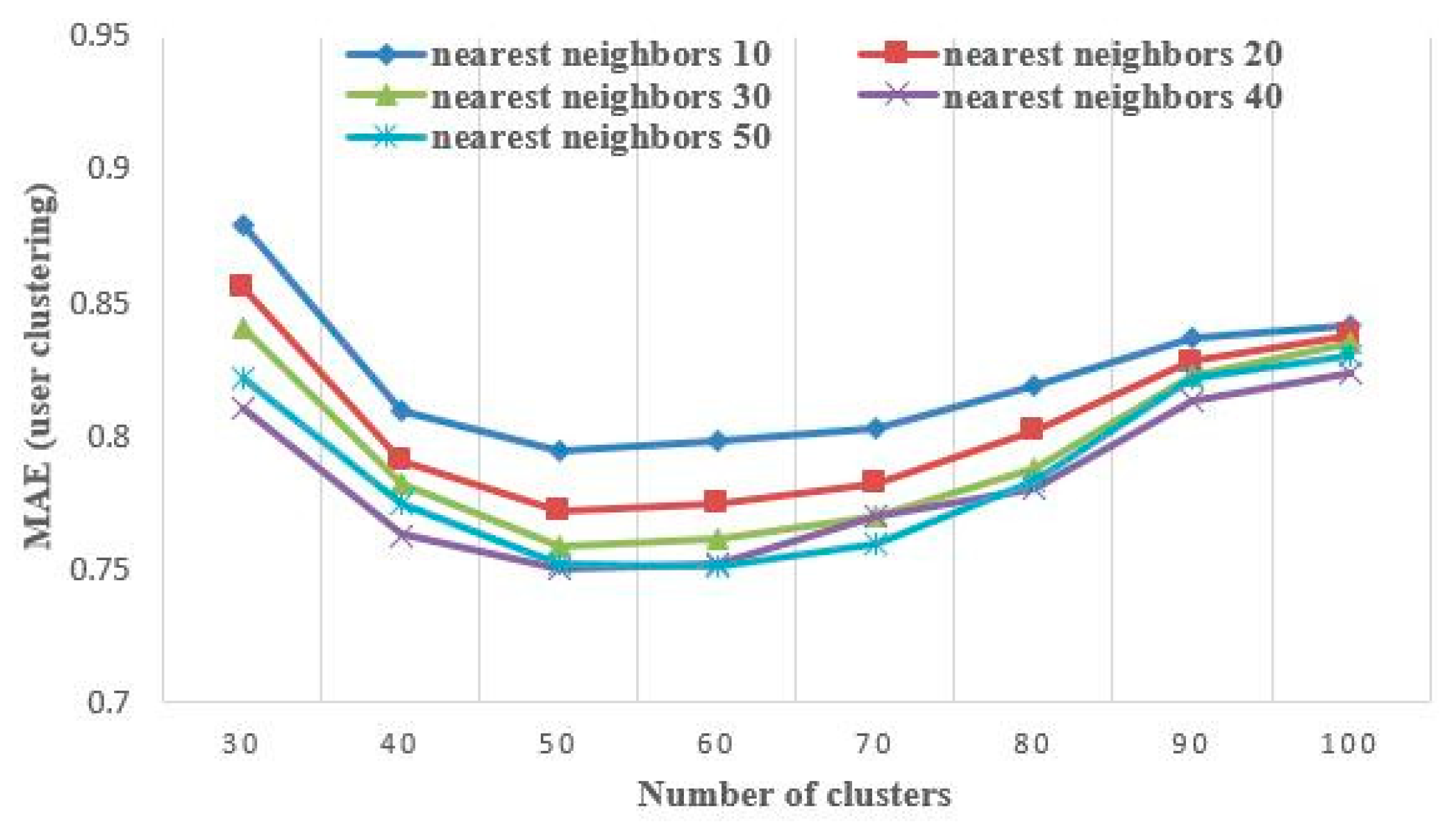
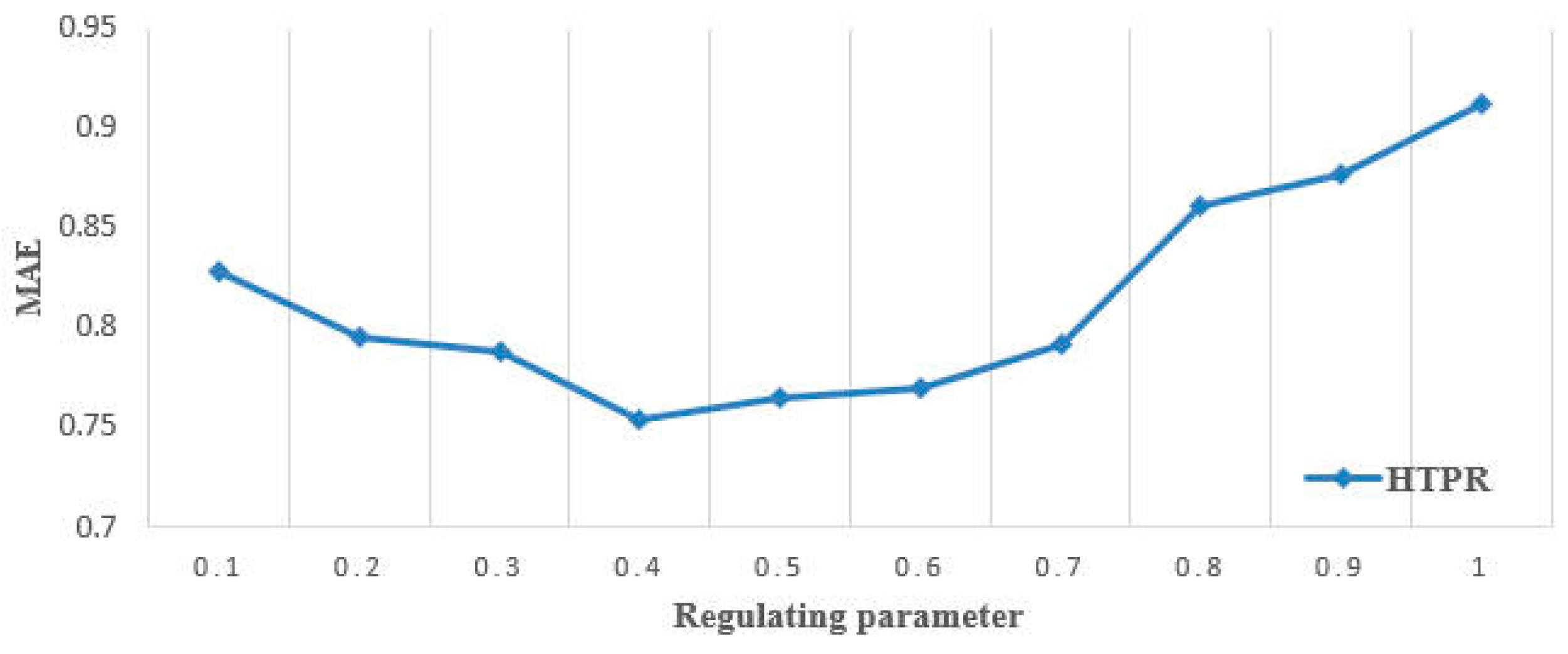
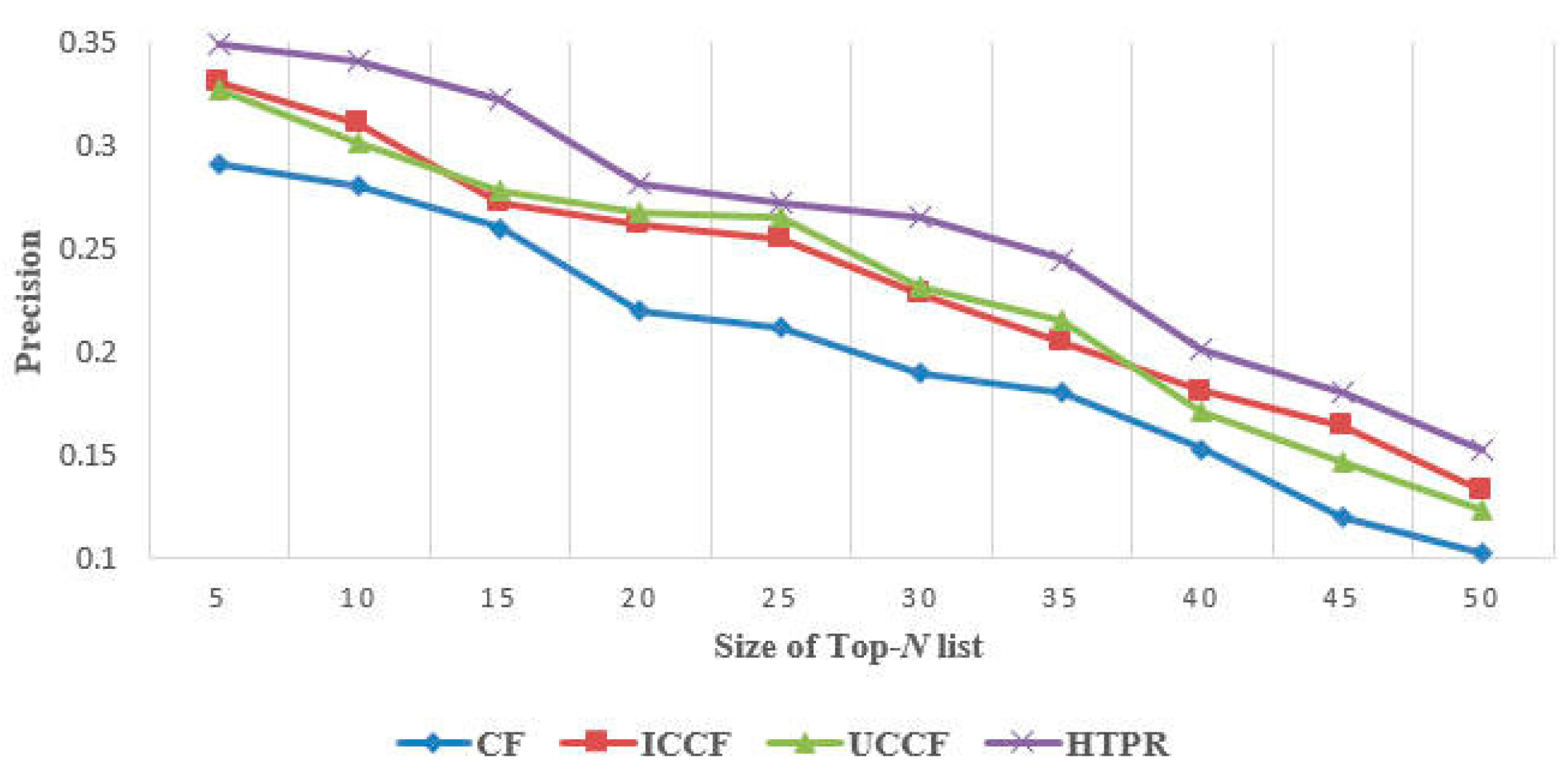
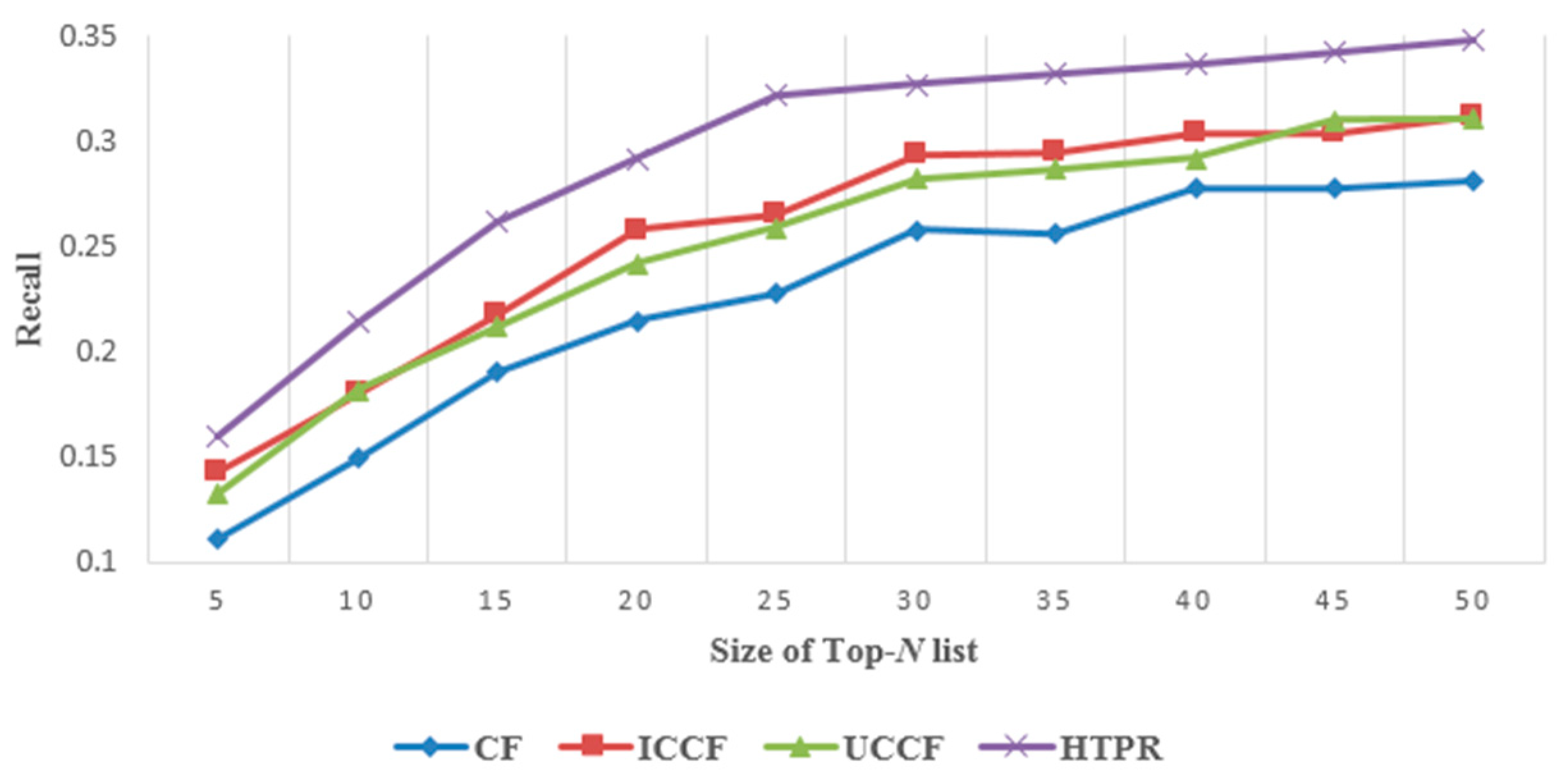
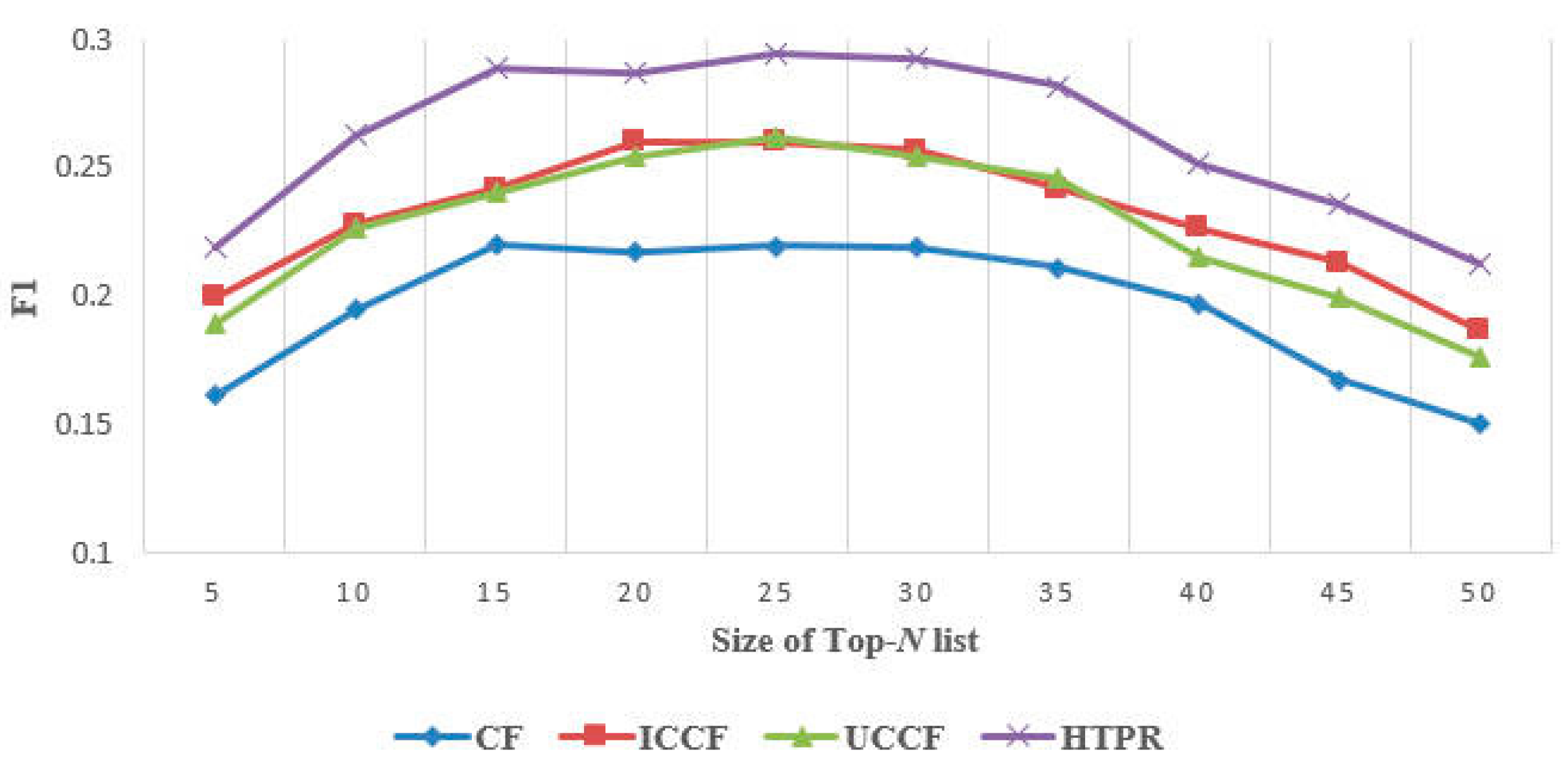
5.2.1. Effectiveness Evaluation
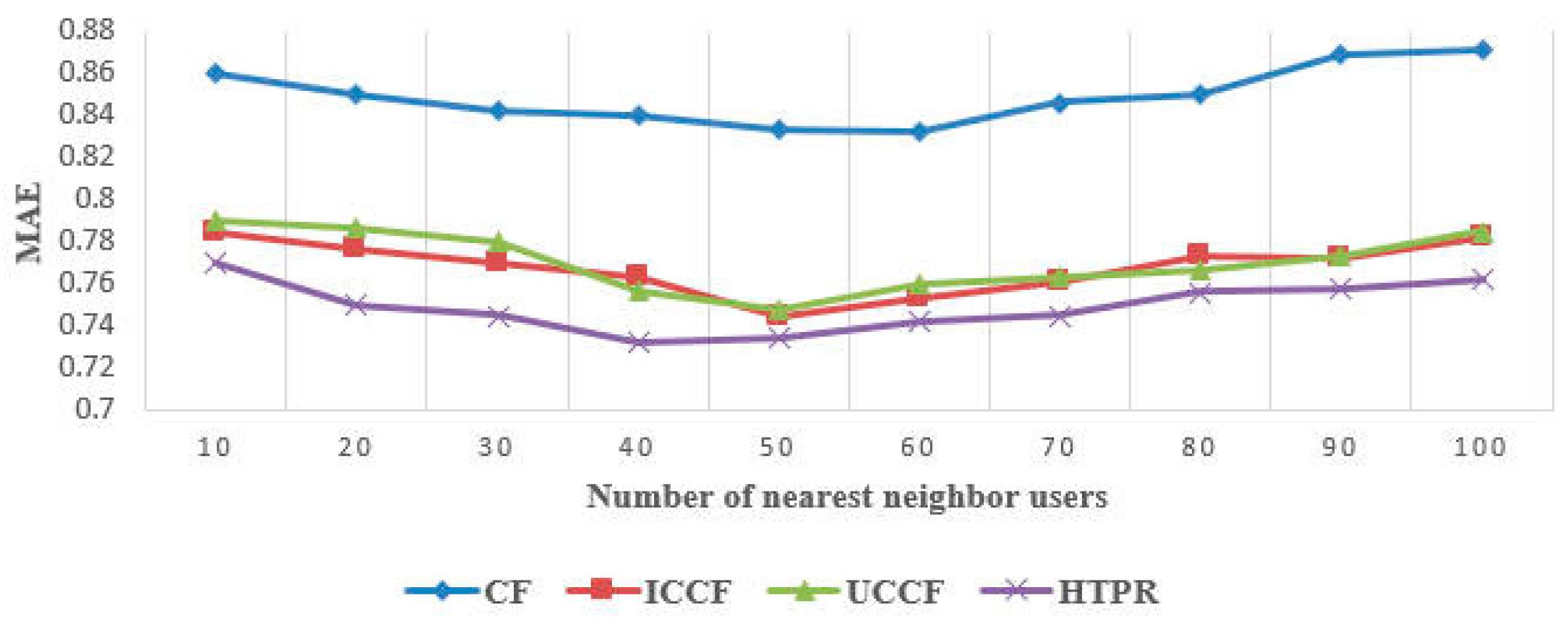
5.2.2. Accuracy Evaluation
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lenhart, A.; Purcell, K.; Smith, A.; Zickuhr, K. Social Media & Mobile Internet Use among Teens and Young Adults; Pew Internet & American Life Project: Washington, DC, USA, 2010. [Google Scholar]
- Berthon, P.R.; Pitt, L.F.; Plangger, K.; Shapiro, D. Marketing meets web 2.0, social media, and creative consumers: Implications for international marketing strategy. Bus. Horiz. 2012, 55, 261–271. [Google Scholar] [CrossRef]
- Andriole, S.J. Business impact of web 2.0 technologies. Commun. ACM 2010, 53, 67–79. [Google Scholar] [CrossRef]
- Zhang, H.D.; Ni, W.C.; Li, X.; Yang, T.P. Modeling the Heterogeneous Duration of User Interest in Time-Dependent Recommendation: A Hidden Semi-Markov Approach. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 177–194. [Google Scholar] [CrossRef]
- Barenji, A.V.; Wang, W.M.; Li, Z.; Guerra-Zubiaga, D.A. Intelligent E-commerce logistics platform using hybrid agent based approach. Transp. Res. Part E Logist. Transp. Res. 2019, 126, 15–31. [Google Scholar] [CrossRef]
- Tomohiro, A. Merchant selection and pricing strategy for a platform firm in the online group buying market. Ann. Oper. Res. 2018, 263, 209–230. [Google Scholar]
- Wu, Y.; Zhu, L. Joint quality and pricing decisions for service online group-buying strategy. Electron. Commer. Res. Appl. 2017, 25, 1–15. [Google Scholar] [CrossRef]
- Bello-Orgaz, G.; Jung, J.J.; Camacho, D. Social big data: Recent achievements and new challenges. Inf. Fusion 2015, 28, 28, 45–59. [Google Scholar] [CrossRef]
- Meng, S.; Dou, W.; Zhang, X.; Chen, J. Kasr: A keyword-aware service recommendation method on mapreduce for big data applications. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3221–3231. [Google Scholar] [CrossRef]
- Parameswaran, S.; Luo, E.; Nguyen, T. Patch Matching for Image Denoising Using Neighborhood-Based Collaborative Filtering. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 392–401. [Google Scholar] [CrossRef]
- Cai, Y.; Leung, H.F.; Li, Q.; Min, H.Q.; Tang, J.; Li, J.Z. Typicality-based collaborative filtering recommendation. IEEE Trans. Knowl. Data Eng. 2014, 26, 766–779. [Google Scholar] [CrossRef]
- Rastin, N.; Jahromi, M.Z. Using content features to enhance the performance of user-based collaborative filtering. Int. J. Artif. Intell. Appl. 2014, 5, 53–62. [Google Scholar]
- Jiang, S.; Fang, S.C.; An, Q.; Lavery, J.E. A sub-one quasi-norm-based similarity measure for collaborative filtering in recommender systems. Inf. Sci. 2019, 487, 142–155. [Google Scholar] [CrossRef]
- Alqadah, F.; Reddy, C.K.; Hu, J.; Alqadah, H.F. Biclustering neighborhood-based collaborative filtering method for top-n, recommender systems. Knowl. Inf. Syst. 2015, 44, 475–491. [Google Scholar] [CrossRef]
- Pavlos, K.; Panagiotis, S.; Yannis, M. Recommendations based on a heterogeneous spatio-temporal social network. World Wide Web-Internet Web Inf. Syst. 2018, 21, 345–371. [Google Scholar]
- Chen, X.; Zheng, Z.; Yu, Q.; Lyu, M.R. Web service recommendation via exploiting location and QoS information. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1913–1924. [Google Scholar] [CrossRef]
- Pereira, A.L.V.; Hruschka, E.R. Simultaneous co-clustering and learning to address the cold start problem in recommender systems. Knowl. Based Syst. 2015, 82, 11–19. [Google Scholar] [CrossRef]
- Tsai, C.F.; Hung, C. Cluster ensembles in collaborative filtering recommendation. Appl. Soft Comput. 2012, 12, 1417–1425. [Google Scholar] [CrossRef]
- Yao, L.; Sheng, Q.Z.; Ngu, A.H.; Yu, J.; Segev, A. Unified Collaborative and Content-Based Web Service Recommendation. IEEE Trans. Serv. Comput. 2015, 8, 453–466. [Google Scholar] [CrossRef]
- Liu, C.H.; Jin, T.; Hoi, S.C.H.; Zhao, P.L.; Sun, J.L. Collaborative topic regression for online recommender systems: An online and Bayesian approach. Mach. Learn. 2017, 106, 651–670. [Google Scholar] [CrossRef]
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Lakiotaki, K.; Matsatsinis, N.F.; Tsoukias, A. Multicriteria user modeling in recommender systems. IEEE Intell. Syst. 2011, 26, 64–76. [Google Scholar] [CrossRef]
- Huang, Z.; Zeng, D.; Chen, H. A comparison of collaborative-filtering recommendation algorithms for e-commerce. IEEE Intell. Syst. 2007, 22, 68–78. [Google Scholar] [CrossRef]
- Kazienko, P.; Musial, K.; Kajdanowicz, T. Multidimensional social network in the social recommender system. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2013, 41, 746–759. [Google Scholar] [CrossRef]
- Lin, W.; Alvarez, S.A.; Ruiz, C. Efficient adaptive-support association rule mining for recommender systems. Data Min. Knowl. Discov. 2002, 6, 83–105. [Google Scholar] [CrossRef]
- Hassannia, R.; Barenji, A.V.; Li, Z.; Alipour, H. Web-Based Recommendation System for Smart Tourism: Multiagent Technology. Sustainability 2019, 11, 323. [Google Scholar] [CrossRef]
- Jeong, B.; Lee, J.; Cho, H. Improving memory-based collaborative filtering via similarity updating and prediction modulation. Inf. Sci. 2010, 180, 602–612. [Google Scholar] [CrossRef]
- Gong, S.J.; Ye, H.W.; Tan, H.S. Combining Memory-Based and Model-Based Collaborative Filtering in Recommender System. In Proceedings of the Pacific-Asia Conference on Circuits, Communications and Systems, Chengdu, China, 16–17 May 2009; pp. 690–693. [Google Scholar]
- Hu, Y.; Peng, Q.; Hu, X.; Yang, R. Time Aware and Data Sparsity Tolerant Web Service Recommendation Based on Improved Collaborative Filtering. IEEE Trans. Serv. Comput. 2015, 8, 782–794. [Google Scholar] [CrossRef]
- Barragáns-Martínez, A.B.; Costa-Montenegro, E.; Burguillo, J.C.; Rey-López, M.; Mikic-Fonte, F.A.; Peleteiro, A. A hybrid content-based and item-based collaborative filtering approach to recommend TV programs enhanced with singular value decomposition. Inf. Sci. 2010, 180, 4290–4311. [Google Scholar] [CrossRef]
- Su, X.Y.; Khoshgoftaar, T.M.; Zhu, X.Q.; Greiner, R. Imputation-Boosted Collaborative Filtering Using Machine Learning Classifiers. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 949–950. [Google Scholar]
- Nilashi, M.; Jannach, D.; Ibrahim, O.B.; Ithnin, N. Clustering and regression-based multi-criteria collaborative filtering with incremental updates. Inf. Sci. 2015, 293, 235–250. [Google Scholar] [CrossRef]
- Jiang, S.; Qian, X.; Shen, J.; Fu, Y. Author topic model-based collaborative filtering for personalized poi recommendations. IEEE Trans. Multimed. 2015, 17, 907–918. [Google Scholar] [CrossRef]
- Wu, J.; Chen, L.; Feng, Y.; Zheng, Z.; Zhou, M.C.; Wu, Z. Predicting quality of service for selection by neighborhood-based collaborative filtering. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 428–439. [Google Scholar] [CrossRef]
- Nilashi, M.; Ibrahim, O.B.; Ithnin, N. Hybrid recommendation approaches for multi-criteria collaborative filtering. Expert Syst. Appl. 2014, 41, 3879–3900. [Google Scholar] [CrossRef]
- Luo, X.; Zhou, M.; Xia, Y.; Zhu, Q. An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems. IEEE Trans. Ind. Inform. 2014, 10, 1273–1284. [Google Scholar]
- Hofmann, T. Latent semantic models for collaborative filtering. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 89–115. [Google Scholar] [CrossRef]
- Pennock, D.M.; Horvitz, E.; Lawrence, S.; Giles, C.L. Collaborative Filtering by Personality Diagnosis: A Hybrid Memory and Model-Based Approach. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, San Francisco, CA, USA, 30 June–3 July 2000; pp. 72–81. [Google Scholar]
- Rafailidis, D.; Nanopoulos, A. Modeling users preference dynamics and side information in recommender systems. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 782–792. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Bernal, J. A collaborative filtering approach to mitigate the new user cold start problem. Knowl. Based Syst. 2012, 26, 225–238. [Google Scholar] [CrossRef]
- Symeonidis, P.; Nanopoulos, A.; Manolopoulos, Y. Providing justifications in recommender systems. IEEE Trans. Syst. Man Cybern. Syst. Hum. 2008, 38, 1262–1272. [Google Scholar] [CrossRef]
- Cacheda, F.; Carneiro, V.; Fernández, D.; Formoso, V. Comparison of collaborative filtering algorithms: Limitations of current techniques and proposals for scalable, high-performance recommender systems. ACM Trans. Web (TWEB) 2011, 5, 2. [Google Scholar] [CrossRef]
- Bobadilla, J.; Serradilla, F.; Bernal, J. A new collaborative filtering metric that improves the behavior of recommender systems. Knowl. Based Syst. 2010, 23, 520–528. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recommendation Technique | Advantages | Disadvantages |
|---|---|---|
| Collaborative filtering | easily realized, handle unstructured complex objects, high automation, personalized | rely on massive historical data, data sparseness problem, cold-start problem |
| Content filtering | more personalized, domain knowledge required, well-understood results | data sparseness problem, difficult to extract and describe feature from complex structured objects |
| Social filtering | feature-distinguished, easily-accepted | user privacy problem, complex social relationship |
| Association rule base | high automation, discover interest point without domain knowledge, no cold-start problem | difficult to extract rules, less personalized |
| Demographic based | discover interest point without domain knowledge, no cold-start problem | difficult to obtain demographic information of users |
| Types of User Behavior | User Behavior |
|---|---|
| Explicit behavior | rating, vote, share/forward, add-to-favorite, purchase, review |
| Implicit behavior | click/browse, time on page |
| Feature | Attribute 1 | Attribute 2 | … | Attribute p | Tag 1 | Tag 2 | … | Tag q | |
|---|---|---|---|---|---|---|---|---|---|
| Item | |||||||||
| Item 1 | 1 | 1 | … | 1 | 0.123 | 0 | … | 0 | |
| Item 2 | 1 | 0 | … | 0 | 0 | 0 | … | 0.248 | |
| … | … | … | … | … | … | … | … | … | |
| Item m | 0 | 0 | … | 0 | 0.387 | 0.472 | … | 0 | |
| Data Table | Format |
|---|---|
| Item attribute | <item id> <attribute id> <attribute weight> |
| Item review tag | <item id> <tag id> <tag relevant value> |
| User/item browse | <user id> <item id> <browse tag> <browse time> |
| User/item wish list | <user id> <item id> <add-to-favorite tag> <add-to-favorite time> |
| User/item purchase | <user id> <item id> <purchase tag> <purchase time> |
| User/item rating | <user id> <item id> <rating value> |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, L.; Hu, M.; Ma, Y.; Liu, M. A Hybrid Two-Phase Recommendation for Group-Buying E-commerce Applications. Appl. Sci. 2019, 9, 3141. https://doi.org/10.3390/app9153141
Bai L, Hu M, Ma Y, Liu M. A Hybrid Two-Phase Recommendation for Group-Buying E-commerce Applications. Applied Sciences. 2019; 9(15):3141. https://doi.org/10.3390/app9153141
Chicago/Turabian StyleBai, Li, Mi Hu, Yunlong Ma, and Min Liu. 2019. "A Hybrid Two-Phase Recommendation for Group-Buying E-commerce Applications" Applied Sciences 9, no. 15: 3141. https://doi.org/10.3390/app9153141
APA StyleBai, L., Hu, M., Ma, Y., & Liu, M. (2019). A Hybrid Two-Phase Recommendation for Group-Buying E-commerce Applications. Applied Sciences, 9(15), 3141. https://doi.org/10.3390/app9153141