Triple-Attention Mixed-Link Network for Single-Image Super-Resolution

Abstract
:Featured Application
Abstract
1. Introduction
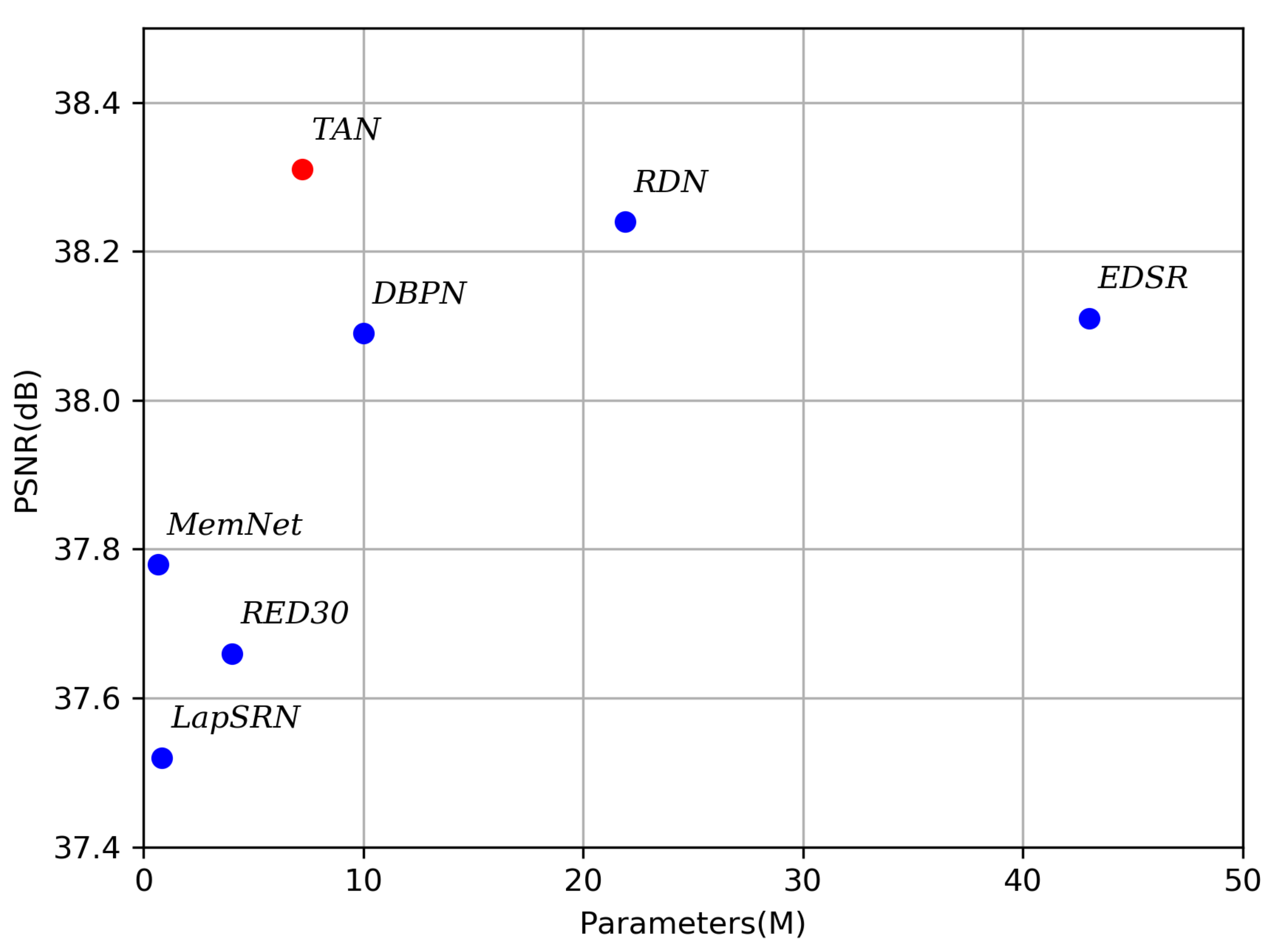
- We propose a triple-attention mixed-link network (TAN) for image super-resolution. The proposed three attention mechanisms provide 0.49 dB, 0.58 dB, and 0.32 dB performance gain when evaluating on Set5, Set14, and BSD100.
- We propose an attention-enhanced multi-kernel mixed-link block which could help achieve better performance with 50% parameter growth rate compared with previous approaches.
- Our model achieved state-of-the-art performance according to the benchmark.
2. Related Works
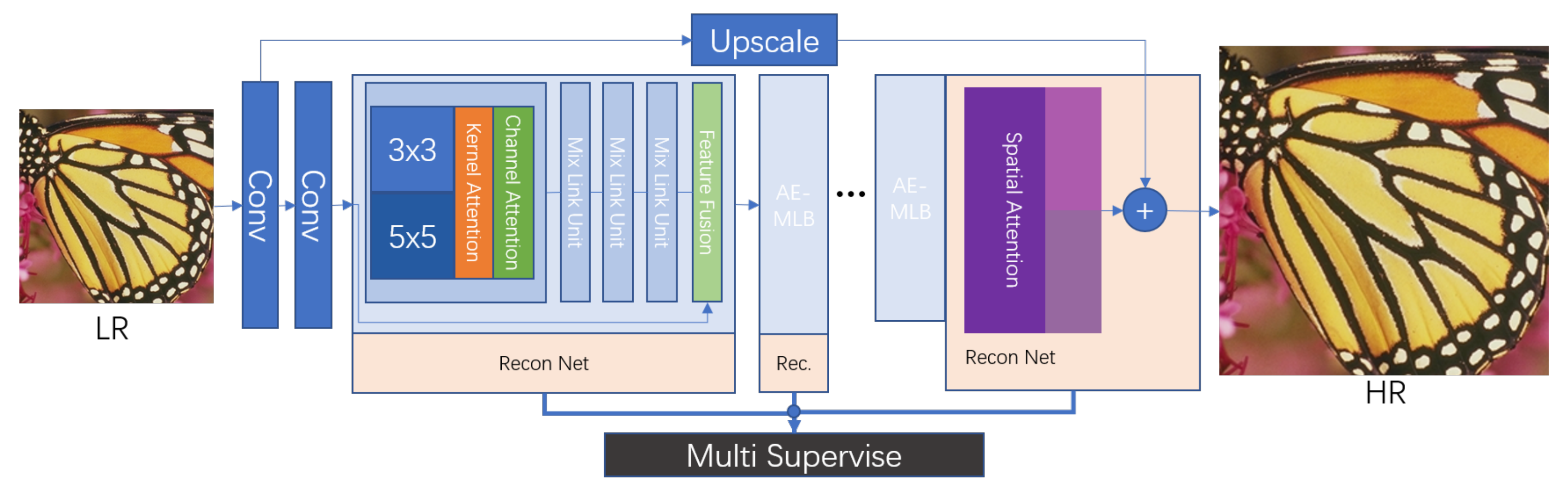
3. Proposed Method
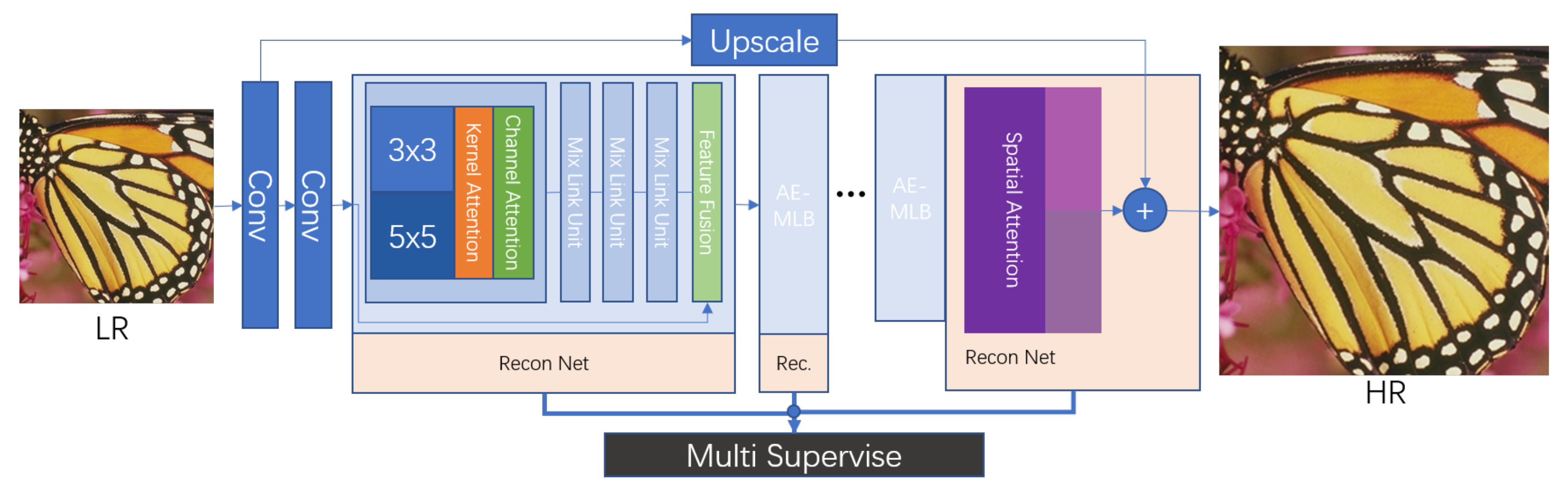
3.1. Overall Model Structure
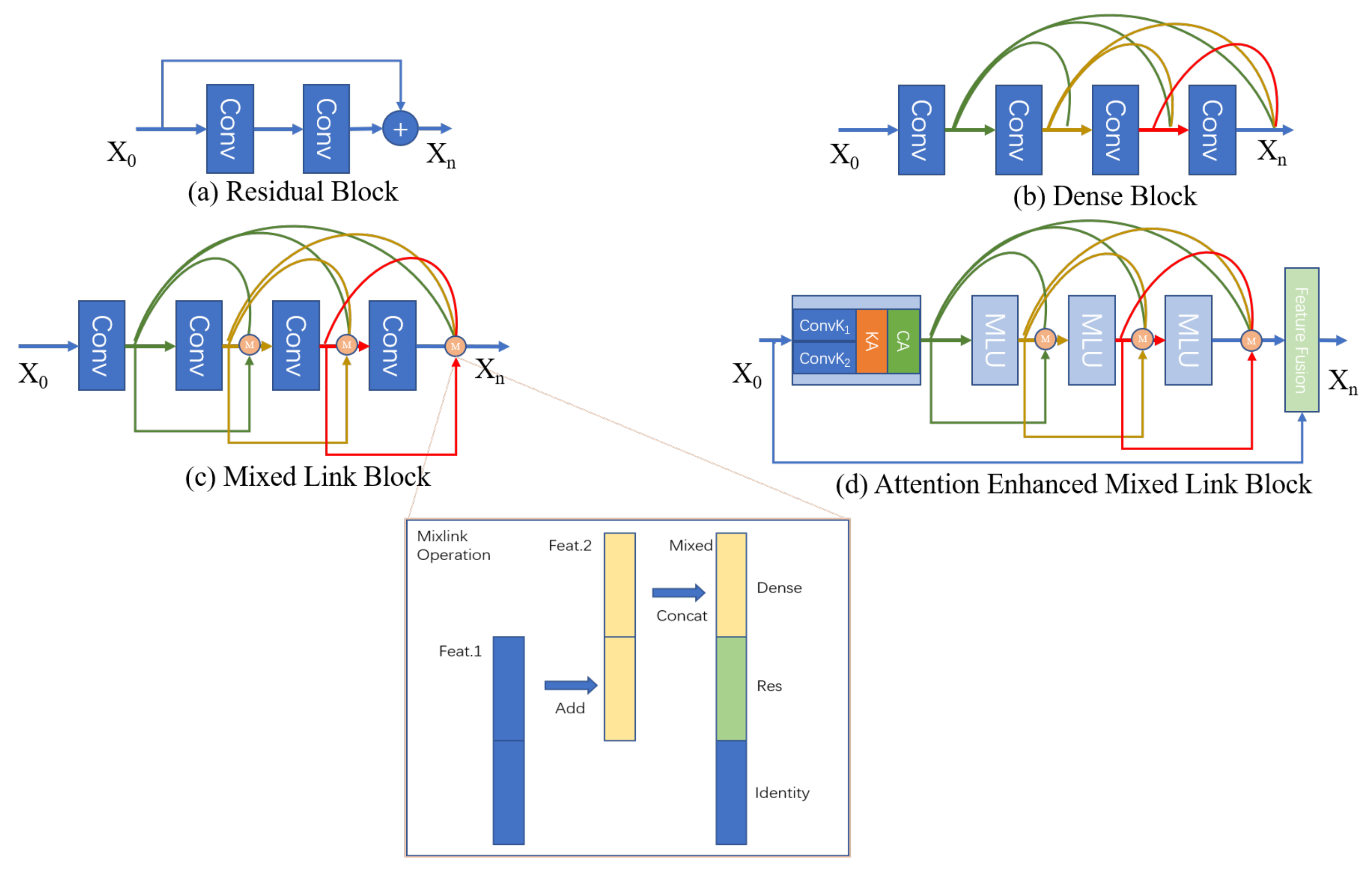
3.2. Mixed-Link Connections
3.3. Triple Attention
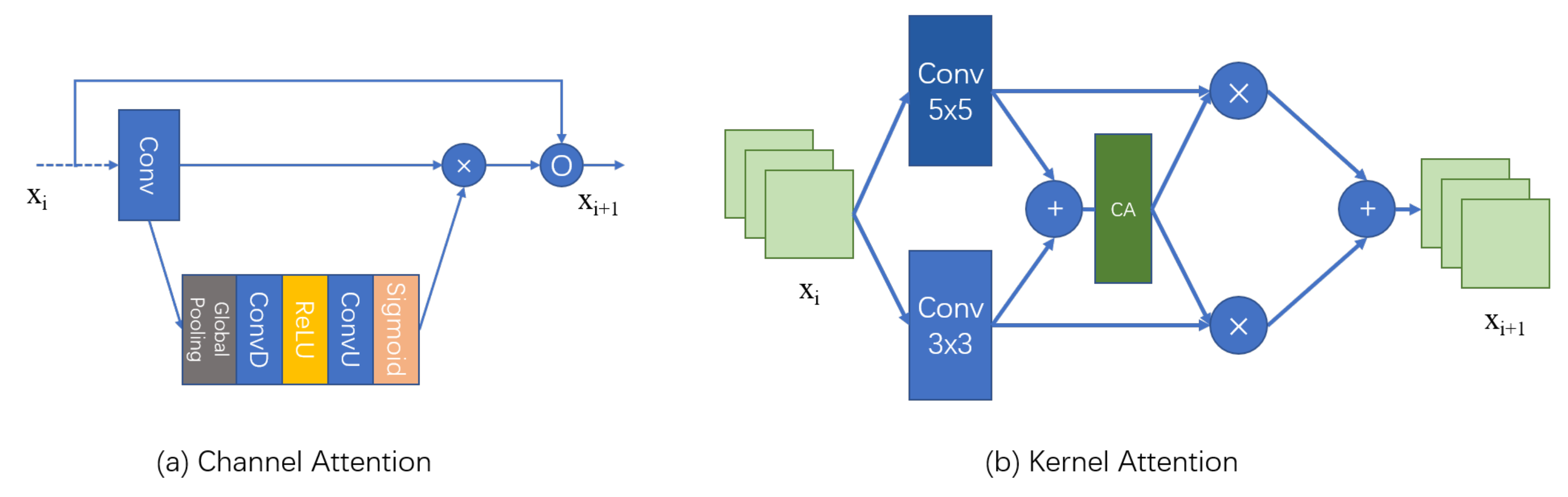
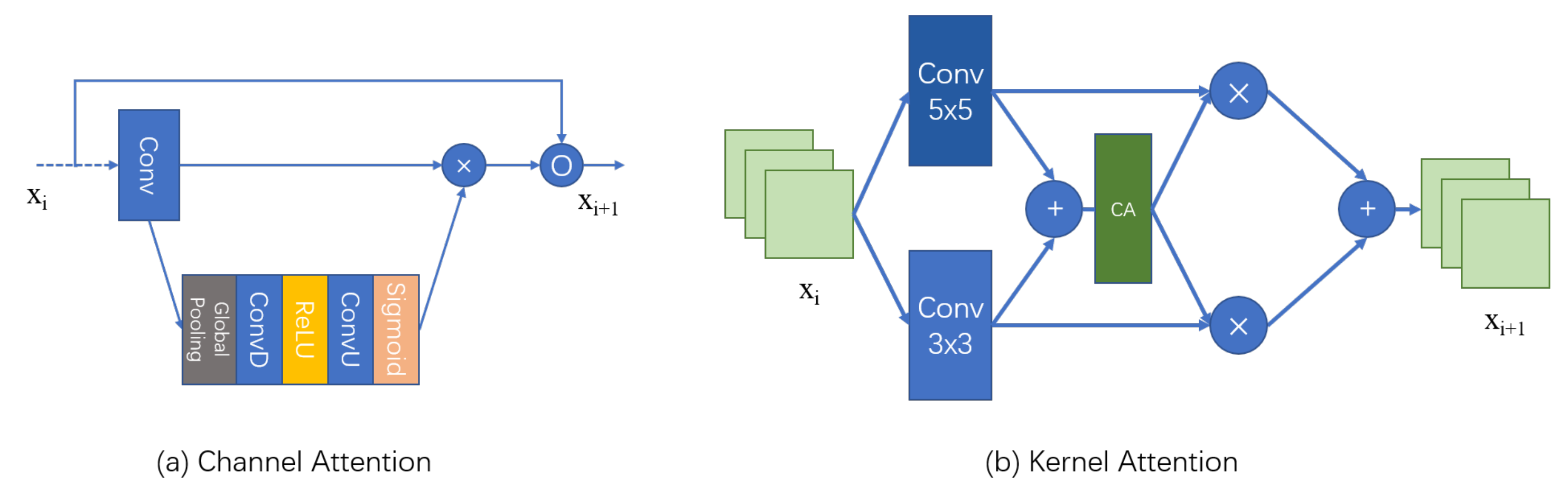
3.3.1. Channel Attention
3.3.2. Kernel Attention
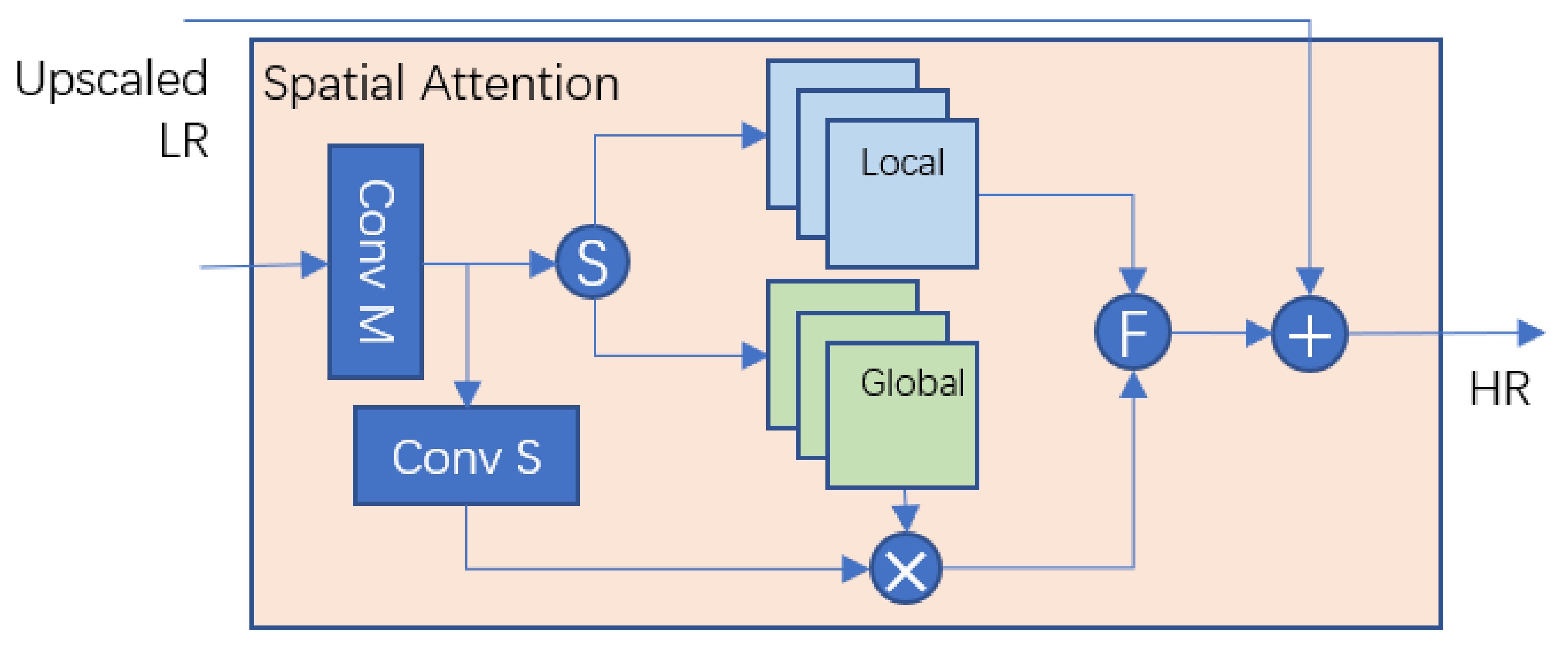
3.3.3. Spatial Attention
3.4. Multi-Supervise and Loss Function
4. Experiment
4.1. Datasets and Training Details
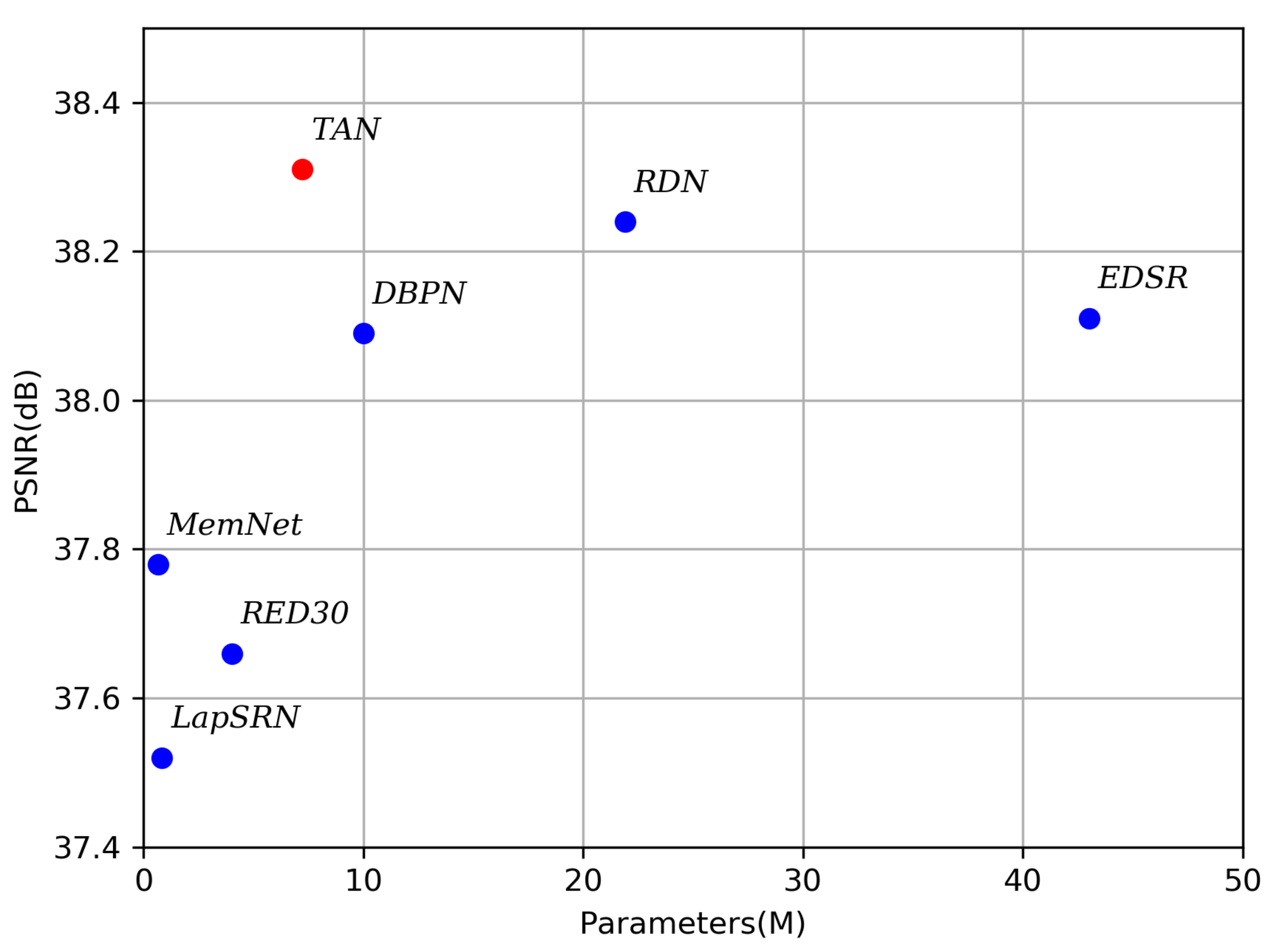
4.2. Compare with State-of-the-Art Methods
4.3. Comparison on Self-Ensemble Results
4.4. Study in Model Structure
4.5. Study in Attention Modules
4.6. Study in the Number of AE-MLBs
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| TAN | Triple-attention mixed-link network |
| CA | Channel attention |
| KA | Kernel attention |
| SA | Spatial attention |
| AE-MLB | Attention-enhanced mixed-link block |
References
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate superresolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2, p. 5. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. arXiv 2018, arXiv:1807.02758. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4539–4547. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Wang, W.; Li, X.; Yang, J.; Lu, T. Mixed Link Networks. arXiv 2018, arXiv:1802.01808. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; Volume 1, p. 5. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4700–4708. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; Volume 4, p. 12. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Venice, Italy, 22–29 October 2017; Volume 3, p. 2. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep backprojection networks for super-resolution. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2802–2810. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4681–4690. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4491–4500. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scale | SRCNN | LapSRN | MemNet | EDSR | RDN | TAN (Ours) | TAN + (Ours) |
|---|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Set5 | ×2 | 36.65/0.955 | 37.52/0.959 | 37.78/0.960 | 38.11/0.960 | 38.24/0.962 | 38.30/0.964 | 38.31/0.965 |
| ×4 | 30.50/0.863 | 31.54/0.885 | 31.74/0.889 | 32.46/0.897 | 32.47/0.899 | 32.34/0.901 | 32.41/0.896 | |
| ×8 | 25.33/0.690 | 26.15/0.738 | 26.16/0.741 | 26.96/0.776 | —-/—- | 26.79/0.772 | 26.84/0.773 | |
| Set14 | ×2 | 32.29/0.908 | 33.08/0.913 | 33.28/0.914 | 33.92/0.920 | 34.01/0.921 | 33.98/0.924 | 34.07/0.925 |
| ×4 | 27.52/0.753 | 28.19/0.772 | 28.26/0.772 | 28.80/0.786 | 28.81/0.787 | 28.78/0.795 | 28.82/0.796 | |
| ×8 | 23.76/0.591 | 24.35/0.620 | 24.38/0.620 | 24.91/0.642 | —-/—- | 25.04/0.659 | 25.08/0.661 | |
| BSD | ×2 | 31.36/0.887 | 31.80/0.895 | 32.08/0.898 | 32.32/0.901 | 32.34/0.901 | 32.37/0.906 | 32.41/0.907 |
| 100 | ×4 | 26.91/0.712 | 27.32/0.727 | 27.40/0.728 | 27.71/0.742 | 27.72/0.742 | 27.62/0.748 | 27.66/0.741 |
| ×8 | 24.13/0.566 | 24.54/0.586 | 24.58/0.584 | 24.81/0.598 | —-/—- | 24.80/0.614 | 24.84/0.615 | |
| Urban | ×2 | 29.23/0.895 | 30.41/0.910 | 31.31/0.920 | 32.93/0.935 | 33.09/0.937 | 33.04/0.938 | 33.13/0.939 |
| 100 | ×4 | 24.53/0.725 | 25.44/0.756 | 25.50/0.763 | 26.64/0.804 | 26.62/0.803 | 26.61/0.808 | 26.73/0.809 |
| ×8 | 21.29/0.544 | 21.81/0.581 | 21.89/0.583 | 22.51/0.622 | —-/—- | 22.74/0.645 | 22.83/0.648 | |
| Manga | ×2 | 35.82/0.969 | 37.27/0.974 | 37.72/0.974 | 39.10/0.977 | 39.18/0.978 | 39.42/0.981 | 39.59/0.981 |
| 109 | ×4 | 27.83/0.866 | 29.09/0.890 | 29.42/0.894 | 31.02/0.915 | 31.00/0.915 | 30.88/0.918 | 31.04/0.919 |
| ×8 | 22.46/0.695 | 23.39/0.735 | 23.56/0.738 | 24.69/0.784 | —-/—- | 24.67/0.796 | 24.80/0.799 |
| Structure | MixNet | ResNet | DenseNet |
|---|---|---|---|
| Parameter | 1.86 M | 2.03 M | 2.55 M |
| (+0.17) | (+0.69) | ||
| Set5 | 37.81 | 37.69 | 37.74 |
| (−0.12) | (−0.07) | ||
| Set14 | 33.40 | 33.28 | 33.32 |
| (−0.12) | (−0.08) | ||
| BSD100 | 32.05 | 31.96 | 31.98 |
| (−0.09) | (−0.07) |
| Module | Set5 | Set14 | BSD100 |
|---|---|---|---|
| Scale × 2 | Scale × 2 | Scale × 2 | |
| Baseline | 37.81 | 33.40 | 32.05 |
| CA | 37.89 | 33.45 | 32.08 |
| (+0.08) | (+0.05) | (+0.03) | |
| KA | 37.95 | 33.54 | 32.14 |
| (+0.14) | (+0.14) | (+0.09) | |
| SA | 37.91 | 33.49 | 32.12 |
| (+0.10) | (+0.09) | (+0.07) | |
| CA + KA | 38.19 | 33.82 | 32.27 |
| (+0.38) | (+0.42) | (+0.22) | |
| CA + SA | 38.15 | 33.54 | 32.17 |
| (+0.34) | (+0.14) | (+0.12) | |
| KA + SA | 38.09 | 33.66 | 32.22 |
| (+0.28) | (+0.26) | (+0.17) | |
| CA + KA + SA | 38.30 | 33.98 | 32.37 |
| (+0.49) | (+0.58) | (+0.32) |
| Number | Set5 | Set14 | BSD100 |
|---|---|---|---|
| Blocks | Scale × 2 | Scale × 2 | Scale × 2 |
| 1 | 37.97 | 33.53 | 32.15 |
| 2 | 38.12 | 33.69 | 32.26 |
| 3 | 38.23 | 33.79 | 32.32 |
| 4 | 38.28 | 33.87 | 32.34 |
| 5 | 38.29 | 33.96 | 32.34 |
| 6 | 38.30 | 33.98 | 32.37 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Li, X.; Yang, J. Triple-Attention Mixed-Link Network for Single-Image Super-Resolution. Appl. Sci. 2019, 9, 2992. https://doi.org/10.3390/app9152992
Cheng X, Li X, Yang J. Triple-Attention Mixed-Link Network for Single-Image Super-Resolution. Applied Sciences. 2019; 9(15):2992. https://doi.org/10.3390/app9152992
Chicago/Turabian StyleCheng, Xi, Xiang Li, and Jian Yang. 2019. "Triple-Attention Mixed-Link Network for Single-Image Super-Resolution" Applied Sciences 9, no. 15: 2992. https://doi.org/10.3390/app9152992
APA StyleCheng, X., Li, X., & Yang, J. (2019). Triple-Attention Mixed-Link Network for Single-Image Super-Resolution. Applied Sciences, 9(15), 2992. https://doi.org/10.3390/app9152992