Multi-Task Learning Using Task Dependencies for Face Attributes Prediction


Abstract
1. Introduction
2. Related Work
- A multi-task learning using task dependencies architecture for face attributes prediction in end-to-end manner. The designed attention modules in our proposed architecture are used for learning task-dependent disentangled representations. We evaluate the performance with the tasks of smile and gender prediction.
- We present experimental results which demonstrate that our proposed architecture outperforms the traditional multi-task learning architecture and show the effectiveness in comparison with the state-of-the-art methods on FotW and LFWA datasets.
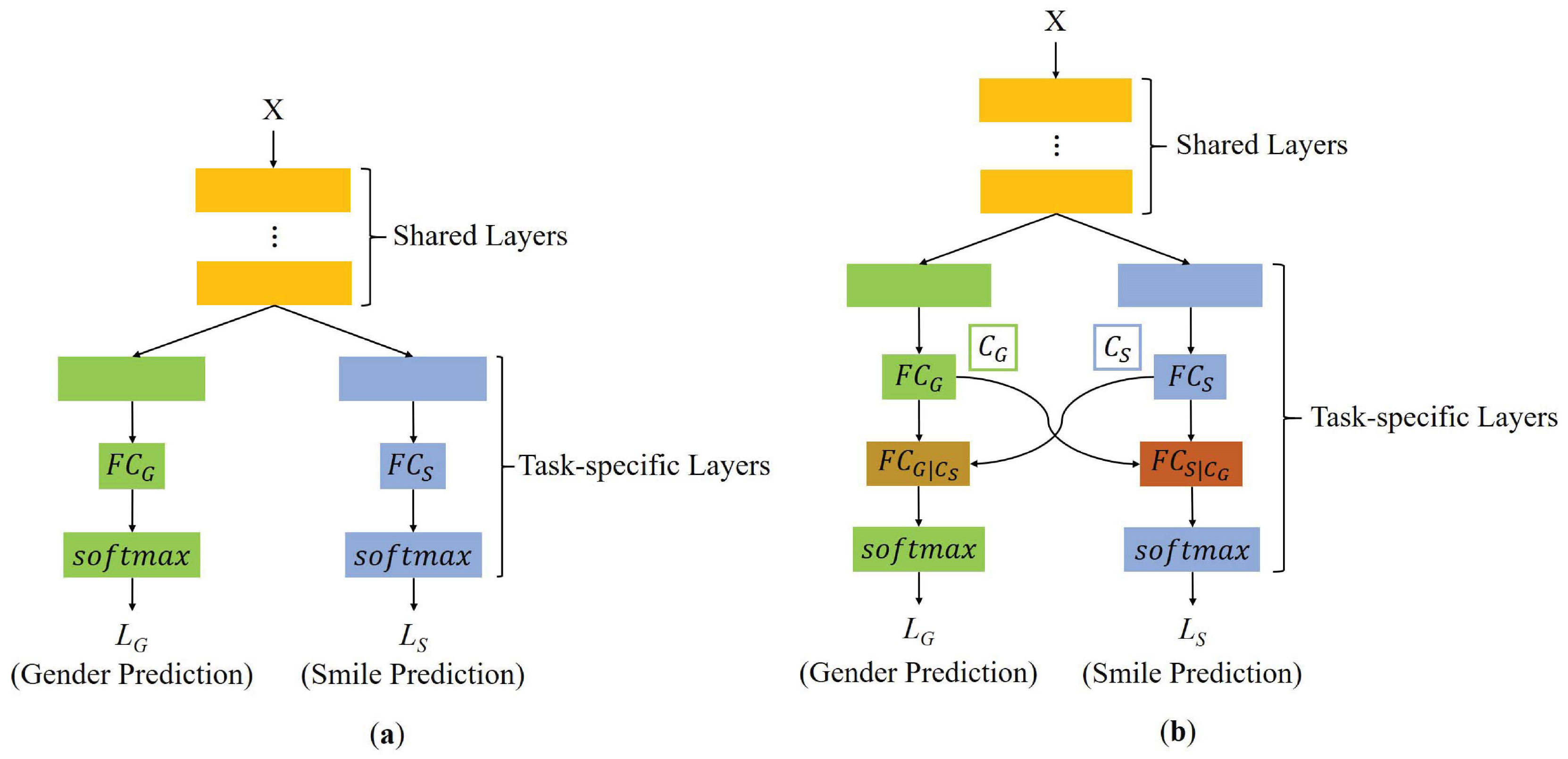
3. Proposed Method
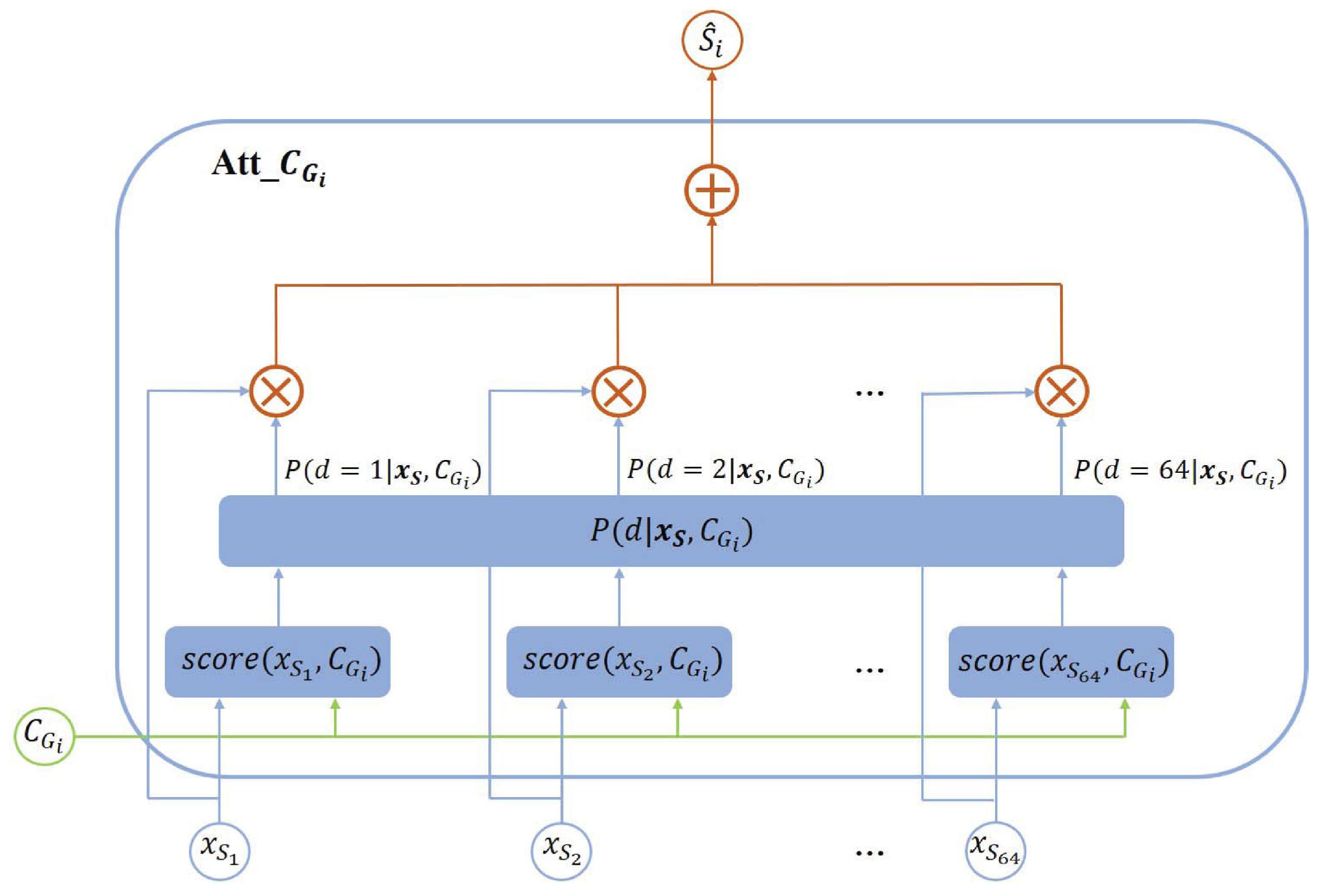
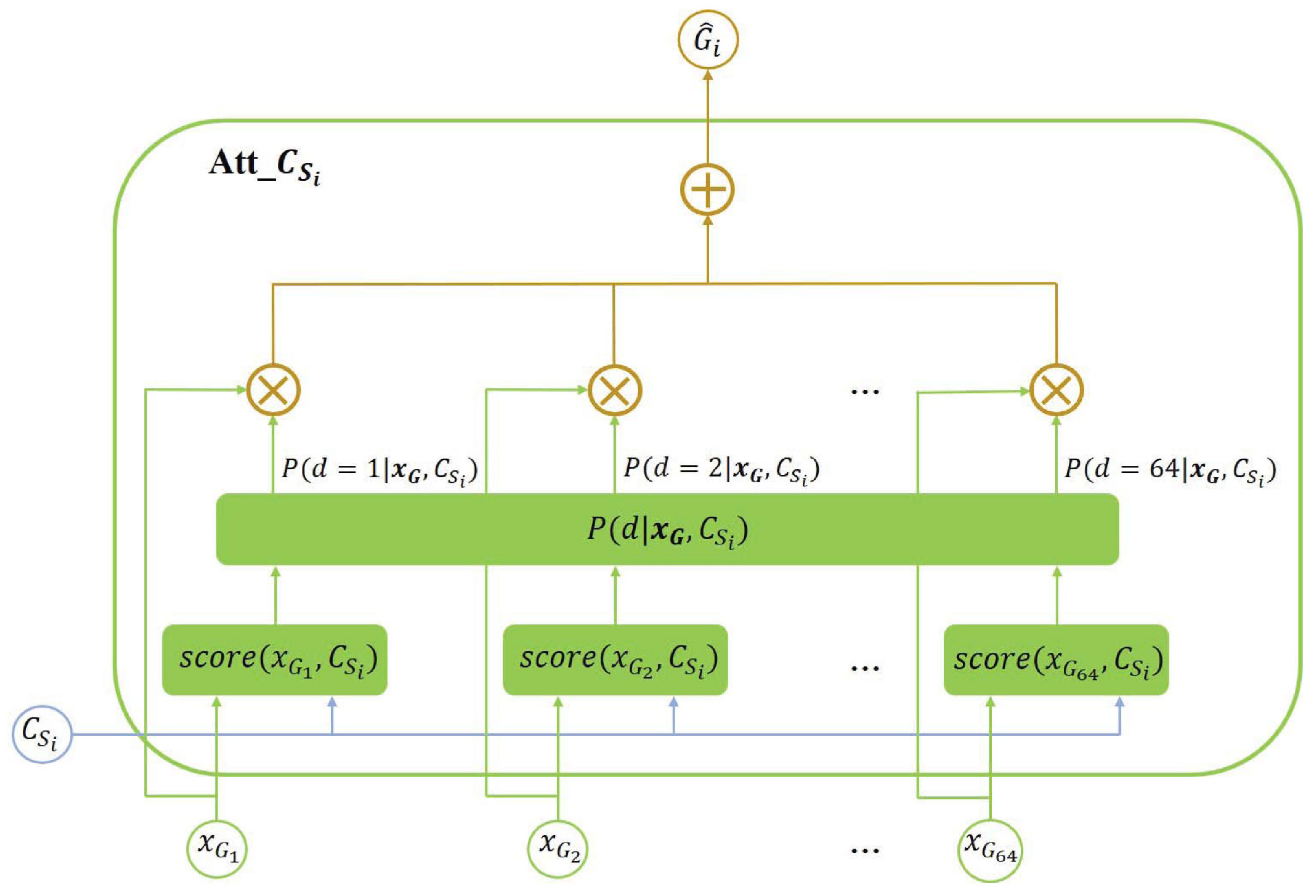
3.1. Modeling
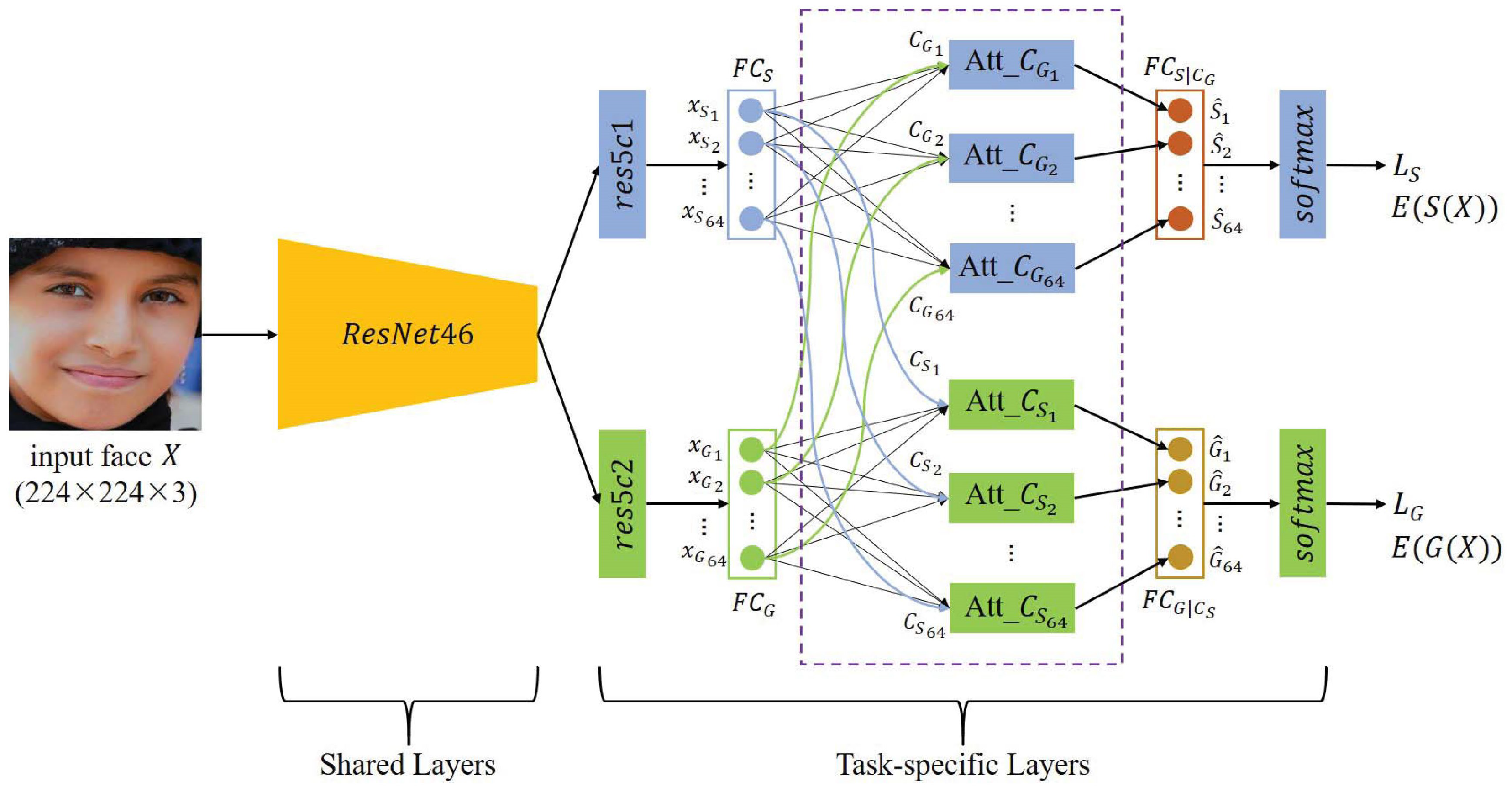
3.2. Network Architecture
3.3. The Model Objective
4. Experiments
4.1. Datasets
4.2. Experimental Configuration
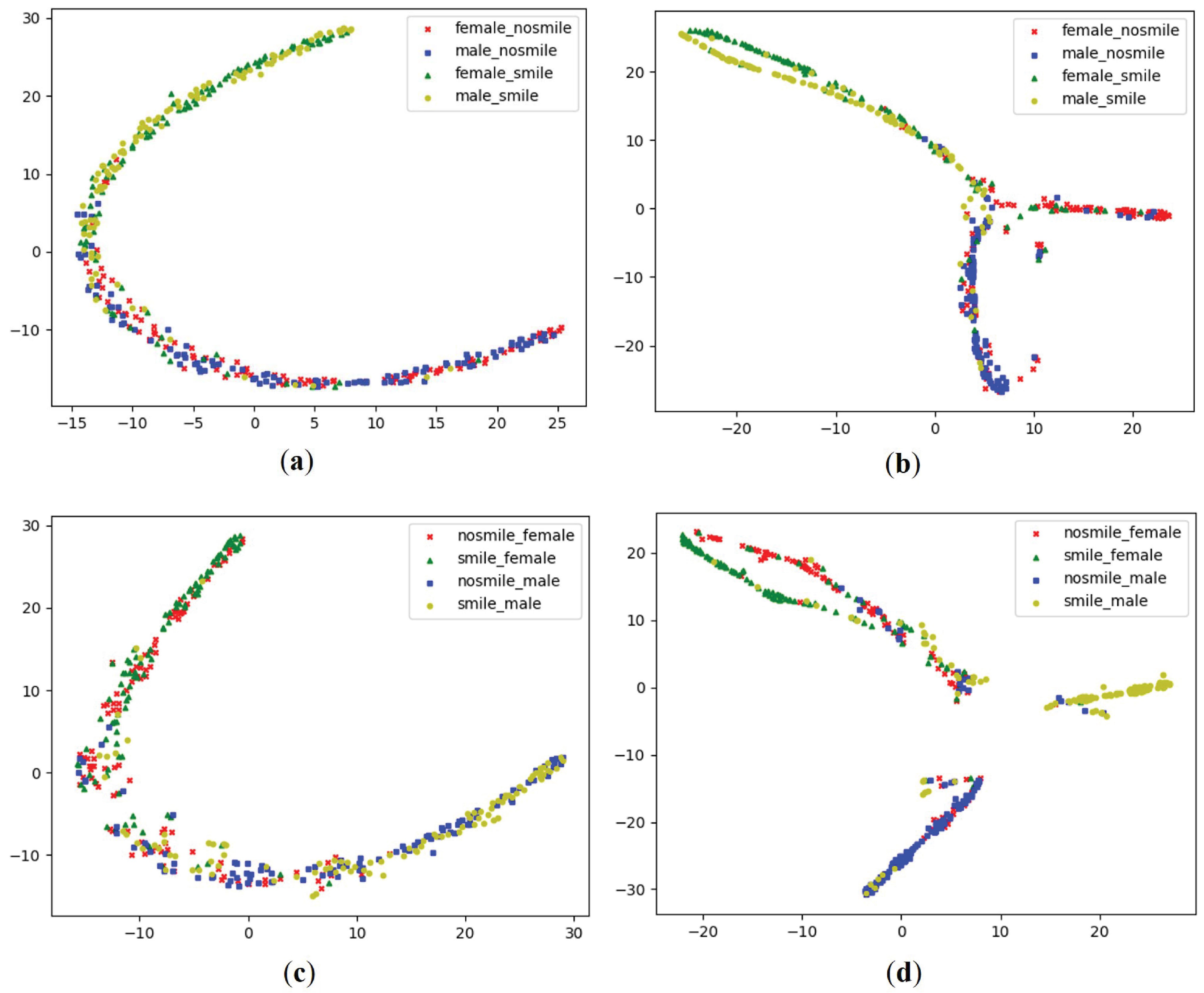
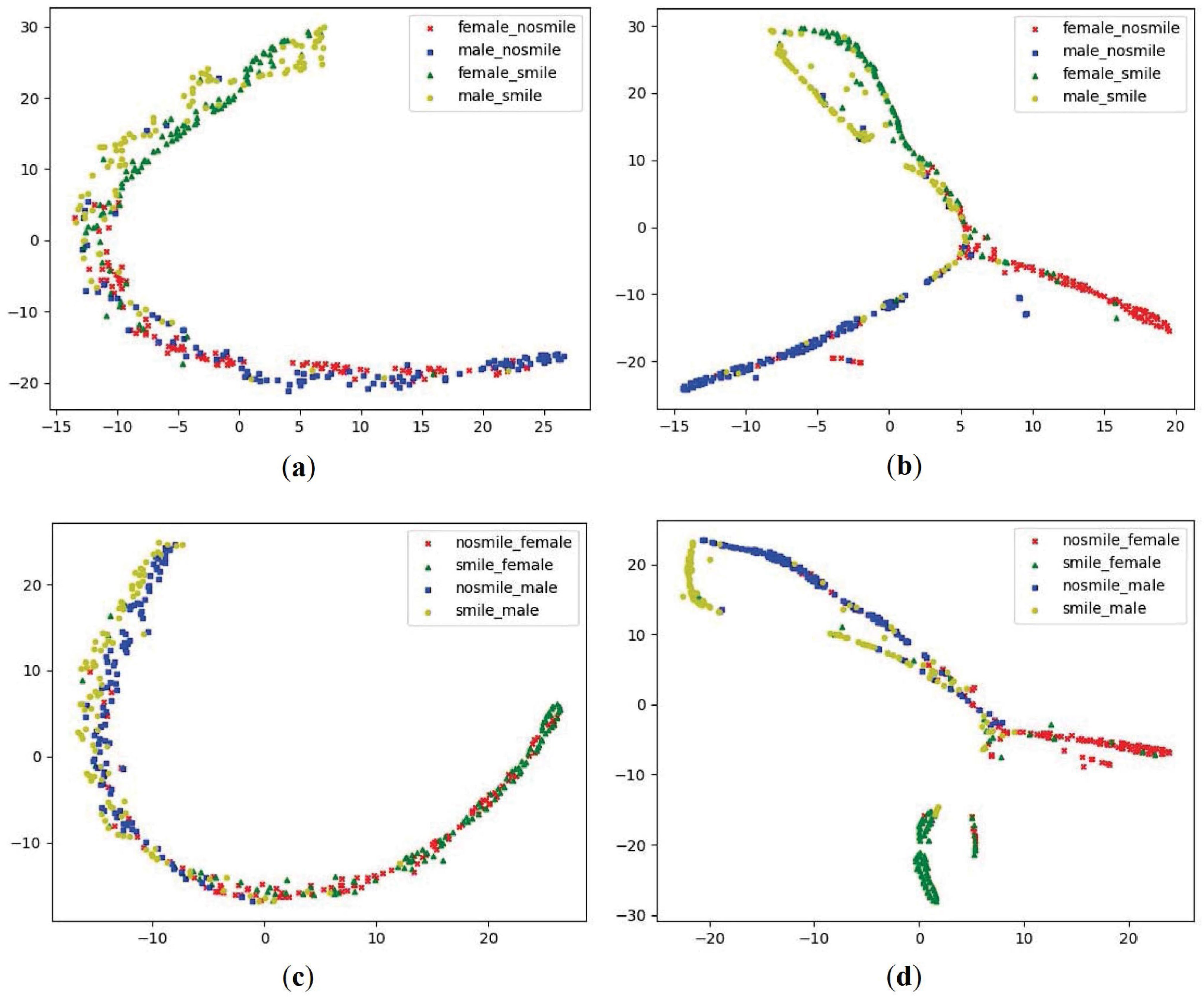
4.3. The Effectiveness of Multi-Task Learning Using Task Dependencies
4.4. Comparison with Previous Approaches
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DCNNs | Deep convolutional neural networks |
| CNN | Convolutional neural networks |
| DCNN | Deep convolutional neural network |
| RNNs | Recurrent neural networks |
| LSTM | Long short term memory |
| TMTL | Traditional multi task learning |
| FotW | Faces of the world |
| LFWA | Labeled faces in the wild-a |
| t-SNE | T-distributed stochastic neighbor embedding |
References
- Kumar, N.; Berg, A.C.; Belhumeur, P.N.; Nayar, S.K. Attribute and simile classifiers for face verification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 365–372. [Google Scholar]
- Song, F.; Tan, X.; Chen, S. Exploiting relationship between attributes for improved face verification. Comput. Vis. Image Underst. 2014, 122, 143–154. [Google Scholar] [CrossRef]
- Vaquero, D.A.; Feris, R.S.; Tran, D.; Brown, L.; Hampapur, A.; Turk, M. Attribute-based people search in surveillance environments. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 111–115. [Google Scholar]
- Glauner, P.O. Deep convolutional neural networks for smile recognition. arXiv 2015, arXiv:1508.06535. [Google Scholar]
- Chen, J.; Ou, Q.; Chi, Z.; Fu, H. Smile detection in the wild with deep convolutional neural networks. Mach. Vis. Appl. 2017, 28, 173–183. [Google Scholar] [CrossRef]
- Nian, F.; Li, L.; Li, T.; Xu, C. Robust gender classification on unconstrained face images. In Proceedings of the 7th International Conference on Internet Multimedia Computing and Service, Zhangjiajie City, China, 19–21 August 2015; p. 77. [Google Scholar]
- Mansanet, J.; Albiol, A.; Paredes, R. Local deep neural networks for gender recognition. Pattern Recognit. Lett. 2016, 70, 80–86. [Google Scholar] [CrossRef]
- Rothe, R.; Timofte, R.; van Gool, L. Dex: Deep expectation of apparent age from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 10–15. [Google Scholar]
- Liu, X.; Li, S.; Kan, M.; Zhang, J.; Wu, S.; Liu, W.; Han, H.; Shan, S.; Chen, X. Agenet: Deeply learned regressor and classifier for robust apparent age estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 16–24. [Google Scholar]
- Brody, L.R.; Hall, J.A. Gender and emotion in context. Handb. Emot. 2008, 3, 395–408. [Google Scholar]
- Bilinski, P.; Dantcheva, A.; Brémond, F. Can a smile reveal your gender? In Proceedings of the 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; pp. 1–6. [Google Scholar]
- Dantcheva, A.; Brémond, F. Gender estimation based on smile-dynamics. IEEE Trans. Inf. Forensics Secur. 2017, 12, 719–729. [Google Scholar] [CrossRef]
- Desai, S.; Upadhyay, M.; Nanda, R. Dynamic smile analysis: Changes with age. Am. J. Orthod. Dentofac. Orthop. 2009, 136, 310. [Google Scholar] [CrossRef]
- Guo, G.; Dyer, C.R.; Fu, Y.; Huang, T.S. Is gender recognition affected by age? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 2032–2039. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- He, R.; Wu, X.; Sun, Z.; Tan, T. Learning invariant deep representation for nir-vis face recognition. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Rifai, S.; Bengio, Y.; Courville, A.; Vincent, P.; Mirza, M. Disentangling factors of variation for facial expression recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 808–822. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. R-cnns for pose estimation and action detection. arXiv 2014, arXiv:1406.5212. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2650–2658. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3994–4003. [Google Scholar]
- Kokkinos, I. Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6129–6138. [Google Scholar]
- Mallya, A.; Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7765–7773. [Google Scholar]
- Kim, E.; Ahn, C.; Torr, P.H.; Oh, S. Deep virtual networks for memory efficient inference of multiple tasks. arXiv 2019, arXiv:1904.04562. [Google Scholar]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3730–3738. [Google Scholar]
- Ranjan, R.; Sankaranarayanan, S.; Castillo, C.D.; Chellappa, R. An all-in-one convolutional neural network for face analysis. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 17–24. [Google Scholar]
- Hyun, C.; Seo, J.; Lee, K.E.; Park, H. Multi-attribute recognition of facial images considering exclusive and correlated relationship among attributes. Appl. Sci. 2019, 9, 2034. [Google Scholar] [CrossRef]
- Yoo, B.; Kwak, Y.; Kim, Y.; Choi, C.; Kim, J. Deep facial age estimation using conditional multitask learning with weak label expansion. IEEE Signal Process. Lett. 2018, 25, 808–812. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Yang, Z.; Hu, Z.; Deng, Y.; Dyer, C.; Smola, A. Neural machine translation with recurrent attention modeling. arXiv 2016, arXiv:1607.05108. [Google Scholar]
- Tang, Y.; Srivastava, N.; Salakhutdinov, R.R. Learning generative models with visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1808–1816. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 6 2015; pp. 2048–2057. [Google Scholar]
- Zhao, B.; Wu, X.; Feng, J.; Peng, Q.; Yan, S. Diversified visual attention networks for fine-grained object classification. IEEE Trans. Multimedia 2017, 19, 1245–1256. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Escalera, S.; Torres, M.T.; Martinez, B.; Baró, X.; Escalante, H.J.; Guyon, I.; Tzimiropoulos, G.; Corneou, C.; Oliu, M.; Bagheri, M.A.; et al. Chalearn looking at people and faces of the world: Face analysis workshop and challenge 2016. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–8. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/keras-team/keras (accessed on 1 March 2018).
- Higgins, I.; Amos, D.; Pfau, D.; Racaniere, S.; Matthey, L.; Rezende, D.; Lerchner, A. Towards a definition of disentangled representations. arXiv 2018, arXiv:1812.02230. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. BMVC 2015, 1, 6. [Google Scholar]
- Han, H.; Jain, A.K.; Wang, F.; Shan, S.; Chen, X. Heterogeneous face attribute estimation: A deep multi-task learning approach. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2597–2609. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Kang, Q.; Ge, G.; Song, Q.; Lu, H.; Cheng, J. Deepbe: Learning deep binary encoding for multi-label classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 39–46. [Google Scholar]
- Zhang, K.; Tan, L.; Li, Z.; Qiao, Y. Gender and smile classification using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 34–38. [Google Scholar]
- Zhang, N.; Paluri, M.; Ranzato, M.; Darrell, T.; Bourdev, L. Panda: Pose aligned networks for deep attribute modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1637–1644. [Google Scholar]
- Zhuang, N.; Yan, Y.; Chen, S.; Wang, H. Multi-task learning of cascaded cnn for facial attribute classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2069–2074. [Google Scholar]
- Zhuang, N.; Yan, Y.; Chen, S.; Wang, H.; Shen, C. Multi-label learning based deep transfer neural network for facial attribute classification. Pattern Recognit. 2018, 80, 225–240. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Architecture | Smile | Gender |
|---|---|---|---|
| FotW | TMTL | 86.83% | 82.54% |
| Ours | 88.53% | 84.83% | |
| LFWA | TMTL | 90.74% | 91.80% |
| Ours | 91.13% | 92.49% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, D.; Kim, H.; Kim, J.; Liu, Y.; Huang, Q. Multi-Task Learning Using Task Dependencies for Face Attributes Prediction. Appl. Sci. 2019, 9, 2535. https://doi.org/10.3390/app9122535
Fan D, Kim H, Kim J, Liu Y, Huang Q. Multi-Task Learning Using Task Dependencies for Face Attributes Prediction. Applied Sciences. 2019; 9(12):2535. https://doi.org/10.3390/app9122535
Chicago/Turabian StyleFan, Di, Hyunwoo Kim, Junmo Kim, Yunhui Liu, and Qiang Huang. 2019. "Multi-Task Learning Using Task Dependencies for Face Attributes Prediction" Applied Sciences 9, no. 12: 2535. https://doi.org/10.3390/app9122535
APA StyleFan, D., Kim, H., Kim, J., Liu, Y., & Huang, Q. (2019). Multi-Task Learning Using Task Dependencies for Face Attributes Prediction. Applied Sciences, 9(12), 2535. https://doi.org/10.3390/app9122535