1. Introduction
In the last few decades, it has been a challenge to standardize the evaluation of overall voice quality in practice. Until now, auditory-perceptual evaluation of voice quality has been considered to be the gold standard due to its accessibility and the perceptual nature of voice quality. Subsequently, it is often used to verify the validity of other evaluation methods [
1]. Several assessment tools have been developed to standardize this perceptual rating of voice quality in practice, of whom the GRBAS (grade, roughness, breathiness, asthenia, and strain) scale [
2], proposed by the Japan Society of Logopedics and Phoniatrics, and the CAPE-V (consensus auditory-perceptual evaluation of voice) [
3], proposed by the American Speech-Language and Hearing Association, are two well-known and widely-used scales. Nevertheless, the subjective nature and the wide range of factors related to listener, stimulus, and scale, influencing intra- and inter-judge reliability, still remains a major drawback [
1,
4]. Consequently, our interest in objective assessment of voice quality has grown and has been the subject of many studies.
Acoustic assessment is a much-discussed and appealing method of objective voice evaluation and is becoming increasingly used in clinical voice practice and research due to its non-invasive and accessible character and its relatively low cost [
5]. To overcome the limited validity of single acoustic parameters and also recognize the multidimensionality of voice, Maryn et al. [
5] developed the acoustic voice quality index (AVQI), a multiparametric tool based on six acoustic measurements, to quantify overall voice quality (an elaborate description of the acoustic measurements is represented in the section ‘Materials and Methods’). This tool (Phonanium, Lokeren, Belgium) is the result of stepwise multiple linear regression analysis of thirteen acoustic measures to sort out the most robust combination yielding a single number predicting dysphonia severity, ranging from 0 to 10. The lower this number, the less dysphonia and the better the voice quality. These measures are all obtained within the software Praat (Paul Boersma and David Weenink, Institute of Phonetic Sciences, University of Amsterdam, The Netherlands). Analysis of both sustained vowels and continuous speech samples is implemented, since both sample types offer valuable information in voice quality assessment. Sustained vowels are relatively unaffected by individual speech characteristics such as speech rate, dialect, intonation, and articulation, and other factors like phonetic context and stress. On the other hand, continuous speech is more representative of daily speech and, therefore, can be considered to be more ‘ecologically valid’ [
6]. Several studies in the last decade already demonstrated the robust diagnostic accuracy of AVQI [
5,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24], its consistent and high concurrent validity [
5,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
19,
21,
22,
23,
24,
25] and its high sensitivity to voice changes across voice therapy [
8,
12,
16,
18,
21]. Furthermore, studies validating the use of AVQI in different languages showed diagnostic accuracy according to inter-language phonetic differences [
9,
10,
11,
12,
13,
14,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25], although AVQI was originally developed for Dutch speakers.
The main contributor of AVQI is the smoothed version of the cepstral peak prominence (CPPS), which represents the distance between the first rahmonic’s peak and the point with equal quefrency on the regression line through the smoothed cepstrum. The more periodic a voice signal, the more harmonic the spectrum and the higher the CPPS value. It was introduced in the field of voice assessment by Hillenbrand et al. [
26] and Hillenbrand and Houde [
27], and, meanwhile, many studies have proven it to be a reliable and valid measure of overall voice quality, especially of breathiness [
5,
8,
28,
29,
30,
31,
32,
33,
34,
35,
36].
Subsequently, it can be concluded that AVQI, with CPPS as its main contributor, is a very promising tool to measure overall voice quality and record voice therapy outcome in practice. A current limitation of AVQI and CPPS is, however, the lack of normative data. Diagnostic thresholds to differentiate between normophonic and dysphonic voices have been proposed for mostly treatment-seeking subjects using receiver operating characteristics (ROC) curve analysis (
Table 1). However, studies investigating the performance of AVQI in strictly normophonic subjects are scarce. Such normative data are valuable to contribute to the interpretation of dysphonic voice samples and thus increase the clinical utility of AVQI and CPPS. Therefore, the primary purpose of the present study was to acquire a normative data set for AVQI and its main contributor, CPPS, in Praat and to evaluate the influence of gender. The second aim was to evaluate the ability of AVQI and CPPS to distinguish the true normophonic cohort from the subclinical slight dysphonia cohort. Finally, their ability to differentiate between the several sub-levels of subclinical dysphonia was assessed.
2. Materials and Methods
2.1. Participants
Normative data were collected from 123 subjects (72 females and 51 males) between 20 and 60 years old. Participants were not selected at random but were recruited by way of snowball sampling, since there was an appeal on volunteers such as family members, friends, and acquaintances. They mainly originated from the West Flemish region of Belgium, Europe. All participants included did not have any voice-related complaints, were not diagnosed with vocal pathology, and were not seeking voice treatment.
2.2. Voice Recordings
All subjects were asked to sustain the vowel /a:/ for at least 5 s and to read a Dutch phonetically balanced text at comfortable pitch and loudness. Both types of voice samples were recorded using an AKG C420 head-mounted condenser microphone (AKG Acoustics, München, Germany), digitized at a sampling rate of 44.1 kHz and a resolution of 16 bits using the Computerized Speech Lab model (KayPentax, Lincoln Park, NJ, USA), and saved in WAV-format. The microphone was positioned at 8–10 centimeters and at a 45° azimuthal angle from the mouth. Recording took place in an anechoic audiometric cabin with a low mean ambient noise of 38 dBA. Vowel samples were edited to include only the medial 3 s and continuous speech samples were cropped to contain only the first two sentences of the speech task.
2.3. Overall Dysphonia Ratings
Using the software Praat both vowel samples and continuous speech samples were edited and emerged resulting into a concatenation of the first two sentences of the speech task, a pause of two seconds, followed by the medial three seconds of the vowel /a:/. The concatenated samples were evaluated by three raters, of whom one experienced speech-language pathologist and two final-year speech-language pathology students with minimal experience with dysphonic voices and voice pathology. Perceptual overall voice quality (i.e., hoarseness) was evaluated using the first parameter ‘Grade’ (i.e., G) following the GRBAS scale [
2], proposed by the Japan Society of Logopedics and Phoniatrics. As recommended by Wuyts et al. [
38], a 4-point equal-appearing interval scale was used (i.e., 0 = normally or absence of hoarseness, 1 = slightly hoarse, 2 = moderately hoarse, 3 = severely hoarse). Rating occurred fully separately and independently. Only those voice samples that were unanimously rated as G = 0 by all three raters, were considered to be true normophonic. Consequently, two cohorts were set up, with the first cohort consisting of 83 subjects with no perceived dysphonia and the second cohort consisting of 40 subjects with slight perceived dysphonia. Furthermore, three sub-levels of slight hoarseness were obtained according to the number of judges rating G as 1 (1 = majority normophonia, 2 = majority slight dysphonia, 3 = unanimously slight dysphonia).
2.4. Acoustic Measures and AVQI
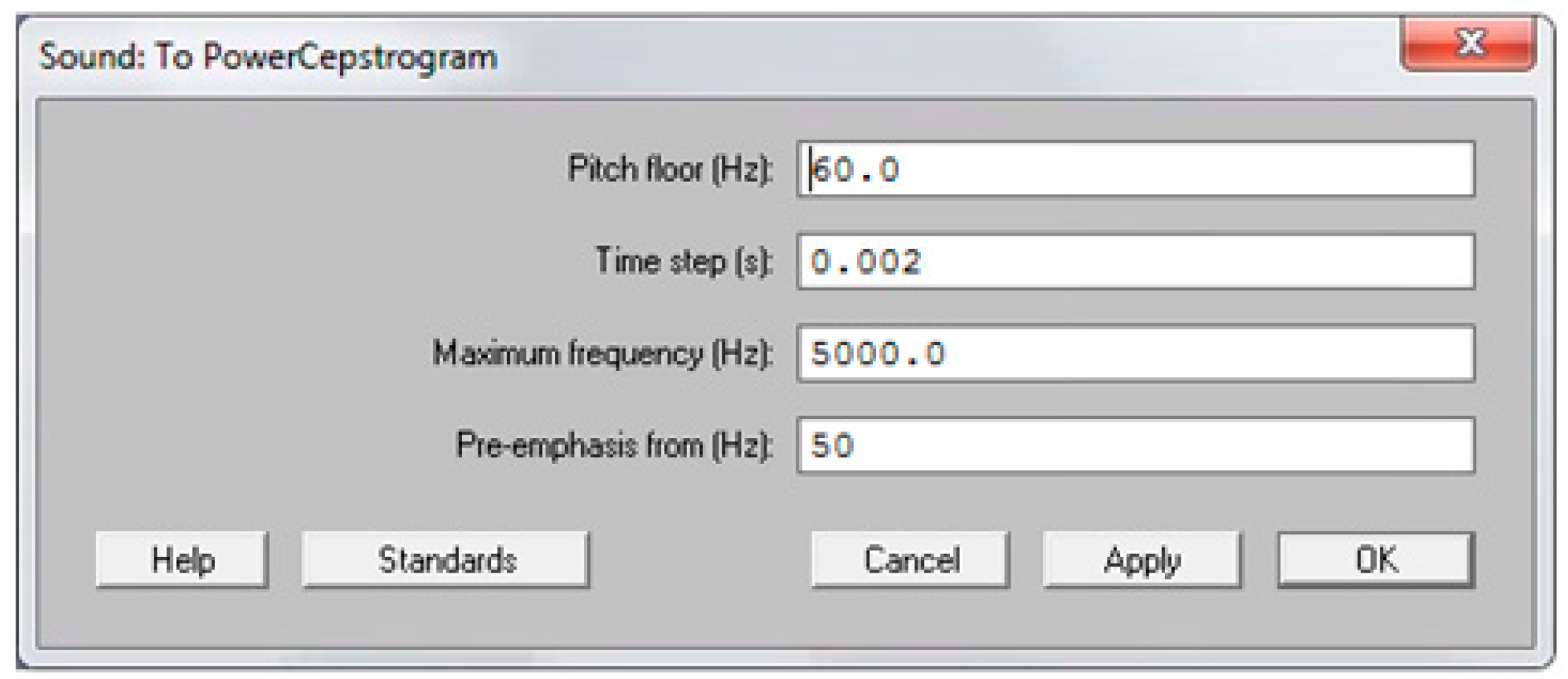
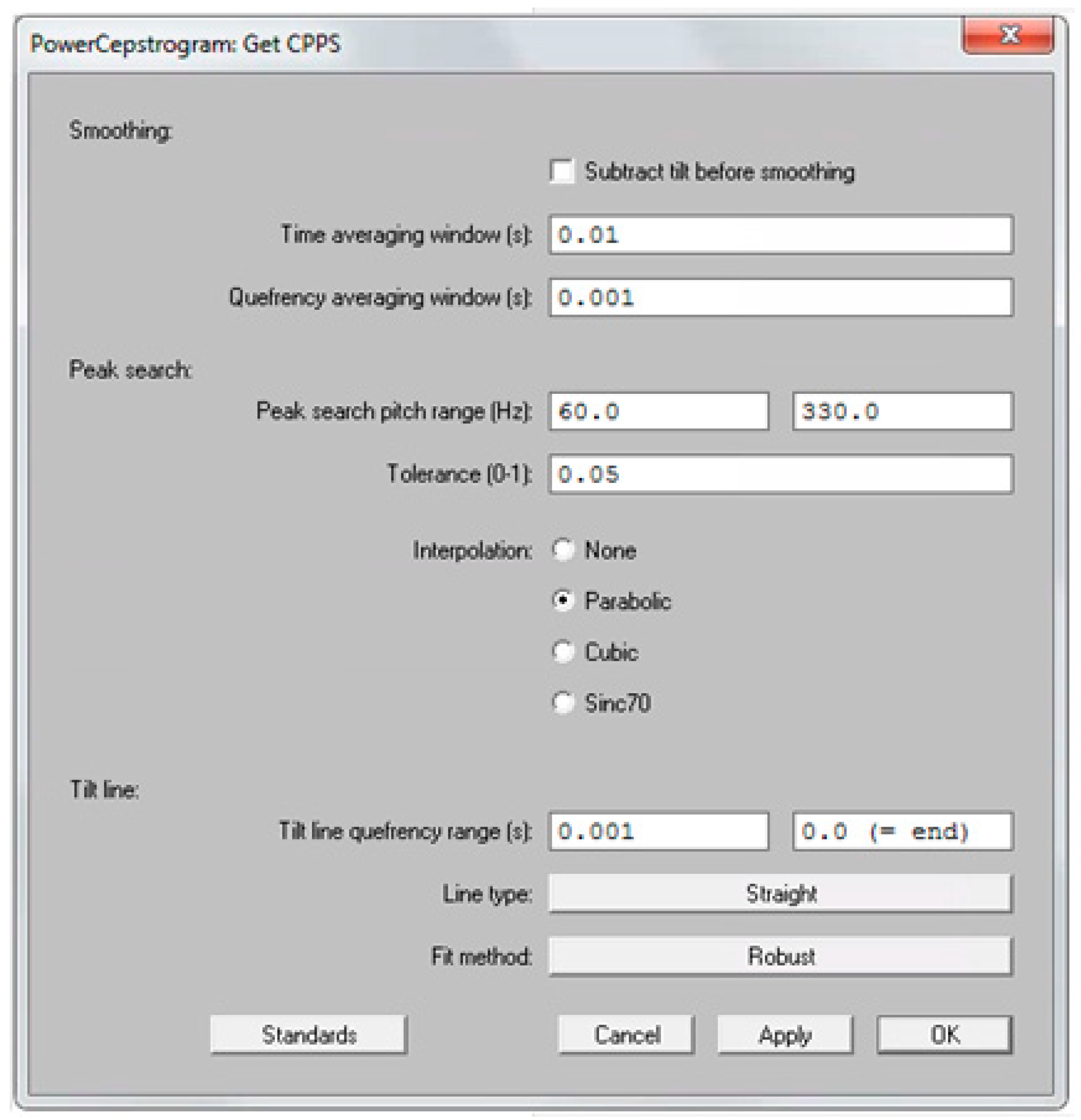
Because certain acoustic measures used in AVQI are only valid for voiced segments, the continuous speech samples needed to be edited. Detection and extraction of voiced segments from the first two sentences of the speech task were performed in the software Praat using the extraction Praat-script from Maryn et al. (2009) [
5], an algorithm based on three criteria, proposed by Parsa and Jamieson (2001) [
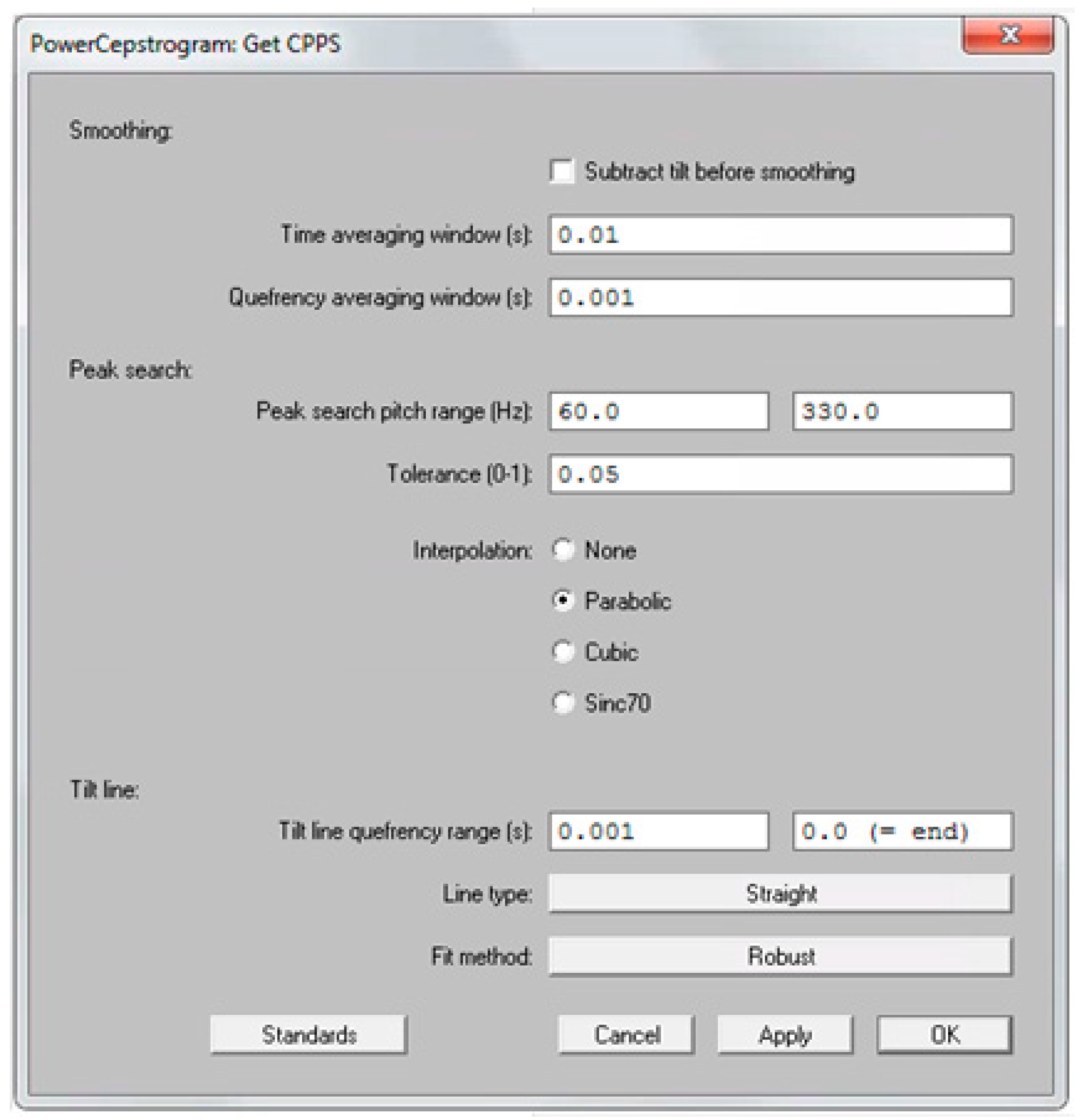
6]. A segment was considered to be voiced if (a) sound energy exceeded 30% of the overall sound energy, (b) zero crossing rate was less than 1500 Hz, and (c) the normalized autocorrelation peak was above 0.3. Subsequently, the medial three seconds of the vowel /a:/ were appended to the voiced segments, resulting in a concatenation sample with a correspondent single sound waveform. The six acoustic measures implemented in AVQI were obtained using the software Praat. First, harmonics-to-noise-ratio (i.e., HNR) was specified as the base-10-logarithm of the ratio between the periodic energy and the noise energy multiplied by 10. Secondly, shimmer local (i.e., SL) was the absolute mean difference between the amplitudes of successive periods divided by the average amplitude. Thirdly, the shimmer local dB (i.e., SLdB) was obtained as the base-10-logarithm of the differences between the amplitudes of successive periods multiplied by 20. Fourthly, the general spectral slope (i.e., Slope) was calculated as the difference between the energy in the 0–1 kHz range and the energy in the 1–10 kHz range of the long-term average spectrum. Fifthly, the spectral trendline inclination (i.e., Tilt) was measured as the difference between the energy in the 0–1 kHz range and the energy in the 1–10 kHz range of the trendline through the long-term average spectrum. Finally, the sixth and main acoustic measure implemented in AVQI, smoothed cepstral peak prominence (i.e., CPPS), was calculated as the distance between the first rahmonic’s peak and the point with equal quefrency on the regression line through the smoothed cepstrum. To determine the CPPS in the software Praat on a Windows or Mac computer, the following steps were completed: First, click on the “Analyze periodicity –” menu, choose “To PowerCepstrogram…”, and then complete the “Sound: To PowerCepstrogram” form as shown in
Figure 1. Second, query the resulting PowerCepstrogram object by clicking on the “Query –” menu, choose the “Get CPPS…” option, and then finally complete the “PowerCepstrogram: Get CPPS” form as shown in
Figure 2. The result of these steps is that the CPPS is shown as a value in dB in a “Praat Info” screen. Ultimately, AVQI (v.02.06) was calculated according to the following regression formula:
2.5. Statistical Analysis
Statistical analysis was completed using the software package SPSS for Windows version 15 (SPSS Inc., Chicago, IL, USA). Non-parametric statistical tests were used for small sample sizes (N < 30), as for larger sample sizes (N ≥ 30) parametric statistical tests were used. Assumptions of normality were checked and verified using the one-sample Kolmogorov–Smirnov test. First, gender effects for AVQI and CPPS were investigated using the Student t-test. Secondly, between-cohort differences in AVQI and CPPS were investigated using the Mann–Whitney U test. Thirdly, differences across the normophonic cohort and the three sub-levels of slight dysphonia were investigated using the omnibus Kruskal–Wallis H test and post-hoc Mann–Whitney U tests. All results were considered statistically significant at p < 0.05. Upper and lower cut-off values were calculated using the standard deviation value: mean + and − (2 × standard deviation), respectively.
4. Discussion
This study investigated the performance of AVQI and CPPS in a strictly normophonic subject group to enhance the interpretation of dysphonic voice samples and to increase the clinical utility of these measures in the assessment of overall voice quality. In 2009, Maryn et al. [
5] developed the multiparametric tool AVQI and found a threshold score of 2.95 using receiver operating characteristics (ROC) curve analysis. This value needs to be interpreted as a cut-off score to discriminate between normophonic and dysphonic voices with a weighted sensitivity and specificity of 74% and 96%, respectively. In the present study, an upper cut-off value of 4.04 was found, which implies a very high specificity of 97.5% but low sensitivity. To our knowledge, only one other normative study on AVQI has been conducted. In 2017, Barsties et al. [
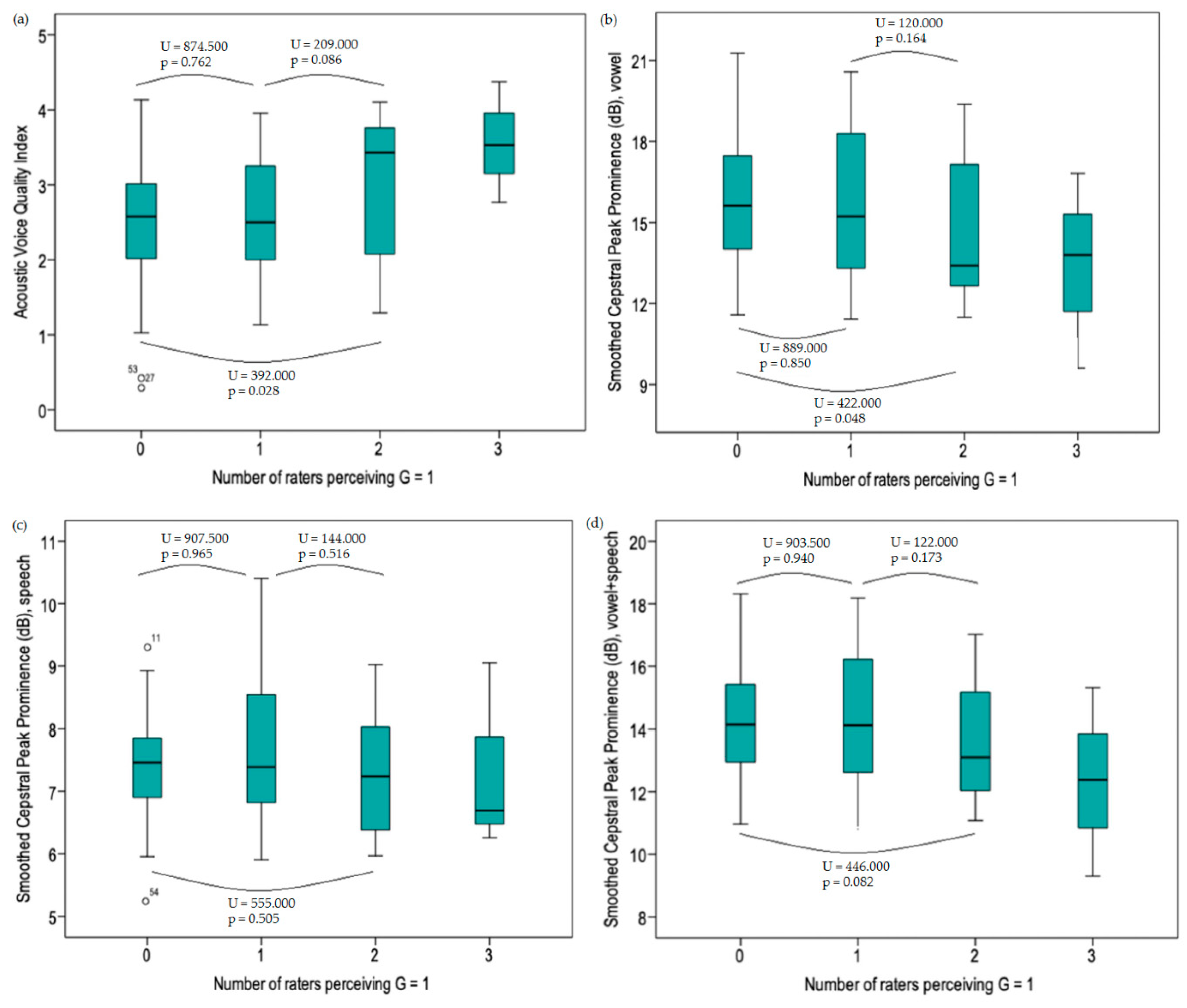
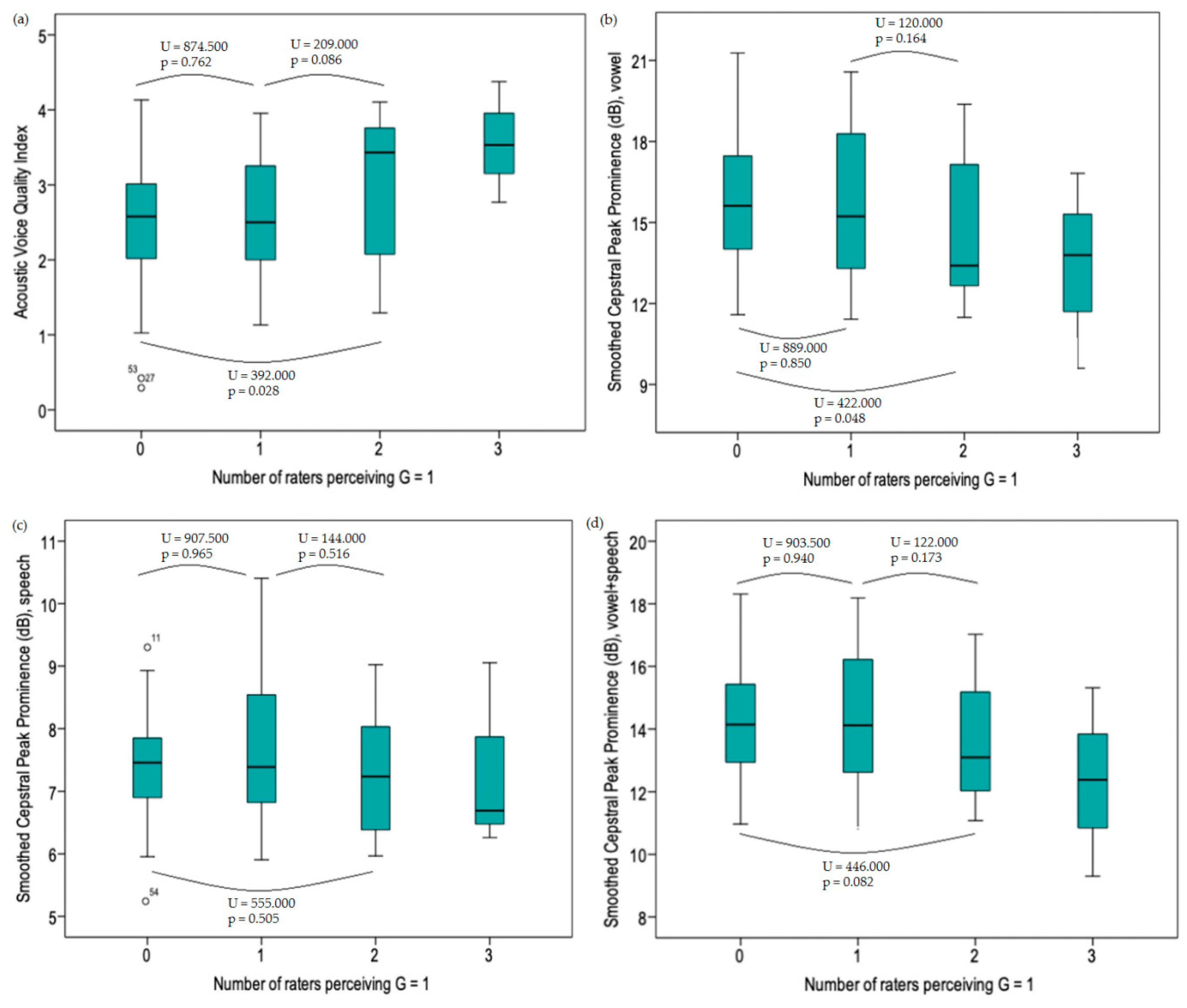
39] performed AVQI analysis on concatenated voice samples of 123 vocally healthy Lithuanian speaking individuals and investigated the influence of age and gender. They reported a mean AVQI score of 2.32 and an upper limit value of 3.90, which approaches our findings. Similar to the present study, no significant gender effects were found. Consequently, one could suggest that AVQI is relatively unaffected by gender-based differences in vocal anatomy and physiology. In the present study, mean AVQI values were higher in subclinical subjects compared to normophonic subjects. This finding, however, did not reach significance. Furthermore, as more judges rated G as 1 (i.e., slight dysphonia), the higher mean AVQI values were observed. A significant difference was only found between the true normophonic cohort and the second subclinical dysphonia cohort.
It is also interesting to compare our CPPS values to those found in other studies with normative data, also using CPPS measurement in the software Praat. Latoszek et al. [
40] performed CPPS measurements on concatenated voice samples of 530 normophonic voices and found a mean CPPS value of 11.92 (SD = 2.15). Phadke et al. [
41] reported a mean value of CPPS of 13.9 (SD = 1.9) and 10.5 (SD = 1.2) for 40 normophonic vowel samples and speech samples, respectively. Heman-Ackah et al. [
35] reported a mean CPPS value of 4.77 (SD = 0.97) for 87 normophonic speech samples using SpeechTool software and reported a cut-off value of 4.0 discriminating between normal and dysphonic voices with a sensitivity and specificity of 92.4% and 79% respectively, using receiver operating characteristic (ROC) curve analysis. These differences in CPPS values can be explained by different settings and methodology within and among software packages. Furthermore, comparisons with CPPS values found in the present study can only be carried out when similar settings in Praat are used (
Figure 1 and
Figure 2). In the present study, specific significant gender effects were found for CPPS. Significantly higher values of CPPS
vowel (t = −3.734, p < 0.001) and CPPS
combination (t = −3.028, p = 0.004) were found in males and significantly higher values of CPPS
sentences (t = 2.182, p = 0.032) in females (
Table 5). It is known that the type of speech task causes important variability in the perceptual-auditory evaluation of voice quality. A previous study conducted by Maryn et al. [
42] showed that the two speech tasks—i.e., sustained vowels and continuous speech—yielded significant differences in their ratings of degree of dysphonia severity (i.e., Grade). There is a tendency towards significantly higher G scores for sustained vowel samples than for continuous speech samples. The gender effect of these different types of speech tasks has however never been investigated. Based on the present study, the presumption could be made that, due to gender-related anatomical and/or physiological differences, males are somehow more fit to produce a clean normophonic sustained vowel and females are somehow more fit to produce a normophonic continuous speech task. This is, however, merely an assumption, which could be interesting to explore in future studies. Sustained vowel samples and concatenated samples show the same trend, which can be explained by the fact that in this study the sustained vowel task represents a greater contribution to the concatenated sample than the continuous speech task does.
There are some limitations regarding this study that are worth mentioning. First, the perceptual evaluation was performed by three raters, of whom two were final-year speech-language pathology students with only limited experience with dysphonic voices. Secondly, subjects mainly originated from the West-Flanders region of Belgium and were recruited by way of snowball sampling, since there was an appeal to volunteers such as family members, friends, and acquaintances. The relevance of this limitation can, however, be questioned, since multiple studies in the last decade already showed that AVQI is relatively unaffected by inter-language phonetic differences. Consequently, the influence of dialect can be negligible. Finally, only 123 subjects between 20 and 60 years old were included in the present study. In the future, a normative study with a greater number of subjects divided into different age groups is warranted to investigate whether AVQI and CPPS are able to differentiate significantly between the true normophonic cohort and the subclinical slight dysphonia cohort, as well to explore possible age effects. If AVQI and/or CPPS are found to be such sensitive measures to remark such small differences between normophonia and slight dysphonia, they could be useful as complementary tools in practice to support perceptual evaluation of voice quality in case of doubt.

 ,
, 

{kind=link}
{kind=link}
{kind=link}