Machine-Learning-Based Side-Channel Evaluation of Elliptic-Curve Cryptographic FPGA Processor



Abstract
1. Introduction
2. Background and Related Terminologies
2.1. Power-Analysis Attacks
2.2. Classification Algorithms
2.2.1. Random Forest (RF)
2.2.2. Support Vector Machine (SVM)
2.2.3. Naive Bayes (NB)
2.2.4. Multilayer Perceptron (MLP)
2.3. Validation
2.4. Feature/Attribute Selection and Extraction
3. Design and Implementation of Elliptic-Curve Cryptosystem F256 on FPGA
3.1. Power Analysis and ECC
| Algorithm 1 double-and-add-always |
| 1: Input: P, k[n] 2: 3: Output: Q = kP 4: 5: R0 = P, R1 = 0 6: 7: for to do 8: 9: 10: 11: 12: 13: if then 14: 15: 16: 17: end if 18: 19: end for 20: 21: return Q = R0 22: |
3.2. Nist Standard for 256-Bit Koblitz Curve
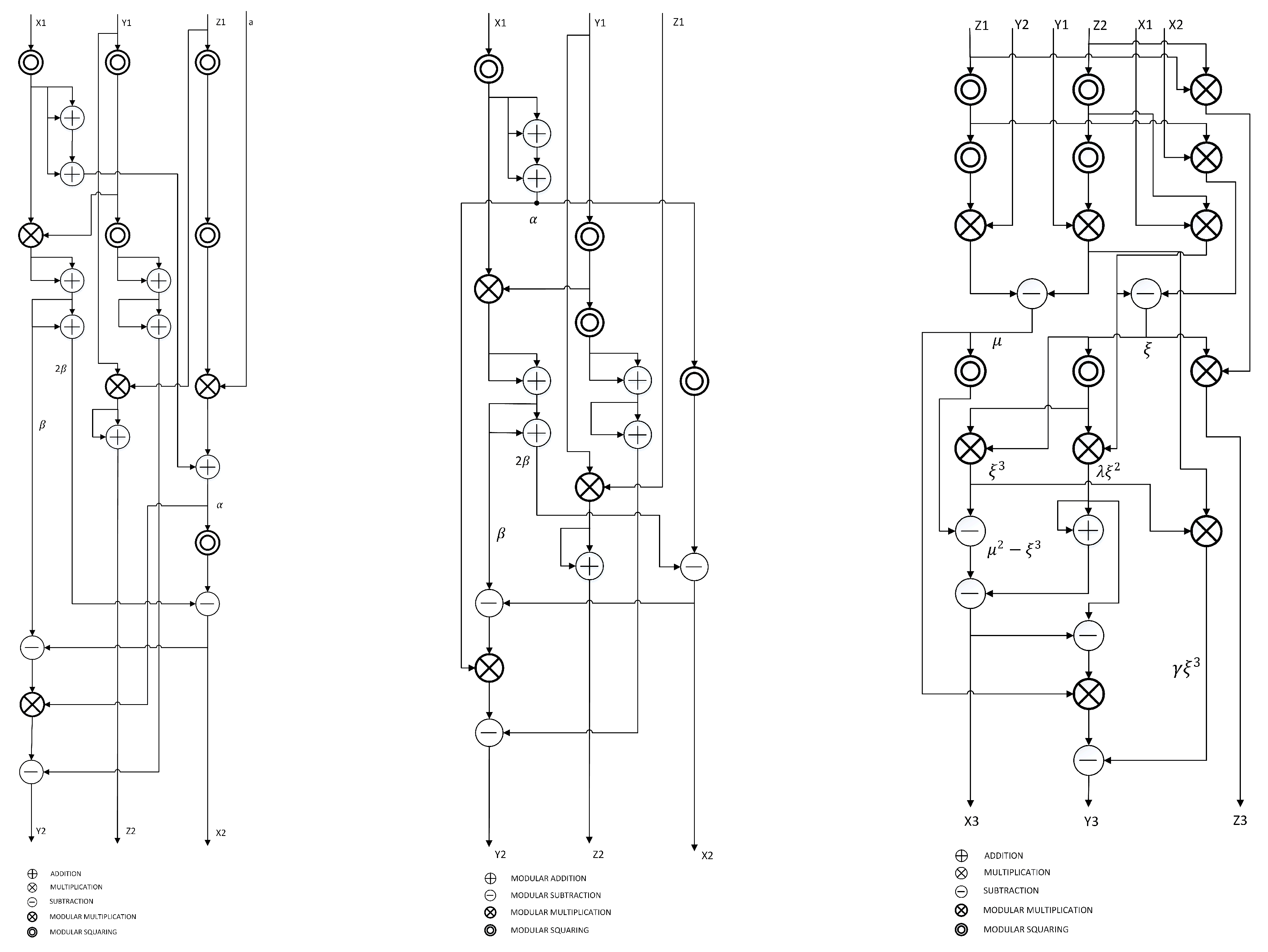
3.3. Point Doubling in Jacobian Coordinates
3.4. Point Addition in Jacobian Coordinates
LUT(1) = Y;
LUT(2) = 2 ∗ 2n mod M;
LUT(3) = (2 ∗ 2n + Y) mod M;
LUT(4) = 4 ∗ 2n mod M;
LUT(5) = (Y + 4 ∗ 2n) mod M;
LUT(6) = 6 ∗ 2n mod M;
LUT(7) = (Y + 7 ∗ 2n) mod M;
and
(S,C) = CSA(A,B,C) is
3.5. ECC Core Design
3.6. Elliptic-Curve Point Doubling—ECPD
3.7. Elliptic-Curve Point Addition
3.8. Scalar Factor (Private Key) k
4. Attack Methodology
- Step 1—Training dataset preparation
- Step 2—Classification using machine learning
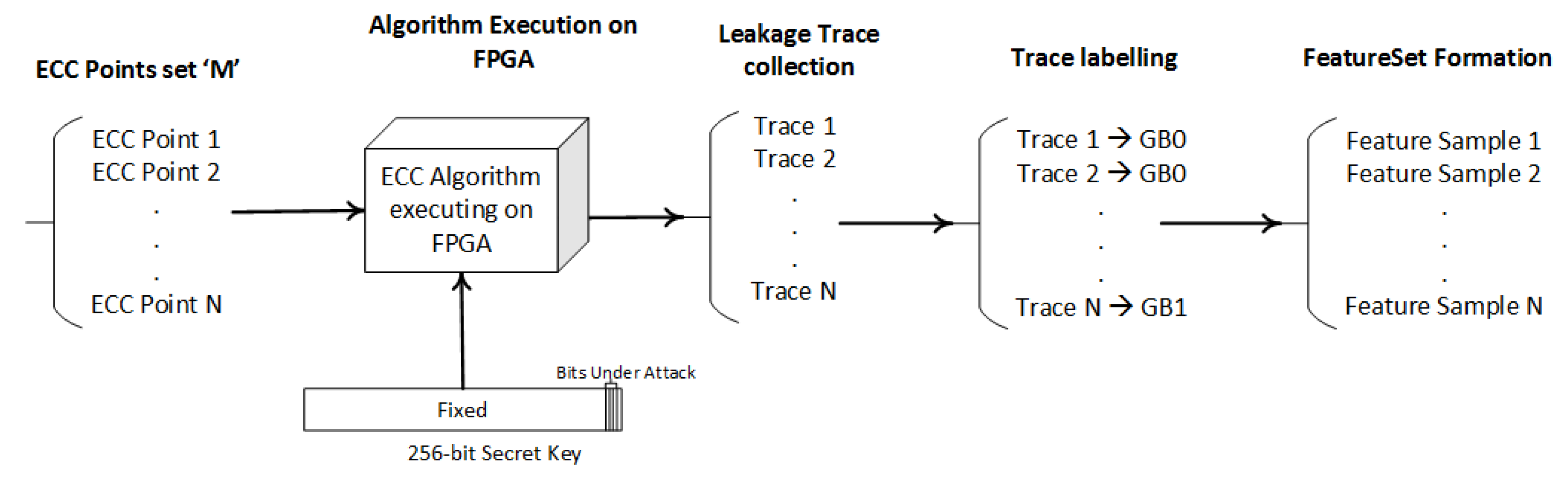
4.1. Step 1—Training Dataset Preparation
4.1.1. Group Labeling
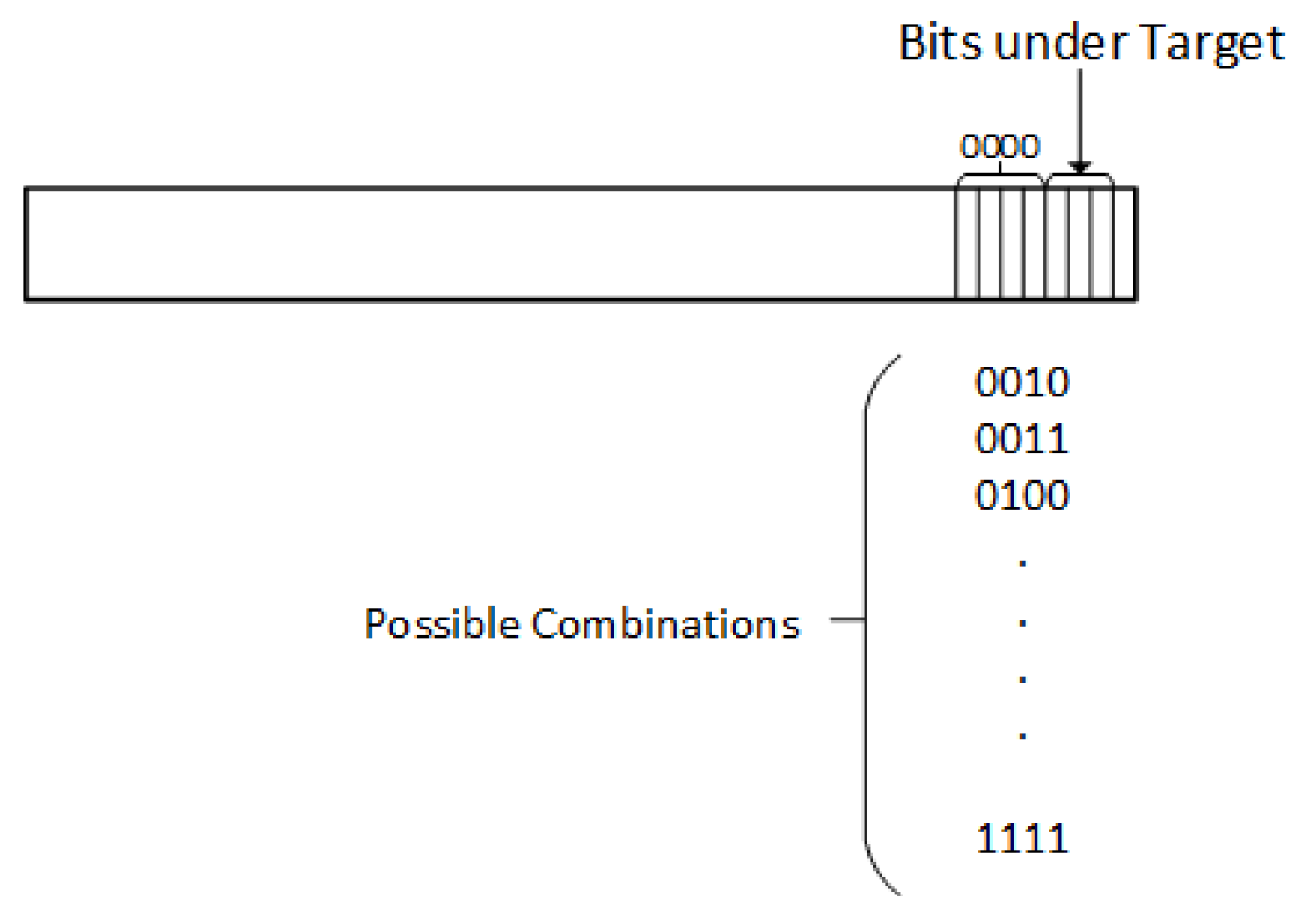
4.1.2. Attack Levels
- LB2—At this attack level, LSB ’2’ is targeted and each sample for the key having ’0’ at the second location is marked as ’GB0’ and all samples for the key byte having ’1’ at the second location are marked as ’GB1’.
- LB3—At this attack level, LSB ’3’ is targeted and each sample for the key having ’0’ at the third location is marked as ’GB0’ and all samples for the key byte having ’1’ at the third location are marked as ’GB1’.
- LB4—At this attack level, LSB ’4’ is targeted and each sample for the key having ’0’ at the fourth location is marked as ’GB0’ and all samples for the key byte having ’1’ at the fourth location are marked as ’GB1’.
4.1.3. Features Dataset Formation
- Mean of Absolute Value (MAV)—Mean of the signal is calculated.
- Kurtosis (Kur)—For Kurtosis, Frequency-distribution curve peak’s sharpness is noted.
- Median PSD (FMD)—For Median PST, median is calculated in frequency domain.
- Frequency Ratio (FR)—For Frequency ratio, frequency ratio of the frequencies is recorded.
- Median Amplitude Spectrum (MFMD)—For MFMD, the median amplitude spectrum of signals is calculated.
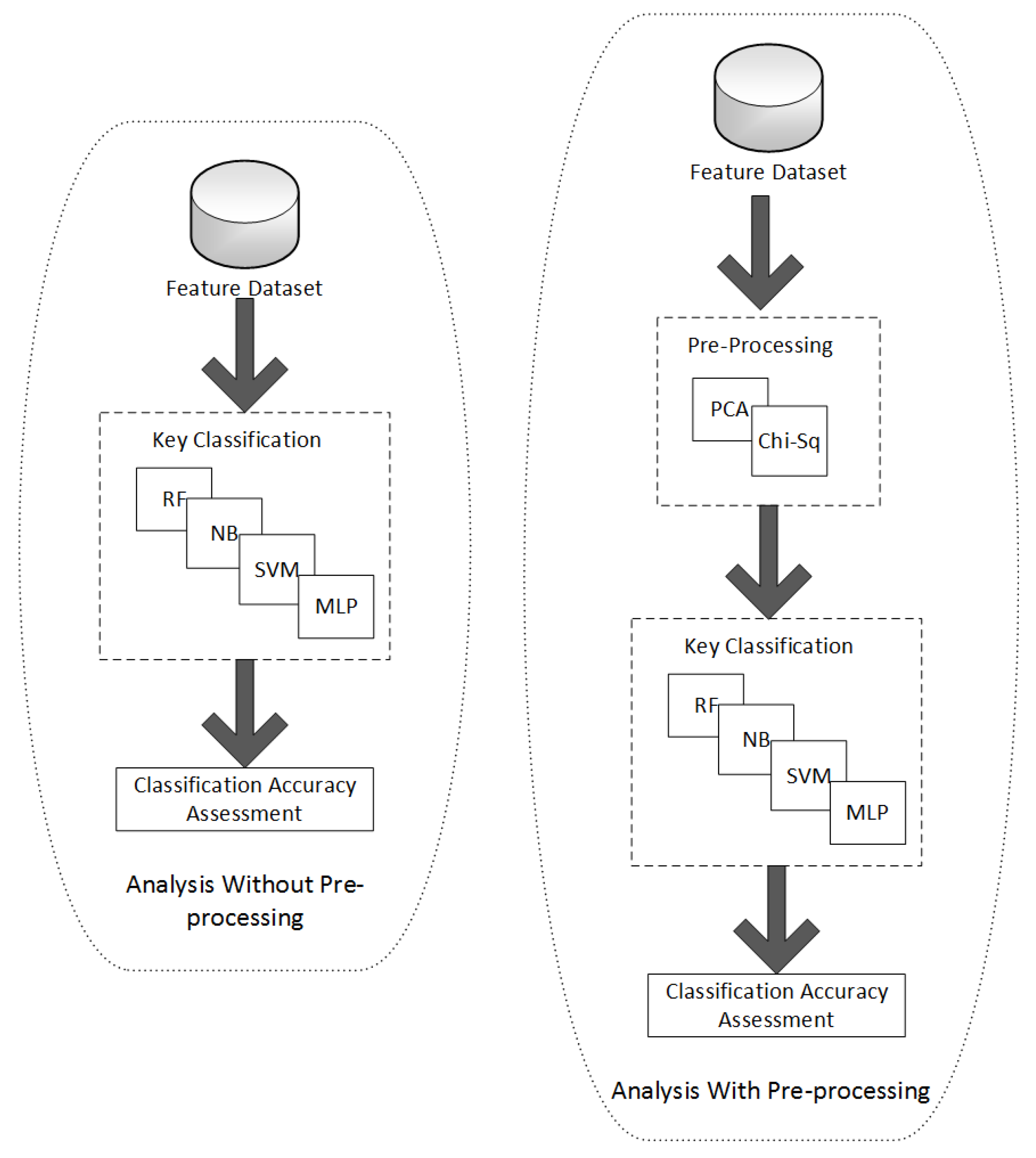
4.2. Step 2—Classification Using Machine Learning
4.2.1. Analysis without Pre-Processing
4.2.2. Analysis with Pre-Processing
5. Experimental Setup
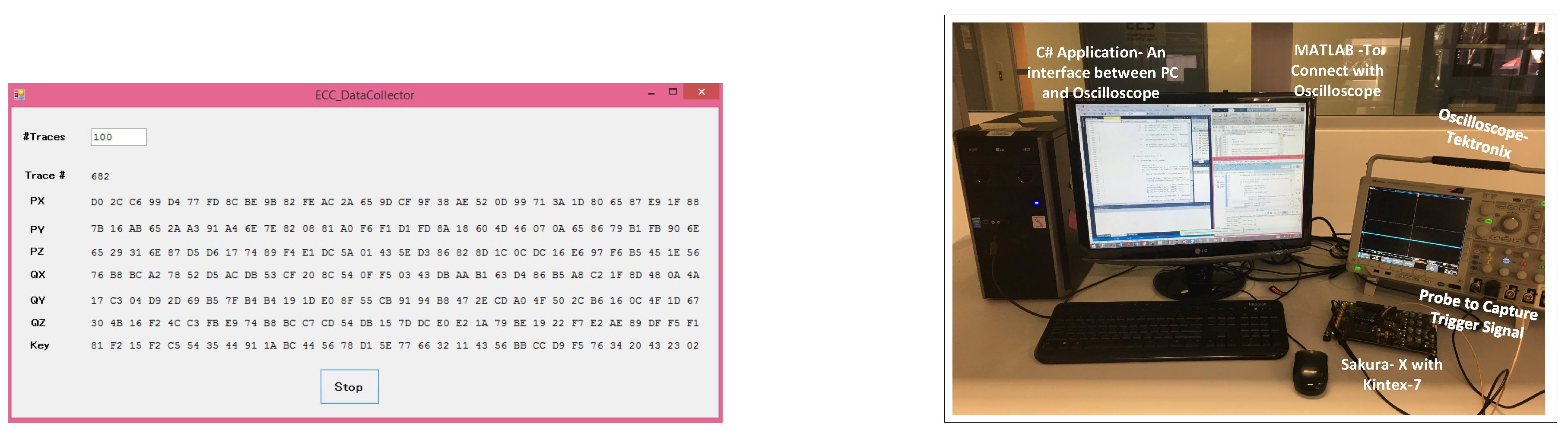
5.1. Step 1—Data Capture
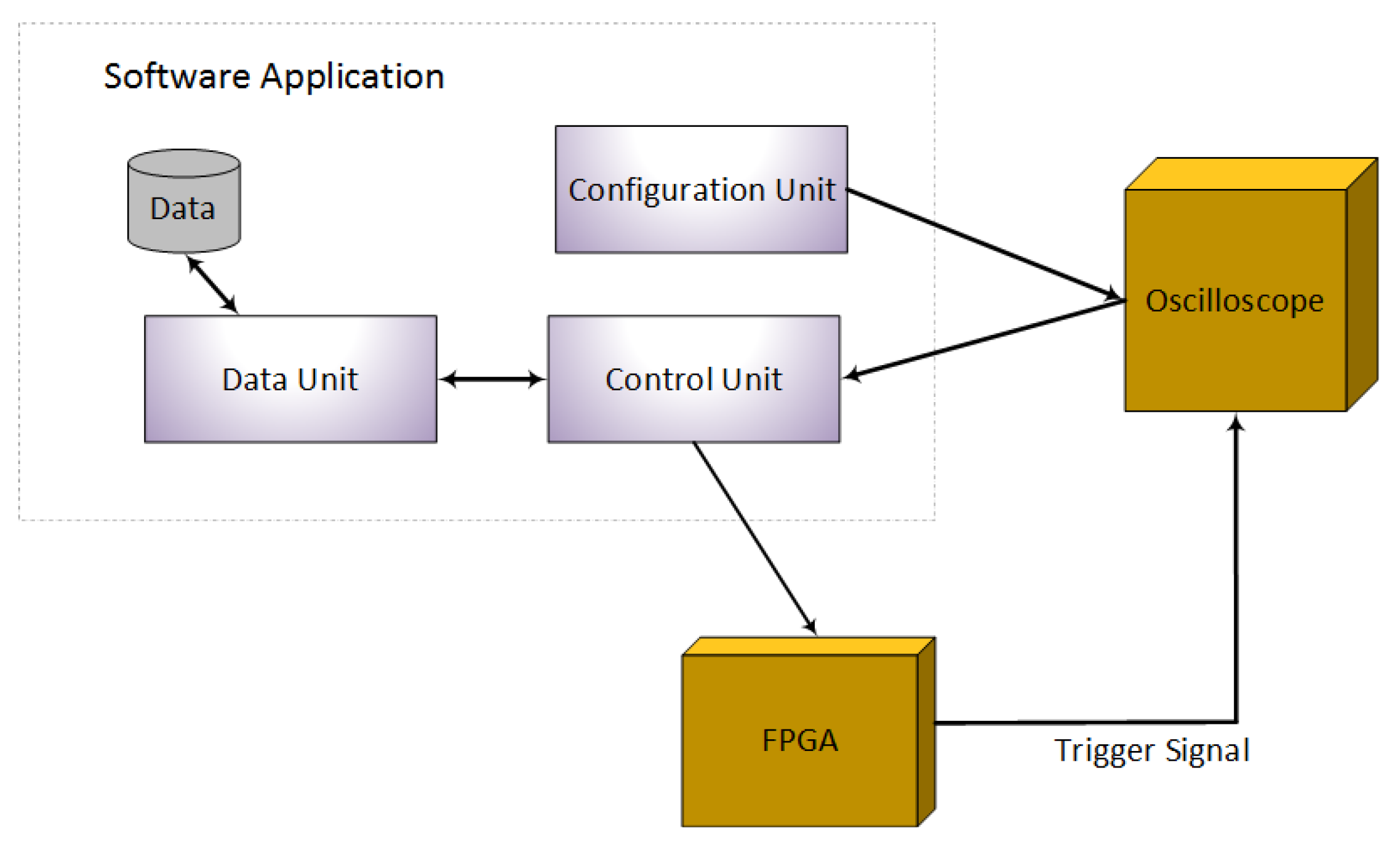
- Configuration Unit—The configuration unit uses MATLAB library support for C# and configures the oscilloscope through the C# application. This eliminates setting up the oscilloscope on every start up; the application automatically restores it to the settings required for the data capturing. The configuration unit communicates with the oscilloscope only.
- Control Unit—The control unit has the role of sending the ECC points to the FPGA after taking them from the data unit. When the FPGA receives an ECC point, it starts the process of encryption and sends a trigger signal to the oscilloscope. As soon as the trigger signal is received at the oscilloscope, it will start collecting the leaked information from the FPGA and will transmit it to the control unit. The control unit then stores the information by communicating with the data unit. The control unit communicates with both the oscilloscope and the FPGA.
- Data Unit—The data unit handles the data. It is responsible for storing and retrieving the data in files. The data unit communicates with the control unit only.
5.2. Step 2—Feature Datasets Formation
5.3. Step 3—Analysis
6. Results and Discussion
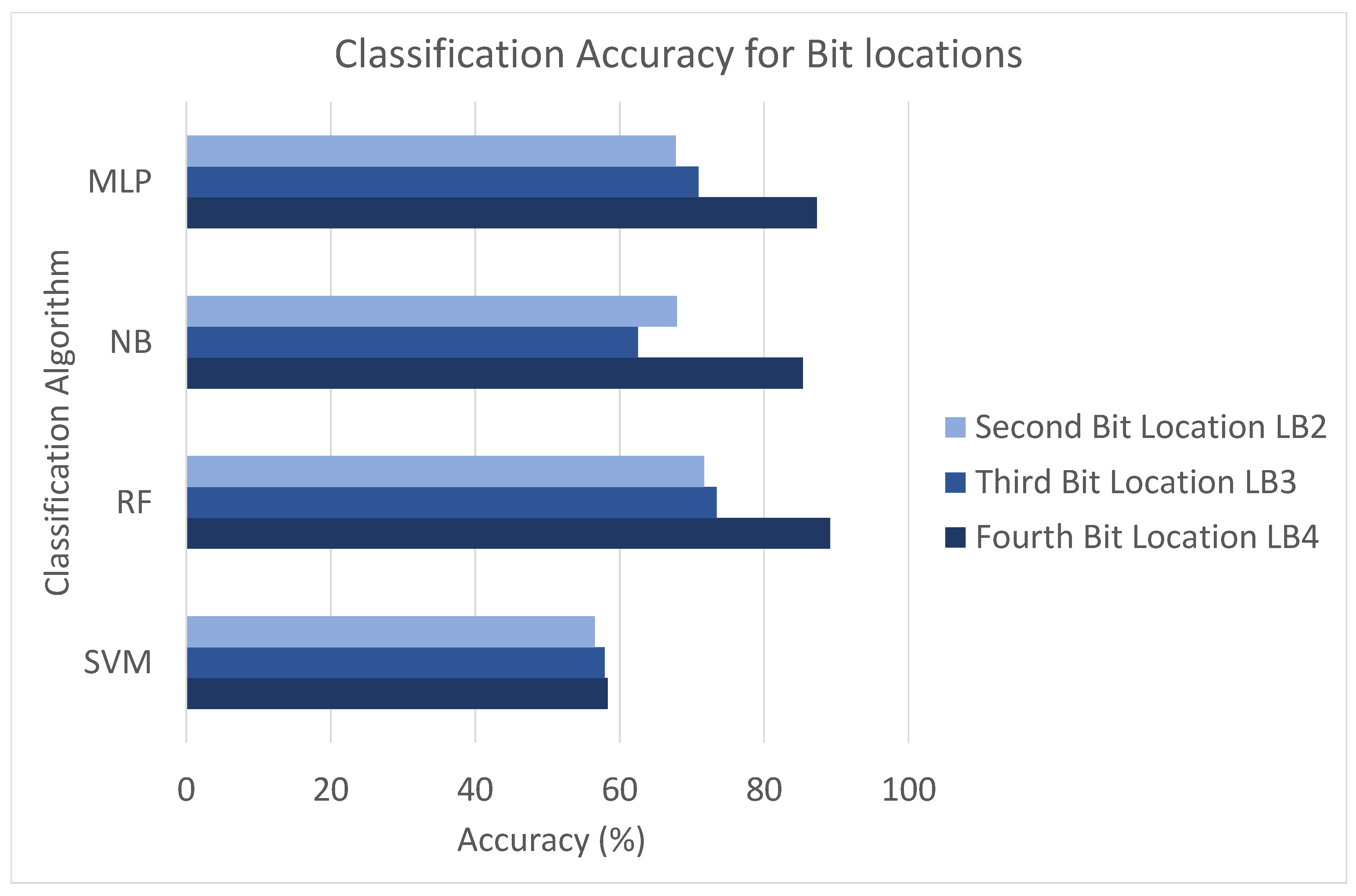
6.1. Analysis Phase 1—Accuracy without Pre-Processing
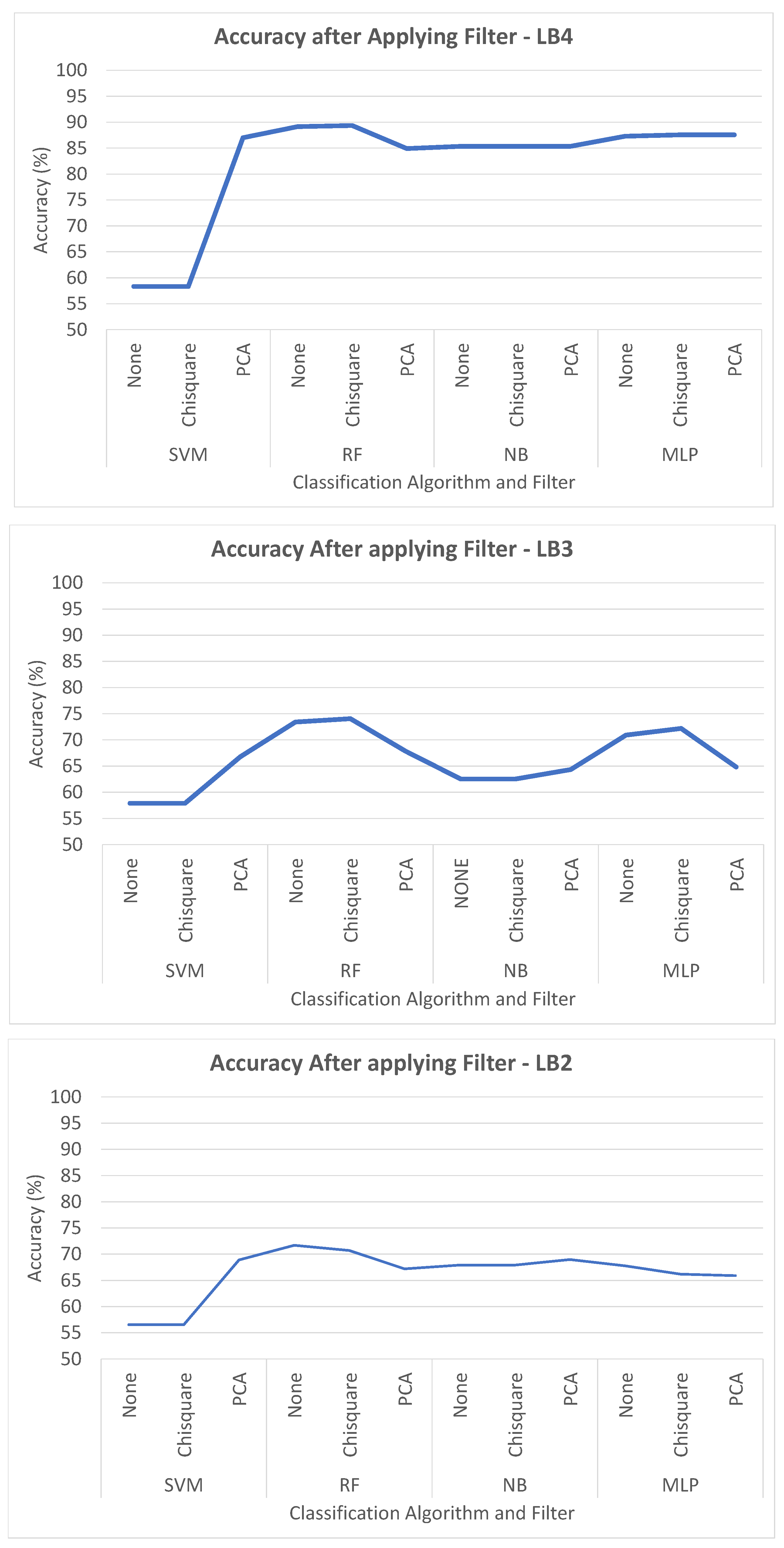
6.2. Analysis Phase 2—Accuracy with Pre-Processing
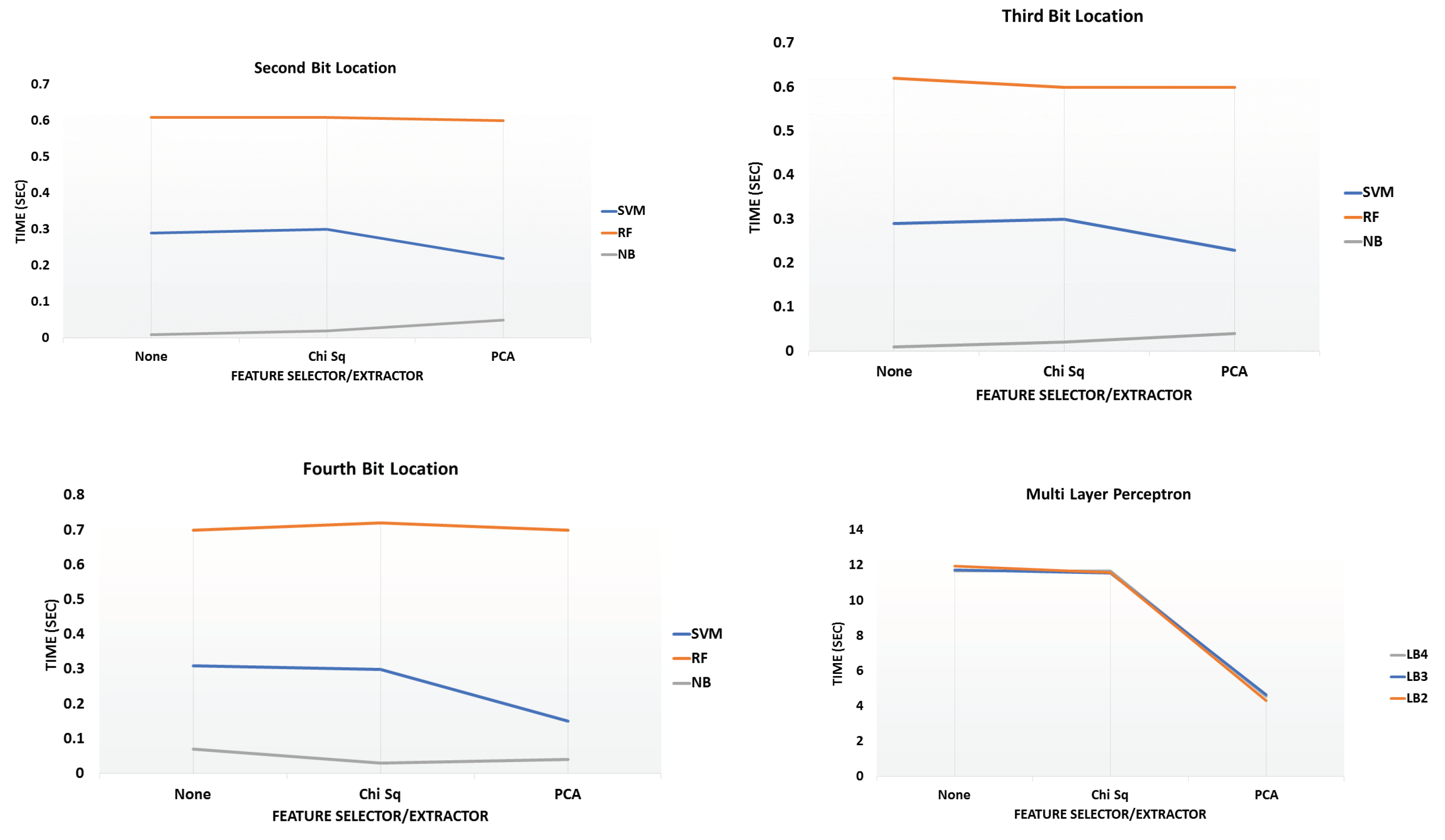
6.3. Analysis Phase 3—Time to Build Models
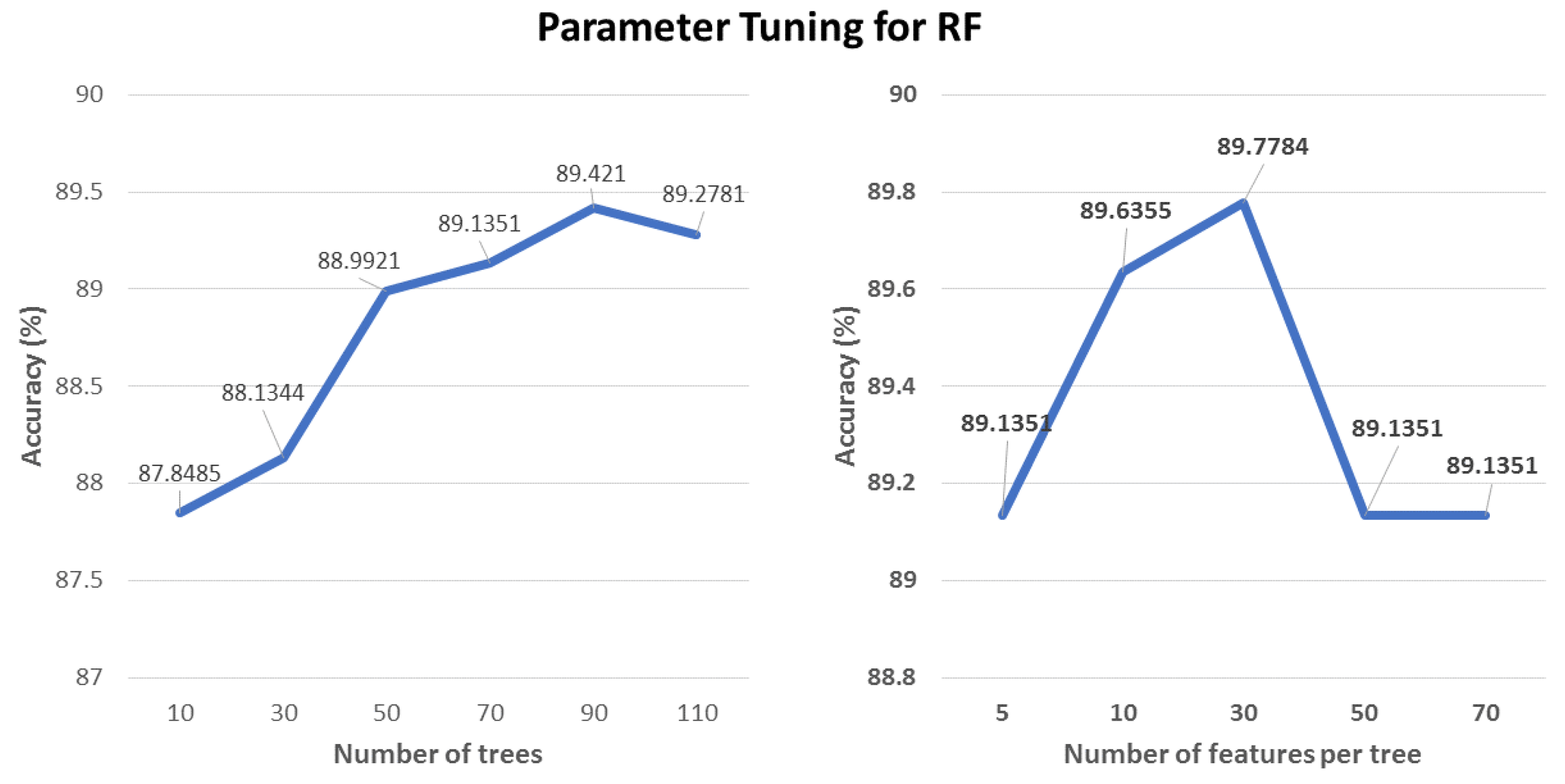
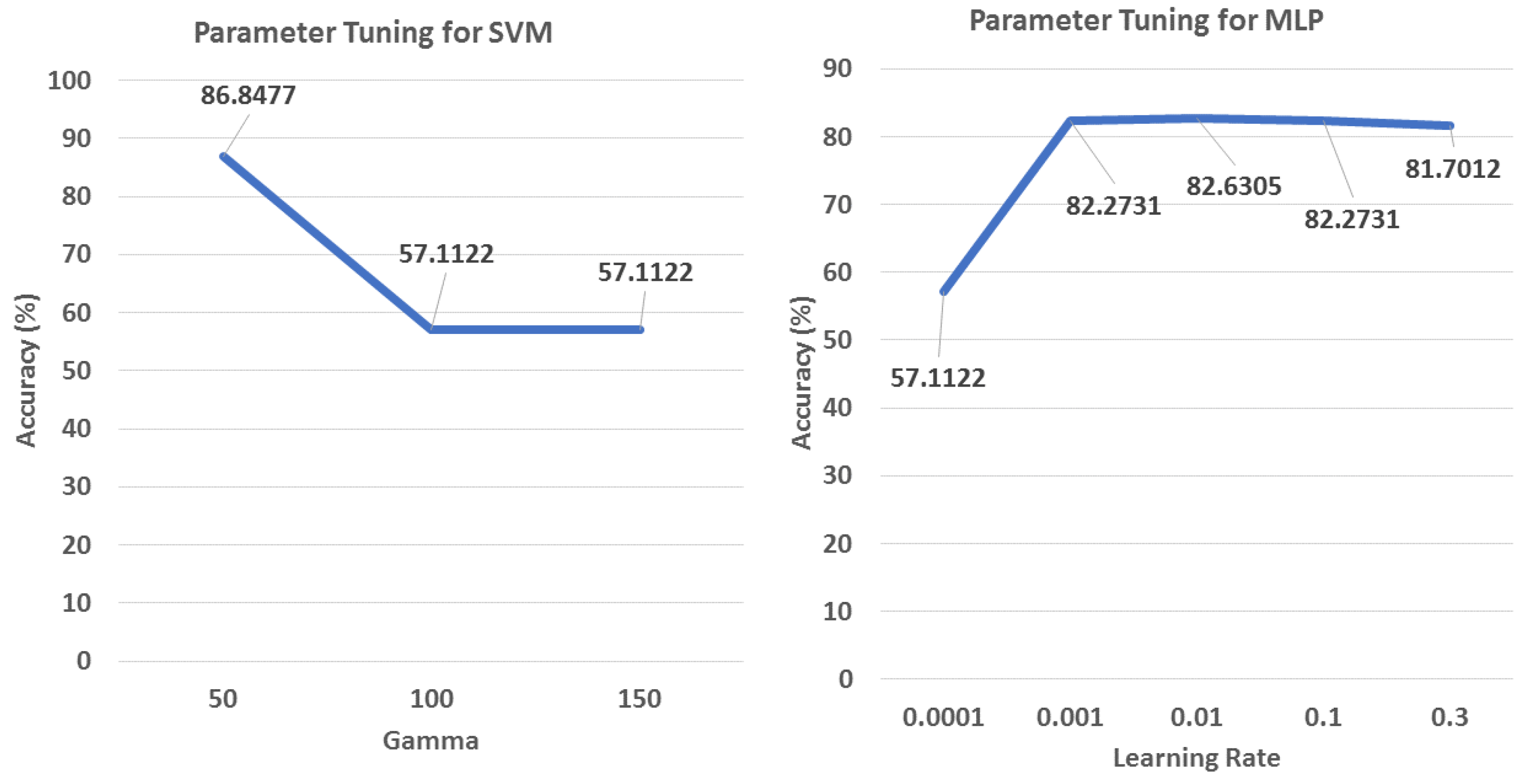
6.4. Hyper-Parameter Tuning
7. Conclusions
8. Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| SCA | Side-Channel Analysis |
| PCA | Principal-Component Analysis |
| Chi-Sq | Chi-Square |
| RF | Random Forest |
| NB | Naive Bayes |
| MLP | Multilayer Perceptron |
| SVM | Support Vector Machines |
| AES | Advanced Encryption Standard |
| ECC | Elliptic-curve Cryptography |
References
- Kocher, P.C. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. In Proceedings of the Advances in Cryptology—CRYPTO ’96: 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 104–113. [Google Scholar]
- Kocher, P.C.; Jaffe, J.; Jun, B. Differential Power Analysis. In Proceedings of the Advances in Cryptology—CRYPTO’ 99: 19th Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 388–397. [Google Scholar]
- Rivest, R.L. Cryptography and machine-learning. In Proceedings of the Advances in Cryptology—ASIACRYPT ’91: International Conference on the Theory and Application of Cryptology, Fuji Yoshida, Japan, 11–14 November 1991; Springer: Berlin/Heidelberg, Germany, 1993; pp. 427–439. [Google Scholar]
- Genkin, D.; Pachmanov, L.; Pipman, I.; Tromer, E.; Yarom, Y. ECDSA Key Extraction from Mobile Devices via Nonintrusive Physical Side Channels. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 2016; ACM: New York, NY, USA; pp. 1626–1638. [Google Scholar]
- Kadir, S.A.; Sasongko, A.; Zulkifli, M. Simple power analysis attack against elliptic curve cryptography processor on FPGA implementation. In Proceedings of the 2011 International Conference on Electrical Engineering and Informatics, Bandung, Indonesia, 17–19 July 2011; pp. 1–4. [Google Scholar]
- Genkin, D.; Shamir, A.; Tromer, E. RSA Key Extraction via Low-Bandwidth Acoustic Cryptanalysis. In Proceedings of the Advances in Cryptology—CRYPTO 2014: 34th Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; pp. 444–461. [Google Scholar]
- Standaert, F.X.; tot Oldenzeel, L.V.O.; Samyde, D.; Quisquater, J.J. Power Analysis of FPGAs: How Practical Is the Attack? In Proceedings of the Field Programmable Logic and Application, Lisbon, Portugal, 1–3 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 701–710. [Google Scholar]
- Yalcin Ors, S.B.; Oswald, E.; Preneel, B. Power-Analysis Attacks on an FPGA—First Experimental Results. In Proceedings of the Cryptographic Hardware and Embedded Systems (CHES), Cologne, Germany, 8–10 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 35–50. [Google Scholar]
- De Mulder, E.; Ors, S.B.; Preneel, B.; Verbauwhede, I. Differential Electromagnetic Attack on an FPGA Implementation of Elliptic Curve Cryptosystems. In Proceedings of the Automation Congres, Budapest, Hungary, 24–26 July 2006; pp. 1–6. [Google Scholar]
- Longo, J.; De Mulder, E.; Page, D.; Tunstall, M. SoC it to EM: Electromagnetic Side-Channel Attacks on a Complex System-on-Chip; Cryptographic Hardware and Embedded Systems—CHES; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; Volume 9293, pp. 620–640. [Google Scholar]
- Gierlichs, B.; Batina, L.; Tuyls, P.; Preneel, B. Mutual information analysis. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES, Washington, DC, USA, 10–13 August 2008. [Google Scholar]
- Renauld, M.; Standaert, F.; Veyrat-Charvillon, N. Algebraic Side-Channel Attacks on the AES: Why Time also Matters in DPA. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2009, Lausanne, Switzerland, 6–9 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 97–111. [Google Scholar]
- Bhasin, S.; Danger, J.; Guilley, S.; Najm, Z. Side-Channel Leakage and Trace Compression using Normalized Inter-Class Variance. In Proceedings of the 3rd International Workshop on Hardware and Architectural Support for Security and Privacy, HASP, Portland, OR, USA, 14 June 2015; p. 7. [Google Scholar]
- Oswald, D.; Paar, C. Improving Side-Channel Analysis with Optimal Linear Transforms. In Proceedings of the 11th International Conference on Smart Card Research, and Advanced Applications, CARDIS, Graz, Austria, 28–30 November 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 219–233. [Google Scholar]
- Hospodar, G.; Mulder, E.D.; Gierlichs, B.; Verbauwhede, I.; Vandewalle, J. Least Squares Support Vector Machines for Side-Channel Analysis. In Proceedings of the 2nd Workshop on Constructive Side-Channel Analysis and Secure Design (COSADE), Darmstadt, Germany, 24–25 February 2011. [Google Scholar]
- Willi, R.; Curiger, A.; Zbinden, P. On Power-Analysis Resistant Hardware Implementations of ECC-Based Cryptosystems. In Proceedings of the 2016 Euromicro Conference on Digital System Design (DSD), Limassol, Cyprus, 31 August–2 September 2016; pp. 665–669. [Google Scholar] [CrossRef]
- Batina, L.; Hogenboom, J.; van Woudenberg, J.G.J. Getting More from PCA: First Results of Using Principal Component Analysis for Extensive Power Analysis. In Proceedings of the Cryptographers? Track at the RSA Conference, San Francisco, CA, USA, 27 February–2 March 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 383–397. [Google Scholar]
- Souissi, Y.; Nassar, M.; Guilley, S.; Danger, J.L.; Flament, F. First Principal Components Analysis: A New Side Channel Distinguisher. In Proceedings of the International Conference on Information Security and Cryptology, Seoul, Korea, 1–3 December 2010; pp. 407–419. [Google Scholar] [CrossRef]
- Lerman, L.; Bontempi, G.; Markowitch, O. A machine learning approach against a masked AES. J. Cryptogr. Eng. 2013, 5, 123–139. [Google Scholar] [CrossRef]
- Lerman, L.; Bontempi, G.; Markowitch, O. Power analysis attack: An approach based on machine learning. Int. J. Appl. Cryptogr. (IJACT) 2014, 3, 97–115. [Google Scholar] [CrossRef]
- Maghrebi, H.; Portigliatti, T.; Prouff, E. Breaking Cryptographic Implementations Using Deep Learning Techniques. In Proceedings of the SPACE, Hyderabad, India, 14–18 December 2016; pp. 3–26. [Google Scholar]
- Gilmore, R.; Hanley, N.; O’Neill, M. Neural network based attack on a masked implementation of AES. In Proceedings of the Hardware Oriented Security and Trust (HOST), Washington, DC, USA, 5–7 May 2015; pp. 106–111. [Google Scholar] [CrossRef]
- Levina, A.; Sleptsova, D.; Zaitsev, O. Side-channel attacks and machine learning approach. In Proceedings of the FRUCT, Saint-Petersburg, Russia, 18–22 April 2016; pp. 181–186. [Google Scholar]
- Kira, K.; Rendell, L.A. A Practical Approach to Feature Selection. In Proceedings of the Ninth International Workshop on Machine Learning, Aberdeen, Scotland, UK, 1–3 July 1992; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA; pp. 249–256. [Google Scholar]
- Yun, C.; Shin, D.; Jo, H.; Yang, J.; Kim, S. An Experimental Study on Feature Subset Selection Methods. In Proceedings of the Seventh International Conference on Computer and Information Technology, Fukushima, Japan, 16–19 October 2007. [Google Scholar]
- Mukhtar, N.; Kong, Y. On features suitable for power analysis?Filtering the contributing features for symmetric key recovery. In Proceedings of the 2018 6th International Symposium on Digital Forensic and Security (ISDFS), Antalya, Turkey, 22–25 March 2018; pp. 1–6. [Google Scholar]
- Messerges, T.S.; Dabbish, E.A.; Sloan, R.H. Investigations of Power Analysis Attacks on Smartcards. In Proceedings of the USENIX Workshop on Smartc ard Technology, Chicago, IL, USA, 11–14 May 1999; pp. 151–162. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mukhtar, N.; Kong, Y. Secret key classification based on electromagnetic analysis and feature extraction using machine-learning approach. In Proceedings of the Future Network Systems and Security: 4th International Conference, FNSS 2018, Paris, France, 9–11 July 2018; Doss, R., Piramuthu, S., Zhou, W., Eds.; Communications in Computer and Information Science. Springer: Cham, Switzerland, 2018; Volume 878, pp. 80–92. [Google Scholar] [CrossRef]
- Blake, I.; Seroussi, G.; Seroussi, G.; Smart, N. Elliptic Curves in Cryptography; Cambridge University Press: Cambridge, UK, 1999; Volume 265. [Google Scholar]
- Standards for Efficient Cryptography (SEC): Recommended Elliptic Curve Domain Parameters. 2000. Available online: http://www.secg.org/ (accessed on 25 December 2018).
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Amanor, D.N.; Paar, C.; Pelzl, J.; Bunimov, V.; Schimmler, M. Efficient Hardware Architectures for Modular multiplication on FPGA. In Proceedings of the International Conference on Field Programmable Logic and Applications, Tampere, Finland, 24–26 August 2005. [Google Scholar]
- AbdelFattah, A.M.; El-Din, A.M.B.; Fahmy, H.M. An Efficient Architecture for Interleaved Modular Multiplication. In Proceedings of the WCSET 2009: World Congress on Science, Engineering and Technology, Singapore, 26–28 August 2009. [Google Scholar]
- Available online: http://satoh.cs.uec.ac.jp/SAKURA/index.html (accessed on 6 December 2018).
- Available online: http://www.cs.waikato.ac.nz/ml/weka/ (accessed on 6 December 2018).
- Saeedi, E.; Hossain, M.S.; Kong, Y. Multi-class SVMs analysis of side-channel information of elliptic curve cryptosystem. In Proceedings of the 2015 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), Chicago, IL, USA, 26–29 July 2015; pp. 1–6. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Utilization |
|---|---|
| CORE AREA (LUT) | 26,570 |
| ECPA (LUT) | 14,382 |
| ECPD (LUT) | 11,760 |
| CLK frequency | 100.00 MHz |
| DYNAMIC POWER | 0.20 W |
| TOTAL POWER | 0.313 W |
| Algorithm | LB4 | LB3 | LB2 |
|---|---|---|---|
| RF | 79.2% | 56.9% | 58.0% |
| SVM | 55.4% | 49.3% | 45.7% |
| MLP | 71.9% | 58.7% | 55.6% |
| NB | 52.5%s | 57.0% | 55.7% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhtar, N.; Mehrabi, M.A.; Kong, Y.; Anjum, A. Machine-Learning-Based Side-Channel Evaluation of Elliptic-Curve Cryptographic FPGA Processor. Appl. Sci. 2019, 9, 64. https://doi.org/10.3390/app9010064
Mukhtar N, Mehrabi MA, Kong Y, Anjum A. Machine-Learning-Based Side-Channel Evaluation of Elliptic-Curve Cryptographic FPGA Processor. Applied Sciences. 2019; 9(1):64. https://doi.org/10.3390/app9010064
Chicago/Turabian StyleMukhtar, Naila, Mohamad Ali Mehrabi, Yinan Kong, and Ashiq Anjum. 2019. "Machine-Learning-Based Side-Channel Evaluation of Elliptic-Curve Cryptographic FPGA Processor" Applied Sciences 9, no. 1: 64. https://doi.org/10.3390/app9010064
APA StyleMukhtar, N., Mehrabi, M. A., Kong, Y., & Anjum, A. (2019). Machine-Learning-Based Side-Channel Evaluation of Elliptic-Curve Cryptographic FPGA Processor. Applied Sciences, 9(1), 64. https://doi.org/10.3390/app9010064