PSI-CNN: A Pyramid-Based Scale-Invariant CNN Architecture for Face Recognition Robust to Various Image Resolutions



Abstract
:1. Introduction
- We present a comprehensive review of the literature which builds foundation to this work.
- Our proposed PSI-CNN model utilizes additionally extracted feature maps from various image resolutions, achieving robustness to scale changes in input images, potentially enabling its application in unconstrained environments with variable z-distance values.
- We provide an extensive analysis of the recognition performance achieved by models employing the PSI-CNN architecture. This is achieved by not only utilizing a publicly available database but also creating our own dataset collected under unconstrained environmental conditions with variable facial-region size.
2. Related Work
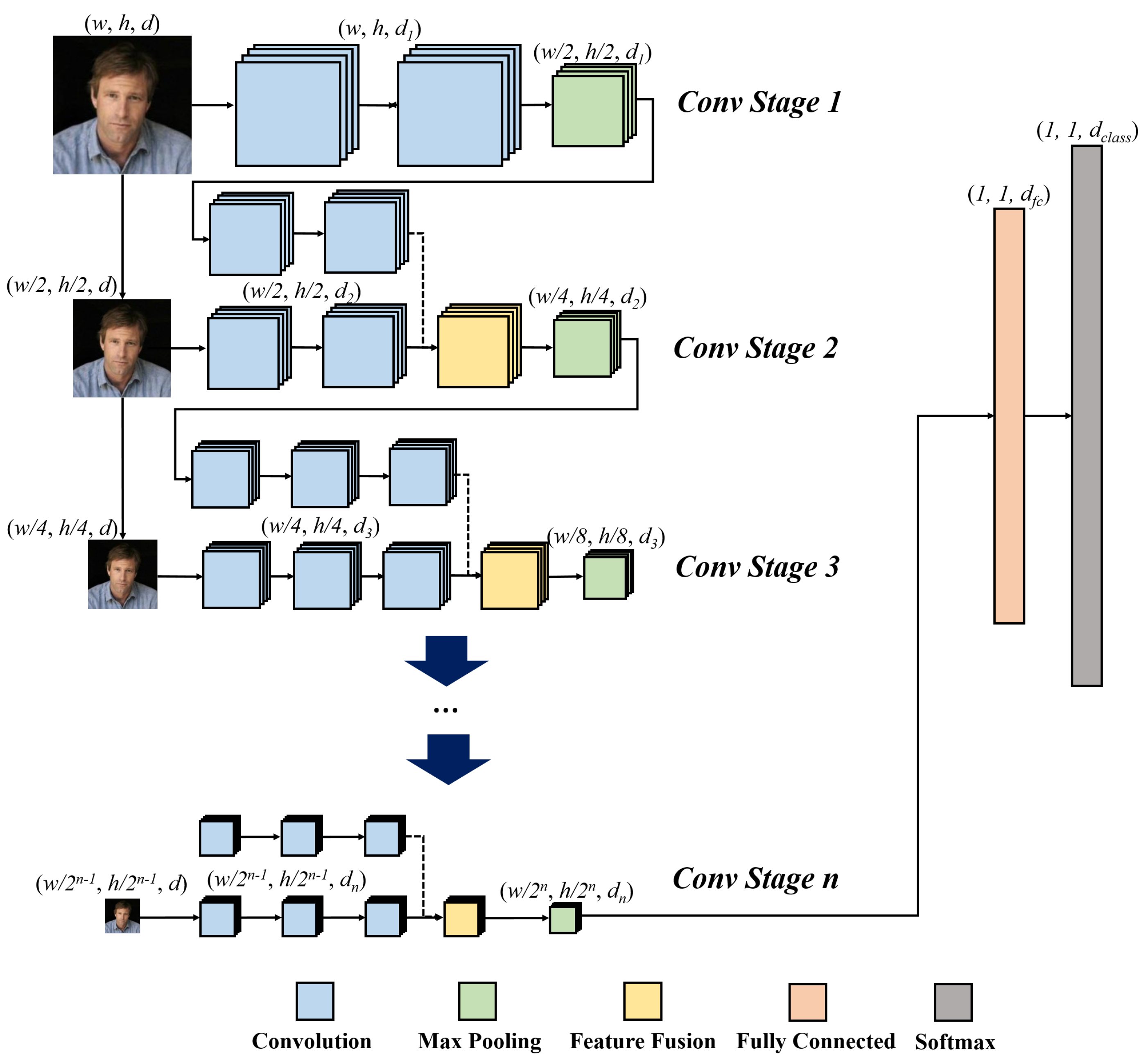
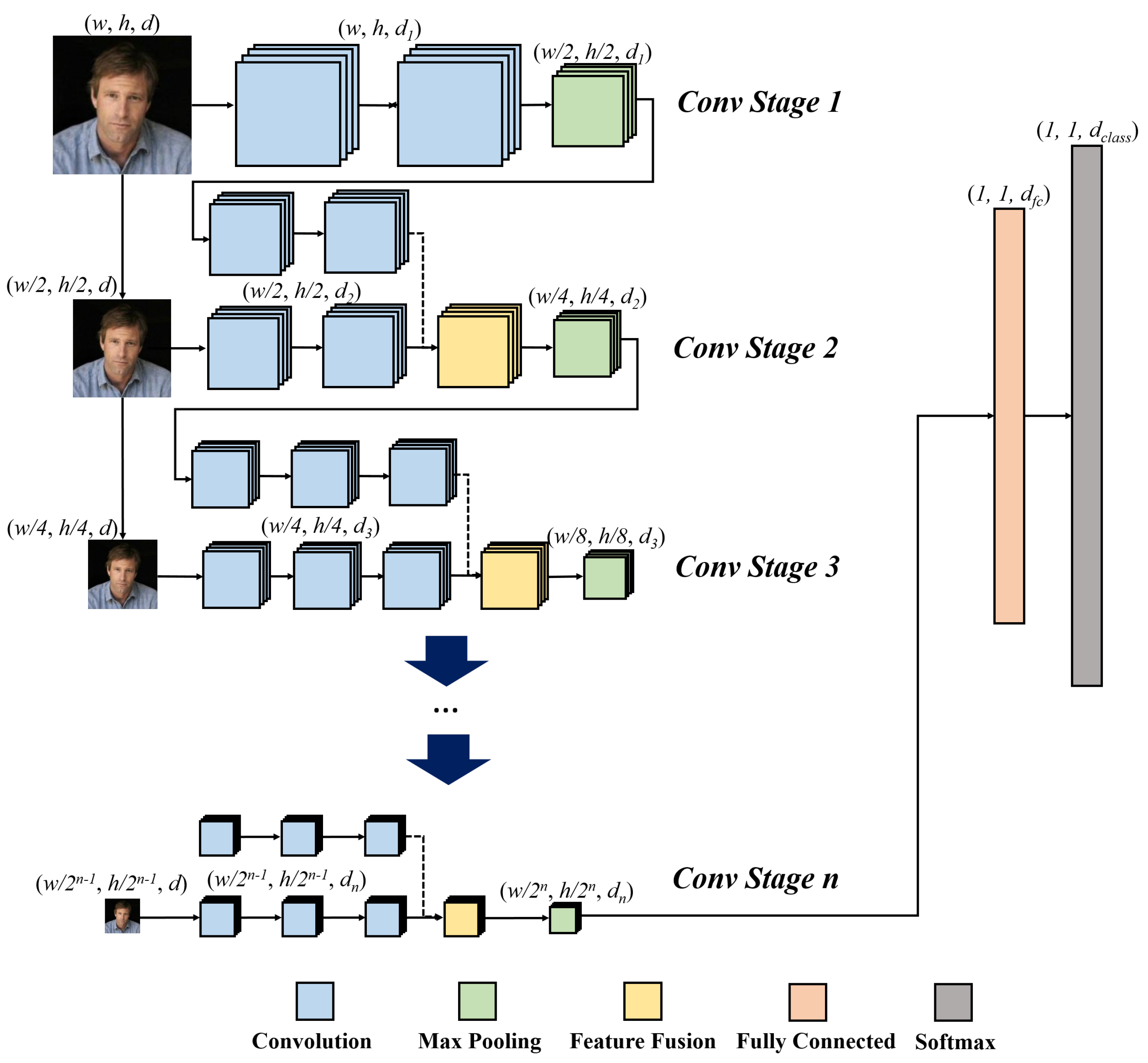
3. Proposed Framework
3.1. PSI-CNN Model
4. Experimental Results and Discussions
4.1. Model Training
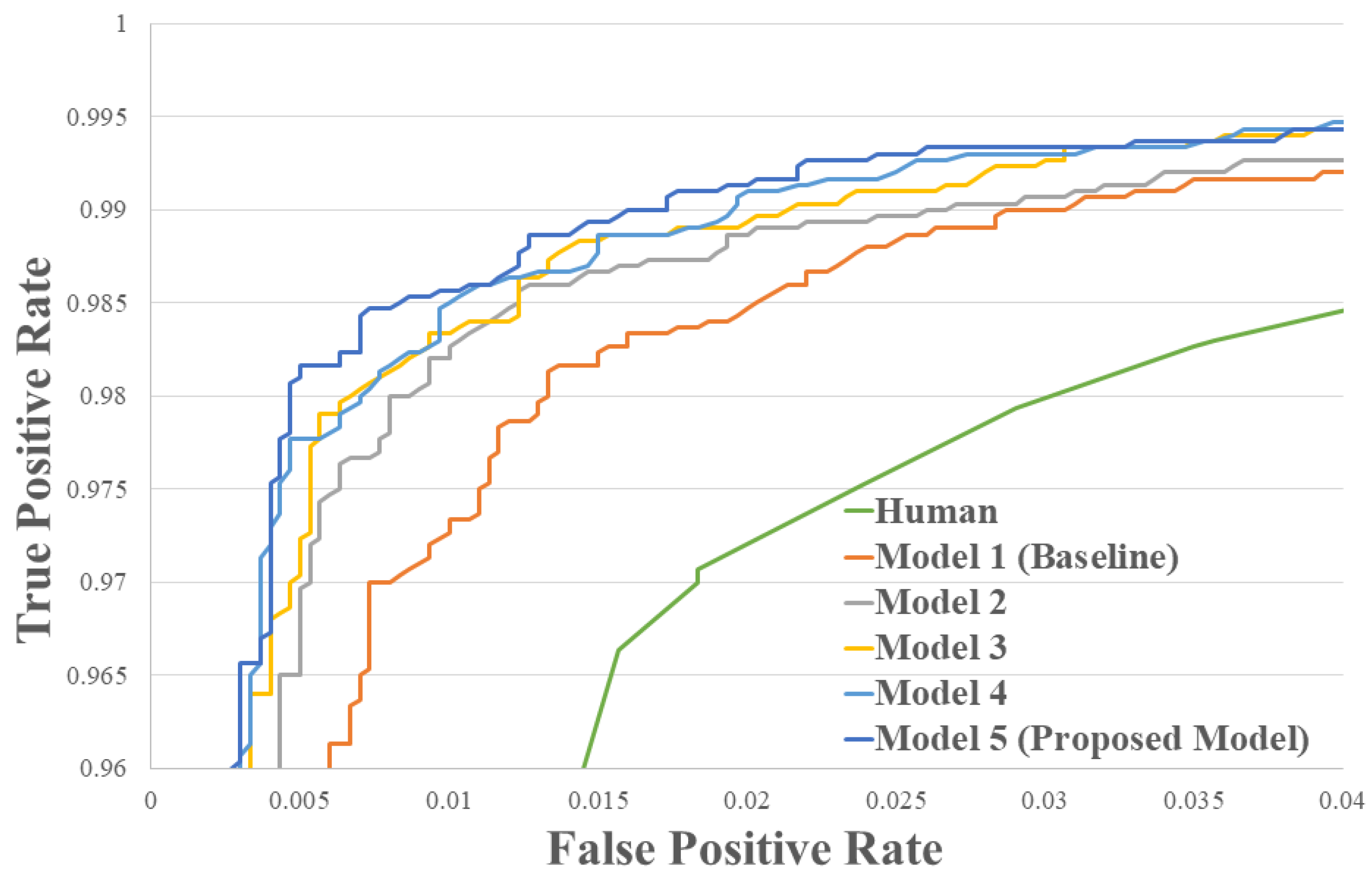
4.2. Performance Comparison on the LFW Dataset
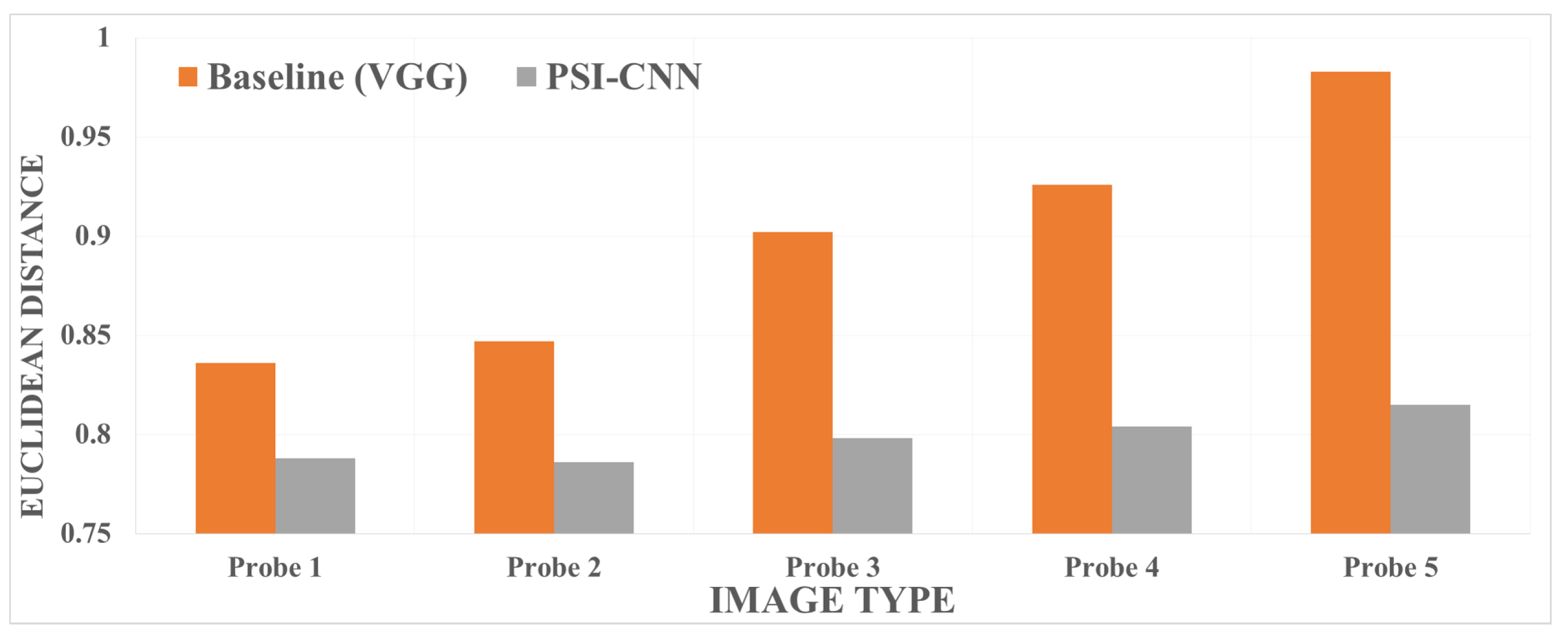
4.3. Performance Comparison on Our CCTV Dataset
4.4. Limitations
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation from Predicting 10,000 Classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for Recognition. J. Cognit. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition using Class Specific Linear Projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face Description with Local Binary Patterns: Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Tan, X.; Triggs, B. Enhanced Local Texture Feature Sets for Face Recognition under Difficult Lighting Conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Wolf, L.; Hassner, T.; Taigman, Y. Effective Unconstrained Face Recognition by Combining Multiple Descriptors And Learned Background Statistics. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1978–1990. [Google Scholar] [CrossRef] [PubMed]
- Geng, C.; Jiang, X. Face Recognition Using SIFT Features. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009. [Google Scholar]
- Deniz, O.; Bueno, G.; Salido, J.; De la Torre, F. Face Recognition Using Histograms of Oriented Gradients. Pattern Reocgnit. Lett. 2011, 32, 1598–1603. [Google Scholar] [CrossRef]
- Chen, D.; Cao, X.; Wen, F.; Sun, J. Blessing of Dimensionality: High-dimensional Feature and Its Efficient Compression for Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3026–3032. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in ’Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008; pp. 7–49. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Convolutional Network Cascade for Facial Point Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3476–3483. [Google Scholar]
- Chen, D.; Cao, X.; Wang, L.; Wen, F.; Sun, J. Bayesian Face Revisited: A Joint Formulation. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 566–579. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning Face Representation from Scratch. arXiv, 2014; arXiv:1411.7923. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Methods | Characteristics |
|---|---|---|
| Holistic-based | Eigenfaces (PCA) [5] | Generates Eigenfaces which represent the global characteristics of faces from training data by extracting principal components. |
| Fisherfaces (LDA) [6] | Computes representative axes which minimize intra-class distances and maximizes inter-class distances simultaneously from the global features of the training data. | |
| Partial-based | Local Binary Patterns [7] | Describes the characteristics of local textures as binary patterns by comparing the center pixel value with that of its neighbors in each local window. |
| SIFT [10] | Applies the SIFT algorithm to extract local facial features which are scale and rotation-invariant. | |
| HoG Descriptor [11] | Extracts local HOG feature from each divided grid and concatenates all feature vectors. | |
| High-dimensional LBP [12] | Extracts 100K-dimensional LBP feature vector from multiple patches by considering scale variations. | |
| Deep learning | DeepFace [1] | Normalizes input face image based on a 3D face model and extracts feature vectors by using a 9-layer CNN. |
| DeepID [2] | Generates 60 patches from input image and extracts a 160-dimensional feature vector from each patch. Also, a joint-Bayesian method is applied to verify whether the same person is observed or not. | |
| FaceNet [3] | Applies triplet loss to minimize distances between images of the same identities and maximize distances between images of different identities. Embeds each feature vector in the Euclidean space. | |
| VGGFace [4] | Consists of 13 convolutional layers and 3 fully connected layers in series. Extracts feature vectors by propagating through the network. |
| Stage | Layer Name | Number of Filters | Size of Feature Map (H × W × D) | Filter Size |
|---|---|---|---|---|
| Conv stage 1 | Input layer | 224 × 224 × 3 | 3 × 3 | |
| Conv1-1 | 64 | 224 × 224 × 64 | 3 × 3 | |
| Conv1-2 | 64 | 224 × 224 × 64 | 3 × 3 | |
| Pooling1 | - | 112 × 112 × 64 | - | |
| Conv stage 2 | Conv2-1-1 | 128 | 112 × 112× 128 | 3 × 3 |
| Conv2-1-2 | 128 | 112 × 112 × 128 | 3 × 3 | |
| ImageResizing2 | - | 112 × 112 × 3 | - | |
| Conv2-2-1 | 128 | 112 × 112 × 128 | 3× 3 | |
| Conv2-2-2 | 128 | 112 × 112 × 128 | 3 × 3 | |
| FeatureFusion2 | - | 112 × 112 × 128 | - | |
| Pooling2 | - | 56 × 56 × 256 | - | |
| Conv stage 3 | Conv3-1-1 | 256 | 56 × 56 × 256 | 3 × 3 |
| Conv3-1-2 | 256 | 56 × 56 × 256 | 3 × 3 | |
| Conv3-1-3 | 256 | 56 × 56 × 256 | 3 × 3 | |
| ImageResizing3 | - | 56 × 56 × 3 | - | |
| Conv3-2-1 | 256 | 56 × 56 × 256 | 3 × 3 | |
| Conv3-2-2 | 256 | 56 × 56 × 256 | 3 × 3 | |
| Conv3-2-3 | 256 | 56 × 56 × 256 | 3 × 3 | |
| FeatureFusion3 | - | 56 × 56 × 256 | - | |
| Pooling3 | - | 28 × 28 × 512 | 3 × 3 | |
| Conv stage 4 | Conv4-1-1 | 512 | 28 × 28 × 512 | 3 × 3 |
| Conv4-1-2 | 512 | 28 × 28 × 512 | 3 × 3 | |
| Conv4-1-3 | 512 | 28 × 28 × 512 | 3 × 3 | |
| ImageResizing4 | - | 28 × 28 × 3 | - | |
| Conv4-2-1 | 512 | 28 × 28 × 512 | 3 × 3 | |
| Conv4-2-2 | 512 | 28 × 28 × 512 | 3 × 3 | |
| Conv4-2-3 | 512 | 28 × 28 × 512 | 3 × 3 | |
| FeatureFusion4 | - | 28 × 28 × 512 | - | |
| Pooling4 | - | 14 × 14 × 512 | - | |
| Conv stage 5 | Conv5-1-1 | 512 | 14 × 14 × 512 | 3 × 3 |
| Conv5-1-2 | 512 | 124 × 14 × 512 | 3 × 3 | |
| Conv5-1-3 | 512 | 14 × 14 × 512 | 3 × 3 | |
| ImageResizing5 | - | 14 × 14 × 3 | - | |
| Conv5-2-1 | 512 | 14 × 14 × 512 | 3 × 3 | |
| Conv5-2-2 | 512 | 14 × 14 × 512 | 3 × 3 | |
| Conv5-2-3 | 512 | 14 × 14 × 512 | 3 × 3 | |
| FeatureFusion5 | - | 14 × 14 × 512 | - | |
| Pooling5 | - | 7 × 7 × 512 | - | |
| FC stage | Fully connected | - | 1 × 1 × 1024 | - |
| Method | Extended Conv. Stages | ||
|---|---|---|---|
| Human | - | 97.53 | - |
| Model 1 (baseline) | - | 98.40 | 0.0024 |
| Model 2 | Stage 2 | 98.60 | 0.0024 |
| Model 3 | Stage 2, 3 | 98.65 | 0.0020 |
| Model 4 | Stage 2, 3, 4 | 98.72 | 0.0018 |
| Model 5 (Proposed model) | Full Stage | 98.87 | 0.0017 |
| Method | EER (%) |
|---|---|
| Baseline model | 22.93 |
| PSI-CNN model | 15.27 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nam, G.P.; Choi, H.; Cho, J.; Kim, I.-J. PSI-CNN: A Pyramid-Based Scale-Invariant CNN Architecture for Face Recognition Robust to Various Image Resolutions. Appl. Sci. 2018, 8, 1561. https://doi.org/10.3390/app8091561
Nam GP, Choi H, Cho J, Kim I-J. PSI-CNN: A Pyramid-Based Scale-Invariant CNN Architecture for Face Recognition Robust to Various Image Resolutions. Applied Sciences. 2018; 8(9):1561. https://doi.org/10.3390/app8091561
Chicago/Turabian StyleNam, Gi Pyo, Heeseung Choi, Junghyun Cho, and Ig-Jae Kim. 2018. "PSI-CNN: A Pyramid-Based Scale-Invariant CNN Architecture for Face Recognition Robust to Various Image Resolutions" Applied Sciences 8, no. 9: 1561. https://doi.org/10.3390/app8091561
APA StyleNam, G. P., Choi, H., Cho, J., & Kim, I.-J. (2018). PSI-CNN: A Pyramid-Based Scale-Invariant CNN Architecture for Face Recognition Robust to Various Image Resolutions. Applied Sciences, 8(9), 1561. https://doi.org/10.3390/app8091561