A Parallel Approach for Frequent Subgraph Mining in a Single Large Graph Using Spark

 ,
, 
Abstract
:1. Introduction
- First, we propose SSiGraM, a novel parallel frequent subgraph mining algorithm in a single large graph using Spark, which is different from the Hadoop MapReduce based and MPI based parallel algorithms. SSiGraM can also easily combine with the bottom Hadoop distributed storage data and other machine learning algorithms.
- Second, we conduct in parallel subgraph extension and support counting, respectively, aiming at the two core steps with high computational complexity in frequent subgraph mining. In addition, we provide a heuristic search strategy and three optimizations for the support computing operation.
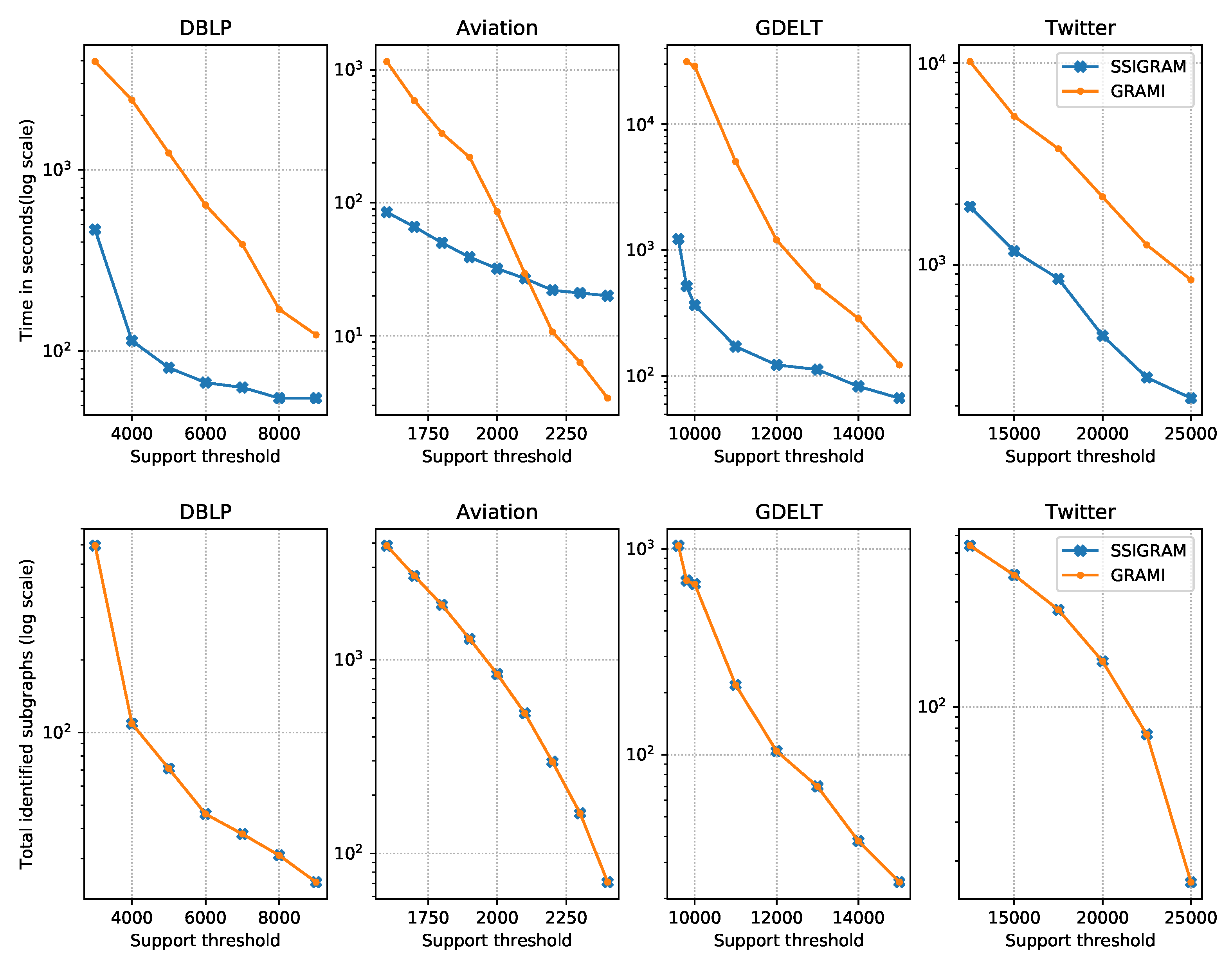
- Third, extensive experimental performance evaluations are conducted with four real-world graphs. The proposed SSiGraM algorithm outperforms the GraMi method by at least one order of magnitude with the same memory allocated.
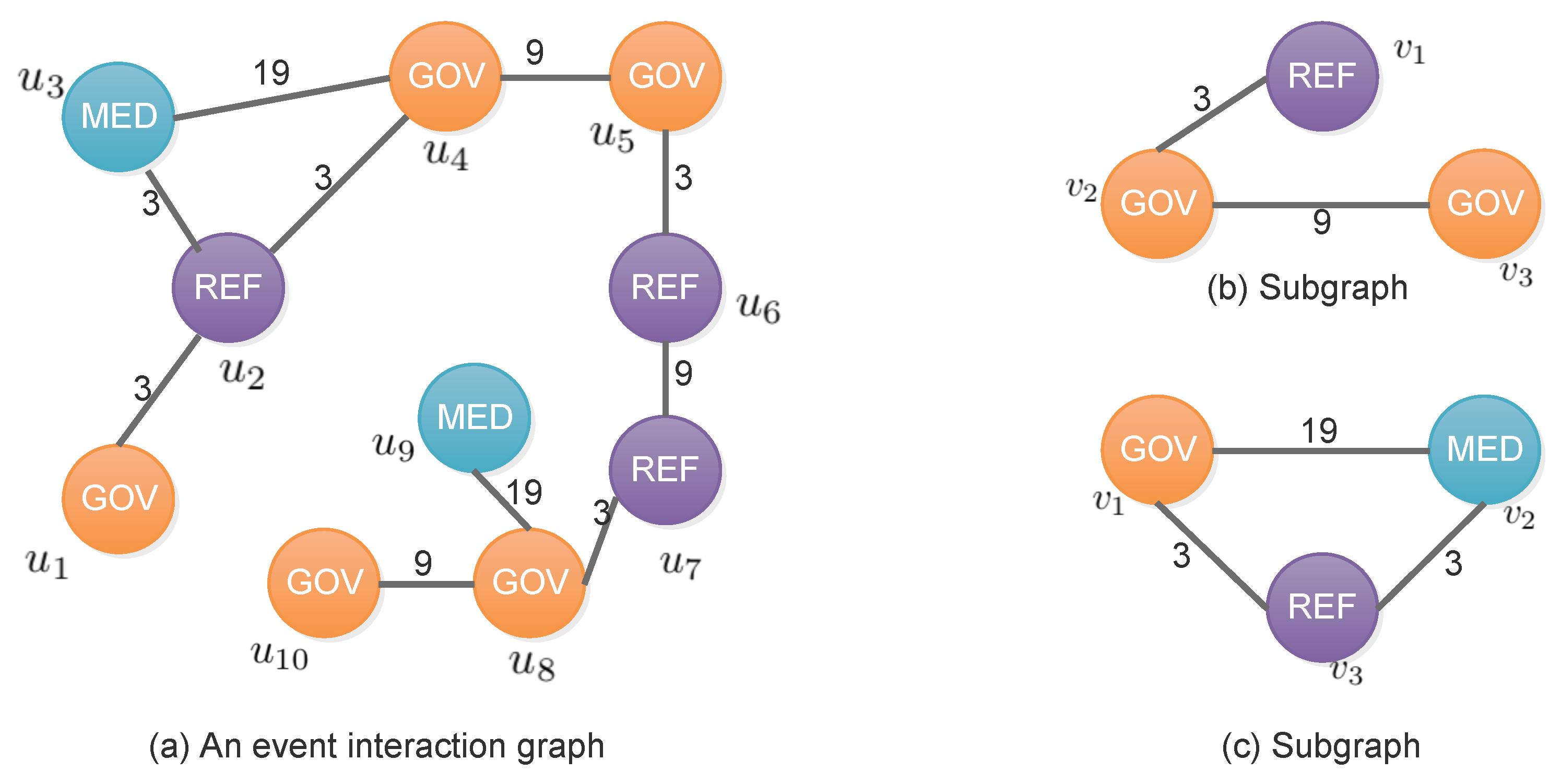
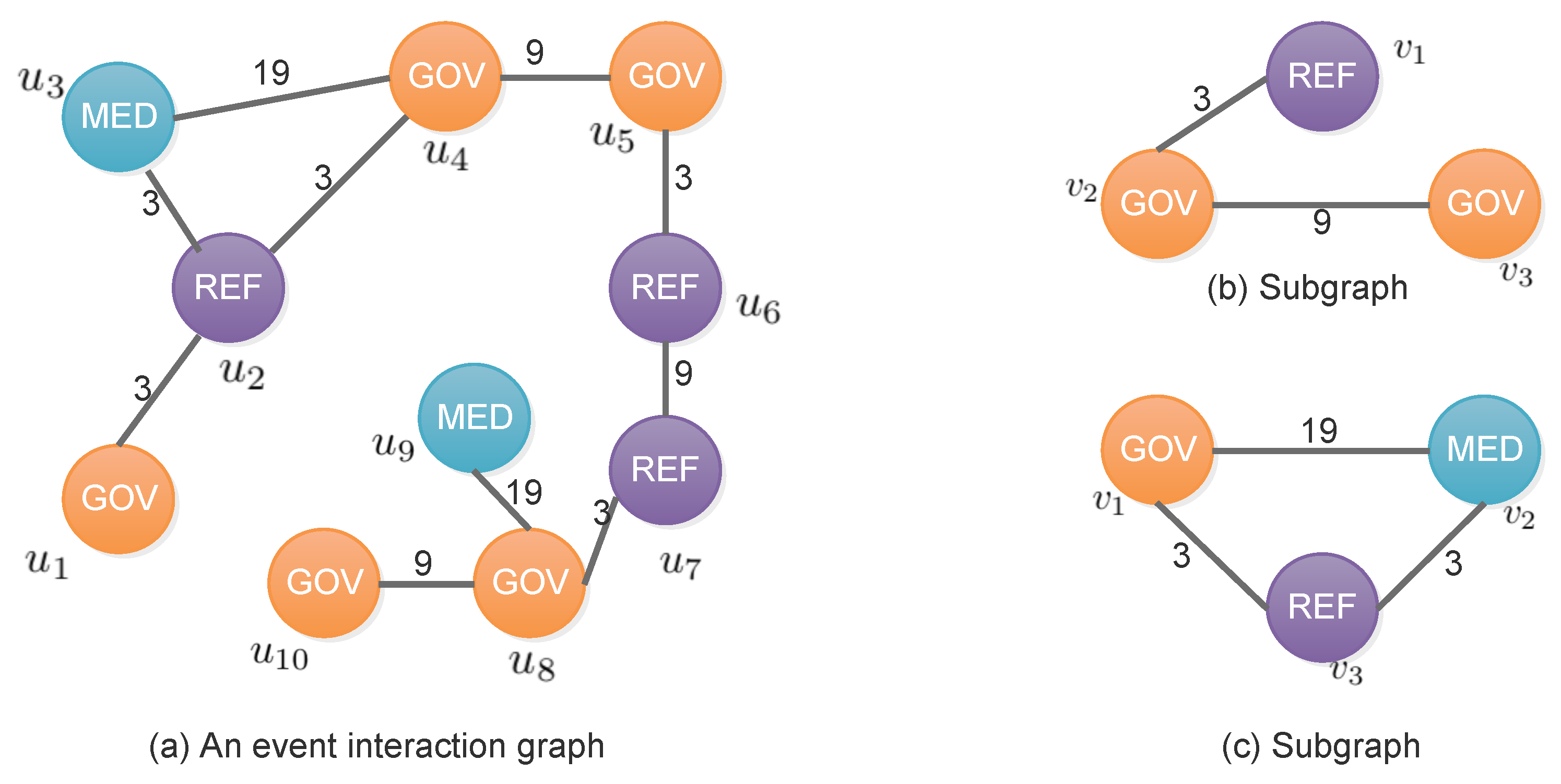
2. Formalism
3. The SSiGraM Approach
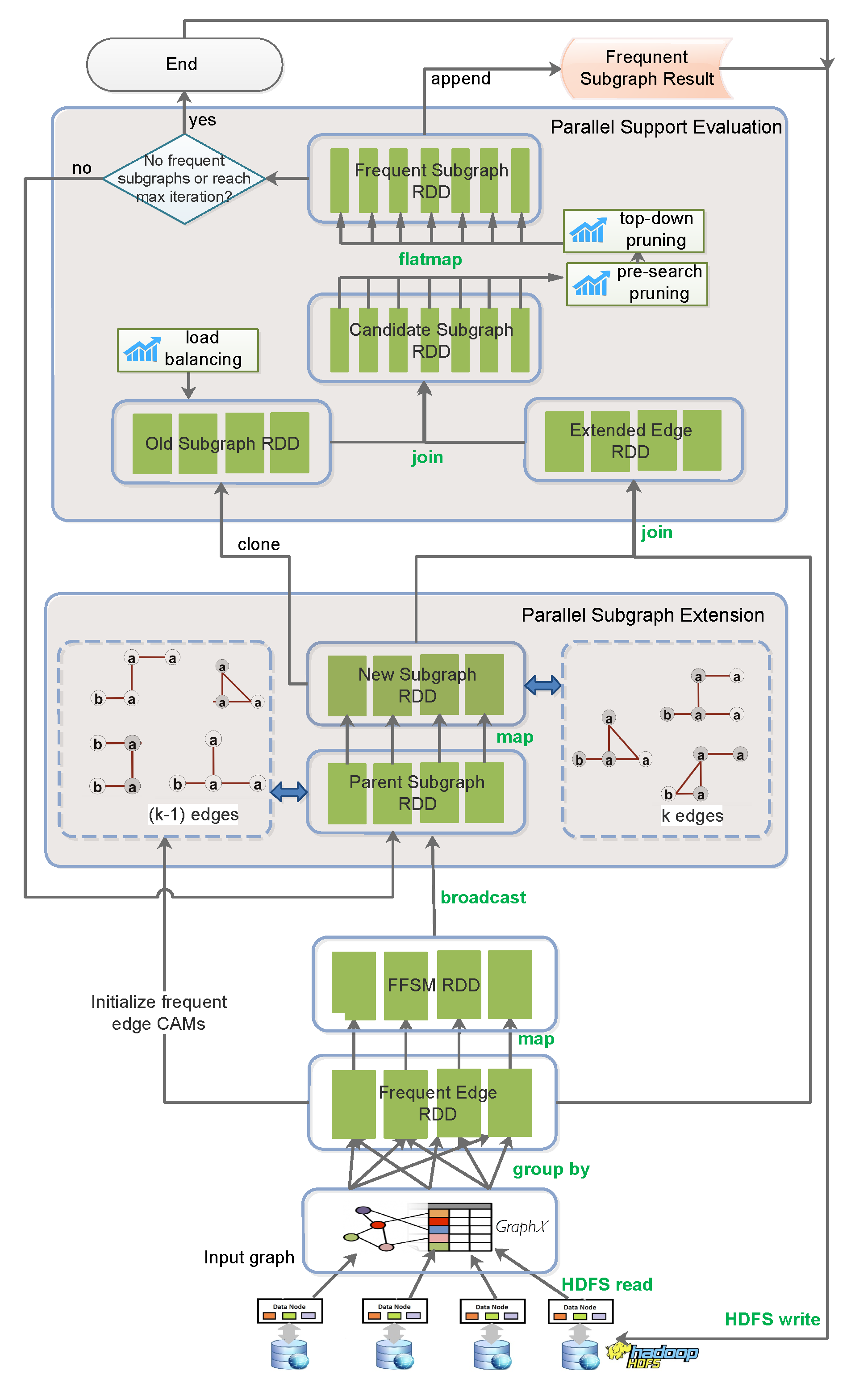
3.1. Framework
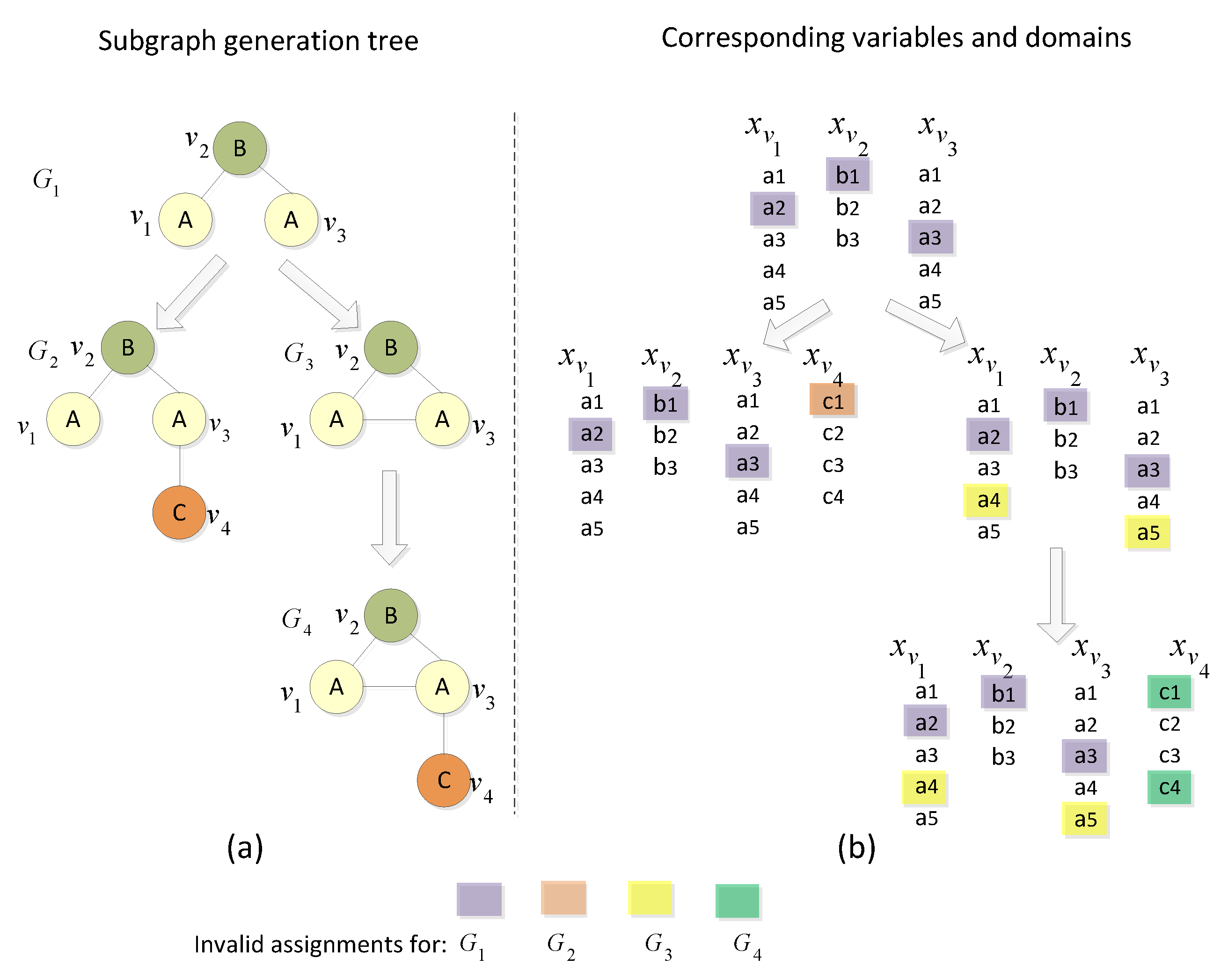
3.2. Parallel Subgraph Extension
| Algorithm 1 Parallel Subgraph Extension. |
| Input: frequent subgraphs , broadcasted FFSM operator , Spark context Output: new generated that extend
|
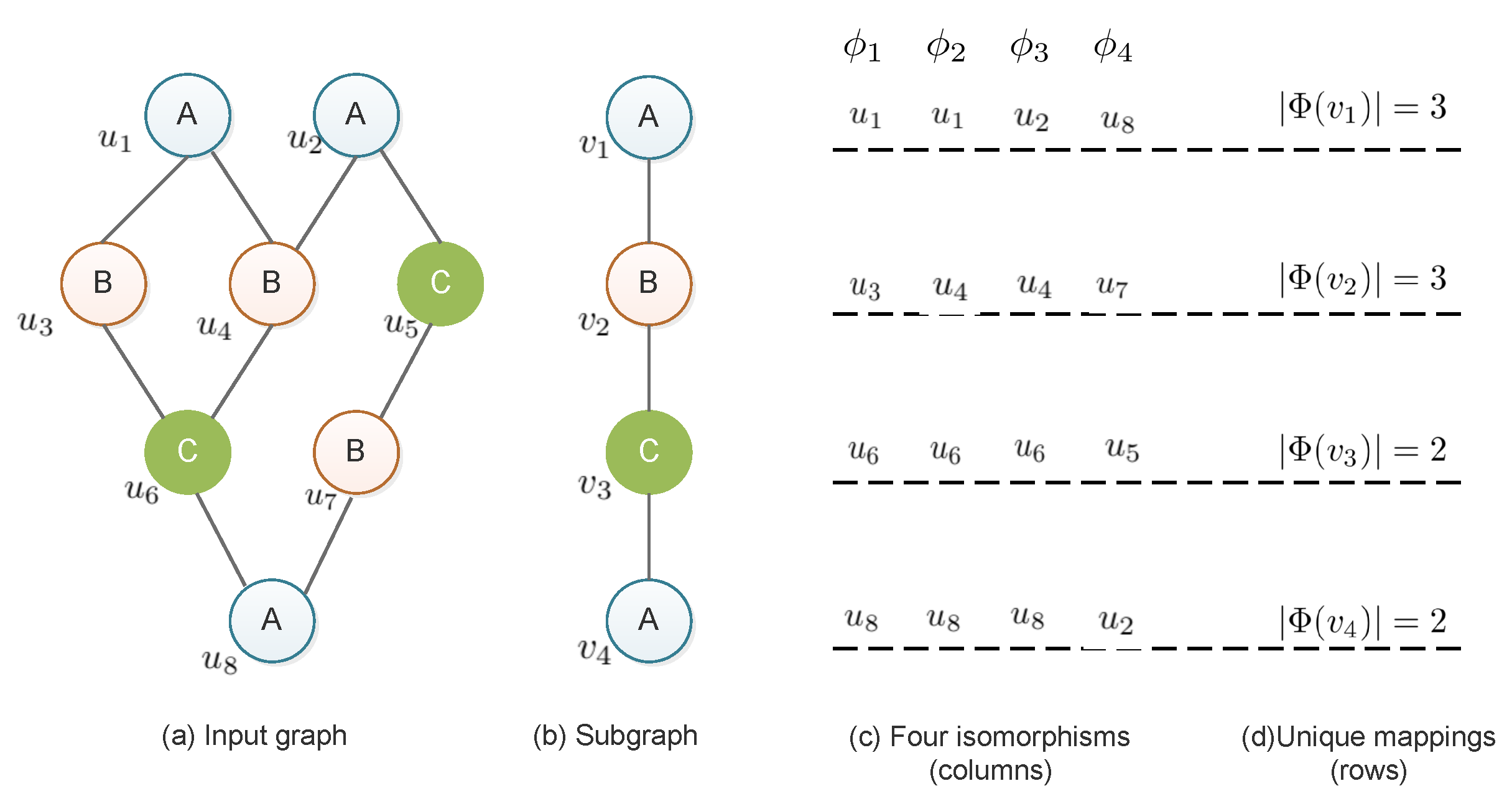
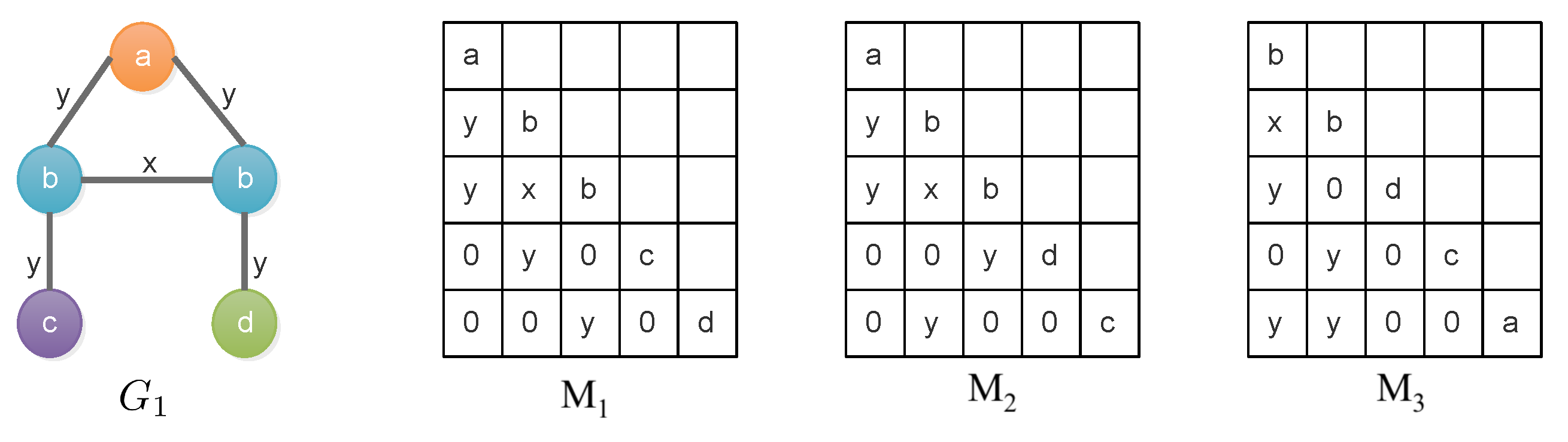
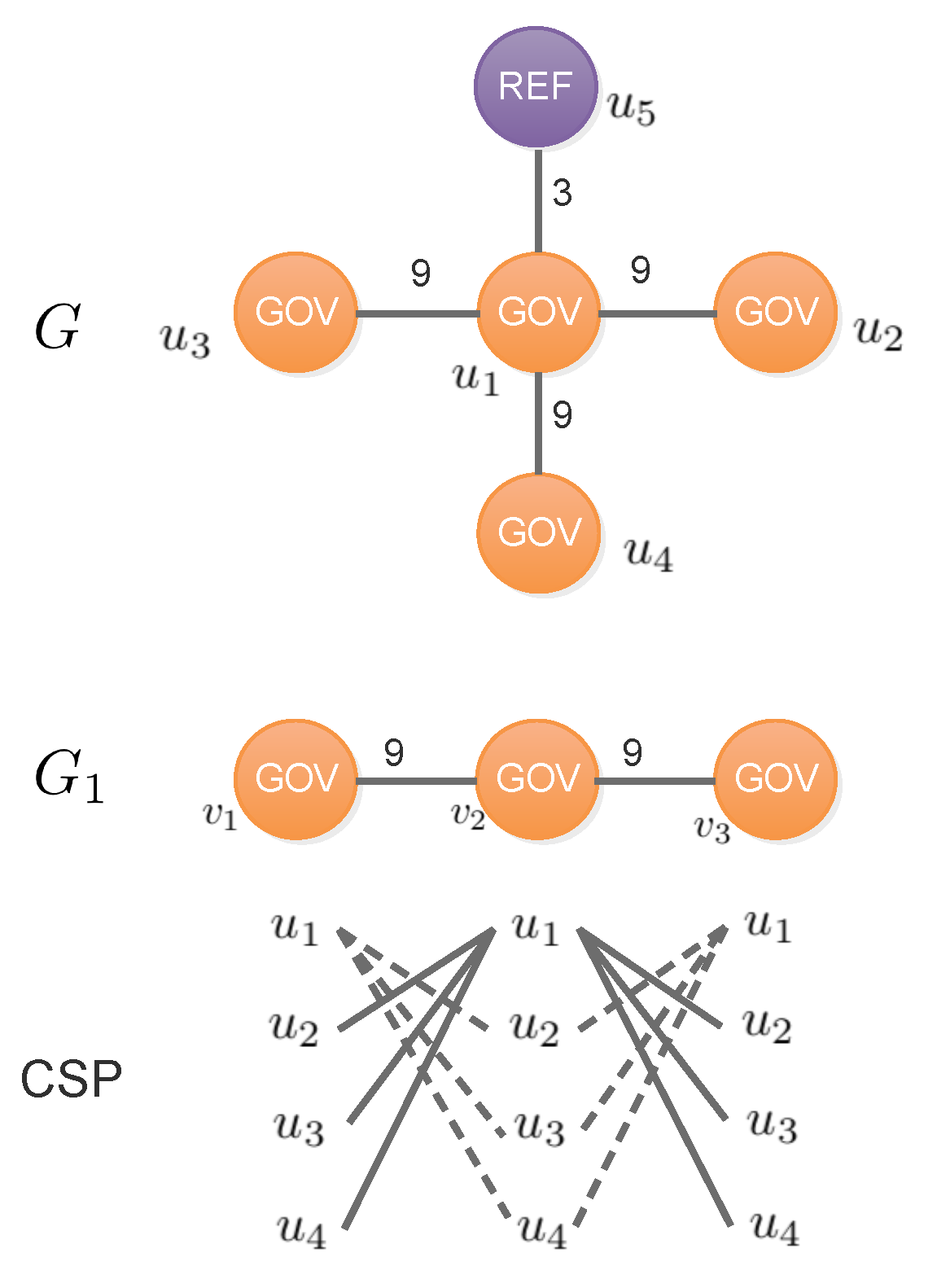
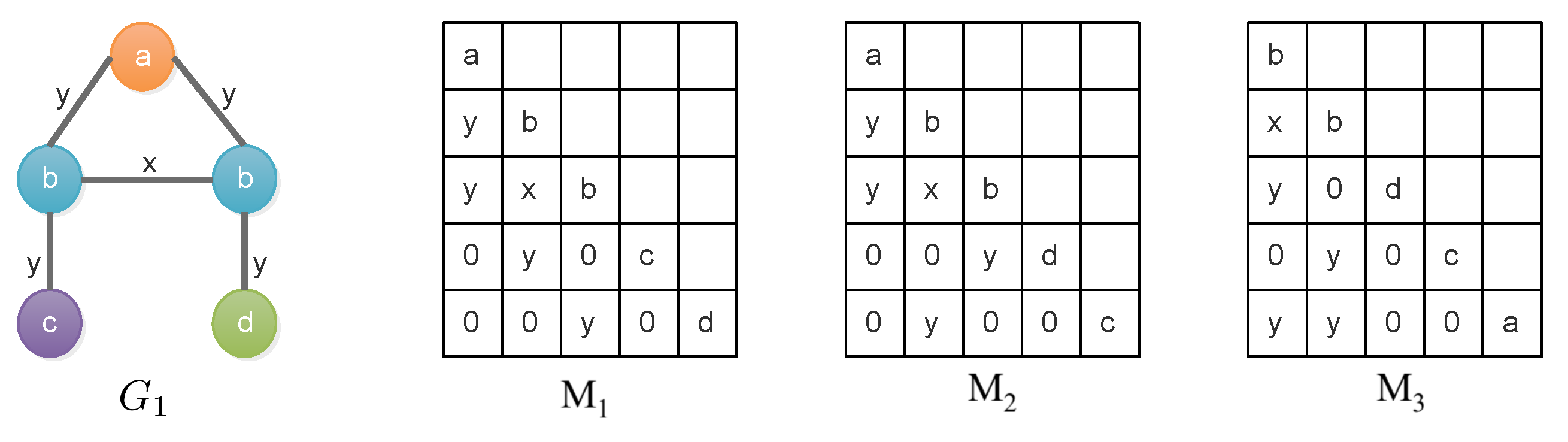
3.3. Parallel Support Evaluation
- 1.
- is an ordered set of variables which contains a variable for each node .
- 2.
- is the set of domains for each variable . Each domain is a subset of V.
- 3.
- Set contains the following constraint rules:
- , .
- and the corresponding , .
- and the corresponding , .
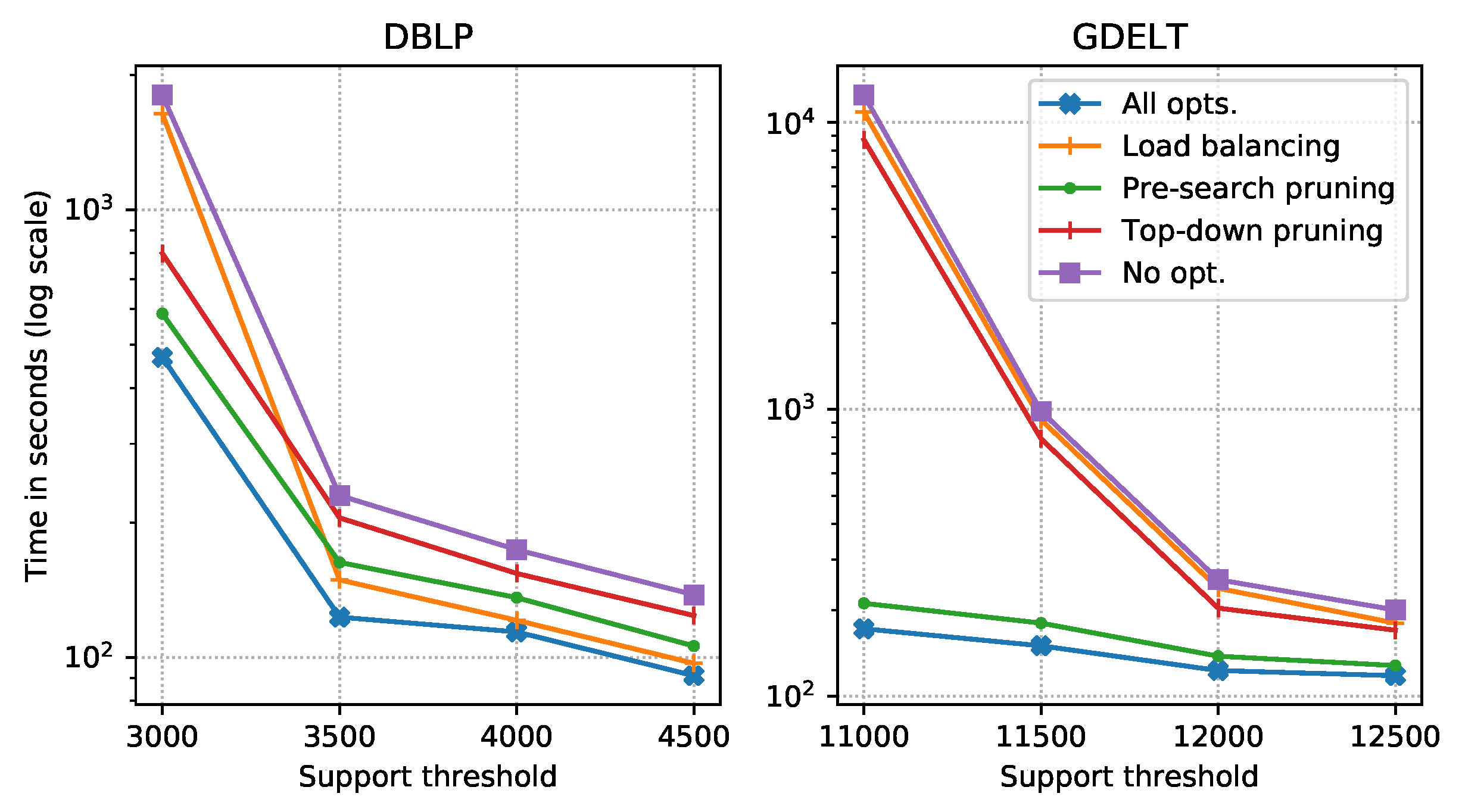
3.4. Optimizing Support Evaluation
3.4.1. Load Balancing
| Algorithm 2 Load Balancing |
| Input: RDD of subgraph set , Spark cluster parallelism n, Spark context Output: : balanced RDD of subgraph set
|
3.4.2. Pre-Search Pruning
3.4.3. Top-Down Pruning
3.5. The SSiGraM Algorithm
| Algorithm 3 Support Evaluation. |
| Input: A subgraph s, domain data , threshold Output: true if s is a frequent subgraph of G, false otherwise
|
4. Experimental Evaluation
4.1. Experimental Setup
| Algorithm 4 The SSiGraM Algorithm. |
| Input: A graph G, support threshold and Spark context , parallelism n Output: All subgraphs S of G such that
|
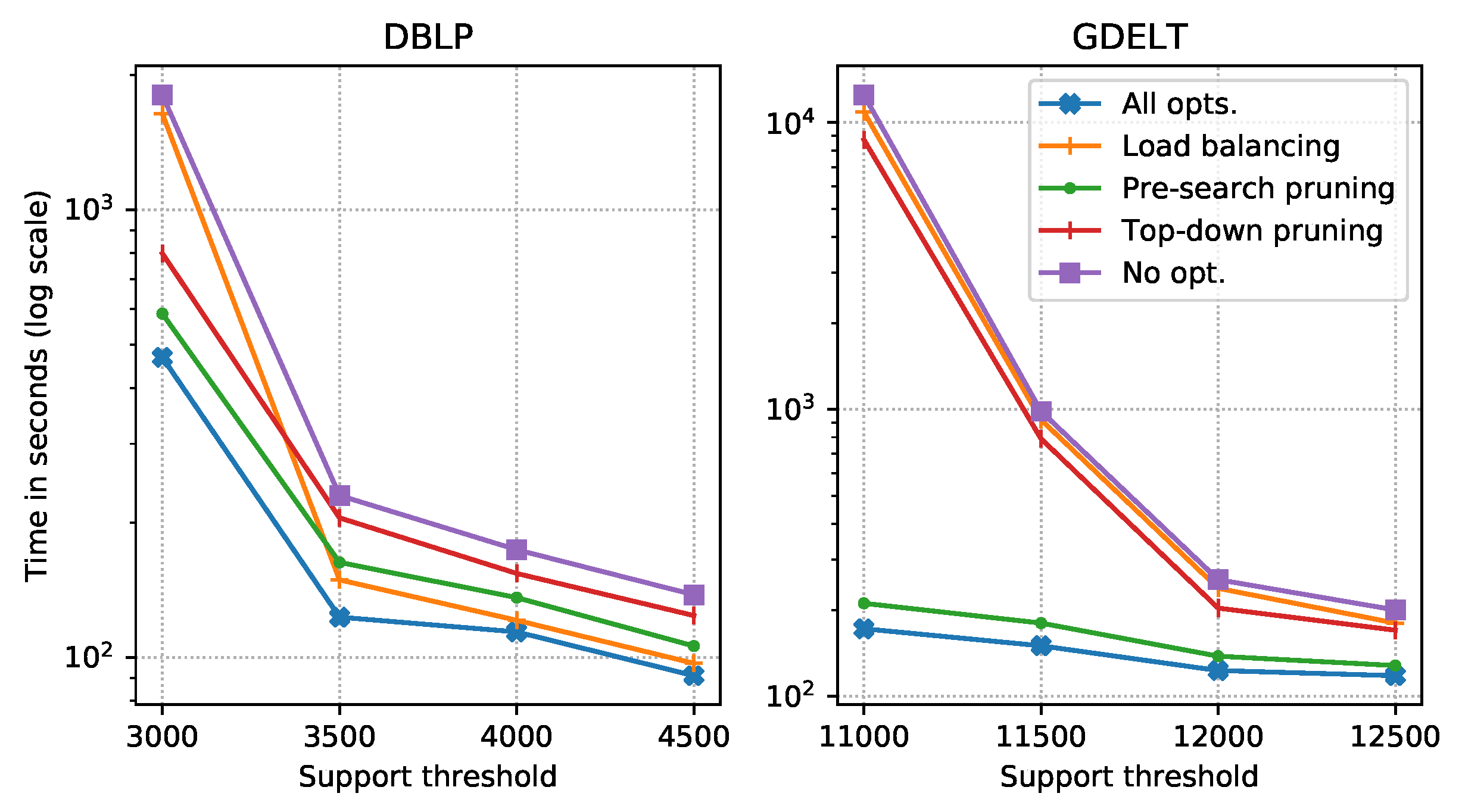
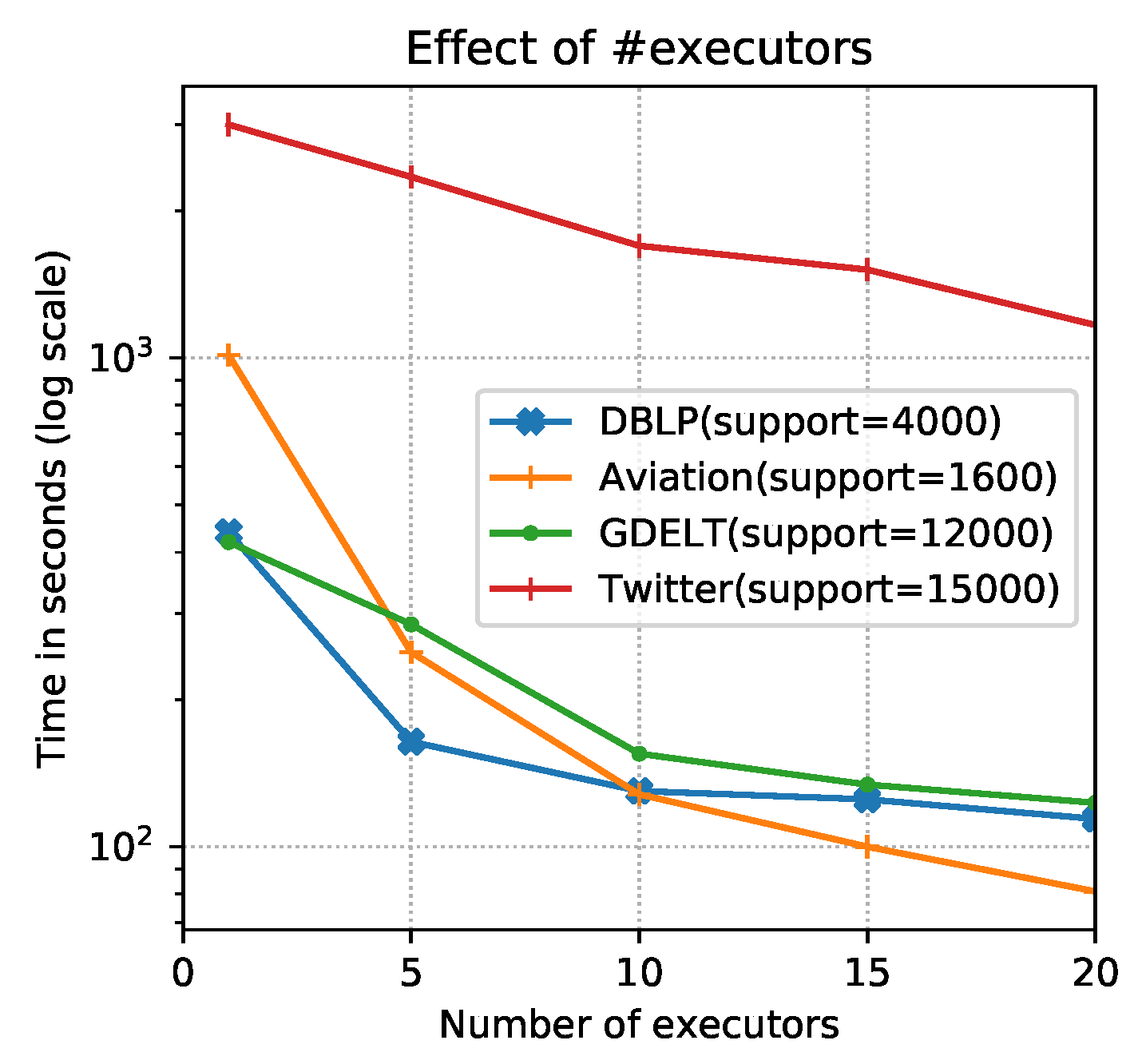
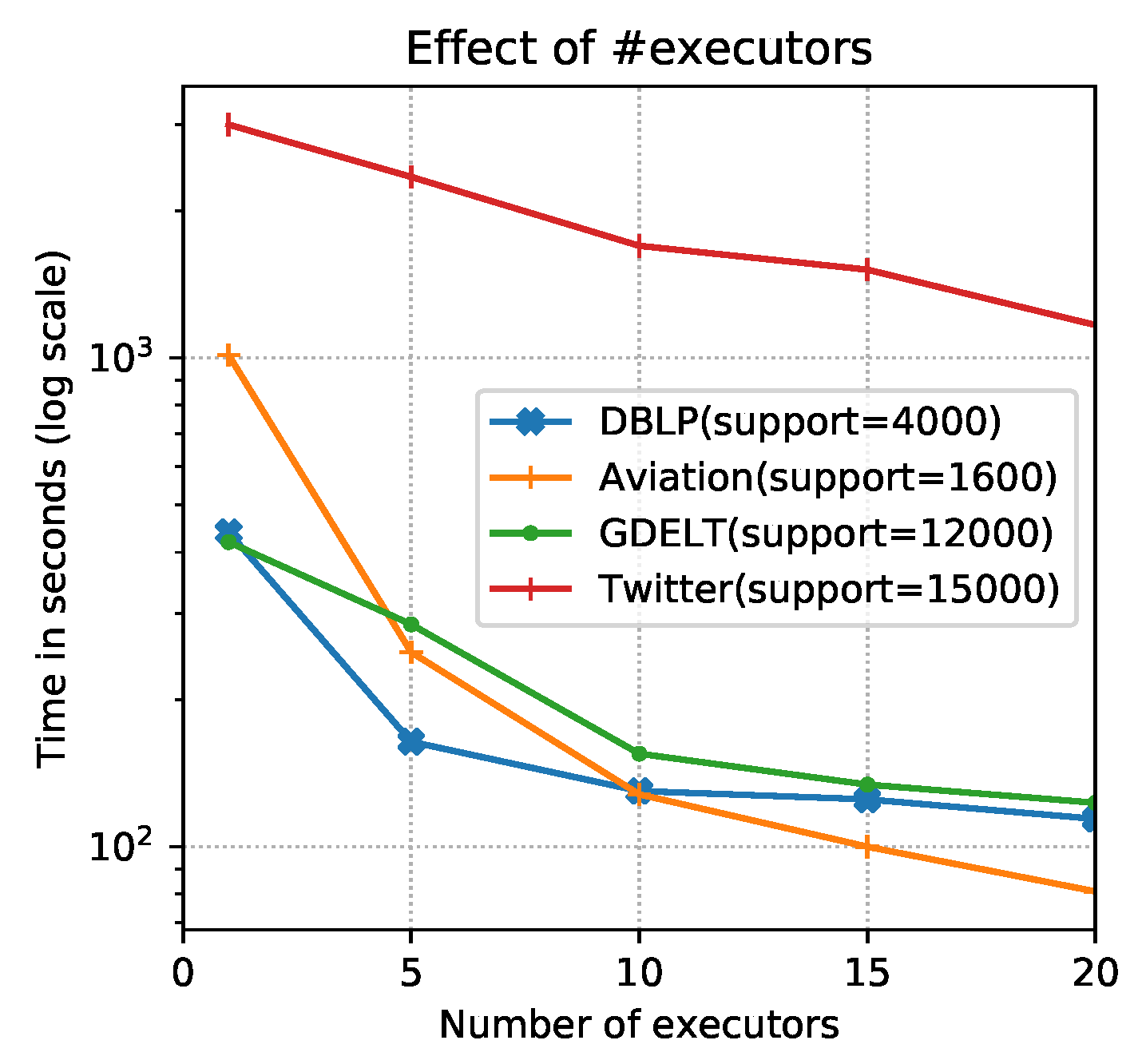
4.2. Experimental Results
5. Conclusions
6. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chakrabarti, D.; Faloutsos, C. Graph mining: Laws, generators, and algorithms. ACM Comput. Surv. (CSUR) 2006, 38, 2. [Google Scholar] [CrossRef]
- Yan, X.; Han, J. gSpan: Graph-based substructure pattern mining. In Proceedings of the 2002 IEEE International Conference on Data Mining (ICDM 2002), Maebashi City, Japan, 9–12 December 2002; pp. 721–724. [Google Scholar]
- Liu, Y.; Xu, S.; Duan, L. Relationship Emergence Prediction in Heterogeneous Networks through Dynamic Frequent Subgraph Mining. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 1649–1658. [Google Scholar]
- Herrera-Semenets, V.; Gago-Alonso, A. A novel rule generator for intrusion detection based on frequent subgraph mining. Ingeniare Rev. Chil. Ing. 2017, 25, 226–234. [Google Scholar] [CrossRef]
- Qiao, F.; Wang, H. Computational Approach to Detecting and Predicting Occupy Protest Events. In Proceedings of the 2015 International Conference on Identification, Information, and Knowledge in the Internet of Things (IIKI), Beijing, China, 22–23 October 2015; pp. 94–97. [Google Scholar]
- Pak, A.; Paroubek, P. Extracting Sentiment Patterns from Syntactic Graphs. In Social Media Mining and Social Network Analysis: Emerging Research; IGI Global: Hershey, PA, USA, 2013; pp. 1–18. [Google Scholar]
- Choi, C.; Lee, Y.; Yoon, S.E. Discriminative subgraphs for discovering family photos. Comput. Vis. Media 2016, 2, 257–266. [Google Scholar] [CrossRef]
- Keneshloo, Y.; Cadena, J.; Korkmaz, G.; Ramakrishnan, N. Detecting and forecasting domestic political crises: A graph-based approach. In Proceedings of the 2014 ACM Conference on Web Science, Bloomington, IN, USA, 23–26 June 2014; ACM: New York, NY, USA, 2014; pp. 192–196. [Google Scholar]
- Jiang, C.; Coenen, F.; Zito, M. A survey of frequent subgraph mining algorithms. Knowl. Eng. Rev. 2013, 28, 75–105. [Google Scholar] [CrossRef]
- Kuramochi, M.; Karypis, G. Finding Frequent Patterns in a Large Sparse Graph. Data Min. Knowl. Discov. 2005, 11, 243–271. [Google Scholar] [CrossRef]
- Berlingerio, M.; Bonchi, F.; Bringmann, B.; Gionis, A. Mining graph evolution rules. In Machine Learning and Knowledge Discovery in Databases; MIT Press: Cambridge, MA, USA, 2009; pp. 115–130. [Google Scholar]
- Elseidy, M.; Abdelhamid, E.; Skiadopoulos, S.; Kalnis, P. GraMi: Frequent Subgraph and Pattern Mining in a Single Large Graph. Proc. VLDB Endow. 2014, 7, 517–528. [Google Scholar] [CrossRef]
- Wang, K.; Xie, X.; Jin, H.; Yuan, P.; Lu, F.; Ke, X. Frequent Subgraph Mining in Graph Databases Based on MapReduce. In Advances in Services Computing, Proceedings of the 10th Asia-Pacific Services Computing Conference (APSCC 2016), Zhangjiajie, China, 16–18 November 2016; Springer: Berlin, Germany, 2016; pp. 464–476. [Google Scholar]
- Liu, Y.; Jiang, X.; Chen, H.; Ma, J.; Zhang, X. Mapreduce-based pattern finding algorithm applied in motif detection for prescription compatibility network. In Advanced Parallel Processing Technologies; Springer International Publishing AG: Cham, Switzerland, 2009; pp. 341–355. [Google Scholar]
- Shahrivari, S.; Jalili, S. Distributed discovery of frequent subgraphs of a network using MapReduce. Computing 2015, 97, 1101–1120. [Google Scholar] [CrossRef]
- Aridhi, S.; d’Orazio, L.; Maddouri, M.; Nguifo, E.M. Density-based data partitioning strategy to approximate large-scale subgraph mining. Inf. Syst. 2015, 48, 213–223. [Google Scholar] [CrossRef]
- Hill, S.; Srichandan, B.; Sunderraman, R. An iterative mapreduce approach to frequent subgraph mining in biological datasets. In Proceedings of the ACM Conference on Bioinformatics, Computational Biology and Biomedicine, Orlando, FL, USA, 7–10 October 2012; ACM: New York, NY, USA, 2012; pp. 661–666. [Google Scholar]
- Luo, Y.; Guan, J.; Zhou, S. Towards Efficient Subgraph Search in Cloud Computing Environments. In Database Systems for Adanced Applications; Springer International Publishing AG: Cham, Switzerland, 2011; pp. 2–13. [Google Scholar]
- Talukder, N.; Zaki, M.J. A distributed approach for graph mining in massive networks. Data Min. Knowl. Discov. 2016, 30, 1024–1052. [Google Scholar] [CrossRef]
- White, T. Hadoop: The Definitive Guide, 1st ed.; O’Reilly Media, Inc.: Newton, MA, USA, 2009. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster Computing with Working Sets. In Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing (HotCloud’10), Boston, MA, USA, 22–25 June 2010; USENIX Association: Berkeley, CA, USA, 2010; p. 10. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. Mllib: Machine learning in apache spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Huan, J.; Wang, W.; Prins, J. Efficient mining of frequent subgraphs in the presence of isomorphism. In Proceedings of the Third IEEE International Conference on Data Mining (ICDM 2003), Melbourne, FL, USA, 22–22 November 2003; pp. 549–552. [Google Scholar]
- Jiang, C. Frequent Subgraph Mining Algorithms on Weighted Graphs. Ph.D. Thesis, University of Liverpool, Liverpool, UK, 2011. [Google Scholar]
- Chen, Y.; Zhao, X.; Lin, X.; Wang, Y. Towards frequent subgraph mining on single large uncertain graphs. In Proceedings of the 2015 IEEE International Conference on Data Mining (ICDM), Atlantic City, NJ, USA, 14–17 November 2015; pp. 41–50. [Google Scholar]
- Gibbons, A. Algorithmic Graph Theory; Cambridge University Press: Cambridge, UK, 1985. [Google Scholar]
- West, D.B. Introduction to Graph Theory; Prentice Hall Upper Saddle River: Bergen County, NJ, USA, 2001; Volume 2. [Google Scholar]
- Gerner, D.J.; Schrodt, P.A.; Yilmaz, O.; Abu-Jabr, R. Conflict and Mediation Event Observations (CAMEO): A New Event Data Framework for the Analysis of Foreign Policy Interactions; International Studies Association: New Orleans, LA, USA, 2002. [Google Scholar]
- He, H.; Singh, A.K. Graphs-at-a-time: Query language and access methods for graph databases. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; ACM: New York, NY, USA, 2008; pp. 405–418. [Google Scholar]
- Fiedler, M.; Borgelt, C. Subgraph support in a single large graph. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDM Workshops 2007), Omaha, NE, USA, 28–31 October 2007; pp. 399–404. [Google Scholar]
- Bringmann, B.; Nijssen, S. What is Frequent in a Single Graph? In Proceedings of the 12th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining (PAKDD’08), Osaka, Japan, 20–23 May 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 858–863. [Google Scholar]
- Wörlein, M.; Meinl, T.; Fischer, I.; Philippsen, M. A quantitative comparison of the subgraph miners MoFa, gSpan, FFSM, and Gaston. In Knowledge Discovery in Database: PKDD 2005; Jorge, A., Torgo, L., Brazdil, P., Camacho, R., Gama, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2011; Volume 3721, pp. 392–403. [Google Scholar]
- Jin, R.; Liu, L.; Aggarwal, C.C. Discovering highly reliable subgraphs in uncertain graphs. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; ACM: New York, NY, USA, 2011; pp. 992–1000. [Google Scholar]
- Zou, Z.; Li, J.; Gao, H.; Zhang, S. Frequent subgraph pattern mining on uncertain graph data. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; ACM: New York, NY, USA, 2009; pp. 583–592. [Google Scholar]
- Jamil, S.; Khan, A.; Halim, Z.; Baig, A.R. Weighted muse for frequent sub-graph pattern finding in uncertain dblp data. In Proceedings of the 2011 International Conference on Internet Technology and Applications (iTAP), Wuhan, China, 16–18 August 2011; pp. 1–6. [Google Scholar]
- Papapetrou, O.; Ioannou, E.; Skoutas, D. Efficient discovery of frequent subgraph patterns in uncertain graph databases. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–24 March 2011; ACM: New York, NY, USA, 2011; pp. 355–366. [Google Scholar]
- Zou, Z.; Gao, H.; Li, J. Discovering frequent subgraphs over uncertain graph databases under probabilistic semantics. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; ACM: New York, NY, USA, 2010; pp. 633–642. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Node | #L(Node) | #Edge | #L(Edge) | Density |
|---|---|---|---|---|---|
| DBLP | 151,574 | 7 | 191,840 | 17 | Medium |
| Aviation | 101,185 | 6173 | 133,087 | 41 | Sparse |
| GDELT | 1,515,712 | 14,816 | 2,832,692 | 8 | Sparse |
| 11,316,811 | 40 | 85,331,846 | 1 | Dense |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, F.; Zhang, X.; Li, P.; Ding, Z.; Jia, S.; Wang, H. A Parallel Approach for Frequent Subgraph Mining in a Single Large Graph Using Spark. Appl. Sci. 2018, 8, 230. https://doi.org/10.3390/app8020230
Qiao F, Zhang X, Li P, Ding Z, Jia S, Wang H. A Parallel Approach for Frequent Subgraph Mining in a Single Large Graph Using Spark. Applied Sciences. 2018; 8(2):230. https://doi.org/10.3390/app8020230
Chicago/Turabian StyleQiao, Fengcai, Xin Zhang, Pei Li, Zhaoyun Ding, Shanshan Jia, and Hui Wang. 2018. "A Parallel Approach for Frequent Subgraph Mining in a Single Large Graph Using Spark" Applied Sciences 8, no. 2: 230. https://doi.org/10.3390/app8020230
APA StyleQiao, F., Zhang, X., Li, P., Ding, Z., Jia, S., & Wang, H. (2018). A Parallel Approach for Frequent Subgraph Mining in a Single Large Graph Using Spark. Applied Sciences, 8(2), 230. https://doi.org/10.3390/app8020230