Deep Learning Case Study for Automatic Bird Identification


Abstract
1. Introduction
2. Hardware
2.1. Radar System
2.2. Video Head Control
2.3. Camera Control
3. Data Processing
3.1. Input Data
3.2. Data Augmentation
4. The Proposed System
5. Classification
5.1. Convolutional Neural Network
5.2. Hyperparameter Selection
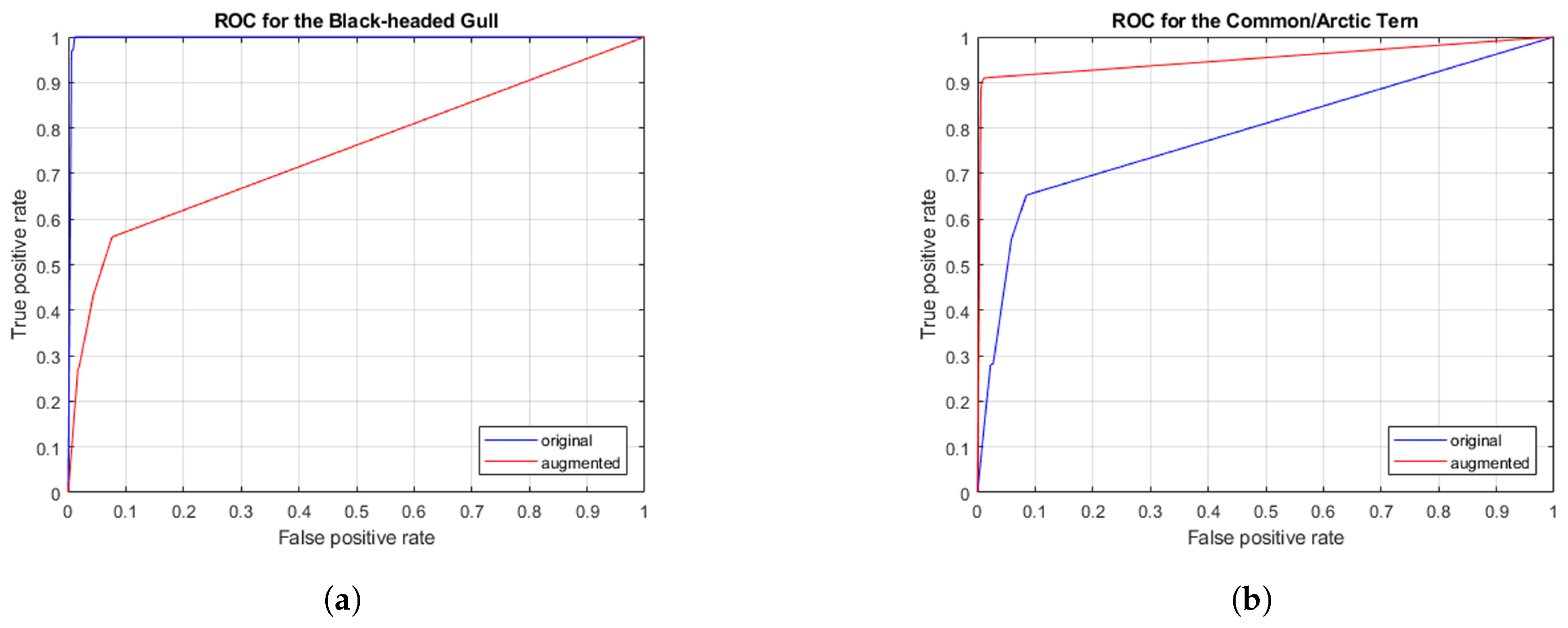
6. Results
7. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application programmable interface |
| AUC | Area under the curve |
| CIE | Commission internationale de l’éclairage |
| CMFs | Color matching functions |
| CNN | Convolutional neural network |
| DSLR | digital single-lens reflex camera |
| LDPR | Learning rate drop period |
| LRDS | Learning rate decay schedule |
| ReLU | Rectified linear units |
| ROC | Receiver operating characteristic |
| SVM | Support vector machine |
| TPR | True positive range |
References
- Desholm, M.; Kahlert, J. Avian Collision Risk at an Offshore Wind Farm. Biol. Lett. 2008, 1, 296–298. [Google Scholar] [CrossRef] [PubMed]
- Marques, A.T.; Rodrigues, S.; Costa, H.; Pereira, M.J.R.; Fonseca, C.; Mascarenhas, M.; Bernardino, J. Understanding bird collisions at wind farms: An updated review on the causes and possible mitigation strategies. Biol. Conserv. 2014, 179, 40–52. [Google Scholar] [CrossRef]
- Baxter, A.T.; Robinson, A.P. A comparison of scavenging bird deterrence techniques at UK landfill sites. Int. J. Pest Manag. 2007, 53, 347–356. [Google Scholar] [CrossRef]
- Verhoef, J.P.; Westra, C.A.; Korterink, H.; Curvers, A. WT-Bird A Novel Bird Impact Detection System. Available online: www.ecn.nl/docs/library/report/2002/rx02055.pdf (accessed on 27 September 2018).
- Wiggelinkhuizen, E.J.; Barhorst, S.A.M.; Rademakers, L.W.M.M.; den Boon, H.J. Bird Collision Monitoring System for Multi-Megawatt Wind Turbines, WT-Bird: Prototype Development and Testing. Available online: www.ecn.nl/publications/PdfFetch.aspx?nr=ECN-E--06-027 (accessed on 27 September 2018).
- Wiggelinkhuizen, E.J.; den Boon, H.J. Monitoring of Bird Collisions in Wind Farm under Offshore-like Conditions Using WT-BIRD System: Final Report. Available online: www.ecn.nl/docs/library/report/2009/e09033.pdf (accessed on 27 September 2018).
- Robin Radar Models. Available online: https://www.robinradar.com/ (accessed on 27 September 2018).
- PT1020 Video Head. Available online: http://www.2bsecurity.com/product/pt-1020-medium-sized-pan-tilt/ (accessed on 27 September 2018).
- Bruxy REGNET for Pelco-D Protocol. Available online: http://bruxy.regnet.cz/programming/rs485/pelco-d.pdf (accessed on 27 September 2018).
- Häkli, P.; Puupponen, J.; Koivula, H. Suomen Geodeettiset Koordinaatistot Ja Niiden VäLiset Muunnokset. Natl. Land Surv. Finl. 2009. Available online: https://www.maanmittauslaitos.fi/sites/maanmittauslaitos.fi/files/fgi/GLtiedote30korjausliite.pdf (accessed on 27 September 2018).
- Canon’s European Developer Programmes. Available online: https://www.developers.canon-europa.com/developer/bsdp/bsdp_pub.nsf (accessed on 27 September 2018).
- Hensman, P.; Masko, D. The Impact of Imbalanced Training Data for Convolutional Neural Networks. Available online: https://www.kth.se/social/files/588617ebf2765401cfcc478c/PHensmanDMasko_dkand15.pdf (accessed on 27 September 2018).
- Speranskaya, N.I. Determination of spectrum color co-ordinates for twenty-seven normal observers. Opt. Spectrosc. 1959, 7, 424–428. [Google Scholar]
- Stiles, W.S.; Burch, J.M. NPL colour-matching investigation: Final report. Opt. Acta 1959, 6, 1–26. [Google Scholar] [CrossRef]
- Wyszecki, G.; Stiles, W.S. Color Science: Concepts and Methods, Quantitative Data and Formulae, 2nd ed.; John Wiley & Sons Inc.: New York, NY, USA, 1982; ISBN 978-0471021063. [Google Scholar]
- Stockman, A.; Sharpe, L.T. Spectral sensitivities of the middle- and long-wavelength sensitive cones derived from measurements in observers of known genotype. Vis. Res. 2000, 40, 1711–1737. [Google Scholar] [CrossRef]
- CIE. CIE Proceedings, Vienna Session; Committee Report E-1.4.1; CIE: Paris, France, 1963; pp. 209–220. [Google Scholar]
- Blackbody Color Datafile. Available online: www.vendian.org/mncharity/dir3/blackbody/UnstableURLs/bbr_color.html (accessed on 27 September 2018).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: www.deeplearningbook.org (accessed on 27 September 2018).
- Richards, M.A. Fundamentals of Radar Signal Processing; The McGraw-Hill Companies: New York, NY, USA, 2005; ISBN 0-07-144474-2. [Google Scholar]
- Bruderer, B. The Study of Bird Migration by Radar, part1: The Technical Basis. Naturwissenschaften 1997, 84, 1–8. [Google Scholar] [CrossRef]
- The MathWorks, Inc. Fuzzy Logic Toolbox Documentation. Available online: https://se.mathworks.com/help/fuzzy/fuzzy.pdf. (accessed on 27 September 2018).
- Yuheng, S.; Hao, J. Image Segmentation Algorithms Overview. Available online: https://arxiv.org/ftp/arxiv/papers/1707/1707.02051.pdf (accessed on 27 September 2018).
- Mamdani, E.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Huang, J.F.; LeCun, Y. Large-Scale Learning with Svm and Convolutional Nets for Generic Object Categorization. Available online: http://yann.lecun.com/exdb/publis/pdf/huang-lecun-06.pdf (accessed on 27 September 2018).
- Moore, R.C.; DeNero, J. L1 and L2 regularization for multiclass hinge loss models. In Proceedings of the Symposium on Machine Learning in Speech and Language Processing, Bellevue, WA, USA, 27 June 2011. [Google Scholar]
- Duan, K.B.; Keerthi, S.S. Which Is the Best Multiclass SVM Method? An Empirical Study. Mult. Classif. Syst. LNCS 2005, 3541, 278–285. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient Mini-batch Training for Stochastic Optimization. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge, New York, NY, USA, 24–27 August 2014; pp. 661–670, ISBN 978-1-4503-2956-9. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA, 2012; ISBN 978-0-262-01802-9. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Jordan, M., Kleinberg, J., Schölkopf, B., Eds.; Springer: New York, NY, USA, 2006; ISBN 0-387-31073-8. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice Hall/Pearson: New York, NY, USA, 1994; p. 470. ISBN 0-13-908385-5. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the best multi-stage architecture for object recognition. In Proceedings of the International Conference on Computer Vision, Kyoto, Japan, 29 Septemer–2 October 2009; pp. 2146–2153. [Google Scholar]
- Srivastave, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Niemi, J.; Tanttu, J.T. Automatic Bird Identification for Offshore Wind Farms: A Case Study for Deep Learning. In Proceedings of the 59th IEEE International Symposium ELMAR-2017, Zadar, Croatia, 18–20 September 2017. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step, s | Number of Images for One Class | Number of Images for 8 Classes |
|---|---|---|
| 1100 | 15,132 | 121,056 |
| 700 | 23,280 | 186,240 |
| 350 | 45,396 | 363,168 |
| 200 | 77,988 | 623,904 |
| 100 | 153,648 | 1,229,184 |
| 50 | 304,968 | 2,439,744 |
| Number of Training Examples | Number of Epochs | LRDP | TPR Training | TPR Generalization |
|---|---|---|---|---|
| 9312 | 30 | 30 | 0.7175 | 0.6995 |
| 9312 | 60 | 60 | 0.7362 | 0.7052 |
| 121,056 | 25 | 10 | 0.8687 | 0.8662 |
| 363,168 | 18 | 7 | 0.9137 | 0.9187 |
| 623,904 | 12 | 12 | 0.9788 | 0.9253 |
| 623,904 | 16 | 16 | 0.9839 | 0.9254 |
| 623,904 | 24 | 24 | 0.9835 | 0.9170 |
| 623,904 | 16 | 5 | 0.9830 | 0.9270 |
| 623,904 | 16 | 6 | 0.9831 | 0.9337 |
| 623,904 | 16 | 9 | 0.9834 | 0.9249 |
| 623,904 | 16 | 13 | 0.9837 | 0.9154 |
| 2,439,744 | 3 | 3 | 0.9960 | 0.9246 |
| 2,439,744 | 5 | 5 | 0.9971 | 0.9313 |
| 2,439,744 | 8 | 8 | 0.9984 | 0.9363 |
| 2,439,744 | 12 | 12 | 0.9984 | 0.9296 |
| 2,439,744 | 5 | 3 | 0.9965 | 0.9250 |
| 2,439,744 | 8 | 3 | 0.9983 | 0.9463 |
| 2,439,744 | 10 | 3 | 0.9984 | 0.9448 |
| 2,439,744 | 12 | 3 | 0.9983 | 0.9425 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niemi, J.; Tanttu, J.T. Deep Learning Case Study for Automatic Bird Identification. Appl. Sci. 2018, 8, 2089. https://doi.org/10.3390/app8112089
Niemi J, Tanttu JT. Deep Learning Case Study for Automatic Bird Identification. Applied Sciences. 2018; 8(11):2089. https://doi.org/10.3390/app8112089
Chicago/Turabian StyleNiemi, Juha, and Juha T. Tanttu. 2018. "Deep Learning Case Study for Automatic Bird Identification" Applied Sciences 8, no. 11: 2089. https://doi.org/10.3390/app8112089
APA StyleNiemi, J., & Tanttu, J. T. (2018). Deep Learning Case Study for Automatic Bird Identification. Applied Sciences, 8(11), 2089. https://doi.org/10.3390/app8112089