Optimal Cluster Expansion-Based Intrusion Tolerant System to Prevent Denial of Service Attacks


Abstract
:1. Introduction
2. Related Work
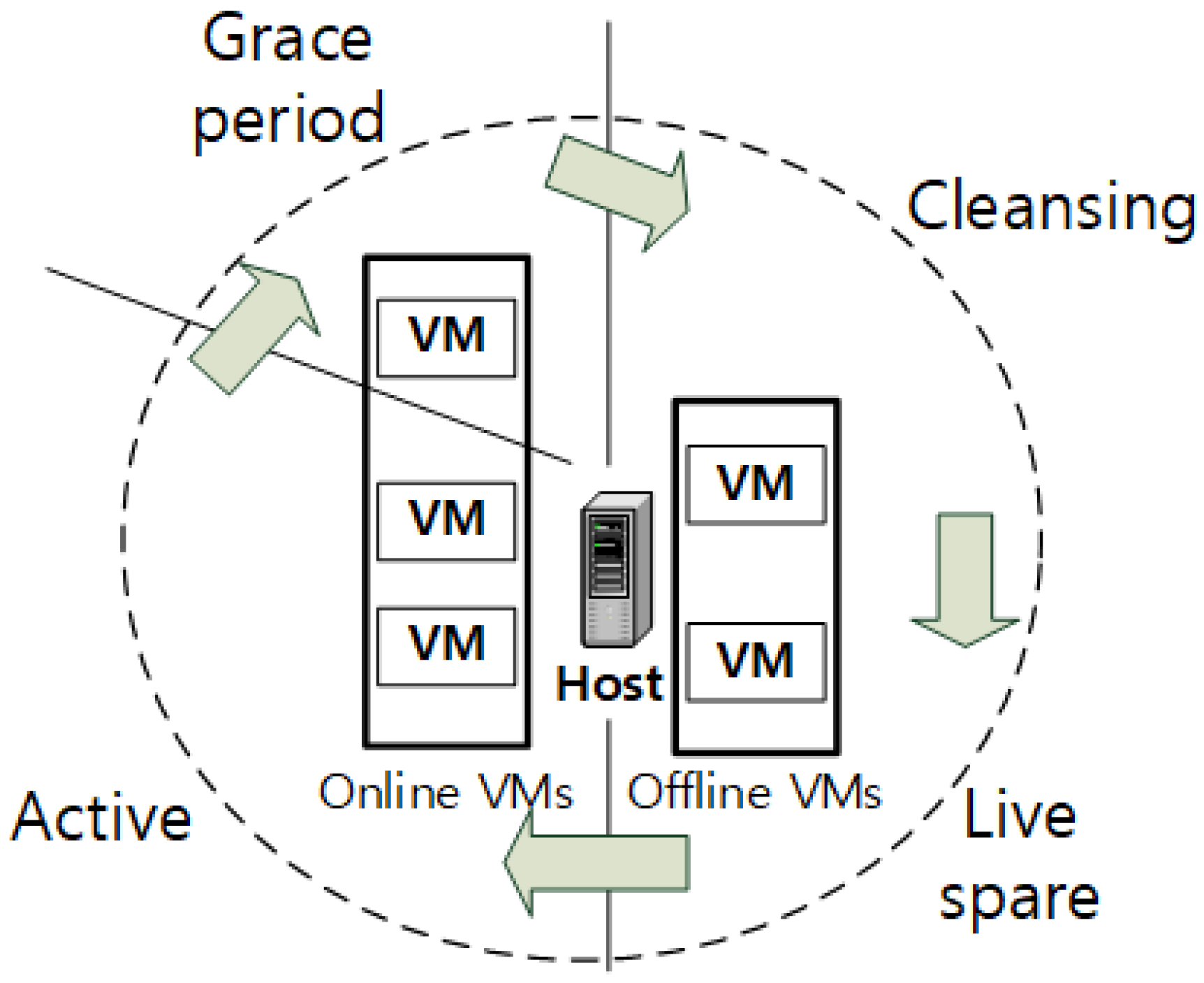
3. Proposed ITS System
- The maximum number of VM processing packets is constant
- The main target scenarios are massive DoS attacks
- The existing attacks are prevented by IDS and IPS
- The considered cloud system has sufficient VMs and hosts
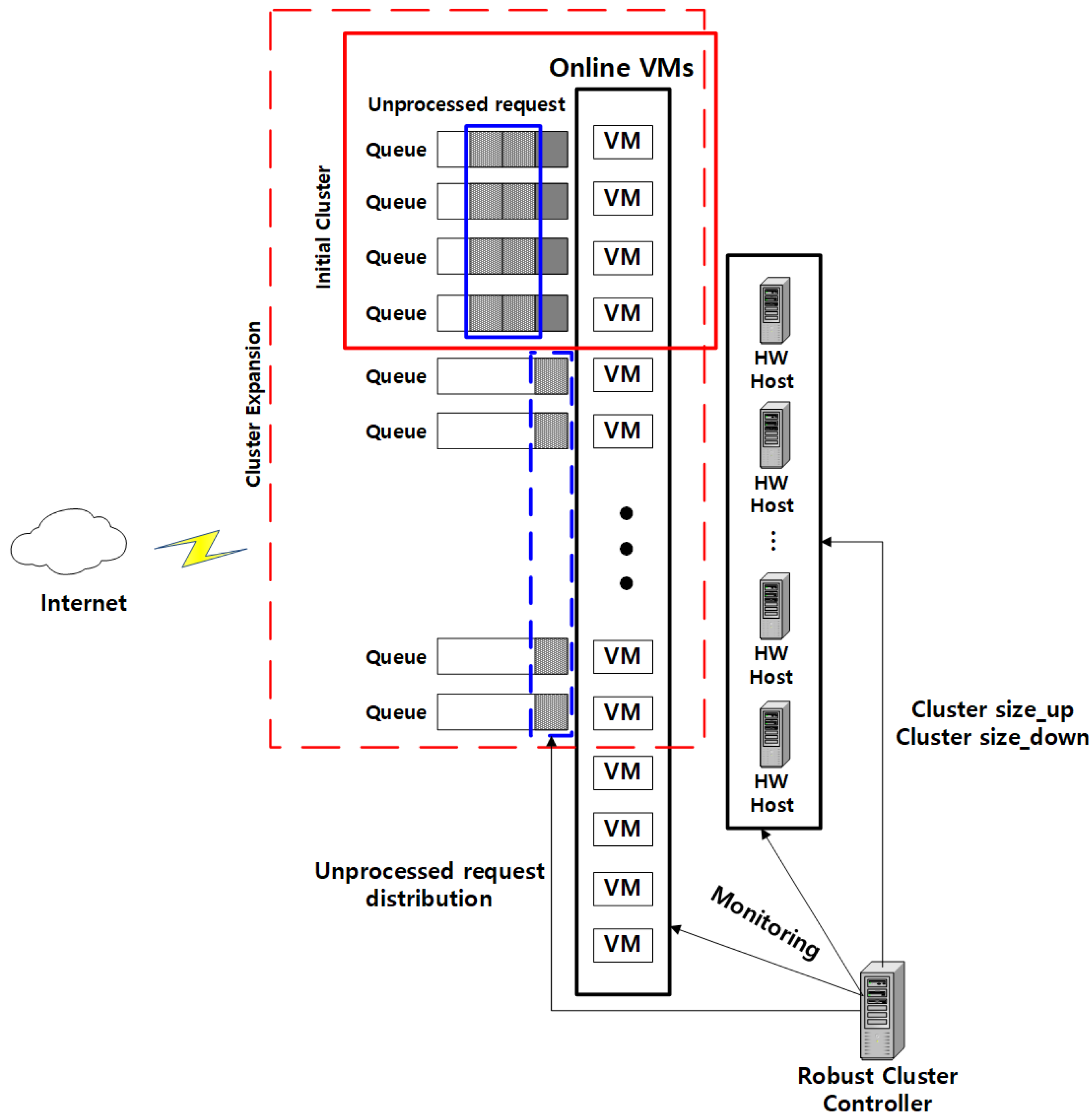
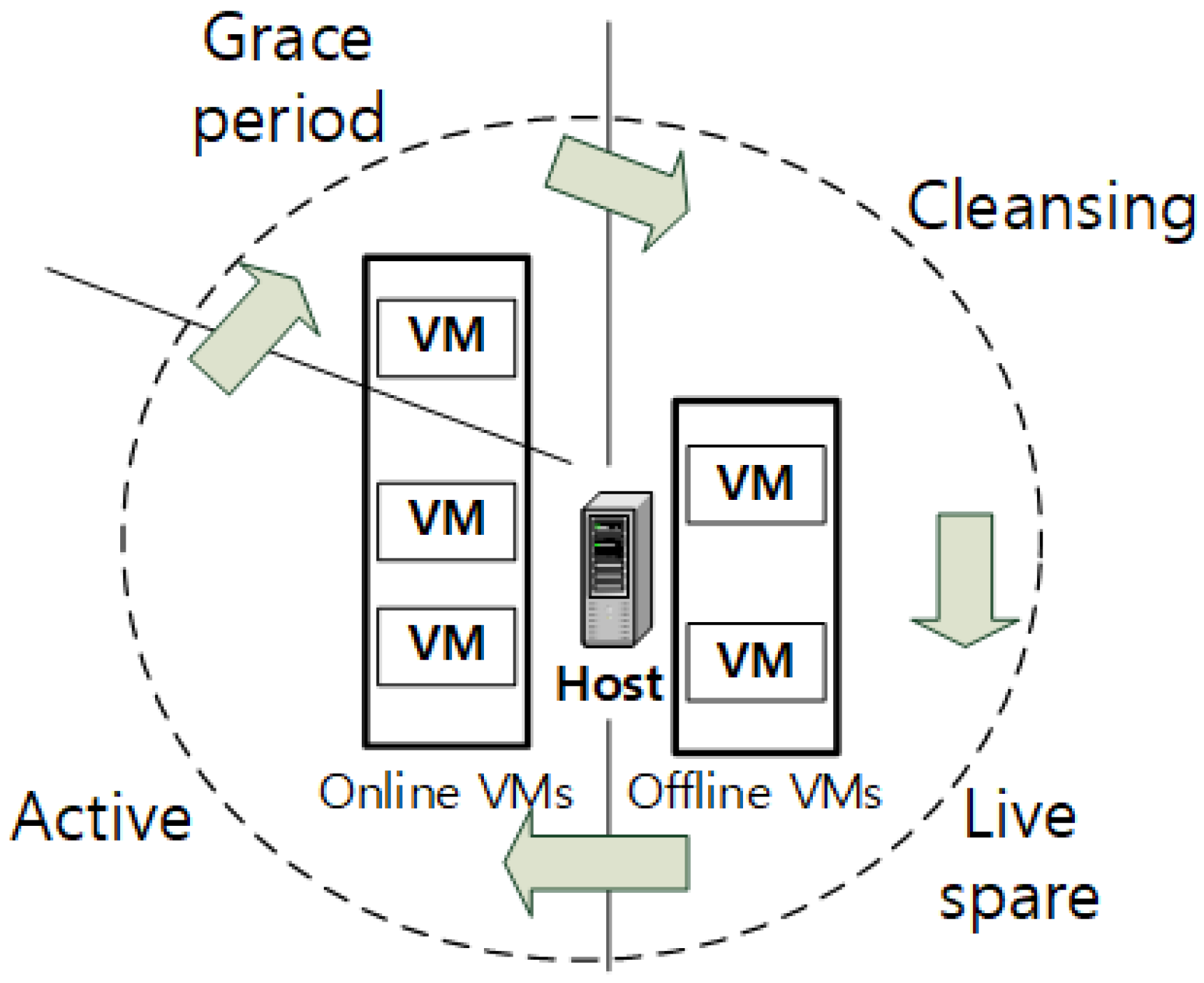
3.1. Cluster Size Expansion
3.2. Unprocessed Packet Distribution
3.3. Cluster Size Reduction
3.4. Cluster Management
| Algorithm 1 Cluster expansion and reduction process | |
| Input: | |
| ▹ Maximum number of online VMs | |
| ▹ Current number of online VMs | |
| ▹ Mean value of CPU usage | |
| ▹ Mean value of response time | |
| ▹ Mean value of queue length | |
| ▹ Number of incoming packets | |
| a | ▹ Number of packets being processed by a VM |
| ▹ Required service level | |
| ▹ Boolean value of system ability | |
| Cluster expansion & reduction process: | |
| while do | |
| if then | |
| end if | |
| if then | |
| end if | |
| end while | |
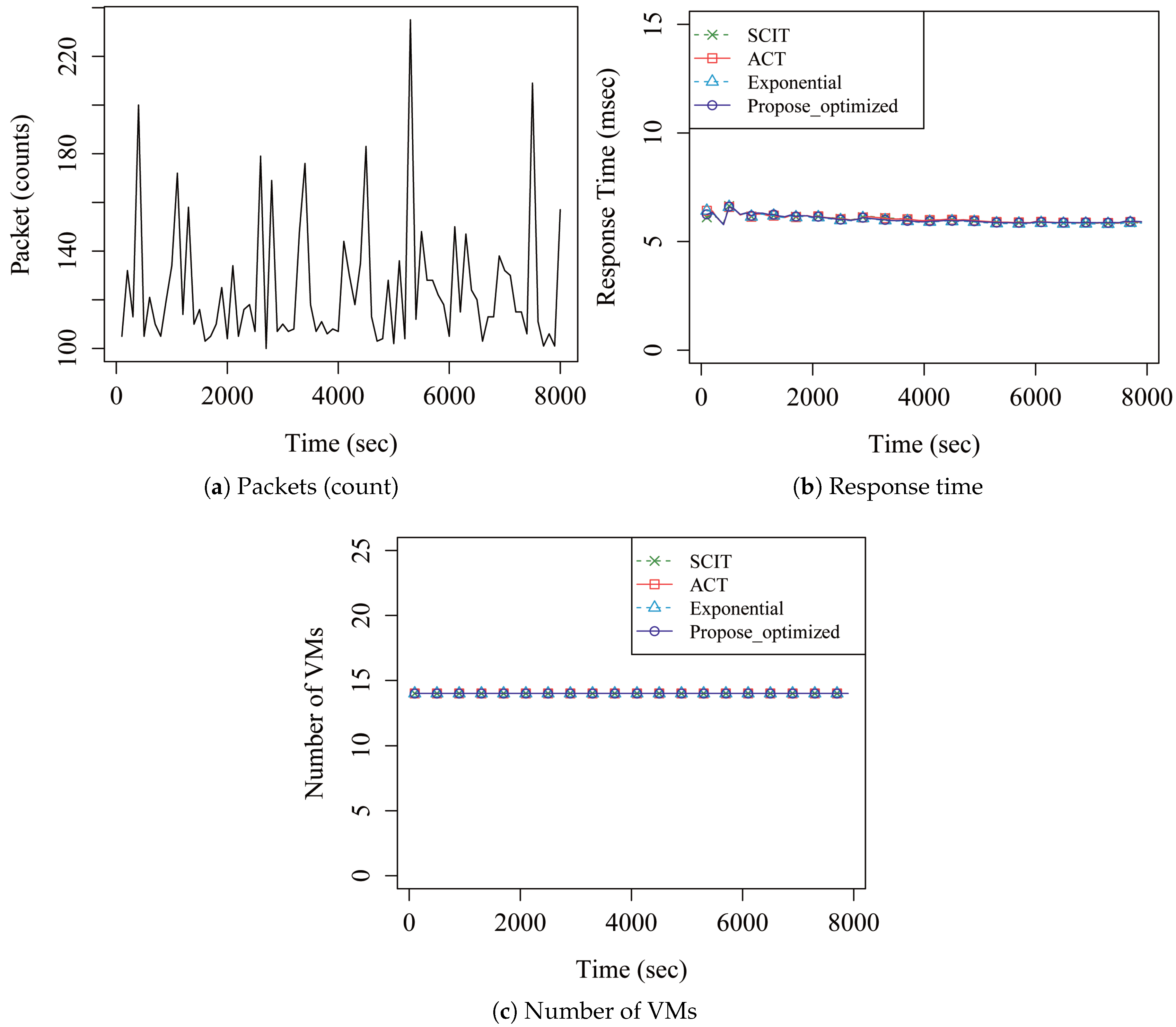
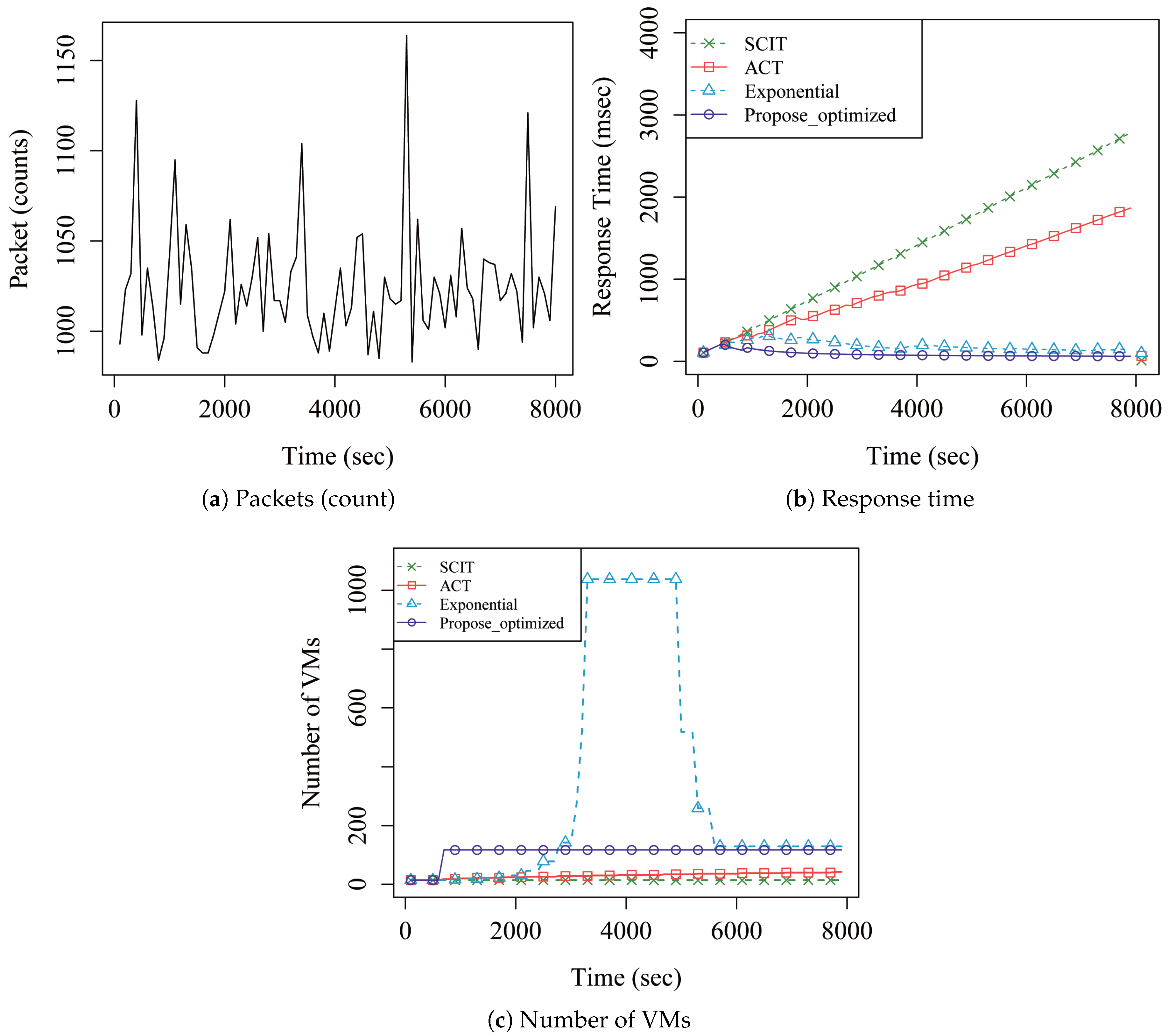
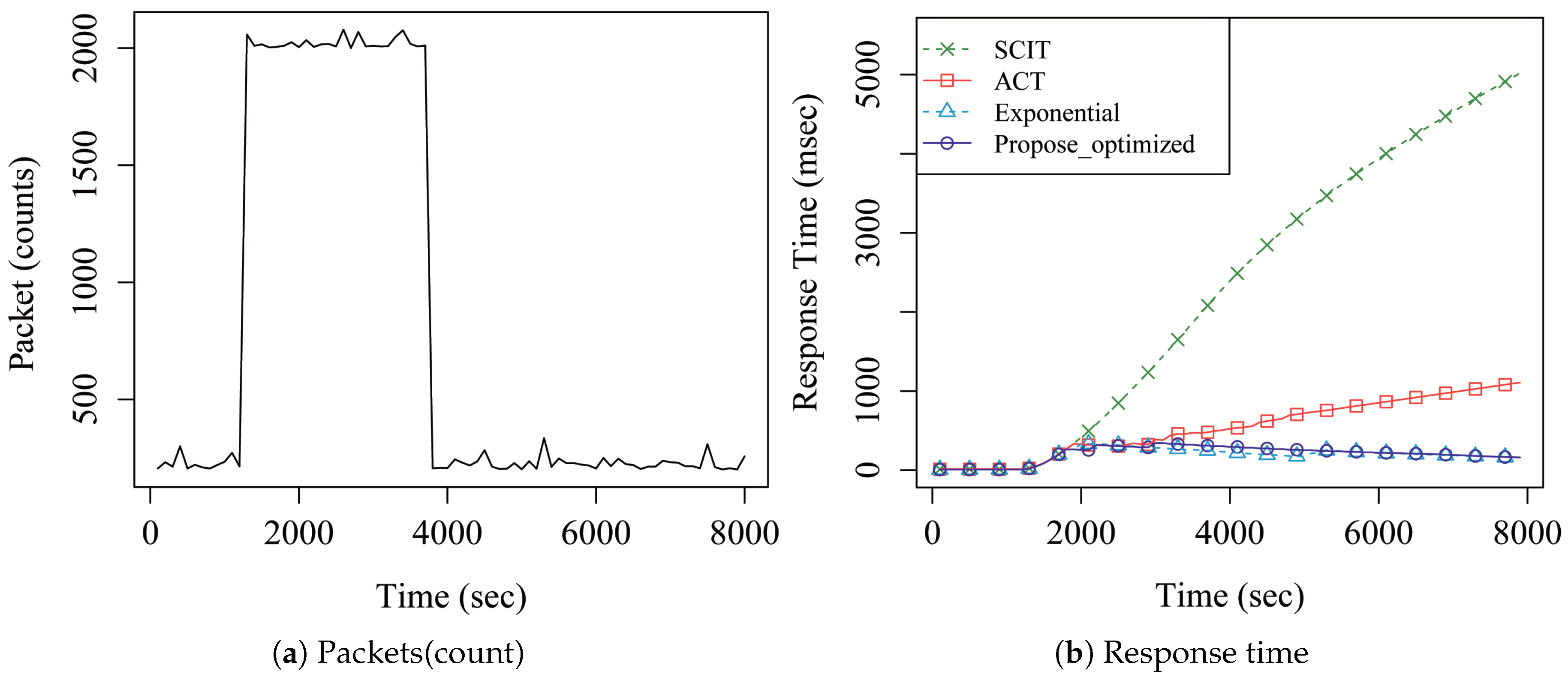
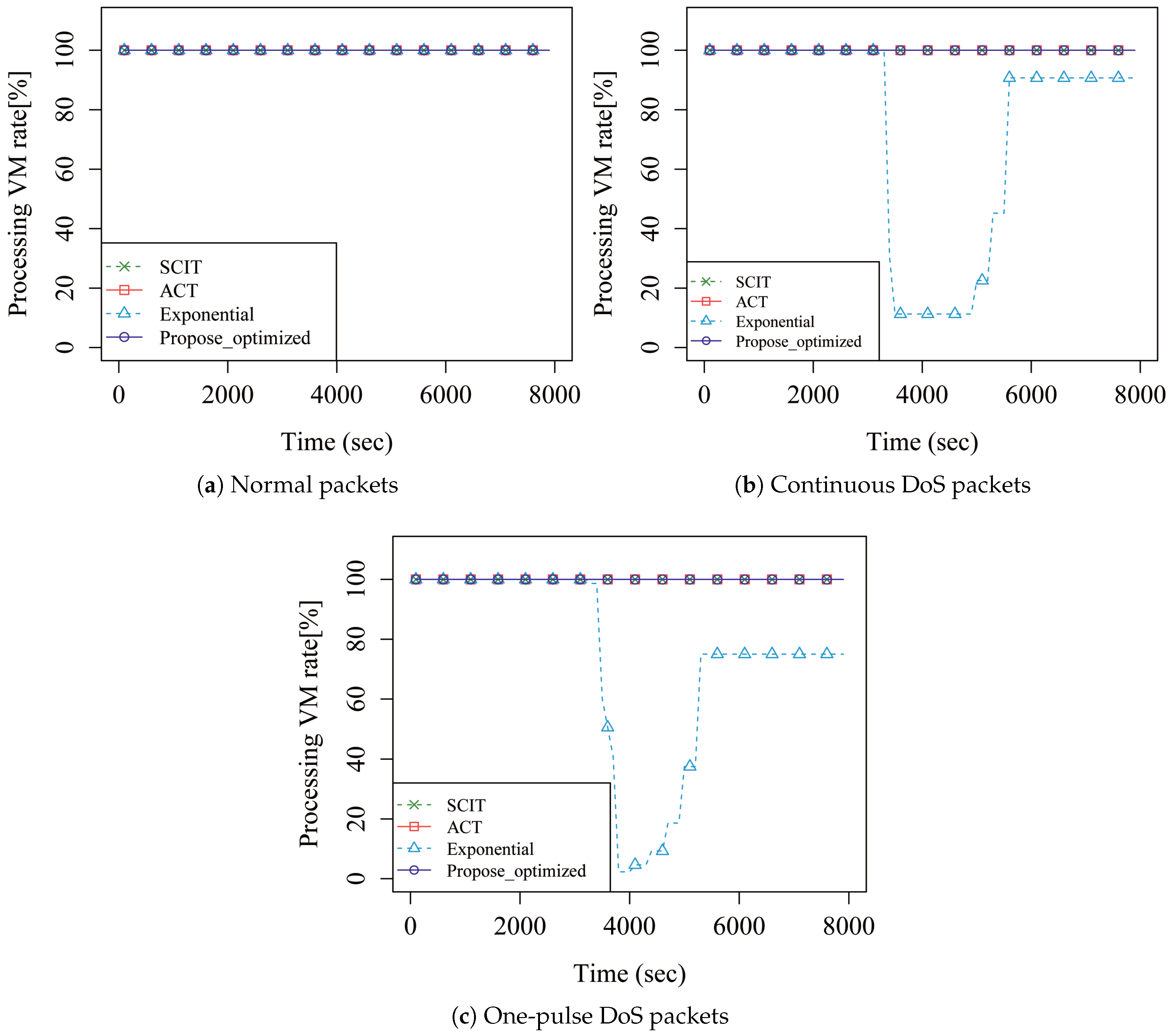
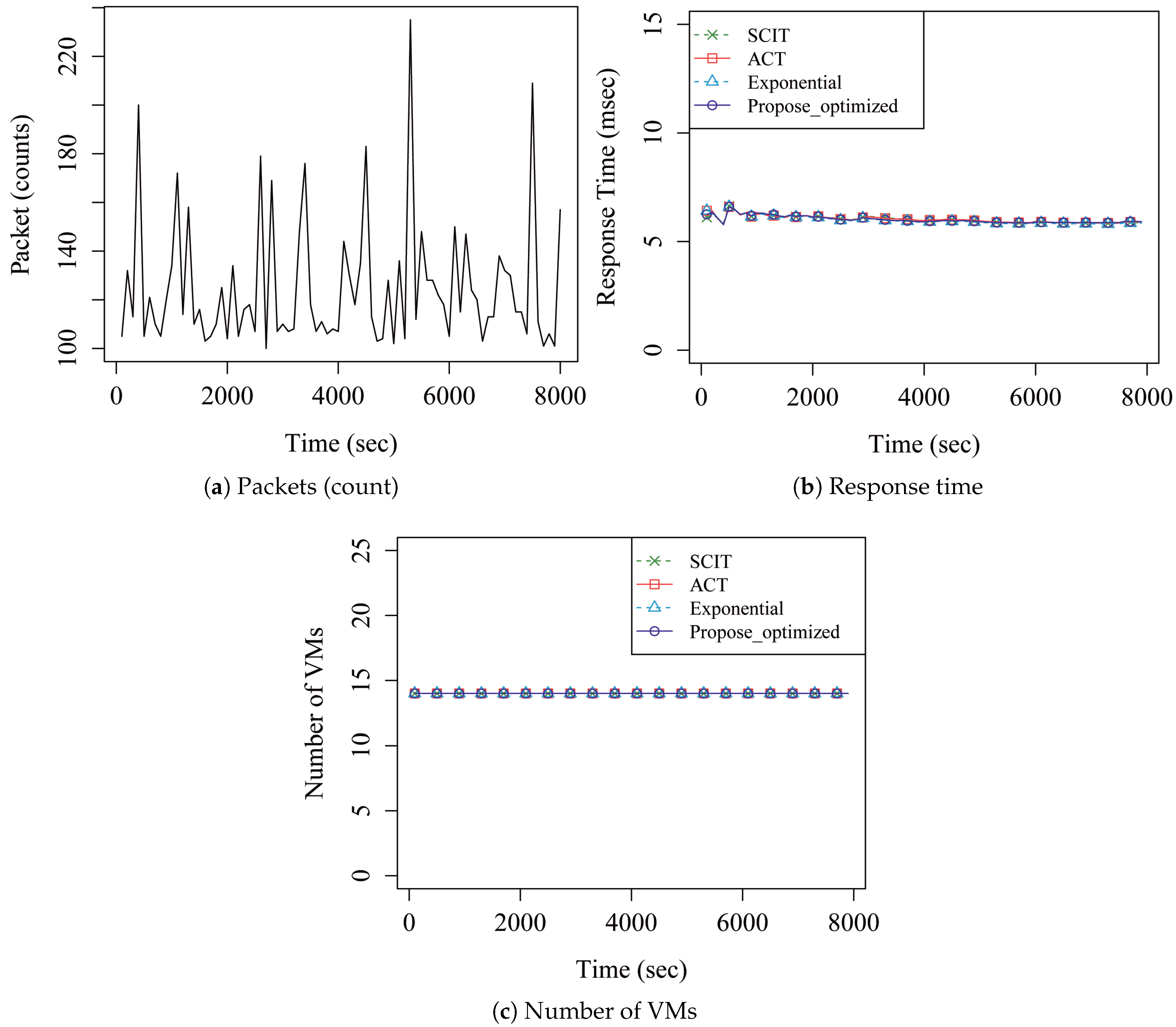
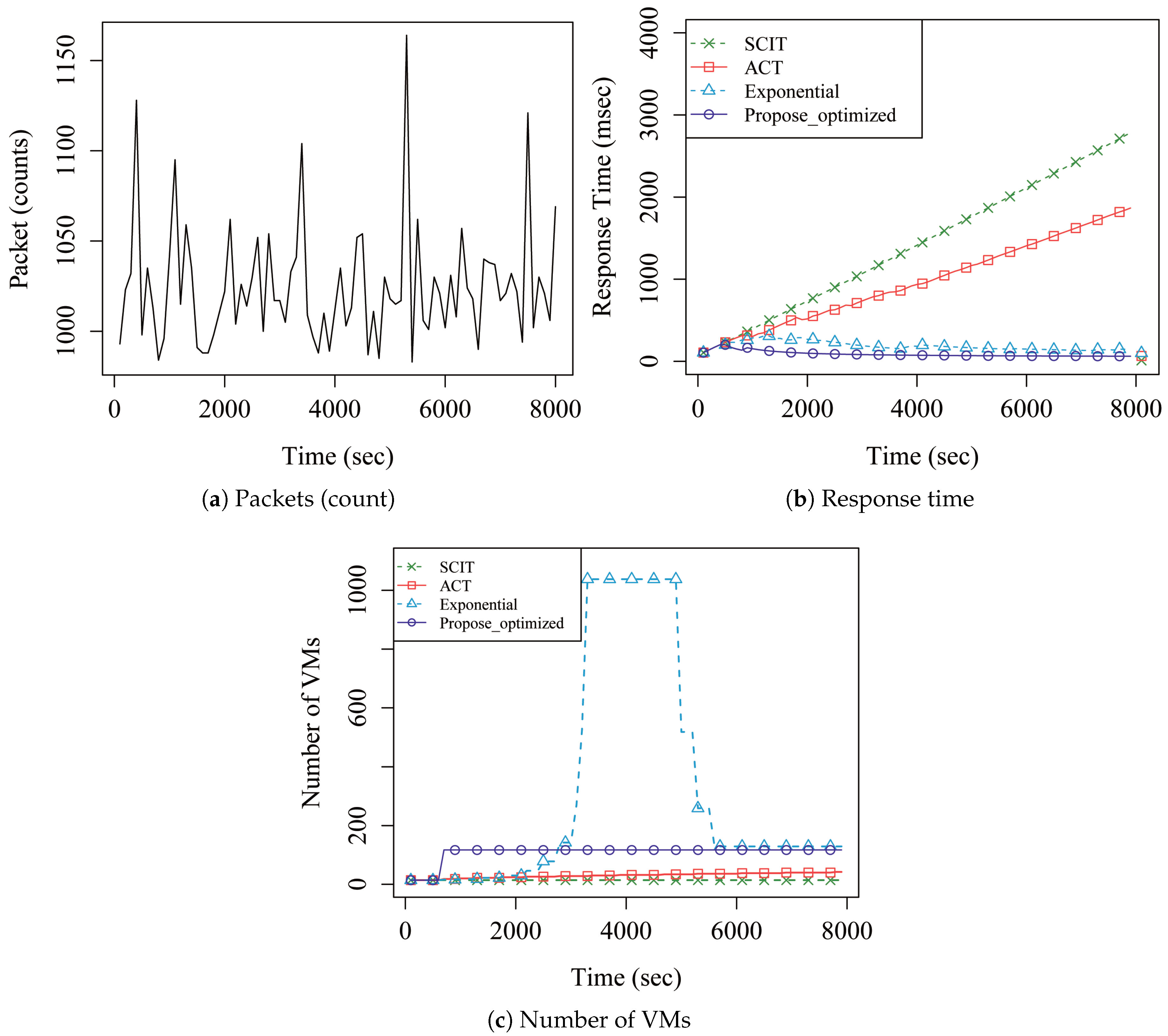
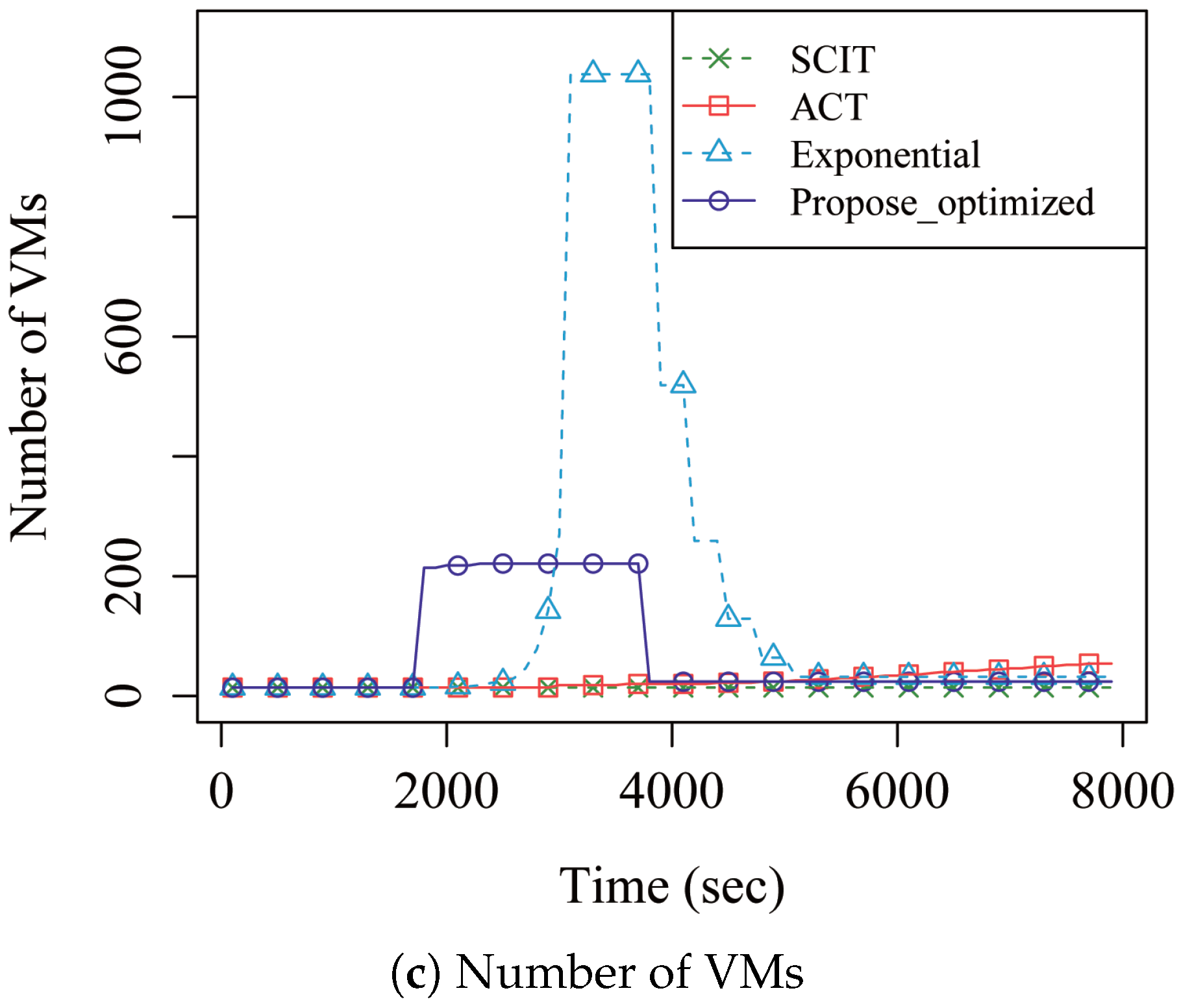
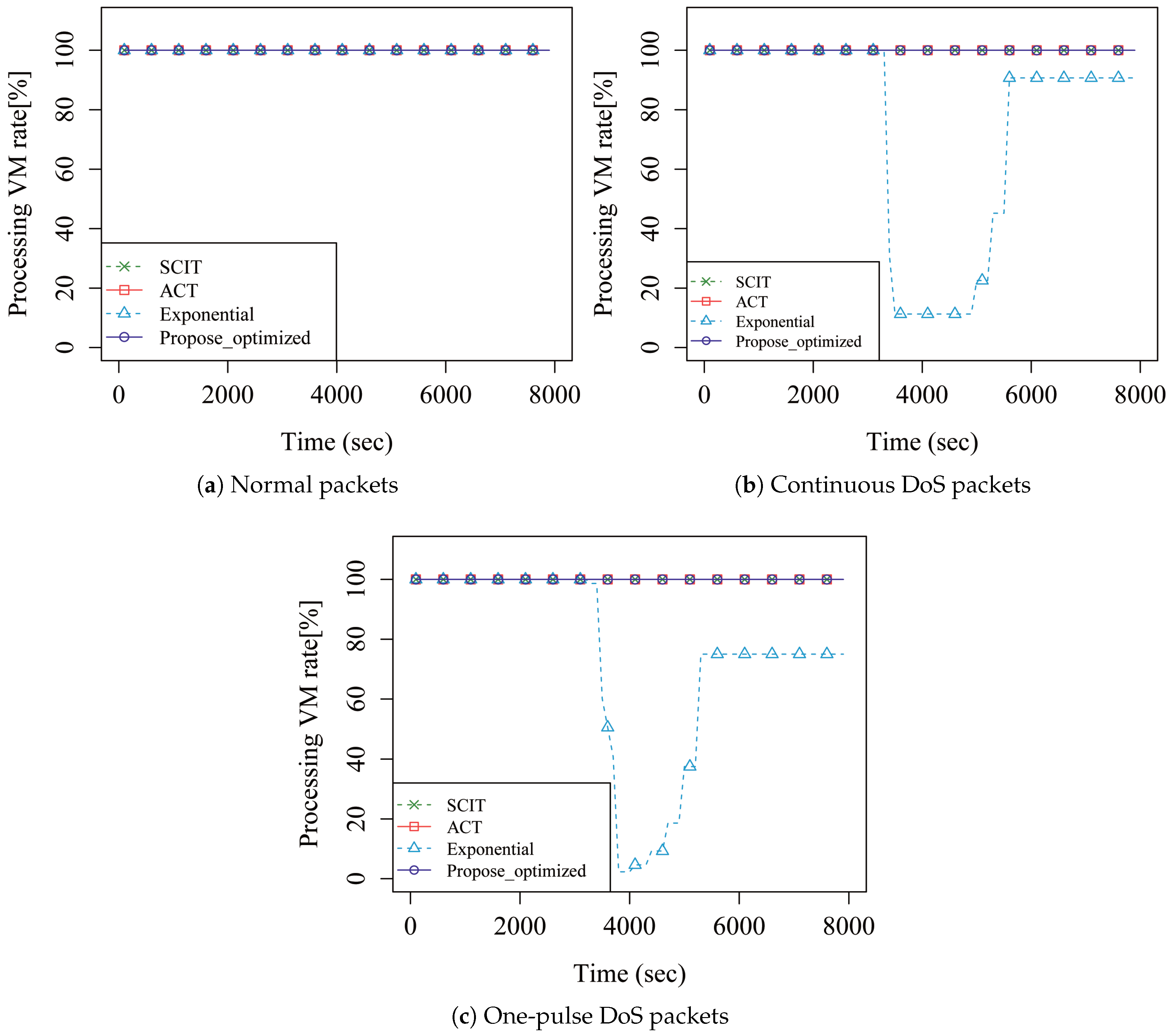
4. Performance Analysis
5. Discussion
6. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kenkre, P.S.; Pai, A.; Colaco, L. Real time intrusion detection and prevention system. In Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing: Theory and Applications (FICTA) 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 405–411. [Google Scholar]
- Patel, A.; Taghavi, M.; Bakhtiyari, K.; JúNior, J.C. An intrusion detection and prevention system in cloud computing: A systematic review. J. Netw. Comput. Appl. 2013, 36, 25–41. [Google Scholar] [CrossRef]
- Veríssimo, P.E.; Neves, N.F.; Correia, M.P. Intrusion-tolerant architectures: Concepts and design. In Architecting Dependable Systems; Springer: Berlin/Heidelberg, Germany, 2003; pp. 3–36. [Google Scholar]
- Heo, S.; Kim, P.; Shin, Y.; Lim, J.; Koo, D.; Kim, Y.; Kwon, O.; Yoon, H. A Survey on Intrusion-Tolerant System. J. Comput. Sci. Eng. 2013, 7, 242–250. [Google Scholar] [CrossRef]
- Guo, M.; Bhattacharya, P. Diverse virtual replicas for improving intrusion tolerance in cloud. In Proceedings of the 9th Annual Cyber and Information Security Research Conference, Oak Ridge, TN, USA, 8–10 April 2014; ACM: New York, NY, USA, 2014; pp. 41–44. [Google Scholar]
- Smith, M.; Schridde, C.; Freisleben, B. Securing stateful grid servers through virtual server rotation. In Proceedings of the 17th International Symposium on High Performance Distributed Computing, Boston, MA, USA, 23–27 June 2008; ACM: New York, NY, USA, 2008; pp. 11–22. [Google Scholar]
- Sousa, P.; Bessani, A.N.; Correia, M.; Neves, N.F.; Verissimo, P. Highly available intrusion-tolerant services with proactive-reactive recovery. IEEE Trans. Parallel Distrib. Syst. 2010, 21, 452–465. [Google Scholar] [CrossRef]
- Huang, Y.; Sood, A. Self-cleansing systems for intrusion containment. In Proceedings of the Workshop on Self-Healing, Adaptive, and Self-Managed Systems (SHAMAN), New York, NY, USA, 23 June 2002. [Google Scholar]
- Huang, Y.; Arsenault, D.; Sood, A. Closing cluster attack windows through server redundancy and rotations. In Proceedings of the IEEE Sixth International Symposium on Cluster Computing and the Grid, Singapore, 16–19 May 2006; Volume 2, p. 12. [Google Scholar]
- Hanczewski, S.; Stasiak, M.; Weissenberg, J.; Zwierzykowski, P. Queuing model of the access system in the packet network. In International Conference on Computer Networks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 283–293. [Google Scholar]
- Saidane, A.; Nicomette, V.; Deswarte, Y. The design of a generic intrusion-tolerant architecture for web servers. IEEE Trans. Dependable Secur. Comput. 2009, 6, 45–58. [Google Scholar] [CrossRef]
- Heo, S.; Lee, S.; Doo, S.; Yoon, H. Design of a secure system considering quality of service. Symmetry 2014, 6, 938–953. [Google Scholar] [CrossRef]
- Heo, S.; Lim, J.; Lee, M.; Lee, S.; Yoon, H. A novel intrusion tolerant system based on adaptive recovery scheme (ARS). In IT Convergence and Security 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 71–78. [Google Scholar]
- Lim, J.; Kim, Y.; Koo, D.; Lee, S.; Doo, S.; Yoon, H. A novel adaptive cluster transformation (ACT)-based intrusion tolerant architecture for hybrid information technology. J. Supercomput. 2013, 66, 918–935. [Google Scholar] [CrossRef]
- Yongjoo, S.; Sihu, S.; Yunho, L.; Hyunsoo, Y. A novel intrusion tolerant system using live migration. IEICE Trans. Inf. Syst. 2014, 97, 984–988. [Google Scholar]
- Bumsoon, J.; Seokjoo, D.; Soojin, L.; Hyunsoo, Y. Hybrid Recovery-Based Intrusion Tolerant System for Practical Cyber-Defense. IEICE Trans. Inf. Syst. 2016, 99, 1081–1091. [Google Scholar]
- Alhamad, M.; Dillon, T.; Wu, C.; Chang, E. Response time for cloud computing providers. In Proceedings of the 12th International Conference on Information Integration and Web-Based Applications & Services, Paris, France, 8–10 November 2010; ACM: New York, NY, USA, 2010; pp. 603–606. [Google Scholar]
- Calheiros, R.N.; Ranjan, R.; Beloglazov, A.; De Rose, C.A.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters & Descriptions | Values |
|---|---|
| VM processing element capacity (PE) | 512 MIPS |
| Maximum number of VMs in system | 10,000 |
| Highest acceptable response time [17] | 0.77 s |
| Initial number of VMs | 14 |
| VM cleansing time [7] | 146 s |
| VM exposure time | 900 s |
| VM attack follows a Poisson distribution with | 0.000485 |
| Description | Normal Packet | Continuous DoS | One-Pulse DoS | |
|---|---|---|---|---|
| Total average response time (ms) | SCIT | 7.41 | 1406.36 | 1810.25 |
| ACT | 7.41 | 955.95 | 529.78 | |
| Exponential | 7.41 | 186.61 | 197.19 | |
| Proposed | 7.41 | 87.41 | 200.98 | |
| Total average VM processing rate (%) | SCIT | 100 | 100 | 100 |
| ACT | 100 | 100 | 100 | |
| Exponential | 100 | 74.42 | 73.29 | |
| Proposed | 100 | 100 | 100 | |
| Total VMs running time (s) | SCIT | 1106 | 1106 | 1106 |
| ACT | 1106 | 2374 | 2002 | |
| Exponential | 1106 | 25,082 | 12,699 | |
| Proposed | 1106 | 8625 | 5499 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, H.; Kim, Y.; Yoon, H.; Choi, D. Optimal Cluster Expansion-Based Intrusion Tolerant System to Prevent Denial of Service Attacks. Appl. Sci. 2017, 7, 1186. https://doi.org/10.3390/app7111186
Kwon H, Kim Y, Yoon H, Choi D. Optimal Cluster Expansion-Based Intrusion Tolerant System to Prevent Denial of Service Attacks. Applied Sciences. 2017; 7(11):1186. https://doi.org/10.3390/app7111186
Chicago/Turabian StyleKwon, Hyun, Yongchul Kim, Hyunsoo Yoon, and Daeseon Choi. 2017. "Optimal Cluster Expansion-Based Intrusion Tolerant System to Prevent Denial of Service Attacks" Applied Sciences 7, no. 11: 1186. https://doi.org/10.3390/app7111186
APA StyleKwon, H., Kim, Y., Yoon, H., & Choi, D. (2017). Optimal Cluster Expansion-Based Intrusion Tolerant System to Prevent Denial of Service Attacks. Applied Sciences, 7(11), 1186. https://doi.org/10.3390/app7111186